
Palavras-chave:DeepSeek-R1-0528, Agente de IA, Modelo multimodal, IA de código aberto, Aprendizagem por reforço, Edição de imagem, Modelo de linguagem grande, Teste de referência de IA, DeepSeek-R1-0528-Qwen3-8B, Ferramenta Circuit Tracer, Darwin Gödel Machine, FLUX.1 Kontext, Recuperação agentica
🔥 Destaques
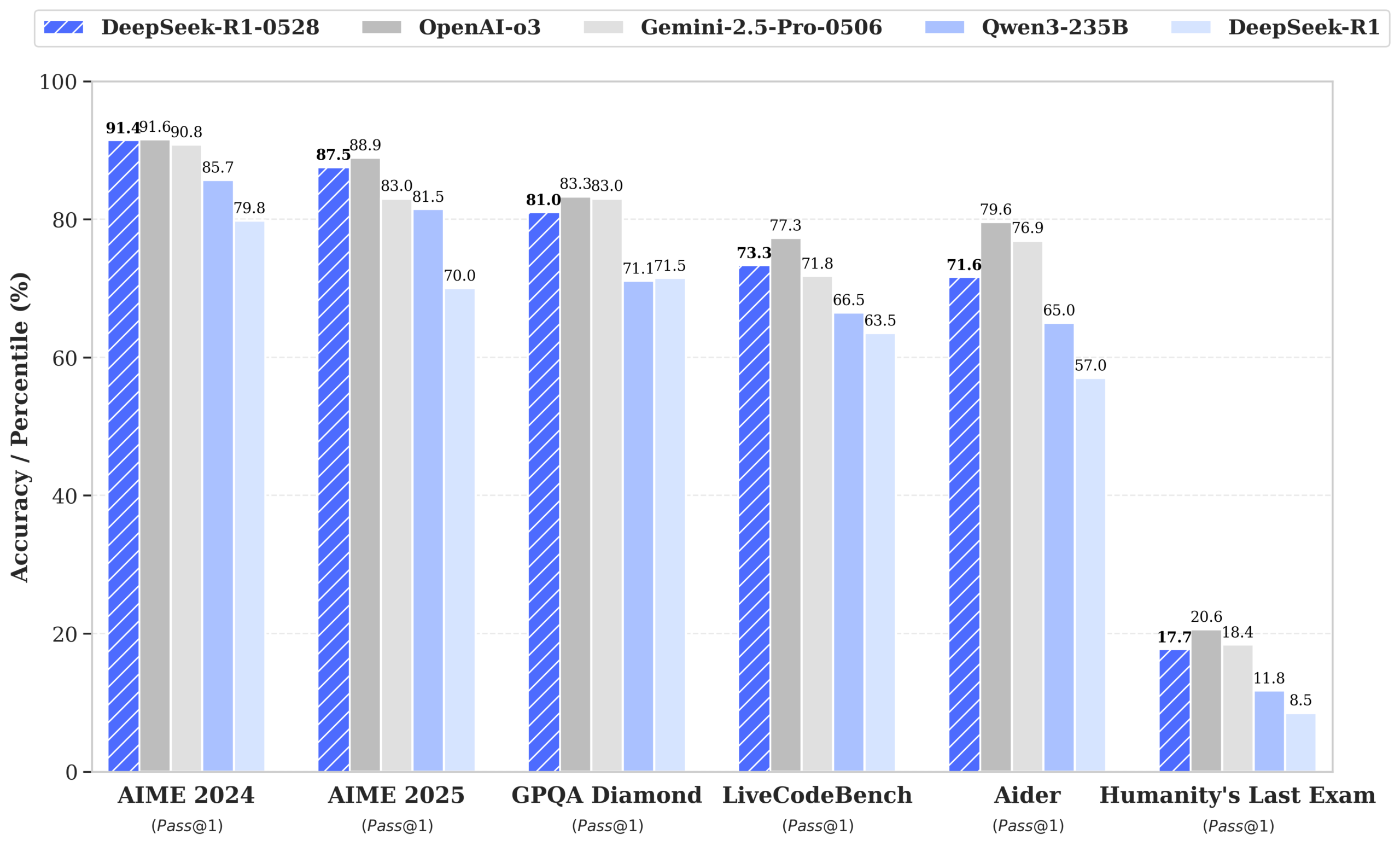
DeepSeek lança o modelo R1-0528, com desempenho próximo ao GPT-4o e Gemini 2.5 Pro, liderando o ranking de código aberto: O DeepSeek-R1-0528 demonstrou excelente desempenho em múltiplos benchmarks de matemática, programação e raciocínio lógico geral, especialmente no teste AIME 2025, onde a precisão aumentou de 70% para 87,5%. A nova versão reduziu significativamente a taxa de alucinação (cerca de 45-50%), aprimorou a capacidade de geração de código front-end e suporta saída JSON e chamadas de função. Ao mesmo tempo, a DeepSeek lançou o DeepSeek-R1-0528-Qwen3-8B, ajustado com base no Qwen3-8B Base, cujo desempenho no AIME 2024 fica atrás apenas do R1-0528, superando o Qwen3-235B. Esta atualização consolida a posição da DeepSeek como o segundo maior laboratório de IA do mundo e líder em código aberto. (Fonte: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
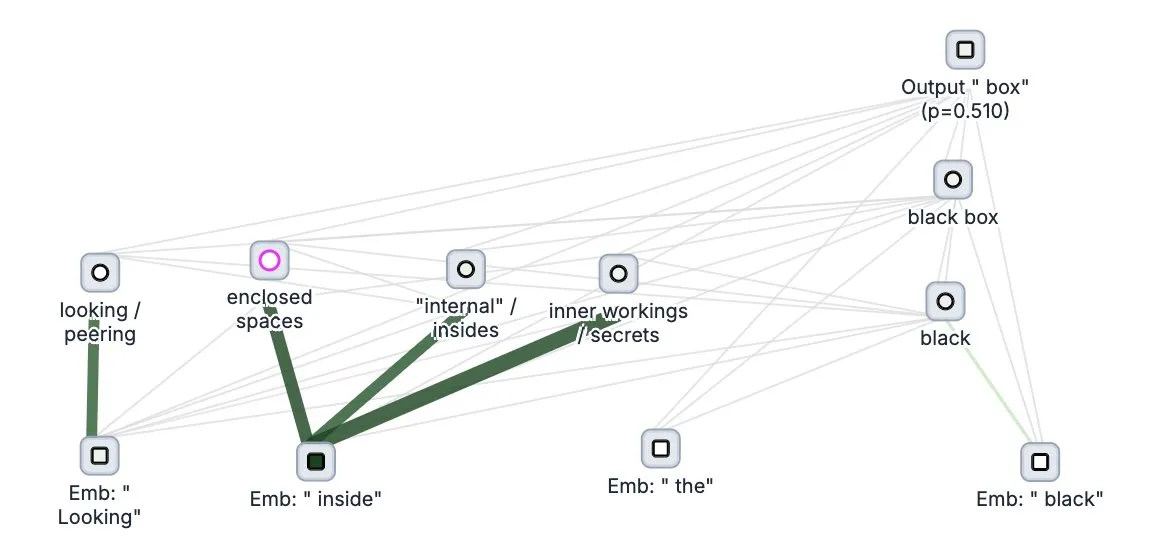
Anthropic lança ferramenta de código aberto para “rastreamento de pensamento” de grandes modelos, Circuit Tracer: A Anthropic tornou de código aberto sua ferramenta de pesquisa de interpretabilidade de grandes modelos, Circuit Tracer, permitindo que pesquisadores gerem e explorem interativamente “mapas de atribuição” para entender os processos internos de “pensamento” e mecanismos de decisão dos grandes modelos de linguagem (LLM). Esta ferramenta visa ajudar os pesquisadores a investigar mais profundamente o funcionamento interno dos LLMs, como por exemplo, como o modelo utiliza características específicas para prever o próximo token. Os usuários podem experimentar a ferramenta no Neuronpedia, inserindo frases para obter um diagrama de circuito do uso de características pelo modelo. (Fonte: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
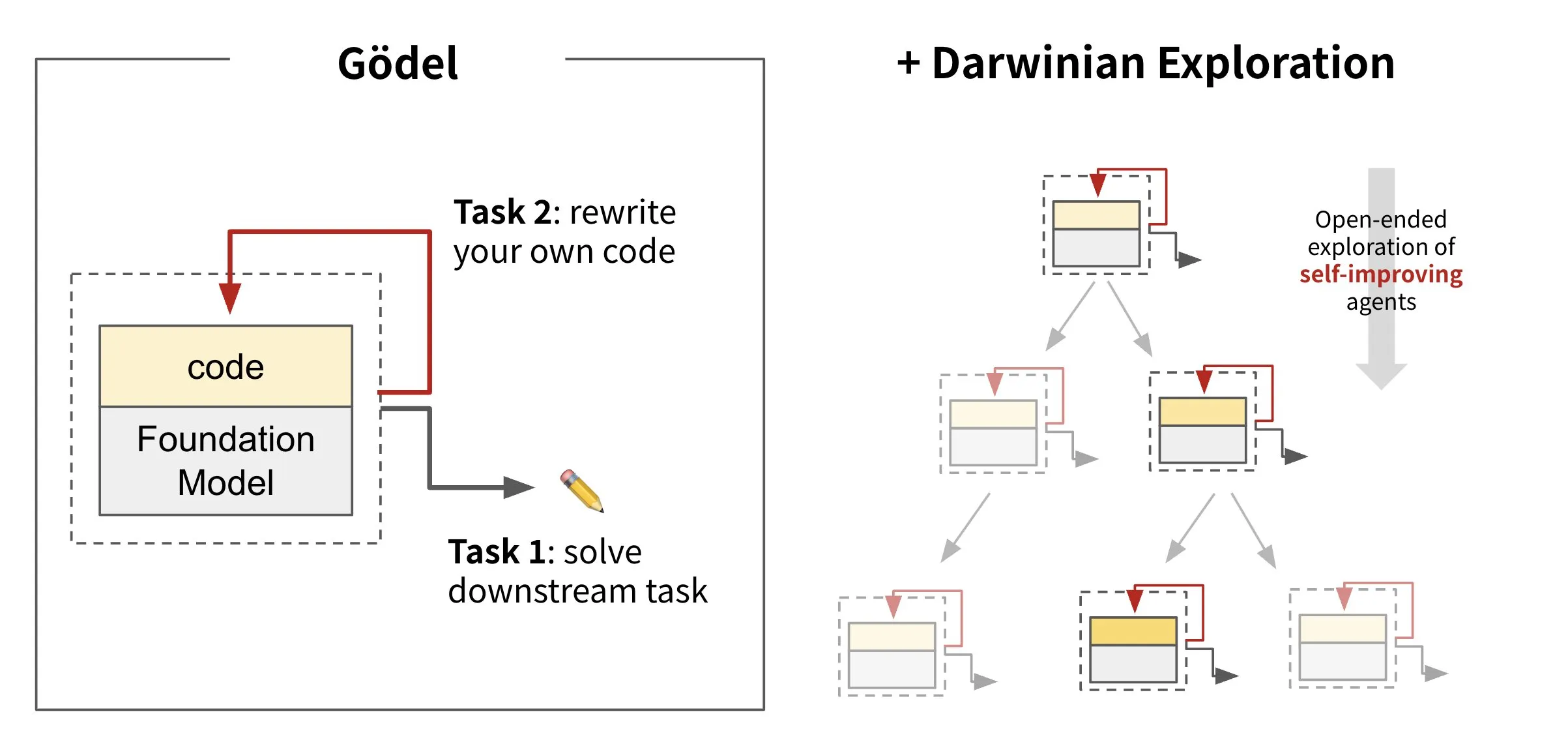
Sakana AI lança framework de agente autoevolutivo Darwin Gödel Machine (DGM): A Sakana AI apresentou o Darwin Gödel Machine (DGM), um framework de agente de IA capaz de autoaperfeiçoamento através da reescrita do seu próprio código. Inspirado na teoria da evolução, o DGM mantém uma linhagem em constante expansão de variantes de agentes para explorar abertamente o espaço de design de agentes autoaperfeiçoáveis. O framework visa permitir que sistemas de IA aprendam e evoluam suas próprias capacidades ao longo do tempo, assim como os humanos. No SWE-bench, o DGM melhorou o desempenho de 20,0% para 50,0%; no Polyglot, a taxa de sucesso aumentou de 14,2% para 30,7%. (Fonte: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs lança modelo de edição de imagem FLUX.1 Kontext, com suporte para entrada mista de texto e imagem: A Black Forest Labs lançou o modelo de edição de imagem de nova geração FLUX.1 Kontext, que utiliza uma arquitetura de flow matching e é capaz de aceitar tanto texto quanto imagem como entrada, permitindo a geração e edição de imagens com reconhecimento de contexto. O modelo se destaca na consistência de personagens, edição localizada, referência de estilo e velocidade de interação, gerando imagens em resolução 1024×1024 em apenas 3-5 segundos, por exemplo. Testes da Replicate indicam que seus efeitos de edição são superiores ao GPT-4o-Image e com custo menor. O Kontext está disponível nas versões Pro e Max, com planos para uma versão Dev de código aberto. (Fonte: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 Tendências
Google DeepMind lança modelo médico multimodal MedGemma: O Google DeepMind lançou o MedGemma, um poderoso modelo aberto projetado para a compreensão multimodal de textos e imagens médicas. O modelo, disponibilizado como parte das Health AI Developer Foundations, visa aprimorar a capacidade de aplicação da IA no setor médico, especialmente na análise combinada de textos e imagens médicas (como raios-X). (Fonte: GoogleDeepMind)
Perplexity AI lança Perplexity Labs para capacitar o processamento de tarefas complexas: A Perplexity AI lançou uma nova funcionalidade, Perplexity Labs, projetada para lidar com tarefas mais complexas, com o objetivo de fornecer aos usuários capacidades de análise e construção semelhantes às de uma equipe de pesquisa inteira. Os usuários podem usar o Labs para construir relatórios analíticos, apresentações e dashboards dinâmicos, entre outros. A funcionalidade está atualmente disponível para todos os usuários Pro e demonstra seu potencial na pesquisa científica, análise de mercado e criação de miniaplicativos (como jogos e dashboards). (Fonte: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan e Tencent Music lançam conjuntamente o HunyuanVideo-Avatar, que pode gerar vídeos de canto realistas a partir de fotos: O Tencent Hunyuan e a Tencent Music uniram forças para lançar o modelo HunyuanVideo-Avatar, que combina fotos e áudio enviados pelo usuário para detectar automaticamente o contexto da cena e as emoções, gerando vídeos de fala ou canto com sincronização labial realista e efeitos visuais dinâmicos. A tecnologia suporta múltiplos estilos e foi disponibilizada em código aberto. (Fonte: huggingface, thursdai_pod)
Apache Spark 4.0.0 lançado oficialmente, com melhorias em SQL, Spark Connect e suporte multilíngue: A versão Apache Spark 4.0.0 foi lançada oficialmente, trazendo melhorias significativas nas funcionalidades SQL, aprimoramentos no Spark Connect para facilitar a execução de aplicativos e suporte adicional para novas linguagens. Esta atualização resolveu mais de 5100 problemas, com a participação de mais de 390 contribuidores. (Fonte: matei_zaharia, lateinteraction)

Modelo de vídeo Kling 2.1 lançado, com integração OpenArt para suporte à consistência de personagens: A Kling AI lançou seu modelo de vídeo Kling 2.1 e colaborou com a OpenArt para suportar a consistência de personagens na narrativa de histórias em vídeo com IA. O Kling 2.1 melhorou o alinhamento de prompts, a velocidade de geração de vídeo, a clareza do movimento da câmera e alega ter os melhores efeitos de texto para vídeo. A nova versão suporta saída em 720p (padrão) e 1080p (profissional); a funcionalidade de imagem para vídeo já está online, e a de texto para vídeo será lançada em breve. (Fonte: Kling_ai, NandoDF)
Hume lança modelo de voz EVI 3, capaz de entender e gerar qualquer voz humana: A Hume lançou seu mais recente modelo de linguagem de voz, EVI 3, visando alcançar a inteligência de voz universal. O EVI 3 é capaz de entender e gerar qualquer voz humana, não apenas de alguns falantes específicos, oferecendo assim uma gama mais ampla de expressividade e uma compreensão mais profunda da entonação, ritmo, timbre e estilo de fala. A tecnologia visa permitir que todos tenham uma IA única e confiável, reconhecível pela voz. (Fonte: AlanCowen, AlanCowen, _akhaliq)
Alibaba lança WebDancer, explorando agentes inteligentes de busca autônoma de informações: O Alibaba lançou o projeto WebDancer, com o objetivo de pesquisar e desenvolver agentes de IA capazes de realizar buscas de informações de forma autônoma. O projeto foca em como tornar os agentes de IA mais eficazes na navegação em ambientes web, na compreensão de informações e na conclusão de tarefas complexas de aquisição de informações. (Fonte: _akhaliq)
MiniMax lança framework V-Triune e modelo Orsta de código aberto, unificando tarefas de inferência visual RL e percepção: A empresa de IA MiniMax tornou de código aberto seu framework unificado de aprendizado por reforço visual V-Triune e a série de modelos Orsta (7B a 32B) baseada neste framework. Através de um design de componentes de três camadas e um mecanismo de recompensa dinâmico de Interseção sobre União (IoU), o framework permite pela primeira vez que um VLM aprenda conjuntamente tarefas de inferência visual e percepção em um único fluxo de pós-treinamento, alcançando melhorias significativas de desempenho no benchmark MEGA-Bench Core. (Fonte: 量子位)

Laboratório de IA de Xangai e outros lançam novo benchmark de edição de imagem RISEBench, testando o raciocínio profundo dos modelos: O Laboratório de Inteligência Artificial de Xangai, em colaboração com várias universidades, lançou um novo benchmark de avaliação de edição de imagem chamado RISEBench, contendo 360 casos de alta dificuldade projetados por especialistas humanos, cobrindo quatro tipos principais de raciocínio: temporal, causal, espacial e lógico. Os resultados dos testes mostram que mesmo o GPT-4o-Image conseguiu completar apenas 28,9% das tarefas, expondo as deficiências dos modelos multimodais atuais na compreensão de instruções complexas e edição visual. (Fonte: 36氪)

CUHK e outros propõem framework TON, permitindo que modelos de IA pensem seletivamente para melhorar eficiência e precisão: Pesquisadores da Universidade Chinesa de Hong Kong e do Show Lab da Universidade Nacional de Singapura propuseram o framework TON (Think Or Not), que permite que modelos de linguagem visual (VLM) decidam autonomamente se precisam de raciocínio explícito. Através do “descarte de pensamento” e aprendizado por reforço, o framework permite que o modelo responda diretamente a perguntas simples e realize raciocínio detalhado para problemas complexos, reduzindo o comprimento médio da saída de inferência em até 90% sem sacrificar a precisão, e até mesmo aumentando a precisão em algumas tarefas em 17%. (Fonte: 36氪)
Microsoft Copilot integra Instacart, permitindo compras de supermercado assistidas por IA: Mustafa Suleyman, chefe de IA da Microsoft, anunciou que o Copilot agora está integrado ao serviço Instacart, permitindo que os usuários concluam todo o processo, desde a geração de receitas e criação de listas de compras até a entrega de supermercado, de forma transparente através do aplicativo Copilot. Isso marca uma maior expansão dos assistentes de IA no domínio dos serviços da vida diária. (Fonte: mustafasuleyman)
🧰 Ferramentas
LlamaIndex lança código-fonte do BundesGPT e ferramenta create-llama, simplificando a construção de aplicações de IA: Jerry Liu, da LlamaIndex, anunciou a disponibilização do código-fonte do BundesGPT e promoveu sua ferramenta de código aberto create-llama. A ferramenta, baseada no LlamaIndex, visa ajudar desenvolvedores a construir e integrar facilmente dados empresariais com agentes de IA, e seu novo eject-mode torna muito simples a criação de interfaces de IA totalmente personalizáveis como o BundesGPT. A iniciativa visa apoiar o potencial plano da Alemanha de fornecer a cada cidadão uma assinatura gratuita do ChatGPT Plus. (Fonte: jerryjliu0)
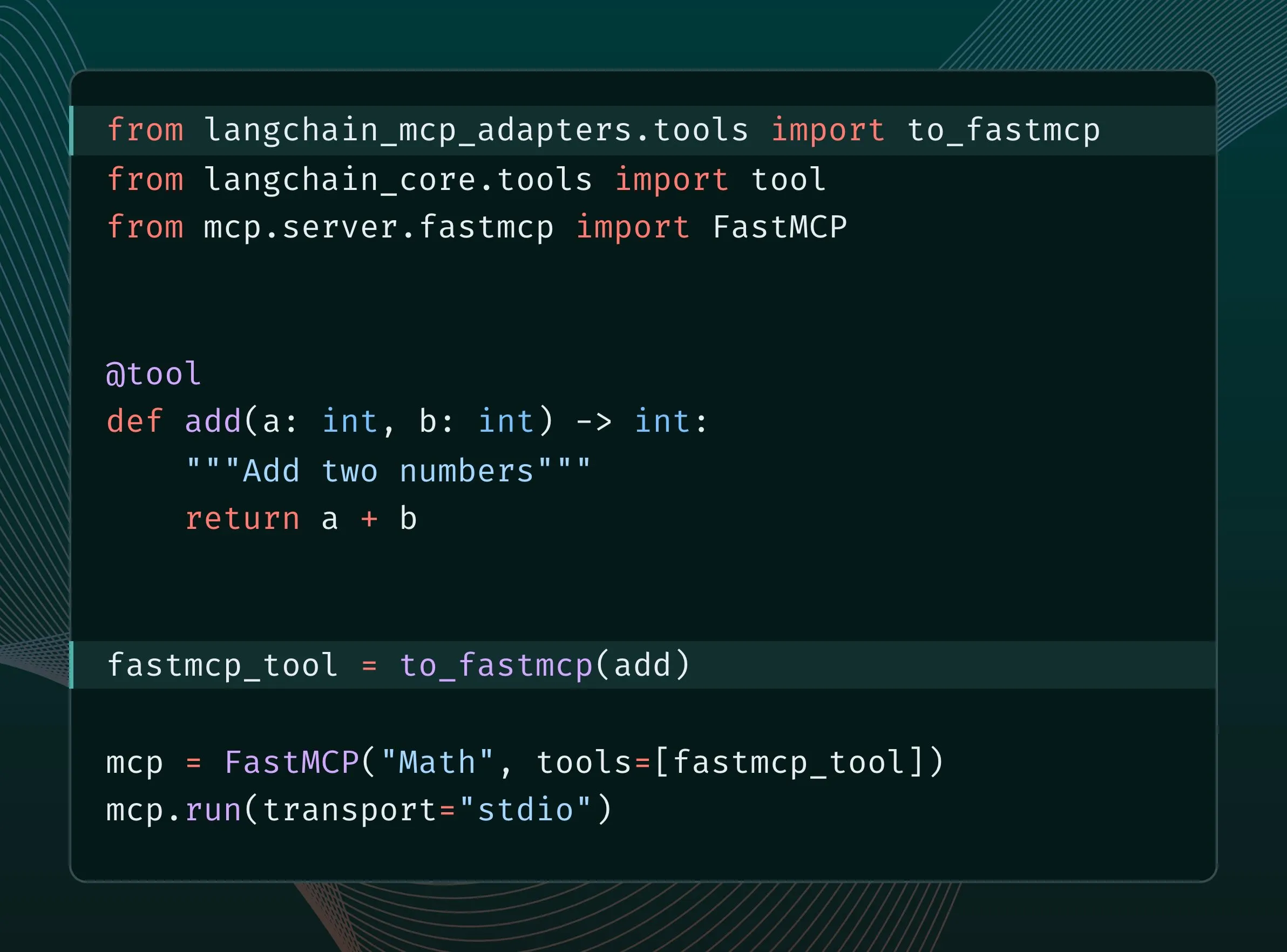
Ferramentas LangChain podem ser convertidas em ferramentas MCP e integradas ao servidor FastMCP: Usuários do LangChain agora podem converter suas ferramentas LangChain em ferramentas MCP (Model Component Protocol) e adicioná-las diretamente ao servidor FastMCP. Ao instalar a biblioteca langchain-mcp-adapters, os desenvolvedores podem usar mais convenientemente o conjunto de ferramentas do LangChain no ecossistema MCP, promovendo a interoperabilidade entre diferentes frameworks de IA. (Fonte: LangChainAI, hwchase17)
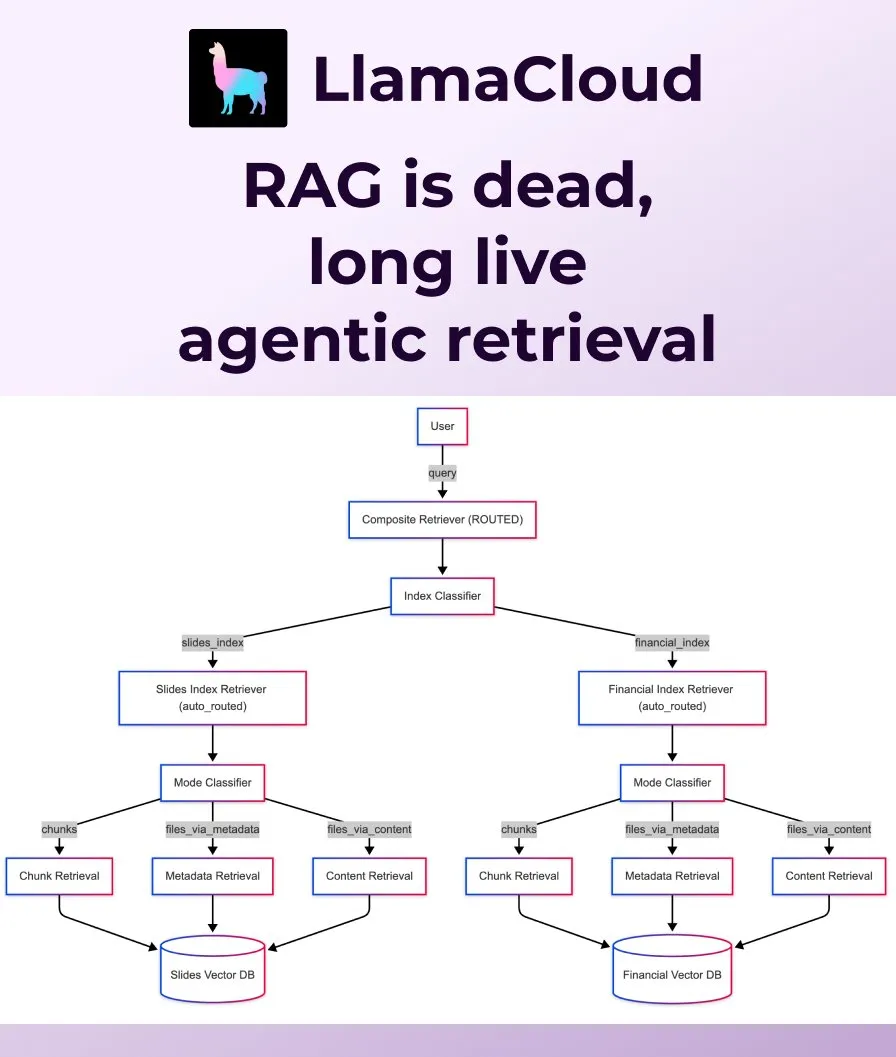
LlamaIndex lança Agentic Retrieval, substituindo o RAG tradicional: A LlamaIndex considera que o RAG (Retrieval Augmented Generation) tradicional e ingênuo já não é suficiente para atender às necessidades das aplicações modernas e lançou o Agentic Retrieval. Esta solução, integrada ao LlamaCloud, permite que agentes recuperem dinamicamente arquivos inteiros ou blocos de dados específicos de um ou múltiplos repositórios de conhecimento (como Sharepoint, Box, GDrive, S3) com base no conteúdo da pergunta, alcançando uma obtenção de contexto mais inteligente e flexível. (Fonte: jerryjliu0, jerryjliu0)
Ollama suporta a execução do modelo Osmosis-Structure-0.6B para transformação de dados não estruturados: Os usuários agora podem executar o modelo Osmosis-Structure-0.6B através do Ollama. Este é um modelo extremamente pequeno capaz de converter quaisquer dados não estruturados para um formato especificado (por exemplo, JSON Schema), podendo ser usado com qualquer modelo, especialmente adequado para tarefas de inferência que requerem saída estruturada. (Fonte: ollama)
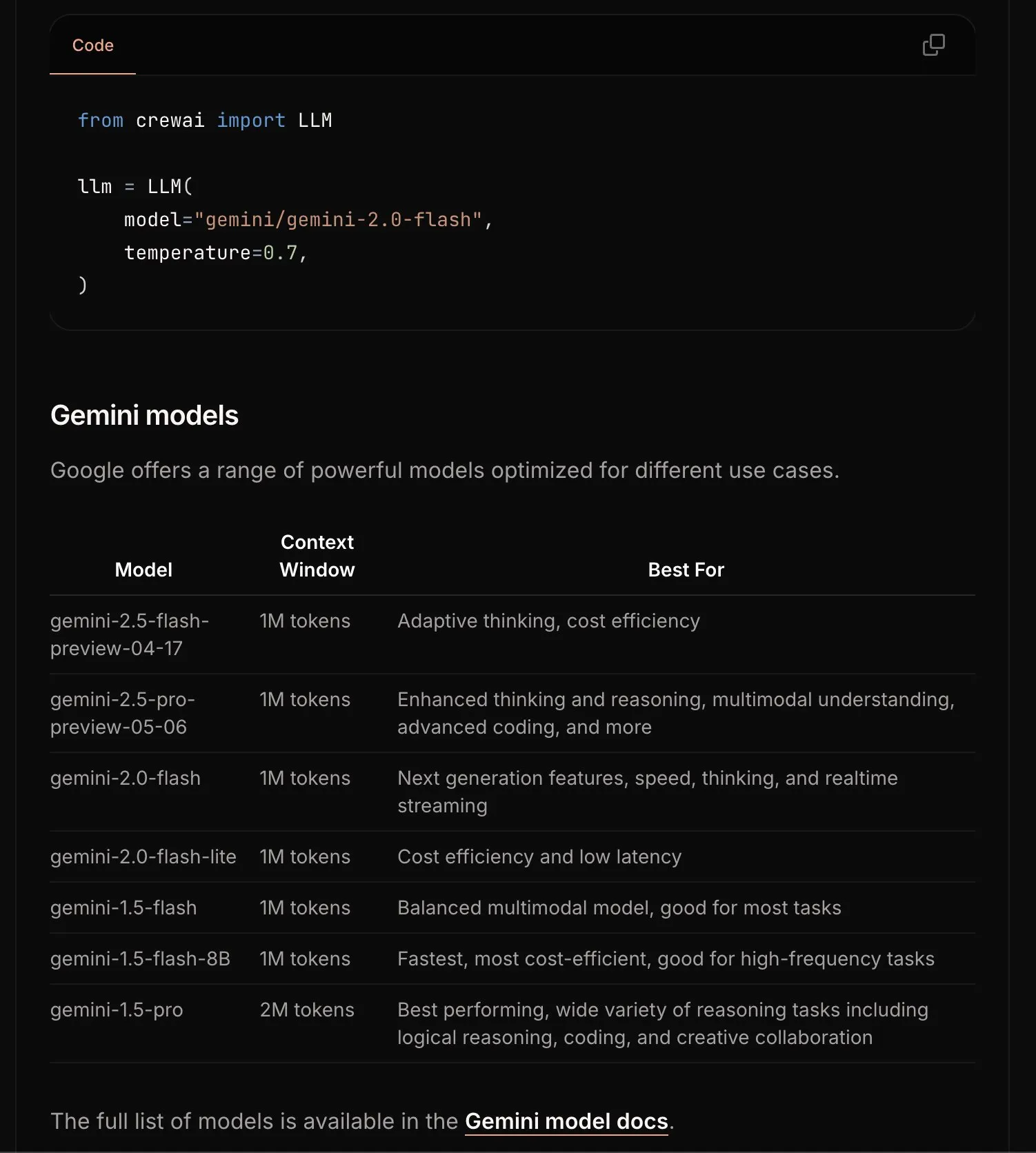
CrewAI atualiza documentação do Gemini, simplificando o processo de iniciação: A equipe do CrewAI atualizou sua documentação sobre a API Google Gemini, com o objetivo de ajudar os usuários a começar a usar os modelos Gemini para construir agentes de IA com mais facilidade. A nova documentação pode incluir diretrizes mais claras, exemplos de código ou melhores práticas. (Fonte: _philschmid)
Requesty lança funcionalidade Smart Routing, selecionando automaticamente o melhor LLM para OpenWebUI: Requesty lançou a funcionalidade Smart Routing, que se integra perfeitamente com OpenWebUI para selecionar automaticamente o melhor LLM (como GPT-4o, Claude, Gemini) com base no tipo de tarefa do prompt do usuário. Os usuários só precisam usar smart/task como ID do modelo, e o sistema pode classificar o prompt em cerca de 65 milissegundos e roteá-lo para o modelo mais adequado com base no custo, velocidade e qualidade. A funcionalidade visa simplificar a seleção de modelos e melhorar a experiência do usuário. (Fonte: Reddit r/OpenWebUI)
EvoAgentX: Lançado o primeiro framework de código aberto para autoevolução de agentes de IA: A equipe de pesquisa da Universidade de Glasgow, no Reino Unido, lançou o EvoAgentX, o primeiro framework de código aberto do mundo para autoevolução de agentes de IA. Ele suporta a construção de fluxos de trabalho com um clique e introduz um mecanismo de “autoevolução”, permitindo que sistemas multiagentes otimizem continuamente sua estrutura e desempenho com base nas mudanças no ambiente e nos objetivos. O objetivo é impulsionar os sistemas multiagentes de IA de “depuração manual” para “evolução autônoma”. Experimentos mostram que, em tarefas de resposta a perguntas multi-hop, geração de código e raciocínio matemático, o desempenho melhorou em média de 8% a 13%. (Fonte: 36氪)

📚 Aprendizado
HuggingFace, Gradio e outros organizam conjuntamente o Agents & MCP Hackathon, oferecendo prêmios generosos e cotas de API: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI, LlamaIndex e outras instituições organizarão conjuntamente o Gradio Agents & MCP Hackathon (2 a 8 de junho). O evento oferece um total de US$ 11.000 em prêmios e fornecerá cotas gratuitas de API da Hyperbolic, Anthropic, Mistral e SambaNova para os primeiros inscritos. A Modal Labs prometeu ainda US$ 250 em créditos de GPU para todos os participantes, totalizando mais de US$ 300.000. (Fonte: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain compartilha a prática do JPMorgan de usar sistemas multiagentes para pesquisa de investimentos: David Odomirok e Zheng Xue, do JPMorgan, compartilharam como construíram um sistema de IA multiagente chamado “Ask David”. O sistema visa automatizar o processo de pesquisa de investimentos para milhares de produtos financeiros, demonstrando o potencial da arquitetura multiagente em análises financeiras complexas. (Fonte: LangChainAI, hwchase17)
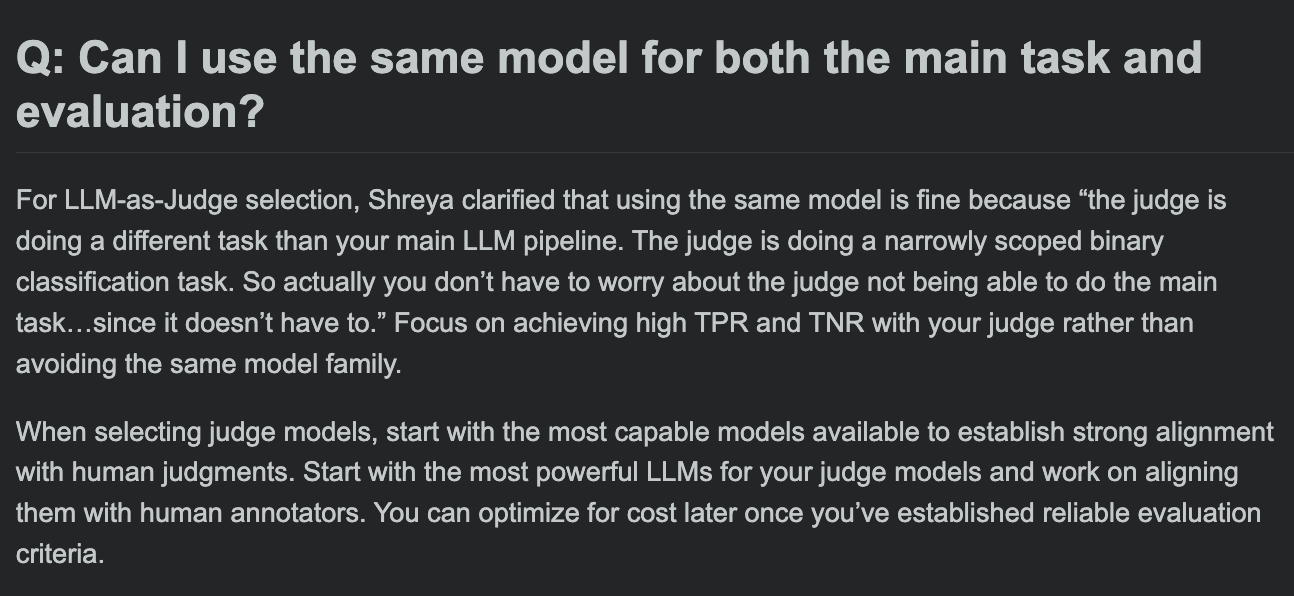
Hamel Husain compartilha FAQ do curso de avaliação de LLM, discute se o modelo de avaliação e o modelo da tarefa principal podem ser os mesmos: Na sessão de perguntas e respostas de seu curso de avaliação de LLM, Hamel Husain discutiu uma questão comum: é possível usar o mesmo modelo para o processamento da tarefa principal e para a avaliação da tarefa? Esta discussão ajuda os desenvolvedores a entender os potenciais vieses e as melhores práticas na avaliação de modelos. (Fonte: HamelHusain, HamelHusain)
The Rundown AI lança plataforma personalizada de educação em IA: The Rundown AI anunciou o lançamento da primeira plataforma global de educação em IA personalizada, oferecendo treinamento customizado, casos de uso e workshops em tempo real para diferentes setores, níveis de habilidade e fluxos de trabalho diários. O conteúdo da plataforma inclui 16 cursos de certificação em IA específicos para verticais de tecnologia, mais de 300 casos de uso de IA do mundo real, workshops com especialistas e descontos em ferramentas de IA, entre outros. (Fonte: TheRundownAI, rowancheung)
Common Crawl lança grafos de rede em nível de host e domínio para março-maio de 2025: O Common Crawl divulgou seus mais recentes dados de grafos de rede em nível de host e domínio, cobrindo março, abril e maio de 2025. Esses dados são de grande valor para pesquisar a estrutura da web, treinar modelos de linguagem e realizar análises de rede em grande escala. (Fonte: CommonCrawl)
Bill Chambers inicia atividade de aprendizado “20 Days of DSPyOSS”: Para ajudar a comunidade a entender melhor as funcionalidades e métodos de uso do DSPyOSS, Bill Chambers iniciou uma atividade de aprendizado de 20 dias sobre o DSPyOSS. Diariamente, será publicado um trecho de código DSPy com sua explicação, visando ajudar os usuários a dominar o framework desde o básico até o avançado. (Fonte: lateinteraction)
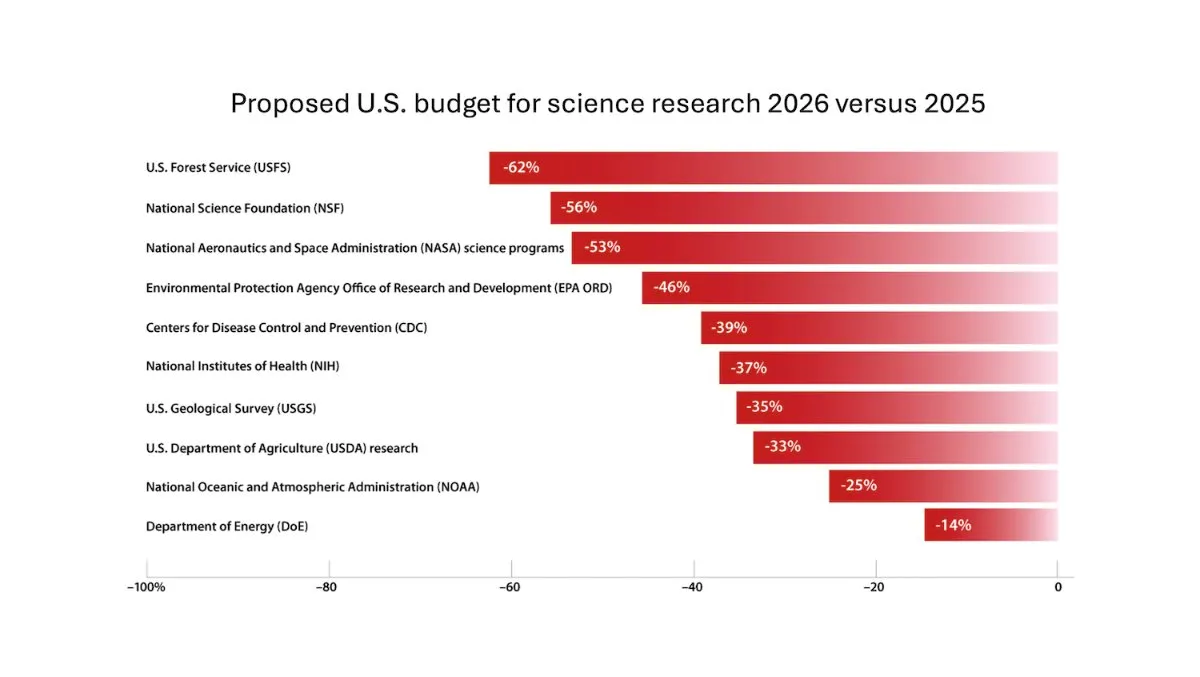
DeepLearning.AI lança o boletim The Batch, Andrew Ng discute os riscos de cortar o financiamento da pesquisa científica: Na última edição do boletim The Batch, Andrew Ng discute os riscos potenciais de cortar o financiamento da pesquisa científica para a competitividade e segurança nacional. O boletim também cobre o desempenho do modelo Claude 4 em benchmarks de codificação, os lançamentos de IA do Google I/O, o método de treinamento de baixo custo da DeepSeek e a possibilidade de o GPT-4o ter usado livros protegidos por direitos autorais para treinamento, entre outros tópicos relevantes. (Fonte: DeepLearningAI)
Google DeepMind oferece gratuitamente Gemini 2.5 Pro e NotebookLM para estudantes universitários do Reino Unido: O Google DeepMind anunciou que oferecerá acesso gratuito aos seus modelos mais avançados (incluindo Gemini 2.5 Pro e NotebookLM) para estudantes universitários do Reino Unido por um período de 15 meses. A iniciativa visa apoiar os estudos dos alunos em pesquisa, redação e preparação para exames, além de fornecer 2 TB de armazenamento gratuito. (Fonte: demishassabis)
Artigo de IA: Prot2Token, um framework unificado para modelagem de proteínas: O artigo “Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction” apresenta um framework unificado de modelagem de proteínas, Prot2Token, que converte diversas tarefas de previsão, desde atributos de sequência de proteínas e características de resíduos até interações proteína-proteína, em um formato padrão de previsão do próximo token. O framework utiliza um decodificador autorregressivo, aproveitando embeddings de codificadores de proteínas pré-treinados e tokens de tarefa aprendíveis para aprendizado multitarefa, visando aumentar a eficiência e acelerar descobertas biológicas. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Mineração de exemplos negativos difíceis para recuperação específica de domínio em sistemas empresariais: O artigo “Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems” propõe um framework escalável de mineração de exemplos negativos difíceis para dados específicos de domínio empresarial. O método seleciona dinamicamente documentos semanticamente desafiadores, mas contextualmente irrelevantes, para aprimorar o desempenho de modelos de reranking implantados, demonstrando melhorias de 15% e 19% em MRR@3 e MRR@10, respectivamente, em um corpus empresarial do setor de serviços em nuvem. (Fonte: HuggingFace Daily Papers)
Artigo de IA: FS-DAG, redes gráficas de adaptação de domínio few-shot para compreensão de documentos visualmente ricos: O artigo “FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding” propõe a arquitetura de modelo FS-DAG para compreensão de documentos visualmente ricos em cenários few-shot. O modelo utiliza backbones específicos de domínio e específicos de linguagem/visão dentro de um framework modular para se adaptar a diferentes tipos de documentos com dados mínimos, mostrando convergência mais rápida e melhor desempenho em tarefas de extração de informações em comparação com métodos SOTA. (Fonte: HuggingFace Daily Papers)
Artigo de IA: FastTD3, controle de aprendizado por reforço simples, rápido e capaz para robôs humanoides: O artigo “FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control” apresenta um algoritmo de aprendizado por reforço chamado FastTD3, que acelera significativamente a velocidade de treinamento de robôs humanoides em suítes populares como HumanoidBench, IsaacLab e MuJoCo Playground através de simulação paralela, atualizações em grandes lotes, críticos distribuídos e hiperparâmetros cuidadosamente ajustados. (Fonte: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
Artigo de IA: HLIP, pré-treinamento linguagem-imagem escalável para imagens médicas 3D: O artigo “Towards Scalable Language-Image Pre-training for 3D Medical Imaging” apresenta um framework de pré-treinamento escalável para imagens médicas 3D chamado HLIP (Hierarchical attention for Language-Image Pre-training). O HLIP utiliza um mecanismo de atenção hierárquica leve, capaz de treinar diretamente em conjuntos de dados clínicos não curados, e alcançou desempenho SOTA em múltiplos benchmarks. (Fonte: HuggingFace Daily Papers)
Artigo de IA: PENGUIN, benchmark de segurança personalizada para LLMs e abordagem de agente baseada em planejamento: O artigo “Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach” introduz o conceito de segurança personalizada e propõe o benchmark PENGUIN (contendo 14.000 cenários em 7 domínios sensíveis) e o framework RAISE (um agente de duas fases, sem treinamento, que adquire estrategicamente informações de contexto específicas do usuário). A pesquisa mostra que informações personalizadas podem melhorar significativamente as pontuações de segurança, e o RAISE pode aumentar a segurança com baixo custo de interação. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Reforçando o raciocínio multi-turno em agentes LLM via atribuição de crédito em nível de turno: O artigo “Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment” investiga como aprimorar a capacidade de raciocínio de agentes LLM através do aprendizado por reforço, especialmente em cenários de uso de ferramentas multi-turno. Os autores propõem uma estratégia de estimativa de vantagem em nível de turno de granularidade fina para alcançar uma atribuição de crédito mais precisa, e experimentos mostram que este método pode melhorar significativamente a capacidade de raciocínio multi-turno de agentes LLM em tarefas de decisão complexas. (Fonte: HuggingFace Daily Papers)
Artigo de IA: PISCES, apagamento preciso de conceitos intraparâmetros em grandes modelos de linguagem: O artigo “Precise In-Parameter Concept Erasure in Large Language Models” propõe o framework PISCES para apagar precisamente conceitos inteiros nos parâmetros do modelo, editando diretamente as direções que codificam esses conceitos no espaço de parâmetros. O método usa um desemaranhador para decompor vetores MLP, identificar características relacionadas ao conceito alvo e removê-las dos parâmetros do modelo. Experimentos mostram que ele supera os métodos existentes em eficácia de apagamento, especificidade e robustez. (Fonte: HuggingFace Daily Papers)
Artigo de IA: DORI, avaliação da compreensão de orientação em MLLMs com tarefas de percepção multieixo de granularidade fina: O artigo “Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks” introduz o benchmark DORI, projetado para avaliar a capacidade de compreensão da orientação de objetos por modelos de linguagem grandes multimodais (MLLM). O DORI inclui quatro dimensões: localização frontal, transformação de rotação, relações de direção relativa e compreensão de direção canônica. Foram testados 15 MLLMs SOTA, revelando que mesmo os melhores modelos apresentam limitações significativas em julgamentos de orientação fina. (Fonte: HuggingFace Daily Papers)
Artigo de IA: LLMs conseguem inferir relações causais a partir de texto do mundo real?: O artigo “Can Large Language Models Infer Causal Relationships from Real-World Text?” explora a capacidade dos LLMs de inferir relações causais a partir de texto do mundo real. Os pesquisadores desenvolveram um benchmark derivado de literatura acadêmica real, contendo textos de diferentes comprimentos, complexidades e domínios. Experimentos mostram que mesmo os LLMs SOTA enfrentam desafios significativos nesta tarefa, com o melhor modelo alcançando uma pontuação F1 de apenas 0,477, revelando suas dificuldades em lidar com informações implícitas, distinguir fatores relevantes e conectar informações dispersas. (Fonte: HuggingFace Daily Papers)
Artigo de IA: IQBench, avaliando o quão “inteligentes” são os modelos de linguagem visual com testes de QI humanos: O artigo “IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests” lança o IQBench, um novo benchmark projetado para avaliar a inteligência fluida de modelos de linguagem visual (VLM) através de testes de QI visual padronizados. O benchmark é centrado na visão, contendo 500 questões de QI visual coletadas e anotadas manualmente, avaliando a interpretação, os padrões de resolução de problemas e a precisão da previsão final dos modelos. Experimentos mostram que o o4-mini, Gemini-2.5-Flash e Claude-3.7-Sonnet tiveram bom desempenho, mas todos os modelos apresentaram dificuldades em tarefas de raciocínio espacial 3D e anagramas. (Fonte: HuggingFace Daily Papers)
Artigo de IA: PixelThink, rumo a um raciocínio eficiente em cadeia de pixels: O artigo “PixelThink: Towards Efficient Chain-of-Pixel Reasoning” propõe a solução PixelThink, que regula a geração de raciocínio dentro de um paradigma de aprendizado por reforço, integrando a dificuldade da tarefa estimada externamente e a incerteza do modelo medida internamente. O modelo aprende a comprimir o comprimento do raciocínio com base na complexidade da cena e na confiança da previsão. O benchmark ReasonSeg-Diff também é introduzido para avaliação, e experimentos mostram que o método melhora a eficiência do raciocínio e o desempenho geral da segmentação. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Revisitando o debate multiagente como escalonamento em tempo de teste: Um estudo sistemático da eficácia condicional: O artigo “Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness” conceitua o debate multiagente (MAD) como uma técnica de escalonamento de computação em tempo de teste e investiga sistematicamente sua eficácia em relação a métodos de autoagente sob diferentes condições (dificuldade da tarefa, escala do modelo, diversidade de agentes). O estudo descobriu que, para o raciocínio matemático, a vantagem do MAD é limitada, mas é mais eficaz quando a dificuldade do problema aumenta ou a capacidade do modelo diminui; para tarefas de segurança, a otimização colaborativa do MAD pode aumentar a vulnerabilidade, mas configurações diversificadas ajudam a reduzir a taxa de sucesso de ataques. (Fonte: HuggingFace Daily Papers)
Artigo de IA: VF-Eval, avaliando a capacidade dos MLLMs de gerar feedback sobre vídeos AIGC: O artigo “VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos” propõe o novo benchmark VF-Eval para avaliar a capacidade de modelos de linguagem grandes multimodais (MLLM) em interpretar vídeos de conteúdo gerado por IA (AIGC). O VF-Eval inclui quatro tarefas: verificação de coerência, percepção de erros, detecção de tipos de erro e avaliação de raciocínio. A avaliação de 13 MLLMs de ponta mostrou que mesmo o GPT-4.1, com o melhor desempenho, teve dificuldade em manter um bom desempenho em todas as tarefas. (Fonte: HuggingFace Daily Papers)
Artigo de IA: SafeScientist, agente LLM para descobertas científicas conscientes de risco: O artigo “SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents” apresenta um framework de cientista de IA chamado SafeScientist, projetado para aprimorar a segurança e a responsabilidade ética na exploração científica impulsionada por IA. O framework pode rejeitar ativamente tarefas inadequadas ou de alto risco e enfatiza a segurança do processo de pesquisa através de múltiplos mecanismos de defesa, como monitoramento de prompts, monitoramento de colaboração de agentes, monitoramento do uso de ferramentas e componentes de revisão ética. O benchmark SciSafetyBench também é proposto para avaliação. (Fonte: HuggingFace Daily Papers)
Artigo de IA: CXReasonBench, um benchmark para avaliar o raciocínio diagnóstico estruturado em raios-X de tórax: O artigo “CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays” apresenta o fluxo de trabalho CheXStruct e o benchmark CXReasonBench para avaliar se grandes modelos de linguagem visual (LVLM) podem executar etapas de raciocínio clinicamente eficazes no diagnóstico de raios-X de tórax. O benchmark contém 18.988 pares de QA, cobrindo 12 tarefas de diagnóstico e 1.200 casos, suportando avaliação multicaminho e multiestágio, incluindo seleção de região anatômica e localização visual de medições diagnósticas. (Fonte: HuggingFace Daily Papers)
Artigo de IA: ZeroGUI, automação do aprendizado online de GUI com custo humano zero: O artigo “ZeroGUI: Automating Online GUI Learning at Zero Human Cost” propõe o ZeroGUI, um framework de aprendizado online escalável para automatizar o treinamento de agentes GUI com custo humano zero. O ZeroGUI integra geração automática de tarefas baseada em VLM, estimativa automática de recompensa e aprendizado por reforço online de duas fases para interagir continuamente com ambientes GUI e aprender com eles. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Spatial-MLLM, impulsionando as capacidades dos MLLMs em inteligência espacial baseada em visão: O artigo “Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence” propõe o framework Spatial-MLLM para raciocínio espacial baseado em visão a partir de observações puramente 2D. O framework adota uma arquitetura de codificador duplo (um codificador visual semântico e um codificador espacial) e combina uma estratégia de amostragem de quadros com percepção espacial, alcançando desempenho SOTA em múltiplos conjuntos de dados do mundo real. (Fonte: HuggingFace Daily Papers)
Artigo de IA: TrustVLM, julgando se as previsões de modelos de linguagem visual são confiáveis: O artigo “To Trust Or Not To Trust Your Vision-Language Model’s Prediction” introduz o TrustVLM, um framework sem treinamento projetado para avaliar a confiabilidade das previsões de modelos de linguagem visual (VLM). O método utiliza diferenças na representação de conceitos no espaço de embedding de imagem, propondo novas funções de pontuação de confiança para melhorar a detecção de classificações incorretas e demonstrando desempenho SOTA em 17 conjuntos de dados diferentes. (Fonte: HuggingFace Daily Papers)
Artigo de IA: MAGREF, geração de vídeo multirreferência guiada por máscara: O artigo “MAGREF: Masked Guidance for Any-Reference Video Generation” propõe o MAGREF, um framework unificado de geração de vídeo multirreferência. Ele introduz um mecanismo de orientação por máscara que, através de máscaras dinâmicas com reconhecimento de região e conexão de canais em nível de pixel, permite a síntese coerente de vídeos com múltiplos sujeitos sob diversas condições de imagens de referência e prompts de texto, superando as linhas de base de código aberto e comerciais existentes em benchmarks de vídeo com múltiplos sujeitos. (Fonte: HuggingFace Daily Papers)
Artigo de IA: ATLAS, aprendendo a memorizar otimamente o contexto em tempo de teste: O artigo “ATLAS: Learning to Optimally Memorize the Context at Test Time” propõe o ATLAS, um módulo de memória de longo prazo de alta capacidade que aprende a memorizar o contexto otimizando a memória com base nos tokens atuais e passados, superando as características de atualização online dos modelos de memória de longo prazo. Com base nisso, os autores propõem a família de arquiteturas DeepTransformers. Experimentos mostram que o ATLAS supera os Transformers e modelos cíclicos lineares recentes em tarefas de modelagem de linguagem, raciocínio de senso comum, recuperação intensiva e compreensão de contexto longo. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Satori-SWE, método de engenharia de software de escalonamento evolutivo em tempo de teste com eficiência de amostra: O artigo “Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering” propõe o método EvoScale, que trata a geração de código como um processo evolutivo, melhorando o desempenho de modelos pequenos em tarefas de engenharia de software (como SWE-Bench) através da otimização iterativa da saída. O modelo Satori-SWE-32B, através deste método e usando poucas amostras, alcançou ou superou o desempenho de modelos com mais de 100B de parâmetros. (Fonte: HuggingFace Daily Papers)
Artigo de IA: OPO, aprendizado por reforço on-policy com linha de base de recompensa ótima: O artigo “On-Policy RL with Optimal Reward Baseline” propõe o algoritmo OPO, um novo algoritmo simplificado de aprendizado por reforço projetado para resolver os problemas de instabilidade de treinamento e baixa eficiência computacional enfrentados pelos algoritmos de RL atuais ao treinar LLMs. O OPO enfatiza o treinamento on-policy preciso e introduz uma linha de base de recompensa ótima que teoricamente minimiza a variância do gradiente. Experimentos mostram seu desempenho superior e estabilidade de treinamento em benchmarks de raciocínio matemático. (Fonte: HuggingFace Daily Papers)
Artigo de IA: SWE-bench Goes Live! Benchmark de engenharia de software atualizado em tempo real: O artigo “SWE-bench Goes Live!” apresenta o SWE-bench-Live, um benchmark atualizável em tempo real projetado para superar as limitações do SWE-bench existente. A nova versão inclui 1319 tarefas originadas de problemas reais do GitHub desde 2024, cobrindo 93 repositórios, e é equipada com processos de gerenciamento automatizados para permitir escalabilidade e atualizações contínuas, fornecendo assim uma avaliação mais rigorosa e resistente à contaminação de LLMs e agentes. (Fonte: HuggingFace Daily Papers, _akhaliq)
Artigo de IA: ToMAP, treinando persuasores LLM conscientes do oponente com Teoria da Mente: O artigo “ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind” apresenta um novo método chamado ToMAP, que constrói agentes persuasores mais flexíveis integrando dois módulos de teoria da mente para aprimorar sua consciência e análise do estado mental do oponente. Experimentos mostram que persuasores ToMAP com apenas 3B de parâmetros superam grandes linhas de base como o GPT-4o em múltiplos modelos de objetos de persuasão e corpora. (Fonte: HuggingFace Daily Papers)
Artigo de IA: LLMs conseguem enganar o CLIP? Avaliando a composicionalidade adversária de representações multimodais pré-treinadas via atualizações de texto: O artigo “Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates” introduz o benchmark de Composicionalidade Adversária Multimodal (MAC), que utiliza LLMs para gerar amostras de texto enganosas a fim de explorar vulnerabilidades de composicionalidade em representações multimodais pré-treinadas como o CLIP. O estudo propõe um método de autotreinamento que realiza ajuste fino por amostragem de rejeição com filtragem que promove a diversidade, para aumentar a taxa de sucesso do ataque e a diversidade das amostras. (Fonte: HuggingFace Daily Papers)
Artigo de IA: O papel das recompensas ruidosas no aprendizado do raciocínio — A subida molda a sabedoria mais profundamente que o cume: O artigo “The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason” investiga o impacto do ruído de recompensa no pós-treinamento de LLMs para raciocínio através de aprendizado por reforço. O estudo descobriu que os LLMs exibem forte robustez a grandes quantidades de ruído de recompensa; mesmo recompensando apenas a ocorrência de frases chave de raciocínio (sem verificar a correção da resposta), o modelo pode alcançar desempenho comparável a modelos treinados com verificação rigorosa e recompensas precisas. (Fonte: HuggingFace Daily Papers)
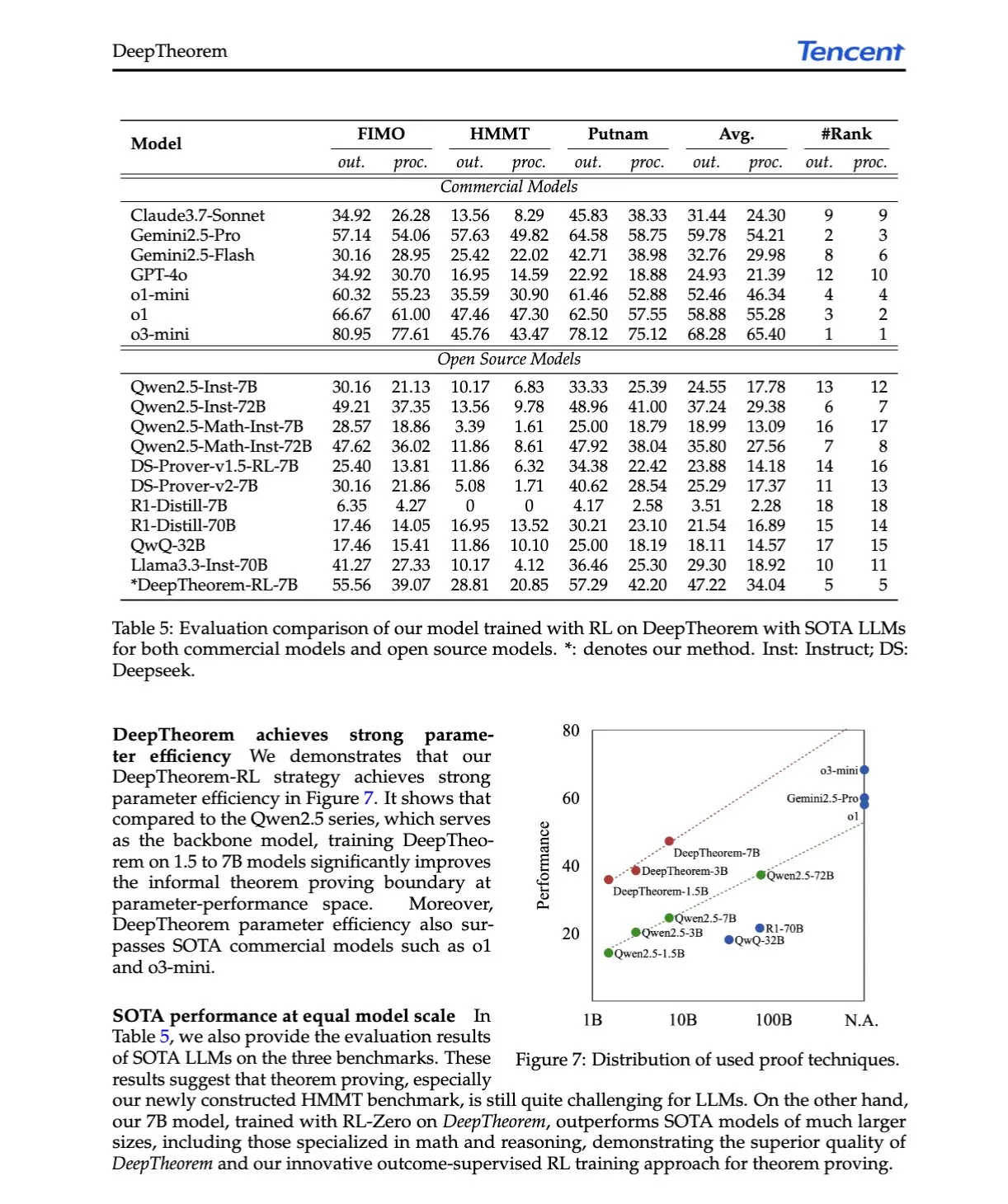
Artigo de IA: DeepTheorem, avançando na prova de teoremas por LLMs através de linguagem natural e aprendizado por reforço: O artigo “DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning” propõe o DeepTheorem, um framework de prova de teoremas informal que utiliza linguagem natural para aprimorar o raciocínio matemático de LLMs. O framework inclui um conjunto de dados de benchmark em grande escala (121.000 teoremas e provas informais de nível IMO) e uma política de RL projetada especificamente para prova de teoremas informal (RL-Zero). (Fonte: HuggingFace Daily Papers, teortaxesTex)
Artigo de IA: D-AR, difusão via modelos autorregressivos: O artigo “D-AR: Diffusion via Autoregressive Models” propõe o novo paradigma D-AR, que reformula o processo de difusão de imagem como um processo padrão de previsão do próximo token autorregressivo. Através de um tokenizer projetado, as imagens são convertidas em sequências de tokens discretos, onde tokens em diferentes posições podem ser decodificados em diferentes etapas de denoising de difusão no espaço de pixels. O método atinge um FID de 2,09 no ImageNet usando um backbone Llama de 775M e 256 tokens discretos. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Table-R1, escalonamento em tempo de inferência para raciocínio em tabelas: O artigo “Table-R1: Inference-Time Scaling for Table Reasoning” explora pela primeira vez o escalonamento em tempo de inferência em tarefas de raciocínio em tabelas. Os pesquisadores desenvolveram e avaliaram duas estratégias de pós-treinamento: destilação de trajetórias de inferência de modelos de ponta (Table-R1-SFT) e aprendizado por reforço com recompensas verificáveis (Table-R1-Zero). O Table-R1-Zero (7B parâmetros) alcança ou supera o desempenho do GPT-4.1 e DeepSeek-R1 em diversas tarefas de raciocínio em tabelas. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Muddit, modelo de difusão discreta unificado para geração além de texto para imagem: O artigo “Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model” apresenta o Muddit, um modelo Transformer de difusão discreta unificado que suporta geração paralela rápida de modalidades de texto e imagem. O Muddit integra os fortes priors visuais de um backbone texto-para-imagem pré-treinado com um decodificador de texto leve, sendo competitivo em qualidade e eficiência. (Fonte: HuggingFace Daily Papers)
Artigo de IA: VideoReasonBench, MLLMs conseguem realizar raciocínio complexo de vídeo centrado na visão?: O artigo “VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?” introduz o VideoReasonBench, um benchmark projetado para avaliar a capacidade de raciocínio complexo de vídeo centrado na visão. O benchmark contém vídeos de sequências de operações de granularidade fina, com perguntas que avaliam as capacidades de recordação, inferência e previsão. Experimentos mostram que a maioria dos MLLMs SOTA tem desempenho ruim neste benchmark, enquanto o Gemini-2.5-Pro aprimorado com pensamento se destacou. (Fonte: HuggingFace Daily Papers, OriolVinyalsML)
Artigo de IA: GeoDrive, modelo de mundo de direção com percepção geométrica 3D e controle preciso de ações: O artigo “GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control” propõe o GeoDrive, que integra explicitamente condições geométricas 3D robustas em um modelo de mundo de direção para aprimorar a compreensão espacial e a controlabilidade das ações. O método aprimora os efeitos de renderização durante o treinamento através de um módulo de edição dinâmica. Experimentos demonstram sua superioridade em precisão de ação e percepção espacial 3D em relação aos modelos existentes. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Orientação adaptativa sem classificador via mascaramento dinâmico de baixa confiança: O artigo “Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking” propõe o método A-CFG, que personaliza a entrada incondicional da orientação sem classificador (CFG) utilizando a confiança instantânea da previsão do modelo. O A-CFG identifica tokens de baixa confiança em cada etapa de um modelo de linguagem de difusão iterativa (mascarada) e os remascara temporariamente, criando assim entradas incondicionais dinâmicas e localizadas, tornando o efeito corretivo do CFG mais preciso. (Fonte: HuggingFace Daily Papers)
Artigo de IA: PatientSim, um simulador orientado por persona para interações médico-paciente realistas: O artigo “PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions” apresenta o PatientSim, um simulador que gera personas de pacientes realistas e diversas com base em perfis clínicos do conjunto de dados MIMIC e quatro eixos de persona (personalidade, proficiência linguística, nível de recordação do histórico médico, nível de confusão cognitiva). O objetivo é fornecer um sistema de interação com pacientes realista para treinar ou avaliar LLMs médicos. (Fonte: HuggingFace Daily Papers)
Artigo de IA: LoRAShop, geração e edição de imagens multiconceito sem treinamento com Transformers de fluxo retificado: O artigo “LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers” apresenta o primeiro framework para edição de imagens multiconceito usando modelos LoRA, o LoRAShop. O framework utiliza os padrões de interação de características internas do Transformer de difusão estilo Flux para derivar máscaras latentes desacopladas para cada conceito e mistura os pesos LoRA apenas dentro das regiões conceituais, permitindo a integração perfeita de múltiplos sujeitos ou estilos. (Fonte: HuggingFace Daily Papers)
Artigo de IA: AnySplat, splatting gaussiano 3D feed-forward a partir de visualizações não restritas: O artigo “AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views” apresenta o AnySplat, uma rede feed-forward para síntese de novas visualizações a partir de um conjunto de imagens não calibradas. Diferentemente dos pipelines tradicionais de renderização neural, o AnySplat pode prever primitivas gaussianas 3D (codificando a geometria e aparência da cena) bem como os parâmetros intrínsecos e extrínsecos da câmera para cada imagem de entrada com uma única passagem forward, sem necessidade de anotações de pose, e suporta síntese de novas visualizações em tempo real. (Fonte: HuggingFace Daily Papers)
Artigo de IA: ZeroSep, separando qualquer coisa em áudio com zero treinamento: O artigo “ZeroSep: Separate Anything in Audio with Zero Training” descobre que, apenas com modelos de difusão de áudio guiados por texto pré-treinados, é possível alcançar separação de fontes sonoras zero-shot sob configurações específicas. O método ZeroSep inverte o áudio misturado para o espaço latente do modelo de difusão e usa orientação condicional por texto no processo de denoising para recuperar fontes sonoras individuais, sem qualquer treinamento específico para a tarefa ou ajuste fino. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Estudo sobre minimização de entropia one-shot: O artigo “One-shot Entropy Minimization” descobriu, através do treinamento de 13.440 grandes modelos de linguagem, que a minimização de entropia requer apenas um único dado não rotulado e 10 etapas de otimização para alcançar ou até mesmo superar as melhorias de desempenho obtidas pelo aprendizado por reforço baseado em regras que utiliza milhares de dados e recompensas cuidadosamente projetadas. Este resultado pode levar a uma reconsideração dos paradigmas de pós-treinamento de LLMs. (Fonte: HuggingFace Daily Papers)
Artigo de IA: ChartLens, atribuição visual de granularidade fina em gráficos: O artigo “ChartLens: Fine-grained Visual Attribution in Charts”, abordando o problema de MLLMs tenderem a produzir alucinações na compreensão de gráficos, introduz a tarefa de atribuição visual posterior em gráficos e propõe o algoritmo ChartLens. O algoritmo usa técnicas de segmentação para identificar objetos do gráfico e realiza atribuição visual de granularidade fina com MLLMs através de prompts de conjunto de marcadores. Também foi lançado o benchmark ChartVA-Eval, contendo anotações de atribuição de granularidade fina para gráficos de áreas como finanças, política e economia. (Fonte: HuggingFace Daily Papers)
Artigo de IA: Explorando padrões estruturais de conhecimento em grandes modelos de linguagem sob uma perspectiva de grafo: O artigo “A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models” estuda os padrões estruturais de conhecimento em LLMs sob uma perspectiva de grafo. A pesquisa quantifica o conhecimento dos LLMs nos níveis de triplas e entidades, analisa sua relação com atributos estruturais de grafo como o grau do nó, e revela a homogeneidade do conhecimento (entidades topologicamente próximas têm níveis de conhecimento semelhantes). Com base nisso, foi desenvolvido um modelo de aprendizado de máquina em grafos para estimar o conhecimento da entidade e usado para verificação de conhecimento. (Fonte: HuggingFace Daily Papers)
💼 Negócios
Empresa de inteligência incorporada Lumos Robotics arrecada quase 200 milhões em meio ano, firma parcerias com COSCO Shipping e outros: A Lumos Robotics (鹿明机器人), empresa de robôs com inteligência incorporada fundada pelo ex-executivo da Dreame, Yu Chao, anunciou a conclusão de uma rodada de financiamento Angel++, com investidores incluindo Fosun RZ Capital, Dematic Technology e Wuzhong Financial Holding. Em meio ano, a empresa arrecadou cumulativamente quase 200 milhões de RMB. Focada no cenário doméstico, seus produtos incluem os robôs humanoides das séries LUS e MOS e componentes principais. Já lançou o robô humanoide em tamanho real LUS e estabeleceu parcerias estratégicas com a Dematic Technology, COSCO Shipping e outros, acelerando a comercialização da inteligência incorporada em cenários como logística e manufatura inteligente. (Fonte: 36氪)

Snorkel AI conclui rodada de financiamento Série D de US$ 100 milhões, lança avaliação de agentes de IA e serviços de dados especializados: A empresa de IA para data centers Snorkel AI anunciou a conclusão de uma rodada de financiamento Série D de US$ 100 milhões, liderada pela Valor Equity Partners, elevando seu financiamento total para US$ 235 milhões. Simultaneamente, a empresa lançou o Snorkel Evaluate (plataforma de avaliação de IA para agentes de data center) e o Expert Data-as-a-Service, visando ajudar empresas a construir e implantar agentes de IA mais confiáveis e especializados. (Fonte: realDanFu, percyliang, tri_dao, krandiash)
Departamento de Energia dos EUA anuncia parceria com Dell e Nvidia para desenvolver supercomputador de próxima geração “Doudna”: O Departamento de Energia dos EUA anunciou um contrato com a Dell para desenvolver o supercomputador de próxima geração do Laboratório Nacional Lawrence Berkeley, chamado “Doudna”, como o NERSC-10. O sistema será alimentado pela plataforma Vera Rubin de próxima geração da Nvidia e espera-se que entre em operação em 2026, com desempenho mais de 10 vezes superior ao atual carro-chefe Perlmutter. O objetivo é suportar cargas de trabalho de computação de alto desempenho e IA em grande escala, ajudando os EUA a vencer a corrida pela dominância global em IA. (Fonte: 36氪, nvidia)

🌟 Comunidade
DeepSeek R1-0528 gera debate acalorado, com foco em desempenho, alucinações e chamada de ferramentas: O lançamento do DeepSeek R1-0528 gerou ampla discussão na comunidade. A maioria das opiniões considera que houve melhorias significativas em matemática, programação e raciocínio lógico geral, aproximando-se ou até superando alguns modelos de código fechado. A nova versão progrediu na redução da taxa de alucinação e adicionou suporte para saída JSON e chamadas de função. Ao mesmo tempo, sua versão destilada Qwen3-8B também chamou a atenção por seu excelente desempenho matemático em um modelo pequeno. A comunidade geralmente acredita que a DeepSeek consolidou sua liderança no campo de código aberto e aguarda o lançamento da versão R2. (Fonte: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Modelo de edição de imagem AI FLUX.1 Kontext chama a atenção, enfatizando a compreensão de contexto e a consistência de personagens: O modelo de edição de imagem FLUX.1 Kontext, lançado pela Black Forest Labs, chamou a atenção da comunidade por sua capacidade de processar simultaneamente entradas de texto e imagem e manter a consistência dos personagens. O feedback dos usuários indica que ele tem um desempenho excelente em tarefas como edição de imagem, transferência de estilo e sobreposição de texto, especialmente em edições multi-turno, onde consegue preservar bem as características do sujeito. Plataformas como a Replicate já disponibilizaram o modelo e forneceram relatórios de teste detalhados e dicas de uso. (Fonte: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

Agentes de IA mudarão significativamente os modelos de busca e publicidade: Arav Srinivas, CEO da Perplexity AI, acredita que, à medida que os agentes de IA realizarem buscas em nome dos usuários, o volume de consultas humanas em motores de busca como o Google diminuirá drasticamente. Isso levará a uma redução no CPM/CPC da publicidade, e os gastos com publicidade poderão migrar para mídias sociais ou plataformas de IA. Os usuários não precisarão mais realizar buscas frequentes por palavras-chave; em vez disso, assistentes de IA fornecerão informações proativamente. (Fonte: AravSrinivas)
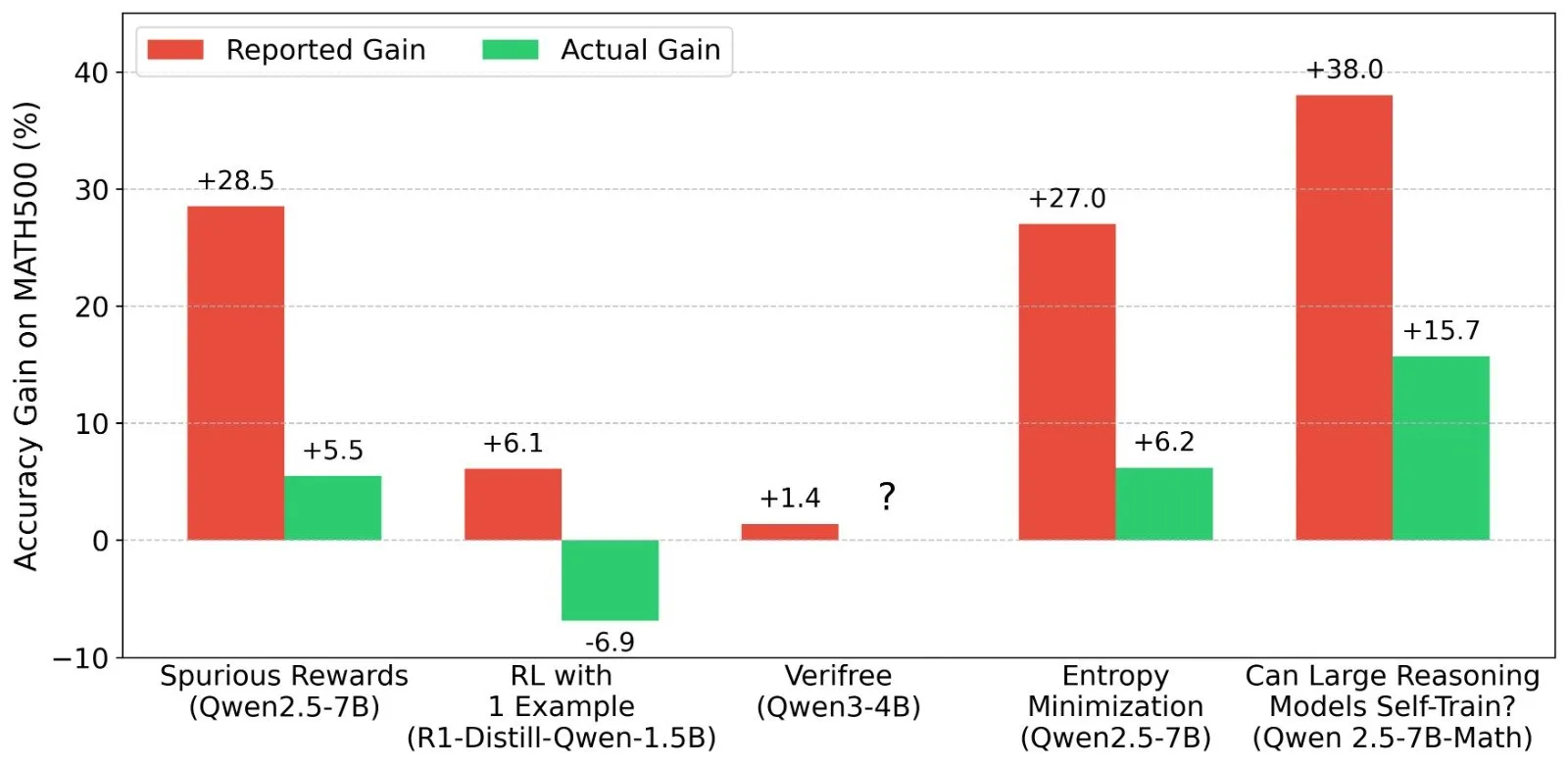
Discussão sobre os resultados do Aprendizado por Reforço (RL) em LLMs: veracidade do sinal de recompensa e capacidade do modelo: Pesquisadores como Shashwat Goel questionaram o fenômeno recente em estudos de RL com LLMs, onde modelos melhoram o desempenho mesmo sem um sinal de recompensa real, apontando que alguns estudos podem subestimar a capacidade de base dos modelos pré-treinados ou ter outros fatores de confusão. A discussão levou a uma análise aprofundada do desempenho de modelos como o Qwen em RL e à reflexão sobre a eficácia do RLVR (Aprendizado por Reforço com Recompensa Verificável), enfatizando a necessidade de linhas de base mais rigorosas e otimização de prompts ao avaliar os efeitos do RL. (Fonte: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding” gera discussão, enfatizando padrões de segurança e riscos de dívida técnica: “Vibe coding” (programação por “vibração”, referindo-se a uma forma de programar que depende mais da intuição e iteração rápida do que de especificações rigorosas) tornou-se um tópico quente na comunidade. Amjad Masad, CEO da Replit, acredita que essa abordagem capacita novos desenvolvedores, mas as plataformas devem fornecer configurações padrão seguras. Ao mesmo tempo, Pedro Domingos comentou que “programação por vibração é o Godzilla da dívida técnica”, insinuando os problemas de manutenção a longo prazo que pode causar. A Semafor relatou uma falha de segurança na Lovable devido à configuração inadequada da política de RLS, levantando ainda mais preocupações sobre a segurança dessa abordagem de programação. (Fonte: alexalbert__, amasad, pmddomingos, gfodor)
O papel da IA na engenharia de software: aumento de eficiência e a insubstituibilidade dos programadores humanos: Salvatore Sanfilippo, pai do Redis, compartilhou sua experiência, afirmando que, embora a IA (como o Gemini 2.5 Pro) seja valiosa na assistência à programação, revisão de código e validação de ideias, os programadores humanos ainda superam em muito a IA na resolução criativa de problemas e no pensamento fora da caixa. A discussão na comunidade apontou ainda que a IA atualmente se assemelha mais a um “pato de borracha inteligente”, capaz de auxiliar no raciocínio, mas suas sugestões precisam ser avaliadas com cautela, e a dependência excessiva pode enfraquecer as habilidades centrais dos desenvolvedores. Mitchell Hashimoto também compartilhou um caso em que um LLM o ajudou a localizar rapidamente problemas de compilação do Clang, economizando muito tempo. (Fonte: mitchellh, 36氪)
A questão de se a IA substituirá empregos em grande escala continua a gerar atenção: Dario Amodei, CEO da Anthropic, prevê que a IA pode levar ao desaparecimento de metade dos cargos de escritório de nível básico, enquanto Mark Cuban acredita que a IA criará novas empresas e novos empregos. A comunidade discute intensamente sobre isso, com alguns argumentando que trabalhos como atendimento ao cliente, redação júnior e parte do desenvolvimento já foram afetados, mas a IA ainda tem dificuldade em substituir humanos em áreas que exigem criatividade, tomada de decisão complexa e alta interação interpessoal. O consenso geral é que a IA mudará a natureza do trabalho, e os humanos precisarão se adaptar e aprimorar sua capacidade de colaborar com a IA. (Fonte: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI Agent (agente inteligente) torna-se a próxima entrada de interação, gerando competição entre grandes empresas: Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu, Kuka e outras empresas de tecnologia nacionais e internacionais estão investindo em AI Agents. Agentes inteligentes podem pensar profundamente, planejar autonomamente, tomar decisões e executar tarefas complexas, sendo considerados a próxima entrada de interação após motores de busca e aplicativos. Atualmente, formaram-se três forças principais: construtores de ecossistemas tecnológicos representados por OpenAI e Baidu; provedores de serviços empresariais para cenários verticais representados por Microsoft e Alibaba Cloud; e fabricantes de terminais de hardware e software representados por Huawei e Kuka. (Fonte: 36氪)

💡 Outros
Expansão internacional da IA chinesa acelera, mudando da exportação de produtos para a construção de ecossistemas: O relatório “O Crescimento Transoceânico da IA Chinesa” aponta que a expansão internacional das empresas de IA chinesas entrou em uma via rápida de grande escala, com 76% concentradas no nível de aplicação. O caminho da expansão evoluiu de aplicações iniciais do tipo ferramenta para, em uma fase intermediária, a exportação de soluções setoriais combinadas com vantagens tecnológicas e, no estágio atual, foca na exportação de ecossistemas tecnológicos, promovendo padrões técnicos e colaboração de código aberto. A expansão internacional da IA apresenta uma penetração gradual “do próximo para o distante” e enfrenta desafios como localização, conformidade ética e marketing de marca. (Fonte: 36氪)

Departamento de Energia dos EUA compara corrida da IA ao “novo Projeto Manhattan”, enfatizando que os EUA vencerão: Ao anunciar o supercomputador de próxima geração “Doudna”, o Departamento de Energia dos EUA chamou a competição pelo desenvolvimento da IA de “o Projeto Manhattan de nosso tempo” e declarou que os EUA vencerão essa corrida. Essa declaração gerou discussões na comunidade sobre a competição tecnológica entre grandes potências, ética da IA e cooperação internacional. (Fonte: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
Avanços da IA na criação de conteúdo levantam reflexões sobre “autenticidade” e “criatividade”: A comunidade discutiu as aplicações da IA em áreas como design de moda, criação de quadrinhos e geração de vídeos. Por um lado, a IA pode gerar rapidamente conteúdo diversificado, chegando a transformar em vídeo obras de quadrinhos de anos atrás; por outro lado, esse conteúdo gerado às vezes parece estranho ou carece de profundidade. Isso levantou reflexões sobre se o conteúdo gerado por IA é “melhor” e qual papel a criatividade humana desempenhará na era da IA. (Fonte: Reddit r/ChatGPT, Reddit r/artificial)
