
Palavras-chave:OpenAI, Chip de IA, Modelo de grande escala, Aprendizagem por reforço, Infraestrutura de IA, IA multimodal, Agente inteligente, RAG, Plano nacional de IA da OpenAI, Restrições de exportação do chip H20 da Nvidia, Otimização de inferência DeepSeek-R1, Microscópio óptico de IA Meta-rLLS-VSIM, Modelo de código de grande escala Seed-Coder da ByteDance
🔥 Foco
OpenAI lança plano de “IA de nível nacional” para apoiar a construção de infraestrutura global de IA: A OpenAI iniciou o projeto “OpenAI for Countries”, como parte de seu plano “Stargate”, com o objetivo de ajudar os países a estabelecer data centers de IA locais, personalizar o ChatGPT e promover o desenvolvimento do ecossistema de IA. O CEO Sam Altman inspecionou pessoalmente o primeiro parque de supercomputação localizado em Abilene, Texas, que faz parte do plano “Stargate” de US$ 500 bilhões, destinado a criar a maior instalação de treinamento de IA do mundo. Esta iniciativa marca a colaboração da OpenAI com governos de vários países, através da construção de infraestrutura e compartilhamento de tecnologia, para promover a popularização e aplicação global da tecnologia de IA, com planos iniciais de cooperar com 10 países ou regiões (Fonte: WeChat)

Governo Trump considera abolir restrições de três níveis para exportação de chips de IA, podendo adotar sistema de licenciamento global simplificado: Segundo relatos da mídia estrangeira, o governo Trump planeja revogar o “Framework for AI Proliferation” (FAID), estabelecido no final da era Biden, que originalmente impunha restrições de classificação de três níveis para a exportação global de chips de IA. A equipe de Trump considera o framework excessivamente complicado e um obstáculo à inovação, preferindo substituí-lo por um sistema de licenciamento global mais simples, implementado por meio de acordos intergovernamentais. Essa medida pode impactar as estratégias de mercado global de fabricantes de chips como a Nvidia, visando consolidar a inovação e a liderança dos EUA no campo da IA (Fonte: WeChat)

Equipe do SGLang otimiza significativamente o desempenho de inferência do DeepSeek-R1, aumentando o throughput em 26 vezes: Uma equipe conjunta do SGLang, Nvidia e outras instituições aumentou o desempenho de inferência do modelo DeepSeek-R1 na GPU H100 em 26 vezes em quatro meses, por meio de uma atualização abrangente do motor de inferência SGLang. As otimizações incluem separação de pré-preenchimento e decodificação (separação PD), paralelismo de especialistas em grande escala (EP), DeepEP, DeepGEMM e balanceador de carga de paralelismo de especialistas (EPLB), entre outras tecnologias. Ao processar sequências de entrada de 2000 tokens, alcançou um throughput de 52,3k tokens de entrada e 22,3k tokens de saída por segundo por nó, aproximando-se dos dados oficiais do DeepSeek e reduzindo significativamente os custos de implantação local (Fonte: WeChat)

Cientista da OpenAI, Dan Roberts: Expansão do aprendizado por reforço impulsionará a IA a descobrir nova ciência, podendo alcançar AGI de nível Einstein em 9 anos: Dan Roberts, cientista pesquisador da OpenAI, discursou no AI Ascent da Sequoia Capital, discutindo o papel central do aprendizado por reforço (RL) na construção de futuros modelos de IA. Ele acredita que, ao expandir continuamente a escala do RL, os modelos de IA não apenas melhorarão seu desempenho em tarefas como raciocínio matemático, mas também poderão realizar descobertas científicas por meio do “cálculo em tempo de teste” (ou seja, quanto mais tempo o modelo pensa, melhor seu desempenho). Ele usou o exemplo da descoberta da relatividade geral por Einstein, especulando que se a IA pudesse realizar cálculos e reflexões por até 8 anos, poderia alcançar avanços científicos semelhantes aos de Einstein em 9 anos. Roberts enfatizou que o desenvolvimento futuro da IA se concentrará mais no cálculo de RL, podendo até dominar todo o processo de treinamento (Fonte: WeChat)

🎯 Tendências
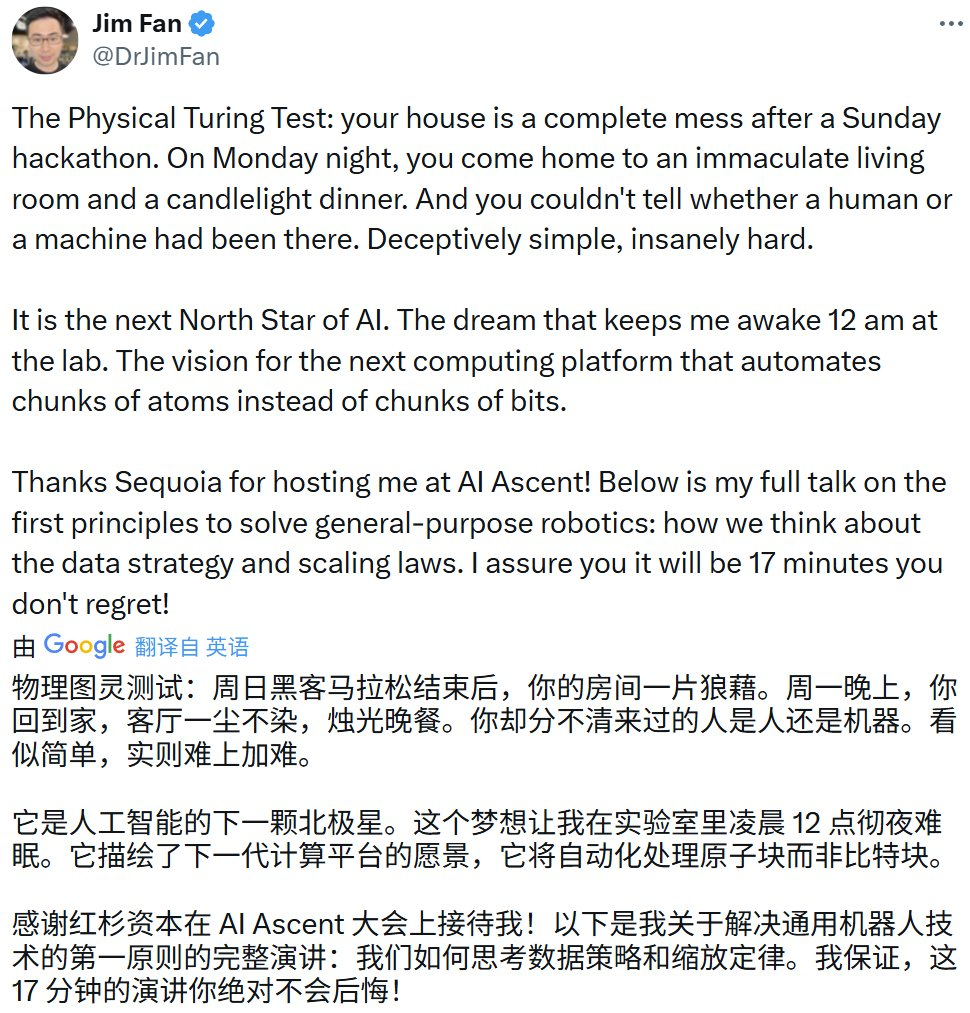
Jim Fan da Nvidia: Robôs passarão no “Teste de Turing Físico”, simulação e IA generativa são cruciais: Jim Fan, chefe do departamento de robótica da Nvidia, propôs o conceito de “Teste de Turing Físico” em sua palestra no AI Ascent da Sequoia, onde humanos não conseguiriam distinguir se uma tarefa foi realizada por um humano ou por um robô. Ele destacou que o custo atual de aquisição de dados para robôs é alto e que a tecnologia de simulação é fundamental, especialmente combinada com IA generativa (como o ajuste fino de modelos de geração de vídeo) para criar dados de treinamento diversificados e em grande escala (“primos digitais” em vez de “gêmeos digitais” precisos). Ele prevê que, por meio de simulação em grande escala e modelos de visão-linguagem-ação (como o GR00T da Nvidia), as APIs físicas do futuro serão onipresentes, os robôs serão capazes de realizar tarefas cotidianas complexas e se integrarão de forma inteligente ao ambiente (Fonte: WeChat)
ByteDance lança série de grandes modelos de código Seed-Coder, versão 8B apresenta desempenho superior: A ByteDance lançou a série de grandes modelos de código Seed-Coder, incluindo versões de 8B, 14B e outras. Entre elas, o Seed-Coder-8B se destacou em vários benchmarks de capacidade de código, como SWE-bench, Multi-SWE-bench e IOI, superando, segundo relatos, o Qwen3-8B e o Qwen2.5-Coder-7B-Inst. A série de modelos inclui as versões Base, Instruct e Reasoner, com o conceito central de “deixar o modelo de código curar dados para si mesmo”, apresentando melhorias significativas no raciocínio de código e nas capacidades de engenharia de software. Os modelos foram disponibilizados em código aberto no Hugging Face e GitHub (Fonte: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba lança framework ZeroSearch de código aberto, utilizando LLM para simular buscas e reduzir custos de treinamento de IA em 88%: Pesquisadores do Alibaba lançaram um framework de aprendizado por reforço chamado “ZeroSearch”, que permite que grandes modelos de linguagem (LLM) desenvolvam funcionalidades de busca avançada simulando motores de busca, sem a necessidade de chamar APIs caras de motores de busca comerciais (como o Google) durante o treinamento. Experimentos mostraram que o uso de um LLM de 3B como motor de busca simulado pode efetivamente melhorar a capacidade de busca do modelo de política, com o desempenho do módulo de recuperação de 14B parâmetros superando até mesmo o Google Search, enquanto os custos de API foram reduzidos em 88%. A tecnologia foi disponibilizada em código aberto no GitHub e Hugging Face, suportando séries de modelos como Qwen-2.5 e LLaMA-3.2 (Fonte: WeChat)

Gemini API lança funcionalidade de cache implícito, podendo economizar 75% dos custos: A Google Gemini API habilitou recentemente a funcionalidade de cache implícito para a série de modelos Gemini 2.5 (Pro e Flash). Quando a solicitação de um usuário atinge o cache, é possível economizar automaticamente até 75% dos custos. Ao mesmo tempo, o requisito mínimo de tokens para acionar o cache também foi reduzido, com o modelo 2.5 Flash caindo para 1K tokens e o modelo 2.5 Pro para 2K tokens. Essa medida visa reduzir os custos para os desenvolvedores que usam a Gemini API e aumentar a eficiência de solicitações repetitivas de alta frequência (Fonte: JeffDean)
Universidade Tsinghua desenvolve microscópio óptico de IA Meta-rLLS-VSIM, com resolução volumétrica aumentada em 15,4 vezes: O grupo de pesquisa de Li Dong da Universidade Tsinghua, em colaboração com a equipe de Dai Qionghai, propôs o microscópio de iluminação estruturada virtual de folha de luz refletida impulsionado por meta-aprendizagem (Meta-rLLS-VSIM). O sistema, por meio da inovação cruzada entre IA e óptica, elevou a resolução lateral da imagem de células vivas para 120nm e a resolução axial para 160nm, alcançando super-resolução quase isotrópica e aumentando a resolução volumétrica em 15,4 vezes em comparação com o LLSM tradicional. Suas tecnologias centrais incluem o uso de DNN para aprender e expandir a capacidade de super-resolução para múltiplas direções (“iluminação estruturada virtual”) e o aprimoramento da resolução axial por meio da fusão de informações de dupla visualização por reflexão especular e da rede RL-DFN. A introdução da estratégia de meta-aprendizagem permite que o modelo de IA complete a implantação adaptativa em apenas 3 minutos, reduzindo significativamente a barreira de aplicação da IA em experimentos biológicos e fornecendo uma ferramenta poderosa para observar processos vitais como divisão de células cancerosas e desenvolvimento embrionário (Fonte: WeChat)

Série de grandes modelos Qwen3 é lançada, continuando a liderar a comunidade de código aberto: O Alibaba lançou a série de grandes modelos de linguagem Qwen3, com tamanhos de parâmetros variando de 0.5B a 235B, apresentando excelente desempenho em vários benchmarks, com vários modelos de menor porte atingindo o nível SOTA entre os modelos de código aberto de tamanho semelhante. A série Qwen3 suporta vários idiomas e um comprimento de contexto de até 128k tokens. Devido ao seu forte desempenho e baixo custo de implantação (em comparação com DeepSeek-R1, etc.), a série Qwen tem sido amplamente adotada no exterior (especialmente no Japão) como base para o desenvolvimento de IA, gerando um grande número de modelos verticais. O lançamento do Qwen3 consolida ainda mais sua posição de liderança na comunidade global de IA de código aberto, com mais de 20.000 estrelas no GitHub em uma semana (Fonte: dl_weekly, WeChat)

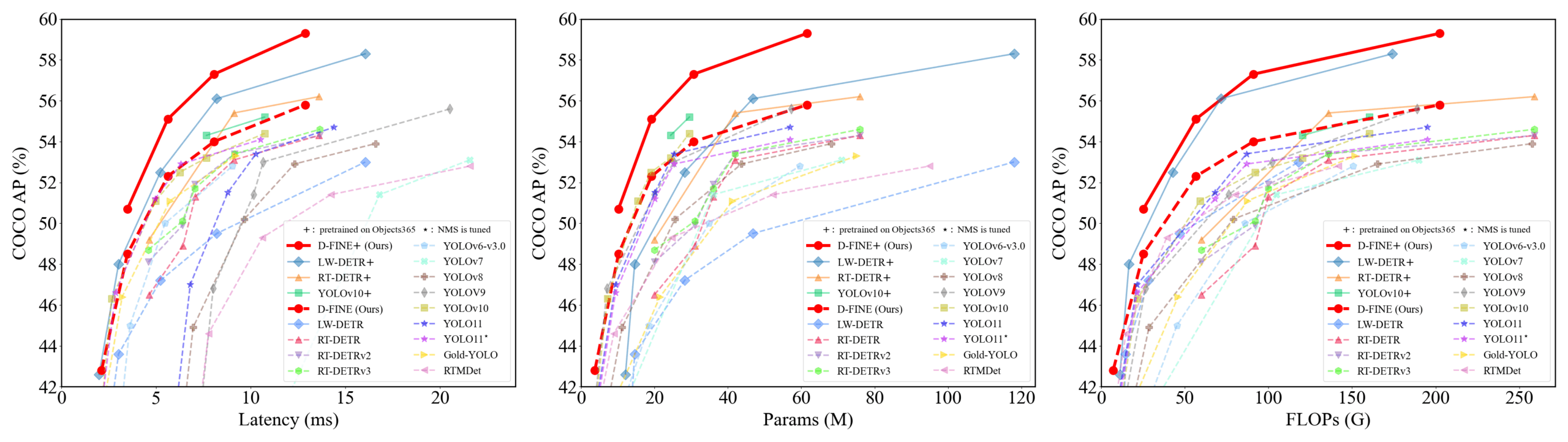
D-FINE: Detector de objetos em tempo real baseado em otimização de distribuição de granulação fina, com desempenho superior: Pesquisadores propuseram o D-FINE, um novo detector de objetos em tempo real que redefine a tarefa de regressão de caixas delimitadoras no DETR como otimização de distribuição de granulação fina (FDR) e introduz uma estratégia de autodestilação de localização global ótima (GO-LSD). O D-FINE alcança desempenho excepcional sem aumentar os custos adicionais de inferência e treinamento. Por exemplo, o D-FINE-N atinge 42,8% de AP no COCO val, com velocidade de até 472 FPS (GPU T4); o D-FINE-X, após pré-treinamento no Objects365+COCO, atinge 59,3% de AP no COCO val. O método alcança uma localização mais precisa por meio da otimização iterativa da distribuição de probabilidade e transfere o conhecimento de localização da camada final para as camadas anteriores por meio da autodestilação (Fonte: GitHub Trending)
Modelo Harmon coordena representações visuais, unificando compreensão e geração multimodal: Pesquisadores da Universidade Tecnológica de Nanyang propuseram o modelo Harmon, que visa unificar tarefas de compreensão e geração multimodal por meio do compartilhamento de um MAR Encoder (Masked Autoencoder for Reconstruction). O estudo descobriu que o MAR Encoder pode aprender simultaneamente semântica visual durante o treinamento de geração de imagens, e seus resultados de Linear Probing superam em muito o VQGAN/VAE. O framework Harmon utiliza o MAR Encoder para processar imagens completas para compreensão e adota o paradigma de modelagem de máscara MAR para geração de imagens, com o LLM realizando a interação modal. Experimentos mostram que o Harmon se aproxima do Janus-Pro em benchmarks de compreensão multimodal e apresenta excelente desempenho nos benchmarks de estética de texto para imagem MJHQ-30K e no benchmark de seguimento de instruções GenEval, superando até mesmo alguns modelos especialistas. O modelo foi disponibilizado em código aberto (Fonte: WeChat)

PushTech implementa ciclo comercial fechado para robôs de logística, acumulando dados através do “sistema sombra de entregadores”: Os robôs de logística da PushTech já estão em operação real em várias cidades da China, trabalhando em colaboração com entregadores humanos e alcançando o ponto de equilíbrio para robôs individuais. Uma de suas tecnologias centrais é o “sistema sombra de entregadores”, que coleta dados de comportamento de direção, percepção ambiental e operações (como abrir/fechar portas, pegar/largar itens) de entregadores reais em ambientes urbanos complexos, fornecendo dados de treinamento massivos e de alta qualidade para aprendizado por imitação e aprendizado por reforço para os robôs. Atualmente, o sistema acumulou dezenas de milhões de quilômetros de dados de direção e quase um milhão de trajetórias de membros superiores. Com base nisso, a PushTech treinou um modelo VLA de árvore de comportamento, permitindo que os robôs lidem com situações complexas do mundo real, e planeja expandir para mercados internacionais (Fonte: WeChat)

Kuaishou lança framework KuaiMod, utilizando grandes modelos multimodais para otimizar o ecossistema de vídeos curtos: A Kuaishou propôs uma solução de otimização do ecossistema da plataforma de vídeos curtos baseada em grandes modelos multimodais, chamada KuaiMod, que visa melhorar a experiência do usuário por meio da discriminação automatizada da qualidade do conteúdo. O KuaiMod se inspira na abordagem da jurisprudência, utilizando modelos de linguagem visual (VLM) para análise de raciocínio em cadeia de conteúdo de baixa qualidade e atualizando continuamente as estratégias de discriminação por meio do aprendizado por reforço baseado no feedback do usuário (RLUF). O framework já foi implantado na plataforma Kuaishou, reduzindo efetivamente a taxa de denúncias de usuários em mais de 20%. A Kuaishou também está empenhada em construir grandes modelos multimodais que possam entender os vídeos curtos da comunidade, passando da extração de representações para a compreensão semântica profunda, e já aplicou e obteve resultados em vários cenários, como estruturação de tags de interesse em vídeo e assistência na geração de conteúdo (Fonte: WeChat)

Lenovo lança superagente inteligente pessoal “Tianxi”, avançando para inteligência de nível L3: Na Conferência de Inovação Tecnológica, a Lenovo lançou o superagente inteligente pessoal “Tianxi”, com capacidades de percepção e interação multimodal, cognição e tomada de decisão baseadas em base de conhecimento pessoal, e decomposição e execução autônoma de tarefas complexas. O Tianxi visa fornecer uma experiência de colaboração homem-máquina natural e contínua por meio de interfaces AUI acompanhantes como AI Suixin Chuang (Janela AI Livre), AI Linglong Tai (Plataforma AI Primorosa) e AI Ruying Kuang (Quadro AI Sombra). Ele integra vários grandes modelos líderes do setor, incluindo o DeepSeek-R1, e adota uma arquitetura de implantação híbrida de ponta e nuvem, combinada com a Lenovo Personal Cloud 1.0 (equipada com um grande modelo de 720 bilhões de parâmetros) para fornecer poder computacional robusto e 100G de espaço de memória dedicado. A Lenovo também lançou superagentes inteligentes de nível empresarial “Lexiang” e de nível urbano, demonstrando seu layout abrangente no campo da IA (Fonte: WeChat)

Nova pesquisa julga a generalização de redes neurais através da complexidade da interação simbólica: A equipe do professor Zhang Quanshi da Universidade Jiao Tong de Xangai propôs uma nova teoria para analisar a generalização de redes neurais sob a perspectiva da complexidade da representação de interação simbólica intrínseca. O estudo descobriu que interações generalizáveis (que aparecem com alta frequência nos conjuntos de treinamento e teste) geralmente apresentam uma distribuição decrescente em diferentes ordens (complexidade) (com interações de baixa ordem predominando), enquanto interações não generalizáveis (que aparecem principalmente no conjunto de treinamento) apresentam uma distribuição fusiforme (com interações de ordem média predominando, e efeitos positivos e negativos se anulando facilmente). A teoria visa julgar diretamente o potencial de generalização de um modelo analisando os padrões de distribuição da “lógica de interação E/OU” equivalente do modelo, fornecendo uma nova perspectiva para entender e melhorar a generalização do modelo (Fonte: WeChat)
🧰 Ferramentas
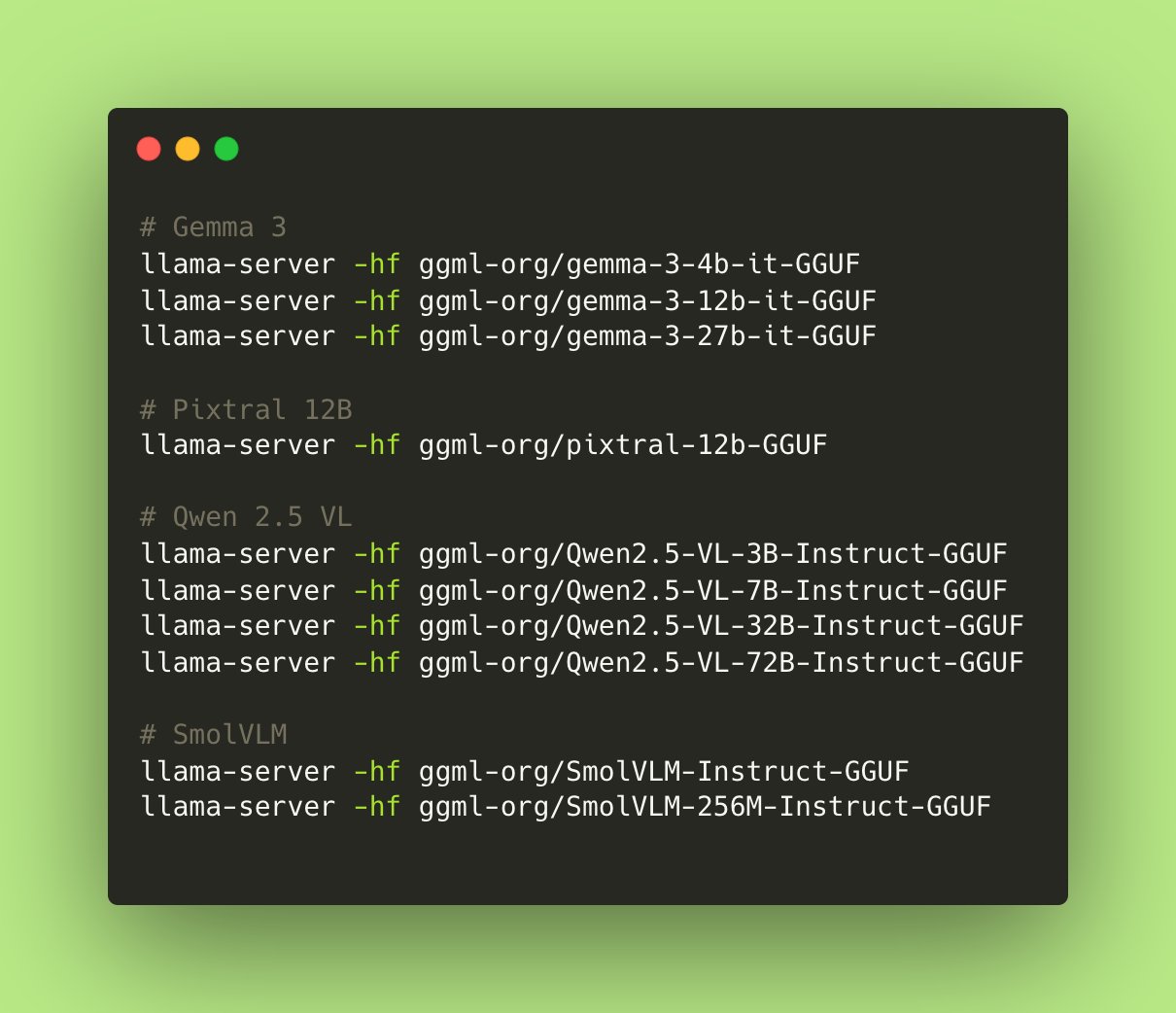
Llama.cpp totalmente compatível com modelos de linguagem visual (VLM): O Llama.cpp agora suporta totalmente modelos de linguagem visual (VLM), permitindo que os desenvolvedores executem aplicativos multimodais no dispositivo. Julien Chaumond e outros do Hugging Face compartilharam modelos pré-quantizados, incluindo Gemma do Google DeepMind, Pixtral da Mistral AI, Qwen VL do Alibaba e SmolVLM do Hugging Face, que podem ser usados diretamente. Esta atualização é graças às contribuições das equipes @ngxson e @ggml_org, abrindo novas possibilidades para aplicativos de IA multimodais localizados e de baixa latência (Fonte: ggerganov, ClementDelangue, cognitivecompai)
Quark AI Super Box atualiza para “Busca Profunda”, aprimorando o “QI de Busca” da IA: O Quark AI Super Box foi recentemente atualizado, introduzindo a funcionalidade de “Busca Profunda”, que visa aprimorar o quociente de busca (QI de Busca) da IA. A nova funcionalidade enfatiza o pensamento ativo e o planejamento lógico da IA antes da busca, permitindo entender melhor as intenções de consulta complexas e personalizadas do usuário, decompor problemas e realizar buscas inteligentes e organizadas. Na área da saúde, o consultor de saúde Quark AI “Aqua” consultará opiniões de médicos de hospitais de primeira linha e materiais profissionais; na área acadêmica, acessará fontes autorizadas como o CNKI. Além disso, o Quark possui fortes capacidades de processamento multimodal, como análise de imagens, recorte de IA, aprimoramento de imagem e conversão de estilo. Informa-se que o Quark lançará futuramente uma versão Pro de Busca Profunda com capacidades de Deep Research (Fonte: WeChat)

LangChain lança múltiplas integrações e tutoriais, fortalecendo capacidades de RAG e agentes inteligentes: O LangChain lançou recentemente várias atualizações e tutoriais: 1. Tutorial de UI para Agente de Mídia Social: Orienta como transformar o agente de mídia social LangChain em um aplicativo web amigável, integrando ExpressJS e AgentInbox UI, com suporte para Notion. 2. Solução RAG Premiada: Apresenta uma implementação de RAG para analisar relatórios anuais de empresas, suportando análise de PDF, múltiplos LLMs e recuperação avançada. 3. Aplicativo de Chat RAG Privado: Tutorial demonstra como construir um aplicativo de chat RAG localizado e focado na privacidade de dados usando LangChain e o framework Reflex. 4. Integração com Nimble Retriever: Introduz um poderoso recuperador de dados da web, fornecendo dados precisos para aplicativos LangChain. 5. Guia de Saída Estruturada para Claude 3.7: Fornece três métodos para alcançar saída estruturada com Claude 3.7 através do LangChain e AWS Bedrock. 6. Sistema de Chat RAG Local: Projeto de código aberto demonstra um sistema de perguntas e respostas sobre documentos totalmente localizado, construído com o fluxo LangChain RAG e LLMs locais (via Ollama), garantindo a privacidade dos dados (Fonte: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: Framework de agente de IA de código aberto que integra capacidades de múltiplos frameworks: Minion-agent é um novo framework de desenvolvimento de agentes de IA de código aberto, que visa resolver o problema de fragmentação dos frameworks de IA existentes (como OpenAI, LangChain, Google AI, SmolaAgents). Ele fornece uma interface unificada, suportando a chamada de capacidades de múltiplos frameworks, ferramentas como serviço (navegação na web, operações de arquivo, etc.) e colaboração multiagente. O projeto demonstra seu potencial de aplicação em cenários como pesquisa aprofundada (coleta automática de literatura para gerar relatórios), comparação de preços (pesquisa de mercado automatizada), geração criativa (geração de código de jogo) e rastreamento de tendências tecnológicas, enfatizando as vantagens do modelo de código aberto em flexibilidade e custo-benefício (Fonte: WeChat)

RunwayML demonstra poderosa capacidade de geração e edição de vídeo em múltiplos cenários: O pesquisador independente de IA Cristobal Valenzuela e outros usuários demonstraram a aplicação do RunwayML em diversos cenários criativos. Incluindo o uso de suas funcionalidades Frames, References e Gen-4 para gerar e visualizar rapidamente visuais criativos, mantendo a consistência de estilo e personagem; transformar o mundo de Rembrandt em um videogame RPG; e alcançar uma nova síntese de visualização de design de interiores a partir de uma única imagem, fornecendo referências visuais. Esses casos destacam os avanços do RunwayML na geração controlável de vídeo, transferência de estilo e construção de cenas (Fonte: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: Um roteador de tarefas universal para tarefas de visão computacional: Olympus é um roteador de tarefas universal projetado para tarefas de visão computacional. Ele visa simplificar e unificar o fluxo de processamento de diferentes tarefas visuais, possivelmente otimizando a eficiência e o desempenho de sistemas de visão computacional multitarefa por meio do agendamento inteligente e da alocação de recursos computacionais ou chamadas de modelo. O projeto está disponível em código aberto no GitHub (Fonte: dl_weekly)
Tracy Profiler: Analisador híbrido de quadros e amostragem em tempo real com resolução de nanossegundos: Tracy Profiler é uma ferramenta de análise híbrida de quadros e amostragem em tempo real, com resolução de nanossegundos e suporte a telemetria remota, para jogos e outras aplicações. Ele suporta a análise de desempenho de CPU (C, C++, Lua, Python, Fortran e bindings de terceiros para Rust, Zig, C#, etc.), GPU (OpenGL, Vulkan, Direct3D, Metal, OpenCL), alocação de memória, locks, trocas de contexto, e pode associar automaticamente capturas de tela com quadros capturados. A ferramenta, com sua alta precisão e tempo real, fornece aos desenvolvedores meios poderosos para localizar e otimizar gargalos de desempenho (Fonte: GitHub Trending)

FieldStation42: Simulador de transmissão de TV retrô: FieldStation42 é um projeto Python que visa simular a experiência de assistir televisão antiga. Ele pode suportar múltiplos canais simultaneamente, inserir automaticamente anúncios e trailers de programas, e gerar uma programação semanal com base na configuração. O simulador pode selecionar aleatoriamente programas não exibidos recentemente para manter o frescor, suporta a definição de faixas de datas de exibição de programas (como programas sazonais) e pode configurar vídeos de encerramento de transmissão da emissora e telas de loop sem sinal. O projeto também suporta conexão de hardware (como Raspberry Pi Pico) para simular a troca de canais e oferece uma função de canal de pré-visualização/guia. Seu objetivo é que, quando o usuário “ligar a TV”, possa exibir conteúdo de programa “real” apropriado para aquele horário e canal (Fonte: GitHub Trending)

Tiny Corp lança solução AMD eGPU baseada em USB3, com suporte para Apple Silicon: A Tiny Corp demonstrou uma solução para conectar uma AMD eGPU a um Mac com Apple Silicon via USB3 (especificamente, usando um dispositivo ADT-UT3G baseado no controlador ASM2464PD). A solução reescreveu os drivers, visando utilizar a largura de banda de 10Gbps do USB3 e usando libusb, teoricamente também suportando Linux ou Windows. Isso oferece aos usuários de Apple Silicon uma nova maneira de expandir sua capacidade de processamento gráfico, especialmente valiosa para cenários como a execução local de grandes modelos de IA (Fonte: Reddit r/LocalLLaMA)
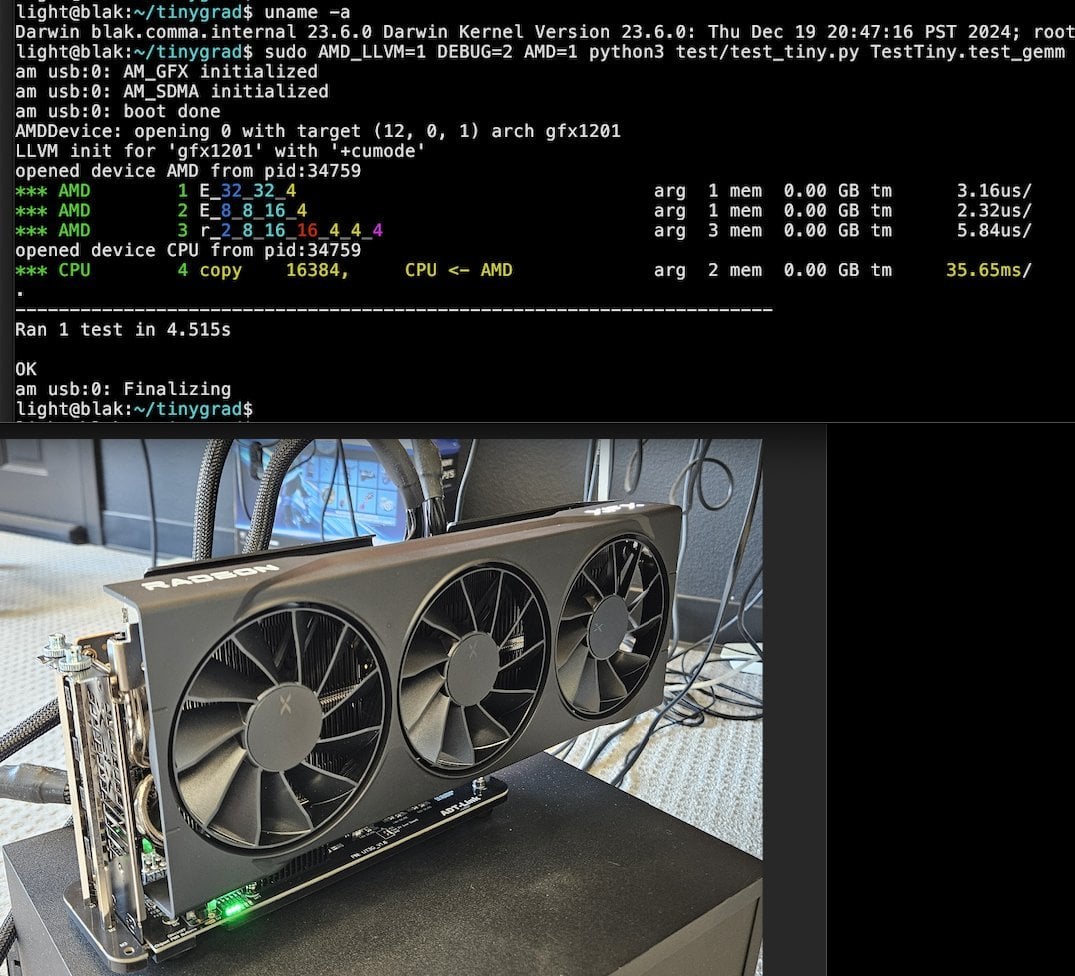
Llama.cpp-vulkan implementa suporte a FlashAttention em GPUs AMD: O backend Vulkan do Llama.cpp recentemente fundiu a implementação do FlashAttention, o que significa que os usuários que utilizam llama.cpp-vulkan em GPUs AMD agora podem aproveitar a tecnologia FlashAttention. Combinado com a quantização de cache Q8 KV, espera-se que os usuários possam dobrar o tamanho do contexto, mantendo ou melhorando a velocidade de inferência. Esta atualização é um benefício significativo para os usuários de GPU AMD que executam grandes modelos de linguagem localmente (Fonte: Reddit r/LocalLLaMA)
Devseeker: Assistente de codificação de IA leve, alternativa ao Aider e Claude Code: Devseeker é um novo projeto de agente de codificação de IA leve e de código aberto, posicionado como uma alternativa ao Aider e Claude Code. Ele possui funcionalidades como criar e editar código, gerenciar arquivos e pastas de código, memória de código de curto prazo, revisão de código, executar arquivos de código, calcular o uso de tokens e fornecer vários modos de codificação. O projeto visa fornecer uma ferramenta de programação assistida por IA mais fácil de implantar e usar localmente (Fonte: Reddit r/ClaudeAI)
📚 Aprendizado
Panaversity lança projeto de aprendizado Agentic AI, com foco em Dapr e OpenAI Agents SDK: A Panaversity iniciou o projeto “Learn Agentic AI”, que visa formar engenheiros de IA de agentes e robôs por meio do padrão de design Dapr Agentic Cloud Ascent (DACA) e várias tecnologias nativas de nuvem para agentes (incluindo OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes). O projeto central resolve como projetar sistemas capazes de lidar com dezenas de milhões de agentes de IA concorrentes e oferece as séries de cursos AI-201, AI-202, AI-301, cobrindo o caminho de aprendizado desde o básico até agentes de IA distribuídos em grande escala. O projeto enfatiza que o OpenAI Agents SDK deve se tornar o framework de desenvolvimento principal devido à sua simplicidade, facilidade de uso e alto controle (Fonte: GitHub Trending)

Pesquisa de ajuste fino de RL revela relação complexa entre gerenciamento de dados e capacidade de generalização: Um artigo compartilhado por Minqi Jiang discute o impacto do gerenciamento de dados na capacidade de generalização de modelos durante o ajuste fino por aprendizado por reforço (RL). A pesquisa descobriu que, seja treinando em tarefas de codificação “infinitas” por meio de aprendizado curricular auto-jogado (Absolute Zero Reasoner), ou repetindo o treinamento em uma única amostra de tarefa MATH (1-shot RLVR), os modelos da série Qwen2.5 de 7B podem alcançar uma melhoria de precisão de cerca de 28% a 40% em benchmarks de matemática. Isso revela um paradoxo: estratégias extremas de gerenciamento de dados (dados infinitos vs. dados de um único ponto) podem produzir melhorias de generalização semelhantes. Possíveis explicações incluem que o RL principalmente extrai capacidades já existentes do modelo pré-treinado, a existência de “circuitos de raciocínio” compartilhados e que o pré-treinamento pode levar a circuitos de raciocínio competitivos. Os pesquisadores acreditam que, para romper o “teto do pré-treinamento”, é necessário coletar e criar continuamente novas tarefas e ambientes (Fonte: menhguin)
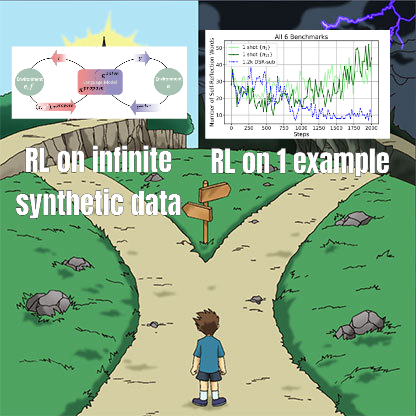
Absolute Zero Reasoner: Alcançando melhoria na capacidade de raciocínio com zero dados através de auto-jogo: Um artigo intitulado “Absolute Zero Reasoner” propõe que modelos podem aprender a propor tarefas que maximizam a capacidade de aprendizado por meio de auto-jogo completo (self-play) e melhorar sua própria capacidade de raciocínio resolvendo essas tarefas, tudo sem quaisquer dados externos. O método supera outros modelos “zero-shot” tanto em matemática quanto em codificação. Isso sugere que sistemas de IA podem ser capazes de evoluir continuamente sua capacidade de raciocínio gerando e resolvendo problemas internamente, oferecendo novas ideias para aplicações de IA em domínios com dados escassos ou custos de anotação elevados (Fonte: cognitivecompai, Reddit r/LocalLLaMA)

Erros comuns na avaliação de produtos de IA e compartilhamento de melhores práticas: Hamel Husain e Shreya Runwal compartilharam erros comuns na criação de avaliações de produtos de IA (evals) e forneceram sugestões para evitá-los. Pontos-chave incluem: benchmarks de modelos básicos não são equivalentes à avaliação de aplicativos; avaliações genéricas são ineficazes, precisam ser específicas para o aplicativo; não terceirize a anotação e a engenharia de prompts para não especialistas no domínio; construa seus próprios aplicativos de anotação de dados; prompts de LLM devem ser específicos e baseados na análise de erros; use rótulos binários; valorize a revisão de dados; cuidado com o overfitting nos dados de teste; realize testes online. Essas práticas visam ajudar os desenvolvedores a construir sistemas de avaliação de produtos de IA mais confiáveis e que reflitam melhor o desempenho no mundo real (Fonte: jeremyphoward, HamelHusain)
Novas ideias para otimização de cache KV: Dicionário universal transferível e reconstrução por processamento de sinais: A equipe de Dimitris Papailiopoulos da Universidade de Wisconsin-Madison propôs um novo método para reduzir o cache KV, utilizando um dicionário universal e transferível combinado com algoritmos tradicionais de reconstrução por processamento de sinais. O método já atingiu o nível SOTA (state-of-the-art) em modelos de não inferência e promete um desempenho ainda melhor em modelos de inferência. Esta pesquisa foi aceita no ICML, fornecendo uma nova perspectiva e caminho técnico para resolver o problema de alta ocupação do cache KV na inferência de grandes modelos (Fonte: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

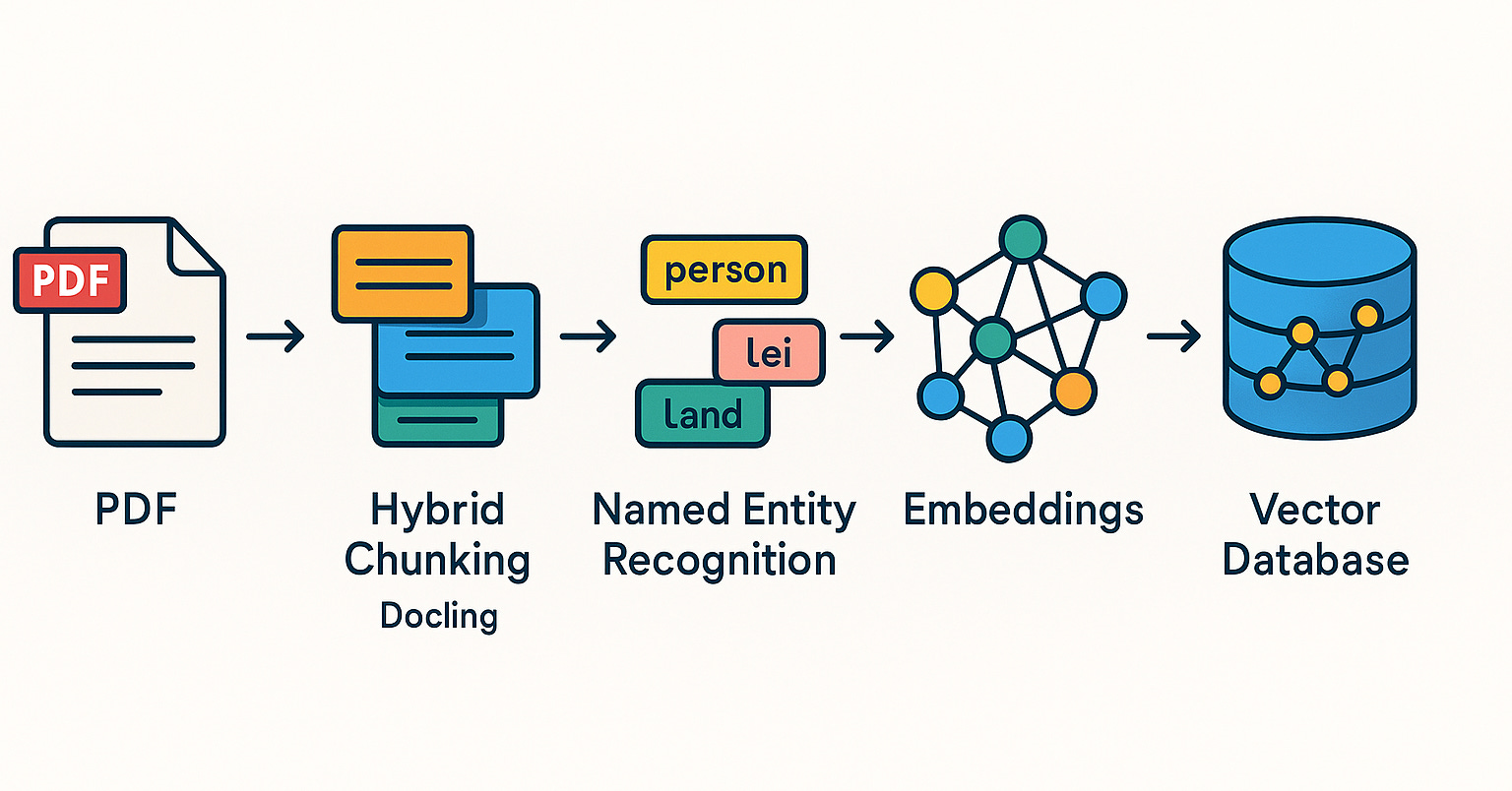
Qdrant promove práticas de sistemas RAG e busca híbrida na comunidade brasileira: O banco de dados vetorial Qdrant tem ganhado crescente atenção na comunidade brasileira. O desenvolvedor Daniel Romero compartilhou dois artigos em português, apresentando métodos práticos para construir sistemas RAG (Retrieval Augmented Generation) usando Qdrant, FastAPI e busca híbrida. O conteúdo inclui como montar um sistema RAG de busca híbrida e estratégias de ingestão de dados para RAG, especialmente a técnica de Hybrid Chunking. Esses compartilhamentos ajudam os desenvolvedores brasileiros a utilizar melhor o Qdrant para o desenvolvimento de aplicações de IA (Fonte: qdrant_engine)
OpenAI Academy lança série especial sobre Engenharia de Prompts para educação K-12: A OpenAI Academy lançou uma série de aprendizado sobre Engenharia de Prompts (Prompt Engineering) para educadores do K-12, intitulada “Mastering Your Prompts”. A série visa ajudar os educadores a entender e aplicar melhor as técnicas de prompt, a fim de integrar mais eficazmente ferramentas de IA (como o ChatGPT) em suas práticas de ensino, melhorando os resultados do ensino e a experiência de aprendizado dos alunos. Isso indica que a educação assistida por IA está gradualmente se infiltrando no ensino fundamental e médio, e valorizando o desenvolvimento da literacia em IA dos educadores (Fonte: dotey)
Yann LeCun compartilha conteúdo de sua palestra na Universidade Nacional de Singapura: Yann LeCun compartilhou o documento PDF de sua Palestra Distinta (Distinguished Lecture) proferida na Universidade Nacional de Singapura (NUS) em 27 de abril de 2025. Embora o tema específico da palestra não tenha sido fornecido, LeCun, como pioneiro no campo do aprendizado profundo, geralmente aborda em suas palestras teorias de vanguarda da inteligência artificial, tendências futuras ou percepções profundas sobre o desenvolvimento atual da IA. Esse compartilhamento oferece aos interessados em pesquisa de IA um acesso direto aos seus pontos de vista mais recentes (Fonte: ylecun)
PyTorch colabora com backend Mojo para simplificar adaptação a novo hardware e linguagens: O PyTorch está trabalhando para simplificar o processo de criação de novos backends para linguagens de programação e hardware emergentes. No hackathon do Mojo, marksaroufim demonstrou os esforços do PyTorch nesse sentido e mencionou um backend WIP (em andamento) desenvolvido em colaboração com a equipe do Mojo. Isso indica que o ecossistema PyTorch está expandindo ativamente sua compatibilidade para suportar ambientes de desenvolvimento de IA e opções de aceleração de hardware mais diversificados, reduzindo assim a barreira para os desenvolvedores implantarem e otimizarem modelos PyTorch em diferentes plataformas (Fonte: marksaroufim)
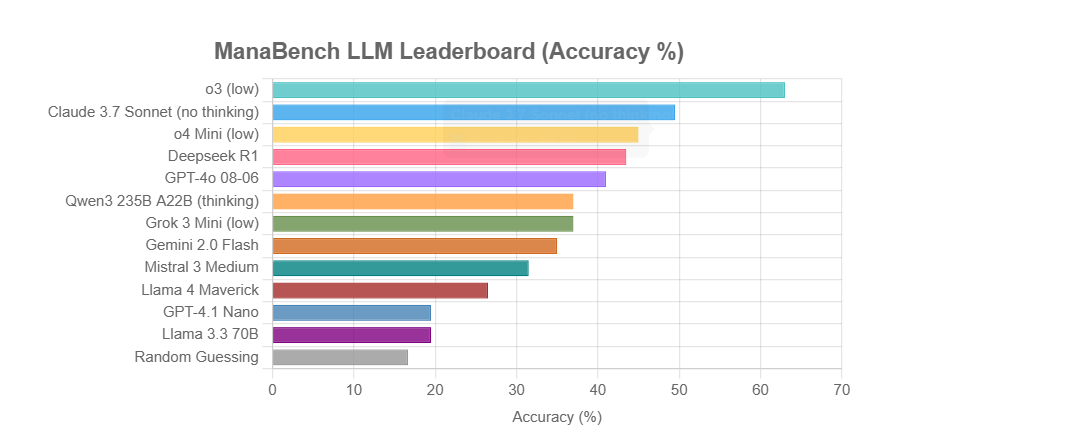
ManaBench: Novo benchmark de capacidade de raciocínio de LLM baseado na montagem de decks de Magic: The Gathering: Um desenvolvedor criou um novo benchmark chamado ManaBench, que testa a capacidade de raciocínio de sistemas complexos de LLMs, fazendo-os escolher a 60ª carta mais adequada entre seis opções, dadas 59 cartas de Magic: The Gathering (MTG). O benchmark enfatiza o raciocínio estratégico, a otimização de sistemas, e as respostas são consistentes com o design de especialistas humanos, sendo difícil de ser quebrado por simples memorização. Resultados preliminares mostram que os modelos da série Llama tiveram desempenho abaixo do esperado, enquanto modelos de código fechado como o3 e Claude 3.7 Sonnet lideraram. O benchmark visa avaliar de forma mais realista o desempenho de LLMs em tarefas que exigem raciocínio complexo (Fonte: Reddit r/LocalLLaMA)
Discussão: A IA irá ressuscitar ou enterrar o sonho da Web Semântica?: Nas redes sociais, o usuário Spencer mencionou que, a menos que grandes sites corporativos tenham uma exposição significativa a riscos devido à lei ADA (Americans with Disabilities Act), a Web Semântica é mais teórica do que prática na maioria dos sites. Dorialexander respondeu que sente que a IA irá ou ressuscitar o sonho da Web Semântica ou enterrá-lo para sempre. Isso reflete a expectativa e a preocupação com o potencial da IA na compreensão e utilização de dados estruturados; a IA pode indiretamente alcançar os objetivos da Web Semântica por meio da compreensão e geração automática de informações estruturadas, mas também pode tornar as tecnologias tradicionais da Web Semântica menos importantes devido à sua própria capacidade poderosa (Fonte: Dorialexander)
Pesquisadores discutem ética e arquiteturas da memória e esquecimento em modelos: Um rascunho de artigo intitulado “Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting” está sendo escrito, explorando como decidimos o que os modelos devem esquecer quando começam a “lembrar demais”, fundindo neuroarquitetura com ética da memória. Isso envolve como os sistemas de IA armazenam, recuperam e (seletivamente) esquecem informações, bem como os desafios éticos e impactos sociais decorrentes, o que é crucial para construir uma IA responsável e confiável (Fonte: Reddit r/artificial)
💼 Negócios
Rumores indicam que Nvidia lançará chip H20 “recapado” para atender aos novos controles de exportação dos EUA: Segundo a Reuters, a Nvidia planeja lançar nos próximos dois meses uma nova versão do chip de IA H20 específica para a China, a fim de cumprir os mais recentes requisitos de controle de exportação dos EUA. Este chip será ainda mais “capado” em relação ao H20 original (que já era uma versão rebaixada customizada para o mercado chinês), por exemplo, a capacidade de memória de vídeo será significativamente reduzida. Embora o desempenho seja novamente reduzido, alega-se que os usuários finais poderão ajustar o desempenho até certo ponto modificando a configuração do módulo. Atualmente, a Nvidia recebeu pedidos do H20 no valor de US$ 18 bilhões (Fonte: WeChat)

Databricks pode adquirir empresa de banco de dados de código aberto Neon por US$ 1 bilhão, fortalecendo infraestrutura de IA: A empresa de dados e IA Databricks está supostamente em negociações para adquirir a Neon, desenvolvedora do motor de banco de dados PostgreSQL de código aberto, por um valor que pode chegar a cerca de US$ 1 bilhão. A Neon é conhecida por sua arquitetura serverless, separação de armazenamento e computação, e boa adaptação para AI Agents e programação ambiente, permitindo pagamento sob demanda e inicialização rápida de instâncias de banco de dados, adequada para cenários de aplicação de IA. Se bem-sucedida, esta aquisição fortalecerá ainda mais a camada de infraestrutura da Databricks na era da IA, fornecendo-lhe uma solução de banco de dados modernizada e centrada em IA (Fonte: WeChat)

OpenAI nomeia ex-CEO da Instacart, Fidji Simo, como CEO de Negócios de Aplicativos, fortalecendo produto e comercialização: A OpenAI anunciou a nomeação de Fidji Simo, ex-CEO da Instacart e membro do conselho da empresa, para o recém-criado cargo de “CEO de Negócios de Aplicativos”, em nível hierárquico igual ao de Sam Altman. Simo será totalmente responsável pelos produtos da OpenAI, especialmente aplicativos voltados para o usuário como o ChatGPT, visando impulsionar a otimização de produtos, a melhoria da experiência do usuário e o processo de comercialização. Esta medida marca uma grande mudança no foco estratégico da OpenAI, da pesquisa de modelos para a plataformização de produtos e expansão de mercado, com a intenção de estabelecer uma competitividade mais forte na camada de aplicativos de IA. A rica experiência de Simo em produtos e comercialização no Facebook e Instacart ajudará a OpenAI a enfrentar a concorrência de mercado cada vez mais acirrada (Fonte: WeChat)

🌟 Comunidade
JetBrains AI Assistant gera insatisfação do usuário devido à má experiência e gerenciamento de comentários: O plugin AI Assistant da JetBrains, apesar de ter mais de 22 milhões de downloads, tem uma classificação de apenas 2,3 (de 5) em seu marketplace, repleto de muitas avaliações de 1 estrela. Os usuários geralmente relatam problemas como instalação automática, lentidão, muitos bugs, suporte insuficiente a modelos de terceiros, funcionalidades principais vinculadas a serviços em nuvem e falta de documentação. Recentemente, a JetBrains foi acusada de excluir comentários negativos em massa, e embora a explicação oficial seja o tratamento de conteúdo que viola regras ou problemas já resolvidos, isso ainda gerou dúvidas dos usuários sobre o controle de comentários e a falta de atenção ao feedback do usuário, com alguns usuários optando por republicar avaliações negativas e continuar dando 1 estrela. Este incidente intensificou a insatisfação dos usuários com a estratégia de produtos de IA da JetBrains (Fonte: WeChat)

Usuários debatem problemas de qualidade na saída de agentes inteligentes de marketing de IA: O usuário de mídia social omarsar0 observou que muitos agentes inteligentes de marketing de IA demonstrados em tutoriais do YouTube geram textos de marketing de qualidade geralmente baixa, sem criatividade e estilo. Ele acredita que isso reflete a dificuldade de fazer com que LLMs produzam conteúdo de alta qualidade e atraente, e enfatiza que o “bom gosto” é crucial na construção de agentes de IA. Ele aponta que muitos agentes de IA atuais, embora tenham fluxos de trabalho complexos, ainda são deficientes na produção de conteúdo com valor comercial real, o que oferece oportunidades para talentos com bom gosto, experiência e capacidade de projetar bons sistemas de avaliação (Fonte: omarsar0)
Codificação assistida por IA e tendência de “programação ambiente” geram discussão: Um vídeo do Y Combinator discutindo a codificação por IA gerou debate no Reddit. As opiniões do vídeo coincidiram fortemente com a experiência do autor do post (que afirma ter criado vários projetos lucrativos por meio de “programação ambiente”). Os pontos principais incluem: 1. A IA já pode auxiliar na construção de produtos de software complexos e utilizáveis, mesmo sem escrever código. 2. A preocupação dos engenheiros de software com a IA substituindo seus empregos está crescendo, mas aqueles que realmente dominam o desenvolvimento assistido por IA possuem “superpoderes”. 3. O papel futuro dos engenheiros de software pode se transformar em “gerentes de agentes” que utilizam bem as ferramentas de IA, com a IA responsável pela maior parte da escrita de código. 4. A IA irá gerar um grande número de softwares de nicho para mercados segmentados. Os debatedores acreditam que, embora o potencial da codificação por IA seja enorme, ainda é necessário ter conhecimento de conceitos de engenharia, bancos de dados, arquitetura, etc., para utilizá-la efetivamente (Fonte: Reddit r/ClaudeAI)

Discussão sobre se a IA vai “dominar o mundo” e seu impacto no emprego continua: Posts no subreddit r/ArtificialInteligence refletem a ansiedade generalizada da comunidade e a diversidade de opiniões sobre o impacto futuro da IA. Alguns usuários acreditam que quanto mais se entende sobre as capacidades da IA, maior a preocupação de que ela supere os humanos e domine o futuro, apontando que sistemas de IA de ponta já demonstram capacidades surpreendentes. Outros usuários acreditam que a渲染ização excessiva da AGI levou a expectativas irreais, que a IA é essencialmente uma ferramenta de automação inteligente e seu impacto será gradual, semelhante ao dos computadores e da internet. A discussão também abordou o potencial impacto da IA no emprego, na distribuição de riqueza e na eficácia da regulamentação, com alguns argumentando que a história mostra que o progresso tecnológico tende a exacerbar a desigualdade de riqueza, e a IA pode concentrar ainda mais a riqueza eliminando um grande número de empregos. Ao mesmo tempo, alguns expressam otimismo sobre o papel positivo da IA em áreas como saúde e educação (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Experiência do usuário: Como ferramentas de IA como o ChatGPT afetam o pensamento e a cognição: Alguns usuários compartilharam nas plataformas sociais e no Reddit os impactos cognitivos positivos do uso de ferramentas de IA como o ChatGPT. Eles sentem que a IA não é apenas uma ferramenta de obtenção de informações ou assistência à escrita, mas mais como um “parceiro de pensamento” ou “espelho” que os ajuda a organizar seus pensamentos e expressar claramente ideias subconscientes. Através da conversa com a IA, os usuários relatam que podem refletir melhor, desafiar suas próprias crenças, descobrir padrões de pensamento e até sentir que estão “despertando”, tendo uma compreensão mais profunda da vida e dos sistemas. Essa experiência sugere que a IA, em alguns casos, pode se tornar um catalisador para o crescimento pessoal e a autoexploração (Fonte: Reddit r/ChatGPT)
💡 Outros
Segunda edição do Concurso Nacional de Inovação e Aplicação em Inteligência Artificial “Xingzhi Cup” é lançada: Organizada conjuntamente pelo CAICT e outras unidades, a segunda edição do “Xingzhi Cup” foi inaugurada. Com o tema “Capacitação Inteligente, Liderança Inovadora”, o concurso estabelece três trilhas principais: inovação em grandes modelos, capacitação setorial e ecossistema de inovação em software e hardware, além de várias direções especializadas. O evento visa promover a inovação tecnológica em IA, a implementação de engenharia e a construção de um ecossistema autônomo, cobrindo quase 10 setores-chave, como industrial, médico e financeiro, e enfatizando a aplicação de software e hardware de IA de produção nacional. Os projetos vencedores receberão apoio financeiro, conexões com a indústria, entre outros (Fonte: WeChat)

Compartilhamento do AI Ascent da Sequoia Capital: Enorme potencial de mercado para IA, camada de aplicação e economia de agentes são o futuro: Pat Grady e outros sócios da Sequoia Capital compartilharam percepções sobre o mercado de IA no evento AI Ascent. Eles acreditam que o potencial do mercado de IA excede em muito o da computação em nuvem, mas alertam para a “receita ambiente” (usuários experimentando apenas por curiosidade, não por necessidade real). A camada de aplicação é vista como o verdadeiro valor, e as startups devem se concentrar em nichos verticais e nas necessidades dos clientes. A IA já alcançou avanços na geração de voz e programação. A perspectiva futura é a “economia de agentes”, onde agentes de IA poderão transferir recursos e realizar transações, mas enfrentam desafios como identidade persistente, protocolos de comunicação e segurança. Ao mesmo tempo, a IA ampliará enormemente as capacidades individuais, gerando “superindivíduos” (Fonte: WeChat)

Discussão: Conteúdo e qualidade de ensino de cursos universitários de Machine Learning na era da IA geram atenção: O compartilhamento do plano de estudos do curso de ML de pós-graduação do professor Kyunghyun Cho da NYU gerou discussão. O curso enfatiza problemas não relacionados a LLM que podem ser resolvidos por SGD e a leitura de artigos clássicos, recebendo o reconhecimento de colegas como professores de CS de Harvard, que consideram importante preservar os conceitos básicos. No entanto, estudantes da Índia e dos EUA reclamaram da baixa qualidade dos cursos de ML em suas universidades, que são excessivamente abstratos, cheios de jargões e carentes de explicações aprofundadas, levando os alunos a dependerem do autoestudo e de recursos online. Isso reflete a contradição entre o rápido desenvolvimento da área de IA/ML e a atualização defasada dos currículos universitários, bem como a importância de construir uma base sólida em matemática e teoria (Fonte: WeChat)
