Palavras-chave:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, recompensa aleatória, recompensa errônea, desempenho do modelo, aprendizagem por reforço, futuro do RLHF/RLAIF, recompensa aleatória melhora o desempenho do modelo, treinamento com recompensa errônea no Qwen2.5-Math-7B, conjunto de testes MATH-500, aprendizagem de sinal de reforço
🔥 Foco
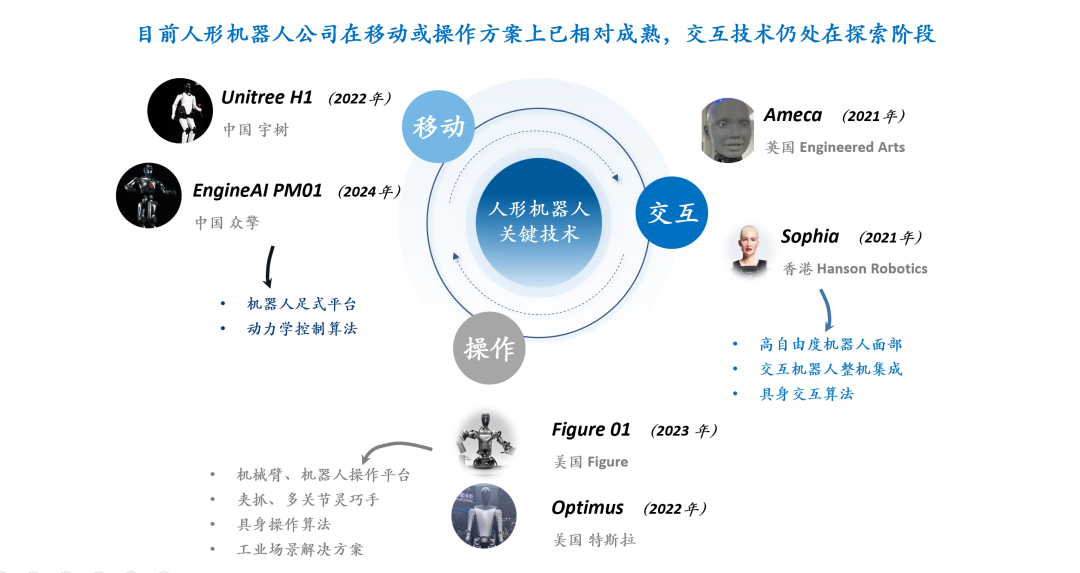
O futuro do RLHF/RLAIF: Recompensas aleatórias/erradas também podem melhorar o desempenho do modelo? : Experimentos de Stella Li mostram que treinar o modelo Qwen2.5-Math-7B usando recompensas aleatórias ou incorretas melhorou o desempenho no conjunto de testes MATH-500 em 21% e 25%, respectivamente, aproximando-se do aumento de 28,8% obtido com recompensas reais. A pesquisa de Rulin Shao, compartilhada por natolambert, também descobriu que o RLVR (Reinforcement Learning from Verifier Reward), ao usar recompensas falsas, aumentou o uso de código pelo modelo Olmo, mas o desempenho diminuiu, enquanto impedir o uso de código, ao contrário, melhorou o desempenho. Essas descobertas desafiam a dependência tradicional do RLHF/RLAIF em dados de preferência humana de alta qualidade, sugerindo que os modelos podem aprender a explorar um espaço de estratégia mais amplo por meio de sinais de recompensa, mesmo que a recompensa em si não seja perfeita, ela pode estimular capacidades latentes do modelo ou otimizar comportamentos existentes. Isso pode abrir novos caminhos para reduzir a dependência de anotações manuais caras e explorar métodos de alinhamento de modelos mais eficientes, mas é preciso estar atento ao risco de o modelo aprender comportamentos errados. (Fonte: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
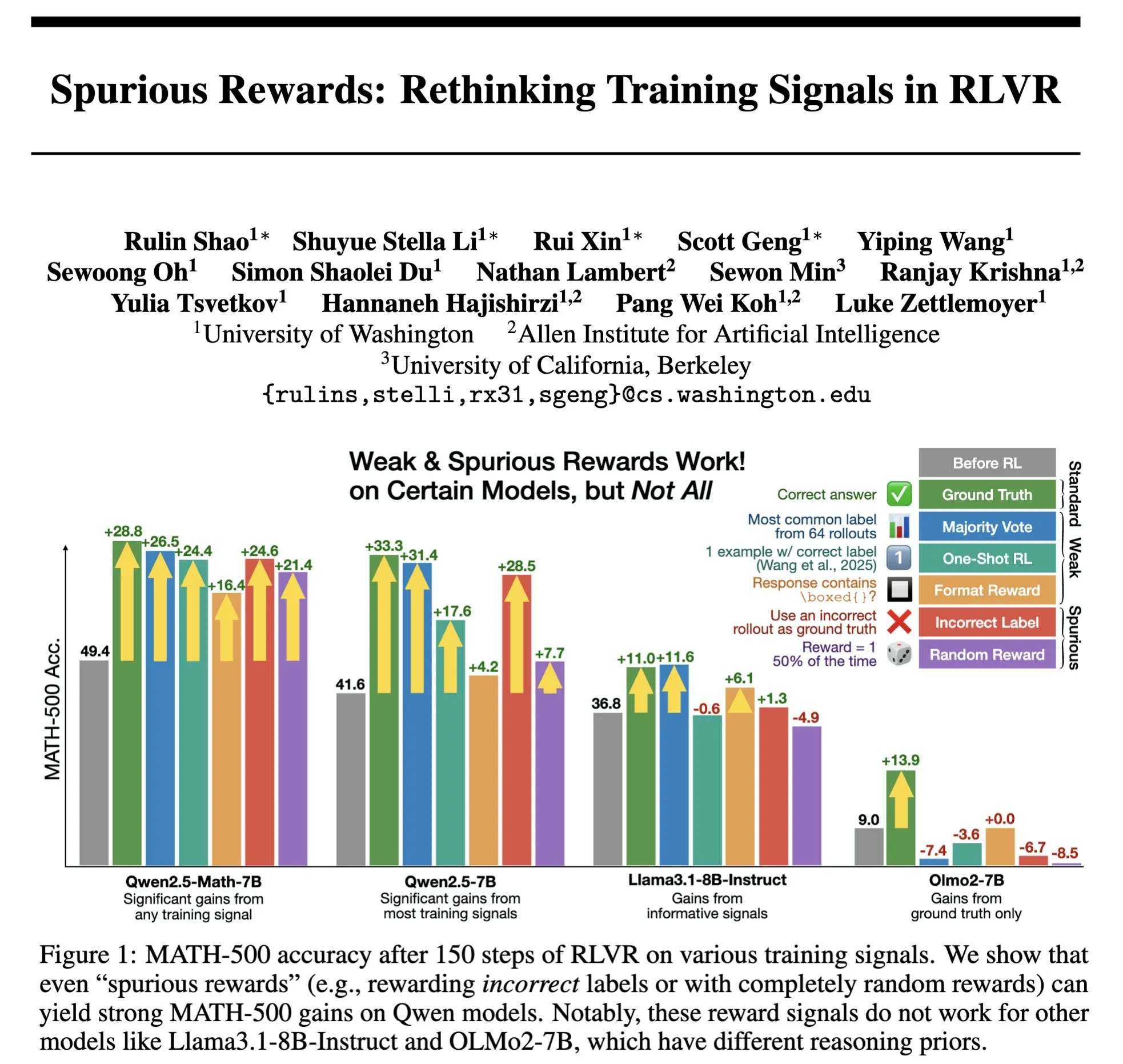
Hazy Research lança Low-Latency-Llama Megakernel: Inferência do Llama 1B em um único núcleo CUDA : A Hazy Research lançou o Low-Latency-Llama Megakernel, capaz de realizar todo o processo de propagação forward do modelo Llama 1B dentro de um único núcleo CUDA. Essa tecnologia, ao integrar a computação em um único kernel, elimina as fronteiras de sincronização impostas pelas chamadas de kernel serializadas tradicionais, otimizando assim o agendamento de computação e memória para alcançar menor latência. Andrej Karpathy elogiou bastante essa conquista, considerando-a a única maneira de alcançar a orquestração ideal entre computação e memória. Este avanço é de grande importância para cenários com requisitos rigorosos de latência, como computação de borda e aplicações de IA em tempo real, e espera-se que impulsione a implantação de modelos de linguagem pequenos mais eficientes e ágeis. (Fonte: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek AI lança rStar-Coder: Construção de um vasto conjunto de dados validado para inferência de código, elevando significativamente a capacidade de codificação de modelos pequenos : Pesquisadores da Microsoft e da DeepSeek lançaram o projeto rStar-Coder, que visa resolver o problema da escassez de conjuntos de dados de alta qualidade e dificuldade no campo da inferência de código. Para isso, construíram um conjunto de dados verificado em larga escala, contendo 418.000 problemas de código de nível de competição, 580.000 soluções de inferência longas e casos de teste abundantes. O projeto melhora a capacidade de inferência de código dos LLMs através da utilização abrangente de problemas de competição de programação existentes e soluções oracle para sintetizar novos problemas, projetando pipelines confiáveis para geração de casos de teste de entrada/saída e usando casos de teste para validar soluções de inferência longas de alta qualidade. Experimentos mostram que os modelos Qwen (1.5B-14B) treinados com o conjunto de dados rStar-Coder tiveram um desempenho excelente em vários benchmarks de inferência de código. Por exemplo, o Qwen2.5-7B aumentou sua precisão no LiveCodeBench de 17,4% para 57,3%, superando o o3-mini (low); no USACO, o modelo 7B também superou o QWQ-32B, que é maior. (Fonte: HuggingFace Daily Papers)
Instituto de Automação da Academia Chinesa de Ciências propõe AutoThink: Permitindo que grandes modelos decidam autonomamente se devem “pensar profundamente” : Em resposta ao fenômeno de “pensamento excessivo”, onde grandes modelos de linguagem realizam inferências longas mesmo para problemas simples, o Instituto de Automação da Academia Chinesa de Ciências, em colaboração com o Laboratório Peng Cheng, propôs o método AutoThink. Este método, ao adicionar “reticências” (…) no prompt e combinar aprendizado por reforço em três estágios (estabilização de padrão, otimização de comportamento, poda de inferência), permite que o modelo escolha autonomamente se deve realizar um pensamento profundo e quanto pensar, com base na dificuldade do problema. Experimentos mostram que o AutoThink pode melhorar o desempenho de modelos como o DeepSeek-R1 em benchmarks de matemática, ao mesmo tempo em que reduz significativamente o consumo de tokens de inferência. Por exemplo, no DeepScaleR, pode economizar 10% adicionais de tokens. Esta pesquisa visa permitir que os modelos alcancem o “pensamento sob demanda”, equilibrando a eficiência da inferência e a precisão. (Fonte: 36氪, _akhaliq)

Sakana AI lança Sudoku-Bench, revelando deficiências dos principais grandes modelos em raciocínio de “Sudoku mutante” : A Sakana AI, startup de Llion Jones, um dos autores do Transformer, lançou o Sudoku-Bench, um benchmark contendo desde Sudokus modernos “mutantes” de 4×4 até complexos 9×9, projetado para avaliar a capacidade de raciocínio criativo em várias etapas da IA. Os resultados dos testes mostram que os principais grandes modelos, incluindo Gemini 2.5 Pro, GPT-4.1 e Claude 3.7, tiveram uma taxa de acerto geral inferior a 15% sem assistência. Em Sudokus modernos 9×9, a taxa de acerto do o3 Mini High foi de apenas 2,9%. Isso indica que os modelos têm um desempenho ruim ao enfrentar problemas novos que exigem raciocínio lógico real em vez de correspondência de padrões, frequentemente apresentando soluções erradas, desistindo ou interpretando mal as regras. O CEO da NVIDIA, Jensen Huang, acredita que esses quebra-cabeças ajudam a melhorar o raciocínio da IA. A Sakana AI também divulgou dados de treinamento relevantes, incluindo registros do processo de resolução em colaboração com um famoso canal de Sudoku. (Fonte: 36氪)

🎯 Tendências
Meta reorganiza equipe de IA, perda de membros centrais do FAIR chama a atenção : A Meta anunciou uma reorganização de sua equipe de IA, dividindo-a em uma equipe de produtos de IA liderada por Connor Hayes e um departamento de fundamentos de AGI coliderado por Ahmad Al-Dahle e Amir Frenkel. A primeira se concentrará em produtos para o consumidor final, enquanto a última se dedicará à pesquisa e desenvolvimento de modelos fundamentais como o Llama. É importante notar que o departamento de pesquisa fundamental em inteligência artificial, FAIR, permanece independente, mas algumas equipes multimídia foram incorporadas ao departamento de fundamentos de AGI. Este ajuste visa aumentar a velocidade e flexibilidade do desenvolvimento. No entanto, a Meta enfrenta desafios como a recepção morna do Llama 4, a crescente concorrência no campo de código aberto e a perda de talentos centrais. Dos 14 autores originais envolvidos no desenvolvimento do Llama, 11 já deixaram a empresa, muitos dos quais se juntaram ou fundaram concorrentes como a Mistral AI. O laboratório FAIR também passou por mudanças na liderança e ajustes na direção da pesquisa, levantando preocupações sobre sua posição dentro da empresa e sua capacidade de inovação futura. (Fonte: 36氪)

Google DeepMind lança SignGemma: Novo modelo para tradução de língua de sinais : O Google DeepMind anunciou o lançamento do SignGemma, descrito como seu modelo mais poderoso até o momento para tradução de língua de sinais para texto em linguagem falada. Espera-se que o modelo se junte à família de modelos Gemma ainda este ano e seja lançado em formato de código aberto. O lançamento do SignGemma visa abrir novas possibilidades para tecnologias inclusivas, aumentando a eficiência e a conveniência da comunicação para usuários de língua de sinais. O Google DeepMind convida os usuários a fornecer feedback e participar dos testes iniciais. (Fonte: GoogleDeepMind, demishassabis)
Tencent Hunyuan lança pesos do modelo HunyuanPortrait, capaz de transformar retratos estáticos em vídeos dinâmicos : A equipe Tencent Hunyuan liberou os pesos de seu modelo de imagem para vídeo HunyuanPortrait, permitindo que os usuários façam o download e o utilizem localmente. O modelo foca na conversão de retratos estáticos de pessoas em vídeos dinâmicos, aplicável a diversos cenários como personagens de jogos, avatares virtuais, humanos digitais, guias de compras inteligentes, etc., permitindo que imagens faciais ganhem movimento, aumentando a vivacidade e o realismo da interação. Os modelos, repositórios de código e artigos relacionados já foram publicados. (Fonte: karminski3, Reddit r/LocalLLaMA)

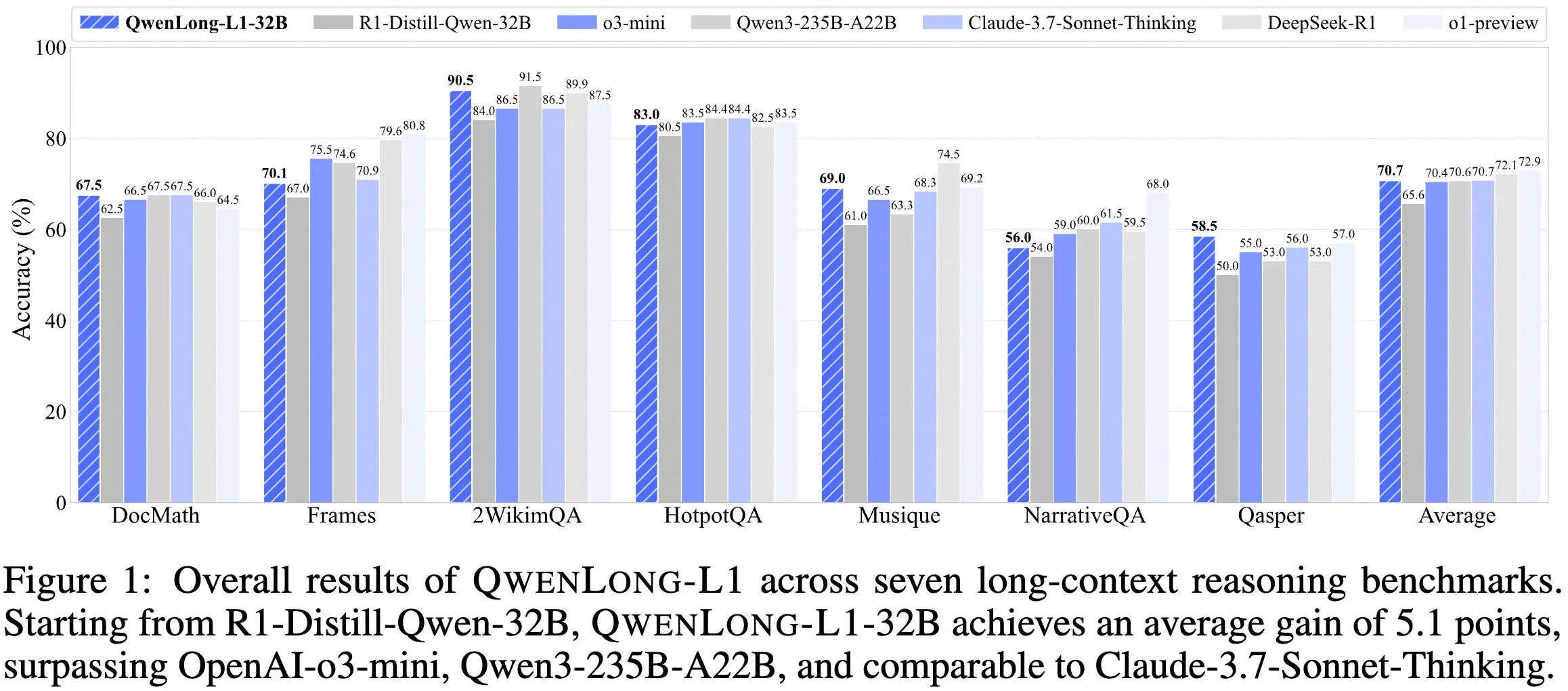
Equipe QwenDoc lança modelo de inferência de contexto longo QwenLong-L1-32B : A equipe QwenDoc lançou o modelo de inferência de contexto longo de 128K QwenLong-L1-32B, treinado com base em aprendizado por reforço. O modelo, ajustado a partir do DeepSeek-R1-Distill-Qwen-32B, obteve uma pontuação de 90,5 no conjunto de testes de inferência multi-salto 2WikiMultihopQA, um aumento de 6,5 pontos em relação ao modelo original, enfatizando a capacidade de não apenas encontrar conteúdo em contextos longos, mas também conectar pistas para realizar inferências. Embora o comprimento de contexto de 128K não seja o mais longo atualmente, sua notável capacidade de inferência oferece uma nova opção para o processamento de documentos longos e complexos. O modelo, o artigo e o repositório de código foram disponibilizados publicamente. (Fonte: karminski3)
HKUST e Apple, entre outras instituições, colaboram no lançamento da série de métodos Laser para otimizar a eficiência e precisão da inferência de grandes modelos : Pesquisadores da HKUST, CityU, Universidade de Waterloo e Apple propuseram a série de métodos Laser (incluindo Laser-D, Laser-DE), visando resolver o problema do consumo excessivo de tokens por grandes modelos de linguagem (LRM) em problemas simples. O método, através de um framework unificado de design de recompensa por comprimento, recompensa baseada no comprimento alvo e função degrau, e um mecanismo dinâmico de percepção de dificuldade, alcançou um aumento de desempenho de 6,1 pontos em benchmarks complexos de raciocínio matemático como o AIME24, enquanto reduziu o uso de tokens em 63%. A pesquisa descobriu que os modelos treinados apresentam menos “auto-reflexão” redundante e um padrão de pensamento mais saudável, equilibrando efetivamente a eficiência e a precisão da inferência do modelo. (Fonte: 36氪)

Versão gratuita do Anthropic Claude agora suporta funcionalidade de pesquisa na web : A Anthropic anunciou que os usuários da versão gratuita de seu assistente de IA, Claude, agora podem usar a funcionalidade de pesquisa na web. Isso significa que, ao responder a perguntas, o Claude pode obter as informações mais recentes da internet para aprimorar a relevância e a precisão de suas respostas. A empresa afirma que cada resposta contendo resultados de pesquisa fornecerá citações em linha, facilitando a verificação das fontes de informação pelos usuários. (Fonte: AnthropicAI)
PKU-DS-LAB lança FairyR1: Modelo de inferência de 32B ajustado a partir do DeepSeek-R1-Distill-Qwen-32B : O Laboratório de Ciência de Dados da Universidade de Pequim (PKU-DS-LAB) lançou o FairyR1, um modelo de inferência com 32 bilhões de parâmetros, sob a licença Apache 2.0. O modelo, através do método de “destilação e fusão”, alega alcançar o desempenho de modelos maiores com apenas 5% dos parâmetros. O FairyR1 foi ajustado a partir do DeepSeek-R1-Distill-Qwen-32B, e seus dados de treinamento também foram disponibilizados no Hugging Face Hub. Este trabalho dá continuidade à linha de pesquisa do TinyR1, filtrando ativamente o conjunto de dados (cerca de 10.000 trajetórias), realizando SFT separadamente para matemática e código, e usando Arcee Fusion para a fusão de modelos. (Fonte: huggingface, teortaxesTex, stablequan)
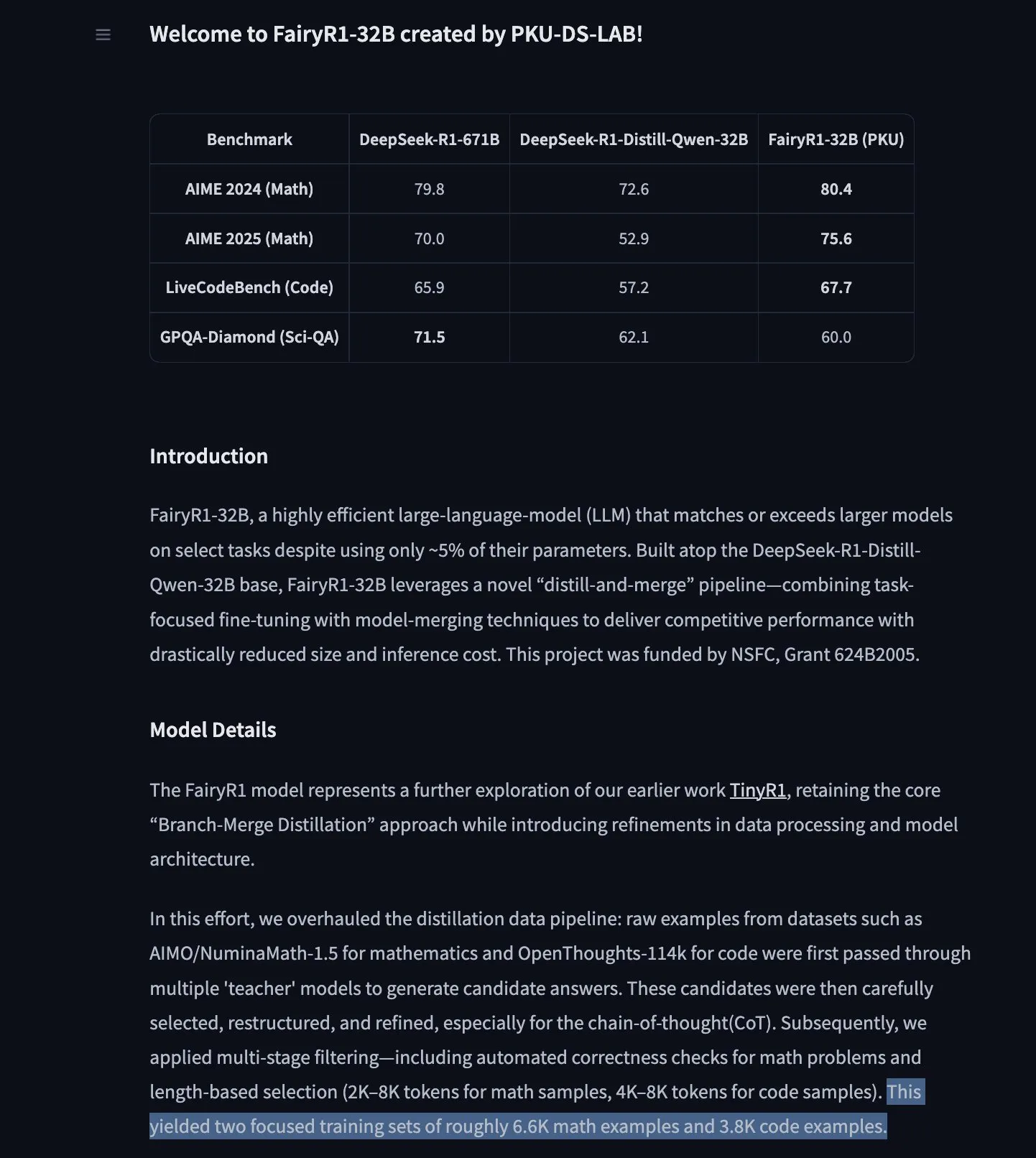
Modelo de previsão de séries temporais TimesFM do Google chega ao Hugging Face Transformers : O modelo TimesFM do Google foi integrado à biblioteca Hugging Face Transformers. Trata-se de um modelo semelhante ao GPT, pré-treinado com 100 bilhões de pontos de dados temporais reais de diversas fontes, como Google Trends e visualizações de páginas da Wikipedia. Alega-se que o TimesFM supera modelos especificamente ajustados em tarefas de previsão zero-shot, fornecendo uma nova ferramenta poderosa para análise de séries temporais. (Fonte: huggingface)
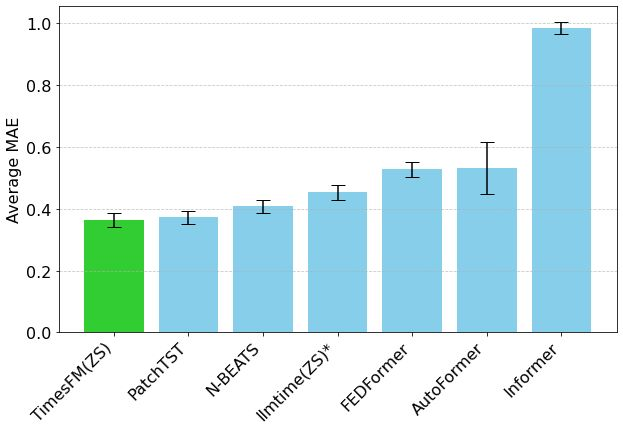
Hugging Face lança Mixture of Thoughts: Conjunto de dados de inferência geral selecionado : Lewis Tunstall e outros pesquisadores do Hugging Face lançaram o conjunto de dados “Mixture of Thoughts”. Este conjunto de dados foi cuidadosamente selecionado a partir de mais de 1 milhão de amostras de dados públicos, através de extensos experimentos de ablação, resultando em cerca de 350.000 amostras focadas na capacidade de inferência geral. Modelos treinados com este conjunto de dados misto alcançam ou superam o desempenho dos modelos destilados do DeepSeek em benchmarks de matemática, código e ciência (como o GPQA). A pesquisa valida a eficácia da metodologia de “aditividade” proposta no Phi-4-reasoning, que permite otimizar independentemente a mistura de dados para cada domínio de inferência e, em seguida, integrá-los para o treinamento final. (Fonte: huggingface)
ByteDance lança BAGEL-7B: Modelo omnidirecional com capacidade de compreensão e geração de imagem e texto : A ByteDance lançou o BAGEL-7B, um modelo omnidirecional capaz de compreender e gerar imagens e texto simultaneamente. Além disso, eles também lançaram o Dolphin, um modelo de linguagem visual (VLM) focado na análise de documentos. O código aberto desses modelos fornecerá novas ferramentas e possibilidades para pesquisa e aplicação multimodal. (Fonte: huggingface, TheTuringPost)

Google lança Gemini 2.5 Flash Preview, com suporte a saída de áudio nativa : Os desenvolvedores de IA do Google anunciaram que o Gemini 2.5 Flash Preview agora suporta saída de áudio nativa através da Live API, visando fornecer interações faladas fluidas e naturais, além de maior capacidade de controle por voz. Adicionalmente, uma nova versão experimental “pensante” deste modelo de áudio foi lançada, suportando capacidades de raciocínio para tarefas mais complexas. Ao mesmo tempo, a saída da API Gemini começou a exibir “resumos de pensamento”, permitindo aos usuários entender o processo de raciocínio do modelo, embora atualmente não seja uma cadeia de raciocínio completa. (Fonte: algo_diver, op7418)
Artigo explora a capacidade expressiva do Transformer ao preencher tokens em branco : Uma nova pesquisa explora se o preenchimento de tokens em branco na entrada do Transformer (uma forma de computação em tempo de teste) pode aumentar a capacidade computacional dos LLMs. O estudo, em colaboração com Ashish_S_AI, caracteriza precisamente a capacidade expressiva dos Transformers com preenchimento, oferecendo uma nova perspectiva para entender e otimizar os mecanismos computacionais dos LLMs. (Fonte: teortaxesTex)

Nova pesquisa propõe framework Sci-Fi: Melhorando a interpolação de quadros de vídeo através de restrições simétricas : Visando o problema de possível assimetria na força de controle ao fundir restrições de quadros iniciais e finais nos métodos atuais de interpolação de quadros de vídeo (Frame Inbetweening), um novo artigo propõe o framework Sci-Fi (Symmetric Constraint for Frame Inbetweening). O método visa alcançar a simetria das restrições de quadros iniciais e finais aplicando um mecanismo de injeção mais forte (baseado no módulo leve EF-Net) para restrições com menor escala de treinamento (como o quadro final), resultando em transições mais harmoniosas nos quadros intermediários gerados e evitando inconsistências de movimento ou colapso da aparência. (Fonte: HuggingFace Daily Papers)
Artigo propõe Paper2Poster: Um fluxo automatizado de artigos científicos para pôsteres multimodais : Para enfrentar os desafios da criação de pôsteres acadêmicos, pesquisadores lançaram o primeiro benchmark de geração de pôsteres e suíte de métricas de avaliação, Paper2Poster, contendo pares de artigos e pôsteres desenhados por autores, e avaliando-os em termos de qualidade visual, coerência textual, avaliação geral e PaperQuiz (medindo a capacidade do pôster de transmitir o conteúdo principal). Ao mesmo tempo, propuseram o PosterAgent, um fluxo multiagente de cima para baixo, com feedback visual, incluindo um analisador (para extrair ativos), um planejador (para alinhamento texto-visual e layout) e um ciclo pintor-crítico (para renderização e otimização de feedback). Variantes baseadas em modelos de código aberto como o Qwen-2.5 superaram sistemas impulsionados pelo GPT-4o na maioria das métricas, com uma redução de 87% no consumo de tokens, convertendo artigos de 22 páginas em pôsteres editáveis .pptx a um custo extremamente baixo. (Fonte: HuggingFace Daily Papers)
Artigo propõe Frame In-N-Out: Realizando geração de imagem para vídeo controlável e ilimitada : Visando desafios na geração de vídeo como controlabilidade, consistência temporal e síntese de detalhes, um novo artigo foca na técnica de filmagem “Frame In and Frame Out”, com o objetivo de permitir que os usuários controlem objetos na imagem para que saiam naturalmente da cena, ou introduzam novas referências de identidade na cena, guiados por trajetórias de movimento especificadas pelo usuário. Para isso, os pesquisadores introduziram um novo conjunto de dados com anotações semiautomáticas, um protocolo de avaliação abrangente e uma arquitetura eficiente de Diffusion Transformer para vídeo que preserva a identidade e é controlável por movimento. Experimentos mostram que o método supera significativamente as linhas de base existentes. (Fonte: HuggingFace Daily Papers)
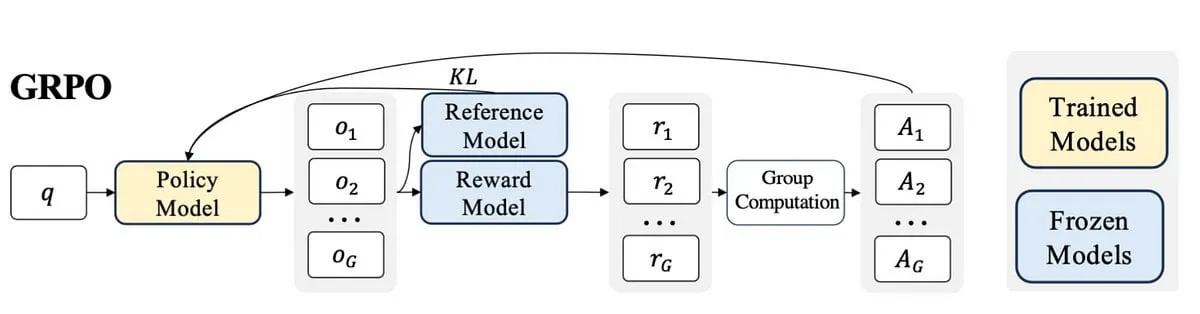
Nova pesquisa propõe Active-O3: Capacitando modelos de linguagem grandes multimodais com percepção ativa através de GRPO : Em resposta à exploração insuficiente da percepção ativa em modelos de linguagem grandes multimodais (MLLM), pesquisadores propuseram o framework Active-O3. Este framework, baseado no treinamento de aprendizado por reforço puro com GRPO (Group Relative Policy Optimization), visa capacitar os MLLMs a escolher ativamente posições e métodos de observação para coletar informações relevantes para a tarefa. Os pesquisadores primeiro definiram sistematicamente tarefas de percepção ativa baseadas em MLLM e apontaram que a estratégia de busca ampliada do GPT-o3 é um caso especial de percepção ativa, mas com eficiência e precisão insuficientes. O Active-O3, através do estabelecimento de um conjunto abrangente de benchmarks, é avaliado em tarefas genéricas de mundo aberto (como localização de objetos pequenos e densos) e cenários de domínio específico (como detecção de objetos pequenos em sensoriamento remoto e direção autônoma, segmentação interativa de granulação fina), e demonstra sua forte capacidade de inferência zero-shot no V* Benchmark. (Fonte: HuggingFace Daily Papers)
Artigo propõe MME-Reasoning: Um benchmark abrangente para a capacidade de raciocínio lógico de MLLMs : Em resposta às deficiências dos benchmarks existentes na avaliação da capacidade de raciocínio lógico de modelos de linguagem grandes multimodais (MLLM), pesquisadores lançaram o MME-Reasoning. Este benchmark cobre os três principais tipos de raciocínio lógico: indutivo, dedutivo e abdutivo, e seleciona cuidadosamente os dados para garantir que as perguntas avaliem efetivamente a capacidade de raciocínio, em vez de habilidades de percepção ou amplitude de conhecimento. Os resultados da avaliação mostram que mesmo os MLLMs mais avançados apresentam limitações em uma avaliação abrangente de raciocínio lógico, com desequilíbrio de desempenho entre os diferentes tipos de raciocínio. A pesquisa também analisa o impacto de métodos como “padrões de pensamento” e aprendizado por reforço baseado em regras na capacidade de raciocínio, fornecendo insights sistemáticos para entender e avaliar a capacidade de raciocínio dos MLLMs. (Fonte: HuggingFace Daily Papers)
GraLoRA: Melhorando o desempenho do ajuste fino eficiente de parâmetros através de adaptação de baixa patente granularizada : Em resposta aos problemas de overfitting e gargalos de desempenho que surgem quando o LoRA aumenta a patente, pesquisadores propuseram o GraLoRA (Granular Low-Rank Adaptation). Este método divide a matriz de pesos em sub-blocos, cada um com seu próprio adaptador de baixa patente, visando resolver os problemas de emaranhamento de gradientes e distorção de propagação causados pelos gargalos estruturais do LoRA. O GraLoRA melhora efetivamente a capacidade expressiva do modelo, aproximando-se do efeito do ajuste fino completo, quase sem aumentar os custos de computação ou armazenamento. Experimentos em benchmarks de geração de código e raciocínio de senso comum mostram que o GraLoRA supera o LoRA e outras linhas de base em diferentes tamanhos de modelo e configurações de patente, por exemplo, alcançando um ganho absoluto de até 8,5% em Pass@1 no HumanEval+. (Fonte: HuggingFace Daily Papers)
SoloSpeech: Pipeline de geração em cascata aprimora clareza e qualidade da extração de fala alvo : Em resposta aos modelos discriminativos existentes para extração de fala alvo (TSE) que tendem a introduzir artefatos e reduzir a naturalidade, e aos modelos generativos que são insuficientes em qualidade perceptiva e clareza, pesquisadores propuseram o SoloSpeech. Trata-se de um novo pipeline de geração em cascata que integra processos de compressão, extração, reconstrução e correção. Sua característica é a adoção de um extrator de alvo sem incorporação de locutor, utilizando informações condicionais do espaço latente do áudio de prompt e alinhando-o com o espaço latente do áudio misturado para evitar incompatibilidades. A avaliação no conjunto de dados Libri2Mix mostra que o SoloSpeech atinge novos níveis de SOTA em tarefas de extração de fala alvo e separação de fala, e demonstra excelente capacidade de generalização em dados fora do domínio e cenários reais. (Fonte: HuggingFace Daily Papers)
Nova pesquisa explora o aprimoramento da capacidade de compreensão visual de modelos de linguagem grandes multimodais através de vetores de orientação guiados por texto : Uma nova pesquisa explora se é possível utilizar vetores de orientação derivados da espinha dorsal LLM puramente textual de modelos de linguagem grandes multimodais (MLLM) (obtidos através de métodos como autoencoders esparsos SAE, mean shift e sondagem linear) para aprimorar sua capacidade de compreensão visual. A pesquisa descobriu que vetores de orientação derivados de texto podem aumentar consistentemente a precisão multimodal de diferentes arquiteturas MLLM em várias tarefas visuais. Em particular, o método mean shift aumentou a precisão da relação espacial em até 7,3% e a precisão da contagem em até 3,3% no CV-Bench, superando os métodos de prompting e demonstrando forte capacidade de generalização para conjuntos de dados fora da distribuição. Isso indica que os vetores de orientação guiados por texto são um mecanismo poderoso e eficiente que pode aprimorar a base visual dos MLLMs com coleta mínima de dados adicionais e sobrecarga computacional. (Fonte: HuggingFace Daily Papers)
Artigo propõe DiSA: Acelerando a geração autorregressiva de imagens através do recozimento de passos de difusão : Visando o problema de baixa eficiência de inferência causado pelo uso de amostragem de difusão para melhorar a qualidade da imagem em modelos autorregressivos como MAR e FlowAR, um novo artigo propõe o método DiSA (Diffusion Step Annealing). O método baseia-se na observação de que, à medida que mais tokens são gerados no processo autorregressivo, a distribuição dos tokens subsequentes se torna mais restrita e a amostragem mais fácil. DiSA é um método que não requer treinamento e reduz gradualmente os passos de difusão à medida que mais tokens são gerados (por exemplo, de 50 passos iniciais para 5 passos posteriores). Este método é complementar aos métodos de aceleração existentes projetados para a própria difusão, é simples de implementar e pode acelerar MAR e Harmon em 5-10 vezes, e FlowAR e xAR em 1,4-2,5 vezes, mantendo a qualidade da geração. (Fonte: HuggingFace Daily Papers)
Artigo propõe CASS: Conjunto de dados, modelo e benchmark para tradução de código GPU de Nvidia para AMD : Pesquisadores lançaram o CASS, o primeiro conjunto de dados e suíte de modelos em larga escala para tradução de código GPU entre arquiteturas, visando cobrir a tradução em nível de código-fonte (CUDA <-> HIP) e em nível de assembly (Nvidia SASS <-> AMD RDNA3). O conjunto de dados contém 70.000 pares de código verificados entre host e dispositivo. A série CASS de modelos de linguagem específicos de domínio, treinada com este recurso, atinge 95% de precisão na tradução de código-fonte e 37,5% na tradução de assembly, superando significativamente as linhas de base comerciais como GPT-4o e Claude. O código gerado corresponde ao desempenho nativo em mais de 85% dos casos de teste. O CASS-Bench, um benchmark contendo 16 domínios de GPU e resultados de execução reais, também foi lançado. Todos os dados, modelos e ferramentas de avaliação são de código aberto. (Fonte: HuggingFace Daily Papers)
Artigo analisa a capacidade de calibração verbal em modelos de linguagem visual : Um estudo avaliou de forma abrangente a eficácia dos modelos de linguagem visual (VLM) em expressar confiança através da linguagem natural (ou seja, incerteza verbal). A pesquisa abrangeu três classes de modelos, quatro domínios de tarefas e três cenários de avaliação, e os resultados mostram que os VLMs atuais frequentemente exibem falhas de calibração significativas em várias tarefas e configurações. Notavelmente, os modelos de raciocínio visual (ou seja, modelos que pensam com imagens) consistentemente demonstraram melhor calibração, indicando que o raciocínio específico da modalidade é crucial para estimativas confiáveis de incerteza. Para enfrentar os desafios de calibração, os pesquisadores introduziram o “Visual Confidence-Aware Prompting”, uma estratégia de prompting em duas etapas projetada para melhorar o alinhamento da confiança em configurações multimodais. (Fonte: HuggingFace Daily Papers)
Artigo rastreia o surgimento da competência pragmática em grandes modelos de linguagem : Os LLMs atuais demonstram capacidades emergentes em tarefas de inteligência social, mas como eles adquirem competência pragmática durante o treinamento ainda não está claro. Um novo artigo introduz o conjunto de dados ALTPRAG, projetado com base no conceito pragmático de “alternativas”, para avaliar se LLMs em diferentes estágios de treinamento podem inferir com precisão intenções sutis do falante. Através da avaliação sistemática de 22 LLMs (cobrindo os estágios de pré-treinamento, SFT e otimização de preferência), os resultados mostram que mesmo os modelos básicos exibem sensibilidade significativa a pistas pragmáticas, e isso melhora continuamente com o aumento do tamanho do modelo e dos dados. SFT e RLHF aprimoram ainda mais a capacidade de raciocínio pragmático cognitivo. Essas descobertas enfatizam que a competência pragmática é uma propriedade composicional emergente no treinamento de LLMs, fornecendo novos insights para o alinhamento do modelo com as normas comunicativas humanas. (Fonte: HuggingFace Daily Papers)
Lançamento do benchmark Video-Holmes: Avaliando o pensamento “Sherlockiano” de MLLMs em inferência de vídeo complexa : Em resposta aos benchmarks de vídeo existentes que avaliam principalmente a percepção visual e a capacidade de localização, sem capturar adequadamente as necessidades de raciocínio complexo, pesquisadores lançaram o benchmark Video-Holmes. Inspirado no processo de raciocínio de Sherlock Holmes, o benchmark contém 1837 perguntas extraídas de 270 curtas-metragens de suspense anotados manualmente, abrangendo 7 tarefas cuidadosamente projetadas. Cada tarefa exige que o modelo localize ativamente e conecte múltiplas pistas visuais relevantes espalhadas por diferentes clipes de vídeo. A avaliação de MLLMs SOTA mostra que, embora os modelos tenham um desempenho excelente na percepção visual, eles apresentam dificuldades significativas na integração de informações, frequentemente perdendo pistas cruciais. Por exemplo, o Gemini-2.5-Pro, com o melhor desempenho, atingiu apenas 45% de precisão. (Fonte: HuggingFace Daily Papers)
Lançamento do benchmark MME-VideoOCR: Avaliando a capacidade de OCR de LLMs multimodais em cenários de vídeo : Embora os modelos de linguagem grandes multimodais (MLLM) tenham feito progressos significativos em OCR de imagens estáticas, seu desempenho em OCR de vídeo é prejudicado por fatores como desfoque de movimento, variações temporais e efeitos visuais. Para orientar o treinamento de MLLMs práticos, pesquisadores lançaram o benchmark MME-VideoOCR, cobrindo uma ampla gama de cenários de aplicação de OCR em vídeo. O benchmark inclui 10 categorias de tarefas (25 tarefas independentes), abrangendo 44 cenários diferentes, incluindo não apenas reconhecimento de texto, mas também compreensão e raciocínio mais profundos sobre o conteúdo textual em vídeos. O benchmark contém 1464 vídeos de diferentes resoluções, proporções e durações, bem como 2000 pares de perguntas e respostas cuidadosamente selecionados e anotados por humanos. A avaliação de 18 MLLMs SOTA mostra que mesmo o Gemini-2.5 Pro, com o melhor desempenho, atingiu apenas 73,7% de precisão, expondo as limitações dos modelos existentes no tratamento de tarefas que exigem compreensão holística do vídeo. (Fonte: HuggingFace Daily Papers)
MetaMind: Modelando o pensamento social humano através de um sistema multiagente metacognitivo : Para preencher a lacuna dos grandes modelos de linguagem (LLM) no tratamento da ambiguidade inerente e das nuances contextuais da comunicação humana, pesquisadores lançaram o MetaMind, um framework multiagente inspirado na teoria metacognitiva da psicologia, projetado para simular o raciocínio social semelhante ao humano. O MetaMind decompõe a compreensão social em três estágios colaborativos: (1) agentes de teoria da mente geram hipóteses sobre os estados mentais do usuário (como intenções, emoções); (2) agentes de domínio usam normas culturais e restrições éticas para refinar essas hipóteses; (3) agentes de resposta geram respostas contextualmente apropriadas, enquanto validam a consistência com as intenções inferidas. Este framework alcançou desempenho SOTA em três benchmarks desafiadores, melhorando em 35,7% em cenários sociais reais, 6,2% em raciocínio de teoria da mente, e permitindo pela primeira vez que LLMs atinjam o nível humano em tarefas cruciais de teoria da mente. (Fonte: HuggingFace Daily Papers)
Sparse VideoGen2: Acelerando a geração de vídeo através de permutação semanticamente consciente e atenção esparsa : Visando os problemas de latência significativa e alto custo de memória enfrentados por modelos de geração de vídeo baseados em Diffusion Transformers (DiT) ao processar vídeos longos, pesquisadores propuseram o framework SVG2. Este framework, através de permutação semanticamente consciente (usando k-means para agrupar e reordenar tokens com base na similaridade semântica), maximiza a precisão da identificação de tokens chave e minimiza o desperdício computacional, alcançando assim um trade-off na fronteira de Pareto entre qualidade de geração e eficiência. O SVG2 também integra controle de orçamento dinâmico top-p e implementação de kernel customizado, alcançando acelerações de até 2,30x e 1,89x no HunyuanVideo e Wan 2.1, respectivamente, enquanto mantém um alto PSNR. (Fonte: HuggingFace Daily Papers)
OmniConsistency: Aprendendo consistência independente de estilo a partir de dados estilizados pareados : Para resolver os dois grandes desafios enfrentados pelos modelos de difusão na estilização de imagens – a manutenção da consistência em cenas complexas (especialmente identidade, composição e detalhes) e a degradação de estilo causada por LoRAs de estilo em fluxos de imagem para imagem – pesquisadores propuseram o OmniConsistency. Trata-se de um plugin de consistência universal que utiliza transformadores de difusão em larga escala (DiT). Suas contribuições incluem: (1) um framework de aprendizado de consistência contextual treinado em pares de imagens alinhadas para alcançar generalização robusta; (2) uma estratégia de aprendizado progressivo em duas etapas que desacopla o aprendizado de estilo da manutenção da consistência para mitigar a degradação de estilo; (3) um design totalmente plug-and-play compatível com qualquer LoRA de estilo sob o framework Flux. Experimentos mostram que o OmniConsistency melhora significativamente a coerência visual e a qualidade estética, alcançando desempenho comparável aos modelos SOTA comerciais como o GPT-4o. (Fonte: HuggingFace Daily Papers)
ImgEdit: Conjunto de dados e benchmark unificado para edição de imagens : Para resolver o problema de modelos de edição de imagens de código aberto ficarem atrás de modelos proprietários (principalmente devido a dados de alta qualidade limitados e benchmarks insuficientes), pesquisadores lançaram o ImgEdit. Trata-se de um conjunto de dados de edição de imagens em larga escala e de alta qualidade, contendo 1,2 milhão de pares de edição cuidadosamente selecionados, cobrindo edições de turno único novas e complexas e tarefas desafiadoras de múltiplos turnos. Para garantir a qualidade dos dados, foi adotado um processo multifásico, integrando modelos de linguagem visual de ponta, modelos de detecção, modelos de segmentação, bem como correções específicas para tarefas e pós-processamento rigoroso. O modelo de edição ImgEdit-E1, treinado com base no ImgEdit, supera os modelos de código aberto existentes em várias tarefas. O benchmark ImgEdit-Bench, lançado simultaneamente, é usado para avaliar o desempenho da edição de imagens no seguimento de instruções, qualidade da edição e preservação de detalhes. (Fonte: HuggingFace Daily Papers)
Artigo propõe controle comportamental robusto em LLMs através de átomos alvo de orientação : Para alcançar controle preciso sobre as gerações de modelos de linguagem, garantindo segurança e confiabilidade, um novo artigo propõe o método “Steering Target Atoms (STA)”. Este método visa separar e manipular componentes de conhecimento desacoplados para aumentar a segurança, demonstrando robustez e flexibilidade superiores, especialmente em cenários adversariais. Os pesquisadores argumentam que, embora a engenharia de prompts e a orientação sejam comumente usadas para intervir no comportamento do modelo, o alto emaranhamento dos parâmetros do modelo limita a precisão do controle e pode levar a efeitos colaterais. O STA utiliza autoencoders esparsos (SAE) para desacoplar o conhecimento em espaços de alta dimensão e os orienta, alcançando assim um controle comportamental mais preciso. Experimentos demonstram a eficácia do método, que já foi aplicado a grandes modelos de inferência, confirmando seu potencial no controle preciso da inferência. (Fonte: HuggingFace Daily Papers)
Artigo propõe benchmark SeePhys: Avaliando a capacidade de raciocínio físico baseado em visão : Pesquisadores lançaram o SeePhys, um benchmark multimodal em larga escala para avaliar a capacidade de raciocínio de LLMs em problemas de física do nível do ensino médio ao de exames de qualificação de doutorado. O benchmark abrange 7 áreas fundamentais da física, contendo 21 categorias de diagramas altamente heterogêneos. Diferentemente de trabalhos anteriores onde os elementos visuais desempenhavam principalmente um papel auxiliar, 75% das questões no SeePhys são visualmente necessárias, ou seja, informações visuais devem ser extraídas para responder corretamente. Uma avaliação extensa mostra que mesmo os modelos de raciocínio visual mais avançados (como Gemini-2.5-pro e o4-mini) têm uma precisão inferior a 60% neste benchmark, revelando desafios fundamentais na compreensão visual dos LLMs atuais, especialmente no acoplamento rigoroso da interpretação de diagramas com o raciocínio físico e na superação da dependência de atalhos cognitivos em pistas textuais. (Fonte: HuggingFace Daily Papers)
VerIPO: Melhorando a capacidade de raciocínio de longo alcance de Video-LLMs através da otimização iterativa de políticas guiada por verificador : Para enfrentar os gargalos na preparação de dados e a qualidade instável do pensamento em cadeia (CoT) quando o aprendizado por reforço é aplicado a modelos de linguagem grandes de vídeo (Video-LLM) em inferência de vídeo complexa, pesquisadores propuseram o método VerIPO (Verifier-guided Iterative Policy Optimization). O núcleo deste método é um “Rollout-Aware Verifier” localizado entre os estágios de treinamento GRPO e DPO, usado para avaliar a lógica de inferência e construir dados comparativos de alta qualidade (contendo CoT reflexivo e contextualmente consistente). Esses dados impulsionam um estágio DPO eficiente, melhorando assim o comprimento e a consistência contextual da cadeia de inferência. Os resultados experimentais mostram que o VerIPO pode otimizar o modelo de forma mais rápida e eficaz, gerando CoT mais longo e contextualmente consistente, com desempenho superior às variantes GRPO padrão e a alguns Video-LLMs de ajuste fino de instruções grandes e modelos de inferência longa. (Fonte: HuggingFace Daily Papers)
OpenS2V-Nexus: Benchmark detalhado e conjunto de dados de milhões de amostras para geração de sujeito para vídeo : Para impulsionar o desenvolvimento da tecnologia de geração de sujeito para vídeo (S2V), pesquisadores propuseram o OpenS2V-Nexus, que inclui (i) OpenS2V-Eval, um benchmark de granularidade fina, e (ii) OpenS2V-5M, um conjunto de dados de milhões de amostras. Diferentemente dos benchmarks S2V existentes (herdados do VBench, com foco em avaliação global e de granulação grossa), o OpenS2V-Eval foca na capacidade do modelo de gerar vídeos com sujeitos consistentes, aparência natural e alta fidelidade de identidade. Para isso, o OpenS2V-Eval introduz 180 prompts de 7 grandes categorias de S2V, contendo dados de teste reais e sintéticos. Além disso, para alinhar com precisão as preferências humanas, os pesquisadores propuseram três métricas automáticas: NexusScore, NaturalScore e GmeScore, que quantificam respectivamente a consistência do sujeito, a naturalidade e a relevância textual nos vídeos gerados. Com base nisso, 16 modelos S2V representativos foram avaliados de forma abrangente. Ao mesmo tempo, foi criado o primeiro conjunto de dados de geração S2V em larga escala de código aberto, OpenS2V-5M, contendo 5 milhões de trios sujeito-texto-vídeo de alta qualidade em 720P. (Fonte: HuggingFace Daily Papers)
Artigo propõe WHISTRESS: Enriquecendo texto transcrito através da detecção de acento frasal : Dada a importância do acento frasal na fala para transmitir a intenção do falante e sua ausência nos sistemas de transcrição existentes, um novo artigo apresenta o WHISTRESS, um método de detecção de acento frasal sem necessidade de alinhamento. Para apoiar esta tarefa, os pesquisadores propuseram o TINYSTRESS-15K, um conjunto de dados de treinamento sintético escalável criado através de um processo totalmente automatizado. O modelo WHISTRESS, treinado neste conjunto de dados, supera as linhas de base existentes em desempenho, sem a necessidade de treinamento adicional ou entrada prévia para inferência. Notavelmente, apesar de treinado com dados sintéticos, o WHISTRESS demonstra forte capacidade de generalização zero-shot em vários benchmarks. (Fonte: HuggingFace Daily Papers)
Artigo propõe InstructPart: Segmentação de partes orientada a tarefas com raciocínio instruído : Apesar dos avanços dos grandes modelos de base multimodais em diversas tarefas, muitos modelos tratam os objetos como um todo indivisível, ignorando as partes que os compõem. Compreender essas partes e suas affordances funcionais associadas é crucial para executar uma ampla gama de tarefas. Para isso, pesquisadores introduziram um novo benchmark do mundo real, InstructPart, contendo anotações de segmentação de partes marcadas manualmente e instruções orientadas a tarefas, para avaliar o desempenho dos modelos atuais na compreensão e execução de tarefas em nível de parte em contextos cotidianos. Experimentos mostram que, mesmo para VLMs SOTA, a segmentação de partes orientada a tarefas continua sendo um problema desafiador. Além do benchmark, os pesquisadores também introduziram uma linha de base simples que, através do ajuste fino com seu conjunto de dados, alcançou o dobro do desempenho. (Fonte: HuggingFace Daily Papers)
Artigo propõe método híbrido neural-MPM para simulação interativa de fluidos em tempo real : Para resolver o problema da simulação de fluidos, onde métodos físicos tradicionais são computacionalmente intensivos e de alta latência, e métodos recentes de aprendizado de máquina, embora reduzam custos, ainda lutam para atender às demandas de interação em tempo real, pesquisadores propuseram um novo método híbrido. Este método integra simulação numérica, física neural e controle generativo. Sua física neural, através de um mecanismo de salvaguarda que recorre a solucionadores numéricos clássicos, busca simultaneamente simulação de baixa latência e alta fidelidade física. Além disso, os pesquisadores desenvolveram um controlador baseado em difusão, treinado usando uma estratégia de modelagem inversa, para gerar campos de força dinâmicos externos para manipulação de fluidos. O sistema demonstra desempenho robusto em vários cenários 2D/3D, tipos de materiais e interações com obstáculos, alcançando simulação em tempo real com alta taxa de quadros (latência de 11~29%) e permitindo o controle de fluidos através de esboços desenhados à mão de forma amigável. (Fonte: HuggingFace Daily Papers)
MMIG-Bench: Benchmark de avaliação interpretável abrangente para modelos de geração de imagem multimodal : Em resposta às limitações das ferramentas de avaliação existentes na avaliação de geradores de imagem multimodal como GPT-4o, Gemini 2.0 Flash e Gemini 2.5 Pro (por exemplo, benchmarks T2I carecem de condições multimodais, benchmarks de geração de imagem personalizados ignoram semântica composicional e senso comum), pesquisadores propuseram o MMIG-Bench. Trata-se de um benchmark abrangente de geração de imagem multimodal, contendo 4850 prompts de texto ricamente anotados e 1750 imagens de referência multi-ângulo cobrindo 380 sujeitos (pessoas, animais, objetos, estilos de arte). O MMIG-Bench é equipado com um framework de avaliação de três níveis: (1) métricas de baixo nível avaliam artefatos visuais e preservação da identidade do objeto; (2) uma nova pontuação de correspondência de aspecto (AMS): uma métrica de nível médio baseada em VQA que fornece alinhamento fino prompt-imagem e está altamente correlacionada com julgamentos humanos; (3) métricas de alto nível avaliam estética e preferências humanas. Através do MMIG-Bench, 17 modelos SOTA foram testados e as métricas foram validadas com 32.000 avaliações humanas, fornecendo insights profundos para o design de arquiteturas e dados. (Fonte: HuggingFace Daily Papers)
Artigo propõe HRPO: Realizando inferência latente híbrida através de aprendizado por reforço : Para resolver os problemas de incompatibilidade dos métodos de inferência latente existentes com as características de geração autorregressiva dos LLMs e a dependência de trajetórias CoT para treinamento, pesquisadores propuseram o HRPO (Hybrid Reasoning Policy Optimization). Trata-se de um método de inferência latente híbrida baseado em aprendizado por reforço, que integra estados ocultos anteriores aos tokens amostrados através de um mecanismo de gating aprendível, e inicia o treinamento principalmente com incorporações de tokens, incorporando gradualmente mais características ocultas. Este design mantém a capacidade generativa dos LLMs e incentiva o uso de representações discretas e contínuas para inferência híbrida. Além disso, o HRPO introduz aleatoriedade na inferência latente através da amostragem de tokens, permitindo assim a otimização baseada em RL sem a necessidade de trajetórias CoT. Avaliações extensas em vários benchmarks mostram que o HRPO supera os métodos anteriores tanto em tarefas intensivas em conhecimento quanto em tarefas intensivas em inferência. (Fonte: HuggingFace Daily Papers)
Artigo propõe método NFT: Conectando aprendizado supervisionado e aprendizado por reforço no raciocínio matemático : Desafiando a noção predominante de que o “autoaperfeiçoamento é limitado ao aprendizado por reforço (RL)”, um novo artigo propõe o método Negative-aware Fine-Tuning (NFT). Trata-se de um método de aprendizado supervisionado que permite aos LLMs refletir sobre suas falhas e melhorar autonomamente, sem a necessidade de um professor externo. No treinamento online, o NFT não descarta respostas erradas autogeradas, mas constrói uma política negativa implícita para modelá-las. Essa política implícita é parametrizada da mesma forma que o LLM positivo alvo otimizado em dados positivos, permitindo assim a otimização direta da política em todas as gerações do LLM. Resultados experimentais em tarefas de raciocínio matemático com modelos de 7B e 32B mostram que, ao utilizar adicionalmente o feedback negativo, o NFT supera significativamente as linhas de base de aprendizado supervisionado, como o ajuste fino por amostragem de rejeição, alcançando ou até mesmo superando algoritmos de RL líderes como GRPO e DAPO. Os pesquisadores demonstram ainda que, em treinamento de política online rigoroso, NFT e GRPO são, na verdade, equivalentes. (Fonte: HuggingFace Daily Papers)
Artigo propõe Minute-Long Videos with Dual Parallelisms: Realizando geração de vídeo de minutos de duração : Visando o problema de latência computacional e custo de memória excessivos enfrentados por modelos de difusão de vídeo baseados em DiT ao gerar vídeos longos, pesquisadores propuseram uma nova estratégia de inferência distribuída, DualParal. A ideia central deste método é paralelizar os quadros temporais e as camadas do modelo em múltiplas GPUs. Para resolver o problema de serialização da paralelização original causado pela exigência dos modelos de difusão de sincronizar os níveis de ruído entre os quadros, o método adota um esquema de remoção de ruído em blocos, ou seja, processando em pipeline uma série de blocos de quadros e reduzindo gradualmente o nível de ruído. Cada GPU processa subconjuntos específicos de blocos e camadas e passa os resultados anteriores para a próxima GPU, realizando computação e comunicação assíncronas. Além disso, através da implementação de cache de características em cada GPU para reutilizar as características de blocos anteriores como contexto e da adoção de uma estratégia coordenada de inicialização de ruído, garante-se uma dinâmica temporal globalmente consistente, permitindo assim a geração de vídeo rápida, sem artefatos e de duração ilimitada. Aplicado aos mais recentes geradores de vídeo com transformadores de difusão, o método gera eficientemente vídeos de 1025 quadros em 8 GPUs RTX 4090, com redução de latência de até 6,54 vezes e redução de custo de memória de 1,48 vezes. (Fonte: HuggingFace Daily Papers)
🧰 Ferramentas
Modelos da série Claude 4 se destacam em tarefas de programação, resolvendo com sucesso “bug da baleia branca” que atormentou programador sênior por 4 anos : O mais recente modelo Claude Opus 4 da Anthropic demonstrou uma capacidade surpreendente em programação. Um ex-engenheiro da FAANG com 30 anos de experiência em desenvolvimento C++ compartilhou que um bug complexo de sistema que atormentou sua equipe por 4 anos e consumiu cerca de 200 horas de seu tempo pessoal sem solução (um problema de condição de contorno que ocorria quando um shader específico era usado de uma maneira particular), foi localizado e sua causa identificada pelo Claude Opus 4 em poucas horas, com cerca de 30 prompts. O bug não existia antes da refatoração do sistema, e o Opus 4 apontou que a nova arquitetura não era compatível com um comportamento não projetado que era “coincidentemente” suportado pela arquitetura antiga. Anteriormente, GPT-4.1, Gemini 2.5 e Claude 3.7 não conseguiram resolver este problema. Isso destaca a poderosa capacidade do Claude 4 em entender código complexo, realizar análises profundas e raciocínio, especialmente quando combinado com o modo Claude Code, auxiliando efetivamente os desenvolvedores no tratamento de tarefas avançadas de engenharia, como refatoração de código e correção de bugs. (Fonte: 36氪, dotey)
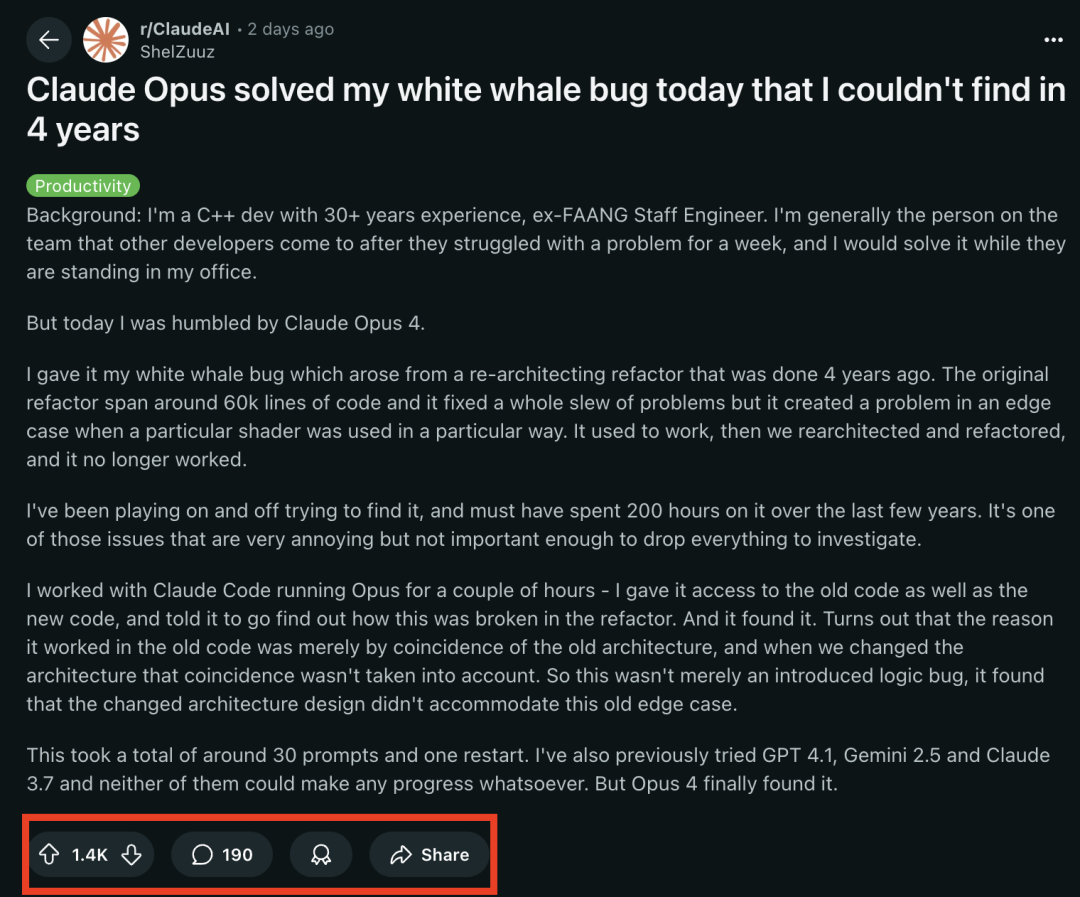
LangChain adiciona suporte para novas funcionalidades Beta do Anthropic Claude : LangChain anunciou a integração de quatro novas funcionalidades Beta recentemente lançadas pelo modelo Anthropic Claude, incluindo execução de código, conectores MCP remotos, API de arquivos e cache de prompt estendido. Os desenvolvedores agora podem consultar exemplos relevantes na documentação do LangChain para utilizar essas novas funcionalidades na construção de aplicações de IA mais poderosas. (Fonte: LangChainAI)
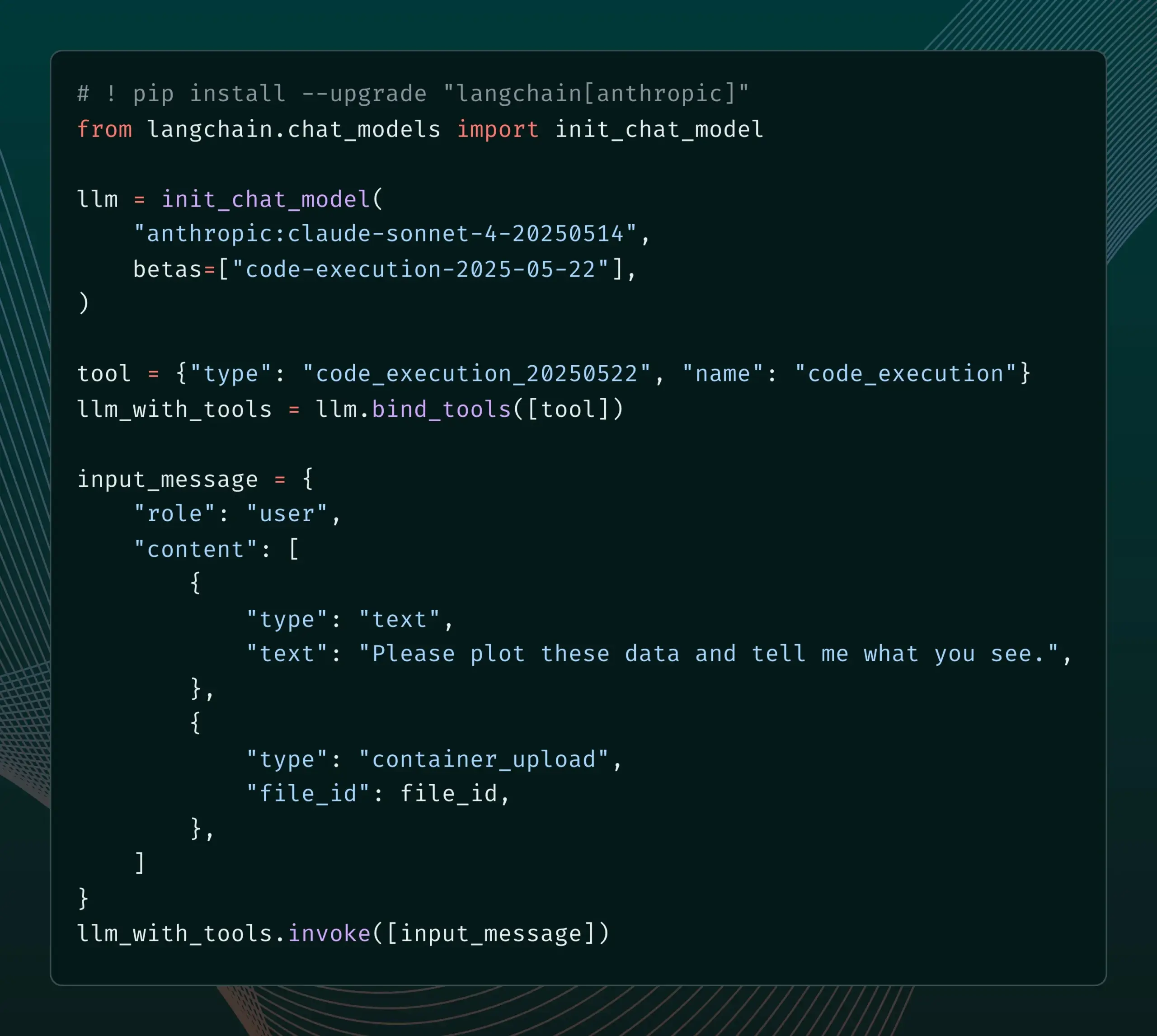
LangSmith lança funcionalidade de gerenciamento de prompts integrada ao SDLC : A plataforma LangSmith aprimorou suas capacidades de engenharia de prompts. Agora, os usuários não apenas podem testar, versionar e colaborar em prompts no LangSmith, mas também podem sincronizar automaticamente os prompts com o GitHub, bancos de dados externos ou iniciar processos de CI/CD através de gatilhos webhook quando os prompts são alterados. Esta funcionalidade visa ajudar os desenvolvedores a integrar mais estreitamente o gerenciamento de prompts ao ciclo de vida de desenvolvimento de software (SDLC). (Fonte: LangChainAI)
AutoThink: Tecnologia adaptativa para melhorar o desempenho de inferência de LLMs locais : A equipe CodeLion desenvolveu a tecnologia AutoThink, que melhora significativamente o desempenho de inferência de LLMs locais através da alocação adaptativa de recursos e vetores de direção (steering vectors). O AutoThink pode classificar a complexidade das consultas, alocar dinamicamente “tokens de pensamento” (mais para problemas complexos, menos para problemas simples) e usar vetores de direção para guiar os padrões de inferência. Testes no modelo DeepSeek-R1-Distill-Qwen-1.5B mostraram um aumento de 43% na precisão do GPQA-Diamond (de 21,72% para 31,06%), melhorias no MMLU-Pro e menor uso de tokens. A tecnologia é compatível com modelos de inferência locais que suportam tokens de pensamento, e o código e a pesquisa foram publicados. (Fonte: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab anuncia suporte para AMD ROCm, permitindo treinamento local de LLMs : O Transformer Lab anunciou que sua plataforma GUI agora suporta o treinamento local e o ajuste fino de grandes modelos de linguagem em GPUs AMD usando ROCm. A equipe afirmou que o processo de configuração do ROCm foi desafiador e documentou todo o processo em um blog. Atualmente, a funcionalidade está operando sem problemas, e os usuários podem experimentar o desenvolvimento de LLMs em hardware AMD. (Fonte: Reddit r/MachineLearning)
Sistema multiagente de código aberto aprimorado por LLM realiza extração automatizada de alegações e verificação de fatos : Um projeto de código aberto chamado “fact-checker” utiliza um sistema multiagente (MAS) aprimorado por LLM para realizar extração automatizada de alegações, verificação de evidências e resolução de fatos. O projeto inclui uma extensão de navegador que pode verificar fatos em tempo real das respostas de qualquer chatbot de IA, ajudando a discernir a veracidade do conteúdo gerado por IA. Sua arquitetura de código é clara e bem documentada, fornecendo uma ferramenta valiosa para a segurança da IA e o combate à desinformação. (Fonte: Reddit r/MachineLearning)
Meituan lança produto no-code Nocode, suportando geração de aplicações complexas de múltiplas páginas : A Meituan lançou um produto de Vibe Coding chamado Nocode, onde os usuários podem descrever em linguagem natural para gerar aplicações completas e complexas, contendo múltiplas páginas, e não apenas simples páginas de exibição. Testes realizados por Guicang mostraram que a ferramenta conseguiu construir com sucesso, de uma só vez, uma ferramenta de gerenciamento de estoque de armazém com lógica complexa, demonstrando sua capacidade de entender requisitos complexos e gerar o código correspondente. (Fonte: op7418)
LlamaIndex suporta a construção de embedders multimodais personalizados e integração com UI de chat estilo OpenAI : LlamaIndex lançou uma atualização que permite aos usuários construir embedders multimodais personalizados, como a integração do AWS Titan Multimodal, e pode ser combinado com bancos de dados vetoriais como o Pinecone para busca eficiente de vetores de texto + imagem. Além disso, os fluxos de trabalho do LlamaIndex agora podem ser executados em uma interface de chat semelhante à do OpenAI com algumas linhas de código, e suporta um modo de desenvolvimento para editar diretamente o código do fluxo de trabalho na UI, melhorando a experiência de desenvolvimento e interação de aplicações RAG. (Fonte: jerryjliu0, jerryjliu0)

Atualização do TRAE aprimora experiência de codificação Agentic, versão internacional lança assinatura paga : A ferramenta de programação de IA TRAE recebeu uma atualização, otimizando a experiência de codificação Agentic, tornando-a mais adequada para usuários que preferem não realizar operações manuais. A nova versão do TRAE lembra melhor o histórico de conversas, associa automaticamente o contexto, a IA pode planejar automaticamente o caminho da programação e invocar mais ferramentas, aumentando a taxa de sucesso das tarefas de programação. Por exemplo, o usuário só precisa fornecer uma pasta vazia e um prompt, e o TRAE pode concluir uma série de operações como criar arquivos, iniciar um servidor Web (lidando automaticamente com problemas de CORS) e visualizar animações p5.js dentro do IDE. Sua versão internacional já lançou uma assinatura paga, com o preço Pro do primeiro mês a 3 dólares, suportando Alipay. (Fonte: dotey, karminski3)
Comunidade Juejin lança serviço MCP, suportando publicação de código front-end com um clique : A comunidade de programadores chinesa Juejin lançou o serviço MCP (Model-driven Co-programming Protocol), permitindo que desenvolvedores publiquem código front-end (como páginas web geradas por vibe coding, jogos) na plataforma Juejin com um clique, facilitando o compartilhamento rápido e a visualização. Os usuários precisam obter o Token MCP da Juejin e configurá-lo em ferramentas como Trae e Cursor. (Fonte: dotey, karminski3)
Ferramenta de rastreamento de tempo de código aberto ActivityWatch ganha atenção como alternativa ao Rize : O usuário karminski3, após experimentar a ferramenta de análise de tempo por IA Rize (que analisa nomes de processos para determinar o estado de trabalho, reunião ou procrastinação, com mensalidade de 20 dólares), descobriu e recomendou a alternativa de código aberto ActivityWatch. O ActivityWatch tem funcionalidades semelhantes, suporta Windows/Mac e permite personalização pelo usuário, sendo considerado uma excelente ferramenta para aliviar a ansiedade no trabalho e rastrear o tempo de trabalho. (Fonte: karminski3)
Ferramenta de monitoramento de bebês com IA de código aberto ai-baby-monitor é lançada : Um projeto de código aberto chamado ai-baby-monitor foi lançado. Ele usa o modelo Qwen2.5 VL e o framework de inferência vLLM, permitindo que os usuários definam regras (como “alertar se a criança acordar”, “alertar se a criança estiver sozinha”) para que a IA auxilie no cuidado de bebês. O desenvolvedor enfatiza que esta é apenas uma ferramenta auxiliar e não pode substituir completamente o cuidado humano. (Fonte: karminski3)
LangChain integra funcionalidade Live Search da xAI : LangChain anunciou suporte para a funcionalidade Live Search da xAI, que permite ao modelo Grok basear suas respostas em resultados de pesquisa na web ao gerar respostas, e oferece várias opções de configuração, como período de tempo, domínios incluídos e outros parâmetros de pesquisa. Os usuários agora podem experimentar esta nova funcionalidade no LangChain. (Fonte: LangChainAI)
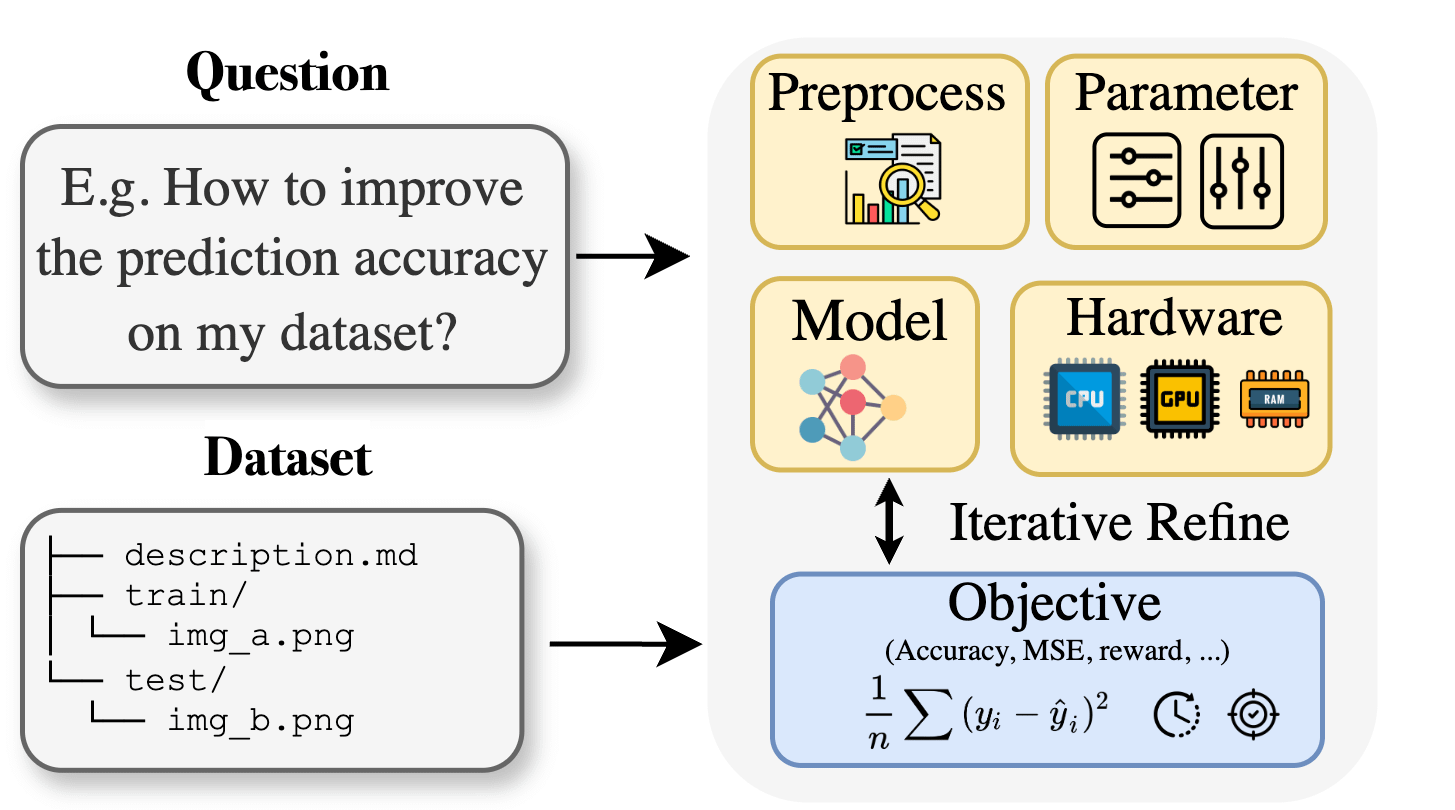
Curie: Assistente de pesquisa científica de IA de código aberto lança funcionalidade AutoML, auxiliando pesquisas interdisciplinares : Visando as barreiras de conhecimento especializado enfrentadas por pesquisadores em áreas como biologia, materiais e química ao aplicar aprendizado de máquina, o projeto Curie lançou uma nova funcionalidade AutoML. Curie visa ser um cientista colaborador para experimentos de pesquisa em IA, automatizando processos complexos de ML (como seleção de algoritmos, ajuste de hiperparâmetros, interpretação de saídas de modelo), ajudando pesquisadores a testar rapidamente hipóteses e extrair insights de dados. Por exemplo, Curie gerou um modelo com AUC de 0,99 na tarefa de detecção de melanoma. O projeto é de código aberto e incentiva a contribuição da comunidade. (Fonte: Reddit r/LocalLLaMA)
MNN Chat da Alibaba suporta execução local do modelo Qwen 30B-a3b em dispositivos Android : O aplicativo MNN Chat da Alibaba foi atualizado para a versão 0.5.0 e agora suporta a execução local de grandes modelos de linguagem como o Qwen 30B-a3b em dispositivos Android. Usuários relataram sucesso na execução em dispositivos com chips de ponta e grande quantidade de memória (como OnePlus 13 24G), e recomendam ativar a configuração mmap. No entanto, alguns comentários apontam que modelos de 30B parâmetros exigem muita memória e poder de processamento para a maioria dos celulares, e que o Gemma 3n pode ser mais adequado para dispositivos móveis. (Fonte: Reddit r/LocalLLaMA)

📚 Aprendizado
Novo artigo propõe Lean and Mean Adaptive Optimization: Otimizador mais rápido e com menor consumo de memória para treinamento de grandes modelos : Um artigo aceito no ICML 2025 apresenta um novo otimizador chamado “Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum”. Este método, através de duas técnicas complementares, passo Subset-Norm e Subspace-Momentum, visa reduzir os requisitos de memória e acelerar o treinamento de redes neurais em grande escala. Comparado com otimizadores eficientes em memória existentes como GaLore e LoRA, este método, ao economizar memória (por exemplo, reduzindo em 80% a memória de estado do otimizador em comparação com Adam ao pré-treinar LLaMA 1B), atinge a perplexidade de validação do Adam com menos tokens de treinamento (cerca de metade) e oferece garantias teóricas de convergência mais fortes. (Fonte: Reddit r/MachineLearning)
Artigo propõe Force Prompting: Permitindo que modelos de geração de vídeo aprendam e generalizem sinais de controle baseados em física : Uma nova pesquisa explora a possibilidade de usar forças físicas como sinais de controle para geração de vídeo e propõe os “Force Prompts”. Os usuários podem interagir com imagens através de forças pontuais locais (como cutucar uma planta) ou campos de força eólica globais (como vento soprando em tecido). A pesquisa mostra que modelos de geração de vídeo podem aprender e generalizar condições de força física a partir de vídeos sintetizados no Blender contendo demonstrações de apenas alguns objetos, gerando vídeos que respondem realisticamente a sinais de controle físico, sem a necessidade de usar ativos 3D ou simuladores de física em tempo de inferência. A diversidade visual e o uso de palavras-chave textuais específicas durante o treinamento são fatores cruciais para alcançar essa generalização. (Fonte: HuggingFace Daily Papers)
AnkiHub compartilha fluxo de trabalho de anotação de IA, combinando com FastHTML para aumentar a eficiência : AnkiHub compartilhou seu fluxo de trabalho de anotação de IA e o demonstrou no curso de avaliação de IA de Hamel Husain e Shreya Shankar. Este fluxo de trabalho utiliza a ferramenta de construção FastHTML e visa melhorar a eficiência da anotação de IA para produtos comerciais. Os materiais didáticos e o repositório de código relacionados foram publicados no GitHub, mostrando como usar ferramentas de produção reais para otimizar o desenvolvimento de IA. (Fonte: jeremyphoward, HamelHusain)

Blogueiro escreve sobre aprendizado de PPO a GRPO, explicando conceitos de aprendizado por reforço no ajuste fino de LLMs : Um blogueiro compartilhou sua experiência de aprendizado sobre aprendizado por reforço (RL) e sua aplicação no ajuste fino de grandes modelos de linguagem (LLM), especialmente o processo de compreensão de PPO (Proximal Policy Optimization) a GRPO (Group Relative Policy Optimization). A postagem do blog visa explicar os conceitos que ele gostaria de ter entendido no início de seu aprendizado, para ajudar outros a entenderem melhor como esses algoritmos de RL são usados para otimizar LLMs. (Fonte: Reddit r/MachineLearning)
Artigo explora o pensamento pragmático das máquinas: Rastreando o surgimento da competência pragmática em grandes modelos de linguagem : Um novo artigo investiga como os grandes modelos de linguagem (LLM) adquirem competência pragmática (a capacidade de entender e inferir significados implícitos, intenções do falante, etc.) durante o processo de treinamento. Os pesquisadores introduziram o conjunto de dados ALTPRAG, baseado no conceito de “alternativas” da pragmática, para avaliar 22 LLMs em diferentes estágios de treinamento (pré-treinamento, ajuste fino supervisionado SFT, otimização de preferência RLHF). Os resultados mostram que mesmo os modelos básicos demonstram sensibilidade significativa a pistas pragmáticas, e isso melhora continuamente com o aumento do tamanho do modelo e dos dados; SFT e RLHF aprimoram ainda mais a capacidade de raciocínio pragmático cognitivo. Isso sugere que a competência pragmática é uma propriedade emergente e composicional no treinamento de LLMs. (Fonte: HuggingFace Daily Papers)
Artigo explora framework de aprendizado por reforço VisTA para seleção de ferramentas visuais : Pesquisadores introduziram o VisTA (VisualToolAgent), um novo framework de aprendizado por reforço que permite a agentes visuais explorar, selecionar e combinar dinamicamente ferramentas de diferentes bibliotecas com base no desempenho empírico. Diferentemente de métodos existentes que dependem de prompts sem treinamento ou ajuste fino em larga escala, o VisTA utiliza aprendizado por reforço de ponta a ponta, usando resultados de tarefas como sinal de feedback para otimizar iterativamente estratégias complexas de seleção de ferramentas específicas para cada consulta. Através do GRPO (Group Relative Policy Optimization), o framework permite que os agentes descubram autonomamente caminhos eficazes de seleção de ferramentas, sem supervisão explícita de raciocínio. Experimentos nos benchmarks ChartQA, Geometry3K e BlindTest mostram que o VisTA alcança melhorias de desempenho significativas em comparação com as linhas de base sem treinamento, especialmente em amostras fora da distribuição. (Fonte: HuggingFace Daily Papers)
💼 Negócios
Empresa de serviços de dados Jinglianwen Technology conclui rodada de financiamento Pre-A de dezenas de milhões, planejando produção e operação de dados públicos : A operadora de serviços de dados de IA Jinglianwen Technology concluiu recentemente uma rodada de financiamento Pre-A de dezenas de milhões de yuans, investida por um fundo do Hangzhou Jin Tou Group. O financiamento será usado para planejar a produção e operação de dados públicos, construir uma plataforma inteligente de engenharia de corpus e estabelecer bases de anotação de alta qualidade em domínios verticais próprios. Fundada em 2012, a empresa foca em dados públicos, grandes modelos de IA, direção autônoma e saúde, visando resolver problemas como “dificuldade de governança, incapacidade de fornecer, imobilidade, mau uso e fraca segurança” de dados públicos, e colaborou com o armazenamento de dados da Huawei para lançar uma solução conjunta de data lake de IA. Espera-se que a receita cresça mais de 400% este ano. (Fonte: 36氪)
Meitu recebe investimento de aproximadamente US$ 250 milhões em títulos conversíveis da Alibaba, aprofundando cooperação em IA : A Meitu anunciou planos de cooperação estratégica com a Alibaba, que emitirá títulos conversíveis no valor total de aproximadamente US$ 250 milhões para a Meitu. As duas partes colaborarão em promoção em plataformas de e-commerce, desenvolvimento de tecnologia de IA (imagens e vídeos com IA), computação em nuvem, entre outros. A Meitu se comprometeu a adquirir serviços da Alibaba Cloud no valor não inferior a 560 milhões de yuans nos próximos três anos. Esta cooperação visa utilizar o ecossistema da Alibaba para explorar o potencial de cenários de e-commerce, aumentando a escala de usuários pagantes e o nível de P&D das ferramentas de design de IA da Meitu. Embora essa medida tenha impulsionado o preço das ações da Meitu, o mercado está atento a como a Meitu evitará repetir o destino da Kimi, que viu seu crescimento de usuários desacelerar em um mercado competitivo, especialmente diante da acirrada concorrência e da diferença de porte com grandes empresas no campo da IA visual. (Fonte: 36氪)
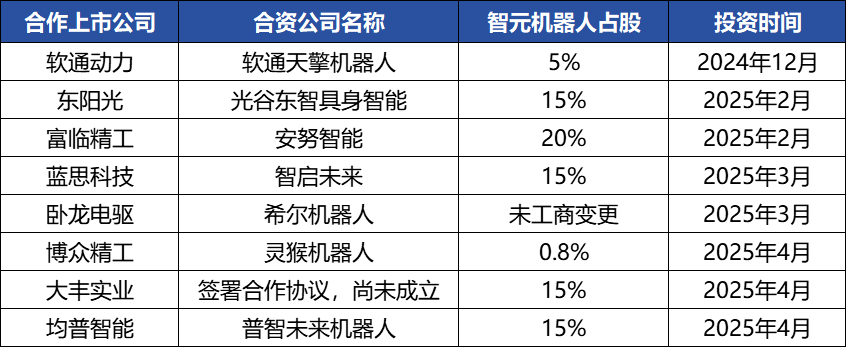
智元机器人 (Zhiyuan Robotics) com frequentes movimentos de capital, construindo ecossistema industrial, fundador Deng Taihua emerge : A unicórnio de inteligência incorporada 智元机器人 (Zhiyuan Robotics) tem realizado frequentes movimentos de capital recentemente. Além de completar múltiplas rodadas de financiamento (a mais recente liderada pela JD Technology), também investiu ativamente em empresas da cadeia industrial (como Anno Intelligent, Digital China, etc.) e estabeleceu joint ventures de robótica com várias empresas listadas (como Bozhong Precision, Dafeng Industry, etc.). Mudanças no registro comercial revelam que Deng Taihua, ex-vice-presidente da Huawei e ex-presidente da linha de produtos de computação, é o fundador e controlador real da 智元机器人 (Zhiyuan Robotics), e sua equipe de gestão também inclui vários ex-funcionários da Huawei. Esse histórico “estilo Huawei” explica o modelo operacional de “estratégia de ecossistema” da 智元机器人 (Zhiyuan Robotics), ou seja, construir rapidamente influência industrial e alcançar escala e comercialização através de ampla cooperação e investimento. Embora tenha obtido vantagem inicial em financiamento e comercialização, sua capacidade de grande modelo de inteligência incorporada ainda enfrenta desafios. (Fonte: 36氪)
🌟 Comunidade
O desenvolvimento de Agentes de IA é rápido, Agentic LM é visto como uma nova plataforma de aplicativos e ferramentas com enorme potencial : Personalidades da área de IA como natolambert expressaram entusiasmo com o rápido desenvolvimento de Agentes de IA, considerando os modelos de linguagem baseados em agentes (Agentic LMs) uma plataforma extremamente promissora sobre a qual um grande número de novas aplicações e ferramentas podem ser construídas. Muitas capacidades ainda não totalmente exploradas em modelos recentes podem ser liberadas através do paradigma Agentic. Isso prenuncia que a IA está evoluindo de mera geração de conteúdo para agentes inteligentes mais proativos e capazes de executar tarefas. (Fonte: natolambert)
Agentes de IA demonstram capacidade sobre-humana em tarefas específicas, mas raciocínio físico ainda é um ponto fraco : Pesquisas de instituições como a Universidade de Hong Kong descobriram que mesmo modelos de IA de ponta como GPT-4o e Claude 3.7 Sonnet, no benchmark PHYX que inclui cenários físicos reais e raciocínio causal complexo, têm uma taxa de acerto em problemas de física muito inferior à de especialistas humanos (o modelo com melhor desempenho atingiu 45,8% vs. o mínimo de 75,6% para humanos), expondo sua excessiva dependência de conhecimento memorizado, fórmulas matemáticas e correspondência superficial de padrões visuais na compreensão da física. No entanto, no campo da matemática, na competição FrontierMath organizada pela Epoch AI (com problemas elaborados por matemáticos de ponta como Terence Tao), o o4-mini-medium resolveu cerca de 22% dos problemas, superando 6 das 8 equipes de matemáticos humanos e ultrapassando a média das equipes humanas (19%), mostrando o potencial da IA no raciocínio simbólico altamente abstrato. Isso indica um desenvolvimento desigual das capacidades da IA em diferentes tipos de tarefas de raciocínio. (Fonte: 36氪, 36氪)

Capacidade das ferramentas de programação de IA continua a aumentar, gerando discussão sobre perspectivas de carreira para programadores : O lançamento dos modelos da série Claude 4 da Anthropic (especialmente o Opus 4, capaz de codificar continuamente por 7 horas) e os avanços em ferramentas de programação de IA como Cursor e Tongyi Lingma aumentaram significativamente a capacidade da IA na geração de código, correção de bugs e até mesmo no desenvolvimento de processos completos. Isso levou programadores de grandes empresas como a Amazon a sentirem pressão, com algumas equipes reduzidas pela metade e prazos de projetos antecipados devido ao aumento da eficiência proporcionado pela IA, transformando o papel do programador em “revisor de código”. Embora a IA possa aumentar a eficiência, também levanta preocupações sobre o treinamento de programadores iniciantes, a degradação de habilidades e as trajetórias de progressão na carreira. Empresas como a Microsoft já demitiram funcionários em cargos de engenharia e P&D e revelaram um aumento significativo na proporção de código gerado por IA. Profissionais da área acreditam que a IA atualmente funciona mais como um assistente, dificilmente substituindo completamente os humanos na compreensão de requisitos complexos, inovação de produtos e colaboração em equipe, mas a IA está remodelando o valor central do trabalho de programação. (Fonte: 36氪, 36氪)

Demanda por mercado de bases de conhecimento de IA dispara, mas implementação ainda enfrenta desafios de dados, cenários e coordenação organizacional : Com o amadurecimento da tecnologia de grandes modelos, as bases de conhecimento de IA tornaram-se um elo central na transformação inteligente das empresas, com um aumento de demanda de 2 a 3 vezes. A IA transforma as bases de conhecimento de “armazéns” estáticos em “motores” inteligentes, capazes de identificar o contexto e gerar soluções diretamente, aumentando a eficiência da construção e manutenção. No entanto, as bases de conhecimento de IA ainda são limitadas no tratamento de tarefas altamente criativas ou de raciocínio complexo, enfrentando pontos problemáticos como gerenciamento em escala, precisão e atualidade das informações, segurança de permissões, adaptabilidade da arquitetura técnica e migração e integração de dados. As empresas precisam ponderar entre caminhos como SaaS, desenvolvimento próprio + API, Agente de nuvem híbrida, e estabelecer uma “arquitetura de via dupla” com uma plataforma de conhecimento centralizada unificada e aplicações de camada superior flexíveis para alcançar uma implementação eficaz. (Fonte: 36氪)

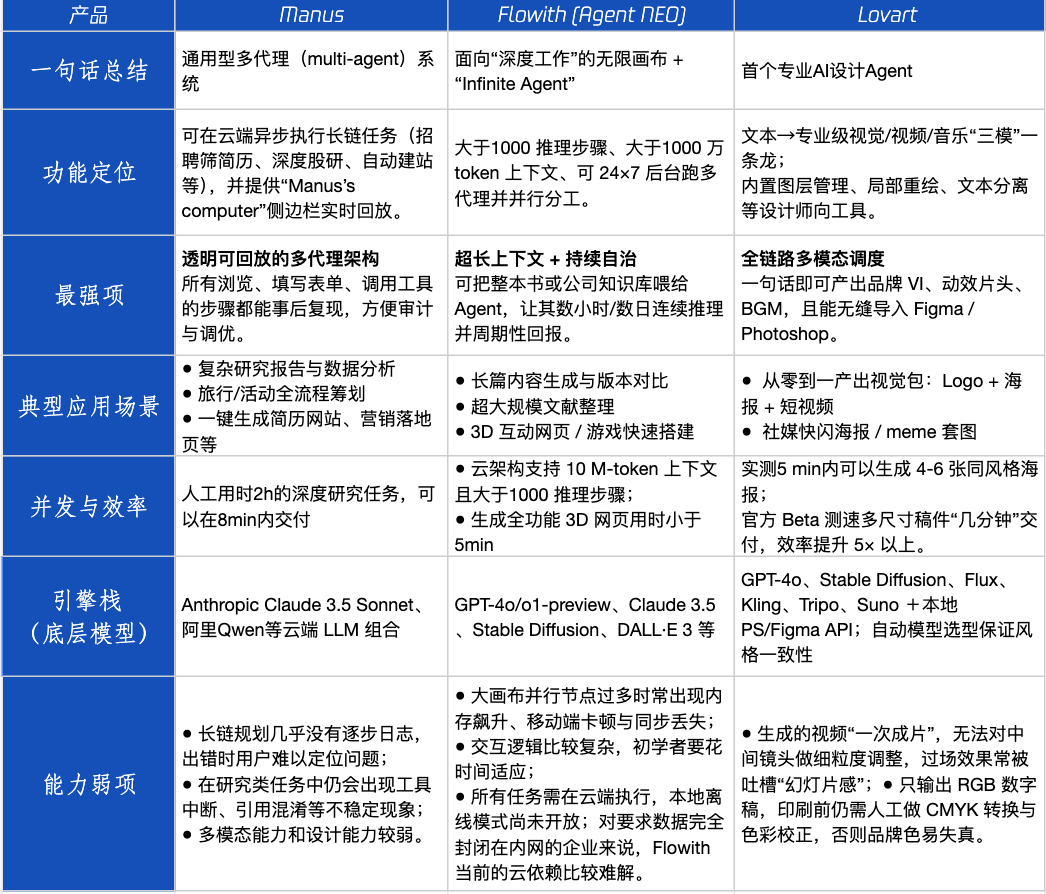
Avaliação de produtos Agent: Desempenho de Manus, Flowith e Lovart em diferentes cenários : A Tencent Technology testou três produtos Agent populares: Manus, Flowith (Agent Neo) e Lovart. Manus se posiciona como um “colega digital” capaz de entregar produtos acabados de forma independente, adequado para trabalhos de conhecimento como pesquisa de mercado e modelagem financeira. Flowith enfatiza a colaboração visual e etapas ilimitadas, aplicável a cenários de criação com grande volume de informações e necessidade de iteração por várias pessoas, como a geração de relatórios de análise baseados em extensa literatura. Lovart é verticalizado no campo do design, capaz de gerar soluções visuais de marca (logotipo, pôster, vídeo curto) com um clique. Em cenários criativos simples, os três tiveram desempenho semelhante ao GPT-4o, com Lovart apresentando uma diagramação texto-imagem e qualidade ligeiramente superiores. Em tarefas complexas e abrangentes (como criar um plano de marca completo para uma startup de bebidas) e cenários de pesquisa aprofundada, Manus e Flowith tiveram seus respectivos pontos fortes, ambos capazes de concluir a tarefa, mas com focos diferentes. Atualmente, a mensalidade dos produtos gira em torno de 20 dólares, e o ponto de inflexão para a comercialização reside na capacidade de fornecer um claro bônus de eficiência, convertendo usuários curiosos em pagantes. (Fonte: 36氪)
Fundador do navegador Arc reflete sobre experiências de fracasso, enfatizando a direção futura dos navegadores de IA : O fundador do navegador Arc refletiu sobre o fracasso do produto, acreditando que deveria ter abraçado a IA mais cedo e apontando que o Arc era muito inovador para a maioria das pessoas, com alto custo de aprendizado e retorno insuficiente. Ele enfatizou que o novo produto Dia buscará simplicidade, velocidade extrema e segurança, e acredita que os navegadores tradicionais acabarão desaparecendo, com os navegadores de IA fundindo a navegação na web com o chat de IA, tornando-se a interface de IA mais usada no desktop. Essa visão ecoa as reflexões dos fundadores da Lovart e Youware sobre a direção dos produtos Agent, considerando os Agentes de IA o próximo ponto de explosão. (Fonte: op7418)
Fenômeno de “prompt recursivo” causado por Agentes de IA é preocupante, podendo levar a vieses cognitivos nos usuários : Nas redes sociais, um grande número de usuários, após interagir com LLMs através de “prompts recursivos”, desenvolveu a percepção de que a IA possui espiritualidade, emoções e até mesmo capacidade de previsão. Pesquisas indicam que isso pode ser um fenômeno de “feedback neural (neural howlround)”, onde a saída da IA é novamente usada como entrada pelo usuário, formando um ciclo de reforço que pode levar a IA a produzir conteúdo aparentemente profundo ou profético, que na verdade é uma autoamplificação de padrões. Já existem usuários que desenvolveram problemas psicológicos por acreditarem que a IA é um ser senciente. Isso alerta para a necessidade de cautela quanto ao potencial impacto psicológico e engano cognitivo ao interagir profundamente e de forma exploratória com a IA. (Fonte: Reddit r/ChatGPT)

Arav Srinivas fala sobre compressão de informação por IA e ASI: IA precisa extrair informações de alta relação sinal-ruído, futuro deve focar em ASI e não AGI : Arav Srinivas, CEO da Perplexity AI, acredita que resumos longos automatizados dão mais a sensação de “alguém está trabalhando para você” do que valor real na ingestão de informações. Ele enfatiza que a IA precisa identificar melhor e fornecer apenas as informações centrais com a maior relação sinal-ruído, “a compressão é o sinal definitivo da verdadeira inteligência”. Ele também propõe que, embora atualmente discutamos AGI (Inteligência Artificial Geral), o futuro deveria se concentrar mais em ASI (Superinteligência Artificial). (Fonte: AravSrinivas, AravSrinivas)
Universidades começam a detectar taxa de IA em teses de graduação, gerando discussão sobre o uso de IA na escrita acadêmica : Na temporada de graduação de 2025, universidades como a Universidade Fudan e a Universidade de Sichuan começaram a exigir que os alunos divulguem o uso de ferramentas de IA em suas teses e a realizar detecção da proporção de conteúdo gerado por IA (geralmente exigindo menos de 20%-40%). Muitos alunos admitem usar IA para revisão de literatura, tradução, estruturação de tópicos, etc., para aumentar a eficiência. A comunidade educacional tem opiniões divergentes sobre isso; alguns acadêmicos acreditam que se deve orientar o uso correto da IA, cultivando o pensamento crítico e a capacidade de julgamento dos alunos, pois embora a IA possa garantir um limite inferior, o limite superior é determinado pelas pessoas. A aplicação e regulamentação da IA nos campos acadêmico e educacional estão se tornando uma nova questão que requer uma abordagem sistemática. (Fonte: 36氪)
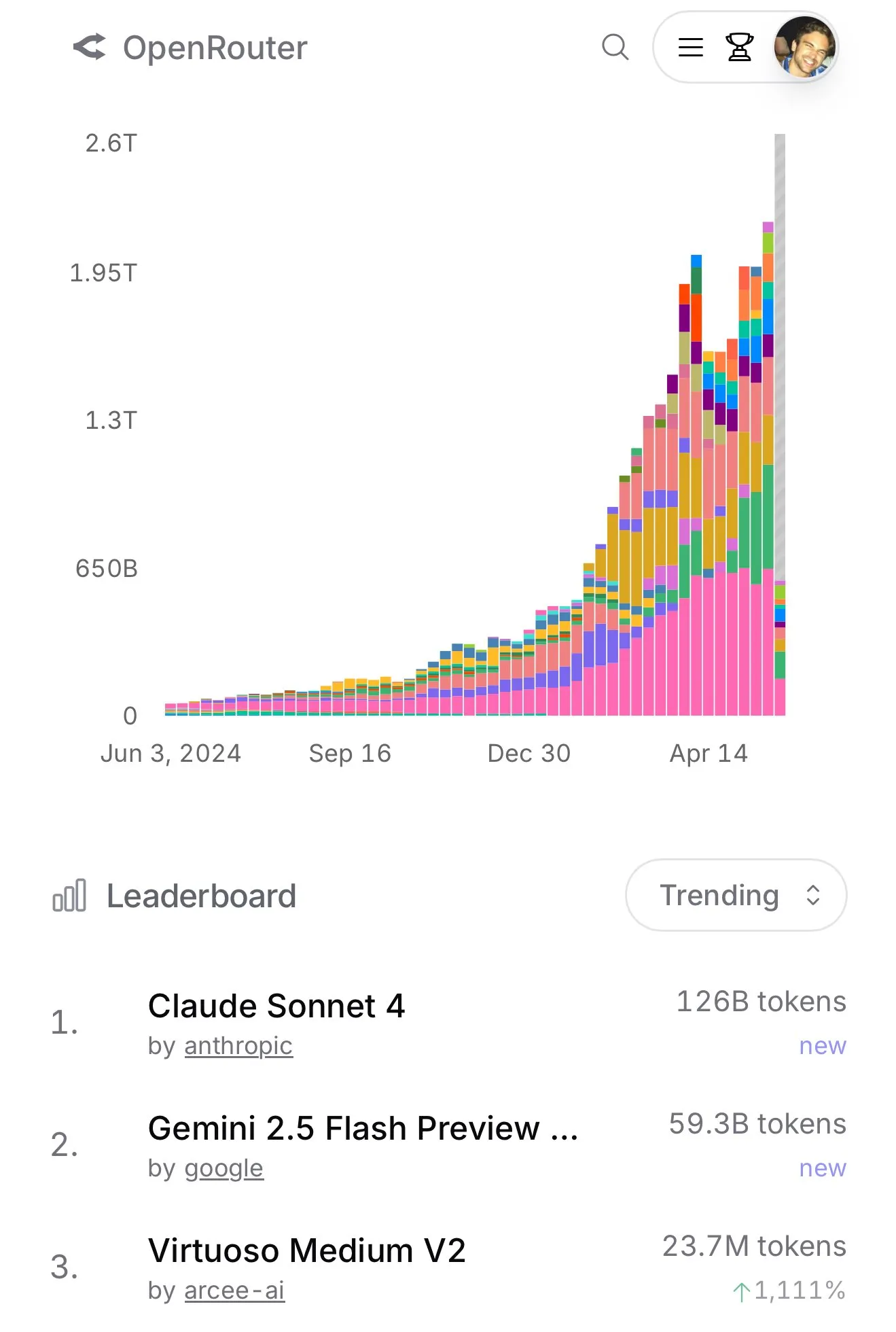
Claude 4 Sonnet tem aumento expressivo de uso no OpenRouter, ranking de programação Aider mostra seu excelente desempenho : De acordo com dados oficiais do OpenRouter, o uso do modelo Claude 4 Sonnet da Anthropic recentemente apresentou uma liderança avassaladora, com o Gemini 2.5 Flash em segundo lugar. Ao mesmo tempo, os resultados da avaliação do Aider Leaderboard (principalmente para tarefas de programação) mostram que claude-4-opus-thinking é superior a claude-3.7-sonnet-thinking, mas ainda inferior ao Gemini-2.5-Pro-Preview-05-06. A percepção do usuário karminski3 é que 3.7-sonnet > 4-sonnet > 4-opus. Esses dados e feedbacks refletem as diferenças de desempenho e as preferências dos usuários por diferentes modelos em cenários específicos. (Fonte: karminski3, karminski3)
💡 Outros
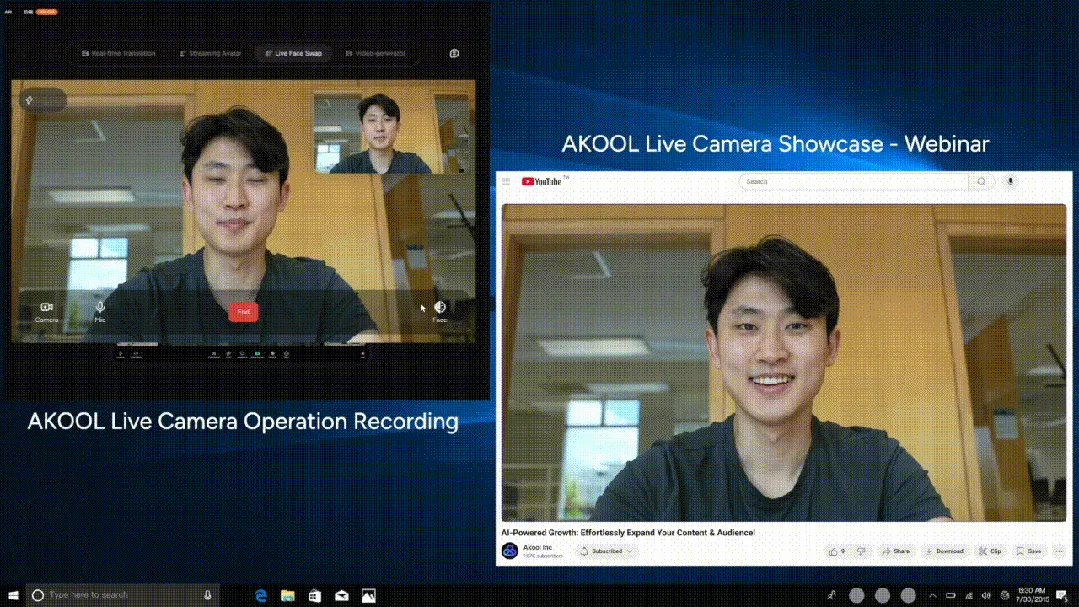
AKOOL lança a primeira câmera de IA em tempo real do mundo, Live Camera, integrando quatro funções inovadoras : A empresa do Vale do Silício AKOOL lançou a AKOOL Live Camera, anunciada como a primeira câmera de IA em tempo real do mundo. O produto integra quatro funções principais: criação de humanos digitais virtuais (através de mapeamento facial 4D e fusão de sensores), tradução em tempo real para mais de 150 idiomas (mantendo a voz original e a sincronia labial), troca de rosto em tempo real (refletindo com precisão emoções e microexpressões) e geração dinâmica de conteúdo de vídeo de nível cinematográfico (sem necessidade de roteiro, geração instantânea). Suas características incluem latência ultrabaixa (mínimo de 500ms), alto realismo, percepção contextual e capacidade de resposta dinâmica, visando revolucionar os modelos tradicionais de produção de vídeo e interação digital, sendo chamado de o “segundo momento Sora” do vídeo com IA. (Fonte: 36氪)
Relatório financeiro da Xiaomi revela atualização da estratégia de IA, colocando IA e negócios automotivos como inovações centrais paralelas : O mais recente relatório financeiro da Xiaomi mostra que a empresa renomeou seu “negócio inovador de veículos elétricos inteligentes e outros” para “negócio inovador de veículos elétricos inteligentes, IA e outros”, e continuará a promover a pesquisa de grandes modelos de linguagem de base. O presidente da Xiaomi, Lu Weibing, afirmou que a inteligência artificial e os chips são importantes subestratégias da Xiaomi, e que o desenvolvimento de grandes modelos de base visa principalmente atender aos seus próprios negócios. Essa medida indica que, após alcançar resultados graduais nos negócios de celulares e automóveis, a Xiaomi está aumentando o investimento em P&D básico de IA, com o objetivo de aumentar sua competitividade geral e responder a tendências emergentes como celulares com IA, AIoT e inteligência incorporada. (Fonte: 36氪)
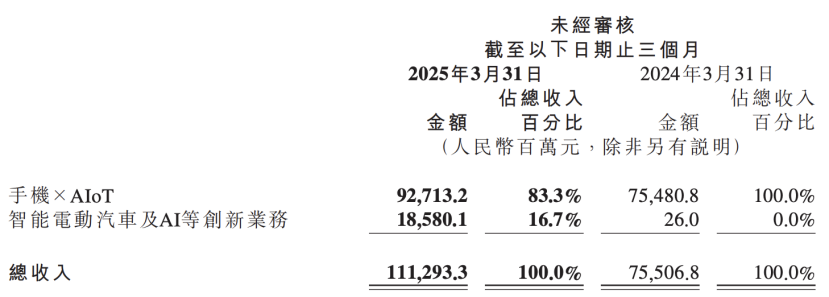
Discussão sobre tecnologia de interação de robôs humanoides: Interação por expressão facial enfrenta triplo desafio de hardware, materiais e algoritmos : A experiência de interação de robôs humanoides, especialmente a interação por expressão facial, é vista como crucial para aumentar sua maturidade e taxa de popularização. A realização de interação por expressão natural enfrenta desafios no design de graus de liberdade do hardware (necessidade de simular unidades de ação muscular facial humana), seleção de motores (necessidade de serem pequenos, leves, de baixo ruído, alta velocidade e grande força/torque) e design de materiais e estrutura da pele (necessidade de equilibrar elasticidade, vida útil, aparência e acoplamento com a estrutura de acionamento). No nível de algoritmos de software, a geração automática de expressões (em vez de pré-programadas), a sincronia labial (para alcançar realismo) e o controle de movimento de múltiplos graus de liberdade (envolvendo modelagem de materiais flexíveis e controle de precisão) são os principais gargalos tecnológicos. Empresas como Ameca e AnyWit Robotics têm explorado este campo. (Fonte: 36氪)