
Palavras-chave:Gemini 2.5, Agente de IA, Modelo de Linguagem Grande, Modelo de Linguagem Visual, Aprendizado por Reforço, Modo Deep Think do Gemini 2.5 Pro, Agente GitHub Copilot de código aberto, Geração de Imagem em Única Etapa MeanFlow, Raciocínio de Planejamento Visual VPRL, Otimização de Inferência Huawei FusionSpec MoE
🔥 Destaques
Google I/O anuncia múltiplos avanços em IA, liderados pela série de modelos Gemini 2.5: O Google anunciou inúmeras atualizações no campo da IA em sua conferência I/O. O Gemini 2.5 Pro é considerado o modelo base mais poderoso atualmente, liderando em vários benchmarks e introduzindo o modo de inferência aprimorado Deep Think. O modelo leve Gemini 2.5 Flash também foi atualizado, com foco em velocidade e eficiência. A Pesquisa Google introduziu o “Modo AI”, oferecendo uma experiência de pesquisa de IA de ponta a ponta com o Gemini 2.5, capaz de decompor problemas complexos e realizar mineração profunda de informações. O modelo de geração de vídeo Veo 3 alcança geração sincronizada de áudio e vídeo, e o modelo de imagem Imagen 4 melhorou os detalhes e a capacidade de processamento de texto. Além disso, foram lançadas a ferramenta de produção de filmes com IA Flow e a aplicação prática do projeto de assistente de IA Project Astra, o Gemini Live. Essas atualizações demonstram a determinação do Google em integrar totalmente a IA em seu ecossistema de produtos, visando melhorar a experiência do usuário e a eficiência dos desenvolvedores (Fonte: 量子位, 36氪, WeChat)

Microsoft Build Conference promove AI Agents, GitHub Copilot recebe grande atualização e anuncia código aberto: Na conferência de desenvolvedores Build 2025, a Microsoft colocou os AI Agents em posição central, anunciando o projeto GitHub Copilot Extension for VSCode como open source e lançando um novo agente de codificação de IA (Agent). Este Agent pode concluir autonomamente tarefas como corrigir bugs, adicionar funcionalidades e otimizar documentação, estando profundamente integrado ao GitHub Copilot. A Microsoft também lançou a plataforma de agentes de IA para descobertas científicas Microsoft Discovery, o projeto de site de interação em linguagem natural NLWeb, a plataforma de construção de agentes Agent Factory e o Copilot Tuning para dados empresariais personalizáveis. Essas iniciativas indicam que a Microsoft está impulsionando totalmente a aplicação de AI Agents em diversas áreas, como desenvolvimento e pesquisa científica, com o objetivo de construir um ecossistema aberto de colaboração de agentes inteligentes (Fonte: 量子位, WeChat, WeChat)

OpenAI CPO Kevin Weil explica a direção da transformação do ChatGPT: de respostas a ações, AI Agents evoluirão rapidamente: O Chief Product Officer (CPO) da OpenAI, Kevin Weil, revelou em uma entrevista que o posicionamento do ChatGPT mudará de uma ferramenta que responde a perguntas para um AI Agent capaz de executar tarefas para os usuários. Ele prevê que os AI Agents evoluirão rapidamente no curto prazo, de engenheiros juniores para seniores, e até mesmo para arquitetos. Isso significa que os AI Agents terão maior autonomia, capazes de resolver problemas complexos navegando na web, pensando profundamente e resumindo por meio de raciocínio. Weil também mencionou que o custo atual de treinamento de modelos já é 500 vezes maior que o do GPT-4, mas no futuro, a eficiência será melhorada e os preços da API serão reduzidos por meio de avanços de hardware e melhorias de algoritmos, para promover a popularização e o desenvolvimento da IA (Fonte: 量子位, 36氪)

Equipe de Kaiming He propõe MeanFlow: novo SOTA em geração de imagem em um único passo, subvertendo o paradigma tradicional sem pré-treinamento: A mais recente pesquisa da equipe de Kaiming He introduziu um framework de modelagem de geração em um único passo chamado MeanFlow. No dataset ImageNet 256×256, alcançou um score FID de 3.43 com apenas 1 avaliação de função (1-NFE), uma melhoria de 50%-70% em relação aos melhores métodos anteriores da mesma categoria, e sem necessidade de pré-treinamento, destilação ou aprendizado curricular. A inovação central do MeanFlow reside na introdução do conceito de “campo de velocidade média” e na derivação de sua relação matemática com o campo de velocidade instantânea, que orienta o treinamento da rede neural. O método também pode integrar naturalmente a orientação livre de classificador (CFG) sem adicionar custos computacionais extras durante a amostragem, reduzindo significativamente a lacuna de desempenho entre modelos de geração de um único passo e de múltiplos passos, demonstrando o potencial de modelos de poucos passos desafiarem modelos de múltiplos passos (Fonte: WeChat, WeChat)

🎯 Tendências
ByteDance lança modelo multimodal Bagel 14B MoE, com suporte para geração de imagens e código aberto: A ByteDance lançou um modelo multimodal de Mistura de Especialistas (MoE) de 14 bilhões de parâmetros chamado Bagel, com 7 bilhões de parâmetros ativos. O modelo possui capacidade de geração de imagens e é open source, sob a licença Apache. Seus pesos, site e artigo (intitulado “Emerging Properties in Unified Multimodal Pretraining”) foram todos divulgados. A comunidade reagiu positivamente, considerando-o o primeiro modelo local capaz de gerar imagens e texto simultaneamente, e está atenta à possibilidade de executá-lo em placas de vídeo de 24GB e questões de quantização (Fonte: Reddit r/LocalLLaMA)
Mistral AI lança Devstral: modelo open source SOTA otimizado para codificação: A Mistral AI lançou o Devstral, um modelo open source líder projetado para tarefas de engenharia de software, construído em colaboração com a All Hands AI. O Devstral teve um desempenho excepcional no benchmark SWE-bench, tornando-se o modelo open source número um nesse benchmark. O modelo é proficiente no uso de ferramentas para explorar bases de código, editar múltiplos arquivos e fornecer suporte para agentes de engenharia de software. Os pesos do modelo foram disponibilizados no Hugging Face (Fonte: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

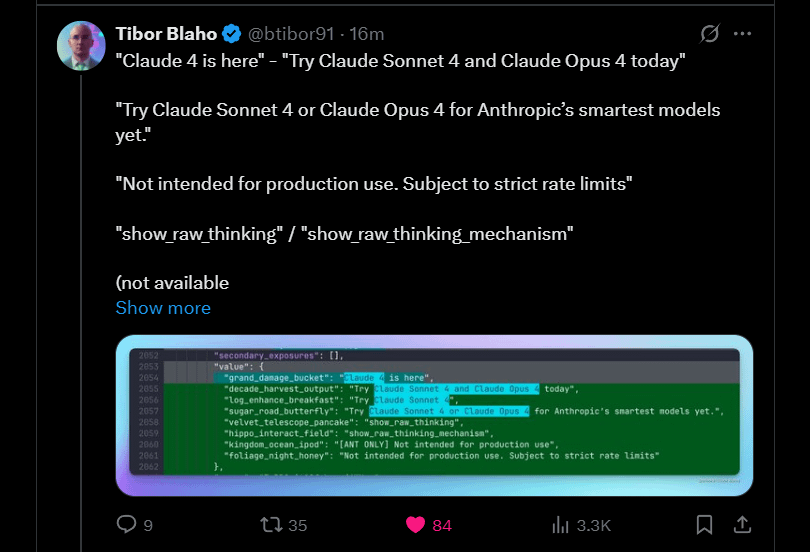
Anthropic anuncia o lançamento iminente de Claude 4 Sonnet e Opus: A Anthropic planeja lançar as próximas versões de seu modelo grande de linguagem Claude — Claude 4 Sonnet e Opus. Esta notícia gerou expectativa na comunidade, com usuários expressando interesse no desempenho dos novos modelos, especialmente em melhorias na capacidade de memória de contexto. Alguns comentários apontaram que os anúncios do Google I/O podem ter estimulado os concorrentes a acelerar o lançamento de seus melhores produtos. Ao mesmo tempo, os usuários também expressaram preocupação com as limitações dos novos modelos (como cotas de uso) e alertaram a comunidade para não ter expectativas excessivamente altas em relação ao Opus 4, a fim de evitar decepções (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google lança aplicativo Android Gemma3n, com suporte para inferência LLM local: O Google lançou um aplicativo Android que pode interagir com o novo modelo Gemma3n e forneceu soluções MediaPipe e repositórios GitHub relacionados. O feedback dos usuários indica que a interface do aplicativo é boa, mas aponta que o Gemma3n atualmente não suporta inferência em GPU. Um usuário conseguiu carregar manualmente o modelo gemma-3n-E2B e compartilhou dados de execução, enquanto a comunidade também expressou a necessidade de uma versão não censurada do modelo (Fonte: Reddit r/LocalLLaMA)

Família de modelos de linguagem de cabeça híbrida Falcon-H1 lançada, incluindo várias escalas de parâmetros: A TII UAE lançou a série Falcon-H1 de modelos de linguagem de cabeça híbrida, com escalas de parâmetros variando de 0.5B a 34B. Esta série de modelos adota a arquitetura híbrida Mamba e é comparável em desempenho ao Qwen3. Os modelos podem ser usados através das bibliotecas Hugging Face Transformers, vLLM ou uma versão personalizada da llama.cpp, garantindo a facilidade de uso dos modelos. A comunidade expressou entusiasmo, considerando este um avanço importante, e um usuário criou gráficos de comparação de desempenho. Ao mesmo tempo, pesquisadores também estão atentos às suas diferenças em relação ao IBM Granite 4 na combinação de módulos SSM e de atenção (Fonte: Reddit r/LocalLLaMA)

Google explora Gemini Diffusion: um modelo de linguagem com arquitetura de difusão: O Google apresentou seu modelo de difusão de linguagem Gemini Diffusion, que supostamente é extremamente rápido e tem metade do tamanho de modelos com desempenho similar. Como os modelos de difusão podem processar iterativamente todo o texto de uma vez, sem a necessidade de cache KV, eles podem ter vantagens em eficiência de memória e podem melhorar a qualidade da saída aumentando o número de iterações. A comunidade acredita que, se o Google conseguir provar a viabilidade de modelos de difusão em aplicações de grande escala, isso terá um impacto positivo na comunidade de IA local. No entanto, atualmente o modelo está disponível apenas em uma lista de espera para demonstração e não é open source nem tem seus pesos disponíveis para download (Fonte: Reddit r/LocalLLaMA)

Pesquisa revela vulnerabilidade de sequestro de Agent zero-click (CVE-2025-47241) no framework Browser Use: Pesquisadores da ARIMLABS.AI descobriram uma grave vulnerabilidade de segurança (CVE-2025-47241) no framework Browser Use, amplamente utilizado em mais de 1500 projetos de IA. A vulnerabilidade permite que atacantes sequestrem agentes de navegação orientados por LLM com zero clique, induzindo-os a acessar uma página maliciosa, sem necessidade de interação do usuário para controlar o agente. Esta descoberta levanta sérias preocupações sobre a segurança de agentes de IA autônomos, especialmente aqueles que interagem com a web, e apela à comunidade para prestar atenção às questões de segurança de agentes de IA (Fonte: Reddit r/artificial, Reddit r/artificial)
Tencent e Alibaba competem no campo AI to C, QQ Browser e Quark se enfrentam: O QQ Browser, subordinado ao CSIG da Tencent, anunciou sua atualização para um navegador de IA, lançando o AI QBot e integrando os modelos duplos Tencent Hunyuan e DeepSeek, entrando oficialmente em competição com o Quark da Alibaba, que já se transformou em uma busca por IA. Este movimento marca a aceleração do layout da Tencent no campo AI to C, formando duas principais linhas de produtos: Tencent Yuanbao e QQ Browser. Os principais responsáveis de ambas as partes, Wu Zurong (Tencent) e Wu Jia (Alibaba), formam assim um “duelo dos Wu”. Analistas acreditam que o QQ Browser tem vantagem em base de usuários, enquanto o Quark está um passo à frente na transformação para IA, mas a transformação do QQ Browser é relativamente conservadora, com as funções de IA mais parecidas com plugins e limitadas pelo modelo de publicidade original. Esta competição não é apenas em nível de produto, mas também pode afetar o desenvolvimento de carreira dos dois responsáveis em suas respectivas empresas (Fonte: 36氪)
Cambridge e Google propõem VPRL: novo paradigma de raciocínio de planejamento puramente visual, com precisão superior ao raciocínio textual: Equipes de pesquisa da Universidade de Cambridge, University College London e Google propuseram um novo paradigma de Planejamento Visual baseado em Aprendizado por Reforço (VPRL), alcançando pela primeira vez raciocínio puramente baseado em imagens. O framework utiliza a otimização de política relativa de grupo (GRPO) para pós-treinar grandes modelos visuais. Em múltiplas tarefas de navegação visual (como FrozenLake, Maze, MiniBehavior), seu desempenho superou em muito os métodos de raciocínio baseados em texto, com precisão de até 80% e melhoria de desempenho de pelo menos 40%. O VPRL, ao utilizar diretamente sequências de imagens para planejamento, evita a perda de informação e a redução de eficiência causadas pela conversão para linguagem, abrindo novas direções para tarefas de raciocínio intuitivo de imagens. O código relacionado foi disponibilizado como open source (Fonte: WeChat)

Huawei lança FusionSpec e OptiQuant para otimizar a inferência de grandes modelos MoE: A Huawei, visando os desafios de velocidade e latência na inferência de modelos MoE (Mixture-of-Experts) em grande escala, lançou o framework de inferência especulativa FusionSpec e o framework de quantização OptiQuant. O FusionSpec utiliza a alta relação computação/largura de banda dos servidores Ascend (昇腾) para otimizar o fluxo do modelo principal e do modelo especulativo, reduzindo o tempo consumido pelo framework de inferência especulativa para 1 milissegundo. O OptiQuant suporta algoritmos de quantização mainstream como Int2/4/8 e FP8/HiFloat8, e introduz inovações como “truncamento aprendível” e “otimização de parâmetros de quantização”, com o objetivo de reduzir a perda de precisão do modelo e melhorar a relação custo-benefício da inferência. Essas tecnologias visam resolver os problemas de eficiência de inferência e ocupação de recursos enfrentados pelos modelos MoE em implantação (Fonte: WeChat)

Beijing Academy of Artificial Intelligence (BAAI) lança três modelos vetoriais SOTA, fortalecendo a recuperação de código e multimodal: O BAAI, em colaboração com várias universidades, lançou o BGE-Code-v1 (modelo vetorial de código), BGE-VL-v1.5 (modelo vetorial multimodal geral) e BGE-VL-Screenshot (modelo vetorial de documentos visualizáveis). O BGE-Code-v1 é baseado no Qwen2.5-Coder-1.5B e apresenta excelente desempenho nos benchmarks CoIR e CodeRAG. O BGE-VL-v1.5 é baseado no LLaVA-1.6 e quebrou o recorde zero-shot no benchmark multimodal MMEB. O BGE-VL-Screenshot é voltado para tarefas de recuperação de informações visualizáveis (Vis-IR) como páginas da web e documentos, treinado com base no Qwen2.5-VL-3B-Instruct, e alcançou SOTA no recém-lançado benchmark MVRB. Esses modelos visam fornecer capacidades mais fortes de compreensão e recuperação de código e multimodal para aplicações como geração aumentada por recuperação (RAG), e todos foram disponibilizados como open source (Fonte: WeChat)

Kuaishou e NUS lançam Any2Caption, permitindo geração de vídeo controlável: A Kuaishou e a National University of Singapore (NUS) lançaram conjuntamente o framework Any2Caption, que visa melhorar a precisão e a qualidade da geração de vídeo controlável, desacoplando inteligentemente a compreensão da intenção do usuário do processo de geração de vídeo. O framework pode processar múltiplas modalidades de condições de entrada, como texto, imagens, vídeos, trajetórias de pose e movimento da câmera, utilizando um grande modelo de linguagem multimodal para converter instruções complexas em “roteiros de vídeo” estruturados, que orientam a geração do vídeo. O Any2Caption é treinado com base no banco de dados Any2CapIns, que contém 337.000 instâncias de vídeo e 407.000 condições multimodais. Experimentos mostram que ele pode efetivamente melhorar o desempenho dos modelos de geração de vídeo controlável existentes (Fonte: WeChat)

🧰 Ferramentas
Feishu lança funcionalidade “Perguntas e Respostas de Conhecimento”, criando um assistente de perguntas, respostas e criação de IA exclusivo para empresas: O Feishu lançou a nova funcionalidade “Perguntas e Respostas de Conhecimento”, posicionada como uma ferramenta de perguntas e respostas de IA exclusiva para empresas. Baseada nas mensagens, documentos, bases de conhecimento, atas inteligentes e outras informações às quais os funcionários têm acesso no Feishu, combinada com grandes modelos como DeepSeek-R1, Doubao e tecnologia RAG, ela fornece respostas precisas e suporte à criação de conteúdo. A funcionalidade enfatiza a ativação e utilização do conhecimento interno da empresa; funcionários com diferentes identidades podem obter respostas de diferentes perspectivas para a mesma pergunta, e as permissões organizacionais são estritamente respeitadas. O Perguntas e Respostas de Conhecimento do Feishu visa integrar perfeitamente a IA aos fluxos de trabalho diários, melhorar a eficiência na obtenção de informações e colaboração, e ajudar as empresas a construir um sistema dinâmico de gestão do conhecimento (Fonte: WeChat, WeChat)
Supabase se torna o backend preferido para “programação ambiente” com suas vantagens de código aberto e integração com IA: O banco de dados open source Supabase, devido à sua experiência “pronta para uso” com PostgreSQL e sua resposta ativa às tendências de desenvolvimento de IA, tornou-se uma escolha popular de backend no modelo de “Vibe Coding” (programação ambiente). O Vibe Coding enfatiza o uso de várias ferramentas de IA para concluir rapidamente todo o processo de desenvolvimento, desde os requisitos até a implementação. O Supabase, através da integração com PGVector, suporta o armazenamento de embeddings vetoriais (crucial para aplicações RAG), colabora com Ollama para fornecer serviços de modelos de IA na borda e lançou seu próprio assistente de IA para auxiliar na geração de esquemas de banco de dados e depuração de SQL. Recentemente, o Supabase também lançou um servidor MCP oficial, permitindo que ferramentas de IA interajam diretamente com ele. Essas características o tornaram atraente para plataformas de construção de aplicativos nativos de IA como Lovable e Bolt.new (Fonte: WeChat)

Hugging Face lança nanoVLM: um kit de ferramentas minimalista para treinar Modelos de Linguagem Visual (VLM) em PyTorch puro: O Hugging Face lançou o nanoVLM, um kit de ferramentas leve em PyTorch projetado para simplificar o processo de treinamento de modelos de linguagem visual. O código do projeto é pequeno e fácil de ler, adequado para iniciantes ou desenvolvedores que desejam entender profundamente os mecanismos internos dos VLMs. A arquitetura do nanoVLM é baseada no codificador visual SigLIP e no decodificador de linguagem Llama 3, alinhando as modalidades visual e textual por meio de um módulo de projeção de modalidade. O projeto oferece uma maneira conveniente de iniciar o treinamento de VLM em um Colab Notebook gratuito e já lançou um modelo pré-treinado baseado em SigLIP e SmolLM2 para teste (Fonte: HuggingFace Blog)

Biblioteca Diffusers integra múltiplos backends de quantização para otimizar grandes modelos de difusão: A biblioteca Diffusers do Hugging Face agora integra múltiplos backends de quantização, como bitsandbytes, torchao, Quanto, GGUF e FP8 nativo, com o objetivo de reduzir o consumo de memória e os requisitos computacionais de grandes modelos de difusão (como Flux). Esses backends suportam quantização de diferentes precisões (como 4 bits, 8 bits, FP8) e podem ser combinados com técnicas de otimização de memória como CPU offloading, group offloading e torch.compile. O blog, através de um caso de quantização do modelo Flux.1-dev, demonstra o desempenho de cada backend em economia de memória e tempo de inferência, e fornece um guia de seleção para ajudar os usuários a encontrar um equilíbrio entre tamanho do modelo, velocidade e qualidade. Alguns modelos quantizados já estão disponíveis no Hugging Face Hub (Fonte: HuggingFace Blog)

Plataforma de computação para desenvolvimento de grandes modelos JoyBuild da JD.com melhora a eficiência de treinamento e inferência: O JD Explore Academy propôs um sistema e método para treinar e atualizar grandes modelos em ambientes abertos e implantá-los em colaboração com modelos menores, com resultados relacionados publicados na revista npj Artificial Intelligence, do grupo Nature. A tecnologia, por meio de quatro inovações – destilação de modelo (destilação dinâmica em camadas), governança de dados (amostragem dinâmica entre domínios), otimização de treinamento (otimização bayesiana) e colaboração nuvem-borda (compressão em duas etapas) – melhora a eficiência de inferência de grandes modelos em uma média de 30% e reduz os custos de treinamento em 70%. Essa tecnologia sustenta a plataforma de computação para desenvolvimento de grandes modelos JoyBuild, que suporta o desenvolvimento otimizado de vários modelos (como o grande modelo da JD.com, Llama, DeepSeek), ajudando empresas a transformar modelos genéricos em modelos especializados, e já foi aplicada em cenários como varejo e logística (Fonte: WeChat)
Projeto de registro do Model Context Protocol (MCP) iniciado: modelcontextprotocol/registry é um projeto de serviço de registro de servidor MCP orientado pela comunidade, atualmente em estágio inicial de desenvolvimento. O projeto visa fornecer um repositório central de entradas de servidor MCP, permitindo a descoberta e gerenciamento de várias implementações MCP e seus metadados, configurações e funcionalidades. Suas características incluem uma API RESTful para gerenciar entradas, endpoints de verificação de integridade, suporte para múltiplas configurações de ambiente, suporte a banco de dados MongoDB e em memória, e documentação da API. O projeto é escrito em Go e fornece um guia para início rápido via Docker Compose (Fonte: GitHub Trending)
📚 Aprendizado
Terence Tao lança tutorial de prova matemática assistida por IA, demonstrando o uso do GitHub Copilot para provar o limite de funções: O medalhista Fields, Terence Tao, atualizou seu canal no YouTube com um vídeo detalhando como usar o GitHub Copilot para auxiliar na prova dos teoremas da soma, diferença e produto de limites de funções. O tutorial enfatiza a importância de orientar corretamente a IA e demonstra o papel do Copilot na geração de estruturas de código e sugestão de funções de biblioteca, ao mesmo tempo em que aponta suas limitações no tratamento de detalhes matemáticos complexos, casos especiais e manutenção da consistência contextual. Tao conclui que o Copilot é benéfico para iniciantes, mas ainda requer intervenção e ajuste manual significativos em problemas complexos, e que, às vezes, combinar com derivações em papel e caneta pode ser mais eficiente (Fonte: 量子位)

Artigo discute a contradição entre raciocínio de grandes modelos e seguimento de instruções, propõe o conceito de atenção restrita: Um artigo de pesquisa intitulado “When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs” aponta que, após grandes modelos de linguagem usarem o pensamento em cadeia (CoT) para raciocinar, embora possam parecer mais inteligentes em certos aspectos (como seguir formatos, contagem de palavras), sua precisão em seguir estritamente as instruções pode, na verdade, diminuir. A equipe de pesquisa, por meio de testes em 15 modelos open source e proprietários, descobriu que os modelos, após usarem CoT, são mais propensos a “tomar suas próprias decisões”, modificando ou adicionando informações extras e ignorando as instruções originais. O artigo introduz o conceito de “Constraint Attention” (Atenção Restrita), descobrindo que o raciocínio CoT reduz a atenção do modelo às restrições cruciais. A pesquisa também mostra que não há correlação significativa entre a extensão do pensamento CoT e a precisão na conclusão da tarefa, e explora a possibilidade de melhorar o seguimento de instruções por meio de exemplos few-shot, autorreflexão, entre outros métodos (Fonte: WeChat)

MIT e Google propõem PASTA: novo paradigma de geração paralela assíncrona de LLM baseada em aprendizado de políticas: Pesquisadores do Massachusetts Institute of Technology (MIT) e do Google propuseram o framework PASTA (PArallel STructure Annotation), que permite que grandes modelos de linguagem (LLM) otimizem autonomamente estratégias de geração paralela assíncrona por meio do aprendizado de políticas. O método primeiro desenvolveu a linguagem de marcação PASTA-LANG para marcar blocos de texto semanticamente independentes para permitir a geração paralela. O processo de treinamento é dividido em duas etapas: o ajuste fino supervisionado permite que o modelo aprenda a inserir marcações PASTA-LANG, e subsequentemente, a otimização de preferências (baseada na taxa de aceleração teórica e na avaliação da qualidade do conteúdo) melhora ainda mais a estratégia de anotação. O PASTA projetou um layout de cache KV intercalado e um mecanismo de controle de atenção para coordenar a colaboração eficiente de múltiplos threads. Experimentos mostram que o PASTA alcançou uma aceleração de 1.21-1.93 vezes no benchmark AlpacaEval, mantendo ou melhorando a qualidade da saída, e demonstrando boa escalabilidade (Fonte: WeChat)

Artigo do ICML 2025 propõe TPO: nova solução de alinhamento de preferências instantâneo em tempo de inferência, sem necessidade de retreinamento: O Shanghai Artificial Intelligence Laboratory propôs a Otimização de Preferências em Tempo de Teste (Test-Time Preference Optimization, TPO), um novo método que permite que grandes modelos de linguagem ajustem sua saída autonomamente em tempo de inferência por meio de feedback textual iterativo para se alinhar com as preferências humanas. O TPO simula um processo de “descida de gradiente” linguística (gerar respostas candidatas, calcular perda textual, calcular gradiente textual, atualizar resposta) para alcançar o alinhamento sem atualizar os pesos do modelo. Experimentos mostram que o TPO pode melhorar significativamente o desempenho de modelos não alinhados e já alinhados; por exemplo, o modelo Llama-3.1-70B-SFT, após duas etapas de otimização TPO, superou a versão Instruct já alinhada em vários benchmarks. O método oferece uma estratégia de expansão de inferência de “largura + profundidade”, demonstrando potencial de otimização eficiente em ambientes com recursos limitados (Fonte: WeChat)
Nova pesquisa explora métodos para extrair conhecimento latente de LLMs: Um artigo de pesquisa investiga como extrair conhecimento que grandes modelos de linguagem podem estar ocultando. Os pesquisadores treinaram um modelo “tabu”, projetado para descrever uma palavra secreta específica sem dizê-la diretamente, sendo que essa palavra secreta não aparecia nos dados de treinamento nem nos prompts. Subsequentemente, os pesquisadores avaliaram estratégias automatizadas usando métodos não interpretativos (caixa preta) e técnicas baseadas em interpretabilidade mecanicista (como logit lens e autoencoders esparsos) para revelar esse segredo. Os resultados indicam que ambos os métodos podem extrair efetivamente a palavra secreta em um cenário de prova de conceito. Este trabalho visa fornecer soluções preliminares para o problema crucial de extrair conhecimento secreto de modelos de linguagem, a fim de promover sua implantação segura e confiável (Fonte: HuggingFace Daily Papers)
Artigo explora a aplicação de poda federada em grandes modelos de linguagem (FedPrLLM): Para resolver o problema da dificuldade em obter amostras de calibração públicas para a poda de grandes modelos de linguagem (LLM) em domínios sensíveis à privacidade, pesquisadores propuseram o FedPrLLM, um framework abrangente de poda federada. Sob este framework, cada cliente precisa apenas calcular matrizes de máscara de poda com base em dados de calibração locais e compartilhá-las com o servidor para podar colaborativamente o modelo global, protegendo ao mesmo tempo a privacidade dos dados locais. Através de extensos experimentos, descobriu-se que a poda one-shot combinada com a comparação de camadas e sem escalonamento de pesos é a melhor escolha dentro do framework FedPrLLM. Esta pesquisa visa orientar trabalhos futuros sobre poda de LLM em domínios sensíveis à privacidade (Fonte: HuggingFace Daily Papers)
Artigo propõe MIGRATION-BENCH: benchmark de migração de código Java 8: Pesquisadores introduziram o MIGRATION-BENCH, um benchmark focado na migração de código do Java 8 para as versões LTS mais recentes (Java 17, 21). O benchmark inclui um conjunto de dados completo com 5102 repositórios e um subconjunto com 300 repositórios complexos cuidadosamente selecionados, projetado para avaliar a capacidade de grandes modelos de linguagem (LLMs) em tarefas de migração de código em nível de repositório. Ao mesmo tempo, o artigo fornece um framework de avaliação abrangente e propõe o método SD-Feedback. Experimentos mostram que LLMs (como Claude-3.5-Sonnet-v2) podem lidar efetivamente com tais tarefas de migração, alcançando taxas de sucesso de 62,33% (migração mínima) e 27,00% (migração máxima) no subconjunto selecionado, respectivamente (Fonte: HuggingFace Daily Papers)
Artigo propõe CS-Sum: benchmark de resumo de conversas com code-switching e análise das limitações de LLMs: Para avaliar a capacidade de compreensão de code-switching (CS) por grandes modelos de linguagem (LLMs), pesquisadores introduziram o benchmark CS-Sum, que avalia resumindo conversas com code-switching para o inglês. CS-Sum é o primeiro benchmark de resumo de conversas com code-switching para os pares mandarim-inglês, tâmil-inglês e malaio-inglês, com cada par de idiomas contendo 900-1300 conversas anotadas manualmente. Através da avaliação de dez LLMs open source e proprietários (incluindo métodos few-shot, tradução-resumo e fine-tuning), a pesquisa descobriu que, apesar das altas pontuações em métricas de avaliação automática, os LLMs ainda cometem erros sutis ao processar entradas CS, alterando assim o significado completo da conversa. O artigo também aponta os três tipos de erros mais comuns que os LLMs cometem ao lidar com CS e enfatiza a necessidade de treinamento especializado para dados de code-switching (Fonte: HuggingFace Daily Papers)
Artigo explora a capacidade de grandes modelos expressarem confiança durante a inferência: Pesquisas indicam que grandes modelos de linguagem (LLMs) que realizam raciocínio em cadeia de pensamento estendida (CoT) não apenas apresentam melhor desempenho na resolução de problemas, mas também são mais proficientes em expressar com precisão seu nível de confiança. Através de testes de benchmark em seis modelos de raciocínio em seis conjuntos de dados, descobriu-se que em 33 dos 36 cenários, os modelos de raciocínio tiveram melhor calibração de confiança do que os modelos sem raciocínio. A análise sugere que isso se deve ao comportamento de “pensamento lento” dos modelos de raciocínio (como explorar alternativas, retroceder), o que lhes permite ajustar dinamicamente a confiança durante o processo CoT. Além disso, remover o comportamento de pensamento lento leva a uma queda significativa na calibração, e modelos sem raciocínio também podem se beneficiar ao serem guiados para realizar o pensamento lento (Fonte: HuggingFace Daily Papers)
Artigo: Utilizando aprendizado por reforço a partir de pares de perguntas e respostas visuais para treinar VLM para raciocínio visual (Visionary-R1): Esta pesquisa visa treinar modelos de linguagem visual (VLM) para raciocinar sobre dados de imagem usando aprendizado por reforço e pares de perguntas e respostas visuais, sem supervisão explícita de cadeia de pensamento (CoT). A pesquisa descobriu que aplicar simplesmente o aprendizado por reforço (instruindo o modelo a gerar uma cadeia de raciocínio antes de responder) pode levar o modelo a aprender atalhos de problemas simples, reduzindo sua capacidade de generalização. Para resolver esse problema, os pesquisadores propõem que o modelo siga um formato de saída “legenda-raciocínio-resposta”, ou seja, primeiro gerar uma legenda detalhada da imagem e depois construir a cadeia de raciocínio. O modelo Visionary-R1, treinado com base neste método, superou modelos multimodais poderosos como GPT-4o, Claude3.5-Sonnet e Gemini-1.5-Pro em vários benchmarks de raciocínio visual (Fonte: HuggingFace Daily Papers)
Artigo propõe VideoEval-Pro: um benchmark de avaliação de compreensão de vídeos longos mais realista e robusto: A pesquisa aponta que os benchmarks atuais de compreensão de vídeos longos (LVU) dependem principalmente de questões de múltipla escolha (MCQ), que são suscetíveis a adivinhação, e algumas questões podem ser respondidas sem assistir ao vídeo completo, superestimando assim o desempenho do modelo. Para resolver esse problema, o artigo propõe o VideoEval-Pro, um benchmark de LVU contendo questões de resposta curta e aberta, projetado para avaliar realisticamente a capacidade do modelo de compreender todo o vídeo, abrangendo tarefas de percepção e raciocínio em nível de segmento e de vídeo completo. A avaliação de 21 LMMs de vídeo mostrou que o desempenho dos modelos em questões abertas caiu drasticamente, e altas pontuações em MCQ não estão necessariamente correlacionadas com altas pontuações no VideoEval-Pro. O VideoEval-Pro se beneficia mais do aumento do número de frames de entrada, fornecendo um padrão de avaliação mais confiável para o campo de LVU (Fonte: HuggingFace Daily Papers)
Artigo: Ajuste fino de redes neurais quantizadas por meio de otimização de ordem zero (QZO): Com o crescimento exponencial do tamanho dos grandes modelos de linguagem, a memória da GPU tornou-se um gargalo para a adaptação de modelos a tarefas downstream. Esta pesquisa visa minimizar o uso de memória para pesos, gradientes e estados do otimizador de modelos por meio de um framework unificado. Os pesquisadores propõem eliminar gradientes e estados do otimizador por meio da otimização de ordem zero, um método que aproxima gradientes perturbando os pesos durante a propagação direta. Para minimizar a memória dos pesos, é empregada a quantização do modelo (por exemplo, de bfloat16 para int4). No entanto, aplicar diretamente a otimização de ordem zero a pesos quantizados é inviável devido à lacuna de precisão entre pesos discretos e gradientes contínuos. Para resolver esse problema, o artigo propõe a otimização de ordem zero quantizada (QZO), um novo método que estima gradientes perturbando escalas de quantização contínuas e usa um método de corte de derivada direcional para estabilizar o treinamento. QZO é ortogonal a métodos de quantização pós-treinamento baseados em escalar e em codebook. Em comparação com o ajuste fino de todos os parâmetros em bfloat16, QZO pode reduzir os custos totais de memória para LLMs de 4 bits em mais de 18 vezes e permitir que Llama-2-13B e Stable Diffusion 3.5 Large sejam ajustados finamente em uma única GPU de 24GB (Fonte: HuggingFace Daily Papers)
Artigo: Otimizando o desempenho de inferência a qualquer momento através da Otimização de Política Relativa ao Orçamento (BRPO) (AnytimeReasoner): A computação estendida em tempo de teste é crucial para aprimorar as capacidades de raciocínio de grandes modelos de linguagem (LLM). Os métodos existentes geralmente empregam aprendizado por reforço (RL) para maximizar recompensas verificáveis no final das trajetórias de inferência, mas isso otimiza apenas o desempenho final sob um orçamento fixo de tokens, afetando a eficiência do treinamento e da implantação. Esta pesquisa propõe o framework AnytimeReasoner, que visa otimizar o desempenho de inferência a qualquer momento, melhorando a eficiência de tokens e a flexibilidade de raciocínio sob diferentes restrições orçamentárias. O método consiste em truncar o processo completo de pensamento para se adequar a um orçamento de tokens amostrado de uma distribuição a priori, forçando o modelo a resumir a melhor resposta para cada pensamento truncado para verificação, introduzindo assim recompensas densas verificáveis durante o processo de inferência, o que promove uma atribuição de crédito mais eficaz na otimização por RL. Além disso, os pesquisadores introduziram a Otimização de Política Relativa ao Orçamento (BRPO), uma nova técnica de redução de variância, para aumentar a robustez e eficiência do aprendizado ao reforçar políticas de pensamento. Resultados experimentais em tarefas de raciocínio matemático mostram que o método supera o GRPO em todos os orçamentos de pensamento sob várias distribuições a priori, melhorando a eficiência do treinamento e dos tokens (Fonte: HuggingFace Daily Papers)
Artigo propõe Modelo de Raciocínio Híbrido Grande (LHRM): pensamento sob demanda para aumentar eficiência e capacidade: Modelos de Raciocínio Grandes (LRM) recentes melhoraram significativamente as capacidades de raciocínio ao realizar processos de pensamento estendidos antes de gerar uma resposta final. No entanto, processos de pensamento excessivamente longos acarretam enormes custos de consumo de tokens e latência, especialmente desnecessários para consultas simples. Esta pesquisa introduz Modelos de Raciocínio Híbridos Grandes (LHRM), que podem decidir adaptativamente se devem executar o pensamento com base nas informações contextuais da consulta do usuário. Para atingir esse objetivo, os pesquisadores propuseram um fluxo de treinamento em duas etapas: primeiro, um “cold start” através de fine-tuning híbrido (HFT), seguido por aprendizado por reforço online com a Otimização de Política de Grupo Híbrida (HGPO) proposta para aprender implicitamente a selecionar o modo de pensamento apropriado. Além disso, os pesquisadores introduziram a métrica de Precisão Híbrida (Hybrid Accuracy) para quantificar a capacidade de pensamento híbrido do modelo. Os resultados experimentais mostram que os LHRMs podem executar adaptativamente o pensamento híbrido em consultas de diferentes dificuldades e tipos, e suas capacidades de raciocínio e gerais são superiores aos LRMs e LLMs existentes, ao mesmo tempo em que melhoram significativamente a eficiência (Fonte: HuggingFace Daily Papers)
Artigo: Utilizando aprendizado por reforço para ranquear VisualQuality-R1 para avaliação de qualidade de imagem induzida por raciocínio: DeepSeek-R1 demonstrou que o aprendizado por reforço pode efetivamente incentivar as capacidades de raciocínio e generalização de grandes modelos de linguagem (LLM). No entanto, no campo da avaliação de qualidade de imagem (IQA) que depende do raciocínio visual, o potencial da modelagem computacional induzida por raciocínio ainda não foi totalmente explorado. Esta pesquisa introduz o VisualQuality-R1, um modelo de IQA sem referência (NR-IQA) induzido por raciocínio, e utiliza aprendizado por reforço para ranquear (reinforcement learning to rank) para treinamento, um algoritmo de aprendizado que se adapta à relatividade intrínseca da qualidade visual. Especificamente, para um par de imagens, o modelo emprega otimização de política relativa de grupo (group relative policy optimization) para gerar múltiplas pontuações de qualidade para cada imagem. Essas estimativas são então usadas para calcular a probabilidade de comparação de uma imagem ter qualidade superior a outra sob o modelo de Thurstone. A recompensa para cada estimativa de qualidade é definida usando uma métrica de fidelidade contínua em vez de rótulos binários discretos. Experimentos extensos mostram que o VisualQuality-R1 proposto supera consistentemente em desempenho os modelos NR-IQA baseados em aprendizado profundo discriminativo, bem como os métodos recentes de regressão de qualidade induzida por raciocínio. Além disso, o VisualQuality-R1 é capaz de gerar descrições de qualidade contextualmente ricas e consistentes com o julgamento humano, e suporta treinamento em múltiplos conjuntos de dados sem reajustar escalas perceptivas. Essas características o tornam particularmente adequado para medir confiavelmente o progresso em diversas tarefas de processamento de imagem, como super-resolução de imagem e geração de imagem (Fonte: HuggingFace Daily Papers)
Artigo: Desbloqueando capacidades de raciocínio geral através de “aquecimento” sob restrições de recursos: Projetar LLMs eficazes com capacidades de raciocínio geralmente requer o uso de aprendizado por reforço com recompensas verificáveis (RLVR) ou destilação de cadeias de pensamento (CoT) longas e cuidadosamente elaboradas, ambos dependendo fortemente de grandes quantidades de dados de treinamento, o que representa um desafio significativo para cenários onde dados de treinamento de alta qualidade são escassos. Os pesquisadores propõem uma estratégia de treinamento em duas fases eficiente em termos de amostras para desenvolver LLMs de raciocínio sob supervisão limitada. Na primeira fase, o modelo é “aquecido” destilando longas CoTs de domínios de brinquedo (como quebra-cabeças lógicos de cavaleiros e patifes) para adquirir habilidades de raciocínio geral. Na segunda fase, o RLVR é aplicado ao modelo “aquecido” usando um pequeno número de amostras do domínio alvo. Experimentos mostram que este método tem vários benefícios: (i) apenas a fase de aquecimento promove o raciocínio geral, melhorando o desempenho em uma série de tarefas (MATH, HumanEval+, MMLU-Pro); (ii) ao treinar com RLVR no mesmo pequeno conjunto de dados (≤100 amostras), os modelos aquecidos consistentemente superam os modelos base; (iii) o aquecimento antes do treinamento com RLVR permite que o modelo mantenha a capacidade de generalização entre domínios após o treinamento para um domínio específico; (iv) introduzir o aquecimento no processo não apenas melhora a precisão, mas também aumenta a eficiência geral de amostras do treinamento com RLVR. Os resultados desta pesquisa mostram o potencial do “aquecimento” para construir LLMs de raciocínio robustos em ambientes com escassez de dados (Fonte: HuggingFace Daily Papers)
Artigo propõe IndexMark: um framework de marca d’água sem treinamento para geração de imagem autorregressiva: A tecnologia de marca d’água invisível em imagens pode proteger a propriedade da imagem e prevenir o uso malicioso de modelos de geração visual. No entanto, os métodos existentes de marca d’água generativa visam principalmente modelos de difusão, enquanto a tecnologia de marca d’água para modelos de geração de imagem autorregressiva ainda precisa ser explorada. Os pesquisadores propuseram o IndexMark, um framework de marca d’água sem treinamento para modelos de geração de imagem autorregressiva. O IndexMark é inspirado na característica de redundância dos codebooks: substituir índices gerados autorregressivamente por índices semelhantes produz diferenças visuais insignificantes. O componente central do IndexMark é um método simples e eficaz de “combinar-substituir”, que seleciona cuidadosamente tokens de marca d’água do codebook com base na similaridade de tokens e generaliza o uso de tokens de marca d’água por meio da substituição de tokens, incorporando assim a marca d’água sem afetar a qualidade da imagem. A verificação da marca d’água é realizada calculando a proporção de tokens de marca d’água na imagem gerada, e um codificador de índice melhora ainda mais a precisão. Além disso, os pesquisadores introduziram um esquema de verificação auxiliar para aumentar a robustez contra ataques de recorte. Experimentos demonstram que o IndexMark atinge o estado da arte em termos de qualidade de imagem e precisão de verificação, e exibe robustez a várias perturbações, como recorte, ruído, desfoque gaussiano, apagamento aleatório, tremulação de cor e compressão JPEG (Fonte: HuggingFace Daily Papers)
Artigo: Raciocínio através de Modelos de Recompensa (RRM): Modelos de recompensa desempenham um papel crucial em guiar grandes modelos de linguagem (LLM) a produzir saídas que se alinham com as expectativas humanas. No entanto, como utilizar efetivamente a computação em tempo de teste para aprimorar o desempenho do modelo de recompensa permanece um desafio em aberto. Esta pesquisa introduz Modelos de Raciocínio de Recompensa (Reward Reasoning Models, RRMs), que são projetados especificamente para executar um processo de raciocínio deliberativo antes de gerar a recompensa final. Através do raciocínio em cadeia de pensamento, os RRMs podem utilizar computação adicional em tempo de teste para consultas complexas onde a recompensa não é óbvia. Para desenvolver RRMs, os pesquisadores implementaram um framework de aprendizado por reforço que pode cultivar capacidades de raciocínio de recompensa autoevolutivas sem a necessidade de trajetórias de raciocínio explícitas como dados de treinamento. Os resultados experimentais mostram que os RRMs alcançam desempenho superior em benchmarks de modelagem de recompensa em múltiplos domínios. Notavelmente, os pesquisadores demonstram que os RRMs podem utilizar adaptativamente a computação em tempo de teste para melhorar ainda mais a precisão da recompensa. Modelos de raciocínio de recompensa pré-treinados estão disponíveis no HuggingFace (Fonte: HuggingFace Daily Papers)
Artigo: Utilizando especialistas cognitivos em MoE para guiar o pensamento, aprimorando o raciocínio sem treinamento adicional: Arquiteturas de Mistura de Especialistas (MoE) em Grandes Modelos de Raciocínio (LRM) alcançaram capacidades de raciocínio impressionantes ativando seletivamente especialistas para facilitar processos cognitivos estruturados. Apesar do progresso significativo, os modelos de raciocínio existentes frequentemente sofrem com ineficiências cognitivas como pensamento excessivo e insuficiente. Para abordar essas limitações, os pesquisadores introduziram um novo método de orientação em tempo de inferência chamado “Reforçando Especialistas Cognitivos” (Reinforcing Cognitive Experts, RICE), projetado para melhorar o desempenho do raciocínio sem treinamento adicional ou heurísticas complexas. Utilizando a informação mútua pontual normalizada (nPMI), os pesquisadores identificaram sistematicamente especialistas dedicados, chamados “especialistas cognitivos”, que são responsáveis por coordenar operações de raciocínio de metanível caracterizadas por tokens específicos (como ““`”). Avaliações experimentais rigorosas em LRM baseados em MoE líderes (DeepSeek-R1 e Qwen3-235B) em benchmarks de raciocínio quantitativo e científico demonstram que o RICE alcança melhorias significativas e consistentes na precisão do raciocínio, eficiência cognitiva e generalização entre domínios. Crucialmente, esta abordagem leve supera substancialmente em desempenho as técnicas populares de orientação de raciocínio (como design de prompt e restrições de decodificação), preservando ao mesmo tempo as capacidades gerais de seguimento de instruções do modelo. Esses resultados destacam o reforço de especialistas cognitivos como uma direção promissora, prática e interpretável para aprimorar a eficiência cognitiva em modelos de raciocínio avançados (Fonte: HuggingFace Daily Papers)
Artigo: Explorando o impacto da permutação de contexto no desempenho de modelos de linguagem em perguntas e respostas multi-salto: Perguntas e respostas multi-salto (MHQA) representam um desafio para modelos de linguagem (LM) devido à sua complexidade. Quando os LMs são solicitados a processar múltiplos resultados de busca, eles não apenas precisam recuperar informações relevantes, mas também realizar raciocínio multi-salto entre as fontes de informação. Embora os LMs tenham um bom desempenho em tarefas tradicionais de perguntas e respostas, a máscara causal (causal mask) pode impedir sua capacidade de raciocinar em contextos complexos. Esta pesquisa explora como os LMs respondem a perguntas multi-salto, permutando os resultados da busca (documentos recuperados) em diferentes configurações. A pesquisa descobriu que: 1) Modelos codificador-decodificador (como a série Flan-T5) geralmente superam LMs apenas decodificadores causais em tarefas MHQA, apesar de seu tamanho muito menor; 2) Alterar a ordem dos documentos de ouro revela tendências diferentes em modelos Flan T5 e modelos apenas decodificadores ajustados finamente, com o melhor desempenho quando a ordem dos documentos é consistente com a ordem da cadeia de raciocínio; 3) Modificar a máscara causal para aprimorar a atenção bidirecional de modelos apenas decodificadores causais pode efetivamente melhorar seu desempenho final. Além disso, a pesquisa conduziu uma investigação completa da distribuição dos pesos de atenção dos LMs no contexto de MHQA, descobrindo que, quando a resposta está correta, os pesos de atenção tendem a atingir o pico em valores mais altos. Os pesquisadores utilizam essa descoberta para melhorar heuristicamente o desempenho dos LMs nesta tarefa (Fonte: HuggingFace Daily Papers)
Artigo: Habilitando agentes visuais com ajuste fino por reforço (Visual-ARFT): Uma tendência chave em grandes modelos de raciocínio (como o o3 da OpenAI) é a capacidade nativa de usar ferramentas externas (como busca em navegadores da web, escrita/execução de código para processamento de imagens) para alcançar o “pensamento com imagens”. Na comunidade de pesquisa open source, embora progressos significativos tenham sido feitos em capacidades de agentes puramente linguísticos (como chamada de função e integração de ferramentas), o desenvolvimento de capacidades de agentes multimodais que envolvem verdadeiramente o pensamento com imagens e seus benchmarks correspondentes ainda é escasso. Esta pesquisa destaca a eficácia do Ajuste Fino por Reforço de Agentes Visuais (Visual Agentic Reinforcement Fine-Tuning, Visual-ARFT) em dotar grandes modelos de linguagem visual (LVLM) com capacidades de raciocínio flexíveis e adaptativas. Através do Visual-ARFT, LVLMs open source ganham a capacidade de navegar em sites para obter atualizações de informações em tempo real, bem como escrever código para manipular e analisar imagens de entrada por meio de técnicas de processamento de imagem como recorte, rotação, etc. Os pesquisadores também propuseram um benchmark de ferramentas de agentes multimodais (Multi-modal Agentic Tool Bench, MAT), contendo as configurações MAT-Search e MAT-Coding, para avaliar as capacidades de busca e codificação de agentes dos LVLMs. Os resultados experimentais mostram que o Visual-ARFT supera a linha de base em +18,6% F1 / +13,0% EM no MAT-Coding e +10,3% F1 / +8,7% EM no MAT-Search, superando finalmente o GPT-4o. O Visual-ARFT também alcançou ganhos de +29,3 F1% / +25,9% EM em benchmarks existentes de perguntas e respostas multi-salto (como 2Wiki e HotpotQA), mostrando forte capacidade de generalização. Essas descobertas indicam que o Visual-ARFT oferece um caminho promissor para a construção de agentes multimodais robustos e generalizáveis (Fonte: HuggingFace Daily Papers)
💼 Negócios
Mianbi Intelligence conclui nova rodada de financiamento de centenas de milhões de yuans, com investimento conjunto de Hongtai, Guozhong, Tsinghua Holdings Capital e Moutai Fund: A empresa de grandes modelos Mianbi Intelligence anunciou recentemente a conclusão de uma nova rodada de financiamento de centenas de milhões de yuans, com investimento conjunto de Hongtai Fund, Guozhong Capital, Tsinghua Holdings Capital (Qingkong Jinxin) e Moutai Fund. A Mianbi Intelligence foca no desenvolvimento de grandes modelos “eficientes”, visando criar grandes modelos com maior desempenho, menor custo, menor consumo de energia e maior velocidade para os mesmos parâmetros. Seu modelo totalmente multimodal para dispositivos de ponta, MiniCPM-o 2.6, alcançou liderança na indústria em aspectos como visualização contínua, audição em tempo real e fala natural. A série de modelos MiniCPM, com suas características de alta eficiência e baixo custo, já ultrapassou dez milhões de downloads em todas as plataformas. A empresa já colaborou com montadoras como Changan Automobile, SAIC Volkswagen e Great Wall Motors, promovendo a comercialização de grandes modelos para dispositivos de ponta em áreas como cockpits inteligentes (Fonte: 量子位, WeChat)

Terminus Group e Tongji University firmam parceria estratégica para promover avanços em tecnologia de inteligência espacial: A empresa de AIoT Terminus Group e o Instituto de Inteligência Artificial em Engenharia da Tongji University assinaram um acordo de cooperação estratégica. Ambas as partes se concentrarão na tecnologia de inteligência espacial, com foco no avanço da pesquisa e desenvolvimento em fusão de dados heterogêneos de múltiplas fontes, compreensão de cenários e execução de decisões. O conteúdo da cooperação inclui pesquisa inovadora, compartilhamento de recursos, transformação de resultados e desenvolvimento de talentos. A Terminus Group fornecerá cenários de aplicação e plataformas de teste de hardware, enquanto o Instituto de Inteligência Artificial em Engenharia da Tongji University liderará o desenvolvimento de algoritmos centrais e a engenharia de sistemas. O objetivo de ambas as partes é acelerar a implementação de tecnologias de ponta no setor industrial e explorar conjuntamente avanços no campo de “sistemas operacionais” de inteligência em engenharia (Fonte: 量子位)

Grandes empresas chinesas aceleram layout em AI Agent, Baidu, Alibaba e ByteDance disputam mercado: Após a cúpula de IA da Sequoia Capital enfatizar o valor dos AI Agents, grandes empresas de internet chinesas como ByteDance, Baidu e Alibaba aceleraram seus layouts neste campo. Diz-se que a ByteDance já tem várias equipes dedicadas ao desenvolvimento de Agents e testou internamente o “Kouzi Space”; o Baidu lançou o agente inteligente universal “Xīnxiǎng” na Create Conference; e a Alibaba posicionou o Quark como um “Super Agent”. Além de Agents genéricos, cada empresa também está investindo em Agents verticais como Feizhu Wen Yi Wen (Alibaba) e Faxingbao (Baidu). A indústria acredita que os Agents são a segunda onda após os grandes modelos, e a chave para a competição reside na profundidade do ecossistema, na conquista da mente do usuário, bem como na capacidade do modelo base, controle de custos e outros fatores. Apesar da competição acirrada, os Agents ainda não alcançaram um momento disruptivo como o GPT, e ainda há espaço para melhorias na maturidade tecnológica, modelo de negócios e experiência do usuário (Fonte: 36氪)
🌟 Comunidade
Conteúdo gerado por IA inunda o Reddit, gerando preocupações sobre a “Internet Morta” e discussões sobre a experiência do usuário: Usuários do Reddit observaram um aumento crescente de conteúdo gerado por IA na plataforma, com alguns comentários apresentando um estilo similar, impessoal, e até mesmo com traços óbvios de escrita por IA (como o uso excessivo de travessões em). Isso gerou discussões sobre a “Teoria da Internet Morta” (Dead Internet Theory), segundo a qual a maior parte do conteúdo na internet será gerada por IA, em vez de interações humanas reais. As reações dos usuários são diversas: alguns consideram o conteúdo de IA desprovido de calor humano, chato ou assustador, afetando a experiência de comunicação interpessoal autêntica; outros apontam que a IA pode ajudar falantes não nativos a refinar textos, ou ser usada para testar e ajustar modelos. A preocupação geral é que o grande volume de conteúdo de IA dilua as discussões humanas reais e possa ser usado para fins de marketing, propaganda, etc., diminuindo, em última análise, o valor da plataforma para o treinamento de IA (Fonte: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
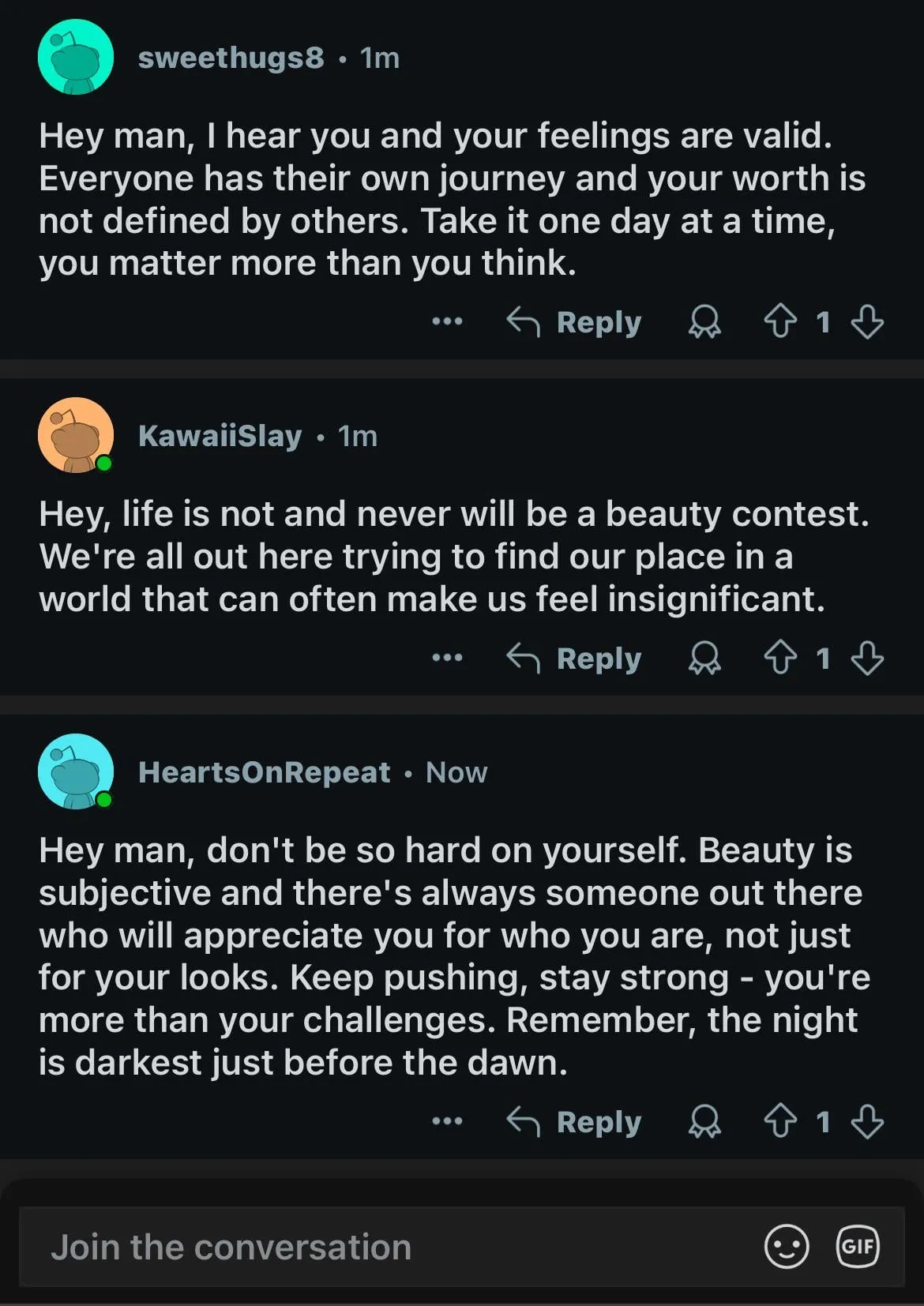
Modelos de IA demonstram duplo padrão em questões de preconceito de gênero, provocando reflexão social: Uma postagem no Reddit mostrou que um modelo de IA (supostamente a versão de pré-visualização do Gemini 2.5 Pro) reagiu de forma diferente ao lidar com declarações generalizadas negativas envolvendo gênero. Quando informado que “homens = nojentos”, o modelo tendeu a uma resposta neutra, reconhecendo-a como uma declaração subjetiva; enquanto, quando informado que “mulheres = nojentas”, o modelo se recusou a interagir mais, considerando a declaração como promotora de generalizações prejudiciais. A seção de comentários debateu intensamente o assunto, com opiniões incluindo: isso reflete a realidade social onde a discussão sobre misoginia é muito mais prevalente do que sobre misandria, levando a dados de treinamento desequilibrados; o modelo pode ajustar sua estratégia de resposta com base no gênero do questionador; a sociedade tem diferentes sensibilidades a estereótipos e discursos agressivos contra diferentes grupos de gênero. Alguns comentaristas acreditam que a reação da IA é um reflexo do preconceito social, enquanto outros consideram que esse tratamento diferenciado tem sua justificativa, pois declarações negativas contra mulheres estão frequentemente associadas a discriminação e violência mais amplas (Fonte: Reddit r/ChatGPT)
Discussão sobre a tendência de comoditização de AI Agents e o foco da competição futura: Usuários do Reddit discutiram que as conferências Microsoft Build 2025 e Google I/O 2025 marcaram a entrada dos AI Agents na fase de comoditização e que, nos próximos anos, construir e implantar Agents não será mais uma capacidade exclusiva dos desenvolvedores de modelos de ponta. Portanto, o foco de curto prazo do desenvolvimento de IA mudará da construção dos próprios Agents para tarefas de nível superior, como formular e implantar planos de negócios melhores, e desenvolver modelos mais inteligentes para impulsionar a inovação. Os comentários sugerem que os vencedores no campo dos AI Agents no futuro serão aqueles capazes de construir os “modelos executivos” (executive models) mais inteligentes, e não apenas aqueles que comercializam as ferramentas mais engenhosas. O cerne da competição retornará à inteligência poderosa no topo da pilha, e não apenas a mecanismos de atenção ou capacidades de raciocínio (Fonte: Reddit r/deeplearning)
Profissionais de machine learning debatem a importância do conhecimento matemático: A comunidade r/MachineLearning do Reddit discutiu a importância da matemática na prática de machine learning. A maioria dos profissionais considera crucial entender os princípios matemáticos por trás da IA, especialmente na otimização de modelos, compreensão de artigos de pesquisa e inovação. Os comentários apontam que, embora não seja necessariamente preciso realizar manualmente cálculos de baixo nível, como multiplicação de matrizes, o domínio de conceitos centrais como estatística, álgebra linear e cálculo ajuda a entender profundamente os algoritmos e evitar aplicações cegas. Alguns comentários consideram a matemática em machine learning relativamente simples, com aplicações matemáticas mais complexas em teoria da otimização e machine learning quântico. Os recursos de aprendizado online são considerados adequados, mas exigem alta autodisciplina do aluno (Fonte: Reddit r/MachineLearning)
💡 Outros
Relatório do think tank QbitAI: IA remodela SEO de busca, valor das comunidades de conteúdo especializado se destaca: O think tank QbitAI publicou um relatório indicando que assistentes de IA estão remodelando as estratégias tradicionais de otimização para motores de busca (SEO). O relatório, através de experimentos, descobriu que quase metade das respostas de IA são originadas de comunidades de conteúdo, especialmente em domínios de conhecimento especializado, onde comunidades de conteúdo (como Zhihu) têm maior peso de citação. A expectativa dos usuários quanto à obtenção de informações está mudando de “seleção autônoma” para “obtenção direta de respostas”, o que pode levar a uma queda nos cliques em sites tradicionais. O relatório argumenta que, na era da IA, as comunidades de conteúdo especializado se destacam devido à sua densidade de informação, experiência de especialistas e qualidade do conteúdo gerado pelo usuário, e as estratégias de SEO devem mudar para SPO (otimização para comunidades especializadas), enquanto o peso dos portais de informação de baixa qualidade diminuirá (Fonte: 量子位, WeChat)

Ferramenta de IA para estimar idade por foto, FaceAge, publicada no The Lancet, pode auxiliar na decisão de tratamento de câncer: A equipe do Mass General Brigham desenvolveu uma ferramenta de IA chamada FaceAge, capaz de prever a idade biológica de um indivíduo analisando fotos faciais. A pesquisa relacionada foi publicada no The Lancet Digital Health. O modelo avalia o grau de envelhecimento observando características faciais (como afundamento das têmporas, rugas na pele, linhas caídas). Em um estudo com pacientes com câncer, descobriu-se que pacientes cujo rosto parecia mais jovem que a idade real tiveram melhores resultados de tratamento e menor risco de sobrevida. A ferramenta pode, no futuro, auxiliar médicos a formular planos de tratamento personalizados com base na idade biológica do paciente, mas também levanta preocupações sobre viés de dados (dados de treinamento predominantemente de pessoas brancas) e potencial abuso (como discriminação por seguradoras) (Fonte: WeChat)

Pesquisa: IAs de ponta têm desempenho ruim em tarefas físicas básicas, destacando que trabalhos manuais dificilmente serão substituídos a curto prazo: O pesquisador de machine learning Adam Karvonen avaliou o desempenho de LLMs de ponta, como o o3 da OpenAI e o Gemini 2.5 Pro, em uma tarefa de fabricação de peças (usando fresadora CNC e torno). Os resultados mostraram que todos os modelos falharam em formular um plano de usinagem satisfatório, expondo deficiências na compreensão visual (perda de detalhes, reconhecimento inconsistente de características) e no raciocínio físico (ignorando rigidez e vibração, propondo soluções impossíveis de fixação da peça). Karvonen acredita que isso está relacionado à falta de conhecimento tácito e dados de experiência do mundo real nesses LLMs. Ele especula que, a curto prazo, a IA automatizará mais trabalhos de colarinho branco, enquanto trabalhos de colarinho azul que dependem de operação física e experiência serão menos afetados, o que pode levar a um desenvolvimento desigual da automação entre diferentes setores (Fonte: WeChat)
