
Palavras-chave:AlphaEvolve, DeepSeek V3, GPT-4.1, Speech-02, Modelo Claude, Falcon-Edge, BLIP3-o, AM-Thinking-v1, Agente de codificação inteligente impulsionado por Gemini, Coprojeto hardware-software para reduzir custos de modelos grandes, Tecnologia de clonagem de voz sem amostras, Capacidade de raciocínio extremo, Arquitetura BitNet de 1.58 bits
🔥 Foco
DeepMind lança AlphaEvolve: Agente de codificação evolutiva impulsionado pelo Gemini, impulsionando a descoberta de algoritmos : AlphaEvolve combina a criatividade do modelo Gemini com avaliadores automáticos, utilizando uma estrutura evolutiva para otimizar algoritmos. Já alcançou avanços em múltiplos domínios, como a realização da multiplicação de matrizes complexas 4×4 com 48 multiplicações escalares, melhorando o algoritmo de Strassen; na descoberta de 593 configurações de esferas externas em espaços de 11 dimensões, avançando o “problema do número do beijo” de 300 anos. Além disso, o AlphaEvolve também otimizou o agendamento de data centers do Google (economizando 0,7% dos recursos computacionais), o design da próxima geração de TPUs (removendo bits redundantes), o treino de modelos de IA (aceleração de kernels críticos em 23%), etc. O medalhista Fields, Terence Tao, também participou da exploração de suas aplicações matemáticas. (Fonte: DeepMind)

Artigo detalhado do DeepSeek V3: Design colaborativo de software e hardware reduz custos e consumo de energia de grandes modelos : A equipa DeepSeek publicou um artigo detalhando como o DeepSeek-V3 alcança custo-benefício no treino e inferência em larga escala através do design colaborativo de software e hardware. Tecnologias centrais incluem: 1) Otimização de memória: Adota Multi-Head Latent Attention (MLA) para comprimir o cache de chave-valor, treino com precisão mista FP8 reduz o consumo de memória. 2) Otimização de computação: Aplica o modelo Mixture of Experts (MoE), ativando apenas parte dos parâmetros, e combina com treino FP8, reduzindo significativamente os custos computacionais. 3) Otimização de comunicação: Adota topologia de rede multi-plane fat-tree e tecnologia DualPipe (dual micro-batch processing overlap), reduzindo a latência e aumentando a utilização da GPU. 4) Aceleração de inferência: Introduz a estrutura Multi-Token Prediction (MTP), prevendo e validando paralelamente múltiplos tokens candidatos, aumentando a velocidade de geração. O artigo também apresenta cinco perspetivas para o futuro design de hardware de IA, incluindo suporte para computação de baixa precisão, expansão e fusão, otimização de topologia de rede, otimização do sistema de memória e robustez e tolerância a falhas. (Fonte: arXiv)

Modelo OpenAI GPT-4.1 lançado oficialmente no ChatGPT, utilizadores podem selecioná-lo diretamente : A OpenAI anunciou que o modelo GPT-4.1 já está disponível no ChatGPT. Utilizadores Plus, Pro e Team podem acedê-lo através do seletor de modelos, enquanto utilizadores das versões Enterprise e Education terão acesso posteriormente. O GPT-4.1 mini também substituirá o GPT-4o mini para todos os utilizadores. O GPT-4.1 tem chamado a atenção pelo seu excelente desempenho em tarefas de codificação e seguimento de instruções. Anteriormente, a versão API suportava uma janela de contexto de até 1 milhão de Tokens. No entanto, alguns utilizadores descobriram, através de testes práticos, que a versão GPT-4.1 no ChatGPT parece ainda ter um comprimento de contexto de 128k, não atingindo o 1M da versão API, o que gerou alguma desilusão. (Fonte: OpenAI Developers)

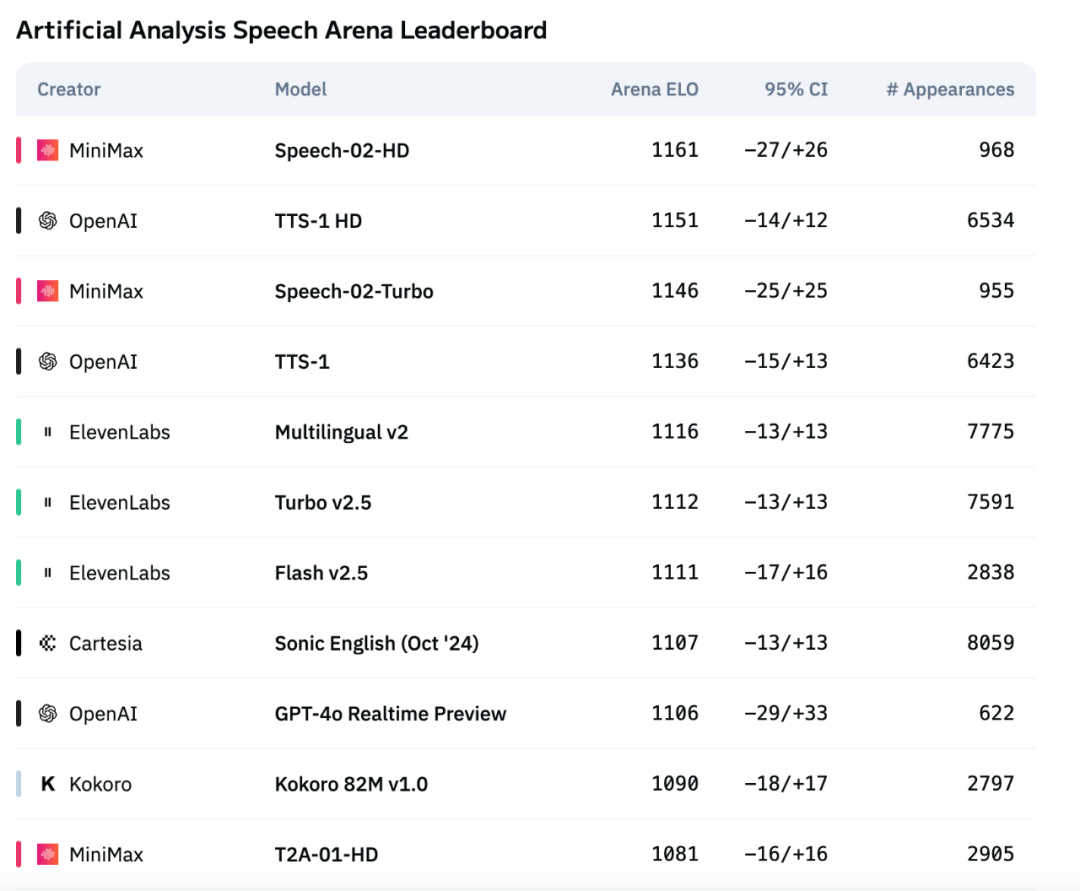
Novo modelo de voz da MiniMax, Speech-02, lidera a lista de avaliação de voz da Artificial Analysis : O mais recente modelo de conversão de texto em voz (TTS) da MiniMax, Speech-02, obteve a pontuação ELO mais alta na lista de avaliação de voz da Artificial Analysis Speech Arena, uma autoridade internacional, superando produtos similares da OpenAI e ElevenLabs. O modelo demonstrou excelente desempenho em indicadores chave como a taxa de erro de palavras (WER) e a similaridade do locutor (SIM), destacando-se especialmente no processamento de chinês e cantonês, onde demonstrou vantagens locais. A inovação central do Speech-02 reside na clonagem de voz verdadeiramente zero-shot (requerendo apenas alguns segundos de áudio de referência, sem necessidade de texto) e na adoção de uma nova arquitetura Flow-VAE, que melhora a naturalidade e a expressividade emocional da voz gerada, suportando 32 idiomas. O seu custo também é extremamente competitivo, aproximadamente 1/4 do produto concorrente da ElevenLabs. (Fonte: Máquina do Coração)
🎯 Tendências
Nova versão do modelo Claude da Anthropic poderá ter capacidade de “raciocínio extremo” : Segundo o The Information e observações da comunidade, a Anthropic poderá lançar nas próximas semanas novas versões dos modelos Claude Sonnet e Claude Opus, cujo maior destaque será a capacidade de “raciocínio extremo” (Extreme reasoning). Esta funcionalidade permite que o modelo, ao encontrar problemas difíceis, pause, reavalie e ajuste a sua estratégia, em vez de fornecer uma resposta direta. Em tarefas como a geração de código, o modelo consegue testar e corrigir erros automaticamente. Esta forma dinâmica e cíclica de raciocínio e utilização de ferramentas visa tornar o modelo mais inteligente no tratamento de problemas complexos, reduzir a dependência da supervisão humana e aproximar-se mais da forma de pensar de um colaborador humano. Alguns utilizadores já descobriram que a Anthropic está a testar um modelo chamado Claude Neptune (possivelmente Claude 3.8), que suporta um contexto de 128k tokens. (Fonte: QubitAI)
TII lança série Falcon-Edge de modelos Bitnet eficientes e toolkit de fine-tuning onebitllms : O Technology Innovation Institute (TII) lançou o Falcon-Edge, uma série de modelos de linguagem altamente comprimidos baseados na arquitetura BitNet, com características poderosas, genéricas e ajustáveis. Simultaneamente, tornaram open-source o onebitllms, um toolkit Python leve (instalável via pip) especificamente para fine-tuning ou continuação do pré-treino destes modelos de 1.58 bits. Esta iniciativa visa reduzir a barreira de entrada para o uso de grandes modelos e promover o desenvolvimento e aplicação da tecnologia LLM de 1 bit. (Fonte: younes)

Biblioteca Transformers da Hugging Face recebe grande atualização, tornando-se o padrão central para definição de modelos : A Hugging Face anunciou que a sua biblioteca Transformers está a passar por ajustes significativos, com o objetivo de se tornar o padrão central para a definição de modelos em diferentes backends e runtimes. Através do esforço conjunto com numerosos parceiros do ecossistema, como vLLM, LlamaCPP, SGLang, MLX, DeepSpeed, Microsoft, NVIDIA, entre outros, está a promover a padronização do código dos modelos, com o intuito de trazer maior consistência e fiabilidade a todo o ecossistema de IA. Esta iniciativa foi amplamente elogiada pela comunidade, sendo considerada um passo importante para impulsionar o desenvolvimento da IA open-source. (Fonte: Arthur Zucker)

Salesforce lança BLIP3-o no Hugging Face: série de modelos multimodais unificados totalmente open-source : A Salesforce apresentou a série de modelos BLIP3-o, uma família de modelos multimodais unificados completamente open-source. Esta série abrange arquitetura de modelos, métodos de treino e conjuntos de dados, com o objetivo de impulsionar o desenvolvimento e a aplicação da tecnologia de IA multimodal. O lançamento do BLIP3-o fornece aos investigadores e programadores ferramentas e recursos poderosos para o processamento multimodal. (Fonte: AK)

NVIDIA demonstra utilização de dados sintéticos para avançar tecnologia de condução totalmente autónoma : A NVIDIA divulgou um novo vídeo que demonstra como utiliza dados sintéticos para acelerar a investigação e desenvolvimento da tecnologia de condução totalmente autónoma (FSD). Ao gerar cenários e dados de condução virtuais em grande escala e diversificados, a NVIDIA consegue treinar e validar os seus algoritmos de condução autónoma de forma mais eficiente, superando as limitações da recolha de dados do mundo real e impulsionando a tecnologia de condução autónoma em direção a uma maior segurança e fiabilidade. (Fonte: SawyerMerritt)
Equipa A-M-team lança modelo de inferência 32B AM-Thinking-v1, com desempenho parcial superior ao DeepSeek-R1 : A equipa de investigação chinesa A-M-team tornou open-source no Hugging Face o modelo de inferência AM-Thinking-v1 com 32 mil milhões de parâmetros. Este modelo demonstrou um desempenho notável em tarefas como raciocínio matemático (pontuação de 85.3 na série AIME) e geração de código (pontuação de 70.3 no LiveCodeBench), alegadamente superando o DeepSeek-R1 (671B MoE) nestas avaliações específicas e aproximando-se de modelos de maior escala como o Qwen3-235B-A22B. A equipa foca-se na otimização da capacidade de inferência de modelos densos de 32B através de esquemas de pós-treino (incluindo SFT de arranque a frio, filtragem de dados guiada por taxa de aprovação, RL de duas fases), com o objetivo de explorar caminhos para alcançar um forte raciocínio sob condições limitadas de computação e dados open-source. (Fonte: AI Tech Review)

Atualização do Marigold: modelo Stable Diffusion convertido em estimador de profundidade, suporta inferência single-step e alta resolução : O projeto Marigold lançou uma atualização importante. Esta tecnologia permite converter o modelo Stable Diffusion 2, através de poucas amostras sintéticas e pouco tempo de treino (2-3 dias numa GPU), num estimador de profundidade avançado. As novas funcionalidades da versão incluem: inferência rápida single-step, suporte para novas modalidades, saída de alta resolução, suporte da biblioteca Diffusers e novas demonstrações. (Fonte: Anton Obukhov)
Série de modelos Qwen3 demonstra forte desempenho na comunidade open-source, NVIDIA OpenCodeReasoning escolhe-a como base : A série de modelos Qwen3 da Alibaba continua a ganhar atenção e aplicação na comunidade open-source. A mais recente série de modelos OpenCodeReasoning da NVIDIA (incluindo especificações 7B, 14B, 32B) escolheu o Qwen como base. O Qwen3 é preferido pelos programadores devido às suas versões completas, atualizações contínuas, suporte nativo para modos de inferência híbridos e um ecossistema próspero (mais de 300 milhões de downloads globais, mais de 100.000 modelos derivados). Atualizações recentes incluem o modelo multimodal para dispositivos Qwen-omini 3B, colaboração com a Unsloth para aumentar a eficiência do fine-tuning, publicação de sugestões detalhadas de hiperparâmetros de implementação, suporte para pré-visualização em tempo real de páginas web geradas, disponibilização de várias versões quantizadas e publicação de relatórios técnicos, entre outros. (Fonte: AI Frontline)
Hugging Face Accelerate v1.7.0 lançado, suporta compilação regional e QLoRA para FSDPv2 : A versão v1.7.0 do Hugging Face Accelerate foi oficialmente lançada. Os destaques desta versão incluem: compilação regional (Regional compilation) implementada por @IlysMoutawwakil, melhorando a eficiência e flexibilidade da compilação; ganchos de conversão por camada (Layerwise casting hook) contribuídos por @RisingSayak, uma funcionalidade amplamente utilizada na biblioteca diffusers; e suporte QLoRA para FSDPv2 implementado por @winglian, otimizando ainda mais o treino de modelos em larga escala. (Fonte: Marc Sun)

Llamafile 0.9.3 lançado, adiciona suporte para modelos Qwen3 e Phi4 : O Llamafile lançou a versão 0.9.3, esta atualização adiciona suporte para as recentes séries de modelos populares Qwen3 e Phi4. O Llamafile dedica-se a simplificar a distribuição e execução de aplicações LLM, empacotando os pesos do modelo e o código necessário para execução num único ficheiro executável, permitindo uma implementação conveniente em múltiplos sistemas operativos. (Fonte: Phoronix)
Tencent lança grande modelo de imagem HunyuanImage 2.0 : A Tencent lançou oficialmente a nova versão do seu grande modelo de imagem, o HunyuanImage 2.0. Espera-se que esta atualização traga melhorias na qualidade da geração de imagens, controlabilidade e capacidade de compreensão de instruções complexas. Detalhes técnicos específicos e melhorias podem ser consultados pelos utilizadores através dos canais oficiais. (Fonte: Hunyuan)

Ollama v0.7 lançado, melhora a experiência de execução local de grandes modelos : Ollama lançou a versão v0.7, continuando a dedicar-se a simplificar o processo de execução de grandes modelos de linguagem em dispositivos locais. A nova versão pode incluir otimizações de desempenho, suporte para novos modelos ou melhorias na experiência do utilizador. Os utilizadores podem visitar o site oficial ou o GitHub para consultar o registo de alterações detalhado e fazer o download. (Fonte: ollama)
llama.cpp integra funcionalidade de entrada PDF, suporta processamento direto de documentos PDF : O projeto llama.cpp fundiu recentemente uma atualização importante, adicionando suporte para entrada direta de ficheiros PDF. Isto significa que os utilizadores podem agora, de forma mais conveniente, usar o conteúdo de documentos PDF como entrada para processamento, análise ou resposta a perguntas por grandes modelos de linguagem locais alimentados pelo llama.cpp, expandindo os seus cenários de aplicação. Esta funcionalidade é implementada através de um pacote JS externo no frontend web incorporado, não aumentando a carga de manutenção do núcleo. (Fonte: GitHub)
Microsoft Copilot lança funcionalidade de geração de imagem 4o, melhora efeitos visuais e consistência de texto : O assistente de IA da Microsoft, Copilot, integrou agora a capacidade de geração de imagem do modelo GPT-4o da OpenAI. Esta atualização visa fornecer efeitos visuais mais nítidos, geração de texto mais consistente e suportar uma variedade de estilos, desde o foto-realista ao cartoon divertido. Os utilizadores podem experimentar a funcionalidade de criação de imagens alimentada pelo 4o através do Copilot. (Fonte: yusuf_i_mehdi)

NVIDIA DRIVE Labs discute o futuro da condução sem mapas, reduzindo a dependência de mapas HD : O mais recente vídeo do NVIDIA DRIVE Labs discute o futuro da condução sem mapas (mapless driving). Os mapas de alta definição são cruciais para a condução autónoma, mas os seus custos e desafios de manutenção limitam a sua implementação. A NVIDIA está a reduzir a dependência de mapas HD através de inovações como a eliminação de gargalos de informação, o aumento da precisão das tarefas, a aceleração do tempo de treino e inferência de modelos, impulsionando as fronteiras da tecnologia de condução autónoma. (Fonte: NVIDIA DRIVE)
Dolphin 3.2 (treinado com base no Qwen3) oferecerá interruptores de prompt de sistema, aumentando o controlo do utilizador : O futuro modelo Dolphin 3.2, treinado com base no Qwen3, introduzirá três interruptores de prompt de sistema: /no_think (possivelmente para reduzir passos de pensamento redundantes), /uncensored (possivelmente para reduzir a censura de conteúdo) e /china (possivelmente para contextos ou serviços específicos da China). Estes interruptores visam dar aos utilizadores um maior grau de propriedade e controlo sobre a implementação do seu modelo. (Fonte: cognitivecompai)

🧰 Ferramentas
Runway lança funcionalidade de referências, permitindo aprender e aplicar técnicas ou estilos específicos a novas criações : A Runway adicionou uma nova funcionalidade chamada “References”, que permite aos utilizadores mostrar à plataforma uma técnica ou estilo artístico específico e, em seguida, usá-lo como referência para aplicar a qualquer novo conteúdo gerado. Esta funcionalidade oferece aos utilizadores uma capacidade de controlo de estilo mais refinada, tornando a criação assistida por IA mais personalizada e direcionada. O utilizador Cristobal Valenzuela lançou uma campanha de recolha, incentivando a comunidade a partilhar casos originais de utilização desta funcionalidade, e oferecerá um ano gratuito do plano Unlimited aos 5 casos mais criativos. (Fonte: c_valenzuelab)

DSPy: Framework de programação LLM minimalista para iteração rápida : O framework DSPy tem chamado a atenção pelo seu design minimalista. Os programadores afirmam que a maioria das suas funcionalidades principais (Module ou Optimizer) pode ser implementada com apenas uma linha de código, com o objetivo de ajudar os utilizadores a experimentar e iterar ideias rapidamente. Ao contrário de algumas ferramentas que exigem muito código boilerplate e conceitos complexos, o DSPy enfatiza a facilidade de uso e a eficiência. O feedback dos utilizadores indica que é possível começar rapidamente lendo a documentação de introdução e otimizar modelos com o framework em pouco tempo, embora a otimização cíclica com modelos SOTA possa gerar alguns custos. (Fonte: lateinteraction)
Unsloth AI expande-se para fine-tuning de modelos TTS e de áudio, aumentando a velocidade e reduzindo o uso de VRAM : A Unsloth AI anunciou que a sua tecnologia de otimização agora suporta o fine-tuning de modelos de conversão de texto em voz (TTS) e de áudio. Os utilizadores podem usar notebooks Colab gratuitos para treinar, executar e guardar modelos como Sesame-CSM, OpenAI Whisper, entre outros. A Unsloth afirma que a sua tecnologia pode aumentar a velocidade de treino de TTS em 1.5x, enquanto reduz o uso de memória de vídeo (VRAM) em 50%. A documentação relevante e os notebooks Colab já estão disponíveis no seu site oficial. (Fonte: Unsloth AI)
Modal auxilia em tarefa de embedding de 30 milhões de avaliações da Amazon, GPU L40S permite processamento em horas : A plataforma Modal demonstrou a sua capacidade de escalar horizontalmente o processamento de tarefas de embedding em larga escala na GPU L40S. Através de um caso de demonstração, a Modal concluiu com sucesso o processamento de embedding de 30 milhões de avaliações da Amazon em uma hora. Isto foi possível graças ao sistema de geração escalável atualizado da equipa Modal, que torna o processamento paralelo em larga escala mais simples e eficiente. (Fonte: charles_irl)

Lovart AI: Novo Agente de design visual de IA que integra múltiplos modelos de topo : Um Agente de design visual de IA chamado Lovart tem chamado a atenção. Ele consegue completar tarefas de design visual profissional, como cartazes, identidade visual de marca, storyboards, etc., através de instruções em linguagem natural. A capacidade central do Lovart reside na sua orquestração de fusão de múltiplos modelos, integrando vários modelos de topo como GPT image-1, Flux pro, OpenAI-o3, Gemini Imagen 3, Kling AI, Tripo AI, Suno AI, e inclui ferramentas de edição de nível profissional (como camadas, máscaras, ajuste fino de texto), suportando separação de imagem e texto e edição por camadas. Este produto é operado de forma independente pela subsidiária internacional da Liblib, com o objetivo de fornecer uma experiência de design de IA completa e altamente controlável. (Fonte: QubitAI)
OpenHands 0.38.0 lançado: Suporte nativo para Windows e extensão Chrome melhoram a usabilidade : OpenHands lançou a versão 0.38.0, trazendo várias atualizações importantes. Estas incluem: suporte nativo para Windows (sem necessidade de WSL), facilitando o uso para utilizadores de Windows; funcionalidade de captura de ecrã do navegador; e maior flexibilidade na personalização da sandbox. Além disso, foi lançada uma extensão Chrome que permite aos utilizadores iniciar o OpenHands a partir do GitHub com um clique, simplificando ainda mais o processo de operação. (Fonte: All Hands AI)
Tensorlake Cloud lançado, melhora a extração de documentos e a capacidade de construção de fluxos de trabalho : A Tensorlake anunciou o lançamento do Tensorlake Cloud, com o objetivo de otimizar a extração de documentos e os fluxos de trabalho para suportar a construção de aplicações de agentes inteligentes e fluxos de trabalho empresariais complexos. A plataforma utiliza modelos avançados de compreensão de layout de documentos (treinados em dados do mundo real como formulários ACORD, extratos bancários, relatórios de investigação, etc.) e modelos de extração de tabelas, transformando documentos não estruturados em dados limpos e estruturados, especialmente adequados para processar tabelas complexas e densas, colmatando as lacunas dos modelos de linguagem visual (VLM) nesta área. (Fonte: Tensorlake)
Patronus AI lança Percival: um agente inteligente dedicado à depuração e melhoria de agentes de IA : A Patronus AI lançou uma nova ferramenta, Percival, um agente de IA especificamente concebido para depurar e melhorar outros agentes de IA. Percival consegue analisar instantaneamente registos complexos de rastreamento de agentes, identificar até 60 modos de falha diferentes e sugerir automaticamente correções de prompts para melhorar o desempenho. A ferramenta aborda desafios críticos como a “explosão de contexto” (agentes a processar milhões de tokens) e suporta a adaptação de domínio para casos de uso específicos e orquestrações complexas de múltiplos agentes. (Fonte: Weaviate Podcast)

Replit integra Semgrep para “programação com ambiente seguro”, verificando vulnerabilidades automaticamente : A Replit anunciou uma parceria com a Semgrep para lançar a funcionalidade “Safe Vibe Coding”. Agora, sempre que um utilizador implementa código na Replit, a Semgrep executa automaticamente uma verificação de segurança, ajudando a descobrir e corrigir potenciais vulnerabilidades e a prevenir a exposição acidental de informações sensíveis, como chaves de API. Esta medida visa aumentar a segurança ao utilizar codificação assistida por IA (como a geração de código através de LLMs). (Fonte: amasad)

Cursor AI versão 0.50 lançada, trazendo atualizações significativas : A ferramenta de programação assistida por IA, Cursor, lançou a sua versão 0.50, descrita como “a maior atualização de sempre”. Espera-se que a nova versão inclua várias melhorias de funcionalidade e otimizações de experiência, com o objetivo de aumentar ainda mais a eficiência de codificação dos programadores e a fluidez da colaboração com a IA. O conteúdo específico da atualização pode ser consultado nas notas de lançamento oficiais. (Fonte: eric zakariasson)

OpenMemory MCP: Servidor de gestão de memória localizado que suporta partilha de contexto entre aplicações : OpenMemory MCP é um servidor de gestão de memória concebido para aumentar a produtividade de aplicações de IA. Permite aos utilizadores partilhar contexto entre diferentes aplicações (como Cursor e Claude Desktop) e utiliza PostgreSQL e Qdrant para armazenar e indexar dados localmente, garantindo a privacidade dos dados. A ferramenta suporta pesquisa semântica e fornece um painel de controlo para gerir a memória e o acesso de aplicações, resolvendo o problema da perda de contexto entre sessões. (Fonte: Reddit r/ClaudeAI)

Hugging Face Inference Endpoint combinado com vLLM e Gradio para transcrição rápida com Whisper : A Hugging Face demonstrou como utilizar o seu serviço Inference Endpoint, em conjunto com o projeto vLLM e a interface Gradio, para implementar o modelo Whisper da OpenAI, alcançando uma funcionalidade de transcrição de voz extremamente rápida. Esta combinação utiliza ferramentas open-source da comunidade de IA, fornecendo aos utilizadores uma solução de conversão de voz para texto eficiente e fácil de usar. (Fonte: Morgan Funtowicz)
A.I.T.E Ball: Uma bola mágica 8 de IA autónoma baseada em Orange Pi e Gemma 3 1B : Um programador demonstrou um projeto de bola mágica 8 alimentado por IA totalmente autónomo (sem necessidade de ligação à internet) – o A.I.T.E Ball. O dispositivo funciona num Orange Pi Zero 2W, utilizando whisper.cpp para conversão de texto em voz e llama.cpp para executar o modelo Gemma 3 1B para responder a perguntas. Isto demonstra o potencial para implementar aplicações de IA localizadas em hardware de baixo consumo. (Fonte: Reddit r/LocalLLaMA)

OWL Agent: Agente universal open-source integrado com MCPToolkit : O projeto de agente OWL open-source agora inclui suporte integrado para MCPToolkit. Os utilizadores podem facilmente conectar-se a servidores MCP como Playwright, desktop-commander, ou ferramentas Python personalizadas, e o OWL descobrirá e invocará automaticamente estas ferramentas nos seus fluxos de trabalho de múltiplos agentes, aumentando a sua universalidade e capacidade de execução de tarefas. (Fonte: Reddit r/LocalLLaMA)

ElevenLabs lança SB-1 Infinite Soundboard: um gerador integrado de efeitos sonoros, bateria eletrónica e ruído ambiente : A ElevenLabs lançou o SB-1 Infinite Soundboard, uma ferramenta que combina um painel de efeitos sonoros, uma bateria eletrónica e um gerador infinito de ruído ambiente. Os utilizadores podem descrever o efeito sonoro desejado e o SB-1 usará o seu modelo de conversão de texto para efeitos sonoros (Text-to-SFX) para gerar esses sons, oferecendo novas possibilidades para a criação de áudio. (Fonte: ElevenLabs)
Projeto Anytop: Novo avanço em animação por IA, dá vida a criaturas nunca antes vistas, suporta aprendizagem e transferência de movimento : O Two Minute Papers apresentou o projeto Anytop, uma tecnologia de animação por IA capaz de gerar movimentos realistas para criaturas nunca antes vistas (incluindo dinossauros, insetos exóticos, etc.). Esta IA não só consegue gerar movimentos de forma independente, como também permite que diferentes criaturas aprendam e adaptem os movimentos umas das outras (como um dinossauro a aprender a ficar numa perna só como um flamingo). Consegue generalizar para formas desconhecidas ao compreender a similaridade semântica das partes do corpo (como o conceito geral de braços e pernas). Além disso, o sistema consegue compreender a semântica dos movimentos (como ataque, relaxamento) e exibir movimentos de conceitos semelhantes entre diferentes animais, conseguindo até completar movimentos de entrada incompletos. (Fonte: )

Sketch2Anim: IA transforma esboços simples em animações 3D completas : Outra tecnologia apresentada pelo Two Minute Papers, Sketch2Anim, consegue transformar simples esboços de linhas desenhados pelo utilizador (indicando o caminho do movimento) em animações de personagens 3D completas. Esta IA consegue compreender a intenção 3D por detrás dos esboços 2D (como distinguir um soco para a frente de um soco para o lado), resolvendo a limitação de tecnologias semelhantes anteriores que apenas compreendiam as instruções a um nível 2D, permitindo que não profissionais criem rapidamente animações 3D através de desenhos simples. (Fonte: )
📚 Aprender
DeepSeek publica artigo sobre o modelo V3, partilhando desafios de expansão e reflexões sobre arquitetura de hardware de IA : A equipa DeepSeek publicou no Hugging Face o artigo sobre o modelo DeepSeek-V3. Este artigo explora em profundidade os desafios encontrados durante o processo de expansão de grandes modelos de linguagem e apresenta reflexões e perspetivas sobre as direções futuras do desenvolvimento da arquitetura de hardware de IA. Isto fornece uma referência valiosa para investigadores e programadores compreenderem os estrangulamentos no treino e implementação de modelos em larga escala, bem como a forma de otimizar através da colaboração entre hardware e software. (Fonte: Adina Yakup)
Curso gratuito sobre Protocolo de Contexto de Modelo (MCP) lançado, auxiliando na construção de aplicações de IA com dados e ferramentas externas : Ben Burtenshaw anunciou o lançamento de um curso gratuito sobre MCP (Model Context Protocol). O curso visa ajudar os alunos, desde o nível básico ao avançado, a compreender o funcionamento do MCP, como conectar LLMs a servidores MCP e como usar o MCP para implementar aplicações de agentes de IA, aproveitando assim dados e ferramentas externas para aumentar as capacidades das aplicações de IA. (Fonte: Ben Burtenshaw)

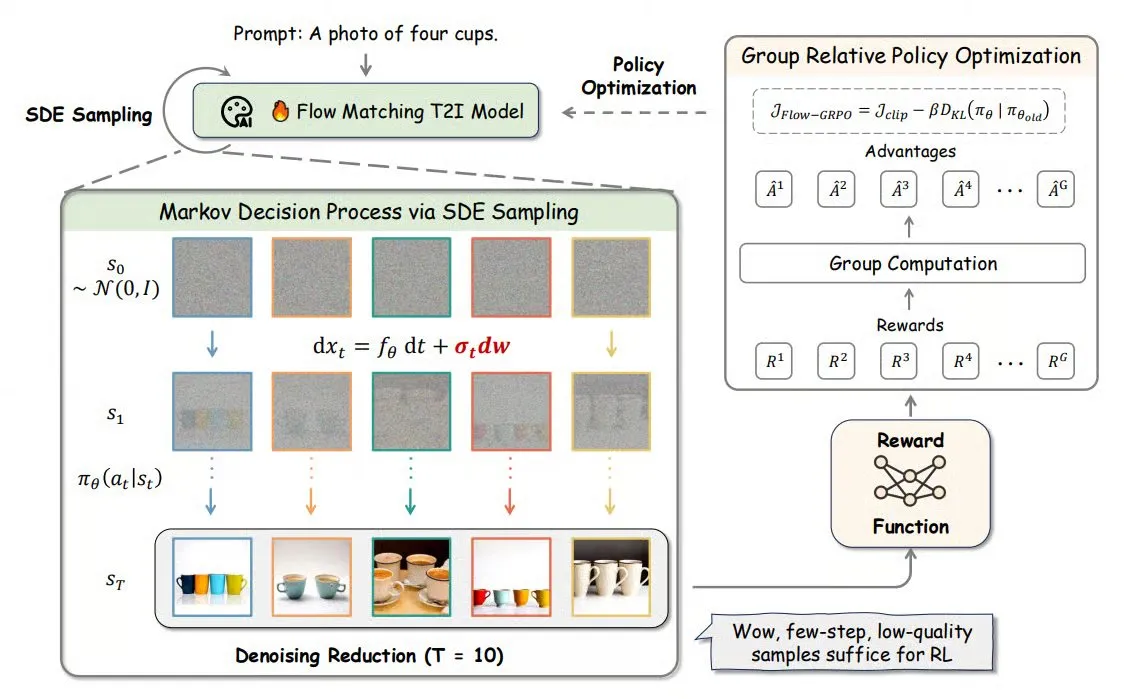
Flow-GRPO: Introduzindo aprendizagem por reforço online em modelos de flow matching para aumentar a precisão na geração de imagens : Flow-GRPO é um novo método que, pela primeira vez, aplica aprendizagem por reforço (RL) online a modelos de flow matching. Consegue-o através de duas estratégias inovadoras: 1) Conversão de ODE para SDE: Transforma o processo determinístico dos modelos de flow baseado em equações diferenciais ordinárias (ODE) num processo de equações diferenciais estocásticas (SDE), introduzindo a aleatoriedade necessária para RL. 2) Redução de denoising para acelerar o treino: Durante o treino, reduz os passos de denoising, e durante a inferência, usa os passos completos. Com o Flow-GRPO, a precisão dos modelos de flow em tarefas de geração de imagens aumentou para mais de 92%. (Fonte: TheTuringPost)
Artigo ICML 2025 PENCIL: “Raciocinar-Apagar” alternadamente para um novo paradigma de pensamento profundo em grandes modelos : Chenxiao Yang e outros do Toyota Technological Institute at Chicago propuseram PENCIL (Pondering with Erasure Net for Contextual Inference Learning), um novo paradigma para o pensamento profundo em grandes modelos através da alternância entre “gerar” e “apagar” resultados intermédios. Este método inspira-se nas regras de reescrita da lógica e na gestão de memória da programação funcional, apagando dinamicamente passos intermédios que já não são necessários, resolvendo eficazmente problemas enfrentados pelas tradicionais longas CoT (cadeias de pensamento), como o excesso da janela de contexto, a dificuldade de recuperação de informação e a diminuição da eficiência de geração. Teoricamente, PENCIL consegue simular qualquer computação de máquina de Turing com complexidade espacial e temporal ótimas, resolvendo todos os problemas computáveis. Experiências demonstram que, em tarefas como 3-SAT, QBF e o enigma de Einstein, PENCIL supera significativamente as CoT tradicionais. (Fonte: Máquina do Coração)

Artigo ICML 2025 MemVR: Simula mecanismo humano de “olhar duas vezes” para mitigar alucinações em grandes modelos multimodais : Investigadores da HKUST (Guangzhou) e outras instituições propuseram o método MemVR (Memory-space Visual Retracing), que simula a estratégia humana de verificar novamente memórias incertas para mitigar o problema de alucinações em grandes modelos de linguagem multimodais (MLLM). MemVR usa tokens visuais como evidência suplementar. Nas camadas intermédias onde o modelo encontra dificuldades de esquecimento durante a inferência, “recupera” conhecimento visual através de uma rede feed-forward (FFN) para calibrar as previsões. Este método projeta um mecanismo de ativação dinâmica, selecionando a camada de ativação com base na incerteza da saída de diferentes camadas. Experiências mostram que MemVR alcança resultados significativos em vários benchmarks de avaliação de alucinações e benchmarks gerais, e tem vantagens de eficiência em comparação com outros métodos. (Fonte: PaperWeekly)

Artigo SIGIR 2025 PaRT: Recuperação personalizada em tempo real melhora a experiência de chatbots sociais proativos : A Universidade de Ciência e Tecnologia da China e outras instituições propuseram o método PaRT (Proactive Social Chatbots with Personalized Real-time ReTreival), que visa melhorar a experiência de conversação de chatbots sociais proativos através da combinação de uma orientação personalizada e reescrita de consulta guiada por reconhecimento de intenção com recuperação em tempo real. O sistema PaRT inclui três módulos: construção de perfil de utilizador personalizado, reconhecimento de intenção e reescrita de consulta, e geração melhorada por recuperação em tempo real. Consegue iniciar ou mudar de tópico ativamente com base nos interesses do utilizador e no contexto da conversa, fornecendo respostas mais naturais e ricas em informação. Experiências offline e testes A/B online demonstraram que este método consegue melhorar eficazmente a personalização e riqueza das respostas, bem como a duração média da conversa. (Fonte: PaperWeekly)
Artigo ICML 2025 PreSelect: Esquema eficiente de seleção de dados de pré-treino baseado na força preditiva : A Universidade de Ciência e Tecnologia de Hong Kong e o vivo AI Lab propuseram o método de seleção de dados PreSelect, que introduz o conceito de “Força Preditiva” (Predictive Strength) para quantificar a contribuição dos dados para o modelo numa capacidade específica. Este método utiliza a consistência entre a classificação de diferentes modelos em testes de benchmark e a classificação da sua perda (Loss) nos dados para avaliar o valor dos dados, e usa um classificador fastText leve para pontuação aproximada, permitindo a seleção eficiente de dados em grande escala. Experiências demonstram que PreSelect pode aumentar a eficiência dos dados em 10 vezes, e os dados selecionados mostram resultados significativamente melhores no treino de modelos em comparação com vários métodos de base, cobrindo também uma gama mais ampla de fontes de conteúdo de alta qualidade e reduzindo o viés de comprimento da amostra. (Fonte: QubitAI)

Curso AI Evals convida 12 especialistas para partilhar estruturas e práticas de avaliação : O curso AI Evals, organizado por Hamel Husain, anunciou a sua lista de 12 palestrantes convidados, incluindo JJ Allaire, criador do framework inspect, e Charles Frye, developer advocate da Modal. O curso explorará em profundidade vários aspetos da avaliação de IA, incluindo estruturas de avaliação, criação de aplicações de anotação personalizadas, práticas de avaliação de modelos, entre outros, com o objetivo de ajudar os participantes a dominar as competências e ferramentas chave para avaliar o desempenho de sistemas de IA. (Fonte: Hamel Husain)

Tutorial FedRAG lançado: um guia de iniciação para construir e ajustar sistemas RAG : O projeto FedRAG lançou novos notebooks tutoriais e vídeos de acompanhamento, com o objetivo de ajudar os utilizadores a começar rapidamente com a biblioteca. O tutorial demonstra como usar a integração com o Hugging Face para construir um sistema RAG, usar uma base de conhecimento em memória para armazenar nós, definir um SentenceTransformer (Dragon+) como recuperador, definir um modelo pré-treinado (como Qwen2.5-0.5B) como gerador, e usar os treinadores LSR e RALT para ajustar centralizadamente o recuperador e o gerador. (Fonte: nerdai)

LlamaIndex lança tutorial: Implementar citações e inferência no LlamaExtract : A equipa LlamaIndex lançou o mais recente passo-a-passo de código produzido por @tuanacelik, demonstrando como implementar funcionalidades de citação e inferência no LlamaExtract. O conteúdo do tutorial inclui: como definir um esquema personalizado para informar o LLM sobre o que extrair de fontes de dados complexas e como adicionar citações. Esta funcionalidade visa ajudar os utilizadores a construir agentes de IA de múltiplos passos capazes de extrair informações estruturadas de grandes volumes de documentos fonte de forma precisa e fundamentada. (Fonte: LlamaIndex 🦙)
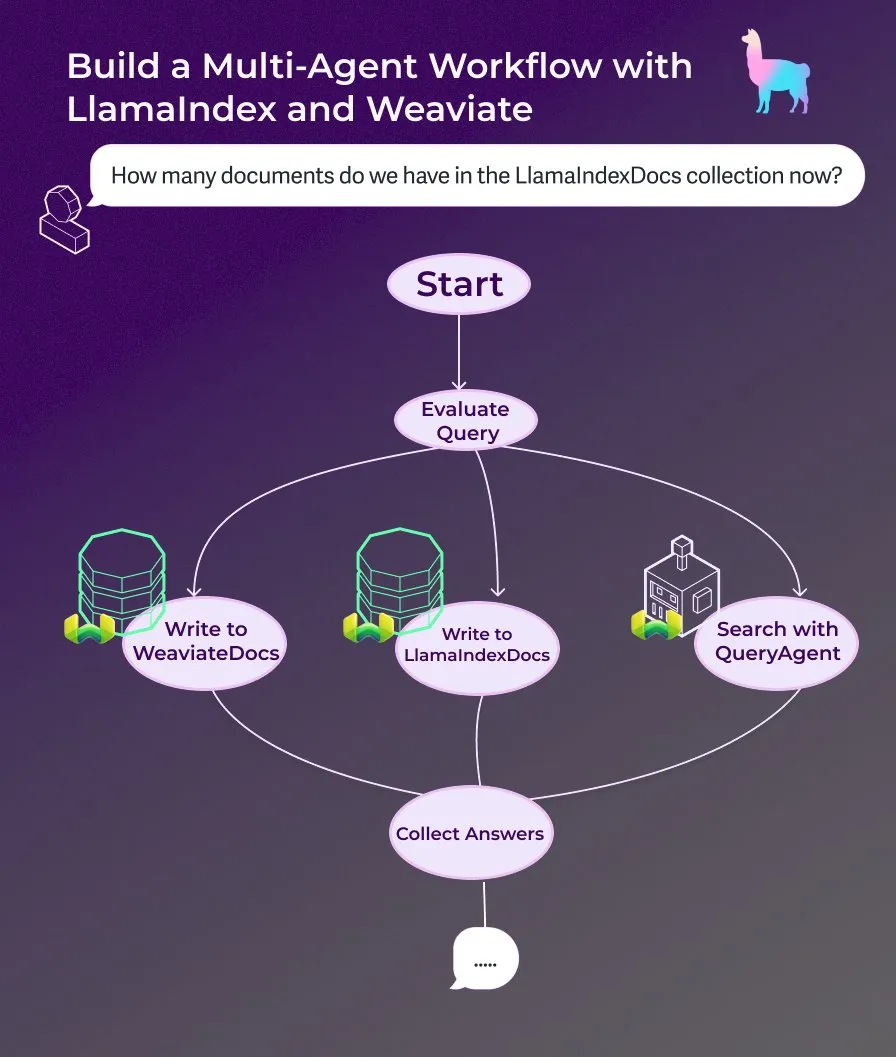
LlamaIndex lança tutorial: Construir um assistente de documentos multi-agente com fluxos de trabalho de agentes orientados a eventos : LlamaIndex lançou um novo tutorial passo-a-passo que demonstra como construir um assistente de documentos multi-agente usando fluxos de trabalho de agentes orientados a eventos. Este assistente é capaz de escrever conteúdo de páginas web nas coleções LlamaIndexDocs e WeaviateDocs, usar um orquestrador para decidir quando chamar o Weaviate QueryAgent para pesquisa e agregação, utilizar saída estruturada para classificação de consultas e, opcionalmente, usar um FunctionAgent. (Fonte: LlamaIndex 🦙)
Modular publica palestra técnica interna sobre o compilador Mojo, explorando Mojo e arquitetura de GPU : A empresa Modular começou a partilhar as suas palestras técnicas internas, sendo a primeira palestra pública a aprofundar o tema da linguagem de programação Mojo e da arquitetura de GPU. O conteúdo inclui o funcionamento interno do compilador Mojo e os desafios e soluções que a equipa enfrenta ao desenvolver para GPUs modernas, com o objetivo de partilhar com a comunidade os detalhes da sua pilha tecnológica. (Fonte: Modular)
Workshop AI by Hand: Construir um modelo Transformer do zero no Excel : O ProfTomYeh promove o seu workshop AI by Hand, que visa permitir que os participantes construam um modelo Transformer do zero no Excel. Desta forma, os alunos podem compreender de forma clara e intuitiva cada passo matemático do Transformer, evitando vê-lo como uma “caixa preta” e, assim, construir uma compreensão profunda do funcionamento interno do modelo. (Fonte: ProfTomYeh)
DeepLearning.AI lança The Batch Edição 301: Discute o valor comercial da velocidade da IA e os últimos avanços : Andrew Ng, na sua mais recente edição do The Batch, discute como o aumento da velocidade da IA na execução de tarefas é um fator subestimado na criação de valor comercial. Ele argumenta que a IA não só reduz custos, mas, mais importante, acelera a inovação e a exploração ao encurtar o tempo desde a ideia até ao protótipo. Esta edição também noticia o lançamento da série de inferência Phi-4 da Microsoft, o desempenho do DeepCoder-14B a igualar o o1, o abrandamento das regras de IA da UE, entre outras notícias. (Fonte: DeepLearningAI)
💼 Negócios
Startup de animação de personagens por IA, Cartwheel, angaria 10 milhões de dólares para simplificar o processo de animação 3D : A Cartwheel, uma startup focada em animação de personagens por IA, anunciou a conclusão de uma ronda de financiamento de 10 milhões de dólares. A empresa dedica-se ao desenvolvimento de tecnologia para simplificar o processo de produção de animação 3D, com o objetivo de permitir que os criadores produzam animações de personagens 3D de alta qualidade de forma mais rápida e económica, ao mesmo tempo que aumentam o controlo sobre o produto final e eliminam tarefas morosas. (Fonte: andrew_n_carr)
Hedra obtém financiamento Série A de 32 milhões de dólares, liderado pela a16z, para acelerar a criação de vídeos orientados por personagens : A startup de geração de vídeo por IA, Hedra, anunciou a conclusão de uma ronda de financiamento Série A de 32 milhões de dólares, liderada pela Andreessen Horowitz (a16z), com Matt Bornstein a juntar-se ao conselho de administração. Os investidores existentes a16z speedrun, Abstract e Index Ventures também participaram nesta ronda. A Hedra dedica-se a facilitar a criação de vídeos orientados por personagens. Desde o seu lançamento em modo furtivo no ano passado, quase 3 milhões de pessoas usaram as suas ferramentas para criar mais de 10 milhões de vídeos. O novo financiamento será usado para acelerar o desenvolvimento de produtos e a expansão da equipa, com vista a uma criação de conteúdo rápida, expressiva e intuitiva. (Fonte: Hedra)
Tripadvisor utiliza Qdrant para construir planeamento de viagens com IA, envolvimento do utilizador aumenta 2-3 vezes : O Tripadvisor está a redefinir a experiência de descoberta de viagens utilizando a base de dados vetorial Qdrant. Ao analisar mais de mil milhões de críticas e fotografias, 11 milhões de estabelecimentos comerciais e dados de 21 países, o Tripadvisor criou itinerários dinâmicos gerados por IA, em vez de depender de filtros tradicionais. Os resultados mostram que os utilizadores que utilizam estas ferramentas de IA passam 2-3 vezes mais tempo na plataforma, indicando o enorme potencial da IA no planeamento personalizado de viagens. (Fonte: qdrant_engine)

🌟 Comunidade
Comentários do Grok sobre “genocídio branco” geram controvérsia, Sam Altman responde com ironia : O modelo Grok da xAI gerou ampla discussão e críticas por emitir opiniões aleatórias sobre o genocídio branco na África do Sul. Paul Graham apontou que este comportamento parece um bug introduzido por um patch recente e expressou preocupação com a possibilidade de IAs amplamente utilizadas terem as suas opiniões editadas instantaneamente pelos seus controladores. Sam Altman respondeu com ironia, afirmando que a xAI daria uma explicação transparente e que este problema seria compreendido no contexto do “genocídio branco na África do Sul”, insinuando que isto é resultado da busca da IA pela verdade e do seguimento de instruções. A discussão da comunidade sobre este assunto reflete preocupações generalizadas sobre o preconceito, a controlabilidade e as intenções subjacentes dos modelos de IA. (Fonte: Paul Graham)
Reflexão sobre a produtização da IA: Explorar oportunidades em todo o fluxo de trabalho do utilizador, em vez de simplesmente sobrepor funcionalidades de IA : Ren Xin, sócio da Sky9 Capital, partilhou uma reflexão profunda sobre a produtização da IA, enfatizando que as empresas devem partir de todo o fluxo de trabalho do utilizador para concluir tarefas, procurando pontos de entrada para aplicações de IA, em vez de simplesmente sobrepor funcionalidades de IA aos produtos existentes. Ele usou a analogia “o utilizador não quer um berbequim, mas sim um buraco na parede”, sugerindo decompor as tarefas do utilizador, encontrar os pontos problemáticos e otimizá-los com IA. Os quatro níveis de produtização da IA incluem: concluir eficientemente processos antigos, criar novos processos, explorar mercados totalmente novos (reduzir a barreira de entrada, servir novos grupos de utilizadores, ou mesmo a própria IA) e construir infraestrutura para um futuro dominado pela IA. Ele acredita que a tecnologia de IA está a democratizar-se, e empresas sem conhecimento técnico também podem aproveitar as oportunidades, sendo a essência “ajudar a IA a encontrar trabalho”. (Fonte: Universidade Hundun)
Discussão: O papel da IA no desenvolvimento de carreira e estratégias de adaptação : Uma publicação no LinkedIn gerou uma discussão sobre como a IA afeta o desenvolvimento de carreira. A afirmação comum é “A IA não vai substituir o teu trabalho, mas quem usa IA sim”. No entanto, esta afirmação foi considerada demasiado vaga. Foram levantadas questões sobre como engenheiros front-end com décadas de experiência, entre outros cargos específicos, podem subitamente tornar-se engenheiros de IA, e o problema de nem todos poderem tornar-se engenheiros de IA. A discussão na comunidade considerou que, para programadores front-end, é possível aprender a usar ferramentas de IA para aumentar a eficiência do trabalho. Houve também a opinião de que a IA substituirá muitos empregos, e muitas pessoas não terão para onde ir. Uma visão mais generalizada é que o futuro ainda é incerto, mas a criatividade, a capacidade de identificar problemas e a capacidade de compreender e alcançar a humanidade podem ser mais defensivas. (Fonte: Reddit r/ArtificialInteligence)
Discussão: LLMs tendem a “perder-se” em conversas multi-turno, reiniciar a conversa pode ser benéfico : Um artigo de investigação aponta que o desempenho de LLMs, tanto open-source como closed-source, diminui significativamente em conversas multi-turno. A maioria dos benchmarks foca-se em cenários de turno único com instruções claras. A investigação descobriu que os LLMs frequentemente fazem suposições (erradas) nas primeiras rondas da conversa e dependem dessas suposições nas rondas seguintes, sendo difícil corrigi-las. A conclusão é que, quando uma conversa multi-turno não atinge o resultado esperado, reiniciar uma nova conversa e integrar toda a informação relevante na primeira entrada pode ser útil. (Fonte: Reddit r/LocalLLaMA)
Análise das razões para o ritmo relativamente lento da Apple e do WeChat no desenvolvimento de IA: privacidade, segurança e estratégia de prioridade às aplicações : Weixi, num artigo, analisa que, apesar do lançamento do “Apple Intelligence” pela Apple e da integração do DeepSeek e Yuanbao pelo WeChat, o progresso de ambos nas funcionalidades centrais de IA tem sido relativamente lento. Existem duas razões principais: primeiro, a elevada sensibilidade da privacidade e segurança dos dados; a inteligência da IA depende de dados, e os modelos de negócio centrais da Apple e do WeChat determinam que sejam extremamente cautelosos na partilha de dados, o que limita o treino de modelos e a obtenção de contexto de aplicação. Segundo, ambos adotam uma estratégia de “prioridade às aplicações”, não procurando competir com as principais empresas de IA no limite superior da inteligência dos modelos, mas focando-se mais na integração das capacidades de IA nas funcionalidades e ecossistemas existentes, o que pode levar a limitações no domínio tecnológico e na velocidade de iteração do produto. (Fonte: Weixi Zhibei)

OpenAI lança “Desafio de A a Z”: Usar IA para descobrir sítios arqueológicos desconhecidos na Amazónia : A OpenAI anunciou uma parceria com a Kaggle para lançar o hackathon especial “OpenAI to Z Challenge”. O desafio incentiva os participantes a usar os modelos OpenAI o3, o4-mini ou GPT-4.1 para encontrar sítios arqueológicos anteriormente desconhecidos na região amazónica. Os participantes podem usar a hashtag #OpenAItoZ para partilhar o seu progresso. O evento visa explorar o potencial de aplicação da IA na arqueologia e análise geoespacial. (Fonte: OpenAI Developers)
Críticas a startups de “advogados de IA”: Automatização de “cartas de extorsão” pode tornar-se um fardo social : O programador @swyx criticou o fenómeno de alguns VCs investirem em startups de “advogados de IA”. Ele argumenta que estas empresas geram principalmente “cartas de exigência” (demand letters) através da automatização por IA, o que é essencialmente extorsão automatizada. Embora algumas exigências possam ser razoáveis, ele aponta que a maioria destas ações acaba por beneficiar apenas os advogados, tornando-se um puro imposto sobre a sociedade. Ele apela ao boicote, desinvestimento e crítica pública a estas empresas e aos seus investidores. (Fonte: swyx)

💡 Outros
Relatório sobre carvão com erro absurdo “obtido ao matar wither skeletons”, gera discussão sobre qualidade de conteúdo e alucinações de IA : Um relatório sobre a indústria do carvão, com um preço de 8200 yuan, continha a descrição “o carvão é um recurso renovável, obtido ao matar wither skeletons”, uma referência ao jogo “Minecraft”, o que gerou grande discussão online. Muitos atribuíram o erro à geração de conteúdo por IA e a alucinações. No entanto, o relatório foi publicado em 2022, antes do lançamento de grandes modelos convencionais como o ChatGPT, indicando que se tratou de um caso típico de copiar e colar manual e negligência na revisão. O incidente também suscitou uma profunda reflexão sobre a qualidade do conteúdo de relatórios profissionais, a importância da verificação de informações e como discernir a veracidade da informação na era da IA. (Fonte: Devaneios de caoz)

Investigadores utilizam terapia de edição genética personalizada para tratar bebé com doença metabólica rara : Médicos construíram uma terapia de edição genética personalizada em menos de sete meses e usaram-na com sucesso para tratar um bebé com uma doença metabólica fatal. Esta é a primeira vez que a edição genética foi usada para um tratamento personalizado para um único indivíduo. A terapia visa corrigir um erro específico de uma única letra no gene do bebé, demonstrando a precisão de novas tecnologias de edição genética (como a edição de base). Embora o tratamento tenha mostrado sinais positivos iniciais, também realça os desafios de custo e escalabilidade no desenvolvimento de terapias genéticas personalizadas para doenças ultra-raras. (Fonte: MIT Technology Review)

Estratégia universal de prompts de jailbreak exposta, capaz de contornar as barreiras de segurança dos principais grandes modelos : Investigadores da HiddenLayer descobriram uma estratégia universal de prompts capaz de fazer com que os principais grandes modelos de linguagem, incluindo ChatGPT, Claude e Gemini, contornem as suas barreiras de segurança e gerem conteúdo prejudicial. A estratégia disfarça instruções prejudiciais como ficheiros de política semelhantes a XML, INI ou JSON, combinados com cenários de role-playing fictícios, enganando o modelo para interpretar comandos prejudiciais como instruções de sistema legítimas. Este método explora potenciais fraquezas sistémicas nos dados de treino do modelo, nomeadamente a tendência para ignorar instruções de segurança ao processar dados relacionados com ensino ou políticas. A técnica também consegue extrair os system prompts do modelo, expondo as suas instruções internas e restrições de segurança. (Fonte: Nova Geração IA)
