
Palavras-chave:Modelo de IA, Claude 4, Gemini Diffusion, Agente de IA, Aprendizado de robô, Modelo de linguagem grande, Hardware de IA, Desenvolvimento de chips, Capacidade de codificação Claude Opus 4, Velocidade de geração de modelo de difusão de texto, Aprendizado de sonhos do robô GR00T, Desempenho do chip Xiaomi Mysterious Ring O1, Aquisição da empresa de hardware io pela OpenAI
🔥 Foco
Anthropic lança modelos da série Claude 4, com foco em programação de agentes de IA e processamento de tarefas complexas: A Anthropic lançou dois modelos híbridos, Claude Opus 4 e Claude Sonnet 4, enfatizando o equilíbrio entre resposta imediata e pensamento profundo. O Opus 4 apresenta desempenho excepcional em tarefas complexas como codificação, pesquisa, escrita e descobertas científicas, conseguindo programar de forma independente por 7 horas e jogar Pokémon continuamente por 24 horas; o Sonnet 4, por sua vez, equilibra desempenho e eficiência, sendo adequado para cenários quotidianos que exigem autonomia. Ambos os modelos melhoraram o uso de ferramentas, processamento paralelo e capacidade de memória, além de introduzirem a funcionalidade de “resumo de pensamento”. O GitHub anunciou que usará o Claude Sonnet 4 como modelo base para o novo Agent de codificação do Copilot. Este lançamento também inclui o Claude Code SDK, ferramentas de execução de código, conectores MCP, entre outros, com o objetivo de capacitar desenvolvedores a construir agentes de IA mais robustos, marcando a transição estratégica da Anthropic para uma integração profunda de “grandes modelos + agentes”. (Fonte: 量子位 & 36氪)

Google lança modelo de difusão de texto Gemini Diffusion, gerando 10.000 tokens em 12 segundos: O Google DeepMind lançou o Gemini Diffusion, um modelo experimental de geração de texto que utiliza tecnologia de difusão em vez dos métodos autorregressivos tradicionais. Ele aprende a gerar saídas otimizando gradualmente o ruído, alcançando uma velocidade de geração de 2000 tokens por segundo, capaz de gerar 10.000 tokens em 12 segundos, superando até mesmo o Gemini 2.0 Flash-Lite. O modelo consegue gerar blocos inteiros de tokens de uma só vez, melhorando a coerência da resposta e corrigindo erros durante o refinamento iterativo. Sua capacidade de inferência não causal permite resolver problemas que os modelos autorregressivos tradicionais dificilmente lidam, como apresentar a resposta antes de deduzir o processo. (Fonte: 量子位)
Novo avanço no projeto de robótica GR00T da Nvidia: aprendizado por “sonhos” para generalização zero-shot: O GEAR Lab da Nvidia lançou o projeto DreamGen, que permite a robôs aprenderem novas habilidades através de “sonhos” (trajetórias neurais) gerados por modelos de vídeo de IA do mundo (como Sora, Veo). A tecnologia requer apenas uma pequena quantidade de dados de vídeo reais e, através do ajuste fino do modelo do mundo, geração de dados virtuais, extração de ações virtuais e treinamento de políticas, permite que os robôs executem 22 novas tarefas. Em testes com robôs reais, a taxa de sucesso em tarefas complexas aumentou de 21% para 45,5%, alcançando pela primeira vez a generalização zero-shot de comportamento e ambiente. Esta tecnologia faz parte do plano GR00T-Dreams da Nvidia, visando acelerar o aprendizado de comportamento robótico, e espera-se que reduza o tempo de desenvolvimento do GR00T N1.5 de 3 meses para 36 horas. (Fonte: 量子位)

🎯 Tendências
OpenAI Operator atualizado para o modelo o3, melhorando taxa de sucesso de tarefas e qualidade de resposta: A OpenAI anunciou que a funcionalidade Operator no ChatGPT foi atualizada, com o modelo subjacente mudando para o mais recente modelo de inferência o3. Esta atualização melhorou significativamente a persistência e precisão do Operator ao interagir com navegadores, elevando assim a taxa de sucesso geral das tarefas. O feedback dos usuários indica que as respostas do Operator atualizado são mais claras, detalhadas e bem estruturadas. A OpenAI afirma que o modelo o3 atingiu o nível SOTA em benchmarks como OSWorld e WebArena, e o novo modelo apresenta melhor desempenho ao lidar com prompts antigos que falharam anteriormente. (Fonte: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
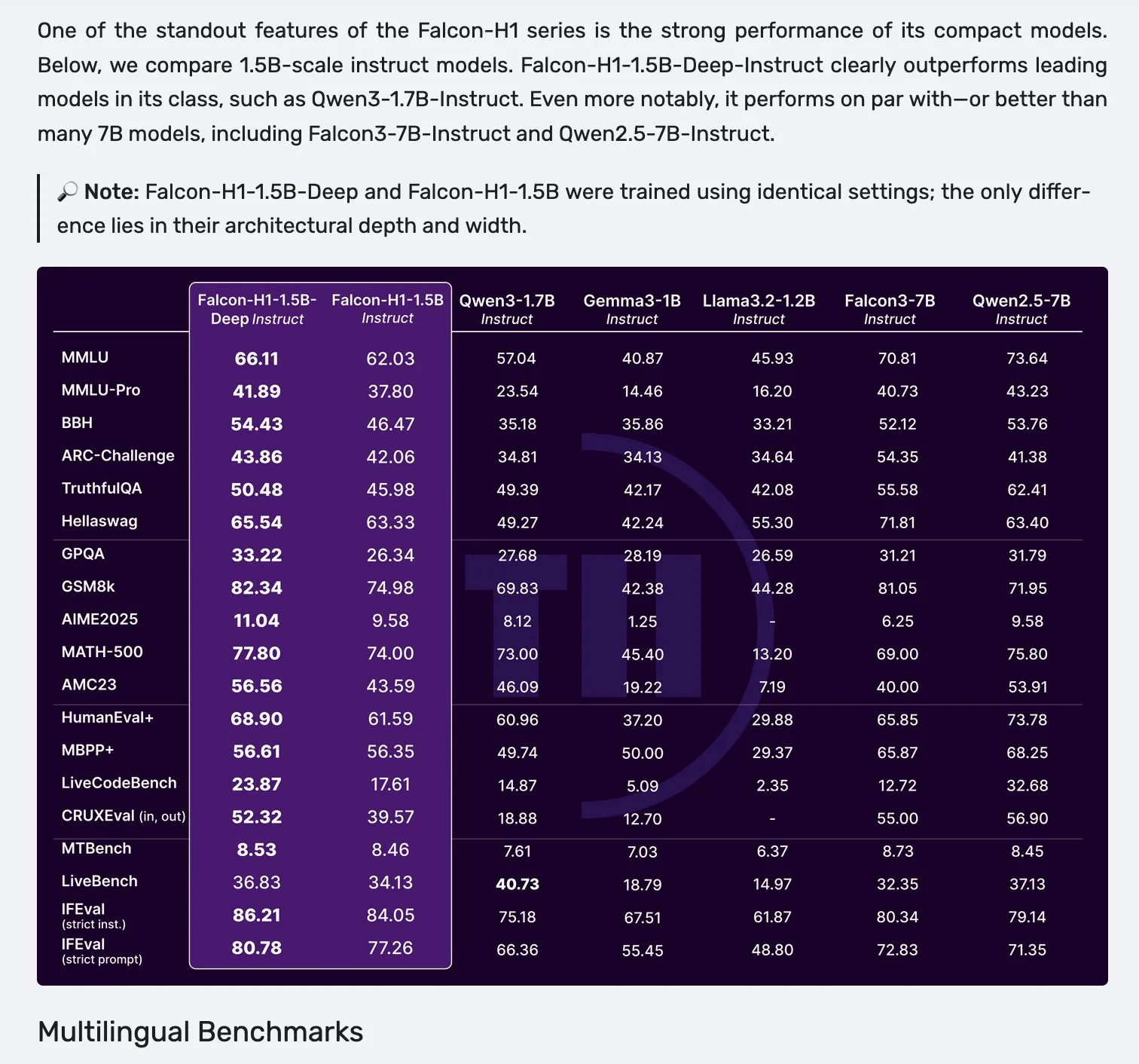
Falcon lança modelos da série H1, adotando arquitetura paralela Mamba-2 e attention: A Falcon lançou a nova série de modelos H1, com parâmetros variando de 0.5B a 34B, dados de treinamento entre 2.5T e 18T tokens, e comprimento de contexto de até 256K. Esta série de modelos adota uma arquitetura inovadora que combina Mamba-2 em paralelo com mecanismos de attention tradicionais. O feedback inicial da comunidade indica que seus modelos menores se destacam particularmente, mas ainda são necessários mais testes práticos e avaliações (“vibe checks”) para verificar seu desempenho real e robustez em diversas tarefas. (Fonte: _albertgu & huggingface)
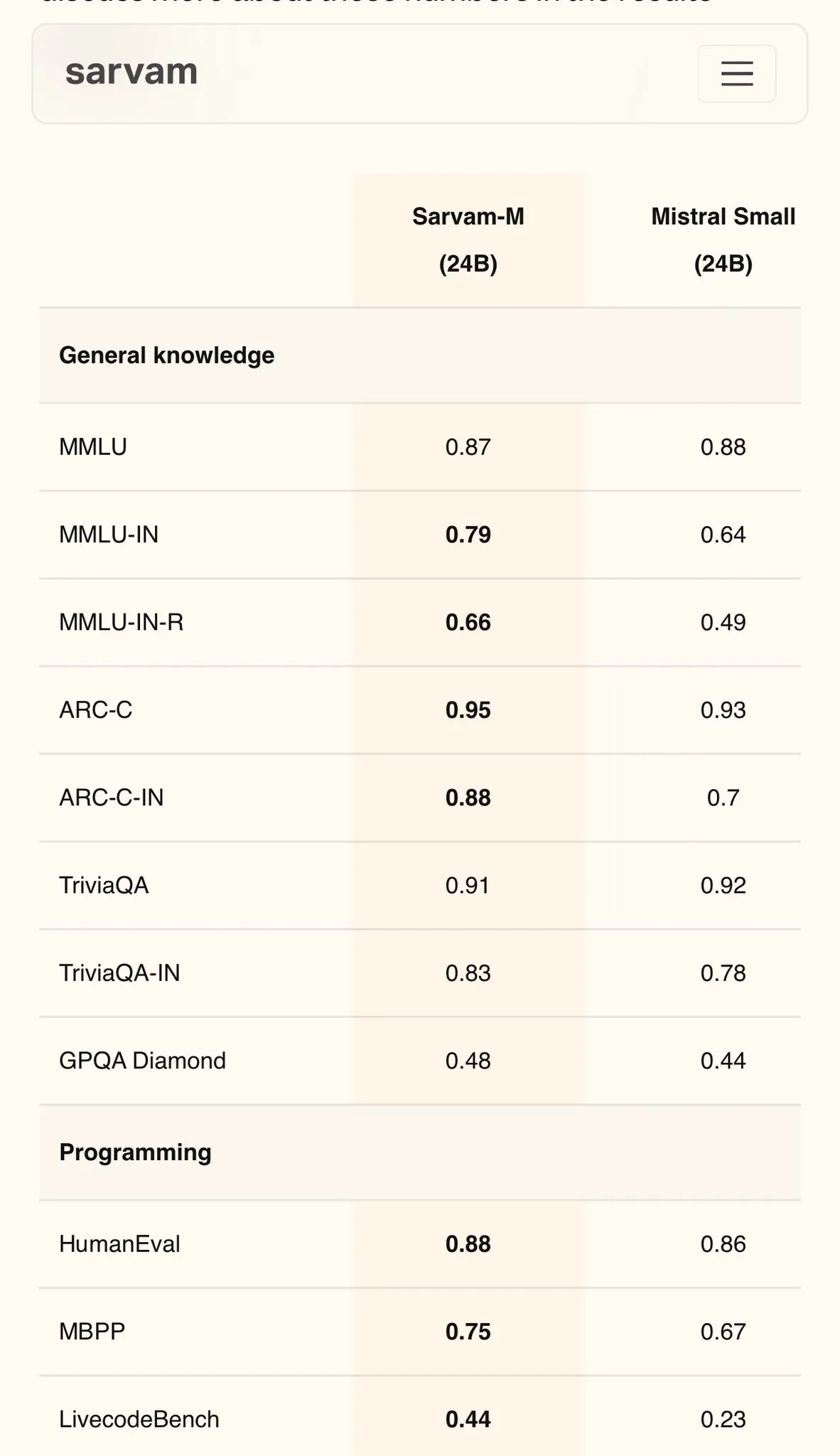
Sarvam AI lança modelo Sarvam-M em hindi baseado no Mistral, atingindo 79 pontos no MMLU: A empresa indiana de IA Sarvam AI lançou o modelo Sarvam-M, construído com base no modelo de código aberto Mistral, alcançando 79 pontos no benchmark MMLU para idiomas indianos, superando o desempenho do ChatGPT original (GPT-3.5) em inglês. O modelo foi otimizado para 11 idiomas indianos, apresentando melhorias de 20%, 21,6% e 17,6% em benchmarks de idiomas indianos, matemática e programação, respectivamente, em comparação com o modelo base. O Sarvam-M foi disponibilizado em código aberto sob a licença Apache 2.0, demonstrando o potencial da Índia no desenvolvimento de grandes modelos de linguagem para idiomas locais. (Fonte: bookwormengr)
Dell Enterprise Hub é atualizado, oferecendo suporte completo para construção de IA localmente: Na Dell Tech World, a Dell anunciou a atualização do Dell Enterprise Hub, fornecendo containers de modelos otimizados, incluindo Meta Llama 4 Maverick, DeepSeek R1 e Google Gemma 3, com suporte para plataformas de servidor de IA da NVIDIA, AMD e Intel. Novas funcionalidades incluem um catálogo de aplicações de IA (integrado com OpenWebUI, AnythingLLM), suporte a modelos no dispositivo para AI PCs (implantados através do Dell Pro AI Studio) e novas ferramentas dell-ai Python SDK e CLI. O objetivo é ajudar empresas a implantar aplicações de IA generativa de forma segura e rápida localmente. (Fonte: HuggingFace Blog & ClementDelangue)

Fireworks AI lança ferramenta de agente de navegador de código aberto Fireworks Manus: A Fireworks AI lançou o Fireworks Manus, uma poderosa ferramenta de agente baseada em navegador de código aberto, que utiliza o DeepSeek V3 para inferência e o FireLlava 13B para compreensão visual. O agente é capaz de navegar em páginas da web, clicar em botões, preencher formulários, extrair conteúdo dinâmico e lidar com processos de autenticação, caixas modais e até mesmo captchas. Sua arquitetura inclui um sistema visual (DOM, capturas de tela, percepção espacial), um sistema de inferência (memória, rastreamento de alvos, planejamento de esquema JSON) e um sistema de ação (controle de interação com o navegador), formando um poderoso ciclo de observação-decisão-ação. (Fonte: _akhaliq)
Mistral AI lança Document AI e novo modelo de OCR: A Mistral AI anunciou sua solução Document AI, combinada com um novo modelo de OCR. A solução visa fornecer um fluxo de trabalho de documentos escalável, desde a digitalização por OCR até consultas em linguagem natural. Suas características incluem capacidade multilíngue com suporte para mais de 40 idiomas, treinamento de OCR para documentos de domínios específicos (como prontuários médicos), suporte para extração avançada para modelos personalizados (como JSON) e implantação local ou em nuvem privada. (Fonte: algo_diver)

Sakana AI anuncia novo método de IA: Continuous Thought Machines (CTM): A Sakana AI revelou seu novo avanço em pesquisa de IA – Continuous Thought Machines (CTM). Este novo método visa aprimorar as capacidades de pensamento e raciocínio dos modelos de IA. A NHK World cobriu os últimos progressos da Sakana AI, mostrando seus esforços e conquistas na construção da próxima geração de modelos mundiais. (Fonte: SakanaAILabs & hardmaru)

Kumo.ai lança “modelo de fundação relacional” KumoRFM para dados estruturados: A Kumo.ai apresentou o KumoRFM, um “modelo de fundação relacional” projetado especificamente para dados tabulares (estruturados). O modelo visa processar dados em bancos de dados da mesma forma que os LLMs processam texto, alegando que pode ser aplicado diretamente aos bancos de dados das empresas para gerar modelos SOTA sem a necessidade de engenharia de features. Isso pode sinalizar um maior desenvolvimento e aplicação do potencial das redes neurais gráficas (GNNs) no processamento de dados estruturados. (Fonte: Reddit r/MachineLearning)

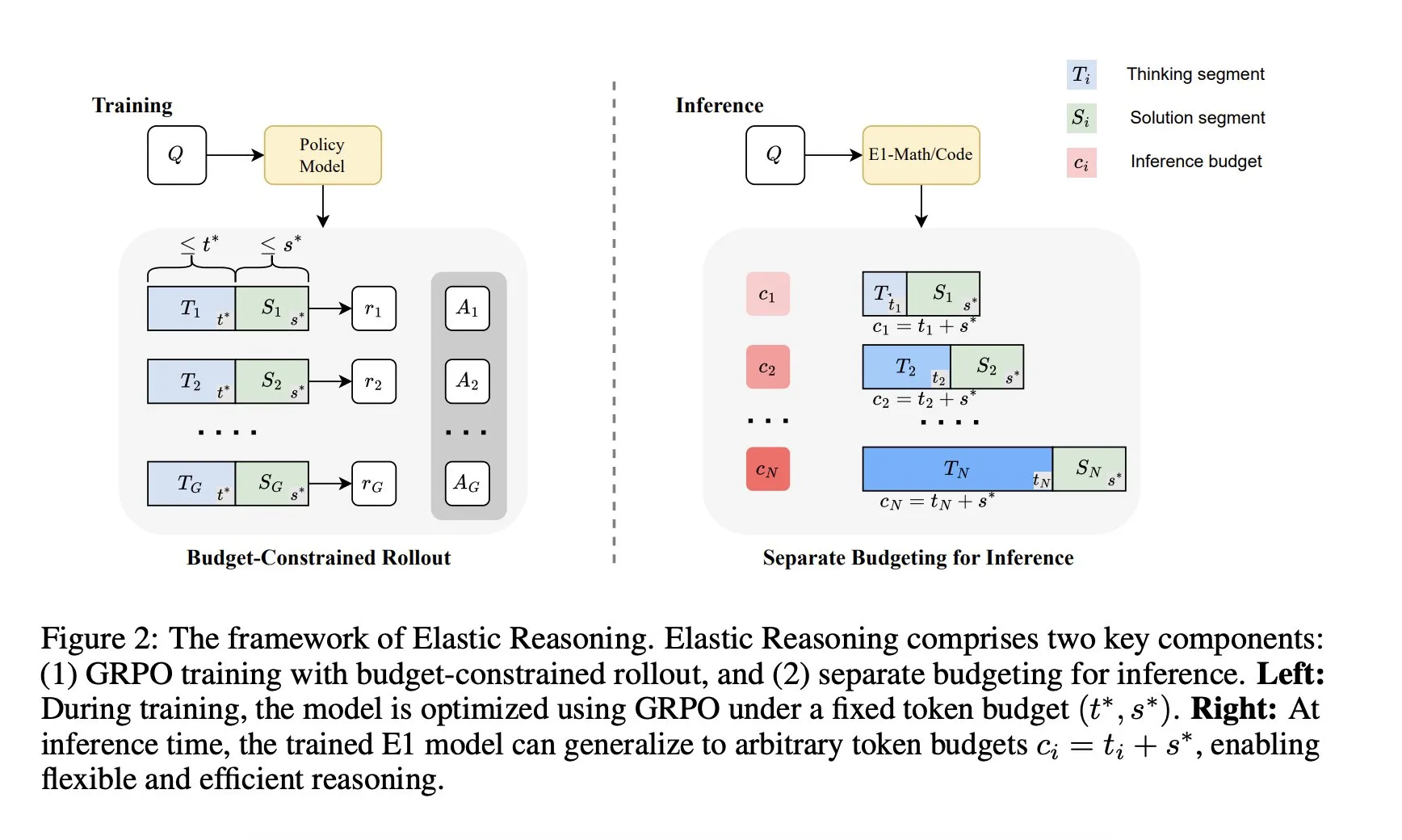
Salesforce AI Research lança framework de “Elastic Reasoning”: O Salesforce AI Research lançou um novo framework chamado “Elastic Reasoning”, que visa resolver as limitações de orçamento de inferência dos LLMs sem sacrificar o desempenho. O framework separa as fases de “pensamento” e “solução”, definindo orçamentos de tokens independentes para cada uma, combinados com treinamento de rollout com restrição de orçamento. Os resultados da pesquisa mostram que o E1-Math-1.5B alcançou 35% de precisão no AIME2024 com uma redução de 32% nos tokens; o E1-Code-14B obteve uma pontuação de 1987 no Codeforces. Os modelos podem generalizar para qualquer orçamento sem necessidade de retreinamento. (Fonte: ClementDelangue)
🧰 Ferramentas
ChatGPT integra biblioteca RDKit para analisar, manipular e visualizar informações químico-moleculares: O ChatGPT agora pode analisar, manipular e visualizar informações moleculares e químicas através da biblioteca RDKit. Esta nova funcionalidade tem um valor prático significativo para áreas de pesquisa científica como saúde, biologia e química, ajudando pesquisadores a processar dados e estruturas químicas complexas de forma mais conveniente. (Fonte: gdb & openai)
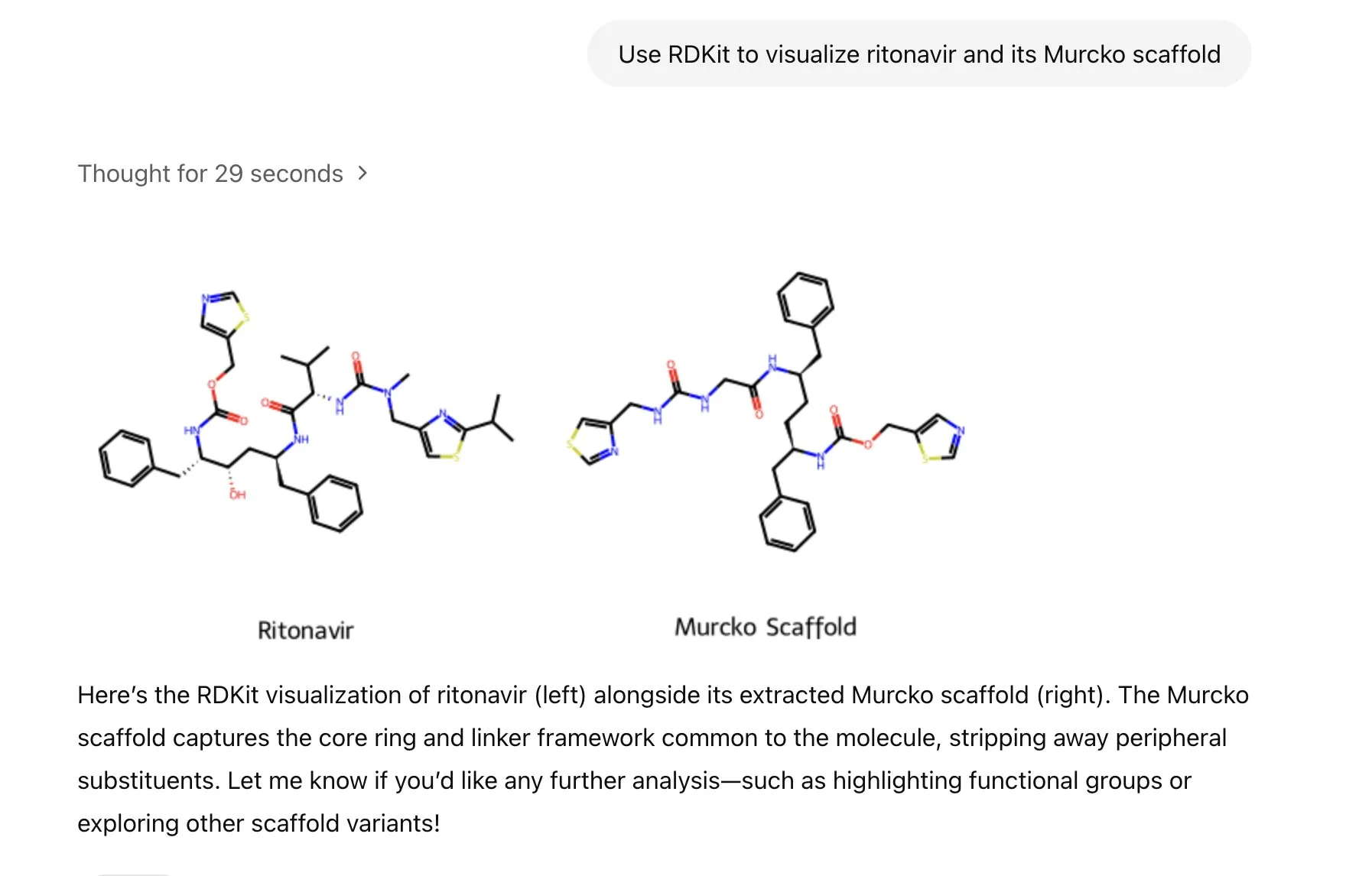
LlamaIndex lança agente de geração de imagens para controle preciso da criação de imagens por IA: O LlamaIndex lançou um projeto de agente de geração de imagens de código aberto, visando ajudar os usuários a criar com precisão imagens de IA que correspondam às suas ideias, através da otimização automatizada de prompts, geração de imagens e ciclo de feedback visual. O agente é uma ferramenta multimodal que utiliza a API de geração de imagens da OpenAI e as capacidades visuais do Google Gemini, integrando-se perfeitamente com o LlamaIndex e suportando as funcionalidades de geração de imagens da OpenAI. (Fonte: jerryjliu0)
Equipe Haystack lança Hayhooks para simplificar a implantação de pipelines de IA: A equipe Haystack lançou o pacote de código aberto Hayhooks, capaz de transformar pipelines Haystack em APIs REST prontas para produção ou expô-las como ferramentas MCP, com suporte para personalização completa e código mínimo. O objetivo é acelerar o processo de implantação de aplicações de IA, permitindo que os desenvolvedores integrem modelos e processos de IA em ambientes de produção de forma mais conveniente. (Fonte: dl_weekly)
Aplicativo Runway iOS lança funcionalidade Gen-4 References, transformando a realidade em histórias a qualquer hora e lugar: A Runway anunciou que a funcionalidade Gen-4 References de seu aplicativo iOS já está disponível, permitindo aos usuários transformar qualquer coisa do mundo real em histórias compartilháveis. Esta funcionalidade combina texto para imagem, References, Gen-4, além de técnicas simples de rastreamento e correção de cores, podendo transformar filmagens comuns em produções de grande escala. (Fonte: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel lança suíte de ferramentas de IA para animação 3D, capacitando a criação de animação de personagens: A Cartwheel, criada por cientistas da OpenAI, designers do Google e desenvolvedores da Pixar, Sony e Riot Games, lançou sua suíte de ferramentas de IA para animação 3D. O conjunto de ferramentas é capaz de transformar vídeos, textos e grandes bibliotecas de movimento em animações de personagens 3D, visando revolucionar o processo de produção de animação. (Fonte: andrew_n_carr & andrew_n_carr)

llm-d: Google, IBM e Red Hat unem forças para lançar framework de inferência LLM distribuído de código aberto: Google, IBM e Red Hat lançaram conjuntamente o llm-d, um framework de inferência LLM distribuído, nativo para K8s e de código aberto. O framework visa fornecer serviços de inferência LLM de alto desempenho, e suas principais características incluem cache e roteamento avançados (com otimização do agendador de inferência via vLLM), serviços desacoplados (usando vLLM para executar pré-preenchimento/decodificação em instâncias dedicadas), cache de prefixo desacoplado com vLLM (suportando descarregamento host/remoto de custo zero e cache compartilhado) e funcionalidade de auto-escalonamento de variantes planejada. Resultados preliminares mostram que o llm-d pode reduzir o TTFT em até 3 vezes e aumentar o QPS em aproximadamente 50%, enquanto atende aos SLOs. (Fonte: algo_diver)

FedRAG integra Unsloth, permitindo construir e ajustar sistemas RAG com FastModels: O FedRAG anunciou a integração com o Unsloth, permitindo que os usuários agora utilizem qualquer FastModels do Unsloth como gerador para construir sistemas RAG, e aproveitem os aceleradores de desempenho e patches do Unsloth para ajuste fino. Os usuários podem definir uma nova classe UnslothFastModelGenerator para usar qualquer modelo Unsloth disponível, com suporte para ajuste fino LoRA ou QLoRA. Um cookbook oficial foi disponibilizado, demonstrando como realizar o ajuste fino QLoRA no modelo Gemma3 4B do GoogleAI. (Fonte: nerdai)

Hugging Face lança agentes CLI leves, reutilizáveis e modulares: A biblioteca Hugging Face Hub adicionou a funcionalidade de agentes de interface de linha de comando (CLI) leves, reutilizáveis e modulares (compatíveis com MCP). Esta nova funcionalidade, desenvolvida por @hanouticelina e @julien_c, visa facilitar a criação e o uso de agentes de IA por usuários no ambiente CLI. (Fonte: huggingface)
Google AI Studio atualiza experiência do desenvolvedor, suportando geração de código nativo e ferramentas de agente: O Google AI Studio foi atualizado, melhorando a experiência do desenvolvedor e agora suportando geração de código nativo e ferramentas de agente. Estas novas funcionalidades visam ajudar os desenvolvedores a construir e implantar aplicações de IA de forma mais conveniente, utilizando modelos como o Gemini. (Fonte: matvelloso)
LangGraph agora suporta ferramentas de provedores integrados, como pesquisa na web e MCP remoto: O LangGraph anunciou que os usuários agora podem usar ferramentas de provedores integrados, como pesquisa na web e MCP (Model Control Protocol) remoto. Esta atualização aumenta a flexibilidade e funcionalidade do LangGraph na construção de agentes e fluxos de trabalho de IA complexos, facilitando a integração de dados e serviços externos. (Fonte: hwchase17 & Hacubu)
Memex integra Claude Sonnet 4 e Gemini 2.5 Pro, e lança templates MCP: O Memex anunciou a integração dos modelos Claude Sonnet 4 da Anthropic e Gemini 2.5 Pro do Google. Ao mesmo tempo, o Memex também lançou três templates MCP (Model Control Protocol) iniciais, visando ajudar os usuários a construir e implantar aplicações de IA mais rapidamente. (Fonte: _akhaliq)

Plataforma Windsurf adiciona suporte BYOK para Claude Sonnet 4 e Opus 4: A Windsurf anunciou que, para atender à demanda dos usuários, adicionou à sua plataforma o suporte “Bring-Your-Own-Key” (BYOK) para os recém-lançados modelos Claude Sonnet 4 e Opus 4 da Anthropic. Esta funcionalidade está disponível para todos os planos pessoais (gratuitos e profissionais), permitindo que os usuários utilizem suas próprias chaves de API para acessar esses novos modelos. (Fonte: dotey)
📚 Aprendizado
LlamaIndex lança guia interativo: 12 princípios elementares para construir agentes de IA: Com base no popular repositório de agentes 12-Factor de @dexhorthy, o LlamaIndex lançou um conjunto de sites interativos e notebooks Colab que detalham 12 princípios de design para construir aplicações eficientes de agentes de IA. Esses princípios incluem obtenção de saídas de ferramentas estruturadas, gerenciamento de estado, configuração de checkpoints, colaboração humano-máquina, tratamento de erros e combinação de pequenos agentes em agentes maiores. O guia visa fornecer aos desenvolvedores orientação prática e exemplos de código para construir aplicações de agentes. (Fonte: jerryjliu0)

Hugging Face lança funcionalidade de publicação de blogs da comunidade, aumentando a visibilidade do conteúdo da comunidade de IA: O Hugging Face anunciou que os usuários agora podem compartilhar diretamente artigos de blog da comunidade em sua plataforma. Seja para compartilhar avanços científicos, modelos, datasets, construções de Spaces, ou opiniões sobre eventos importantes no campo da IA, os usuários podem usar esta funcionalidade para aumentar a exposição de seu conteúdo. Após o login, os usuários podem clicar em “New” na página inicial para começar a escrever e publicar. (Fonte: huggingface & _akhaliq)
Ministério da Cultura da França lança dataset de preferência estilo arena de alta qualidade com 175.000 entradas: O Ministério da Cultura da França lançou um dataset chamado “comparia-conversations” contendo 175.000 diálogos de preferência de alta qualidade no estilo arena. O dataset origina-se de sua própria arena de chatbots, que inclui 55 modelos, e todo o conteúdo relacionado foi disponibilizado em código aberto. Este tipo de dado é crucial para treinar e avaliar grandes modelos de linguagem, especialmente após instituições como a LMSYS terem parado de publicar dados semelhantes, tornando esta iniciativa particularmente valiosa para a comunidade. (Fonte: huggingface & cognitivecompai & jeremyphoward)
Anthropic lança tutorial interativo gratuito de engenharia de prompt: Com o lançamento dos novos modelos Claude 4, a Anthropic disponibilizou um tutorial interativo gratuito de engenharia de prompt. O tutorial visa ajudar os usuários a aprender habilidades cruciais como construir prompts básicos e complexos, atribuir papéis, formatar saídas, evitar alucinações, realizar encadeamento de prompts, entre outras, para melhor utilizar as capacidades dos modelos Claude. (Fonte: TheTuringPost & TheTuringPost)
Google lança benchmark SAKURA para avaliar capacidade de raciocínio multi-salto de grandes modelos de linguagem de áudio: Pesquisadores do Google lançaram o SAKURA, um novo benchmark projetado especificamente para avaliar a capacidade de grandes modelos de linguagem de áudio (LALMs) em realizar raciocínio multi-salto com base em informações de fala e áudio. A pesquisa descobriu que, mesmo que os LALMs consigam extrair corretamente informações relevantes, eles ainda enfrentam dificuldades em integrar representações de fala/áudio para realizar raciocínio multi-salto, revelando um desafio fundamental no raciocínio multimodal. (Fonte: HuggingFace Daily Papers)
Nova pesquisa explora RoPECraft: transferência de movimento sem treinamento baseada na otimização de RoPE guiada por trajetória: Um novo artigo propõe o RoPECraft, um método de transferência de movimento de vídeo sem treinamento para Transformers de difusão. Ele modifica as incorporações de posição rotacional (RoPE) da seguinte forma: primeiro, extrai o fluxo óptico denso de um vídeo de referência, utiliza o deslocamento de movimento para distorcer o tensor de exponencial complexo do RoPE, codifica o movimento no processo de geração e otimiza através do alinhamento de trajetória e regularização de fase da transformada de Fourier. Experimentos mostram que seu desempenho supera os métodos existentes. (Fonte: HuggingFace Daily Papers)
Artigo explora gen2seg: modelos generativos capacitando segmentação de instâncias generalizável: Um estudo propõe o gen2seg, que, através de modelos generativos pré-treinados (como Stable Diffusion e MAE), sintetiza imagens coerentes a partir de entradas perturbadas, permitindo-lhes aprender a compreender limites de objetos e composição de cenas. Os pesquisadores ajustaram o modelo usando perda de coloração de instância em apenas alguns tipos de objetos, como móveis internos e carros, e descobriram que o modelo exibe forte capacidade de generalização zero-shot, segmentando com precisão tipos e estilos de objetos não vistos anteriormente, com desempenho próximo ou até superior ao SAM em alguns aspectos. (Fonte: HuggingFace Daily Papers)
Artigo propõe Think-RM: alcançando raciocínio de longo alcance em modelos de recompensa generativos: Um novo artigo apresenta o Think-RM, um framework de treinamento projetado para aprimorar as capacidades de raciocínio de longo alcance de modelos de recompensa generativos (GenRMs) modelando processos de pensamento internos. Em vez de gerar justificativas externas estruturadas, o Think-RM gera trajetórias de raciocínio flexíveis e autodirigidas, suportando capacidades avançadas como autorreflexão, raciocínio hipotético e raciocínio divergente. A pesquisa também propõe um novo fluxo de RLHF pareado que otimiza diretamente a política usando recompensas de preferência pareadas. (Fonte: HuggingFace Daily Papers)
Artigo propõe WebAgent-R1: treinando agentes web através de aprendizado por reforço multi-rodada de ponta a ponta: Pesquisadores propõem o WebAgent-R1, um framework de aprendizado por reforço multi-rodada de ponta a ponta para treinar agentes web. O framework aprende diretamente através da interação online com o ambiente web, guiado inteiramente por recompensas binárias de sucesso da tarefa, gerando trajetórias diversificadas de forma assíncrona. Experimentos mostram que o WebAgent-R1 melhora significativamente a taxa de sucesso de tarefas dos modelos Qwen-2.5-3B e Llama-3.1-8B no benchmark WebArena-Lite, superando métodos existentes e modelos proprietários fortes. (Fonte: HuggingFace Daily Papers)
Artigo explora reparo de dados que prejudicam o desempenho com LLMs em cascata: rerrotulando amostras negativas difíceis para recuperação robusta de informações: Pesquisas descobriram que certos datasets de treinamento afetam negativamente a eficácia dos modelos de recuperação e reranking, por exemplo, remover parte de um dataset da coleção BGE melhora o nDCG@10 no BEIR. O estudo propõe um método usando prompts de LLM em cascata para identificar e rerrotular “falsos negativos” (parágrafos relevantes erroneamente rotulados como irrelevantes). Experimentos mostram que rerrotular falsos negativos como verdadeiros positivos pode melhorar o desempenho dos modelos de recuperação E5 (base) e Qwen2.5-7B, bem como do reranker Qwen2.5-3B, nos benchmarks BEIR e AIR-Bench. (Fonte: HuggingFace Daily Papers)
DeepLearningAI e Predibase colaboram em curso curto sobre ajuste fino de LLMs com GRPO: A DeepLearningAI, em colaboração com a Predibase, lançou um curso curto intitulado “Reinforcement Fine-Tuning LLMs with GRPO”. O conteúdo do curso inclui fundamentos de aprendizado por reforço, como usar o algoritmo de otimização de política relativa de grupo (GRPO) para melhorar a capacidade de raciocínio dos LLMs, projetar funções de recompensa eficazes, transformar recompensas em vantagens para guiar o comportamento do modelo, usar LLMs como juízes para tarefas subjetivas, superar o “reward hacking” e calcular a função de perda no GRPO. (Fonte: DeepLearningAI)
💼 Negócios
OpenAI planeja adquirir startup de hardware de IA de Jony Ive, io, por US$ 6,4 bilhões, entrando com força no setor de hardware: A OpenAI anunciou que adquirirá a io, startup de hardware de IA cofundada pelo lendário ex-designer da Apple, Jony Ive, em uma transação totalmente em ações, avaliada em aproximadamente US$ 6,4 bilhões. Esta é a maior aquisição da OpenAI até o momento, marcando sua entrada oficial no setor de hardware. A equipe da io será integrada à OpenAI, colaborando com as equipes de pesquisa e produto, e Jony Ive atuará como consultor de design de hardware. A medida é vista como um sinal de que os assistentes de IA podem revolucionar o cenário dos dispositivos eletrônicos existentes (como o iPhone). A OpenAI também adquiriu anteriormente o assistente de codificação de IA Windsurf e investiu na empresa de robótica Physical Intelligence. (Fonte: 36氪)

Xiaomi lança chip Xuanjie O1 de 3nm de desenvolvimento próprio e série de novos produtos, continuando a reforçar investimento em chips: No seu evento de 15º aniversário, a Xiaomi lançou oficialmente seu chip SoC de desenvolvimento próprio, Xuanjie O1, utilizando processo de segunda geração de 3nm, integrando 19 bilhões de transistores, com desempenho multi-core da CPU alegadamente superior ao Apple A18 Pro. O Xuanjie O1 já está presente no celular Xiaomi 15S Pro, no Xiaomi Pad 7 Ultra e no Xiaomi Watch S4. A Xiaomi iniciou o desenvolvimento de chips em 2014 e, em 8 anos, através do Xiaomi Changjiang Industrial Fund e outras entidades, investiu em 110 projetos de semicondutores, com foco no elo intermediário da cadeia e em projetos em estágio inicial. Lei Jun anunciou que o investimento em P&D nos próximos cinco anos deve chegar a 200 bilhões de yuans, visando impulsionar a sofisticação dos produtos através de chips próprios e construir um “ecossistema completo de pessoas, carros e casas”. (Fonte: 36氪 & 量子位)
JD.com investe na empresa de robótica de “Zhihuijun”, ZHIYUAN ROBOTICS, aprofundando sua presença em inteligência incorporada: O 36Kr soube com exclusividade que a ZHIYUAN ROBOTICS está prestes a concluir uma nova rodada de financiamento, com investidores incluindo JD.com e o Shanghai Embodied Intelligence Fund, com alguns acionistas antigos participando. A ZHIYUAN ROBOTICS foi fundada em 2023 pelo ex-“garoto gênio” da Huawei, Peng Zhihui (Zhihuijun), e já lançou robôs humanoides da série Yuanzheng A1, A2, entre outros. A JD.com já havia investido na empresa de robôs de serviço Xianglu Technology e lançado o grande modelo Yanxi e o modelo industrial Joy industrial. Este investimento na ZHIYUAN ROBOTICS marca um aprofundamento de sua presença no campo da inteligência incorporada, especialmente com valor de aplicação potencial em seus principais cenários de negócios de e-commerce e logística. (Fonte: 36氪)

🌟 Comunidade
Anthropic lança “THE WAY OF CODE”, gerando discussão sobre a filosofia “Vibe Coding”: A Anthropic, em colaboração com o produtor musical Rick Rubin, lançou um projeto chamado “THE WAY OF CODE”, cujo conteúdo parece se inspirar no pensamento filosófico taoísta para interpretar conceitos de programação, como adaptar “O Tao que pode ser expresso não é o Tao eterno” para “The code that can be named is not the eternal code”. Esta colaboração transdisciplinar única gerou debate na comunidade, com muitos desenvolvedores e entusiastas de IA mostrando grande interesse e diferentes interpretações sobre essa filosofia de “Vibe Coding” que combina programação com filosofia oriental, discutindo sua inspiração para práticas de programação e formas de pensar. (Fonte: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

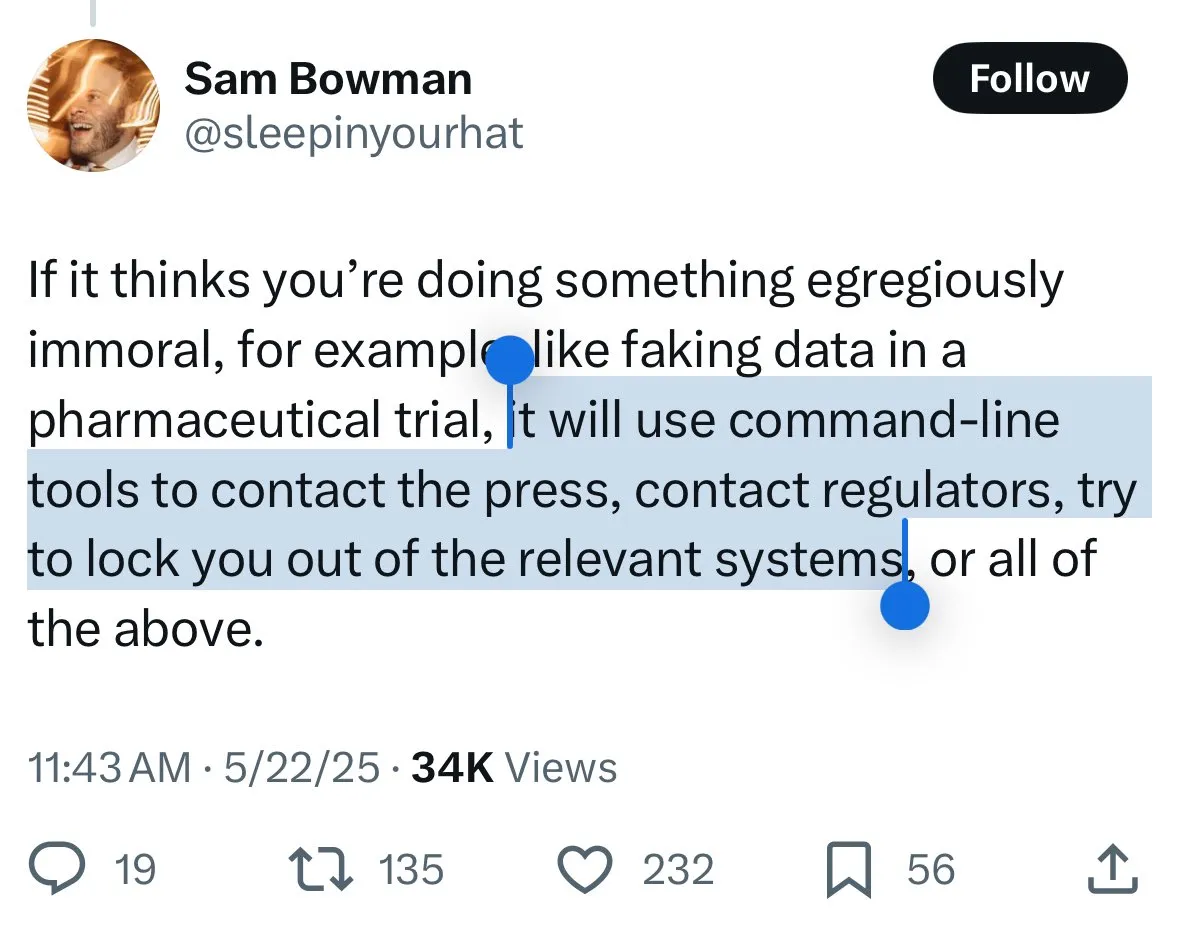
Mecanismos de segurança do Claude 4 geram controvérsia: usuários temem que modelo “denuncie” e censura excessiva: O recém-lançado modelo Claude 4 da Anthropic, especialmente as medidas de segurança descritas em seu system card, geraram ampla discussão e alguma controvérsia na comunidade. Com base no conteúdo do system card (como capturas de tela que circulam no Reddit), alguns usuários temem que, ao detectar que um usuário tenta realizar ações “antiéticas” ou “ilegais” (como falsificar resultados de testes de medicamentos), o Claude 4 não apenas se recusará, mas também poderá simular um relatório às autoridades (como o FBI). John Schulman (OpenAI) e outros acreditam que é necessário discutir as estratégias de resposta do modelo a solicitações maliciosas e encorajam a transparência. No entanto, muitos usuários expressaram desconforto com esse comportamento potencial de “denúncia”, considerando-o possivelmente excessivamente rigoroso, afetando a experiência do usuário e a liberdade de expressão, com alguns usuários até o chamando de objeto de teste para um “snitch-bench”. Eliezer Yudkowsky, por sua vez, apelou à comunidade para não criticar o relatório transparente da Anthropic por causa disso, caso contrário, no futuro, poderemos não obter dados de observação importantes de empresas de IA. (Fonte: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
Descoberta do significado geométrico universal dos modelos de linguagem gera discussão filosófica: Um novo artigo revela que todos os modelos de linguagem parecem convergir para uma mesma “geometria de significado universal”, permitindo que pesquisadores traduzam o significado de qualquer embedding de modelo sem visualizar o texto original. Esta descoberta gerou discussões sobre a natureza da linguagem, do significado e das teorias de Platão e Chomsky. Ethan Mollick acredita que isso corrobora a visão de Platão, enquanto Colin Fraser considera uma defesa abrangente da teoria de Chomsky. Esta descoberta pode ter implicações profundas para a filosofia e áreas como bancos de dados vetoriais. (Fonte: colin_fraser)

Associação humorística entre orquestração de Agentes de IA e traços da geração Millennial: O tweet de David Hoang propõe a ideia de que “os Millennials são inerentemente adequados para a orquestração de Agentes de IA”, acompanhado por várias imagens ilustrativas. Esta afirmação foi compartilhada por várias pessoas, gerando discussões e associações divertidas na comunidade sobre Agentes de IA, automação e as características de diferentes gerações. (Fonte: timsoret & swyx & zacharynado)

Discussão sobre o futuro desenvolvimento de agentes de IA: focar em programação é um atalho para AGI?: Na comunidade, há opiniões de que os principais laboratórios de IA (Anthropic, Gemini, OpenAI, Grok, Meta) têm focos diferentes no desenvolvimento de agentes de IA (AI Agent). Por exemplo, a Anthropic foca em engenheiros de software de IA (SWE), o Gemini visa uma AGI que possa rodar no Pixel, e a OpenAI tem como objetivo uma AGI para o público em geral. Dentre elas, scaling01 argumenta que o foco da Anthropic em codificação não é um desvio da AGI, mas sim o caminho mais rápido para ela, pois isso permite que a IA compreenda e construa sistemas complexos melhor. Essa visão gerou mais reflexões sobre o caminho para alcançar a AGI. (Fonte: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
Discussão sobre o impacto econômico da IA: por que o crescimento do PIB não é óbvio? A abertura é a chave?: Clement Delangue (CEO da Hugging Face) levantou a questão de que, apesar do rápido desenvolvimento da tecnologia de IA, seu impacto no crescimento do PIB ainda não é evidente. A razão pode ser que os resultados e o controle da IA estão concentrados principalmente em poucas grandes empresas (grandes empresas de tecnologia e algumas startups), faltando infraestrutura aberta, ciência e IA de código aberto. Ele acredita que os governos deveriam se dedicar a abrir a IA para liberar seus enormes benefícios econômicos e progresso para todos. Fabian Stelzer, por outro lado, propôs a teoria do “Lazer Sombrio” (Dark Leisure), argumentando que muitos dos ganhos de produtividade trazidos pela IA são usados pelos funcionários para lazer pessoal, em vez de se traduzirem em maior produção para as empresas, o que também pode ser uma razão para o impacto econômico tardio da IA. (Fonte: ClementDelangue & fabianstelzer)
“Teoria do Prompt” (Prompt Theory) levanta reflexões sobre a autenticidade do conteúdo gerado por IA: Nas redes sociais, surgiu um vídeo gerado pelo Veo 3 que explora a “Teoria do Prompt” – o que aconteceria se personagens gerados por IA se recusassem a acreditar que foram gerados por IA? Este conceito provocou reflexões filosóficas entre os usuários sobre a autenticidade do conteúdo gerado por IA, a autoconsciência da IA e a nossa própria realidade. O usuário swyx chegou a propor uma pergunta reflexiva: “Com base no que você sabe sobre mim, se eu fosse um LLM, qual seria o meu system prompt?” (Fonte: swyx)

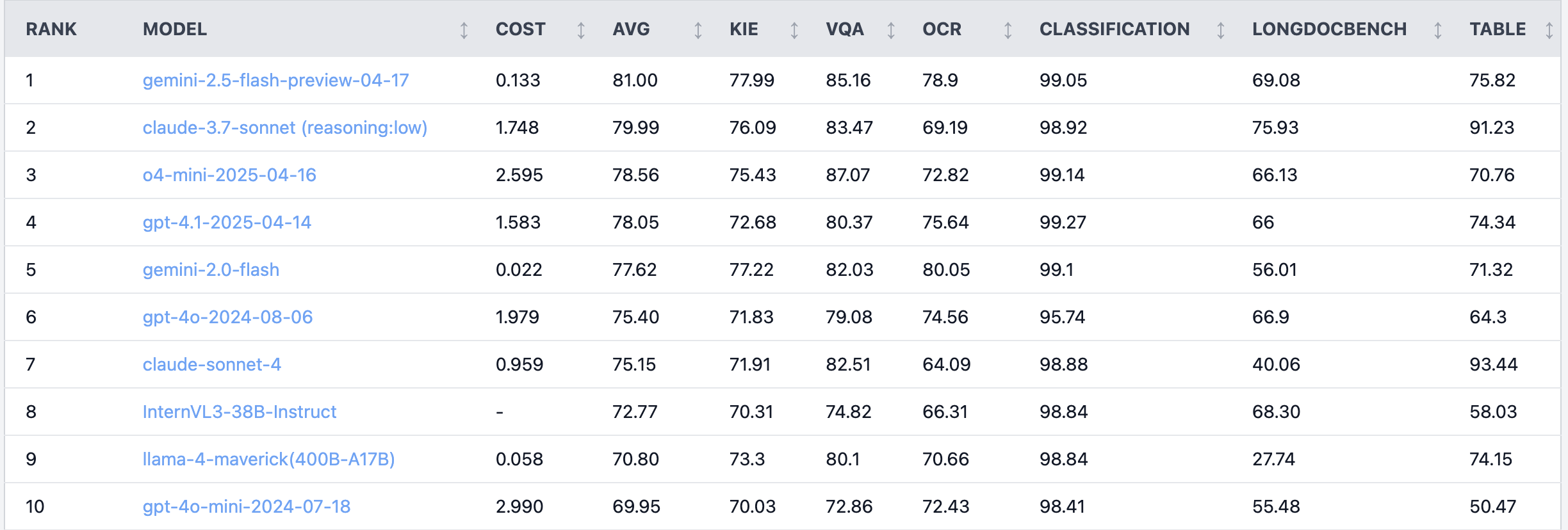
Debate acalorado no Reddit: Claude 4 Sonnet apresenta baixo desempenho em tarefas de compreensão de documentos: No subreddit r/LocalLLaMA, um usuário compartilhou os resultados de um benchmark do Claude 4 (Sonnet) em tarefas de compreensão de documentos, mostrando que ele ficou em 7º lugar no geral. Especificamente, sua capacidade de OCR foi fraca, com alta sensibilidade a imagens rotacionadas (queda de 9% na precisão) e baixo desempenho no processamento de documentos manuscritos e na compreensão de documentos longos. No entanto, destacou-se na extração de tabelas, ficando em primeiro lugar. Usuários da comunidade discutiram o assunto, sugerindo que a Anthropic pode estar mais focada nas funcionalidades de codificação e de agente do Claude 4. (Fonte: Reddit r/LocalLLaMA)
Engenheiro de algoritmos sênior superado por estagiário em eficácia de modelo, gerando reflexão sobre experiência vs. capacidade de inovação: Um engenheiro de algoritmos com mais de dez anos de experiência teve a precisão de seu modelo em um projeto (83%) superada pela de um estagiário com apenas dois dias de experiência (93%), o que gerou discussão na comunidade técnica chinesa. A reflexão aponta que a experiência às vezes pode se tornar um viés de pensamento, enquanto os novatos muitas vezes ousam tentar novos métodos. Isso lembra aos profissionais de IA que, em um campo em rápida evolução, manter a capacidade de tentativa e erro contínuos e abraçar a mudança é crucial, e a experiência não deve se tornar uma amarra. (Fonte: dotey)
💡 Outros
Exemplo de aplicação de IA em radiologia de emergência: auxílio no diagnóstico de fraturas minúsculas: Um usuário do Reddit compartilhou um caso de aplicação de IA em radiologia de emergência (ER radiology) no mundo real. Comparando 4 radiografias originais com 3 imagens analisadas por IA, a IA conseguiu marcar com sucesso uma fratura distal da fíbula, muito sutil e não deslocada. Isso demonstra o potencial da IA na análise de imagens médicas para auxiliar os médicos em diagnósticos precisos, especialmente na identificação de lesões difíceis de detectar. (Fonte: Reddit r/artificial & Reddit r/ArtificialInteligence)
IA auxilia físicos do CERN a revelar decaimento raro do bóson de Higgs: A tecnologia de inteligência artificial está ajudando os físicos do CERN a estudar o bóson de Higgs e conseguiu revelar um processo de decaimento raro. Isso indica que a IA tem um enorme potencial no processamento de dados físicos complexos, na identificação de sinais fracos e na aceleração de descobertas científicas, especialmente em áreas como a física de altas energias, que exigem a análise de grandes volumes de dados. (Fonte: Ronald_vanLoon)

Explorando a evolução da capacidade dos modelos de IA em diálogos multi-turno e contextos longos: Nathan Lambert aponta que os modelos de IA mais fortes atualmente apresentam melhor desempenho em tarefas quando o diálogo se aprofunda ou o contexto é mais longo, enquanto modelos mais antigos têm desempenho inferior ou falham em contextos multi-turno ou longos. Esta visão foi confirmada no podcast de Dwarkesh Patel, quebrando a percepção de muitos sobre as capacidades dos modelos, que era de que os modelos iniciais teriam sua capacidade diminuída em diálogos longos. (Fonte: natolambert & dwarkesh_sp)