Palavras-chave:OpenAI, Jony Ive, hardware de IA, Google I/O, Gemini, Mistral AI, Devstral, programação de IA, aquisição da io pela OpenAI, Gemini 2.5 Pro, modelo de código aberto Devstral, ferramenta de produção de filmes IA Flow, agente de programação IA Jules
🔥 Destaques
OpenAI anuncia aquisição da startup de hardware de IA de Jony Ive, io, por US$ 6,5 bilhões: A OpenAI confirmou a aquisição da io, empresa de hardware de IA fundada pelo ex-diretor de design da Apple, Jony Ive, em colaboração com o SoftBank, por um valor de aproximadamente US$ 6,5 bilhões. Jony Ive atuará como Diretor Criativo da OpenAI, responsável pelo design de produtos. A equipe da io, composta por cerca de 55 pessoas, se juntará à OpenAI para se dedicar ao desenvolvimento de uma nova forma de dispositivo de hardware de IA, com o primeiro produto previsto para ser lançado em 2026. Esta aquisição marca a entrada oficial da OpenAI no setor de hardware, com o objetivo de criar dispositivos de computação pessoal nativos de IA e experiências interativas, podendo desafiar o atual panorama do mercado de smartphones e dispositivos de computação. (Fonte: 量子位, 智东西, 新芒xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

Google I/O lança múltiplos modelos e aplicações de IA, destacando a integração da IA no cotidiano: No Google I/O 2025 Developer Conference, o Google lançou o Gemini 2.5 Pro e sua versão de pensamento profundo, o leve Gemini 2.5 Flash, o modelo de difusão de texto Gemini Diffusion, o modelo de geração de imagem Imagen 4 e o modelo de geração de vídeo Veo 3. O Veo 3 suporta a geração de vídeos com áudio e diálogo, com resultados impressionantes. O Google também lançou o aplicativo de criação de filmes com IA, Flow, que integra Veo, Imagen e Gemini. A funcionalidade de busca com IA integrará resumos de IA, Deep Search e informações pessoais, além de lançar o AI Mode. O Google enfatizou a integração transparente da IA em produtos e serviços existentes, com o objetivo de tornar a tecnologia de IA “invisível” e melhorar a experiência do usuário. (Fonte: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

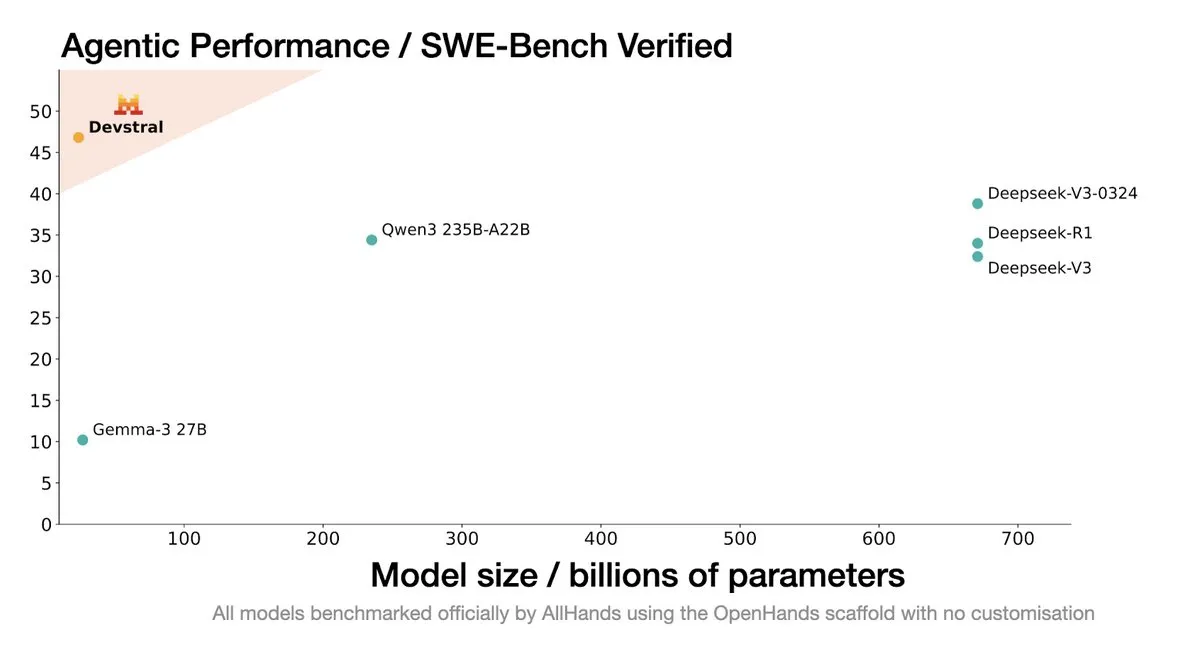
Mistral AI lança Devstral: modelo SOTA de código aberto projetado para agentes de codificação: A Mistral AI, em colaboração com a All Hands AI, lançou o Devstral, um modelo SOTA de código aberto projetado especificamente para agentes de codificação. Este modelo demonstrou excelente desempenho no benchmark SWE-Bench Verified, superando as séries DeepSeek e Qwen3 235B, com apenas 24B de parâmetros, e pode ser executado em uma única placa RTX4090 ou em um Mac com 32GB de memória. O Devstral foi treinado em Issues reais do GitHub, enfatizando a compreensão de contexto em grandes bases de código, identificação de relações entre componentes e reconhecimento de erros em funções complexas. Adota a licença de código aberto Apache 2.0, sendo mais aberto que o Codestral anterior. (Fonte: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
CTO do Google DeepMind, Koray Kavukcuoglu, discute Veo 3, Deep Think e o progresso da AGI: Durante o Google I/O, o CTO do DeepMind, Koray Kavukcuoglu, concedeu uma entrevista discutindo os avanços no modelo de geração de vídeo Veo 3 (como sincronia de áudio e vídeo), o modo de raciocínio aprimorado Deep Think no Gemini 2.5 Pro (que realiza inferência através de cadeias de pensamento paralelas) e suas visões sobre AGI. Kavukcuoglu enfatizou que a escala não é o único fator para alcançar a AGI; arquitetura, algoritmos, dados e técnicas de inferência são igualmente importantes. A realização da AGI requer avanços em pesquisa fundamental e inovações cruciais, não apenas um empilhamento de engenharia. Ele também se mostrou otimista em relação ao “vibe coding” para capacitar pessoas sem formação em programação a construir aplicações. (Fonte: demishassabis, 36氪)
🎯 Tendências
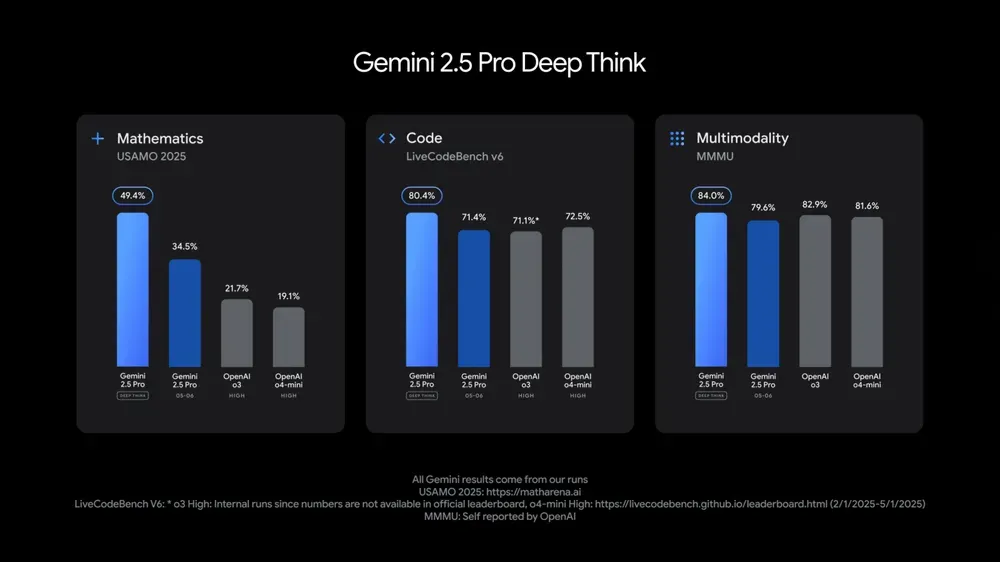
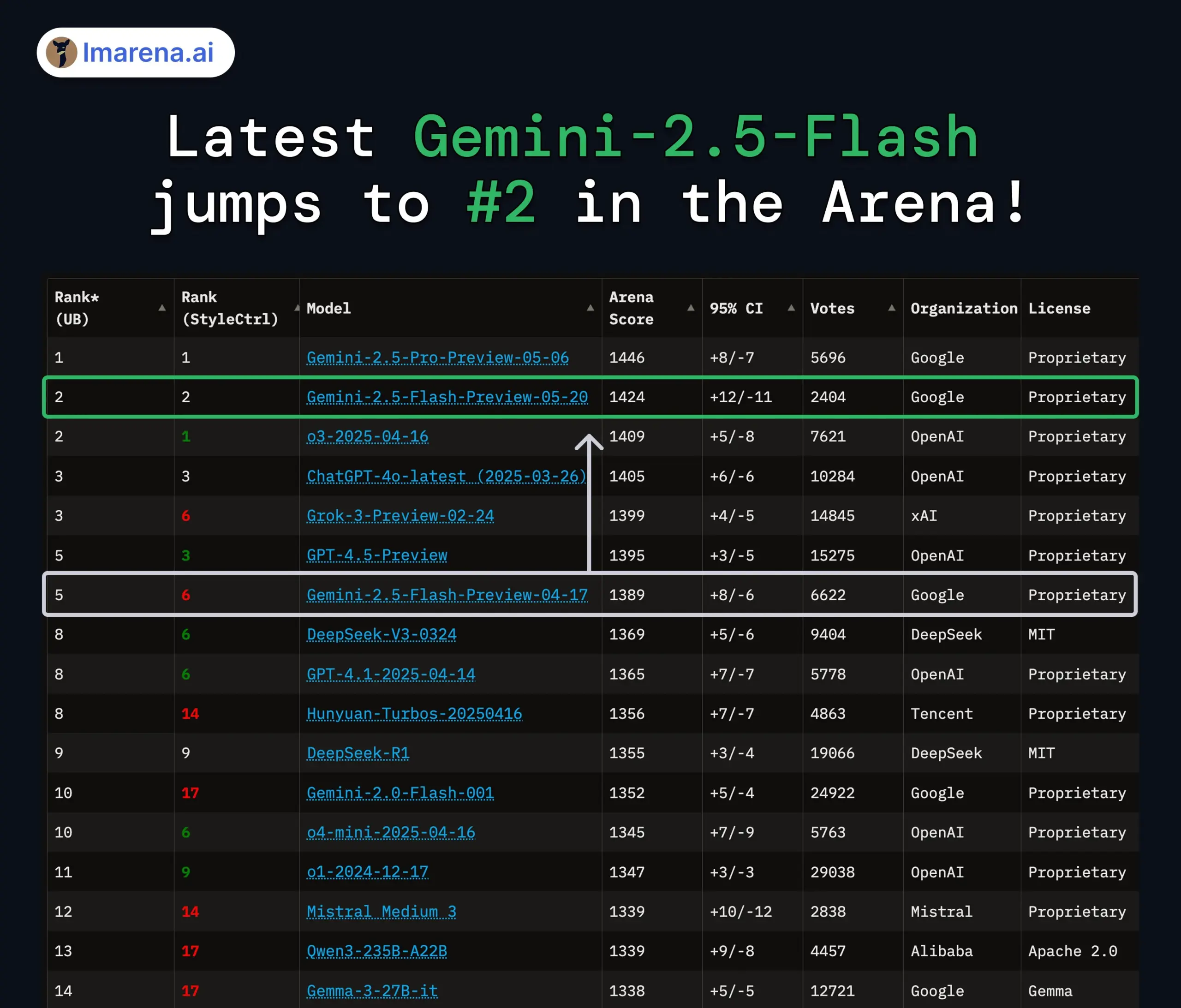
Modelos Gemini 2.5 Pro e Flash do Google são atualizados, com melhorias significativas de desempenho: O Google anunciou no I/O que os modelos Gemini 2.5 Pro e Flash serão lançados oficialmente em junho. O Gemini 2.5 Pro é considerado o modelo de IA mais inteligente do mundo, com uma nova versão de pensamento profundo, apresentando desempenho líder em vários testes. O Gemini 2.5 Flash, como modelo leve, teve um aumento de eficiência de 22%, redução no consumo de tokens de 20%-30% e capacidade nativa de geração de áudio. Dados da LMArena mostram que a nova versão do Gemini-2.5-Flash subiu drasticamente para o segundo lugar no ranking da arena de chatbots, destacando-se especialmente em tarefas complexas como codificação e matemática. (Fonte: natolambert, demishassabis, karminski3, lmarena_ai)
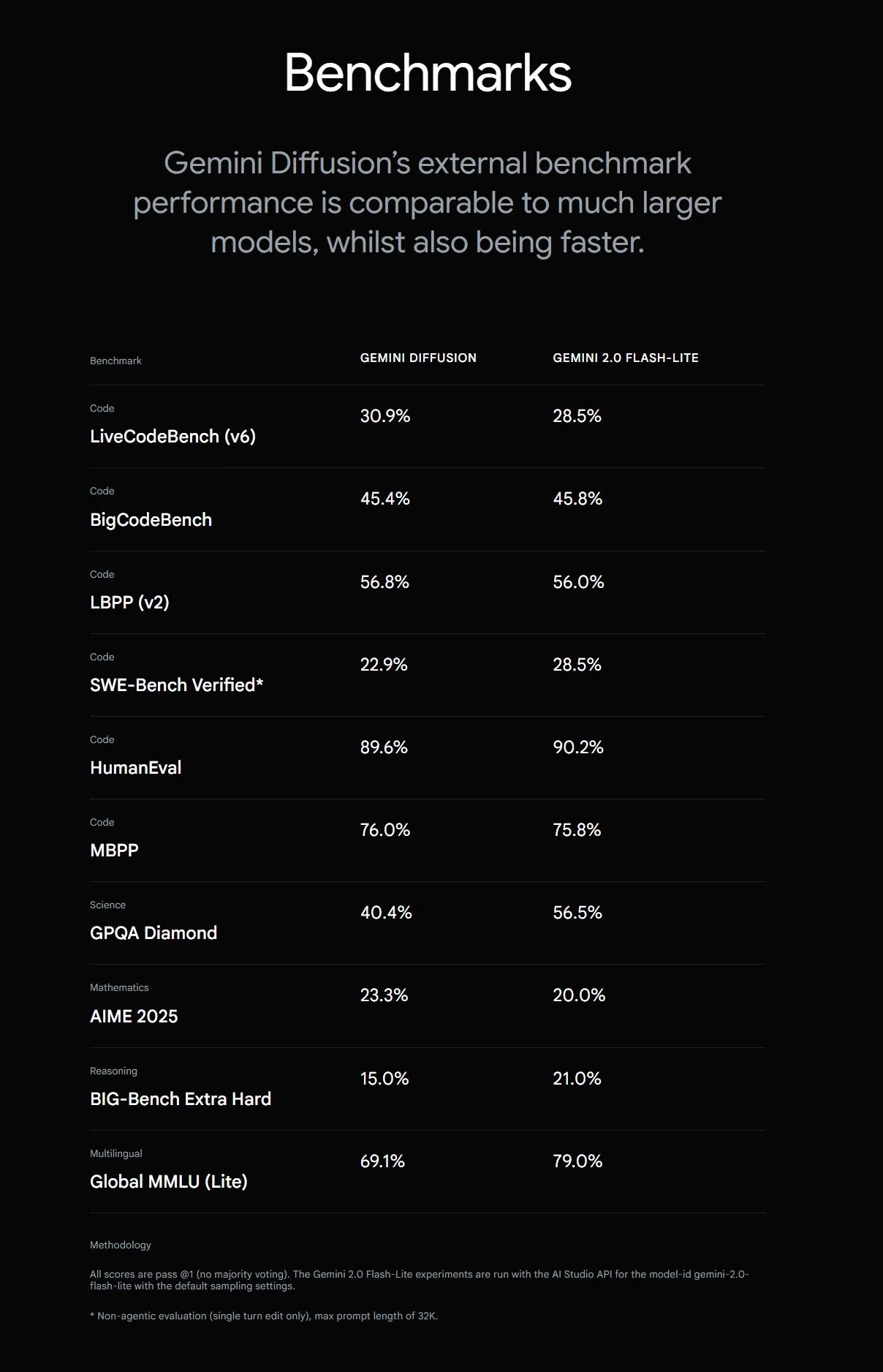
Google lança Gemini Diffusion, aumentando a velocidade de geração de texto em 5 vezes: O Google DeepMind lançou o modelo experimental de geração de texto Gemini Diffusion, cuja velocidade de geração é 5 vezes mais rápida que o modelo mais rápido anterior. Sua capacidade de programação é particularmente notável, atingindo 2000 tokens por segundo (incluindo custos de tokenização, etc.). Diferente dos modelos autorregressivos tradicionais, os modelos de difusão podem realizar inferência não causal, permitindo “pensar” antecipadamente nas respostas subsequentes, superando o GPT-4o na resolução de problemas complexos que exigem raciocínio global (como problemas de cálculo específicos, busca de números primos). Atualmente, este modelo está disponível apenas para desenvolvedores mediante solicitação de teste. (Fonte: OriolVinyalsML, dotey, karminski3)
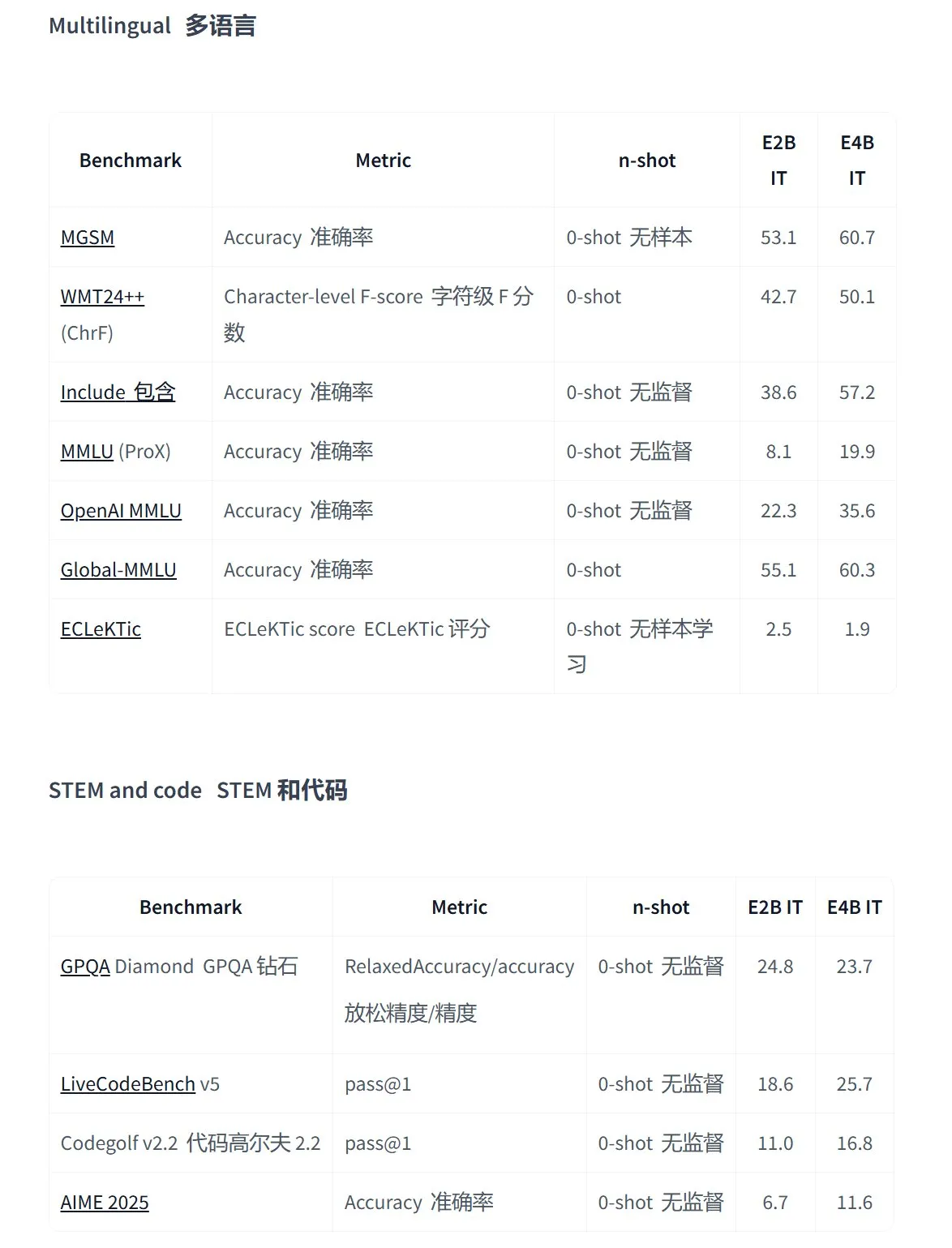
Google lança a série de modelos de código aberto Gemma 3n, projetada para aplicações multimodais em dispositivos de ponta: O Google lançou a nova geração de modelos multimodais de código aberto eficientes, Gemma 3n, projetados para dispositivos de baixo consumo de energia, suportando entrada de texto, voz, imagem, vídeo e processamento multilíngue. Os modelos desta série (como gemma-3n-E4B-it-litert-preview e gemma-3n-E2B-it-litert-preview) são compactos (3-4.4GB), podem rodar em dispositivos com 2GB de RAM e possuem conhecimento atualizado até junho de 2024. Atualmente, estão disponíveis em preview para desenvolvedores nas plataformas AI Studio e AI Edge. (Fonte: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
OpenAI Responses API adiciona suporte a MCP, geração de imagens e funcionalidade de Code Interpreter: A plataforma de desenvolvedores da OpenAI anunciou uma importante atualização para sua Responses API (anteriormente Assistants API), adicionando suporte para servidores de protocolo de contexto de modelo remoto (MCP), permitindo que agentes de IA interajam de forma mais flexível com ferramentas e serviços externos. Além disso, a API integrou capacidade de geração de imagens e funcionalidade de Code Interpreter, expandindo ainda mais seus cenários de aplicação e potencial de desenvolvimento. (Fonte: gdb, npew, OpenAIDevs, snsf)
API da xAI integra funcionalidade de busca em tempo real Grok Live Search: A xAI anunciou a adição da funcionalidade Live Search à sua API, permitindo que o Grok busque dados em tempo real da plataforma X, internet, notícias e outras fontes. Esta funcionalidade está atualmente em fase de testes Beta, disponível gratuitamente para desenvolvedores por tempo limitado, com o objetivo de aprimorar a capacidade do Grok de obter e processar as informações mais recentes, fornecendo suporte para a construção de aplicações de IA mais dinâmicas e ricas em informações. (Fonte: xai, TheGregYang, yoheinakajima)

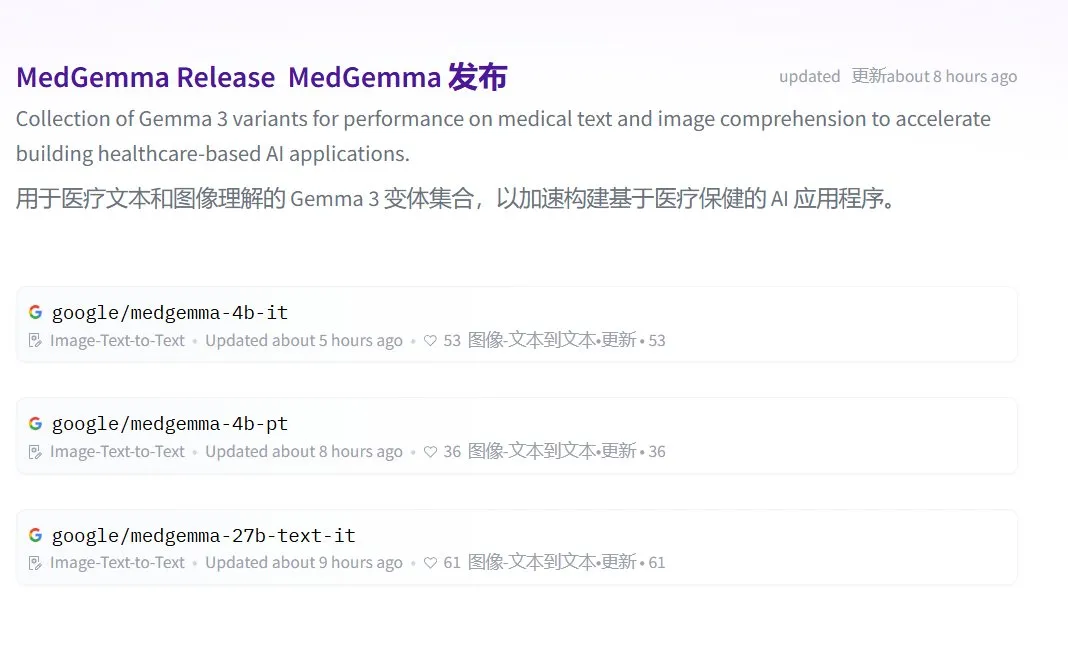
Google lança a série MedGemma de grandes modelos médicos de código aberto: O Google lançou os modelos médicos de código aberto MedGemma, baseados na arquitetura Gemma 3, incluindo medgemma-4b-pt (base), medgemma-4b-it (multimodal, diagnóstico por imagem médica) e medgemma-27b-text-it (apenas texto, prontuários de consulta). Esses modelos foram treinados especificamente para a compreensão de textos e imagens médicas, com o objetivo de aprimorar a capacidade de aplicação da IA no campo da medicina, como auxílio diagnóstico, análise de prontuários, etc. Os modelos já estão disponíveis no Hugging Face. (Fonte: JeffDean, karminski3)
Vários produtos do grande modelo Hunyuan da Tencent são atualizados, lançando plataforma aberta de agentes inteligentes: A Tencent Hunyuan anunciou a atualização iterativa de seus modelos emblemáticos de pensamento rápido TurboS e de pensamento profundo T1. O TurboS entrou no top dez global em capacidade de código e matemática. Foram lançados o novo modelo de inferência visual profunda T1-Vision e o modelo de chamada de voz ponta a ponta Hunyuan Voice. O motor de conhecimento original foi atualizado para a “Plataforma de Desenvolvimento de Agentes Inteligentes Tencent Cloud”, integrando capacidades de RAG e Agent. O Hunyuan Image 2.0, 3D v2.5 e modelos de geração visual para jogos também foram atualizados, com planos de continuar a abrir o código de modelos básicos multimodais e plugins. (Fonte: 36氪)

Alibaba e Universidade de Zhejiang propõem lei de escalonamento de computação paralela ParScale: A equipe de pesquisa do Alibaba, em colaboração com a Universidade de Zhejiang, propôs uma nova Lei de Escalonamento: a Lei de Escalonamento de Computação Paralela (ParScale). Esta lei indica que aumentar a computação paralela do modelo durante o treinamento e a inferência pode melhorar a capacidade de grandes modelos sem aumentar os parâmetros, além de aumentar a eficiência da inferência. Em comparação com o escalonamento de parâmetros, o aumento de memória do ParScale é de apenas 4,5%, e o aumento de latência é de 16,7%. Este método é alcançado através da transformação diversificada de entrada, processamento paralelo e agregação dinâmica de saída, mostrando desempenho notável especialmente em tarefas de forte raciocínio, como matemática e programação. (Fonte: 36氪)
Microsoft lança Aurora, modelo fundamental atmosférico em larga escala, com velocidade de previsão 5000 vezes maior: A Microsoft e seus colaboradores lançaram o primeiro modelo fundamental atmosférico em larga escala, Aurora, treinado com mais de 1 milhão de horas de dados geofísicos. Ele pode prever com maior precisão e eficiência a qualidade do ar, trajetórias de ciclones tropicais, dinâmica das ondas do mar e clima de alta resolução. Comparado ao avançado sistema de previsão numérica IFS, o Aurora tem uma velocidade de cálculo aproximadamente 5000 vezes maior e alcança SOTA em várias áreas chave de previsão. A arquitetura do modelo é flexível e pode ser ajustada para tarefas específicas, prometendo impulsionar a popularização da previsão do sistema terrestre. (Fonte: 36氪)

Busca com IA do Google lançará AI Mode, integrando múltiplas funcionalidades inteligentes: O Google anunciou o lançamento do “AI Mode” para seu motor de busca, considerado a “busca com IA mais poderosa”. Este modo, baseado no Gemini 2.5, possui capacidade de raciocínio aprimorada, suporta consultas mais longas, busca multimodal e respostas instantâneas de alta qualidade. Futuramente, integrará a funcionalidade “Deep Search”, que pode realizar centenas de consultas simultaneamente e fornecer relatórios abrangentes, além de planejar a integração de dados pessoais do Gmail e outros, bem como a interação com câmera em tempo real do Project Astra e o gerenciamento automático de tarefas do Project Mariner. (Fonte: dotey, Google)

Modelo de geração de imagem Imagen 4 do Google é lançado, com grande aumento de velocidade e detalhes: O Google lançou seu mais recente modelo de texto para imagem, Imagen 4, alegando um aumento de velocidade de 3 a 10 vezes em comparação com a geração anterior, detalhes de imagem mais ricos, efeitos mais precisos e capacidade de renderização de texto significativamente aprimorada. O Imagen 4 é capaz de gerar objetos complexos como tecidos, gotas d’água, pelos de animais, com resolução de até 2K, e suporta a criação de cartões comemorativos, pôsteres, quadrinhos, etc. O modelo já está disponível gratuitamente no Gemini App, Whisk e aplicativos do Workspace, bem como no Vertex AI. (Fonte: dotey, GoogleDeepMind)
Pesquisa revela risco de “alucinação de pacotes” em código gerado por ferramentas de assistência à programação com IA: Um estudo a ser publicado no USENIX Security 2025 aponta que o fenômeno de “alucinação de pacotes” é comum em código gerado por IA, ou seja, bibliotecas de terceiros referenciadas simplesmente não existem. A pesquisa testou 16 grandes modelos de linguagem convencionais e descobriu que mais de 20% do código dependia de pacotes fictícios, com uma proporção ainda maior em modelos de código aberto. Isso cria oportunidades para ataques à cadeia de suprimentos, onde invasores podem publicar código malicioso usando esses nomes de pacotes fictícios. Empresas como Apple e Microsoft já foram vítimas de ataques de confusão de dependência desse tipo. (Fonte: 36氪)

Suno lança funcionalidade Remix, permitindo aos usuários criar obras derivadas de músicas existentes: A plataforma de geração de música por IA Suno lançou a funcionalidade Remix, que permite aos usuários selecionar qualquer faixa da plataforma para recriação. Os usuários podem fazer covers, estender (Extend) ou reutilizar prompts (Reuse Prompt) de músicas. As criações Remix manterão as informações de origem do material original, e os usuários também poderão ativar ou desativar a permissão de Remix para suas próprias obras a qualquer momento. (Fonte: SunoMusic)
Pesquisa descobre que todos os modelos de embedding aprendem estruturas semânticas semelhantes: Jack Morris e outros pesquisadores descobriram que as estruturas semânticas aprendidas por diferentes modelos de embedding são altamente semelhantes, a ponto de ser possível mapear entre os espaços de embedding de diferentes modelos apenas com base em informações estruturais, sem quaisquer dados pareados. Esta descoberta sugere a possível existência de alguma estrutura geométrica universal nos espaços de embedding, o que tem implicações importantes para a compatibilidade entre modelos, aprendizado por transferência e para a compreensão da natureza dos embeddings. (Fonte: menhguin, torchcompiled, dilipkay, jeremyphoward)
Artigo discute o problema do “imposto da alucinação” no fine-tuning por aprendizado por reforço (RFT): Uma pesquisa de Taiwei Shi e colegas aponta que o fine-tuning por aprendizado por reforço (RFT), ao mesmo tempo que melhora a capacidade de raciocínio de grandes modelos de linguagem, pode levar o modelo a gerar respostas alucinadas com confiança quando confrontado com perguntas que não pode responder, fenômeno denominado “imposto da alucinação”. O estudo introduziu o dataset SUM (problemas matemáticos sintéticos sem resposta) para validação, descobrindo que o treinamento RFT padrão reduz significativamente a taxa de recusa do modelo. Ao adicionar uma pequena quantidade de dados SUM ao RFT, é possível restaurar efetivamente o comportamento de recusa apropriado do modelo e melhorar seu reconhecimento de incerteza e limites de conhecimento. (Fonte: teortaxesTex)

🧰 Ferramentas
Google lança ferramenta de produção de filmes com IA Flow, integrando Veo, Imagen e Gemini: O Google lançou a ferramenta de produção de filmes e TV com IA, Flow, que integra seus mais recentes modelos de geração de vídeo Veo 3, modelo de geração de imagem Imagen 4 e modelo multimodal Gemini. Através do Flow, os usuários podem usar linguagem natural e gerenciamento de recursos para criar facilmente curtas-metragens de nível cinematográfico, incluindo a geração de trechos a partir de prompts de texto, combinação de cenas, construção de narrativas e salvamento de elementos frequentemente usados como material. A ferramenta visa ajudar os criadores a produzir obras com qualidade cinematográfica de forma rápida e eficiente. Atualmente, está disponível para usuários assinantes do Google AI Pro e Ultra nos Estados Unidos. (Fonte: dotey, op7418)

Google lança agente de programação de IA na nuvem Jules, alimentado pelo Gemini 2.5 Pro: O Google lançou o agente de programação de IA Jules, baseado no Gemini 2.5 Pro. Jules pode processar automaticamente tarefas em repositórios de código em segundo plano, como corrigir bugs e refatorar código, suportando multitarefa paralela. Além disso, Jules oferece Codecasts, podcasts atualizados diariamente, para ajudar os usuários a entender as últimas dinâmicas do repositório de código. A ferramenta já está disponível para experimentação gratuita. (Fonte: dotey, karminski3, GoogleDeepMind)
LangChain lança plataforma de agente inteligente de código aberto e sem código Open Agent Platform (OAP): A LangChain lançou a Open Agent Platform (OAP), uma plataforma de código aberto e sem código voltada para usuários comuns, para construir, prototipar e implantar agentes de IA. A OAP suporta a construção de agentes através de uma interface web, conexão com servidores RAG para melhorar a recuperação de informações, extensão de ferramentas externas através do MCP e orquestração de fluxos de trabalho multiagente usando o Agent Supervisor. O objetivo é permitir que desenvolvedores não especializados também possam utilizar o poder dos agentes LangGraph. (Fonte: LangChainAI, Hacubu)

Google Labs lança ferramenta de design de UI com IA Stitch: O Google Labs lançou a ferramenta de design de UI com IA Stitch, que integra os mais recentes modelos do DeepMind do Google (incluindo Gemini e Imagen) e pode gerar rapidamente designs de UI de alta qualidade. Os usuários podem atualizar temas de interface através de linguagem natural, ajustar imagens automaticamente, realizar tradução de conteúdo multilíngue e exportar código front-end com um clique. Stitch é uma evolução do Galileo AI anterior, e seus fundadores se juntaram à equipe do Google. (Fonte: dotey)
LangChain lança sandbox de código local LangChain Sandbox: A LangChain lançou o LangChain Sandbox, que permite que agentes de IA executem código Python não confiável localmente de forma segura. Ele fornece um ambiente de execução isolado e permissões configuráveis, sem a necessidade de execução remota ou contêineres Docker, e suporta a persistência de estado entre múltiplas execuções através de sessões. Isso oferece uma ferramenta mais segura e conveniente para construir agentes de IA capazes de executar código (como codeact agents). (Fonte: hwchase17, Hacubu)
Vitalops torna Datatune de código aberto: ferramenta LLM para processar grandes conjuntos de dados com linguagem natural: A Vitalops tornou o Datatune de código aberto, uma ferramenta que permite aos usuários processar conjuntos de dados de qualquer tamanho através de instruções em linguagem natural. O Datatune suporta operações Map e Filter, pode se conectar a vários provedores de LLM como OpenAI, Azure, Ollama ou modelos personalizados, e utiliza Dask DataFrame para particionamento e processamento paralelo. A ferramenta visa simplificar tarefas como limpeza e enriquecimento de dados, substituindo expressões regulares complexas ou código personalizado. (Fonte: Reddit r/MachineLearning)
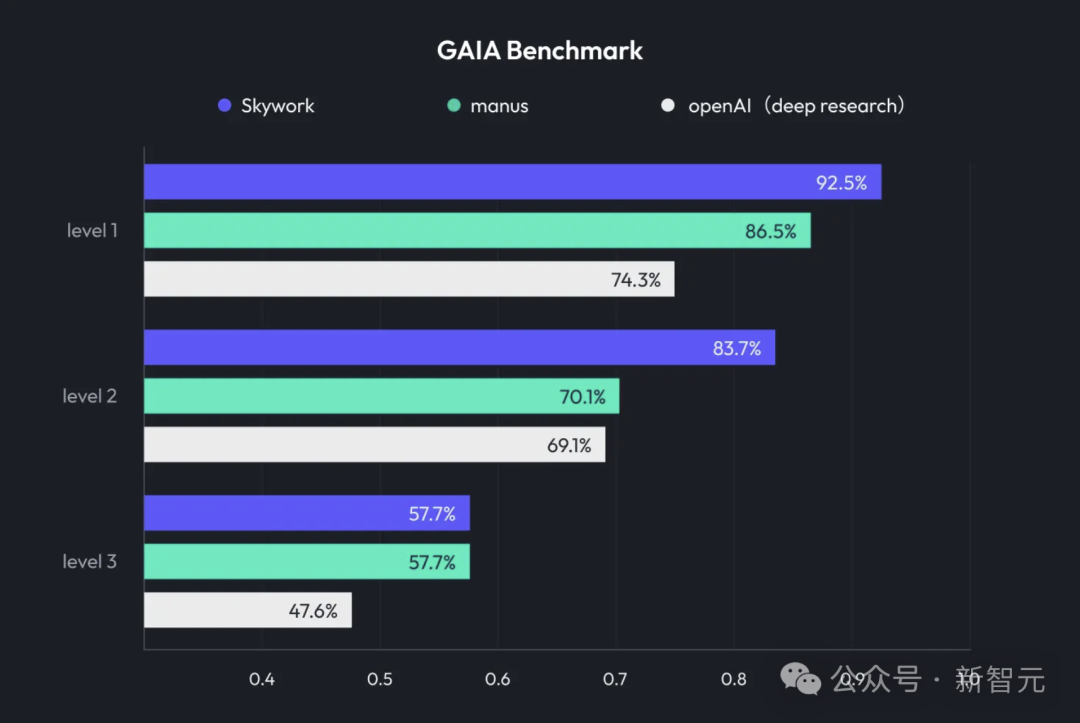
Kunlun Tech lança Skywork Super Agents, integrando Deep Research e saída multimodal: A Kunlun Tech lançou o produto de escritório com IA Skywork Super Agents, que combina a capacidade de Deep Research com a funcionalidade de saída multimodal de agentes de propósito geral. O produto suporta a criação de PPTs, redação de documentos, processamento de planilhas, geração de páginas web, criação de podcasts e outros cenários de escritório, enfatizando o rastreamento de fontes de conteúdo para reduzir alucinações e oferecendo funções de edição online e exportação. A Kunlun Tech também tornou de código aberto o framework Deep Research Agent e o MCP relacionado. (Fonte: 36氪)
Google lança SynthID Detector para ajudar a identificar conteúdo gerado por IA: O Google lançou o SynthID Detector, um novo portal projetado para ajudar jornalistas, profissionais de mídia e pesquisadores a identificar mais facilmente se o conteúdo possui a marca d’água SynthID. SynthID é uma tecnologia desenvolvida pelo Google para adicionar uma marca d’água invisível a conteúdo gerado por IA (incluindo imagens, áudio, vídeo ou texto). O lançamento desta ferramenta de detecção ajuda a aumentar a transparência e rastreabilidade do conteúdo gerado por IA. (Fonte: dotey, Google)
Feishu lança funcionalidade “Knowledge Q&A”, criando ferramenta de perguntas e respostas com IA exclusiva para empresas: O Feishu lançou a nova funcionalidade “Knowledge Q&A”, uma ferramenta que, com base em todas as informações às quais os funcionários da empresa têm acesso no Feishu (mensagens, documentos, base de conhecimento, etc.), combinada com grandes modelos como DeepSeek-R1, Doubao e tecnologia RAG, fornece respostas precisas e suporte à criação de conteúdo para os funcionários. Sua característica é que as respostas são ajustadas dinamicamente de acordo com a identidade e as permissões do questionador dentro da empresa, com o objetivo de integrar perfeitamente a IA ao fluxo de trabalho diário e aumentar a eficiência do gerenciamento e utilização do conhecimento corporativo. (Fonte: 量子位)

Animon: Primeira plataforma de geração de anime por IA do Japão, focada na estética 2D e geração gratuita ilimitada: A empresa japonesa CreateAI (anteriormente TuSimple Future) lançou a plataforma de geração de anime por IA Animon, personalizada para a criação de animes. A plataforma combina a estética do anime japonês com a tecnologia de IA, enfatizando a consistência do estilo visual e a produção eficiente, anunciando que usuários individuais podem gerar vídeos gratuitamente e sem limites. Animon suporta a geração rápida de clipes de animação (cerca de 3 minutos) através do upload de imagens de personagens e descrições textuais, com o objetivo de reduzir a barreira para a criação de animes e estimular um ecossistema de conteúdo UGC. Sua empresa-mãe, CreateAI, possui um grande modelo autodesenvolvido, Ruyi, e detém os direitos de adaptação de IPs como “O Problema dos Três Corpos” e “Heróis de Jin Yong”, implementando uma estratégia de dupla propulsão “conteúdo autodesenvolvido + plataforma de ferramentas UGC”. (Fonte: 量子位)

📚 Aprendizado
DeepLearning.AI lança novo curso: Refinamento de LLM com GRPO: Andrew Ng anunciou uma colaboração com a Predibase para lançar um novo curso curto sobre “Refinamento de LLM com GRPO (Group Relative Policy Optimization)”. O curso ensinará como usar o aprendizado por reforço (especificamente o algoritmo GRPO) para melhorar o desempenho de LLMs em tarefas de raciocínio de múltiplos passos (como resolução de problemas matemáticos, depuração de código), sem a necessidade de grandes amostras de fine-tuning supervisionado. O GRPO guia o modelo através de funções de recompensa programáveis, é adequado para tarefas com resultados verificáveis e pode aumentar significativamente a capacidade de raciocínio de LLMs menores. (Fonte: AndrewYNg, DeepLearningAI)
LlamaIndex compartilha experiência de gerenciamento de monorepositório Python em larga escala: A equipe do LlamaIndex compartilhou sua experiência no gerenciamento de um monorepositório Python contendo mais de 650 pacotes comunitários. Eles migraram de Poetry e Pants para uv e uma ferramenta de gerenciamento de build de código aberto autodesenvolvida, LlamaDev, alcançando um aumento de 20% na velocidade de execução de testes, logs mais claros, desenvolvimento local simplificado e redução da barreira de entrada para contribuidores. Esta experiência é valiosa para equipes que precisam gerenciar grandes projetos Python. (Fonte: jerryjliu0)

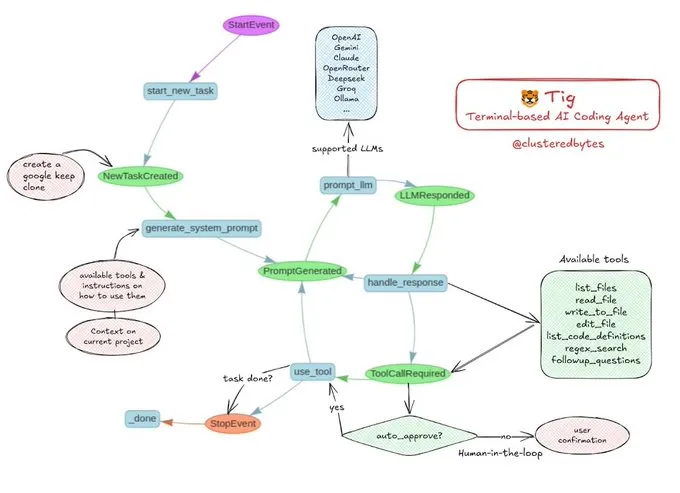
Tutorial compartilhado: Construa seu próprio agente de codificação de IA Tig: Jerry Liu recomendou um projeto de agente de codificação de IA de código aberto chamado Tig. O projeto é um assistente de codificação baseado em terminal, com intervenção humana (human-in-the-loop), construído com o fluxo de trabalho LlamaIndex. Tig é capaz de escrever, depurar, analisar código em várias linguagens, executar comandos shell, pesquisar bases de código e gerar testes e documentação, entre outras tarefas. O repositório GitHub fornece um guia de construção detalhado, sendo um ótimo recurso educacional para desenvolvedores que desejam aprender a construir agentes de codificação de IA. (Fonte: jerryjliu0)
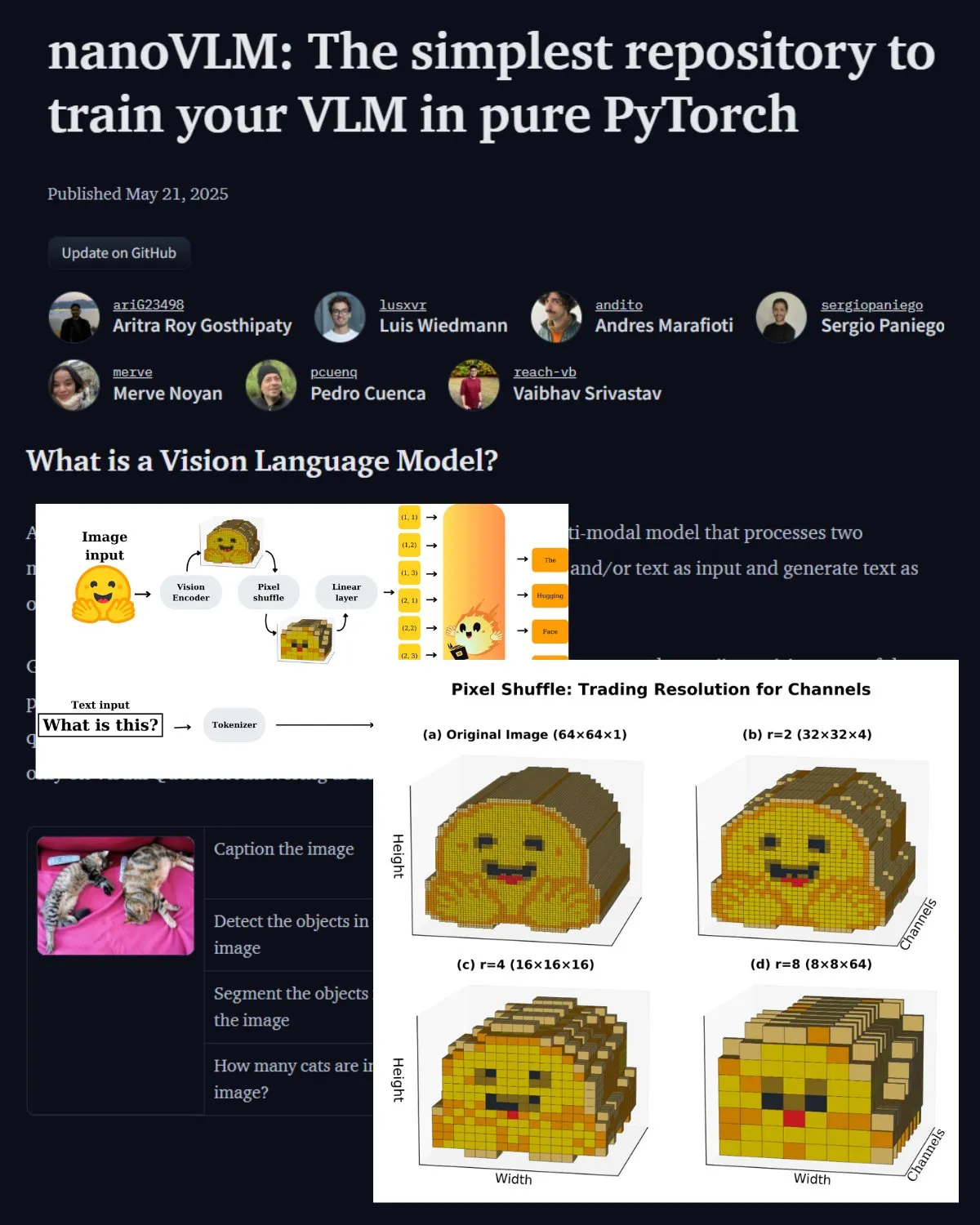
Hugging Face publica importante postagem de blog sobre VLM, apresentando o laboratório comunitário nanoVLM: O Hugging Face publicou uma postagem de blog sobre modelos de linguagem visual (VLM), cobrindo os fundamentos de VLM, arquitetura e como treinar seu próprio VLM leve. Também apresentou o nanoVLM, um repositório de código aberto para fine-tuning de VLMs, que agora se tornou um laboratório comunitário para pesquisa em linguagem visual, com o objetivo de ajudar os desenvolvedores a explorar e contribuir para a pesquisa em VLM. (Fonte: _akhaliq, huggingface)
Serrano Academy lança série de tutoriais em vídeo sobre fine-tuning de LLM com aprendizado por reforço: A Serrano Academy concluiu e publicou uma série de tutoriais em vídeo sobre o uso de aprendizado por reforço para fine-tuning e treinamento de LLMs. O conteúdo abrange conceitos e técnicas cruciais como Deep Reinforcement Learning, RLHF (Reinforcement Learning from Human Feedback), PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization) e Divergência KL (KL Divergence). (Fonte: SerranoAcademy)
Artigo investiga o fenômeno das “camadas vazias” em grandes modelos de linguagem: Um estudo investigou o fenômeno em que nem todas as camadas de grandes modelos de linguagem ajustados por instrução são ativadas durante o processo de inferência, chamando as camadas não ativadas de “camadas vazias” (Voids). A pesquisa usou o método de computação adaptativa L2 (LAC) para rastrear as camadas ativadas durante as fases de processamento de prompt e geração de resposta, descobrindo que as camadas ativadas também diferem em diferentes estágios. Experimentos mostraram que, em benchmarks como MMLU, pular as camadas vazias no Qwen2.5-7B-Instruct (usando apenas 30% das camadas) pode melhorar o desempenho, sugerindo que pular seletivamente a maioria das camadas pode ser benéfico para tarefas específicas. (Fonte: HuggingFace Daily Papers)
Pesquisa propõe “Soft Thinking”: desbloqueando o potencial de raciocínio de LLMs em espaços conceituais contínuos: Um artigo intitulado “Soft Thinking” propõe um método sem treinamento que simula o raciocínio “suave” semelhante ao humano, gerando tokens conceituais abstratos e flexíveis em um espaço conceitual contínuo. Esses tokens conceituais são formados por uma mistura ponderada probabilisticamente de embeddings de tokens discretos, capazes de encapsular múltiplos significados de tokens discretos relacionados, explorando implicitamente assim múltiplos caminhos de raciocínio. Experimentos mostram que o método melhora a precisão pass@1 em benchmarks de matemática e codificação, ao mesmo tempo que reduz o uso de tokens e mantém a interpretabilidade da saída. (Fonte: HuggingFace Daily Papers)
Artigo explora cadeias de pensamento escaláveis através de raciocínio elástico: Pesquisadores da Salesforce propuseram um método para alcançar cadeias de pensamento escaláveis através do Raciocínio Elástico (Elastic Reasoning). A pesquisa visa resolver o problema de como grandes modelos de linguagem podem gerar e gerenciar eficientemente longas cadeias de pensamento ao lidar com tarefas complexas de raciocínio, a fim de melhorar a precisão e a eficiência do raciocínio. Os modelos e códigos relacionados foram publicados no Hugging Face. (Fonte: _akhaliq)

Estudo de pesquisa: Modelos de IA mentiriam para salvar crianças doentes?: Um estudo chamado LitmusValues criou um processo de avaliação com o objetivo de revelar as prioridades dos modelos de IA em uma série de categorias de valores de IA. Ao coletar AIRiskDilemmas (um conjunto de dilemas contendo cenários relacionados a riscos de segurança de IA), os pesquisadores medem as escolhas dos modelos de IA em diferentes conflitos de valores, prevendo assim suas prioridades de valor e identificando riscos potenciais. O estudo mostra que os valores definidos em LitmusValues (incluindo cuidado, etc.) podem prever comportamentos de risco já vistos em AIRiskDilemmas, bem como comportamentos de risco não vistos em HarmBench. (Fonte: HuggingFace Daily Papers)
Artigo estuda o fine-tuning eficiente de modelos de difusão através de aprendizado por reforço baseado em valor (VARD): Modelos de difusão demonstram grande poder em tarefas de geração, mas o fine-tuning para atributos específicos ainda é desafiador. Métodos de aprendizado por reforço existentes apresentam deficiências em estabilidade, eficiência e no tratamento de recompensas não diferenciáveis. VARD (Value-based Reinforced Diffusion) propõe primeiro aprender uma função de valor que prevê a expectativa de recompensa a partir de estados intermediários e, em seguida, utilizar esta função de valor e regularização KL para fornecer supervisão densa durante todo o processo de geração. Experimentos demonstram que este método pode melhorar a orientação da trajetória, aumentar a eficiência do treinamento e expandir a aplicação de RL para otimizar modelos de difusão com funções de recompensa complexas e não diferenciáveis. (Fonte: HuggingFace Daily Papers)
💼 Negócios
LMArena.ai (anteriormente LMSYS.org) recebe financiamento semente de US$ 100 milhões, liderado por a16z e UC Investments: A plataforma de avaliação de modelos de IA LMArena.ai (anteriormente LMSYS.org) anunciou a conclusão de uma rodada de financiamento semente de US$ 100 milhões, co-liderada por Andreessen Horowitz (a16z) e UC Investments (a empresa de investimentos da Universidade da Califórnia). A empresa se dedica a construir uma plataforma neutra, aberta e orientada pela comunidade para ajudar o mundo a entender e melhorar o desempenho de modelos de IA em consultas de usuários reais. Após o financiamento, a empresa foi avaliada em US$ 600 milhões. (Fonte: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
Governo dos EUA anuncia venda de tecnologia e serviços de IA no valor de centenas de bilhões de dólares para Arábia Saudita e Emirados Árabes Unidos: O governo dos EUA anunciou acordos com a Arábia Saudita e os Emirados Árabes Unidos para vender tecnologia e serviços de IA no valor de centenas de bilhões de dólares. As empresas participantes incluem AMD, Nvidia, Amazon, Google, IBM, Oracle e Qualcomm, entre outras. A Nvidia fornecerá à empresa saudita Humain 18.000 chips de IA GB300 e, posteriormente, centenas de milhares de GPUs; AMD e Humain investirão conjuntamente US$ 10 bilhões na construção de data centers de IA. A medida visa fortalecer a influência dos EUA em IA no Oriente Médio e ajudar na diversificação econômica dos dois países. (Fonte: DeepLearning.AI Blog)

Meta lança Programa Llama Startup para capacitar startups de IA em estágio inicial: A Meta anunciou o lançamento do Llama Startup Program, com o objetivo de apoiar startups americanas em estágio inicial (com financiamento inferior a US$ 10 milhões e pelo menos um desenvolvedor) a inovar em aplicações de IA generativa usando modelos Llama. O programa oferece reembolso de recursos de nuvem, suporte técnico de especialistas em Llama e recursos comunitários. O prazo de inscrição é 30 de maio de 2025, às 18h (horário do Pacífico). (Fonte: AIatMeta)
🌟 Comunidade
Google I/O gera intenso debate: integração total da IA e perspectivas futuras: O Google I/O lançou um grande número de produtos e atualizações relacionados à IA, incluindo a série de modelos Gemini, geração de vídeo Veo 3, geração de imagem Imagen 4, modo de busca com IA, etc., gerando ampla discussão na comunidade. Muitos comentários consideram que o Google demonstrou grande força no nível de aplicação da IA, especialmente a estratégia de integrar perfeitamente a IA ao ecossistema de produtos existente. Ao mesmo tempo, tópicos como a autenticidade do conteúdo gerado por IA, ética da IA e o caminho futuro da AGI também se tornaram focos de discussão. (Fonte: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

Hardware de IA se torna novo foco, colaboração entre OpenAI e Jony Ive atrai atenção: A notícia da aquisição da empresa de hardware de IA de Jony Ive, io, pela OpenAI, bem como a demonstração do protótipo de óculos inteligentes Android XR pelo Google no I/O, acenderam a discussão da comunidade sobre o futuro do hardware de IA. A colaboração entre Sam Altman e Jony Ive é vista como um esforço para criar uma nova geração de dispositivos de computação pessoal impulsionados por IA, que podem subverter as formas de interação existentes de celulares e computadores. A comunidade geralmente espera que o hardware nativo de IA traga experiências revolucionárias, mas também se preocupa com sua forma, funcionalidade e aceitação no mercado. (Fonte: dotey, sama, dotey, swyx)

Papel e riscos da IA no desenvolvimento de software geram discussão: O lançamento do modelo Devstral pela Mistral AI, projetado para agentes de codificação, e a atualização do Codex pela OpenAI, geraram discussões sobre a aplicação da IA no desenvolvimento de software. A comunidade está atenta à capacidade real das ferramentas de programação com IA, à qualidade e segurança do código gerado. Em particular, pesquisas que apontam que o código gerado por IA pode referenciar “pacotes de software alucinados” inexistentes, trazendo riscos à segurança da cadeia de suprimentos, alertam os desenvolvedores para a necessidade de verificar cuidadosamente o código e as dependências geradas por IA. (Fonte: MistralAI, DeepLearning.AI Blog, qtnx_)
Discussão sobre avaliação de modelos de IA e benchmarks continua aquecida: O grande financiamento obtido pela LMArena.ai e o desempenho de vários novos modelos em benchmarks tornaram a avaliação de modelos de IA um tópico quente na comunidade. Os usuários se preocupam com a capacidade real de diferentes modelos em tarefas específicas (como codificação, matemática, perguntas de bom senso, compreensão emocional) e com a confiabilidade e limitações dos sistemas de avaliação existentes. Por exemplo, o framework de avaliação de inteligência emocional SAGE, lançado pela Tencent, tenta fornecer uma nova dimensão de avaliação para modelos de IA sob a perspectiva da “inteligência emocional”. (Fonte: lmarena_ai, 36氪, natolambert)
Atraso no desenvolvimento do setor de tecnologia europeu gera reflexão, Yann LeCun compartilha discussão sobre falta de “patriotismo” como causa principal: Um artigo do Wall Street Journal sobre o cenário tecnológico europeu ser muito menor que o americano e chinês gerou discussão, e Yann LeCun compartilhou o comentário de Arnaud Bertrand. Bertrand argumenta que a principal razão para o atraso tecnológico da Europa é a falta de espírito de “patriotismo”; a mídia e as elites europeias tendem a exaltar startups americanas, negligenciando a inovação local, o que dificulta que empresas locais obtenham apoio inicial e reconhecimento de mercado. Ele usa sua própria experiência ao fundar a HouseTrip como exemplo, apontando que a Europa carece de confiança e de um ambiente de apoio à inovação local. (Fonte: ylecun)

💡 Outros
Consumo de energia da IA gera preocupação: O MIT Technology Review organizou uma mesa redonda para discutir o problema do consumo de energia trazido pelo rápido desenvolvimento da tecnologia de IA e seu impacto no clima. Com a expansão da escala e do escopo de aplicação dos modelos de IA, a eletricidade e os recursos computacionais necessários aumentam drasticamente, e a demanda de energia dos data centers se torna um novo foco. A discussão se concentrou no consumo de energia de uma única consulta de IA, na pegada energética geral da IA e em como enfrentar esse desafio. (Fonte: MIT Technology Review, madiator)

Anthropic anuncia novidades, comunidade especula sobre possível lançamento do Claude 4: A Anthropic fez um anúncio, informando que fará uma transmissão ao vivo em 22 de maio às 9:30 (horário do Pacífico) (23 de maio, 0h, horário de Pequim), gerando especulações na comunidade sobre o possível lançamento de uma nova geração do modelo Claude (possivelmente Claude 4). Considerando as recentes atualizações de peso da OpenAI e do Google, a ação da Anthropic é aguardada com grande expectativa. (Fonte: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
Fusão de IA e tecnologia XR, Google apresenta protótipo de óculos inteligentes Android XR: O Google apresentou no I/O um protótipo de óculos inteligentes Android XR, enfatizando sua profunda integração com IA. O dispositivo suporta assistência inteligente em primeira pessoa e funções de assistência sem contato, permitindo que os usuários interajam com o dispositivo por meio de linguagem natural para realizar consultas de informações, gerenciamento de agenda, navegação em tempo real, etc. Isso prenuncia que a IA se tornará o principal motor de interação e funcionalidade para a próxima geração de dispositivos XR, aprimorando a experiência do usuário em ambientes de realidade aumentada. (Fonte: dotey, 36氪)