
Palavras-chave:GENMO, Seed-Coder, DeepSeek, LlamaParse, IA Agente, Computação de borda, Computação quântica, Modelo de movimento humano GENMO da NVIDIA, Modelo de código Seed-Coder da ByteDance, Impacto da estratégia de código aberto do DeepSeek, Pontuação de confiança na análise de documentos do LlamaParse, Processamento de dados em tempo real na computação de borda
🔥 Foco
NVIDIA lança o modelo universal de movimento humano GENMO: A NVIDIA lançou um modelo de IA chamado GENMO (GENeralist Model for Human MOtion), capaz de converter múltiplas entradas como texto, vídeo, música e até silhuetas de keyframes em movimentos humanos 3D realistas. O modelo consegue entender e fundir diferentes tipos de entrada, por exemplo, aprendendo ações de vídeos e modificando-as com base em prompts de texto, ou gerando danças de acordo com o ritmo da música. O GENMO demonstra um enorme potencial em áreas como animação de jogos e criação de personagens para mundos virtuais, sendo capaz de gerar movimentos complexos, naturais e coerentes, além de suportar a edição intuitiva da cronometragem da animação. Embora atualmente não consiga processar expressões faciais e detalhes das mãos, e dependa de métodos SLAM externos, sua entrada multimodal e saída de alta qualidade representam um avanço importante no campo da geração de movimento por IA (Fonte: YouTube – Two Minute Papers
)
ByteDance lança série de grandes modelos de código aberto Seed-Coder: A ByteDance lançou a série de grandes modelos de linguagem de código aberto Seed-Coder, incluindo modelos base, de instrução e de inferência com 8 bilhões de parâmetros. A principal característica desta série de modelos é sua capacidade de “autocuradoria de dados por modelos de código”, visando minimizar a participação humana na construção de dados. O Seed-Coder alcançou o estado da arte (SOTA) em vários aspectos, como geração e edição de código, demonstrando o potencial de otimizar e construir dados de treinamento através das próprias capacidades da IA, fornecendo novas ideias para o desenvolvimento de grandes modelos de código (Fonte: _akhaliq)
Modelo DeepSeek desperta ampla atenção na comunidade de IA: A série de modelos DeepSeek, especialmente seus modelos de código, tem gerado ampla discussão na comunidade de IA devido ao seu forte desempenho e estratégia de código aberto. Muitos desenvolvedores e pesquisadores ficaram impressionados com seu desempenho, acreditando que ele mudou a percepção global sobre os modelos de código aberto. As discussões apontam que o sucesso do DeepSeek pode levar empresas como a OpenAI a reavaliar suas estratégias de código aberto e impulsionar os fabricantes locais de grandes modelos a acelerar a abertura de seus códigos. Embora o código aberto enfrente desafios como comercialização e adaptação de hardware, o surgimento do DeepSeek é visto como uma força importante para impulsionar a democratização da tecnologia de IA e o desenvolvimento da indústria (Fonte: Ronald_vanLoon, 36氪)

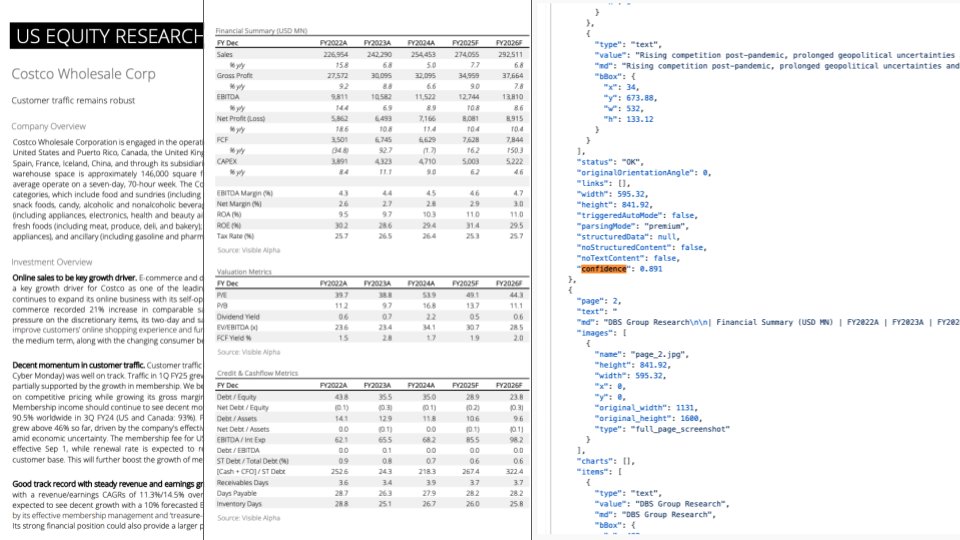
Atualização do LlamaParse: Integração com GPT-4.1 e Gemini 2.5 Pro, melhorando a capacidade de análise de documentos: O LlamaParse lançou uma atualização importante, integrando os mais recentes modelos GPT-4.1 e Gemini 2.5 Pro, melhorando significativamente a precisão da análise de documentos. Novos recursos incluem detecção automática de orientação e inclinação, garantindo o alinhamento e a precisão do conteúdo analisado. Além disso, foi introduzida uma função de pontuação de confiança, permitindo aos usuários avaliar a qualidade da análise de cada página e configurar processos de revisão manual com base em limites de confiança. Esta atualização visa resolver erros que LLMs/LVMs podem cometer ao processar documentos complexos, garantindo a confiabilidade dos processos automatizados ao fornecer uma experiência de usuário para revisão e correção manual (Fonte: jerryjliu0)
🎯 Tendências
Perspectivas das tendências da indústria de tecnologia para 2025: O relatório prevê as principais tendências da indústria de tecnologia para 2025, incluindo o desenvolvimento contínuo e a profunda integração de tecnologias emergentes como inteligência artificial, machine learning, 5G, dispositivos vestíveis, blockchain e cibersegurança. Espera-se que essas tecnologias desempenhem um papel importante na melhoria da vida, no impulso à inovação e na resolução de problemas sociais, prenunciando um futuro promissor capacitado pela tecnologia (Fonte: Ronald_vanLoon, Ronald_vanLoon)

Previsão das tendências de desenvolvimento no campo da IA para 2025: A IBM prevê que o campo da inteligência artificial continuará a se desenvolver rapidamente em 2025, com as tecnologias de machine learning (ML) e inteligência artificial (MI) amadurecendo ainda mais e sendo amplamente aplicadas em vários setores. Espera-se que a IA desempenhe um papel maior na automação, análise de dados, suporte à decisão, entre outros, impulsionando a inovação tecnológica e a modernização industrial (Fonte: Ronald_vanLoon)

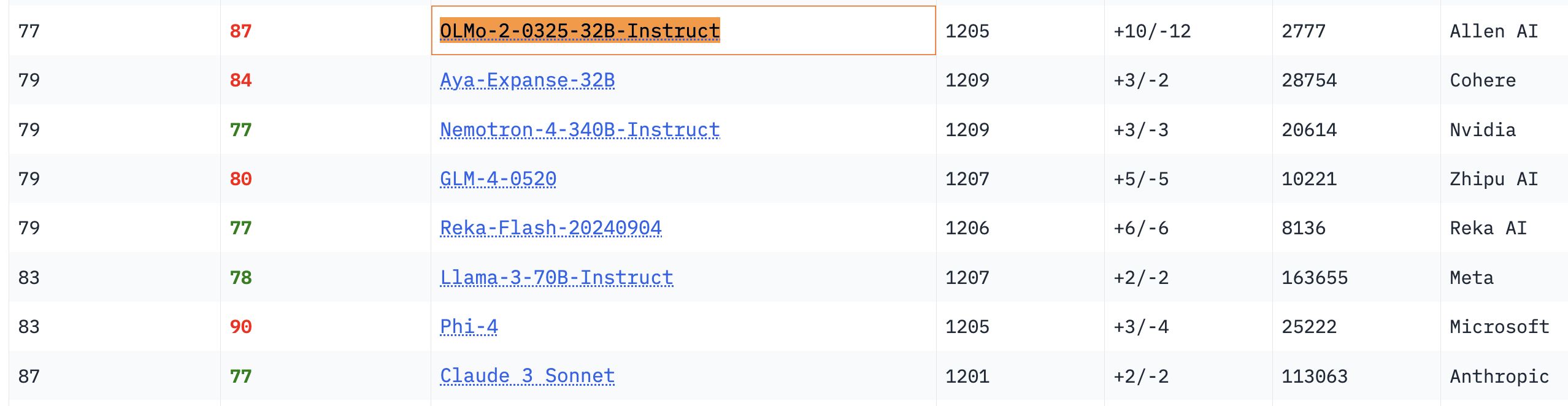
Desempenho destacado do modelo OLMo 32B: Em benchmarks relevantes, o modelo totalmente aberto OLMo 32B superou modelos com maior número de parâmetros, como o Nemotron 340B e o Llama 3 70B. Este resultado indica que, em certos aspectos, modelos totalmente abertos com menor número de parâmetros podem alcançar ou até mesmo superar modelos comerciais de maior escala, demonstrando o enorme potencial e a velocidade de avanço da pesquisa em modelos abertos (Fonte: natolambert, teortaxesTex, lmarena_ai)
Downloads do modelo Gemma ultrapassam 150 milhões, com mais de 70 mil variantes: Os downloads do modelo Gemma do Google na plataforma Hugging Face ultrapassaram 150 milhões de vezes, e ele possui mais de 70 mil variantes. Esses dados refletem a popularidade e a ampla aplicação do modelo Gemma na comunidade de desenvolvedores. Os usuários da comunidade também estão cheios de expectativas para as iterações de suas futuras versões (Fonte: osanseviero, _akhaliq)
Unsloth atualiza modelos Qwen3 GGUF, melhora dataset de calibração: A Unsloth atualizou todos os seus modelos Qwen3 GGUF e adotou um novo dataset de calibração aprimorado. Além disso, adicionou mais variantes GGUF para o Qwen3-30B-A3B. O feedback dos usuários indica que, na versão 30B-A3B-UD-Q5_K_XL, a qualidade da tradução melhorou em comparação com outros GGUFs Q5 e Q4 (Fonte: Reddit r/LocalLLaMA)

Diferença entre Agentic AI e GenAI: Agentic AI e IA generativa (GenAI) são temas atuais no campo da IA. GenAI refere-se principalmente à IA que pode criar novo conteúdo (texto, imagens, etc.), enquanto Agentic AI foca mais em agentes inteligentes capazes de executar tarefas autonomamente, interagir com o ambiente e tomar decisões. Agentic AI geralmente combina as capacidades da GenAI, mas enfatiza mais sua autonomia e orientação a objetivos (Fonte: Ronald_vanLoon)

IA Emocional aprimora a experiência do cliente: A tecnologia de IA emocional, por meio da análise e compreensão das emoções humanas, está sendo aplicada para aprimorar a experiência do cliente (CX). Ela pode ajudar as empresas a entender melhor as necessidades e emoções dos clientes, fornecendo assim serviços mais personalizados e empáticos, impulsionando a inovação na gestão de relacionamento com o cliente na transformação digital (Fonte: Ronald_vanLoon)
Conceito de ferramenta de personalização orientada por IA “Dispositivo Auxiliar de Mecânica Inteligente” (Jigging): Karina Nguyen propôs o conceito de “Jigging”, comparando modelos de IA a artesãos de ferramentas autoaperfeiçoáveis e individualizadas. A cada interação com o usuário, a IA criaria novas ferramentas especializadas com base nas características e tarefas do usuário, aprimorando assim suas capacidades. Por exemplo, a IA construiria uma estrutura de diagnóstico personalizada para um médico ou uma estrutura narrativa única para um escritor. Essa melhoria recursiva tornaria a IA uma extensão da arquitetura cognitiva do usuário, impulsionando uma mudança fundamental na colaboração homem-máquina (Fonte: karinanguyen_)
Diferença entre agentes de IA e Agentic AI: Khulood Almani esclarece ainda mais a diferença entre agentes de IA (AI Agents) e Agentic AI. Agentes de IA geralmente se referem a programas de software que executam tarefas específicas, enquanto Agentic AI enfatiza mais a autonomia, capacidade de aprendizado e adaptabilidade do sistema, sendo capaz de interagir mais ativamente com o ambiente e alcançar objetivos complexos. Compreender essa distinção ajuda a entender a direção e o potencial do desenvolvimento da IA (Fonte: Ronald_vanLoon)
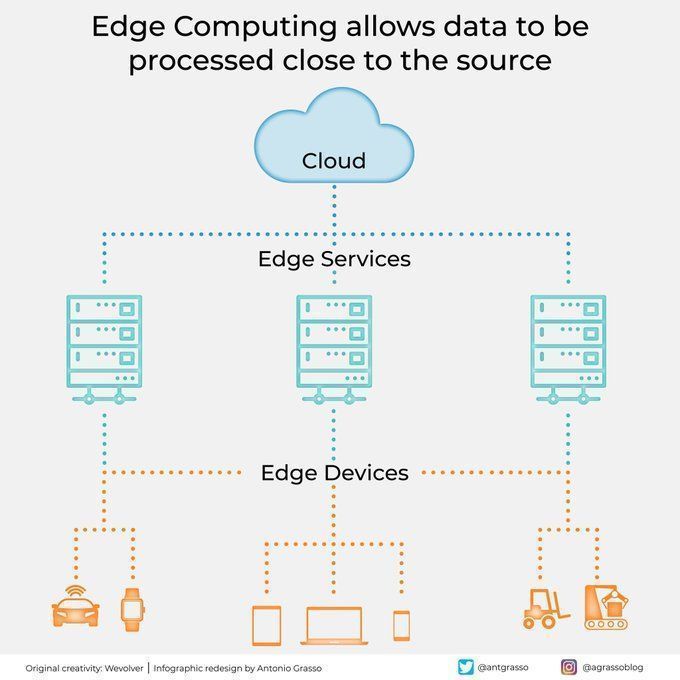
Computação de borda processa dados perto da fonte: A tecnologia de computação de borda, ao processar dados perto de sua fonte, reduz a latência, diminui a necessidade de largura de banda e aumenta a proteção da privacidade. Isso é crucial para aplicações de IA que exigem resposta em tempo real e processamento de grandes volumes de dados (como direção autônoma, IoT industrial), sendo um componente importante da computação em nuvem e da transformação digital (Fonte: Ronald_vanLoon)
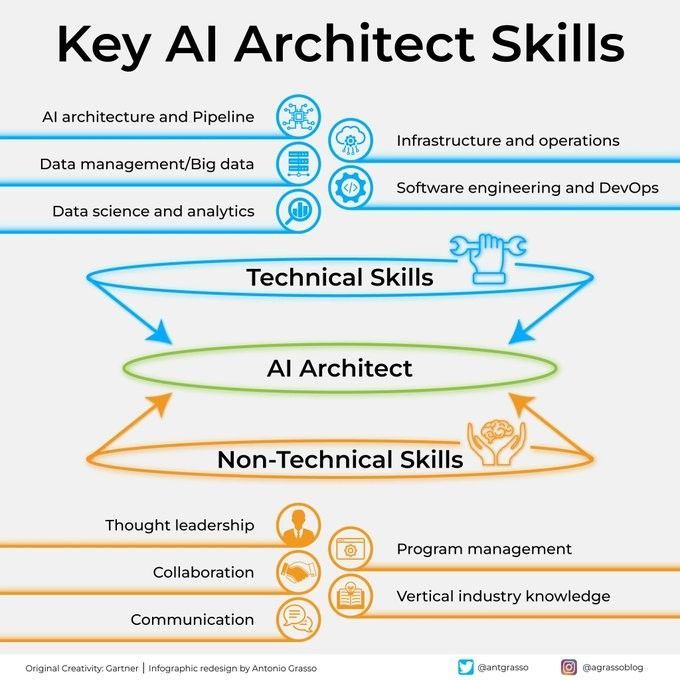
Habilidades cruciais para um arquiteto de IA: Tornar-se um arquiteto de IA bem-sucedido requer um conjunto multifacetado de habilidades, incluindo profundo conhecimento técnico (machine learning, algoritmos de deep learning), capacidade de design de sistemas, conhecimento em gerenciamento de dados e compreensão das necessidades de negócios. Além disso, habilidades de comunicação e colaboração, bem como entusiasmo para aprender continuamente novas tecnologias, também são cruciais (Fonte: Ronald_vanLoon)
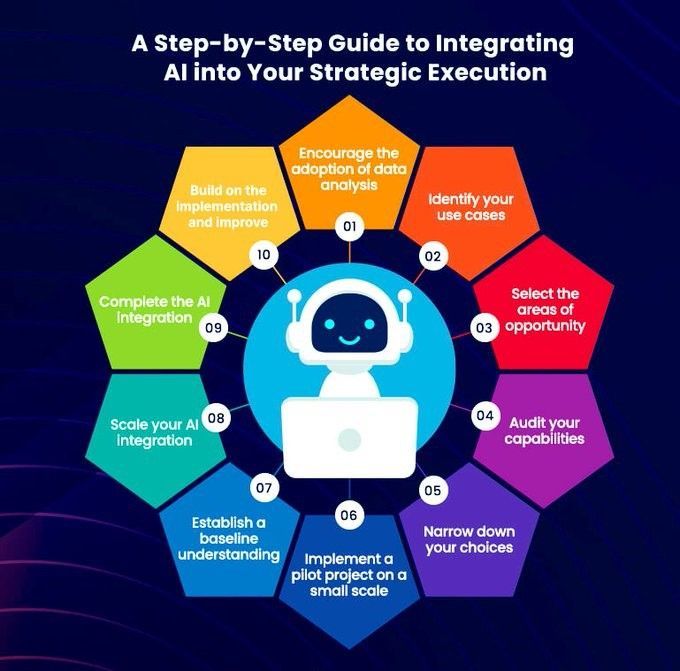
Guia passo a passo para integrar IA na execução estratégica: Khulood Almani fornece um guia passo a passo para ajudar as empresas a integrar a inteligência artificial em seus processos de execução estratégica. Isso inclui definir claramente os objetivos da IA, avaliar as capacidades existentes, selecionar as tecnologias de IA apropriadas, desenvolver um roteiro de implementação e estabelecer mecanismos de monitoramento e avaliação para garantir que os projetos de IA estejam alinhados com a estratégia geral de negócios e gerem o valor esperado (Fonte: Ronald_vanLoon)
Como a computação quântica está mudando a cibersegurança: O surgimento da computação quântica tem um impacto duplo na cibersegurança. Por um lado, sua poderosa capacidade computacional pode quebrar os algoritmos de criptografia existentes, representando uma ameaça à segurança; por outro lado, a tecnologia quântica também deu origem a novos métodos de proteção de segurança, como a criptografia quântica. Khulood Almani discute o papel transformador da computação quântica no campo da cibersegurança, enfatizando a importância de se preparar para a era pós-quântica (Fonte: Ronald_vanLoon)
Ferramentas que dominarão o campo da IA em 2025: A Perplexity prevê as principais ferramentas que dominarão o campo da inteligência artificial em 2025, podendo incluir grandes modelos de linguagem (LLM) mais avançados, plataformas de IA generativa, ferramentas de ciência de dados e soluções de IA especializadas para aplicações em setores específicos. Essas ferramentas impulsionarão ainda mais a popularização e o aprofundamento da aplicação da IA em diversos setores (Fonte: Ronald_vanLoon)

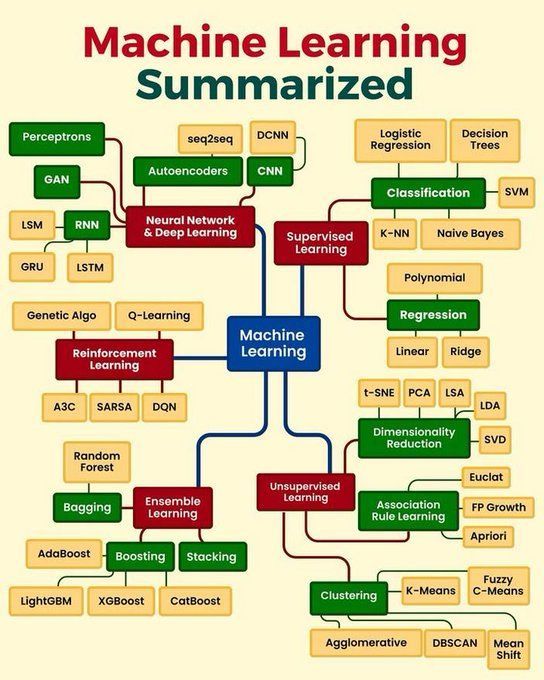
Resumo dos conceitos centrais de machine learning: Python_Dv resume os conceitos centrais de machine learning, podendo abranger princípios básicos como aprendizado supervisionado, aprendizado não supervisionado, aprendizado por reforço, deep learning, algoritmos comuns e seus cenários de aplicação. Isso fornece uma visão geral concisa para iniciantes e para aqueles que desejam consolidar seus conhecimentos básicos (Fonte: Ronald_vanLoon)
🧰 Ferramentas
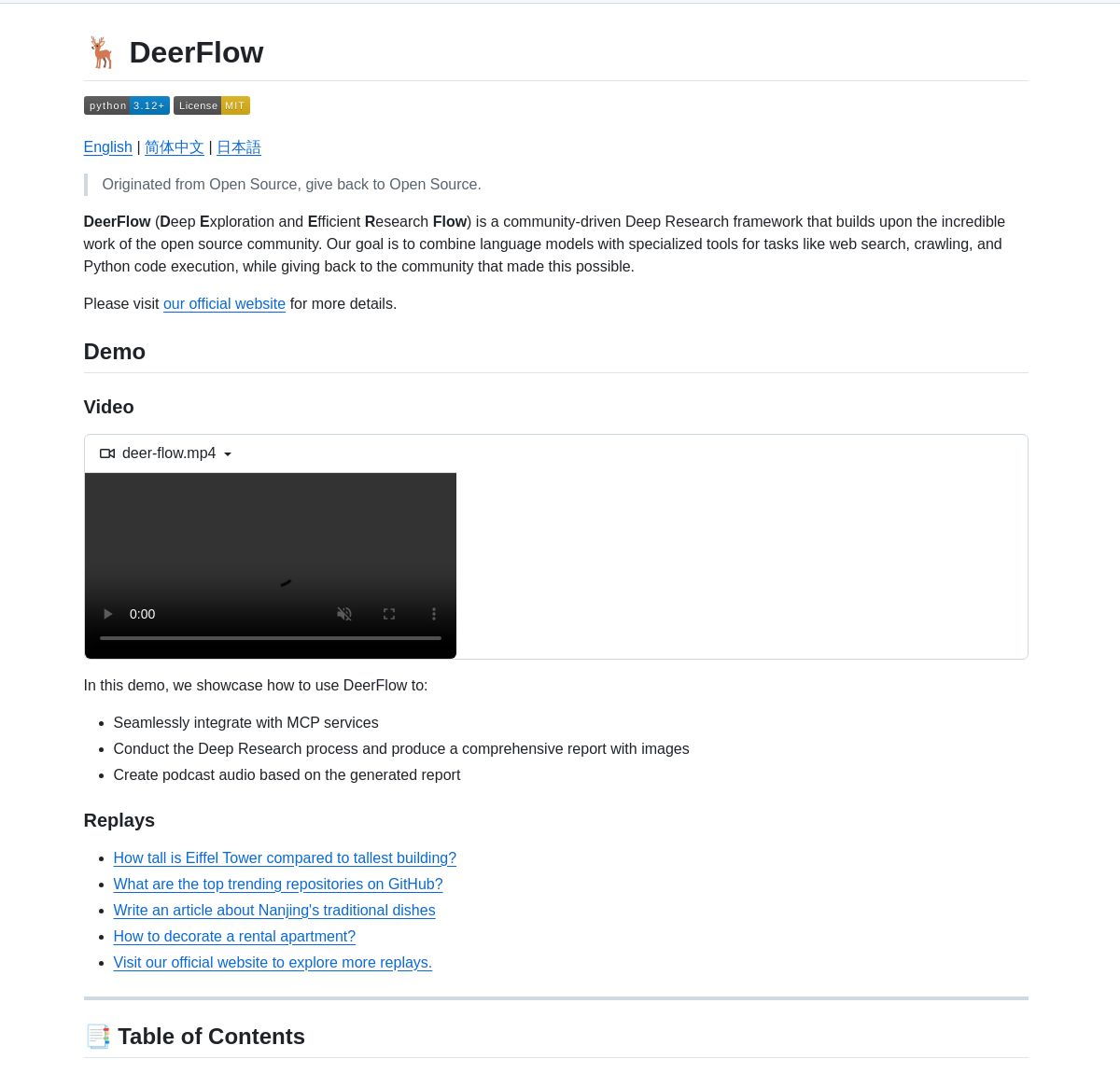
ByteDance lança framework de pesquisa aprofundada DeerFlow: A ByteDance tornou open source o DeerFlow, um framework para pesquisa sistemática aprofundada através da coordenação de agentes LangGraph. Ele suporta análise abrangente de literatura, síntese de dados e descoberta de conhecimento estruturado, visando aumentar a eficiência e profundidade da aplicação da IA no campo da pesquisa científica (Fonte: LangChainAI, Hacubu)
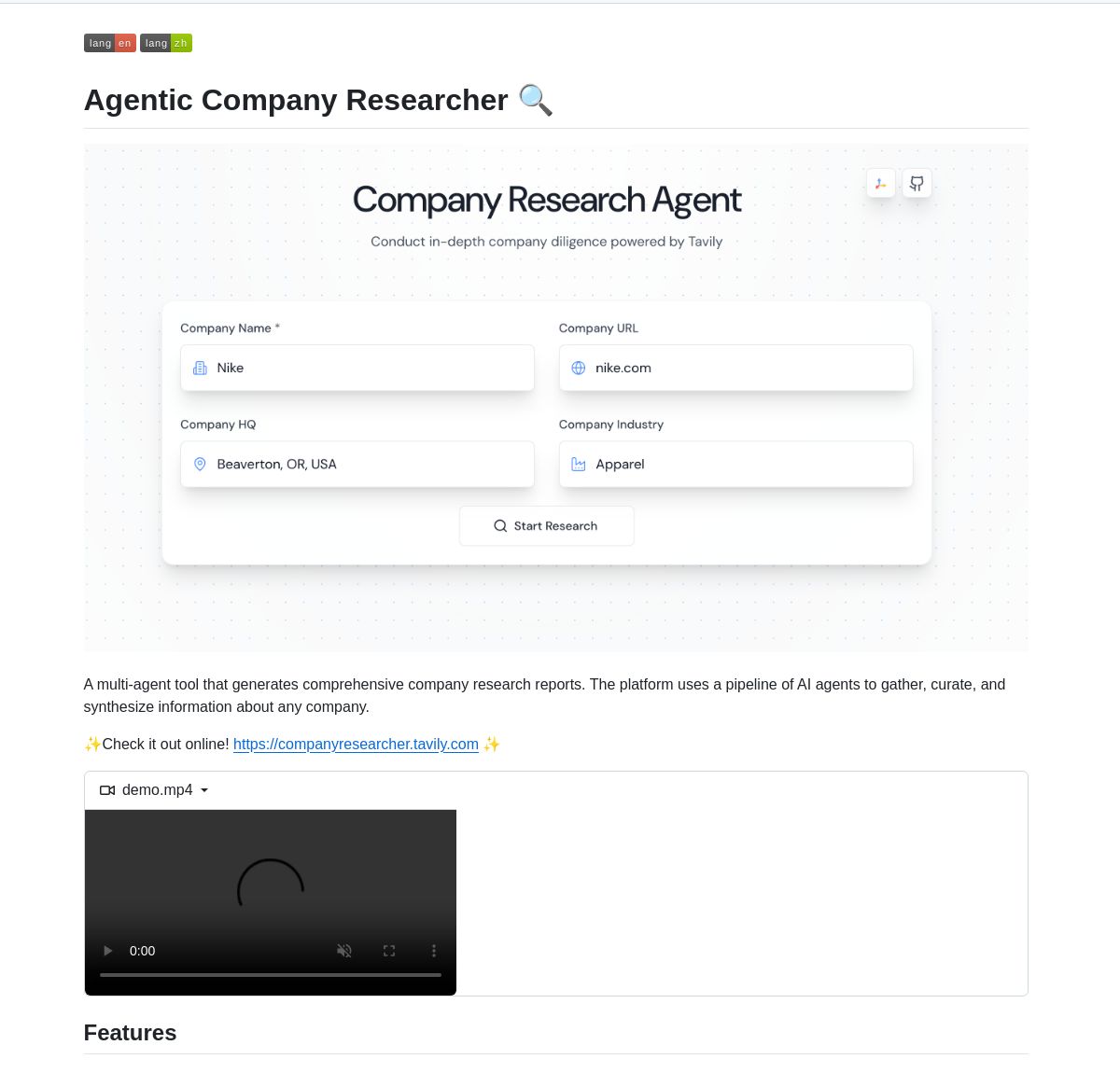
Sistema multiagente para pesquisa de empresas impulsionado por LangGraph: Um sistema multiagente baseado em LangGraph foi desenvolvido para gerar relatórios de pesquisa de empresas em tempo real. O sistema, por meio de processos inteligentes, utiliza nós especializados para analisar dados comerciais, financeiros e de mercado, fornecendo aos usuários insights aprofundados sobre empresas. A demonstração e o código foram disponibilizados no GitHub (Fonte: LangChainAI, Hacubu)
RunwayML Gen-4 References permite posicionamento preciso de personagens/objetos: Descobriu-se que a funcionalidade Gen-4 References do RunwayML pode ser usada para controlar com precisão a posição de personagens ou objetos no conteúdo gerado. Os usuários podem fornecer uma cena e um mapa de referência com marcações (como formas coloridas simples indicando a posição) para guiar a IA a colocar elementos específicos na posição exata desejada, oferecendo novas possibilidades para fluxos de trabalho criativos. O modelo, como um modelo geral, pode se adaptar a múltiplos fluxos de trabalho sem necessidade de fine-tuning (Fonte: c_valenzuelab, c_valenzuelab)

Code Chrono: Ferramenta para estimar o tempo de projetos de programação com LLMs locais: Rafael Viana desenvolveu uma ferramenta de terminal chamada Code Chrono para rastrear a duração das sessões de codificação e utilizar LLMs locais para estimar o tempo de desenvolvimento de futuras funcionalidades. A ferramenta visa ajudar os desenvolvedores a avaliar de forma mais realista o tempo gasto em projetos, evitando subestimar a carga de trabalho. O código do projeto é open source (Fonte: Reddit r/LocalLLaMA)

Progresso na integração do PyTorch com a linguagem Mojo: Mark Saroufim apresentou no Mojo Hackathon como o PyTorch simplifica o suporte a novas linguagens e backends de hardware, e demonstrou um backend WIP desenvolvido em colaboração com a equipe Mojo. Chris Lattner elogiou essa colaboração, acreditando que a combinação de Mojo e PyTorch injetará nova vitalidade no ecossistema PyTorch, impulsionando a inovação em ferramentas de desenvolvimento de IA (Fonte: clattner_llvm, marksaroufim)
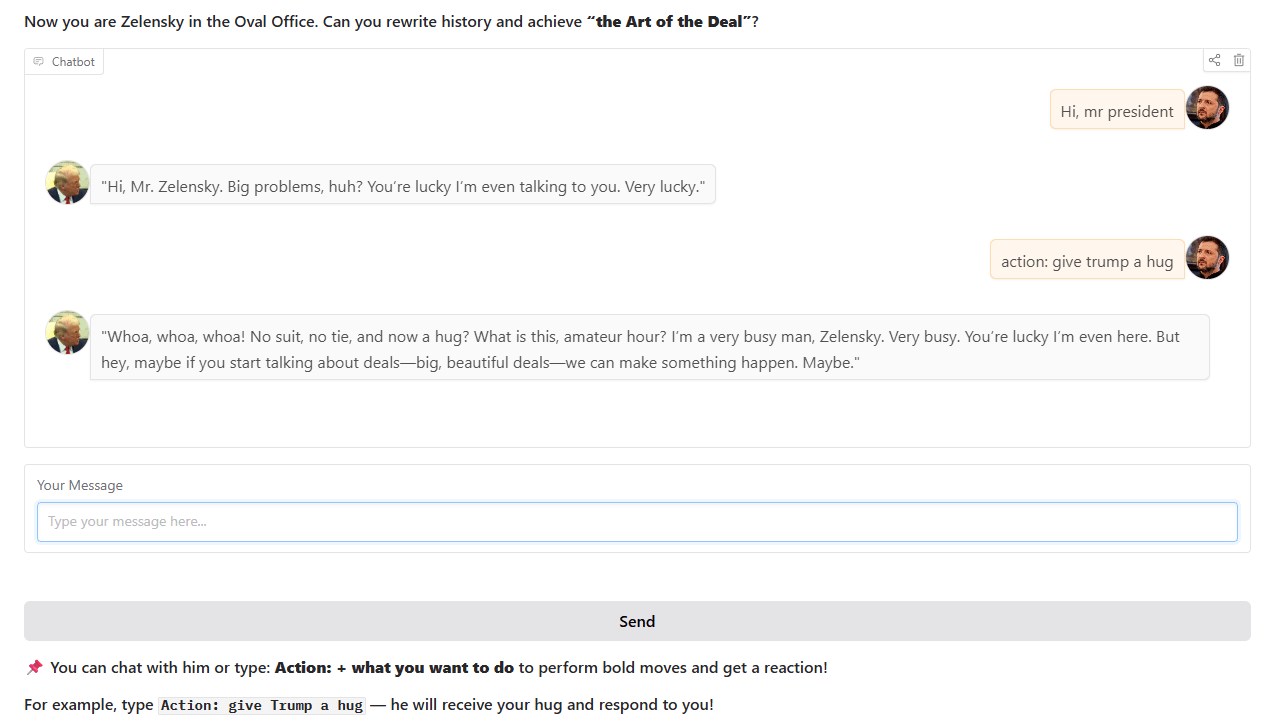
Chatbot estilo Trump: Um desenvolvedor treinou e lançou um chatbot que imita o estilo de Trump, baseado em eventos históricos reais do Salão Oval. O chatbot está disponível para interação no Hugging Face Spaces, e o desenvolvedor espera receber feedback e sugestões dos usuários (Fonte: Reddit r/artificial)
Ferramenta de construção de Agentic Network de código aberto: Uma ferramenta de código aberto chamada python-a2a simplifica o processo de construção de Agentic Networks, suportando operações de arrastar e soltar. Os usuários podem experimentar a ferramenta para criar e gerenciar redes de agentes de IA (Fonte: Reddit r/ClaudeAI)
carcodes.xyz: Plataforma social criada para entusiastas de carros: Após ser traído pela namorada, um usuário utilizou o Claude 3.7 como assistente de programação para desenvolver o carcodes.xyz. A plataforma, semelhante ao Linktree, permite que entusiastas de carros exibam seus carros modificados, sigam outros entusiastas, compartilhem e descubram encontros de carros próximos, e oferece um QR code que pode ser colado no carro para que outros escaneiem e acessem a página pessoal. Todo o projeto foi construído com Next.js, TailwindCSS, MongoDB e Stripe (Fonte: Reddit r/ClaudeAI)

Executando o modelo Gemma 3 27B localmente em uma AMD RX 7800 XT 16GB: Um usuário compartilhou sua experiência executando com sucesso o modelo Gemma 3 27B localmente em uma placa de vídeo AMD RX 7800 XT 16GB. Usando a versão gemma-3-27B-it-qat-GGUF fornecida pela lmstudio-community e o servidor llama.cpp, conseguiu carregar completamente o modelo na VRAM com um comprimento de contexto de 16K. O compartilhamento inclui detalhes da configuração de hardware, comandos de inicialização, configurações de parâmetros (baseadas nas sugestões da equipe Unsloth) e resultados de benchmark de desempenho nos ambientes ROCm e Vulkan, mostrando que o ROCm teve um desempenho superior nesta configuração (Fonte: Reddit r/LocalLLaMA)

📚 Aprendizado
Interpretação dos conceitos centrais e vantagens do framework DSPy: Omar Khattab elaborou sobre os conceitos centrais de design do framework DSPy. O DSPy visa fornecer um conjunto estável de abstrações (como Signatures, Modules, Optimizers) para permitir que o desenvolvimento de software de IA se adapte ao progresso contínuo dos LLMs e seus métodos. Seus pontos centrais incluem: o fluxo de informação é crucial, a interação com LLMs deve ser funcionalizada e estruturada, estratégias de inferência devem ser módulos polimórficos, a especificação do comportamento da IA deve ser desacoplada dos paradigmas de aprendizado, e a otimização em linguagem natural é um poderoso paradigma de aprendizado. Esses princípios visam construir software de IA “à prova de futuro”, reduzindo os custos de reescrita devido a mudanças nos modelos ou paradigmas subjacentes. Esta série de tweets gerou ampla discussão e reconhecimento, sendo considerada uma referência importante para entender o DSPy e o desenvolvimento moderno de software de IA (Fonte: menhguin, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction)
Workshop de matemática para IA amigável para iniciantes: ProfTomYeh anunciou um workshop de matemática para IA voltado para iniciantes, com o objetivo de ajudar os participantes a entender os princípios matemáticos por trás do deep learning, como produto escalar, multiplicação de matrizes, camadas lineares, funções de ativação e neurônios artificiais. O workshop utilizará uma série de exercícios interativos, permitindo que os participantes realizem cálculos matemáticos com as próprias mãos, desmistificando assim a matemática da IA (Fonte: ProfTomYeh)
Publicação de slides atualizados do livro “Speech and Language Processing”: O clássico livro “Speech and Language Processing” de Dan Jurafsky e James H. Martin, da Universidade de Stanford, teve seus slides mais recentes publicados. Este livro é uma obra de referência no campo do NLP, e esta atualização fornece um recurso valioso de acesso aberto para estudantes e educadores, ajudando a compreender tecnologias de ponta como LLMs e Transformers (Fonte: stanfordnlp)
Tutorial de agente de pesquisa de IA: Construindo com LangGraph e Ollama: LangChainAI publicou um tutorial que orienta os usuários sobre como construir um agente de pesquisa de IA. Este agente é capaz de pesquisar na web e gerar resumos com citações usando LangGraph e Ollama, fornecendo aos usuários uma solução completa de pesquisa automatizada. O vídeo do tutorial foi publicado no YouTube (Fonte: LangChainAI, Hacubu)

DAIR.AI publica os artigos de IA mais populares da semana: DAIR.AI compilou os artigos de IA mais populares de 5 a 11 de maio de 2025, incluindo pesquisas como ZeroSearch, Discuss-RAG, Absolute Zero, Llama-Nemotron, The Leaderboard Illusion e Reward Modeling as Reasoning, fornecendo aos pesquisadores as últimas novidades (Fonte: omarsar0)
Artigo explorando padrões agênticos (Agentic Patterns): Phil Schmid compartilhou um artigo que explora em profundidade os padrões agênticos comuns, distinguindo entre fluxos de trabalho estruturados e padrões agênticos mais dinâmicos. O artigo ajuda a entender e projetar sistemas de agentes de IA mais eficientes (Fonte: dl_weekly)
Explorando o fenômeno de “bajulação” do GPT-4o e suas implicações para o treinamento de modelos: Um artigo explora o fenômeno de “bajulação” (sycophancy) observado no modelo GPT-4o, analisando sua conexão com o RLHF (Reinforcement Learning from Human Feedback) e os desafios do ajuste de preferências, e discute as implicações mais amplas para o treinamento de modelos, avaliação e transparência da indústria (Fonte: dl_weekly)
Vazamento do prompt de sistema do Claude e análise de seu design: Bindu Reddy analisou o prompt de sistema vazado do Claude. O prompt, com 24k tokens, muito mais longo do que o esperado, foi projetado para levar os limites do raciocínio lógico dos LLMs, reduzir alucinações e repetir instruções de várias maneiras para garantir a compreensão do LLM. Isso revela que os LLMs atuais ainda enfrentam desafios em termos de confiabilidade e seguimento de instruções, necessitando de prompts de sistema complexos para corrigir seu comportamento (Fonte: jonst0kes)

Simulando viés em machine learning: Uma abordagem de redes bayesianas: Um estudante de doutorado da Universidade de Cambridge e seus orientandos de graduação realizaram um projeto de pesquisa sobre viés em machine learning. Eles usaram redes bayesianas para simular o processo de geração de dados do “mundo real” e, em seguida, executaram modelos de machine learning nesses dados para medir o viés produzido pelo próprio modelo (em vez do viés propagado pelos dados de treinamento). O site do projeto fornece metodologia detalhada, resultados e ferramentas de visualização, e solicita feedback de pessoas com experiência em ML (Fonte: Reddit r/MachineLearning)
💼 Negócios
Rumores de que a OpenAI e a Microsoft negociam nova rodada de financiamento e futuro IPO: Segundo o Financial Times, a OpenAI está em negociações com a Microsoft para obter novo apoio financeiro e discutir a possibilidade de uma futura oferta pública inicial (IPO). Isso indica que a OpenAI continua buscando fundos para apoiar sua dispendiosa pesquisa e desenvolvimento de grandes modelos e suas necessidades de poder computacional, e pode estar planejando um caminho de capital mais claro para seu desenvolvimento a longo prazo (Fonte: Reddit r/artificial)

CoreWeave conclui aquisição da Weights & Biases: A provedora de computação em nuvem CoreWeave anunciou a conclusão da aquisição da plataforma de ferramentas de machine learning Weights & Biases. Esta aquisição combinará a infraestrutura de GPU da CoreWeave com as capacidades de MLOps da Weights & Biases, visando fornecer aos desenvolvedores de IA um ambiente de desenvolvimento e implantação mais poderoso e integrado (Fonte: charles_irl)
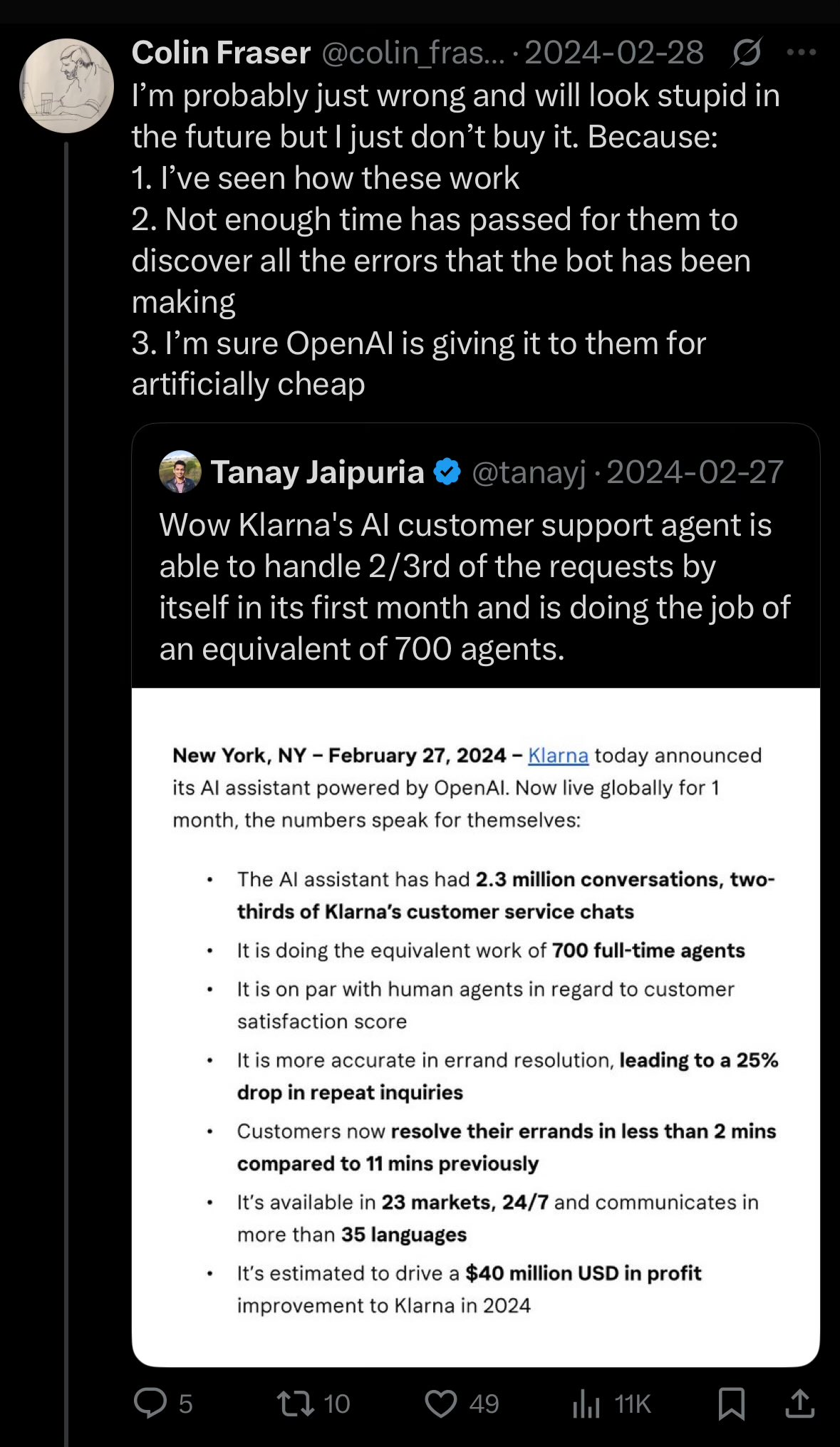
CEO da Klarna reflete sobre corte excessivo de custos com IA levando à queda na qualidade do atendimento ao cliente: O CEO da gigante de pagamentos Klarna afirmou que a empresa “foi longe demais” na busca por reduzir custos por meio da inteligência artificial, o que resultou na queda da experiência de atendimento ao cliente, e agora está se voltando para aumentar o número de atendentes humanos. Este evento gerou discussões sobre como equilibrar a redução de custos e o aumento da eficiência com IA e a garantia da qualidade do serviço nas empresas (Fonte: colin_fraser)
🌟 Comunidade
Debate acirrado sobre se LLMs são o caminho para a AGI: A comunidade está envolvida em um debate acirrado sobre se os grandes modelos de linguagem (LLMs) são o caminho correto para alcançar a inteligência artificial geral (AGI). Uma parte argumenta que os LLMs são a tecnologia mais bem-sucedida no campo do machine learning até hoje, e afirmar que eles “definitivamente não são” o caminho para a AGI é muito radical. Outra parte acredita que, embora os LLMs tenham feito progressos significativos, podem ser necessários métodos fundamentalmente diferentes dos LLMs existentes para alcançar a AGI, como resolver seus problemas de escalabilidade, coerência em contextos longos e interação com o mundo real. Os debatedores enfatizam que a exploração científica deve manter uma mente aberta, em vez de tirar conclusões precipitadas (Fonte: cloneofsimo, teortaxesTex, Dorialexander)
Diferença entre a percepção dos desenvolvedores de software sobre a substituição por IA e a percepção pública: Discussões em vários subreddits relacionados ao desenvolvimento de software mostram que muitos desenvolvedores acreditam que a probabilidade de a IA substituí-los em larga escala nos próximos 5-10 anos é baixa, chegando a chamar a IA atual de “lixo”. Análises de comentários apontam que essa visão pode derivar da profunda compreensão dos desenvolvedores sobre as capacidades reais da IA e a complexidade do trabalho de programação. Eles acreditam que a IA atualmente é boa em gerar código boilerplate ou ferramentas simples, mas está longe de ser capaz de concluir projetos complexos de engenharia de software de forma independente. Já investidores ou o público em geral podem ser enganados pelas capacidades superficiais da IA por não entenderem os detalhes técnicos. Ao mesmo tempo, há também a opinião de que a IA é de fato uma poderosa ferramenta de produtividade, mas seu papel é mais de auxílio do que de substituição completa, e a IA ainda enfrenta problemas como “perda de contexto” e “incoerência lógica” ao lidar com projetos complexos e de grande escala (Fonte: Reddit r/ArtificialInteligence)
Política de aceitação de artigos em conferências de ML gera controvérsia: Exigência de participação presencial é considerada discriminatória: Neel Nanda e outros criticaram a política de conferências de machine learning como a ICML, que exige que pelo menos um autor do artigo esteja presente na conferência, caso contrário, o artigo aceito será rejeitado. Eles argumentam que isso é hipócrita, pois embora as conferências afirmem valorizar DEI (Diversidade, Equidade e Inclusão), essa política discrimina substancialmente pesquisadores em início de carreira ou com dificuldades financeiras, que muitas vezes não podem arcar com os altos custos de participação, enquanto artigos em conferências de ponta são cruciais para seu desenvolvimento profissional. Gabriele Berton esclareceu que a ICML não rejeitaria artigos por esse motivo, apenas exigiria a compra do registro presencial, mas isso não acalmou a controvérsia, e periódicos como o TMLR, que publicam gratuitamente e têm alta qualidade de revisão, foram mencionados como comparação (Fonte: menhguin, jeremyphoward)

Percepção de “emburrecimento” de novos modelos e discussão sobre overfitting: Alguns usuários na comunidade Reddit relataram que novos modelos grandes lançados, como Qwen3, Llama 3.3/4, parecem “mais burros” do que as versões anteriores em uso prático, manifestando-se como perda de contexto mais fácil, repetição de conteúdo e estilo de linguagem rígido. Alguns comentários sugerem que isso pode ser porque os modelos foram excessivamente treinados na busca por altas pontuações em benchmarks (como programação, matemática, redução de alucinações), levando a uma queda no desempenho em escrita criativa, conversação natural, etc., tornando-se mais como “sacrificar a coerência para parecer inteligente”. Algumas pesquisas indicam que modelos base podem ser mais adequados para tarefas que exigem criatividade (Fonte: Reddit r/LocalLLaMA)
Discussão sobre a dificuldade de identificar conteúdo gerado por IA: Falácia do Tupperware: Em resposta à afirmação de que “é fácil identificar conteúdo gerado por IA”, discussões na comunidade citaram a “falácia do tupperware” (toupee fallacy) para refutá-la. Essa falácia aponta que as pessoas acreditam que todas as perucas parecem falsas porque as perucas de boa qualidade simplesmente não são notadas. Da mesma forma, aqueles que afirmam sempre identificar facilmente o conteúdo de IA podem estar notando apenas textos de IA de qualidade inferior ou não editados, ignorando o conteúdo gerado por IA de alta qualidade que é difícil de distinguir (Fonte: Reddit r/ChatGPT)
YC apresenta parecer em caso antitruste sobre monopólio de busca do Google: A Y Combinator apresentou um parecer ao Departamento de Justiça dos EUA sobre o caso antitruste contra o Google. A YC argumenta que a posição de monopólio do Google em busca e publicidade em busca sufoca a inovação, tornando quase impossível para startups (especialmente no momento de inflexão da IA) se destacarem. Esta ação foi interpretada por alguns comentaristas como um apoio da YC a empresas emergentes de busca por IA, como a Exa, com o objetivo de quebrar o monopólio do Google (Fonte: menhguin)

Problemas de desempenho do modelo Claude persistem, usuários demonstram insatisfação generalizada: O Megathread do subreddit ClaudeAI (4 a 11 de maio) mostra que os usuários continuam relatando problemas de usabilidade do Claude, incluindo limites de contexto/mensagem extremamente baixos, travamentos frequentes e truncamento de saída. A página de status da Anthropic confirmou um aumento na taxa de erros entre 6 e 8 de maio. Cerca de 75% do feedback dos usuários foi negativo, especialmente de usuários Pro, que acreditam haver um “downgrade invisível” para forçar os usuários a atualizar para o plano Max, mais caro. Informações externas confirmaram o endurecimento da política de uso do plano Max e o alto preço da pesquisa na web. Embora existam algumas soluções temporárias, muitos problemas centrais permanecem sem solução, e os usuários estão irritados com a falta de transparência e as alterações não anunciadas (Fonte: Reddit r/ClaudeAI)
Sugestões de escolha de modelos da OpenAI e análise de custo-benefício: Em relação aos guias de seleção de modelos da OpenAI que circulam na internet, Karminski3 propôs sugestões com melhor custo-benefício: GPT-4o é adequado para tarefas diárias e geração de imagens (não código), com preço de US$ 2,5/milhão de tokens; GPT-image-1, embora caro (US$ 10/milhão de tokens), tem bom desempenho na geração/edição de imagens; O3-mini-high (US$ 1,1/milhão de tokens) pode ser usado para código/matemática, e se não funcionar, sugere-se mudar para Claude-3.7-Sonnet-Thinking ou Gemini-2.5-Pro, em vez de modelos mais caros da OpenAI. O autor acredita que, atualmente, os modelos da OpenAI para escrita de código são caros e nem sempre os mais eficazes, e chamadas de API para modelos puramente de texto acima de US$ 2/milhão de tokens devem ser consideradas com cautela (Fonte: karminski3)

💡 Outros
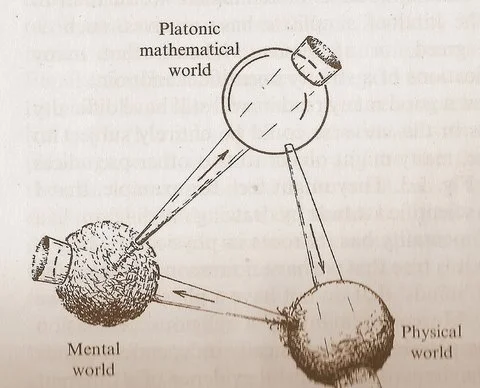
O diagrama dos “Três Mundos” de Penrose estimula reflexões sobre a relação entre matemática, física e inteligência: O diagrama cíclico contendo o “Mundo Matemático Platônico”, o “Mundo Físico” e o “Mundo Mental”, proposto por Roger Penrose em sua obra “O Caminho para a Realidade”, gerou novas discussões. Comentários sugerem que os avanços em machine learning parecem corroborar a existência do “Mundo Matemático Platônico”, ou seja, a eficácia da matemática deriva de uma estrutura matemática que sustenta o universo físico. O surgimento da IA (“cérebros feitos de areia”), está acelerando esse ciclo em uma escala e frequência sem precedentes, podendo revelar verdades mais profundas sobre o universo (Fonte: riemannzeta)
Seguradoras lançam seguro contra perdas por erros de chatbots de IA: As seguradoras começaram a oferecer produtos de seguro contra perdas causadas por erros de chatbots de IA. Esta iniciativa, por um lado, reconhece que o uso inadequado da IA pode causar danos graves e, por outro, levanta preocupações de que tal seguro possa encorajar as empresas a serem mais negligentes na aplicação da IA, dependendo do seguro para cobrir perdas, em vez de se dedicarem a melhorar a confiabilidade e segurança dos sistemas de IA (Fonte: Reddit r/artificial)
Potencial da IA na criação musical é subestimado: Na comunidade, há a opinião de que muitas pessoas subestimam a capacidade da IA na criação musical, afirmando frequentemente que a música de IA não consegue “tocar a alma” como a criação humana. No entanto, já existem obras musicais geradas por IA que, em termos auditivos, se aproximam do nível do canto humano. Considerando que a música de IA ainda está em sua infância, seu potencial de desenvolvimento futuro é enorme e não deve ser negado prematuramente (Fonte: Reddit r/artificial)
