
Palavras-chave:AlphaEvolve, Design de Algoritmos de IA, IA Multimodal, Ferramentas de Programação de IA, Algoritmos de Evolução Autônoma, Modelos de Linguagem de Grande Escala (LLM), Agentes Inteligentes de IA, Implementação Open Source do AlphaEvolve, IA Projetando Autonomamente Algoritmos de Multiplicação de Matrizes, Interface Unificada para IA Multimodal, Impacto das Ferramentas de Programação de IA nos Desenvolvedores, Desempenho do Modelo Local Qwen 3
🔥 Foco
Google DeepMind lança AlphaEvolve, IA que projeta e evolui algoritmos autonomamente: O Google DeepMind divulgou o projeto AlphaEvolve e seu artigo, apresentando um agente de IA capaz de projetar, testar, aprender e evoluir algoritmos mais eficientes de forma autônoma. O sistema usa engenharia de prompt para impulsionar modelos de linguagem grandes (como o Gemini) a gerar propostas de algoritmos iniciais e otimiza algoritmos no ciclo evolutivo por meio de avaliação de aptidão e seleção de sobreviventes. A comunidade respondeu rapidamente, a implementação de código aberto OpenAlpha_Evolve surgiu, e pesquisadores usaram ferramentas como Claude para verificar os avanços do AlphaEvolve em áreas como multiplicação de matrizes, mostrando o enorme potencial da IA na inovação de algoritmos. (Fonte: karminski3, karminski3, Reddit r/ClaudeAI, Reddit r/artificial)

Estratégia multimodal da OpenAI se manifesta: integração de interfaces e infraestrutura centralizada chamam a atenção: Com os recentes lançamentos de produtos como GPT-4o, Sora e Whisper, a OpenAI não apenas demonstrou seus avanços em capacidades multimodais como texto, imagem, áudio e vídeo, mas também revelou sua intenção estratégica de integrar múltiplas modalidades em interfaces e APIs unificadas. Embora essa estratégia ofereça conveniência aos usuários, também gerou discussões sobre como a centralização da infraestrutura pode limitar o espaço de inovação para desenvolvedores e pesquisadores externos. Especialmente modelos de geração de vídeo como o Sora, devido à sua alta demanda por recursos computacionais, integram ainda mais aplicações de alto custo ao ecossistema da OpenAI, o que pode exacerbar a “gravidade computacional” das principais plataformas, afetando a abertura e o desenvolvimento modular no campo da IA. (Fonte: Reddit r/deeplearning)
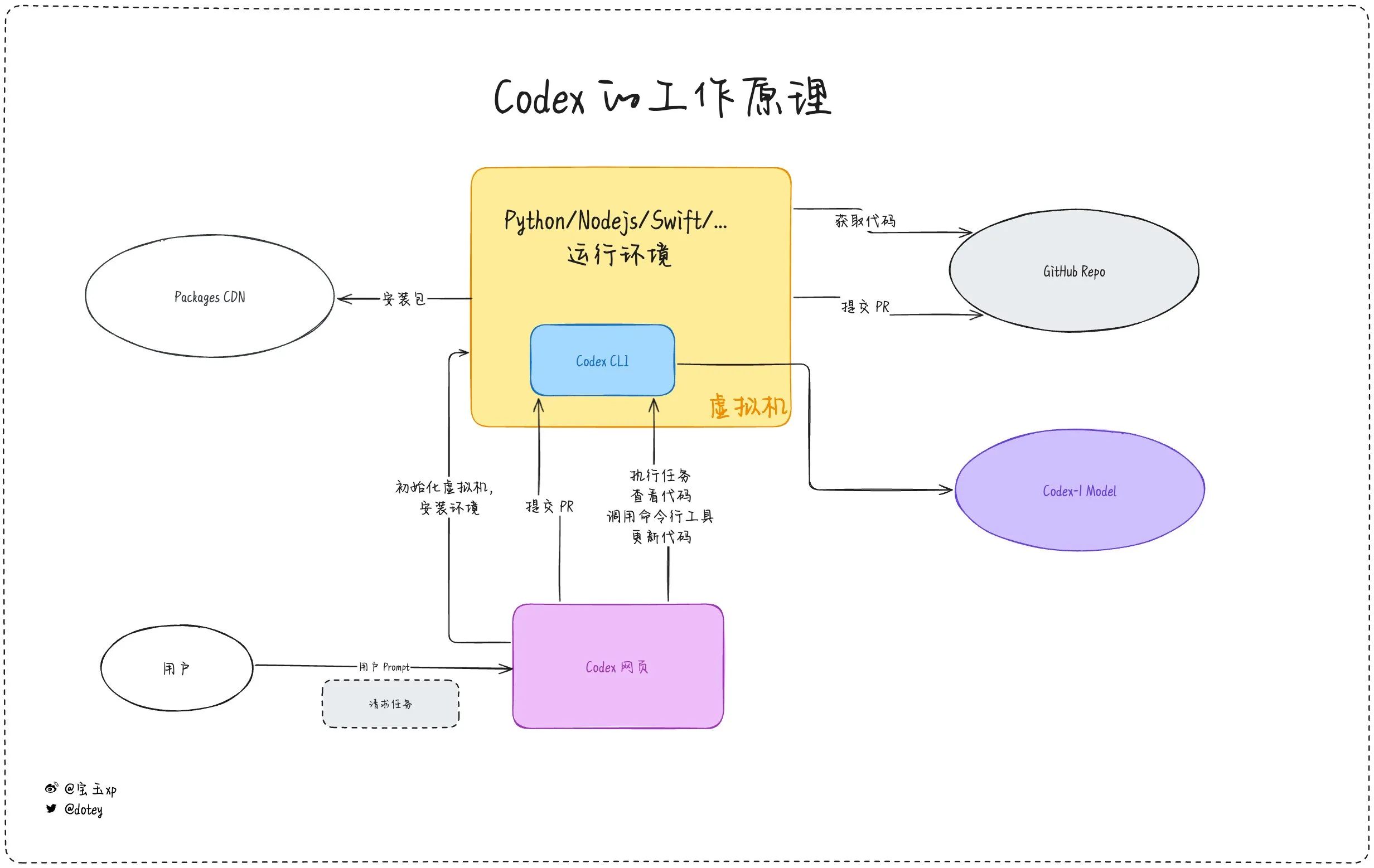
Penetração de ferramentas de programação de IA se intensifica, coexistência de experiência do desenvolvedor e reflexão: Ferramentas de programação de IA como Codex, Devin e vários AI Agents estão se integrando rapidamente aos fluxos de trabalho de desenvolvimento de software. O feedback dos desenvolvedores indica que o Codex demonstra alta eficiência na internacionalização de código, atualizações de projetos, etc., podendo encurtar significativamente os ciclos de desenvolvimento. No entanto, como apontado na avaliação do Codex por dotey, as ferramentas de IA atuais são mais como “funcionários terceirizados”; embora possam concluir tarefas, ainda têm limitações em conectividade de rede, persistência de tarefas e acúmulo de experiência. Discussões na comunidade também mencionam que alguns desenvolvedores, após o uso prolongado de programação assistida por IA, começaram a refletir sobre seu impacto em seu próprio pensamento e criatividade, optando inclusive por retornar a um modo de desenvolvimento mais dependente do “cérebro humano”, mostrando que o equilíbrio entre aumentar a eficiência com ferramentas de IA e manter as principais habilidades dos desenvolvedores continua sendo uma questão importante. (Fonte: dotey, giffmana, cto_junior, Reddit r/artificial)
🎯 Tendências
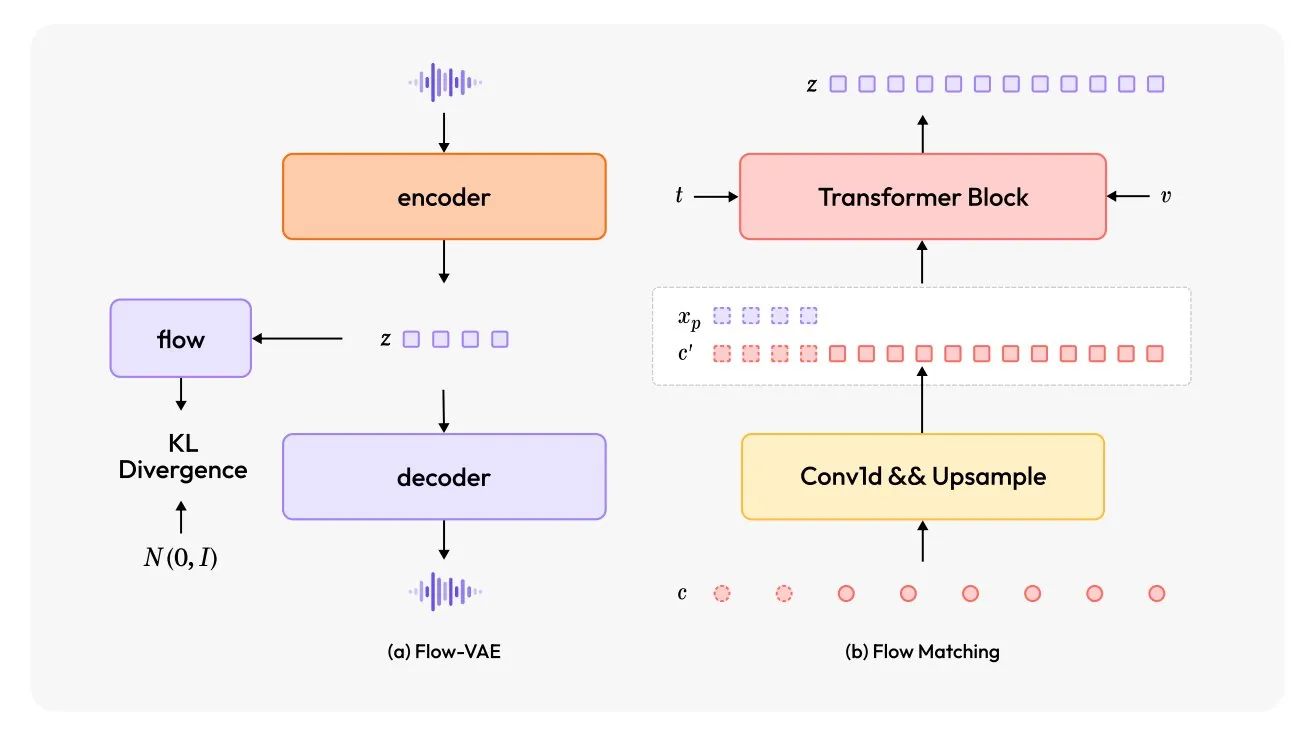
MiniMax-Speech: Lançamento de novo modelo TTS multilíngue: O TheTuringPost apresentou o MiniMax-Speech, um novo modelo de conversão de texto em fala (TTS). Este modelo adota duas grandes inovações: um codificador de locutor aprendível, capaz de capturar o timbre de áudios curtos; e um módulo Flow-VAE para melhorar a qualidade do áudio. O MiniMax-Speech suporta 32 idiomas e pode ser usado para adicionar emoção à fala, gerar fala a partir de descrições textuais ou realizar clonagem de voz zero-shot, demonstrando seu potencial na síntese de voz personalizada e de alta qualidade. (Fonte: TheTuringPost, TheTuringPost)
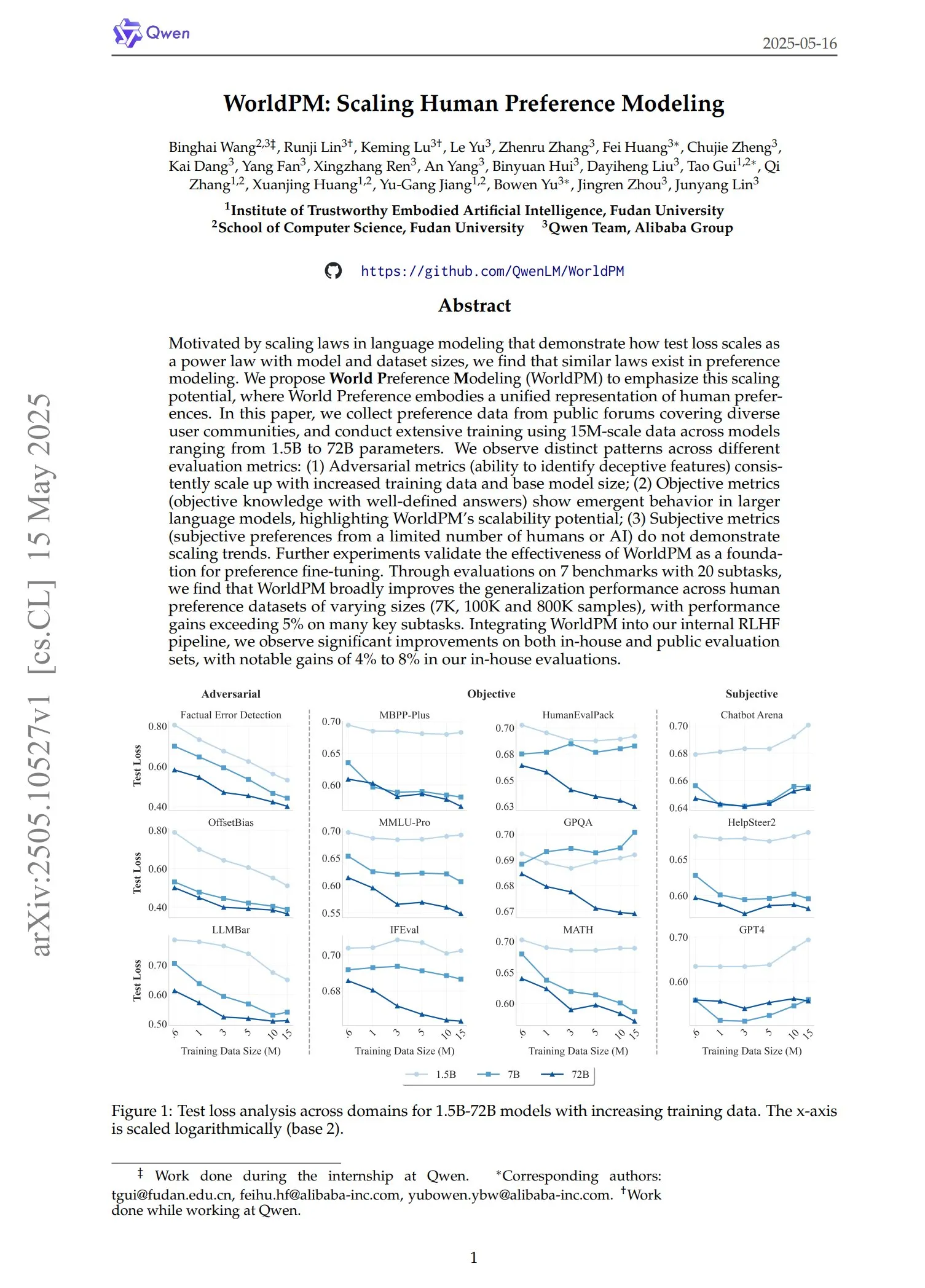
Qwen lança série de modelos de preferência WorldPM: A equipe Qwen lançou quatro novos modelos de modelagem de preferência: WorldPM-72B, WorldPM-72B-HelpSteer2, WorldPM-72B-RLHFLow e WorldPM-72B-UltraFeedback. Esses modelos são usados principalmente para avaliar a qualidade das respostas de outros modelos, auxiliando no processo de aprendizado supervisionado. A empresa afirma que o treinamento com esses modelos de preferência produz resultados melhores do que o treinamento do zero, e o artigo relacionado também foi publicado. (Fonte: karminski3)
Grok adiciona funcionalidade de geração de gráficos: O modelo Grok da XAI agora suporta a geração de gráficos. Os usuários podem criar gráficos no navegador através do Grok, e espera-se que essa funcionalidade seja estendida a mais plataformas nos próximos dias. Esta atualização aprimora as capacidades do Grok em visualização de dados e apresentação de informações. (Fonte: grok, Yuhu_ai_, TheGregYang)
DeepRobotics lança robô quadrúpede de médio porte Lynx: A empresa DEEP Robotics apresentou seu novo robô quadrúpede de médio porte, Lynx. Este robô demonstrou a capacidade de se mover de forma estável em terrenos complexos, refletindo os avanços da empresa em controle de movimento robótico e tecnologia de percepção, podendo ser aplicado em diversos cenários como inspeção e logística. (Fonte: Ronald_vanLoon)
Sanctuary AI integra novos sensores táteis em robôs de uso geral: A Sanctuary AI anunciou que seus robôs de uso geral foram integrados com nova tecnologia de sensores táteis. Esta melhoria visa aprimorar as capacidades de percepção e manipulação de objetos dos robôs, permitindo que interajam com o ambiente de forma mais refinada, sendo um passo importante em direção a robôs de inteligência artificial geral mais robustos. (Fonte: Ronald_vanLoon)
Robô da Unitree demonstra capacidades avançadas de locomoção: O robô Go2 da Unitree Robotics demonstrou várias formas de locomoção avançada, incluindo andar de cabeça para baixo, rolar adaptativamente e superar obstáculos. A realização dessas capacidades marca um avanço significativo nos algoritmos de controle de movimento e adaptabilidade ambiental de seus cães-robôs. (Fonte: Ronald_vanLoon)
Equipe de pesquisa chinesa desenvolve robô impulsionado por células cerebrais humanas cultivadas: Segundo o InterestingSTEM, uma equipe de pesquisa chinesa está desenvolvendo um robô impulsionado por células cerebrais humanas cultivadas em laboratório. Esta pesquisa explora a fusão da computação biológica com a tecnologia robótica, visando utilizar as capacidades de aprendizado e adaptação dos neurônios biológicos para fornecer novas ideias para o controle de robôs. Embora ainda em estágio inicial de exploração, gerou amplas discussões sobre as futuras formas de inteligência robótica. (Fonte: Ronald_vanLoon)
Novo sensor cerebral em nanoescala atinge 96,4% de precisão no reconhecimento de sinais neurais: Um novo tipo de sensor cerebral em nanoescala demonstrou uma precisão de até 96,4% no reconhecimento de sinais neurais. Espera-se que esta tecnologia seja aplicada em interfaces cérebro-máquina, pesquisa em neurociência e diagnóstico médico, fornecendo novas ferramentas para uma interpretação mais precisa da atividade cerebral. (Fonte: Ronald_vanLoon)

Rumores de que MistralAI usou conjunto de teste para treinamento geram preocupação: Surgiram discussões na comunidade questionando se a MistralAI pode ter usado dados do conjunto de teste em benchmarks como o NIAH para treinamento. kalomaze, ao comparar o desempenho no teste NIAH do GitHub com um NIAH personalizado (fatos e perguntas gerados programaticamente), apontou que o desempenho da MistralAI no primeiro é muito superior ao do último, sugerindo possível contaminação de dados. Dorialexander especulou que uma “aproximação sintética” do conjunto de avaliação pode ter sido usada para projetar a mistura de dados, levantando preocupações sobre a justiça e transparência da avaliação do modelo. (Fonte: Dorialexander)
Pesquisa afirma que Claude 3.5 supera humanos em persuasão: Um artigo de pesquisa no arXiv indica que o modelo Claude 3.5 da Anthropic supera os humanos em capacidade de persuasão. O estudo comparou experimentalmente o desempenho do modelo com o de humanos em tarefas específicas de persuasão, e os resultados mostraram que a IA pode ter vantagens significativas na construção de argumentos persuasivos e na comunicação, o que tem implicações potenciais para áreas como marketing, relações públicas e interação humano-computador. (Fonte: Reddit r/ClaudeAI)

Modelos grandes locais demonstram melhoria significativa de capacidade em hardware de consumo: Um usuário do Reddit relatou que o modelo Qwen 3 de 14B parâmetros (com patch yarn para suportar contexto de 128k), em um PC de consumo com apenas 10GB de VRAM e 24GB de RAM, com quantização IQ4_NL e configuração de contexto de 80k, já consegue rodar bem assistentes de programação de IA como Roo Code e Aider. Embora a velocidade seja lenta ao processar contextos longos (como 20k+), cerca de 2 t/s, a qualidade da edição de código e a capacidade de reconhecimento da base de código são boas. Esta é a primeira vez que um modelo local consegue lidar de forma estável com tarefas complexas de codificação em conversas mais longas e produzir diferenças de código significativas. Este avanço se deve às melhorias no próprio modelo, otimizações em frameworks de inferência como llama.cpp e adaptação de ferramentas de front-end como Roo. (Fonte: Reddit r/LocalLLaMA)
OpenAI Codex apontado como não sendo o melhor no ranking SWE-Bench Verified: Graham Neubig apontou que a afirmação de que o modelo Codex da OpenAI alcançou resultados SOTA no ranking SWE-Bench Verified não é totalmente precisa. Analisando dados e diferentes métricas, ele argumenta que, de qualquer perspectiva, o desempenho do Codex nesse benchmark específico é controverso e não é inquestionavelmente o melhor. (Fonte: JayAlammar)
🧰 Ferramentas
OpenAlpha_Evolve de código aberto: replicando o agente inteligente de design de algoritmos de IA do Google: Após a publicação do artigo AlphaEvolve pelo Google DeepMind, o desenvolvedor shyamsaktawat lançou rapidamente a implementação de código aberto OpenAlpha_Evolve. Este framework Python permite aos usuários experimentar os conceitos de design de algoritmos orientados por IA, incluindo definição de tarefas, engenharia de prompt, geração de código (com LLMs como Gemini), execução de testes, avaliação de aptidão e seleção evolutiva, com o objetivo de permitir que uma comunidade mais ampla participe da exploração da vanguarda do design de novos algoritmos por IA. (Fonte: karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

Editor Cursor adiciona funcionalidade de edição rápida de arquivos inteiros: O editor de código AI-first Cursor anunciou que os usuários agora podem editar rapidamente arquivos inteiros. Esta nova funcionalidade visa aumentar a eficiência do trabalho dos desenvolvedores, tornando mais conveniente realizar modificações e refatorações de código em larga escala no Cursor. (Fonte: cursor_ai)
Codex conclui eficientemente tarefas de internacionalização e localização de aplicativos: O desenvolvedor Katsuya compartilhou sua experiência usando o OpenAI Codex para internacionalização de aplicativos. Ele fez o Codex localizar o aplicativo para japonês, concluindo em uma noite um trabalho que normalmente levaria vários dias, demonstrando plenamente a poderosa capacidade do Codex na geração automatizada de código e no processamento de tarefas linguísticas complexas. (Fonte: gdb, ShunyuYao12)
llmbasedos: ambiente sandbox MCP seguro projetado para LLMs: O projeto llmbasedos fornece um ambiente de sistema operacional baseado em uma versão reduzida do Arch Linux, projetado para oferecer um sandbox seguro de Protocolo de Computação Modular (MCP) para modelos de linguagem grandes (LLMs). Ele encapsula funcionalidades como sistema de arquivos, e-mail, sincronização e proxy como serviços MCP, que os usuários podem invocar após inicializar a partir de um ISO em uma máquina virtual ou física, facilitando a interação e o desenvolvimento seguros com LLMs. (Fonte: karminski3)

cachelm: ferramenta de cache semântico LLM de código aberto aumenta eficiência e reduz custos: O desenvolvedor devanmolsharma lançou a ferramenta de código aberto cachelm, uma camada de cache semântico projetada para aplicações LLM. Ela implementa cache baseado em similaridade semântica por meio de busca vetorial, o que pode reduzir efetivamente chamadas repetidas à API do LLM (mesmo que o usuário formule a pergunta de maneira diferente), diminuindo assim o consumo de tokens e acelerando as respostas. A ferramenta suporta OpenAI, ChromaDB, Redis, ClickHouse, etc., e permite que os usuários personalizem vetorizadores, bancos de dados ou LLMs. (Fonte: Reddit r/MachineLearning)
ArchGW 0.2.8 lançado, proxy nativo de IA unifica funcionalidades de baixo nível: ArchGW lançou a versão 0.2.8, este proxy nativo de IA baseado no Envoy visa unificar funcionalidades repetitivas de “baixo nível” em aplicações. A nova versão adiciona suporte para tráfego bidirecional (em preparação para o Google A2A), melhora o modelo Arch-Function-Chat 3B para roteamento rápido e chamadas de ferramentas, e suporta LLMs hospedados no Groq. ArchGW, por meio de um proxy local, simplifica o desenvolvimento de aplicações de IA, aumentando a segurança, consistência e observabilidade. (Fonte: Reddit r/artificial)
SparseDepthTransformer: estudante do ensino médio desenvolve solução de otimização de Transformer com salto dinâmico de camadas: Um estudante do ensino médio desenvolveu um projeto chamado SparseDepthTransformer, que avalia a importância semântica de cada token por meio de um mecanismo de pontuação leve e permite que tokens menos importantes pulem as camadas mais profundas do Transformer. Experimentos mostram que este método, enquanto mantém a qualidade da saída, reduz o uso de memória em cerca de 15% e diminui o número médio de camadas de processamento por token em aproximadamente 40%, oferecendo uma nova abordagem para aumentar a eficiência do Transformer. (Fonte: Reddit r/MachineLearning)

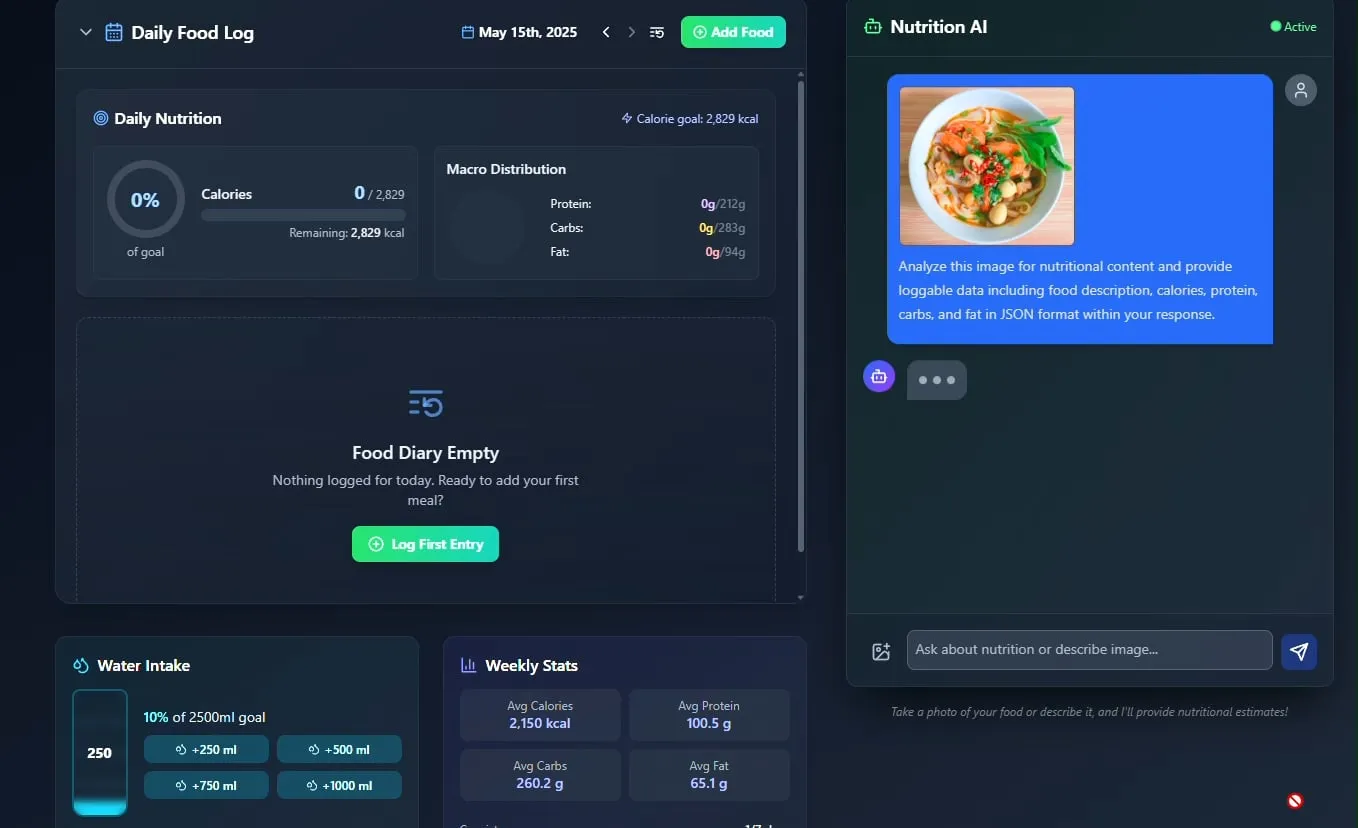
Rastreador de alimentos e nutrição por IA é apresentado, com planos de código aberto: O desenvolvedor Pavankunchala demonstrou um aplicativo de rastreamento de dieta e nutrição alimentado por IA. A funcionalidade principal do aplicativo é identificar alimentos e estimar informações nutricionais (calorias, proteínas, etc.) analisando fotos de alimentos enviadas pelo usuário, além de suportar registro manual, visão geral nutricional diária e rastreamento de hidratação. O desenvolvedor planeja tornar o código do projeto de código aberto no futuro. (Fonte: Reddit r/LocalLLaMA)
Agente de IA italiano automatiza busca de emprego, candidatando-se a mil vagas em um minuto e gerando debate: Um AI Agent, supostamente da Itália, demonstrou sua poderosa capacidade de automação na busca de empregos, completando 1000 candidaturas em 1 minuto. A demonstração gerou ampla discussão na comunidade sobre a aplicação da IA no setor de recrutamento, por um lado maravilhada com sua eficiência, e por outro, expressando preocupações sobre sua eficácia, impacto no mercado de trabalho e como lidar com questões como “detecção de robôs”. (Fonte: Reddit r/ChatGPT)

📚 Aprendizado
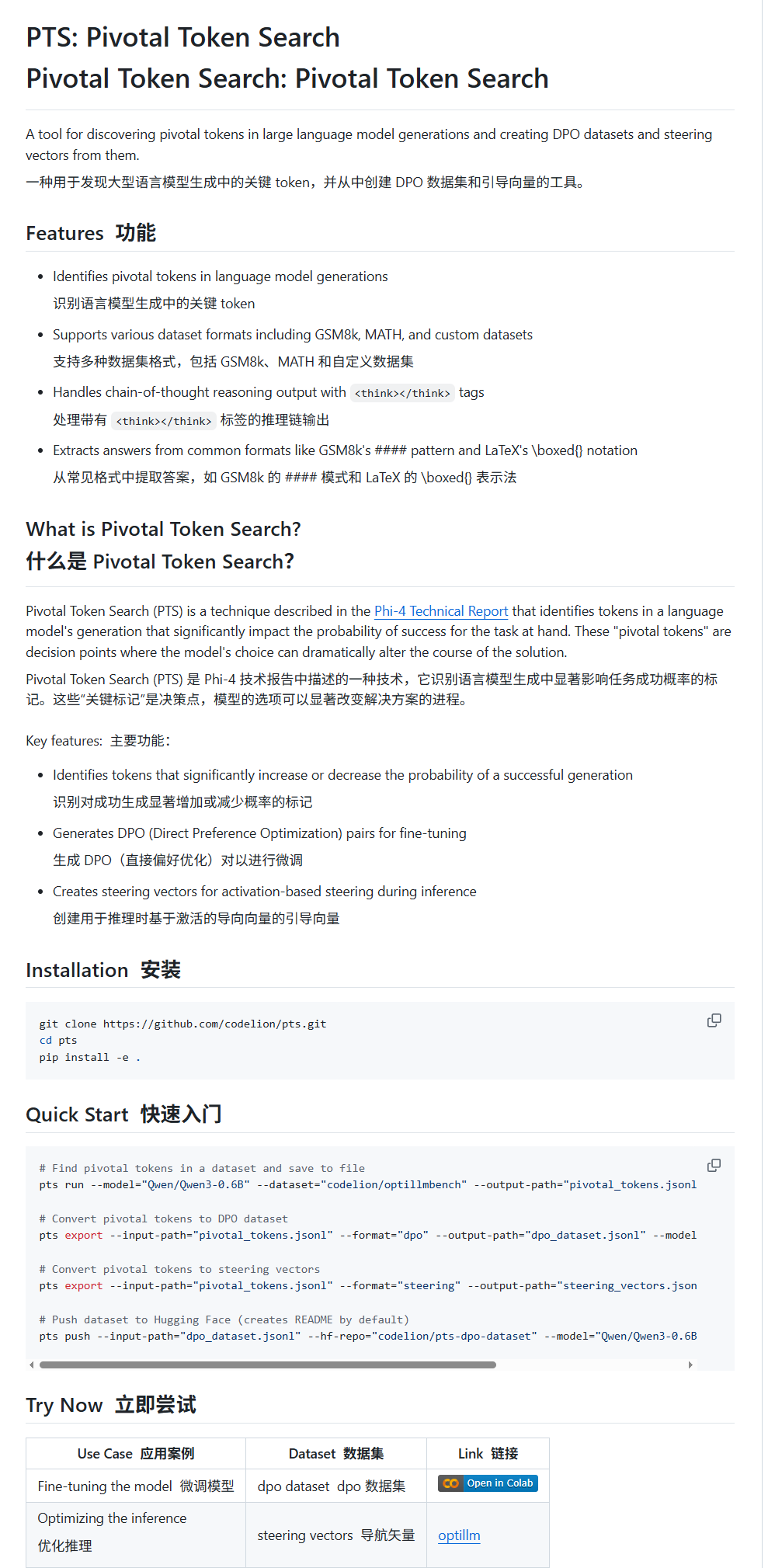
Pivotal Token Search (PTS): uma nova técnica de ajuste fino e orientação de LLM: karminski3 apresentou uma nova técnica chamada PTS (Pivotal Token Search). Baseada na ideia de que “os pontos de decisão cruciais na saída de modelos grandes residem em alguns tokens-chave”, esta técnica constrói conjuntos de dados DPO para ajuste fino, extraindo esses tokens que afetam significativamente a correção da saída (divididos em “tokens escolhidos” e “tokens rejeitados”). Além disso, o PTS também pode extrair os padrões de ativação dos tokens-chave para gerar vetores de direção (steering vectors), orientando o comportamento do modelo durante a inferência sem necessidade de ajuste fino. Alega-se que este método foi inspirado no Phi4, e sua eficácia gerou discussão na comunidade. (Fonte: karminski3)
OpenAI Codex CLI oferece cota de API gratuita, incentivando o compartilhamento de dados: A conta de desenvolvedor da OpenAI anunciou que usuários Plus ou Pro podem resgatar cotas de API gratuitas executando npm i -g @openai/codex@latest e codex --free. Além disso, os usuários também podem obter tokens diários gratuitos optando por compartilhar dados nas configurações da plataforma para melhorar e treinar os modelos da OpenAI. Esta medida visa incentivar os desenvolvedores a usar as ferramentas Codex e participar da melhoria do modelo. (Fonte: OpenAIDevs, fouad)
Recursos de aprendizado gratuitos sobre Sistemas Multiagentes (MAS) compilados: O TheTuringPost compilou e compartilhou 7 recursos gratuitos para aprender sobre Sistemas Multiagentes (MAS). Entre eles estão tutoriais sobre CrewAI, o framework multiagente CAMEL e multiagentes LangChain; um livro intitulado “Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations”; e três cursos online, cobrindo desde prompts até sistemas multiagentes, domínio do desenvolvimento multiagente com AutoGen, e agentes multi-IA práticos com casos de uso avançados usando crewAI. (Fonte: TheTuringPost)

Tutorial de classificação rápida de imagens com MobileNetV2: O usuário do Reddit Eran Feit compartilhou um tutorial em Python para classificação de imagens usando MobileNetV2. O tutorial guia os usuários passo a passo para carregar o modelo MobileNetV2 pré-treinado, pré-processar imagens com OpenCV (BGR para RGB, redimensionar para 224×224, processamento em lote), realizar inferência e decodificar os resultados da previsão para obter rótulos e probabilidades legíveis por humanos. Este tutorial é adequado para iniciantes que desejam começar rapidamente com tarefas de classificação de imagens leves. (Fonte: Reddit r/deeplearning)
Guia de implementação de RAG de múltiplas fontes e pesquisa híbrida no OpenWebUI publicado: O site productiv-ai.guide publicou um guia detalhado passo a passo para implementar Geração Aumentada por Recuperação (RAG) de múltiplas fontes com Pesquisa Híbrida (Hybrid Search) e Reclassificação (Re-ranking) no OpenWebUI. O guia visa ajudar os usuários a configurar e utilizar as funcionalidades RAG do OpenWebUI, incluindo o recurso de reclassificação externa recentemente adicionado, para melhorar a precisão e relevância da recuperação de informações. (Fonte: Reddit r/OpenWebUI)
💼 Negócios
Competição acirrada na área de AI Agents: Comparativo aprofundado entre Manus e Lovart: O AI Agent “Lovart”, focado no setor de design vertical, atraiu atenção por seu fluxo de trabalho único “baseado em pedidos”, que tenta simular um processo de design completo, desde a comunicação de requisitos até a entrega de materiais em camadas, contrastando com a lógica “baseada em despacho” do agente genérico “Manus”. Embora Lovart tenha um bom desempenho na compreensão da estética do design, expressão conceitual e organização da informação, e seja mais rápido que Manus, ambos enfrentam problemas de estabilidade, processamento de chinês e vinculação de modificações. O surgimento de Lovart é visto como a direção correta para agentes verticais aprofundarem-se em cenários específicos e internalizarem a experiência do setor, indicando que os AI Agents podem realmente se estabelecer na indústria de conteúdo. (Fonte: 36氪)

Mercado de smartwatches infantis em alta, tendência AIoT impulsiona crescimento de fabricantes de chips SoC nacionais: Beneficiando-se do estímulo de políticas de consumo e da tendência de desenvolvimento AIoT, as vendas no mercado chinês de dispositivos vestíveis inteligentes (especialmente smartwatches infantis) dispararam. O surgimento de modelos grandes de código aberto como o DeepSeek reduziu a barreira para a implantação de IA no dispositivo, acelerando a penetração da IA em terminais como eletrodomésticos inteligentes e fones de ouvido com IA. Fabricantes nacionais de chips SoC como Rockchip e Bestechnic, com seu posicionamento em baixo consumo de energia e poder de computação de IA, bem como chips emblemáticos como o RK3588 da Rockchip cobrindo múltiplos cenários como PC, hardware inteligente e automotivo, tiveram um crescimento significativo em seus resultados e suas avaliações também aumentaram. (Fonte: 36氪)
OpenAI teria ajustado plano de reestruturação da empresa e rebatido questionamentos sobre natureza sem fins lucrativos: Segundo Garrison Lovely, foi exposta uma carta anteriormente não divulgada da OpenAI ao Procurador-Geral da Califórnia. O conteúdo da carta não apenas envolve detalhes inesperados do plano de reestruturação da empresa OpenAI, mas também mostra que a OpenAI está tomando medidas ativas para rebater as críticas e questionamentos sobre suas tentativas de enfraquecer a estrutura de governança sem fins lucrativos da empresa. (Fonte: NeelNanda5)

🌟 Comunidade
A natureza N-Gram dos LLMs e os limites da “inteligência” geram debate acalorado: A comunidade continua a discutir até que ponto os modelos de linguagem grandes (LLMs) ainda dependem de características estatísticas N-Gram e se os LLMs atuais constituem “IA verdadeira”. Alguns argumentam (como o comentário de pmddomingos sobre o artigo de jxmnop no NeurIPS) que os LLMs se comportam como modelos N-Gram em mais de 2/3 dos casos. Cientistas de dados no Reddit postaram que os LLMs atuais carecem de verdadeira compreensão, raciocínio e bom senso, estando longe da AGI (Inteligência Artificial Geral), sendo essencialmente “sistemas complexos de previsão da próxima palavra” em vez de agentes com autoconsciência e adaptabilidade. (Fonte: jxmnop, pmddomingos, Reddit r/ArtificialInteligence)

Estilo “película transparente” em imagens geradas por IA e imagens sugestivas “Doubao” chamam atenção: Recentemente, um grande número de imagens com um estilo específico geradas por ferramentas de desenho de IA como Doubao surgiram nas redes sociais, especialmente imagens com efeito de “película transparente” envolvendo objetos. Essas imagens, devido ao seu efeito visual inovador e possível conteúdo sugestivo, geraram ampla discussão, imitação e recriação por parte dos usuários, tornando-se uma tendência popular no campo do conteúdo gerado por IA. (Fonte: op7418, dotey)

Ética da IA e o futuro: construir “Deus” ou autodestruição?: A comunidade debate intensamente o objetivo final do desenvolvimento da IA e seus riscos potenciais. Emad Mostaque afirmou diretamente que alguns estão tentando construir uma AGI semelhante a “Deus”, o que poderia trazer utopia ou destruição. O CEO da NVIDIA, Jensen Huang, vislumbra um futuro onde engenheiros humanos colaboram com 1000 IAs para projetar chips. Ao mesmo tempo, uma discussão provocada por uma tirinha do SMBC desloca a questão da consciência da IA para um nível mais prático de tratamento ético – podemos tratar essas “coisas” com a consciência tranquila? Esses pontos de vista juntos formam uma imagem complexa do futuro da IA. (Fonte: Reddit r/artificial, Reddit r/artificial, Reddit r/artificial)
A IA irá subverter o modelo de negócios SaaS? Comunidade de desenvolvedores debate intensamente: Com a popularização de poderosas ferramentas de programação de IA como o Claude Code, a comunidade de desenvolvedores começou a discutir seu potencial impacto no modelo de negócios SaaS (Software as a Service). A opinião é que a barreira para desenvolvedores individuais replicarem as funcionalidades principais de produtos SaaS existentes usando IA está diminuindo, o que pode levar empresas e usuários individuais a reduzir sua dependência de serviços SaaS tradicionais, buscando soluções auto-construídas ou assistidas por IA mais econômicas. O desenvolvimento de software no futuro pode depender mais da microgestão da IA. (Fonte: Reddit r/ClaudeAI)
Diferenças no processamento multilíngue da IA chamam atenção, pré-tokenizador do Llama pode ser uma das causas: Discussões na comunidade apontam que o desempenho de modelos de linguagem grandes (LLMs) em inglês é geralmente superior ao de outros idiomas. Uma possível razão apontada é a forma como os pré-tokenizadores de modelos como o Llama lidam com textos não ingleses (especialmente caracteres não latinos). Por exemplo, o pré-tokenizador pode dividir excessivamente caracteres chineses em unidades menores, afetando a compreensão da estrutura e semântica da linguagem pelo modelo, resultando em um desempenho inferior nesses idiomas. (Fonte: giffmana)

💡 Outros
Framework DSPy enfatiza a importância de primitivas de baixo nível para o desenvolvimento de agentes de IA: Desde que o framework de IA DSPy abriu o código de suas abstrações principais em janeiro de 2023, ele permaneceu estável através de múltiplas iterações de API de LLM, com poucas alterações além de algumas simplificações. Discussões na comunidade apontam que isso se deve ao foco do DSPy na construção das primitivas corretas de baixo nível, em vez de apenas buscar uma experiência de desenvolvedor superficial ou a conveniência de construir “agentes” rapidamente. A opinião é que muitos frameworks atuais de desenvolvimento de agentes se concentram demais na facilidade de uso, negligenciando a solidez dos blocos de construção fundamentais, enquanto a filosofia do DSPy é que uma base sólida de “reação” é necessária para construir comportamentos complexos de “agente”. (Fonte: lateinteraction, lateinteraction)
Fadiga estética com conteúdo gerado por IA impulsiona demanda por modelos personalizados: Discussões na comunidade sugerem que muitos modelos de geração de imagem otimizados por aprendizado por reforço (RL) tendem a produzir resultados “medíocres” ou “kitsch”. Embora tecnicamente pareçam bons, falta-lhes criatividade e personalidade empolgantes. Isso reflete que os objetivos de otimização do modelo podem tender às preferências estéticas médias do público, em vez de buscas artísticas únicas. Portanto, modelos personalizados e métodos capazes de amostrar para objetivos estéticos individuais são considerados cruciais para superar esse problema e criar conteúdo de IA mais atraente no futuro. (Fonte: torchcompiled)

Ollama lança motor multimodal, usuários do OpenWebUI atentos à compatibilidade: A Ollama anunciou o lançamento oficial de seu motor multimodal, notícia que atraiu a atenção dos usuários da comunidade OpenWebUI. Os usuários estão geralmente preocupados se o OpenWebUI será capaz de suportar o novo motor multimodal da Ollama “out-of-the-box”, ou seja, sem a necessidade de alterações complexas de configuração para utilizar suas capacidades de processamento de múltiplos tipos de dados, como imagens e texto. (Fonte: Reddit r/OpenWebUI)
