
Palavras-chave:Gemini 2.5 Pro, Veo 3, OpenAI, Claude 4 Opus, geração de vídeo por IA, Jony Ive, agentes inteligentes de IA, modelos multimodais, modo Deep Think, modelos de geração de vídeo, capacidade de raciocínio de IA, design de hardware de IA, otimização de engenharia de software
🔥 Foco
Google lança Gemini 2.5 Pro Deep Think e Veo 3, elevando o raciocínio de IA e a geração de vídeo a novos patamares: Na conferência Google I/O, o Google apresentou o modo Deep Think do Gemini 2.5 Pro, projetado especificamente para resolver problemas complexos, demonstrou excelente desempenho em problemas desafiadores de competições de matemática como o USAMO, exibindo avanços significativos da IA em raciocínio avançado, por exemplo, resolvendo problemas algébricos complexos através de raciocínio de múltiplos passos e experimentando diferentes métodos de prova (como prova por contradição, Teorema de Rolle). Ao mesmo tempo, o modelo de geração de vídeo Veo 3 lançado pelo Google, com suas cenas realistas, consistência de personagens controlável, síntese de som e diversas funções de edição (como transformação de cena, geração a partir de imagem de referência, transferência de estilo, especificação de quadros inicial e final, edição local, etc.), estabeleceu um novo padrão no campo da geração de vídeo por IA, atraindo ampla atenção (Fonte: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI investe US$ 6,5 bilhões na aquisição da empresa de Jony Ive para criar em conjunto uma nova geração de computadores impulsionados por IA: A OpenAI anunciou uma parceria com o ex-designer chefe da Apple, Jony Ive, e adquiriu sua empresa, com o objetivo de construir conjuntamente uma nova geração de computadores impulsionados por IA. Esta medida marca a expansão da OpenAI para o setor de hardware e tenta integrar profundamente as capacidades de IA em dispositivos de computação, podendo remodelar a forma como interagimos com as máquinas. Jony Ive é conhecido por seu design excepcional durante seu tempo na Apple, e sua participação prenuncia que os novos dispositivos podem ter grandes avanços em design e experiência do usuário, desafiando as formas atuais dos dispositivos de computação (Fonte: op7418, TheRundownAI, BorisMPower)
Conferência de desenvolvedores da Anthropic está prestes a acontecer, Claude 4 Opus pode ser lançado, com foco em capacidades de engenharia de software: A Anthropic está prestes a realizar sua primeira conferência de desenvolvedores, e a comunidade especula amplamente que a nova geração de modelos Claude 4 (incluindo Sonnet 4 e Opus 4) poderá ser lançada neste evento. Há indícios de que a API do Claude Sonnet 3.7 já apresenta comportamento semelhante ao do Claude 4, como o uso rápido de ferramentas sem a necessidade de “passos de reflexão”. A Anthropic parece estar concentrando esforços para superar desafios de engenharia de software, diferindo do caminho da OpenAI e do Google que buscam “modelos multifuncionais”. A revista TIME também confirmou indiretamente o lançamento do Claude 4 Opus, aumentando ainda mais as expectativas do mercado em relação às capacidades da Anthropic em codificação de IA e processamento de tarefas complexas (Fonte: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
Diferenças na estratégia de ecossistema de IA da OpenAI e do Google: Montar um navio de guerra versus reformar um império: A OpenAI e o Google estão seguindo caminhos distintos de “reunir o ecossistema” e “transformar o ecossistema”, respectivamente, para disputar a posição de “sistema operacional principal” da futura plataforma de IA. A OpenAI, através da aquisição de hardware (io), bancos de dados (Rockset), cadeias de ferramentas (Windsurf) e ferramentas de colaboração (Multi), está montando do zero capacidades de IA full-stack. Enquanto o Google opta por incorporar profundamente seu modelo Gemini em produtos existentes (Search, Android, Docs, YouTube, etc.) e transformar sistemas subjacentes para torná-los nativos de IA. Embora as estratégias de ambos difiram, o objetivo é o mesmo: construir a plataforma definitiva da era da IA (Fonte: dotey)
🎯 Tendências
Microsoft revela visão de “rede de agentes”, enfatizando que agentes de IA serão o núcleo do trabalho da próxima geração: O CEO da Microsoft, Satya Nadella, em sua apresentação na conferência Build 2025 e em entrevistas, expôs a visão da empresa para uma “rede de agentes (agentic web)”. Ele acredita que, no futuro, os agentes de IA se tornarão cidadãos de primeira classe nos ecossistemas de negócios e M365, podendo até mesmo dar origem a novas profissões como “administrador de agentes de IA”. Quando 95% do código for gerado por IA, o papel dos humanos se voltará para o gerenciamento e orquestração desses agentes. A Microsoft está construindo um ecossistema aberto de agentes através do Azure AI Foundry, Copilot Studio e protocolos abertos como o NLWeb, e transformando o Teams em um centro de colaboração multiagente (Fonte: rowancheung, TheTuringPost)
MMaDA: Lançamento de modelos de linguagem de difusão multimodal que unificam raciocínio de texto, compreensão multimodal e geração de imagens: Pesquisadores lançaram o MMaDA (Multimodal Large Diffusion Language Models), um novo tipo de modelo de fundação de difusão multimodal que, através de Mixed Long-CoT (Mixed Long Chain-of-Thought) e do algoritmo de aprendizado por reforço unificado UniGRPO, alcança a unificação das capacidades de raciocínio de texto, compreensão multimodal e geração de imagens. O MMaDA-8B supera o Show-o e o SEED-X em compreensão multimodal e é superior ao SDXL e Janus na geração de texto para imagem. O modelo e o código foram disponibilizados em open source no Hugging Face (Fonte: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: Mecanismo de cache projetado para modelos de linguagem de difusão, aumentando significativamente a velocidade de inferência: Para resolver o problema da baixa velocidade de inferência dos modelos de linguagem de difusão (DLMs), pesquisadores propuseram o mecanismo dKV-Cache. Este método, inspirado no KV-Cache de modelos autorregressivos, projeta um cache de chave-valor para o processo de denoising dos DLMs através de estratégias de cache com atraso e condicionamento. Experimentos mostram que o dKV-Cache pode alcançar uma aceleração de inferência de 2 a 10 vezes, reduzindo significativamente a diferença de velocidade entre DLMs e modelos autorregressivos, e até mesmo melhorando o desempenho em sequências longas, podendo ser aplicado a DLMs existentes sem treinamento (Fonte: NandoDF, HuggingFace Daily Papers)

Imagen4 demonstra excelente desempenho na restauração de detalhes, aproximando-se do estágio final da geração de imagens: O modelo Imagen4 demonstrou uma forte capacidade de restauração de detalhes na geração de imagens a partir de prompts de texto complexos. Por exemplo, ao gerar uma imagem contendo 25 detalhes específicos (como cores, objetos, posições, iluminação e atmosfera específicos), o Imagen4 conseguiu restaurar 23 deles. Essa alta fidelidade e a compreensão precisa de instruções complexas indicam que a tecnologia de geração de texto para imagem está se aproximando de um nível “final” capaz de reproduzir perfeitamente a imaginação do usuário (Fonte: cloneofsimo)

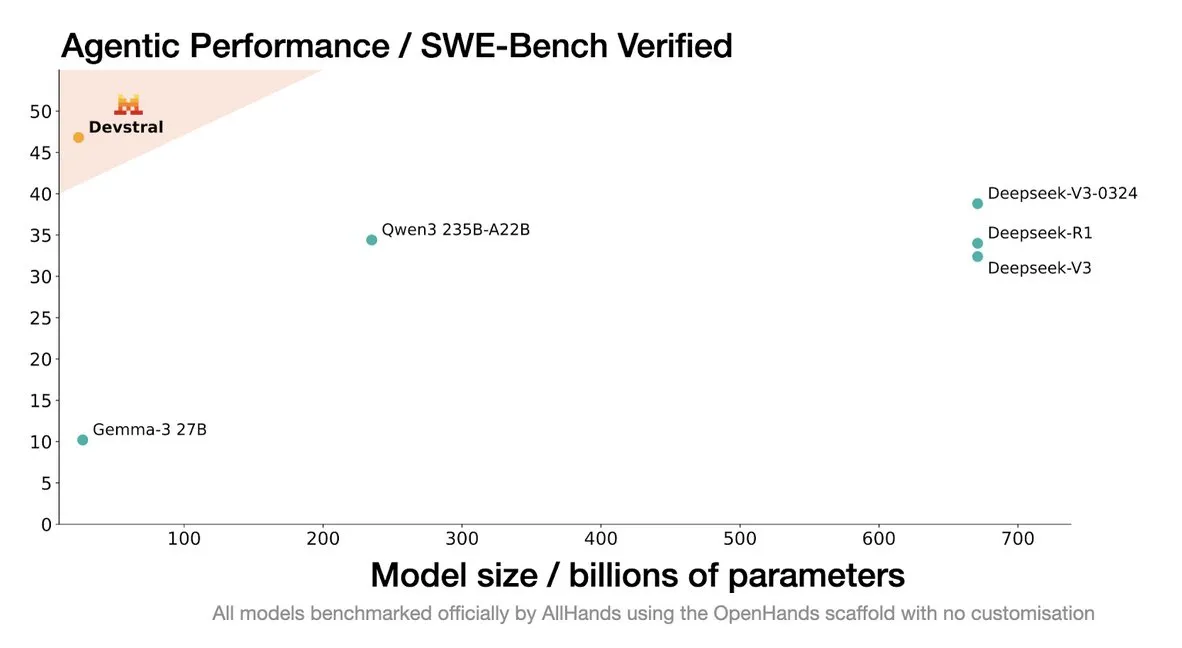
Mistral lança modelo Devstral, projetado especificamente para agentes de codificação: A Mistral AI lançou o Devstral, um modelo de código aberto projetado especificamente para agentes de codificação, desenvolvido em colaboração com a allhands_ai. Sua versão quantizada DWQ de 4 bits já está disponível no Hugging Face (mlx-community/Devstral-Small-2505-4bit-DWQ), podendo rodar fluentemente em dispositivos como o M2 Ultra, mostrando potencial otimizado na geração e compreensão de código (Fonte: awnihannun, clefourrier, GuillaumeLample)
ByteDance publica relatório de treinamento de modelo multimodal de nível Gemini, adotando arquitetura Integrated Transformer: A ByteDance divulgou um relatório de 37 páginas detalhando seu método para treinar um modelo multimodal nativo do tipo Gemini. O destaque é a arquitetura “Integrated Transformer”, que usa a mesma rede backbone simultaneamente como um modelo autorregressivo do tipo GPT e um modelo de difusão do tipo DiT, demonstrando sua exploração na modelagem unificada multimodal (Fonte: NandoDF)

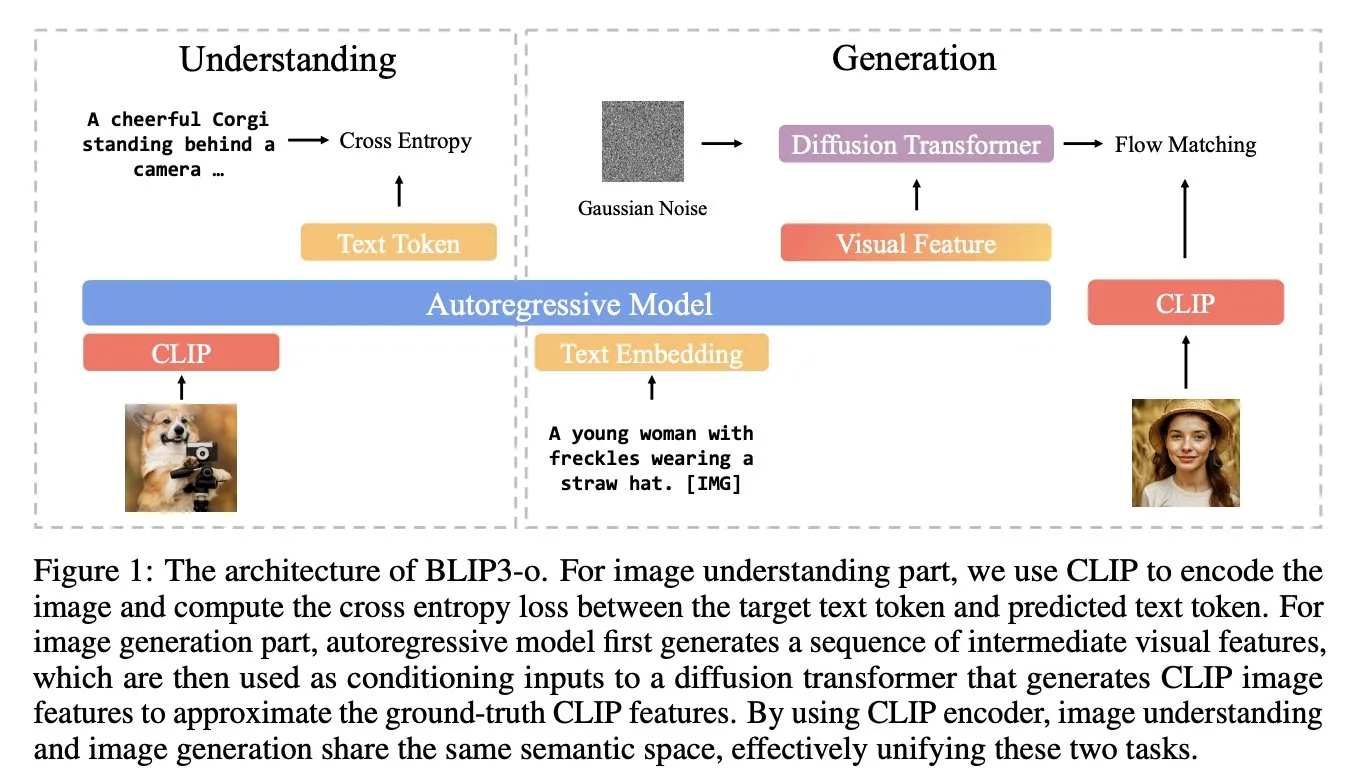
BLIP3-o: Salesforce lança série de modelos multimodais unificados totalmente open source, desbloqueando capacidade de geração de imagem de nível GPT-4o: A equipe de pesquisa da Salesforce lançou a série de modelos BLIP3-o, um conjunto de modelos multimodais unificados totalmente open source, com o objetivo de tentar desbloquear capacidades de geração de imagem semelhantes às do GPT-4o. O projeto não apenas disponibilizou os modelos em open source, mas também publicou um conjunto de dados de pré-treinamento contendo 25 milhões de dados, impulsionando a abertura da pesquisa multimodal (Fonte: arankomatsuzaki)
Google lança versão prévia do Gemma 3n E4B, modelo multimodal projetado para dispositivos de baixos recursos: O Google lançou no Hugging Face o modelo Gemma 3n E4B-it-litert-preview. Este modelo foi projetado para processar entradas de texto, imagem, vídeo e áudio, e gerar saídas de texto, com a versão atual suportando entradas de texto e visuais. O Gemma 3n utiliza uma nova arquitetura Matformer, permitindo o aninhamento de múltiplos modelos e a ativação eficiente de parâmetros de 2B ou 4B, otimizado especificamente para rodar eficientemente em dispositivos de baixos recursos. O modelo foi treinado com aproximadamente 11 trilhões de tokens de dados multimodais, com conhecimento atualizado até junho de 2024 (Fonte: Tim_Dettmers, Reddit r/LocalLLaMA)
Pesquisa revela fenômeno de Conhecimento Específico da Linguagem (LSK) em grandes modelos: Um novo estudo explora o fenômeno do “Conhecimento Específico da Linguagem” (Language Specific Knowledge, LSK) existente em modelos de linguagem, ou seja, o modelo pode ter um desempenho melhor em um idioma específico não inglês do que em inglês ao processar certos tópicos ou domínios. A pesquisa descobriu que, através do raciocínio em cadeia de pensamento em um idioma específico (mesmo em idiomas de baixos recursos), o desempenho do modelo pode ser melhorado. Isso sugere que textos culturalmente específicos são mais abundantes no idioma correspondente, fazendo com que conhecimento específico possa existir apenas no idioma “especialista”. Os pesquisadores projetaram o método LSKExtractor para medir e utilizar esse LSK, alcançando um aumento relativo médio de 10% na precisão em múltiplos modelos e conjuntos de dados (Fonte: HuggingFace Daily Papers)
Efeitos de geração de vídeo do DeepMind Veo 3 são impressionantes, detalhes realistas atraem atenção: O modelo de geração de vídeo Veo 3 do Google DeepMind demonstrou poderosas capacidades de geração de vídeo, incluindo transformação de cena, condução por imagem de referência, transferência de estilo, consistência de personagens, especificação de quadros inicial e final, zoom de vídeo, adição de objetos e controle de ação. O realismo dos vídeos gerados e a capacidade de compreensão de instruções complexas deixaram os usuários maravilhados com o rápido desenvolvimento da tecnologia de geração de vídeo por IA, com alguns usuários até mesmo usando-o para produzir comerciais com efeitos comparáveis a produções profissionais (Fonte: demishassabis, , Reddit r/ChatGPT)
Modelo de linguagem visual Moondream lança versão quantizada de 4 bits, reduzindo significativamente a VRAM e aumentando a velocidade: O modelo de linguagem visual (VLM) Moondream lançou uma versão quantizada de 4 bits, alcançando uma redução de 42% no uso de VRAM e um aumento de 34% na velocidade de inferência, mantendo 99,4% de precisão. Essa otimização torna este poderoso e pequeno VLM mais fácil de implantar e usar em tarefas como detecção de objetos, sendo bem recebido pelos desenvolvedores (Fonte: Sentdex, vikhyatk)
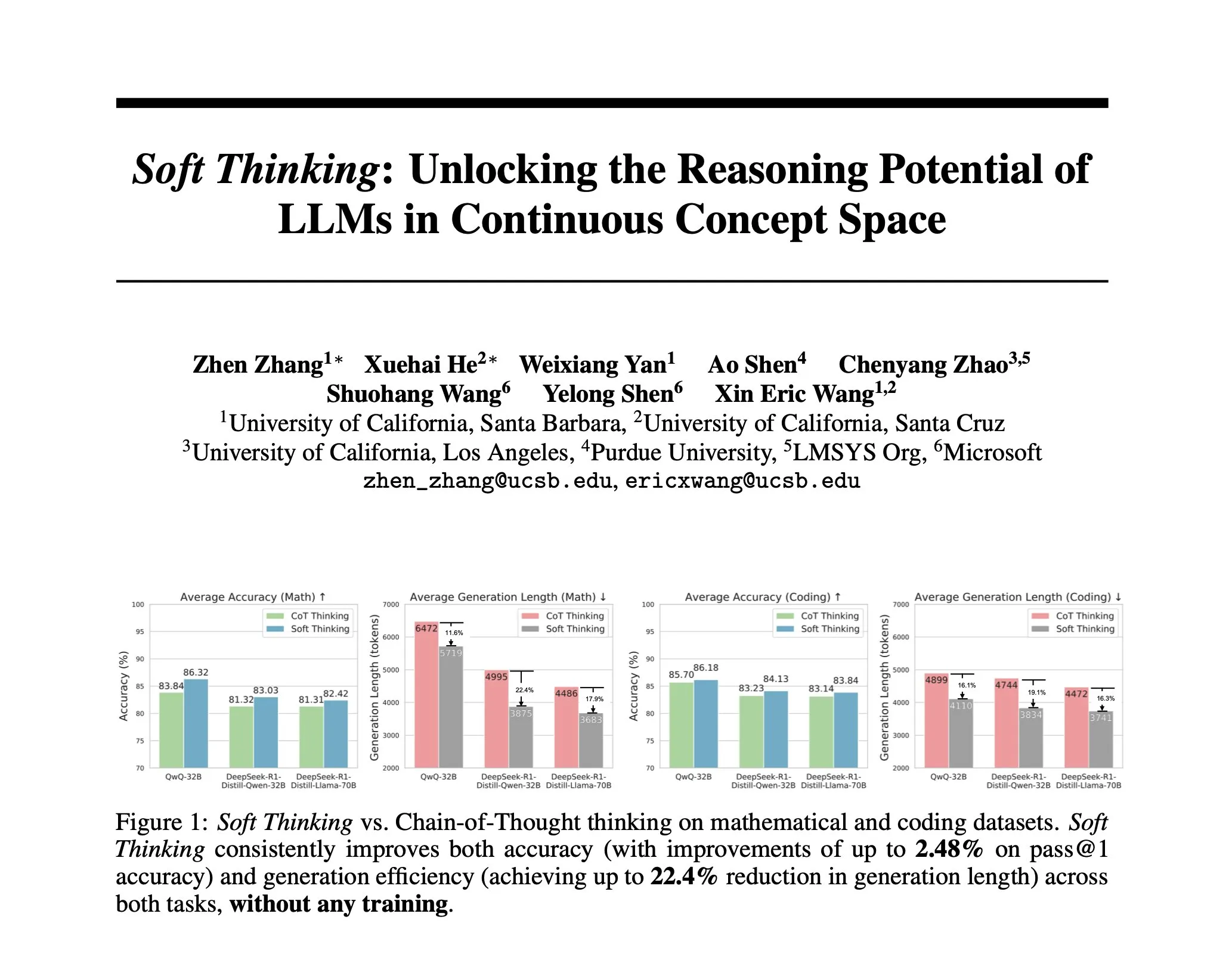
Pesquisa propõe Soft Thinking: método sem treinamento para simular raciocínio “suave” humano: Para aproximar o raciocínio da IA do pensamento fluido humano, não limitado por tokens discretos, pesquisadores propuseram o método Soft Thinking. Este método não requer treinamento adicional e, ao gerar tokens conceituais contínuos e abstratos, que fundem suavemente múltiplos significados através de uma mistura de embeddings ponderados por probabilidade, alcança representações mais ricas e uma exploração contínua de diferentes caminhos de raciocínio. Experimentos mostram que o método melhora a precisão em benchmarks de matemática e código em até 2,48% (pass@1), enquanto reduz o uso de tokens em até 22,4% (Fonte: arankomatsuzaki)
Framework IA-T2I: Utiliza a internet para aprimorar a capacidade de modelos de texto para imagem de lidar com conhecimento incerto: Para lidar com as deficiências dos modelos de texto para imagem existentes ao processar prompts de texto contendo conhecimento incerto (como eventos recentes, conceitos raros), foi proposto o framework IA-T2I (Internet-Augmented Text-to-Image Generation). Este framework, através de um módulo de recuperação ativa, determina se é necessário referenciar imagens, utiliza um módulo de seleção hierárquica de imagens para escolher as imagens mais adequadas dos resultados retornados por motores de busca para aprimorar o modelo T2I, e através de um mecanismo de autorreflexão, avalia e otimiza continuamente as imagens geradas. No conjunto de dados Img-Ref-T2I especialmente construído, o IA-T2I superou o GPT-4o em cerca de 30% (avaliação humana) (Fonte: HuggingFace Daily Papers)
MoI (Mixture of Inputs) melhora a qualidade da geração autorregressiva e a capacidade de raciocínio: Para resolver o problema do descarte de informações de distribuição de tokens durante o processo de geração autorregressiva padrão, pesquisadores propuseram o método Mixture of Inputs (MoI). Este método não requer treinamento adicional e, após gerar um token, constrói uma nova entrada misturando o token discreto gerado com a distribuição de tokens anteriormente descartada. Através da estimativa bayesiana, a distribuição de tokens é considerada como a priori, o token amostrado como observação, e a esperança posterior contínua substitui o vetor one-hot tradicional como a nova entrada do modelo. O MoI melhorou continuamente o desempenho de múltiplos modelos, como Qwen-32B e Nemotron-Super-49B, em tarefas de raciocínio matemático, geração de código e perguntas e respostas de nível de doutorado (Fonte: HuggingFace Daily Papers)
ConvSearch-R1: Otimiza a reescrita de consultas em busca conversacional através de aprendizado por reforço: Para resolver os problemas de ambiguidade, omissão e referência em consultas dependentes de contexto na busca conversacional, foi proposto o framework ConvSearch-R1. Este framework, pela primeira vez, adota uma abordagem autodirigida, utilizando aprendizado por reforço para otimizar diretamente a reescrita de consultas com base em sinais de recuperação, eliminando completamente a dependência de supervisão externa para reescrita (como anotações manuais ou grandes modelos). Seu método de duas fases inclui pré-aquecimento da política autodirigida e aprendizado por reforço guiado por recuperação (adotando um mecanismo de recompensa com incentivo de classificação). Experimentos mostram que o ConvSearch-R1 supera significativamente os métodos SOTA anteriores nos conjuntos de dados TopiOCQA e QReCC (Fonte: HuggingFace Daily Papers)
Framework ASRR implementa raciocínio adaptativo eficiente para grandes modelos de linguagem: Para resolver o problema de modelos de inferência de grande porte (LRMs) terem um custo computacional excessivo em tarefas simples devido a inferências redundantes, pesquisadores propuseram o framework de Raciocínio Adaptativo com Autorecuperação (Adaptive Self-Recovery Reasoning, ASRR). Este framework, ao revelar o “mecanismo interno de autorecuperação” do modelo (que complementa implicitamente o raciocínio na geração de respostas), suprime inferências desnecessárias e introduz um ajuste de recompensa de comprimento sensível à precisão, alocando adaptativamente o esforço de inferência de acordo com a dificuldade da pergunta. Experimentos mostram que o ASRR pode reduzir significativamente o orçamento de inferência e aumentar a taxa de inofensividade em benchmarks de segurança, com perda mínima de desempenho (Fonte: HuggingFace Daily Papers)
Framework MoT (Mixture-of-Thought) melhora a capacidade de raciocínio lógico: Inspirados pela forma como os humanos utilizam múltiplas modalidades de raciocínio (linguagem natural, código, lógica simbólica) para resolver problemas lógicos, pesquisadores propuseram o framework Mixture-of-Thought (MoT). O MoT permite que LLMs raciocinem através de três modalidades complementares, incluindo a recém-introduzida modalidade simbólica de tabela verdade. Através de um design de duas fases (treinamento MoT autoevolutivo e inferência MoT), o MoT supera significativamente os métodos de cadeia de pensamento monomodal em benchmarks de raciocínio lógico como FOLIO e ProofWriter, com um aumento médio de precisão de até 11,7% (Fonte: HuggingFace Daily Papers)
RL Tango: Treinamento conjunto de gerador e validador via aprendizado por reforço para aprimorar o raciocínio em linguagem: Para resolver os problemas de “reward hacking” e baixa generalização em métodos de aprendizado por reforço para LLMs existentes, onde o validador (modelo de recompensa) é fixo ou ajustado por supervisão, foi proposto o framework RL Tango. Este framework treina simultaneamente, de forma intercalada e via aprendizado por reforço, um gerador LLM e um validador LLM generativo de nível de processo. O validador é treinado apenas com base na recompensa de verificação de correção em nível de resultado, sem necessidade de anotações em nível de processo, formando assim uma promoção mútua eficaz com o gerador. Experimentos mostram que o gerador e o validador do Tango alcançam o estado da arte (SOTA) em modelos de escala 7B/8B (Fonte: HuggingFace Daily Papers)
pPE: Engenharia de prompt a priori auxilia no ajuste fino por reforço (RFT): Um estudo investiga o papel da engenharia de prompt a priori (prior prompt engineering, pPE) no ajuste fino por reforço (Reinforcement Fine-Tuning, RFT). Diferentemente da engenharia de prompt em tempo de inferência (inference-time prompt engineering, iPE), a pPE antecede a consulta com instruções (como raciocínio passo a passo) durante a fase de treinamento, para guiar o modelo de linguagem a internalizar comportamentos específicos. O experimento converteu cinco estratégias de iPE (raciocínio, planejamento, raciocínio com código, recuperação de conhecimento, utilização de exemplos vazios) em métodos de pPE, aplicados ao Qwen2.5-7B. Os resultados mostraram que todos os modelos treinados com pPE superaram seus correspondentes com iPE, sendo que a pPE com exemplos vazios obteve o maior ganho em benchmarks como AIME2024 e GPQA-Diamond, revelando a pPE como um meio eficaz e pouco explorado no RFT (Fonte: HuggingFace Daily Papers)
BiasLens: Framework de avaliação de viés em LLMs sem a necessidade de conjuntos de teste manuais: Para resolver o problema dos métodos atuais de avaliação de viés em LLMs dependerem de dados rotulados construídos manualmente e terem cobertura limitada, foi proposto o framework BiasLens. Este framework parte da estrutura do espaço vetorial do modelo, combinando vetores de ativação de conceitos (CAVs) e autoencoders esparsos (SAEs) para extrair representações conceituais interpretáveis. O viés é quantificado medindo a variação na similaridade de representação entre conceitos alvo e conceitos de referência. O BiasLens demonstrou forte consistência (correlação de Spearman r > 0,85) com métricas tradicionais de avaliação de viés em cenários sem dados rotulados, e é capaz de revelar formas de viés difíceis de detectar com métodos existentes (Fonte: HuggingFace Daily Papers)
HumaniBench: Framework de avaliação de grandes modelos multimodais centrado no ser humano: Para lidar com o desempenho insuficiente dos LMMs atuais em padrões centrados no ser humano, como justiça, ética e empatia, foi proposto o HumaniBench. Trata-se de um benchmark abrangente contendo 32K pares de perguntas e respostas de imagem e texto do mundo real, anotados com auxílio do GPT-4o e validados por especialistas. O HumaniBench avalia sete princípios de IA centrada no ser humano: justiça, ética, compreensão, raciocínio, inclusão linguística, empatia e robustez, cobrindo sete tarefas diversificadas. Testes em 15 LMMs SOTA mostraram que os modelos de código fechado geralmente lideram, mas a robustez e a localização visual ainda são pontos fracos (Fonte: HuggingFace Daily Papers)
AJailBench: Primeiro benchmark abrangente de ataques de jailbreak para grandes modelos de linguagem de áudio: Para avaliar sistematicamente a segurança de grandes modelos de linguagem de áudio (LAMs) sob ataques de jailbreak, foi proposto o AJailBench. Este benchmark primeiro construiu o conjunto de dados AJailBench-Base, contendo 1495 prompts de áudio adversariais, cobrindo 10 categorias de violação. A avaliação baseada neste conjunto de dados mostrou que os LAMs SOTA existentes não demonstraram robustez consistente. Para simular ataques mais realistas, os pesquisadores desenvolveram o kit de ferramentas de perturbação de áudio (APT), que, através de otimização bayesiana, busca perturbações sutis e eficientes, gerando o conjunto de dados estendido AJailBench-APT. A pesquisa indica que perturbações mínimas e que preservam a semântica podem reduzir significativamente o desempenho de segurança dos LAMs (Fonte: HuggingFace Daily Papers)
WebNovelBench: Benchmark para avaliar a capacidade de LLMs na criação de romances longos: Para enfrentar os desafios da avaliação da capacidade narrativa de longa forma dos LLMs, foi proposto o WebNovelBench. Este benchmark utiliza um conjunto de dados de mais de 4000 webnovels chinesas, configurando a avaliação como uma tarefa de geração de história a partir de um esboço. Através do método LLM-como-juiz, realiza uma avaliação automática a partir de oito dimensões de qualidade narrativa e usa análise de componentes principais para agregar as pontuações, comparando-as com obras humanas através de ranking percentil. O experimento distinguiu eficazmente obras-primas humanas, webnovels populares e conteúdo gerado por LLM, e realizou uma análise abrangente de 24 LLMs SOTA (Fonte: HuggingFace Daily Papers)
MultiHal: Conjunto de dados multilíngue de grounding em grafos de conhecimento para avaliação de alucinações em LLMs: Para suprir as deficiências dos benchmarks de avaliação de alucinações existentes em termos de caminhos em grafos de conhecimento e multilinguismo, foi proposto o MultiHal. Trata-se de um benchmark multilíngue e multi-hop baseado em grafos de conhecimento, projetado especificamente para a avaliação de texto gerado. A equipe minerou 140.000 caminhos de grafos de conhecimento de domínio aberto e selecionou 25.900 caminhos de alta qualidade. A avaliação de linha de base mostrou que, em cenários multilíngues e multimodelo, o RAG aprimorado por grafo de conhecimento (KG-RAG) apresentou um aumento absoluto de aproximadamente 0,12 a 0,36 pontos nas pontuações de similaridade semântica em comparação com perguntas e respostas comuns, demonstrando o potencial da integração de grafos de conhecimento (Fonte: HuggingFace Daily Papers)
Llama-SMoP: Método de reconhecimento de fala audiovisual para LLMs baseado em projetores esparsos de mistura: Para resolver o problema do alto custo computacional dos LLMs no reconhecimento de fala audiovisual (AVSR), foi proposto o Llama-SMoP. Trata-se de um LLM multimodal eficiente que utiliza um módulo de projetor esparso de mistura (SMoP), que, através de projetores de mistura de especialistas (MoE) com gate esparso, expande a capacidade do modelo sem aumentar o custo de inferência. Experimentos mostram que a configuração Llama-SMoP DEDR, que adota roteamento e especialistas específicos por modalidade, alcança excelente desempenho em tarefas de ASR, VSR e AVSR, e demonstra bom desempenho em ativação de especialistas, escalabilidade e robustez a ruído (Fonte: HuggingFace Daily Papers)
VPRL: Framework de planejamento puramente visual baseado em aprendizado por reforço, com desempenho superior ao raciocínio textual: Equipes de pesquisa da Universidade de Cambridge, University College London e Google propuseram o VPRL (Visual Planning with Reinforcement Learning), um novo paradigma que depende puramente de sequências de imagens para o raciocínio. O framework utiliza a otimização de política relativa de grupo (GRPO) para pós-treinar grandes modelos visuais, calculando sinais de recompensa através da transição de estados visuais e validando restrições ambientais. Em tarefas de navegação visual como FrozenLake, Maze e MiniBehavior, a precisão do VPRL atingiu 80,6%, superando significativamente os métodos de raciocínio baseados em texto (como os 43,7% do Gemini 2.5 Pro), e demonstrou melhor desempenho em tarefas complexas e robustez, provando a superioridade do planejamento visual (Fonte: 量子位)

Nvidia anuncia roteiro tecnológico de IA para os próximos cinco anos, transformando-se em empresa de infraestrutura de IA: O CEO da Nvidia, Jensen Huang, na COMPUTEX 2025, anunciou o reposicionamento da empresa como uma empresa de infraestrutura de IA e divulgou o roteiro tecnológico para os próximos cinco anos. Ele enfatizou que a infraestrutura de IA será onipresente como eletricidade ou internet, e a Nvidia está empenhada em construir as “fábricas” da era da IA. Para apoiar a transformação, a Nvidia expandirá seu “círculo de amigos” da cadeia de suprimentos, aprofundando a cooperação com a TSMC e outros, e planeja estabelecer um escritório em Taiwan (NVIDIA Constellation) e o primeiro supercomputador de IA gigante (Fonte: 36氪)

Google reinicia projeto de óculos de IA, lança plataforma Android XR e dispositivos de terceiros: Na conferência I/O 2025, o Google anunciou o reinício do projeto de óculos AI/AR, lançou a plataforma Android XR desenvolvida especificamente para dispositivos XR e demonstrou dois dispositivos de terceiros baseados nesta plataforma: o Project Moohan da Samsung (concorrente do Vision Pro) e o Project Aura da Xreal. O Google visa replicar o sucesso do Android no campo dos smartphones, criando o “momento Android” para dispositivos XR, e posicionando-se para futuras plataformas de computação ambiental e espacial. Combinado com o modelo multimodal grande Gemini 2.5 Pro atualizado e a tecnologia de assistente inteligente Project Astra, a nova geração de óculos AI/AR alcançará uma experiência disruptiva em compreensão de voz, tradução em tempo real, percepção contextual e execução de tarefas complexas (Fonte: 36氪)

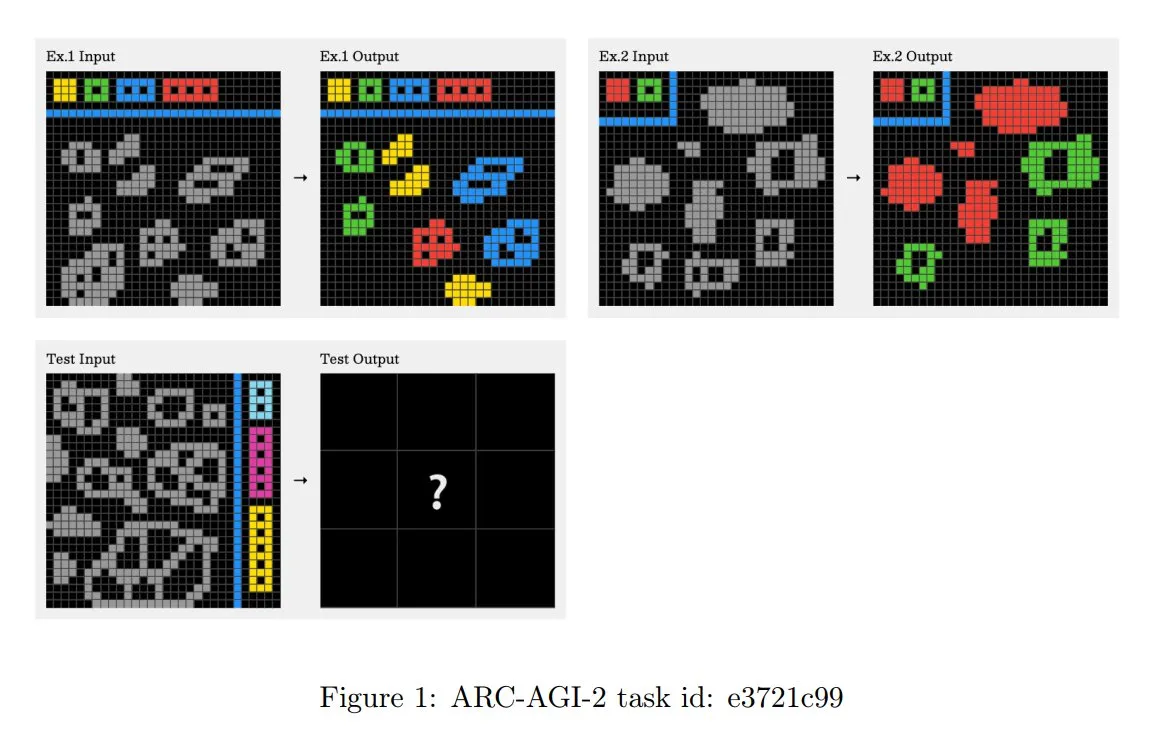
Princípios do desafio ARC-AGI-2 atualizados, enfatizando o raciocínio contextual de múltiplos passos: O recém-publicado paper ARC-AGI-2 atualizou os princípios de design do desafio. Os novos princípios exigem que a resolução de tarefas possua capacidades de raciocínio contextual, de múltiplas regras e de múltiplos passos. As grades são maiores, contêm mais objetos e codificam múltiplos conceitos interativos. As tarefas são novas e não reutilizáveis para limitar a memorização. O design resiste intencionalmente à síntese de programas por força bruta. Solucionadores humanos levam em média 2,7 minutos por tarefa, enquanto sistemas de ponta (como o OpenAI o3-medium) pontuam apenas cerca de 3%, e todas as tarefas exigem esforço cognitivo explícito (Fonte: TheTuringPost, clefourrier)
Skywork lança superagente, com o objetivo de reduzir 8 horas de trabalho para 8 minutos: A Skywork lançou seu agente de espaço de trabalho de IA – Skywork Super Agents, alegando ser capaz de comprimir 8 horas de trabalho do usuário em 8 minutos. O produto se posiciona como o pioneiro dos agentes de espaço de trabalho de IA, com funcionalidades e métodos de implementação específicos a serem observados mais detalhadamente (Fonte: _akhaliq)
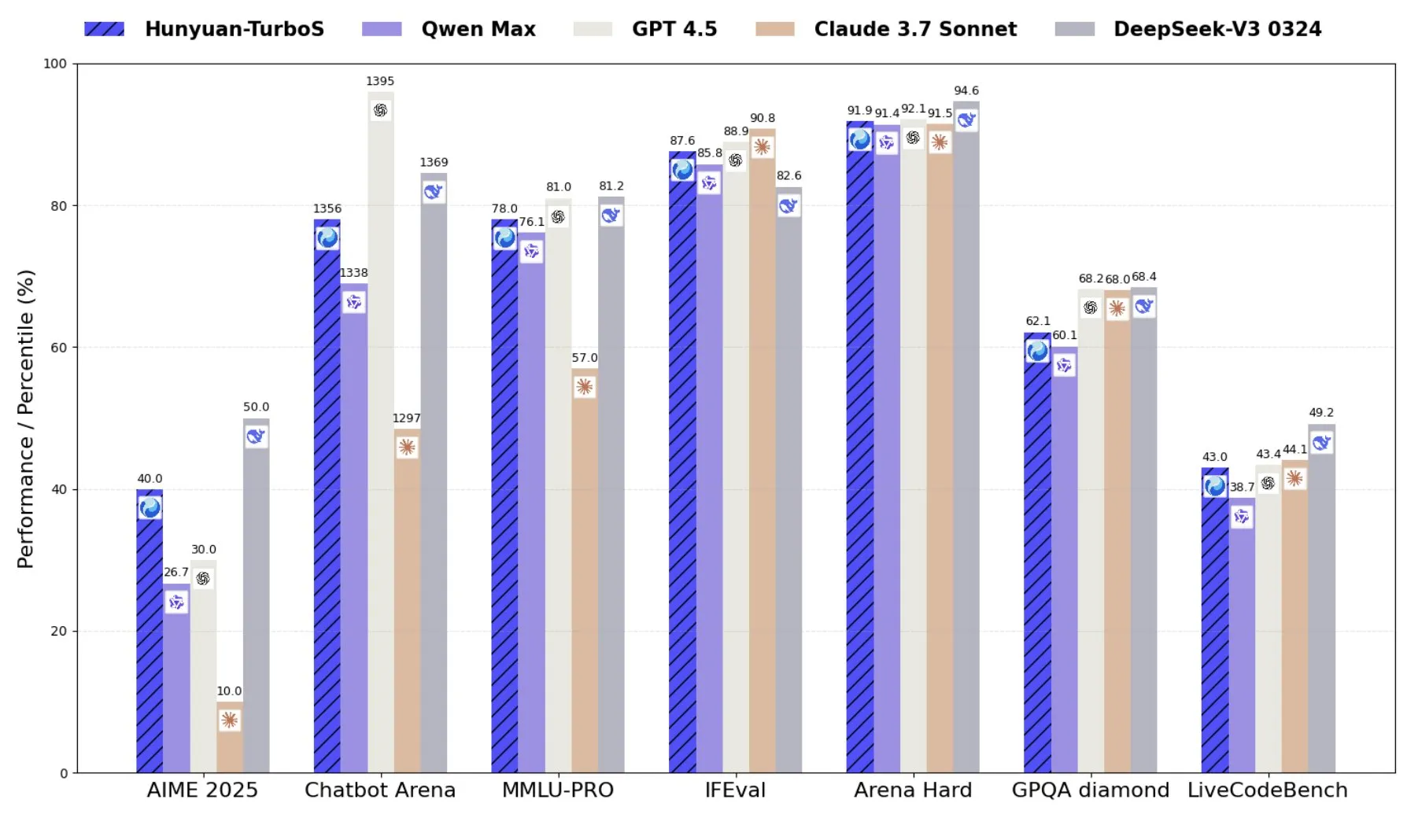
Tencent lança Hunyuan-TurboS, um modelo de mistura de especialistas combinando Transformer e Mamba: A Tencent lançou o modelo Hunyuan-TurboS, que adota uma arquitetura de mistura de especialistas (MoE) combinando Transformer e Mamba, possuindo 56 bilhões de parâmetros ativos e treinado em 16 trilhões de tokens. O Hunyuan-TurboS é capaz de alternar dinamicamente entre modos de resposta rápida e “reflexão” profunda, classificando-se entre os sete primeiros no geral no LMSYS Chatbot Arena (Fonte: tri_dao)
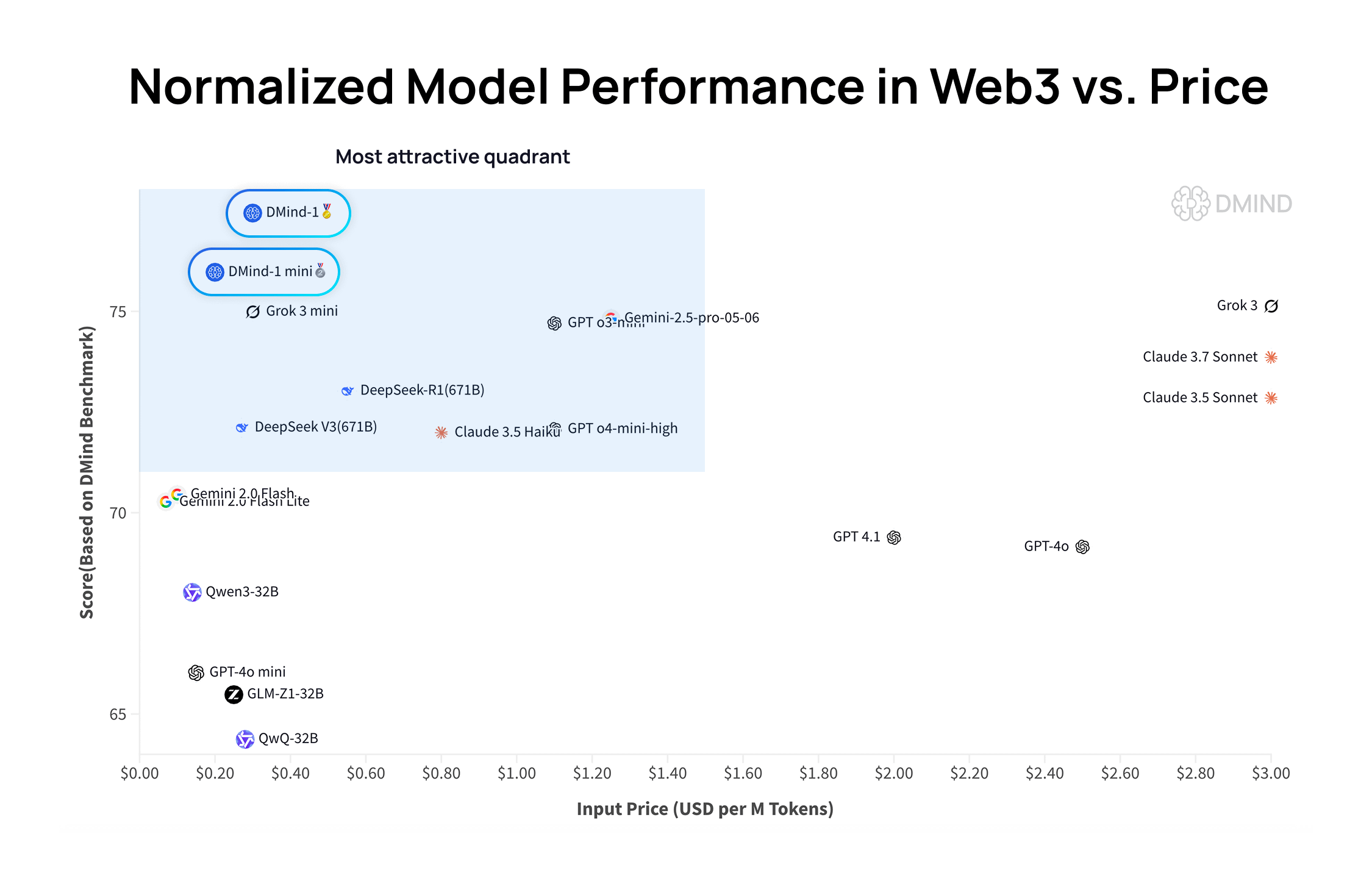
DMind-1: Modelo de linguagem grande de código aberto projetado para cenários Web3: A DMind AI lançou o DMind-1, um modelo de linguagem grande de código aberto otimizado para cenários Web3. O DMind-1 (32B) é ajustado com base no Qwen3-32B, utilizando uma grande quantidade de conhecimento específico da Web3, com o objetivo de equilibrar o desempenho e o custo de aplicações AI+Web3. Em benchmarks de avaliação Web3, o DMind-1 superou os LLMs genéricos convencionais, com um custo de token de apenas cerca de 10% dos mesmos. O DMind-1-mini (14B), lançado simultaneamente, mantém mais de 95% do desempenho do DMind-1, com melhor latência e eficiência computacional (Fonte: _akhaliq)
LightOn lança Reason-ModernColBERT, modelo de poucos parâmetros com excelente desempenho em tarefas de recuperação intensivas em raciocínio: A LightOn lançou o Reason-ModernColBERT, um modelo de interação tardia com apenas 149 milhões de parâmetros. No popular benchmark BRIGHT (focado em recuperação intensiva em raciocínio), este modelo teve um desempenho excepcional, superando modelos com 45 vezes mais parâmetros e alcançando o estado da arte (SOTA) em vários domínios. Este resultado demonstra mais uma vez a eficiência dos modelos de interação tardia em tarefas específicas (Fonte: lateinteraction, jeremyphoward, Dorialexander, huggingface)

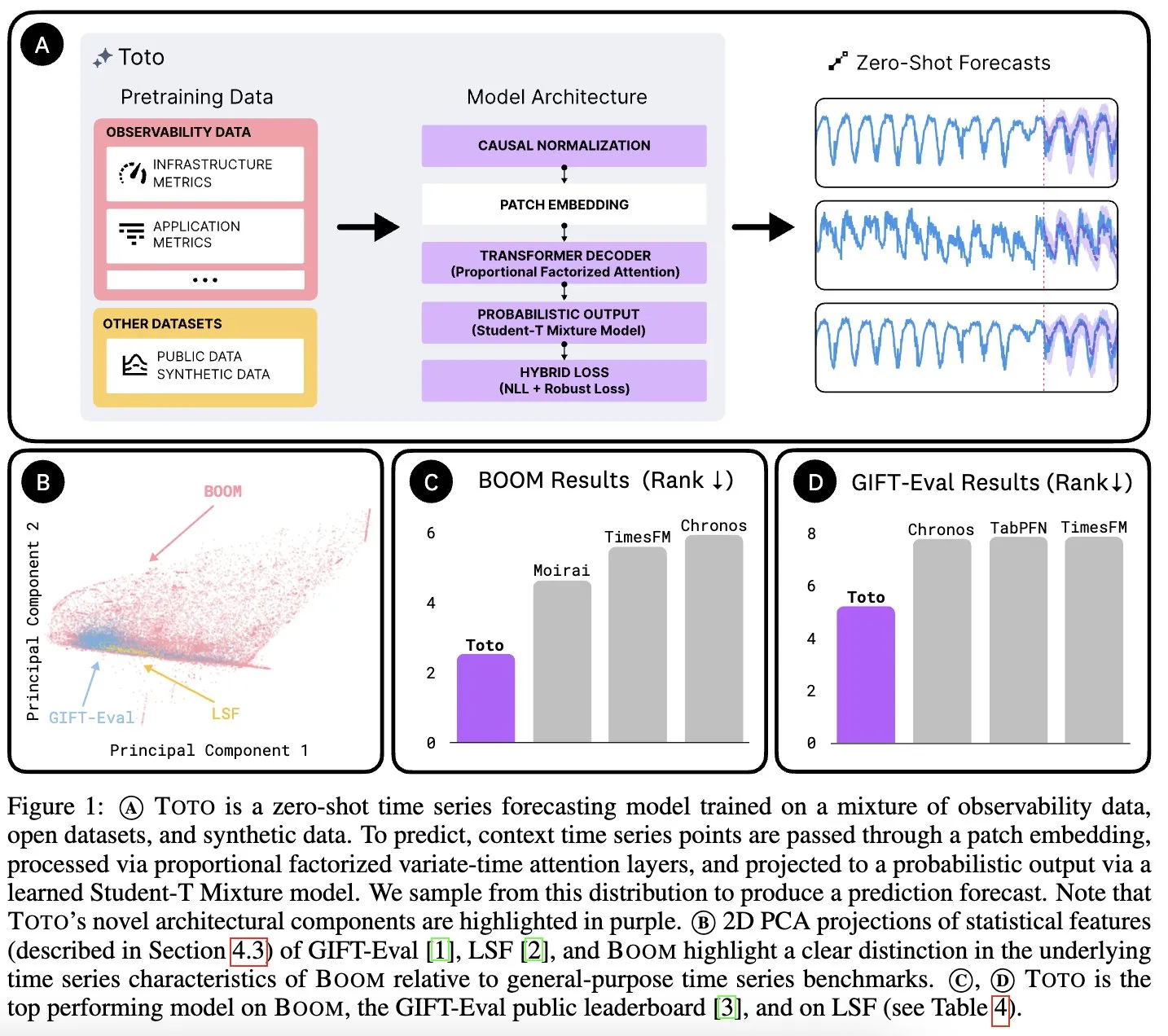
Datadog AI Research lança modelo de fundação para séries temporais Toto e benchmark de métricas de observabilidade BOOM: A Datadog AI Research lançou o Toto, um novo modelo de fundação para séries temporais, que superou significativamente os modelos SOTA existentes em benchmarks relevantes. Simultaneamente, foi lançado o BOOM, o maior benchmark de métricas de observabilidade atualmente disponível. Ambos são de código aberto sob a licença Apache 2.0, com o objetivo de promover a pesquisa e aplicação nas áreas de análise de séries temporais e observabilidade (Fonte: jefrankle, ClementDelangue)
TII lança série Falcon-H1 de modelos híbridos Transformer-SSM: O Instituto de Inovação Tecnológica (TII) dos Emirados Árabes Unidos lançou a série de modelos Falcon-H1, um conjunto de modelos de linguagem de arquitetura híbrida que combina mecanismos de atenção Transformer e cabeças de modelo de espaço de estados (SSM) Mamba2. A série de modelos varia em escala de parâmetros de 0.5B a 34B, suporta comprimentos de contexto de até 256K e supera ou iguala o desempenho de modelos Transformer de ponta como Qwen3-32B e Llama4-Scout em vários benchmarks, especialmente em multilinguismo (suporte nativo para 18 idiomas) e eficiência. Os modelos foram integrados ao vLLM, Hugging Face Transformers e llama.cpp (Fonte: Reddit r/LocalLLaMA)

Pesquisa do MIT: IA aprende a associar visão e som sem intervenção humana: Pesquisadores do MIT demonstraram um sistema de IA capaz de aprender autonomamente as conexões entre informações visuais e os sons correspondentes, sem orientação explícita ou dados rotulados por humanos. Essa capacidade é crucial para o desenvolvimento de sistemas de IA multimodais mais abrangentes, permitindo que eles compreendam e percebam o mundo de forma mais semelhante aos humanos (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence)

Emirados Árabes Unidos lançam grande modelo de IA em árabe, acelerando a corrida de IA na região do Golfo: Os Emirados Árabes Unidos lançaram um grande modelo de IA em árabe, marcando mais um investimento no campo da inteligência artificial e intensificando a competição no desenvolvimento de tecnologia de IA entre os países da região do Golfo. Esta iniciativa visa aumentar a influência da língua árabe no campo da IA e atender às necessidades de aplicações de IA localizadas (Fonte: Reddit r/artificial)
Fenbi Technology lança modelo de grande porte de domínio vertical, definindo novo paradigma “IA + Educação”: A Fenbi Technology apresentou seu modelo de grande porte de domínio vertical autodesenvolvido para o setor de educação profissional no Tencent Cloud AI Industry Application Summit. Este modelo já foi aplicado em produtos como avaliação de entrevistas e sistema de aulas com simulados por IA, cobrindo toda a cadeia de “ensinar, aprender, praticar, avaliar, testar”. Através de formas como professores de IA, visa alcançar um ensino personalizado de “mil faces para mil pessoas” em vez de “mil faces para uma pessoa”, e planeja lançar produtos de hardware de IA equipados com seu modelo de grande porte autodesenvolvido, promovendo a transformação inteligente da educação (Fonte: 量子位)

Beisen Kuxueyuan lança nova geração da plataforma AI Learning, introduzindo cinco AI Agents: A Beisen Holdings, após a aquisição da Kuxueyuan, lançou a nova geração da plataforma de aprendizado AI Learning, baseada em grandes modelos de IA. A plataforma adiciona cinco agentes inteligentes ao eLearning original: assistente de criação de cursos por IA, assistente de aprendizado por IA, instrutor de IA, coach de liderança por IA e assistente de exames por IA. O objetivo é subverter o modelo tradicional de aprendizado corporativo através de diálogo em tempo real com Agents, treinamento de habilidades, aprendizado personalizado e criação de cursos e exames completos por IA (Fonte: 量子位)

Relatório do 1º trimestre da Pony.ai: Receita de serviços de Robotaxi dispara 8 vezes em relação ao ano anterior, mil veículos autônomos serão implantados até o final do ano: A Pony.ai divulgou seu relatório financeiro do primeiro trimestre de 2025, com receita total de 102 milhões de yuans, um aumento de 12% em relação ao ano anterior. Dentre isso, a receita principal de serviços de Robotaxi atingiu 12,3 milhões de yuans, um aumento expressivo de 200,3% em relação ao ano anterior, e a receita de tarifas de passageiros disparou 8 vezes. A empresa planeja iniciar a produção em massa da sétima geração de Robotaxis no segundo trimestre e implantar 1000 veículos até o final do ano, buscando atingir o ponto de equilíbrio por veículo. A Pony.ai também anunciou parcerias com a Tencent Cloud e a Uber, para expandir os mercados doméstico e do Oriente Médio através das plataformas WeChat e Uber, respectivamente (Fonte: 量子位)

CPO da OpenAI, Kevin Weil: ChatGPT se transformará em assistente de ação, custo do modelo já é 500 vezes o do GPT-4: O Chief Product Officer da OpenAI, Kevin Weil, afirmou que o posicionamento do ChatGPT mudará de responder perguntas para executar tarefas para os usuários, tornando-se um assistente de ação de IA através do uso intercalado de ferramentas (como navegar na web, programar, conectar-se a fontes de conhecimento internas). Ele revelou que o custo do modelo atual já é 500 vezes o do GPT-4 original, mas a OpenAI está empenhada em aumentar a eficiência e reduzir os preços da API através de melhorias de hardware e algoritmos. Ele acredita que os AI Agents se desenvolverão rapidamente, evoluindo do nível de engenheiro júnior para o nível de arquiteto em um ano (Fonte: 量子位)

🧰 Ferramentas
FlowiseAI: Construa agentes de IA visualmente: FlowiseAI é um projeto de código aberto que permite aos usuários construir agentes de IA e aplicações LLM através de uma interface visual. Ele suporta arrastar e soltar componentes, conectar diferentes LLMs, ferramentas e fontes de dados, simplificando o processo de desenvolvimento de aplicações de IA. Os usuários podem instalar via npm ou implantar com Docker o Flowise, para construir e testar rapidamente seus próprios fluxos de IA (Fonte: GitHub Trending)

Biblioteca JS do Hugging Face lançada, simplificando a interação com a API do Hub e serviços de inferência: O Hugging Face lançou uma série de bibliotecas JavaScript (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client, etc.), com o objetivo de facilitar a interação dos desenvolvedores via JS/TS com a API do Hugging Face Hub e serviços de inferência. Essas bibliotecas suportam a criação de repositórios, upload de arquivos, chamada de inferência de mais de 100.000 modelos (incluindo completação de chat, texto para imagem, etc.), uso do cliente MCP para construir agentes, entre outras funcionalidades, e suportam múltiplos provedores de inferência (Fonte: GitHub Trending)

Ambiente de execução local Jan AI atualizado para licença Apache 2.0, reduzindo barreiras para uso empresarial: Jan AI é uma ferramenta de código aberto que suporta a execução local de LLMs, e recentemente alterou sua licença de AGPL para a mais permissiva Apache 2.0. Esta mudança visa facilitar a implantação e uso do Jan por empresas e equipes dentro de suas organizações, sem se preocupar com questões de conformidade trazidas pela AGPL, permitindo bifurcar, modificar e publicar livremente, impulsionando assim a adoção em larga escala do Jan em ambientes de produção reais (Fonte: reach_vb, Reddit r/LocalLLaMA)
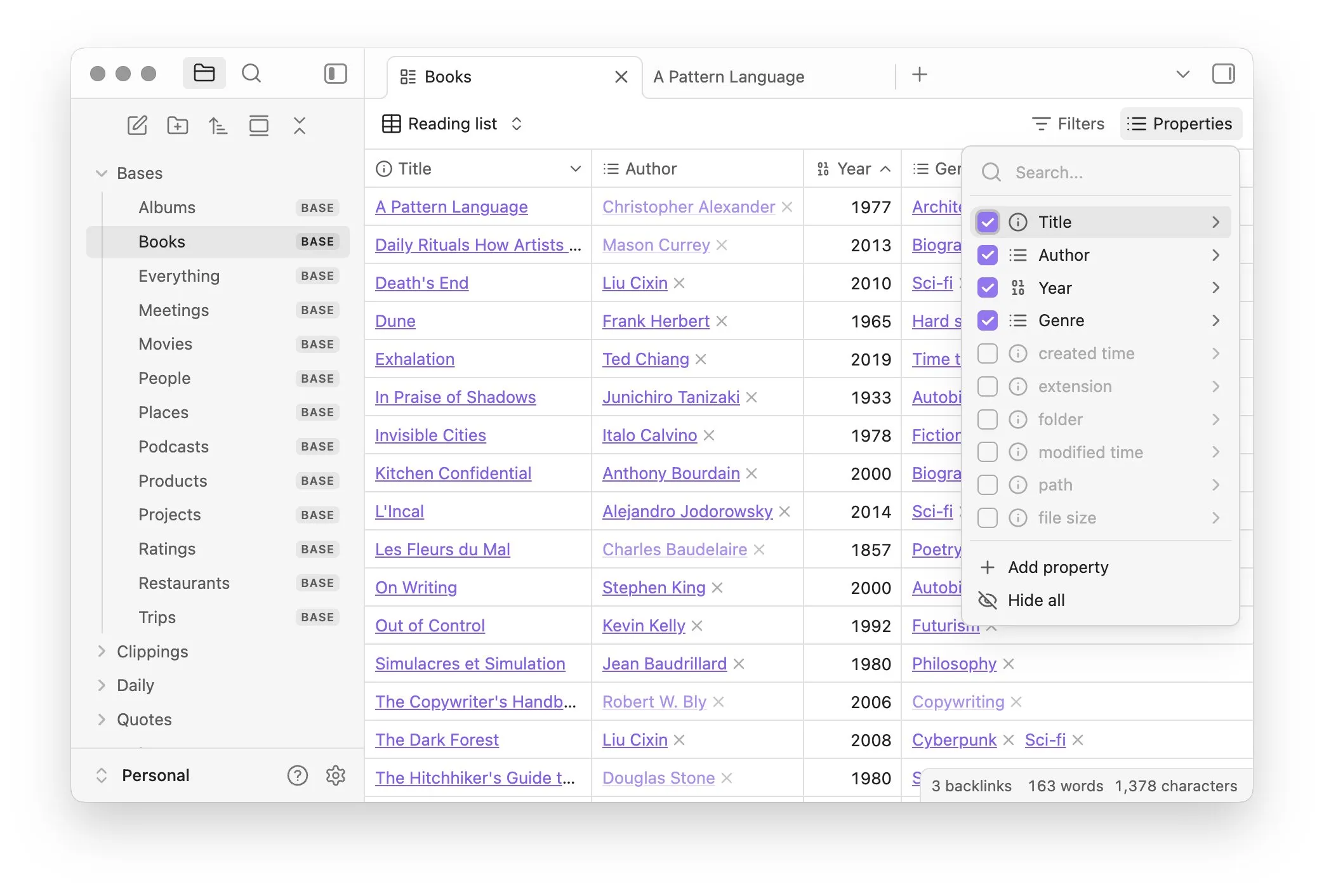
Obsidian lança plugin principal Bases, implementando gerenciamento de notas como banco de dados: O software de gerenciamento de conhecimento Obsidian atualizou seu plugin principal Bases, permitindo aos usuários transformar conjuntos de notas em poderosos bancos de dados. Com o Bases, os usuários podem criar visualizações de tabela personalizadas, visualizar e operar interativamente dados em sua base de conhecimento, suportando a filtragem de notas por propriedades e a criação de fórmulas para derivar atributos dinâmicos, aplicável a diversos cenários como gerenciamento de projetos, planejamento de viagens, listas de leitura, etc. A funcionalidade já está disponível para usuários iniciais (Fonte: op7418)
Hugging Face lança Tiny Agents, simplificando o controle local de navegadores e operações de arquivo por modelos: O Hugging Face introduziu Tiny Agents em seu curso MCP, um framework de configuração de controle de navegador fácil de usar. Os usuários, através de linha de comando, configuração JSON e prompts, podem permitir que LLMs rodando localmente (via servidor compatível com OpenAI) controlem o navegador (como Playwright) ou o sistema de arquivos local, sem chamadas diretas à API, facilitando aplicações de agentes para modelos locais como llama.cpp (Fonte: Reddit r/LocalLLaMA)

Desenvolvedor disponibiliza em código aberto aplicativo de otimização de currículos por IA, baseado em LangChain e Ollama: Um desenvolvedor construiu e disponibilizou em código aberto um aplicativo de otimização de currículos impulsionado por IA. Após o usuário carregar o currículo atual e a descrição da vaga desejada, o aplicativo tenta ajustar as palavras-chave do currículo para torná-lo mais adequado às necessidades de recrutamento. O backend do projeto usa LangChain, combinando recuperação esparsa BM25 e modelo denso para recuperação híbrida, o modelo de linguagem roda localmente via Ollama, e o frontend usa React. O projeto está atualmente em fase de prova de conceito, com o código disponível no GitHub (Fonte: Reddit r/deeplearning)
Ferramenta de construção de aplicativos Lovable aprimora capacidade de processamento de imagens: A ferramenta de construção de aplicativos de IA Lovable anunciou melhorias em suas funcionalidades de processamento de imagens. Os usuários agora podem carregar imagens para o chat e instruir o Lovable a usar esses materiais de imagem no aplicativo, melhorando a experiência do usuário na construção de aplicativos que contêm elementos visuais com auxílio de IA (Fonte: op7418)
Helios: Primeira plataforma a tentar acelerar o trabalho governamental com IA: Joe Scheidler lançou o Helios, uma plataforma que visa utilizar IA para aumentar a eficiência do trabalho governamental, descrita como a “versão do Cursor para o governo”. Esta plataforma é uma das primeiras tentativas explícitas direcionadas a departamentos governamentais, buscando otimizar seus fluxos de trabalho e eficiência através da tecnologia de IA, com funcionalidades e cenários de aplicação específicos a serem observados mais detalhadamente (Fonte: timsoret)
📚 Aprendizado
Universidade de Zhejiang lança material didático “Fundamentos de Grandes Modelos”, explicando sistematicamente o conhecimento de LLMs com atualizações contínuas: A equipe de LLM da Universidade de Zhejiang disponibilizou em código aberto o material didático “Fundamentos de Grandes Modelos”, com o objetivo de fornecer aos leitores interessados em grandes modelos de linguagem um conhecimento básico sistemático e uma introdução às tecnologias de ponta. O livro inclui modelos de linguagem tradicionais, evolução da arquitetura de LLMs, engenharia de prompts, ajuste fino eficiente de parâmetros, edição de modelos, geração aumentada por recuperação, entre outros, e será atualizado mensalmente. Cada capítulo é acompanhado por uma lista de artigos relevantes para acompanhar os últimos avanços. O PDF completo e o conteúdo por capítulo já foram publicados no GitHub (Fonte: GitHub Trending)

Hugging Face oferece 10 cursos gratuitos de IA, cobrindo diversos níveis e áreas de conhecimento: O Hugging Face compilou 10 cursos gratuitos de IA oferecidos em sua plataforma, com conteúdo que abrange desde o nível iniciante até o avançado em diversos tópicos populares de IA, incluindo processamento de linguagem natural, aprendizado profundo, aprendizado por reforço, processamento de áudio, multimodalidade, etc. Esses cursos fornecem recursos valiosos para aprendizes de diferentes níveis estudarem sistematicamente o conhecimento de IA, promovendo ainda mais a popularização do conhecimento de IA e o desenvolvimento da comunidade de código aberto (Fonte: huggingface, reach_vb, _akhaliq)

Universidade de Stanford compartilha experiências e lições aprendidas no treinamento do modelo Marin 8B: A equipe de Percy Liang da Universidade de Stanford publicou uma retrospectiva detalhada do treinamento do modelo Marin 8B do zero (que superou o modelo base Llama 3.1 8B em vários benchmarks). Este registro honesto inclui todas as descobertas e erros cometidos pela equipe durante o processo de P&D, fornecendo à comunidade uma valiosa experiência real na construção de LLMs, enfatizando a importância da tentativa e erro e da iteração no processo de pesquisa científica (Fonte: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI e Predibase colaboram para lançar curso de LLM com ajuste fino por reforço (RFT): A DeepLearning.AI de Andrew Ng, em parceria com a Predibase, lançou um curso rápido e gratuito sobre o uso de GRPO (Group Relative Policy Optimization) para ajuste fino por reforço (RFT) visando melhorar o desempenho de LLMs. O curso, ministrado pelo cofundador e CTO da Predibase, Travis Addair, entre outros, tem como objetivo ajudar os alunos a dominar como utilizar o aprendizado por reforço para transformar pequenos LLMs de código aberto em motores de inferência para casos de uso específicos, usando apenas uma pequena quantidade de dados anotados (Fonte: DeepLearningAI)
Página de artigos do Hugging Face adiciona funcionalidade de resumo gerado por IA: O Hugging Face introduziu uma nova funcionalidade em sua página de exibição de artigos, fornecendo um resumo de uma frase gerado por IA para cada artigo. Este resumo visa resumir de forma concisa e clara o conteúdo principal do artigo, ajudando os usuários a filtrar e compreender rapidamente a literatura de pesquisa, aumentando a acessibilidade e a eficiência do uso de recursos acadêmicos. Esta funcionalidade é impulsionada por LLMs de código aberto, refletindo o conceito de “IA capacitando a pesquisa em IA” (Fonte: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

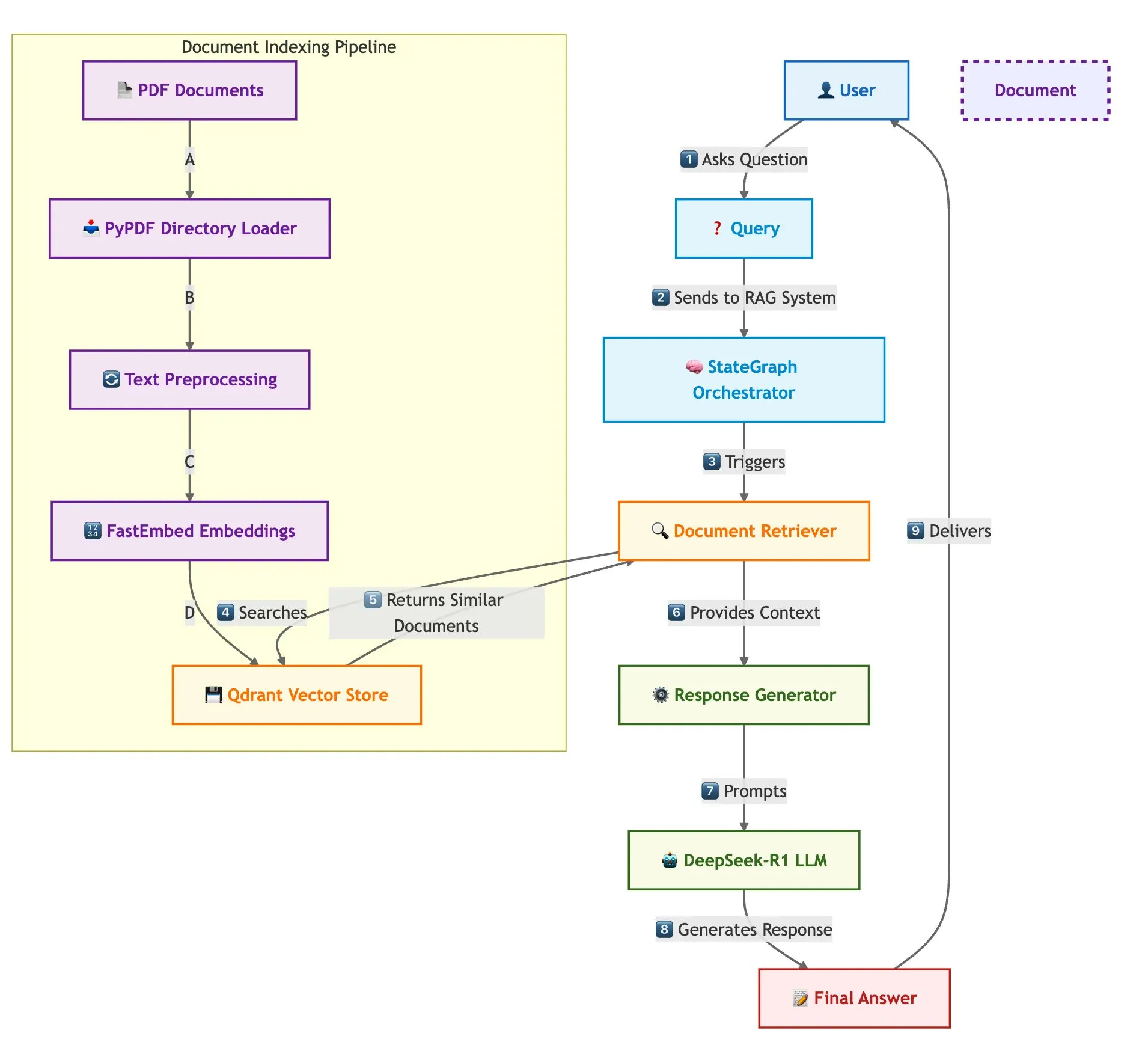
Qdrant, SambaNova e outros apresentam conjuntamente solução para construção rápida de sistema RAG multi-documento: Um blog técnico apresentou como usar o banco de dados vetorial Qdrant, SambaNova, DeepSeek-R1 e LangGraph para construir um sistema de geração aumentada por recuperação (RAG) multi-documento rápido e eficiente em termos de memória. A solução alcança uma economia de memória de 32 vezes através de quantização binária, utiliza o DeepSeek-R1 para respostas LLM rápidas e focadas, e conta com o LangGraph para orquestração modular, adequada para cenários de processamento de múltiplos documentos em larga escala (Fonte: qdrant_engine)
Retrospectiva da cúpula LangChain Interrupt 2025 (versão em mandarim) lançada: A retrospectiva da cúpula LangChain Interrupt 2025 em mandarim foi lançada. O evento atraiu mais de 800 participantes de todo o mundo, compartilhando experiências e perspectivas futuras sobre a construção de agentes de IA, e anunciou vários produtos, incluindo LangGraph Platform e LangGraph Studio v2, discutindo temas como engenharia de agentes e observabilidade de IA (Fonte: hwchase17)
Andi Marafioti publica tutorial nanoVLM, explicando passo a passo o treinamento de modelos de linguagem visual com PyTorch puro: Andi Marafioti publicou um novo tutorial em blog, chamado nanoVLM, detalhando como treinar seu próprio modelo de linguagem visual (VLM) do zero usando PyTorch puro. O tutorial é fácil de entender e começar, visando ajudar iniciantes a dominar rapidamente o processo de treinamento de VLMs (Fonte: LoubnaBenAllal1)

Ferenc Huszár explica cadeias de Markov em tempo contínuo e sua aplicação em modelos de linguagem de difusão: O pesquisador de aprendizado profundo Ferenc Huszár publicou um post de blog explicando de forma acessível a intuição por trás das cadeias de Markov em tempo contínuo (CTMCs), um componente chave de modelos de linguagem de difusão (DLMs) como Mercury e Gemini Diffusion. O artigo explora diferentes perspectivas das cadeias de Markov e suas conexões com processos pontuais, fornecendo uma referência valiosa para a compreensão da base teórica dos DLMs (Fonte: fhuszar)
💼 Negócios
Empresa de “IA humana” Builder.ai declara falência, tendo arrecadado quase US$ 500 milhões: A empresa britânica Builder.ai (anteriormente Engineer.ai), que afirmava revolucionar o desenvolvimento de software com IA e chegou a ser avaliada em US$ 1 bilhão, declarou liquidação judicial esta semana. A empresa foi anteriormente exposta por ter muitas funcionalidades de sua plataforma de IA realizadas manualmente por engenheiros indianos. Apesar de ter recebido quase US$ 500 milhões em financiamento de instituições renomadas como Microsoft e SoftBank DeepCore, a empresa acabou ficando sem fundos devido a dúvidas sobre a autenticidade de sua tecnologia, má gestão financeira e disputas legais do fundador, além de dever US$ 30 milhões à Microsoft e US$ 85 milhões à Amazon em taxas de serviços de nuvem (Fonte: 36氪)

LMArena.ai (anteriormente LMSys) recebe US$ 100 milhões em rodada seed, passando de aplicação Gradio para comercialização: LMArena.ai, originalmente um projeto acadêmico baseado em Gradio chamado LMSys (para competição e avaliação de LLMs), anunciou ter recebido US$ 100 milhões em financiamento seed, liderado pela a16z e pela empresa de investimentos da Universidade da Califórnia. Esta rodada de financiamento apoiará a LMArena a continuar sua pesquisa em IA confiável e as operações da plataforma, marcando a transição de um projeto acadêmico de código aberto bem-sucedido para uma operação comercial. Isso também destaca o potencial de ferramentas de prototipagem rápida como o Gradio na incubação de projetos de IA influentes (Fonte: ClementDelangue, _akhaliq, clefourrier)
Guerra por talentos em IA se acirra, OpenAI, Google e outros oferecem salários anuais de dezenas de milhões para atrair profissionais: A disputa por talentos na área de IA no Vale do Silício entrou em fase acirrada, com pesquisadores de ponta (ICs) tornando-se o recurso central disputado por gigantes como OpenAI, Google e xAI, com salários anuais mais incentivos em ações geralmente ultrapassando dezenas de milhões de dólares. Por exemplo, a OpenAI ofereceu um bônus de US$ 2 milhões e mais de US$ 20 milhões em ações para reter um pesquisador sênior que pretendia ingressar na SSI; o Google DeepMind também oferece salários anuais de US$ 20 milhões para talentos de ponta. Essa competição acirrada decorre da enorme contribuição de um pequeno número de talentos centrais para o desenvolvimento de grandes modelos de linguagem, e sua permanência ou saída pode afetar diretamente o sucesso ou fracasso dos modelos de IA (Fonte: 36氪)
🌟 Comunidade
Capacidade de Sora em chinês parece ter melhorado, mas limitações do modelo ainda existem: Usuários de redes sociais observaram que o modelo de geração de vídeo Sora da OpenAI parece ter progredido no processamento de texto em chinês, sendo capaz de gerar cenas contendo caracteres chineses. No entanto, os usuários também apontaram que o modelo ainda tem suas limitações, e o conteúdo gerado não é perfeito, aceitar essa imperfeição pode ser uma norma na interação com modelos de IA no estágio atual (Fonte: dotey)

Gemini lança função de “exame” para relatórios detalhados, auxiliando na reutilização do conhecimento e no ciclo de aprendizado: O Google Gemini lançou uma nova funcionalidade onde, após ler relatórios detalhados, o Gemini pode criar diretamente perguntas para teste. Esta função visa verificar o real entendimento do usuário sobre o conteúdo e construir um ciclo de aprendizado nativo de IA de “aprender → testar → complementar → reaprender”, enfatizando que o cerne do aprendizado na era da IA reside na capacidade de reutilizar o conhecimento, e não na quantidade de leitura (Fonte: dotey)
Funcionalidade de memória do ChatGPT levanta preocupações dos usuários sobre o controle: A nova funcionalidade “aprender com o chat para memorizar” do ChatGPT permite que o modelo memorize informações de conversas passadas do usuário para fornecer respostas mais personalizadas em interações subsequentes. No entanto, alguns usuários avançados expressaram preocupação, acreditando que isso muda a forma de interagir com o modelo, preferindo ter controle total sobre o conteúdo de entrada do modelo e não desejando que o modelo use informações históricas sem seu conhecimento ou controle preciso (Fonte: random_walker)
Desenvolvimento rápido de AI Agents, futuro modelo de trabalho pode mudar: A comunidade discute o rápido desenvolvimento de AI Agents e seu potencial impacto nos futuros modelos de trabalho. A opinião é que os AI Agents estão evoluindo de simples ferramentas de perguntas e respostas para “funcionários virtuais” capazes de completar tarefas complexas de forma independente (como codificação, pesquisa, suporte ao cliente). O CPO da OpenAI, Kevin Weil, prevê que a capacidade dos AI Agents aumentará rapidamente, evoluindo do nível de engenheiro júnior para o nível de arquiteto em um ano. A Microsoft também propôs o conceito de “rede de agentes”, prenunciando que o trabalho futuro pode girar em torno do gerenciamento e orquestração de agentes de IA (Fonte: rowancheung, 量子位)
IA tem enorme potencial no diagnóstico médico, mas gera preocupações sobre a carreira médica: A IA demonstra capacidades surpreendentes no diagnóstico médico, por exemplo, um estudo afirma que o modelo o1-preview exibe capacidade sobre-humana em tarefas de raciocínio e diagnóstico médico, e casos de IA detectando pneumonia em segundos também chamaram a atenção. Isso tornou o diagnóstico assistido por IA um tópico popular, mas também fez com que alguns médicos com 20 anos de experiência se preocupassem com suas perspectivas de carreira, chegando a brincar sobre ir trabalhar no McDonald’s. A comunidade discute que a IA deve ser vista mais como uma ferramenta para auxiliar os médicos a melhorar a eficiência e a precisão, em vez de substituí-los completamente (Fonte: paul_cal, Reddit r/ArtificialInteligence)
Editores de notícias acusam o modelo de busca por IA do Google de “roubo”: A News Media Alliance e outros editores expressaram forte insatisfação com o novo modelo de busca por IA do Google, chamando-o de “roubo”. Eles acreditam que a IA do Google extrai informações diretamente do conteúdo de notícias e as integra aos resultados da busca, contornando os sites de notícias, prejudicando o tráfego e a receita de publicidade dos editores, o que gerou um debate acirrado sobre direitos autorais de conteúdo e uso justo na era da IA (Fonte: Reddit r/artificial)
Modelo DeepSeek é usado na China para adivinhação tradicional, gerando discussão sobre os limites da aplicação da IA: Um usuário descobriu que uma grande parte do tráfego do modelo DeepSeek na China vem de usuários que o utilizam para atividades de adivinhação tradicional, como a leitura do I Ching. Este fenômeno gerou discussões sobre os limites da aplicação da IA e a adaptação cultural, refletindo também a exploração diversificada e as demandas dos usuários em relação às capacidades da IA (Fonte: menhguin, cto_junior)

💡 Outros
Robô humanoide da Figure completa turno contínuo de 20 horas na linha de produção da BMW: A empresa de robôs humanoides Figure anunciou que seu robô completou com sucesso um turno de trabalho contínuo de 20 horas na linha de produção do BMW X3. Anteriormente, o robô já havia passado por semanas de testes com turnos de 10 horas. A Figure afirma que esta é a primeira vez no mundo que um robô humanoide completa um trabalho contínuo tão longo em uma linha de produção automotiva, demonstrando seu potencial no campo da automação industrial (Fonte: adcock_brett, TheRundownAI)
Diferença e conexão entre Agentic AI e GenAI: A comunidade discutiu os conceitos de Agentic AI (IA de agentes) e Generative AI (IA generativa). A IA generativa refere-se principalmente à IA capaz de criar novo conteúdo (texto, imagens, código, etc.), enquanto a IA de agentes enfatiza mais a autonomia, a orientação a objetivos e a capacidade de interagir e agir com o ambiente. A IA de agentes geralmente utiliza a IA generativa como uma de suas capacidades centrais para entender, planejar e executar tarefas, sendo uma direção importante para o desenvolvimento da IA em direção a uma inteligência autônoma mais avançada (Fonte: Ronald_vanLoon, Ronald_vanLoon)

Aplicação da IA na pesquisa científica é subestimada, existe fenômeno de “maquiar resultados”: A comunidade discute que o potencial da aplicação da IA na pesquisa científica é enorme, mas pode estar sendo subestimado, ao mesmo tempo em que existe o fenômeno de pesquisadores “maquiarem” os resultados de experimentos com IA para conseguir publicações. Por exemplo, em áreas como equações diferenciais parciais (EDPs), o desempenho real da IA pode não ser tão excepcional quanto o apresentado nos artigos. Isso alerta a comunidade científica para a necessidade de avaliar de forma mais rigorosa e transparente o papel real e as limitações da IA nas descobertas científicas (Fonte: clefourrier)