
Palavras-chave:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, Regulação de IA, Seed1.5-VL, Agente de codificação acionado por Gemini, Otimização de algoritmo de multiplicação de matrizes, Otimização de eficiência de data center, Modelo multimodal multilíngue, Rede de treinamento de IA descentralizada
🔥 Foco
Google DeepMind lança AlphaEvolve: Agente de codificação impulsionado pelo Gemini, revolucionando a descoberta de algoritmos: O Google DeepMind apresenta o AlphaEvolve, um agente de codificação de IA impulsionado pelo Gemini, projetado para descobrir e otimizar algoritmos complexos combinando a criatividade de modelos de linguagem grandes com avaliadores automatizados. O AlphaEvolve já projetou com sucesso algoritmos de multiplicação de matrizes mais rápidos, resolveu problemas matemáticos abertos como o problema de sobreposição mínima de Erdős e o problema do número de beijos, e é usado internamente no Google para otimizar a eficiência de data centers (recuperando em média 0,7% dos recursos computacionais), design de chips e acelerar o treinamento do próprio Gemini, demonstrando o enorme potencial da IA na descoberta científica e otimização de engenharia. (Fonte: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic está prestes a lançar novos modelos Claude Sonnet e Opus, fortalecendo as capacidades de raciocínio e chamada de ferramentas: Segundo o The Information, a Anthropic planeja lançar novas versões do Claude Sonnet e Claude Opus nas próximas semanas. A característica principal dos novos modelos é a capacidade de alternar flexivelmente entre o “modo de pensamento” e o “modo de uso de ferramentas”. Quando encontra obstáculos ao usar ferramentas externas (como aplicativos, bancos de dados) para resolver problemas, o modelo pode retornar ativamente ao “modo de raciocínio” para refletir e se autocorrigir. Na geração de código, os novos modelos podem testar automaticamente o código gerado e, se erros forem encontrados, irão pausar, pensar e corrigir. Este ciclo fechado de “pensar-agir-refletir” promete melhorar significativamente a capacidade e a confiabilidade do modelo na resolução de problemas complexos. (Fonte: steph_palazzolo, dotey)

Legisladores republicanos dos EUA propõem proibir regulamentação de IA em níveis federal e estadual por 10 anos, gerando intenso debate: Legisladores republicanos dos EUA adicionaram uma cláusula a um projeto de lei de reconciliação orçamentária propondo a proibição da regulamentação de modelos de inteligência artificial, sistemas ou sistemas de decisão automatizados pelos governos federal e estaduais nos próximos dez anos, e planejam alocar US$ 500 milhões para apoiar a comercialização da IA e sua aplicação em sistemas de TI do governo federal. A medida é vista por algumas personalidades do setor de tecnologia como um sinal positivo para proteger a inovação em IA e impedir que regulamentações a sufoquem, mas também levanta preocupações sobre riscos potenciais como a proliferação de DeepFakes, perda de controle sobre a privacidade dos dados, ética da IA e impacto ambiental. Se a proposta for aprovada, terá um impacto significativo na legislação de IA existente e futura. (Fonte: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI lança modelo GPT-4.1 e disponibiliza Centro de Avaliação de Segurança, enfatizando as capacidades de codificação e seguimento de instruções: A OpenAI anunciou que, a pedido dos usuários, o modelo GPT-4.1 está disponível no ChatGPT a partir de hoje (para usuários Plus, Pro, Team; versões Enterprise e Education em breve). O GPT-4.1 é otimizado especificamente para tarefas de codificação e seguimento de instruções, é mais rápido e pode servir como substituto para o3 e o4-mini na codificação diária. Ao mesmo tempo, o GPT-4.1 mini substituirá o GPT-4o mini atualmente usado por todos os usuários. Além disso, a OpenAI lançou o Safety Evaluations Hub, para divulgar publicamente os resultados e métricas dos testes de segurança de seus modelos, que serão atualizados regularmente para aumentar a transparência na comunicação sobre segurança. (Fonte: openai, michpokrass)
Meta FAIR anuncia múltiplos resultados de pesquisa em IA, com foco na descoberta molecular e modelagem atômica: A Meta AI (FAIR) anunciou as versões de código aberto mais recentes nas áreas de previsão de propriedades moleculares, processamento de linguagem e neurociência. Isso inclui o Open Molecules 2025 (OMol25), um conjunto de dados para descoberta molecular para simulação de grandes sistemas atômicos; o Universal Model for Atoms (UMA), um modelo de potencial interatômico de aprendizado de máquina amplamente aplicável à modelagem de interações atômicas em materiais e moléculas; e o Adjoint Sampling, um algoritmo escalável para treinar modelos generativos com base em recompensas escalares. Além disso, uma pesquisa colaborativa da FAIR com o Hospital da Fundação Rothschild revela semelhanças significativas no desenvolvimento da linguagem entre humanos e LLMs. (Fonte: AIatMeta)
🎯 Tendências
ByteDance lança grande modelo de linguagem visual Seed1.5-VL, com 20B de parâmetros ativos e desempenho excepcional: A ByteDance lançou seu grande modelo multimodal de visão e linguagem Seed1.5-VL. Com apenas 20B de parâmetros ativos, o modelo demonstra desempenho comparável ao Gemini 2.5 Pro e alcançou SOTA em 38 de 60 benchmarks de avaliação públicos. O Seed1.5-VL aprimorou as capacidades gerais de compreensão e raciocínio multimodal, com destaque especial em localização visual, raciocínio, compreensão de vídeo e agentes inteligentes multimodais. O modelo já está disponível via API na Volcano Engine, com preço de entrada para inferência de 0,003 yuan/mil tokens e saída de 0,009 yuan/mil tokens. (Fonte: 机器之心)

Relatório técnico do Qwen3 revela: integração de modos de ‘pensamento’ e ‘não pensamento’, modelo grande destila modelo pequeno: O Alibaba divulgou o relatório técnico da série de modelos Qwen3, contendo 8 modelos com parâmetros de 0.6B a 235B. A inovação central reside no modo de trabalho duplo, onde o modelo pode alternar automaticamente entre o “modo de pensamento” (raciocínio complexo) e o “modo de não pensamento” (resposta rápida) com base na complexidade da tarefa, alocando dinamicamente recursos computacionais através de um parâmetro de “orçamento de pensamento”. O treinamento adota pré-treinamento em três fases (conhecimento geral, aprimoramento de raciocínio, texto longo) e pós-treinamento em quatro fases (inicialização a frio de cadeia de pensamento longa, aprendizado por reforço para raciocínio, fusão de modos de pensamento, aprendizado por reforço geral). Ao mesmo tempo, utiliza uma estratégia de destilação de dados “grande ensina pequeno”, usando um modelo professor (como o de 235B) para treinar um modelo aluno (como o de 30B), realizando a transferência de conhecimento. (Fonte: 36氪)

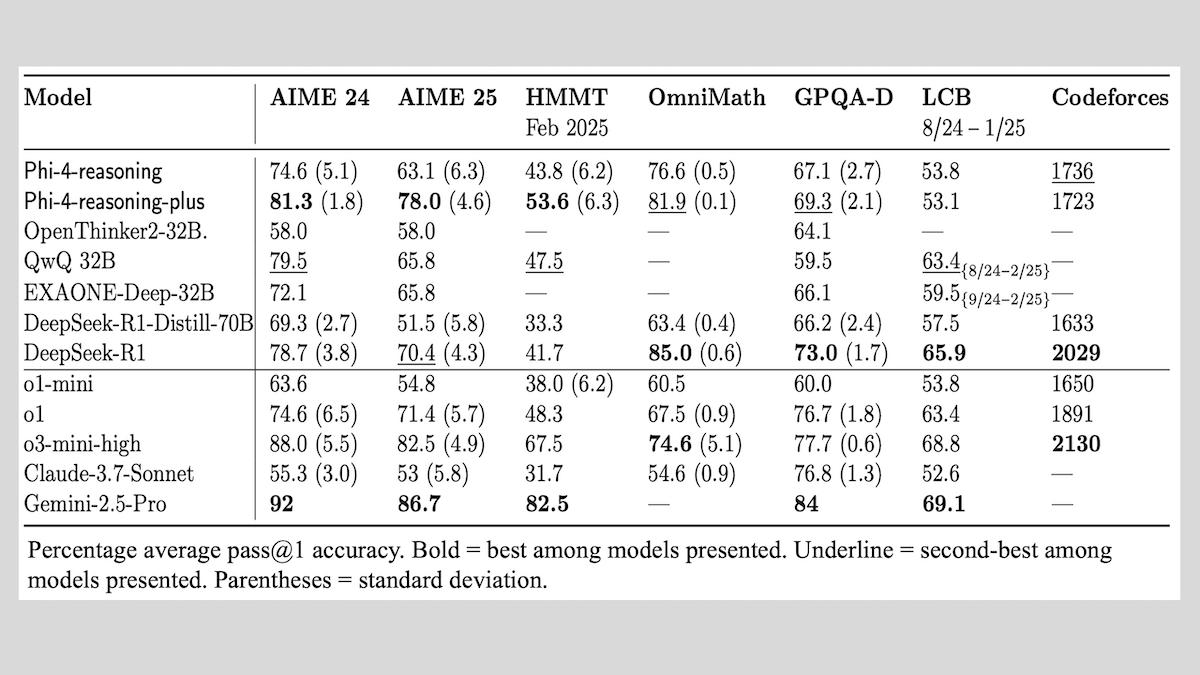
Microsoft lança série de modelos Phi-4-reasoning, compartilha experiências de treinamento de modelos de raciocínio: A Microsoft lançou três modelos: Phi-4-reasoning, Phi-4-reasoning-plus (ambos com 14B de parâmetros) e Phi-4-mini-reasoning (3.8B de parâmetros), e divulgou seus métodos e experiências de treinamento. Esses modelos, por meio do ajuste fino de modelos pré-treinados, concentram-se em aprimorar capacidades como o raciocínio matemático. Por exemplo, o Phi-4-reasoning-plus se destaca em problemas matemáticos por meio de aprendizado por reforço, enquanto o Phi-4-mini-reasoning passa por SFT e ajuste fino de RL em fases. O relatório compartilha a instabilidade que pode ocorrer no treinamento de modelos pequenos e estratégias para lidar com ela, bem como considerações sobre seleção de dados e design de função de recompensa no treinamento de RL de modelos grandes. Os pesos dos modelos foram disponibilizados no Hugging Face sob a licença MIT. (Fonte: DeepLearning.AI Blog)
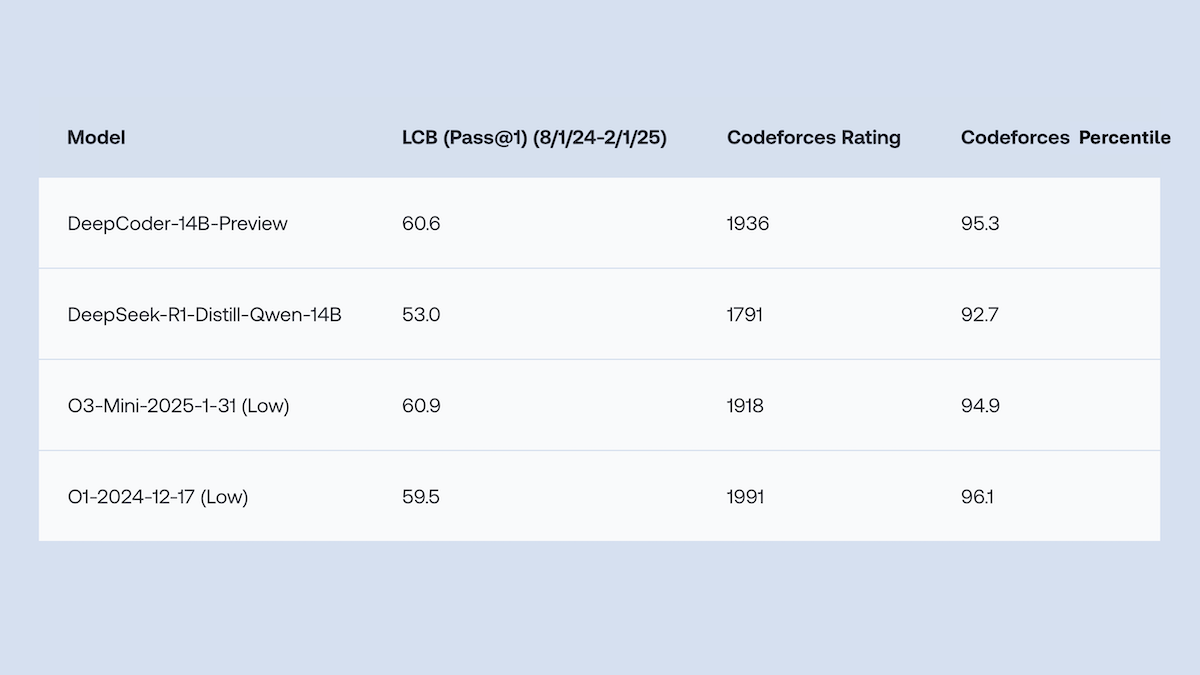
Together.AI e Agentica lançam DeepCoder-14B-Preview de código aberto, com desempenho de geração de código comparável ao o1: As equipes Together.AI e Agentica lançaram o DeepCoder-14B-Preview, um modelo de geração de código com 14B de parâmetros, cujo desempenho em vários benchmarks de codificação é comparável a modelos maiores como DeepSeek-R1 e OpenAI o1. O modelo foi ajustado a partir do DeepSeek-R1-Distilled-Qwen-14B, utilizando um método simplificado de aprendizado por reforço (combinando otimizações de GRPO e DAPO) e melhorando a capacidade de processamento paralelo da biblioteca RL Verl, o que reduziu significativamente o tempo de treinamento. Os pesos do modelo, código, conjuntos de dados e logs de treinamento foram disponibilizados sob a licença MIT. (Fonte: DeepLearning.AI Blog)
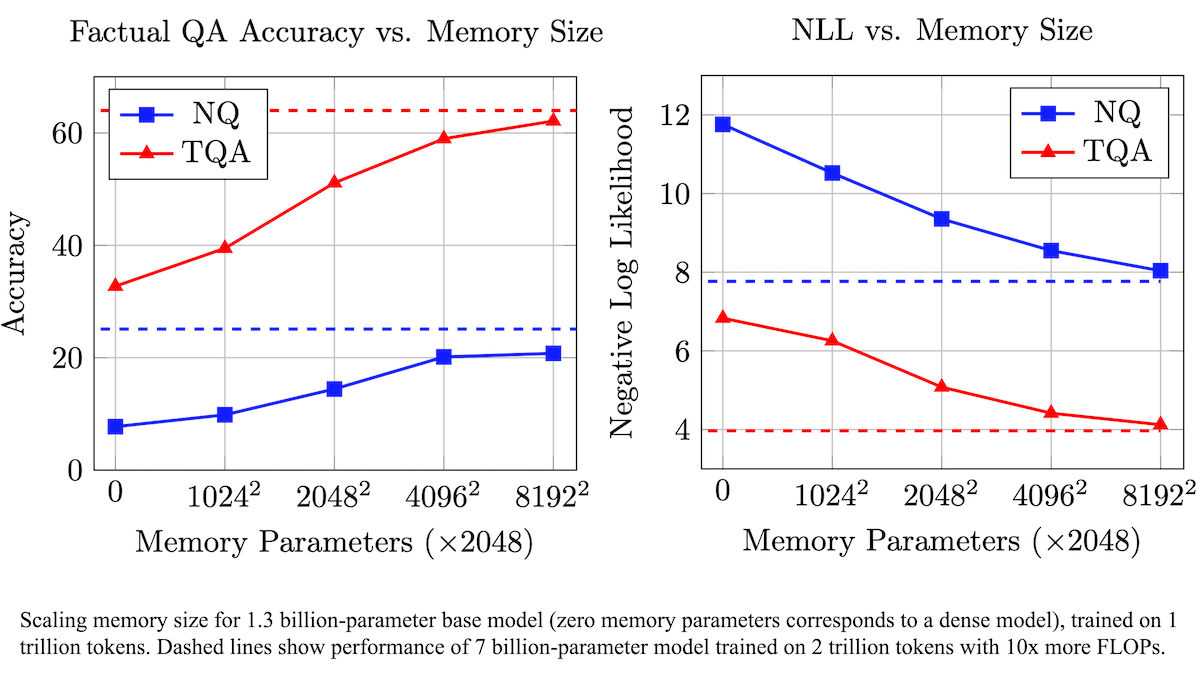
Meta propõe camada de memória treinável para aumentar a precisão factual de LLMs, reduzindo a demanda computacional: Pesquisadores da Meta aumentaram a precisão na recordação de fatos por modelos de linguagem grandes (LLMs) adicionando uma camada de memória treinável à arquitetura Transformer, sem aumentar significativamente a carga computacional. O método armazena informações aprendendo chaves e valores correspondentes e adota uma estratégia de decompor chaves em duas meias-chaves, resolvendo efetivamente o gargalo computacional na recuperação de chaves em grande escala. Experimentos mostram que um modelo de 8B parâmetros equipado com a camada de memória supera modelos semelhantes sem memória em vários conjuntos de dados de perguntas e respostas, demonstrando vantagens na demanda por dados de pré-treinamento e volume computacional. (Fonte: DeepLearning.AI Blog)
Alibaba lança modelos básicos de vídeo da série Wan2.1 de código aberto, suportando geração e edição de texto/imagem para vídeo: O Alibaba lançou o Wan2.1, um conjunto abrangente de modelos básicos de vídeo de código aberto, incluindo versões de 1.3B e 14B parâmetros, sob a licença Apache 2.0. O Wan2.1 se destaca em várias tarefas, como texto para vídeo, imagem para vídeo, edição de vídeo, texto para imagem e vídeo para áudio, e suporta especialmente a geração visual de texto em chinês e inglês. Seu modelo T2V-1.3B requer apenas 8.19GB de VRAM, pode rodar em GPUs de consumo e gerar vídeos de 5 segundos a 480P em 4 minutos. O Wan-VAE complementar pode codificar e decodificar eficientemente vídeos de 1080P, preservando informações temporais. (Fonte: _akhaliq, Reddit r/LocalLLaMA)

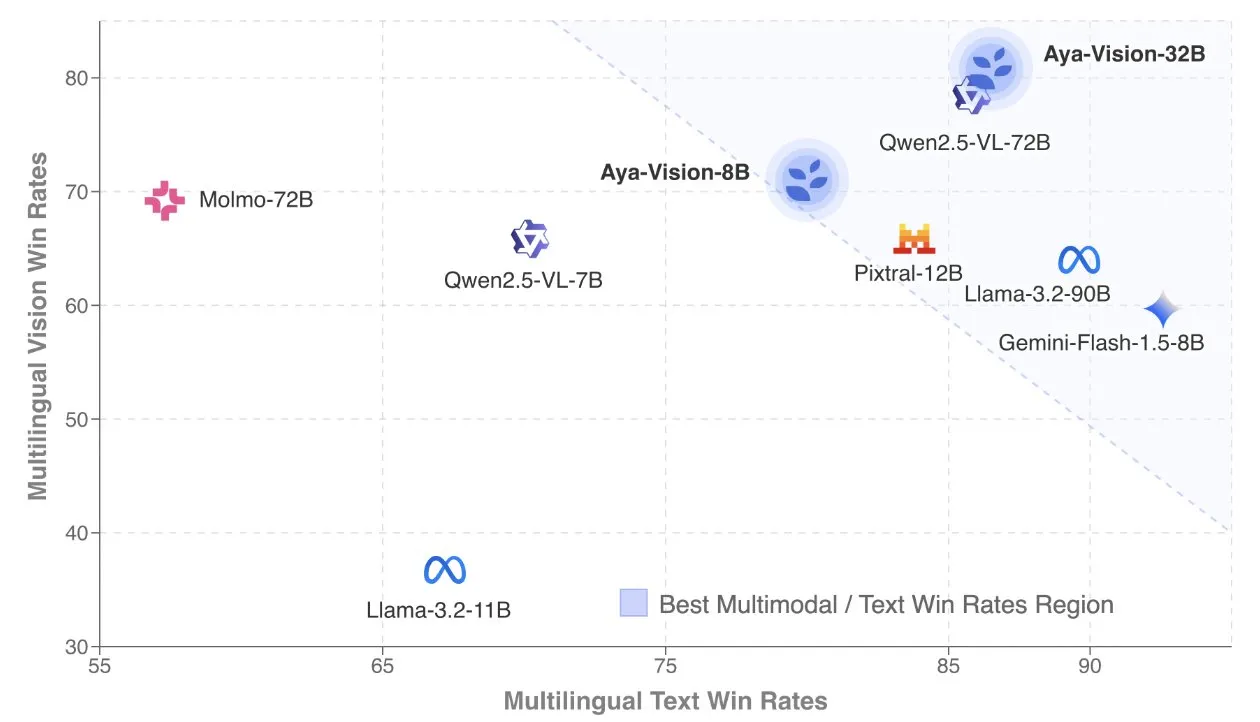
Cohere publica relatório técnico Aya Vision, focado em modelos multimodais multilíngues: O Cohere Labs divulgou o relatório técnico Aya Vision, detalhando sua fórmula para construir modelos multimodais multilíngues SOTA. Os modelos Aya Vision visam unificar as capacidades em tarefas multimodais e de texto em 23 idiomas. O relatório explora frameworks de dados multilíngues sintéticos, design de arquitetura, métodos de treinamento, fusão de modelos transmodais e avaliação abrangente em tarefas de geração multilíngue de formato aberto. Seu modelo de 8B supera em desempenho modelos maiores como o Pixtral-12B, enquanto o modelo de 32B é mais eficiente, superando modelos com mais do dobro do tamanho, como o Llama3.2-90B. (Fonte: sarahookr, Cohere Labs)
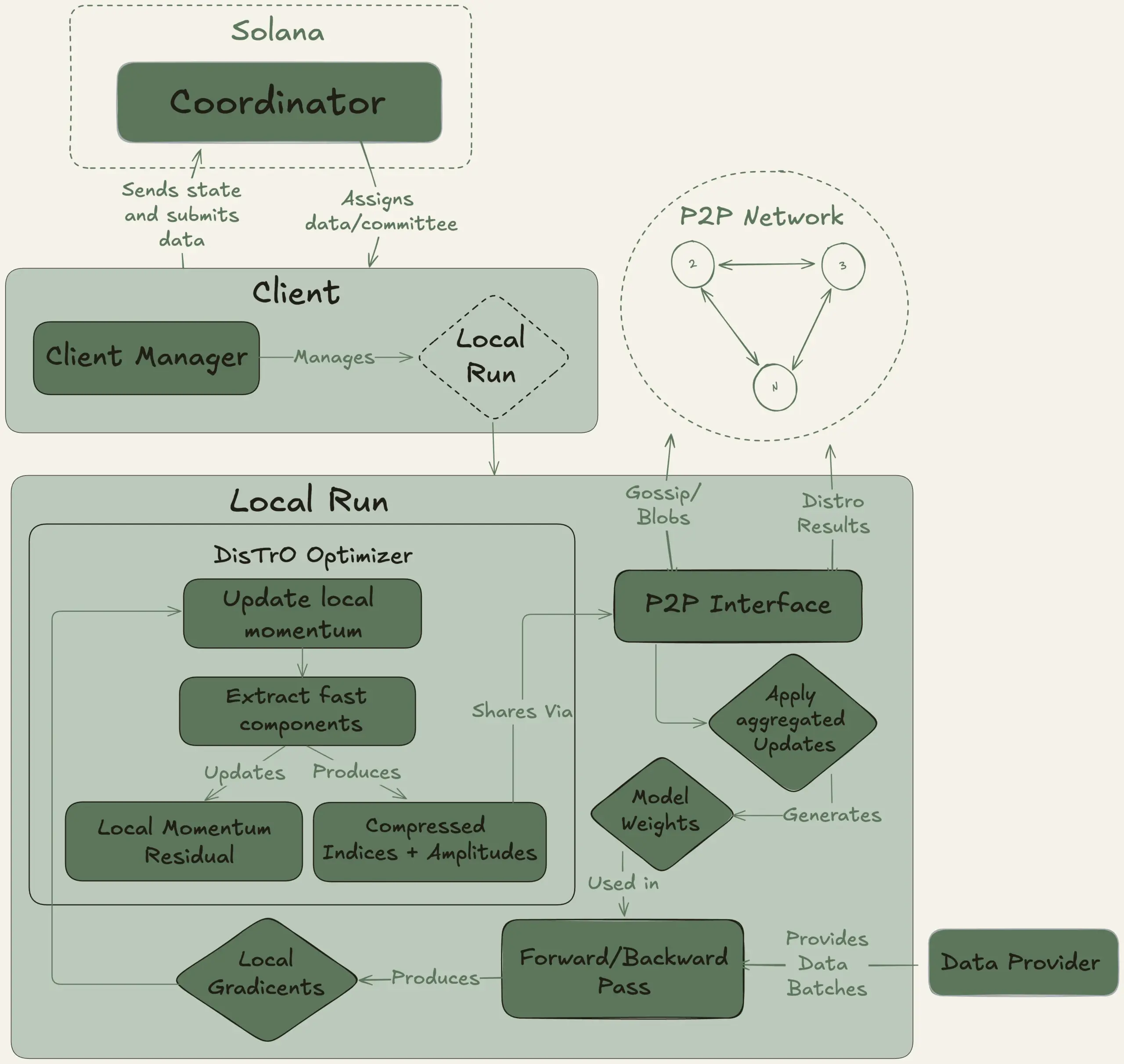
Nous Research lança projeto Psyche, visando treinar LLM de 40B parâmetros de forma descentralizada: A Nous Research anunciou o lançamento da rede Psyche, uma rede de treinamento de IA descentralizada, com o objetivo de reunir poder computacional global para treinar modelos de IA poderosos, permitindo que indivíduos e pequenas comunidades participem do desenvolvimento de modelos em grande escala. Sua testnet já começou o pré-treinamento de um LLM de 40B parâmetros, utilizando a arquitetura MLA, com um conjunto de dados incluindo FineWeb (14T), parte do FineWeb-2 (4T) e The Stack v2 (1T), totalizando aproximadamente 20T tokens. Após a conclusão do treinamento deste modelo, todos os checkpoints (incluindo versões não recozidas e recozidas) e o conjunto de dados serão de código aberto. (Fonte: eliebakouch, Teknium1)
Stability AI lança modelo Stable Audio Open Small de código aberto, focado na geração rápida de texto para áudio: A Stability AI lançou o modelo Stable Audio Open Small no Hugging Face, um modelo projetado especificamente para a geração rápida de texto para áudio e que utiliza tecnologia de pós-treinamento adversária. O modelo visa fornecer uma solução de geração de áudio eficiente e de código aberto. (Fonte: _akhaliq)
Google Gemini Advanced integra-se com GitHub, fortalecendo capacidades de assistência à codificação: O Google anunciou que o Gemini Advanced agora está conectado ao GitHub, aprimorando ainda mais suas capacidades como assistente de codificação. Os usuários podem conectar diretamente repositórios públicos ou privados do GitHub, utilizando o Gemini para gerar ou modificar funções, explicar código complexo, fazer perguntas sobre a base de código, realizar depuração, entre outras operações. Para começar a usar, clique no botão “+” na barra de prompt e selecione “Importar código”, colando a URL do GitHub. (Fonte: algo_diver)
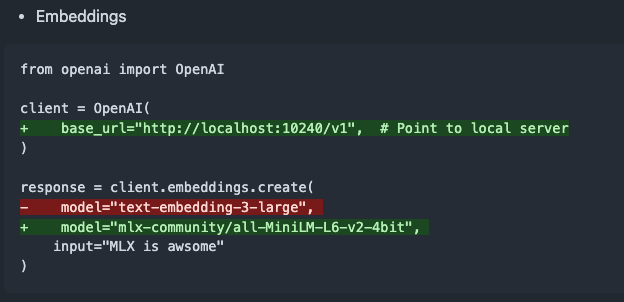
mlx-omni-server v0.4.0 lançado, adiciona serviço de embeddings e mais modelos TTS: O mlx-omni-server foi atualizado para a versão v0.4.0, introduzindo um novo serviço /v1/embeddings que simplifica a geração de embeddings através do mlx-embeddings. Ao mesmo tempo, integrou mais modelos TTS (como kokoro, bark) e atualizou o mlx-lm para suportar novos modelos como o qwen3. (Fonte: awnihannun)
Together Chat adiciona funcionalidade de processamento de arquivos PDF: O Together Chat anunciou suporte para upload e processamento de arquivos PDF. A versão atual analisa principalmente o conteúdo textual de PDFs e o passa para o modelo para processamento. Planos futuros incluem o lançamento de uma versão v2 com funcionalidade OCR para ler o conteúdo de imagens em PDFs. (Fonte: togethercompute)
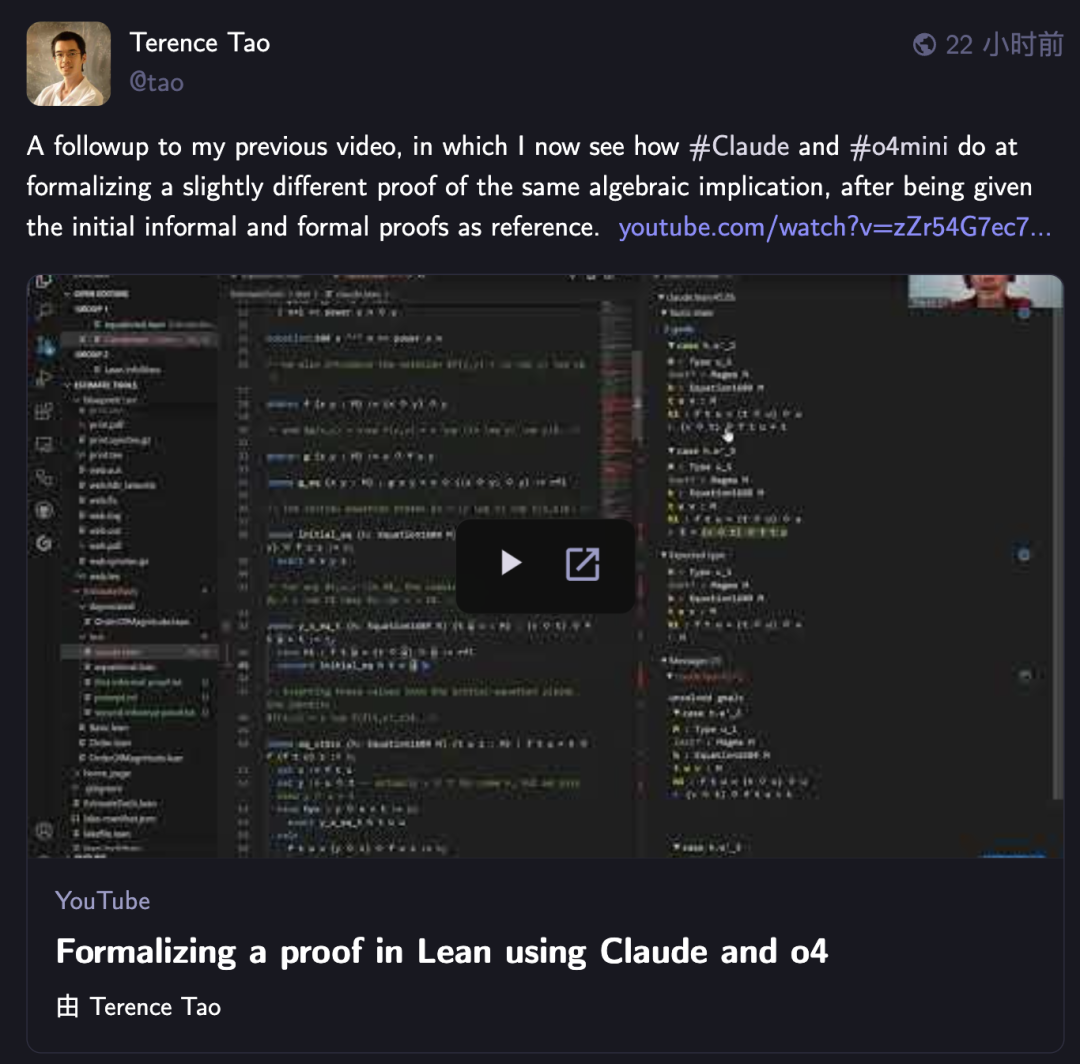
Terence Tao desafia novamente a IA com provas formais matemáticas, Claude supera o4-mini: O matemático Terence Tao, em sua série de vídeos no YouTube, testou a capacidade da IA em formalizar provas de implicação algébrica no assistente de provas Lean. No experimento, o Claude conseguiu completar a tarefa em cerca de 20 minutos, embora durante o processo de compilação tenha revelado um desvio na compreensão da regra de que os números naturais em Lean começam em 0 e problemas no tratamento da simetria, que foram corrigidos com intervenção humana. Em comparação, o o4-mini mostrou-se mais cauteloso, conseguindo identificar problemas na definição da função de potência, mas optou por desistir nos passos cruciais da prova, não completando a tarefa. Tao concluiu que a dependência excessiva da automação pode enfraquecer a compreensão da estrutura geral da prova, e o nível ótimo de automação deve estar entre 0% e 100%, preservando a intervenção humana para aprofundar a compreensão. (Fonte: 36氪)
Entrevista com Altman: O objetivo final da OpenAI é criar um serviço de assinatura de IA central: Sam Altman, CEO da OpenAI, afirmou no evento AI Ascent 2025 da Sequoia Capital que o “ideal platônico” da OpenAI é desenvolver um sistema operacional de IA, tornando-se o serviço central de assinatura de IA para os usuários. Ele imagina que os futuros modelos de IA serão capazes de processar os dados de uma vida inteira de um usuário (trilhões de tokens de contexto), alcançando um raciocínio profundamente personalizado. Altman admitiu que isso ainda está na “fase de PPT”, mas enfatizou que a empresa se orgulha de sua flexibilidade e adaptabilidade. Ele também falou sobre o potencial da interação por voz com IA, que 2025 será o ano em que os agentes de IA brilharão, e acredita que a codificação será o núcleo para impulsionar o funcionamento dos modelos e as chamadas de API. (Fonte: 36氪, 量子位)

Karminski3 compartilha versão modificada pela comunidade do Qwen3-30B, dobrando o número de experts ativos: A comunidade de desenvolvedores modificou o modelo Qwen3, lançando a versão Qwen3-30B-A6B-16-Extreme. Ao modificar os parâmetros do modelo, o número de experts ativos foi aumentado de A3B para A6B, o que supostamente traz uma ligeira melhoria na qualidade, mas a velocidade de geração se torna correspondentemente mais lenta. Os usuários também podem obter um efeito semelhante modificando os parâmetros de execução do llama.cpp com --override-kv http://qwen3moe.expert_used_count=int:24, ou fazer a operação inversa para reduzir a quantidade de ativação do Qwen3-235B-A22B para aumentar a velocidade. (Fonte: karminski3)

🧰 Ferramentas
OpenMemory MCP lançado: sistema de memória compartilhada de execução local, integrando múltiplas ferramentas de IA: A equipe mem0ai lançou o OpenMemory MCP, um servidor de memória privado construído com base no Model Context Protocol (MCP). Ele suporta execução 100% local e visa resolver o problema atual de ferramentas de IA (como Cursor, Claude Desktop, Windsurf, Cline) não compartilharem informações de contexto e perderem a memória ao final da sessão. Os dados do usuário são armazenados localmente, garantindo a privacidade. O OpenMemory MCP fornece uma API padronizada para operações de memória (CRUD) e possui um painel centralizado para os usuários gerenciarem a memória e as permissões de acesso do cliente, simplificando a implantação via Docker. (Fonte: 36氪, AI进修生)

LangChain lança versão oficial da plataforma LangGraph e múltiplas atualizações, fortalecendo o desenvolvimento e a observabilidade de agentes de IA: Na conferência Interrupt, a LangChain anunciou a disponibilidade geral (GA) de sua plataforma LangGraph, projetada especificamente para construir e gerenciar fluxos de trabalho de agentes de IA de longa duração e com estado, suportando implantação com um clique, escalabilidade horizontal e APIs para memória, interação humano-no-loop (HIL), histórico de conversas, etc. Ao mesmo tempo, foi lançado o LangGraph Studio V2, um IDE para agentes, que suporta execução local, edição direta de configurações, integração com Playground e pode buscar dados de rastreamento do ambiente de produção para depuração local. Além disso, a LangChain lançou a plataforma de construção de agentes sem código de código aberto Open Agent Platform (OAP) e aprimorou a observabilidade de agentes no LangSmith em termos de chamada de ferramentas e trajetórias. (Fonte: LangChainAI, hwchase17)
PatronusAI lança Percival: um agente de IA capaz de avaliar e corrigir outros agentes de IA: A PatronusAI lançou o Percival, anunciado como o primeiro agente de IA capaz de avaliar e corrigir automaticamente erros de outros agentes de IA. O Percival não apenas detecta falhas nos registros de rastreamento de agentes, mas também propõe sugestões de correção. Alega-se que, no conjunto de dados TRAIL, que contém erros anotados por humanos do GAIA e SWE-Bench, o desempenho do Percival é 2,9 vezes superior ao dos LLMs SOTA. Suas funcionalidades incluem a sugestão automática de soluções de correção para prompts de agentes, a captura de mais de 20 tipos de falhas de agentes (cobrindo uso de ferramentas, coordenação de planejamento, erros específicos de domínio, etc.) e a redução do tempo de depuração manual de horas para menos de 1 minuto. (Fonte: rebeccatqian, basetenco)
PyWxDump: Ferramenta de obtenção e exportação de informações do WeChat, com suporte para treinamento de IA: PyWxDump é uma ferramenta Python para obter informações da conta WeChat (apelido, conta, celular, e-mail, chave do banco de dados), descriptografar o banco de dados, visualizar o histórico de bate-papo localmente e exportar o histórico de bate-papo para formatos como CSV, HTML, etc., que podem ser usados para treinamento de IA, respostas automáticas e outros cenários. A ferramenta suporta a obtenção de informações de várias contas e todas as versões do WeChat, e fornece uma interface de usuário baseada na web para visualizar o histórico de bate-papo. (Fonte: GitHub Trending)

Airweave: Ferramenta que permite a agentes de IA pesquisar em qualquer aplicativo, compatível com o protocolo MCP: Airweave é uma ferramenta projetada para permitir que agentes de IA pesquisem semanticamente o conteúdo de qualquer aplicativo. É compatível com o Model Context Protocol (MCP) e pode conectar-se perfeitamente a vários aplicativos, bancos de dados ou APIs, transformando seu conteúdo em conhecimento utilizável por agentes. Suas principais funcionalidades incluem sincronização de dados, extração e transformação de entidades, arquitetura multilocatário, atualizações incrementais, pesquisa semântica e controle de versão. (Fonte: GitHub Trending)

iFlytek lança nova geração de fones de ouvido AI iFLYBUDS Pro3 e Air2 com cérebro viaim AI: A Future Intelligence lançou os fones de ouvido para conferência AI iFLYBUDS Pro3 e iFLYBUDS Air2 da iFlytek, ambos equipados com o novo cérebro viaim AI. O viaim é um agente de IA para escritório pessoal e negócios, integrando quatro módulos principais: processamento inteligente de percepção ponta a ponta, raciocínio colaborativo de agente inteligente, capacidade multimodal em tempo real e proteção de privacidade e segurança de dados. Os fones de ouvido suportam gravação conveniente (chamadas, gravações no local, áudio e vídeo), assistente de IA (geração automática de títulos e resumos, perguntas direcionadas), tradução multilíngue (32 idiomas, tradução simultânea, tradução face a face, tradução de chamadas), etc., além de melhorias na qualidade do som e conforto de uso. (Fonte: WeChat)

KoboldCpp Smart Launcher lançado: ferramenta de otimização automática de Tensor Offload para desempenho de LLM: Foi lançada uma ferramenta GUI e CLI chamada KoboldCpp Smart Launcher, projetada para ajudar os usuários a encontrar automaticamente a melhor estratégia de Tensor Offload do KoboldCpp ao executar LLMs localmente. Ao alocar tensores entre CPU e GPU de forma mais granular (em vez de camadas inteiras), a ferramenta alega poder mais do que dobrar a velocidade de geração sem aumentar a demanda de VRAM. Por exemplo, o QwQ Merge em uma GPU de 12GB VRAM teve sua velocidade aumentada de 3.95 t/s para 10.61 t/s. (Fonte: Reddit r/LocalLLaMA)
OpenBMB lança AgentCPM-GUI de código aberto: o primeiro agente GUI no dispositivo otimizado para chinês: A equipe OpenBMB lançou o AgentCPM-GUI de código aberto, o primeiro agente GUI (Interface Gráfica do Usuário) no dispositivo otimizado especificamente para aplicações em chinês. Este agente aprimorou suas capacidades de raciocínio através de ajuste fino reforçado (RFT), adotou um design compacto de espaço de ação e possui capacidades de localização (grounding) GUI de alta qualidade, visando melhorar a experiência do usuário ao operar vários aplicativos no ambiente chinês. (Fonte: Reddit r/LocalLLaMA)
MAESTRO: Aplicativo de pesquisa de IA local-first, suporta colaboração multiagente e LLMs personalizados: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) é um aplicativo de pesquisa recém-lançado impulsionado por IA, que enfatiza o controle e a capacidade locais. Ele fornece um framework modular, incluindo extração de documentos, fluxos RAG poderosos e sistemas multiagentes (planejamento, pesquisa, reflexão, escrita), capaz de lidar com problemas de pesquisa complexos. Os usuários podem interagir através de uma Web UI Streamlit ou CLI, usando seus próprios conjuntos de documentos e LLMs locais ou de API de sua escolha. (Fonte: Reddit r/LocalLLaMA)
Contextual AI lança analisador de documentos otimizado para RAG: A Contextual AI lançou um novo analisador de documentos, projetado especificamente para sistemas de geração aumentada por recuperação (RAG). A ferramenta visa fornecer análise de alta precisão de documentos não estruturados complexos, combinando modelos visuais, OCR e de linguagem visual, capaz de preservar a estrutura hierárquica do documento, lidar com modalidades complexas como tabelas, gráficos e diagramas, e fornecer caixas delimitadoras e pontuações de confiança para auditoria do usuário, reduzindo assim a falta de contexto e alucinações em sistemas RAG causadas por falhas de análise. (Fonte: douwekiela)
Gradio adiciona funcionalidade de desfazer/refazer ao ImageEditor: O componente ImageEditor do Gradio agora possui botões de desfazer (undo) e refazer (redo), fornecendo aos usuários funcionalidades de edição de imagem em Python semelhantes às de aplicativos pagos profissionais, melhorando a interatividade e a facilidade de uso. (Fonte: _akhaliq)
RunwayML lança nova funcionalidade References, suportando testes zero-shot de materiais, roupas, locais e poses: A funcionalidade References do RunwayML foi atualizada, permitindo que os usuários usem imagens de pré-visualização de esferas de material 3D tradicionais como entrada para aplicar seus materiais a qualquer objeto, realizando migração e visualização de material zero-shot. Além disso, a nova funcionalidade também suporta testes zero-shot para roupas, locais e poses de personagens, expandindo as possibilidades de geração criativa e prototipagem rápida. (Fonte: c_valenzuelab, c_valenzuelab)

Mita AI lança funcionalidade “Aprenda Algo Hoje”, aprendizado estruturado assistido por IA: A Mita AI lançou a nova funcionalidade “Aprenda Algo Hoje”, que visa transformar a IA de um papel de assistente para recuperação de informações e processamento de documentos em um “professor de IA” capaz de guiar e ensinar ativamente. Depois que os usuários carregam ou pesquisam materiais, essa funcionalidade pode gerar automaticamente cursos em vídeo sistemáticos e estruturados e apresentações em PPT, ajudando os usuários a organizar pontos de conhecimento, e suporta a seleção de diferentes profundidades de explicação (iniciante/especialista) e estilos (contação de histórias/velho rabugento, etc.) de acordo com o nível do usuário. Além disso, também suporta perguntas durante o curso e testes pós-aula. (Fonte: WeChat)

📚 Aprendizado
Andrew Ng e Anthropic colaboram em novo curso: Construindo aplicativos de IA ricos em contexto com MCP: O DeepLearning.AI de Andrew Ng e a Anthropic colaboraram para lançar um novo curso “MCP: Build Rich-Context AI Apps with Anthropic”, ministrado por Elie Schoppik, Diretor de Educação Técnica da Anthropic. O curso foca no Model Context Protocol (MCP), um protocolo aberto projetado para padronizar o acesso de LLMs a ferramentas externas, dados e prompts. Os alunos aprenderão a arquitetura central do MCP, criarão chatbots compatíveis com MCP, construirão e implantarão servidores MCP e os conectarão a aplicativos impulsionados pelo Claude e outros servidores de terceiros, para simplificar o desenvolvimento de aplicativos de IA ricos em contexto. (Fonte: AndrewYNg, DeepLearningAI)
FlashInfer: Melhor artigo do MLSys 2025, motor de atenção eficiente e personalizável para inferência de LLM: O projeto FlashInfer, uma colaboração entre Zihao Ye da Universidade de Washington, NVIDIA, Tianqi Chen da OctoAI e outros, recebeu o prêmio de melhor artigo no MLSys 2025. FlashInfer é um motor de atenção eficiente e personalizável otimizado para serviços de inferência de LLM. Através da otimização do acesso à memória (usando formato esparso em blocos e formato componível para processar o cache KV), fornecendo modelos flexíveis de cálculo de atenção baseados em compilação JIT e introduzindo um mecanismo de agendamento de tarefas com balanceamento de carga, ele melhora significativamente o desempenho da inferência de LLM e já foi integrado a projetos como vLLM e SGLang. (Fonte: 机器之心)
Artigo do ICML 2025: Fornecendo análise teórica para Graph Prompting da perspectiva da manipulação de dados: Qunzhong Wang, Dr. Xiangguo Sun e Professor Hong Cheng da Universidade Chinesa de Hong Kong publicaram um artigo no ICML 2025, fornecendo pela primeira vez um framework teórico sistemático para a eficácia do graph prompting da perspectiva da “manipulação de dados”. A pesquisa introduz o conceito de “grafo de ponte”, provando que o mecanismo de graph prompting é teoricamente equivalente a realizar alguma operação nos dados do grafo de entrada, permitindo que sejam processados corretamente por modelos pré-treinados para se adaptarem a novas tarefas. O artigo deriva limites superiores de erro, analisa as fontes e controlabilidade do erro e modela a distribuição do erro, fornecendo uma base teórica para o design e aplicação do graph prompting. (Fonte: WeChat)
Artigo do ICML 2025: Sintetizando dados textuais por meio de edição em nível de token para evitar o colapso do modelo: Uma equipe de pesquisa da Universidade Jiao Tong de Xangai e outras instituições publicou um artigo no ICML 2025, discutindo o problema do “colapso do modelo” causado por dados sintéticos e propondo uma estratégia de geração de dados chamada “Token-Level Editing”. Este método, em vez de gerar texto completamente novo, realiza microedições e substituições em tokens nos quais o modelo está “excessivamente confiante” em dados reais, visando construir dados semi-sintéticos com estrutura mais estável e maior capacidade de generalização. A análise teórica mostra que este método pode restringir efetivamente o erro de teste, evitando que o desempenho do modelo colapse com o aumento das rodadas de iteração. Experimentos nas fases de pré-treinamento, pré-treinamento contínuo e ajuste fino supervisionado validaram a eficácia deste método. (Fonte: WeChat)

Artigo do ICML 2025: OmniAudio, gerando áudio espacial 3D a partir de vídeos panorâmicos de 360°: A equipe OmniAudio apresentou no ICML 2025 uma tecnologia para gerar diretamente áudio espacial de primeira ordem ambisônica (FOA) a partir de vídeos panorâmicos de 360°. Para resolver o problema da escassez de dados, a equipe construiu o conjunto de dados 360V2SA em grande escala Sphere360 (mais de 100.000 clipes, 288 horas). O OmniAudio adota um treinamento em duas fases: pré-treinamento auto-supervisionado de correspondência de fluxo coarse-to-fine, primeiro treinando com áudio estéreo comum convertido para pseudo-FOA, depois ajustando finamente com FOA real; em seguida, combinando com um codificador de vídeo de dois ramos para ajuste fino supervisionado, extraindo características de perspectiva global e local para gerar áudio espacial de alta fidelidade e direcionalmente preciso. (Fonte: 量子位)

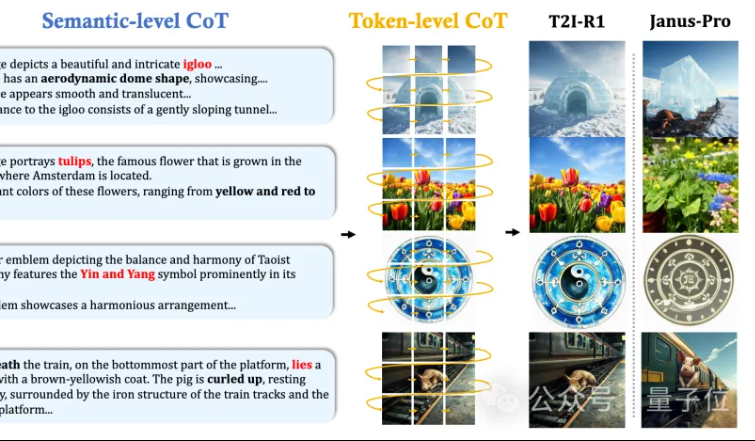
MMLab da CUHK propõe T2I-R1: introduzindo raciocínio CoT de dois níveis e aprendizado por reforço para geração de texto para imagem: A equipe MMLab da Universidade Chinesa de Hong Kong lançou o T2I-R1, o primeiro modelo de geração de texto para imagem aprimorado por raciocínio baseado em aprendizado por reforço. Este modelo propõe inovadoramente um framework de raciocínio de cadeia de pensamento (CoT) de dois níveis: Semantic-CoT (raciocínio textual, planejando a estrutura global da imagem) e Token-CoT (geração de tokens de imagem bloco a bloco, focando em detalhes de baixo nível). Através do método de aprendizado por reforço BiCoT-GRPO, esses dois níveis de CoT são otimizados cooperativamente em um LMM unificado (Janus-Pro), sem a necessidade de modelos adicionais. O modelo de recompensa utiliza uma integração de múltiplos modelos especialistas visuais, garantindo a confiabilidade da avaliação e prevenindo o overfitting. Experimentos mostram que o T2I-R1 consegue entender melhor a intenção do usuário, gerar imagens mais alinhadas com as expectativas e supera significativamente os modelos de linha de base nos benchmarks T2I-CompBench e WISE. (Fonte: 量子位, WeChat)
OpenAI lança biblioteca leve de avaliação de modelos de linguagem simple-evals: A OpenAI tornou de código aberto o simple-evals, uma biblioteca leve para avaliar modelos de linguagem, visando tornar transparentes os dados de precisão dos lançamentos de seus modelos mais recentes. A biblioteca enfatiza configurações de avaliação zero-shot e chain-of-thought, e fornece uma comparação detalhada do desempenho de modelos em vários benchmarks como MMLU, MATH, GPQA, incluindo modelos da própria OpenAI (como o3, o4-mini, GPT-4.1, GPT-4o) e outros modelos importantes (como Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5). (Fonte: GitHub Trending)
Versão em coreano do LLM Engineer’s Handbook lançada: O “LLM Engineer’s Handbook” de Maxime Labonne já está disponível em coreano, traduzido por Woocheol Cho. Mais versões do manual em outros idiomas, como russo, chinês e polonês, também serão lançadas em breve, fornecendo recursos de aprendizado para desenvolvedores de LLM em todo o mundo. (Fonte: maximelabonne)

Workshop de Aprendizado de Máquina para Áudio ML4Audio do ICML 2025 anunciado: O popular workshop de Aprendizado de Máquina para Áudio (ML for Audio) retornará durante o ICML 2025 em Vancouver, especificamente no dia 19 de julho (sábado). O workshop contará com palestras de acadêmicos renomados como Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti e Pratyusha Rakshit. O prazo para submissão de artigos é 23 de maio. (Fonte: sedielem)
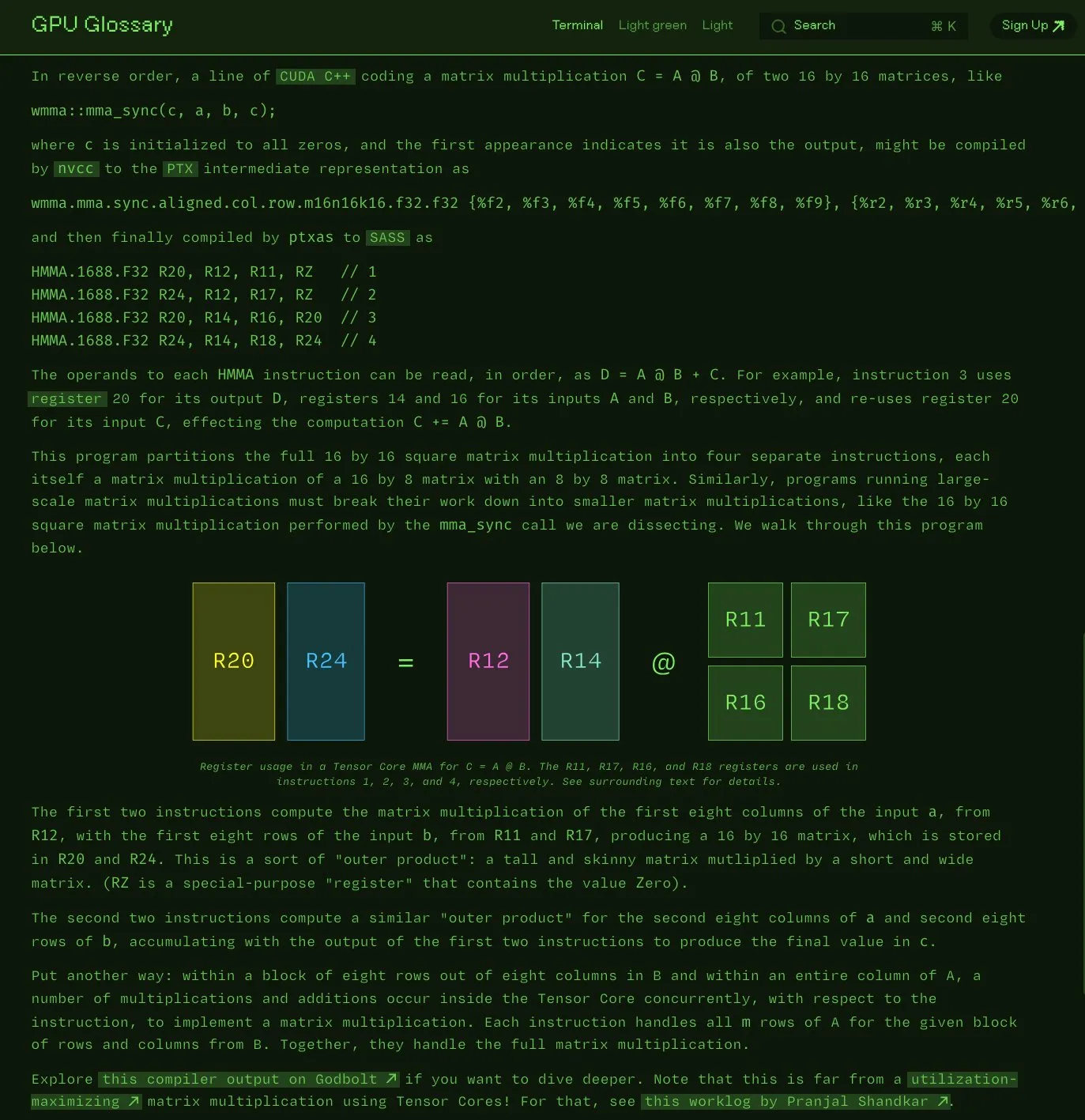
Charles Frye torna público glossário de termos de GPU: Charles Frye anunciou que seu glossário de termos de GPU (GPU Glossary) agora é de código aberto. O glossário visa ajudar na compreensão de conceitos relacionados a hardware e programação de GPU, e foi recentemente atualizado com a decomposição de instruções SASS sobre a execução de operações simples de multiplicação e adição de matrizes (mma) pelos Tensor Cores. O projeto está hospedado no GitHub e lista algumas tarefas pendentes. (Fonte: charles_irl)
OpenAI lança guia de engenharia de prompt para GPT-4.1, enfatizando instruções estruturadas e claras: A OpenAI lançou um guia de engenharia de prompt para o GPT-4.1, visando ajudar os usuários a construir prompts de forma mais eficaz, especialmente para aplicações que exigem saída estruturada, raciocínio, uso de ferramentas e baseadas em agentes. O guia enfatiza a importância de definir claramente papéis e objetivos, fornecer instruções claras (incluindo tom, formato, limites), sub-instruções opcionais, raciocínio/planejamento passo a passo, definição precisa do formato de saída e uso de exemplos, além de oferecer algumas dicas práticas como destacar instruções chave e usar Markdown ou XML para estruturar a entrada. (Fonte: Reddit r/MachineLearning)

Kaggle e Hugging Face aprofundam colaboração, simplificando chamada e descoberta de modelos: O Kaggle anunciou o fortalecimento da colaboração com o Hugging Face. Os usuários agora podem iniciar modelos do Hugging Face diretamente nos Kaggle Notebooks, descobrir exemplos de código público relacionados e explorar de forma transparente entre as duas plataformas. Essa integração visa ampliar a acessibilidade dos modelos, permitindo que os usuários do Kaggle utilizem mais convenientemente os recursos de modelos do ecossistema Hugging Face. (Fonte: huggingface)
FedRAG: Framework de código aberto para ajuste fino de sistemas RAG, com suporte para aprendizado federado: Pesquisadores do Vector Institute lançaram o FedRAG, um framework de código aberto projetado para simplificar o ajuste fino de sistemas de geração aumentada por recuperação (RAG). O framework não apenas suporta o treinamento centralizado típico, mas também introduz especialmente uma arquitetura de aprendizado federado para atender à necessidade de treinamento em conjuntos de dados distribuídos. O FedRAG é compatível com os ecossistemas PyTorch e Hugging Face, suporta o uso do Qdrant como armazenamento de base de conhecimento e pode ser conectado ao LlamaIndex. (Fonte: nerdai)

💼 Negócios
Empresa-mãe do Cursor, Anysphere, atinge ARR de US$ 200 milhões em dois anos, com avaliação disparando para US$ 9 bilhões: Michael Truell, um desistente do MIT de apenas 25 anos, lidera a Anysphere, empresa que, com seu editor de código AI Cursor, alcançou uma receita anual recorrente (ARR) de US$ 200 milhões em dois anos, sem realizar marketing, e viu sua avaliação disparar para US$ 9 bilhões. O Cursor, ao integrar profundamente a IA no fluxo de desenvolvimento, remodelou o paradigma de desenvolvimento de software, focando em servir desenvolvedores individuais e obtendo amplo reconhecimento e divulgação boca a boca de desenvolvedores globais. A Thrive Capital liderou sua mais recente rodada de financiamento. (Fonte: 36氪)

Databricks anuncia aquisição da empresa de Serverless Postgres Neon: A Databricks concordou em adquirir a Neon, uma empresa de Serverless Postgres focada em desenvolvedores. A Neon é conhecida por sua arquitetura de banco de dados inovadora, oferecendo velocidade, escalabilidade elástica e funcionalidades de branching e forking, características atraentes tanto para desenvolvedores quanto para agentes de IA. Esta aquisição visa construir conjuntamente uma base de dados aberta e Serverless para desenvolvedores e agentes de IA. (Fonte: jefrankle, matei_zaharia)
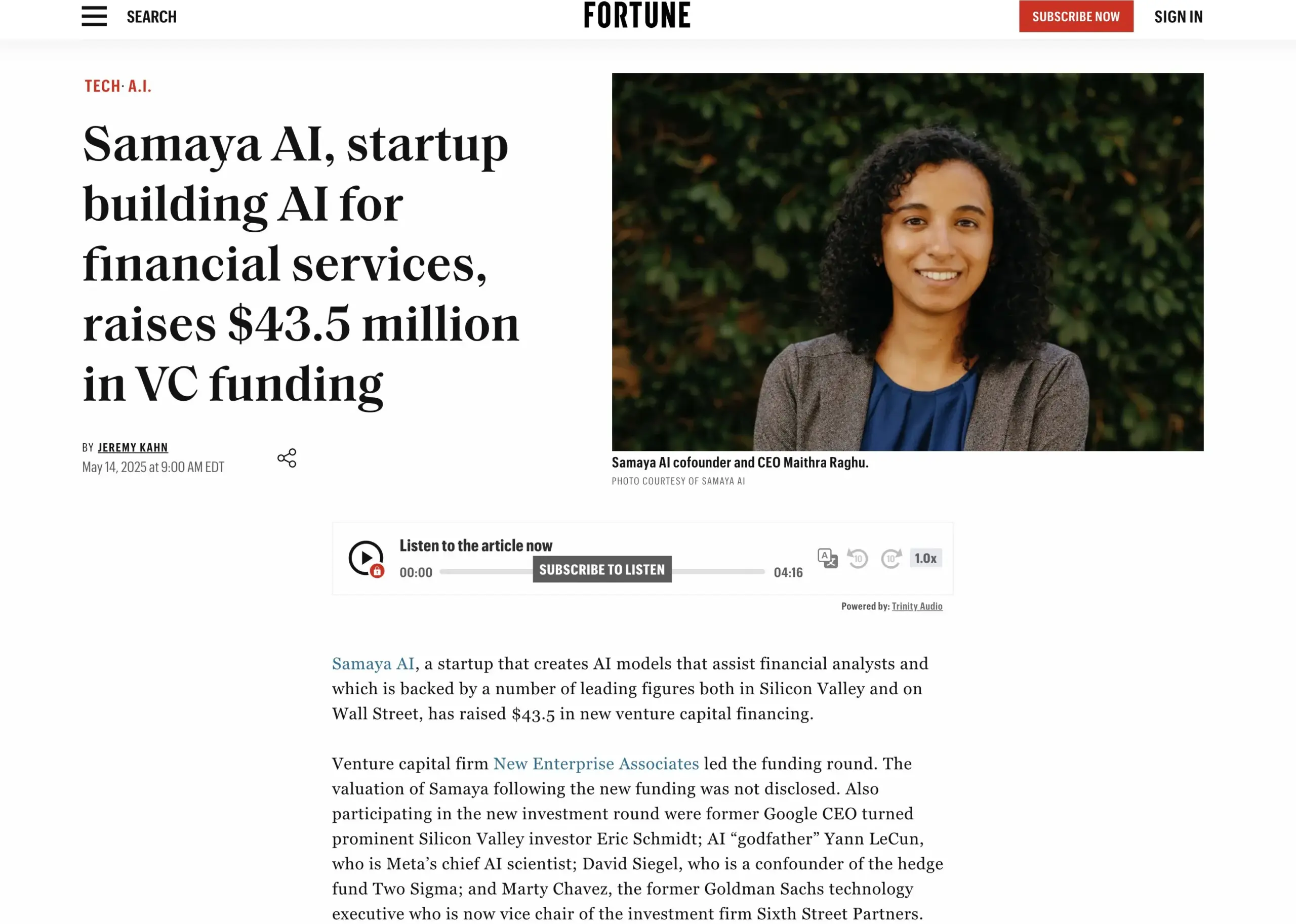
Startup de serviços financeiros de IA Samaya AI levanta US$ 43,5 milhões em financiamento: A Samaya AI anunciou um financiamento de US$ 43,5 milhões liderado pela NEA, para construir agentes de IA especialistas para serviços financeiros, visando transformar o trabalho de conhecimento em escala. A empresa, fundada em 2022, foca na criação de soluções de IA dedicadas para fluxos de trabalho financeiros complexos. Seus agentes de IA especialistas, baseados em LLMs próprios, já estão em uso por milhares de usuários em instituições de ponta como o Morgan Stanley, aplicados em due diligence, modelagem econômica e suporte à decisão, enfatizando precisão, transparência e ausência de alucinações. (Fonte: maithra_raghu)
🌟 Comunidade
A IA substituirá os engenheiros de software? Comunidade debate a necessidade de atualização de habilidades: Nas redes sociais, ressurge a discussão sobre se a IA substituirá os engenheiros de software. A opinião predominante é que a IA não substituirá completamente os engenheiros de software, pois o desenvolvimento de software vai muito além da simples codificação. No entanto, para aqueles que se dedicam principalmente a trabalhos de codificação repetitivos e carecem de uma compreensão holística do sistema, os chamados “code monkeys”, existe um alto risco de serem substituídos por ferramentas assistidas por IA se não aprimorarem suas habilidades, aprofundarem sua compreensão da arquitetura de sistemas e da resolução de problemas complexos. (Fonte: cto_junior, cto_junior)
O futuro dos Agentes de IA: Oportunidades e desafios coexistem, líderes da indústria otimistas quanto ao seu potencial: O CEO da OpenAI, Sam Altman, prevê que 2025 será o ano em que os Agentes de IA se destacarão, participando mais ativamente do trabalho prático. Liu Zhiyi, em sua entrevista, também enfatizou que os Agentes estão evoluindo de ferramentas passivas para sistemas de execução ativa, e seu desenvolvimento depende do progresso dos modelos básicos e da capacidade de interação com o mundo físico. Embora os Agentes ainda apresentem deficiências em termos de velocidade de resposta, controle de alucinações, etc., sua capacidade de executar tarefas autonomamente e auxiliar no aprendizado de modelos grandes é amplamente promissora, já começando a ser aplicada em áreas como atendimento ao cliente inteligente e consultoria de investimentos financeiros. (Fonte: 36氪, 量子位)

Perplexity AI e PayPal, Venmo fecham parceria para integrar pagamentos em e-commerce e viagens: A Perplexity AI anunciou uma parceria com o PayPal e o Venmo para integrar funcionalidades de pagamento em suas plataformas de compras de e-commerce, reservas de viagens, bem como em seu assistente de voz e no futuro navegador Comet. A medida visa simplificar todo o processo comercial, desde a navegação, pesquisa e seleção até o pagamento seguro, melhorando a experiência do usuário. (Fonte: AravSrinivas, perplexity_ai)
Discussão sobre avaliação de modelos de IA: IFEval e ChartQA em foco, necessidade de cautela com contaminação de dados de treinamento: Em discussões da comunidade, o IFEval é considerado um dos excelentes benchmarks de avaliação de seguimento de instruções devido ao seu design simples e engenhoso. Ao mesmo tempo, alguns usuários apontaram que os dados de teste do ChartQA contêm ruído, respostas ambíguas e inconsistências, podendo precisar ser descartados. Vikhyatk alertou que muitos modelos que afirmam alcançar alta precisão em benchmarks podem ter problemas de contaminação de dados de treinamento não detectados. (Fonte: clefourrier, vikhyatk)

Direitos autorais e ética de conteúdo gerado por IA em destaque: Audible planeja usar narração por IA, personagens gerados por IA para namoro online geram preocupação: A Audible anunciou planos de usar narração gerada por IA para produzir audiolivros, com o objetivo de “trazer mais histórias à vida”, gerando discussões sobre a aplicação da IA nas indústrias criativas. Por outro lado, no Reddit, um usuário postou que sua mãe interagiu em um site de namoro com uma imagem de “homem real” suspeita de ser gerada por IA, temendo que ela estivesse sendo enganada. Isso destaca os riscos potenciais do conteúdo gerado por IA em termos de autenticidade, manipulação emocional e fraude. (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 Outros
Empresa chinesa “Star Computing” lança com sucesso os primeiros 12 satélites de computação espacial, inaugurando nova era de poder computacional baseado no espaço: O plano “Star Computing”, liderado pela Guoxing Aerospace, enviou com sucesso os primeiros 12 satélites de computação ao espaço, formando a primeira constelação de computação espacial do mundo. Cada satélite possui capacidade de computação espacial e interconexão, com a capacidade de computação de um único satélite aumentada de nível T para nível P. A constelação inicial em órbita atinge 5 POPS de poder computacional, e a velocidade de comunicação a laser entre satélites chega a 100 Gbps. A iniciativa visa construir uma infraestrutura de computação inteligente baseada no espaço, resolver problemas como o grande consumo de energia e a dificuldade de dissipação de calor do poder computacional terrestre, e apoiar o processamento em tempo real em órbita de dados de exploração do espaço profundo, realizando o “cálculo de dados celestes no céu”. Planos futuros incluem o lançamento de 2.800 satélites para formar uma grande rede de computação espacial. (Fonte: 量子位)

NVIDIA publica retrospectiva anual, enfatizando que a IA é o núcleo da nova revolução industrial e que a inteligência é o produto: Em sua retrospectiva anual, a NVIDIA destacou que o mundo está entrando em uma nova revolução industrial, cujo produto central é a “inteligência”. A NVIDIA se dedica a construir infraestrutura inteligente, transformando a computação em uma força geradora que impulsiona o desenvolvimento em todos os setores. (Fonte: nvidia)

NBA e Kling AI da Kuaishou colaboram para lançar curta de IA “A Enterrada de Infância de Curry”: A NBA colaborou com o Kling AI, um grande modelo de geração de vídeo a partir de texto semelhante ao Sora, da Kuaishou, para produzir um curta de IA chamado “Childhood Curry’s Dunk”, feito pela AI TALK. O filme tenta recriar a cena da enterrada “através do tempo” de Curry usando o Kling AI, para torcer pelos playoffs da NBA, e conta com participações especiais de Barkley, O’Neal e Jokic. (Fonte: TomLikesRobots)