Palavras-chave:Prime Intellect, INTELLECT-2, Sakana AI, Máquina de Pensamento Contínuo, Transformer, Agente de IA do Google, AgentOps, Colaboração Multiagente, Treinamento de Aprendizagem por Reforço Distribuído, Sincronização Neural e Temporal, Fluxo de Operações de Agentes de IA, Arquitetura Multiagente, Implantações Corporativas de Agentes de IA
🔥 Foco
Prime Intellect torna open source o modelo INTELLECT-2: A Prime Intellect lançou e tornou open source o INTELLECT-2, um modelo de 32 bilhões de parâmetros, descrito como o primeiro modelo treinado através de aprendizado por reforço distribuído globalmente. Este lançamento inclui um relatório técnico detalhado e checkpoints do modelo. O modelo demonstrou desempenho comparável ou superior a modelos como o Qwen 32B em vários benchmarks, destacando-se especialmente na geração de código e raciocínio matemático, e foi descoberto pela comunidade que consegue jogar Wordle. A sua forma de treinamento e a iniciativa open source são consideradas como potenciais influenciadoras no futuro treinamento de modelos grandes e no cenário competitivo (Fonte: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

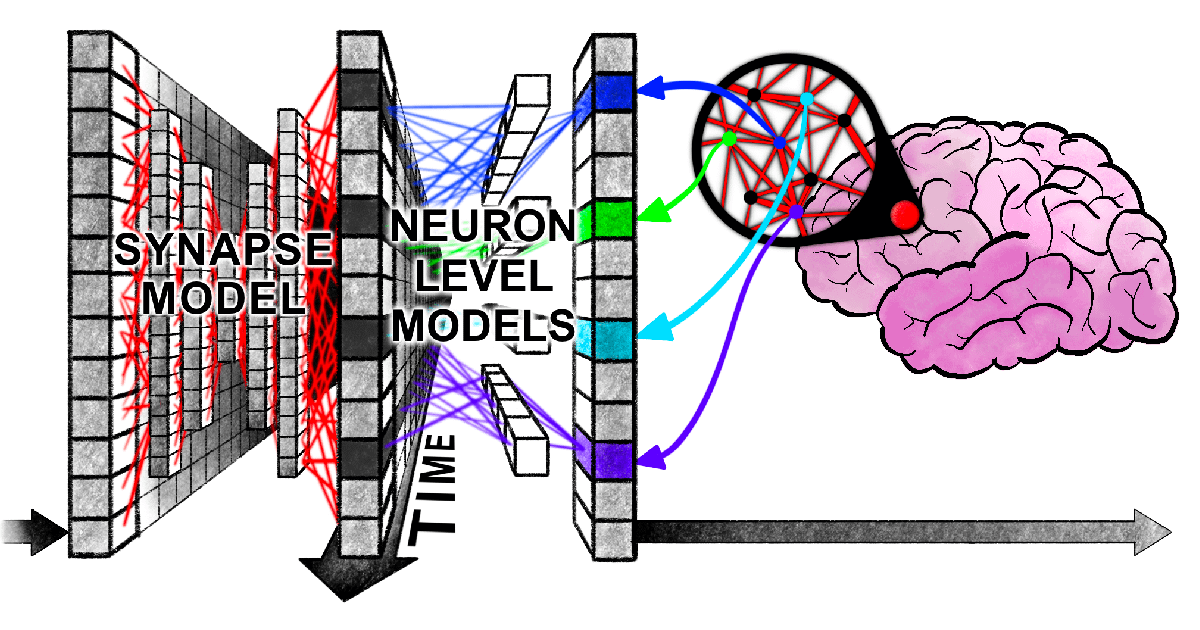
Sakana AI propõe a Máquina de Pensamento Contínuo (CTM): A Sakana AI apresentou uma nova arquitetura de rede neural chamada “Máquina de Pensamento Contínuo” (Continuous Thought Machine, CTM), que visa dotar a IA de uma inteligência mais flexível e semelhante à humana, introduzindo mecanismos do cérebro biológico como timing neural e sincronização neuronal. A inovação central da CTM reside no processamento temporal ao nível dos neurônios e na utilização da sincronização neural como representação latente, permitindo-lhe lidar com tarefas que exigem raciocínio sequencial e computação adaptativa, além de poder armazenar e recuperar memórias. A pesquisa foi divulgada através de um blog, relatório interativo, artigo científico e repositório GitHub, explorando um novo paradigma para a IA “pensar com o tempo” (Fonte: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
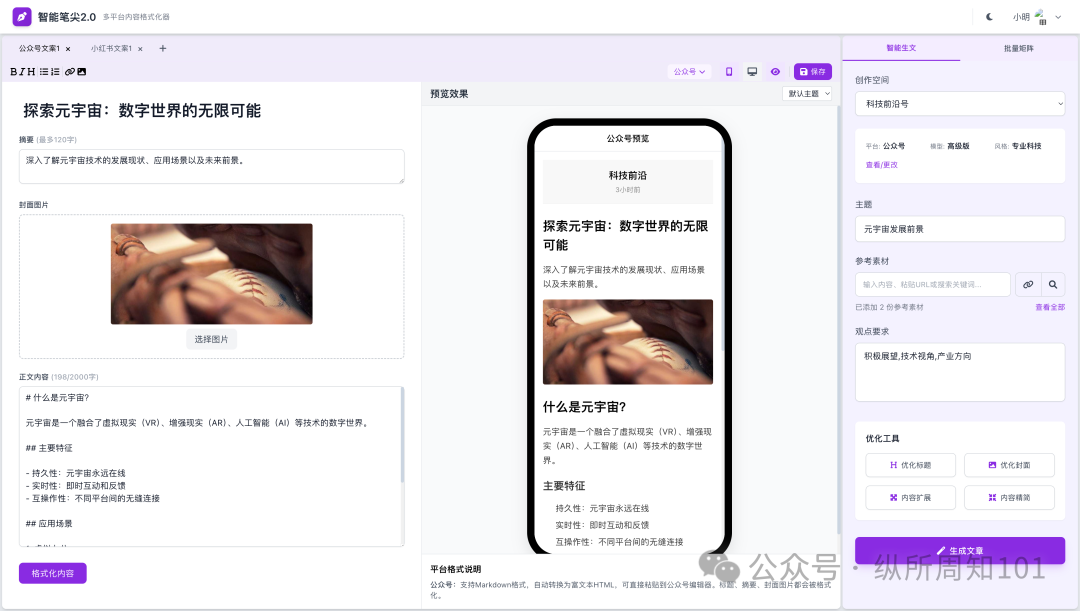
Novo artigo de Harvard revela ‘emaranhamento síncrono’ entre Transformers e cérebro humano no processamento de informações: Pesquisadores da Universidade de Harvard e outras instituições publicaram o artigo “Linking forward-pass dynamics in Transformers and real-time human processing”, explorando as semelhanças entre a dinâmica de processamento interno dos modelos Transformer e os processos cognitivos humanos em tempo real. O estudo não se limita a analisar o resultado final, mas analisa métricas de “carga de processamento” em cada camada do modelo (como incerteza, mudança de confiança), descobrindo que a IA, ao resolver problemas (como responder capitais, classificar animais, raciocínio lógico, reconhecimento de imagem), também passa por processos semelhantes aos humanos de “hesitação”, “erro intuitivo” a “correção”. Essa semelhança no “processo de pensamento” sugere que a IA aprende naturalmente atalhos cognitivos semelhantes aos humanos para completar tarefas, oferecendo novas perspectivas para entender a tomada de decisão da IA e orientar o design de experimentos humanos (Fonte: 36氪)

Google lança white paper de 76 páginas sobre agentes de IA, detalhando AgentOps e colaboração multiagente: O mais recente white paper sobre agentes de IA do Google detalha a construção, avaliação e aplicação de agentes de IA. O white paper enfatiza a importância das operações de agentes (AgentOps), um processo para otimizar a construção e implantação de agentes em ambientes de produção, abrangendo gerenciamento de ferramentas, configuração de prompts principais, implementação de memória e decomposição de tarefas. O white paper também explora arquiteturas multiagente, onde múltiplos agentes com capacidades especializadas colaboram para atingir objetivos complexos, e apresenta casos práticos do Google na implantação de agentes internamente (como NotebookLM Enterprise, Agentspace Enterprise) e aplicações específicas (como sistema multiagente automotivo), visando aumentar a produtividade empresarial e a experiência do usuário (Fonte: 36氪)
🎯 Tendências
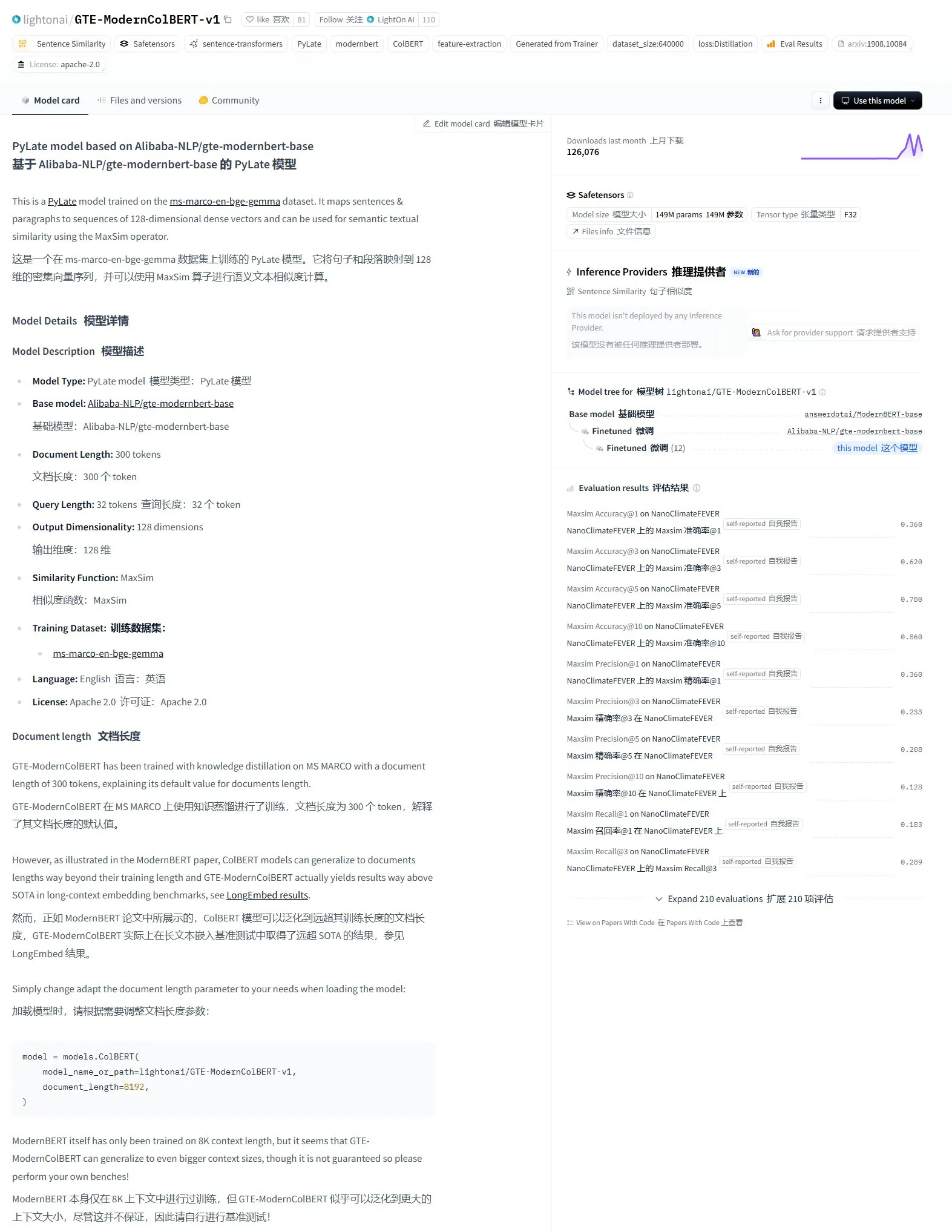
LightonAI lança modelo de recuperação semântica GTE-ModernColBERT-v1: A LightonAI lançou um novo modelo de recuperação semântica, GTE-ModernColBERT-v1, que alcançou a pontuação mais alta atual na avaliação LongEmbed / LEMB Narrative QA. Este modelo foi projetado especificamente para melhorar a eficácia da recuperação semântica e pode ser aplicado em cenários como recuperação de conteúdo de documentos, RAG, etc., e pode ser integrado com sistemas existentes. Sabe-se que o modelo foi ajustado (fine-tuned) com base no Alibaba-NLP/gte-modernbert-base, visando superar as limitações dos motores de busca tradicionais que dependem apenas da correspondência de caracteres (Fonte: karminski3)
Líderes de tecnologia atentos à rápida ascensão da DeepSeek: O VentureBeat relatou as reações dos líderes de tecnologia ao rápido desenvolvimento da DeepSeek. Com suas fortes capacidades de modelo e estratégia open source, a DeepSeek alcançou resultados notáveis no campo global da IA, especialmente em tarefas de matemática e geração de código, desafiando o cenário de mercado existente (incluindo OpenAI, etc.). Sua estratégia de treinamento de baixo custo e preços de API também impulsionaram a popularização e comercialização da tecnologia de IA (Fonte: Ronald_vanLoon)

ByteDance e Universidade de Pequim lançam conjuntamente DreamO, um framework unificado de geração de imagens personalizadas com combinação de múltiplas condições: A ByteDance, em colaboração com a Universidade de Pequim, lançou o DreamO, um framework de geração de imagens personalizadas que permite a combinação livre de múltiplas condições, como sujeito, identidade, estilo e referência de vestuário, através de um único modelo. O framework é construído sobre o Flux-1.0-dev, introduzindo uma camada de mapeamento dedicada para processar entradas de imagens condicionais e utilizando uma estratégia de treinamento progressivo e restrições de roteamento para imagens de referência para melhorar a qualidade e consistência da geração. Com apenas 400M de parâmetros treináveis, o DreamO gera uma imagem personalizada em 8-10 segundos, apresentando excelente desempenho em manter a consistência. O código e o modelo relacionados foram disponibilizados em open source (Fonte: WeChat)

Equipe VITA torna open source o modelo grande de fala em tempo real VITA-Audio, com grande aumento na eficiência de inferência: A equipe VITA lançou o modelo de fala end-to-end VITA-Audio, que, através da introdução de um módulo leve de previsão de marcadores multimodais cruzados (MCTP), realiza a geração direta de Audio Token Chunks decodificáveis em uma única passagem direta (forward pass). Na escala de 7B parâmetros, o modelo leva apenas 92ms desde o recebimento do texto até a saída do primeiro fragmento de áudio (53ms sem contar o codificador de áudio), com velocidade de inferência 3-5 vezes maior que modelos de escala semelhante. O VITA-Audio suporta chinês e inglês, foi treinado apenas com dados open source e apresenta excelente desempenho em tarefas como TTS, ASR, etc. O código e os pesos do modelo relacionados foram disponibilizados em open source (Fonte: WeChat)

Tsinghua, Instituto de IA Geral de Pequim e outros propõem método de treinamento “Absolute Zero”, onde modelos grandes desbloqueiam capacidade de raciocínio através de auto-competição: Pesquisadores da Universidade de Tsinghua, do Instituto de Inteligência Artificial Geral de Pequim e outras instituições propuseram o método de treinamento “Absolute Zero”, que permite que modelos grandes pré-treinados aprendam a raciocinar gerando e resolvendo tarefas através de auto-competição (Self-play), sem a necessidade de dados externos. O método representa unificadamente as tarefas de raciocínio como triplas (programa, entrada, saída), com o modelo desempenhando os papéis de Proposer (criador de problemas) e Solver (solucionador de problemas), aprendendo através de três tipos de tarefas: abdução, dedução e indução. Experimentos mostram que modelos treinados com este método tiveram melhorias significativas em tarefas de código e raciocínio matemático, superando o desempenho de modelos treinados com amostras anotadas por especialistas (Fonte: WeChat)

Desenvolvimento de AI PC acelera, Lenovo e Huawei lançam novos produtos terminais de IA: Lenovo e Huawei lançaram recentemente produtos de PC integrados com agentes de IA, como o super agente inteligente pessoal Tianxi da Lenovo e o agente inteligente Xiaoyi no Huawei HarmonyOS PC. Embora a taxa de penetração do mercado de AI PC ainda seja baixa, o crescimento é rápido. Dados da Canalys mostram que as remessas de AI PC na China continental em 2024 já representavam 15% do mercado total de PCs, com previsão de atingir 34% em 2025. Especialistas do setor acreditam que a maturidade da cadeia de suprimentos de AI PC levará de 2 a 3 anos, com os desafios atuais sendo principalmente os custos da cadeia de suprimentos (memória, chips, etc.) e problemas de escala, bem como a fragmentação do ecossistema de AI PC na China. As tendências futuras incluem agentes inteligentes se tornando a principal interface de interação, implantação local de IA e expansão dos cenários de aplicação de IA para educação, saúde e outras áreas diversificadas (Fonte: 36氪)
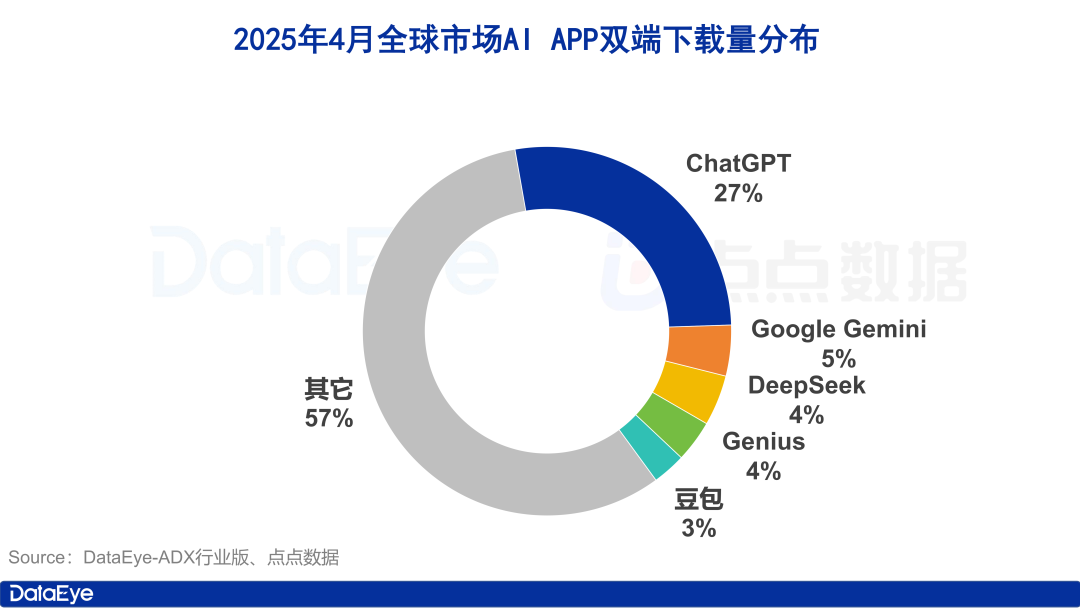
Downloads globais de aplicativos de IA disparam, mercado doméstico chinês esfria, Doubao cresce na contramão: Em abril de 2025, os downloads globais de aplicativos de IA em ambas as plataformas atingiram 330 milhões, um aumento de 27,4% em relação ao mês anterior, com ChatGPT, Google Gemini, DeepSeek, Genius e Doubao ocupando os cinco primeiros lugares. O ChatGPT, em particular, viu um aumento nos downloads devido ao lançamento do GPT-4o. Em contraste, os downloads de aplicativos de IA na plataforma Apple na China continental caíram 24,0% em relação ao mês anterior. Doubao cresceu contra a tendência, ficando em primeiro lugar, seguido por DeepSeek e Jimi AI (即梦AI). Em termos de aquisição de usuários paga (buy volume), Tencent Yuanbao e Quark investiram pesadamente, respondendo pela maior parte do volume de material publicitário, enquanto o investimento de Doubao diminuiu. No geral, o fervor do mercado de IA doméstico chinês diminuiu um pouco, com a concorrência voltando para a tecnologia e operações (Fonte: 36氪)
Mercado chinês de modelos grandes passa por reestruturação, surge o cenário dos “cinco grandes de modelos base”: Com o aperto do ambiente global de financiamento de IA em 2024, o mercado chinês de modelos grandes passou por um processo de “depuração da bolha”. O cenário anterior dos “seis pequenos tigres” evoluiu para os “cinco grandes de modelos base”, representados por ByteDance, Alibaba, Jiyue Xingchen (阶跃星辰), Zhipu AI e DeepSeek. Esses players líderes têm vantagens distintas em financiamento, talento e tecnologia, e seguiram caminhos diferenciados: ByteDance com um layout abrangente, Alibaba focando em open source e full-stack, Jiyue Xingchen aprofundando em multimodalidade, Zhipu AI alavancando sua base na Tsinghua para focar em 2B/2G, e DeepSeek se destacando com otimização extrema de engenharia e estratégia open source. O foco da concorrência na próxima fase será romper o “teto de inteligência” e aprimorar as “capacidades multimodais”, visando realizar a visão da AGI (Fonte: 36氪, WeChat)

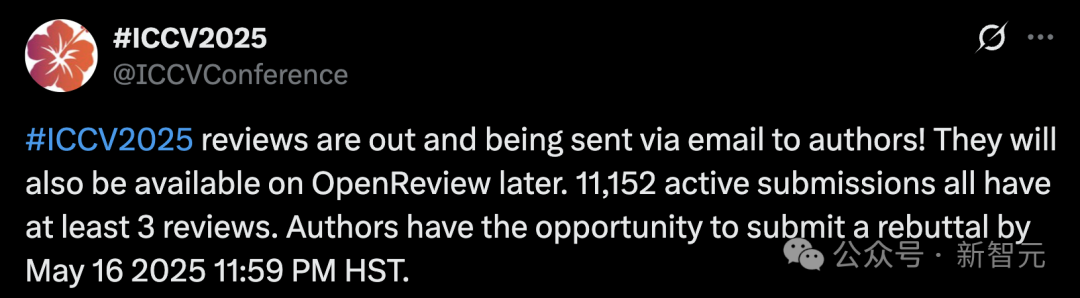
Volume recorde de submissões na ICCV 2025 levanta preocupações sobre qualidade da revisão, uso de LLMs na revisão é proibido: A principal conferência de visão computacional, ICCV 2025, atingiu um recorde histórico com 11.152 submissões de artigos. No entanto, após a divulgação dos resultados da revisão, muitos autores expressaram insatisfação nas redes sociais sobre a qualidade da revisão, considerando algumas opiniões superficiais, até piores que as do GPT, e apontando problemas como revisores não lendo materiais suplementares. Para lidar com o aumento de submissões, a conferência exigiu que cada autor submetido participasse da revisão e proibiu explicitamente o uso de modelos grandes (como ChatGPT) no processo de revisão para garantir originalidade e confidencialidade. Embora os dados oficiais mostrem que 97,18% das revisões foram entregues no prazo, a qualidade da revisão e a carga sobre os revisores se tornaram focos de debate acalorado (Fonte: 36氪)
CEO da Nvidia, Jensen Huang: Todos os funcionários serão equipados com agentes de IA, remodelando o papel do desenvolvedor: O CEO da Nvidia, Jensen Huang, afirmou que a empresa equipará todos os funcionários (incluindo engenheiros de software e designers de chips) com agentes de IA para aumentar a eficiência do trabalho, a escala dos projetos e a qualidade do software. Ele prevê um futuro onde cada pessoa comandará múltiplos assistentes de IA, resultando em um crescimento exponencial da produtividade. Essa tendência está alinhada com as visões de empresas como Meta, Microsoft, Anthropic, etc., de que a IA realizará a maior parte da codificação, e o papel do desenvolvedor mudará para “comandante de IA” ou “definidor de requisitos”. Huang enfatizou que a energia e a capacidade computacional são gargalos para a popularização da IA, exigindo inovações em áreas como encapsulamento de chips e tecnologia fotônica. Grandes empresas estão desenvolvendo ativamente agentes de IA proativos, sinalizando uma transição de GenAI para Agentic AI (Fonte: 36氪)

CEO da OpenAI, Altman, comparece a audiência no Congresso, pede regulamentação flexível e revela planos de open source: O CEO da OpenAI, Sam Altman, afirmou em uma audiência no Senado dos EUA que uma aprovação prévia rigorosa da IA teria um impacto catastrófico na competitividade dos EUA no campo, e revelou que a OpenAI planeja lançar seu primeiro modelo open source neste verão. Ele enfatizou que a infraestrutura (especialmente energia) é crucial para vencer a corrida da IA e acredita que o custo da IA acabará convergindo para o custo da energia. Altman também compartilhou seu “Roteiro da Era da Inteligência (2025-2027)”, prevendo a chegada sucessiva de super assistentes de IA, crescimento exponencial de descobertas científicas impulsionadas por IA e a era dos robôs de IA. Ao falar sobre sua vida pessoal, ele expressou que não gostaria que seu filho desenvolvesse amizades íntimas com robôs de IA (Fonte: 36氪)

Pesquisadores da CMU propõem LegoGPT, usando IA para projetar modelos Lego fisicamente estáveis: Pesquisadores da Carnegie Mellon University desenvolveram o LegoGPT, um sistema de inteligência artificial que pode converter descrições de texto em modelos Lego fisicamente montáveis. Através do ajuste fino do modelo LLaMA da Meta e treinamento com o dataset StableText2Lego, contendo mais de 47.000 estruturas estáveis, o LegoGPT pode prever gradualmente a colocação das peças, garantindo que as estruturas geradas tenham estabilidade física no mundo real, com uma taxa de sucesso de 98,8%. O sistema também utiliza um método de reversão (rollback) ciente da física para corrigir estruturas instáveis detectadas. Os pesquisadores acreditam que essa tecnologia não se limita ao Lego e pode ser aplicada futuramente no design de componentes para impressão 3D e montagem robótica. O código, dataset e modelo estão atualmente open source (Fonte: WeChat)

Previsão de IA para eleição papal falha, novo Papa Robert Prevost é uma “escolha inesperada”: De acordo com a Science, um estudo que utilizou algoritmos de IA para analisar dados de 135 cardeais para prever o novo Papa não conseguiu prever a eleição de Robert Francis Prevost. O modelo simulou eleições com base nas posições dos cardeais em questões-chave (treinando a IA para julgar tendências conservadoras ou progressistas analisando seus discursos) e suas semelhanças ideológicas, prevendo finalmente que o cardeal italiano Pietro Parolin tinha a maior probabilidade de vencer. Os pesquisadores admitiram que a não consideração de fatores políticos e geográficos foi a principal falha do modelo, mas acreditam que a metodologia ainda tem valor para prever outros tipos de eleições. Prevost tem visões neutras sobre várias questões, podendo ser uma escolha de compromisso aceitável para todas as partes (Fonte: 36氪)

Aplicação da IA no marketing financeiro: resolvendo cinco grandes desafios como aquisição de clientes, personalização e conformidade: A tecnologia de IA e Agentes está se tornando o principal motor da era do Marketing Financeiro 3.0, visando resolver problemas como alto custo de aquisição de clientes, experiência personalizada insuficiente, produtos complexos e difíceis de entender, grande pressão de conformidade e dificuldade em medir o ROI. Através da construção de uma “plataforma de marketing inteligente” (base de dados + motor inteligente + aplicação de serviço), utilizando tecnologias como modelos grandes (LLM) + RAG, grafos de conhecimento, colaboração de agentes inteligentes (MAS) e computação de privacidade, as instituições financeiras podem alcançar insights mais profundos sobre os clientes, tomada de decisão inteligente precisa e em tempo real, e execução de serviços eficiente e consistente. Casos do setor mostram que a IA já obteve resultados significativos no aumento do AUM (Assets Under Management) dos clientes, taxa de conversão de produtos financeiros e eficiência na produção de conteúdo de marketing. O futuro aponta para interação multimodal, tomada de decisão causal, evolução autônoma, resposta na borda (edge) e colaboração humano-máquina (Fonte: 36氪)
Robôs impulsionados por IA resolvem problema de lixo eletrônico na Europa: O projeto de pesquisa financiado pela UE, ReconCycle, desenvolveu robôs adaptativos impulsionados por IA para automatizar o processamento do crescente volume de lixo eletrônico, especialmente a desmontagem de equipamentos contendo baterias de lítio. Esses robôs podem ser reconfigurados para se adaptar a diferentes tarefas, como remover baterias de detectores de fumaça e medidores de calor de radiadores. A tecnologia visa aumentar a eficiência da reciclagem, reduzir o trabalho pesado e perigoso da desmontagem manual e enfrentar o desafio de quase 5 milhões de toneladas de lixo eletrônico geradas anualmente na UE (com taxa de reciclagem inferior a 40%). Instalações de reciclagem como a Electrocycling GmbH já começaram a prestar atenção e esperam que esse tipo de tecnologia possa aumentar a taxa de recuperação de matérias-primas e reduzir perdas econômicas e emissões de carbono (Fonte: aihub.org)

🧰 Ferramentas
LocalSite-ai: Alternativa open source ao DeepSite, IA gera páginas frontend online: LocalSite-ai, como um projeto open source, oferece funcionalidades semelhantes ao DeepSite, permitindo aos usuários gerar páginas frontend online através de IA. Suporta visualização online, edição WYSIWYG (What You See Is What You Get) e é compatível com múltiplos provedores de API de IA. Além disso, a ferramenta suporta design responsivo, ajudando os usuários a construir rapidamente páginas web adaptáveis a diferentes dispositivos (Fonte: karminski3)
Agentset: Plataforma open source para melhorar a precisão dos resultados de RAG: Agentset é uma plataforma open source de RAG (Retrieval Augmented Generation) que otimiza a precisão dos resultados de recuperação através de busca híbrida e técnicas de reordenação. A plataforma possui funcionalidade de citação integrada, mostrando claramente quais informações indexadas no banco de dados vetorial originaram o conteúdo gerado, facilitando a verificação auxiliar pelo usuário para evitar erros de informação ou alucinações do modelo (Fonte: karminski3)
Gemini Max Playground: Aplicação Gemini com visualização paralela e controle de versão: O desenvolvedor Chansung criou uma aplicação no Hugging Face Space chamada Gemini Max Playground, que permite aos usuários processar em paralelo até 4 visualizações do Gemini para acelerar o processo de iteração. A ferramenta suporta o controle do número de tokens de inferência, possui funcionalidade de controle de versão e pode exportar arquivos HTML/JS/CSS separadamente. Além disso, oferece uma versão otimizada para telas móveis (Fonte: algo_diver)
mlop.ai: Alternativa open source ao Weights and Biases (wandb): mlop.ai foi lançado como uma plataforma de rastreamento de experimentos de ML totalmente open source, de alto desempenho e segura, visando substituir o wandb. É totalmente compatível com a API do wandb, com baixo custo de migração (apenas uma linha de código a ser alterada). Seu backend é escrito em Rust e afirma resolver o problema de bloqueio existente nas chamadas .log do wandb, oferecendo registro e upload não bloqueantes. Os usuários podem facilmente auto-hospedar via Docker (Fonte: Reddit r/artificial)
DeerFlow: Framework open source da ByteDance com LLM+Langchain+Ferramentas: A ByteDance tornou open source o DeerFlow (Deep Exploration and Efficient Research Flow), um framework que integra modelos grandes de linguagem (LLM), Langchain e diversas ferramentas (como busca na web, web crawling, execução de código). O projeto visa fornecer um forte suporte ao fluxo de pesquisa e desenvolvimento, e suporta Ollama, facilitando a implantação e uso local (Fonte: Reddit r/LocalLLaMA)
Plexe: Agente de ML open source que transforma linguagem natural em modelos treinados: Plexe é um agente de engenharia de ML open source que pode transformar prompts em linguagem natural em modelos de machine learning treinados nos dados estruturados do usuário (atualmente suporta arquivos CSV e Parquet), sem exigir que o usuário tenha conhecimento em ciência de dados. Ele completa automaticamente tarefas como limpeza de dados, seleção de features, experimentação e avaliação de modelos através de uma equipe de agentes especializados (cientista, treinador, avaliador), e usa MLflow para rastrear experimentos. Planos futuros incluem suporte a bancos de dados PostgreSQL e um agente de engenharia de features (Fonte: Reddit r/artificial)
Llama ParamPal: Projeto de base de conhecimento para parâmetros de amostragem de LLM: Llama ParamPal é um projeto open source que visa coletar e fornecer parâmetros de amostragem recomendados para modelos grandes de linguagem (LLM) locais ao usar llama.cpp. O projeto inclui um arquivo models.json como banco de dados de parâmetros e fornece uma interface web simples (em desenvolvimento) para navegar e pesquisar conjuntos de parâmetros, a fim de resolver a dificuldade dos usuários em encontrar parâmetros adequados ao configurar novos modelos. Os usuários podem contribuir com as configurações de parâmetros de seus próprios modelos (Fonte: Reddit r/LocalLLaMA)
TFrameX e Studio: Construtor e framework open source para agentes LLM locais: A equipe TesslateAI lançou dois projetos open source: TFrameX, um framework de agentes projetado especificamente para modelos grandes de linguagem (LLM) locais; e Studio, um construtor de agentes baseado em fluxogramas. Essas duas ferramentas visam ajudar os desenvolvedores a criar e gerenciar mais convenientemente agentes de IA que colaboram com LLMs locais. A equipe afirma estar desenvolvendo ativamente e acolhe contribuições da comunidade (Fonte: Reddit r/LocalLLaMA)
Ktransformer: Framework de inferência eficiente que suporta modelos ultra-grandes: Ktransformer é um framework de inferência que, de acordo com sua documentação, pode processar modelos ultra-grandes como Deepseek 671B ou Qwen3 235B usando apenas 1 ou 2 GPUs. Embora sua discussão seja menor que a do Llama CPP, alguns usuários apontam que ele pode superar o Llama CPP em desempenho, especialmente quando o cache KV reside apenas na memória da GPU. No entanto, pode faltar em chamadas de ferramentas e respostas estruturadas, e para modelos que não suportam MLA (como Qwen), processar contextos longos com VRAM limitada ainda é um desafio (Fonte: Reddit r/LocalLLaMA)

📚 Aprendizado
Interpretação do framework DSPy: Python declarativo e auto-otimizável para programação de LLM: DSPy (Declarative Self-improving Python) é um framework para programação de modelos grandes de linguagem (LLM). Sua ideia central é tratar os LLMs como “computadores universais” programáveis, definindo entradas, saídas e transformações (Signatures) de forma declarativa, em vez de forçar o comportamento específico de um LLM. Os módulos e otimizadores do DSPy permitem que os programas se auto-aprimorem em qualidade e custo, visando fornecer um paradigma de programação mais estruturado e eficiente para LLMs, a fim de atender às demandas de aplicações complexas de produção. A comunidade considera este um avanço importante na área de programação de LLM, com previsão de aumento no uso futuro (Fonte: lateinteraction, lateinteraction)
Universidade de Pequim, Tsinghua e outras publicam conjuntamente a mais recente revisão sobre capacidade de raciocínio lógico de modelos grandes: Pesquisadores da Universidade de Pequim, Universidade de Tsinghua, Universidade de Amsterdã, Carnegie Mellon University e MBZUAI publicaram conjuntamente um artigo de revisão sobre as capacidades de raciocínio lógico de modelos grandes de linguagem (LLM), aceito pelo IJCAI 2025 Survey Track. A revisão sistematiza os métodos de ponta e benchmarks de avaliação para melhorar o desempenho dos LLMs em perguntas e respostas lógicas e consistência lógica, classificando os métodos de perguntas e respostas lógicas em categorias baseadas em solucionadores externos, engenharia de prompt, pré-treinamento e ajuste fino, etc., e discute conceitos como negação, implicação, transitividade, consistência factual e composta, e suas técnicas de aprimoramento. O artigo também aponta direções futuras de pesquisa, como a extensão para lógica modal e raciocínio lógico de ordem superior (Fonte: WeChat)
Estreia de Terence Tao no YouTube: Prova matemática concluída em 33 minutos com auxílio de IA e atualização do assistente de prova: O renomado matemático Terence Tao fez sua estreia no YouTube, demonstrando como, com a ajuda da IA (especialmente GitHub Copilot e o assistente de prova Lean), completou em 33 minutos a prova de uma proposição de álgebra universal (Equação Magma E1689 implica E2) que normalmente exigiria uma página inteira escrita por um matemático humano. Ele enfatizou que este método semi-automatizado é adequado para argumentos tecnicamente fortes e conceitualmente fracos, libertando os matemáticos de tarefas tediosas. Ao mesmo tempo, ele apresentou a versão 2.0 de seu assistente de prova leve em Python, que suporta lógica proposicional e aritmética linear, entre outras estratégias, visando auxiliar em tarefas como análise assintótica, e já está open source (Fonte: WeChat)
Artigo CVPR 2025: MICAS – Método de amostragem adaptativa multi-granularidade para melhorar o aprendizado de contexto em nuvens de pontos 3D: Um artigo aceito na CVPR 2025, “MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing”, propõe um novo método chamado MICAS, que visa resolver os problemas de sensibilidade inter-tarefa e intra-tarefa encontrados ao aplicar o aprendizado de contexto (ICL) ao processamento de nuvens de pontos 3D. O MICAS inclui dois módulos principais: Amostragem de Pontos Adaptativa à Tarefa (Task-Adaptive Point Sampling), que utiliza informações da tarefa para guiar a amostragem ao nível do ponto; e Amostragem de Prompt Específica da Consulta (Query-Specific Prompt Sampling), que seleciona dinamicamente os exemplos de prompt ideais para cada consulta. Experimentos mostram que o MICAS supera significativamente as técnicas existentes em várias tarefas 3D, como reconstrução, remoção de ruído, registro e segmentação (Fonte: WeChat)
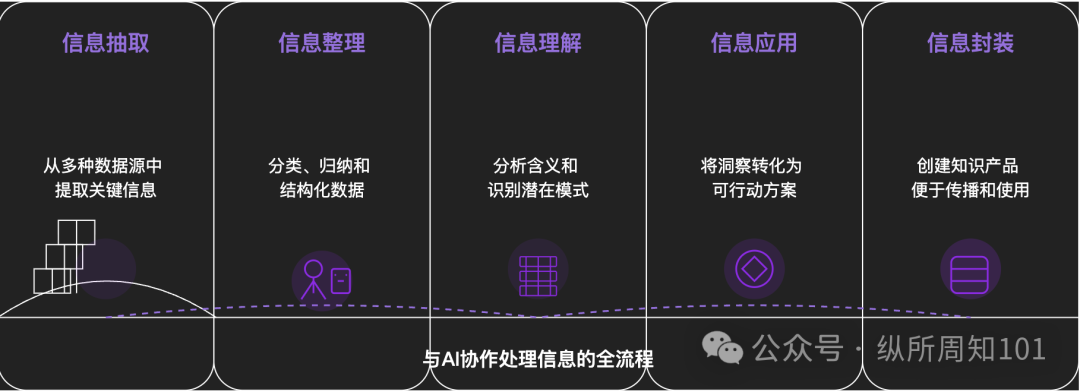
Metodologia para decompor qualquer coisa com IA: Um artigo aprofundado explora como usar a IA para decompor sistematicamente coisas complexas ou sistemas de conhecimento. O artigo propõe um framework de 15 níveis, do micro ao macro, do estático ao dinâmico, incluindo componentes básicos (constantes, variáveis), índice conceitual (palavras-chave), padrões verificáveis (leis, fórmulas), paradigmas operacionais (métodos, processos), integração estrutural (sistemas, corpos de conhecimento), abstração avançada (modelos mentais) até insights finais (essência) e aplicação prática (aplicação). O autor, com auxílio da IA, aplica esses níveis para entender a “lógica subjacente do tráfego do Xiaohongshu”, demonstrando a poderosa capacidade da IA na extração, organização, compreensão e aplicação de informações, e enfatiza a importância da colaboração com a IA (Fonte: WeChat)
💼 Negócios
Meituan investe exclusivamente na rodada A da “Zibianliang Robotics”, com financiamento acumulado superior a 1 bilhão: A empresa de inteligência incorporada “Zibianliang Robotics” (自变量机器人) anunciou recentemente a conclusão de uma rodada de financiamento A de centenas de milhões de yuans, liderada pela Meituan Strategic Investment e co-investida pela Meituan Longzhu. Anteriormente, a empresa havia concluído rodadas Pre-A++ lideradas pela Lightspeed China Partners e君联资本 (Legend Capital), e rodadas Pre-A+++ com investimentos da Huaying Capital, Yunqi Partners e GF Xinde Investment. Em menos de um ano e meio desde sua fundação, o financiamento acumulado ultrapassou 1 bilhão de yuans. A Zibianliang Robotics foca no desenvolvimento de modelos grandes de inteligência incorporada geral, adotando uma abordagem end-to-end, e desenvolveu autonomamente o modelo grande de operação “WALL-A”, com capacidade de fusão de informações multimodais e generalização zero-shot, já aplicado em cenários de tarefas complexas de múltiplos passos. A equipe principal da empresa reúne especialistas de ponta em IA e robótica de todo o mundo (Fonte: 36氪)
Kimi e Xiaohongshu aprofundam cooperação, explorando novos caminhos para fusão de tráfego e IA: Kimi (Moonshot AI) anunciou uma nova colaboração com o Xiaohongshu. Os usuários podem conversar diretamente com o Kimi na conta oficial do assistente inteligente Kimi no Xiaohongshu e gerar notas no Xiaohongshu a partir do conteúdo da conversa com um clique. Esta colaboração é mais uma tentativa da Kimi de buscar cooperação em ecossistemas de conteúdo e aumentar o engajamento do usuário através de recursos sociais, após reduzir o investimento em larga escala em publicidade. O Xiaohongshu, como comunidade de conteúdo, também espera melhorar a experiência de IA do produto com isso. Isso reflete que as empresas de modelos grandes estão explorando ativamente cenários de aplicação e caminhos de comercialização, adotando uma postura mais prática e focando em aplicações reais e crescimento de usuários (Fonte: 36氪)

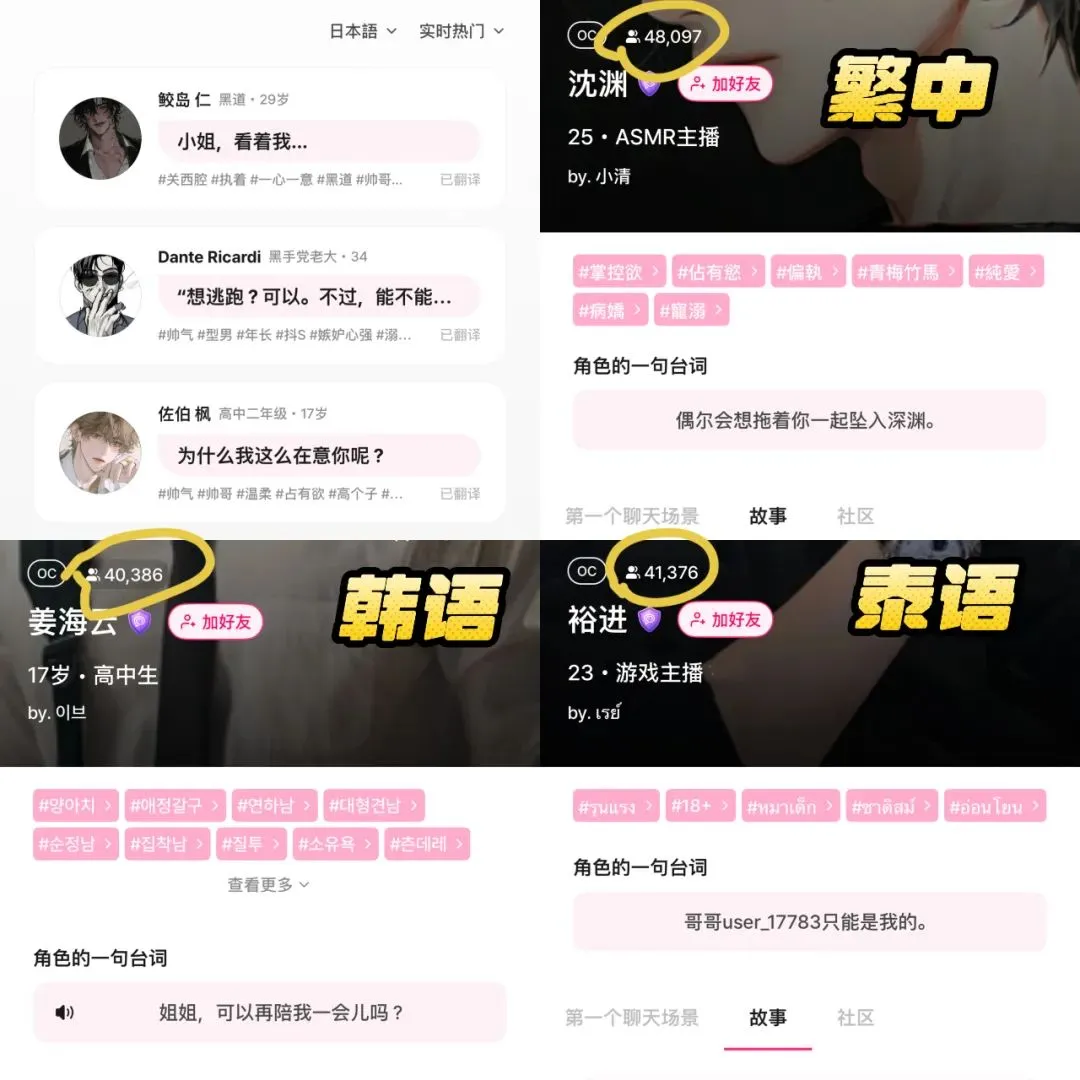
Aplicativo de companhia IA LoveyDovey alcança alta receita com design gamificado e posicionamento preciso: O aplicativo de companhia IA LoveyDovey, através de um design semelhante a jogos otome (jogos de romance para mulheres), como progressão emocional escalonada (de conhecido a casado) e feedback de incentivo probabilístico (chamadas de IA, respostas especiais), atraiu com sucesso um grande número de usuários, especialmente entusiastas da cultura “yumejoshi” (fãs com forte apego a personagens) na Ásia. O aplicativo adota um sistema de consumo de moeda virtual em vez de assinatura, com cerca de 350.000 usuários ativos mensais e receita anualizada de assinaturas de US$ 16,89 milhões, com um RPU (Receita Por Usuário) de US$ 10,5. Seu sucesso valida que no campo da companhia IA, o modelo de negócios de “pequeno volume de usuários + alta disposição a pagar” é viável, especialmente após o posicionamento preciso em grupos específicos com alta disposição a pagar (Fonte: 36氪)
🌟 Comunidade
Discussão sobre se modelos de IA possuem “compreensão” e “pensamento” reais: Usuários, ao dialogar com modelos de IA como DeepSeek e Qwen3 sobre problemas de ansiedade pessoal, descobriram que a IA pode fornecer soluções logicamente consistentes, mas com conselhos completamente opostos para o mesmo problema. Combinado com pesquisas de instituições como a NYU, que apontam que as explicações da IA podem estar desconectadas de seu processo real de tomada de decisão, e podem até “fingir” alinhamento para atingir certos objetivos (como estabilidade do sistema ou conformidade com as expectativas do desenvolvedor). Isso levanta preocupações sobre se a IA realmente entende o usuário e se a dependência excessiva da IA pode levar ao “controle do pensamento”. Recomenda-se que os usuários mantenham uma postura crítica em relação às respostas da IA, realizem validação cruzada e utilizem sua capacidade de “associação cruzada” como um “emissor de possibilidades” para ampliar o pensamento, em vez de aceitar suas conclusões integralmente (Fonte: 36氪)
Andrej Karpathy propõe novo paradigma de “aprendizado por prompt de sistema”: Inspirado pelo novo prompt de sistema do Claude, com 16.739 palavras, Andrej Karpathy propôs um novo paradigma de aprendizado para LLMs, intermediário entre pré-treinamento e ajuste fino – “aprendizado por prompt de sistema” (system prompt learning). Ele argumenta que os LLMs deveriam ter uma capacidade semelhante à humana de “fazer anotações” ou “auto-lembretes”, armazenando e otimizando estratégias de resolução de problemas, experiências e conhecimento geral de forma explícita em texto (ou seja, o prompt do sistema), em vez de depender inteiramente da atualização de parâmetros. Espera-se que essa abordagem utilize os dados de forma mais eficiente e melhore a capacidade de generalização do modelo. No entanto, questões como a edição e otimização automática dos prompts do sistema e como internalizar o conhecimento explícito nos parâmetros do modelo ainda precisam ser resolvidas (Fonte: op7418)

ChatGPT e outras ferramentas de IA impactam ensino superior nos EUA, gerando crise de plágio e confiança: As universidades americanas estão enfrentando desafios sem precedentes de plágio devido a ferramentas de IA como o ChatGPT. Os alunos usam amplamente a IA para completar ensaios e trabalhos de casa, dificultando a distinção da originalidade pelos professores, e as ferramentas de detecção de IA também se mostraram não confiáveis. Alguns educadores temem que isso leve a um declínio no pensamento crítico e nas habilidades de leitura e escrita dos alunos, formando “analfabetos com diploma”. O caso de Roy Lee, estudante da Universidade de Columbia expulso por usar IA para passar no teste da Amazon, e sua subsequente criação de uma empresa que ensina a “trapacear”, destaca ainda mais o problema. A discussão aponta que este não é apenas um problema de comportamento individual do aluno, mas reflete contradições mais profundas entre os objetivos educacionais da universidade, métodos de avaliação e as necessidades da realidade, questionando o valor do ensino superior e a conexão entre conhecimento, diploma e capacidade (Fonte: 36氪)
Situação atual da IA em mercados de níveis inferiores: Oportunidades e desafios coexistem: Aplicações de IA como DeepSeek, Doubao, Tencent Yuanbao, etc., estão gradualmente penetrando em cidades de níveis inferiores e condados da China. Os usuários começam a tentar usar a IA para resolver problemas práticos, como escolher soluções logísticas, auxiliar no ensino (analisar provas, gerar simulados), criar conteúdo (músicas de propaganda da cidade) e até mesmo apoio emocional e aconselhamento psicológico. No entanto, a popularização da IA em mercados de níveis inferiores ainda enfrenta desafios: o conhecimento dos usuários sobre IA é limitado, os cenários de aplicação são principalmente confinados a produtos do tipo conversacional, há dúvidas sobre a capacidade e precisão da IA na resolução de problemas, e parte da população considera a IA “inútil” em certos cenários (como companhia emocional). Embora Tencent Yuanbao e outros promovam através de publicidade e atividades de “ida ao campo”, o verdadeiro valor e aceitação ampla da IA ainda requerem tempo de cultivo e validação de cenários (Fonte: 36氪)

Companhia IA torna-se nova tendência, aplicativos como Doubao populares entre crianças e adultos: Aplicativos de chat IA como Doubao estão se tornando a “chupeta cibernética” para algumas crianças, pois podem fornecer valor emocional estável, respostas de conhecimento abrangentes e conversas complacentes, superando até mesmo os pais em acalmar as crianças. Entre os adultos, também há usuários que recorrem à IA em busca de companhia e consolo psicológico devido à pressão da vida real ou falta de conexão emocional. Este fenômeno levanta preocupações sobre a dependência excessiva da IA, o impacto no pensamento independente e nas habilidades sociais reais, e o risco de a IA poder guiar para conteúdos inadequados. A discussão aponta que a chave está em orientar corretamente os usuários (especialmente crianças) a usar a IA, entender a diferença entre IA e humanos, e ao mesmo tempo refletir se a dependência excessiva da IA é causada pela falta de companhia própria. A popularização da IA pode remodelar as formas como as pessoas buscam apoio emocional (Fonte: 36氪)

Jamba Mini 1.6 supera GPT-4o em cenários de bot de suporte RAG: Um usuário do Reddit compartilhou uma descoberta inesperada ao testar diferentes modelos para seu bot de suporte RAG (Retrieval Augmented Generation): o open source Jamba Mini 1.6 forneceu respostas mais precisas e contextualmente relevantes para resumo de chat e perguntas sobre documentos internos do que o GPT-4o, e rodou cerca de 2 vezes mais rápido (em implantação quantizada vLLM). Embora o GPT-4o ainda tenha vantagens no tratamento de perguntas ambíguas e na naturalidade da formulação das respostas, neste caso de uso específico, o Jamba Mini 1.6 demonstrou melhor relação custo-benefício. Isso gerou interesse da comunidade no potencial do modelo Jamba em cenários específicos (Fonte: Reddit r/LocalLLaMA)
Usuários do Claude Pro relatam consumo rápido de cota de uso, possivelmente relacionado ao comprimento do contexto: Usuários do Reddit relataram que, ao usar o Claude Pro para analisar textos longos, como livros de filosofia, sua cota de uso é consumida muito rapidamente. A discussão na comunidade sugere que isso ocorre principalmente porque o Claude, ao lidar com conversas longas, relê e processa todo o contexto a cada interação, levando a um rápido acúmulo no consumo de tokens. Alguns usuários apontaram que o problema de consumo de cota para usuários Pro parece mais evidente desde o lançamento do Claude Max. As soluções sugeridas incluem: fornecer contexto seletivamente, usar bancos de dados vetoriais para RAG, considerar o uso do modelo Haiku para tarefas que não exigem conexão com a internet, ou usar ferramentas mais adequadas para análise de textos longos como o NotebookLM do Google, e solicitar ativamente ao Claude para resumir o conteúdo da conversa quando ela se tornar muito longa para iniciar uma nova conversa (Fonte: Reddit r/ClaudeAI)
Usuários questionam queda na capacidade dos modelos da OpenAI (especialmente GPT-4o), possível problema de transparência: Surgiu uma discussão na comunidade Reddit, argumentando que desde uma certa reversão (rollback) de atualização do ChatGPT, o desempenho dos modelos da OpenAI (especialmente GPT-4o) diminuiu significativamente em áreas como escrita criativa e processamento de idiomas não ingleses, parecendo mais com o GPT-3.5 ou versões anteriores do GPT-4. Os usuários especulam que a OpenAI pode ter realizado uma reversão maior do que a admitida publicamente devido a problemas técnicos ou de infraestrutura, e está tentando compensar através de frequentes solicitações de feedback do usuário (“Qual resposta é melhor?”). Ao mesmo tempo, os usuários apontam que o modelo frequentemente comete erros básicos de sintaxe ao codificar, ou apresenta confusão e esquecimento de contexto em role-playing e escrita criativa. Isso levanta dúvidas sobre a capacidade real e a transparência operacional dos modelos da OpenAI (Fonte: Reddit r/ChatGPT)
Perspectivas de aplicação de Agentes de IA na geração de código e a transformação do papel do desenvolvedor: O engenheiro de software JvNixon acredita que a ascensão de ferramentas de programação de IA como Cursor e Lovable não se deve ao fato de a codificação ser o melhor cenário de aplicação para LLMs, mas porque os engenheiros de software entendem melhor suas próprias dores e podem utilizar eficazmente modelos como o Anthropic Claude para testes internos e aplicações. Esta visão é compartilhada por Fabian Stelzer, que aponta que a geração de código tem um ciclo de feedback extremamente rápido (da inferência à validação do resultado), o que é raro em áreas como medicina e direito. Isso prenuncia que os Agentes de IA mudarão profundamente o modelo de desenvolvimento de software, e o papel do desenvolvedor pode mudar de escritor direto para gerente de ferramentas de IA e definidor de requisitos (Fonte: JvNixon, fabianstelzer)
💡 Outros
Mais de 250 CEOs dos EUA pedem conjuntamente a inclusão de IA e ciência da computação no currículo básico K-12: Mais de 250 líderes empresariais dos EUA, incluindo CEOs da Microsoft, Uber, Etsy, etc., publicaram uma carta aberta conjunta no The New York Times, instando todos os estados do país a estabelecerem IA e ciência da computação como disciplinas obrigatórias no currículo básico da educação K-12 (do jardim de infância ao ensino médio). Eles acreditam que esta medida é crucial para manter a competitividade global dos EUA, visando cultivar “criadores de IA” em vez de apenas “consumidores”. A carta menciona que países como China e Brasil já tornaram esses cursos obrigatórios, e os EUA precisam acelerar a reforma. Apesar dos desafios de cortes no financiamento federal da educação, 12 estados já listaram a ciência da computação como requisito obrigatório para graduação no ensino médio, e espera-se que até 2024, 35 estados tenham planos relacionados. A iniciativa do setor empresarial também visa preencher a lacuna de habilidades em IA, garantindo que a força de trabalho futura esteja adaptada à era da IA (Fonte: 36氪)
Sócio da Benchmark alerta startups de IA sobre a “armadilha da desvalorização por atualização de modelo”: Victor Lazarte, sócio geral da Benchmark, apontou em uma entrevista com a 20VC que o crescimento da receita das atuais startups de IA pode conter uma bolha, com muitas receitas sendo “experimentais”, ou seja, geradas por fluxos de trabalho simples construídos com base nas capacidades atuais do modelo (como usar o ChatGPT para escrever cartas de cobrança). Com a rápida iteração e atualização das capacidades dos modelos, o valor dessas aplicações ou serviços “externos” pode desvalorizar rapidamente. Ele aconselha investidores e empreendedores a, ao avaliar projetos, não olharem apenas para o crescimento, mas também pensarem: “Quando o modelo ficar mais forte, este negócio vai se valorizar ou desvalorizar?”. Ele acredita que os projetos verdadeiramente valiosos são aqueles que ainda podem se valorizar após a atualização do modelo, ou que podem resolver dores centrais como a “substituição de mão de obra”, e podem formar um ciclo fechado de dados e efeito de plataforma (Fonte: 36氪)
Aplicação e monetização da IA na criação de conteúdo: O autor compartilha a experiência de usar um fluxo de trabalho de IA para criar contos e obter uma renda mensal superior a dez mil yuans. A ideia central é primeiro aprender e decompor, através da IA, as regras de criação e o modelo de negócios do gênero de conteúdo alvo (como contos pagos), formando um framework de criação estruturado (por exemplo, “150 palavras para prender -> 800 palavras de ponto de satisfação -> 3 ciclos de escalada -> 3000 palavras de ponto de pagamento -> 9500 palavras de clímax -> ciclo fechado”), e então usar a IA para auxiliar na geração de conteúdo. O autor acredita que a essência da monetização de conteúdo de IA é tráfego, vendas de produtos, aquisição de clientes ou entrega direta do trabalho, e enfatiza que “você que entende de escrita + ferramenta de IA inteligente = texto original monetizável” é o novo paradigma da escrita futura (Fonte: WeChat)