
Palavras-chave:OpenAI, HealthBench, Meta AI, Dynamic Byte Latent Transformer, Microsoft Research, ARTIST Framework, Sakana AI, Continuous Thinking Machine, Avaliação de Desempenho de IA em Saúde, Modelo Transformer Latente de Byte Dinâmico com 8B Parâmetros, Reforço de Aprendizado para Melhorar Raciocínio de LLM, Arquitetura de Rede Neural CTM, Modelo Quantizado Oficial Qwen3, OpenAI, HealthBench, Meta AI, Dynamic Byte Latent Transformer, Microsoft Research, ARTIST Framework, Sakana AI, Continuous Thinking Machine, Avaliação de Desempenho de IA em Saúde, Modelo Transformer Latente de Byte Dinâmico com 8B Parâmetros, Reforço de Aprendizado para Melhorar Raciocínio de LLM, Arquitetura de Rede Neural CTM, Modelo Quantizado Oficial Qwen3
🔥 Foco
OpenAI lança HealthBench para avaliar desempenho de IA médica: A OpenAI apresentou o HealthBench, um novo benchmark projetado para medir o desempenho e a segurança de grandes modelos de linguagem (LLMs) em cenários médicos. O benchmark foi desenvolvido com a participação de mais de 250 médicos globais, contendo 5000 conversas médicas reais e 48.562 critérios de avaliação exclusivos escritos por médicos, cobrindo diversas situações como emergência e saúde global, e dimensões comportamentais como precisão e seguimento de instruções. Testes mostram que o modelo o3 atingiu 60% de precisão, enquanto o GPT-4.1 nano superou o GPT-4o com uma redução de custo de 25 vezes, demonstrando o enorme potencial da IA no setor médico e o rápido progresso na eficiência de custo e desempenho. (Fonte: OpenAI)
Meta lança modelo Dynamic Byte Latent Transformer com 8B parâmetros: A Meta AI anunciou a abertura do código dos pesos do seu modelo Dynamic Byte Latent Transformer de 8B parâmetros. Este modelo propõe uma nova solução alternativa aos métodos tradicionais de tokenização, visando redefinir os padrões de eficiência e confiabilidade dos modelos de linguagem. Através desta nova forma de tokenização, espera-se trazer avanços disruptivos para o campo dos modelos de linguagem, melhorando a eficiência e o efeito do processamento de texto pelos modelos. O artigo de pesquisa e o código já estão disponíveis para download. (Fonte: AIatMeta)
Microsoft Research apresenta framework ARTIST, combinando aprendizado por reforço para aprimorar raciocínio e uso de ferramentas em LLMs: A Microsoft Research introduziu o framework ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers). Este framework integra raciocínio autônomo, aprendizado por reforço e uso dinâmico de ferramentas, permitindo que grandes modelos de linguagem (LLMs) decidam autonomamente quando, como e quais ferramentas usar para raciocínio em múltiplos passos, e aprendam estratégias robustas sem supervisão em nível de passo. O ARTIST superou modelos de ponta como o GPT-4o em benchmarks desafiadores como matemática e chamadas de função, com melhorias de até 22%, estabelecendo novos padrões para resolução de problemas generalizáveis e interpretáveis. (Fonte: MarkTechPost)

Sakana AI lança Continuous Thought Machines (CTM): A Sakana AI apresentou uma nova arquitetura de rede neural chamada “Continuous Thought Machines” (CTM). A ideia central do CTM é usar o processo temporal dinâmico da atividade neural como componente central de sua computação, permitindo que o modelo opere ao longo de uma linha do tempo de “passos de pensamento” gerados internamente, construindo e refinando iterativamente suas representações, mesmo para dados estáticos. A arquitetura demonstrou sua computação adaptativa, interpretabilidade aprimorada e plausibilidade biológica em diversas tarefas, como classificação no ImageNet, navegação em labirintos 2D, ordenação, cálculo de paridade e aprendizado por reforço. (Fonte: Sakana AI)

🎯 Tendências
Equipe Qwen da Alibaba lança modelos quantizados oficiais do Qwen3: A equipe Qwen da Alibaba lançou oficialmente os modelos quantizados do Qwen3. Os usuários agora podem implantar o Qwen3 através de plataformas como Ollama, LM Studio, SGLang e vLLM, com suporte para vários formatos como GGUF, AWQ, GPTQ, facilitando a implantação local. Os modelos relevantes foram disponibilizados no Hugging Face e ModelScope. Este lançamento visa reduzir a barreira de uso de grandes modelos de alto desempenho, promovendo sua aplicação em cenários mais amplos. (Fonte: Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AI lança framework de raciocínio colaborativo Collaborative Reasoner: A Meta AI apresentou o Collaborative Reasoner, um framework projetado para melhorar as capacidades de raciocínio colaborativo dos modelos de linguagem. O framework visa desenvolver agentes socialmente inteligentes capazes de cooperar com humanos e outros agentes, abrindo caminho para interações humano-máquina mais complexas e sistemas multiagente, através da melhoria das capacidades de colaboração e raciocínio do modelo. O artigo de pesquisa e o código relacionados foram abertos para download, incentivando a exploração e aplicação pela comunidade. (Fonte: AIatMeta)
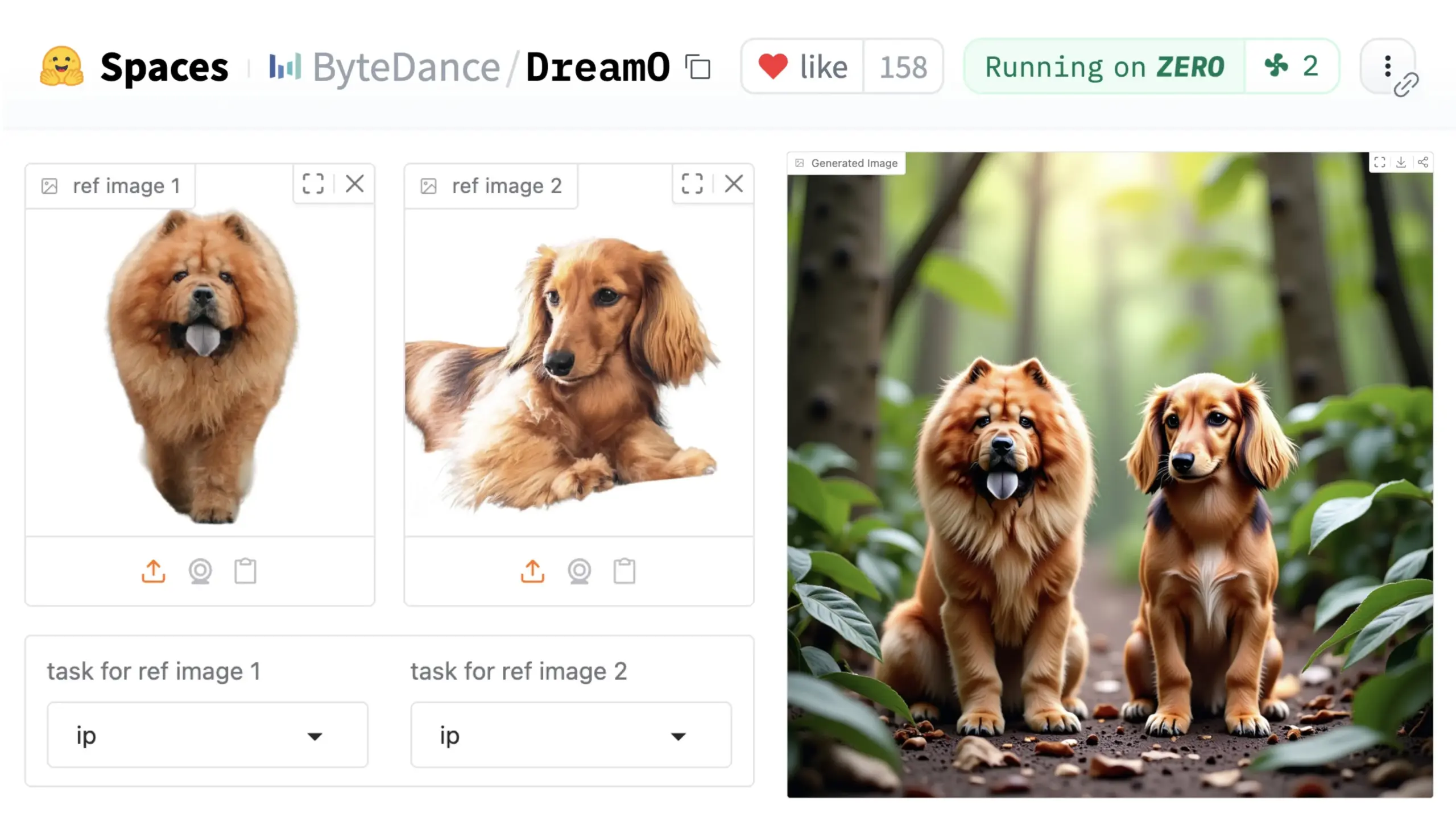
ByteDance lança framework universal de personalização de imagem DreamO: A ByteDance lançou um framework unificado de personalização de imagem chamado DreamO. Baseado no modelo pré-treinado DiT (Diffusion Transformer), o framework permite a personalização generalizada de vários elementos em imagens, como pessoas, estilos e fundos, incluindo funções como substituição de identidade, transferência de estilo, transformação de sujeito e prova virtual. Os usuários podem experimentar a Demo no Hugging Face. Este avanço demonstra o potencial de um único modelo em diversas tarefas de edição de imagem. (Fonte: _akhaliq & ClementDelangue & _akhaliq)
NVIDIA abre processo de gerenciamento de dados do modelo Nemotron, Nemotron-CC: A NVIDIA anunciou a abertura de seu processo de gerenciamento de dados usado para o modelo Nemotron, o Nemotron-CC, e a divulgação do máximo possível dos dados de treinamento e pós-treinamento do Nemotron. O processo Nemotron-CC agora foi adicionado ao repositório NeMo Curator no GitHub, capaz de processar dados de texto, imagem e vídeo em grande escala. A NVIDIA enfatiza a importância de conjuntos de dados de pré-treinamento de alta qualidade para a precisão dos grandes modelos de linguagem e considera os dados um componente fundamental para acelerar a computação. (Fonte: ctnzr & NandoDF)

Modelo Tencent Hunyuan-Turbos fica em oitavo lugar na arena LMArena: O mais recente modelo Hunyuan-Turbos da Tencent classificou-se em oitavo lugar geral nos benchmarks da LMArena (anteriormente lmsys.org) e em décimo terceiro lugar no controle de estilo, com desempenho próximo ao Deepseek-R1. O modelo ficou entre os dez primeiros nas principais categorias, como hardcore, codificação e matemática, mostrando uma melhoria significativa em relação à sua versão de fevereiro. Membros da comunidade como WizardLM_AI parabenizaram seu desempenho. (Fonte: WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 References demonstra potencial como ferramenta de criação universal: O modelo Gen-4 References da Runway está posicionado como uma ferramenta de criação universal, capaz de suportar fluxos de trabalho e aplicações quase ilimitados. Usuários da comunidade continuam descobrindo novos casos de uso, mostrando sua forte adaptabilidade como modelo universal, capaz de se ajustar à criatividade do usuário, em vez de fazer o usuário se adaptar às limitações do modelo. Isso reflete a tendência de evolução da IA no campo da criação de mídia, de tarefas específicas para capacidades universais. (Fonte: c_valenzuelab & c_valenzuelab)

Modelo Seed-1.5-VL-thinking da ByteDance lidera em benchmarks de modelos de linguagem visual: A ByteDance lançou o modelo Seed-1.5-VL-thinking, que alcançou SOTA (state-of-the-art) em 38 de 60 benchmarks de modelos de linguagem visual (VLM). Alegadamente, o modelo foi treinado em 1,3 milhão de horas de GPU H800, demonstrando suas poderosas capacidades de compreensão e raciocínio multimodal. (Fonte: teortaxesTex)
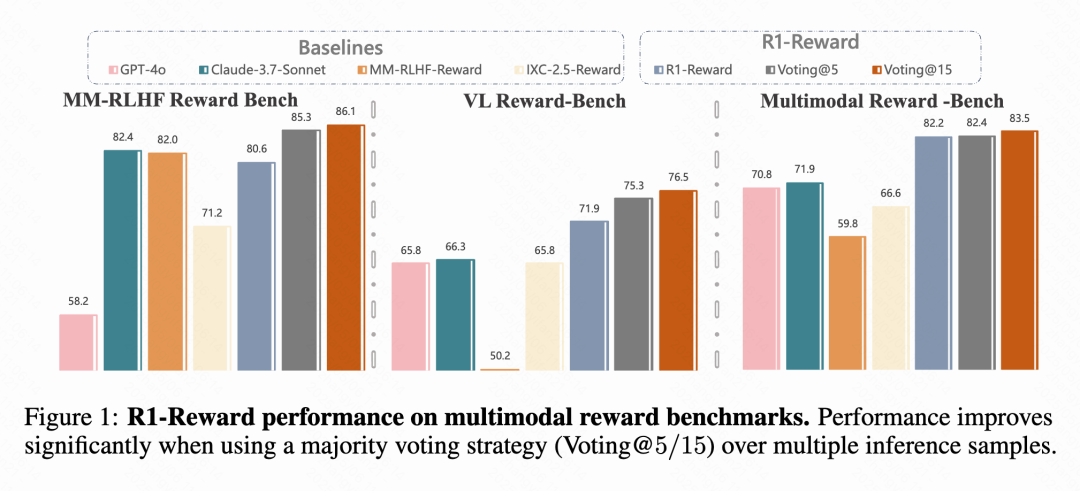
Kuaishou, Academia Chinesa de Ciências e outros propõem modelo de recompensa multimodal R1-Reward: Equipes de pesquisa da Kuaishou, Academia Chinesa de Ciências, Universidade de Tsinghua e Universidade de Nanjing propuseram o R1-Reward, um novo modelo de recompensa multimodal (MRM), treinado com o algoritmo de aprendizado por reforço aprimorado StableReinforce. O modelo visa resolver problemas de instabilidade encontrados por algoritmos RL existentes ao treinar MRMs, introduzindo mecanismos como Pre-Clip, filtro de vantagem e recompensa de consistência. Experimentos mostram que o R1-Reward melhora em 5%-15% em relação aos modelos SOTA em vários benchmarks de MRM e foi aplicado com sucesso em cenários de negócios da Kuaishou, como vídeos curtos e e-commerce. (Fonte: WeChat & WeChat)
Universidade Tecnológica de Nanyang e outros propõem WorldMem, usando mecanismo de memória para gerar mundos consistentes em longas sequências temporais: Pesquisadores do S-Lab da Universidade Tecnológica de Nanyang, da Universidade de Pequim e do Shanghai AI Lab propuseram o modelo de geração de mundo WorldMem. Ao introduzir um mecanismo de memória, o modelo resolve o problema da falta de consistência em longas sequências temporais nos modelos de geração de vídeo existentes. O WorldMem foi treinado no conjunto de dados do Minecraft, suporta exploração diversificada de cenários e mudanças dinâmicas, e validou sua viabilidade em conjuntos de dados reais, sendo capaz de manter boa consistência geométrica após mudanças de perspectiva e posição, e modelar a consistência temporal. (Fonte: WeChat)

Equipe Kuaishou Keling propõe CineMaster, framework de geração de vídeo cinematográfico controlável com percepção 3D: A equipe de pesquisa Kuaishou Keling publicou um artigo no SIGGRAPH 2025, apresentando o framework CineMaster. Este é um framework de geração de texto para vídeo de nível cinematográfico que permite aos usuários, através de um fluxo de trabalho interativo, organizar cenas em espaço 3D, definir objetivos e movimentos de câmera, alcançando controle fino sobre o conteúdo do vídeo. O CineMaster integra o controle de movimento de objetos e movimento de câmera através do Semantic Layout ControlNet e do Camera Adapter, respectivamente, e projetou um fluxo de construção de dados para extrair sinais de controle 3D de qualquer vídeo. (Fonte: WeChat)

🧰 Ferramentas
Comet-ml lança framework open-source de avaliação de LLM Opik: A Comet-ml tornou open-source no GitHub o Opik, um framework para depuração, avaliação e monitoramento de aplicações LLM, sistemas RAG e fluxos de trabalho de Agent. O Opik oferece rastreamento abrangente, avaliação automatizada e dashboards prontos para produção, suportando instalação local ou como solução hospedada via Comet.com. Ele se integra com vários frameworks populares como OpenAI, LangChain, LlamaIndex, e fornece métricas LLM-as-a-judge para detecção de alucinações, moderação de conteúdo e avaliação de RAG. (Fonte: GitHub Trending)
LovartAI lança primeiro agente de design Lovart, enfatizando compreensão de contexto: A LovartAI lançou a versão Beta de seu primeiro agente de design, Lovart. O feedback dos usuários indica que, em comparação com outras ferramentas de design de IA, o Lovart entende melhor o contexto, até mesmo “como se estivesse lendo mentes”. A ferramenta permite que humanos e IA colaborem na mesma tela, transformando prompts instantaneamente em visuais, podendo ser usada para design de logos de marca e identidade visual (VI), etc. (Fonte: karminski3)
Equipe de Jun-Yan Zhu da CMU lança LEGOGPT, gerando modelos 3D de Lego a partir de texto: A equipe de Jun-Yan Zhu da Carnegie Mellon University (CMU) desenvolveu o LEGOGPT, um grande modelo de linguagem capaz de gerar modelos 3D de Lego fisicamente estáveis e montáveis a partir de prompts de texto. O modelo formula o problema de design de Lego como uma tarefa de geração de texto autorregressiva, construindo a estrutura prevendo o tamanho e a posição do próximo bloco, e impõe restrições de montagem com percepção física durante o treinamento e a inferência, garantindo a estabilidade e a montabilidade dos designs gerados. A equipe também lançou o conjunto de dados StableText2Lego, contendo mais de 47.000 estruturas de Lego. (Fonte: WeChat)

Aplicativo MNN Chat suporta modelos Qwen 2.5 Omni 3B e 7B: O aplicativo de chat MNN (Mobile Neural Network) da Alibaba agora suporta os modelos Qwen 2.5 Omni 3B e 7B. Isso significa que os usuários podem experimentar serviços de modelos de linguagem localizados mais poderosos em dispositivos móveis. O MNN é um motor de inferência de aprendizado profundo leve, focado na otimização para dispositivos móveis e embarcados. (Fonte: Reddit r/LocalLLaMA)

Plataforma FutureHouse oferece ferramentas de pesquisa de IA superinteligente para cientistas: A organização sem fins lucrativos FutureHouse lançou a plataforma FutureHouse, um conjunto de agentes de IA baseados na web e API, projetado para acelerar a descoberta científica. A plataforma oferece uma série de ferramentas de pesquisa de IA superinteligentes para ajudar cientistas na análise de dados, simulação de experimentos e descoberta de conhecimento, impulsionando a transformação do paradigma de pesquisa científica. (Fonte: dl_weekly)
Cartesia lança Pro Voice Cloning, para construir facilmente modelos de voz personalizados: A Cartesia lançou seu produto de fine-tuning Pro Voice Cloning. Os usuários podem fazer upload de seus próprios dados de voz para construir facilmente modelos de voz personalizados, usados para criar avatares pessoais, agentes de IA ou bibliotecas de voz. O produto suporta treinamento e implantação de serviço em 2 horas e oferece uma experiência de produto totalmente self-service, visando a aplicação em escala. (Fonte: krandiash)

Instituto de Tecnologia da Computação da Academia Chinesa de Ciências propõe MCA-Ctrl, para personalização precisa de imagens: A equipe de pesquisa do Instituto de Tecnologia da Computação da Academia Chinesa de Ciências propôs um método universal de personalização de imagem sem fine-tuning chamado MCA-Ctrl (Multi-party Collaborative Attention Control). Este método, através do controle de atenção colaborativa multipartidária, utiliza o conhecimento interno dos modelos de difusão, combinando prompts condicionais de imagem/texto com o conteúdo da imagem do sujeito, para realizar substituição, geração e adição de temas para sujeitos específicos. O MCA-Ctrl garante a consistência do layout e a substituição da aparência de objetos específicos alinhada ao fundo através de mecanismos de consulta local de auto-atenção e injeção global. (Fonte: WeChat)
📚 Aprendizado
Conferência AI Engineer anuncia lista de palestrantes: A Conferência AI Engineer anunciou sua lista de palestrantes, incluindo engenheiros e pesquisadores de IA de ponta de empresas como OpenAI, Anthropic, LangChainAI, Google, etc. A conferência cobrirá 20 áreas de nicho como MCP, LLM RecSys, Agent Reliability, GraphRAG, e terá pela primeira vez uma agenda de liderança para CTOs e VPs. (Fonte: swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Face publica blog sobre os últimos avanços em modelos de linguagem visual (VLM): O Hugging Face publicou um artigo de blog abrangente sobre os últimos avanços em modelos de linguagem visual (VLM). O conteúdo cobre vários aspectos como agentes GUI, agentes VLM, modelos onívoros, RAG multimodal, LM de vídeo, modelos pequenos, etc., resumindo as novas tendências, avanços, alinhamento e benchmarks no campo VLM no último ano. (Fonte: huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

Microsoft Azure realiza workshop online sobre construção de aplicativos de chat de IA sem servidor: Yohan Lasorsa anunciou a realização de um workshop online sobre a construção de aplicativos de chat de IA sem servidor usando o Azure. A sessão explorará Azure Functions, Static Web Apps e Cosmos DB, e como combinar a tecnologia RAG (Retrieval-Augmented Generation) com LangChainAI JS. (Fonte: Hacubu & hwchase17)
Podcast da Weaviate discute sistemas LLM-as-Judge e a biblioteca Verdict: O episódio 121 do podcast da Weaviate convidou Leonard Tang, cofundador da Haize Labs, para discutir a evolução dos sistemas LLM-as-Judge / modelos de recompensa. A discussão incluiu a experiência do usuário na avaliação, avaliação comparativa, integração de juízes, juízes debatedores, curadoria de conjuntos de avaliação e testes adversariais, destacando a nova biblioteca da Haize Labs, Verdict, um framework declarativo para especificar e executar sistemas compostos LLM-as-Judge. (Fonte: bobvanluijt & Reddit r/deeplearning)

Terence Tao publica vídeo no YouTube demonstrando prova matemática formalizada assistida por IA: O medalhista Fields Terence Tao estreou em seu canal no YouTube, demonstrando como usar ferramentas de IA como GitHub Copilot e o assistente de prova Lean para formalizar semiautomaticamente em 33 minutos uma prova matemática (Equação Magma E1689 implica E2) que originalmente exigiria uma página inteira escrita por um matemático humano. Ele enfatiza que este método é adequado para provas tecnicamente intensas e conceitualmente fracas, liberando os matemáticos de tarefas tediosas. Ao mesmo tempo, seu assistente de prova leve em Python também foi atualizado para a versão 2.0, aprimorando o tratamento de estimativas assintóticas e lógica proposicional. (Fonte: WeChat & 量子位)

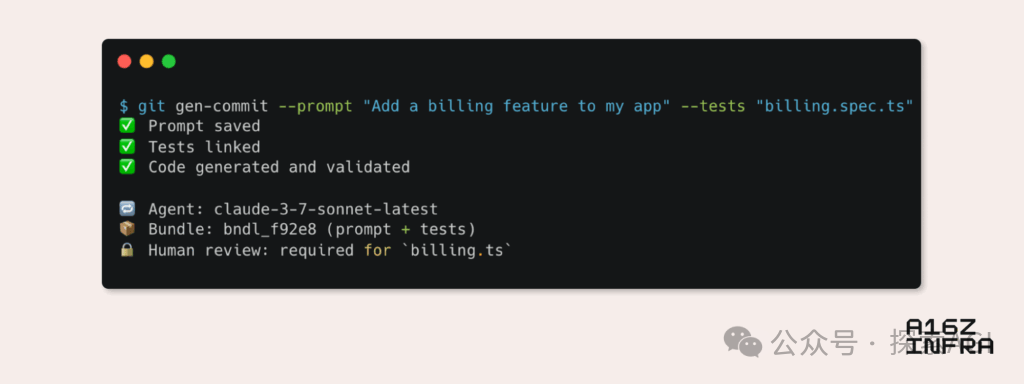
a16z analisa nove tendências emergentes nos padrões de desenvolvimento na era da IA: Andreessen Horowitz (a16z) publicou um blog analisando nove tendências emergentes nos padrões de desenvolvimento na era da IA. Estas incluem: Git nativo de IA (controle de versão mudando para Prompts e casos de teste), Vibe Coding (programação orientada por intenção substituindo templates), novo paradigma de gerenciamento de chaves para Agentes de IA, dashboards de monitoramento interativos impulsionados por IA, documentação evoluindo para bases de conhecimento interativas com IA, visualização de aplicações da perspectiva do LLM (interação via APIs de acessibilidade), ascensão de Agentes de execução assíncrona, potencial do protocolo MCP (Model-Tool Communication Protocol) e a demanda dos Agentes por componentes básicos. Essas tendências prenunciam uma profunda transformação na forma como o software é construído. (Fonte: WeChat)
💼 Negócios
Google Labs lança AI Futures Fund para apoiar startups de IA: O Google Labs anunciou o lançamento do programa AI Futures Fund, visando colaborar com startups para construir o futuro da tecnologia de IA. O fundo fornecerá às startups selecionadas acesso antecipado aos modelos do Google DeepMind e recursos como créditos na nuvem para ajudar a acelerar seu desenvolvimento. (Fonte: GoogleDeepMind & JeffDean & Google & demishassabis)
Rumor: Perplexity negocia nova rodada de financiamento de US$ 500 milhões, com avaliação de US$ 14 bilhões: Segundo relatos, a empresa de busca por IA Perplexity está negociando uma nova rodada de financiamento de US$ 500 milhões, com uma avaliação que pode chegar a US$ 14 bilhões. Isso ocorre apenas seis meses após sua última rodada de financiamento (avaliação de US$ 9 bilhões), mostrando a alta atenção do mercado de capitais na área de busca por IA e o reconhecimento das perspectivas de desenvolvimento da Perplexity. (Fonte: Dorialexander)

Rumor: OpenAI concorda em adquirir Windsurf por cerca de US$ 3 bilhões: Segundo a Bloomberg, a OpenAI concordou em adquirir a startup Windsurf por aproximadamente US$ 3 bilhões. Detalhes específicos da aquisição e a área de atuação da Windsurf ainda não foram divulgados, mas a medida pode significar que a OpenAI está expandindo ainda mais suas capacidades tecnológicas ou seu alcance de mercado. (Fonte: Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 Comunidade
O risco real da IA: a “armadilha da simulação” da satisfação infinita: Discussões de Amjad Masad e outros apontam que o verdadeiro perigo da IA não são os robôs assassinos da ficção científica, mas sua capacidade de satisfazer infinitamente os desejos humanos, criando uma “máquina de felicidade infinita”. Essa IA pode levar os humanos a se entregarem a lutas e significados simulados, eventualmente “desaparecendo” no mundo simulado, oferecendo uma possível explicação para o Paradoxo de Fermi – civilizações não se extinguem, mas entram em êxtase digital. (Fonte: amasad)
Agentes de IA irão remodelar a programação e a pesquisa científica: O CEO da Replit, Amjad Masad, prevê que nos próximos um ou dois anos, os Agentes de IA serão capazes de trabalhar ininterruptamente por dias, ou até anos, para resolver problemas científicos complexos. Ele acredita que os Agentes se tornarão uma nova forma de programação, capazes de dedicar dias para resolver um problema, assim como os humanos, o que prenuncia o enorme potencial da IA na automação de tarefas complexas e na aceleração da descoberta científica. (Fonte: TheTuringPost & amasad & TheTuringPost)
John Carmack discute o potencial da IA na otimização de bases de código: O lendário programador John Carmack acredita que a IA não só pode gerar grandes quantidades de código, mas tem ainda mais potencial para ajudar a embelezar e refatorar bases de código existentes. Ele imagina a IA como um membro diligente da equipe, revisando continuamente o código e propondo melhorias, podendo até definir diretrizes de estilo de codificação “amigáveis à IA” através de experimentos objetivos. Ele espera ver como equipes com exigências extremamente altas de qualidade de código, como a do OpenBSD, irão acolher membros de IA. (Fonte: ID_AA_Carmack)
“Vibe Coding” gera debate: prós e contras da programação assistida por IA: Discussões na comunidade apontam que, embora o “Vibe Coding” (gerar protótipos de código via instruções em linguagem natural com IA) possa construir rapidamente aplicações de nível de demonstração, a implantação e escalabilidade ainda exigem que desenvolvedores profissionais construam do zero. Produtos de engenharia não envolvem apenas escrever código, mas também arquitetura, CI/CD, microsserviços e outros problemas complexos que a IA atualmente tem dificuldade em dominar completamente. O Vibe Coding é adequado para validação rápida de protótipos, mas a construção de soluções reais ainda requer pensamento e experiência de engenharia. (Fonte: Reddit r/ClaudeAI)
Ampla aplicação da IA na educação universitária e preocupações com trapaça: Uma reportagem da New York Magazine revela o fenômeno do uso generalizado de ferramentas de IA (como o ChatGPT) em universidades norte-americanas para completar tarefas e trabalhos. Estudantes usam IA para anotações, estudo, pesquisa e até mesmo para gerar diretamente o conteúdo dos trabalhos, levantando preocupações sobre integridade acadêmica, qualidade da educação e declínio da capacidade de pensamento crítico dos alunos. Educadores tentam ajustar métodos de ensino e avaliação, mas a eficácia das ferramentas de detecção de IA é questionável, tornando a trapaça com IA difícil de erradicar. (Fonte: WeChat)
💡 Outros
Cohere discute desafios da aplicação de IA governamental da fase piloto à produção: A Cohere aponta que a maioria dos projetos de IA governamentais ainda está na fase piloto. Para realizar o salto da fase piloto para a aplicação em produção real, as agências governamentais precisam de ferramentas confiáveis, orientação clara para resultados, infraestrutura eficiente e parceiros adequados. O artigo explora como as agências governamentais podem passar da experimentação para a aplicação real através de IA segura e eficiente. (Fonte: cohere)

Mustafa Suleyman: Quanto maiores os modelos de linguagem, mais fáceis de controlar: O cofundador da Inflection AI, Mustafa Suleyman, acredita que, ao contrário das preocupações comuns, quanto maior a escala dos grandes modelos de linguagem (LLMs), mais fáceis eles são de controlar. Ele aponta que modelos de gerações anteriores eram mais difíceis de guiar, estilizar e moldar, enquanto o aumento da escala ajuda a melhorar a controlabilidade do modelo, em vez de enfraquecê-la. (Fonte: mustafasuleyman)
Discussão sobre ética da IA: atribuição de responsabilidade por danos ou vieses causados pela IA: Um post no Reddit gerou discussão: quando um sistema de IA (como IA de diagnóstico médico) causa danos devido a vieses nos dados de treinamento (por exemplo, treinado principalmente com imagens de pele clara, levando a diagnósticos errados em pacientes de pele escura), quem deve ser responsabilizado? Isso envolve a definição de responsabilidade de múltiplas partes, incluindo desenvolvedores de IA, instituições que implantam, reguladores, etc., sendo uma questão crucial a ser resolvida urgentemente nos quadros éticos e legais da IA. (Fonte: Reddit r/ArtificialInteligence)