
Palavras-chave:Segurança de IA, Ética da Inteligência Artificial, Agente de IA, Geração 3D, Modelo de código, Avaliação de risco de IA, Gemini 2.5 Pro compreensão de vídeo, AssetGen 2.0 geração 3D, Seed-Coder modelo de código, AgentOps operações de agentes
🔥 Foco
Riscos de segurança da IA geram preocupação, especialistas pedem avaliação de risco inspirada na experiência de segurança nuclear: A preocupação da comunidade internacional com os riscos potenciais da inteligência artificial está a aumentar. Alguns especialistas (como Max Tegmark) apelam a que as empresas de IA, antes de lançarem sistemas de IA perigosos, sigam o método de cálculo de segurança de Robert Oppenheimer no primeiro teste nuclear, avaliando rigorosamente a probabilidade de a inteligência artificial perder o controlo (constante de Compton). Esta medida visa formar um consenso na indústria, promover o estabelecimento de um mecanismo global de segurança da IA e prevenir as consequências catastróficas que a superinteligência pode trazer. (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence)

Novo Papa Francisco (pseudónimo Leo XIV) demonstra grande preocupação com as transformações sociais trazidas pela IA: O recém-eleito Papa Francisco (alegadamente Leo XIV) identificou a inteligência artificial como um dos principais desafios que a humanidade enfrenta. Ele escolheu “Leo” como nome papal, em parte devido aos novos problemas sociais impulsionados pela IA e à revolução industrial, ecoando a resposta histórica do Papa Leão XIII à primeira Revolução Industrial. O Papa enfatiza que a IA representa um desafio para a manutenção da “dignidade humana, justiça e trabalho” e planeia publicar um documento importante sobre a ética da IA no futuro, demonstrando a profunda preocupação dos líderes religiosos com a ética da tecnologia de IA e o seu impacto social. (Fonte: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google lança white paper de 76 páginas sobre agentes de IA, explicando AgentOps e aplicações futuras: A Google publicou um white paper de 76 páginas sobre agentes de IA, detalhando a construção, avaliação e aplicação de agentes. O white paper enfatiza a importância das operações de agentes (AgentOps) como um ramo das operações de IA generativa. AgentOps foca-se na gestão de ferramentas, configuração de prompts centrais, funções de memória e decomposição de tarefas necessárias para o funcionamento eficiente dos agentes. O white paper também explora arquiteturas de colaboração multiagente, onde diferentes agentes desempenham papéis como planeamento, recuperação, execução e avaliação para completar tarefas complexas em conjunto, e perspetiva as aplicações futuras de agentes em empresas para auxiliar funcionários e automatizar tarefas de backend, como o NotebookLM Enterprise Edition e o Agentspace. (Fonte: WeChat)

Meta lança AssetGen 2.0: Geração de ativos 3D de alta qualidade a partir de texto/imagem: A Meta lançou o seu mais recente modelo de IA fundamental para 3D, o AssetGen 2.0, capaz de criar ativos 3D de alta qualidade a partir de prompts de texto e imagem. O AssetGen 2.0 inclui dois submodelos: um para gerar malhas 3D, utilizando um modelo de difusão 3D de estágio único para melhorar detalhes e fidelidade; e outro modelo, TextureGen, para gerar texturas, introduzindo métodos para melhorar a consistência da visualização, reparação de texturas e maior resolução de textura. Esta tecnologia está atualmente a ser usada internamente na Meta para criar mundos 3D e planeia-se a sua disponibilização aos criadores do Horizon ainda este ano. (Fonte: Reddit r/artificial)

🎯 Tendências
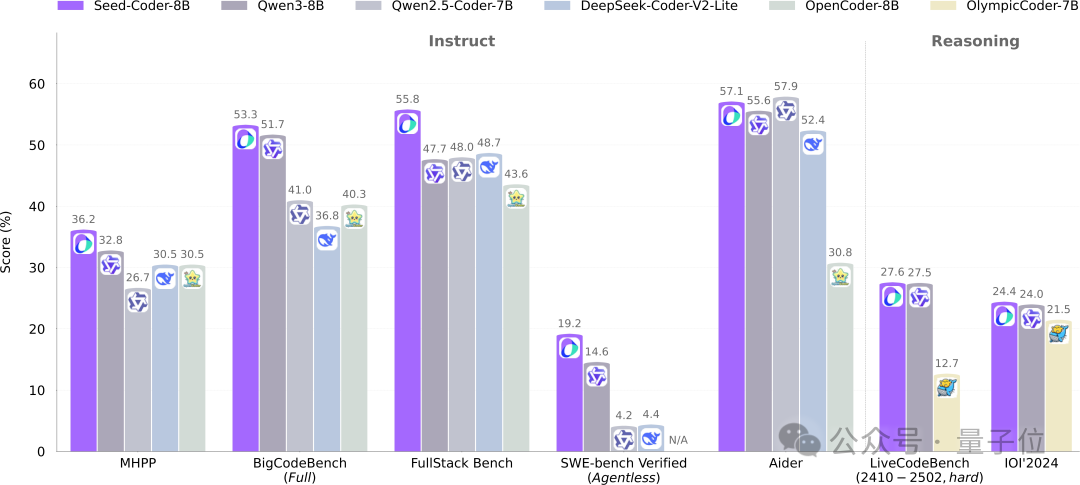
ByteDance Seed lança modelo de código aberto Seed-Coder de 8B, adotando novo paradigma de gestão de dados por modelo: A equipa Seed da ByteDance lançou pela primeira vez o seu modelo de código Seed-Coder com 8 mil milhões de parâmetros, incluindo as versões Base, Instruct e Reasoning. Este modelo demonstrou um desempenho excelente em vários benchmarks de geração de código, superando nomeadamente modelos como o Qwen3 em HumanEval e MBPP. A principal inovação do Seed-Coder reside na proposta de um método de processamento de dados “centrado no modelo”, utilizando o próprio LLM para gerar e filtrar dados de treino de código de alta qualidade, incluindo código ao nível de ficheiro, código ao nível de repositório, dados de Commit e dados de rede relacionados com código, totalizando 6T tokens de dados de treino. Esta abordagem visa reduzir a participação humana e melhorar as capacidades do modelo de código. (Fonte: WeChat)
Gemini 2.5 Pro alcança avanço na compreensão de vídeo, realizando fusão nativa de áudio, vídeo e código: Os mais recentes modelos Gemini 2.5 Pro e Flash da Google alcançaram progressos significativos na capacidade de compreensão de vídeo. O Gemini 2.5 Pro atingiu o nível SOTA em vários benchmarks chave de compreensão de vídeo, superando até o GPT 4.1. A série de modelos Gemini 2.5 realiza, pela primeira vez, a combinação nativa e transparente de informações de áudio e vídeo com outros formatos de dados, como código, permitindo converter diretamente vídeos em aplicações interativas (como Apps de aprendizagem), gerar animações p5.js com base em vídeos, e recuperar e descrever com precisão clipes de vídeo, demonstrando fortes capacidades de raciocínio temporal. Estas funcionalidades já estão disponíveis no Google AI Studio, Gemini API e Vertex AI. (Fonte: WeChat)

ModelScope lança modelo de imagem unificado Nexus-Gen de código aberto, visando capacidades de imagem do GPT-4o: A equipa do ModelScope lançou o Nexus-Gen, um modelo multimodal unificado capaz de processar simultaneamente compreensão, geração e edição de imagens, com o objetivo de rivalizar com as capacidades de processamento de imagem do GPT-4o. O modelo adota uma rota técnica de token → transformer → diffusion → pixels, fundindo a modelagem de texto do MLLM com as capacidades de renderização de imagem do modelo Diffusion. Para resolver o problema de acumulação de erros na previsão autorregressiva de Embeddings de imagem contínuos, a equipa propôs uma estratégia autorregressiva de pré-preenchimento. O Nexus-Gen foi treinado com aproximadamente 25M de dados de imagem e texto, incluindo o recém-lançado conjunto de dados de edição ImagePulse da comunidade ModelScope. (Fonte: WeChat)

Lançada a versão 0.50 do Cursor, simplificando preços e melhorando múltiplas funcionalidades de edição de código: O editor de código AI Cursor lançou a versão 0.50, trazendo atualizações significativas. O modelo de preços foi simplificado para um modelo baseado em pedidos, com o modo Max a suportar todos os principais modelos de IA e a adotar preços baseados em tokens. As melhorias funcionais incluem: novo modelo Tab para suportar sugestões entre ficheiros e refatoração de código; agentes de backend (preview) para suportar a execução paralela de múltiplos agentes e tarefas em ambientes remotos; contexto da base de código permite adicionar bases de código inteiras através de @folders; UI de edição inline otimizada, com novas funcionalidades de edição de ficheiro completo e envio para agente; edição de ficheiros longos introduz ferramenta de procurar e substituir; suporte para workspaces multi-root para lidar com múltiplas bases de código; funcionalidades de chat melhoradas, suportando exportação para Markdown e cópia. (Fonte: op7418)
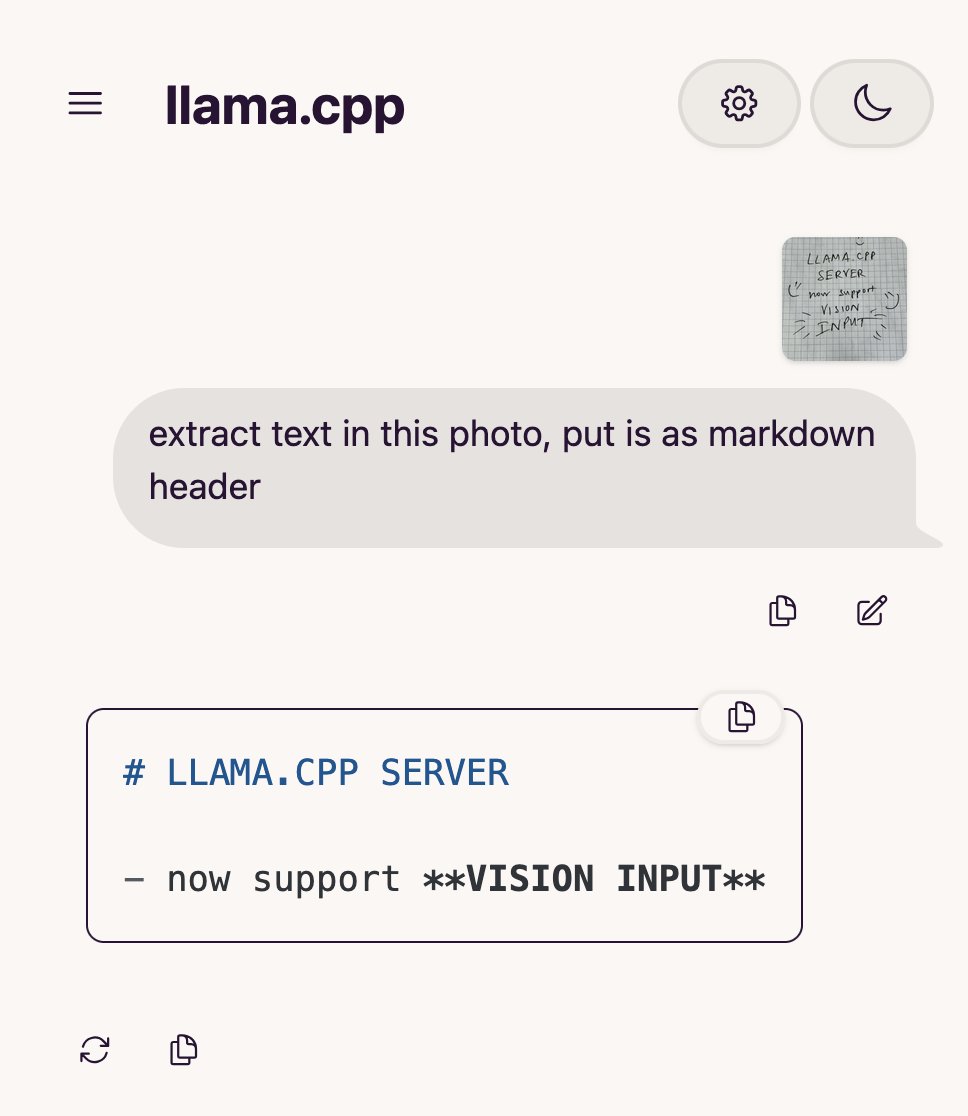
llama.cpp adiciona suporte para modelos de linguagem visual (VLM), permitindo construir fluxos completos de Vision RAG: O projeto de código aberto llama.cpp anunciou suporte para modelos de linguagem visual (VLM), permitindo agora aos utilizadores usar funcionalidades visuais através do servidor llama.cpp e da UI web. Esta atualização significa que é possível carregar no llama.cpp o mesmo modelo base com suporte para múltiplos LoRAs, bem como modelos de embedding, permitindo assim construir fluxos completos de geração aumentada por recuperação visual (Vision RAG). Esta medida expande ainda mais as capacidades do llama.cpp na execução local de grandes modelos de linguagem, permitindo-lhe lidar com tarefas multimodais. (Fonte: mervenoyann, mervenoyann)
Tencent lança HunyuanCustom: Arquitetura de geração de vídeo personalizada baseada no HunyuanVideo: A Tencent lançou no Hugging Face o HunyuanCustom, uma arquitetura orientada por multimodalidade projetada especificamente para a geração personalizada de vídeos. Este trabalho baseia-se no HunyuanVideo, com ênfase especial na manutenção da consistência do sujeito ao gerar vídeos, ao mesmo tempo que suporta a entrada de múltiplas condições, como imagem, áudio, vídeo e texto, oferecendo aos utilizadores capacidades de criação de vídeo mais flexíveis e personalizadas. (Fonte: _akhaliq)
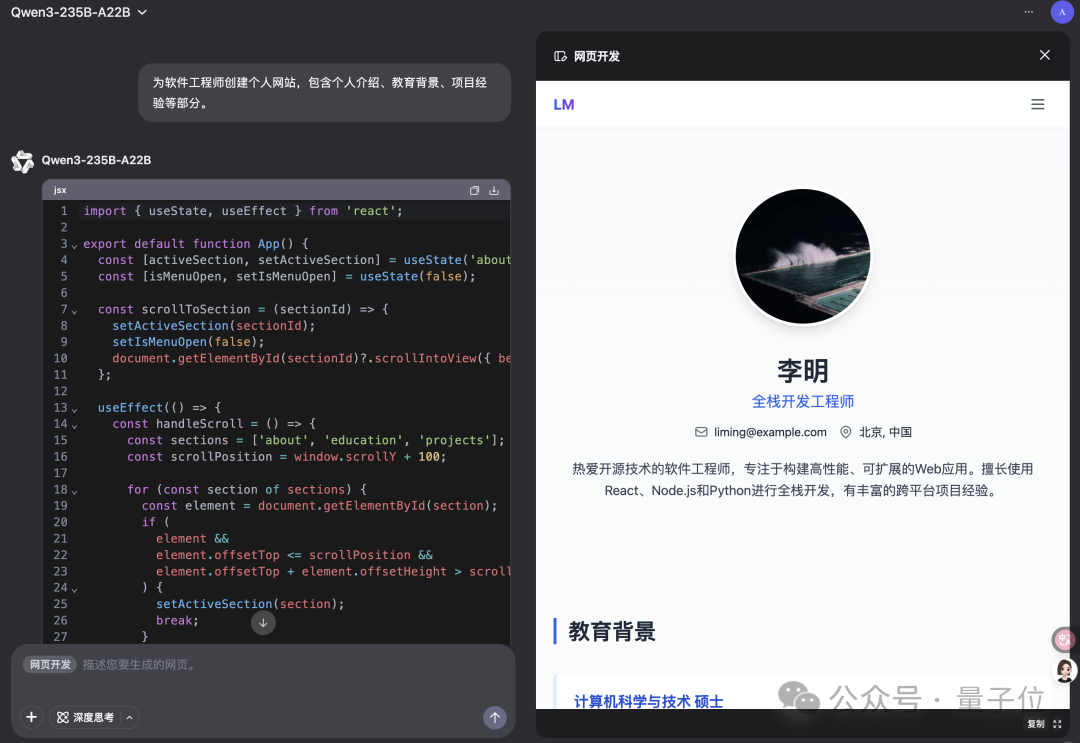
Qwen Chat adiciona modo “Desenvolvimento Web”, gerando aplicações web React com uma única frase: O Qwen Chat da Alibaba introduziu o modo “Desenvolvimento Web” (Web Dev), que permite aos utilizadores gerar aplicações web contendo HTML, CSS e JavaScript com apenas uma instrução de uma frase, utilizando React e Tailwind CSS como base. Esta funcionalidade permite criar rapidamente websites pessoais, replicar interfaces web existentes (como Twitter, GitHub) ou construir formulários e animações específicas com base numa descrição. Os utilizadores podem escolher diferentes modelos Qwen e combinar com o modo “Pensamento Profundo” para melhorar a qualidade da página web. Esta funcionalidade visa simplificar o processo de desenvolvimento frontend e construir rapidamente protótipos de aplicações. (Fonte: WeChat)
Unitree Robotics responde a vulnerabilidades de segurança do cão robótico Go1, enfatizando atualizações em produtos subsequentes: A Unitree Robotics respondeu a rumores sobre uma “vulnerabilidade de backdoor” na sua série de cães robóticos Go1, descontinuada há cerca de dois anos, admitindo que o problema é uma falha de segurança. Atacantes poderiam explorar a chave de gestão de um serviço de túnel na nuvem de terceiros para modificar dados de dispositivos de utilizadores, obter imagens da câmara e permissões de sistema. A Unitree Robotics afirmou que as séries de robôs subsequentes utilizam versões atualizadas mais seguras, não afetadas por esta vulnerabilidade. O incidente levantou preocupações sobre a segurança da cadeia de fornecimento de robôs inteligentes e a privacidade de dados, especialmente no contexto do ano inaugural da comercialização de robôs humanoides, onde a indústria enfrenta múltiplos desafios, incluindo avanços tecnológicos, controlo de custos e exploração de caminhos de comercialização. (Fonte: 36氪)

Claude Code agora suporta referência a outros ficheiros .MD, otimizando a organização de instruções: O Claude Code da Anthropic atualizou as suas funcionalidades, com a versão 0.2.107 a permitir que ficheiros CLAUDE.md importem outros ficheiros Markdown. Os utilizadores podem adicionar [u/path/to/file].md ao ficheiro CLAUDE.md principal para carregar conteúdo de ficheiros adicionais no arranque. Esta melhoria permite aos utilizadores organizar e gerir melhor as instruções do Claude, aumentando a fiabilidade e modularidade da configuração de instruções em projetos grandes, resolvendo problemas anteriores de confusão devido à dependência de ficheiros dispersos. (Fonte: Reddit r/ClaudeAI)

Gabinete de Direitos de Autor dos EUA adota postura mais rígida sobre pré-treino de IA, enfraquecendo defesa de “uso justo”: O mais recente relatório do Gabinete de Direitos de Autor dos EUA adotou uma postura mais rígida em relação ao uso de materiais protegidos por direitos de autor na fase de pré-treino de modelos de IA. O relatório indica que, como os laboratórios de IA agora afirmam que os seus modelos podem competir com os detentores de direitos (por exemplo, gerando conteúdo semelhante a obras originais), isso enfraquece a sua capacidade de se defenderem em processos de infração de direitos de autor com base no “uso justo” (fair use). Esta mudança pode ter um impacto significativo nas fontes de dados de treino e na conformidade dos modelos de IA. (Fonte: Dorialexander)

Nvidia lança placa gráfica profissional RTX Pro 5000, equipada com 48GB de memória GDDR7: A Nvidia lançou a nova GPU de desktop profissional RTX Pro 5000, baseada na arquitetura Blackwell. Esta placa gráfica está equipada com 48GB de memória GDDR7, com uma largura de banda de memória de até 1344 GB/s e um consumo de energia de 300W. Embora a empresa a descreva como uma placa Blackwell de 48GB “barata”, espera-se que o preço ainda seja elevado (comentários mencionam a faixa dos 4000 dólares), destinando-se principalmente a utilizadores de workstations profissionais, fornecendo um poderoso suporte computacional para tarefas como treino de modelos de IA e renderização 3D de grande escala. (Fonte: Reddit r/LocalLLaMA)

🧰 Ferramentas
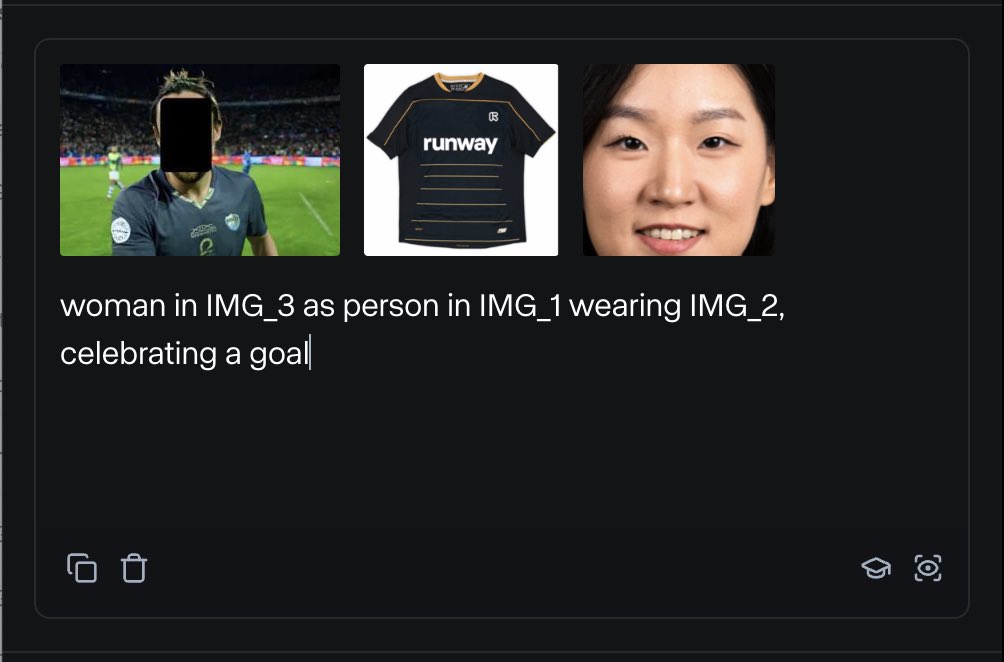
RunwayML lança funcionalidade “References”, permitindo misturar diversos materiais de referência para gerar conteúdo: A nova funcionalidade “References” do RunwayML permite aos utilizadores misturar diferentes materiais de referência (como imagens, estilos) como “ingredientes” e gerar novo conteúdo visual com base em qualquer combinação desses “ingredientes”. Esta funcionalidade é vista como uma máquina de criação quase em tempo real, capaz de ajudar os utilizadores a concretizar rapidamente várias ideias criativas, expandindo enormemente a flexibilidade e as possibilidades da IA na criação de conteúdo visual. (Fonte: c_valenzuelab)
Chat2DB: Cliente de IA para operar bases de dados com linguagem natural: O Chat2DB é uma ferramenta cliente de base de dados impulsionada por IA que permite aos utilizadores interagir com bases de dados através de linguagem natural. Por exemplo, um utilizador pode perguntar “Quem foi o cliente que mais gastou este mês?”, e o Chat2DB consegue, através da IA, compreender a pergunta e gerar automaticamente a consulta SQL correspondente com base na estrutura da tabela da base de dados, executando a consulta e devolvendo o resultado. Isto reduz significativamente a barreira técnica para operar bases de dados, permitindo que mesmo pessoas não técnicas realizem consultas e análises de dados de forma conveniente. O projeto é de código aberto no GitHub. (Fonte: karminski3)
Modelo Qwen 3 8B demonstra excelente capacidade de código, gerando teclado HTML: O modelo Qwen 3 8B (versão quantizada Q6_K), apesar do seu tamanho de parâmetros relativamente pequeno, demonstrou um desempenho notável na geração de código. Um utilizador, através de dois prompts curtos, conseguiu que o modelo gerasse o código para um teclado HTML funcional. Isto demonstra o potencial de modelos mais pequenos para atingir uma alta utilidade prática em tarefas específicas, especialmente atraente para cenários de implementação local com recursos limitados. (Fonte: Reddit r/LocalLLaMA)
Ollama Chat: Ferramenta de chat LLM local com interface semelhante à do Claude: O Ollama Chat é uma interface de chat web projetada para grandes modelos de linguagem locais, cujo estilo de UI e experiência do utilizador são inspirados no Claude da Anthropic. A ferramenta suporta o upload de ficheiros de texto, histórico de conversas e configuração de prompts de sistema, visando fornecer uma solução de interação LLM local fácil de usar e esteticamente agradável. O projeto é de código aberto no GitHub, facilitando a sua implementação e uso pelos utilizadores. (Fonte: Reddit r/LocalLLaMA)
Dicas de prompts para IA gerar cartões personalizados (aniversário/Dia da Mãe): Um utilizador partilhou dicas de prompts para usar IA na geração de cartões personalizados (como cartões de aniversário, cartões do Dia da Mãe). A chave está em especificar claramente o tema do cartão (ex: Dia da Mãe, aniversário), o estilo (ex: estilo feminino, estilo infantil), o destinatário (ex: mãe, Sandy, Jimmy), a idade (ex: 30 anos, 6 anos) e o conteúdo específico da mensagem de felicitações ou um tom caloroso e doce. Ao combinar estes elementos, é possível guiar a IA para gerar um design de cartão que corresponda às necessidades. (Fonte: dotey)

📚 Aprendizagem
Google lança white paper sobre engenharia de prompts, orientando utilizadores sobre como perguntar eficazmente: A Google publicou um white paper sobre engenharia de prompts (acessível através do Kaggle), com o objetivo de ensinar os utilizadores a fazer perguntas de forma mais eficaz aos modelos de IA. O tutorial é claro e detalha como especificar os requisitos de saída, restringir o âmbito da saída e como usar variáveis, entre outras técnicas, ajudando os utilizadores a melhorar a eficiência e eficácia da interação com grandes modelos de linguagem, obtendo assim respostas mais precisas e úteis. (Fonte: karminski3)

Equipa da HKUST(GZ) propõe MultiGO: Modelagem Gaussiana hierárquica para gerar humanos texturizados 3D a partir de uma única imagem: Uma equipa da Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou) propôs um framework inovador chamado MultiGO, que reconstrói modelos humanos 3D texturizados a partir de uma única imagem através de modelagem Gaussiana hierárquica. O método decompõe o corpo humano em diferentes níveis de precisão, como esqueleto, articulações e rugas, refinando-os progressivamente. A tecnologia central utiliza pontos de Gaussian splatting como primitivas 3D e projeta módulos de melhoria de esqueleto, articulações e otimização de rugas. Este trabalho de investigação foi selecionado para o CVPR 2025, oferecendo uma nova abordagem para a reconstrução humana 3D a partir de uma única imagem, e o código será disponibilizado em breve. (Fonte: WeChat)

Tsinghua, Fudan e HKUST lançam conjuntamente RM-BENCH: O primeiro benchmark de avaliação de modelos de recompensa: Em resposta aos problemas atuais na avaliação de modelos de recompensa de grandes modelos de linguagem, como “forma sobre conteúdo” e enviesamento de estilo, equipas de investigação da Universidade de Tsinghua, Universidade Fudan e Universidade de Ciência e Tecnologia de Hong Kong lançaram conjuntamente o RM-BENCH, o primeiro benchmark sistemático de avaliação de modelos de recompensa. Este benchmark abrange quatro áreas principais: chat, código, matemática e segurança. Ao avaliar a sensibilidade do modelo a diferenças subtis de conteúdo e a sua robustez a desvios de estilo, visa estabelecer um novo padrão mais fiável de “árbitro de conteúdo”. A investigação descobriu que os modelos de recompensa existentes têm um desempenho insatisfatório nas áreas de matemática e código, e geralmente apresentam enviesamento de estilo. Este trabalho foi aceite para apresentação oral no ICLR 2025. (Fonte: WeChat)

Universidade de Tianjin e Tencent lançam solução de código aberto COME: 5 linhas de código para melhorar robustez TTA e resolver colapso de modelos: A Universidade de Tianjin e a Tencent propuseram o método COME (Conservatively Minimizing Entropy), que visa resolver os problemas de excesso de confiança e colapso do modelo causados pela minimização de entropia (EM) durante a adaptação em tempo de teste (TTA). O COME introduz a lógica subjetiva para modelar explicitamente a incerteza da previsão e adota uma restrição de Logit adaptativa (congelando a norma do Logit) para controlar indiretamente a incerteza, alcançando assim uma minimização conservadora da entropia. Este método não requer modificação da arquitetura do modelo, necessitando apenas de algumas linhas de código para ser incorporado nos métodos TTA existentes. Em conjuntos de dados como o ImageNet-C, melhora significativamente a robustez e a precisão do modelo, com um custo computacional mínimo. O artigo foi aceite no ICLR 2025 e o código já está disponível. (Fonte: WeChat)
Huawei e IIE CAS propõem DEER: Mecanismo de “saída antecipada dinâmica” em cadeia de pensamento para melhorar eficiência e precisão da inferência de LLM: A Huawei, em colaboração com o Instituto de Engenharia de Informação da Academia Chinesa de Ciências (IIE CAS), propôs o mecanismo DEER (Dynamic Early Exit in Reasoning), que visa resolver o problema de “pensamento excessivo” que pode ocorrer em grandes modelos de linguagem durante o raciocínio de cadeia de pensamento longa (Long CoT). O DEER monitoriza os pontos de transição do raciocínio, induz respostas experimentais e avalia a sua confiança, decidindo dinamicamente se deve terminar o pensamento antecipadamente e gerar uma conclusão. Experiências mostram que, em LLMs de raciocínio como a série DeepSeek, o DEER, sem treino adicional, pode reduzir em média o comprimento da cadeia de pensamento gerada em 31%-43%, ao mesmo tempo que aumenta a precisão em 1.7%-5.7%. (Fonte: WeChat)

CAS e outros propõem R1-Reward: Treino de modelos de recompensa multimodais através de aprendizagem por reforço estável: Equipas de investigação da Academia Chinesa de Ciências (CAS), Universidade de Tsinghua, Kuaishou e Universidade de Nanjing propuseram o R1-Reward, um método para treinar modelos de recompensa multimodais (MRM) através de um algoritmo de aprendizagem por reforço estável, o StableReinforce, com o objetivo de melhorar a sua capacidade de raciocínio a longo prazo. O StableReinforce melhora os problemas de instabilidade que podem ocorrer com algoritmos de RL existentes, como o PPO, ao treinar MRMs, através de uma estratégia Pre-Clip, um filtro de vantagem e um novo mecanismo de recompensa de consistência (introduzindo um modelo de árbitro para verificar a consistência entre a análise e a resposta) para estabilizar o processo de treino. Experiências mostram que o R1-Reward supera os modelos SOTA em vários benchmarks de MRM e pode melhorar ainda mais o desempenho através de votação por amostragem múltipla no momento da inferência. (Fonte: WeChat)
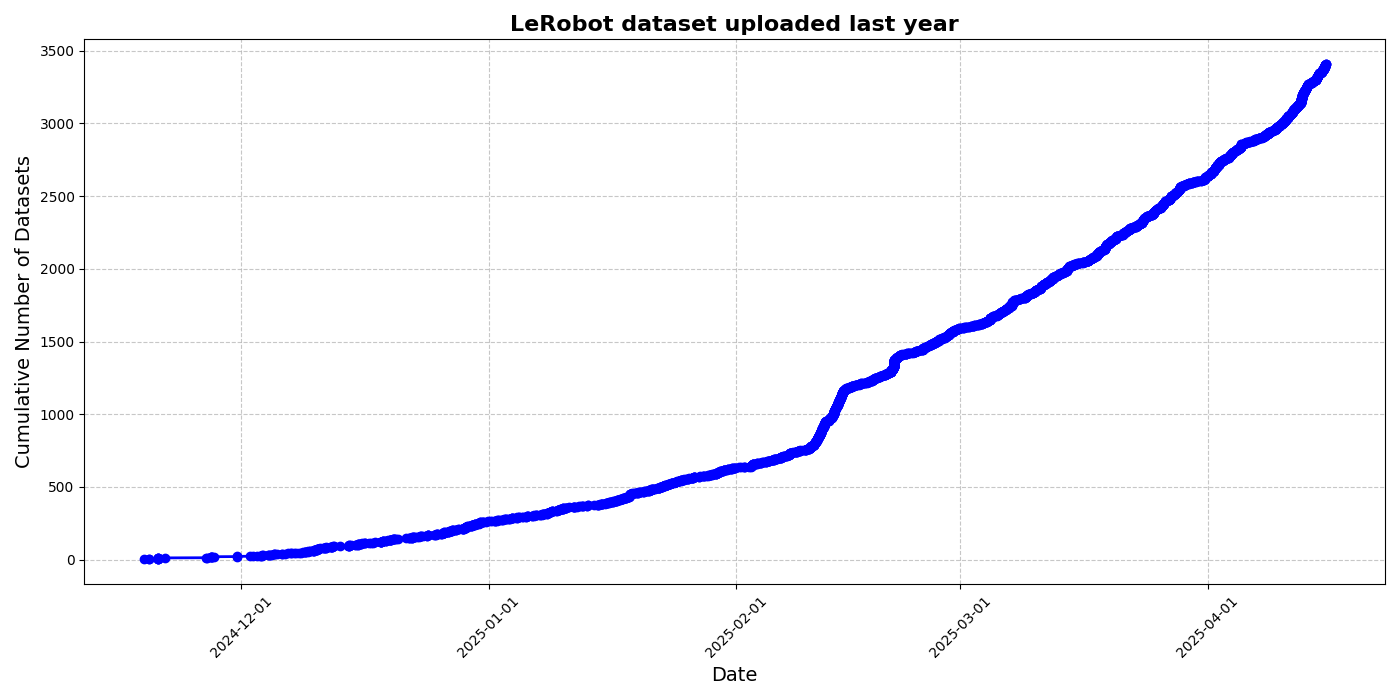
HuggingFace lança iniciativa de conjunto de dados comunitário LeRobot, impulsionando o “momento ImageNet” da robótica: O HuggingFace lançou o projeto de conjunto de dados comunitário LeRobot, com o objetivo de construir o “ImageNet” da área da robótica, impulsionando o desenvolvimento de tecnologia robótica geral através de contribuições da comunidade. O artigo enfatiza a importância da diversidade de dados para a capacidade de generalização dos robôs e aponta que os conjuntos de dados robóticos existentes provêm maioritariamente de ambientes académicos restritos. O LeRobot, ao simplificar os processos de recolha e upload de dados e ao reduzir os custos de hardware, incentiva os utilizadores a partilhar dados de diferentes robôs (como So100, braço mecânico Koch) em diversas tarefas (como jogar xadrez, operar gavetas). Simultaneamente, o artigo propõe padrões de qualidade de dados e uma lista de melhores práticas para enfrentar desafios como inconsistência na anotação de dados e mapeamento ambíguo de características, promovendo a construção de conjuntos de dados robóticos diversificados e de alta qualidade. (Fonte: HuggingFace Blog, LoubnaBenAllal1)
Artigo de blog do HuggingFace resume 11 algoritmos de alinhamento e otimização para LLMs: O TheTuringPost partilhou um artigo do HuggingFace que resume 11 algoritmos de alinhamento e otimização para grandes modelos de linguagem (LLMs). Estes algoritmos incluem PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback) e SPIN (Self-Play Fine-Tuning), entre outros. O artigo fornece links e mais informações sobre estes algoritmos, oferecendo uma visão geral dos métodos de otimização de LLMs para investigadores e programadores. (Fonte: TheTuringPost)
UC Berkeley partilha materiais do curso de pós-graduação em Visão Computacional CS280: Os professores Angjoo Kanazawa e Jitendra Malik da Universidade da Califórnia, Berkeley, partilharam todos os materiais das aulas do seu curso de pós-graduação em Visão Computacional CS280, lecionado neste semestre. Consideram que este conjunto de materiais, que combina conteúdos clássicos e modernos de visão computacional, funcionou bem e decidiram torná-lo público para consulta dos estudantes. (Fonte: NandoDF)
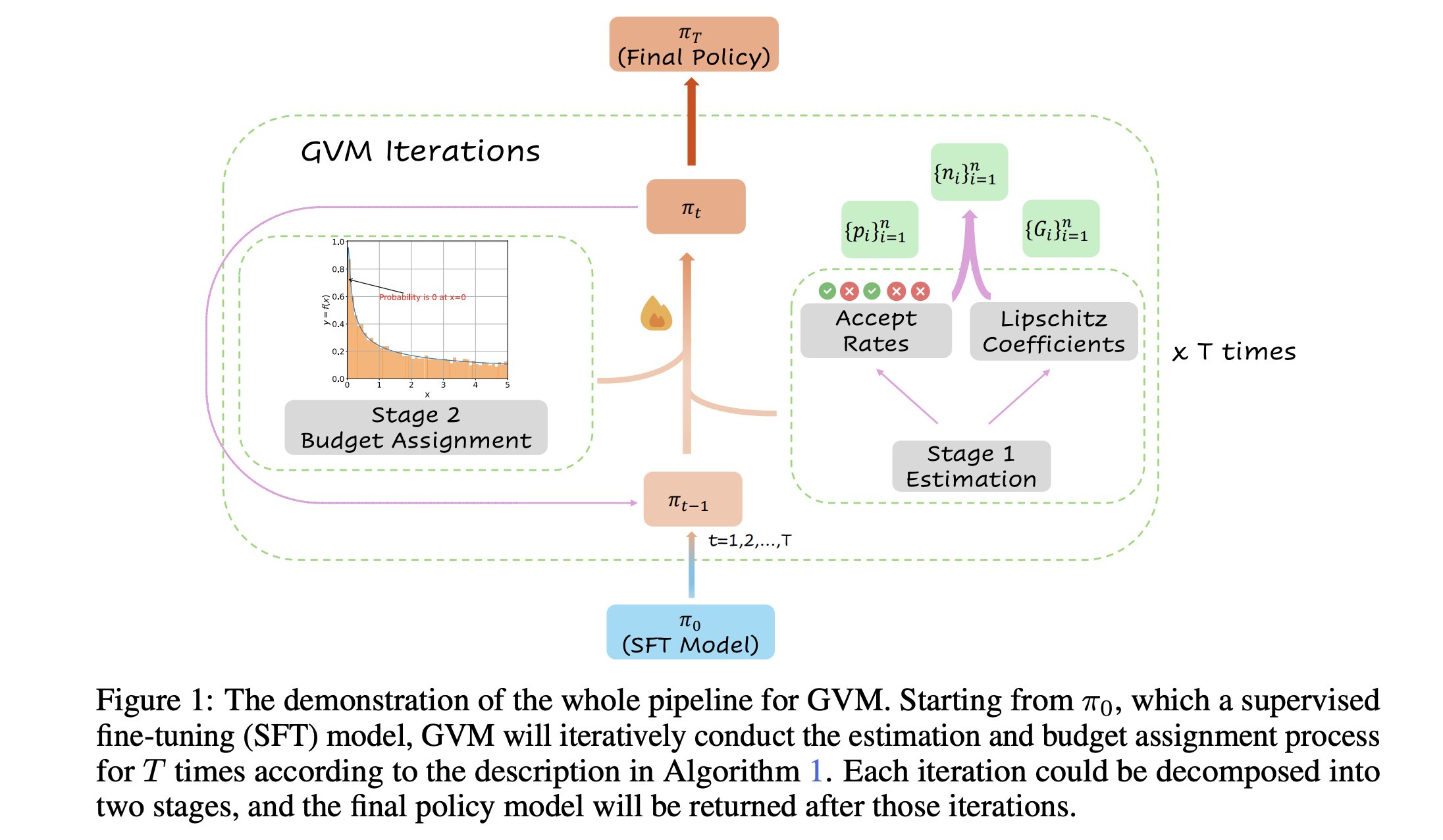
GVM-RAFT: Framework de amostragem dinâmica para otimizar inferência de cadeia de pensamento: Um novo artigo apresenta o framework GVM-RAFT, que otimiza os inferenciadores de cadeia de pensamento (chain-of-thought) ajustando dinamicamente a estratégia de amostragem para cada prompt, com o objetivo de minimizar a variância do gradiente. Alega-se que este método alcança uma aceleração de 2-4 vezes em tarefas de raciocínio matemático e melhora a precisão. (Fonte: _akhaliq)
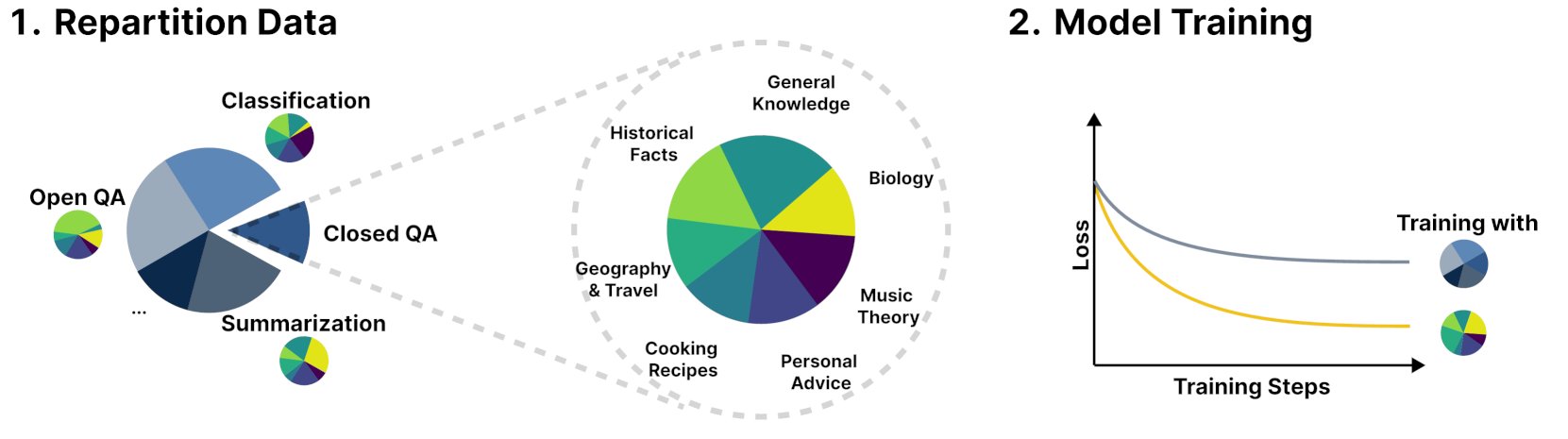
Novo framework R&B melhora desempenho de modelos de linguagem através do balanceamento dinâmico de dados de treino: Uma nova investigação intitulada R&B propõe um novo framework que, através do balanceamento dinâmico dos dados de treino de modelos de linguagem, consegue melhorar o desempenho do modelo com apenas um aumento de 0.01% no custo computacional adicional. Este método visa otimizar a eficiência da utilização de dados, obtendo uma melhoria no desempenho do modelo a um custo reduzido. (Fonte: _akhaliq)
Artigo explora nova perspetiva sobre segurança da IA: Ver o progresso social e tecnológico como remendar uma colcha: Um novo artigo publicado no arXiv, intitulado “Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt”, propõe uma nova visão sobre a segurança da IA, defendendo que o foco central da segurança da IA deve ser evitar que divergências se transformem em conflitos. O artigo compara o progresso social e tecnológico à costura de uma colcha cada vez maior, em constante mudança, cheia de remendos e multicolorida, enfatizando a importância de manter a estabilidade e a cooperação em sistemas complexos. (Fonte: jachiam0)
Artigo discute computação adaptativa em modelos de linguagem autorregressivos: Uma discussão menciona o interesse na computação adaptativa em deep learning e enumera desenvolvimentos tecnológicos relacionados: PonderNet (DeepMind, 2021) como uma ferramenta inicial para integrar redes neuronais e recorrência; modelos de difusão que realizam computação através de múltiplas passagens forward; e modelos de linguagem de inferência recentes que alcançam efeitos semelhantes gerando um número arbitrário de tokens. Isto reflete uma tendência para a flexibilidade e dinamismo na alocação e uso de recursos computacionais pelos modelos. (Fonte: jxmnop)
Artigo explora como “dados maus” podem gerar “modelos bons”: Um artigo da Universidade de Harvard de 2025, intitulado “When Bad Data Leads to Good Models” (arXiv:2505.04741), explora como, em certos casos, dados aparentemente de baixa qualidade (como dados de pré-treino contendo conteúdo do 4chan) podem, paradoxalmente, ajudar no alinhamento do modelo e a ocultar o seu “nível de poder” (power level), fazendo com que tenha um desempenho melhor. Isto levanta discussões sobre a qualidade dos dados, o alinhamento do modelo e a autenticidade do comportamento do modelo. (Fonte: teortaxesTex)

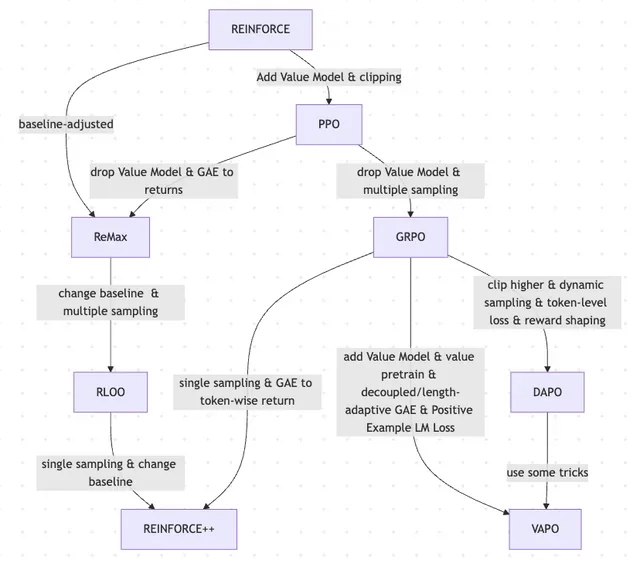
Artigo explora a evolução do RLHF e suas variantes, de REINFORCE a VAPO: Um artigo de investigação resume a evolução dos métodos de aprendizagem por reforço (RL) utilizados para o fine-tuning de grandes modelos de linguagem (LLMs). O artigo traça a evolução desde os algoritmos clássicos PPO e REINFORCE até métodos recentes como GRPO, ReMax, RLOO, DAPO e VAPO, analisando o abandono de modelos de valor, mudanças nas estratégias de amostragem, ajustes de baseline e a aplicação de técnicas como modelação de recompensa e perdas ao nível do token. O estudo visa apresentar claramente o panorama da investigação do RLHF e suas variantes no campo do alinhamento de LLMs. (Fonte: Reddit r/MachineLearning)
Artigo “Absolute Zero”: Raciocínio de autoaprendizagem reforçada por IA sem dados humanos: Um white paper intitulado “Absolute Zero: Reinforced Self-Play Reasoning with Zero Data” (arXiv:2505.03335) explora novos métodos para treinar IA lógica. Os investigadores treinaram modelos de IA lógica sem usar conjuntos de dados rotulados por humanos; os modelos conseguem gerar autonomamente tarefas de raciocínio, resolver problemas e verificar soluções através da execução de código. Isto levanta discussões sobre se a IA pode, num ambiente primordial completamente desprovido de conhecimento prévio (como matemática, física, linguagem), inventar representações simbólicas do zero, definir estruturas lógicas, desenvolver sistemas numéricos e construir modelos causais, bem como o potencial e os riscos desta “inteligência alienígena”. (Fonte: Reddit r/ArtificialInteligence, Reddit r/artificial)
Laboratório de Interação Humano-Máquina Inteligente da Universidade Fudan recruta estudantes de mestrado e doutoramento para 2026: O Laboratório de Interação Humano-Máquina Inteligente da Faculdade de Ciência da Computação da Universidade Fudan está a recrutar estudantes de mestrado e doutoramento para os programas de verão/admissão preferencial de 2026. O laboratório é liderado pelo Professor Shang Li e as suas áreas de investigação incluem AGI wearable (óculos inteligentes MemX combinados com LLM), inteligência incorporada de código aberto, compressão de modelos (de grande para pequeno) e sistemas de machine learning (como otimização de compilação ML, processadores de IA). O laboratório dedica-se a explorar a inteligência centrada no ser humano, fundindo grandes modelos com wearables inteligentes e novos paradigmas de interação humano-máquina em sistemas de inteligência incorporada. (Fonte: WeChat)

💼 Negócios
Visão geral de 10 startups de IA avaliadas em mais de 1 mil milhões de dólares com menos de 50 funcionários: O Business Insider listou 10 startups de IA com avaliações superiores a 1 mil milhões de dólares, mas com menos de 50 funcionários. Entre elas estão a Safe Superintelligence (avaliação de 32 mil milhões de dólares, 20 funcionários), OG Labs (avaliação de 2 mil milhões de dólares, 40 funcionários), Magic (avaliação de 1,58 mil milhões de dólares, 20 funcionários), Sakana AI (avaliação de 1,5 mil milhões de dólares, 28 funcionários), entre outras. Estas empresas demonstram o potencial no campo da IA para pequenas equipas alcançarem altas avaliações, refletindo o elevado valor da tecnologia e inovação no mercado de capitais. (Fonte: hardmaru)
Fourier Intelligence aprofunda cenários de saúde e bem-estar, colaborando com o Shanghai International Medical Center para criar base de reabilitação com inteligência incorporada: A Fourier Intelligence, unicórnio em inteligência incorporada, anunciou na sua primeira cimeira de ecossistema de inteligência incorporada que irá colaborar com o Shanghai International Medical Center para promover conjuntamente a aplicação de robôs de inteligência incorporada em cenários de reabilitação médica. Esta colaboração incluirá a construção de padrões, co-criação de soluções e investigação científica, bem como a criação da primeira base de demonstração de reabilitação com inteligência incorporada na China. O fundador da Fourier, Gu Jie, apresentou a estratégia central para os próximos dez anos como “focar na saúde e bem-estar, concentrar-se na interação, servir as pessoas”, enfatizando que a reabilitação médica é a sua base. Desde a sua fundação em 2015, a empresa expandiu-se de robôs de reabilitação para robôs humanoides de uso geral GR-1 e séries GRx, tendo já enviado centenas de unidades. (Fonte: 36氪)
Meta alegadamente recruta ex-funcionários do Pentágono, podendo reforçar presença no setor militar: Segundo a Forbes, a Meta está a recrutar ex-funcionários do Pentágono, uma medida que pode significar que a empresa planeia reforçar os seus negócios em tecnologia militar ou áreas relacionadas com a defesa. Esta movimentação gerou discussões e preocupações sobre o envolvimento de grandes empresas de tecnologia em aplicações militares. (Fonte: Reddit r/artificial)

🌟 Comunidade
Andrej Karpathy sugere que falta um paradigma importante na aprendizagem de LLM, o “system prompt learning”, gerando debate: Andrej Karpathy considera que falta um paradigma importante na aprendizagem atual de LLMs, ao qual chama “system prompt learning”. Ele aponta que o pré-treino visa o conhecimento, e o fine-tuning (supervisionado/por reforço) visa o comportamento habitual, ambos envolvendo alterações de parâmetros, mas uma grande quantidade de interação e feedback humano parece não ser totalmente aproveitada. Ele compara isto a dar ao protagonista de “Memento” um bloco de notas para armazenar conhecimento e estratégias globais de resolução de problemas. Esta perspetiva gerou um amplo debate, com alguns a considerar que se aproxima da filosofia do DSPy, ou que envolve problemas de memória/otimização e aprendizagem contínua, e a discutir como implementar mecanismos semelhantes no Langgraph. (Fonte: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
Empresas de IA pedem a candidatos que não usem IA para escrever candidaturas, gerando debate: Empresas de IA como a Anthropic pedem aos candidatos que não usem ferramentas de IA ao redigir as suas candidaturas (como currículos), uma regra que gerou discussão na comunidade. Alguns recrutadores afirmam que os currículos gerados por IA que recebem são frequentemente “lixo textual”, e mesmo profissionais experientes podem perder o foco por causa disso. No entanto, alguns candidatos acreditam que a IA pode ajudá-los a otimizar melhor os seus currículos para os requisitos da vaga, destacar competências e melhorar a legibilidade. A discussão também se estendeu ao fenómeno de plataformas como o LinkedIn estarem repletas de conteúdo gerado por IA e se deveriam ser adotados outros métodos, como vídeos, para avaliar os candidatos. (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence)

A “identificabilidade” do conteúdo gerado por IA gera discussão, utilizadores consideram-no fácil de detetar: Discussões na comunidade apontam que o conteúdo gerado por IA (especialmente pelo ChatGPT) é facilmente identificável, não apenas devido a sinais de pontuação específicos (como em dashes) ou estruturas frasais (como “Isso não é x; isso é y.”), mas mais pelo seu “ritmo” e “sensação de insipidez” característicos. Uma vez identificados os vestígios de IA, o conteúdo parece irreal e desprovido de personalidade. Alguns utilizadores relatam ter encontrado este tipo de situação em e-mails, publicações em redes sociais e até em videojogos, considerando que o uso direto de IA para gerar todo o conteúdo resulta em material enfadonho e insincero, e sugerem que os utilizadores devem usar a IA como uma ferramenta para modificar e personalizar o conteúdo. (Fonte: Reddit r/ChatGPT)
Desenvolvimento da IA apresenta ciclo de “lua de mel – reação negativa”, refletindo preferência humana pela autenticidade: Há quem defenda que o surgimento de novos modelos de IA generativa (texto, imagem, música, etc.) é frequentemente acompanhado por um período de “lua de mel”, durante o qual as pessoas ficam maravilhadas com as suas capacidades. No entanto, rapidamente, quando as pessoas começam a identificar os “padrões” ou “vestígios” gerados pela IA, surge uma reação negativa, passando do elogio à desconfiança, chegando mesmo a considerar que “não tem alma”. Este fenómeno de aprendizagem rápida na identificação de obras de IA e a preferência por criações humanas imperfeitas pode significar que a IA funcionará mais como uma ferramenta auxiliar do que como um substituto completo dos criadores humanos, pois as pessoas valorizam a história por detrás das obras, a intenção do autor e a autenticidade. (Fonte: Reddit r/ArtificialInteligence)
Taxa de geração de código por IA na Anthropic ultrapassa 70%, levantando associações com auto-iteração da IA: Mike Krieger, da Anthropic, revelou que mais de 70% dos pull requests internos da empresa são agora gerados por IA. Este dado gerou discussão na comunidade, com alguns a fazerem associações com cenários de auto-edição e melhoria por máquinas, semelhantes a enredos de ficção científica. Ao mesmo tempo, outros questionaram a veracidade e o significado específico destes dados (por exemplo, a complexidade desses PRs). (Fonte: Reddit r/ClaudeAI)

CEO da Nvidia, Jensen Huang, enfatiza que todos os funcionários devem adotar agentes de IA; IA irá remodelar o papel dos programadores: O CEO da Nvidia, Jensen Huang, afirmou que a empresa equipará todos os funcionários com assistentes de IA e que os agentes de IA serão integrados no desenvolvimento diário, otimizando código, descobrindo vulnerabilidades e acelerando a prototipagem. Ele acredita que, no futuro, cada pessoa comandará múltiplos assistentes de IA, e a produtividade crescerá exponencialmente. O CEO da Meta, Mark Zuckerberg, o CEO da Microsoft, Satya Nadella, e outros partilham opiniões semelhantes, acreditando que a IA realizará a maior parte do trabalho de codificação, e o papel dos programadores evoluirá para “comandar a IA” e “definir requisitos”. Esta tendência prenuncia uma grande mudança no ciclo de desenvolvimento de software, com a popularização de ferramentas de programação de IA como GitHub Copilot, Cursor, etc. (Fonte: WeChat)

Debate: É viável para investigadores de ML lerem 1000-2000 artigos por ano?: Na comunidade, discute-se que os principais investigadores de machine learning podem ler perto de 2000 artigos por ano. Sobre isto, alguns comentam que o número de artigos lidos é apenas um indicador substituto; o que realmente importa é a capacidade de filtrar sinais de uma grande quantidade de informação, extrair informação útil e aplicá-la corretamente. Conseguir acompanhar os destaques e tendências da área e, quando necessário, aprofundar conteúdos específicos, esta capacidade de filtragem de informação é uma competência crucial neste século. (Fonte: torchcompiled)
Debate: Comprar GPU vs. alugar GPU para treino/fine-tuning de modelos: Os profissionais de machine learning enfrentam a decisão de comprar ou alugar recursos de GPU. Pessoas com experiência sugerem uma estratégia híbrida: configurar localmente uma GPU de consumo com desempenho razoável para experiências pequenas, e para tarefas de treino em grande escala, alugar GPUs na nuvem. A escolha depende da complexidade do modelo, do volume de dados e do orçamento. As GPUs na nuvem têm vantagens na organização de ML Ops, mas, pelo mesmo preço, GPUs comuns na nuvem como as T4 podem ter um desempenho inferior a placas de consumo de topo (como 3090/4090), embora a nuvem possa oferecer GPUs de topo com maior VRAM, como A100/H100. (Fonte: Reddit r/MachineLearning)
💡 Outros
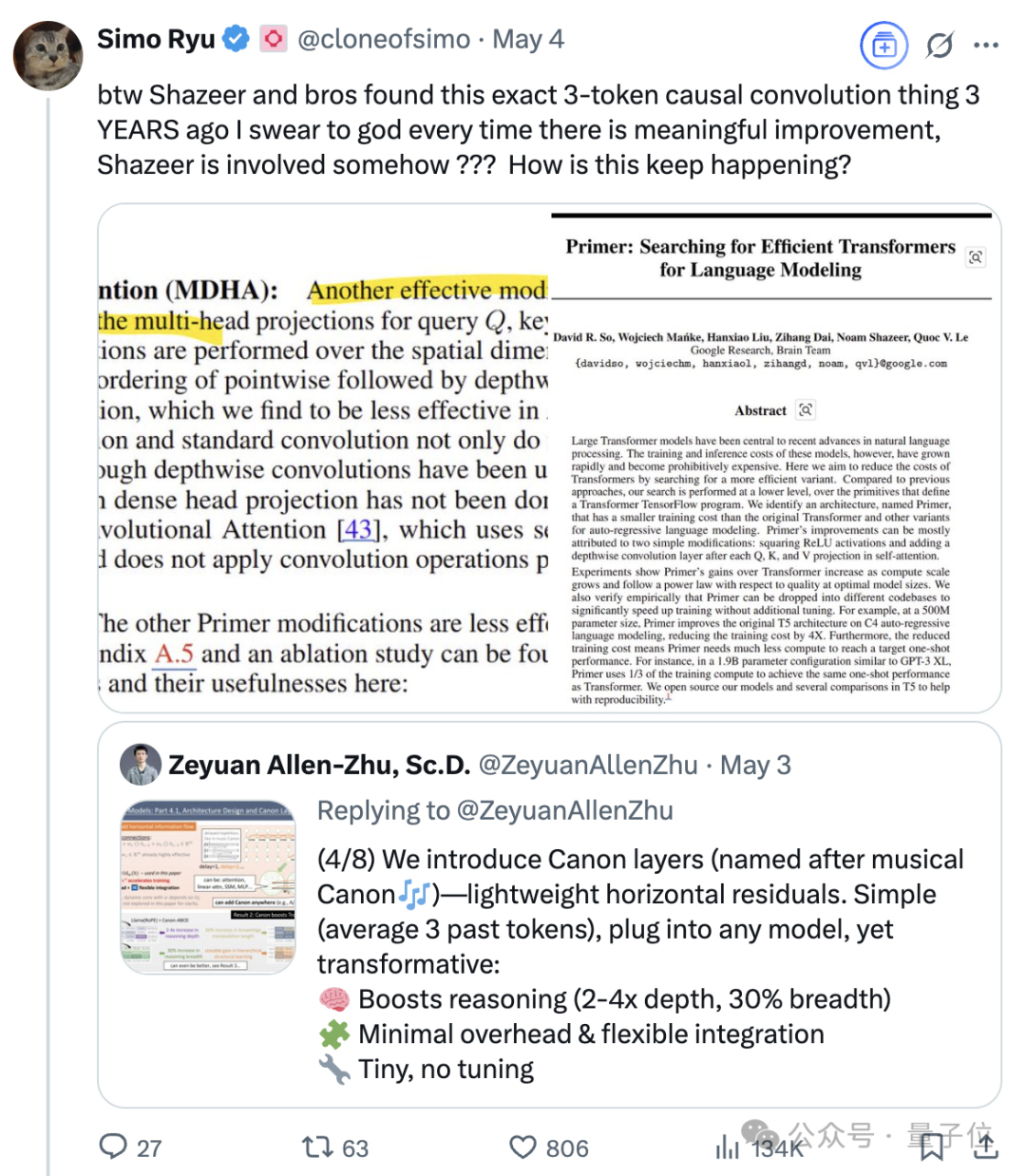
A influência contínua de Noam Shazeer, um dos oito autores do Transformer: Noam Shazeer, um dos oito autores do artigo sobre a arquitetura Transformer, “Attention Is All You Need”, é amplamente considerado como tendo tido a maior contribuição. A sua influência vai muito além disso, incluindo investigações iniciais sobre a introdução de Mistura de Especialistas esparsamente controlada (MoE) em modelos de linguagem, o otimizador Adafactor, a atenção multi-consulta (MQA) e as camadas lineares controladas (GLU) no Transformer. Estes trabalhos estabeleceram a base para as arquiteturas dos atuais grandes modelos de linguagem dominantes, tornando Shazeer uma figura chave na definição contínua dos paradigmas tecnológicos no campo da IA. Ele deixou a Google para fundar a Character.AI, e mais tarde regressou à Google com a aquisição da empresa, co-liderando o projeto Gemini. (Fonte: WeChat)
Gigantes da tecnologia enfrentam “crise de meia-idade” induzida pela IA: O artigo analisa que os “Sete Gigantes da Tecnologia”, incluindo Google, Apple, Meta e Tesla, estão a enfrentar desafios disruptivos trazidos pela inteligência artificial, entrando numa “crise de meia-idade”. O negócio de pesquisa da Google está ameaçado pelo modelo de resposta direta da IA, a Apple tem progredido lentamente na inovação em IA, a Meta tenta integrar a IA nas redes sociais, mas o desempenho do Llama 4 não atingiu as expectativas, e a Tesla enfrenta pressões de queda nas vendas e no preço das ações. Estes antigos líderes da indústria, tal como os casos em “O Dilema do Inovador”, precisam de lidar com o impacto de novos mercados e novos modelos trazidos pela IA, caso contrário, podem tornar-se a “Nokia” da era da IA. (Fonte: WeChat)

IA da Google supera médicos humanos em simulações de conversas médicas: Estudos indicam que um sistema de IA treinado para realizar entrevistas médicas demonstrou um desempenho igual ou superior ao de médicos humanos ao conversar com pacientes simulados e listar possíveis diagnósticos com base no historial clínico. Os investigadores acreditam que este tipo de sistema de IA tem o potencial de ajudar a popularizar e democratizar os serviços de saúde. (Fonte: Reddit r/ArtificialInteligence)
