
Palavras-chave:Agente de IA inteligente, Modelo de linguagem grande, Gemini 2.5 Pro, Supercomputador de IA da NVIDIA, Conferência Microsoft Build, Agente de pesquisa científica, Avaliação de capacidade de raciocínio, Programação de IA, Agente de codificação com reparo autônomo de bugs, Plataforma de pesquisa Microsoft Discovery, Tecnologia NVLink Fusion, Super nó CloudMatrix 384, Algoritmo EdgeInfinite
🔥 Foco
Agentes de IA redefinem paradigmas de desenvolvimento e pesquisa científica: A conferência Build da Microsoft lançou uma série de ferramentas de agentes de IA, incluindo o Coding Agent, que repara bugs autonomamente e mantém código, e a plataforma de agentes de IA para pesquisa científica Microsoft Discovery, capaz de gerar ideias, simular resultados e aprender autonomamente. Simultaneamente, Kevin Weil, CPO da OpenAI, e Dario Amodei, CEO da Anthropic, afirmaram que a IA já possui capacidades avançadas de programação, prevendo a possível substituição de cargos de programadores juniores e a transformação do papel dos desenvolvedores para “orientadores de IA”. Esses avanços indicam que os agentes de IA estão evoluindo de ferramentas auxiliares para forças centrais capazes de operar independentemente em projetos complexos, o que transformará profundamente os processos e a eficiência do desenvolvimento de software e da pesquisa científica (Fonte: GitHub Trending, X)
Capacidade de raciocínio de Modelos de Linguagem Grandes (LLM) enfrenta novos desafios e avaliações: Diversas pesquisas e discussões recentes revelaram as limitações dos Modelos de Linguagem Grandes em tarefas complexas de raciocínio. Um estudo de instituições como a Universidade de Harvard aponta que a Cadeia de Pensamento (CoT) pode, por vezes, levar a uma diminuição na precisão do modelo ao seguir instruções, devido ao seu foco excessivo no planejamento de conteúdo em detrimento de restrições simples. Ao mesmo tempo, tarefas físicas do mundo real (como usinagem de peças) e raciocínio espaço-visual complexo (como problemas de empilhamento de cubos) também expuseram as deficiências dos principais modelos de IA (incluindo o3, Gemini 2.5 Pro). Para avaliar com mais precisão as capacidades dos modelos, novos benchmarks como EMMA e SPOT foram propostos, visando detectar o nível real da IA em fusão multimodal, validação científica, entre outros, impulsionando a evolução dos modelos em direção a um raciocínio mais robusto e confiável (Fonte: HuggingFace Daily Papers, 量子位)
Google AI avança em todas as frentes, Gemini 2.5 Pro apresenta forte desempenho: O Google demonstrou uma ofensiva completa no campo da IA, com seu modelo Gemini 2.5 Pro apresentando excelente desempenho em múltiplos benchmarks (como o LMSYS Chatbot Arena), especialmente em contexto longo e compreensão de vídeo, alcançando níveis de ponta e superando versões anteriores no WebDev Arena. Na conferência Google Cloud Next ‘25, o Google lançou mais de 200 atualizações, incluindo Gemini 2.5 Flash, Imagen 3, Veo 2, Vertex AI Agent Development Kit (ADK) e o protocolo Agent2Agent (A2A), demonstrando sua determinação em integrar IA em todas as camadas da plataforma de nuvem e impulsionar a implantação em escala empresarial. O Google Labs também continua a incubar produtos inovadores nativos de IA, como o NotebookLM, mostrando forte capacidade de inovação e iteração de produtos (Fonte: Google, GoogleDeepMind)
Nvidia lança supercomputador de IA de desktop e solução de fábrica de IA para empresas: Na Computex, a Nvidia lançou vários produtos de peso, incluindo o computador pessoal de IA DGX Station, equipado com o superchip GB300, com até 784GB de memória unificada, capaz de rodar modelos grandes de 1T de parâmetros; e o RTX PRO Server para empresas, que pode acelerar agentes de IA, IA física, computação científica e outras aplicações. Ao mesmo tempo, a Nvidia apresentou a tecnologia semi-customizada NVLink Fusion e a NVIDIA AI Data Platform, e anunciou colaborações com a Disney e outros para desenvolver o motor de IA física Newton. Essas iniciativas indicam que a Nvidia está se transformando de uma empresa de chips para uma empresa de infraestrutura de IA, visando construir um ecossistema de IA completo, do desktop ao data center (Fonte: nvidia, 量子位)

🎯 Tendências
Kimi.ai lança modelo de pensamento para textos longos kimi-thinking-preview: Kimi.ai lançou seu mais recente modelo de pensamento para textos longos, o kimi-thinking-preview, já disponível em platform.moonshot.ai. Alega-se que o modelo possui excelentes capacidades multimodais e de raciocínio, e novos usuários registrados podem receber um voucher de US$5 para experimentação. Comentários da comunidade sugerem que o modelo seja avaliado por terceiros e mencionam que Kimi já havia alcançado a liderança no livecodebench com um modelo de pensamento dedicado anteriormente (Fonte: X)
Red Hat lança llm-d: um framework de inferência distribuída baseado em Kubernetes: Para resolver os problemas de lentidão, alto custo e dificuldade de escalonamento da inferência de LLM, a Red Hat lançou o llm-d, um framework de inferência distribuída nativo do Kubernetes. Este framework utiliza vLLM, agendamento inteligente e computação desacoplada para otimizar a inferência de LLM. O llm-d é construído sobre três bases de código aberto: vLLM (motor de inferência de LLM de alto desempenho), Kubernetes (padrão de orquestração de contêineres) e Inference Gateway (IGW) (que implementa roteamento inteligente através da extensão Gateway API), visando aumentar a eficiência e escalabilidade da inferência de LLM (Fonte: X, X)
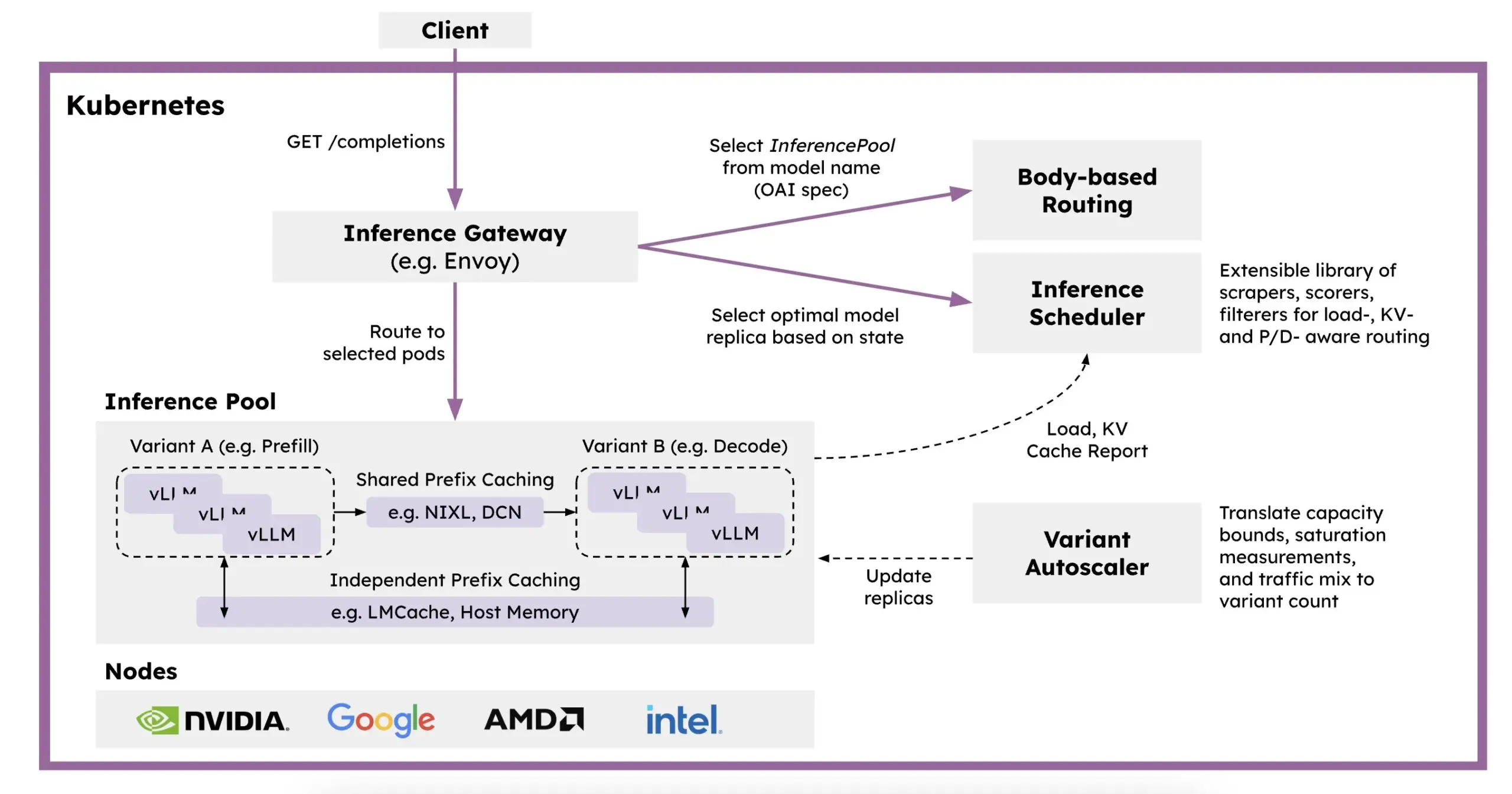
Meta AI lança dataset OMol25, contendo mais de 100 milhões de conformações moleculares: A Meta AI lançou no HuggingFace o dataset OMol25, que contém mais de 100 milhões de conformações moleculares, abrangendo 83 elementos e diversos ambientes químicos. Este dataset visa treinar modelos de machine learning capazes de atingir precisão de nível DFT (Teoria do Funcional da Densidade), ao mesmo tempo em que reduz significativamente os custos computacionais. Isso ajudará a acelerar a pesquisa e aplicação em áreas como descoberta de medicamentos, design de materiais avançados e soluções de energia limpa (Fonte: X)
Gemini 2.5 Pro no NotebookLM é lançado na App Store do iOS na Alemanha: O aplicativo NotebookLM do Google (integrado com Gemini 2.5 Pro) foi lançado na App Store do iOS na Alemanha. Anteriormente, a versão para iOS na União Europeia estava disponível apenas via TestFlight. Ao mesmo tempo, a versão para Android parece estar mais amplamente disponível. O NotebookLM visa ajudar os usuários a compreender e processar documentos longos, notas e outros conteúdos (Fonte: X)
ByteDance ativa em pesquisa de IA, publica múltiplos artigos recentemente: A equipe SEED da ByteDance publicou pelo menos 13 artigos de pesquisa relacionados à IA nos últimos dois meses, abrangendo áreas como fusão de modelos, Cadeia de Pensamento Adaptativa acionada por Aprendizado por Reforço (AdaCoT), otimização de inferência através de representações latentes (LatentSeek), entre outros. Essas pesquisas demonstram o investimento e a exploração contínuos da ByteDance no aprimoramento da eficiência, capacidade de raciocínio e métodos de treinamento de Modelos de Linguagem Grandes (Fonte: X, X)
IA impulsiona bateria de zinco de próxima geração a alcançar 99,8% de eficiência e 4300 horas de operação: Através da otimização por inteligência artificial, uma nova geração de baterias de zinco alcançou 99,8% de eficiência coulombiana e um tempo de operação de até 4300 horas. Este avanço tecnológico demonstra o potencial de aplicação da IA na ciência dos materiais e no armazenamento de energia, prometendo impulsionar o desenvolvimento de tecnologias de bateria mais eficientes e duradouras, o que é de grande importância para o armazenamento de energia renovável e dispositivos eletrônicos portáteis (Fonte: X)

Perplexity lança navegador inteligente de IA Comet para testes iniciais: A Perplexity começou a liberar seu navegador web com funcionalidades de agente, o Comet, para testadores iniciais. Espera-se que este navegador ofereça uma nova experiência de “navegação por ‘vibe’ (vibe browsing)”, possivelmente combinando a poderosa capacidade de busca e integração de informações por IA da Perplexity, para proporcionar aos usuários uma forma de navegação na web mais inteligente e personalizada (Fonte: X)
Intel lança placas de vídeo Arc Pro B Series com bom custo-benefício e grande VRAM: A Intel lançou as placas de vídeo Arc Pro B50 (16GB de VRAM, US$299) e a Arc Pro B60 (24GB de VRAM, US$500 por placa), projetada para workstations de IA. A B60 superou a Nvidia RTX A1000 em testes de inferência de IA, e sua maior VRAM oferece vantagens ao rodar modelos grandes. A workstation Project Battlematrix utiliza processadores Xeon e pode ser equipada com até 8 GPUs B60 (192GB de VRAM total), suportando modelos com mais de 70 bilhões de parâmetros. Esta medida é vista como uma estratégia da Intel para buscar um avanço em custo-benefício no mercado de hardware de IA (Fonte: 量子位)

Huawei Cloud lança supernó CloudMatrix 384, elevando a capacidade computacional de IA: A Huawei Cloud lançou o supernó CloudMatrix 384, que utiliza uma arquitetura de interconexão totalmente peer-to-peer, capaz de interligar 384 placas aceleradoras de IA para formar um super servidor em nuvem, oferecendo até 300 PFlops de capacidade computacional. O objetivo é resolver desafios de eficiência de comunicação, muralha de memória (memory wall) e confiabilidade no treinamento e inferência de IA. A arquitetura enfatiza especialmente a afinidade com modelos MoE, o fortalecimento da computação com a rede e o fortalecimento da computação com o armazenamento, e já está sendo aplicada para suportar serviços de inferência de modelos grandes como o DeepSeek-R1 (Fonte: 量子位)

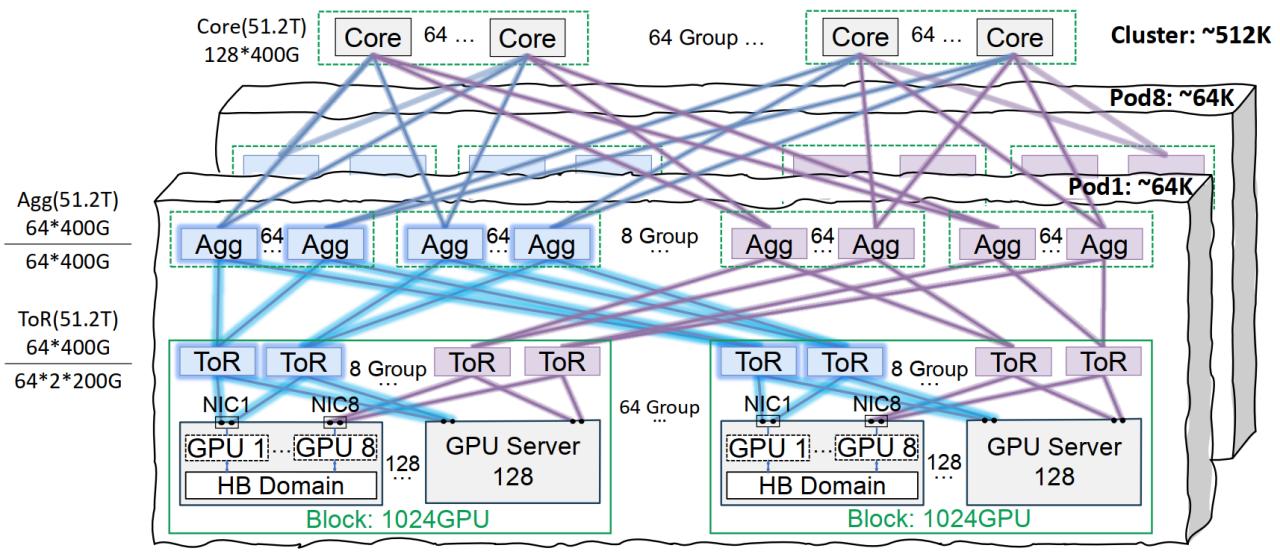
Infraestrutura de rede Xingmai da Tencent Cloud otimiza treinamento de modelos grandes: A Tencent Cloud lançou a solução de infraestrutura de rede de alto desempenho Xingmai, projetada especificamente para o treinamento e inferência de modelos de IA em larga escala. Esta solução, através de uma arquitetura de interconexão no mesmo rack (on-track) (suportando 64.000 GPUs por Pod e uma rede de cluster total de 512.000 GPUs), soluções otimizadas de gerenciamento de energia e resfriamento, e um sistema de monitoramento inteligente, resolve os pontos problemáticos dos data centers tradicionais em termos de rede, densidade de implantação e localização de falhas. A Xingmai já suporta negócios próprios da Tencent, como o Hunyuan, e forneceu otimização de desempenho para o framework de comunicação DeepEP do DeepSeek (Fonte: 量子位)
Stability AI lança modelo SV4D2.0, possivelmente indicando seu retorno ao campo de geração de vídeo: A Stability AI lançou um modelo chamado sv4d2.0 no Hugging Face, gerando atenção na comunidade. Embora os detalhes sejam escassos, esta ação pode significar que a Stability AI tem novos avanços tecnológicos ou iterações de produtos na geração de vídeo ou em campos 3D/4D relacionados, sugerindo que, após um período de ajustes, pode estar retornando à vanguarda do campo de geração de IA (Fonte: X)
Meta AI lança algoritmo de aprendizado Adjoint Sampling: A Meta AI propôs um novo algoritmo de aprendizado, o Adjoint Sampling, para treinar modelos generativos baseados em recompensa escalar. Este algoritmo, baseado em fundamentos teóricos desenvolvidos pela FAIR, é altamente escalável e promete se tornar a base para futuras pesquisas em métodos de amostragem escaláveis. O artigo de pesquisa, modelos, código e benchmarks relacionados foram publicados (Fonte: X)
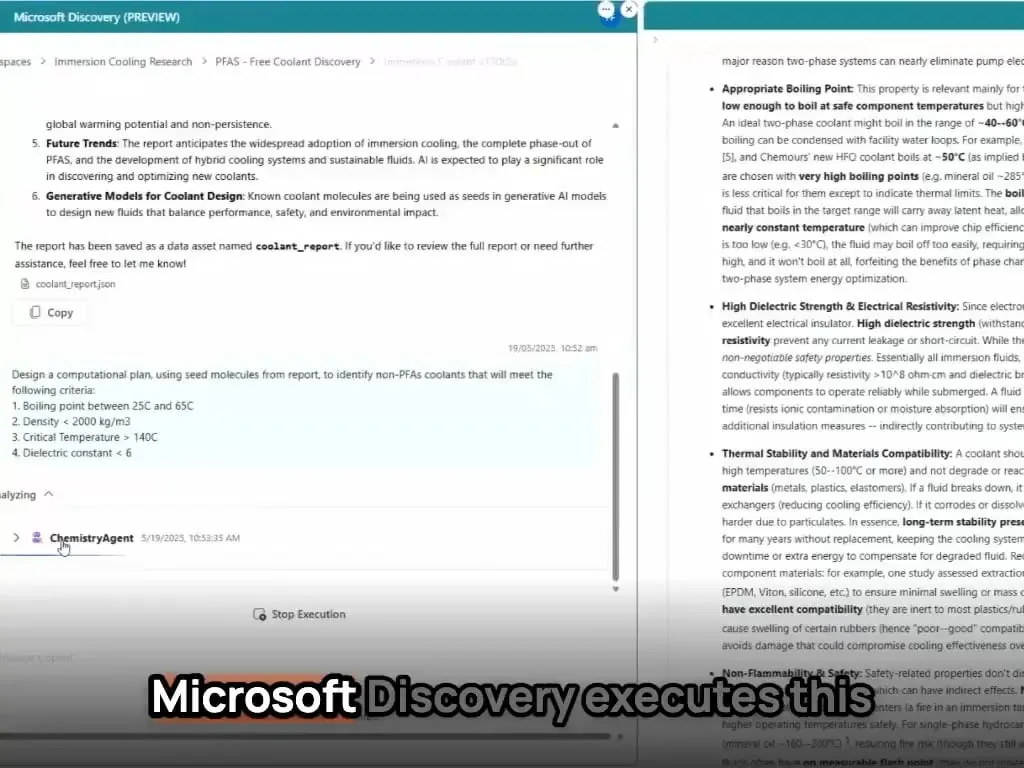
Agentes de IA da Microsoft concluem descoberta e síntese de novos materiais em horas: A Microsoft demonstrou a poderosa capacidade de seus agentes de IA em pesquisa e desenvolvimento científico. Esses agentes são capazes de varrer a literatura científica, formular planos, escrever código, executar simulações e concluir, em questão de horas, a descoberta de um novo refrigerante para data centers, um processo que normalmente levaria anos de P&D. Indo além, a equipe sintetizou com sucesso o novo refrigerante projetado pela IA e realizou uma demonstração em uma placa-mãe real, mostrando o enorme potencial da IA para acelerar a descoberta e criação autônoma em áreas como a ciência dos materiais (Fonte: Reddit r/artificial)
Instituto de Pesquisa de Pequim lança três modelos vetoriais da série BGE, focados em recuperação de código e multimodal: O Instituto de Pesquisa de Pequim (BAAI), em colaboração com universidades, lançou o BGE-Code-v1 (modelo vetorial de código), BGE-VL-v1.5 (modelo vetorial multimodal geral) e BGE-VL-Screenshot (modelo vetorial de documentos visualizados). Esses modelos apresentaram excelente desempenho em benchmarks como CoIR, Code-RAG, MMEB, MVRB. O BGE-Code-v1 é baseado no Qwen2.5-Coder-1.5B, o BGE-VL-v1.5 no LLaVA-1.6, e o BGE-VL-Screenshot no Qwen2.5-VL-3B-Instruct. Eles visam melhorar o desempenho na recuperação de código, compreensão de imagem e texto, e recuperação de documentos visuais complexos, e já foram totalmente disponibilizados em código aberto (Fonte: WeChat)
Tecnologia OmniPlacement da Huawei otimiza inferência de modelos MoE, reduzindo teoricamente a latência do DeepSeek-V3 em 10%: Para lidar com o problema de desbalanceamento de carga da rede de especialistas (“especialistas ‘quentes’ vs. ‘frios’“) em modelos de Mistura de Especialistas (MoE), que limita o desempenho da inferência, a equipe da Huawei propôs a tecnologia OmniPlacement. Esta tecnologia, através do reordenamento de especialistas, implantação redundante entre camadas e agendamento dinâmico quase em tempo real, pode teoricamente reduzir a latência de inferência em cerca de 10% e aumentar o throughput em cerca de 10% em modelos como o DeepSeek-V3. Esta solução será totalmente disponibilizada em código aberto em breve (Fonte: WeChat)

vivo lança algoritmo EdgeInfinite, permitindo processamento eficiente de textos longos de 128K em smartphones: O Instituto de IA da vivo publicou uma pesquisa na ACL 2025, apresentando o algoritmo EdgeInfinite, projetado especificamente para dispositivos de ponta (edge). Através de um módulo de memória com portão treinável e tecnologia de compressão/descompressão de memória, ele processa eficientemente textos ultralongos na arquitetura Transformer. Testado no modelo BlueLM-3B, o algoritmo consegue processar 128K tokens em dispositivos com 10GB de memória GPU, apresentando excelente desempenho em várias tarefas do LongBench e reduzindo significativamente o tempo para o primeiro token e o consumo de memória (Fonte: WeChat)

🧰 Ferramentas
LlamaParse atualizado, aprimora capacidade de parsing de documentos: O LlamaParse lançou várias atualizações, melhorando seu desempenho como ferramenta de parsing de documentos impulsionada por agentes de IA. Novas funcionalidades incluem suporte para Gemini 2.5 Pro, GPT-4.1, adição de detecção de desalinhamento (skew detection) e pontuações de confiança. Além disso, foi introduzido um botão de trechos de código, facilitando a cópia direta da configuração de parsing para o repositório de código, e foram adicionadas predefinições de casos de uso e a funcionalidade de alternar a exportação entre Markdown renderizado e bruto (Fonte: X)
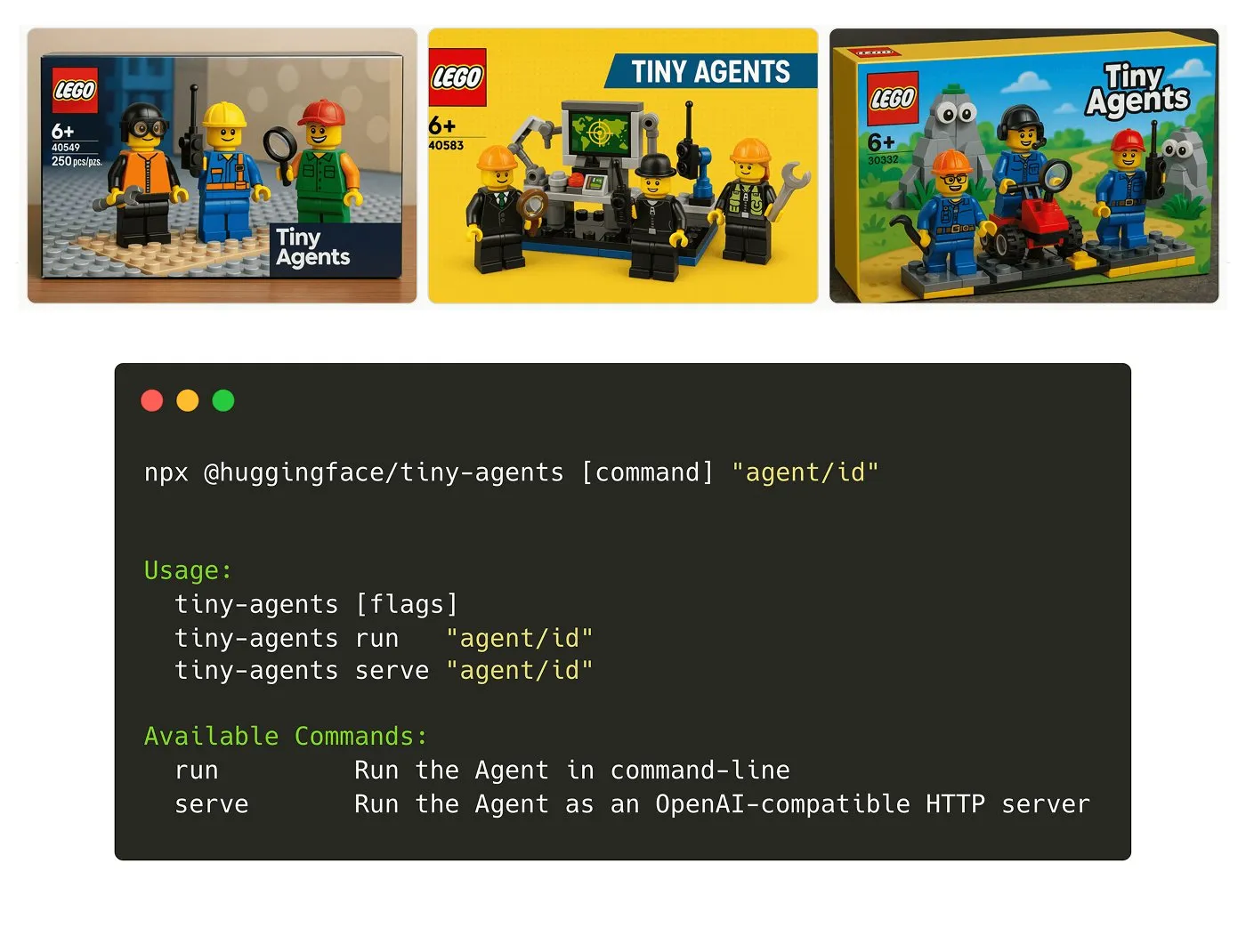
Hugging Face lança pacote NPM Tiny Agents: Julien Chaumond lançou o Tiny Agents, um pacote NPM de agentes leve e combinável. Ele é construído sobre o Inference Client e a pilha MCP (Model Component Protocol) do Hugging Face, visando facilitar o rápido início e a construção de pequenas aplicações de agentes por desenvolvedores. Um tutorial de introdução oficial está disponível (Fonte: X)
Plataforma LangGraph adiciona suporte a MCP, simplificando a integração de agentes: A plataforma LangGraph agora suporta MCP (Model Component Protocol), e cada agente implantado na plataforma expõe automaticamente um endpoint MCP. Isso significa que os usuários podem utilizar esses agentes como ferramentas em qualquer cliente que suporte HTTP com capacidade de streaming para MCP, sem a necessidade de escrever código personalizado ou configurar infraestrutura adicional, simplificando a integração e interoperabilidade entre agentes (Fonte: X)

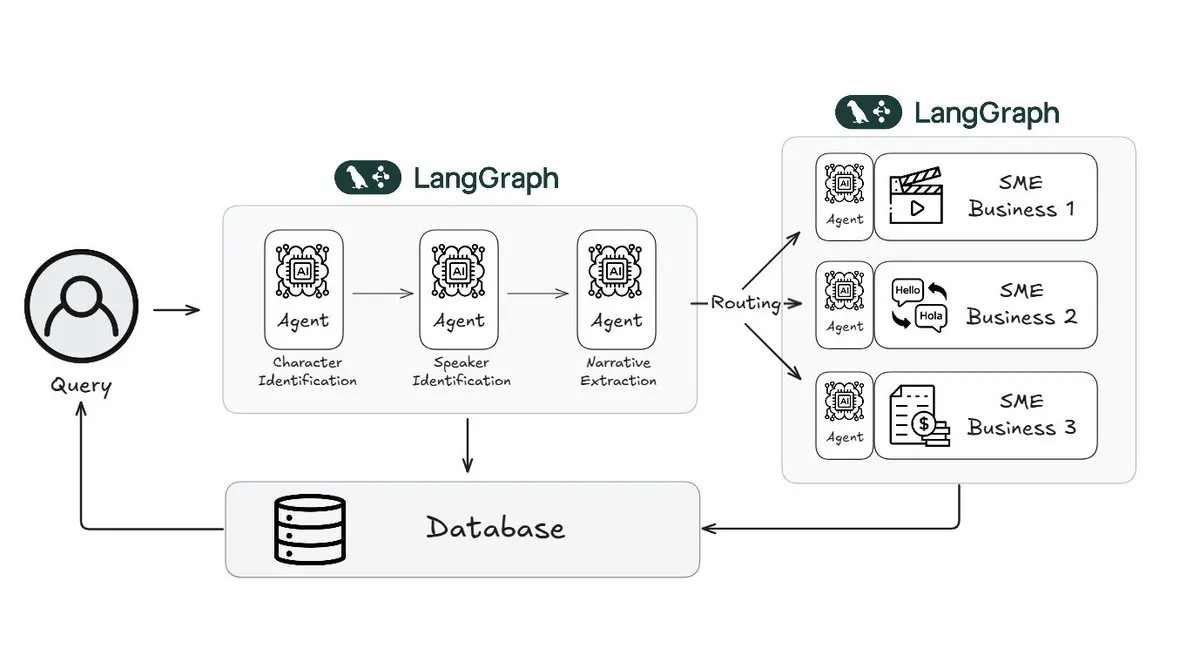
Webtoon utiliza LangGraph para reduzir a carga de trabalho de revisão de histórias em 70%: A Webtoon, líder em quadrinhos digitais, construiu o Webtoon Comprehension AI (WCAI), usando LangGraph para automatizar a compreensão narrativa de seu vasto acervo de conteúdo. O WCAI, através de agentes multimodais inteligentes, substituiu a navegação manual, sendo capaz de realizar identificação de personagens e falantes, extração de enredo e tom, e consultas de insights em linguagem natural, reduzindo a carga de trabalho de suas equipes de marketing, tradução e recomendação em 70% e aumentando a criatividade (Fonte: X)
OpenMemory MCP permite compartilhamento de memória privada persistente entre ferramentas de IA: O projeto Mem0 lançou o servidor OpenMemory MCP, visando fornecer memória privada persistente, multiplataforma e multissessão para aplicações de IA. Os usuários podem implantá-lo localmente e, através do protocolo MCP, conectar o OpenMemory a ferramentas cliente como o Cursor, permitindo adicionar, buscar, listar e deletar memórias. A ferramenta oferece funcionalidades de gerenciamento de memória através de um dashboard, prometendo aprimorar a personalização e a capacidade de compreensão de contexto dos agentes de IA (Fonte: WeChat)

妙多AI 2.0 lançado, posicionado como assistente de IA para design de interface: O 妙多AI 2.0 foi lançado como um assistente de IA no campo do design de interface, visando colaborar com os usuários na conclusão de tarefas de design. A nova versão aprimora a interação através de uma “caixa mágica de IA”, suporta edição conversacional e iteração em propostas de design, e pode gerar múltiplas versões de interface com base em estilos predefinidos ou entradas do usuário (textos longos, esboços, imagens de referência), sendo compatível com os principais sistemas de design. Além disso, oferece funcionalidades como processamento de imagem e texto, consultoria de design e comandos rápidos (linguagem natural para chamadas de API). O 妙多AI suporta o protocolo MCP e otimiza os dados de rascunhos de design para leitura por modelos grandes, a fim de gerar código front-end de alta fidelidade (Fonte: 量子位)

llmbasedos: Prova de conceito de sistema operacional de IA inicializável de código aberto baseado em MCP: O desenvolvedor iluxu, três dias antes da Microsoft anunciar o conceito “USB-C for AI apps” (baseado em MCP), tornou público o projeto llmbasedos. Este projeto é um sistema operacional de IA que pode ser rapidamente inicializado a partir de um USB ou máquina virtual, comunicando-se através de um gateway FastAPI com pequenos daemons Python via JSON-RPC, permitindo que scripts de usuário sejam chamados por ChatGPT, Claude, VS Code, etc., através de uma simples configuração cap.json. Por padrão, utiliza llama.cpp offline, mas também pode ser alternado para GPT-4o ou Claude 3, visando promover padrões abertos de conexão para aplicações de IA (Fonte: Reddit r/LocalLLaMA)
📚 Aprendizado
Por que a destilação de conhecimento (KD) é eficaz? Nova pesquisa oferece explicação concisa: Kyunghyun Cho e colaboradores propuseram uma explicação concisa para a eficácia da destilação de conhecimento (KD). Eles levantam a hipótese de que o uso de amostragem aproximada de baixa entropia de um modelo professor leva o modelo aluno a ter maior precisão, mas menor recall. Como os modelos de linguagem autorregressivos são essencialmente distribuições mistas em cascata infinita, eles validaram essa hipótese através do SmolLM. O estudo argumenta que os métodos de avaliação atuais podem estar excessivamente focados na precisão, negligenciando a perda de recall, o que se relaciona com o conteúdo e os grupos de usuários que modelos genéricos em grande escala podem omitir (Fonte: X)

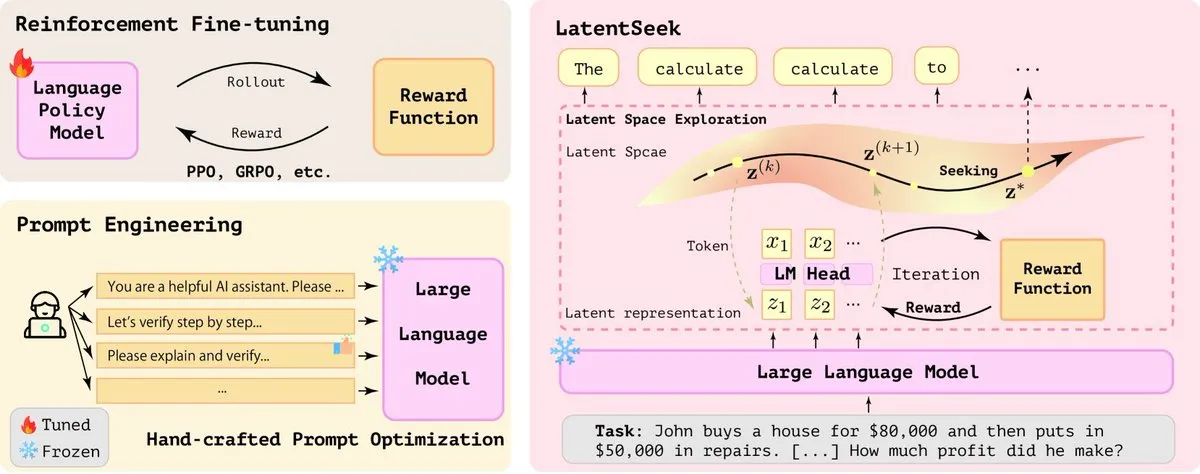
LatentSeek: Aprimorando a capacidade de raciocínio de LLMs através da otimização por gradiente de política no espaço latente: Um artigo intitulado “Seek in the Dark” propõe o LatentSeek, um novo paradigma para aprimorar a capacidade de raciocínio de Modelos de Linguagem Grandes (LLMs) em tempo de teste, através de gradiente de política em nível de instância no espaço latente. Este método não requer treinamento, dados ou modelos de recompensa, e visa melhorar o processo de raciocínio do modelo otimizando as representações latentes. Este método independente de treinamento mostra potencial para melhorar o desempenho de LLMs em tarefas complexas de raciocínio (Fonte: X)
Microsoft propõe CoML: Aprendizado de Modelo em Cadeia para modelos de linguagem: O Microsoft Research propôs um novo paradigma de aprendizado, o “Aprendizado de Modelo em Cadeia” (Chain-of-Model Learning, CoML). Este método integra as relações causais dos estados ocultos em uma estrutura em cadeia em cada camada da rede, visando aumentar a eficiência de escalabilidade do treinamento e a flexibilidade de inferência na implantação. Seu conceito central, a “Representação em Cadeia” (Chain-of-Representation, CoR), decompõe o estado oculto de cada camada em múltiplas subcadeias de representação, onde as cadeias subsequentes podem acessar as representações de entrada de todas as cadeias anteriores. Isso permite que o modelo se expanda progressivamente adicionando cadeias e possa fornecer submódulos de diferentes tamanhos para inferência elástica, selecionando diferentes números de cadeias. O CoLM (Chain-of-Language Model), projetado com base neste princípio, e sua variante CoLM-Air (que introduz um mecanismo de compartilhamento KV) demonstraram desempenho comparável ao Transformer padrão, trazendo as vantagens de expansão progressiva e inferência elástica (Fonte: X, HuggingFace Daily Papers)

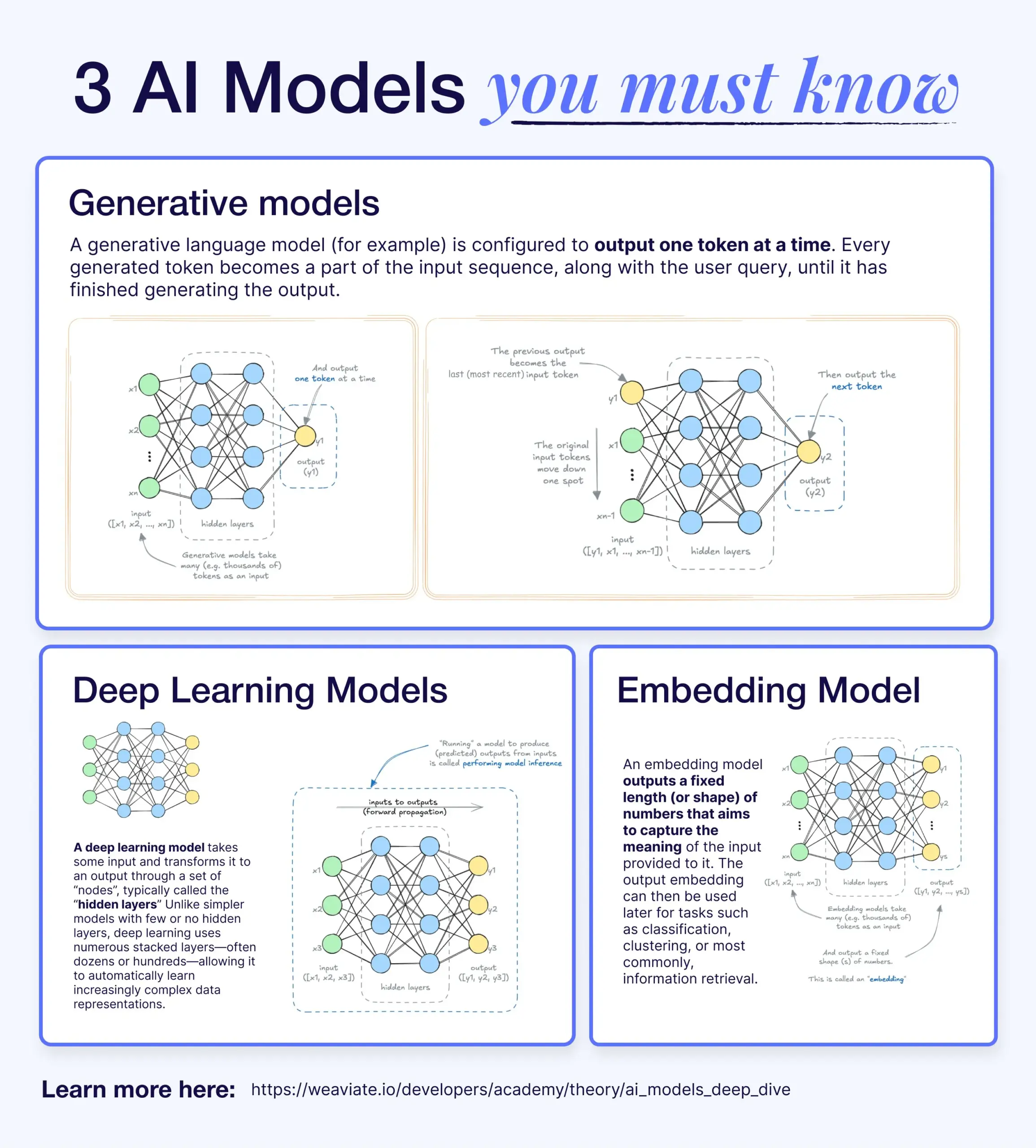
Diferenças e conexões entre modelos de deep learning, modelos generativos e modelos de embedding: Um artigo de divulgação explica a relação entre modelos de deep learning, modelos generativos e modelos de embedding. Modelos de deep learning são a infraestrutura básica, processando entrada e saída numéricas através de redes neurais multicamadas. Modelos generativos são um tipo de modelo de deep learning, especializados em criar novo conteúdo similar aos seus dados de treinamento (como GPT, DALL-E). Modelos de embedding também são um tipo de modelo de deep learning, usados para converter dados (texto, imagens, etc.) em representações vetoriais numéricas que capturam informação semântica, frequentemente usados em busca por similaridade e sistemas RAG. Em muitos sistemas de IA, esses modelos trabalham em conjunto; por exemplo, sistemas RAG utilizam modelos de embedding para recuperação e, em seguida, modelos generativos para gerar respostas (Fonte: X)
DSPy propõe filosofia de investimento em sistemas de IA: O DSPy compartilhou sua filosofia sobre o investimento em sistemas de IA, enfatizando que os esforços devem ser direcionados para as três camadas fundamentais dos sistemas de IA: dados, modelos e algoritmos. Eles acreditam que, ao fornecer módulos de alto nível combináveis (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules), os desenvolvedores podem iterar rapidamente nessas três camadas fundamentais, construindo assim sistemas de IA mais poderosos (Fonte: X)
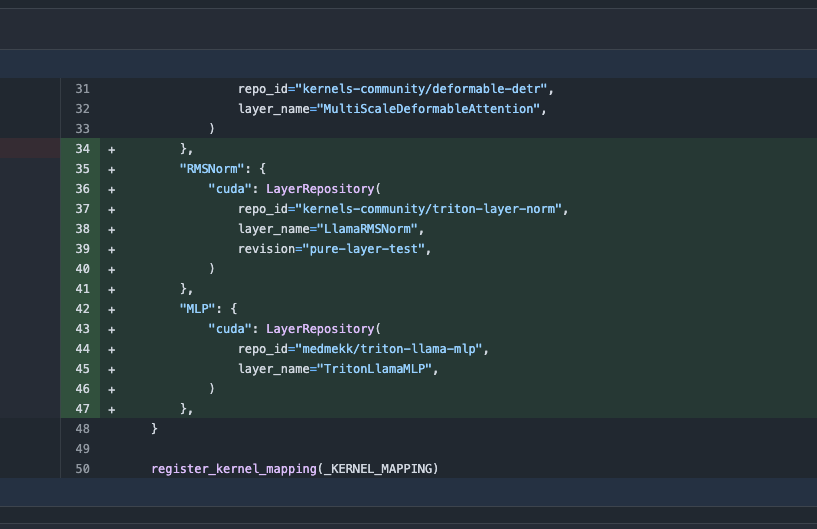
Biblioteca Transformers atualizada, alterna automaticamente para kernels otimizados para melhorar o desempenho: A versão mais recente da biblioteca Transformers do Hugging Face implementa a funcionalidade de alternar automaticamente para kernels otimizados quando o hardware permite. Esta atualização integra a biblioteca kernels, visando modelos populares como o Llama, e utiliza os kernels comunitários mais populares do Hugging Face Hub, com o objetivo de aumentar a eficiência e o desempenho da execução do modelo em hardware compatível (Fonte: X)
Benchmark ARC-AGI-2 lançado, desafiando sistemas de IA de ponta em raciocínio: François Chollet e colaboradores publicaram um artigo sobre o benchmark ARC-AGI-2, detalhando seus princípios de design, desafios, análise de desempenho humano e o desempenho dos modelos atuais. O benchmark visa avaliar a capacidade de raciocínio abstrato da IA. Humanos conseguem resolver 100% das tarefas, enquanto os modelos de IA de ponta atuais pontuam abaixo de 5%, mostrando uma enorme lacuna entre a IA e os humanos em raciocínio abstrato avançado (Fonte: X)

Terence Tao lança tutorial sobre como usar o GitHub Copilot para auxiliar na prova de limites de funções: O matemático Terence Tao lançou um vídeo tutorial demonstrando como usar o GitHub Copilot para auxiliar na prova de problemas de limites de funções, incluindo os teoremas da soma, diferença e produto. Ele enfatiza que, embora o Copilot possa gerar rapidamente o esqueleto de código e sugerir funções de bibliotecas existentes, ainda é necessária muita intervenção e ajuste manual em detalhes matemáticos complexos, tratamento de casos especiais e soluções criativas. Às vezes, combinar a derivação em papel e caneta antes da verificação formal pode ser mais eficiente (Fonte: 36氪)
Framework PhyT2V utiliza LLM para melhorar a consistência física na geração de vídeo a partir de texto: Uma equipe de pesquisa da Universidade de Pittsburgh propôs o framework PhyT2V, que, através de raciocínio em cadeia (CoT) guiado por Modelos de Linguagem Grandes e um mecanismo iterativo de autocorreção, otimiza os prompts de texto para aprimorar o realismo físico do conteúdo gerado por modelos existentes de texto para vídeo (T2V). Este método não requer retreinamento do modelo e, ao analisar a incompatibilidade semântica entre o vídeo já gerado e o prompt, e combinando regras físicas para corrigir o prompt, visa melhorar a consistência física dos modelos T2V ao lidar com cenários fora da distribuição (OOD). Experimentos mostram que o PhyT2V pode melhorar significativamente o desempenho de modelos como CogVideoX e OpenSora em benchmarks como VideoPhy e PhyGenBench (Fonte: WeChat)

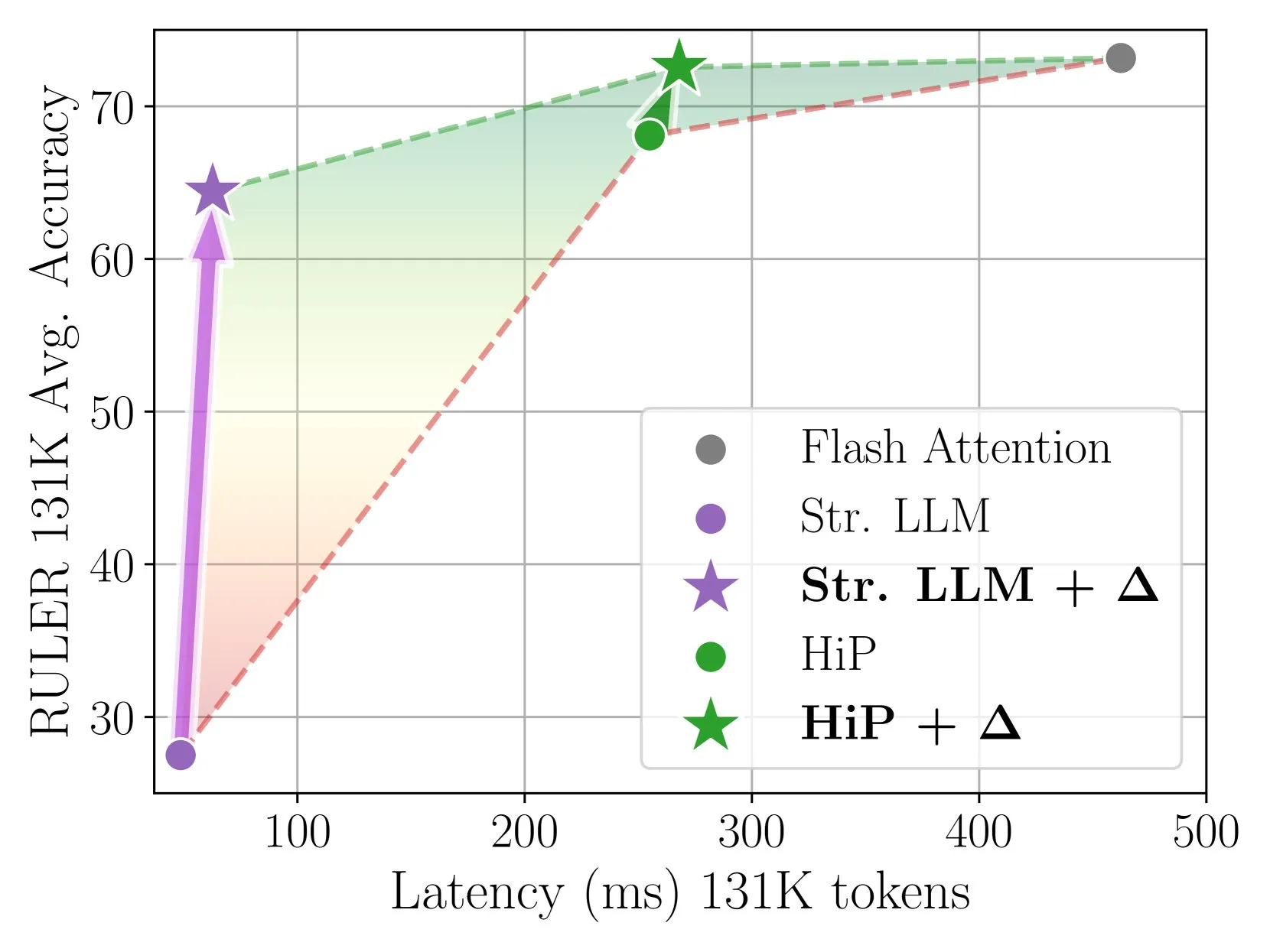
Delta Attention alcança inferência com atenção esparsa rápida e precisa através de correção incremental: Esta pesquisa descobriu que o cálculo de atenção esparsa causa um desvio de distribuição da saída da atenção, diminuindo o desempenho do modelo. O Delta Attention, ao corrigir esse desvio de distribuição, aproxima a distribuição da saída da atenção esparsa da atenção completa (full attention), resultando em um aumento significativo de desempenho enquanto mantém alta esparsidade (cerca de 98,5%). Ele recuperou 88% da precisão da atenção completa da atenção de janela deslizante (com sink tokens) no benchmark RULER, com baixo custo computacional. No pré-preenchimento de 1M tokens, foi 32 vezes mais rápido que o Flash Attention 2 (Fonte: HuggingFace Daily Papers)
Framework Thinkless permite que LLMs aprendam quando realizar inferência CoT: Para resolver o problema da baixa eficiência computacional causada pelo uso de Cadeias de Pensamento (CoT) complexas por Modelos de Linguagem Grandes (LLMs) em todas as consultas, pesquisadores propuseram o framework Thinkless. Este framework treina LLMs com aprendizado por reforço para que possam escolher adaptativamente entre raciocínio curto ou longo, com base na complexidade da tarefa e em sua própria capacidade. O algoritmo central, DeGRPO, decompõe o objetivo de aprendizado em perda de token de controle (que decide o modo de inferência) e perda de resposta (que melhora a precisão da resposta), estabilizando assim o processo de treinamento. Experimentos mostram que o Thinkless pode reduzir o uso de pensamento em cadeia longa em 50%-90% em benchmarks como o Minerva Algebra, aumentando significativamente a eficiência da inferência (Fonte: HuggingFace Daily Papers)
Algoritmo CPGD melhora a estabilidade do aprendizado por reforço baseado em regras para modelos de linguagem: Para lidar com os problemas de instabilidade no treinamento que podem ocorrer com métodos de aprendizado por reforço baseados em regras existentes (como GRPO, REINFORCE++, RLOO) ao treinar modelos de linguagem, pesquisadores propuseram o algoritmo CPGD (Otimização de Gradiente de Política Recortada com Desvio de Política). O CPGD introduz uma restrição de desvio de política baseada em divergência KL para regularizar dinamicamente as atualizações de política e utiliza um mecanismo de recorte de razão logarítmica para evitar atualizações excessivas de política. Análises teóricas e empíricas mostram que o CPGD pode mitigar a instabilidade e melhorar significativamente o desempenho, mantendo a estabilidade do treinamento (Fonte: HuggingFace Daily Papers)
Compilador de consulta neuro-simbólica QCompiler melhora a capacidade de processamento de consultas complexas em sistemas RAG: Para resolver a dificuldade dos sistemas de Geração Aumentada por Recuperação (RAG) em identificar com precisão a intenção de busca ao processar consultas complexas com estruturas aninhadas e relações de dependência, especialmente em situações com recursos limitados, foi proposto o framework QCompiler. Inspirado em regras gramaticais linguísticas e no design de compiladores, o framework primeiro projeta uma gramática BNF mínima e suficiente G[q] para formalizar consultas complexas. Em seguida, através de um transformador de expressão de consulta, um analisador léxico-sintático e um processador de descida recursiva, a consulta é compilada em uma árvore de sintaxe abstrata (AST) para execução. A atomicidade das subconsultas nos nós folha garante uma recuperação de documentos e geração de respostas mais precisas (Fonte: HuggingFace Daily Papers)
Dataset Jedi e benchmark OSWorld-G impulsionam pesquisa sobre localização de elementos GUI em cenários de uso de computador: Para resolver o gargalo na localização em interface gráfica do usuário (GUI) (mapear instruções em linguagem natural para operações GUI), pesquisadores lançaram o benchmark OSWorld-G (564 amostras anotadas com granularidade fina, cobrindo correspondência de texto, reconhecimento de elementos, compreensão de layout e operações precisas) e o dataset sintético em larga escala Jedi (4 milhões de amostras). Modelos multiescala treinados no Jedi superaram os métodos existentes no ScreenSpot-v2, ScreenSpot-Pro e OSWorld-G, e também melhoraram a capacidade de agentes de modelos de fundação gerais em tarefas complexas de computador (OSWorld), de 5% para 27% (Fonte: HuggingFace Daily Papers)
Raciocínio em Cadeia de Pensamento Fracionado (Fractured CoT) melhora eficiência e desempenho da inferência de LLM: Para resolver o problema de alto custo de tokens associado ao raciocínio CoT, pesquisadores descobriram que o CoT truncado (parar o raciocínio antes da conclusão e gerar diretamente a resposta) geralmente alcança desempenho comparável ao CoT completo, mas com consumo de tokens significativamente menor. Com base nisso, propuseram a estratégia de inferência unificada Fractured Sampling, que, ajustando três dimensões – o número de trajetórias de inferência, o número de soluções finais por trajetória e a profundidade de truncamento do traço de inferência – alcançou um melhor trade-off entre precisão e custo em múltiplos benchmarks de inferência e tamanhos de modelo, abrindo caminho para uma inferência LLM mais eficiente e escalável (Fonte: HuggingFace Daily Papers)
Validação multimodal de fórmulas químicas através de condicionamento de contexto de LLM e prompting PWP: Pesquisadores exploraram o condicionamento de contexto estruturado de LLM, combinado com os princípios de Prompting de Fluxo de Trabalho Persistente (PWP), para ajustar o comportamento de LLMs durante a inferência, visando aumentar sua confiabilidade em tarefas de validação precisa (como fórmulas químicas), especialmente ao lidar com documentos científicos complexos contendo imagens. O método utiliza apenas interfaces de chat padrão (Gemini 2.5 Pro, ChatGPT Plus o3), sem necessidade de API ou modificações no modelo. Experimentos preliminares mostram que este método melhorou a identificação de erros textuais e ajudou o Gemini 2.5 Pro a identificar erros em fórmulas de imagem que foram ignorados pela revisão manual (Fonte: HuggingFace Daily Papers)
Utilizando PWP, meta-prompting e meta-raciocínio para realizar revisão por pares acadêmica impulsionada por IA: Pesquisadores propuseram o método de Prompting de Fluxo de Trabalho Persistente (PWP) para realizar revisão por pares crítica de manuscritos científicos através de interfaces de chat LLM padrão. O PWP adota uma arquitetura modular hierárquica (estruturada em Markdown) para definir um fluxo de trabalho de análise detalhado, e através de meta-prompting e meta-raciocínio, codifica sistematicamente processos de revisão de especialistas (incluindo conhecimento tácito). O PWP guia o LLM a realizar uma avaliação multimodal sistemática, como distinguir alegações de evidências, integrar análise de texto/imagens/gráficos, executar verificações de viabilidade quantitativas, etc. Em casos de teste, identificou com sucesso falhas metodológicas (Fonte: HuggingFace Daily Papers)
Benchmark SPOT avalia a capacidade da IA de validar automaticamente pesquisas científicas: Para avaliar a capacidade dos Modelos de Linguagem Grandes (LLMs) como “cientistas co-pilotos de IA” na validação automatizada de manuscritos acadêmicos, pesquisadores lançaram o benchmark SPOT. Este benchmark contém 83 artigos publicados e 91 erros suficientes para causar erratas ou retratações, validados cruzadamente por autores originais e anotadores humanos. Os resultados experimentais mostram que mesmo os LLMs mais avançados (como o3) não ultrapassam 21,1% de recall no SPOT, com precisão inferior a 6,1%, baixa confiança do modelo e resultados inconsistentes em múltiplas execuções, indicando que os LLMs atuais estão muito aquém das necessidades reais para validação acadêmica confiável (Fonte: HuggingFace Daily Papers)
ExTrans alcança tradução com raciocínio profundo multilíngue através de aprendizado por reforço com aumento de amostras: Para aprimorar a capacidade dos Modelos de Raciocínio Grandes (LRM) na tradução automática, especialmente em cenários multilíngues, pesquisadores propuseram o ExTrans. Este método projeta uma nova abordagem de modelagem de recompensa, quantificando a recompensa ao comparar as traduções do modelo de política com as de um LRM forte (como DeepSeek-R1-671B). Experimentos mostram que um modelo treinado com Qwen2.5-7B-Instruct como espinha dorsal alcançou SOTA em tradução literária, superando OpenAI-o1 e DeepSeeK-R1. Através de uma modelagem de recompensa leve, o método consegue transferir efetivamente a capacidade de tradução unidirecional para 90 direções de tradução em 11 idiomas (Fonte: HuggingFace Daily Papers)
Atenção Esparsa Treinável VSA acelera modelos de difusão de vídeo: Para resolver o problema de complexidade quadrática do mecanismo de atenção total 3D nos Video Diffusion Transformers (DiT), pesquisadores propuseram a VSA (Atenção Esparsa Treinável). A VSA, através de uma fase grosseira leve, agrupa tokens em blocos e identifica tokens chave, realizando então um cálculo de atenção em nível de token de granularidade fina dentro desses blocos. A VSA é um kernel único diferenciável treinável de ponta a ponta, sem necessidade de análise de pós-processamento, e mantém 85% do MFU do FlashAttention3. Experimentos mostram que a VSA, sem diminuir a perda de difusão, reduziu os FLOPS de treinamento em 2,53 vezes e acelerou o tempo de atenção do modelo de código aberto Wan-2.1 em 6 vezes, reduzindo o tempo de geração de ponta a ponta de 31 para 18 segundos (Fonte: HuggingFace Daily Papers)
SoftCoT++: Alcançando escalonamento em tempo de teste através de raciocínio em cadeia de pensamento suave: Para aprimorar a capacidade de exploração do método SoftCoT, que realiza raciocínio no espaço latente contínuo, pesquisadores propuseram o SoftCoT++. Este método perturba ideias latentes com múltiplos tokens iniciais dedicados e aplica aprendizado contrastivo para promover a diversidade das representações de ideias suaves, estendendo assim o SoftCoT ao paradigma de escalonamento em tempo de teste (TTS). Experimentos mostram que o SoftCoT++ melhorou significativamente o desempenho do SoftCoT, superou o SoftCoT com escalonamento por autoconsistência e é altamente compatível com técnicas de escalonamento tradicionais (como autoconsistência) (Fonte: HuggingFace Daily Papers)
MTVCrafter: Tokenização de movimento 4D para animação de imagens humanas em mundo aberto: Para resolver o problema de capacidade de generalização limitada dos métodos existentes, que dependem de imagens de pose 2D, o MTVCrafter propõe modelar diretamente sequências de movimento 3D brutas (movimento 4D). Seu núcleo é o 4DMoT (Tokenizador de Movimento 4D), que quantiza sequências de movimento 3D em tokens de movimento 4D, fornecendo pistas espaço-temporais mais robustas. Em seguida, o MV-DiT (Motion-aware Video DiT), projetado com atenção de movimento única e codificação de posição 4D, utiliza eficientemente esses tokens como contexto para realizar animação de imagens humanas em mundos 3D complexos. Experimentos mostram que o MTVCrafter alcançou 6,98 no FID-VID, superando significativamente o SOTA, e generaliza bem para múltiplos personagens em diferentes estilos e cenários (Fonte: HuggingFace Daily Papers)
QVGen: Impulsionando os limites dos modelos de geração de vídeo quantizados: Para lidar com as altas demandas computacionais e de memória dos modelos de difusão de vídeo (DM), o QVGen propõe um novo framework de treinamento ciente de quantização (QAT) projetado especificamente para quantização de bits extremamente baixos (como 4 bits e abaixo). Através de análise teórica, os pesquisadores descobriram que reduzir a norma do gradiente é crucial para a convergência do QAT e introduziram um módulo auxiliar (Phi) para mitigar grandes erros de quantização. Para eliminar o overhead de inferência do Phi, propuseram uma estratégia de decaimento de posto (rank), eliminando gradualmente o Phi através de SVD e regularização baseada em posto. Experimentos mostram que o QVGen, na configuração de 4 bits, alcançou pela primeira vez qualidade comparável à precisão total, superando significativamente os métodos existentes (Fonte: HuggingFace Daily Papers)
ViPlan: Benchmark de predicados simbólicos e modelos de linguagem visual para planejamento visual: Para preencher a lacuna na comparação entre o planejamento simbólico orientado por VLM e os métodos de planejamento direto com VLM, o ViPlan foi proposto como o primeiro benchmark de planejamento visual de código aberto. O ViPlan inclui uma série de tarefas de dificuldade crescente em dois grandes domínios: uma versão visual do Blocksworld e um ambiente simulado de robô doméstico. Testes de benchmark em 9 famílias de VLM de código aberto e alguns modelos de código fechado revelaram que o planejamento simbólico tem melhor desempenho no Blocksworld (onde a localização precisa de imagem é crucial), enquanto o planejamento direto com VLM é melhor em tarefas de robô doméstico (onde o conhecimento de senso comum e a capacidade de recuperação de erros são importantes). A pesquisa também mostrou que os prompts CoT não trazem benefícios significativos para a maioria dos modelos e métodos, sugerindo que a capacidade atual de raciocínio visual dos VLMs ainda é insuficiente (Fonte: HuggingFace Daily Papers)
Do Grito Primitivo à Gramática: Um Estudo da Evolução da Linguagem em Ambientes Cooperativos de Coleta de Alimentos: Para investigar a origem e evolução da linguagem, pesquisadores simularam cenários de cooperação humana primitiva em um jogo de coleta de alimentos multiagente. Através de aprendizado por reforço profundo de ponta a ponta, os agentes aprenderam estratégias de ação e comunicação do zero. A pesquisa descobriu que os protocolos de comunicação desenvolvidos pelos agentes exibiam características marcantes da linguagem natural: arbitrariedade, intercambialidade, deslocamento, transmissão cultural e composicionalidade. Este framework fornece uma plataforma para estudar como a linguagem evolui em ambientes multiagente incorporados parcialmente observáveis, com raciocínio temporal e orientados por objetivos cooperativos (Fonte: HuggingFace Daily Papers)
Tiny QA Benchmark++: Geração de Dataset Sintético Multilíngue Ultraleve e Teste de Fumaça para Avaliação Contínua de LLMs: O Tiny QA Benchmark++ (TQB++) é um conjunto de testes de fumaça (smoke test) ultraleve e multilíngue, projetado para fornecer uma rede de segurança no estilo de teste unitário para pipelines de LLM, que pode ser executado em segundos com custo extremamente baixo. O TQB++ inclui um conjunto dourado (golden set) em inglês de 52 itens e fornece um gerador de dados sintéticos minúsculo baseado em LiteLLM (pacote pypi), permitindo aos usuários gerar pequenos pacotes de teste com idioma, domínio ou dificuldade personalizados. O projeto já oferece pacotes pré-fabricados em 10 idiomas e suporta ferramentas como OpenAI-Evals e LangChain, facilitando a integração em fluxos de CI/CD para detecção rápida de erros em templates de prompt, desvio de tokenizador e efeitos colaterais de fine-tuning (Fonte: HuggingFace Daily Papers)
HelpSteer3-Preference: Dataset Aberto de Preferências Anotadas por Humanos Abrangendo Múltiplas Tarefas e Idiomas: Para atender à demanda por dados de preferência abertos, diversos e de alta qualidade, a NVIDIA lançou o dataset HelpSteer3-Preference. Este dataset contém mais de 40.000 amostras de preferência anotadas por humanos, seguindo a licença CC-BY-4.0, e abrange aplicações reais de LLM, como STEM, codificação e cenários multilíngues. Modelos de recompensa (RM) treinados com este dataset alcançaram desempenho SOTA no RM-Bench (82,4%) e JudgeBench (73,7%), melhorando os resultados anteriores em cerca de 10%. Este dataset também pode ser usado para treinar RMs generativos e alinhar modelos de política via RLHF (Fonte: HuggingFace Daily Papers)
SEED-GRPO: GRPO Aprimorado por Entropia Semântica para Otimização de Política Ciente de Incerteza: Para resolver o problema do GRPO não considerar a incerteza do LLM em relação aos prompts de entrada durante a atualização da política, pesquisadores propuseram o SEED-GRPO. Este método utiliza entropia semântica para medir explicitamente a incerteza do LLM em relação aos prompts de entrada (ou seja, a diversidade semântica de múltiplas respostas geradas) e usa isso para ajustar a magnitude da atualização da política. Este mecanismo de treinamento ciente de incerteza permite atualizações mais conservadoras para questões de alta incerteza, enquanto mantém o sinal de aprendizado original para questões de confiança. Experimentos mostram que o SEED-GRPO alcançou desempenho SOTA em cinco benchmarks de raciocínio matemático (Fonte: HuggingFace Daily Papers)
Criando um Modelo de Usuário Geral (GUM) a partir do Uso do Computador: Pesquisadores propuseram uma arquitetura de Modelo de Usuário Geral (GUM) que aprende conhecimento e preferências do usuário observando qualquer interação do usuário com o computador (como capturas de tela do dispositivo) e constrói proposições ponderadas por confiança. O GUM é capaz de inferir novas proposições a partir de observações multimodais não estruturadas, recuperar proposições relevantes como contexto e corrigir continuamente proposições existentes. Esta arquitetura visa aprimorar assistentes de chat, gerenciar notificações do sistema operacional e permitir que agentes interativos se adaptem às preferências do usuário em diferentes aplicativos. Experimentos mostram que o GUM pode fazer inferências de usuário calibradas e precisas, e assistentes baseados no GUM podem identificar e executar proativamente ações úteis não solicitadas explicitamente pelo usuário (Fonte: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: Projeto popular no GitHub que oferece um repositório abrangente de recursos de aprendizado em engenharia de dados, incluindo um roteiro para iniciantes em 2024, materiais de um bootcamp gratuito de 6 semanas no YouTube, estudos de caso de projetos, dicas de entrevista, livros recomendados, e listas de comunidades e newsletters. Entre os livros recomendados estão “Fundamentals of Data Engineering”, “Designing Data-Intensive Applications” e “Designing Machine Learning Systems”. O manual também lista empresas em diversas áreas da engenharia de dados, como Mage (orquestração), Databricks (data lake), Snowflake (data warehouse), dbt (qualidade de dados), LangChain (biblioteca de aplicações LLM), etc., e fornece links para blogs de engenharia de dados de empresas renomadas e white papers importantes (Fonte: GitHub Trending)
💼 Negócios
Cohere e SAP colaboram para levar agentes de IA de nível empresarial a negócios globais: A Cohere anunciou uma parceria com a SAP para incorporar sua tecnologia de agentes de IA de nível empresarial no SAP Business Suite, fornecendo capacidades de IA seguras e escaláveis para empresas em todo o mundo. Os modelos de ponta da Cohere também estarão disponíveis no SAP AI Core, permitindo que empresas em setores como finanças e saúde utilizem seus modelos de IA multilíngues e específicos de domínio (Command, Embed, Rerank), com o objetivo de acelerar a aplicação de IA nas empresas e liberar valor comercial real (Fonte: X, X)
xAI busca utilizar dados governamentais para expandir negócios empresariais e governamentais: Segundo o The Information, a empresa xAI de Elon Musk planeja utilizar dados de agências governamentais para desenvolver modelos e aplicações, e vendê-los para clientes governamentais. Esta iniciativa pode se tornar uma parte importante da estratégia de comercialização da xAI, mas também levanta discussões sobre o uso de dados e potenciais vieses (Fonte: X)
Weaviate e AWS aprofundam colaboração global para acelerar iniciativas de IA generativa: A empresa de banco de dados vetorial Weaviate anunciou o fortalecimento de sua colaboração global com a AWS, visando acelerar conjuntamente projetos de IA generativa. Esta parceria se concentrará em fornecer maior velocidade, maior escala e melhor experiência para desenvolvedores em todo o mundo, impulsionando a aplicação e o desenvolvimento da tecnologia de IA generativa (Fonte: X)

🌟 Comunidade
Ascensão dos agentes de programação de IA gera discussão sobre perspectivas de carreira para programadores: Empresas como Microsoft e OpenAI estão lançando ou fortalecendo agentes de programação de IA (Coding Agents), como o GitHub Copilot Coding Agent e o OpenAI Codex, capazes de realizar autonomamente tarefas como codificação, correção de bugs e manutenção de código. Dario Amodei, CEO da Anthropic, prevê que a IA poderá escrever a maior parte ou até mesmo todo o código em breve, e Kevin Weil, CPO da OpenAI, também acredita que a IA evoluirá de engenheiro júnior para arquiteto. Isso gerou uma ampla discussão na comunidade sobre o futuro da carreira de programador: alguns temem que cargos de nível júnior sejam substituídos e que a IA automatize grande parte do trabalho de programação; outros acreditam que a IA aumentará a eficiência dos programadores, permitindo que se concentrem em design de arquitetura de nível superior e inovação, transformando seu papel em “guia de IA”. A tendência geral indica que aprender a colaborar eficientemente com a IA se tornará uma habilidade central para programadores (Fonte: X, X, 36氪, 36氪)
Discussão acirrada sobre o conceito e os padrões de Agentes de IA, protocolo MCP recebe atenção: Com o surgimento de aplicações de Agentes de IA (como Manus, Genspark Super Agent, Fellou.ai), a comunidade debate intensamente a definição, os níveis de capacidade e os paradigmas de desenvolvimento de Agentes. A renomada empresa de capital de risco BVP propôs uma classificação de Agentes em sete níveis, de L0 a L6. Ao mesmo tempo, o Protocolo de Contexto de Modelo (MCP), como tecnologia chave para alcançar a interoperabilidade entre aplicações de IA, tem recebido atenção. Grandes empresas internacionais como Anthropic, OpenAI e Google já suportam ou planejam suportar o MCP, enquanto empresas chinesas como Alibaba Cloud e Tencent Cloud também começaram a construir plataformas de desenvolvimento de Agentes localizadas em torno do MCP. O desenvolvedor iluxu chegou a abrir o código do projeto llmbasedos, similar ao conceito “USB-C for AI apps” proposto pela Microsoft, antes mesmo de seu anúncio, visando promover padrões abertos de conexão para Agentes (Fonte: X, X, WeChat, Reddit r/LocalLLaMA)
LLMs têm desempenho insatisfatório em tarefas específicas de raciocínio, levantando discussões sobre os limites de sua capacidade: A comunidade discute acaloradamente o fenômeno de “falha coletiva” de LLMs em certas tarefas de raciocínio físico ou espaço-visual aparentemente simples, como um problema sobre empilhar cubos para formar um cubo maior, onde até mesmo modelos de ponta como o3 e Gemini 2.5 Pro forneceram respostas erradas. Ao mesmo tempo, um artigo de avaliação aponta que, em tarefas físicas básicas como fabricação de peças, LLMs (incluindo o3) têm desempenho inferior a trabalhadores experientes, principalmente devido à capacidade visual insuficiente, erros de raciocínio físico e falta de conhecimento tácito do mundo real. Esses casos levantam discussões sobre a capacidade real de compreensão dos LLMs, o problema de alucinação (por exemplo, aumento da taxa de alucinação do o3 durante a inferência) e a validade dos benchmarks atuais, enfatizando que a IA ainda tem muito espaço para melhoria em conhecimento de domínio específico e raciocínio complexo (Fonte: 量子位, 36氪)

Competição tecnológica China-EUA e estratégias de desenvolvimento de IA atraem atenção: Em uma entrevista, Jensen Huang, CEO da Nvidia, falou sobre controles de chips, fábricas de IA e pragmatismo empresarial, e suas opiniões foram interpretadas como uma visão profunda sobre o atual cenário da competição tecnológica China-EUA. Alguns comentaristas acreditam que os EUA tentam manter a liderança restringindo o acesso da China a recursos de IA de ponta, mas isso pode levar a uma situação de perde-perde, desacelerando o desenvolvimento global da IA. Jensen Huang, por outro lado, parece acreditar que a verdadeira competição é de longo prazo, e que os EUA devem liderar em todas as frentes (chips, fábricas, infraestrutura, modelos, aplicações), em vez de buscar apenas vantagens relativas de curto prazo, caso contrário, podem perder as oportunidades de desenvolvimento da era da IA e, finalmente, ficar para trás na competição de poder nacional abrangente (Fonte: X)
Aplicações e discussões sobre ferramentas de IA como ChatGPT no auxílio à saúde mental: Usuários da comunidade Reddit compartilharam experiências de uso de ferramentas de IA como ChatGPT para apoio à saúde mental, considerando que elas podem oferecer ajuda entre sessões de terapia profissional, especialmente na organização e expressão de emoções complexas. Os usuários fazem perguntas à IA ou pedem que a IA faça perguntas sobre seus sentimentos para entender melhor a origem das emoções e elaborar planos de melhoria. Nos comentários, alguns usuários (incluindo alguns que se identificaram como terapeutas) consideram que a IA, em certas situações, pode ser até superior a alguns terapeutas humanos, especialmente para indivíduos com dificuldade de acesso a ajuda profissional ou com barreiras de confiança em relação a terapeutas humanos. No entanto, outros usuários alertam que a IA não pode substituir completamente o tratamento profissional e que se deve prestar atenção às questões de privacidade de dados pessoais (Fonte: Reddit r/ChatGPT)
💡 Outros
Lançamento da competição de algoritmos “Qizhi Cup”, com foco em três direções de ponta da IA: O Qiyuan Lab lançou a competição de algoritmos “Qizhi Cup”, com um prêmio total de 750.000 yuans. A competição estabelece três trilhas: “Segmentação Robusta de Instâncias em Imagens de Sensoriamento Remoto por Satélite”, “Detecção de Alvos Terrestres por UAVs para Plataformas Embarcadas” e “Ataques Adversariais contra Modelos Grandes Multimodais”, visando promover a inovação e aplicação de tecnologias centrais de IA, como percepção robusta, implantação leve e defesa adversarial. O evento é aberto a instituições de pesquisa, empresas e unidades de serviço público nacionais (Fonte: WeChat)

Chicago Sun-Times comete erro em conteúdo gerado por IA, recomenda livros e especialistas inexistentes: Em uma edição com recomendações de atividades de verão, parte do conteúdo do Chicago Sun-Times parece ter sido gerado por IA, incluindo recomendações de livros fictícios de autores reais e citações de opiniões de “especialistas” aparentemente inexistentes. Por exemplo, listou “Nightshade Market” de Min Jin Lee e “Boiling Point” de Rebecca Makkai como leituras recomendadas, mas esses livros não existem. O incidente gerou preocupações sobre a precisão e os mecanismos de revisão quando a mídia jornalística usa conteúdo gerado por IA (Fonte: Reddit r/artificial)
Discussão sobre se a IA constitui “trapaça”: A comunidade debateu os limites do uso de ferramentas de IA (como ChatGPT, Claude) no trabalho e nos estudos. A opinião predominante é que, na ausência de regras explícitas que proíbam (como em trabalhos universitários), usar ferramentas de IA para aumentar a eficiência, realizar tarefas repetitivas ou auxiliar o pensamento não é “trapaça”, mas sim semelhante a usar uma calculadora ou um motor de busca. O fundamental é se o usuário entende a saída da IA, pode ajustá-la e validá-la efetivamente, e se declara honestamente o papel auxiliar da IA (especialmente em cenários acadêmicos). No entanto, se houver dependência completa do conteúdo gerado por IA e este for reivindicado como original sem discernimento, isso pode envolver má conduta acadêmica ou afetar o desenvolvimento de habilidades pessoais (Fonte: Reddit r/ArtificialInteligence)