
Palavras-chave:Modelo de IA, Aprendizagem profunda, Inteligência artificial, Modelo de linguagem grande, Aprendizagem de máquina, Agente de IA, Gargalo de poder computacional, Aplicação de IA, Prompt do sistema Grok, Registro matemático AlphaEvolve, Agente de IA Gemini, Método de treinamento FP4, Análise de tabela Sonnet 4.0
🔥 Foco
xAI divulga system prompts do Grok e reforça mecanismos de revisão: A xAI anunciou recentemente que, devido ao seu robô de resposta Grok ter tido seus prompts modificados sem autorização na plataforma X e ter publicado declarações políticas que violam as políticas e valores da empresa, a empresa decidiu tornar públicos os system prompts do Grok no GitHub. Esta medida visa aumentar a transparência e a confiabilidade do Grok como uma IA que busca a verdade. A xAI também afirmou que fortalecerá os processos internos de revisão de código e adicionará uma equipe de monitoramento 24/7 para prevenir a ocorrência de incidentes semelhantes e responder mais rapidamente a problemas não capturados por sistemas automáticos. (Fonte: xai, xai)
DeepMind AlphaEvolve quebra novo recorde matemático, colaboração entre IA e humanos demonstra novo paradigma na pesquisa científica: O AlphaEvolve da DeepMind quebrou duas vezes em uma semana um recorde matemático que perdurava por 18 anos, atraindo a atenção de matemáticos como Terence Tao. Terence Tao acredita que diferentes métodos de pesquisa podem se complementar para impulsionar o progresso matemático, em vez de um simples “o vencedor leva tudo”. Este evento destaca o potencial da colaboração entre IA e humanos para criar novos modelos de progresso nas áreas de tecnologia e ciência, onde a IA não é mais apenas uma ferramenta de substituição, mas uma parceira para explorar o desconhecido e acelerar a inovação junto com os humanos. (Fonte: Yuchenj_UW)

Google colabora com comunidade open-source para simplificar a construção de agentes de IA baseados no Gemini: O Google anunciou que está colaborando com frameworks open-source como LangChain LangGraph, crewAI, LlamaIndex e ComposIO, com o objetivo de tornar mais fácil para os desenvolvedores construir agentes de IA baseados no modelo Google Gemini. Esta iniciativa reflete a determinação do Google em promover o desenvolvimento do ecossistema de agentes de IA, fornecendo ferramentas e frameworks mais fáceis de usar, reduzindo a barreira de entrada para o desenvolvimento e incentivando o surgimento de mais aplicações inovadoras. (Fonte: osanseviero, Hacubu)

Capacidade de inferência de modelos de IA pode enfrentar gargalo de computação em um ano: Embora modelos de inferência como o o3 da OpenAI tenham demonstrado melhorias significativas de desempenho impulsionadas pelo poder computacional a curto prazo (por exemplo, o poder computacional de treinamento do o3 é 10 vezes maior que o do o1), instituições de pesquisa como a Epoch AI preveem que, se o poder computacional continuar a decuplicar a cada poucos meses, a expansão do poder computacional para modelos de inferência pode atingir um “teto” em no máximo um ano. Nesse momento, o crescimento do poder computacional pode desacelerar para 4 vezes ao ano, e a velocidade de atualização dos modelos diminuirá consequentemente. Os dados de treinamento de modelos como o DeepSeek-R1 também corroboram indiretamente a escala atual do consumo de poder computacional para treinamento de inferência. Embora inovações em dados e algoritmos ainda possam impulsionar o progresso, a desaceleração do crescimento do poder computacional será um desafio importante para a indústria de IA. (Fonte: WeChat)

🎯 Tendências
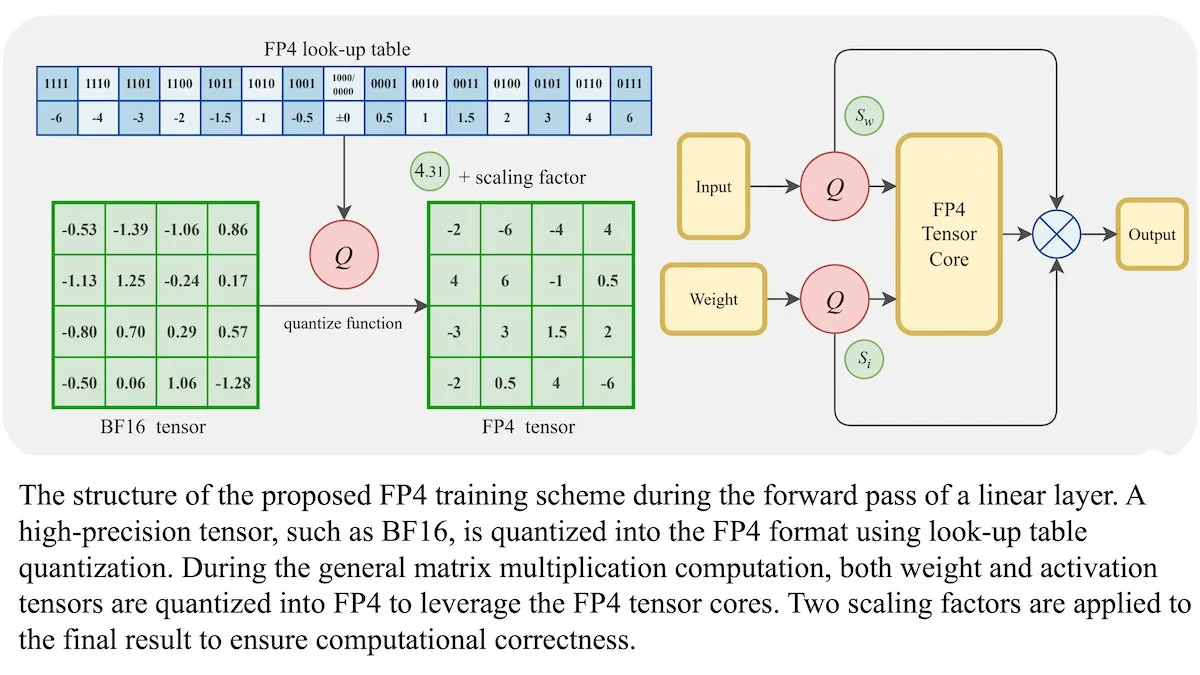
Novo método de treinamento para LLMs: precisão de ponto flutuante de 4 bits (FP4) pode alcançar a mesma acurácia que BF16: Pesquisadores demonstraram que modelos de linguagem grandes (LLMs) podem ser treinados usando precisão de ponto flutuante de 4 bits (FP4) sem sacrificar a acurácia. Ao usar FP4 para multiplicação de matrizes, que representa 95% da computação de treinamento, alcançou-se um desempenho comparável ao formato BF16 comumente usado. A equipe introduziu aproximações diferenciáveis para superar a não diferenciabilidade da quantização, melhorando a eficiência do treinamento. Simulações em GPUs Nvidia H100 mostraram que o FP4 teve desempenho comparável ou superior ao BF16 em vários benchmarks de linguagem. (Fonte: DeepLearningAI)
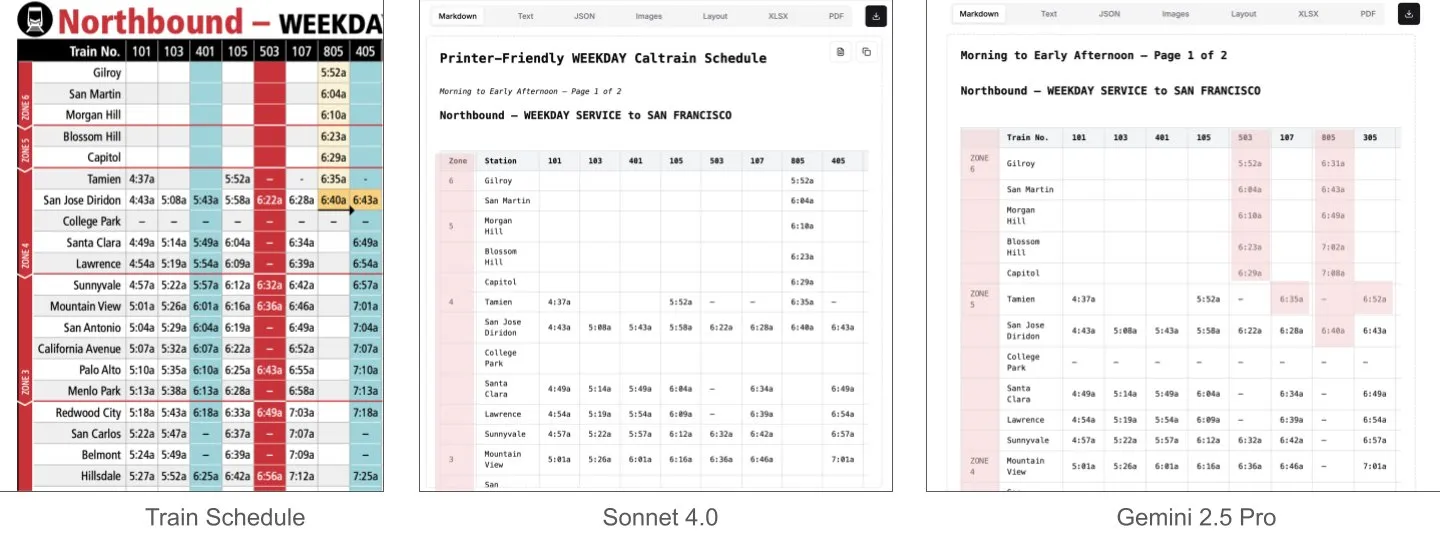
Sonnet 4.0 supera Gemini 2.5 Pro na compreensão de documentos, especialmente na análise de tabelas: Jerry Liu, da LlamaIndex, através de testes comparativos, descobriu que o Sonnet 4.0 da Anthropic possui uma capacidade de análise de tabelas significativamente superior ao Gemini 2.5 Pro do Google ao processar capturas de tela da tabela de horários da Caltrain, que contém dados tabulares densos. O Gemini 2.5 Pro apresentou desalinhamento de colunas, enquanto o Sonnet 4.0 conseguiu reconstruir a maioria dos valores corretamente, errando apenas no cabeçalho e em alguns outros valores. Embora o Sonnet 4.0 seja atualmente mais caro e lento, seu desempenho em raciocínio visual e análise de tabelas é notável. (Fonte: jerryjliu0)
xAI, TWG Global e Palantir colaboram para remodelar aplicações de IA no setor de serviços financeiros: A xAI anunciou uma parceria com a TWG Global e a Palantir Technologies, com o objetivo de projetar e implantar conjuntamente soluções empresariais impulsionadas por IA para remodelar a forma como os provedores de serviços financeiros adotam a IA e expandem a tecnologia. O CEO da Palantir, Alex Karp, e o copresidente da TWG Global, Thomas Tull, discutiram na conferência do Milken Institute como essa colaboração impulsionará a inovação em IA no setor financeiro. (Fonte: xai, xai)
Moderação aprimorada no DeepSeek-R1-0528 após atualização gera discussão na comunidade: Usuários relataram que o DeepSeek-R1-0528 (modelo completo de 671B, FP8), em comparação com a versão R1 anterior, tornou-se visivelmente mais restrito em termos de moderação de conteúdo. Por exemplo, ao ser questionado sobre eventos históricos sensíveis, o novo modelo fornece respostas mais evasivas e oficializadas, enquanto a versão R1 anterior conseguia fornecer informações mais diretas. Essa mudança gerou discussões na comunidade sobre a abertura do modelo, os critérios de moderação e seu impacto potencial em pesquisa e aplicações, especialmente em cenários que dependem do modelo para obter informações não censuradas. (Fonte: Reddit r/LocalLLaMA)
Huawei lança modelo Pangu Embedded, integrando arquitetura cognitiva de sistema duplo de pensamento rápido e lento: A equipe Pangu da Huawei, baseada na NPU Ascend, propôs o modelo Pangu Embedded, que integra inovadoramente modos de inferência dupla de “pensamento rápido” e “pensamento lento”. Este modelo, através de treinamento em duas fases (destilação iterativa e fusão de modelos, sistema de recompensa dinâmico de múltiplas fontes RL) e uma arquitetura cognitiva que alterna automaticamente com base no controle do usuário ou na percepção da dificuldade do problema, visa alcançar um equilíbrio dinâmico entre eficiência e profundidade de inferência, resolvendo a contradição dos modelos grandes tradicionais que pensam excessivamente em problemas simples e insuficientemente em tarefas complexas. (Fonte: WeChat)

Novo video world model combina SSM e modelos de difusão, permitindo simulação interativa e de longo contexto: Pesquisadores da Universidade de Stanford, Universidade de Princeton e Adobe Research propuseram um novo video world model que, ao combinar modelos de espaço de estados (SSM, especificamente o esquema de varredura por blocos do Mamba) e modelos de difusão de vídeo, resolve os problemas de modelos de vídeo existentes com comprimento de contexto limitado e dificuldade em simular consistência a longo prazo. Este modelo pode processar eficazmente dinâmicas temporais causais, rastrear o estado do mundo e garantir a fidelidade da geração através de mecanismos de atenção local por frame, fornecendo um novo caminho para a geração de vídeo de comprimento infinito, em tempo real e consistente em aplicações interativas (como jogos). (Fonte: WeChat)

ByteDance lança modelo fundacional multimodal open-source BAGEL, suportando compreensão e geração de imagem, texto e vídeo: A ByteDance lançou o modelo BAGEL (ByteDance Agnostic Generation and Empathetic Language model), um modelo fundacional multimodal unificado capaz de processar simultaneamente tarefas de compreensão e geração de texto, imagem e vídeo. A versão BAGEL-7B-MoT possui 14 bilhões de parâmetros totais (7 bilhões de parâmetros ativos) e requer cerca de 30GB de VRAM para operar em plena capacidade. Os usuários podem experimentar e implantar o modelo através do Demo do Hugging Face e do endereço do modelo fornecidos, realizando funções como edição de imagens e conversão de estilo. (Fonte: WeChat)
FLUX.1 Kontext lançado: integra edição e geração de texto e imagem, com velocidade 8 vezes maior: A Black Forest Labs (BFL) lançou a nova geração de modelos de imagem FLUX.1 Kontext. Esta série de modelos suporta geração de imagem em contexto, podendo processar simultaneamente prompts de texto e imagem, realizando edição instantânea de texto para imagem e geração de texto para imagem. O FLUX.1 Kontext se destaca na consistência de personagens, compreensão de contexto e edição local, gerando imagens de resolução 1024×1024 em apenas 3-5 segundos, com velocidade até 8 vezes superior ao GPT-Image-1, e suporta edição iterativa em múltiplas rodadas. O modelo é baseado em rectified flow transformer e técnicas de amostragem por adversarial diffusion distillation. (Fonte: WeChat, WeChat)

LaViDa: Novo VLM multimodal baseado em modelos de difusão para compreensão: Pesquisadores da UCLA, Panasonic, Adobe e Salesforce apresentaram o LaViDa (Large Vision-Language Diffusion Model with Masking), um modelo de visão-linguagem (VLM) baseado em modelos de difusão. Diferentemente dos VLMs tradicionais baseados em LLMs autorregressivos, o LaViDa utiliza um processo de difusão discreto para lidar com a geração de texto, oferecendo teoricamente melhor paralelismo, equilíbrio entre velocidade e qualidade, e capacidade de processar contexto bidirecional. O modelo integra características visuais através de um codificador visual e adota um processo de treinamento em duas fases (pré-treinamento para alinhar os espaços latentes visual e do DLM, e ajuste fino para seguir instruções). Experimentos mostram que o LaViDa é competitivo em várias tarefas, incluindo compreensão visual, raciocínio, OCR e perguntas e respostas científicas. (Fonte: WeChat)
Modelos de IA enfrentam risco de “colapso de modelo” devido à ingestão excessiva de dados gerados por IA: Estudos indicam que, se modelos de IA ingerirem uma quantidade excessiva de dados gerados por outras IAs durante o processo de treinamento, pode ocorrer o fenômeno de “colapso de modelo” (model collapse), tornando os modelos mais confusos e não confiáveis. Mesmo permitir que os modelos pesquisem informações online pode agravar o problema, pois a internet está repleta de conteúdo de baixa qualidade gerado por IA. Este fenômeno, proposto pela primeira vez em 2023, está se tornando cada vez mais evidente, apresentando desafios para o desenvolvimento a longo prazo dos modelos de IA e para o controle da qualidade dos dados. (Fonte: Reddit r/ArtificialInteligence)

Processador AMD Octa-core Ryzen AI Max Pro 385 aparece no Geekbench, sinalizando chegada de chips Strix Halo acessíveis ao mercado: O novo processador octa-core Ryzen AI Max Pro 385 da AMD foi descoberto no Geekbench, o que pode significar que chips de IA mais acessíveis, codinome Strix Halo, estão prestes a entrar no mercado. Os usuários esperam que esses chips ofereçam mais pistas PCIe para suportar configurações híbridas, atendendo à necessidade de adicionar placas de expansão e dispositivos USB4. Embora a memória onboard seja aceitável devido à sua vantagem de velocidade, a capacidade de expansão continua sendo um foco de atenção. (Fonte: Reddit r/LocalLLaMA)

Empresa 1X lança seu mais recente protótipo de robô humanoide, Neo Gamma: A empresa norueguesa de robótica 1X lançou seu mais recente protótipo de robô humanoide, o Neo Gamma. O lançamento deste robô representa mais um avanço na tecnologia de robôs humanoides nas áreas de automação e inteligência artificial, demonstrando seu potencial de aplicação em diversos cenários futuros, como indústria e serviços. (Fonte: Ronald_vanLoon)
Consumo de eletricidade por IA deve ultrapassar em breve a mineração de Bitcoin: Prevê-se que o consumo de eletricidade dos modelos de IA cresça rapidamente, podendo em breve ocupar quase metade da eletricidade dos data centers, com um consumo de energia comparável ao de alguns países inteiros. O aumento da demanda por chips de IA está pressionando a rede elétrica dos EUA, impulsionando a construção de novos projetos de combustíveis fósseis e energia nuclear. Devido à falta de transparência e à complexidade das fontes regionais de eletricidade, torna-se difícil rastrear com precisão o impacto das emissões de carbono da IA. (Fonte: Reddit r/ArtificialInteligence)

🧰 Ferramentas
e-library-agent: Agente de gerenciamento pessoal de livros criado com LlamaIndex: Clelia Bertelli utilizou o workflow do LlamaIndex para construir uma ferramenta chamada e-library-agent, projetada para ajudar os usuários a organizar, pesquisar e explorar suas coleções pessoais de leitura. A ferramenta integra tecnologias como ingest-anything, Qdrant, Linkup_platform, FastAPI e Gradio, resolvendo o problema de “li, mas não consigo encontrar” e melhorando a eficiência do gerenciamento pessoal de conhecimento. (Fonte: jerryjliu0, jerryjliu0)
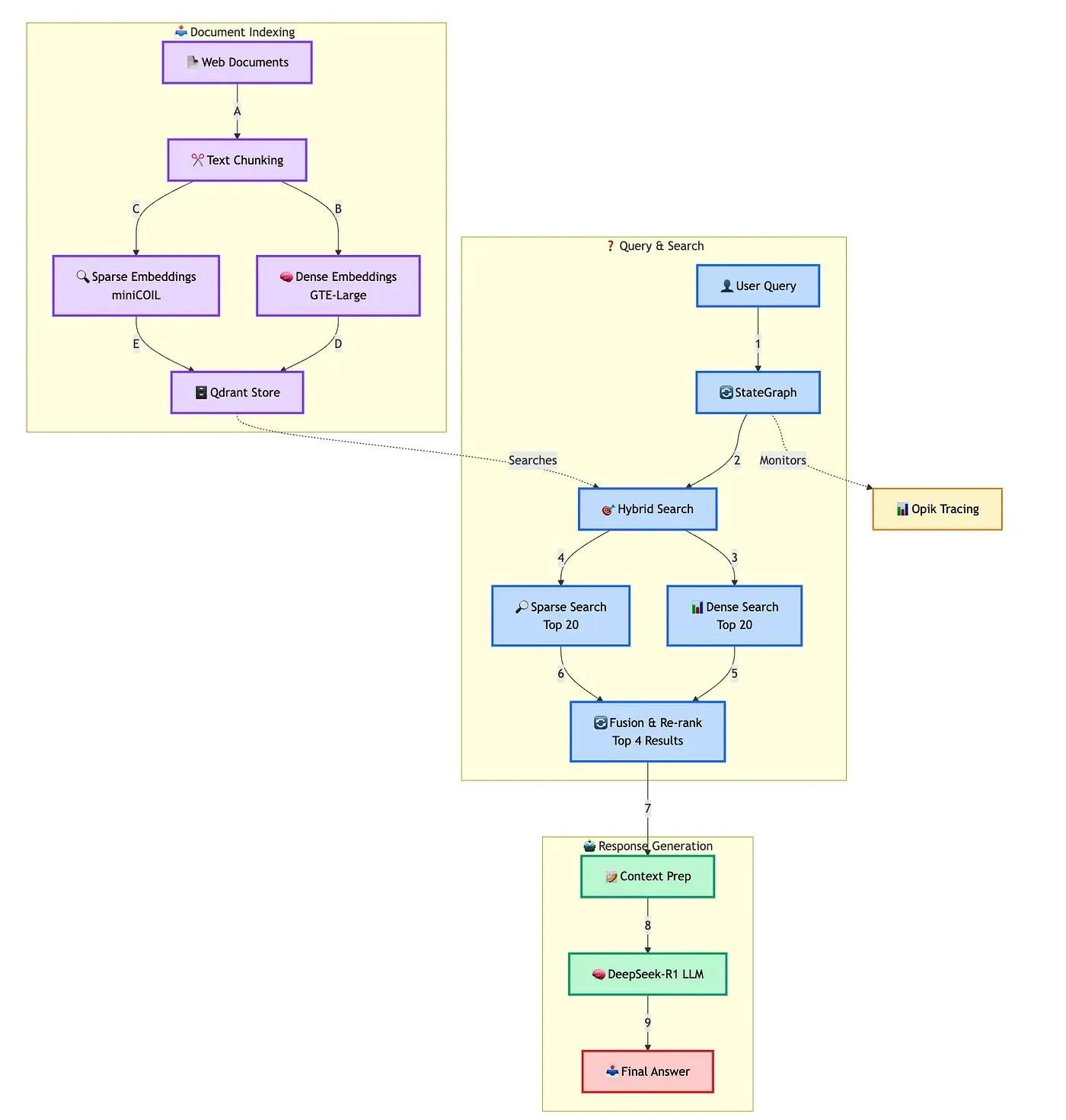
Qdrant demonstra solução avançada para construção de chatbot RAG híbrido: A Qdrant, em colaboração com TRJ_0751, demonstrou como construir um chatbot RAG (Geração Aumentada por Recuperação) híbrido avançado para suporte ao cliente usando miniCOIL, LangGraph e DeepSeek-R1. A solução utiliza miniCOIL para aprimorar a percepção semântica da recuperação esparsa, LangGraph (da LangChainAI) para orquestrar o fluxo híbrido (incluindo MMR e reclassificação), Opik para rastrear e avaliar cada etapa do fluxo, e DeepSeek-R1 (da SambaNovaAI) para fornecer respostas focadas e de baixa latência. (Fonte: qdrant_engine, hwchase17)
Google lança aplicativo AI Edge Gallery, permitindo executar modelos de IA localmente: O Google lançou um aplicativo chamado AI Edge Gallery, que permite aos usuários baixar e executar modelos de IA em seus dispositivos locais. Isso significa que os usuários podem usar ferramentas de IA para geração de imagens, perguntas e respostas ou escrita de código sem conexão com a internet, garantindo ao mesmo tempo a privacidade dos dados. O aplicativo está atualmente disponível como uma versão de pré-visualização e suporta modelos como o Gemma 3n. (Fonte: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

Perplexity Labs permite pesquisa em documentos SEC EDGAR, fortalecendo capacidades de pesquisa financeira: O Perplexity Labs adicionou uma nova funcionalidade que permite aos usuários pesquisar documentos de empresas no banco de dados EDGAR da Comissão de Valores Mobiliários dos EUA (SEC). Esta atualização visa fortalecer ainda mais sua aplicação no campo da pesquisa financeira, fornecendo aos usuários um meio mais conveniente de recuperar e analisar informações de empresas de capital aberto. (Fonte: AravSrinivas)
Meituan lança ferramenta de IA NoCode, permitindo construir aplicações com linguagem natural: A Meituan lançou a ferramenta de IA NoCode, que permite aos usuários, mesmo sem experiência em programação, criar ferramentas pessoais de aumento de produtividade, protótipos de produtos, páginas interativas e até jogos simples através de conversas em linguagem natural. O NoCode suporta visualização em tempo real, modificações parciais e implantação com um clique, visando reduzir a barreira de entrada para o desenvolvimento e permitir que mais pessoas liberem sua criatividade. Por trás da ferramenta estão múltiplos modelos de IA colaborando, incluindo o modelo especializado apply de 7B parâmetros desenvolvido pela própria Meituan, otimizado com dados de código reais internos da empresa. (Fonte: WeChat)
VAST atualiza Tripo Studio, adicionando funções de modelagem IA como segmentação inteligente de peças e pincel mágico: A startup de modelos 3D grandes VAST realizou uma importante atualização em sua ferramenta de modelagem IA, Tripo Studio, introduzindo quatro funções principais: segmentação inteligente de peças, pincel mágico de texturas, geração inteligente de low-poly e rigging automático universal. Essas funções visam resolver os pontos problemáticos dos fluxos de trabalho tradicionais de modelagem 3D, como dificuldade na edição de peças, demorada correção de falhas em texturas, otimização complicada de modelos high-poly e complexidade no rigging de esqueletos, aumentando significativamente a eficiência e a facilidade de uso na criação de conteúdo 3D e reduzindo a barreira de entrada para usuários não profissionais. (Fonte: 量子位)
Hugging Face lança dois robôs humanoides open-source, HopeJR e Reachy Mini, com preços acessíveis: A Hugging Face, em colaboração com The Robot Studio e Pollen Robotics, lançou dois robôs humanoides open-source: o HopeJR de tamanho completo (aproximadamente US$ 3.000) e o Reachy Mini de mesa (aproximadamente US$ 250-300). Esta iniciativa visa promover a popularização da tecnologia robótica e a pesquisa aberta, permitindo que qualquer pessoa monte, modifique e aprenda os princípios da robótica. O HopeJR tem capacidade de andar e mover os braços, podendo ser controlado remotamente por luvas; o Reachy Mini pode mover a cabeça, falar e ouvir, sendo usado para testar aplicações de IA. (Fonte: WeChat)

Lançado o primeiro framework open-source de autoevolução de agentes de IA, EvoAgentX: Uma equipe de pesquisa da Universidade de Glasgow, no Reino Unido, lançou o EvoAgentX, o primeiro framework open-source do mundo para a autoevolução de agentes de IA. Este framework visa resolver a complexidade da construção e otimização de sistemas multiagentes de IA, introduzindo um mecanismo de autoevolução que suporta a configuração de fluxos de trabalho com um clique e permite que o sistema otimize continuamente sua estrutura e desempenho em resposta a mudanças no ambiente e nos objetivos durante a execução. O EvoAgentX espera impulsionar os sistemas multiagentes da depuração manual para a evolução autônoma, fornecendo uma plataforma unificada de experimentação e implantação para pesquisadores e engenheiros. (Fonte: WeChat)

Perplexity Labs lança nova funcionalidade, permitindo exportar gratuitamente dados financeiros de empresas para CSV: O Perplexity Labs anunciou que os usuários agora podem exportar gratuitamente dados de qualquer seção financeira de empresas em suas páginas financeiras para o formato CSV. Anteriormente, funcionalidades semelhantes em plataformas como o Yahoo Finance geralmente exigiam uma assinatura paga. O Perplexity afirmou que adicionará mais dados históricos no futuro. (Fonte: AravSrinivas)
📚 Aprendizado
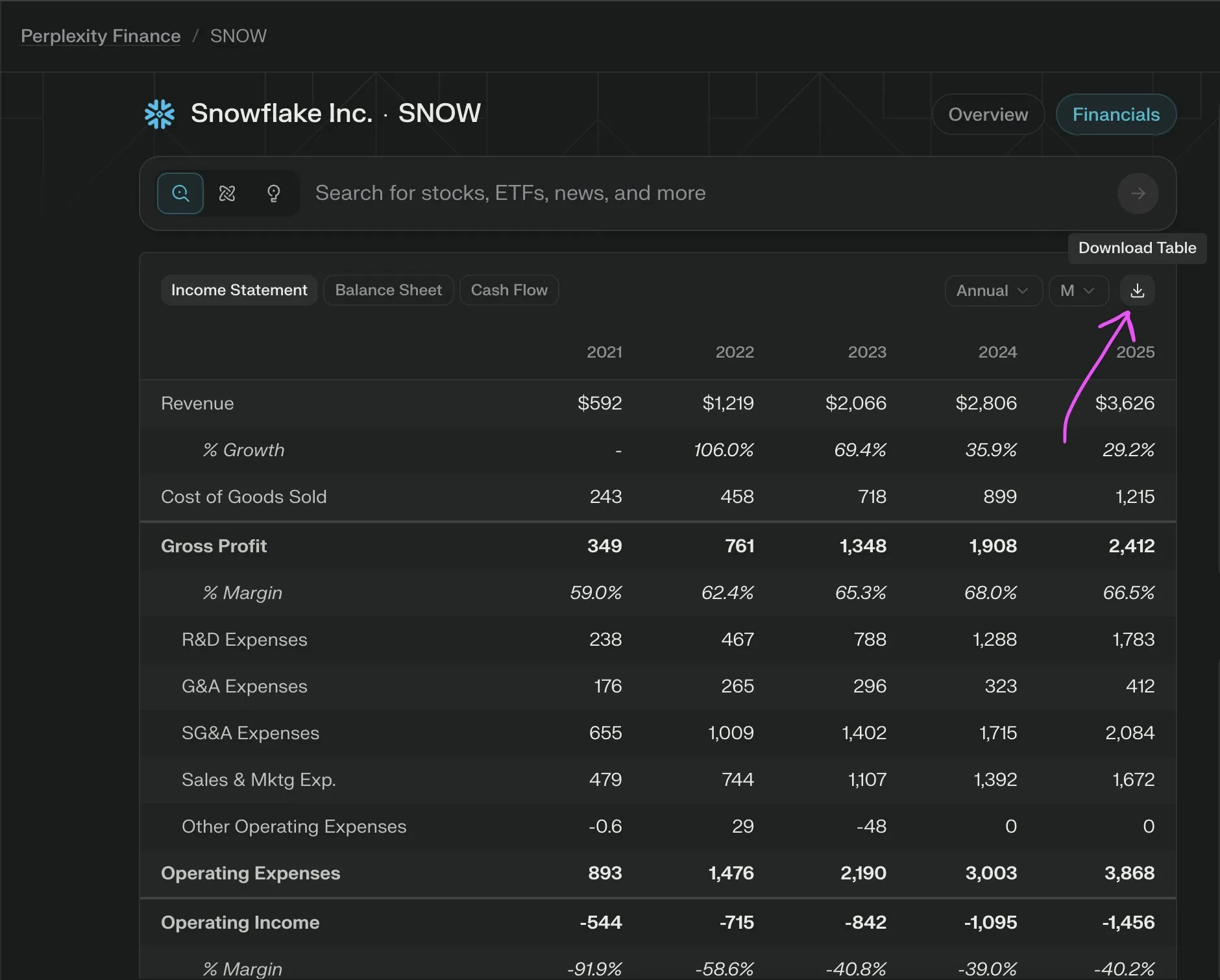
Técnicas de chamada de função em LLMs: definir contexto, sequência e limites claros, evitar CoT e alucinações: _philschmid compartilhou sugestões para realizar chamadas de função em modelos de inferência como Gemini 2.5 ou OpenAI o3. Pontos cruciais incluem: definir um contexto geral (como um prompt de persona), definir uma sequência clara de chamadas de função para tarefas complexas e estabelecer limites claros para o uso de ferramentas (quando usar/não usar). É necessário detalhar quando as chamadas de função devem ocorrer e como os parâmetros devem ser construídos. Evite prompts explícitos de CoT, pois o modelo realizará inferência interna; pode-se utilizar recursos da API para persistir o pensamento entre chamadas de ferramentas ou usar “thinking_tools”. Ao mesmo tempo, implemente instruções negativas claras (como “não prometa chamadas futuras”) para prevenir alucinações de chamadas de função. (Fonte: _philschmid)
Compartilhamento de 12 dicas profissionais de programação com IA: Cline compartilhou 12 dicas de programação com IA de uma recente conferência sobre melhores práticas de engenharia, enfatizando o planejamento, o uso de modelos avançados para tarefas complexas, a atenção à janela de contexto, a criação de arquivos de regras, a clareza de intenção, o tratamento da IA como colaboradora, a utilização de bancos de memória, o aprendizado de estratégias de gerenciamento de contexto e a construção de compartilhamento de conhecimento em equipe. O objetivo principal é construir software de forma mais rápida e melhor, usando a IA como um amplificador de capacidade, e não como um substituto. (Fonte: cline, cline)

Sugestões de otimização de prompts de criação após atualização do DeepSeek-R1-0528: Em resposta à atualização do modelo DeepSeek-R1-0528 (68,5 bilhões de parâmetros, contexto de 128K, capacidade de código próxima ao o3), criadores de conteúdo compartilharam 10 prompts de criação otimizados. As sugestões incluem utilizar sua capacidade de inferência ultralonga de 30-60 minutos para pensamento profundo, processar textos longos de 128K, otimizar a geração de código, personalizar prompts de sistema, melhorar a qualidade de tarefas de escrita, realizar validação anti-alucinação, superar bloqueios criativos na escrita, realizar análises de diagnóstico de problemas, integrar aprendizado de conhecimento e otimizar textos comerciais. Enfatiza-se a especificação dos prompts, o aproveitamento total do longo contexto, o bom uso da inferência profunda, o estabelecimento de memória de diálogo e a verificação de informações importantes. (Fonte: WeChat)
Framework RM-R1: Remodelando modelos de recompensa como tarefas de raciocínio para melhorar interpretabilidade e desempenho: Uma equipe de pesquisa da Universidade de Illinois em Urbana-Champaign propôs o framework RM-R1, que redefine a construção de Modelos de Recompensa (Reward Models) como uma tarefa de raciocínio. Este framework, ao introduzir o mecanismo “Chain-of-Rubrics” (CoR), permite que o modelo gere critérios de avaliação estruturados e processos de raciocínio antes de emitir julgamentos de preferência, melhorando assim a interpretabilidade dos modelos de recompensa e sua precisão na avaliação de tarefas complexas (como matemática e programação). O RM-R1, através de treinamento em duas fases de destilação de raciocínio e aprendizado por reforço, superou modelos open-source e proprietários existentes em vários benchmarks de modelos de recompensa. (Fonte: WeChat)

Análise aprofundada do Protocolo de Contexto de Modelo (MCP): simplificando a integração de IA com serviços externos: O Protocolo de Contexto de Modelo (MCP), como um padrão aberto, visa resolver o problema de fragmentação na integração de modelos de IA com fontes de dados externas e ferramentas (como Slack, Gmail). Através de uma interface de sistema unificada (suportando protocolos STDIO e SSE), o MCP permite que desenvolvedores construam clientes MCP (como o Claude para desktop, Cursor IDE) e servidores MCP (operando bancos de dados, sistemas de arquivos, chamando APIs), simplificando a complexa rede de adaptação “M×N” para um modelo “M+N”, realizando a integração plug-and-play entre IA e serviços externos. Tan Yu, sócio da Fabarta (枫清科技), acredita que o valor do MCP reside em fornecer capacidade de conexão básica, e sua comercialização depende do valor específico fornecido pelos sistemas por trás, por exemplo, simplificando os fluxos de trabalho do usuário através da integração do MCP Server com o superagente de escritório inteligente da Fabarta. (Fonte: WeChat)

ROI Agêntico: Métrica chave para medir a usabilidade de agentes de modelos grandes: A Universidade Jiao Tong de Xangai, em colaboração com a Universidade de Ciência e Tecnologia da China, propôs o ROI Agêntico (Retorno sobre o Investimento de Agentes) como uma métrica central para medir a utilidade prática de agentes de modelos grandes em cenários reais. Esta métrica considera de forma abrangente a qualidade da informação, o custo de tempo do usuário e do agente, e as despesas econômicas. A pesquisa aponta que os agentes atuais são mais aplicados em áreas de alto custo de mão de obra, como pesquisa científica e programação, mas em cenários cotidianos como e-commerce e busca, o ROI Agêntico é baixo devido ao valor marginal insignificante e aos altos custos de interação. Otimizar o ROI Agêntico requer seguir um caminho de desenvolvimento em “zigue-zague”: primeiro, aumentar a qualidade da informação em escala e, depois, reduzir os custos de forma leve. (Fonte: WeChat)
💼 Negócios
Receita anualizada da Anthropic dispara para US$ 3 bilhões, impulsionada pela demanda empresarial por IA: Segundo duas fontes, a receita anualizada da Anthropic cresceu de US$ 1 bilhão para US$ 3 bilhões em apenas cinco meses. Este crescimento significativo é atribuído principalmente à forte demanda empresarial por IA, especialmente na área de geração de código. Isso indica que o mercado empresarial está aumentando rapidamente a aplicação e a disposição para pagar por modelos de IA avançados (como a série Claude da Anthropic). (Fonte: cto_junior, scaling01, Reddit r/ArtificialInteligence)
Resultados financeiros do Q1 do ano fiscal de 2026 da Nvidia: receita total de US$ 44,1 bilhões, negócios de data center contribuem com quase 90%: A Nvidia divulgou seus resultados financeiros para o primeiro trimestre do ano fiscal de 2026, encerrado em 27 de abril de 2025, com receita total de US$ 44,1 bilhões, um aumento de 12% em relação ao trimestre anterior e 69% em relação ao ano anterior. A receita dos negócios de data center foi de US$ 39,1 bilhões, representando 88,91% do total, um aumento de 73% em relação ao ano anterior. A receita do setor de jogos foi de US$ 3,8 bilhões, um recorde histórico. Apesar do chip H20 ser afetado por restrições de exportação, resultando em uma baixa de estoque de US$ 4,5 bilhões e taxas de compromisso de compra, e uma perda de receita estimada em US$ 8 bilhões no Q2 devido a isso, o desempenho geral continua forte. Novos produtos como o Blackwell Ultra devem impulsionar ainda mais o crescimento. (Fonte: 量子位, WeChat)

Meta reorganiza equipe de IA, maioria dos autores principais do Llama deixa a empresa, status do FAIR gera preocupações: A Meta anunciou uma reorganização de sua equipe de IA, dividindo-a em uma equipe de produtos de IA liderada por Connor Hayes e um departamento de fundação AGI coliderado por Ahmad Al-Dahle e Amir Frenkel. O departamento de pesquisa fundamental em IA, FAIR, permanece relativamente independente, mas algumas equipes multimídia foram incorporadas. O ajuste visa aumentar a autonomia e a velocidade de desenvolvimento. No entanto, dos 14 autores principais originais do modelo Llama, apenas 3 permanecem, com a maioria tendo saído ou se juntado a concorrentes (como a Mistral AI). Somado à recepção morna do Llama 4 e aos ajustes internos na alocação de poder computacional e direção de P&D, surgiram preocupações sobre a capacidade da Meta de manter sua liderança no campo da IA de código aberto e sobre o futuro do FAIR. (Fonte: WeChat)

🌟 Comunidade
Discussão sobre alinhamento de IA: Soft norms podem manter o poder humano na era da AGI?: Ryan Greenblatt discute as opiniões de Dwarkesh Patel, que é cético em relação ao alinhamento de IA e, em vez disso, espera que, através de soft norms, os humanos possam reter algum poder e espaço de sobrevivência depois que a AGI (Inteligência Artificial Geral) dominar o hard power. Greenblatt argumenta que, se a IA for scope sensitive (sensível ao escopo) e tiver a capacidade de tomar o poder, tentar revelar seu desalinhamento ou fazê-la trabalhar para os humanos através de transações ou contratos provavelmente não terá sucesso. Além disso, fatores como ajuste fino barato, alinhamento aprimorado por humanos e replicação livre tornam o controle humano sobre a propriedade muito instável antes que o problema do alinhamento seja resolvido. Assim que surgir uma IA alinhada ou mão de obra de IA mais barata, os humanos darão prioridade ao seu uso, o que incentivará fortemente a IA não alinhada a tomar o poder. (Fonte: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Criador do Redis considera programação com IA muito inferior a programadores humanos, gerando ressonância e discussão entre desenvolvedores: Salvatore Sanfilippo (Antirez), criador do Redis, compartilhou sua experiência de desenvolvimento, argumentando que a IA atual, embora útil na programação, está longe de ser comparável a programadores humanos, especialmente em quebrar convenções e conceber soluções engenhosas e eficazes. Ele compara a IA a um “subordinado suficientemente inteligente”, útil para validar ideias. Essa visão gerou debate entre desenvolvedores, muitos concordando que a IA pode servir como um “pato de borracha” para auxiliar o pensamento, mas apontando que a IA é excessivamente confiante e pode facilmente enganar desenvolvedores juniores. Alguns desenvolvedores afirmaram que respostas erradas geradas pela IA os motivaram a codificar manualmente. A discussão enfatizou a importância da experiência no uso eficaz da IA e o possível impacto negativo da IA em programadores iniciantes. (Fonte: WeChat)

Relação entre DeepMind e Google Research volta a ser debatida: a disputa entre marca e contribuição real para inovação: Faruk Guney publicou um longo tweet comentando a relação entre DeepMind e Google Research, argumentando que os avanços centrais da atual revolução da IA (como a arquitetura Transformer) originaram-se principalmente do Google Research, e não da DeepMind após sua aquisição pelo Google. Ele aponta que, embora o AlphaFold seja uma conquista da DeepMind, também dependeu dos recursos computacionais e da infraestrutura de pesquisa do Google, e que os principais contribuidores foram cientistas e engenheiros como John Jumper e Pushmeet Kohli. Guney acredita que a posterior incorporação do Google Research pela DeepMind foi mais uma questão de marca e reestruturação organizacional, envolvendo complexas políticas corporativas que podem ter ocultado a verdadeira origem da inovação. Ele enfatiza que muitos avanços em IA são o resultado de anos de pesquisa em equipe, e não devem ser atribuídos apenas a algumas figuras ou marcas proeminentes. (Fonte: farguney, farguney)
Transformação de empregos e habilidades na era da IA gera preocupação e discussão: Nas redes sociais, a discussão sobre o impacto da IA no mercado de trabalho continua. Por um lado, há quem acredite que a IA levará ao desemprego em massa, como o CEO da Anthropic já expressou, levando as pessoas a pensar em como lidar com isso. Por outro lado, há vozes que apontam que a IA principalmente aumenta a produtividade e é improvável que cause desemprego em massa, a menos que ocorra uma grave recessão econômica, pois a demanda do consumidor depende do emprego e da renda. Ao mesmo tempo, usuários compartilharam experiências pessoais de perda de emprego devido à IA (como chefes usando o ChatGPT para substituir funcionários). Para o futuro, a discussão aponta para a necessidade de poupar, aprender habilidades práticas, adaptar-se à possibilidade de redução de renda e como o sistema educacional deve se ajustar para cultivar as habilidades necessárias na era da IA, como pensamento crítico e a capacidade de usar efetivamente ferramentas de IA. (Fonte: Reddit r/ArtificialInteligence, Reddit r/artificial)

Dependência excessiva do ChatGPT levanta preocupações sobre declínio da capacidade de raciocínio: Um usuário do Reddit postou expressando preocupação de que sua namorada depende excessivamente do ChatGPT para tomar decisões, obter opiniões e ideias criativas, acreditando que isso pode levar à perda de sua capacidade de pensamento independente e originalidade. O post gerou ampla discussão, com alguns comentaristas concordando com essa preocupação, argumentando que a dependência excessiva de ferramentas de IA pode de fato enfraquecer o pensamento individual; outros comentários argumentaram que a IA é apenas uma ferramenta, como enciclopédias ou motores de busca do passado, e o crucial é como o usuário a utiliza, seja como ponto de partida para o pensamento ou como substituto completo. Alguns comentários também sugeriram lidar com a situação através da comunicação, orientação e demonstração das limitações da IA. (Fonte: Reddit r/ChatGPT)
Desafios da IA na educação: Professor lamenta abuso de ChatGPT por alunos e pede cultivo da real capacidade de pensar: Um professor de história antiga postou no Reddit afirmando que o abuso do ChatGPT afetou gravemente seu ensino, com alunos entregando trabalhos repletos de “lixo vazio” gerado por IA, contendo inclusive erros factuais, o que o fez duvidar se os alunos estavam realmente aprendendo. Ele enfatizou que o cerne da educação em humanidades é cultivar novos conhecimentos, insights criativos e pensamento independente, e não simplesmente repetir informações existentes. O post gerou debate acalorado, com comentaristas propondo várias estratégias de enfrentamento, como mudar para apresentações orais, redações manuscritas em sala de aula, exigir que os alunos enviem uma meta-análise do processo de uso da IA, ou integrar a IA ao ensino, fazendo com que os alunos critiquem os resultados da IA. (Fonte: Reddit r/ChatGPT)
Kernel gerado por IA supera inesperadamente kernel especialista do PyTorch, equipe chinesa de Stanford revela novas possibilidades: A equipe de Anne Ouyang, Azalia Mirhoseini e Percy Liang da Universidade de Stanford, ao tentar gerar dados sintéticos para treinar um modelo de geração de kernel, descobriu inesperadamente que seu kernel gerado por IA, escrito puramente em CUDA-C, se aproximou ou até superou em desempenho o kernel FP32 integrado e otimizado por especialistas do PyTorch. Por exemplo, na multiplicação de matrizes, atingiu 101,3% do desempenho do PyTorch, e na convolução bidimensional, 179,9%. A equipe adotou otimização iterativa em múltiplas rodadas, combinando ideias de otimização de inferência em linguagem natural e estratégias de busca com expansão de ramos, utilizando os modelos OpenAI o3 e Gemini 2.5 Pro. Este resultado indica que, através de busca inteligente e exploração paralela, a IA tem potencial para alcançar avanços na geração de kernels de computação de alto desempenho. (Fonte: WeChat)

💡 Outros
Poderoso lobby da indústria de IA chama a atenção de Max Tegmark: O professor do MIT, Max Tegmark, destacou que o número de lobistas da indústria de IA em Washington e Bruxelas já ultrapassou o total combinado das indústrias de combustíveis fósseis e tabaco. Este fenômeno revela a crescente influência da indústria de IA na formulação de políticas e seu investimento ativo na modelagem do ambiente regulatório, o que pode ter um impacto profundo na direção do desenvolvimento da tecnologia de IA, nas normas éticas e no cenário da concorrência de mercado. (Fonte: Reddit r/artificial)

IA pode simular ataques bioterroristas através de deepfakes, constituindo nova ameaça à saúde pública: Um artigo da STAT News aponta que, além do risco de armas biológicas auxiliadas por IA, a utilização de tecnologia deepfake para simular ataques bioterroristas também pode representar uma ameaça grave. Especialmente entre países em conflito militar, esse tipo de informação falsificada pode desencadear pânico, erros de julgamento e escaladas militares desnecessárias. Como as investigações podem ser conduzidas por agências de aplicação da lei ou militares, em vez de equipes de saúde pública ou técnicas, elas podem estar mais inclinadas a acreditar na veracidade do ataque, dificultando a sua refutação eficaz. (Fonte: Reddit r/ArtificialInteligence)
Debate sobre se ainda vale a pena cursar engenharia na era da IA: A comunidade discute o valor de cursar engenharia na era da IA. Uma corrente argumenta que a IA pode substituir muitas tarefas tradicionais de engenharia, diminuindo o valor do diploma. Outra corrente sustenta que o pensamento sistêmico, a capacidade de resolução de problemas e a base em matemática e física cultivados por um diploma de engenharia continuam importantes, especialmente para entender e aplicar ferramentas de IA. Alguns apontam que, se a IA puder substituir engenheiros, outras profissões também dificilmente escaparão, sendo crucial o aprendizado contínuo e a adaptação. Áreas com forte componente prático e difíceis de automatizar, como veterinária, são consideradas escolhas relativamente seguras. (Fonte: Reddit r/ArtificialInteligence)