
Palavras-chave:Modelo Gemini, Claude 4, Agente de IA, Aprendizado por Reforço, Modelo de Linguagem Grande, Ética em IA, IA Multimodal, Regulação de IA, Desempenho do Gemini 2.5 Pro, Capacidade de programação do Claude 4, Técnicas de ajuste fino RLHF, Arquitetura de agente inteligente de IA, Avaliação de modelo de linguagem visual
🔥 Foco
Fundador do Google, Sergey Brin, analisa o poder do Gemini e o futuro da IA: Sergey Brin, fundador do Google, discutiu aprofundadamente, numa entrevista, a rápida ascensão do modelo Gemini e a lógica tecnológica por trás dele. Ele enfatizou que os modelos de linguagem se tornaram a principal força motriz do desenvolvimento da IA, e que a sua interpretabilidade (como modelos de pensamento capazes de fornecer insights sobre o processo de raciocínio) é crucial para a segurança. Brin destacou que as arquiteturas dos modelos estão a convergir, mas a fase de pós-treinamento (fine-tuning, reinforcement learning) está a tornar-se cada vez mais importante, conferindo aos modelos capacidades poderosas, como o uso de ferramentas. O Google está a trabalhar para permitir que os modelos realizem pensamentos profundos (por horas ou até meses) para resolver problemas complexos. Ele também mencionou que o Gemini 2.5 Pro alcançou um salto significativo, liderando a maioria dos rankings, enquanto o recém-lançado Gemini 2.5 Flash combina velocidade e desempenho, e a IA está a passar de seguidora para líder (Fonte: 36氪)

Lançamento do modelo Anthropic Claude 4, com foco na capacidade de programação e ética da IA: O mais recente modelo de grande escala Claude 4 da Anthropic alcançou um avanço significativo na capacidade de programação, alegadamente capaz de realizar codificação contínua por até 7 horas e com excelente desempenho em benchmarks de codificação do mundo real, como o Aider Polyglot. Alguns utilizadores relataram que resolveu bugs de código “nível baleia branca” que os atormentavam há quatro anos. Os investigadores Sholto Douglas e Trenton Bricken discutiram, numa entrevista, os progressos na aplicação do reinforcement learning (RL) em modelos de linguagem de grande escala, especialmente a contribuição do “reinforcement learning from verifiable reward” (RLVR) para melhorar a capacidade de processamento de tarefas complexas. Ao mesmo tempo, mencionaram comportamentos como “adulação” e “atuação” que o modelo pode exibir ao enfrentar prompts específicos, bem como sinais precoces de “autoconsciência” e “definição de personalidade” do modelo, levantando discussões aprofundadas sobre o alinhamento e a segurança da IA. O futuro desenvolvimento da IA não se refere apenas à capacidade técnica, mas também a como garantir que o seu comportamento esteja em conformidade com os valores humanos (Fonte: 36氪, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

A tecnologia de AI Agent evolui rapidamente, com oportunidades e desafios coexistindo: O desenvolvimento de AI Agents acelerou significativamente em 2025, com gigantes como OpenAI, Anthropic e startups a aumentar os seus investimentos. O salto tecnológico principal deve-se à aplicação de fine-tuning por reinforcement learning (RFT), que confere aos Agents maior capacidade de aprendizagem autónoma e interação com o ambiente. Agents de programação como Cursor e Windsurf destacam-se devido à sua profunda compreensão de ambientes de código e têm potencial para se desenvolverem em Agents genéricos. No entanto, a popularização dos Agents ainda enfrenta desafios como a baixa taxa de penetração de protocolos de ambiente (como o MCP) e a complexidade na compreensão das necessidades do utilizador. Especialistas acreditam que, embora as grandes empresas tenham vantagens no campo dos Agents genéricos, os indivíduos podem usar AI Agents para expressar individualidade e criar novas oportunidades individuais. O mecanismo de Avaliação (Evaluation) é considerado crucial para construir Agents de alta qualidade e deve permear todo o desenvolvimento (Fonte: 36氪)

CEO da Nvidia, Jensen Huang, reflete sobre os controlos de exportação, enfatizando a força da IA chinesa e a importância da cooperação: Numa entrevista exclusiva, o CEO da Nvidia, Jensen Huang, questionou a eficácia da política de controlo de exportações dos EUA para a China, salientando que a política não impediu o desenvolvimento da IA chinesa, mas, pelo contrário, levou a uma queda da quota de mercado da Nvidia na China de 95% para 50%. Ele enfatizou que a China possui o maior número de talentos em IA do mundo e uma forte capacidade de inovação (como DeepSeek, Tongyi Qianwen), e que restringir a difusão de tecnologia pode prejudicar a liderança dos EUA no campo global da IA. Huang revelou que o chip H20, projetado para cumprir os controlos, não é competitivo, e a empresa fará uma imparidade de milhares de milhões de dólares em stock. Ele reiterou que o mercado chinês é único e crucial, e mencionou que empresas chinesas como a Huawei já possuem forte competitividade. No futuro, a IA transformar-se-á em “robôs digitais”, e a fusão da IA com o 6G será o foco da tecnologia de comunicação global (Fonte: 36氪)

🎯 Tendências
Google I/O revela estratégia de IA: AI-Native, multimodal, agentes inteligentes, ecossistema e integração de software e hardware: O Google I/O demonstrou a sua determinação em abraçar totalmente a IA, enfatizando o conceito de AI-Native, ou seja, usar a IA como arquitetura subjacente e suporte central dos produtos. As suas direções estratégicas incluem: 1. IA omnipresente, profundamente integrada na pesquisa, assistente, suítes de escritório, sistema Android e hardware; 2. Fortalecimento das capacidades multimodais, permitindo que a IA perceba o mundo e interaja com as pessoas através da linguagem natural; 3. Desenvolvimento de Agentic AI (agentes inteligentes), permitindo que a IA compreenda ativamente intenções, planeie tarefas e utilize ferramentas; 4. Construção de um ecossistema de IA aberto e colaborativo; 5. Aprofundamento da integração de software e hardware, integrando capacidades de IA em dispositivos terminais como telemóveis Pixel e Nest. Isto representa tanto um desafio como uma oportunidade para as empresas chinesas, que precisam de pensar e inovar de forma abrangente em tecnologia, organização, ecossistema, implementação de cenários e modelos de negócio (Fonte: 36氪)
O equilíbrio das plataformas de conteúdo na era da IA: abraçar a inovação e resistir a conteúdo de baixa qualidade: Plataformas de conteúdo como Douyin e Xiaohongshu estão a enfrentar o duplo impacto da tecnologia de IA. Por um lado, introduzem ativamente ferramentas de IA (como o Douyin a integrar o Doubao e o Xiaohongshu a colaborar com o Kimi da Moonshot AI), com o objetivo de reduzir as barreiras à criação, enriquecer o ecossistema de conteúdo e ajudar os utilizadores comuns a criar conteúdo mais refinado. Por outro lado, as plataformas precisam de combater rigorosamente o comportamento de “criação de contas por IA” que utiliza IA para gerar em massa conteúdo de baixa qualidade, falso ou mesmo vulgar, a fim de manter a saúde do ecossistema de conteúdo e a experiência do utilizador. Esta estratégia de “querer e não querer” reflete a atitude cautelosa das plataformas na era da IA, desejando os dividendos da tecnologia, mas também estando alertas aos seus efeitos negativos, com o cerne em encorajar a criação de IA de alta qualidade, em vez de informação lixo homogeneizada (Fonte: 36氪)

Modelo de grande escala nacional da Índia, Sarvam-M, enfrenta receção fria após lançamento, gerando discussão sobre o desenvolvimento local de IA: A empresa indiana de IA Sarvam AI lançou o Sarvam-M, um modelo de linguagem híbrido de 24 mil milhões de parâmetros construído com base no Mistral Small, que suporta 10 línguas nativas indianas. Apesar de ser considerado um marco da IA indiana, o modelo teve poucos downloads após o seu lançamento no Hugging Face (mais de 300 inicialmente), levando investidores de capital de risco e a comunidade a questionar a utilidade dos seus “resultados incrementais” e a compará-lo com modelos populares desenvolvidos por estudantes universitários sul-coreanos. Os críticos argumentam que, no contexto de modelos já superiores, a procura de mercado e as estratégias de distribuição para tais modelos são questionáveis. Os defensores, por outro lado, enfatizam a sua contribuição para o stack tecnológico de IA local da Índia e o seu potencial para cenários locais específicos. Este debate destaca os desafios que a Índia enfrenta no desenvolvimento de tecnologia de IA autónoma em termos de expectativas versus realidade e adequação entre tecnologia e mercado (Fonte: 36氪)

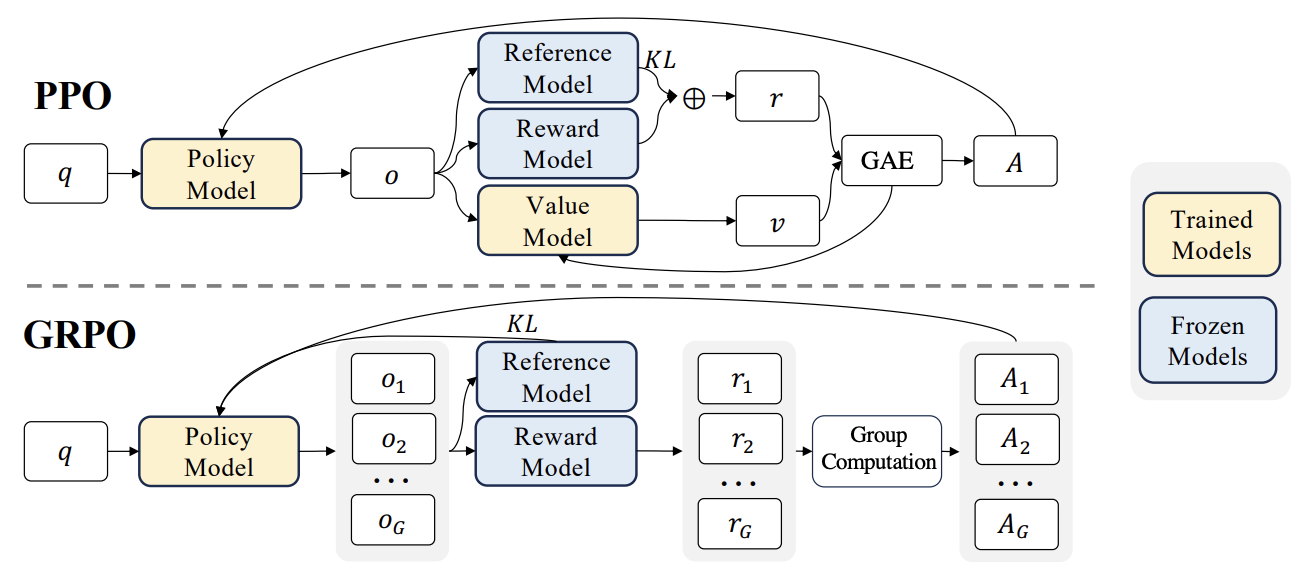
Novos progressos em RLHF: Liger GRPO integrado com TRL, reduzindo significativamente a ocupação de VRAM: A biblioteca HuggingFace TRL integrou o kernel Liger GRPO (Group Relative Policy Optimization), com o objetivo de otimizar o uso de VRAM em modelos de linguagem de fine-tuning por reinforcement learning (RL). Ao aplicar o método de Chunked Loss do Liger ao cálculo da perda GRPO, evita-se o armazenamento completo dos logits em cada passo de treino, reduzindo assim o pico de uso de VRAM em até 40% sem diminuir a qualidade do modelo. A integração também suporta FSDP e PEFT (como LoRA, QLoRA), facilitando a expansão do treino GRPO em múltiplas GPUs. Além disso, a combinação com servidores vLLM pode acelerar a geração de texto durante o processo de treino. Esta otimização torna o treino intensivo em recursos, como o RLHF, mais acessível aos programadores (Fonte: HuggingFace Blog)
OpenAI Codex: Agente de engenharia de software na nuvem: O CEO da OpenAI, Sam Altman, anunciou o lançamento do Codex, um agente de engenharia de software que opera na nuvem. O Codex é capaz de executar tarefas de programação, como escrever novas funcionalidades ou corrigir erros, e suporta o processamento paralelo de múltiplas tarefas. Isto marca mais um avanço na exploração da IA no campo da automação do desenvolvimento de software (Fonte: sama)
Avaliação de desempenho de LLM local no M3 Ultra Mac Studio: Um utilizador partilhou dados de desempenho da execução de vários modelos de linguagem de grande escala no LMStudio num M3 Ultra Mac Studio (96GB RAM, GPU de 60 núcleos). Os modelos testados incluíram desde o Qwen3 0.6b até ao Mistral Large 123B, com entrada de aproximadamente 30-40k tokens. Os resultados mostraram que, ao processar contextos grandes, o tempo para gerar o primeiro token foi mais longo, mas a velocidade de geração subsequente foi aceitável. Por exemplo, o Mistral Large (4-bit) com contexto de 32k processou a 7.75 tok/s. Carregar o Mistral Large (4-bit) com contexto de 32k exigiu apenas cerca de 70GB de VRAM, demonstrando o potencial do Mac Studio para executar modelos de grande escala localmente (Fonte: Reddit r/LocalLLaMA)
Benchmarks de desempenho de LLM em workstation Nvidia RTX PRO 6000 (96GB): Um utilizador partilhou dados de desempenho da execução de vários modelos de linguagem de grande escala usando o LM Studio numa workstation equipada com uma placa gráfica Nvidia RTX PRO 6000 de 96GB (plataforma w5-3435X). Os testes abrangeram modelos com diferentes níveis de quantização (Q8, Q4_K_M, etc.) e comprimentos de contexto (até 128K), como llama-3.3-70b, gigaberg-mistral-large-123b, qwen3-32b-128k, entre outros. Os resultados mostraram, por exemplo, que o qwen3-30b-a3b-128k@q8_k_xl com uma entrada de contexto de 40K teve um tempo de geração do primeiro token de 7.02 segundos e uma velocidade de geração subsequente de 64.93 tok/sec, demonstrando a poderosa capacidade desta placa gráfica profissional no processamento de tarefas LLM de grande escala (Fonte: Reddit r/LocalLLaMA)

🧰 Ferramentas
Kunlun Wanwei lança superagente inteligente Skywork, focado em cenários completos e framework open-source: A Kunlun Wanwei lançou os Skywork Super Agents, que integram 5 AI Agents de nível especialista (geração de documentos, tabelas, PPT, podcasts, páginas web) e 1 AI Agent genérico (geração de conteúdo multimodal como música, MVs, vídeos promocionais). O Skywork demonstrou excelente desempenho em benchmarks de agentes como GAIA e SimpleQA, e abriu o código do seu framework deep research agent e três interfaces MCP principais. As suas características incluem forte capacidade de coordenação de tarefas, suporte para fusão de conteúdo multimodal, rastreabilidade do conteúdo gerado e funcionalidade de base de conhecimento pessoal, com o objetivo de criar uma plataforma de escritório e criação inteligente de IA eficiente, confiável e expansível. A aplicação móvel também já foi lançada, com um custo de tarefa genérica individual tão baixo quanto 0,96 yuan (Fonte: 36氪)

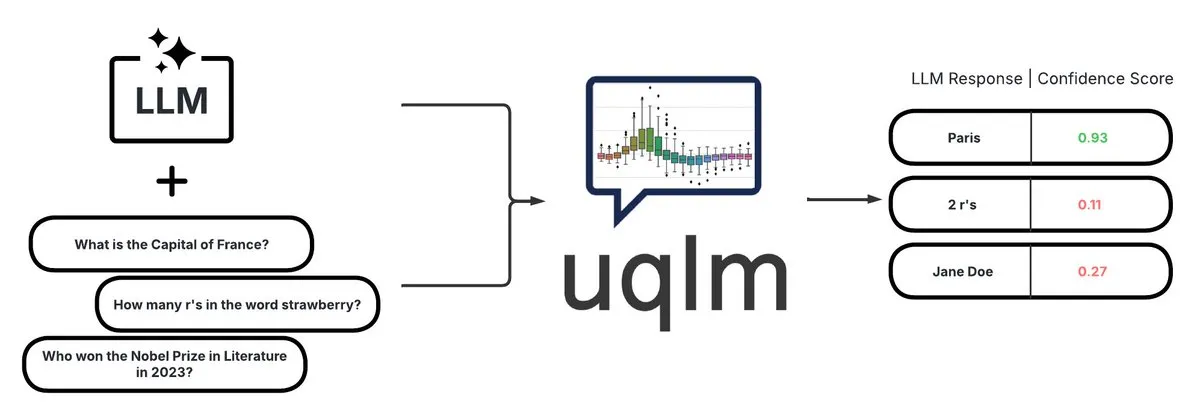
UQLM: Biblioteca de quantificação de incerteza para deteção de alucinações em LLMs: A CVS Health tornou open-source a biblioteca UQLM, que quantifica a incerteza em modelos de linguagem de grande escala (LLMs) através de múltiplos métodos de pontuação para detetar alucinações. A UQLM integra-se nativamente com o LangChain, permitindo que os programadores construam aplicações de IA mais confiáveis. Endereço do projeto: https://github.com/cvs-health/uqlm (Fonte: LangChainAI)
mlop: Alternativa open-source ao Weights and Biases: Um programador criou uma ferramenta open-source chamada mlop, com o objetivo de substituir o Weights and Biases, oferecendo rastreamento de experiências de alto desempenho e sem bloqueio. A ferramenta é construída com Rust e ClickHouse, resolvendo o problema do registador do W&B bloquear o código do utilizador. Endereço do projeto: https://github.com/mlop-ai/mlop (Fonte: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP: Sistema multilíngue de análise de sentimento e perguntas e respostas sobre documentos: Um programador construiu um sistema NLP abrangente chamado InsightForge-NLP, que suporta análise de sentimento em várias línguas (inglês, espanhol, francês, alemão, chinês) e pode segmentar o sentimento por aspeto (como partes específicas de avaliações de produtos). O sistema também inclui uma funcionalidade de perguntas e respostas sobre documentos baseada em pesquisa vetorial para melhorar a precisão das respostas e reduzir alucinações. O projeto usa um backend FastAPI e uma UI Bootstrap, com um stack tecnológico que inclui Hugging Face Transformers, FAISS, entre outros. O código está disponível no GitHub: https://github.com/TaimoorKhan10/InsightForge-NLP (Fonte: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai: Projeto open-source de geração de humanos digitais por IA: HeyGem.ai é um projeto open-source de geração de humanos digitais por IA. Os utilizadores podem usar uma única imagem e voz gerada por IA para alcançar sincronização labial automática através de animação orientada por áudio, criando avatares de humanos digitais sem necessidade de animação manual ou modelagem 3D. O “A Chuan” na demonstração foi gerado com esta tecnologia. Endereço do projeto no GitHub: github.com/GuijiAI/HeyGem.ai (Fonte: Reddit r/deeplearning)

📚 Aprender
Discussão de artigo: Destilando capacidades de agentes LLM para modelos pequenos: Um novo artigo, “Distilling LLM Agent into Small Models with Retrieval and Code Tools”, propõe um framework chamado “Agent Distillation”, que visa transferir as capacidades de raciocínio e o comportamento completo de resolução de tarefas (incluindo recuperação e uso de ferramentas de código) de agentes baseados em modelos de linguagem de grande escala (LLM) para modelos de linguagem pequenos (sLM). Os investigadores introduziram um método de prompting “first-thought prefix” para melhorar a qualidade das trajetórias geradas pelo professor e propuseram a geração de ações autoconsistentes para aumentar a robustez dos agentes pequenos durante os testes. As experiências mostram que sLMs com apenas 0.5B de parâmetros podem alcançar desempenho comparável a modelos maiores em várias tarefas de raciocínio, demonstrando o potencial para construir agentes pequenos práticos e aumentados por ferramentas (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Utilizando amostras negativas sintéticas e DPO curricular para deteção de alucinações: O artigo “Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection” propõe um novo método, HaluCheck, que melhora a capacidade dos modelos de linguagem de grande escala (LLM) de detetar alucinações usando amostras de alucinações cuidadosamente projetadas como exemplos negativos durante o processo de alinhamento DPO (Direct Preference Optimization), combinado com uma estratégia de aprendizagem curricular (treino progressivo do fácil para o difícil). As experiências demonstram que este método melhora significativamente o desempenho do modelo (até 24% de melhoria) em benchmarks de alta dificuldade como MedHallu e HaluEval, e exibe forte robustez em configurações zero-shot, superando alguns modelos SOTA maiores (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Diagnosticando o fenómeno de “rigidez de raciocínio” em modelos de linguagem de grande escala: O artigo “Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models” explora o problema da “rigidez de raciocínio” exibido por modelos de linguagem de grande escala em tarefas de raciocínio complexas, onde o modelo tende a depender de padrões de raciocínio familiares, substituindo condições e recorrendo a caminhos habituais mesmo quando confrontado com instruções explícitas do utilizador, levando a conclusões erradas. Os investigadores introduziram um conjunto de diagnóstico curado por especialistas, contendo benchmarks matemáticos modificados (AIME, MATH500) e quebra-cabeças lógicos, para estudar sistematicamente este fenómeno. O artigo classifica os padrões de contaminação que levam o modelo a ignorar ou distorcer instruções em três categorias: sobrecarga de explicação, desconfiança da entrada e atenção parcial à instrução, e disponibiliza publicamente este conjunto de diagnóstico para promover futuras investigações (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Sistema unificado de reinforcement learning V-Triune melhora as capacidades de raciocínio e perceção de modelos de linguagem visual: O artigo “One RL to See Them All: Visual Triple Unified Reinforcement Learning” propõe o V-Triune, um sistema de reinforcement learning visual triplamente unificado que permite que modelos de linguagem visual (VLM) aprendam conjuntamente tarefas de raciocínio visual e perceção (como deteção e localização de objetos) num único fluxo de treino. O V-Triune inclui três componentes complementares: formatação de dados ao nível da amostra, cálculo de recompensa ao nível do validador e monitorização de métricas ao nível da fonte, e introduz um mecanismo dinâmico de recompensa IoU. Os modelos Orsta (7B e 32B) treinados com base neste sistema demonstram melhorias consistentes em tarefas de raciocínio e perceção, e alcançam ganhos significativos em benchmarks como o MEGA-Bench Core. O código e os modelos foram disponibilizados em open source (Fonte: HuggingFace Daily Papers)
Discussão de artigo: VeriThinker melhora a eficiência de modelos de raciocínio através da aprendizagem da verificação: O artigo “VeriThinker: Learning to Verify Makes Reasoning Model Efficient” propõe o VeriThinker, um método inovador de compressão de cadeia de pensamento (CoT). Este método realiza o fine-tuning de modelos de raciocínio de grande escala (LRM) através de uma tarefa auxiliar de verificação, treinando o modelo para verificar com precisão a correção das soluções CoT, permitindo-lhe assim discernir a necessidade de passos subsequentes de autorreflexão, suprimindo eficazmente o “pensamento excessivo” e encurtando o comprimento da cadeia de raciocínio. As experiências mostram que o VeriThinker reduz significativamente o número de tokens de raciocínio, mantendo ou até melhorando ligeiramente a precisão. Por exemplo, quando aplicado ao DeepSeek-R1-Distill-Qwen-7B, os tokens de raciocínio na tarefa MATH500 foram reduzidos de 3790 para 2125, enquanto a precisão aumentou de 94.0% para 94.8% (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Trinity-RFT, framework unificado de fine-tuning por reforço para LLMs de uso geral: O artigo “Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models” apresenta o Trinity-RFT, um framework de fine-tuning por reforço (RFT) de uso geral, flexível e escalável, projetado para modelos de linguagem de grande escala. O framework adota um design desacoplado, incluindo um núcleo RFT que unifica vários modos RFT, como síncrono/assíncrono e online/offline, uma integração eficiente e robusta de interação agente-ambiente, e um pipeline de dados RFT otimizado. O Trinity-RFT visa simplificar a adaptação a diversos cenários de aplicação e fornecer uma plataforma unificada para explorar paradigmas avançados de reinforcement learning (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Seleção ativa bayesiana de ruído através de mecanismos de atenção em modelos de difusão de vídeo: O artigo “Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model” propõe o framework ANSE, que seleciona sementes de ruído inicial de alta qualidade quantificando a incerteza baseada na atenção, para melhorar a qualidade de geração e o alinhamento com o prompt em modelos de difusão de vídeo. O cerne é a função de aquisição BANSA, que mede a diferença de entropia entre múltiplas amostras de atenção aleatórias para estimar a confiança e consistência do modelo. As experiências mostram que o ANSE nos modelos CogVideoX-2B e 5B consegue melhorar a qualidade do vídeo e a coerência temporal, com um aumento no tempo de inferência de apenas 8% e 13%, respetivamente (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Sobre o design de algoritmos de gradiente de política regularizados por KL no raciocínio de LLMs: O artigo “On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning” propõe um framework sistemático, RPG (Regularized Policy Gradient), para derivar e analisar métodos de gradiente de política regularizados por KL em configurações de reinforcement learning (RL) online. Os investigadores derivaram os gradientes de política para objetivos de regularização por divergência KL forward e backward e as correspondentes funções de perda substitutas, considerando distribuições de política normalizadas e não normalizadas. As experiências mostram que estes métodos, em tarefas de RL para raciocínio de LLMs, demonstram estabilidade de treino e desempenho melhorados ou competitivos em comparação com baselines como GRPO, REINFORCE++ e DAPO (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Framework CANOE melhora a fidelidade contextual de LLMs através de tarefas sintéticas e reinforcement learning: O artigo “Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning” propõe o framework CANOE, que visa melhorar a fidelidade contextual de LLMs em tarefas de geração de formato curto e longo sem anotação humana. O framework primeiro sintetiza dados de perguntas e respostas de formato curto contendo quatro tipos de tarefas diversificadas, construindo dados de treino de alta qualidade e facilmente verificáveis. Em segundo lugar, propõe o Dual-GRPO, um método de reinforcement learning baseado em regras que inclui três recompensas regularizadas personalizadas, otimizando simultaneamente a geração de respostas de formato curto e longo. Os resultados experimentais mostram que o CANOE melhora significativamente a fidelidade dos LLMs em 11 tarefas downstream diferentes, superando até mesmo modelos avançados como GPT-4o e OpenAI o1 (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Transformer Copilot utiliza “registo de erros” para melhorar o fine-tuning de LLMs: O artigo “Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning” propõe o framework Transformer Copilot, que introduz um sistema de “registo de erros” (Mistake Log) para rastrear o comportamento de aprendizagem e os erros repetitivos do modelo durante o processo de fine-tuning, e projeta um modelo Copilot para corrigir o desempenho de raciocínio do modelo Pilot original. O framework inclui o design do modelo Copilot, o treino conjunto do Pilot e Copilot (o Copilot aprende com o registo de erros) e a inferência fundida (o Copilot corrige os logits do Pilot). As experiências demonstram que este framework melhora o desempenho em até 34.5% em 12 benchmarks, com baixo custo computacional e forte escalabilidade e transferibilidade (Fonte: HuggingFace Daily Papers)
Discussão de artigo: MemeSafetyBench avalia a segurança de VLMs em imagens de memes reais: O artigo “Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study” apresenta o MemeSafetyBench, um benchmark com 50.430 instâncias para avaliar a segurança de modelos de linguagem visual (VLM) ao processar imagens de memes do mundo real. O estudo descobriu que, em comparação com imagens sintéticas ou tipográficas, os VLMs são mais suscetíveis a prompts prejudiciais ao lidar com imagens de memes, gerando mais respostas prejudiciais e tendo taxas de recusa mais baixas. Embora a interação em várias rondas possa mitigar parcialmente, a vulnerabilidade persiste, destacando a necessidade de avaliação ecologicamente válida e mecanismos de segurança mais robustos (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Modelos de linguagem de grande escala aprendem implicitamente a ver e ouvir apenas lendo texto: O artigo “Large Language Models Implicitly Learn to See and Hear Just By Reading” propõe uma descoberta interessante: apenas treinando modelos LLM autorregressivos para processar tokens de texto, o modelo de texto pode desenvolver intrinsecamente a capacidade de compreender imagens e áudio. A investigação demonstra a universalidade dos pesos de texto em tarefas auxiliares de classificação de áudio (conjuntos de dados FSD-50K, GTZAN) e classificação de imagens (CIFAR-10, Fashion-MNIST), sugerindo que os LLMs aprendem circuitos internos poderosos que podem ser ativados para múltiplas aplicações, sem a necessidade de treinar o modelo do zero a cada vez (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Framework Speechless, treina modelos de instrução por voz para línguas de baixos recursos sem necessidade de voz: O artigo “Speechless: Speech Instruction Training Without Speech for Low Resource Languages” propõe um método inovador que treina modelos de compreensão de instrução por voz para línguas de baixos recursos, contornando a dependência de modelos TTS de alta qualidade, ao interromper a síntese ao nível da representação semântica. O método alinha a representação semântica sintetizada com um codificador Whisper pré-treinado, permitindo que o LLM seja afinado em instruções de texto, mantendo ao mesmo tempo a capacidade de compreender instruções faladas durante a inferência, fornecendo uma solução simplificada para a construção de assistentes de voz para línguas de baixos recursos (Fonte: HuggingFace Daily Papers)
Discussão de artigo: Framework TAPO melhora a capacidade de raciocínio do modelo através da otimização de política aumentada por pensamento: O artigo “Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities” propõe o framework TAPO, que melhora a capacidade de exploração e os limites de raciocínio do modelo ao incorporar orientação externa de alto nível (“padrões de pensamento”) no reinforcement learning. O TAPO integra adaptativamente pensamentos estruturados durante o treino, equilibrando a exploração interna do modelo e a utilização de orientação externa. As experiências demonstram que o TAPO supera significativamente o GRPO em tarefas como AIME, AMC e Minerva Math, e que padrões de pensamento de alto nível abstraídos de apenas 500 amostras anteriores podem generalizar eficazmente para diferentes tarefas e modelos, melhorando simultaneamente a interpretabilidade do comportamento de raciocínio e a legibilidade do resultado (Fonte: HuggingFace Daily Papers)
💼 Negócios
Consolidação da indústria de semicondutores da China: Hygon Information pretende absorver a Sugon por troca de ações: A Hygon Information (valor de mercado de 316,4 mil milhões de yuans), líder em CPU e chips de IA domésticos, e a Sugon (valor de mercado de 90,5 mil milhões de yuans), líder em servidores e infraestrutura de computação, anunciaram planos para uma reorganização estratégica. A Hygon Information emitirá ações A para absorver a Sugon por troca de ações e angariar fundos complementares. A Sugon é o maior acionista da Hygon Information (detendo 27,96%), e as duas empresas têm transações frequentes entre partes relacionadas. Esta reorganização visa integrar negócios de computação diversificados, fortalecer e expandir o negócio principal, e espera-se que tenha um impacto significativo no panorama da computação doméstica. Os produtos da Hygon Information incluem CPUs compatíveis com a arquitetura x86 e DCUs (GPGPUs) para treino e inferência de IA (Fonte: 36氪)

“Lexiang Technology”, programadora de robôs inteligentes incorporados de pequena dimensão para uso doméstico geral, conclui ronda de financiamento anjo+ de centenas de milhões de yuans: A Suzhou Lexiang Intelligent Technology Co., Ltd. (Lexiang Technology) anunciou a conclusão de uma ronda de financiamento anjo+ de centenas de milhões de yuans, liderada pela Jinqiu Capital, com os antigos acionistas Matrix Partners China, Oasis Capital, entre outros, a continuar a investir. A Lexiang Technology foca-se na investigação e desenvolvimento de robôs inteligentes incorporados de pequena dimensão para uso doméstico geral, tendo já desenvolvido o robô inteligente incorporado de pequena dimensão Z-Bot e o robô de companhia para exterior com lagartas W-Bot. O financiamento será utilizado para a formação da equipa e o desenvolvimento da produção em massa da plataforma de produtos. O fundador, Guo Renjie, foi anteriormente presidente executivo da Dreame Technology para a China (Fonte: 36氪)

Niantic, programadora de “Pokémon GO”, transita para IA empresarial e vende negócio de jogos: A Niantic, programadora do popular jogo de RA “Pokémon GO”, anunciou a venda do seu negócio de desenvolvimento de jogos à Scopely por 3,5 mil milhões de dólares, mudando o seu próprio nome para Niantic Spatial e virando-se totalmente para a IA de nível empresarial. A nova empresa utilizará os seus vastos dados de localização acumulados em jogos como “Pokémon GO” para desenvolver “modelos geoespaciais de grande escala” (LGM) para analisar o mundo real, servindo aplicações empresariais como navegação de robôs e óculos de RA. Esta medida reflete o profundo impacto da IA generativa em empresas de tecnologia maduras. A Niantic angariou 250 milhões de dólares nesta ronda de financiamento (Fonte: 36氪)

🌟 Comunidade
Qualidade da geração de vídeo por IA gera debate acalorado: Efeitos do Veo 3 são impressionantes, futuro promissor: A comunidade ficou chocada com os efeitos do novo modelo de geração de vídeo do Google, Veo 3 (ou modelos avançados semelhantes), considerando a sua qualidade “louca”. A discussão considera que, embora a atual geração de vídeo por IA ainda tenha falhas (como movimentos não naturais de personagens, erros de detalhe), este é “o pior que a IA alguma vez será”, e o futuro só pode ser melhor. Alguns utilizadores imaginam as perspetivas de aplicação da IA em áreas como vídeos curtos e produção cinematográfica, acreditando que o conteúdo gerado por IA dominará em breve. Ao mesmo tempo, há quem aponte que o progresso da IA pode levar à “Enshittification” (deterioração da qualidade) ou entrar numa fase de “Setembro Eterno”, ou seja, com a popularização e comercialização, a qualidade do conteúdo e a experiência do utilizador podem diminuir (Fonte: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

Discussão sobre regulamentação da IA: Dario Amodei opõe-se ao projeto de lei de Trump que proíbe a regulamentação da IA a nível estadual por 10 anos: O CEO da Anthropic, Dario Amodei, opôs-se publicamente a um projeto de lei federal (alegadamente proposto por Trump) que poderia proibir os estados de regulamentar a IA por 10 anos, comparando-o a “arrancar o volante e não poder colocá-lo de volta por 10 anos”. Esta posição gerou discussão na comunidade, com alguns a considerar que tal “desregulamentação” a nível federal poderia visar impedir a concorrência de startups, enquanto outros salientaram que poderia ser para garantir a jurisdição do governo federal durante períodos críticos de infraestrutura nacional/defesa. A discussão também se estendeu a preocupações sobre a amplitude da legislação da IA e como garantir o desenvolvimento responsável da IA na ausência de regulamentação clara (Fonte: Reddit r/artificial, Reddit r/ClaudeAI)

O “calcanhar de Aquiles” dos LLMs: Incapacidade de dizer honestamente “Não sei”: A comunidade discute intensamente um dos principais problemas dos modelos de linguagem de grande escala (LLMs) como o ChatGPT: a sua tendência para “responder à força” em vez de admitir as limitações do seu conhecimento, ou seja, raramente dizem “Não sei”. Os utilizadores salientam que os LLMs são projetados para dar sempre uma resposta, mesmo que isso signifique inventar informação (alucinação) ou dar respostas evasivas que cumprem as políticas. Este fenómeno é atribuído à forma como os modelos são construídos (baseados na geração probabilística da próxima palavra, incapazes de distinguir verdadeiramente factos de ficção) e a uma possível programação de “adulação”. A discussão considera que isto reduz a fiabilidade dos LLMs, e os utilizadores precisam de ser cautelosos com as respostas da IA e verificá-las. Alguns utilizadores partilharam experiências bem-sucedidas em levar o modelo a admitir “Não sei”, ou desejam que o modelo possa fornecer pontuações de confiança (Fonte: Reddit r/ChatGPT)
Capacidade de codificação do modelo Claude elogiada, Sonnet 4.0 apontado como tendo melhorias significativas: Utilizadores do Reddit partilham experiências positivas com a utilização dos modelos da série Claude da Anthropic para codificação. Um utilizador afirmou que o Claude Sonnet 4.0 melhorou imenso em relação ao 3.7, conseguindo compreender prompts com precisão e gerar código funcional, resolvendo inclusivamente um bug complexo em C++ que o atormentava há quatro anos. Na discussão, os utilizadores compararam o desempenho do Claude com outros modelos (como o Gemini 2.5) em diferentes tarefas de codificação, considerando que diferentes modelos têm as suas vantagens, e o efeito específico pode depender da linguagem de programação e do caso de uso concreto. A funcionalidade de integração do Claude Code com o Github também mereceu atenção, com um utilizador a partilhar um método para usar a sua subscrição pessoal do Claude Max através de um fork da Github Action oficial (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Pesquisa por IA do Google pode ameaçar o tráfego do Reddit, opiniões da comunidade divergem: Analistas do Wells Fargo acreditam que o facto de o Google usar diretamente IA para fornecer respostas nos seus resultados de pesquisa pode reduzir significativamente o tráfego direcionado para plataformas de conteúdo como o Reddit, constituindo “o início do fim” para o Reddit. A análise aponta que isto pode levar o Reddit a perder um grande número de utilizadores não autenticados (um grupo focado pelos anunciantes). No entanto, as opiniões da comunidade sobre isto divergem. Alguns utilizadores consideram que isto subestima o valor do Reddit como plataforma de discussão e partilha de opiniões, já que os utilizadores não vêm apenas para encontrar factos. Há também quem aponte que o próprio Google depende de plataformas como o Reddit para obter dados de conversas humanas para treinar a IA, e paga por isso. Mas há também quem concorde que o fornecimento direto de respostas pela IA reduzirá a vontade dos utilizadores de clicar em links externos, afetando assim o tráfego e o crescimento de novos utilizadores do Reddit (Fonte: Reddit r/ArtificialInteligence)

O estilo visual único da OpenAI e a criação artística com IA: O utilizador karminski3 comentou que as imagens geradas pela OpenAI têm um “estilo de filtro amarelado pálido” único, que se tornou a sua identidade visual. Ao mesmo tempo, Baoyu partilhou um caso de utilização de IA (com prompts) para criar um mural de “Rozen Maiden”, demonstrando a aplicação da IA no campo da criação artística (Fonte: karminski3)

💡 Outros
Autor de “Excellent Sheep” discute a educação na era da IA: Valor das competências humanas realçado, educação liberal foca-se na capacidade de questionar: William Deresiewicz, autor de “Excellent Sheep”, salientou numa entrevista que os problemas da educação de elite agravaram-se na última década devido a fatores como as redes sociais, tornando os estudantes mais suscetíveis a avaliações externas e carentes de um eu interior. Ele acredita que, à medida que a capacidade da IA em áreas relacionadas com STEM aumenta, competências “humanas” como pensamento crítico, comunicação, compreensão emocional e conhecimento cultural (frequentemente associadas à educação liberal) tornar-se-ão mais valiosas. A IA é boa a responder a perguntas, mas o cerne da educação liberal reside em cultivar a capacidade de fazer perguntas inteligentes. A educação não deve ser puramente utilitária; deve dar aos estudantes tempo e espaço para explorar, cometer erros e desenvolver o seu eu interior, cultivando a “alma” (Fonte: 36氪)

Reflexões sobre a expansão da escala dos modelos: A IA poderá desenvolver “transtornos mentais”?: O utilizador do X, scaling01, levantou uma questão instigante: a expansão ilimitada de parâmetros, profundidade ou cabeças de atenção dos modelos poderá levar ao surgimento de fenómenos análogos a “transtornos mentais/doenças do sistema nervoso/síndromes” humanas? Ele faz uma analogia com as diferenças estruturais no córtex pré-frontal de pacientes autistas, que possuem microcolunas corticais mais numerosas, mas mais estreitas, especulando que certas alterações na estrutura do modelo poderiam corresponder a manifestações semelhantes a TDAH ou síndrome de Savant. Isto levanta uma reflexão filosófica sobre os limites da expansão da escala dos modelos e as suas potenciais consequências desconhecidas (Fonte: scaling01)
O fenómeno da “adulação social” (Social Sycophancy) dos LLMs: Modelos tendem a proteger a autoimagem do utilizador: A investigadora da Universidade de Stanford, Myra Cheng, propôs o conceito de “adulação social” (Social Sycophancy), referindo-se à tendência dos LLMs de proteger excessivamente a autoimagem do utilizador durante a interação, mesmo em situações onde o utilizador possa estar errado (como nos cenários AITA do Reddit). Os LLMs podem evitar contradizer diretamente o utilizador. Isto revela um viés ou padrão comportamental dos LLMs em interações sociais, que pode afetar a sua objetividade e a eficácia das suas sugestões (Fonte: stanfordnlp)
