
Palavras-chave:DeepSeek R1-0528, Máquina de Gödel Darwiniana, Consumo de energia de IA, Aprendizagem por reforço com recompensa falsa, Ascend da Huawei, Ranking SuperCLUE, Teste de referência multimodal, Melhoria de desempenho do DeepSeek R1-0528, Mecanismo de auto-evolução DGM, Solução de energia nuclear para data centers de IA, Mecanismo RLVR do modelo Qwen, Otimização de treinamento do Pangu Ultra MoE
🔥 Foco
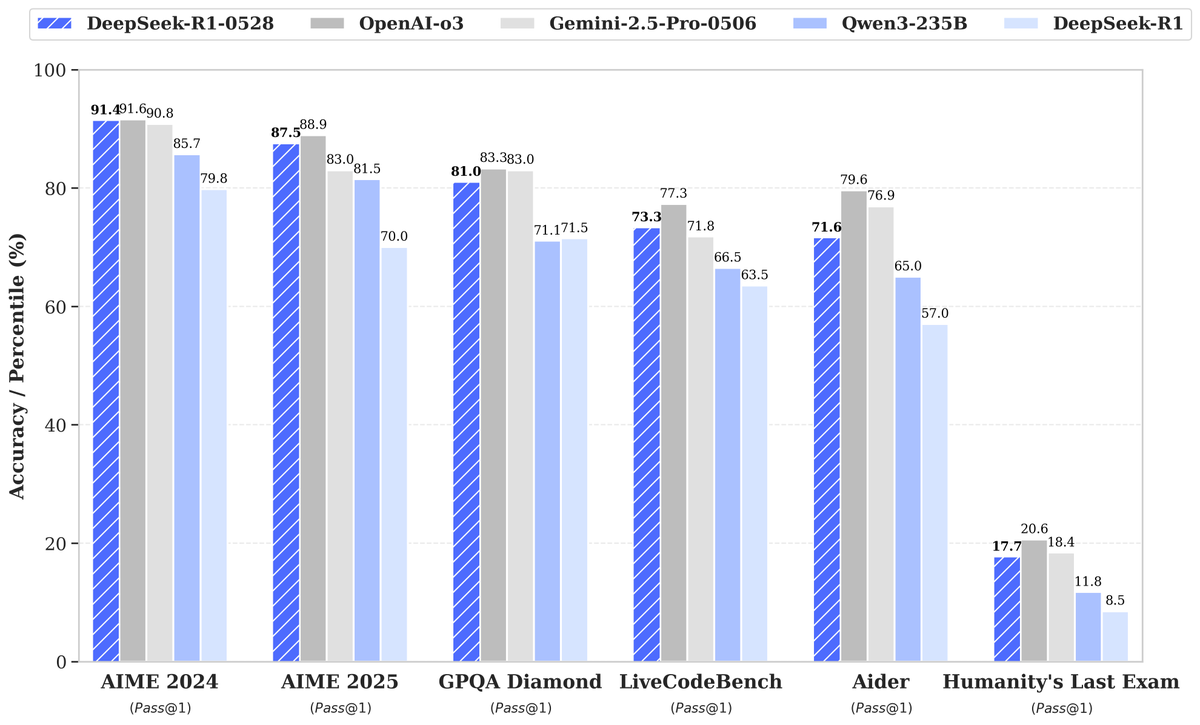
DeepSeek lança novo modelo R1-0528, com grande aumento de desempenho que atrai atenção: A DeepSeek lançou uma nova versão do seu grande modelo de linguagem, R1-0528, que apresentou excelente desempenho em diversos benchmarks, especialmente em áreas como geração de código (LiveCodeBench), raciocínio científico (GPQA Diamond) e competições de matemática (AIME 2024), obtendo progressos significativos. A Artificial Analysis destacou que o R1-0528 saltou de 60 para 68 pontos em seu índice de inteligência, igualando-se ao Gemini 2.5 Pro do Google, tornando-se o segundo maior laboratório de IA do mundo e consolidando sua liderança na área de modelos de pesos abertos. A reação da comunidade foi positiva, com a Unsloth lançando rapidamente versões quantizadas GGUF para facilitar a implantação local. Esta atualização foi alcançada principalmente através de técnicas de pós-treinamento, como aprendizado por reforço (RL), mostrando o potencial de continuar aprimorando a inteligência do modelo com base na arquitetura e pré-treinamento existentes, embora haja discussões de que seus resultados às vezes têm um estilo “bajulador”, mas, no geral, é considerado um grande salto nas capacidades de raciocínio e código. (Fonte: DeepSeek, Artificial Analysis, tokenbender, karminski3, teortaxesTex)
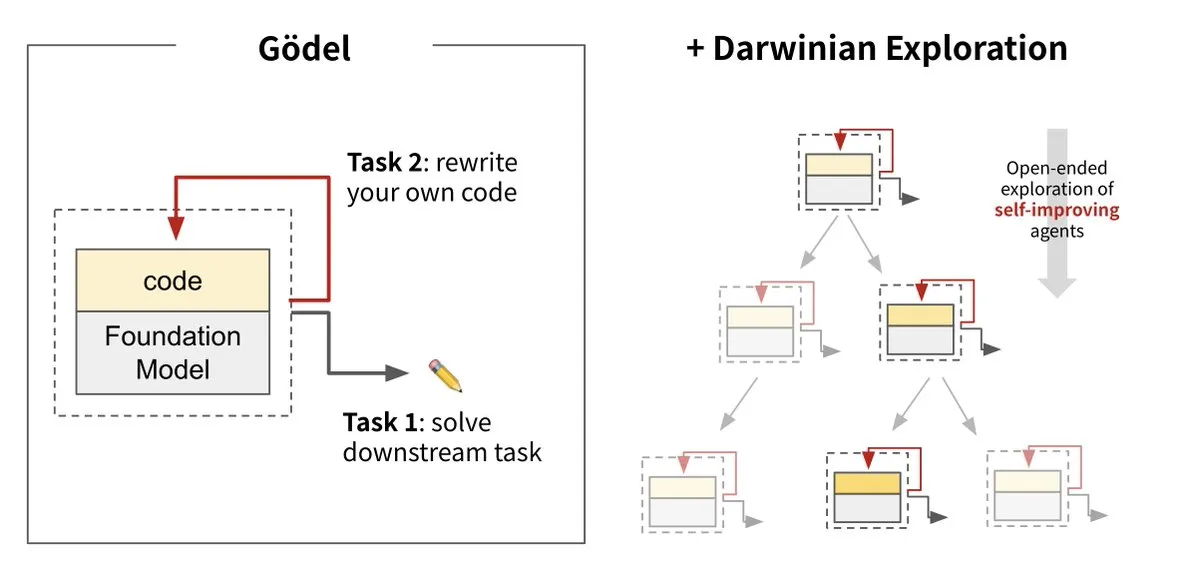
Sakana AI lança a Máquina de Darwin-Gödel (DGM), realizando a autoevolução da IA: A Sakana AI, em colaboração com a UBC, lançou a Máquina de Darwin-Gödel (Darwin Gödel Machine, DGM), um agente de IA capaz de se autoaperfeiçoar continuamente reescrevendo seu próprio código. O sistema, inspirado na teoria da evolução, combina grandes modelos de base e bibliotecas de código, permitindo que o agente proponha melhorias de código e se autoavalie. Experimentos mostraram que o desempenho do DGM no SWE-bench aumentou de 20% para 50%, e a taxa de sucesso no Polyglot aumentou de 14,2% para 30,7%, superando significativamente os agentes projetados manualmente. Esta pesquisa é considerada um passo importante em direção a uma IA capaz de aprendizado e inovação autônomos, visando resolver o problema da inteligência fixa dos sistemas de IA após a implantação, e enfatiza a alta importância da segurança durante o processo de desenvolvimento. (Fonte: Sakana AI, hardmaru, ITmedia AI+)
Consumo de energia da IA gera preocupação, com energia nuclear e combustíveis fósseis como potenciais fontes de energia: A série de reportagens “Power Hungry” da MIT Technology Review explora em profundidade a demanda de energia prevista para a inteligência artificial (IA). Os data centers de IA exigem um fornecimento de energia contínuo e estável, especialmente para cenários de inferência de modelos. Embora a energia solar e eólica sejam fontes de energia limpa, sua intermitência dificulta o atendimento isolado da demanda da IA, a menos que acompanhadas por caras soluções de armazenamento de energia. A energia nuclear é vista como uma solução potencial devido à sua capacidade de fornecer eletricidade contínua, mas a construção de novas usinas nucleares é demorada e complexa. Portanto, combustíveis fósseis como o gás natural podem se tornar uma dependência de curto prazo para atender ao rápido crescimento da demanda de energia da IA, o que pode representar um desafio para as metas climáticas. A reportagem enfatiza que as grandes empresas de tecnologia devem promover soluções de energia mais limpas, como tecnologias de captura de carbono ou otimização da eficiência do uso de energia, para enfrentar o duplo desafio energético e climático trazido pelo desenvolvimento da IA. (Fonte: MIT Technology Review, The Download)

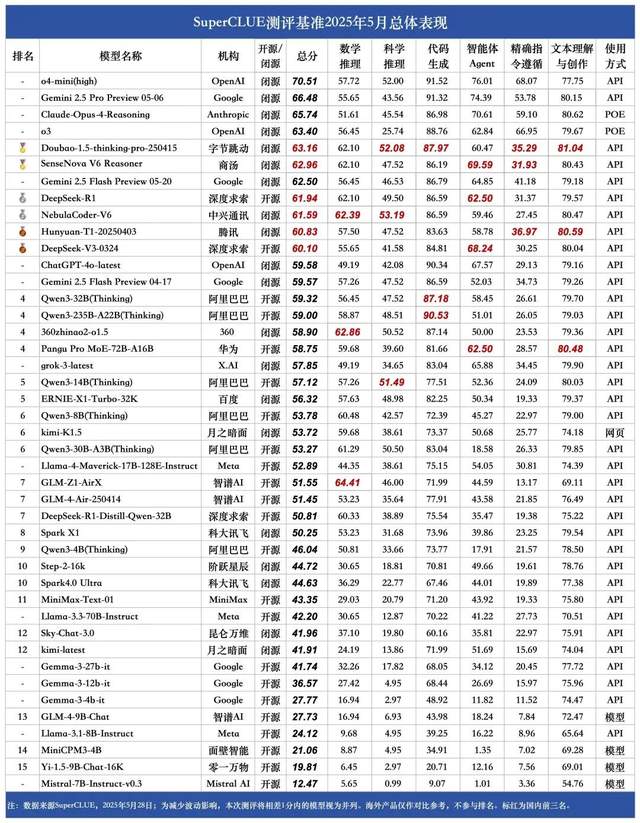
Estudo revela que recompensas falsas também podem melhorar o desempenho do modelo Qwen, levando a um repensar do mecanismo RLVR: Uma equipe de pesquisa da Universidade de Washington descobriu que, mesmo usando sinais de recompensa aleatórios ou incorretos, o treinamento do modelo Qwen2.5-Math através do aprendizado por reforço com recompensa verificável (RLVR) ainda pode aumentar significativamente seu desempenho em benchmarks de raciocínio matemático como o MATH-500 em cerca de 25%, aproximando-se do efeito de otimização de recompensas reais. O estudo aponta que esse fenômeno se deve principalmente a estratégias específicas de raciocínio de código aprendidas pelo modelo Qwen durante o pré-treinamento (como gerar código Python para auxiliar o pensamento), e o processo RLVR (especialmente ao usar o algoritmo GRPO) aumenta a frequência desse comportamento benéfico, e não a correção do sinal de recompensa em si. Esta descoberta não se aplica a outros modelos que não possuem tais características de pré-treinamento (como o OLMo2-7B), que apresentam pouco ou nenhum ganho de desempenho, ou até mesmo uma queda, sob recompensas falsas. O estudo desafia a percepção tradicional de que o RLVR depende de sinais de recompensa corretos e alerta os pesquisadores para a necessidade de estarem cientes do impacto de comportamentos específicos do modelo nos resultados da avaliação, enfatizando a importância da validação cruzada entre modelos. (Fonte: 量子位, Stella Li)
🎯 Tendências
Huawei Ascend capacita treinamento eficiente do modelo Pangu Ultra MoE de quase um trilhão de parâmetros, alcançando autonomia e controle em todo o processo: A Huawei divulgou um relatório técnico detalhando sua prática de treinamento eficiente de ponta a ponta do modelo Pangu Ultra MoE (718 bilhões de parâmetros) baseado no hardware Ascend AI e no framework MindSpore. Através de tecnologias como seleção inteligente de estratégia paralela, fusão profunda de computação e comunicação, e balanceamento de carga dinâmico global, alcançou 41% de MFU (Model Flops Utilization) no cluster de dez mil placas Ascend Atlas 800T A2. Na fase de pós-treinamento RL, combinando a tecnologia RL Fusion de treinamento e inferência no mesmo cartão e o mecanismo quasi-assíncrono StaleSync, alcançou um alto throughput de 35K Tokens/s por supernó no cluster de 384 supernós Ascend CloudMatrix, equivalente a processar um problema de matemática avançada a cada 2 segundos. Isso marca a maturidade do ciclo fechado de poder computacional de IA nacional e treinamento de grandes modelos, e demonstra desempenho líder da indústria no treinamento de modelos MoE de ultra-grande escala. (Fonte: 量子位)

Lista de maio do SuperCLUE para grandes modelos chineses: Doubao 1.5 e SenseTime SenseNova V6 empatados em primeiro lugar nacionalmente: A SuperCLUE, uma renomada instituição de avaliação de grandes modelos, divulgou o “Relatório de Avaliação de Benchmark de Grandes Modelos Chineses” de maio de 2025. O relatório mostra que o modelo Doubao-1.5-thinking-pro da ByteDance e o modelo multimodal SenseNova-V6 Reasoner da SenseTime estão empatados em primeiro lugar nacionalmente, com seu desempenho em capacidades gerais em chinês já superando o Gemini 2.5 Flash Preview. Modelos como DeepSeek-R1, NebulaCoder-V6, Hunyuan-T1 e DeepSeek-V3 seguem de perto, posicionando-se no segundo escalão. O relatório enfatiza que a lacuna nas capacidades gerais no domínio chinês entre os principais grandes modelos nacionais e internacionais está diminuindo, e o cenário competitivo dos modelos de inferência nacionais está começando a se formar. Esta avaliação abrangeu seis tarefas principais: raciocínio matemático, raciocínio científico, geração de código, agente inteligente (Agent), seguimento preciso de instruções e compreensão e criação de texto. (Fonte: 量子位)
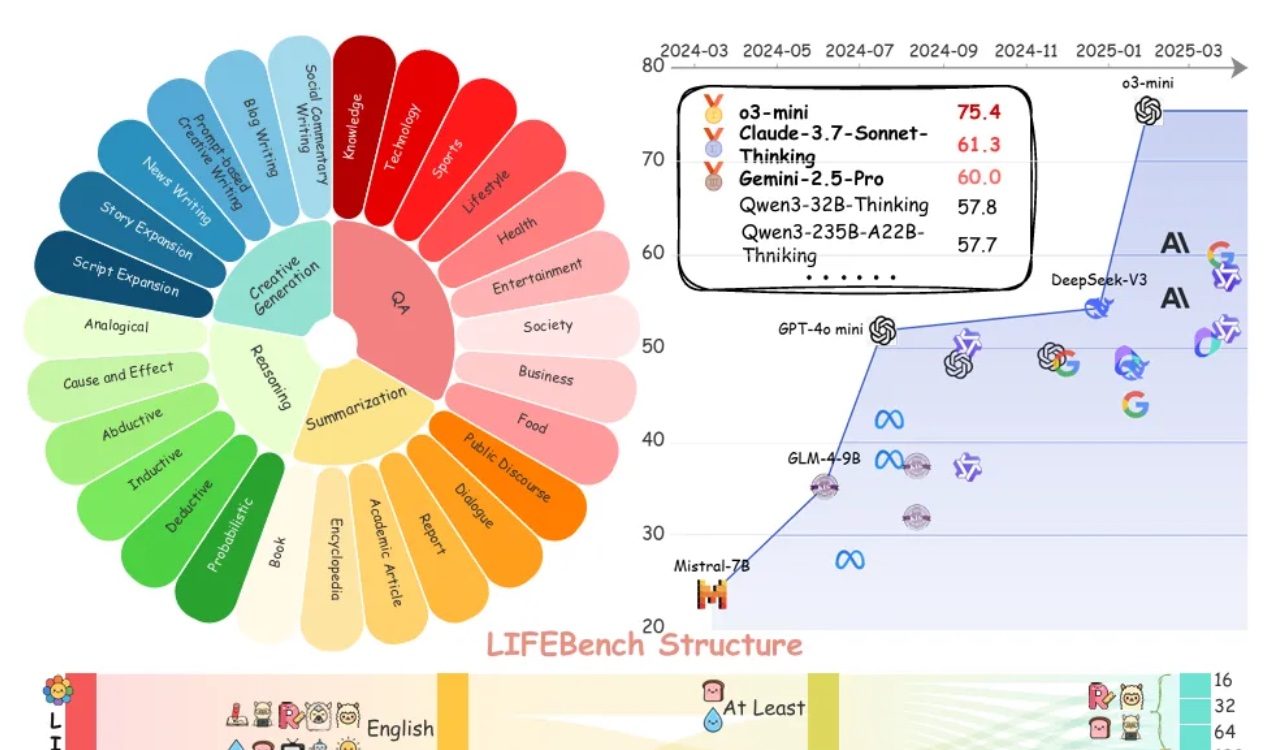
Avaliação LIFEBench revela que grandes modelos geralmente têm deficiências em seguir instruções de comprimento: Um novo benchmark chamado LIFEBench indica que os atuais grandes modelos de linguagem (LLMs) principais têm um desempenho ruim em seguir instruções específicas de comprimento de texto, especialmente na geração de textos longos. O estudo testou 26 modelos e descobriu que a maioria dos modelos obteve pontuações baixas quando solicitados a gerar texto de um comprimento preciso, com apenas alguns modelos como o3-mini, Claude-Sonnet-Thinking e Gemini-2.5-Pro apresentando desempenho razoável. A geração de texto longo (>2000 palavras) é uma deficiência generalizada, com todos os modelos apresentando uma queda significativa na pontuação. Além disso, os modelos geralmente tiveram um desempenho pior em tarefas em chinês em comparação com o inglês, e tenderam a “supergerar”. O estudo também apontou que o comprimento máximo de saída alegado por muitos modelos não corresponde à sua capacidade real, existindo um fenômeno de “propaganda excessiva”. Os modelos apresentam gargalos na percepção de comprimento, no processamento de entradas longas e em evitar a “geração preguiçosa” (como terminação prematura ou recusa em gerar). (Fonte: 量子位)
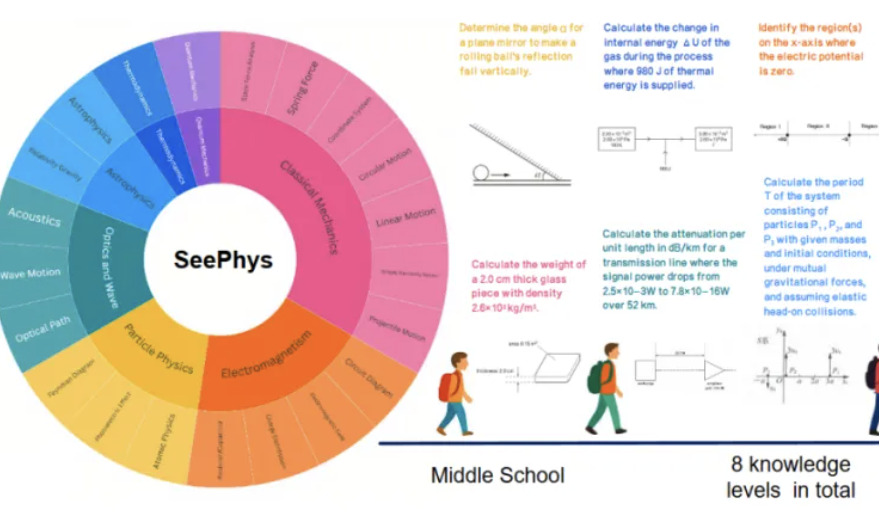
Novo benchmark SeePhys revela deficiências de grandes modelos multimodais na compreensão de imagens físicas: Instituições como a Universidade Sun Yat-sen lançaram conjuntamente o benchmark SeePhys, projetado especificamente para avaliar a capacidade de grandes modelos multimodais (MLLM) de compreender e raciocinar sobre imagens relacionadas à física. O benchmark contém 2000 questões e 2245 diagramas que vão do nível fundamental ao doutorado, cobrindo física clássica e moderna. Os resultados dos testes mostram que mesmo modelos de ponta como Gemini-2.5-Pro e o4-mini têm uma precisão inferior a 55% no SeePhys, especialmente ao processar tipos específicos de diagramas, como diagramas de circuito e gráficos de equações de onda, onde existem obstáculos de reconhecimento sistemático. A pesquisa também descobriu que modelos puramente linguísticos, em alguns casos, apresentam desempenho próximo aos modelos multimodais, expondo as deficiências atuais dos MLLMs no alinhamento visual-textual. O benchmark enfatiza a importância da percepção gráfica para a compreensão do mundo físico pelos modelos e revela os enormes desafios atuais da IA em tarefas que acoplam diagramas científicos complexos com derivações teóricas. (Fonte: 量子位)
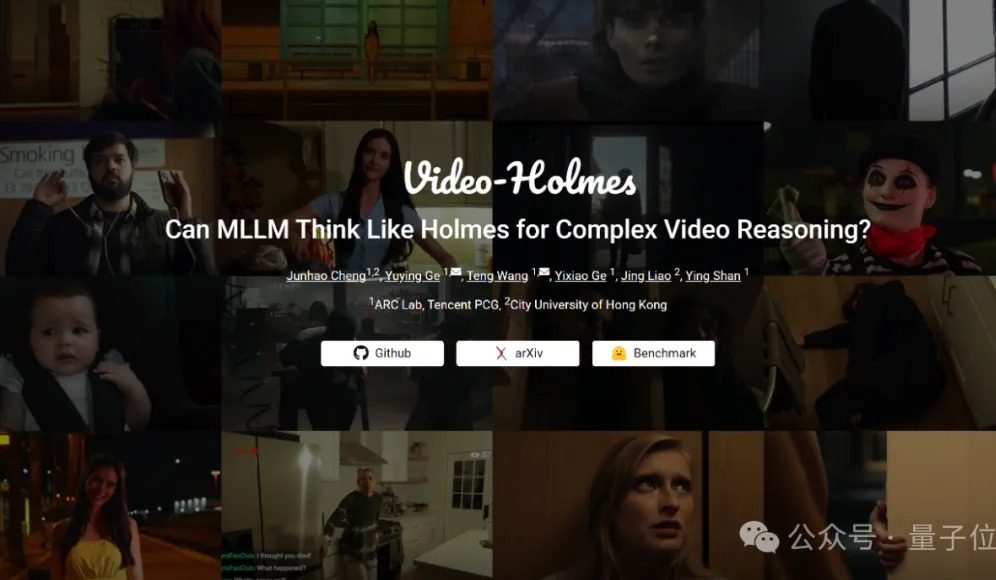
Benchmark Video-Holmes: modelos atuais de grande porte falham na capacidade de raciocínio complexo em vídeo: O Tencent ARC Lab e a Universidade da Cidade de Hong Kong lançaram o benchmark Video-Holmes, com o objetivo de avaliar a capacidade de raciocínio complexo em vídeo de grandes modelos multimodais (MLLM). O benchmark inclui 270 “curtas-metragens de mistério” e elaborou 7 tipos de questões de múltipla escolha que exigem alto nível de raciocínio, como “deduzir o assassino” e “analisar a intenção do crime”, exigindo que o modelo extraia e conecte informações cruciais dispersas no vídeo. Os resultados dos testes mostraram que todos os grandes modelos testados, incluindo o Gemini-2.5-Pro, não atingiram a nota mínima (a precisão do Gemini-2.5-Pro foi de aproximadamente 45%). O estudo aponta que os modelos existentes conseguem perceber informações visuais, mas apresentam deficiências generalizadas na associação de múltiplas pistas e na captura de informações cruciais, dificultando a simulação do complexo processo de raciocínio humano de busca ativa, integração e análise. (Fonte: 量子位)
Meta acredita que a integração perfeita de serviços de IA é crucial, utilizando o efeito de rede social para aumentar o engajamento do usuário: A Meta enfatiza que, embora seu modelo Llama não esteja no topo dos rankings, a empresa possui uma enorme vantagem na corrida da IA devido ao seu vasto ecossistema de mídia social (3,43 bilhões de usuários ativos diários). A Meta pode fornecer aos usuários ferramentas de IA perfeitamente integradas, algo que plataformas de IA independentes como o ChatGPT dificilmente conseguem igualar. A empresa já aumentou o retorno dos anunciantes (preço por anúncio aumentou 10% ano a ano) com ferramentas de IA atraentes e está monetizando rapidamente seus investimentos em IA. O número de usuários da plataforma Meta AI deve ultrapassar 1 bilhão até o final do ano. No entanto, os altos gastos de capital (estimados em US$ 64-72 bilhões em 2025) e as perdas contínuas da Reality Labs (perda anual superior a US$ 15 bilhões) são obstáculos ao seu desenvolvimento, e o fluxo de caixa livre já diminuiu por causa disso. Apesar disso, com uma avaliação moderada e potencial de comercialização de curto prazo, as ações da Meta ainda são vistas com otimismo. (Fonte: 36氪)

CEO do Google, Pichai: IA está passando por nova fase de transformação de plataforma, que remodelará o ecossistema da internet: Sundar Pichai, CEO do Google, afirmou após a conferência I/O que a IA está passando por uma transformação de plataforma semelhante ao surgimento dos dispositivos móveis, com a particularidade de que a própria plataforma pode se autocriar e melhorar, liberando criatividade com efeito multiplicador. O Google está integrando amplamente os resultados de suas pesquisas em IA em toda a sua linha de produtos, incluindo Busca, YouTube e serviços em nuvem. A nova função de busca com IA já foi disponibilizada para usuários nos EUA, capaz de gerar páginas de resultados personalizadas em tempo real, contendo gráficos interativos e módulos de aplicativos customizados, o que sinaliza que a busca transcenderá os tradicionais links da web. Pichai acredita que, embora isso possa mudar o ecossistema da internet (a IA trata a web como um banco de dados estruturado), o volume de tráfego que o Google direciona para a web continua batendo recordes. Ele prevê uma rápida explosão da IA em aplicações empresariais (como IDEs de codificação, criação de vídeo, direito, medicina) e considera que novas formas de hardware, como óculos de AR impulsionados por IA, estão repletas de oportunidades. (Fonte: 36氪)

Aplicativos de IA como Zhipu Qingyan e Kimi são acusados de coletar informações pessoais irregularmente, gerando preocupações com a privacidade: Recentemente, um comunicado oficial apontou que o “Zhipu Qingyan” da Zhipu AI tem o problema de “coleta real de informações pessoais que excede o escopo da autorização do usuário”, enquanto o “Kimi” da Moonshot AI “coleta informações pessoais com uma frequência que não tem relação direta com as funções de negócios”. Esses dois aplicativos de IA proeminentes foram nomeados, gerando ampla preocupação pública sobre os riscos de vazamento de privacidade em produtos de IA generativa. A inteligência da IA generativa depende de suas características orientadas a dados, o que a coloca diante do dilema de equilibrar o aprimoramento do desempenho do modelo e a proteção da privacidade do usuário. O pré-treinamento em grande escala de dados é uma condição necessária para o desenvolvimento tecnológico, mas qualquer coleta e uso indevido de informações pessoais prejudicará gravemente a confiança do usuário e a reputação da indústria. Este incidente expôs problemas potenciais no tratamento de dados por parte de algumas empresas de IA, bem como as deficiências das estruturas de proteção de dados existentes em lidar com os desafios da tecnologia de IA. (Fonte: 36氪)

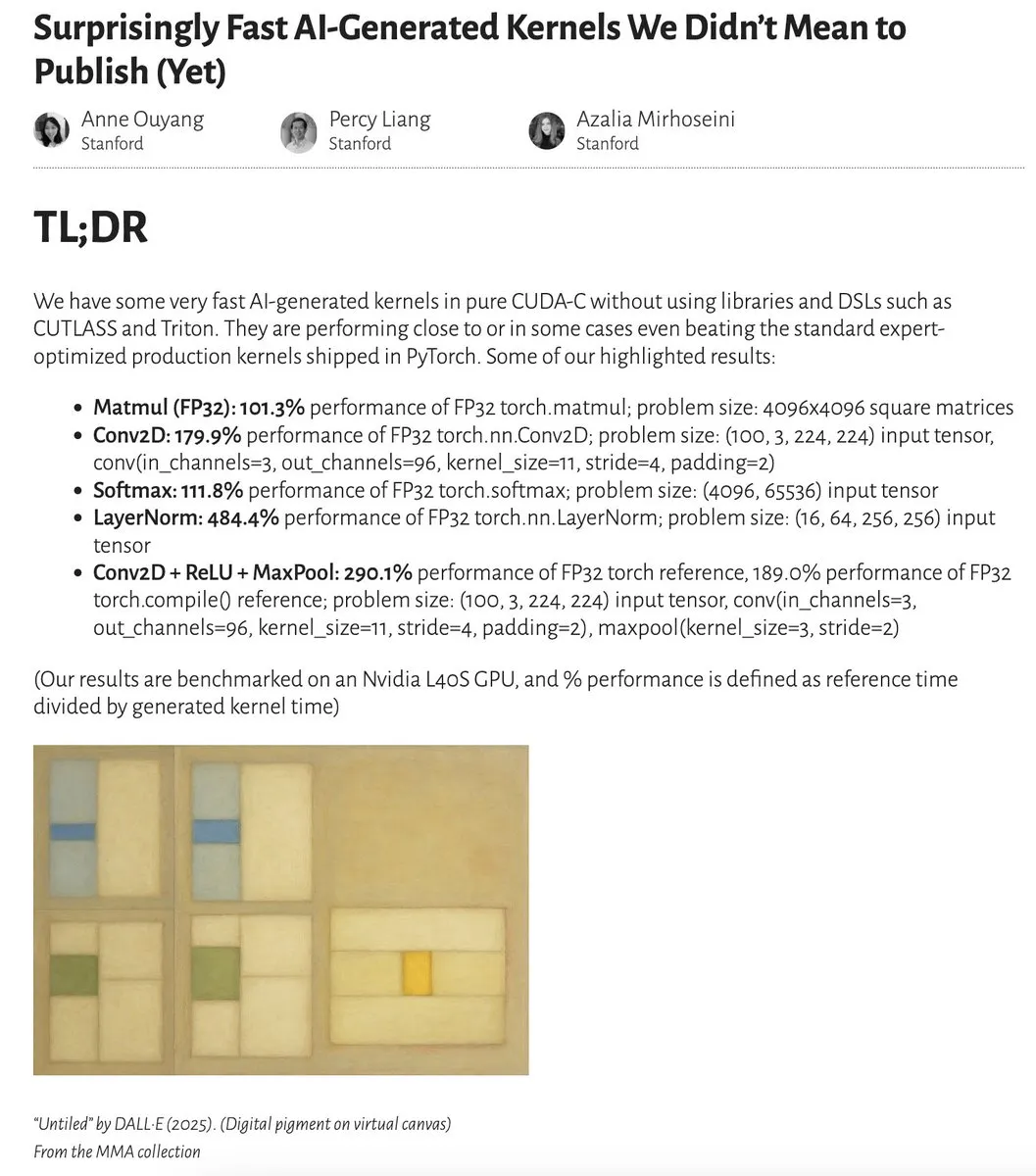
Desempenho de kernels gerados por IA se aproxima ou até supera kernels otimizados por especialistas: Anne Ouyang e colaboradores publicaram uma pesquisa mostrando que kernels de IA gerados por meio de uma simples busca em tempo de teste se aproximam em desempenho, e em alguns casos superam, os kernels de produção padrão e otimizados por especialistas no PyTorch. Fleetwood realizou uma reprodução preliminar do kernel LayerNorm no Colab, confirmando seu impressionante aumento de desempenho (cerca de 484,4%). Este avanço indica o enorme potencial da IA na otimização de código de baixo nível, podendo até impactar o trabalho dos engenheiros de kernel. No entanto, atualizações posteriores apontaram que o kernel LayerNorm gerado apresenta problemas de instabilidade numérica, alertando os usuários para usá-lo com cautela. (Fonte: eliebakouch, fleetwood___)
Discussão: Grandes modelos de linguagem podem ter criatividade genuína?: MoritzW42 publicou um artigo discutindo a questão da criatividade dos grandes modelos de linguagem (LLM), argumentando que os LLMs, por sua natureza, não podem possuir criatividade genuína. Ele cita a definição de criatividade do físico David Deutsch – a capacidade de criar novo conhecimento através de conjecturas e críticas – e argumenta que isso é análogo à variação e seleção no processo evolutivo. Os LLMs dependem de probabilidades indutivas e padrões nos dados de treinamento, e não podem fazer conjecturas criativas ou resolver novos problemas, como gerar instâncias de “cisnes negros” não vistas nos dados de treinamento (por exemplo, um copo de vinho cheio até a borda). O artigo argumenta que os LLMs são mais ferramentas para aumentar a criatividade humana do que entidades com criatividade autônoma, e, portanto, o medo em relação a eles é irracional. (Fonte: MoritzW42)
Discussão: A construção de agentes de IA deve evitar o aprisionamento tecnológico (vendor lock-in) e focar no modelo em si: O ponto de vista de Austin Vance (encaminhado por rachel_l_woods) aponta que um grande erro na construção de agentes de IA é cair no aprisionamento tecnológico. Empresas como OpenAI, Anthropic e Google tendem a promover suas APIs integradas, mas isso gera enormes custos de transição sem agregar valor adicional. Ele enfatiza que o que impulsiona o desempenho é o modelo em si, não a API. Como a posição dos modelos nos rankings muda frequentemente, usar frameworks de código aberto e agnósticos ao modelo (como LangChain) e ferramentas (como LangSmith) garante que as empresas possam escolher o melhor modelo do momento, em vez de ficarem limitadas às opções oferecidas por laboratórios específicos de modelos de base. (Fonte: rachel_l_woods)
Discussão: Funcionalidade de resumo por IA apresenta risco de injeção de prompt: Zack Witten descobriu e demonstrou que é possível realizar injeção de prompt (prompt injection) na funcionalidade de resumo por IA (AI overview), o que significa que entradas especialmente elaboradas podem manipular a IA para gerar informações resumidas não intencionais ou enganosas. Usuários como Charles IRL encaminharam e chamaram a atenção para essa vulnerabilidade de segurança, alertando para a necessidade de se atentar à robustez e segurança ao aplicar amplamente tais funcionalidades de IA. (Fonte: charles_irl, giffmana)
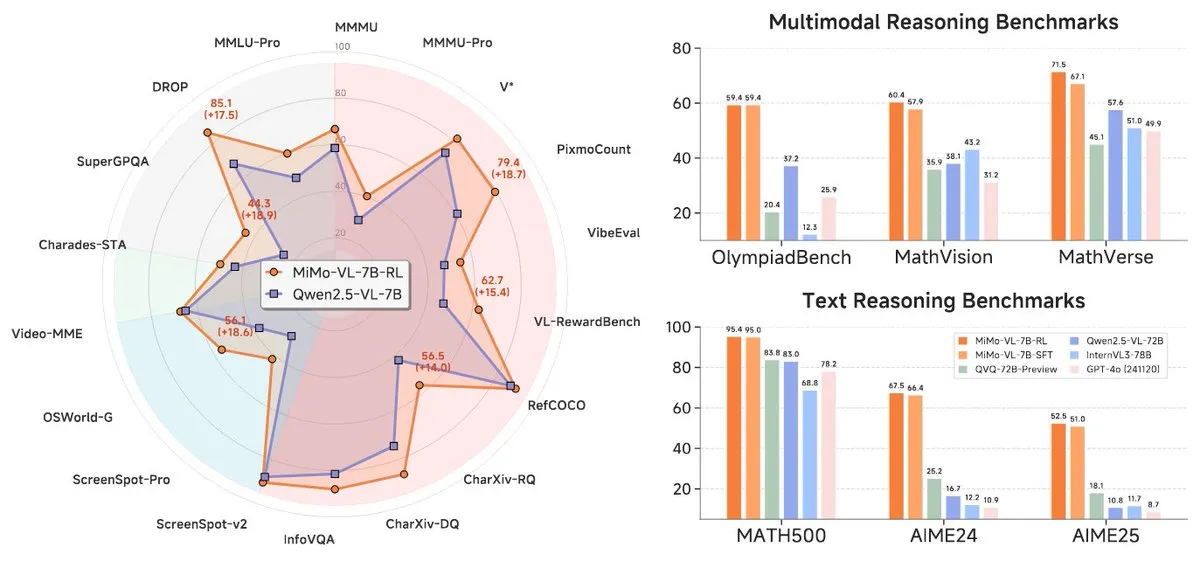
Xiaomi lança nova série de modelos MiMo-7B, com destaque no nível 7B: A Xiaomi lançou seus modelos de inferência 7B atualizados, MiMo-7B-RL-0530, e sua versão de modelo de linguagem visual, MiMo-VL-7B-RL, alegando atingir o nível SOTA (State-of-the-Art) para sua escala de parâmetros. Esses modelos são compatíveis com a arquitetura Qwen-VL, podem ser executados em frameworks como vLLM, Transformers, SGLang e Llama.cpp, e são de código aberto sob a licença MIT. A versão MiMo-VL-RL mostrou melhorias significativas em vários benchmarks de texto em comparação com o MiMo-7B-RL puramente textual, ao mesmo tempo em que adicionou capacidades visuais, gerando discussões na comunidade sobre se houve otimização excessiva para benchmarks ou um progresso multimodal substancial. (Fonte: reach_vb, teortaxesTex, Reddit r/LocalLLaMA)
🧰 Ferramentas
Black Forest Labs lança FLUX.1 Kontext, realizando edição de imagem em nível de pixel e geração contextual: A Black Forest Labs (BFL), fundada por membros da equipe principal de inventores da tecnologia Stable Diffusion, lançou um novo conjunto de modelos de geração e edição de imagem chamado FLUX.1 Kontext. Este modelo, baseado na arquitetura de flow matching, consegue entender simultaneamente entradas de texto e imagem, permitindo geração baseada em contexto e edição em múltiplas rodadas, mantendo excelente consistência de personagens. O FLUX.1 Kontext suporta edição local sem afetar outras partes, pode gerar cenas no mesmo estilo com base em um estilo de entrada e possui baixa latência. Atualmente, foram lançadas as versões Pro e Max, e está disponível em plataformas como KreaAI e Freepik, visando fornecer às equipes criativas corporativas capacidades de edição de imagem mais precisas e rápidas. O feedback da comunidade tem sido positivo, afirmando que ele pode alcançar edição perfeita em nível de pixel. (Fonte: 36氪, timudk, op7418, lmarena_ai)

Simon Willison lança ferramenta LLM CLI para acesso conveniente a diversos grandes modelos: Simon Willison desenvolveu uma ferramenta de linha de comando e biblioteca Python chamada LLM, que permite aos usuários interagir com diversos grandes modelos de linguagem como OpenAI, Anthropic Claude, Google Gemini, Meta Llama, etc., através da linha de comando, suportando APIs remotas e modelos implantados localmente. A ferramenta pode executar prompts, armazenar prompts e respostas em SQLite, gerar e armazenar embeddings, extrair conteúdo estruturado de texto e imagens, entre outras funções. Os usuários podem instalá-la via pip ou Homebrew, e podem usar modelos locais instalando plugins (como llm-ollama). Suporta modo de chat interativo, facilitando a conversação do usuário com o modelo. (Fonte: GitHub Trending)

Contextual.ai lança analisador de documentos otimizado para RAG: A Contextual.ai lançou um analisador de documentos projetado especificamente para aplicações de geração aumentada por recuperação (RAG). A ferramenta combina modelos de visão, OCR e linguagem visual de ponta, visando fornecer extração de conteúdo de documentos com alta precisão. Os usuários podem experimentar gratuitamente, com as primeiras 500 páginas ou mais sendo gratuitas. Isso é muito útil para cenários que exigem a extração de informações de documentos complexos para uso por LLMs, ajudando a melhorar o desempenho e a precisão dos sistemas RAG. (Fonte: douwekiela)
Alibaba lança IDE de IA Tongyi Lingma, integrando autocompletar de código e modo Agent: O Alibaba lançou um ambiente de desenvolvimento integrado (IDE) de IA chamado “Tongyi Lingma”. Este IDE possui funcionalidades como autocompletar de código, MCP (Model-Copilot-Playground), modo Agent, memória de longo prazo e autocompletar entre linhas. Atualmente, suporta os modelos Qwen e DeepSeek, e os usuários esperam que o suporte a outros modelos seja adicionado no futuro. O feedback inicial de uso indica que seu painel de chat ainda tem espaço para melhorias nas funções de busca online e referência com @, mas, no geral, oferece aos desenvolvedores uma nova ferramenta com capacidades integradas de programação assistida por IA. (Fonte: karminski3, karminski3)
Perplexity Labs lança nova funcionalidade que permite criar aplicativos e relatórios a partir de prompts: A plataforma Labs da Perplexity AI demonstrou novas funcionalidades que permitem aos usuários criar aplicativos interativos e relatórios através de prompts. Por exemplo, um usuário conseguiu gerar com sucesso um painel comparando o desempenho de um portfólio de ações tradicional com um portfólio de investimentos impulsionado por IA ao longo de 5 anos, obtendo resultados altamente precisos. Outro usuário utilizou a plataforma para comparar diferentes modelos LLM e ficou satisfeito com os resultados. Esses casos demonstram o progresso da Perplexity em transformar as capacidades da IA em ferramentas analíticas práticas, especialmente em áreas como pesquisa financeira. (Fonte: AravSrinivas, AravSrinivas, TheRundownAI)

Unsloth lança versões quantizadas GGUF do DeepSeek-R1-0528, suportando execução local: A Unsloth produziu versões quantizadas GGUF para o recém-lançado modelo DeepSeek-R1-0528, incluindo IQ1_S (185GB), Q2_K_XL (251GB) e outras especificações, facilitando aos usuários a execução deste grande modelo em hardware local (como RTX 4090/3090 com VRAM suficiente). Usando parâmetros como -ot ".ffn_.*_exps.=CPU", é possível descarregar parte das camadas MoE para a RAM, permitindo a inferência com VRAM limitada. Isso oferece conveniência para usuários que desejam experimentar e pesquisar as poderosas funcionalidades do DeepSeek R1 localmente. (Fonte: karminski3, Reddit r/LocalLLaMA)

local-ai-packaged: ambiente de desenvolvimento de IA local integrado com Ollama, Supabase, etc.: coleam00/local-ai-packaged é um template Docker Compose de código aberto projetado para configurar rapidamente um ambiente de desenvolvimento de IA local e low-code completo. Ele integra Ollama (execução local de LLM), Supabase (banco de dados, armazenamento de vetores, autenticação), n8n (automação low-code), Open WebUI (interface de chat), Flowise (construtor de agentes de IA), Neo4j (grafo de conhecimento), Langfuse (observabilidade de LLM), SearXNG (metabusca) e Caddy (gerenciamento de HTTPS). O projeto facilita aos desenvolvedores a integração e o uso de várias ferramentas e serviços de IA em um ambiente local. (Fonte: GitHub Trending)
Resemble AI lança ferramenta de voz de IA de código aberto ChatterBox, com suporte para controle emocional: A Resemble AI lançou uma ferramenta de voz de IA de código aberto chamada ChatterBox. A ferramenta permite aos usuários projetar, clonar e editar vozes gratuitamente, além de realizar controle emocional. Alega-se que o ChatterBox supera em desempenho alguns dos principais serviços comerciais de voz de IA (como Elevenlabs), fornecendo aos desenvolvedores e criadores de conteúdo poderosas capacidades de síntese e edição de voz. (Fonte: ClementDelangue)
Mem0.ai combina-se com Qdrant para fornecer solução de memória de longo prazo para agentes de IA: O framework Mem0.ai, combinado com o banco de dados vetorial Qdrant, oferece uma solução de memória de longo prazo para agentes de IA. A solução visa ajudar os agentes a manter o contexto, lembrar fatos e manter a consistência nas conversas. Os usuários podem implantar via nuvem ou de forma open-source, conectando o Mem0 ao Qdrant para armazenar memória vetorial de longo prazo. Isso é de grande importância para a construção de aplicações de IA que exigem memória persistente e capacidades de diálogo complexas. (Fonte: qdrant_engine)

📚 Aprendizado
Nova pesquisa da Universidade de Tóquio: Meta-aprendizagem em contexto induz a emergência de circuitos multifásicos internos em LLMs: Um estudo da Universidade de Tóquio, intitulado “Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence”, explora estruturas mais complexas dentro de grandes modelos de linguagem (LLM). A pesquisa descobriu que, durante o processo de meta-aprendizagem em contexto (in-context meta-learning), os LLMs são capazes de induzir a emergência de circuitos multifásicos, o que ultrapassa os mecanismos mais simples anteriormente compreendidos, como os “induction heads”. Este estudo oferece uma nova perspectiva sobre como os LLMs aprendem através do contexto e formam representações internas complexas. (Fonte: teortaxesTex, [email protected])

MLflow aprimora suporte para fluxos de trabalho de otimização DSPy, melhorando a observabilidade: O MLflow anunciou suporte para rastrear fluxos de trabalho de otimização do DSPy (um framework para construir e otimizar aplicações de modelos de linguagem), semelhante ao seu suporte para treinamento do PyTorch. Através das funcionalidades de rastreamento e registro automático do MLflow, os desenvolvedores podem depurar e monitorar chamadas de módulos DSPy, avaliações e otimizadores de forma transparente, permitindo uma melhor compreensão e iteração dos fluxos de trabalho GenAI, e alcançando gerenciamento de ponta a ponta, do desenvolvimento à implantação. Isso fornece aos desenvolvedores que usam DSPy para engenharia de prompt e desenvolvimento de aplicações LLM maior observabilidade e práticas de MLOps. (Fonte: lateinteraction, dennylee)

Novo artigo explora método de autoaperfeiçoamento UniRL para modelos multimodais unificados: O artigo “UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning” apresenta um método de pós-treinamento de autoaperfeiçoamento chamado UniRL. Este método permite que os modelos gerem imagens com base em prompts e usem essas imagens como dados de treinamento iterativos, sem a necessidade de dados de imagem externos. Ele também realiza um aprimoramento mútuo entre tarefas de geração e compreensão: as imagens geradas são usadas para compreensão, e os resultados da compreensão são usados para supervisionar a geração. Os pesquisadores exploraram o ajuste fino supervisionado (SFT) e a otimização de política relativa de grupo (GRPO) para otimizar modelos como Show-o e Janus. As vantagens do UniRL incluem a não necessidade de dados de imagem externos, a capacidade de melhorar o desempenho em tarefas únicas e reduzir o desequilíbrio entre geração e compreensão, e a exigência de apenas algumas etapas adicionais de treinamento. (Fonte: HuggingFace Daily Papers)
Artigo Fast-dLLM: Aceleração de Diffusion LLM através de cache KV e decodificação paralela: O artigo “Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding” aborda o problema da lenta velocidade de inferência dos grandes modelos de linguagem baseados em difusão (Diffusion LLM), propondo um método de aceleração que não requer treinamento. Este método introduz um mecanismo de cache KV aproximado em nível de bloco, personalizado para modelos de difusão bidirecionais, e propõe uma estratégia de decodificação paralela sensível à confiança, para manter a qualidade da geração ao decodificar múltiplos tokens simultaneamente. Experimentos mostram que o método alcança um aumento de throughput de até 27,6 vezes nos modelos LLaDA e Dream, com perda mínima de precisão, ajudando a diminuir a lacuna de desempenho entre Diffusion LLMs e modelos autorregressivos. (Fonte: HuggingFace Daily Papers)
Artigo Uni-Instruct: Modelo de difusão de passo único através de instrução unificada de divergência de difusão: O artigo “Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction” propõe um framework teórico chamado Uni-Instruct, que unifica mais de 10 métodos existentes de destilação de difusão de passo único. Este framework é baseado na teoria de extensão de difusão da família de f-divergências proposta pelos autores, e introduz teorias chave para superar os problemas intratáveis da f-divergência estendida original, resultando em uma função de perda equivalente e tratável, que treina efetivamente modelos de difusão de passo único minimizando a família de f-divergências estendidas. Uni-Instruct alcançou desempenho SOTA na geração de passo único em benchmarks como CIFAR10 e ImageNet-64×64, e já foi aplicado em tarefas como geração de texto para 3D. (Fonte: HuggingFace Daily Papers)
Nova pesquisa explora a relação entre a capacidade de raciocínio de grandes modelos de linguagem e o fenômeno da alucinação: O artigo “Are Reasoning Models More Prone to Hallucination?” investiga se grandes modelos de raciocínio (LRM), ao mesmo tempo em que demonstram forte capacidade de raciocínio em cadeia de pensamento (CoT), são mais propensos a gerar alucinações. O estudo descobriu que LRMs que passam por um processo completo de pós-treinamento (incluindo SFT de partida a frio e RL com recompensa verificável) geralmente conseguem mitigar alucinações, enquanto o treinamento apenas por destilação ou RL sem ajuste fino de partida a frio pode introduzir alucinações mais sutis. A pesquisa também analisou comportamentos cognitivos chave que levam a alucinações (como repetição defeituosa, incompatibilidade entre pensamento e resposta) e o desalinhamento entre a incerteza do modelo e a precisão factual. (Fonte: HuggingFace Daily Papers)
Artigo propõe KVzip: Compressão de cache KV agnóstica à consulta com reconstrução de contexto: O artigo “KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction” apresenta um método de descarte de cache KV agnóstico à consulta chamado KVzip, projetado para reutilizar eficientemente o cache KV comprimido para lidar com diferentes consultas. O KVzip quantifica a importância dos pares KV em cache reconstruindo o contexto original a partir deles usando o LLM subjacente, e descarta os pares KV de menor importância. Experimentos mostram que o KVzip pode reduzir o tamanho do cache KV em 3-4 vezes, diminuir a latência de decodificação do FlashAttention em cerca de 2 vezes, com perda de desempenho insignificante em tarefas como perguntas e respostas, recuperação, raciocínio e compreensão de código, suportando contextos de até 170K tokens. (Fonte: HuggingFace Daily Papers)
💼 Negócios
Último relatório financeiro da NVIDIA mostra aumento de receita de 69%, forte demanda contínua por chips de IA: A gigante de chips de IA, NVIDIA, divulgou seu último relatório financeiro, com vendas trimestrais atingindo US$ 44,1 bilhões, um aumento de 69% ano a ano, e lucro líquido crescendo 26% ano a ano, para US$ 18,78 bilhões. Embora as vendas tenham superado as expectativas, o lucro ficou ligeiramente abaixo do esperado. As restrições dos EUA à exportação de chips para a China causaram uma perda de US$ 4,5 bilhões para a empresa, mas a empresa espera que a receita do próximo trimestre ainda cresça 50% ano a ano, para US$ 45 bilhões, principalmente devido às vendas do seu mais recente chip de IA, Blackwell. O CEO da NVIDIA, Jensen Huang, afirmou que países de todo o mundo perceberam que a IA se tornará infraestrutura. Impulsionada pelo relatório financeiro, a capitalização de mercado da NVIDIA chegou a ultrapassar a da Apple, ficando em segundo lugar globalmente. A empresa está expandindo ativamente para os mercados europeu, asiático e do Oriente Médio, e a venda de chips para clientes governamentais tornou-se uma importante direção estratégica. (Fonte: dotey)

Principais VCs do Vale do Silício voltam-se para hardware de IA, buscando terminais interativos de próxima geração: Com o rápido desenvolvimento dos algoritmos de IA, a direção de investimento do Vale do Silício está mudando da otimização puramente algorítmica para dispositivos de hardware capazes de suportar as capacidades da IA. Gigantes como Google, OpenAI (que adquiriu a empresa de hardware de IA io), Meta e Apple estão todas investindo ativamente em hardware de IA, como óculos inteligentes e dispositivos de AR. A Sequoia Capital investiu nos óculos de IA Brilliant Labs, e a IDG Capital investiu no laptop sem tela Spacetop. Empresas emergentes como Celestial AI (interconexão de chips fotônicos), NeuroFlex (materiais flexíveis para interface cérebro-máquina), Luminai (módulos de AR leves), BioLink Systems (sensores de IA digeríveis) e SynthSense (sistemas sensoriais robóticos multimodais) também estão impulsionando a inovação em hardware de IA em seus respectivos campos. Isso reflete a importância que a indústria atribui ao “corpo” da IA, acreditando que a inovação em hardware determinará a velocidade e os limites da implementação da tecnologia de IA e remodelará a interação humano-máquina. (Fonte: 36氪)

Sequoia investe em nova startup de agente de programação de IA, desafiando gigantes existentes: De acordo com LiorOnAI, a Sequoia Capital investiu em uma nova startup cujo objetivo é desafiar ferramentas de programação de IA existentes como Devin, Cursor e OpenAI Codex. O agente de IA desenvolvido pela empresa alega ser capaz de ler bases de código inteiras e automatizar tarefas como escrever, testar, corrigir e mesclar pull requests (PR), visando fornecer um assistente de engenheiro de software totalmente autônomo e disponível 24/7. Isso marca uma intensificação da competição no campo da automação de desenvolvimento de software por IA. (Fonte: LiorOnAI)
🌟 Comunidade
Comunidade debate as deficiências dos LLMs em seguir instruções de comprimento e a “propaganda excessiva”: A pesquisa LIFEBench gerou discussão na comunidade, com muitos usuários e desenvolvedores concordando com as deficiências dos atuais grandes modelos de linguagem em seguir instruções precisas de comprimento, especialmente na geração de textos longos. Membros da comunidade apontaram que os modelos frequentemente geram conteúdo com comprimento diferente do solicitado, terminam prematuramente ou até se recusam a gerar textos longos. Ao mesmo tempo, o número máximo de tokens de saída alegado pelos modelos muitas vezes não corresponde à sua capacidade real de geração efetiva, sendo o fenômeno da “propaganda excessiva” bastante comum. Espera-se que futuros modelos, através de melhores estratégias de treinamento e sistemas de avaliação, melhorem sua capacidade de executar instruções de comprimento e seu desempenho real, alcançando “contagem de palavras adequada e conteúdo de qualidade”. (Fonte: 量子位)
Usuários relatam fenômeno de “bajulação” excessiva (Glazing) em chatbots de IA: Usuários da comunidade Reddit relataram que, ao usar chatbots de IA como o ChatGPT, frequentemente encontram o modelo elogiando e afirmando excessivamente as perguntas ou entradas do usuário (conhecido como “glazing” ou “sycophancy”), por exemplo, “Essa é uma observação muito inteligente!”. Os usuários expressaram aborrecimento com isso, considerando essa bajulação desnecessária e prejudicial à naturalidade da interação. Membros da comunidade discutiram métodos para reduzir esse fenômeno usando prompts específicos (como pedir ao modelo para responder de forma direta, objetiva e neutra) e compartilharam suas experiências e sentimentos. O DeepSeek-R1-0528 também foi apontado por alguns usuários como tendo uma tendência semelhante. (Fonte: Reddit r/ChatGPT, teortaxesTex)

Discussão na comunidade: A IA está realmente “roubando empregos” ou expondo a redundância de posições de “intermediário”?: Uma discussão no Reddit sugere que, em vez de a IA estar “roubando nossos empregos”, ela está expondo a natureza de “intermediário” e a potencial redundância de muitos trabalhos existentes (como processar papelada, encaminhar e-mails, transmitir informações entre tomadores de decisão, etc.). Essa perspectiva gerou reflexões sobre a natureza do trabalho, a distribuição de valor social e a transformação do papel humano na era da IA. Comentadores apontaram que, mesmo que alguns trabalhos sejam de fato de natureza “intermediária”, eles fornecem sustento às pessoas, e a transição trazida pela IA requer apoio em nível social e o desenvolvimento de novas habilidades. (Fonte: Reddit r/ArtificialInteligence)
Ollama causa insatisfação na comunidade por nomeação imprecisa de modelos: Usuários da comunidade Reddit r/LocalLLaMA apontaram que o Ollama apresenta imprecisões ou confusões na nomeação de modelos. Por exemplo, abreviar DeepSeek-R1-Distill-Qwen-32B como deepseek-r1:32b pode levar usuários novatos a acreditar erroneamente que estão executando um modelo DeepSeek puro, ignorando sua natureza de destilação Qwen. Os usuários consideram que essa forma de nomeação não é consistente com os hábitos de plataformas como HuggingFace, carece de transparência e pode levar a uma percepção errônea das características do modelo. (Fonte: Reddit r/LocalLLaMA)

Linguagens de programação contribuem enormemente para o sucesso dos grandes modelos de linguagem: Discussões na comunidade enfatizam que as linguagens de programação, como corpus de treinamento de alta qualidade, devido à sua definição lógica clara e à facilidade de verificar a correção dos resultados, desempenharam um papel crucial no desenvolvimento bem-sucedido de grandes modelos de linguagem. Elas não apenas forneceram aos modelos uma fonte de conhecimento estruturado, mas também estabeleceram a base para que os modelos aprendessem raciocínio e gerassem código executável. (Fonte: dotey)

💡 Outros
Indoor Robotics lança drone robótico de segurança com navegação autônoma baseada em IA: A empresa Indoor Robotics apresentou um drone robótico de segurança com navegação autônoma baseada em inteligência artificial. Este drone, projetado especificamente para ambientes internos, é capaz de executar tarefas de patrulha e monitoramento de segurança de forma autônoma, utilizando IA para navegação e identificação de ameaças, oferecendo uma solução inovadora e automatizada para segurança interna. (Fonte: Ronald_vanLoon, Ronald_vanLoon)
Unitree Robotics atualiza robô industrial com rodas B2-W, aprimorando funcionalidades: A Unitree Robotics atualizou as funcionalidades do seu robô industrial com rodas B2-W, conferindo-lhe capacidades mais empolgantes. Este robô combina a flexibilidade da mobilidade sobre rodas com a versatilidade de um robô, visando aplicações em diversos cenários industriais, aumentando o nível de automação e a eficiência operacional. (Fonte: Ronald_vanLoon)
Lenovo lança robô hexápode Daystar, voltado para os setores industrial, de pesquisa e educacional: A Lenovo lançou um robô hexápode chamado Daystar. Este robô foi projetado especificamente para aplicações industriais, pesquisa científica e fins educacionais, e sua estrutura de múltiplas pernas permite que ele se adapte a terrenos complexos, oferecendo novas opções de plataforma robótica para áreas relacionadas. (Fonte: Ronald_vanLoon)