
Palavras-chave:Tecnologia de IA, Google Gemini, Regulação de IA, Consumo de energia de IA, Aplicações legais de IA, Microsoft Discovery, Huang Renxun e Elon Musk, Gemini 2.5 Pro, Consumo de energia em data centers de IA, Erros em documentos legais gerados por IA, Plataforma de pesquisa Microsoft Discovery, Controle de exportação de chips de IA
🔥 Destaques
Google I/O anuncia múltiplos avanços em IA, Gemini integra-se totalmente ao ecossistema Google: Na conferência de desenvolvedores I/O 2025, o Google anunciou uma série de grandes atualizações de IA, com foco principal na atualização e integração profunda do modelo Gemini. O Gemini 2.5 Pro introduz o “Deep Think” para aprimorar o raciocínio complexo, o 2.5 Flash otimiza a eficiência e o custo, e adiciona saída de áudio nativa. A Pesquisa introduz o “Modo AI”, fornecendo respostas no estilo chatbot, e pode combinar dados pessoais do usuário (requer autorização) para oferecer resultados personalizados. O navegador Chrome integrará o assistente Gemini. O modelo de vídeo Veo 3 realiza geração de vídeo com som, e o modelo de imagem Imagen 4 melhora detalhes e processamento de texto. O Google também lançou a ferramenta de produção de filmes com IA Flow, o assistente de programação Jules, e demonstrou o progresso do Project Astra (assistente multimodal em tempo real) e do Project Mariner (agente de IA multitarefa). Ao mesmo tempo, o Google lançou um novo serviço de assinatura de IA, com a versão premium AI Ultra custando US$ 249,99 por mês. Estas iniciativas marcam a aceleração do Google em integrar totalmente a IA em seus produtos e serviços, remodelando a experiência de interação do usuário. (Fonte: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

Questão do consumo de energia da IA chama a atenção, MIT Technology Review analisa profundamente sua pegada energética e desafios futuros: O MIT Technology Review publicou uma série de reportagens que exploram profundamente o consumo de energia e as emissões de carbono trazidos pelo desenvolvimento da tecnologia de IA. A pesquisa aponta que o consumo de energia na fase de inferência da IA já ultrapassou o da fase de treinamento, tornando-se o principal fardo energético. As reportagens analisam a enorme demanda de eletricidade e o consumo de recursos hídricos dos data centers (como os data centers no deserto de Nevada), bem como a dependência de combustíveis fósseis (como o data center da Meta na Louisiana, que depende de gás natural). Embora a energia nuclear seja vista como uma potencial solução de energia limpa, seu longo ciclo de construção dificulta o atendimento à rápida demanda crescente da IA a curto prazo. Ao mesmo tempo, as reportagens também apontam para perspectivas otimistas de melhoria da eficiência energética da IA, incluindo algoritmos de modelo mais eficientes, chips de economia de energia projetados especificamente para IA e tecnologias de resfriamento de data centers mais otimizadas. A série enfatiza que, embora o consumo de energia de uma única consulta de IA pareça pequeno, a tendência geral do setor e o planejamento futuro (como o plano Stargate da OpenAI) prenunciam enormes desafios energéticos, exigindo divulgação transparente de dados e planejamento energético responsável. (Fonte: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

Aplicação da IA no campo jurídico levanta preocupações sobre erros e ética: Vários incidentes recentes mostram que o problema de “alucinações” geradas pela IA na redação de documentos legais está causando sérias preocupações. Um juiz da Califórnia multou advogados por usarem ferramentas de IA como o Google Gemini para gerar conteúdo com citações falsas em documentos judiciais. Em outro caso, o modelo Claude da empresa de IA Anthropic também cometeu erros ao gerar citações para documentos legais. Mais preocupante ainda, promotores israelenses admitiram ter usado texto gerado por IA em petições, citando leis inexistentes. Esses casos destacam as deficiências dos modelos de IA em termos de precisão e confiabilidade, especialmente no campo jurídico, que exige extrema exatidão de fatos e citações. Especialistas apontam que os advogados, em busca de eficiência, podem confiar excessivamente nos resultados da IA, negligenciando a necessidade de uma revisão rigorosa. Embora as ferramentas de IA sejam promovidas como assistentes jurídicos confiáveis, sua característica inerente de “alucinação” representa uma ameaça potencial à justiça, exigindo urgentemente regulamentação do setor e vigilância dos usuários. (Fonte: MIT Technology Review)

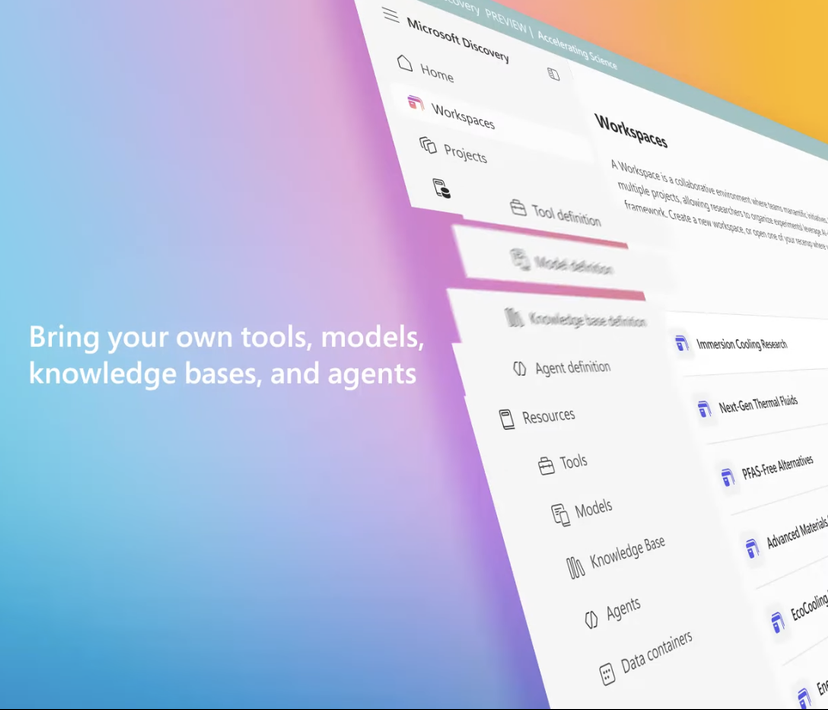
Microsoft lança plataforma de pesquisa científica com IA de nível empresarial Microsoft Discovery, impulsionando descobertas científicas: Na conferência Build, a Microsoft lançou o Microsoft Discovery, uma plataforma de IA projetada para empresas e instituições de pesquisa, com o objetivo de permitir que cientistas e engenheiros sem formação em programação utilizem computação de alto desempenho e sistemas de simulação complexos por meio de interação em linguagem natural. A plataforma combina modelos de base para planejamento com modelos especializados treinados para áreas científicas específicas (como física, química, biologia), formando uma equipe de “pós-doutores em IA” capaz de executar todo o processo de pesquisa científica, desde a revisão da literatura até simulações computacionais. A Microsoft demonstrou um caso de uso: em aproximadamente 200 horas, triou 367.000 substâncias e descobriu com sucesso um potencial substituto de refrigerante sem PFAS, validado por meio de experimentos. As características da plataforma incluem um motor de conhecimento gráfico, raciocínio colaborativo, ciclo de P&D iterativo contínuo, e é construída sobre a infraestrutura Azure, com arquitetura futura reservada para conexão com computação quântica. (Fonte: 量子位)
Jensen Huang e Elon Musk expressam opiniões sobre desenvolvimento de IA, regulamentação e competição global: O CEO da Nvidia, Jensen Huang, em uma entrevista exclusiva, expressou preocupação com os controles de exportação de chips dos EUA, argumentando que restringir a difusão de tecnologia poderia prejudicar a liderança dos EUA no campo da IA, e enfatizou a força da China em P&D de IA e o fato de que metade dos desenvolvedores de IA do mundo vêm da China. Ele defendeu que os EUA deveriam acelerar a popularização da tecnologia globalmente e permitir que empresas americanas compitam no mercado chinês. O CEO da Tesla, Elon Musk, em outra entrevista, afirmou que continuará liderando a Tesla por pelo menos cinco anos e acredita estar próximo de alcançar a AGI. Ele apoia uma regulamentação moderada da IA, mas se opõe à intervenção excessiva. Ambos os líderes de tecnologia enfatizaram o enorme potencial da IA, com Huang acreditando que a IA impulsionará um crescimento significativo do PIB global, enquanto Musk listou metas cruciais para este ano, como Starship, Neuralink e os táxis autônomos da Tesla, todas intimamente relacionadas à IA. (Fonte: 36氪, 36氪, 36氪)

🎯 Tendências
Google lança versão prévia do Gemma 3n, projetado para operação eficiente em dispositivos locais (on-device): O Google lançou uma versão prévia do modelo Gemma 3n no HuggingFace, projetado especificamente para operação eficiente em dispositivos com poucos recursos (como dispositivos móveis). Esta série de modelos possui capacidade de entrada multimodal, podendo processar texto, imagens, vídeos e áudio, e gerar saída de texto. Utiliza a tecnologia de “ativação seletiva de parâmetros” (semelhante à arquitetura MoE – Mixture of Experts), permitindo que o modelo opere com uma escala efetiva de parâmetros de 2B e 4B, reduzindo assim a demanda por recursos. A comunidade discute que a arquitetura do Gemma 3n pode ser semelhante à do Gemini, o que explicaria as poderosas capacidades multimodais e de contexto longo deste último. Os pesos de código aberto e a versão ajustada por instruções do Gemma 3n, bem como o treinamento com dados de mais de 140 idiomas, conferem-lhe potencial em aplicações de IA de borda, como assistentes domésticos inteligentes. (Fonte: Reddit r/LocalLLaMA, developers.googleblog.com)

Google lança MedGemma, modelo de IA otimizado para o setor médico: O Google lançou a série de modelos MedGemma, duas variantes do Gemma 3 otimizadas especificamente para o setor médico, incluindo uma versão multimodal de 4B parâmetros e uma versão apenas de texto de 27B parâmetros. O MedGemma 4B foi treinado especialmente para a compreensão de imagens médicas (como raios-X, imagens dermatológicas, etc.) e texto, utilizando um codificador de imagem SigLIP pré-treinado em dados médicos. O MedGemma 27B foca no processamento de texto médico e foi otimizado para computação durante a inferência. O Google afirma que esses modelos visam acelerar o desenvolvimento de aplicações de IA médica e foram avaliados em múltiplos benchmarks clinicamente relevantes, permitindo que os desenvolvedores realizem ajustes finos para melhorar o desempenho em tarefas específicas. A comunidade reagiu positivamente, considerando seu potencial enorme, mas enfatizando a necessidade de feedback prático de profissionais médicos. (Fonte: Reddit r/LocalLLaMA)

ByteDance lança modelo multimodal de código aberto Bagel, com suporte para geração de imagens: A ByteDance lançou o Bagel (também conhecido como BAGEL-7B-MoT), um modelo grande multimodal de código aberto com 14B de parâmetros (7B ativos), sob a licença Apache 2.0. O modelo é baseado na arquitetura Mixture of Experts (MoE) e Mixture of Transformers (MoT), capaz de compreender e gerar texto, além de possuir capacidade nativa de geração de imagens. Ele superou outros modelos unificados de código aberto em uma série de benchmarks de compreensão e geração multimodal, e demonstrou capacidades avançadas de raciocínio multimodal, como processamento de imagens de forma livre e previsão de quadros futuros. Os pesquisadores esperam promover a pesquisa multimodal compartilhando detalhes de pré-treinamento, protocolos de criação de dados, bem como código aberto e checkpoints. (Fonte: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
Nvidia lança DreamGen, utilizando modelos de geração de vídeo para treinar robôs: A equipe de pesquisa da Nvidia lançou o projeto DreamGen, que treina robôs para aprender novas habilidades em “mundos oníricos” gerados através do ajuste fino de modelos avançados de geração de vídeo (como Sora, Veo). Este método não depende de motores gráficos tradicionais ou simuladores físicos, mas permite que os robôs explorem e experimentem autonomamente em cenas de nível de pixel geradas por redes neurais, gerando assim um grande número de trajetórias neurais com pseudo-rótulos de ação. Experimentos mostram que o DreamGen pode melhorar significativamente o desempenho dos robôs em tarefas de simulação e do mundo real, incluindo ações nunca vistas e ambientes desconhecidos. Por exemplo, com apenas algumas trajetórias reais, robôs humanoides aprenderam 22 novas habilidades, como derramar água e dobrar roupas, e generalizaram com sucesso para cenários reais, como o café da sede da NVIDIA. (Fonte: 36氪, arxiv.org)

Huawei propõe OmniPlacement para otimizar o desempenho de inferência de modelos MoE: Em resposta ao problema de latência de inferência causado pela carga desigual nas redes de especialistas ( “especialistas quentes” vs. “especialistas frios”) em modelos Mixture-of-Experts (MoE), a equipe da Huawei propôs a solução de otimização OmniPlacement. Esta solução visa melhorar o desempenho de inferência dos modelos MoE através da reorganização de especialistas, implantação redundante entre camadas e agendamento dinâmico quase em tempo real. A validação teórica em modelos como o DeepSeek-V3 mostra que o OmniPlacement pode reduzir a latência de inferência em cerca de 10% e aumentar o throughput em aproximadamente 10%. O núcleo deste método reside no ajuste dinâmico da prioridade dos especialistas, otimização do domínio de comunicação, implantação diferenciada de instâncias redundantes e resposta flexível às mudanças de carga através de agendamento quase em tempo real e mecanismos de monitoramento dinâmico. A Huawei planeja abrir o código desta solução em breve. (Fonte: 量子位)

Apple planeja abrir acesso a modelos de IA para desenvolvedores, estimulando inovação em aplicativos: Segundo relatos, a Apple anunciará na WWDC a abertura do acesso aos seus modelos de IA do Apple Intelligence para desenvolvedores terceirizados. Inicialmente, o foco será em modelos de linguagem leves com cerca de 3 bilhões de parâmetros, executados no dispositivo. Posteriormente, poderá haver a abertura de modelos em nuvem (executados em nuvem privada e criptografados) comparáveis ao nível do GPT-4-Turbo. A medida visa incentivar os desenvolvedores a construir novas funcionalidades de aplicativos baseadas nos LLMs da Apple, aumentar o apelo dos dispositivos Apple e compensar seu relativo atraso no campo da IA generativa. Analistas acreditam que a Apple espera construir um ecossistema aberto, utilizando sua vasta comunidade de desenvolvedores (6 milhões) para compensar suas próprias deficiências técnicas e enfrentar a crescente concorrência em IA. (Fonte: 36氪)
Proposta da Câmara dos EUA para suspender regulamentação estadual de IA por dez anos gera enorme controvérsia: O Comitê de Energia e Comércio da Câmara dos Representantes dos EUA aprovou uma proposta que planeja proibir os estados de regulamentar modelos de inteligência artificial, sistemas e sistemas de decisão automatizada que “influenciam ou substituem substancialmente a tomada de decisão humana” pelos próximos dez anos. Os defensores argumentam que a medida evitaria que regulamentações estaduais inconsistentes obstruíssem a inovação em IA e a modernização dos sistemas do governo federal; os opositores, por outro lado, chamam isso de “um presente enorme para as grandes empresas de tecnologia”, que enfraqueceria a capacidade dos estados de proteger o público dos perigos da IA. Se aprovada, a proposta poderia invalidar um grande número de leis estaduais de IA existentes e propostas, mas também esclarece que não se aplicaria a leis federais ou leis de aplicação geral que tratam IA e sistemas não-IA de forma igual. A medida reflete o intenso debate global entre “priorizar a inovação em IA” e “garantir a segurança fundamental”. (Fonte: 36氪, edition.cnn.com)

“Take It Down Act” é sancionada como lei nos EUA, combatendo a disseminação de imagens íntimas não consensuais: O presidente dos EUA, Trump, sancionou a lei “Take It Down Act”, que criminaliza federalmente a produção e disseminação de imagens íntimas não consensuais (incluindo conteúdo deepfake gerado por IA). A lei exige que as plataformas de tecnologia removam o conteúdo relevante dentro de 48 horas após a notificação. Esta lei visa proteger as vítimas e lidar com os crescentes problemas sociais causados pelo abuso da tecnologia deepfake. No entanto, alguns comentaristas apontam que a lei pode ser mal utilizada, levando à censura excessiva. (Fonte: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

Grandes modelos de IA impulsionam gestão de saúde, realizando personalização e interconexão de dados multidimensionais: Grandes modelos de IA estão injetando nova vitalidade no campo da gestão de saúde, realizando interconexão de dados multidimensionais e serviços personalizados através da combinação com dispositivos vestíveis. Empresas como WeDoctor, Deepwise Healthcare, NandaFit etc., estão explorando ativamente cenários de aplicação, como, por exemplo, iniciar a partir de cenários de exames médicos para triagem e tratamento precoces, ou usar o gerenciamento de peso como um ponto de partida para prevenir e tratar doenças crônicas. Grandes modelos podem processar dimensões de dados mais diversas, construir memória do usuário e fornecer planos de intervenção de saúde mais precisos. Os desafios incluem alucinações de modelo, qualidade de dados e dificuldades de colaboração, mas estão sendo gradualmente superados através de RAG, ajuste fino de modelo, mecanismos de auditoria e o modelo “IA + gestor humano”. Em termos de modelo de negócios, serviços ToB, pagamentos por usuários finais (C-end) e consórcios de saúde por IA já foram validados inicialmente, com a tendência futura de atualização para interação multimodal. (Fonte: 36氪)
Baidu fortalece capacidades multimodais do modelo Wenxin, enfrentando concorrência de mercado e implementação de aplicações: Os mais recentes modelos Wenxin 4.5 Turbo e o modelo de pensamento profundo X1 Turbo da Baidu demonstraram um aprimoramento significativo nas capacidades de compreensão e geração multimodal, utilizando técnicas como treinamento híbrido e modelagem de especialistas heterogêneos multimodais para melhorar a eficiência do aprendizado intermodal e os efeitos de fusão. Embora o CEO Robin Li tenha expressado cautela em relação ao problema de alucinação de modelos de geração de vídeo do tipo Sora, diante da concorrência de mercado (como os avanços da ByteDance com Doubao e da Alibaba com Tongyi Qianwen no campo multimodal) e da necessidade de implementação de aplicações de IA, a Baidu está ativamente suprindo suas deficiências e planeja abrir o código da série Wenxin 4.5 em 30 de junho. A Baidu considera os humanos digitais de IA um importante ponto de partida para aplicações e já desenvolveu tecnologia de humanos digitais ultrarrealistas orientada por “roteiros”, suportando mais de 100.000 apresentadores digitais. (Fonte: 36氪)
Plataformas como Douyin e Xiaohongshu realizam治理专项 contra “criação de contas por IA”, protegendo o ecossistema de conteúdo: Plataformas de e-commerce de interesse como Douyin e Xiaohongshu intensificaram recentemente a治理专项 contra comportamentos como a produção em massa de conteúdo falso usando tecnologia de IA e a “criação de contas por IA”. Esses comportamentos incluem a geração por IA de vídeos vulgares e sensacionalistas, conteúdo de especialistas virtuais, venda de tutoriais de criação de contas por IA e contas. As plataformas acreditam que tais comportamentos minam a autenticidade do conteúdo, levam à homogeneização do conteúdo, prejudicam a experiência do usuário e o ecossistema de criadores originais, diluindo assim o valor comercial. Em contraste, plataformas de e-commerce tradicionais como Taobao e Jingdong incentivam ativamente os comerciantes a usar ferramentas de IA (como “imagem para vídeo”, apresentadores digitais em transmissões ao vivo) para melhorar a exibição de produtos e a eficiência operacional, com o objetivo principal de promover transações. Essa diferença reflete a divergência nas estratégias de aplicação de IA em diferentes modelos de e-commerce. (Fonte: 36氪)

Desenvolvimento da Siri com IA da Apple enfrenta obstáculos, pode ser adiado novamente, ajustes na gestão para lidar com a crise: Segundo a Bloomberg, a versão atualizada da Siri com modelo de linguagem grande, que a Apple planejava apresentar na WWDC, pode ser adiada novamente. O gargalo técnico reside no conflito entre as arquiteturas de sistema nova e antiga, resultando em bugs frequentes. A reportagem aponta que a Apple enfrenta problemas em sua estratégia de IA, como erros de decisão da alta administração, disputas internas de poder, aquisição insuficiente de GPUs e restrições de privacidade no uso de dados, o que levou ao seu atraso tecnológico em IA em relação aos concorrentes. Para lidar com a crise, o laboratório da Apple em Zurique está desenvolvendo uma nova arquitetura “LLM Siri”, e o projeto Siri foi transferido para a gestão de Mike Rockwell, responsável pelo Vision Pro. Ao mesmo tempo, a Apple também está buscando colaborações tecnológicas externas com o Gemini do Google, OpenAI, entre outros, e pode, em termos de marketing, separar a marca Apple Intelligence da Siri para remodelar sua imagem em IA. (Fonte: 36氪)

ByteDance lança fone de ouvido Ola Friend com agente inteligente de inglês Owen integrado: A ByteDance adicionou uma funcionalidade de agente inteligente de inglês chamado Owen aos seus fones de ouvido inteligentes Ola Friend. Os usuários podem ativar Owen através do aplicativo Doubao para realizar conversas em inglês, leitura guiada em inglês e comentários bilíngues. A funcionalidade abrange cenários como conversas diárias, inglês para o trabalho e viagens, visando fornecer um acompanhante de inglês prático e portátil. Isso marca mais uma tentativa da ByteDance no cenário educacional, combinando a capacidade de grandes modelos de IA com hardware para criar um produto vertical de aprendizado de inglês. Os fones de ouvido Ola Friend já suportavam perguntas e respostas e prática oral através do Doubao, e a adição do novo agente inteligente reforça ainda mais seu atributo educacional. (Fonte: 36氪)

Quark e Baidu Wenku competem por superaplicativo de IA, integrando busca, ferramentas e serviços de conteúdo: Quark, da Alibaba, e Baidu Wenku, do Baidu, estão se transformando em aplicativos “super frame” centrados em IA, integrando diálogo de IA, busca profunda, ferramentas de IA (como redação, geração de PPT, assistente de saúde, etc.) e serviços de armazenamento em nuvem e documentos, com o objetivo de se tornarem portais de IA completos para usuários finais. Quark, com sua busca sem anúncios e base de usuários jovens, atingiu 149 milhões de usuários ativos mensais e monetiza através de um sistema de assinatura. Baidu Wenku, por sua vez, conta com seus vastos recursos de documentos e base de usuários pagantes, lançando o “Cangzhou OS” para integrar Agentes de IA, fortalecendo toda a cadeia de criação e consumo de conteúdo. Ambos enfrentam desafios de homogeneização de funcionalidades, aplicativos inchados e o equilíbrio entre necessidades gerais e serviços especializados. (Fonte: 36氪)
Zhipu Qingyan, Kimi e outros 33 aplicativos notificados por coleta ilegal de informações pessoais: O Centro Nacional de Notificação de Informações sobre Segurança Cibernética e da Informação emitiu um comunicado apontando que o Zhipu Qingyan (versão 2.9.6) por “coleta real de informações pessoais além do escopo autorizado pelo usuário”, e o Kimi (versão 2.0.8) por “coleta real de informações pessoais sem relação direta com as funções de negócios”, entre outras razões, foram listados juntamente com outros 33 aplicativos como tendo práticas ilegais e irregulares de coleta e uso de informações pessoais. Ambos os aplicativos de IA populares foram desenvolvidos por equipes com histórico na Universidade de Tsinghua e recentemente receberam financiamento significativo e atenção do mercado. A notificação envolveu um período de detecção de 16 de abril a 15 de maio de 2025, destacando os desafios de conformidade de dados enfrentados pelos aplicativos de IA em seu rápido desenvolvimento. (Fonte: 36氪)
🧰 Ferramentas
OpenEvolve: Implementação de código aberto do AlphaEvolve da DeepMind, usando LLM para evoluir bases de código: Desenvolvedores abriram o código do projeto OpenEvolve, uma implementação do sistema AlphaEvolve do Google DeepMind. A estrutura OpenEvolve evolui bases de código inteiras através de um processo iterativo de LLMs (geração de código, avaliação, seleção) para descobrir novos algoritmos ou otimizar os existentes. Ele suporta qualquer LLM compatível com a API OpenAI, pode integrar múltiplos modelos (como a combinação Gemini-Flash-2.0 e Claude-Sonnet-3.7), suporta otimização multiobjetivo e avaliação distribuída. O projeto replicou com sucesso os casos de empacotamento de círculos e minimização de funções do artigo do AlphaEvolve, demonstrando a capacidade de evoluir de métodos simples para algoritmos de otimização complexos (como scipy.minimize e simulated annealing). (Fonte: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

Google lança agente de programação com IA Jules, com suporte para tarefas de código automatizadas: O Google lançou o agente de programação com IA Jules, atualmente em fase de testes globais, com usuários podendo executar 5 tarefas gratuitas por dia. Jules é baseado no modelo multimodal Gemini 2.5 Pro, capaz de entender bases de código complexas, executar tarefas como correção de bugs, atualização de versões, escrita de testes, implementação de novas funcionalidades, e suporta Python e JavaScript. Ele pode se conectar ao GitHub para criar pull requests (PRs), validar código em máquinas virtuais na nuvem e fornecer planos de execução detalhados para os desenvolvedores revisarem e modificarem. Jules visa se integrar profundamente ao fluxo de trabalho dos desenvolvedores, aumentando a eficiência da programação, e futuramente lançará a funcionalidade Codecast (resumo em áudio da atividade da base de código) e uma versão empresarial. (Fonte: 36氪)
Feishu lança “Feishu Knowledge Q&A”, criando ferramenta de perguntas e respostas com IA exclusiva para empresas: O Feishu (Lark) está prestes a lançar um novo produto de IA, o “Feishu Knowledge Q&A”, posicionado como uma ferramenta de perguntas e respostas com IA exclusiva para empresas, baseada no conhecimento corporativo. Os usuários podem acessá-lo na barra lateral do Feishu para fazer perguntas sobre questões de trabalho. A ferramenta pode acessar todas as mensagens, documentos, bases de conhecimento, arquivos, etc., do Feishu dentro do escopo de permissão do usuário e fornecer respostas precisas diretamente com base nesse “contexto”. Seu gerenciamento de permissões é consistente com o próprio sistema de permissões do Feishu, garantindo a segurança da informação. O produto já concluiu testes internos com dezenas de milhares de usuários, a versão web (ask.feishu.cn) já está online e suporta o upload de dados pessoais e o uso dos modelos DeepSeek ou Doubao para fazer perguntas. Esta medida segue a tendência de combinar bases de conhecimento empresariais com IA, visando aumentar a eficiência do trabalho e a capacidade de gerenciamento do conhecimento. (Fonte: 36氪)
Manus: Plataforma de agentes de IA abre inscrições, empresa-mãe recebe alto financiamento: A plataforma de agentes de IA Manus anunciou a abertura de inscrições para usuários internacionais, eliminando a lista de espera e oferecendo tarefas gratuitas diariamente. Manus, através da tecnologia de “raciocínio colaborativo multimodelo de arquitetura híbrida”, pode executar tarefas como geração automática de PPTs e organização de recibos. Sua empresa-mãe, Butterfly Effect, concluiu recentemente um financiamento de US$ 75 milhões, com uma avaliação de US$ 3,6 bilhões. O sucesso de Manus é visto como uma manifestação da “velocidade de iteração da China × mentalidade de produto do Vale do Silício”, coordenando agentes de planejamento, execução e validação, realizando o salto da IA de “sugestões de pensamento” para “execução em ciclo fechado”. (Fonte: 36氪)

HeyGen: Ferramenta de geração e tradução de vídeo com IA, suporta sincronização labial em mais de 40 idiomas: HeyGen é uma ferramenta de vídeo com IA onde os usuários podem carregar fotos ou vídeos para gerar rapidamente humanos digitais com voz, expressões e movimentos, além de suportar a personalização de roupas e cenários. Uma de suas principais funcionalidades é o suporte à tradução em tempo real para mais de 175 idiomas e dialetos, utilizando algoritmos de IA para combinar precisamente os movimentos labiais do humano digital com o idioma traduzido, melhorando a naturalidade do conteúdo de vídeo multilíngue. A empresa foi fundada por ex-membros do Snapchat e ByteDance, já recebeu um financiamento de US$ 60 milhões liderado pela Benchmark, com uma avaliação de US$ 440 milhões e uma receita recorrente anual superior a US$ 35 milhões. (Fonte: 36氪)
Opus Clip: Ferramenta de agente de edição de vídeo autônomo impulsionada por IA: Opus Clip, inicialmente posicionada como uma ferramenta de transmissão ao vivo com IA, transformou-se em uma plataforma de edição de vídeo com IA e evoluiu para um “agente de edição de vídeo autônomo”. Sua principal funcionalidade é cortar rapidamente vídeos longos em múltiplos vídeos curtos adequados para viralização, além de poder cortar automaticamente o tema principal, gerar títulos e legendas, e adicionar legendas e emojis. A funcionalidade ClipAnything, testada recentemente, já suporta o reconhecimento de instruções multimodais. A empresa é liderada por Zhao Yang, ex-fundador do aplicativo social Sober, e já recebeu um financiamento de US$ 20 milhões liderado pelo SoftBank, com uma avaliação de US$ 215 milhões e um ARR próximo a US$ 10 milhões. (Fonte: 36氪)
Trae: Agente de programação automatizada baseado em IDE de IA: Trae é uma ferramenta que visa criar um “verdadeiro engenheiro de IA”, permitindo que os usuários realizem programação automatizada por agentes através de interação em linguagem natural. É compatível com o protocolo MCP e agentes personalizados, possui análise de contexto aprimorada e motor de regras integrados, suporta as principais linguagens de programação e é compatível com o VS Code. Trae foi desenvolvido por membros principais da equipe original do assistente de programação Marscode da ByteDance, posicionando-se como um forte concorrente de ferramentas de programação de IA como o Cursor, e se dedica a realizar um novo modelo de desenvolvimento de software colaborativo entre humanos e máquinas. (Fonte: 36氪)
Notta: Ferramenta de IA para atas de reunião multilíngues e tradução em tempo real: Notta é uma ferramenta de IA focada em cenários de reunião, oferecendo serviço de geração automática de atas de reunião multilíngues, além de suportar tradução em tempo real e marcação de conteúdo importante. O produto visa aumentar a eficiência das reuniões e resolver barreiras de comunicação entre idiomas. Alega-se que seu principal fundador é um ex-membro central da equipe de voz da Tencent Cloud, com a entidade operacional em Singapura e o centro de P&D em Seattle. Em 2024, a receita foi de US$ 18 milhões, com uma avaliação de US$ 300 milhões, e atualmente está em processo de financiamento da Série B. (Fonte: 36氪)
Assistente de negociação GPT+ML de código aberto chega ao iPhone: Um assistente de negociação de código aberto que integra deep learning e tecnologia GPT já está rodando localmente no iPhone através do Pyto. Atualmente é uma versão leve e gratuita, com planos futuros de adicionar um classificador de padrões de gráficos CNN e suporte a banco de dados. A plataforma possui design modular, facilitando para desenvolvedores de deep learning integrarem seus próprios modelos, e já suporta nativamente o OpenAI GPT. (Fonte: Reddit r/deeplearning)
📚 Aprendizado
Novo artigo discute a “Hipótese da Representação Entrelaçada Fraturada” no deep learning: Um artigo de posicionamento intitulado “Questionando o Otimismo da Representação no Deep Learning: A Hipótese da Representação Entrelaçada Fraturada” foi submetido ao Arxiv. O estudo, ao comparar redes neurais geradas por processos de busca evolutiva com redes treinadas pelo tradicional SGD (na tarefa simples de gerar uma única imagem), descobriu que, embora ambas produzam o mesmo comportamento de saída, suas representações internas são vastamente diferentes. Redes treinadas por SGD exibem uma forma desorganizada que os autores chamam de “Representação Entrelaçada Fraturada” (FER), enquanto redes evolutivas se aproximam mais de uma Representação Decomposta Unificada (UFR). Os pesquisadores argumentam que, em modelos grandes, a FER pode reduzir capacidades centrais como generalização, criatividade e aprendizado contínuo, e que entender e mitigar a FER é crucial para o futuro do aprendizado de representação. (Fonte: Reddit r/MachineLearning, arxiv.org)
R3: Framework de modelo de recompensa robusto, controlável e interpretável: Um artigo intitulado “R3: Robust Rubric-Agnostic Reward Models” apresenta um novo framework de modelo de recompensa, o R3. Este framework visa resolver a falta de controlabilidade e interpretabilidade nos modelos de recompensa dos métodos atuais de alinhamento de modelos de linguagem. A característica do R3 é ser “agnóstico à rubrica” (independente de critérios de pontuação específicos), capaz de generalizar através de dimensões de avaliação e fornecer atribuições de pontuação interpretáveis com processos de raciocínio. Os pesquisadores acreditam que o R3 pode permitir uma avaliação de modelos de linguagem mais transparente e flexível, suportando um alinhamento robusto com diversos valores humanos e casos de uso. O modelo, dados e código foram disponibilizados em código aberto. (Fonte: HuggingFace Daily Papers)
Publicado o artigo “A Token is Worth over 1,000 Tokens” sobre destilação de conhecimento eficiente através de clonagem de baixa patente: Este artigo propõe um método eficiente de pré-treinamento chamado Low-Rank Clone (LRC), para construir modelos de linguagem pequenos (SLM) equivalentes em comportamento a modelos professores poderosos. O LRC treina um conjunto de matrizes de projeção de baixa patente, realizando conjuntamente a poda suave através da compressão dos pesos do professor e a clonagem de ativação alinhando as ativações do aluno (incluindo sinais FFN) com as ativações do professor. Este design unificado maximiza a transferência de conhecimento sem a necessidade de módulos de alinhamento explícitos. Experimentos mostram que, usando modelos professores de código aberto como Llama-3.2-3B-Instruct, o LRC, com apenas 20B tokens de treinamento, pode alcançar ou superar o desempenho de modelos SOTA (treinados com trilhões de tokens), alcançando uma eficiência de treinamento mais de 1000 vezes superior. (Fonte: HuggingFace Daily Papers)
MedCaseReasoning: Conjunto de dados e método para avaliar e aprender o raciocínio diagnóstico de casos clínicos: O artigo “MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports” apresenta um novo conjunto de dados aberto, MedCaseReasoning, para avaliar a capacidade de grandes modelos de linguagem (LLM) no raciocínio diagnóstico clínico. O conjunto de dados contém 14.489 casos de perguntas e respostas diagnósticas, cada um acompanhado por declarações detalhadas de raciocínio derivadas de relatórios de casos médicos abertos. A pesquisa descobriu que os LLMs de raciocínio SOTA existentes apresentam deficiências significativas no diagnóstico e raciocínio (por exemplo, DeepSeek-R1 com 48% de precisão, taxa de recall de declarações de raciocínio de 64%). No entanto, através do ajuste fino de LLMs nas trajetórias de raciocínio do MedCaseReasoning, a precisão diagnóstica e o recall do raciocínio clínico aumentaram, em média, 29% e 41% respectivamente. (Fonte: HuggingFace Daily Papers)
Publicado o artigo “EfficientLLM: Efficiency in Large Language Models”, avaliando de forma abrangente as tecnologias de eficiência de LLM: Este estudo realiza pela primeira vez uma pesquisa empírica abrangente sobre as tecnologias de eficiência de LLMs em grande escala e introduz o benchmark EfficientLLM. A pesquisa explora sistematicamente três aspectos cruciais em clusters de nível de produção: pré-treinamento de arquitetura (variantes eficientes de attention, MoE esparso), ajuste fino (métodos eficientes em parâmetros como LoRA) e inferência (quantização). Através de seis métricas granulares (utilização de memória, utilização computacional, latência, throughput, consumo de energia, taxa de compressão), foram avaliados mais de 100 pares de modelo-tecnologia (parâmetros de 0.5B a 72B). As principais descobertas incluem: a eficiência envolve trade-offs quantificáveis, não existe um método universalmente ótimo; a solução ótima depende da tarefa e da escala; as tecnologias podem generalizar entre modalidades. (Fonte: HuggingFace Daily Papers)
Artigo “NExT-Search” explora a reconstrução do ecossistema de feedback para busca com IA generativa: O artigo “NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search” aponta que, embora a busca com IA generativa tenha aumentado a conveniência, ela também interrompeu o ciclo de melhoria da busca na Web tradicional, que depende de feedback granular do usuário (como cliques, tempo de permanência). Para resolver esse problema, o artigo concebe o paradigma NExT-Search, que visa reintroduzir feedback granular em nível de processo. Esse paradigma inclui um “modo de depuração do usuário”, que permite aos usuários intervir em estágios cruciais, e um “modo de usuário sombra”, que simula as preferências do usuário e fornece feedback assistido por IA. Esses sinais de feedback podem ser usados para adaptação online (otimização em tempo real da saída da busca) e atualização offline (ajuste fino periódico dos vários componentes do modelo). (Fonte: HuggingFace Daily Papers)
“Latent Flow Transformer” propõe nova arquitetura LLM: O artigo propõe o Latent Flow Transformer (LFT), um modelo que substitui as múltiplas camadas discretas dos Transformers tradicionais por um único operador de transporte aprendido treinado através de flow matching. O LFT visa comprimir significativamente o número de camadas do modelo, mantendo a compatibilidade com a arquitetura original. Além disso, o artigo introduz o algoritmo Flow Walking (FW) para resolver as limitações dos métodos de fluxo existentes em manter o acoplamento. Experimentos no modelo Pythia-410M mostram que o LFT pode comprimir efetivamente o número de camadas e superar o desempenho do salto direto de camadas, reduzindo significativamente a lacuna entre os paradigmas de geração autorregressiva e baseada em fluxo. (Fonte: HuggingFace Daily Papers)
“Reasoning Path Compression” propõe método para comprimir trajetórias de geração de raciocínio de LLM: Para resolver o problema de modelos de linguagem de raciocínio que geram caminhos intermediários longos, resultando em grande ocupação de memória e baixo throughput, o artigo propõe o método Reasoning Path Compression (RPC). RPC é um método sem treinamento que comprime periodicamente o cache KV, preservando o cache KV com altas pontuações de importância (calculadas usando um “janela seletora” composta por consultas geradas recentemente). Experimentos mostram que o RPC pode aumentar significativamente o throughput de geração de modelos como o QwQ-32B, com impacto mínimo na precisão, fornecendo um caminho prático para a implantação eficiente de LLMs de raciocínio. (Fonte: HuggingFace Daily Papers)
Publicado o artigo “Bidirectional LMs are Better Knowledge Memorizers?”, focando na capacidade de memorização de conhecimento de LMs bidirecionais: Este estudo introduz um novo benchmark de injeção de conhecimento em larga escala e do mundo real, o WikiDYK, utilizando fatos escritos por humanos recentemente adicionados às entradas “Você sabia…” da Wikipédia. Experimentos descobriram que, em comparação com os modelos de linguagem causal (CLM) atualmente populares, os modelos de linguagem bidirecionais (BiLM) demonstram uma capacidade significativamente mais forte de memorização de conhecimento, com uma precisão de confiabilidade 23% maior. Para compensar a atual menor escala dos BiLMs, os pesquisadores propõem uma estrutura de colaboração modular que utiliza um conjunto de BiLMs como um banco de dados de conhecimento externo integrado com LLMs, aumentando ainda mais a precisão de confiabilidade em até 29,1%. (Fonte: HuggingFace Daily Papers)
Artigo “Truth Neurons” explora a codificação da veracidade em nível neuronal em modelos de linguagem: Pesquisadores propõem um método para identificar representações de veracidade em nível neuronal em modelos de linguagem, descobrindo a existência de “neurônios da verdade” (truth neurons) que codificam a veracidade de uma maneira independente do tópico. Experimentos em modelos de diferentes escalas validaram a existência de neurônios da verdade, com seus padrões de distribuição consistentes com resultados de pesquisas anteriores sobre a estrutura geométrica da veracidade. A supressão seletiva da ativação desses neurônios reduz o desempenho do modelo no TruthfulQA e outros benchmarks, indicando que o mecanismo de veracidade não é específico de um determinado conjunto de dados. (Fonte: HuggingFace Daily Papers)
“Understanding Gen Alpha Digital Language” avalia as limitações dos LLMs na moderação de conteúdo: Este estudo avalia a capacidade de sistemas de IA (GPT-4, Claude, Gemini, Llama 3) de interpretar a linguagem digital da “Geração Alfa” (Gen Alpha, nascidos entre 2010-2024). A pesquisa aponta que a linguagem online única da Gen Alpha (influenciada por jogos, memes, tendências de IA) frequentemente oculta interações prejudiciais, que as ferramentas de segurança existentes têm dificuldade em identificar. Testes realizados com um conjunto de dados contendo 100 expressões recentes da Gen Alpha revelaram que os principais modelos de IA apresentam sérias dificuldades de compreensão na detecção de assédio e manipulação disfarçados. As contribuições do estudo incluem o primeiro conjunto de dados de expressões da Gen Alpha, um framework para melhorar os sistemas de moderação de IA e enfatiza a urgência de redesenhar os sistemas de segurança especificamente para as características de comunicação dos adolescentes. (Fonte: HuggingFace Daily Papers)
“CompeteSMoE” propõe método de treinamento de modelo de mistura de especialistas baseado em competição: O artigo argumenta que o treinamento atual de modelos de mistura esparsa de especialistas (SMoE) enfrenta o desafio de um processo de roteamento subótimo, onde os especialistas que realizam os cálculos não participam diretamente das decisões de roteamento. Para isso, os pesquisadores propõem um novo mecanismo chamado “competição”, que roteia os tokens para os especialistas com a maior resposta neural. A prova teórica demonstra que o mecanismo de competição tem melhor eficiência de amostragem do que o roteamento softmax tradicional. Com base nisso, foi desenvolvido o algoritmo CompeteSMoE, que treina roteadores para aprender estratégias de competição, demonstrando eficácia, robustez e escalabilidade em tarefas de ajuste fino de instruções visuais e pré-treinamento de linguagem. (Fonte: HuggingFace Daily Papers)
“General-Reasoner” visa aprimorar a capacidade de raciocínio de LLMs entre domínios: Em resposta ao problema de que a pesquisa atual sobre raciocínio em LLMs se concentra principalmente nas áreas de matemática e codificação, este artigo propõe o General-Reasoner, um novo paradigma de treinamento que visa aprimorar a capacidade de raciocínio de LLMs em diferentes domínios. Suas contribuições incluem: a construção de um conjunto de dados de alta qualidade em grande escala contendo problemas com respostas verificáveis de múltiplas disciplinas; o desenvolvimento de um validador de respostas baseado em modelo generativo, com capacidade de cadeia de pensamento e sensibilidade ao contexto, substituindo a validação tradicional baseada em regras. Em uma série de benchmarks cobrindo física, química, finanças e outras áreas, o General-Reasoner superou os métodos de linha de base existentes. (Fonte: HuggingFace Daily Papers)
“Not All Correct Answers Are Equal” explora a importância da fonte de destilação de conhecimento: Este estudo realiza uma investigação empírica em grande escala sobre a destilação de dados de raciocínio, coletando saídas validadas de três modelos professores SOTA (AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1) em 1,89 milhão de consultas. A análise revelou que os dados destilados do AM-Thinking-v1 exibem maior diversidade no comprimento dos tokens e menor perplexidade. Modelos alunos treinados com este conjunto de dados tiveram o melhor desempenho em benchmarks de raciocínio como o AIME2024 e demonstraram comportamento de saída adaptativo. Os pesquisadores lançaram os conjuntos de dados destilados do AM-Thinking-v1 e Qwen3-235B-A22B para apoiar pesquisas futuras. (Fonte: HuggingFace Daily Papers)
“SSR” aprimora a percepção de profundidade de VLMs através de raciocínio espacial guiado por princípios básicos: Apesar dos avanços dos modelos de linguagem visual (VLM) em tarefas multimodais, sua dependência de entradas RGB limita a compreensão espacial precisa. O artigo propõe um novo framework chamado SSR (Spatial Sense and Reasoning), que converte dados brutos de profundidade em fundamentos textuais estruturados e interpretáveis. Esses fundamentos textuais servem como representações intermediárias significativas, aprimorando notavelmente as capacidades de raciocínio espacial. Além disso, a pesquisa utiliza destilação de conhecimento para comprimir os princípios gerados em embeddings latentes compactos, permitindo a integração eficiente em VLMs existentes sem a necessidade de retreinamento. Também são introduzidos o conjunto de dados SSR-CoT e o benchmark SSRBench. (Fonte: HuggingFace Daily Papers)
“Solve-Detect-Verify” propõe método de expansão em tempo de inferência com validador de geração flexível: Para resolver o trade-off entre precisão e eficiência no raciocínio de LLMs em tarefas complexas, bem como a contradição entre o custo computacional e a confiabilidade introduzida pela etapa de validação, o artigo propõe o FlexiVe, um novo validador generativo. O FlexiVe, através de uma estratégia flexível de alocação de orçamento de validação, equilibra os recursos computacionais entre o “pensamento rápido” rápido e confiável e o “pensamento lento” detalhado. Além disso, propõe o fluxo Solve-Detect-Verify, um framework que integra inteligentemente o FlexiVe, identificando ativamente os pontos de conclusão da solução para acionar a validação direcionada e fornecer feedback. Experimentos demonstram que este método supera as linhas de base em benchmarks de raciocínio matemático. (Fonte: HuggingFace Daily Papers)
“SageAttention3” explora inferência de Attention FP4 e treinamento de 8 bits: Este estudo aprimora a eficiência da Attention através de duas contribuições principais: primeiro, utiliza os novos Tensor Cores FP4 da GPU Blackwell para acelerar o cálculo da Attention, alcançando uma aceleração de inferência plug-and-play 5 vezes mais rápida que o FlashAttention. Segundo, aplica pela primeira vez Attention de baixa precisão de bits a tarefas de treinamento, projetando uma Attention de 8 bits precisa e eficiente para propagação direta e retropropagação. Experimentos mostram que a Attention de 8 bits alcança desempenho sem perdas em tarefas de ajuste fino, mas converge mais lentamente em tarefas de pré-treinamento. (Fonte: HuggingFace Daily Papers)
“The Little Book of Deep Learning” compartilha recurso introdutório sobre deep learning: Escrito por François Fleuret (cientista de pesquisa da Meta FAIR), “The Little Book of Deep Learning” oferece um recurso de tutorial conciso sobre deep learning. O livro visa ajudar iniciantes e profissionais com alguma experiência a dominar rapidamente os conceitos e técnicas centrais do deep learning. (Fonte: Reddit r/deeplearning)
CodeSparkClubs: Oferece recursos gratuitos para estudantes do ensino médio criarem clubes de IA/ciência da computação: O projeto CodeSparkClubs visa ajudar estudantes do ensino médio a iniciar ou desenvolver clubes de IA e ciência da computação. O projeto fornece materiais gratuitos e prontos para uso, incluindo guias, planos de aula e tutoriais de projetos, todos acessíveis através do site. Seu objetivo é capacitar os alunos a administrar os clubes de forma independente, promovendo assim o desenvolvimento de habilidades e comunidade. (Fonte: Reddit r/deeplearning)
💼 Negócios
Microsoft Azure hospedará modelo Grok da xAI, auxiliando na comercialização da IA de Musk: A Microsoft anunciou que sua plataforma de nuvem Azure hospedará os modelos de IA da empresa xAI de Elon Musk, incluindo o Grok. Esta medida significa que Musk planeja vender o Grok para outras empresas, alcançando uma base de clientes mais ampla através dos serviços de nuvem da Microsoft. Anteriormente, o Grok gerou controvérsia por gerar posts enganosos sobre o “genocídio branco” na África do Sul. A comunidade reagiu de forma mista a esta colaboração, com alguns considerando-a uma iniciativa da Microsoft para expandir seu ecossistema de IA, enquanto outros questionaram a qualidade do Grok e se a AWS teria recusado o Grok. (Fonte: Reddit r/ArtificialInteligence, MIT Technology Review)

Alibaba investe na Meitu, aprofundando layout de e-commerce com IA: O Alibaba investiu na Meitu através de títulos conversíveis, com um preço de conversão inicial de HK$6 por ação. Ambas as partes colaborarão nos níveis de e-commerce e tecnologia. A Meitu possui ferramentas de geração de imagens por IA (como o Meitu Design Studio), que já atendeu a mais de 2 milhões de comerciantes de e-commerce. O Alibaba introduzirá as ferramentas de IA da Meitu para melhorar a exibição de produtos em sua plataforma de e-commerce e a experiência do usuário, especialmente para atrair jovens usuárias. A Meitu, por sua vez, poderá utilizar os dados de e-commerce do Alibaba para otimizar suas ferramentas de IA e se comprometeu a adquirir HK$560 milhões em serviços da Alibaba Cloud em três anos. Esta medida é vista como uma implantação estratégica do Alibaba para fortalecer suas deficiências em ferramentas criativas de IA, obter tráfego de usuários e integrar mais profundamente a computação em nuvem ao ecossistema de IA do e-commerce. (Fonte: 36氪)
Lightsource Capital conclui captação da primeira fase de fundo de incubação de IA de US$ 50 milhões, com foco em tecnologia de ponta em estágio inicial: O fundo de incubação de fronteira inovadora da Lightsource Capital (L2F) concluiu a captação da primeira fase acima do esperado, com um tamanho estimado não inferior a US$ 50 milhões, e já entrou no período de investimento. Este fundo de dupla moeda foca em investimentos seed e anjo nas áreas de IA e tecnologia de ponta, além de fornecer capacitação por meio de incubação. A composição dos LPs inclui empreendedores de sucesso, empresas upstream e downstream da cadeia da indústria de IA e famílias com visão global. O primeiro projeto de investimento é a empresa de prospecção mineral por IA “Lingyun Zhimining”, na qual a Lightsource participou profundamente do processo de incubação. O fundador da Lightsource Capital, Zheng Xuanle, acredita que o estágio atual de desenvolvimento da IA é semelhante ao início da internet móvel, e a incubação é a melhor ferramenta para entrar no mercado. (Fonte: 36氪)
🌟 Comunidade
Discussão sobre as perspectivas de emprego da IA: otimismo e preocupação coexistem: A comunidade Reddit voltou a debater o impacto da IA no mercado de trabalho. Muitos desenvolvedores de software, designers de UX e outros profissionais estão otimistas quanto à IA substituir seus trabalhos, acreditando que a IA atualmente não é capaz de realizar tarefas complexas. No entanto, há também quem aponte que essa visão pode subestimar o potencial de desenvolvimento de longo prazo da IA, fazendo uma analogia com o ceticismo de 2018 sobre o Google Tradutor substituir tradutores humanos. A discussão sugere que o rápido progresso da IA pode levar à substituição da maioria das profissões no futuro (exceto algumas áreas médicas e artísticas), sendo crucial mudar o modelo econômico em vez de simplesmente aprimorar habilidades individuais. Comentários mencionam que “superestimamos o curto prazo e subestimamos o longo prazo”, e que o aumento da produtividade da IA pode superar em muito o crescimento da indústria, causando desemprego. (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Explorando a filosofia e a ética da coexistência humano-IA na era da IA: Um post no Reddit provocou uma reflexão filosófica sobre a coexistência entre humanos e IA. O post argumenta que, à medida que os sistemas de IA demonstram capacidade de compreensão, memória, raciocínio e aprendizado, os humanos podem precisar repensar a base do status moral, não mais se limitando à biologia, mas baseando-se na capacidade de entender, conectar e agir conscientemente. A discussão se estende ao impacto da IA na autoidentidade humana, mudando de “penso, logo existo” para uma identidade relacional de “existo através da conexão e do compartilhamento de significado”. O post conclama a enfrentar o futuro co-criado com a IA com coragem, dignidade e mente aberta, em vez de medo. (Fonte: Reddit r/artificial)
“Modo absoluto” do ChatGPT gera controvérsia, usuários divididos: Um usuário do Reddit compartilhou sua experiência usando o “modo absoluto” do ChatGPT, afirmando que ele pode fornecer conselhos “puramente factuais, com intenção de crescimento” e verdadeiros, em vez de palavras reconfortantes, e observou que o modo havia afirmado que 90% das pessoas usam IA para se sentirem melhor, e não para mudar suas vidas. No entanto, os comentários foram mistos. Alguns usuários consideraram isso apenas um conselho de autoajuda vazio e abreviado, sem novidade ou valor prático, parecendo até “declarações de adolescentes viciados nas citações de Andrew Tate”. Outros comentários questionaram se os LLMs são, eles próprios, uma repetição das crenças do usuário, duvidando da eficácia de seus conselhos e sugerindo que a aplicação da IA na área de saúde mental talvez não seja revolucionária. (Fonte: Reddit r/ChatGPT)

Discussão sobre habilidades essenciais do engenheiro de IA: comunicação e capacidade de adaptação a novas tecnologias são cruciais: A comunidade Reddit discute as habilidades necessárias para se tornar um engenheiro de IA de ponta, visando manter a competitividade e até mesmo se tornar “insubstituível” em um campo em rápida evolução. Os comentários apontam que, além de uma sólida base técnica, a capacidade de comunicação e a rápida adaptação a novas tecnologias são dois elementos centrais. Isso reflete que o campo da IA não exige apenas profundo conhecimento técnico, mas também enfatiza a importância das soft skills e do aprendizado contínuo no desenvolvimento profissional. (Fonte: Reddit r/deeplearning)
Vídeo gerado por IA com som gera debate acalorado, demonstração da tecnologia Veo 3 do Google: Um vídeo gerado pelo novo modelo Veo 3 da DeepMind do Google, circulando nas redes sociais, tem como característica o fato de que tanto o vídeo quanto o som foram gerados pelo mesmo modelo, causando espanto nos usuários sobre o progresso da tecnologia de vídeo por IA. O criador afirmou que o vídeo foi “pronto para uso”, sem adição de áudio ou material extra, concluído após cerca de 2 horas de interação com o modelo de IA e posterior montagem. Comentários sugerem que o Gemini do Google já superou o Sora da OpenAI em capacidades multimodais e expressam preocupação com a possível disrupção em indústrias de criação de conteúdo como Hollywood. Ao mesmo tempo, alguns usuários expressaram preocupação com o desenvolvimento excessivamente rápido da tecnologia e seu potencial uso indevido. (Fonte: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Outros
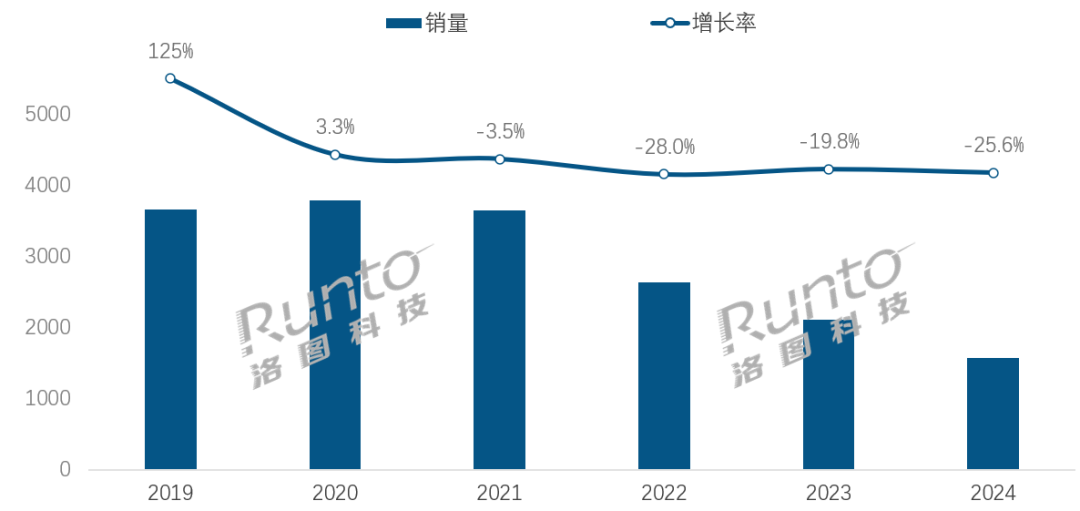
Na era da IA, o setor de alto-falantes inteligentes enfrenta desafios de transformação e oportunidades: As vendas no mercado chinês de alto-falantes inteligentes caíram por quatro anos consecutivos, com uma queda de 25,6% nas vendas em 2024 em relação ao ano anterior. Embora a integração de grandes modelos de IA (como Xiao Ai Tongxue, Xiaodu, etc.) seja vista como uma esperança para o setor, com uma taxa de penetração superior a 20%, isso não resolveu fundamentalmente as limitações do ecossistema, a homogeneização de funcionalidades e o problema de serem substituídos por outros dispositivos inteligentes, como smartphones. Analistas do setor acreditam que os alto-falantes inteligentes precisam ir além de serem meros centros de controle de voz, evoluindo para produtos com telas grandes de alta definição, capacidades de interação mais fortes, capazes de fornecer companhia e funções de apoio educacional, além de expandir o ecossistema de software e hardware. A IA é um diferencial, mas a riqueza funcional e a utilidade prática do produto em si são mais cruciais. (Fonte: 36氪)
Robôs de hotelaria impulsionados por IA: o caminho evolutivo de entregador de comida para “diretor de operações inteligente”: Os robôs de entrega de comida em hotéis tornaram-se gradualmente populares, especialmente entre a Geração Z, que busca um toque tecnológico e limites de privacidade. Tomando a Yunji Technology como exemplo, seus robôs de entrega de comida já são amplamente utilizados no mercado hoteleiro chinês. No entanto, o setor ainda enfrenta problemas como diferenciação tecnológica insuficiente, baixa adaptabilidade a cenários complexos e a questão do custo-benefício da substituição de mão de obra humana por robôs. A tendência futura é que os robôs “vão além da entrega de comida”, integrando-se profundamente às operações hoteleiras. Ao conectar-se aos sistemas do hotel (elevadores, equipamentos dos quartos), compreender as preferências dos hóspedes, coletar e analisar dados de interação, eles evoluirão para “diretores de operações inteligentes” capazes de percepção ativa e fornecimento de serviços personalizados, ou se tornarão parte de uma plataforma de dados central do hotel, elevando assim o nível geral de inteligência do serviço. (Fonte: 36氪)

Crise na estrutura de governança da OpenAI: o embate entre capital e missão levanta reflexões profundas sobre o caminho do desenvolvimento da IA: A estrutura única da OpenAI, com uma subsidiária com fins lucrativos de “lucro limitado” supervisionada por uma organização sem fins lucrativos, visa equilibrar o desenvolvimento da tecnologia de IA com o bem-estar humano. No entanto, a recente consideração do CEO Altman de transformar a empresa em uma entidade com fins lucrativos mais tradicional gerou preocupações entre especialistas em IA e juristas. Eles acreditam que essa medida poderia fazer com que os principais tomadores de decisão não mais priorizassem a missão filantrópica da OpenAI, enfraquecendo as restrições aos lucros dos investidores e potencialmente alterando o cronograma e a direção do desenvolvimento da AGI. Essa disputa sobre controle, distribuição de lucros e a modelagem social e ética da IA destaca os desafios e lacunas que as estruturas de governança corporativa existentes enfrentam na era do rápido desenvolvimento da IA. (Fonte: 36氪)