

Palavras-chave:Agente de programação de IA, Codex, AlphaEvolve, Paradigma de inferência de IA, Modelo MoE, Chip de IA, Educação em IA, Minissérie de IA, Modelo OpenAI Codex-1, Google DeepMind AlphaEvolve, ByteDance Seed1.5-VL, Tecnologia Qwen ParScale, Sistema NVIDIA GB300
🔥 Foco
OpenAI lança agente de programação de IA na nuvem Codex, impulsionado pelo novo modelo codex-1: A OpenAI lançou o Codex, um agente de programação de IA na nuvem, baseado no codex-1, uma versão o3 especialmente ajustada e otimizada para engenharia de software. O Codex pode processar múltiplas tarefas em paralelo de forma segura em um sandbox na nuvem e, integrado ao GitHub, pode chamar diretamente repositórios de código, permitindo a construção rápida de módulos, resolução de problemas em bases de código, correção de vulnerabilidades, submissão de PRs e validação automática por testes. Tarefas que antes levavam dias ou horas podem ser concluídas pelo Codex em 30 minutos. A ferramenta já está disponível para usuários do ChatGPT Pro, Enterprise e Team, com o objetivo de se tornar o “engenheiro 10x” dos desenvolvedores, remodelando o processo de desenvolvimento de software. (Fonte: 36氪)
Google DeepMind lança AlphaEvolve, IA evolui autonomamente e alcança avanços em matemática e algoritmos: O sistema de IA AlphaEvolve do Google DeepMind, através da autoevolução e treinamento de grandes modelos de linguagem, alcançou avanços em diversas áreas da matemática e ciência. Ele aprimorou o algoritmo de multiplicação de matrizes 4×4 (pela primeira vez em 56 anos), otimizou o problema de empacotamento de hexágonos (pela primeira vez em 16 anos) e avançou no “problema do número de beijos”. O AlphaEvolve pode otimizar algoritmos autonomamente, encontrando inclusive métodos para acelerar o treinamento do modelo Gemini, e já foi aplicado para otimizar a infraestrutura de computação interna do Google, economizando 0,7% dos recursos computacionais. Isso marca um ponto onde a IA não apenas resolve problemas, mas também descobre novos conhecimentos, prometendo revolucionar o paradigma da pesquisa científica e realizar a criação científica por IA. (Fonte: 36氪)
Discurso de Altman na Cúpula de IA da Sequoia: IA entrará no mundo real em três anos, remodelando a vida e o trabalho: O CEO da OpenAI, Sam Altman, previu na Cúpula de IA da Sequoia que em 2025 os agentes de IA se tornarão práticos (especialmente na área de codificação), em 2026 a IA impulsionará grandes descobertas científicas e em 2027 os robôs entrarão no mundo físico para criar valor. Ele relembrou a jornada da OpenAI desde as primeiras explorações até o nascimento do ChatGPT e propôs que os futuros produtos de IA serão um serviço de “assinatura de IA central”, capaz de acomodar toda a experiência de vida de um indivíduo, tornando-se a interface inteligente padrão. A OpenAI se concentrará nos modelos centrais e cenários de aplicação, mantendo a eficiência organizacional de “pequena equipe, grande responsabilidade”. (Fonte: 36氪)
Apresentação da Nvidia na Computex: Computador pessoal de IA entra em produção, lança sistema GB300 de próxima geração, planeja construir supercomputador de IA em Taiwan: O CEO da Nvidia, Jensen Huang, anunciou na Computex 2025 que o computador pessoal de IA DGX Spark já está em plena produção e será lançado em algumas semanas; o sistema de IA de próxima geração GB300 (equipado com 72 GPUs Blackwell Ultra e 36 CPUs Grace) será lançado no terceiro trimestre. A Nvidia se unirá à TSMC e à Foxconn para construir um centro de supercomputação de IA em Taiwan. Simultaneamente, lançou a série de workstations Blackwell RTX Pro 6000 e o Grace Blackwell Ultra Superchip, e planeja abrir o código do motor de física Newton em julho para treinamento de robôs. Huang enfatizou que a IA estará em toda parte, reiterando seu impacto revolucionário. (Fonte: 36氪)

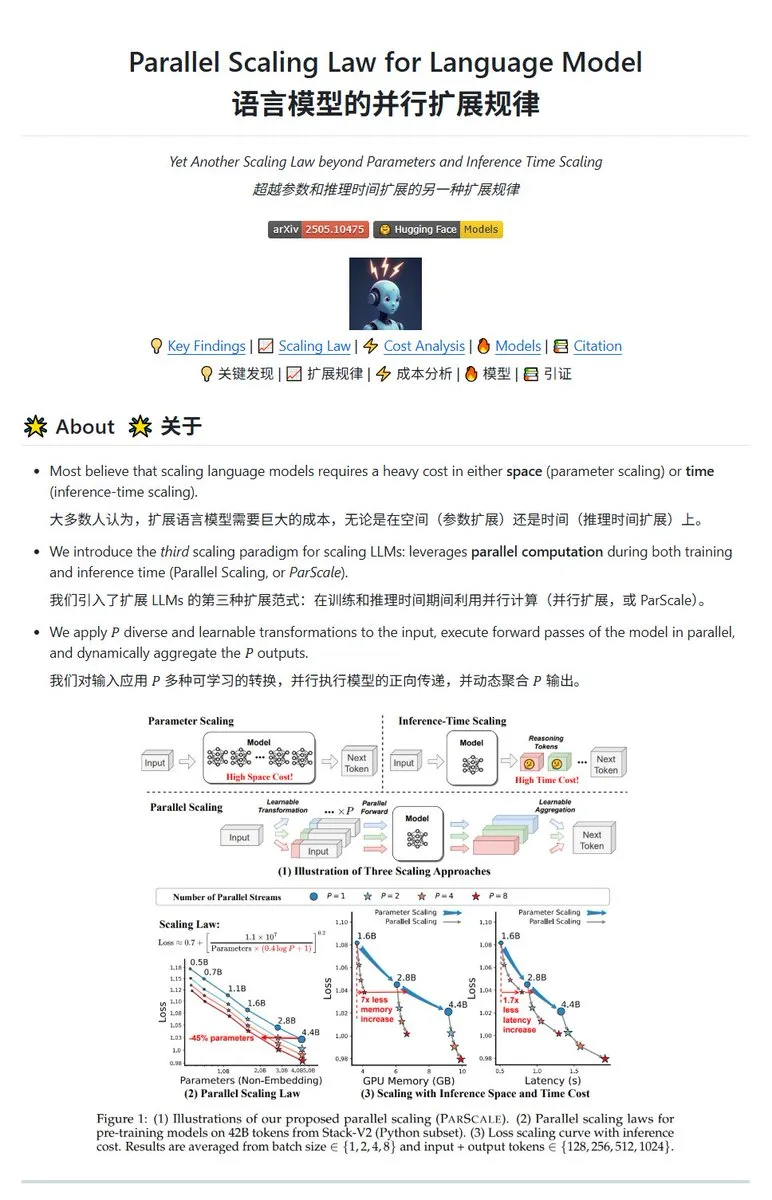
Qwen lança tecnologia de escalonamento paralelo ParScale, modelos pequenos podem alcançar efeitos de modelos grandes: A equipe Qwen lançou a tecnologia ParScale, que melhora a capacidade do modelo através da inferência paralela. O método usa n fluxos paralelos para inferência, cada fluxo adota transformações diferenciais aprendíveis para processar a entrada, e finalmente os resultados são combinados através de um mecanismo de agregação dinâmica. Pesquisas indicam que o efeito de P fluxos paralelos é aproximadamente equivalente a aumentar a quantidade de parâmetros do modelo em O(log P) vezes, por exemplo, um modelo de 30B através de 8 fluxos paralelos pode alcançar o efeito de um modelo de 42.5B. Espera-se que esta tecnologia melhore o desempenho do modelo sem aumentar significativamente o uso de VRAM, ou reduza o tamanho dos modelos existentes aumentando o paralelismo, mas pode vir ao custo de maior demanda computacional e menor velocidade de inferência. (Fonte: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 Tendências
Relatório da Poe: OpenAI e Google lideram corrida da IA, Anthropic mostra sinais de enfraquecimento: O mais recente relatório de uso da Poe (janeiro-maio de 2025) mostra uma mudança drástica no cenário do mercado de IA. No campo da geração de texto, o GPT-4o (35,8%) lidera, enquanto o Gemini 2.5 Pro (31,5%) se destaca na capacidade de raciocínio. A geração de imagens é dominada pelas séries Imagen3, GPT-Image-1 e Flux. No campo da geração de vídeo, o Kling-2.0-Master surgiu com destaque, e a participação da Runway caiu significativamente. Em termos de agentes, o o3 teve o melhor desempenho. O relatório aponta que a capacidade de raciocínio se tornou um campo de batalha crucial, a participação de mercado do Claude da Anthropic diminuiu, e a proporção de usuários do DeepSeek R1 também recuou do pico. As empresas precisam prestar atenção à precisão e confiabilidade dos modelos em tarefas complexas e escolher modelos de IA de forma flexível. (Fonte: 36氪)

Lançamento do modelo de IA principal da Meta, Behemoth (Llama 4), adiado, pode desencadear ajuste na estratégia de IA: Segundo relatos, o lançamento do modelo grande de 2 trilhões de parâmetros Behemoth (Llama 4) da Meta, originalmente planejado para abril, foi adiado para o outono ou mais tarde devido ao desempenho não ter atingido as expectativas. O modelo usa 30T de tokens multimodais pré-treinados em 32K GPUs, com o objetivo de competir com OpenAI, Google, etc. As dificuldades de desenvolvimento geraram decepção interna com o desempenho da equipe Llama 4 e podem levar a ajustes na equipe de produtos de IA. Ao mesmo tempo, dos 14 membros da equipe inicial do Llama 1, 11 já saíram. Executivos da Meta negaram os rumores de “demissão de 80% da equipe”, enfatizando que os que saíram eram principalmente da equipe do paper do Llama 1. Este evento intensificou as preocupações externas sobre se a Meta está enfrentando um gargalo na corrida da IA. (Fonte: 36氪)

ByteDance e Google DeepMind publicam nova pesquisa sobre modelo MoE, focando em eficiência e aplicação em sistemas de produção: O paper da ByteDance “MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production” introduz um sistema de produção projetado para o treinamento eficiente de modelos MoE em larga escala. Ao sobrepor comunicação e computação no nível do operador, alcançou um aumento de eficiência de 1,88 vezes em relação ao Megatron-LM e já foi implantado em seus data centers para treinar modelos de produção (como o Internal-352B, 32 experts, top-3). O Google DeepMind lançou o AlphaEvolve, que, através da autoevolução da IA e do treinamento de LLMs, obteve avanços em matemática e algoritmos, como a melhoria da multiplicação de matrizes 4×4 e do problema de empacotamento de hexágonos, mostrando o potencial da IA na descoberta científica. (Fonte: teortaxesTex, 36氪)

OpenAI discute paradigma de inferência em IA, enfatizando seu papel crucial na melhoria do desempenho: O pesquisador da OpenAI, Noam Brown, destacou que o desenvolvimento da IA passou do paradigma de pré-treinamento (prever a próxima palavra através de dados massivos) para o paradigma de inferência. O custo do pré-treinamento é alto, enquanto o paradigma de inferência melhora a qualidade da resposta aumentando o tempo de “pensamento” do modelo (volume de computação de inferência), mesmo que o custo de treinamento permaneça o mesmo. Por exemplo, os modelos da série o, em competições de matemática (AIME) e problemas científicos de nível de doutorado (GPQA), alcançaram taxas de precisão muito superiores ao GPT-4o através de um tempo de inferência mais longo. O economista-chefe da OpenAI, Ronnie Chatterji, discutiu a remodelação do cenário empresarial pela IA, argumentando que o ponto crucial é como as empresas integram a IA para aprimorar ou substituir papéis humanos e como a tecnologia de IA se encaixa na cadeia de valor. (Fonte: 36氪)

CEO do Google, Pichai, responde à “teoria da morte do Google”, enfatizando a evolução da busca impulsionada por IA e vantagens de infraestrutura: O CEO do Google, Sundar Pichai, em uma entrevista exclusiva, respondeu às preocupações sobre “a busca do Google ser substituída pela IA”, afirmando que o Google está transformando a busca de consultas reativas para um assistente inteligente preditivo e personalizado através de recursos como “AI Overview” e “AI Mode”. Ele enfatizou que o investimento de longo prazo do Google em infraestrutura de IA (TPUs autodesenvolvidos, data centers em larga escala) e eficiência de modelo são vantagens centrais, permitindo oferecer modelos avançados com alta relação custo-benefício. Pichai acredita que a IA é uma “plataforma tecnológica para todos os cenários”, que remodelará negócios centrais como Busca, YouTube e Cloud, e dará origem a novas formas. Ele também mencionou que a competitividade da IA chinesa (como o DeepSeek) não deve ser subestimada e apontou que a eletricidade será um gargalo crucial para o desenvolvimento da IA. (Fonte: 36氪)

Levantamento de startups de IA aplicadas à educação: O artigo lista 13 startups de IA na educação que merecem atenção em 2025. Elas estão mudando o ensino por meio de trilhas de aprendizado personalizadas, sistemas de tutoria inteligente, correção automática e criação de conteúdo imersivo. Por exemplo, Merlyn é um assistente de IA controlado por voz que alivia a carga administrativa dos professores; Brisk Teaching é uma extensão do Chrome que simplifica tarefas de ensino; Edexia é uma plataforma de correção por IA que aprende o estilo do professor; Storytailor combina biblioterapia com IA para criar histórias personalizadas; Brainly oferece ajuda com lição de casa aprimorada por IA. Essas empresas demonstram o amplo potencial de aplicação da IA na educação, desde o aumento da eficiência até a personalização do aprendizado e a equidade educacional. (Fonte: 36氪)
Minisséries de IA enfrentam desafios técnicos e de comercialização, com resultados de produção aquém das expectativas: Embora as ferramentas de IA prometam reduzir os custos de produção de minisséries e encurtar os ciclos, os profissionais da área descobriram que as minisséries de IA apresentam dificuldades técnicas significativas em termos de consistência do personagem principal, sincronia labial e naturalidade da linguagem cinematográfica, resultando em muitas obras que se assemelham mais a “minisséries no estilo PPT”. A IA tem dificuldade em compreender ideias surreais, limitando a exploração de gêneros de fantasia e ficção científica. Atualmente, a tecnologia de IA é mais adequada para a produção de curtas-metragens do que minisséries completas, e as perspectivas de comercialização são incertas. Grandes empresas de cinema e televisão, como Bona Film Group e Huace Group, têm maior probabilidade de se destacar devido às suas vantagens de recursos, enquanto a maioria dos pequenos criadores enfrenta altos custos de tentativa e erro e o problema de suas obras se tornarem rapidamente obsoletas devido à rápida iteração tecnológica. (Fonte: 36氪)
MSI lança PC com IA integrado com superchip NVIDIA GB10, incluindo 6144 núcleos CUDA e 128GB de memória LPDDR5X: A MSI apresentou seu EdgeExpert MS-C931 S, um PC com IA equipado com o superchip NVIDIA GB10. O chip foi confirmado como tendo 6144 núcleos CUDA e 128GB de memória LPDDR5X. Esta é mais uma fabricante, depois da ASUS, Dell e Lenovo, a lançar um computador pessoal de IA baseado na arquitetura NVIDIA DGX Spark. O lançamento de tais produtos sinaliza que a capacidade de computação de IA de alto desempenho está gradualmente se tornando popular em dispositivos pessoais e de borda, mas alguns comentários apontam que seu preço pode dificultar a competição com produtos como o Mac Mini. (Fonte: Reddit r/LocalLLaMA)
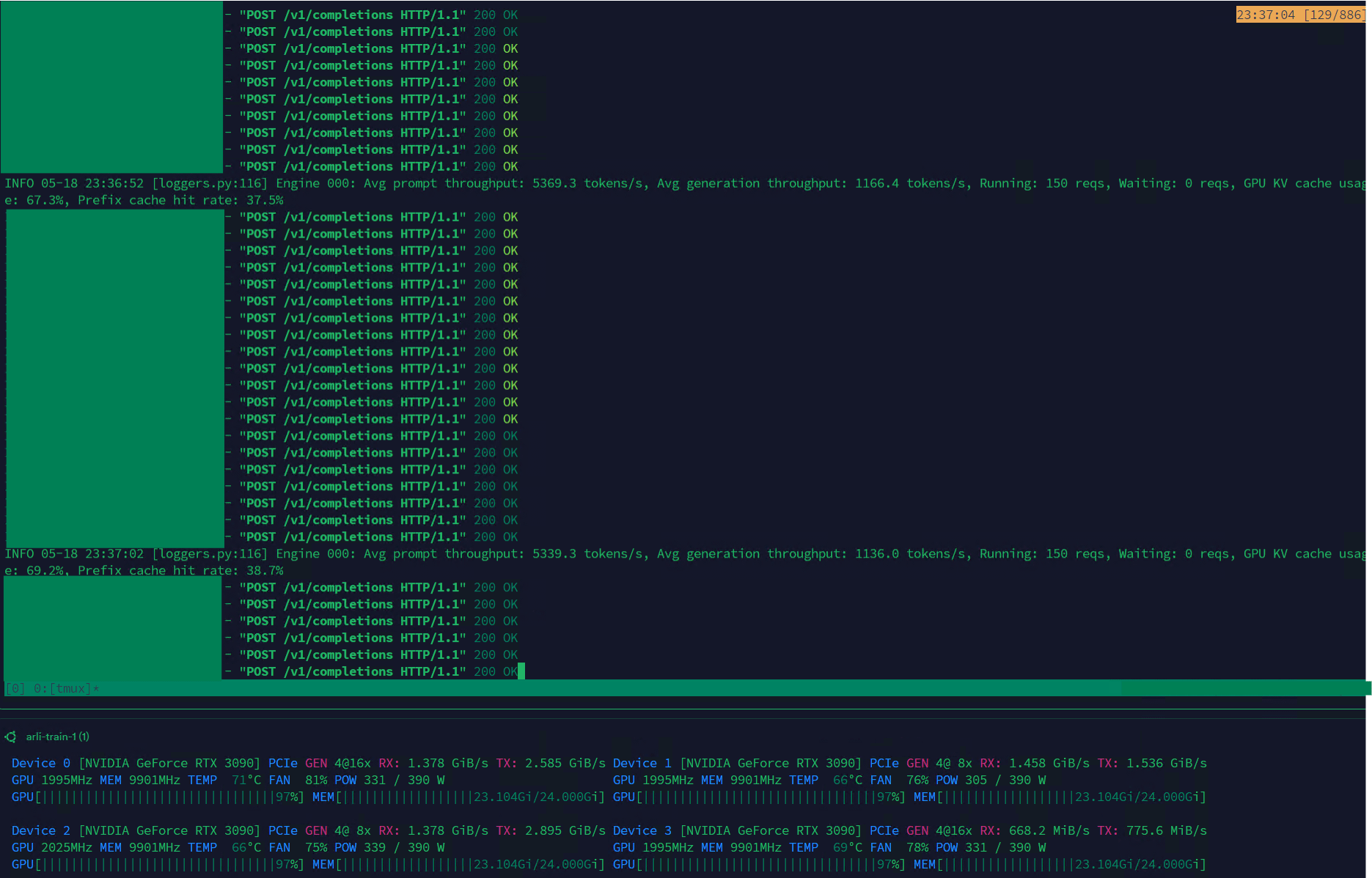
Qwen3-30B alcança alto throughput no VLLM, adequado para gerenciamento de datasets: O modelo Qwen3-30B-A3B demonstrou excelente velocidade de inferência (5K t/s pré-preenchimento, 1K t/s geração) no framework VLLM e em placas de vídeo RTX 3090s, tornando-o muito adequado para tarefas como filtragem e gerenciamento de datasets. Embora possa haver uma ligeira regressão em comparação com o QwQ, sua vantagem de velocidade o torna mais prático no processamento de dados. O principal problema existente é a velocidade de treinamento extremamente lenta, mas já existe um PR na biblioteca Hugging Face Transformers tentando resolver esse problema, e espera-se que no futuro sejam lançados modelos RpR com datasets aprimorados baseados no Qwen3-30B. (Fonte: Reddit r/LocalLLaMA)
Bilibili lança modelo de geração de vídeo de animação de código aberto Index-AniSora, suportando vários estilos de anime/2D: O Bilibili lançou o Index-AniSora, um modelo de código aberto projetado especificamente para a geração de vídeos no estilo anime/2D, baseado em sua estrutura tecnológica AniSora (aceita pelo IJCAI25). O modelo pode gerar animações a partir de mangás com um clique, suportando vários estilos como séries de anime, produções nacionais, adaptações de mangá e VTubers. O sistema AniSora, através da construção de um dataset de dezenas de milhões de pares texto-vídeo de alta qualidade, desenvolveu uma estrutura unificada de geração por difusão e introduziu um mecanismo de máscara espaço-temporal, alcançando controle refinado sobre a sincronia labial e os movimentos dos personagens. Ao mesmo tempo, o Bilibili projetou um benchmark de avaliação para vídeos de animação e um sistema de avaliação automatizado otimizado baseado em VLM. O conteúdo de código aberto incluirá AniSoraV1.0 (baseado no CogVideoX-5B), AniSoraV2.0 (baseado no Wan2.1-14B, suportando treinamento em Huawei 910B) e ferramentas relacionadas para construção de datasets e avaliação. (Fonte: WeChat)

ByteDance lança modelo de linguagem visual Seed1.5-VL, com excelente desempenho em tarefas multimodais: A ByteDance lançou o Seed1.5-VL, um modelo de linguagem visual composto por um codificador visual de 532M de parâmetros e um LLM de Mixture-of-Experts (MoE) com 20B de parâmetros ativos. O modelo alcançou desempenho SOTA em 38 de 60 benchmarks públicos e superou sistemas líderes como OpenAI CUA e Claude 3.7 em tarefas centradas em agentes, como controle de GUI e jogabilidade, demonstrando forte capacidade de compreensão e raciocínio multimodal. (Fonte: WeChat)
Nous Research lança Psyche Network, realizando pré-treinamento distribuído de LLM com 40B de parâmetros: A Nous Research lançou a Psyche Network, uma rede de treinamento descentralizada baseada na arquitetura DeepSeek V3 MLA, que em seu primeiro teste realizou o pré-treinamento de um modelo de linguagem grande com 40 bilhões de parâmetros. A rede utiliza o otimizador DisTrO e uma pilha de rede ponto a ponto personalizada, integrando poder computacional de GPU distribuído globalmente, permitindo que indivíduos e pequenos grupos treinem em um único H/DGX e executem em GPUs 3090. Esta iniciativa visa quebrar o monopólio de poder computacional das gigantes da tecnologia, tornando o treinamento de modelos em larga escala mais acessível. (Fonte: 量子位)

🧰 Ferramentas
Sim Studio: Construtor de workflow de agentes de IA de código aberto: Sim Studio é uma plataforma de construção de workflow de agentes de IA de código aberto e leve, que oferece uma interface intuitiva onde os usuários podem construir e implantar rapidamente aplicações LLM conectadas a várias ferramentas. Suporta versão hospedada na nuvem e auto-hospedagem (recomendado ambiente Docker, suporta modelos locais como Ollama). Sua pilha tecnológica inclui Next.js, Bun, PostgreSQL, Drizzle ORM, Better Auth, Shadcn UI, Tailwind CSS, Zustand, ReactFlow e Turborepo. (Fonte: GitHub Trending)

Cherry Studio: Aplicativo de desktop LLM frontend de código aberto com funcionalidades abrangentes ganha atenção: Cherry Studio é um aplicativo de desktop LLM frontend de código aberto que integra RAG, busca na web, modelos locais (conectados via Ollama, LM Studio) e acesso a modelos na nuvem (como Gemini, ChatGPT), entre outras funcionalidades. Usuários relatam que seu suporte e gerenciamento de MCP (Multi-Control Protocol) são superiores ao Open WebUI e LibreChat, e é fácil de instalar e configurar. O aplicativo também suporta conexão direta com a base de conhecimento Obsidian. Embora alguns usuários expressem preocupação com sua origem, seu conjunto abrangente de funcionalidades o torna uma opção atraente. (Fonte: Reddit r/LocalLLaMA)

MLX-LM-LoRA: Adiciona LoRA a modelos MLX e suporta vários métodos de treinamento: O projeto de código aberto mlx-lm-lora permite que os usuários integrem módulos LoRA (Low-Rank Adaptation) em modelos sob o framework Apple MLX. O projeto não apenas suporta a adição de LoRA, mas também incorpora vários métodos de treinamento de alinhamento, como ORPO, DPO, CPO, GRPO, facilitando para os usuários o ajuste fino de modelos de acordo com suas necessidades, a geração de módulos LoRA personalizados e sua aplicação em seus modelos MLX preferidos. (Fonte: karminski3)
DeepDrone: Projeto de drone controlado por IA baseado em Qwen é de código aberto: Um desenvolvedor criou um projeto de drone controlado por IA chamado DeepDrone, baseado no modelo grande Qwen, e o disponibilizou em código aberto no HuggingFace e GitHub. O projeto demonstra o potencial de aplicar modelos de linguagem grandes ao controle autônomo de drones, gerando discussões sobre IA em automação e potenciais aplicações militares. (Fonte: karminski3)
Qwen Web Dev: Gere e implante sites com um único prompt: A equipe Qwen do Alibaba anunciou que sua ferramenta Qwen Web Dev foi aprimorada, permitindo aos usuários gerar um site com apenas um prompt e implantá-lo com um clique. A ferramenta visa reduzir a barreira para o desenvolvimento web, permitindo que os usuários transformem ideias em sites acessíveis de forma mais conveniente e os compartilhem com o mundo. (Fonte: Alibaba_Qwen, huybery)
SuperGo.AI: Ferramenta de interface única integrando oito modelos LLM: Entusiastas de IA desenvolveram uma ferramenta chamada SuperGo.AI, que integra oito LLMs com diferentes papéis (como AI Super Brain, AI Imagination, AI Ethics, AI Universe, etc.) em uma única interface. Esses papéis de IA podem perceber e interagir uns com os outros, e os usuários podem selecionar os modos “Criativo”, “Científico” e “Misto” para obter respostas híbridas. A ferramenta visa fornecer uma nova experiência de colaboração multi-IA e atualmente não possui paywall. (Fonte: Reddit r/artificial)
Kokoro-JS: Realiza conversão ilimitada de texto para fala (TTS) localmente: Kokoro-JS é uma ferramenta de conversão de texto para fala 100% local e 100% de código aberto, que funciona baixando um modelo de IA de aproximadamente 300MB no lado do navegador. O texto inserido pelo usuário não é enviado para nenhum servidor, garantindo privacidade e disponibilidade offline. A ferramenta visa fornecer funcionalidade TTS ilimitada. (Fonte: Reddit r/LocalLLaMA)
📚 Aprendizado
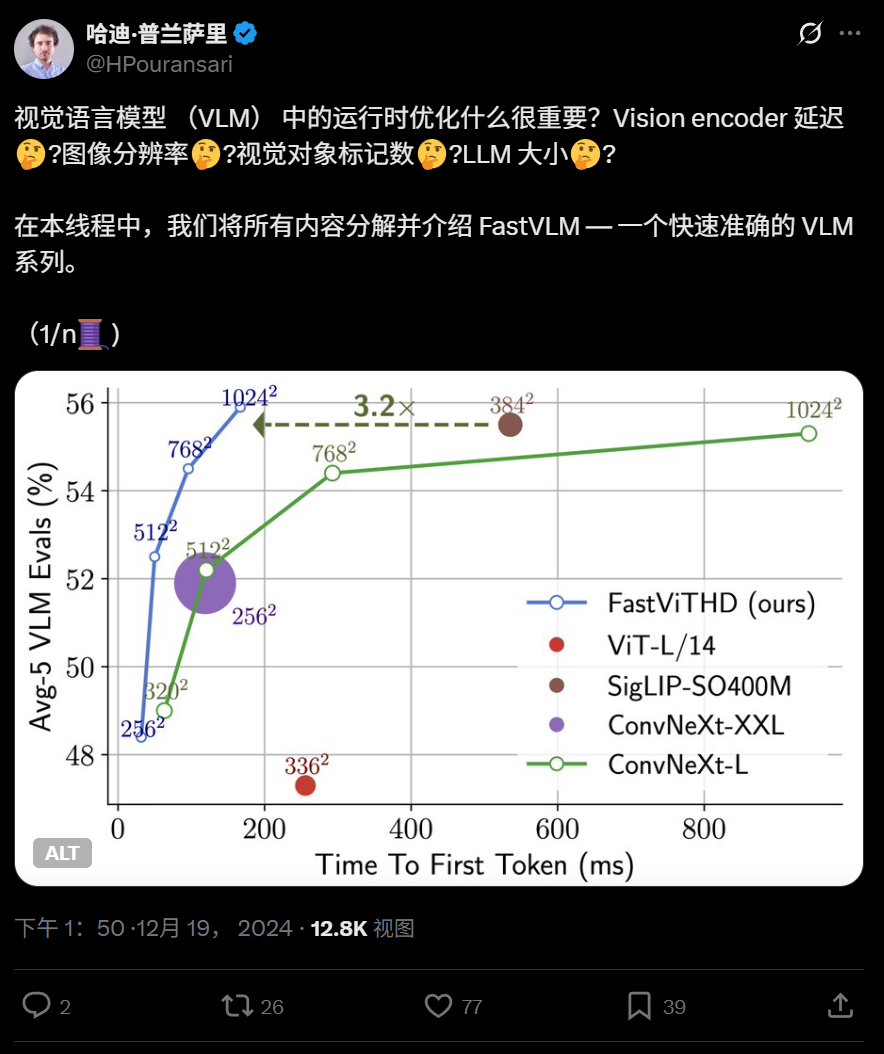
Apple lança modelo de linguagem visual eficiente FastVLM de código aberto, otimizado para execução em dispositivos: A Apple lançou o FastVLM de código aberto, um modelo de linguagem visual projetado especificamente para execução eficiente em dispositivos como o iPhone. O FastVLM introduz um novo codificador visual híbrido, o FastViTHD, que combina camadas convolucionais com módulos Transformer, e adota técnicas de pooling multiescala e downsampling, reduzindo significativamente o número de tokens visuais necessários para processar imagens (16 vezes menos que o ViT tradicional), com a velocidade de saída do primeiro token aumentada em 85 vezes. O modelo é compatível com LLMs convencionais e já forneceu um aplicativo de demonstração para iOS/macOS baseado no framework MLX, adequado para dispositivos de borda e tarefas de imagem e texto em tempo real. (Fonte: WeChat)
Harbin Institute of Technology e University of Pennsylvania propõem PointKAN, baseado em KAN para aprimorar análise de nuvem de pontos 3D: Equipes de pesquisa do Harbin Institute of Technology (Shenzhen) e da University of Pennsylvania lançaram o PointKAN, uma nova arquitetura para percepção 3D baseada em Kolmogorov-Arnold Networks (KANs). O PointKAN substitui as funções de ativação fixas nos MLPs tradicionais por funções de ativação aprendíveis, aprimorando a capacidade de aprender características geométricas complexas. Ele inclui um módulo afim geométrico e um módulo de extração de características locais paralelas. A equipe também propôs uma versão PointKAN-elite, que adota a estrutura Efficient-KANs, usando funções racionais como funções base e compartilhando parâmetros em grupos, reduzindo significativamente a quantidade de parâmetros e a complexidade computacional, ao mesmo tempo em que demonstra desempenho SOTA em tarefas de classificação, segmentação parcial e aprendizado com poucas amostras. (Fonte: 量子位)

Universidade de Pittsburgh propõe framework PhyT2V, melhorando o realismo físico de vídeos gerados por IA: O Laboratório de Sistemas Inteligentes da Universidade de Pittsburgh desenvolveu o framework PhyT2V, com o objetivo de aumentar a consistência física do conteúdo gerado por modelos de texto para vídeo (T2V). O método não requer retreinamento de modelos ou dados externos em larga escala, utilizando raciocínio em cadeia (CoT) guiado por grandes modelos de linguagem (LLM) e um mecanismo de autocorreção iterativa para analisar e otimizar as prompts de texto em múltiplas rodadas de regras físicas. O PhyT2V é capaz de identificar regras físicas, incompatibilidades semânticas e gerar prompts corrigidas, melhorando assim a capacidade de generalização dos principais modelos T2V (como CogVideoX, OpenSora) em cenários físicos realistas (sólidos, fluidos, gravidade, etc.), especialmente em cenários fora da distribuição, com métricas de bom senso físico (PC) e adesão semântica (SA) aumentando em até 2,3 vezes. (Fonte: WeChat)
Últimas pesquisas em LLM: Multimodalidade, alinhamento em tempo de teste, Agentes, otimização de RAG, etc.: Os avanços da pesquisa em LLM de uma semana incluem: 1. A Universidade de Washington propôs o QALIGN, um método de alinhamento em tempo de teste que não requer modificação do modelo ou acesso aos logits, alcançando um melhor alinhamento na geração de texto através de MCMC. 2. A UCLA pré-treinou o Clinical ModernBERT, expandindo o comprimento do contexto do codificador no domínio biomédico para 8192 tokens. 3. A Skoltech propôs um método leve de recuperação RAG adaptável e independente de LLM, baseado em informações externas (popularidade da entidade, tipo de pergunta). 4. A PSU definiu o problema de atribuição automatizada de falhas em sistemas multi-agente de LLM e desenvolveu um dataset e método de avaliação. 5. A Universidade Fudan propôs uma estrutura de restrição multidimensional e um processo de geração automatizada de instruções para melhorar a capacidade de seguimento de instruções dos LLMs. 6. A a-m-team lançou o AM-Thinking-v1 (32B) de código aberto, com capacidade de codificação matemática comparável ao DeepSeek-R1-671B. 7. A Xiaomi lançou o MiMo-7B, que, através da otimização do pré-treinamento e pós-treinamento, apresenta excelente desempenho em tarefas de raciocínio. 8. A MiniMax propôs o modelo TTS autorregressivo MiniMax-Speech, que suporta clonagem de timbre zero-shot em 32 idiomas. 9. A ByteDance construiu o modelo de linguagem visual Seed1.5-VL, com desempenho destacado em tarefas multimodais e tarefas centradas em agentes. 10. O primeiro modelo de linguagem de 32B parâmetros do mundo, INTELLECT-2, alcançou treinamento por aprendizado por reforço distribuído, propondo o framework PRIME-RL. (Fonte: WeChat)
Workshops da AAAI 2025 focam em raciocínio neural, descobertas matemáticas e IA para acelerar ciência e engenharia: Os workshops da AAAI 2025 discutiram extensivamente as aplicações da IA no campo científico. Entre eles, o workshop “Raciocínio Neural e Descoberta Matemática” enfatizou que redes neurais de caixa preta podem ser usadas para propor conjecturas matemáticas e gerar novas figuras geométricas, mas também apontou sua incapacidade de alcançar raciocínio lógico de nível simbólico, defendendo abordagens interdisciplinares. Outro workshop, “IA para Acelerar Ciência e Engenharia” (quarta edição, com tema em biociências de IA), focou em modelos fundamentais para design terapêutico, modelos generativos para descoberta de fármacos, design de anticorpos em ciclo fechado em laboratório, aprendizado profundo em genômica e inferência causal em aplicações biológicas, além de discutir os desafios e oportunidades dos modelos generativos em biociências. (Fonte: aihub.org)

Google e Anthropic divergem em pesquisa sobre interpretabilidade da IA, interpretabilidade mecanicista enfrenta desafios: A natureza de “caixa preta” da IA limita sua aplicação em muitas áreas cruciais. O Google DeepMind anunciou recentemente a redução da prioridade da pesquisa em “interpretabilidade mecanicista” (mechanistic interpretability), argumentando que a engenharia reversa dos mecanismos internos da IA através de métodos como Sparse Autoencoders (SAE) enfrenta inúmeros problemas, como falta de referência objetiva, cobertura incompleta de conceitos, distorção de características, etc., e que as tecnologias SAE existentes não conseguiram identificar os “conceitos” necessários em tarefas críticas. Por outro lado, o CEO da Anthropic, Dario Amodei, defende o fortalecimento da pesquisa nessa área e expressa otimismo quanto à realização de uma “ressonância magnética da IA” nos próximos 5-10 anos. Essa controvérsia destaca os profundos desafios na compreensão e controle do comportamento da IA. (Fonte: 36氪)

Peking University/StepStar/Lightelligence propõem InfiniteHBD: Nova geração de arquitetura de domínio de alta largura de banda para GPU reduz custos e aumenta eficiência: Visando as limitações das arquiteturas de domínio de alta largura de banda (HBD) existentes em escalabilidade, custo e tolerância a falhas, equipes da Peking University, StepStar e Lightelligence propuseram a arquitetura InfiniteHBD. Esta arquitetura é centrada em módulos de comutação óptica (OCSTrx) e, ao incorporar capacidade de comutação óptica de baixo custo (OCS) em módulos de conversão optoeletrônica, realiza uma topologia K-Hop Ring dinamicamente reconfigurável em escala de data center e isolamento de falhas em nível de nó. O custo unitário do InfiniteHBD é de apenas 31% do NVL-72, a taxa de desperdício de GPU é quase zero, e o MFU (Model FLOPs Utilization) é até 3,37 vezes maior em comparação com o NVIDIA DGX, fornecendo uma solução superior para treinamento de modelos grandes em larga escala. O artigo foi aceito pela SIGCOMM 2025. (Fonte: WeChat)

OceanBase lança PowerRAG, abraçando totalmente a IA e construindo uma base de dados integrada Data×AI: Na conferência de desenvolvedores, a OceanBase lançou o PowerRAG, um produto de aplicação voltado para IA, com o objetivo de fornecer capacidade de desenvolvimento RAG pronta para uso, conectando dados, plataforma, interface e camada de aplicação. O CTO Yang Chuanhui detalhou a estratégia de IA da OceanBase: construir capacidade Data×AI, evoluindo de um banco de dados integrado para uma base de dados integrada. A OceanBase aprimorará as capacidades vetoriais, melhorará a busca híbrida, realizará atualizações dinâmicas do armazenamento de conhecimento empresarial, integrará profundamente o pós-treinamento e o ajuste fino de modelos, e já se adaptou às principais plataformas de Agent como Dify, FastGPT e ao protocolo MCP. Seu desempenho vetorial liderou nos testes VectorDBBench e reduziu significativamente a necessidade de memória através do algoritmo de quantização BQ. (Fonte: WeChat)

💼 Negócios
Fundo estatal de Xangai investe em empresas de chips de IA como Xinyaohui, Enflame Technology e Biren Technology: A Shanghai State-owned Capital Investment Co., Ltd. (Shanghai Guotou) assinou recentemente acordos de investimento com três empresas de semicondutores: Xinyaohui, Enflame Technology e Biren Technology. Anteriormente, seu fundo mãe de IA líder já havia liderado o financiamento pré-IPO da Biren Technology. A Shanghai Guotou afirmou que irá ativamente se posicionar em áreas como modelos básicos, chips de computação e inteligência incorporada. A Xinyaohui foca em IP de semicondutores, especialmente tecnologia Chiplet, e seu fundador, Zeng Keqiang, foi vice-presidente da Synopsys China. Enflame Technology e Biren Technology são ambas empresas de design de chips GPU. Esta ação demonstra o foco da Shanghai Guotou na cadeia de suprimentos upstream da IA, especialmente no campo de chips de computação. (Fonte: 36氪)
Sakana AI e Mitsubishi UFJ Bank estabelecem parceria abrangente para desenvolver IA específica para bancos: A startup japonesa de IA Sakana AI anunciou a assinatura de um acordo de parceria de vários anos com o Mitsubishi UFJ Bank (MUFG). A Sakana AI desenvolverá agentes de IA especializados para as operações bancárias do MUFG, com o objetivo de impulsionar a transformação das operações bancárias e a aplicação prática da IA. Ao mesmo tempo, o cofundador e COO da Sakana AI, Ren Ito, atuará como consultor do MUFG, auxiliando o banco na implementação de sua estratégia de IA. Esta colaboração marca um passo importante para a Sakana AI na aplicação de tecnologia avançada de IA para resolver questões específicas do setor financeiro japonês. (Fonte: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

Cofundadora da 01.AI, Gu Xuemei, deixa a empresa para empreender; foco da empresa muda para o setor B2B: Gu Xuemei, cofundadora da 01.AI e responsável pelo pré-treinamento de modelos e produtos C-end, deixou a empresa há alguns meses e está atualmente se preparando para empreender. A 01.AI confirmou o fato e agradeceu sua contribuição. Desde 2025, o foco de negócios da 01.AI mudou de aplicações AI ToC e APIs de modelo para cenários B2B, como humanos digitais, personalização e implantação de modelos. Seus produtos C-end, como a ferramenta de escritório versão doméstica “Wanzhi”, foram descontinuados devido ao volume de usuários abaixo do esperado, e a comercialização do produto de RPG internacional Mona também não foi ideal. Anteriormente, o cofundador Dai Zonghong também havia deixado a empresa para empreender. (Fonte: 36氪)

🌟 Comunidade
Detecção de AIGC em teses causa controvérsia, precisão questionada, formaturas de estudantes afetadas: Este ano, muitas universidades introduziram a detecção de AIGC como parte do processo de revisão de teses de graduação, com o objetivo de impedir que os alunos abusem da escrita por IA. No entanto, a medida gerou ampla controvérsia. Os alunos relatam que o conteúdo que eles próprios escreveram é frequentemente mal interpretado como gerado por IA, e após a modificação assistida por IA, a suspeita de geração por IA paradoxalmente aumenta. Testes mostraram até mesmo que o “Prefácio ao Pavilhão do Príncipe Teng” teve uma suspeita de geração por IA de 99,2%. As próprias ferramentas de detecção de AIGC são impulsionadas por IA, e seu princípio é analisar as características linguísticas do texto em comparação com os padrões de escrita da IA, mas sua precisão é questionável; uma ferramenta inicial da OpenAI tinha apenas 26% de precisão. Essa incerteza não apenas causa problemas e despesas extras para os alunos (diferentes sites de detecção fornecem resultados variados, e os serviços de redução de plágio são pagos), mas também levanta questões sobre a natureza das ferramentas de IA: a IA imita a escrita humana, e então usamos a IA para detectar se o texto humano se assemelha à IA, o que é um paradoxo lógico. (Fonte: 36氪)

Nova funcionalidade do ChatGPT com conexão direta ao Github: Pesquisa aprofundada em repositórios de código e documentação especializada: A funcionalidade Deep Research recentemente lançada pelo ChatGPT adicionou a capacidade de se conectar diretamente a repositórios do Github, permitindo que os usuários autorizem o ChatGPT a acessar seus repositórios públicos ou privados para análise aprofundada de código, resumo da arquitetura funcional, identificação da pilha tecnológica, avaliação da qualidade do código e análise da aplicabilidade do projeto, entre outros. Essa funcionalidade não se limita a código; os usuários podem fazer upload de PDFs, documentos do Word e outros tipos de documentos para repositórios do Github e usar o ChatGPT para pesquisa aprofundada em materiais de domínios específicos, o que equivale a uma combinação de RAG+MCP com escopo limitado. A funcionalidade está atualmente disponível para usuários Plus e, ao limitar o escopo da pesquisa, espera-se melhorar o profissionalismo e a precisão dos relatórios de pesquisa, reduzindo as alucinações. (Fonte: 36氪)
Concorrência no mercado de Agentes de IA se acirra, Manus abre registro para todos, gigantes como ByteDance e Baidu entram na disputa: O Manus, conhecido como “Agente multifuncional”, anunciou em 12 de maio a abertura total de registros, permitindo que os usuários obtenham cotas de uso sem espera. Ao mesmo tempo, circulam rumores no mercado de que o Manus está buscando uma nova rodada de financiamento com uma avaliação de US$ 1,5 bilhão. Desde seu lançamento em março, o Manus desencadeou uma onda de projetos do tipo Agente, mas também enfrenta desafios como queda de tráfego e o surgimento de produtos concorrentes. A ByteDance lançou o Coze Space, o Baidu lançou “Miaoda” e “Xinxiang”, e o Agente de design Lovart também iniciou testes. O mercado de Agentes está passando da validação de conceito inicial para uma competição abrangente em funcionalidades de produto, modelos de negócios e crescimento de usuários. (Fonte: 36氪)
Codificação assistida por IA transforma o fluxo de trabalho dos desenvolvedores, aumentando a produtividade, mas exige cautela contra a dependência excessiva: Um usuário do Reddit compartilhou como os assistentes de código de IA mudaram significativamente sua experiência de codificação, especialmente ao lidar com grandes projetos legados e entender códigos complexos. As ferramentas de IA podem explicar o código linha por linha, fornecer sugestões, destacar problemas potenciais, resumir arquivos, encontrar trechos e gerar comentários, como ter um especialista disponível 24 horas por dia. Os comentários apontaram que a IA pode realizar codificação repetitiva, aumentar a eficiência, orientar para novas abordagens, adicionar comentários e até ajudar os desenvolvedores a concluir tarefas além de suas capacidades, reduzindo dias de trabalho para horas. No entanto, isso também levanta questões sobre a evolução das habilidades dos desenvolvedores e a dependência de ferramentas de IA. (Fonte: Reddit r/artificial)
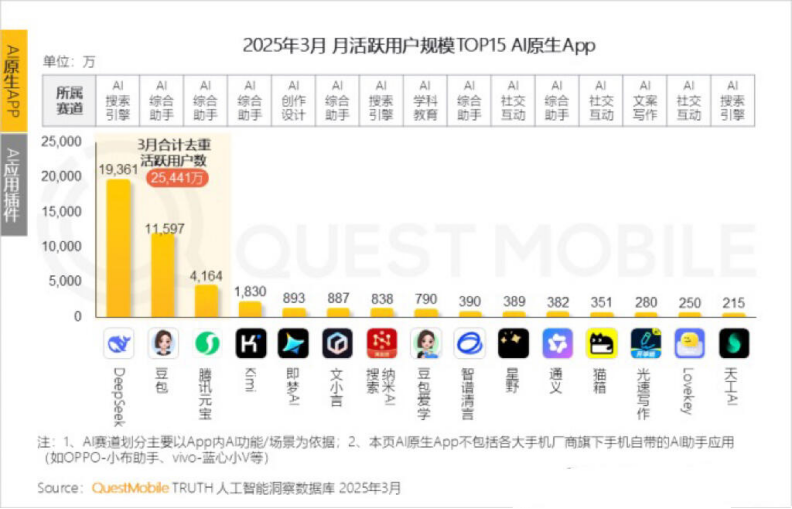
Kimi Chat da Moonshot AI vê queda de usuários ativos mensais, empresa busca avanços em nichos e transformação social: O Kimi Chat da Moonshot AI viu seus usuários ativos mensais caírem de 36 milhões em outubro do ano passado para 18,2 milhões em março deste ano, segundo dados da QuestMobile, caindo para o quarto lugar. Para aumentar a retenção de usuários, Kimi está se expandindo de um modelo grande geral para domínios de nicho, como colaborar com a Caixin Media para melhorar a qualidade da busca de conteúdo financeiro, planejar a busca médica por IA e introduzir conteúdo de vídeo do Bilibili. Ao mesmo tempo, Kimi lançou um desafio de check-in no Xiaohongshu, tentando alcançar mais usuários C-end através de plataformas sociais. Sua interface de usuário também está se ajustando em direção a multimodalidade, um estilo semelhante ao Doubao e orientação para a comunidade. Enfrentando concorrentes como DeepSeek e a entrada de grandes empresas em aplicações de IA, o posicionamento de liderança tecnológica de Kimi está sob pressão, e a pressão de comercialização aumenta, levando a uma busca ativa por novos pontos de crescimento. (Fonte: 36氪)
Discussão sobre se a IA deve se referir a si mesma na primeira pessoa: Um usuário do Reddit iniciou uma discussão, argumentando que LLMs como o ChatGPT se referirem a si mesmos como “eu” ou ao usuário como “você” pode ser inadequado, pois são essencialmente “coisas” e não “pessoas”. Sugeriu que eles usem a terceira pessoa, como “O ChatGPT irá ajudá-lo…”, para evitar dar aos usuários a impressão de que são entidades personificadas, o que poderia levar a perigos potenciais ou questões éticas. Nos comentários, alguns argumentaram que a terceira pessoa, ao contrário, implicaria autoconsciência, enquanto outros acharam que a terceira pessoa soava tola e desconfortável. A discussão reflete a reflexão dos usuários sobre o posicionamento da identidade da IA e as formas de interação humano-computador. (Fonte: Reddit r/ArtificialInteligence)
💡 Outros
MIT retira urgentemente um artigo de IA amplamente divulgado, citando dúvidas sobre a autenticidade dos dados e da pesquisa: O Massachusetts Institute of Technology (MIT) retirou o artigo “Inteligência Artificial, Descoberta Científica e Inovação de Produto”, de autoria de Aidan Toner-Rogers, doutorando em economia do MIT. O artigo havia ganhado notoriedade por propor que ferramentas de IA poderiam aumentar significativamente a eficiência da inovação de cientistas de ponta, mas também poderiam exacerbar a “disparidade entre ricos e pobres” na pesquisa científica e reduzir o bem-estar de pesquisadores comuns, recebendo elogios de professores renomados, incluindo ganhadores do Prêmio Nobel. O MIT declarou que, após receber uma denúncia de integridade de pesquisa e conduzir uma investigação interna, perdeu a confiança nas fontes de dados, confiabilidade, validade e autenticidade da pesquisa do artigo, e solicitou ao arXiv e ao Quarterly Journal of Economics que removessem o artigo. O autor deixou o MIT, e os professores envolvidos também emitiram declarações se distanciando. Alega-se que o autor comprou nomes de domínio falsos durante a investigação para se passar por e-mails de grandes empresas, foi descoberto e processado. (Fonte: 36氪)

Imagens geradas por IA usadas em golpes online, gerando alerta entre usuários: Um usuário do Reddit compartilhou casos de imagens de pessoas geradas por IA sendo usadas para promoção de produtos em mídias sociais como o Facebook. As pessoas e cenários nessas imagens frequentemente apresentam elementos ilógicos (como modelos entrando e saindo de caixas de maneira bizarra, ou pessoas irrelevantes aparecendo ao fundo), mas a consistência da imagem do personagem é relativamente alta. Comentaristas apontaram que esse tipo de conteúdo gerado por IA já está sendo usado em golpes, alertando os usuários para ficarem atentos. Blogueiros como Pleasant Green também produziram vídeos expondo esses golpes. (Fonte: Reddit r/ChatGPT)
Discussão sobre imitação de estilo e extração de prompts em imagens geradas por IA: Usuários discutiram como fazer modelos de IA (como o DALL-E 3) imitarem estilos artísticos específicos (como o estilo Pixar combinado com o estilo Designer Toy de Salvador Dalí) para criar retratos de personagens, e compartilharam prompts detalhados, enfatizando características do personagem, fundo, iluminação e sombra, e conceitos centrais (como a sombra como uma projeção mental). Além disso, outros usuários forneceram modelos de prompt para extrair parâmetros de estilo de imagens e exportá-los em formato JSON, com o objetivo de ajudar os usuários a fazer engenharia reversa de estilos de imagem, embora a reprodução precisa ainda seja difícil. (Fonte: dotey, dotey)
