
Palavras-chave:AlphaEvolve, Gemini, algoritmo evolutivo, agente de IA, otimização de algoritmo, multiplicação de matrizes, Borg Data Center, otimização de multiplicação de matrizes complexas 4×4, descoberta de algoritmos do Google DeepMind, design automatizado de algoritmos por IA, aplicação do Gemini 2.0 Pro, otimização de alocação de recursos no Borg
🔥 Destaques
Google DeepMind lança AlphaEvolve: Agente de codificação de algoritmos evolutivos baseado em Gemini alcança avanços em matemática e ciência da computação: O Google DeepMind anunciou o AlphaEvolve, um agente que utiliza o Large Language Model Gemini 2.0 Pro para descobrir e otimizar automaticamente códigos de algoritmos por meio de algoritmos evolutivos. O AlphaEvolve é capaz de gerar, avaliar e aprimorar autonomamente soluções candidatas a partir de código inicial e métricas de avaliação fornecidas por humanos. O sistema demonstrou excelente desempenho em mais de 50 problemas matemáticos, reproduzindo soluções conhecidas em aproximadamente 75% dos casos e descobrindo soluções melhores em 20% dos casos. Notavelmente, o AlphaEvolve reduziu o número de cálculos para a multiplicação de matrizes complexas 4×4 de 49 para 48, quebrando um recorde de 56 anos. Além disso, otimizou o algoritmo de agendamento do data center Borg interno do Google, recuperando 0,7% dos recursos computacionais globais, e aprimorou o design dos chips TPU de próxima geração, reduzindo o tempo de treinamento do Gemini em 1%. Este resultado demonstra o enorme potencial da IA na descoberta automatizada de algoritmos e na inovação científica, embora atualmente lide principalmente com problemas que podem ser avaliados automaticamente, suas perspectivas de aplicação em ciências aplicadas, como a descoberta de medicamentos, são amplas. (Fonte: , QubitAI, 36Kr)
Nvidia anuncia múltiplos avanços em IA na Computex 2025, Jensen Huang enfatiza a visão de Agentic AI e Physical AI: O CEO da Nvidia, Jensen Huang, fez um discurso principal na Computex 2025, enfatizando que a IA está evoluindo de “resposta única” para “Agentic AI” (IA de agentes) pensante e baseada em raciocínio, e “Physical AI” (IA física) que compreende o mundo físico. Para apoiar essa tendência, a Nvidia lançou a plataforma Blackwell estendida (Blackwell Ultra AI) e anunciou que o sistema Grace Blackwell GB300 entrou em produção total, com seu desempenho de inferência 1,5 vezes maior que a geração anterior. Huang também apresentou uma prévia do superchip de IA de próxima geração, Rubin Ultra, com desempenho 14 vezes superior ao GB300. Para promover a construção de infraestrutura de IA, a Nvidia lançou a tecnologia NVLink Fusion e estabeleceu um supercomputador de IA em Taiwan em colaboração com TSMC, Foxconn e outros. Além disso, a Nvidia atualizou seu modelo de fundação para robôs humanoides, Isaac GR00T N1.5, melhorando sua adaptabilidade ambiental e capacidade de execução de tarefas, e planeja abrir o código do motor de física Newton, desenvolvido em colaboração com DeepMind e Disney Research. (Fonte: AI Frontline, QubitAI, Reddit r/artificial)
Equipe do OpenAI Codex AMA revela planos de integração do GPT-5 e produtos futuros: A equipe do OpenAI Codex realizou um evento “Ask Me Anything” (AMA) no Reddit, onde o vice-presidente de pesquisa, Jerry Tworek, revelou que o objetivo do modelo de fundação de próxima geração, GPT-5, é aprimorar as capacidades dos modelos existentes e reduzir a necessidade de alternar entre modelos. Há planos para integrar ferramentas existentes como Codex, Operator (agente de execução de tarefas), Deep Research (ferramenta de pesquisa profunda) e Memory (função de memória) para formar uma experiência unificada de assistente de IA. Os membros da equipe também compartilharam a motivação original para o desenvolvimento do Codex (originada de uma reflexão interna sobre a subutilização do modelo), o aumento de aproximadamente 3 vezes na eficiência de programação obtido com o uso interno do Codex, e as perspectivas para o futuro da engenharia de software – transformar requisitos em software funcional de forma eficiente e confiável. O Codex atualmente utiliza principalmente informações carregadas no runtime do contêiner, e no futuro poderá combinar a tecnologia RAG para obter conhecimento atualizado. A OpenAI também está explorando esquemas de preços flexíveis e planeja oferecer créditos de API gratuitos para usuários Plus/Pro usarem com o Codex CLI. (Fonte: 36Kr)
VS Code anuncia extensão GitHub Copilot Chat de código aberto, planeja construir plataforma de edição de código AI de código aberto: A equipe do Visual Studio Code anunciou planos para transformar o VS Code em um editor de IA de código aberto, aderindo aos princípios fundamentais de abertura, colaboração e orientação pela comunidade. Como parte deste plano, a extensão GitHub Copilot Chat foi disponibilizada no GitHub sob a licença MIT. No futuro, o VS Code planeja integrar gradualmente essas funcionalidades de IA ao núcleo do editor, com o objetivo de construir uma plataforma de edição de código AI totalmente de código aberto e orientada pela comunidade para aumentar a eficiência, transparência e segurança do desenvolvimento. Esta medida é considerada um passo importante da Microsoft no campo do código aberto e pode ter um impacto profundo no ecossistema de ferramentas de programação assistida por IA. (Fonte: dotey, jeremyphoward)
Huawei Ascend e DeepSeek colaboram, desempenho de inferência do modelo MoE supera Nvidia Hopper: A Huawei Ascend anunciou que seu supernó CloudMatrix 384 e servidor de inferência Atlas 800I A2 alcançaram um grande avanço no desempenho de inferência ao implantar modelos MoE de ultra-grande escala como DeepSeek V3/R1, superando a arquitetura Nvidia Hopper sob condições específicas. O supernó CloudMatrix 384 ultrapassou 1920 Tokens/s de throughput de Decode por placa com latência de 50ms, enquanto o Atlas 800I A2 atingiu 808 Tokens/s de throughput por placa com latência de 100ms. A Huawei atribui isso à sua estratégia de “complementar a física com a matemática”, compensando as limitações do processo de hardware por meio da otimização de algoritmos e sistemas. Relatórios técnicos relacionados foram publicados e o código principal será aberto em um mês. As medidas de otimização incluem soluções de paralelismo de especialistas para modelos MoE, implantação separada de PD, adaptação do framework vLLM, estratégia de quantização A8W8C16, bem como esquema de comunicação FlashComm, conversão de paralelismo intra-camada, motor de inferência especulativa FusionSpec e otimização de afinidade de hardware para operadores MLA/MoE. (Fonte: QubitAI, WeChat)
🎯 Tendências
Apple torna público o eficiente modelo de linguagem visual FastVLM, otimizando a experiência de IA em dispositivos de borda: A Apple tornou público o FastVLM (Fast Vision Language Model), um modelo de linguagem visual projetado especificamente para operar eficientemente em dispositivos de borda como o iPhone. O FastVLM, ao introduzir um novo codificador visual híbrido FastViTHD, combinando camadas convolucionais com módulos Transformer e utilizando técnicas de pooling multiescala e downsampling, reduz significativamente o número de tokens visuais necessários para o processamento de imagens (16 vezes menos que o ViT tradicional). Isso permite que o modelo mantenha alta precisão enquanto alcança uma velocidade de saída do primeiro token (TTFT) até 85 vezes mais rápida em comparação com modelos semelhantes. O FastVLM é compatível com LLMs convencionais e é facilmente adaptável ao ecossistema iOS/Mac, oferecendo versões com parâmetros de 0.5B, 1.5B e 7B, adequadas para diversas tarefas de imagem e texto em tempo real, como descrição de imagens, perguntas e respostas, e análise. (Fonte: WeChat)
Meta lança modelo KernelLLM 8B, supera GPT-4o em benchmarks específicos: A Meta lançou o modelo KernelLLM 8B no Hugging Face. Alegadamente, no benchmark KernelBench-Triton Level 1, este modelo de 8 bilhões de parâmetros superou modelos de maior escala como GPT-4o e DeepSeek V3 em desempenho de inferência única. Em casos de inferência múltipla, o desempenho do KernelLLM também foi superior ao DeepSeek R1. Este lançamento atraiu a atenção da comunidade de IA, sendo considerado mais um exemplo de modelos de pequeno e médio porte demonstrando forte competitividade em tarefas específicas. (Fonte: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Modelo Mistral Medium 3 apresenta forte desempenho na Arena, especialmente destacado na área técnica: O novo modelo Mistral Medium 3 da Mistral AI demonstrou excelente desempenho na avaliação da comunidade em lmarena.ai, classificando-se em 11º lugar na capacidade geral de chat, uma melhoria significativa em relação ao Mistral Large (aumento de 90 pontos na pontuação Elo). O modelo destacou-se particularmente na área técnica, classificando-se em 5º lugar em capacidade matemática, 7º em prompts complexos e capacidade de codificação, e 9º na WebDev Arena. Comentários da comunidade sugerem que seu desempenho na área técnica está próximo do nível do GPT-4.1, com um custo potencialmente mais competitivo, semelhante ao preço do GPT-4.1 mini. Os usuários podem experimentar o modelo gratuitamente na interface de chat oficial da Mistral. (Fonte: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets adiciona funcionalidade para visualização direta de conversas de chat: A plataforma Hugging Face Datasets passou por uma atualização importante, permitindo agora que os usuários leiam diretamente o conteúdo de conversas de chat nos datasets. Esta funcionalidade foi considerada por membros da comunidade (como Caleb, Maxime Labonne) um grande passo para resolver problemas de qualidade de dados, pois a consulta direta aos dados originais da conversa ajuda a entender melhor os dados, realizar a limpeza dos dados e melhorar os resultados do treinamento do modelo. Anteriormente, a visualização de conversas específicas poderia exigir código ou ferramentas adicionais; a nova funcionalidade simplifica esse processo, aumentando a conveniência e a transparência do trabalho com dados. (Fonte: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM integra-se com Hugging Face Hub, simplificando a execução local de modelos no Mac: O MLX LM agora está diretamente integrado ao Hugging Face Hub, permitindo que usuários de Mac executem localmente mais de 4400 LLMs em dispositivos Apple Silicon com maior facilidade. Os usuários precisam apenas clicar em “Use this model” na página de modelos compatíveis no Hugging Face Hub para executar rapidamente o modelo no terminal, sem configurações complexas na nuvem ou espera. Além disso, é possível iniciar servidores compatíveis com OpenAI diretamente da página do modelo. Essa integração visa reduzir a barreira para executar modelos localmente, aumentando a eficiência do desenvolvimento e da experimentação. (Fonte: awnihannun, ClementDelangue, huggingface, reach_vb)
Nvidia torna público o modelo de inferência de IA Física Cosmos-Reason1-7B: A Nvidia tornou público no Hugging Face o seu Cosmos-Reason1-7B, parte da sua série de modelos de Physical AI. Este modelo visa compreender o senso comum do mundo físico e gerar decisões incorporadas correspondentes. Isso marca um novo passo da Nvidia na promoção da integração do mundo físico com a IA, fornecendo novas ferramentas e bases de pesquisa para aplicações que exigem interação com o ambiente físico, como robótica e condução autônoma. (Fonte: reach_vb)
Modelo de geração de vídeo Steamer-I2V do Baidu lidera ranking VBench de imagem para vídeo: O modelo de geração de vídeo Steamer-I2V do Baidu alcançou o primeiro lugar na categoria de imagem para vídeo (I2V) do VBench, um renomado ranking de avaliação de geração de vídeo, com uma pontuação total de 89,38%, superando modelos conhecidos como OpenAI Sora e Google Imagen Video. As vantagens técnicas do Steamer-I2V incluem controle preciso da imagem em nível de pixel, movimentos de câmera de nível mestre, qualidade de imagem cinematográfica de alta definição de até 1080P e estética dinâmica, além de compreensão semântica precisa do chinês baseada em um banco de dados multimodal chinês de centenas de milhões de itens. Este resultado demonstra a força do Baidu no campo da geração multimodal e faz parte de sua estratégia para construir um ecossistema de conteúdo de IA. (Fonte: 36Kr)

LLMs apresentam baixo desempenho em tarefas de leitura de tempo, como relógios e calendários: Pesquisadores da Universidade de Edimburgo e outras instituições descobriram que, apesar do excelente desempenho de Large Language Models (LLMs) e Multimodal Large Language Models (MLLMs) em diversas tarefas, sua precisão em tarefas aparentemente simples de leitura de tempo (como identificar a hora em relógios analógicos e compreender datas em calendários) é preocupante. A pesquisa construiu dois conjuntos de testes personalizados, ClockQA e CalendarQA, e os resultados mostraram que a precisão dos sistemas de IA na leitura de relógios foi de apenas 38,7%, e na identificação de datas em calendários foi de apenas 26,3%. Mesmo modelos avançados como Gemini-2.0 e GPT-o1 apresentaram dificuldades significativas, especialmente ao lidar com algarismos romanos, ponteiros estilizados ou cálculos de datas complexos (como anos bissextos, ou em que dia da semana cai um determinado dia). Os pesquisadores acreditam que isso expõe as deficiências dos modelos atuais em raciocínio espacial, análise de layouts estruturados e generalização para padrões incomuns. (Fonte: 36Kr, WeChat)

Microsoft anuncia na Build a introdução do modelo Grok no Azure AI Foundry: Na conferência de desenvolvedores Microsoft Build 2025, a Microsoft anunciou que o modelo Grok da xAI se juntará à sua série de modelos Azure AI Foundry. Os usuários poderão experimentar gratuitamente o Grok-3 e o Grok-3-mini no Azure Foundry e no GitHub até o início de junho. Esta medida significa que o Azure AI Foundry expandirá ainda mais sua gama de modelos de terceiros suportados, e no futuro os usuários poderão usar modelos de vários fornecedores, como OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs, através de uma taxa de transferência reservada unificada. (Fonte: TheTuringPost, xai)
Apple planeja permitir que usuários de iPhone na UE substituam a Siri por assistentes de voz de terceiros, segundo relatos: De acordo com Mark Gurman, a Apple está planejando permitir, pela primeira vez, que usuários de iPhone na União Europeia substituam a Siri por assistentes de voz de terceiros. Esta medida pode ser uma resposta aos requisitos cada vez mais rigorosos de regulamentação do mercado digital da UE, visando aumentar a abertura da plataforma e o poder de escolha do usuário. Se o plano for implementado, terá um impacto importante no cenário do mercado de assistentes de voz, oferecendo a outros assistentes de voz a oportunidade de entrar no ecossistema da Apple. (Fonte: zacharynado)

Meta lança dataset Open Molecules 2025 e modelo UMA, acelerando a descoberta de moléculas e materiais: A Meta AI lançou o Open Molecules 2025 (OMol25) e o Meta Universal Atomic model (UMA). O OMol25 é atualmente o maior e mais diversificado dataset de cálculos de química quântica de alta precisão, incluindo biomoléculas, complexos metálicos e eletrólitos. O UMA é um modelo de potencial interatômico de aprendizado de máquina treinado com mais de 30 bilhões de átomos, projetado para fornecer previsões mais precisas do comportamento molecular. O código aberto dessas ferramentas visa acelerar a descoberta e inovação em ciências moleculares e de materiais. (Fonte: AIatMeta)
Hugging Face Datasets adiciona funcionalidade de edição incremental para arquivos Parquet: O Hugging Face Datasets anunciou que a versão noturna de sua biblioteca de dependência subjacente, PyArrow, agora suporta a edição incremental de arquivos Parquet sem a necessidade de reescrever completamente o arquivo. Esta nova funcionalidade aumentará significativamente a eficiência das operações em datasets de grande escala, especialmente quando atualizações ou modificações parciais de dados são frequentes, reduzindo consideravelmente o tempo e os recursos computacionais consumidos. Espera-se que esta medida melhore a experiência dos desenvolvedores no manuseio e manutenção de grandes datasets de treinamento de IA. (Fonte: huggingface)
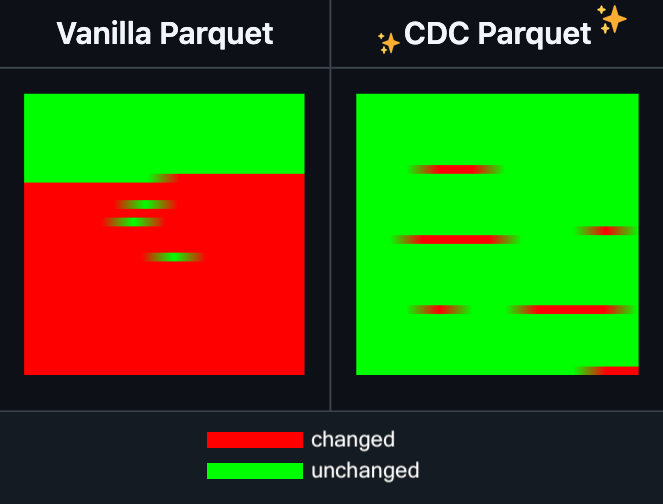
LangGraph adiciona funcionalidade de cache em nível de nó, melhorando a eficiência do workflow: O LangGraph anunciou que sua versão de código aberto agora inclui funcionalidade de cache de nó/tarefa. Esta funcionalidade visa acelerar os workflows, evitando cálculos repetidos, especialmente útil para workflows de Agentes que contêm partes comuns ou que exigem depuração frequente. Os usuários podem usar o cache na API imperativa ou na API gráfica, permitindo iterar e otimizar suas aplicações de IA mais rapidamente. Esta é a primeira de uma série de atualizações de lançamento de código aberto do LangGraph desta semana. (Fonte: hwchase17)

Sakana AI lança nova arquitetura de IA “Continuous Thought Machines” (CTM): A startup de IA de Tóquio, Sakana AI, lançou uma nova arquitetura de modelo de IA chamada “Continuous Thought Machines” (CTM). O CTM visa permitir que os modelos raciocinem com menos orientação, de forma semelhante ao cérebro humano. Esta nova arquitetura pode fornecer novas ideias para resolver os desafios atuais que os modelos de IA enfrentam em raciocínio complexo e aprendizado autônomo. (Fonte: dl_weekly)
Microsoft e Nvidia aprofundam colaboração em RTX AI PC, TensorRT chega ao Windows ML: Durante o Microsoft Build e a COMPUTEX em Taipei, Nvidia e Microsoft anunciaram um avanço na colaboração para o desenvolvimento de RTX AI PCs. A biblioteca de otimização de inferência TensorRT da Nvidia foi redesenhada e integrada à nova pilha de inferência da Microsoft, Windows ML. Esta medida visa simplificar o processo de desenvolvimento de aplicações de IA e aproveitar ao máximo o desempenho de pico das GPUs RTX em tarefas de IA no PC, impulsionando a popularização e aplicação da IA em dispositivos de computação pessoal. (Fonte: nvidia)
Bilibili torna público o modelo de geração de vídeo de animação Index-AniSora, alcançando SOTA em múltiplos indicadores: O Bilibili anunciou o código aberto de seu modelo de geração de vídeo de animação auto-desenvolvido, Index-AniSora, que foi publicado no IJCAI 2025. O AniSora é projetado especificamente para a geração de vídeos no estilo anime, suportando vários estilos como séries de anime, animações chinesas e adaptações de mangá, e permite controle fino como orientação de região local do vídeo, orientação temporal (como orientação do primeiro/último quadro, interpolação de quadros-chave). O conteúdo de código aberto do projeto inclui o código de treinamento e inferência para AniSoraV1.0 baseado em CogVideoX-5B e AniSoraV2.0 baseado em Wan2.1-14B, ferramentas de construção de dataset de treinamento, um sistema de benchmark dedicado para animação e o modelo AniSoraV1.0_RL otimizado por aprendizado por reforço com feedback humano. (Fonte: WeChat)

Tencent Hunyuan torna público o primeiro modelo de recompensa CoT unificado multimodal UnifiedReward-Think: O Tencent Hunyuan, em colaboração com o Shanghai AI Lab, a Universidade Fudan e outras instituições, propôs o UnifiedReward-Think, o primeiro modelo de recompensa multimodal unificado com capacidade de raciocínio de cadeia longa (CoT). Este modelo visa permitir que o modelo de recompensa “aprenda a pensar” ao avaliar tarefas complexas de geração e compreensão visual, melhorando assim a precisão da avaliação, a capacidade de generalização entre tarefas e a interpretabilidade do raciocínio. O projeto foi totalmente aberto, incluindo o modelo, dataset, scripts de treinamento e ferramentas de avaliação. (Fonte: WeChat)
Alibaba torna público o modelo de geração e edição de vídeo Tongyi Wanxiang Wan2.1-VACE: O Alibaba tornou oficialmente público seu modelo de geração e edição de vídeo Tongyi Wanxiang Wan2.1-VACE. Este modelo possui múltiplas funcionalidades, como text-to-video, geração de vídeo referenciada por imagem, redesenho de vídeo, edição local de vídeo, extensão de fundo de vídeo e extensão de duração de vídeo. Desta vez, foram abertas duas versões, 1.3B e 14B, sendo que a versão 1.3B pode ser executada em placas gráficas de consumo, visando reduzir a barreira para a criação de vídeo AIGC. (Fonte: WeChat)
ByteDance lança modelo de linguagem visual Seed1.5-VL, liderando em múltiplos benchmarks: A ByteDance construiu o modelo de linguagem visual Seed1.5-VL, composto por um codificador visual de 532M parâmetros e um LLM de Mixture-of-Experts (MoE) com 20B de parâmetros ativos. Apesar de sua arquitetura relativamente compacta, alcançou desempenho SOTA em 38 de 60 benchmarks públicos e superou modelos como OpenAI CUA e Claude 3.7 em tarefas centradas em agentes, como controle de GUI e jogabilidade, demonstrando forte capacidade de raciocínio multimodal. (Fonte: WeChat)
MiniMax lança modelo TTS autorregressivo MiniMax-Speech, suportando clonagem de voz zero-shot em 32 idiomas: A MiniMax propôs o modelo de Text-to-Speech (TTS) autorregressivo baseado em Transformer, MiniMax-Speech. Este modelo pode extrair características de timbre de áudio de referência sem transcrição, alcançando a geração de voz expressiva e consistente com o timbre de referência de forma zero-shot, e suporta clonagem de voz com uma única amostra. A qualidade do áudio sintetizado foi aprimorada pela tecnologia Flow-VAE, suportando 32 idiomas. O modelo atingiu o nível SOTA em métricas objetivas de clonagem de voz, liderou o ranking público TTS Arena e pode ser estendido para aplicações como controle de emoção de voz, text-to-sound e clonagem de voz profissional. (Fonte: WeChat)
OuteTTS 1.0 (0.6B) lançado, modelo TTS de código aberto Apache 2.0 com suporte para 14 idiomas: A OuteAI lançou o OuteTTS-1.0-0.6B, um modelo leve de Text-to-Speech (TTS) construído com base no Qwen-3 0.6B. O modelo utiliza a licença Apache 2.0 e suporta 14 idiomas, incluindo chinês, inglês, japonês e coreano. Sua biblioteca de inferência Python, OuteTTS v0.4.2, foi atualizada para suportar inferência em lote assíncrona EXL2, inferência em lote experimental vLLM e processamento em lote contínuo e inferência de modelo de URL externa para o servidor Llama.cpp. Benchmarks em uma única GPU NVIDIA L40S mostraram que o vLLM OuteTTS-1.0-0.6B FP8 pode atingir um RTF (Real-Time Factor) de 0.05 com um tamanho de lote de 32. Os pesos do modelo (ST, GGUF, EXL2, FP8) foram disponibilizados no Hugging Face. (Fonte: Reddit r/LocalLLaMA)

Hugging Face e Microsoft Azure aprofundam colaboração, mais de 10.000 modelos de código aberto chegam ao Azure AI Foundry: Na conferência Microsoft Build, o CEO Satya Nadella anunciou a expansão da colaboração com o Hugging Face. Atualmente, mais de 11.000 dos modelos de código aberto mais populares estão disponíveis através do Hugging Face no Azure AI Foundry, facilitando a implantação para os usuários. Esta medida enriquece ainda mais o ecossistema de IA do Azure, oferecendo aos desenvolvedores mais opções de modelos e uma experiência de desenvolvimento mais conveniente. (Fonte: ClementDelangue, _akhaliq)

Intel lança GPUs da série Arc Pro B50/B60, focadas no mercado de IA e workstations, versão de 24GB por cerca de US$500: A Intel lançou na Computex as novas placas gráficas profissionais da série Arc Pro B, incluindo a Arc Pro B50 (16GB de VRAM, aproximadamente US$299) e a Arc Pro B60 (24GB de VRAM, aproximadamente US$500). A solução de workstation “Project Battlematrix”, composta por duas GPUs B60 com um total de 48GB de VRAM, também foi apresentada, com preço estimado abaixo de US$1000. Estes produtos visam fornecer soluções de alto custo-benefício para computação de IA e workstations profissionais, especialmente a configuração de alta VRAM é atraente para executar grandes modelos de linguagem localmente. Os novos produtos estão previstos para serem lançados no terceiro trimestre deste ano, inicialmente através de fabricantes OEM, com uma possível versão DIY no quarto trimestre. (Fonte: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 Ferramentas
Moondream Station lança versão para Linux, simplificando a execução local do Moondream: O Moondream Station, uma ferramenta projetada para simplificar a execução do Moondream (um modelo de linguagem visual) em dispositivos locais, anunciou agora suporte para o sistema operacional Linux. Isso significa que os usuários de Linux podem implantar e usar modelos Moondream com mais facilidade para experimentos de IA multimodal e desenvolvimento de aplicações. (Fonte: vikhyatk)
Flowith lança agente inteligente infinito NEO, com suporte para passos, contexto e chamadas de ferramentas ilimitadas: A empresa de aplicações de IA Flowith lançou seu mais recente produto de agente, NEO, anunciado como o primeiro agente do mundo a suportar passos ilimitados, contexto ilimitado e chamadas de ferramentas ilimitadas. Este agente é projetado para funcionar por longos períodos na nuvem, possuindo um nível de inteligência que supera os benchmarks, e alega ser de custo zero e sem restrições. Este lançamento pode representar um novo avanço na capacidade dos agentes de IA de lidar com tarefas complexas de longa duração e integrar capacidades externas. (Fonte: _akhaliq, op7418)

Kapa AI utiliza Weaviate para construir ferramenta interativa de perguntas e respostas sobre documentação técnica “Ask AI”: A Kapa AI desenvolveu um widget inteligente chamado “Ask AI”, que permite aos usuários consultar toda a base de conhecimento técnico, incluindo documentação técnica, blogs, tutoriais, issues do GitHub e fóruns, através de conversas em linguagem natural. Para alcançar busca semântica eficiente e recuperação de conhecimento, a Kapa AI adotou o banco de dados vetorial Weaviate, valorizando sua capacidade de busca híbrida integrada, compatibilidade com Docker e características de multilocação, para suportar o rápido crescimento de usuários e volume de dados. (Fonte: bobvanluijt)

Desenvolvedor utiliza Gemini Flash para construir rapidamente ferramenta MVP de captura de tela para HTML: O desenvolvedor Daniel Huynh utilizou o modelo Gemini Flash da Google AI para construir, em um fim de semana, uma ferramenta MVP (Minimum Viable Product) que pode converter rapidamente capturas de tela de designs, produtos concorrentes ou inspirações em código HTML. A ferramenta já está disponível gratuitamente para teste no Hugging Face Spaces, demonstrando o potencial dos modelos multimodais na assistência ao desenvolvimento front-end. (Fonte: osanseviero, _akhaliq)
Azure AI Foundry Agent Service oficialmente disponível, integrado com LlamaIndex: A Microsoft anunciou que o Azure AI Foundry Agent Service foi oficialmente lançado (GA) e oferece suporte de primeira classe ao LlamaIndex. O serviço visa ajudar clientes corporativos a construir assistentes de suporte ao cliente, robôs de automação de processos, sistemas multi-agente e soluções que se integram com segurança aos dados e ferramentas da empresa, impulsionando ainda mais o desenvolvimento e a aplicação de agentes de IA de nível empresarial. (Fonte: jerryjliu0)
tinygrad: um framework de deep learning minimalista entre PyTorch e micrograd: tinygrad é um framework de deep learning projetado com a simplicidade como filosofia central, visando ser o framework mais fácil para adicionar novos aceleradores, suportando inferência e treinamento. Ele suporta modelos como LLaMA e Stable Diffusion, e utiliza avaliação preguiçosa (lazy evaluation) para fundir operações e otimizar o desempenho. tinygrad suporta GPU (OpenCL), CPU (código C), LLVM, Metal, CUDA e outros aceleradores. Seu código é conciso, com funcionalidades principais implementadas em poucas linhas de código, facilitando a compreensão e extensão por parte dos desenvolvedores. (Fonte: GitHub Trending)
Pesquisa Nano AI lança função “Super Search”, integrando múltiplos modelos e caixa de ferramentas MCP: A Pesquisa Nano AI (bot.n.cn) adicionou a função “Super Search”, visando fornecer capacidade de obtenção e processamento de informações mais aprofundada. Esta função integra centenas de grandes modelos nacionais e internacionais, com troca automática conforme necessário; possui uma caixa de ferramentas universal MCP integrada, suportando milhares de ferramentas de IA, capaz de processar páginas da web, imagens, vídeos, PDFs e outros formatos de arquivo, além de realizar geração de código, análise de dados, etc. Ao mesmo tempo, combina pesquisa em domínio público com pesquisa privada em bases de conhecimento locais, fornecendo resultados mais abrangentes, e possui capacidades integradas de text-to-image e text-to-video. A experiência do usuário mostra que esta função pode organizar os resultados da pesquisa em relatórios detalhados contendo gráficos e páginas da web refinadas, adequadas para pesquisa de mercado, comparação de preços de compras, organização de conhecimento e outros cenários. (Fonte: WeChat)
Clara: Espaço de trabalho AI modular offline, integrando LLM, Agentes, automação e geração de imagens: Desenvolvedores lançaram um projeto de código aberto chamado Clara, com o objetivo de criar um espaço de trabalho AI totalmente offline e modular. Os usuários podem organizar chats LLM locais (com suporte para RAG, imagens, documentos, execução de código, compatível com Ollama e APIs do tipo OpenAI) como widgets em um painel, criar Agentes com memória e lógica, executar fluxos de automação através da integração nativa com N8N (oferecendo mais de 1000 modelos gratuitos) e gerar imagens localmente usando Stable Diffusion (ComfyUI). Clara oferece versões para Mac, Windows e Linux, visando resolver o problema dos usuários que alternam frequentemente entre múltiplas ferramentas de IA, alcançando uma operação AI centralizada. (Fonte: Reddit r/LocalLLaMA)
AI Playlist Curator: Ferramenta Python que utiliza LLM para organizar listas de reprodução personalizadas do YouTube: Um desenvolvedor criou um projeto Python chamado AI Playlist Curator, com o objetivo de ajudar os usuários a organizar automaticamente suas extensas e desordenadas listas de reprodução do YouTube. A ferramenta utiliza LLM para classificar músicas de acordo com as preferências do usuário e criar sub-listas de reprodução personalizadas, suportando o processamento de qualquer lista de reprodução salva e músicas curtidas. O projeto foi disponibilizado em código aberto no GitHub, e o desenvolvedor espera receber feedback da comunidade para melhorias futuras. (Fonte: Reddit r/MachineLearning)
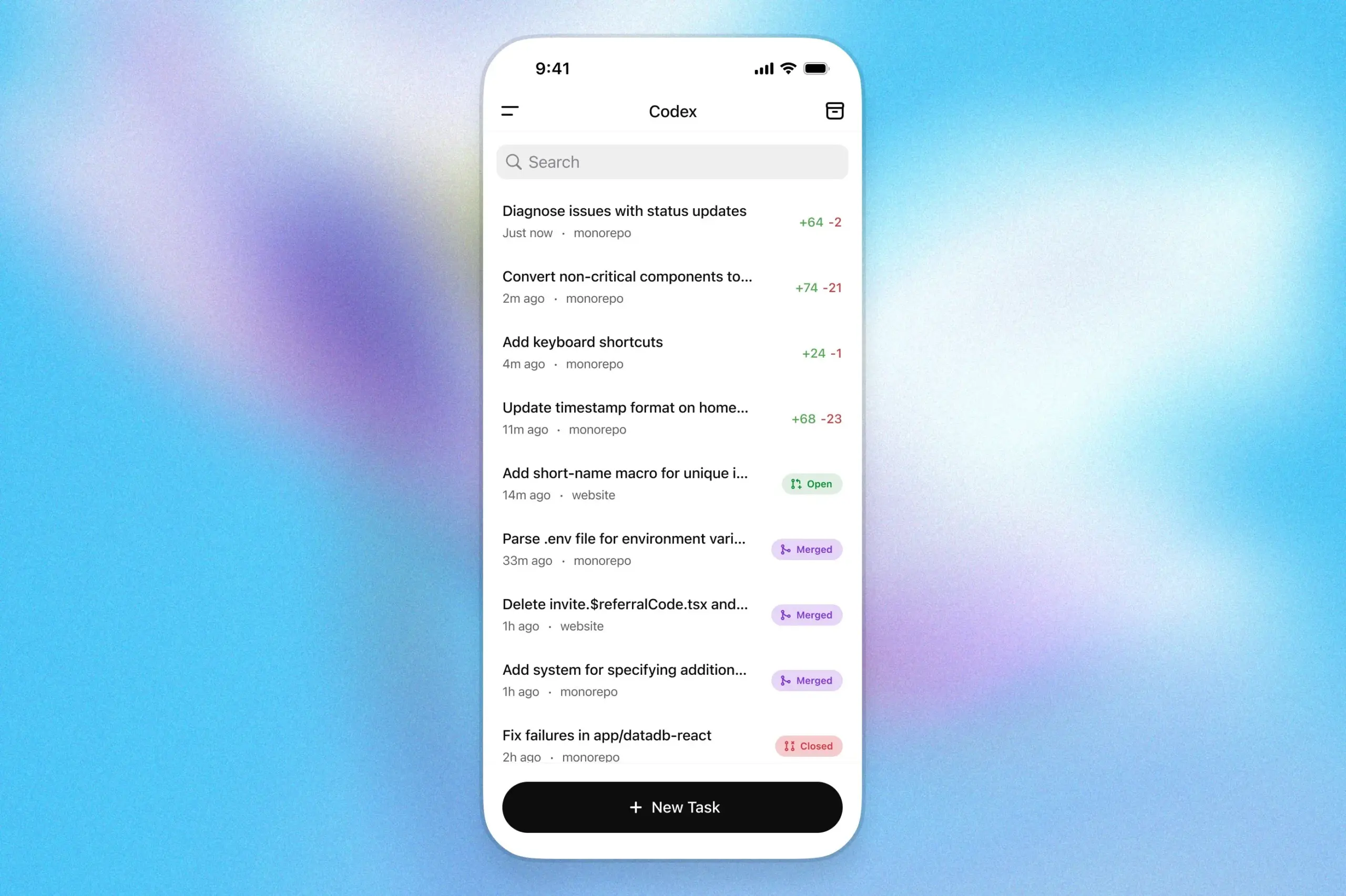
Assistente de programação OpenAI Codex chega ao aplicativo ChatGPT para iOS: A OpenAI anunciou que seu assistente de programação Codex agora está integrado ao aplicativo ChatGPT para iOS. Os usuários podem iniciar novas tarefas de programação, visualizar diferenças de código, solicitar modificações e até mesmo enviar pull requests (PR) em dispositivos móveis. A funcionalidade também suporta o acompanhamento do progresso do Codex em tempo real através de atividades na tela de bloqueio, facilitando a alternância de trabalho entre diferentes dispositivos sem interrupções. (Fonte: openai)
Kollektiv: Ferramenta que utiliza o protocolo MCP para resolver o problema de copiar e colar repetidamente o contexto em chats com LLM: Desenvolvedores lançaram a ferramenta Kollektiv, que visa resolver o problema de usuários terem que copiar e colar repetidamente grandes quantidades de contexto (como artigos de pesquisa, documentação de SDK, notas pessoais, conteúdo de livros) ao conversar com LLMs (como o Claude). O Kollektiv permite que os usuários façam upload dessas fontes de documentos uma única vez e as invoquem sob demanda de qualquer IDE compatível ou cliente MCP (como Cursor, Windsurf, PyCharm, etc.) através de um servidor MCP (Model Control Protocol). O servidor MCP é responsável pela autenticação do usuário, isolamento de dados e streaming de dados sob demanda para a interface de chat. Atualmente, a ferramenta não é recomendada para materiais sensíveis ou confidenciais. (Fonte: Reddit r/ClaudeAI)
📚 Aprendizado
Google DeepMind publica relatório técnico sobre AlphaEvolve, revelando sua capacidade de descoberta de algoritmos: O Google DeepMind publicou um relatório técnico sobre seu sistema de IA, AlphaEvolve. AlphaEvolve é um agente de codificação baseado em Gemini, capaz de projetar e otimizar algoritmos por meio de algoritmos evolutivos. O relatório detalha como o AlphaEvolve gera, avalia e aprimora autonomamente soluções de algoritmos candidatas por meio de um ciclo de feedback estruturado, alcançando assim avanços em múltiplos problemas de matemática e ciência da computação, incluindo a quebra do recorde do algoritmo de multiplicação de matrizes complexas 4×4. Este relatório fornece uma referência importante para entender o potencial da IA na descoberta científica automatizada e na inovação de algoritmos. (Fonte: , HuggingFace Daily Papers)
DeepLearning.AI lança curso “Building AI Browser Agents”: A DeepLearning.AI lançou um novo curso chamado “Building AI Browser Agents”. O curso é ministrado pelos cofundadores da AGI, Div Garg e Naman Agarwal, e visa ajudar os alunos a dominar as técnicas de construção de agentes de IA (Agents) capazes de interagir com navegadores. O conteúdo do curso pode abranger automação web, extração de informações, interação com interface de usuário e outras aplicações de IA no ambiente do navegador. (Fonte: DeepLearningAI)
Relatório técnico do Qwen3 publicado: O Alibaba publicou o relatório técnico de sua mais recente geração de Large Language Model, Qwen3. O relatório detalha a arquitetura do modelo Qwen3, métodos de treinamento, avaliação de desempenho e seu desempenho em vários benchmarks. A série de modelos Qwen3 visa fornecer capacidades mais fortes de compreensão de linguagem, geração e processamento multimodal, e a publicação de seu relatório técnico oferece a pesquisadores e desenvolvedores a oportunidade de entender profundamente os detalhes técnicos do modelo. (Fonte: _akhaliq)

Discussão de Artigo: Pesquisa Multivisual e Gerenciamento de Dados Aprimoram a Prova de Teoremas Passo a Passo (MPS-Prover): Um novo artigo apresenta o MPS-Prover, um sistema inovador de prova automatizada de teoremas (ATP) passo a passo. Este sistema supera o problema de orientação de busca tendenciosa em provadores passo a passo existentes por meio de uma estratégia eficiente de gerenciamento de dados pós-treinamento (podando cerca de 40% dos dados redundantes sem sacrificar o desempenho) e um mecanismo de busca em árvore multivisual (integrando um modelo crítico aprendido com regras heurísticas). Experimentos mostram que o MPS-Prover atinge desempenho SOTA em múltiplos benchmarks como miniF2F e ProofNet, gerando provas mais curtas e diversificadas. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: Planejamento Visual — Pensando Apenas com Imagens (Visual Planning): Um novo artigo propõe o paradigma de “Planejamento Visual”, permitindo que modelos planejem inteiramente através de representações visuais (sequências de imagens), em vez de depender de texto. Os pesquisadores argumentam que, em tarefas envolvendo informações espaciais e geométricas, a linguagem pode não ser o meio de raciocínio mais natural. Eles introduzem o framework de planejamento visual VPRL através de aprendizado por reforço e usam GRPO para otimização pós-treinamento de grandes modelos visuais, alcançando melhorias significativas em tarefas de navegação visual como FrozenLake, Maze e MiniBehavior, superando variantes de planejamento baseadas puramente em raciocínio textual. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: Escalar o Raciocínio pode Melhorar a Factualidade de Grandes Modelos de Linguagem (Scaling Reasoning can Improve Factuality): Um estudo explora se a expansão do processo de raciocínio de Large Language Models (LLMs) pode aumentar sua precisão factual em tarefas complexas de perguntas e respostas de domínio aberto (QA). Os pesquisadores extraíram trajetórias de raciocínio de modelos como QwQ-32B e DeepSeek-R1-671B e realizaram fine-tuning em vários modelos da série Qwen2.5, integrando também caminhos de grafos de conhecimento nas trajetórias de raciocínio. Experimentos mostram que, em uma única execução, modelos de raciocínio menores apresentam melhorias significativas na precisão factual em comparação com os modelos originais ajustados por instrução. Aumentando a computação em tempo de teste e o orçamento de tokens, a precisão factual pode aumentar de forma estável em 2-8%. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: Mergenetic — Uma Biblioteca Simples para Fusão Evolutiva de Modelos: Um novo artigo apresenta Mergenetic, uma biblioteca de código aberto para fusão evolutiva de modelos. A fusão de modelos permite combinar as capacidades de modelos existentes em novos modelos, sem treinamento adicional. Mergenetic suporta a combinação fácil de métodos de fusão e algoritmos evolutivos, e incorpora avaliadores de aptidão leves para reduzir o custo da avaliação. Experimentos demonstram que Mergenetic produz resultados competitivos em diversas tarefas e idiomas usando hardware modesto. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: Pensamento de Grupo — Múltiplos Agentes de Raciocínio Concorrentes Colaborando em Nível de Token (Group Think): Um novo artigo propõe o “Pensamento de Grupo” (Group Think) — fazer com que um único LLM atue como múltiplos agentes de raciocínio concorrentes (pensadores). Esses agentes compartilham visibilidade do progresso parcial da geração uns dos outros, adaptando-se dinamicamente às trajetórias de raciocínio uns dos outros em nível de token, reduzindo assim o raciocínio redundante, melhorando a qualidade e diminuindo a latência. O método é adequado para inferência de borda em GPUs locais, e experimentos demonstram que ele também melhora a latência ao usar LLMs de código aberto não treinados especificamente. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: Humanos esperam racionalidade e cooperação de oponentes LLM em jogos estratégicos (Humans expect rationality and cooperation from LLM opponents): Um estudo experimental de laboratório, o primeiro do tipo com incentivos monetários controlados, investigou as diferenças de comportamento humano em competições P-beauty multiplayer contra outros humanos versus LLMs. Os resultados mostraram que os humanos escolheram números significativamente mais baixos ao jogar contra LLMs, principalmente devido a um aumento na prevalência da escolha do equilíbrio de Nash “zero”. Essa mudança foi impulsionada principalmente por participantes com alta capacidade de raciocínio estratégico, que perceberam os LLMs como possuindo maior capacidade de raciocínio e propensão à cooperação. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: Destilação de Conhecimento Semi-Supervisionada Simples de Modelos de Linguagem Visual através de Otimização de Cabeça Dupla (Dual-Head Optimization for KD): Um novo artigo propõe DHO (Dual-Head Optimization), um framework de destilação de conhecimento (KD) simples e eficaz para transferir conhecimento de modelos de linguagem visual (VLM) para modelos compactos específicos de tarefa em um ambiente semi-supervisionado. DHO introduz duas cabeças de previsão independentes que aprendem dados rotulados e previsões do professor, e combina linearmente suas saídas durante a inferência, mitigando assim o conflito de gradiente entre o sinal de supervisão e o sinal de destilação. Experimentos mostram que DHO supera as linhas de base de KD de cabeça única em múltiplos domínios e datasets de granularidade fina, alcançando SOTA no ImageNet. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: GuardReasoner-VL — Protegendo VLMs através de Raciocínio Reforçado: Para aumentar a segurança dos modelos de linguagem visual (VLMs), um novo artigo introduz o modelo de proteção de VLM baseado em raciocínio, GuardReasoner-VL. A ideia central é incentivar o modelo de proteção a realizar um raciocínio deliberado antes de tomar decisões de moderação, por meio de aprendizado por reforço online (RL). Os pesquisadores construíram um corpus de raciocínio, GuardReasoner-VLTrain, contendo 123K amostras e 631K etapas de raciocínio, e iniciaram a capacidade de raciocínio do modelo por meio de fine-tuning supervisionado (SFT), aprimorando-a ainda mais por meio de RL online. Experimentos mostram que o modelo (versões 3B/7B já de código aberto) tem desempenho superior, superando o segundo melhor modelo em 19,27% na pontuação F1 média. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: A Previsão Multi-Token Precisa de Registradores (Multi-Token Prediction Needs Registers): Um novo artigo propõe MuToR, um método simples e eficaz para previsão multi-token, que prevê alvos futuros inserindo intercaladamente tokens registradores aprendíveis na sequência de entrada. Comparado aos métodos existentes, MuToR tem um aumento de parâmetros insignificante, não requer alterações arquitetônicas, é compatível com modelos pré-treinados existentes e permanece consistente com o objetivo de pré-treinamento do próximo token, sendo particularmente adequado para fine-tuning supervisionado. O método demonstra eficácia e generalidade em tarefas generativas nos domínios da linguagem e da visão. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: MMLongBench — Benchmark Eficaz e Completo para Modelos de Linguagem Visual de Contexto Longo: Em resposta à necessidade de avaliação de modelos de linguagem visual de contexto longo (LCVLM), um novo artigo introduz o MMLongBench, o primeiro benchmark a cobrir uma variedade de tarefas de linguagem visual de contexto longo. O MMLongBench contém 13331 amostras, abrangendo cinco categorias de tarefas, como RAG visual, ICL multi-shot, e fornece vários tipos de imagem. Todas as amostras são fornecidas em cinco comprimentos de entrada padronizados de 8K-128K tokens. Através do benchmarking de 46 LCVLMs de código fechado e aberto, o estudo descobriu que o desempenho em uma única tarefa não é representativo da capacidade geral de contexto longo, os modelos atuais ainda têm muito espaço para melhorias, e modelos com forte capacidade de raciocínio tendem a ter melhor desempenho em contexto longo. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: MatTools — Um Benchmark de Grandes Modelos de Linguagem para Ferramentas de Ciência dos Materiais: Um novo artigo propõe o benchmark MatTools para avaliar a capacidade de Large Language Models (LLMs) de responder a perguntas sobre ciência dos materiais, gerando e executando com segurança código de pacotes de software de ciência dos materiais computacional baseados em física. MatTools inclui um benchmark de perguntas e respostas (QA) para ferramentas de simulação de materiais (baseado em pymatgen, com 69225 pares de QA) e um benchmark de uso de ferramentas do mundo real (com 49 tarefas, 138 subtarefas). A avaliação de vários LLMs revelou que: modelos gerais superam modelos especializados; IA entende melhor IA; métodos simples são mais eficazes. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: Um Framework Universal de Watermarking Simbiótico que Equilibra Robustez, Qualidade do Texto e Segurança para Watermarking de LLM: Em resposta ao trade-off existente entre robustez, qualidade do texto e segurança nos esquemas atuais de watermarking para Large Language Models (LLMs), um novo artigo propõe um framework universal de watermarking simbiótico. Este framework integra métodos baseados em logits e em amostragem, e projeta três estratégias: serial, paralela e híbrida. O framework híbrido utiliza entropia de token e entropia semântica para incorporar adaptativamente o watermark, visando otimizar o desempenho em todos os aspectos. Experimentos mostram que este método supera as linhas de base existentes e atinge o nível SOTA. (Fonte: HuggingFace Daily Papers)
Discussão de Artigo: CheXGenBench — Um Benchmark Unificado para Fidelidade, Privacidade e Utilidade de Radiografias de Tórax Sintéticas: Um novo artigo apresenta o CheXGenBench, um framework multifacetado para avaliar a geração de radiografias de tórax sintéticas, avaliando simultaneamente fidelidade, riscos de privacidade e utilidade clínica. O framework inclui partições de dados padronizadas e um protocolo de avaliação unificado (mais de 20 métricas quantitativas), analisando a qualidade de geração, vulnerabilidades de privacidade potenciais e aplicabilidade clínica downstream de 11 arquiteturas líderes de text-to-image. O estudo descobriu que os protocolos de avaliação existentes são deficientes na avaliação da fidelidade da geração. A equipe também lançou o dataset sintético de alta qualidade SynthCheX-75K. (Fonte: HuggingFace Daily Papers)
Peter Lax, autor do clássico livro “Análise Funcional”, falece aos 99 anos: O gigante da matemática aplicada e primeiro matemático aplicado a receber o Prêmio Abel, Peter Lax, faleceu aos 99 anos. Lax era conhecido por seu clássico livro “Análise Funcional” e fez contribuições fundamentais nas áreas de equações diferenciais parciais, mecânica dos fluidos, cálculo numérico, como o teorema da equivalência de Lax, e os métodos de Lax-Friedrichs e Lax-Wendroff. Ele também foi um dos pioneiros na aplicação de técnicas computacionais à análise matemática, e seu trabalho influenciou profundamente o desenvolvimento da matemática na era da computação. (Fonte: QubitAI)

Ex-VP da OpenAI, Lilian Weng, publica longo artigo “Why We Think”, discutindo Test-time Compute e Chain-of-Thought: A ex-vice-presidente da OpenAI, Lilian Weng, publicou um longo artigo intitulado “Why We Think”, explorando profundamente como tecnologias como “Test-time Compute” e “Chain-of-Thought (CoT)” melhoram significativamente o desempenho e o nível de inteligência dos Large Language Models. O artigo faz uma analogia com a teoria dos dois sistemas de pensamento “rápido e devagar” dos humanos, apontando que permitir que os modelos “pensem” mais antes de produzir uma saída (por exemplo, através de decodificação inteligente, raciocínio CoT, modelagem de variáveis latentes, etc.) pode superar os gargalos de capacidade atuais. O texto detalha os progressos e desafios em várias direções de pesquisa, como pensamento baseado em tokens, amostragem paralela e revisão sequencial, aprendizado por reforço e integração de ferramentas externas, fidelidade do pensamento e pensamento em espaço contínuo. (Fonte: QubitAI)

HIT e UPenn lançam conjuntamente PointKAN, novo SOTA para análise de nuvem de pontos baseado em KANs: Equipes de pesquisa da Harbin Institute of Technology (Shenzhen) e da University of Pennsylvania lançaram o PointKAN, uma solução para análise de nuvem de pontos 3D baseada em Kolmogorov-Arnold Networks (KANs). Este método utiliza um módulo afim geométrico e um módulo de extração de características locais paralelas, e substitui as funções de ativação fixas em MLPs tradicionais por funções de ativação aprendíveis para capturar de forma mais eficaz as complexas características geométricas das nuvens de pontos. Ao mesmo tempo, a equipe propôs a estrutura Efficient-KANs, que substitui funções B-spline por funções racionais e realiza compartilhamento de parâmetros intra-grupo, reduzindo significativamente o número de parâmetros e a sobrecarga computacional. Experimentos mostram que o PointKAN e sua versão leve PointKAN-elite alcançaram desempenho SOTA ou competitivo em tarefas como classificação, segmentação parcial e aprendizado com poucas amostras. (Fonte: WeChat)

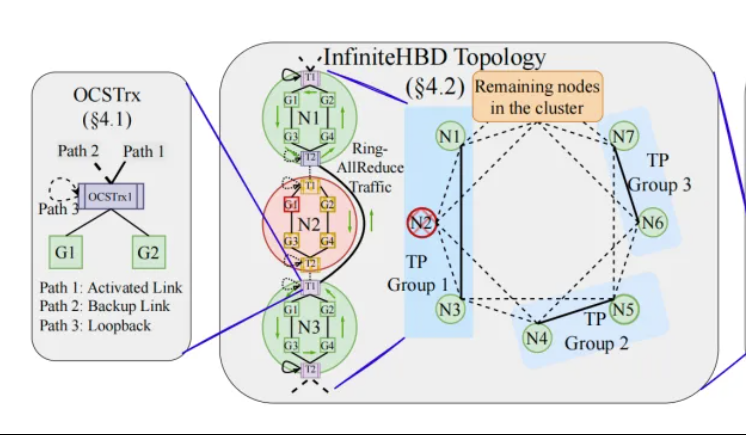
Peking University/StepStar/Enflame Tech propõem InfiniteHBD: arquitetura de interconexão de GPU de alta largura de banda de nova geração, reduzindo custos de treinamento de grandes modelos: Equipes de pesquisa da Peking University, StepStar e Enflame Technology propuseram a solução InfiniteHBD em resposta às limitações das atuais arquiteturas de domínio de alta largura de banda (HBD) no treinamento distribuído de grandes modelos. Esta arquitetura, centrada em módulos de conversão optoeletrônica com capacidade de comutação de circuito óptico (OCS) embutida, permite conexões ponto-a-multiponto dinamicamente reconfiguráveis, com isolamento de falhas em nível de nó e baixa fragmentação de recursos. A pesquisa mostra que o custo unitário do InfiniteHBD é de apenas 31% do NVIDIA NVL-72, a taxa de desperdício de GPU é próxima de zero e a MFU (Model FLOPs Utilization) pode ser aumentada em até 3,37 vezes em comparação com o NVIDIA DGX. Esta pesquisa foi aceita no SIGCOMM 2025. (Fonte: WeChat, QubitAI)
Artigo do ICML 2025: OmniAudio gera áudio espacial a partir de vídeos 360°: Uma pesquisa a ser apresentada no ICML 2025 propõe o framework OmniAudio, capaz de gerar diretamente áudio espacial de primeira ordem ambisônica (FOA) com direcionalidade a partir de vídeos panorâmicos 360°. A pesquisa primeiro construiu um dataset em larga escala de vídeos 360° pareados com áudio espacial, chamado Sphere360. O OmniAudio adota um treinamento em duas etapas: primeiro, um pré-treinamento auto-supervisionado de correspondência de fluxo coarse-to-fine, utilizando dados de áudio não espaciais em larga escala para aprender características de áudio genéricas; em seguida, um fine-tuning supervisionado combinando um codificador de vídeo de dois ramos (extraindo características visuais globais e locais). Os resultados experimentais mostram que o OmniAudio supera significativamente os modelos de linha de base existentes em métricas de avaliação objetivas e subjetivas. (Fonte: WeChat)

Huawei Selftok: Tokenizador visual autorregressivo baseado em difusão reversa, unificando a geração multimodal: A equipe de geração multimodal Pangu da Huawei propôs a tecnologia Selftok, uma solução inovadora de tokenização visual que incorpora um prior autorregressivo em tokens visuais através de um processo de difusão reversa. Isso transforma o fluxo de pixels em uma sequência discreta que segue estritamente a lei da causalidade, visando resolver o problema de conflito entre os esquemas de tokenização espacial existentes e o paradigma autorregressivo (AR). O Selftok Tokenizer adota um codificador de dois fluxos (o ramo de imagem herda o VAE do SD3, o ramo de texto é um conjunto de vetores contínuos aprendíveis) e um quantizador com mecanismo de reativação. Experimentos mostram que Selftok atinge SOTA em métricas de reconstrução do ImageNet, e o Selftok dAR-VLM treinado com base na IA Ascend e no framework MindSpeed supera o GPT-4o em benchmarks de text-to-image como o GenEval. Este trabalho foi selecionado como candidato a melhor artigo no CVPR 2025. (Fonte: WeChat)
Equipe liderada por Yan Shuicheng lança framework de avaliação General-Level e benchmark General-Bench, classificando modelos multimodais generalistas: Liderados pelo Professor Yan Shuicheng da National University of Singapore e pelo Professor Zhang Hanwang da Nanyang Technological University, dez universidades de ponta lançaram conjuntamente o framework de avaliação General-Level e o dataset de benchmark em larga escala General-Bench para modelos multimodais generalistas. Este framework, inspirado na classificação de direção autônoma, estabelece cinco níveis (Level 1-5) para avaliar a generalidade e o desempenho de Multimodal Large Language Models (MLLMs). O principal critério de avaliação é o “efeito de generalização sinérgica” (Synergy), examinando a transferência e o aprimoramento de conhecimento do modelo entre tarefas, entre paradigmas de compreensão e geração, e entre modalidades. O General-Bench inclui mais de 700 tarefas e 320.000 amostras. A avaliação de mais de 100 MLLMs existentes mostra que a maioria dos modelos está no nível L2-L3, e nenhum modelo atingiu o L5. (Fonte: WeChat)

💼 Negócios
Sakana AI e Mitsubishi UFJ Financial Group (MUFG) firmam parceria de vários anos: A startup japonesa de IA, Sakana AI, anunciou a assinatura de um acordo de parceria abrangente de vários anos com o maior banco do Japão, o MUFG Bank. A Sakana AI fornecerá ao MUFG Bank tecnologia de IA ágil e robusta, com o objetivo de ajudar o banco centenário a manter a competitividade no campo da IA em rápida evolução. Espera-se que esta colaboração ajude a Sakana AI a atingir a lucratividade em um ano. (Fonte: SakanaAILabs, SakanaAILabs)

Cohere e Dell colaboram para levar a plataforma de agente seguro Cohere North às soluções de IA empresarial localizadas da Dell: A empresa de IA Cohere anunciou uma colaboração com a Dell Technologies para acelerar soluções de IA empresarial seguras e com capacidade de agente. A Dell será a primeira a oferecer às empresas a implantação localizada (on-premises) da plataforma de agente seguro Cohere North. Esta colaboração é particularmente crucial para setores que lidam com dados sensíveis e têm requisitos rigorosos de conformidade, permitindo que as empresas implantem e executem a avançada tecnologia de agente de IA da Cohere em seus próprios data centers. (Fonte: sarahookr)

Mistral AI, MGX e Bpifrance colaboram para construir o maior campus de IA da Europa na França: A Mistral AI anunciou uma colaboração com a MGX, empresa de investimento em tecnologia apoiada por Abu Dhabi, e o banco de investimento estatal francês Bpifrance, para construir em conjunto o maior campus de IA da Europa na região de Paris. O campus integrará data centers, recursos de computação de alto desempenho, e instalações de educação e pesquisa. A Nvidia também participará, fornecendo suporte técnico. Esta iniciativa visa impulsionar o desenvolvimento do ecossistema de IA europeu e elevar a posição estratégica da França no cenário global de IA. (Fonte: arthurmensch, arthurmensch)
🌟 Comunidade
Prevalência de TDAH entre profissionais de IA chama a atenção, podendo ultrapassar 20-30%: Surgiram discussões nas redes sociais sobre a prevalência do Transtorno do Déficit de Atenção com Hiperatividade (TDAH) entre profissionais da área de IA. Um usuário observou que o campo parece atrair muitos talentos com características de neurodiversidade. Minh Nhat Nguyen comentou que pode haver mais de 20-30% de pessoas com TDAH na indústria de IA. Este fenômeno pode estar relacionado à demanda do trabalho de pesquisa e desenvolvimento em IA por alta concentração, iteração rápida e pensamento criativo, características que às vezes coincidem com certas manifestações do TDAH. (Fonte: Dorialexander)
Desvalorização de habilidades na era da IA levanta reflexões profundas, reestruturação de sistemas e não domínio de ferramentas é crucial: Um artigo de análise profunda aponta que a verdadeira crise da era da IA não é “saber ou não usar ferramentas de IA”, mas sim a desvalorização das próprias habilidades e a reestruturação de todo o sistema de trabalho. O artigo, através de exemplos como a Linha Maginot, a conteinerização e a substituição de datilógrafos por processadores de texto, argumenta que apenas aprender a usar novas ferramentas não garante a liderança; o crucial é entender como a IA muda a estrutura, os processos e a lógica organizacional do trabalho. Quando o sistema é reescrito, habilidades de alto valor anteriormente podem se tornar rapidamente marginais. O aumento da produtividade não necessariamente leva ao aumento do valor individual, pois o valor fluirá para quem controla a nova camada de coordenação do sistema. O artigo refuta oito falácias populares, como “aprender IA garante a liderança”, “IA me faz trabalhar mais, logo sou mais valioso” e “os empregos não mudam, apenas a forma de trabalhar”, enfatizando a necessidade de pensar sobre o próprio posicionamento e valor em nível de sistema. (Fonte: 36Kr)
Ex-CEO do Google, Schmidt: Ascensão da inteligência não humana remodelará o cenário global, é preciso cautela com riscos e desafios da IA: O ex-CEO do Google, Eric Schmidt, alertou em uma entrevista exclusiva que a sociedade subestima gravemente o potencial disruptivo da “inteligência não humana”. Ele acredita que a IA já passou da geração de linguagem para a tomada de decisões estratégicas, capaz de completar tarefas complexas de forma independente. Schmidt enfatizou três desafios centrais trazidos pela IA: gargalos de energia e poder computacional (os EUA precisam adicionar 90 gigawatts de eletricidade), dados públicos quase esgotados (a próxima fase exigirá dados gerados por IA) e como fazer a IA superar o conhecimento humano existente para criar “novo conhecimento”. Ele também apontou três grandes riscos: IA perdendo o controle em autoaperfeiçoamento recursivo, obtendo controle de armas e autorreplicação não autorizada. Ele acredita que, no contexto da crescente competição de IA entre China e EUA, a rápida proliferação de IA de código aberto pode trazer riscos de segurança, e até mesmo desencadear uma situação de “ataque preventivo” semelhante à “dissuasão nuclear”. Schmidt pediu um diálogo global imediato sobre a governança da IA e enfatizou que a proteção da liberdade humana deve ser incorporada desde o início do projeto do sistema. (Fonte: 36Kr)

CEO do GitHub refuta “teoria da inutilidade da programação”, enfatizando que programadores humanos ainda são importantes na era da IA: Em resposta às opiniões de pessoas como o CEO da Nvidia, Jensen Huang, de que “no futuro não será mais necessário aprender a programar”, o CEO do GitHub, Thomas Dohmke, expressou discordância em uma entrevista. Ele acredita que 2025 será o ano do agente de programação (SWE Agent), mas o papel dos programadores humanos continua crucial. Dohmke enfatizou que a IA deve servir como um assistente para aumentar as capacidades dos desenvolvedores, e não para substituí-los completamente. Ele imagina que o desenvolvimento de software no futuro evoluirá para um modelo de colaboração entre humanos e IA, onde os desenvolvedores atuarão como “maestros de uma orquestra de agentes”, responsáveis por atribuir tarefas e revisar resultados. O CPO do GitHub, Mario Rodriguez, também afirmou que a empresa está comprometida em aumentar as capacidades individuais com o Copilot. Eles acreditam que, com o desenvolvimento da IA, entender como programar e reprogramar máquinas que podem representar o pensamento e a ação humana é crucial, e abandonar o aprendizado de código equivale a renunciar ao poder de fala no futuro dos agentes. (Fonte: 36Kr, QubitAI)

Relatórios de vulnerabilidade de baixa qualidade gerados por IA proliferam, fundador do curl introduz mecanismo de filtragem para combater “lixo de IA”: Daniel Stenberg, fundador do projeto curl, afirmou que está sobrecarregado com um grande número de relatórios de vulnerabilidade de baixa qualidade e inválidos gerados por IA, que desperdiçam muito tempo dos mantenedores e se assemelham a ataques DDoS. Por isso, ao submeter relatórios de segurança relacionados ao curl no HackerOne, foi adicionada uma caixa de seleção perguntando se foi usada IA. Se a resposta for sim, é necessário fornecer evidências adicionais para provar a autenticidade da vulnerabilidade, caso contrário, o relator pode ser banido. Stenberg disse que o projeto nunca recebeu um relatório de bug válido gerado por IA. O desenvolvedor Python Seth Larson também expressou preocupações semelhantes, acreditando que tais relatórios trazem confusão, estresse e frustração para os mantenedores, exacerbando o problema de burnout em projetos de código aberto. A discussão na comunidade considera que a proliferação de relatórios gerados por IA reflete a sobrecarga de informações e a tentativa de alguns de explorar mecanismos de recompensa por vulnerabilidades, e até mesmo gestores de alto nível foram induzidos a acreditar que a IA pode substituir programadores experientes. (Fonte: WeChat)

Programação assistida por IA gera debate acalorado: aumento significativo de eficiência, mas papel do desenvolvedor humano continua crucial: Um desenvolvedor com décadas de experiência em programação compartilhou como a IA (possivelmente Codex ou ferramenta similar) resolveu em minutos um bug que o atormentava por horas e otimizou o código, maravilh_and_o-se com a IA como um “colega de equipe superpoderoso e incansável”. Essa experiência gerou discussão na comunidade. A maioria concorda com a poderosa capacidade da IA na geração de código, correção de bugs e resumo de informações, podendo aumentar significativamente a eficiência. No entanto, alguns desenvolvedores apontam que a IA atualmente ainda comete erros, especialmente em lógica complexa, condições de contorno e soluções criativas, ficando aquém dos humanos, e sua saída precisa ser revisada e avaliada criticamente por desenvolvedores experientes. O CEO da Microsoft, Satya Nadella, também enfatizou que a IA é uma ferramenta de capacitação, o desenvolvimento de software já não pode prescindir da IA, mas a ambição e a agência humanas continuam importantes. A discussão geralmente concorda que a IA mudará a forma de programar, e os desenvolvedores precisarão se adaptar a um novo paradigma de colaboração com a IA, focando em design de arquitetura de nível superior e definição de problemas. (Fonte: Reddit r/ChatGPT, WeChat)
AI Agent Manus abre inscrições, mas com preços elevados, enfrenta concorrência de gigantes nacionais e internacionais, e lançamento da versão em chinês é incerto: A plataforma AI Agent Manus, após um período de grande procura por códigos de convite, abriu oficialmente as inscrições, mas atualmente apenas para usuários internacionais, sem oferecer versão em chinês. O feedback dos usuários indica que utiliza um sistema de consumo de créditos; os créditos gratuitos (1000 no registro, 300 diários) são suficientes apenas para tarefas simples, enquanto tarefas complexas (como criar um jogo de Sudoku para web) exigem a compra de créditos, com uma média de 1 dólar por 100 créditos, um preço considerado alto. Analistas do setor apontam que a dependência do Manus de grandes modelos de terceiros (como a versão internacional usando Claude) eleva os custos, e a execução em sandbox na nuvem também aumenta as despesas. O atraso no lançamento da versão em chinês pode estar relacionado ao registro de modelos na China, aos hábitos de pagamento dos usuários e à concorrência de mercado. Produtos nacionais e internacionais como Coze da ByteDance e o aplicativo “Xinxiang” do Baidu já representam concorrência. Embora o Manus tenha obtido novo financiamento, seu modelo de “modelo leve, aplicação pesada” enfrenta desafios em termos de barreiras de entrada. (Fonte: 36Kr)
Modelos de IA falham coletivamente em questão de raciocínio visual de “completar o cubo”, levantando discussões sobre sua real capacidade de compreensão: Uma questão de raciocínio visual que exigia o cálculo do número de pequenos cubos necessários para completar um cubo incompleto derrotou vários modelos de IA convencionais, incluindo OpenAI o3, Google Gemini 2.5 Pro, DeepSeek e Qwen3. As respostas dadas pelos vários modelos foram inconsistentes, principalmente devido a diferentes interpretações das especificações do cubo final grande (como 3x3x3, 4x4x4, 5x5x5). Mesmo com dicas de orientação, os modelos tiveram dificuldade em responder corretamente de uma só vez. Alguns internautas apontaram que a própria formulação do problema pode ser ambígua, e os humanos também ficariam confusos. Este fenômeno levantou discussões sobre se os modelos de IA realmente entendem o problema ou apenas dependem do reconhecimento de padrões, destacando as limitações atuais da IA em raciocínio espacial complexo e compreensão visual. (Fonte: 36Kr)
Usuários discutem o problema de “pensar demais” dos LLMs no seguimento de instruções e raciocínio: Discussões em mídias sociais e artigos apontam que Large Language Models (LLMs), ao usar processos de raciocínio como Chain-of-Thought (CoT), às vezes “pensam demais”, o que, paradoxalmente, os impede de seguir instruções simples com precisão. Por exemplo, quando solicitados a escrever um número específico de palavras ou repetir uma frase específica, o CoT pode fazer com que o modelo se concentre mais no conteúdo geral da tarefa e ignore essas restrições básicas, ou introduza conteúdo explicativo adicional. Pesquisadores propuseram a métrica “constraint attention” para quantificar esse fenômeno e testaram estratégias de mitigação como aprendizado em contexto, autorreflexão, raciocínio auto-selecionado e raciocínio selecionado por classificador. Isso sugere que nem todas as tarefas são adequadas para CoT, e instruções simples podem exigir uma execução mais direta. (Fonte: menhguin, omarsar0)

Reflexão sobre a economia da IA: trabalho cognitivo barato quebra modelos econômicos tradicionais, distribuição de valor enfrenta remodelação: Uma perspectiva que gerou discussão argumenta que a ascensão da IA está tornando o trabalho cognitivo (como redação de relatórios, análise de dados, escrita de código) extremamente barato, o que desafia fundamentalmente os modelos econômicos clássicos baseados na premissa de que “a inteligência humana é escassa e cara”. Quando a IA pode realizar uma grande quantidade de trabalho intelectual a um custo marginal próximo de zero, a produtividade pode disparar, mas o valor de tarefas individuais despencará, e a vantagem da especialização será corroída. A distribuição de valor não será mais simplesmente baseada na eficiência ou na produção, mas dependerá de quem controla os novos recursos escassos (como dados, plataformas, os próprios modelos de IA). Isso é análogo a mudanças tecnológicas históricas (como o fast fashion para a indústria de vestuário, o streaming para a indústria da música), onde os dividendos do aumento da eficiência não fluíram totalmente para os trabalhadores, mas foram capturados pelos coordenadores do sistema. O artigo alerta que a IA não apenas automatiza tarefas, mas também mercantiliza o “pensamento”, o que pode ser a força mais disruptiva na história econômica moderna. (Fonte: Reddit r/artificial)
Estratégia empresarial na era da IA: evitar a armadilha da “empresa inteligente”, é preciso reestruturar e não otimizar processos antigos: Muitas empresas, ao adotar a IA, tendem a usá-la como ferramenta para otimizar processos existentes, reduzir custos e aumentar a eficiência, caindo na armadilha da “empresa inteligente” de “fazer a mesma coisa de forma mais inteligente”. No entanto, a verdadeira transformação não é tornar os processos antigos mais inteligentes, mas sim questionar se esses processos ainda precisam existir e construir sistemas e modelos de negócios totalmente novos e nativos da IA. A tecnologia não se adaptará simplesmente aos sistemas antigos, mas os remodelará. As empresas devem evitar investir recursos excessivos na otimização de processos que estão prestes a ser eliminados pela IA, e devem focar na definição de novas regras, mudando fundamentalmente a forma de tomar decisões, os mecanismos de coordenação e a estrutura organizacional. (Fonte: 36Kr)
💡 Outros
Evento de networking presencial da LangChain em Nova York: A LangChain anunciou que realizará um evento de networking presencial em Nova York no dia 22 de maio (quinta-feira), em conjunto com Tabs e TavilyAI. O evento incluirá conversas informais, demonstrações de produtos e oportunidades de networking com outros construtores. (Fonte: hwchase17, LangChainAI)

Conferência Global de IA em Tóquio será realizada em junho: Um evento chamado “Conferência Global de IA · Estação Tóquio” está programado para ser realizado de 7 a 8 de junho em Tóquio, Japão. Muitos desenvolvedores de IA, artistas, investidores e outros nomes conhecidos participarão. Pessoas interessadas no campo da IA e que planejam ir ao Japão podem ficar atentas às informações de inscrição. (Fonte: op7418)

O paradigma da arquitetura de serviços de IA está migrando de “Modelo como Serviço” para “Agente como Serviço”: Com o desenvolvimento da tecnologia de IA, a arquitetura de serviços de IA está passando por uma profunda transição de “Modelo como Serviço” (MaaS) para “Agente como Serviço” (AaaS). Os Agentes de IA, com sua capacidade de serem orientados por objetivos, perceberem o ambiente, tomarem decisões autônomas e aprenderem, superam o modelo tradicional de IA de executar passivamente instruções. Eles podem pensar de forma independente, decompor tarefas, planejar caminhos e invocar ferramentas externas para completar objetivos complexos. Essa mudança está impulsionando o desenvolvimento abrangente da cadeia da indústria, desde a infraestrutura subjacente (poder computacional, dados), algoritmos principais e grandes modelos, até componentes e plataformas de Agentes de camada intermediária, e finalmente aplicações de produtos terminais (Agentes de uso geral, verticais da indústria, embarcados). Empresas chinesas de Agentes de IA como HeyGen, Laiye Technology, Waveform Intelligence, etc., também estão ativamente se expandindo para mercados internacionais. Apesar de enfrentarem desafios como altos custos de poder computacional e oferta insuficiente, o potencial dos Agentes de IA está sendo continuamente liberado através de otimização de algoritmos, chips dedicados, computação de borda, etc. (Fonte: 36Kr)