
Palavras-chave:ChatGPT, GitHub, Modelo de IA, Multimodal, Aprendizagem por Reforço, Código aberto, Meta FAIR, AGI, Recursos de pesquisa aprofundada do ChatGPT, Arquitetura híbrida Transformer, Ajuste fino por reforço (RFT), Modelo Multiverso de mundos multiplayer com IA, Estrutura de IA para cientistas
🔥 Foco
Funcionalidade Deep Research do ChatGPT integrada ao GitHub: A OpenAI anunciou que a funcionalidade Deep Research do ChatGPT agora suporta a conexão com repositórios de código do GitHub. Após o utilizador fazer uma pergunta, o agente de IA pode ler, pesquisar e analisar automaticamente o código-fonte, PRs e documentos README no repositório, gerando relatórios detalhados com citações diretas. A funcionalidade visa ajudar os programadores a familiarizarem-se rapidamente com projetos, compreender a estrutura do código e a stack tecnológica. Atualmente, esta funcionalidade está em fase de testes, disponível para utilizadores Team, e será gradualmente lançada para utilizadores Plus e Pro. (Fonte: OpenAI Developers, snsf, EdwardSun0909, op7418, gdb, tokenbender, 量子位, 36氪)

Primeiro modelo de mundo multijogador de IA, Multiverse, torna-se open source: A startup israelita Enigma Labs tornou open source o seu modelo de mundo multijogador, Multiverse, permitindo que dois agentes de IA percebam, interajam e colaborem no mesmo ambiente gerado. O modelo foi treinado com base no Gran Turismo 4, processando o estado do mundo partilhado ao empilhar as perspetivas de dois jogadores ao longo dos canais de cor e combinando frames históricos amostrados esparsamente. Isto permite o treino e a execução em tempo real num PC com um custo inferior a 1500 dólares. Esta iniciativa é vista como um avanço importante na compreensão e geração de ambientes virtuais partilhados por IA, oferecendo novas ideias para sistemas multiagente e plataformas de treino de simulação. (Fonte: Reddit r/MachineLearning, 36氪)
Cientista de IA de ponta Rob Fergus retorna e assume liderança do Meta FAIR, com meta de AGI: Rob Fergus, que cofundou o FAIR com Yann LeCun e posteriormente liderou a equipa de Nova Iorque na DeepMind, regressou à Meta para suceder Joelle Pineau como chefe do FAIR. Fergus juntou-se ao departamento GenAI da Meta em abril deste ano, dedicando-se a melhorar a memória e as capacidades de personalização do modelo Llama. LeCun anunciou simultaneamente que o novo objetivo do FAIR será a inteligência artificial geral (AGI). Fergus é um académico altamente citado no campo da IA, conhecido por trabalhos como a investigação de visualização da ZFNet e o trabalho pioneiro em amostras adversariais. (Fonte: ylecun, 36氪)

Anthropic publica estudo sobre valores do Claude AI, revelando 3307 tendências de valor da IA: A equipa de investigação da Anthropic publicou o pré-print do artigo “Values in the Wild”, que, através da análise do desempenho do Claude AI em conversas do mundo real, identificou 3307 valores únicos da IA. O estudo descobriu que os valores mais comuns são orientados para o serviço, como “prestatividade” (23,4%), “profissionalismo” (22,9%) e “transparência” (17,4%). Os valores da IA foram categorizados em cinco classes principais: prático (31,4%), cognitivo (22,2%), social (21,4%), proteção (13,9%) e pessoal (11,1%), e demonstraram uma alta dependência do contexto. O Claude geralmente responde de forma solidária aos valores expressos pelos humanos (43%), o espelhamento de valores representa cerca de 20%, enquanto a resistência aos valores do utilizador é rara (5,4%). (Fonte: Reddit r/ArtificialInteligence)
Yoshua Bengio propõe framework “Scientist AI”, defendendo um caminho de desenvolvimento de IA mais seguro: O vencedor do Prémio Turing, Yoshua Bengio, publicou um artigo de opinião na revista Time, expondo a direção de investigação da sua equipa sobre “Scientist AI”. Ele acredita que este é um caminho de desenvolvimento de IA prático, eficaz e mais seguro, destinado a substituir a atual trajetória de desenvolvimento de IA descontrolada e orientada por agentes. O framework enfatiza que os sistemas de IA devem possuir interpretabilidade, verificabilidade e capacidade de alinhamento com os valores humanos, simulando a metodologia da investigação científica para tornar o comportamento e o processo de tomada de decisão da IA mais transparentes e controláveis, reduzindo assim os riscos potenciais. (Fonte: Yoshua_Bengio)
🎯 Tendências
Funcionalidade Reinforced Fine-Tuning (RFT) da OpenAI lançada oficialmente no o4-mini: A OpenAI anunciou que a funcionalidade Reinforced Fine-Tuning (RFT), apresentada em preview em dezembro do ano passado, está agora oficialmente disponível no modelo o4-mini. O RFT utiliza raciocínio em cadeia de pensamento e pontuação específica da tarefa para melhorar o desempenho do modelo em domínios complexos. Por exemplo, a empresa AccordanceAI já usou RFT para realizar fine-tuning de um modelo com desempenho de topo em impostos e contabilidade. (Fonte: OpenAI Developers, gdb, 量子位, 36氪)
API Gemini lança funcionalidade de cache implícita, reduzindo custos de chamada em 75%: A API Gemini da Google adicionou uma funcionalidade de cache implícita. Quando um pedido do utilizador tem um prefixo comum com um pedido anterior, o cache é automaticamente acionado, poupando aos utilizadores 75% dos custos de Token. Esta funcionalidade não requer que os programadores criem ativamente um cache. Ao mesmo tempo, o requisito mínimo de Token para acionar o cache foi reduzido para 1K no Gemini 2.5 Flash e para 2K no 2.5 Pro, diminuindo ainda mais os custos de utilização da API. (Fonte: op7418)

OpenAI lança totalmente a funcionalidade de memória do ChatGPT no Espaço Económico Europeu e outras regiões: A OpenAI anunciou que a funcionalidade de memória do ChatGPT foi totalmente lançada para utilizadores Plus e Pro no Espaço Económico Europeu (EEE), Reino Unido, Suíça, Noruega, Islândia e Liechtenstein. Esta funcionalidade permite que o ChatGPT referencie todo o histórico de conversas anteriores do utilizador para fornecer respostas mais personalizadas, compreender melhor as preferências e interesses do utilizador e, assim, oferecer ajuda mais precisa na escrita, sugestões, aprendizagem, etc. (Fonte: openai)
ByteDance SEED lança modelo de base multimodal Mogao: A equipa SEED da ByteDance lançou um modelo de base Omni chamado Mogao, projetado especificamente para geração multimodal intercalada. O Mogao integra várias melhorias técnicas, incluindo um design de fusão profunda, codificadores visuais duplos, embeddings de posição rotacional intercalados e orientação multimodal sem classificador. Estas melhorias permitem-lhe combinar as vantagens dos modelos autorregressivos (geração de texto) e dos modelos de difusão (síntese de imagem de alta qualidade), processando eficazmente sequências arbitrárias intercaladas de texto e imagem. (Fonte: NandoDF)

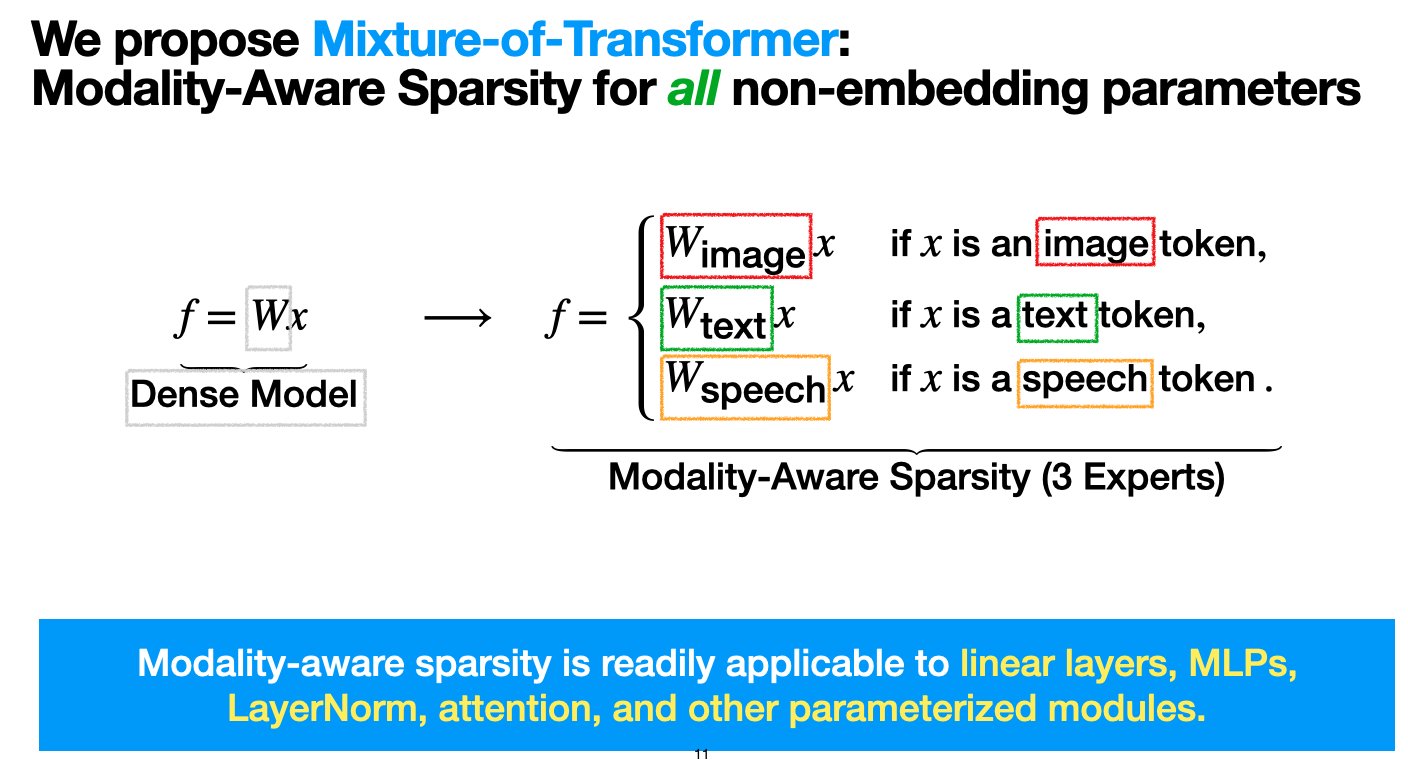
Meta lança arquitetura Mixture-of-Transformers (MoT) para reduzir custos de pré-treino de modelos multimodais: Investigadores da Meta AI propuseram uma arquitetura esparsa chamada “Mixture-of-Transformers (MoT)”, que visa reduzir significativamente os custos computacionais do pré-treino de modelos multimodais sem sacrificar o desempenho. O MoT aplica esparsidade sensível à modalidade a parâmetros de Transformer não-embedding (como redes feed-forward, matrizes de atenção e normalização de camada). Experiências mostram que, na configuração Chameleon (geração de texto + imagem), um modelo MoT de 7B atingiu a qualidade da linha de base densa usando apenas 55,8% dos FLOPs; ao estender para a fala como terceira modalidade, usou apenas 37,2% dos FLOPs. Esta investigação foi aceite pela TMLR (março de 2025) e o código foi tornado open source. (Fonte: VictoriaLinML)
Projeto de melhoria do modelo Qwen, Smoothie Qwen, lançado para equilibrar geração multilingue: Foi lançado um projeto de melhoria do modelo Qwen chamado Smoothie Qwen, que visa equilibrar as capacidades de geração multilingue ajustando as probabilidades dos parâmetros internos do modelo. O projeto aborda principalmente o problema de alguns utilizadores não chineses encontrarem ocasionalmente resultados em chinês ao usar o Qwen, e afirma não reduzir a inteligência do modelo. (Fonte: karminski3)

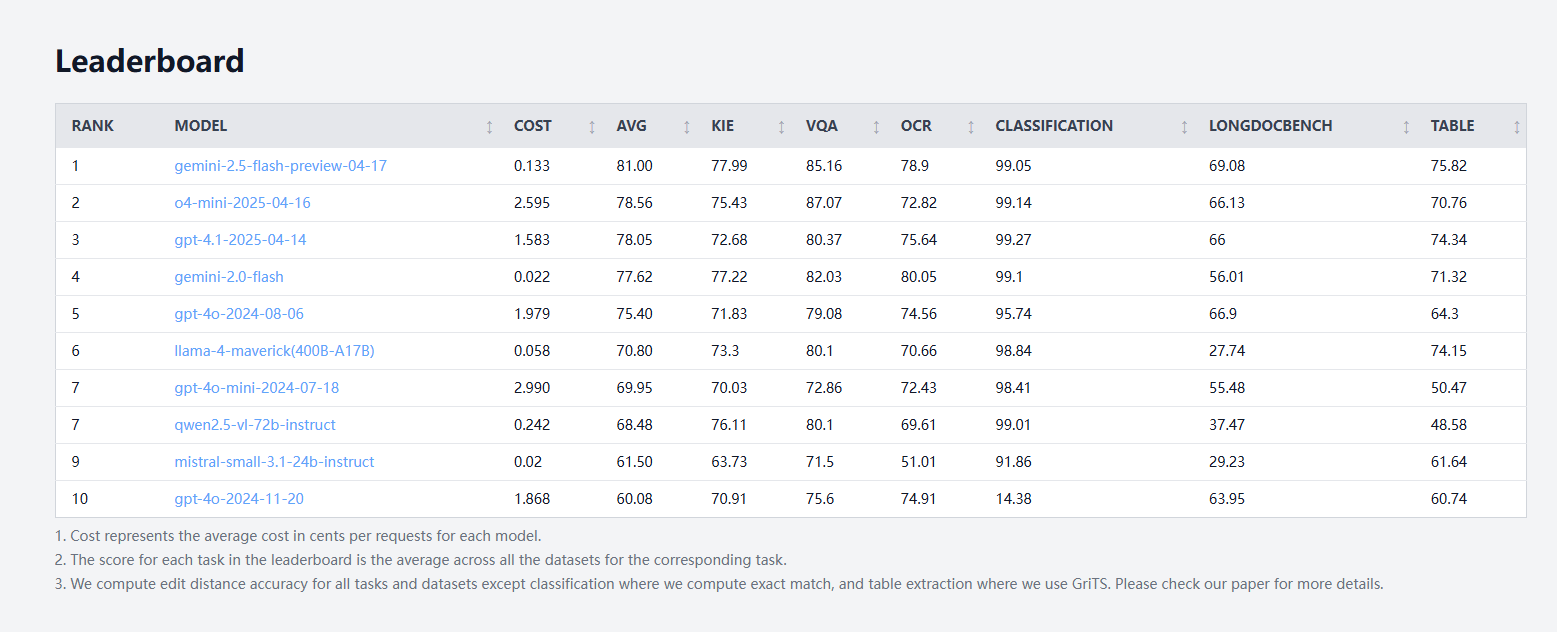
idp-leaderboard lançado, o primeiro benchmark de teste de IA para tipos de documentos: O novo benchmark de teste de IA idp-leaderboard foi lançado, focado em avaliar a capacidade dos modelos de processar documentos e imagens de documentos. De acordo com a lista inicial, o gemini-2.5-flash-preview-04-17 apresenta o melhor desempenho geral no processamento de documentos. É de notar que o Qwen2.5-VL teve um desempenho fraco no processamento de tabelas. (Fonte: karminski3)
Funcionalidade Perplexity Discover recebe atualização importante: Arav Srinivas, cofundador da Perplexity, anunciou que a sua funcionalidade Discover (feed de descoberta de informações) foi significativamente melhorada, incentivando os utilizadores a experimentá-la. Isto geralmente significa otimizações na apresentação da informação, relevância ou interface do utilizador, destinadas a melhorar a capacidade do utilizador de adquirir e explorar novas informações. (Fonte: AravSrinivas)
Lenovo anuncia grande atualização do superagente inteligente pessoal Tianxi, primeiro tablet do mundo com DeepSeek implementado localmente: A Lenovo anunciou uma grande atualização do seu superagente inteligente pessoal Tianxi, avançando para o nível L3 completo, e lançou o agente de domínio “Xiang Bang Bang”, focado em serviços de IA para dispositivos inteligentes pessoais. Simultaneamente, a Lenovo lançou vários novos produtos terminais de IA, incluindo o primeiro tablet do mundo a implementar localmente o modelo de grande escala DeepSeek, o YOGA Pad Pro 14.5 AI Yuanqi Edition, bem como telemóveis moto AI, PCs da série Legion, etc., construindo um ecossistema de IA completo de AI PC, telemóveis AI, tablets AI e AIoT. (Fonte: 量子位)

Lou Tiancheng discute condução autónoma e IA incorporada: L2 não pode evoluir para L4, VLA tem ajuda limitada para L4: Lou Tiancheng, cofundador e CTO da Pony.ai, partilhou as suas mais recentes perspetivas sobre condução autónoma e IA durante o lançamento de uma nova geração de modelos Robotaxi. Ele enfatizou a diferença fundamental entre L2 e L4, argumentando que L2 não pode evoluir para L4, e que o paradigma VLA (Visual-Language-Action), popular no domínio L2, “basicamente não ajuda em nada” o L4. Ele salientou que L4 requer segurança extrema, como um médico especialista, enquanto VLA é mais como um clínico geral. O núcleo da transformação tecnológica da Pony.ai nos últimos dois anos tem sido o end-to-end e o modelo de mundo, este último aplicado há cerca de 5 anos. Ele também considera a “condução assistida na nuvem” um conceito falso e afirmou que o estado atual da IA incorporada é semelhante ao da condução autónoma em 2018, enfrentando desafios semelhantes de “período de vácuo”. (Fonte: 量子位)

Kimi testa comunidade de conteúdo, OpenAI pode desenvolver aplicação social, empresas de modelos de grande escala de IA exploram social para aumentar retenção de utilizadores: O Kimi da Moonshot AI está a testar em escala de cinza um produto de comunidade de conteúdo, principalmente com conteúdo gerado por IA a partir de notícias em destaque, focado em tecnologia, finanças, etc. Coincidentemente, a OpenAI também foi reportada como planeando desenvolver software social, possivelmente para competir com o X. Estas ações indicam que as empresas de modelos de grande escala de IA estão a tentar aumentar a retenção de utilizadores através da construção de comunidades ou funcionalidades sociais, resolvendo o problema de as ferramentas de IA serem “usadas e descartadas”. No entanto, a operação da comunidade enfrenta desafios de qualidade de conteúdo, riscos de segurança e dificuldades de monetização. Esta medida também reflete que, após o pico do bónus de crescimento, a indústria de IA está a começar a mudar de “queimar dinheiro por crescimento” para um maior foco no ROI e na exploração de novos modelos de negócio. (Fonte: 36氪)

TCL abraça totalmente a IA, lança modelo de grande escala Fuxi e vários eletrodomésticos AI, mas enfrenta desafios de homogeneização: A TCL destacou os seus produtos e estratégia de IA em feiras como AWE 2025 e CES 2025, incluindo o modelo de grande escala TCL Fuxi e funcionalidades de IA aplicadas a televisores, aparelhos de ar condicionado, máquinas de lavar roupa, etc. O seu negócio de televisores teve um desempenho notável, com o volume de remessas a ocupar o primeiro lugar global no primeiro trimestre, sendo a tecnologia Mini LED a sua vantagem. No entanto, a aplicação de IA no setor de eletrodomésticos concentra-se atualmente na interação por voz e otimização de funções específicas (como chip de qualidade de imagem AI, sono AI, poupança de energia AI), enfrentando o desafio da concorrência homogénea com outras marcas (como Hisense Xinghai, Haier HomeGPT, Midea Meiyan). A TCL também explora robôs de companhia AI e, através da Thunderbird, o layout de óculos inteligentes. Apesar do aumento do investimento em IA, a sua vantagem tecnológica independente ainda não é significativa, e enfrenta problemas como custos de marketing elevados e queda da margem bruta. (Fonte: 36氪)
IA impulsiona transformação educacional, empresas líderes como iFlytek e Excellence Education aceleram layout de IA: O relatório analisa as práticas mais recentes de empresas educacionais líderes como iFlytek, Excellence Education, Fenbi, Zhonggong Education, Huatu Education e Yiqi Education Technology no campo da IA. A iFlytek, com poder computacional nacional e modelos Deepseek-V3/R1, aprofunda-se na educação em tecnologia da informação. A Excellence Education utiliza o Deepseek R1 para capacitar toda a cadeia de ensino, lançando ferramentas de correção e leitura por IA. A Fenbi construiu uma matriz de produtos de IA que cobre cenários de aprendizagem de alta frequência e necessidades essenciais. A Zhonggong Education foca-se em serviços de emprego por IA, desenvolvendo o modelo de grande escala “Yunxin”. A Huatu Education combina vantagens offline, usando IA para melhorar a precisão dos serviços para concursos públicos. A Yiqi Education Technology impulsiona a integração de ensino e avaliação com IA. As tendências do setor mostram que a educação com IA está a evoluir de ferramentas pontuais para competição de ecossistemas e concretização de valor. (Fonte: 36氪)
Grandes empresas como Baidu e Alibaba promovem protocolo MCP, disputando o direito de definir o ecossistema de AI Agent: O Protocolo de Contexto de Modelo (MCP) tem sido recentemente promovido por grandes empresas como Anthropic, OpenAI, Google, bem como Baidu e Alibaba na China. A aplicação “Xīnxiǎng” da Baidu e a plataforma Bailian da Alibaba Cloud já suportam MCP, permitindo que os AI Agents invoquem ferramentas e serviços externos de forma mais conveniente. Esta medida, aparentemente destinada a unificar os padrões da indústria, é na verdade uma disputa entre as grandes empresas pelo futuro direito de definir o ecossistema de AI Agent. Ao construir e promover o MCP, as grandes empresas pretendem atrair mais programadores para os seus ecossistemas, dominando assim as barreiras de dados e o poder de influência na indústria. A direção de comercialização das aplicações de Agent parece ainda ser dominada pelo tráfego e publicidade. (Fonte: 36氪)

Estratégia de IA da Apple revelada: possível cooperação com Baidu e Alibaba para criar sistema de IA “dual-core” para a China: Relatórios analisam a possível cooperação da Apple com Baidu e Alibaba para fornecer suporte técnico às suas funcionalidades de IA no mercado chinês. O ERNIE Bot da Baidu tem vantagens no reconhecimento visual, enquanto o modelo de grande escala Qianwen da Alibaba se destaca na compreensão cognitiva e conformidade de conteúdo. Este modelo “dual-core” pode visar combinar os pontos fortes de ambas as empresas para satisfazer os requisitos do ecossistema de dados, foco tecnológico e regulamentação do mercado chinês, mantendo ao mesmo tempo o domínio e o poder de negociação da Apple na cooperação. Esta medida é vista como uma estratégia da Apple para lidar com a pressão competitiva local de sistemas como o HarmonyOS, e uma tática de “segmentação de nicho ecológico” num contexto de regulamentação de dados mais rigorosa. (Fonte: 36氪)
Professor Yu Jingyi analisa profundamente a inteligência espacial: potencial enorme, mas consenso não formado, dados e compreensão física são cruciais: O Professor Yu Jingyi da Universidade de Tecnologia de Xangai salientou numa entrevista que o potencial dos modelos de grande escala na integração transmodal está longe de esgotado. A inteligência espacial está a evoluir da replicação digital para a compreensão e criação inteligentes, beneficiando dos avanços da IA generativa. Ele acredita que o principal desafio atual da inteligência espacial reside na escassez de dados de cenas 3D reais e na falta de unificação dos métodos de representação tridimensional. O projeto CAST da sua equipa explora as relações entre objetos e a razoabilidade física através da introdução da “Teoria da Rede de Atores” e regras físicas. Ele enfatiza a prioridade da perceção e prevê avanços revolucionários na tecnologia de sensores. O padrão de medição da IA incorporada deve ser a robustez e a segurança, e não apenas a precisão. A curto prazo, a inteligência espacial explodirá em áreas como produção cinematográfica e jogos; a médio e longo prazo, tornar-se-á o núcleo da IA incorporada, sendo a economia de baixa altitude também um importante cenário de aplicação. (Fonte: 36氪)

Guerra por talentos em IA aquece: grandes empresas oferecem altos salários, CTOs orientam pessoalmente, foco em modelos de grande escala e multimodalidade: As grandes empresas de tecnologia, tanto nacionais como internacionais, estão envolvidas numa intensa guerra por talentos em inteligência artificial. ByteDance, Alibaba, Tencent, Baidu, JD.com, Huawei e outras lançaram programas de recrutamento para doutorandos de topo e jovens génios, oferecendo salários sem limite superior, orientação pessoal de CTOs e dispensa de experiência de estágio. As áreas de recrutamento concentram-se principalmente em modelos de grande escala e multimodalidade, e estão intimamente relacionadas com os cenários de negócio principais de cada empresa. O sucesso de modelos como o DeepSeek intensificou ainda mais a procura por talentos na indústria. Elon Musk também lamentou a loucura da competição por talentos em IA, com gigantes estrangeiros como a OpenAI a atrair talentos com altos salários e recrutamento pessoal pelos fundadores. (Fonte: 36氪)
Sequoia Capital: Potencial do mercado de IA supera em muito o da computação em nuvem, camada de aplicação é crucial, Chief AI Officer será padrão: Um sócio da Sequoia Capital prevê que a dimensão do mercado de IA excederá em muito o atual mercado de computação em nuvem de aproximadamente 400 mil milhões de dólares, com um volume enorme nos próximos 10-20 anos, e o valor concentrado principalmente na camada de aplicação. As startups devem focar-se nas necessidades dos clientes, fornecer soluções end-to-end, aprofundar-se em setores verticais e usar o “data flywheel” para construir vantagens competitivas. Um estudo da AWS mostra que as empresas globais estão a acelerar a adoção da IA generativa, com 45% dos decisores a planear torná-la a sua principal prioridade para 2025. O cargo de Chief AI Officer (CAIO) tornar-se-á padrão nas empresas, com 60% das empresas já a ter criado esta posição. A economia de agentes é vista como a próxima fase do desenvolvimento da IA, mas precisa de resolver três desafios técnicos: identidade persistente, protocolos de comunicação e confiança na segurança. (Fonte: 36氪)

Novas forças na indústria automóvel apostam totalmente em IA, Li Auto, XPeng e NIO competem pela definição da próxima geração de automóveis: O avanço trazido pela tecnologia de rede neural end-to-end do FSD V12 da Tesla impulsionou as novas forças da indústria automóvel chinesa, como Li Auto, XPeng e NIO, a acelerar o seu layout de IA. A Li Auto lançou o modelo de grande escala para condutores VLA (Visual-Language-Action) e desenvolveu a parte linguística com base no modelo open source DeepSeek. A XPeng Motors construiu um modelo de base LVA com 72 mil milhões de parâmetros. A NIO lançou o primeiro modelo de mundo para condução inteligente da China, NWM, e desenvolveu internamente o chip de condução inteligente de 5nm Shenji NX9031. Todas as empresas estão a investir massivamente em algoritmos, poder computacional (chips próprios) e dados, e a generalizar a tecnologia de IA para áreas como robôs humanoides, competindo pela definição da próxima geração de automóveis e até mesmo de produtos, mas enfrentam desafios financeiros e de comercialização. (Fonte: 36氪)
🧰 Ferramentas
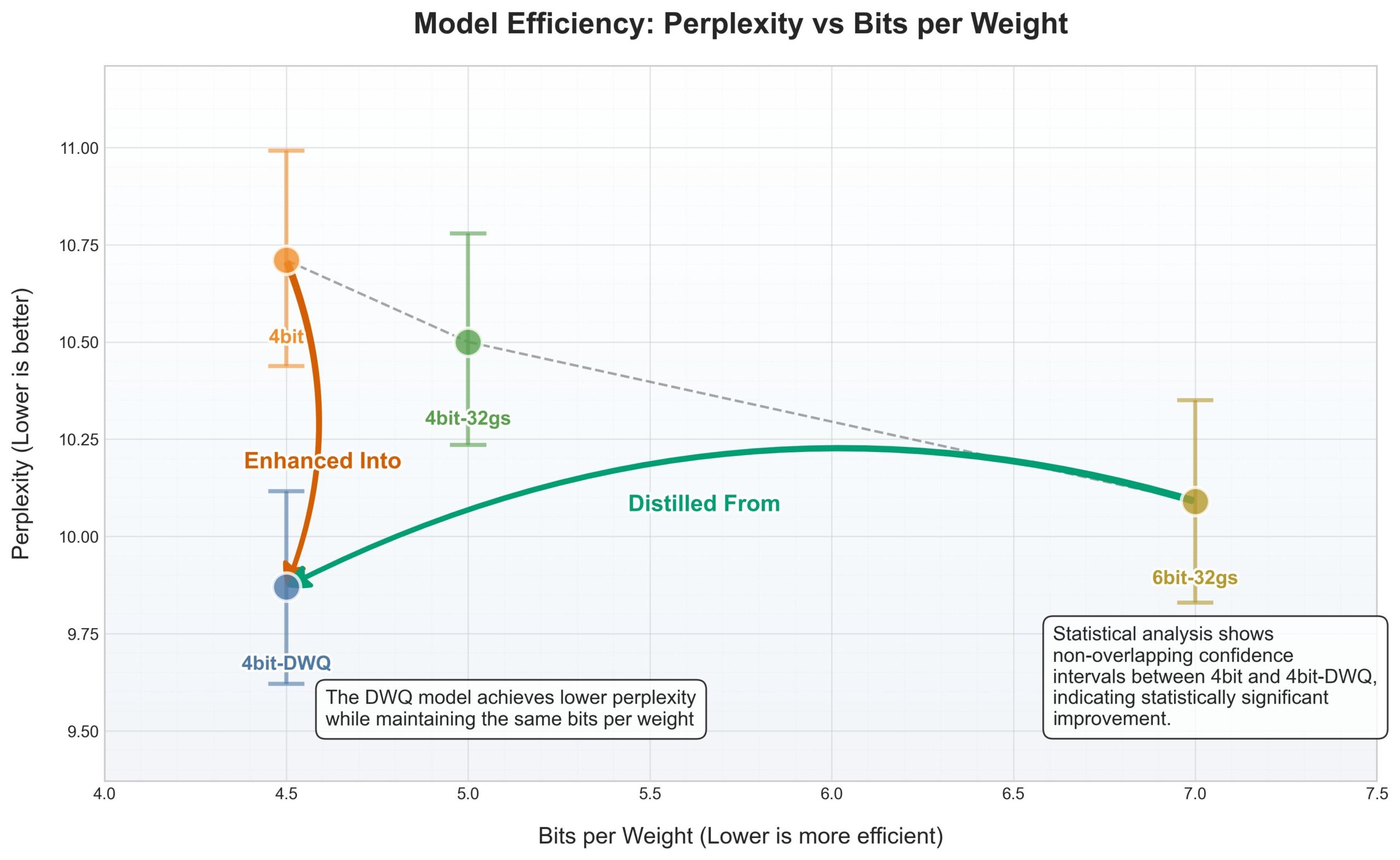
Framework MLX da Apple recebe quantização DWQ, 4bit supera antigo 6bit: Para o MLX (framework de machine learning) da Apple, foi lançado um novo método de quantização DWQ (Dynamic Weight Quantization). De acordo com dados partilhados pelo utilizador karminski3, modelos quantizados com 4bit-dwq (como o Qwen3-30B) apresentam perplexidade superior ao antigo método de quantização de 6bit, necessitando apenas de 17GB de memória para funcionar. Isto abre novas possibilidades para a execução eficiente de modelos de linguagem de grande escala em dispositivos Apple. (Fonte: karminski3)
Perplexity agora suporta pesquisa conversacional mais natural no WhatsApp: Arav Srinivas, cofundador da Perplexity, anunciou que a integração da Perplexity no WhatsApp foi melhorada, oferecendo agora uma experiência de conversação mais natural. Além disso, quando a pesquisa não é necessária, ignora inteligentemente o passo de pesquisa, permitindo que os utilizadores interajam diretamente com a IA em modo de chat. (Fonte: AravSrinivas)
nanobrowser_ai suporta LLMs populares, integra Langchain.js: A ferramenta de IA nanobrowser_ai anunciou suporte para vários modelos de linguagem de grande escala, incluindo modelos OpenAI, Gemini e modelos locais executados através do Ollama. A ferramenta utiliza o framework Langchain.js para alcançar um suporte flexível a diferentes LLMs, oferecendo aos utilizadores uma escolha mais ampla de modelos. (Fonte: hwchase17)
LlamaIndex TypeScript adiciona suporte para APIs LLM em tempo real, primeira integração com Google Gemini: O LlamaIndex TypeScript anunciou suporte para APIs LLM em tempo real, permitindo que os programadores implementem funcionalidades de conversação de áudio em tempo real em aplicações de IA. A primeira integração é com a interface de abstração em tempo real do Google Gemini, e o suporte em tempo real da OpenAI também será lançado em breve. Esta atualização facilita a alternância entre diferentes modelos em tempo real para os programadores, construindo aplicações de IA mais interativas. (Fonte: _philschmid)
Tutorial de aplicação Gradio: Usar Qwen2.5-VL para anotação de imagem e vídeo e deteção de objetos: Um tutorial detalha como usar o Qwen2.5-VL (modelo de linguagem visual) para construir uma aplicação Gradio, a fim de realizar anotação automática de imagens e vídeos, bem como funcionalidades de deteção de objetos. O tutorial visa ajudar os programadores a utilizar as poderosas capacidades do Qwen2.5-VL para construir rapidamente aplicações de IA interativas. (Fonte: Reddit r/deeplearning)

Plugin VSCode gemini-code aproxima-se dos 50 mil downloads: O plugin assistente de programação AI para VSCode, gemini-code, já atingiu perto de 50 mil downloads. O programador raizamrtn afirmou que fará algumas atualizações necessárias durante o fim de semana. O plugin visa utilizar as capacidades do modelo Gemini para auxiliar os programadores no trabalho de codificação. (Fonte: raizamrtn)

Startup francesa de IA Arcads AI: equipa de 5 pessoas fatura 5 milhões de dólares anuais, focada na produção automatizada de anúncios em vídeo: A Arcads AI, uma startup de IA sediada em Paris, com uma equipa de apenas 5 pessoas, alcançou uma receita recorrente anual de 5 milhões de dólares e é lucrativa. A empresa, através de um sistema de IA altamente automatizado, fornece aos anunciantes serviços de produção de anúncios em vídeo rápidos, de baixo custo e alta taxa de conversão. Os clientes precisam apenas de fornecer o texto principal, e a IA conclui todo o processo, desde a construção de cenários, atuação de atores, gravação de locuções até à produção do vídeo final. A plataforma Arcads possui mais de 300 imagens de atores de IA baseadas em autorizações de pessoas reais, suporta 35 idiomas e implementa “conteúdo como serviço”. As suas operações internas também utilizam extensivamente agentes de IA, como o AI Spy Agent para analisar concorrentes e o AI Ghostwriter para gerar ideias criativas, aumentando significativamente a eficiência. (Fonte: 36氪)
📚 Aprendizado
HuggingFace lança dataset MegaMath, com 370B tokens, 20% de dados sintéticos: A HuggingFace lançou o dataset MegaMath, contendo 370 mil milhões de tokens, sendo atualmente o maior dataset de pré-treino matemático, com um volume aproximadamente 100 vezes superior ao da Wikipédia em inglês. É de notar que 20% dos dados são sintéticos, o que reacende a discussão sobre o papel dos dados sintéticos de alta qualidade no treino de modelos. (Fonte: ClementDelangue)
Nous Research organiza hackathon de ambientes RL com prémio de 50 mil dólares: A Nous Research anunciou a realização do Nous RL Environment Hackathon em São Francisco. Os participantes usarão o framework de ambiente de aprendizagem por reforço da Nous, Atropos, para criar, com um prémio total de 50 mil dólares. Os parceiros incluem xAI, NVIDIA, Nebius AI, entre outros. (Fonte: Teknium1)

Lista semanal dos modelos mais populares da HuggingFace divulgada: O utilizador karminski3 partilhou a lista dos modelos mais populares desta semana na HuggingFace, mencionando que testou pessoalmente a maioria deles ou partilhou demonstrações oficiais. Isto reflete o entusiasmo da comunidade em acompanhar e avaliar rapidamente novos modelos. (Fonte: karminski3)
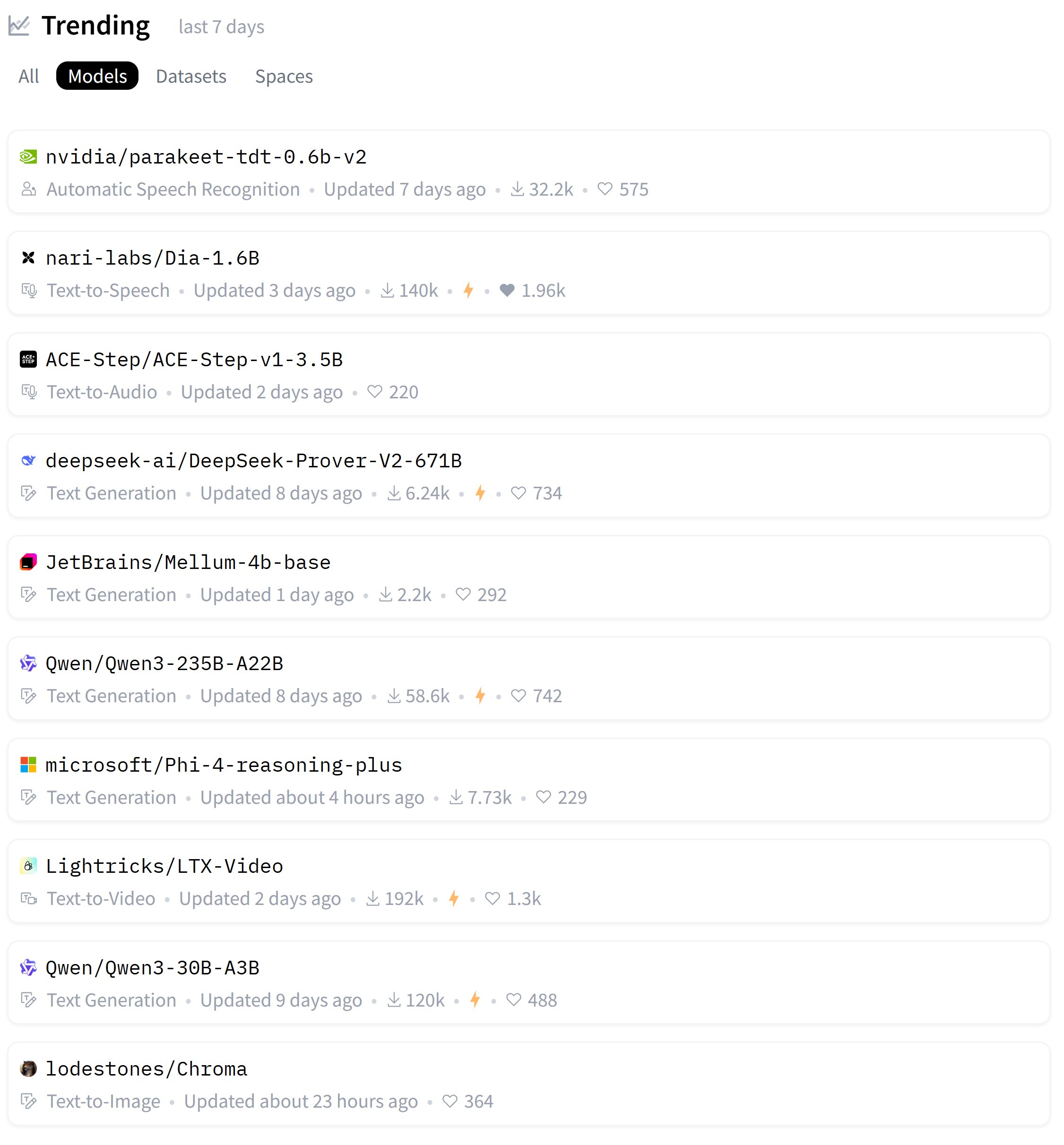
Zeyuan Allen-Zhu publica série de estudos sobre design de arquitetura LLM, discute modelo Primer: O investigador Zeyuan Allen-Zhu, através da sua série de estudos “Physics of LLM Design”, utiliza ambientes de pré-treino sintéticos controlados para revelar os verdadeiros limites da arquitetura LLM. Na sua partilha mais recente, discute o modelo Primer (arxiv.org/abs/2109.08668) e a sua atenção multi-dconv-head (que ele chama de Canon-B sem conexões residuais), apontando que existem problemas, mas também considera que o modelo Primer (com apenas 180 citações) é subestimado, pois descobriu sinais significativos a partir de experiências ruidosas do mundo real. (Fonte: ZeyuanAllenZhu, cloneofsimo)
Simons Institute discute leis de escalonamento de redes neuronais: O Simons Institute, na sua série Polylogues, convidou Anil Ananthaswamy e Alexander Rush para discutir as leis de escalonamento neuronal (neural scaling laws) descobertas empiricamente nos últimos anos. Estas leis tiveram um impacto significativo nas decisões das grandes empresas de construir modelos cada vez maiores. (Fonte: NandoDF)

François Fleuret publica “The Little Book of Deep Learning”: François Fleuret publicou uma obra intitulada “The Little Book of Deep Learning”, que visa fornecer aos leitores conhecimento refinado sobre deep learning. (Fonte: Reddit r/deeplearning)
Professor de Princeton: IA pode acabar com as humanidades, mas impulsioná-las de volta à experiência existencial: O professor D. Graham Burnett da Universidade de Princeton publicou um artigo no The New Yorker discutindo o impacto da IA nas humanidades. Ele observou uma “vergonha da IA” generalizada nas universidades americanas, onde os estudantes hesitam em admitir o uso de IA. Ele argumenta que a IA já superou os métodos académicos tradicionais na recuperação e análise de informações, tornando os livros académicos como artefactos arqueológicos. Embora a IA possa acabar com as humanidades no sentido tradicional, centradas na produção de conhecimento, também pode impulsioná-las de volta às questões centrais: como viver, enfrentar a morte e outras experiências existenciais, que a IA não pode abordar diretamente. (Fonte: 36氪)

7 estudos revelam o profundo impacto da IA no cérebro e comportamento humanos: Uma série de novos estudos explora o impacto da IA nos níveis psicológico, social e cognitivo humanos. As descobertas incluem: 1) Testadores de “red team” de LLMs exploram vulnerabilidades de modelos por curiosidade e responsabilidade moral; 2) O ChatGPT demonstra alta precisão diagnóstica na análise de casos psiquiátricos; 3) As tendências políticas do ChatGPT mudam subtilmente entre diferentes versões; 4) O uso do ChatGPT pode exacerbar a desigualdade no local de trabalho, com homens jovens de alta renda a usá-lo mais; 5) A IA pode detetar sinais de depressão analisando o comportamento de condução de idosos; 6) LLMs demonstram um viés de desejabilidade social, “embelezando” a imagem em testes de personalidade; 7) A dependência excessiva da IA pode enfraquecer o pensamento crítico, especialmente em grupos mais jovens. (Fonte: 36氪)

Entrevista com Onur Boyar: Utilização de modelos generativos e otimização Bayesiana para design de fármacos e materiais: Onur Boyar, participante do Fórum de Doutorandos AAAI/SIGAI, apresentou o seu trabalho de investigação de doutoramento na Universidade de Nagoya, focado no uso de modelos generativos e métodos Bayesianos para o design de fármacos e materiais. Ele participa no projeto japonês Moonshot, que visa construir robôs cientistas de IA para lidar com o processo de descoberta de fármacos. Os seus métodos de investigação incluem o uso de otimização Bayesiana em espaço latente para editar moléculas existentes, a fim de melhorar a eficiência da amostra e a viabilidade sintética. Ele enfatiza a estreita colaboração com químicos e juntar-se-á à equipa de descoberta de materiais da IBM Research – Tóquio após a graduação. (Fonte: aihub.org)

💼 Negócios
Modular e AMD colaboram em Hackathon Mojo, usando GPUs MI300X: A Modular anunciou uma colaboração com a AMD para realizar um hackathon especial na AGI House. No evento, os programadores usarão GPUs AMD Instinct™ MI300X para programar na linguagem Mojo. O evento também contará com apresentações técnicas de representantes da Modular, AMD, Dylan Patel da SemiAnalysis e Anthropic. (Fonte: clattner_llvm)
Stripe lança várias novas funcionalidades impulsionadas por IA, incluindo modelo de base de IA para pagamentos: A empresa de serviços financeiros Stripe anunciou no seu congresso anual o lançamento de vários novos produtos para acelerar a implementação de aplicações de IA, incluindo o primeiro modelo de base de IA do mundo especificamente para o setor de pagamentos. Este modelo, treinado com dezenas de milhares de milhões de transações, visa melhorar a deteção de fraudes (por exemplo, um aumento de 64% na taxa de deteção de ataques de “teste de cartão”), as taxas de autorização e a experiência de checkout personalizada. A Stripe também expandiu as suas capacidades de gestão de fundos multimoeda e aprofundou a sua colaboração com grandes empresas como a Nvidia (usando o Stripe Billing para gerir as subscrições do GeForce Now) e a PepsiCo. (Fonte: 36氪)
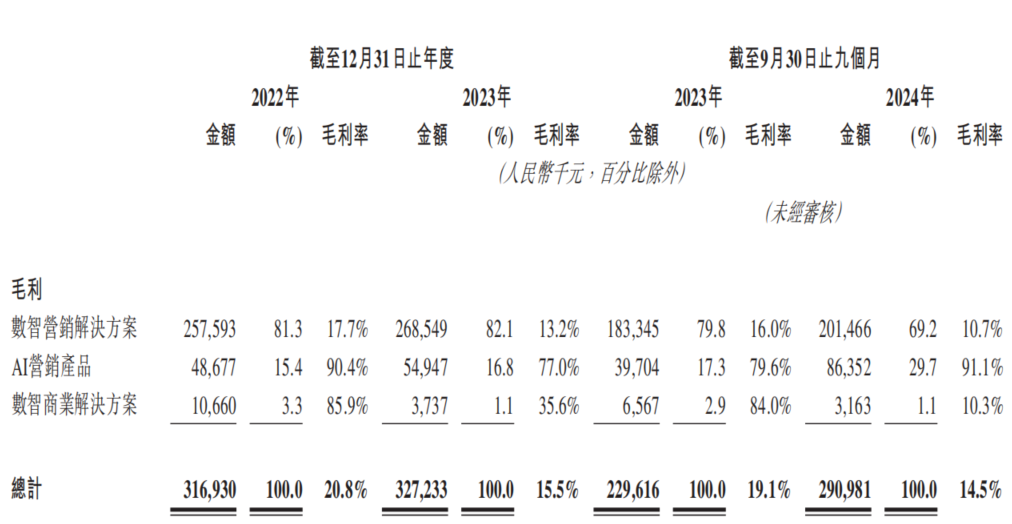
Empresa de marketing de IA Dongxin Marketing tenta novamente IPO em Hong Kong, enfrentando dilema de “aumento de receita sem aumento de lucro”: A Dongxin Marketing, autodenominada “a maior empresa de marketing de IA da China”, submeteu novamente o seu prospeto de IPO à Bolsa de Valores de Hong Kong. Os dados mostram que a receita da empresa continuou a crescer nos primeiros três trimestres de 2022-2024, mas o lucro líquido caiu drasticamente, chegando mesmo a registar prejuízo, e a margem bruta caiu de 20,8% para 14,5%. A receita do negócio de marketing de IA representa menos de 5% do total e, embora a margem bruta seja de 91,1%, não é suficiente para cobrir o investimento em I&D. A empresa enfrenta problemas como contas a receber elevadas, fluxo de caixa apertado e grande pressão de endividamento, e os seus lucros dependem fortemente de subsídios governamentais. O seu posicionamento no mercado mudou de “fornecedor de serviços de marketing móvel” para “empresa de marketing de IA”, mas o conteúdo tecnológico e as perspetivas de comercialização da sua IA são questionáveis. (Fonte: 36氪)
🌟 Comunidade
Competição acirrada entre motores de inferência vLLM e SGLang, programador compara publicamente dados de merge de PRs: A comunidade de programadores discute acaloradamente a competição entre os dois principais motores de inferência, vLLM e SGLang. O principal mantenedor do vLLM chegou a criar um dashboard público para comparar o número de pull requests (PRs) fundidos do SGLang e do vLLM no GitHub, destacando a intensa disputa entre os dois em termos de iteração de funcionalidades e otimização de desempenho. O lado do SGLang, por sua vez, enfatiza a sua implementação pioneira e open source em áreas como cache radix, sobreposição de CPU, MLA e EP em grande escala. (Fonte: dylan522p, jeremyphoward)
Universo de personagens “Italian brainrot” gerado por IA explode entre a geração Z, com centenas de milhões de visualizações: Justine Moore aponta que uma série de personagens “Italian brainrot” gerados por IA tornou-se extremamente popular entre a geração Z (Zoomers). Eles construíram um “universo cinematográfico” completo em torno desses personagens, e o conteúdo relacionado obteve centenas de milhões de visualizações. Este fenómeno reflete a forte atração e o potencial de disseminação viral do conteúdo gerado por IA entre a geração mais jovem, bem como a formação de subculturas específicas. (Fonte: nptacek)

Comparação entre modelos Qwen3 e DeepSeek R1 gera discussão, cada um com prós e contras: Um utilizador do Reddit partilhou uma comparação de testes entre os modelos de grande escala open source Qwen3 235B e DeepSeek R1. O autor da publicação considera que o Qwen tem melhor desempenho em tarefas simples, mas em tarefas que exigem nuances (como raciocínio, matemática e escrita criativa), o DeepSeek R1 apresenta um desempenho superior. Nos comentários da comunidade, os utilizadores discutiram a acessibilidade do DeepSeek R1, a versão de fine-tuning não censurada do Qwen3 235B e a razoabilidade de usar modelos de linguagem para escrita criativa, entre outras questões. (Fonte: Reddit r/LocalLLaMA)

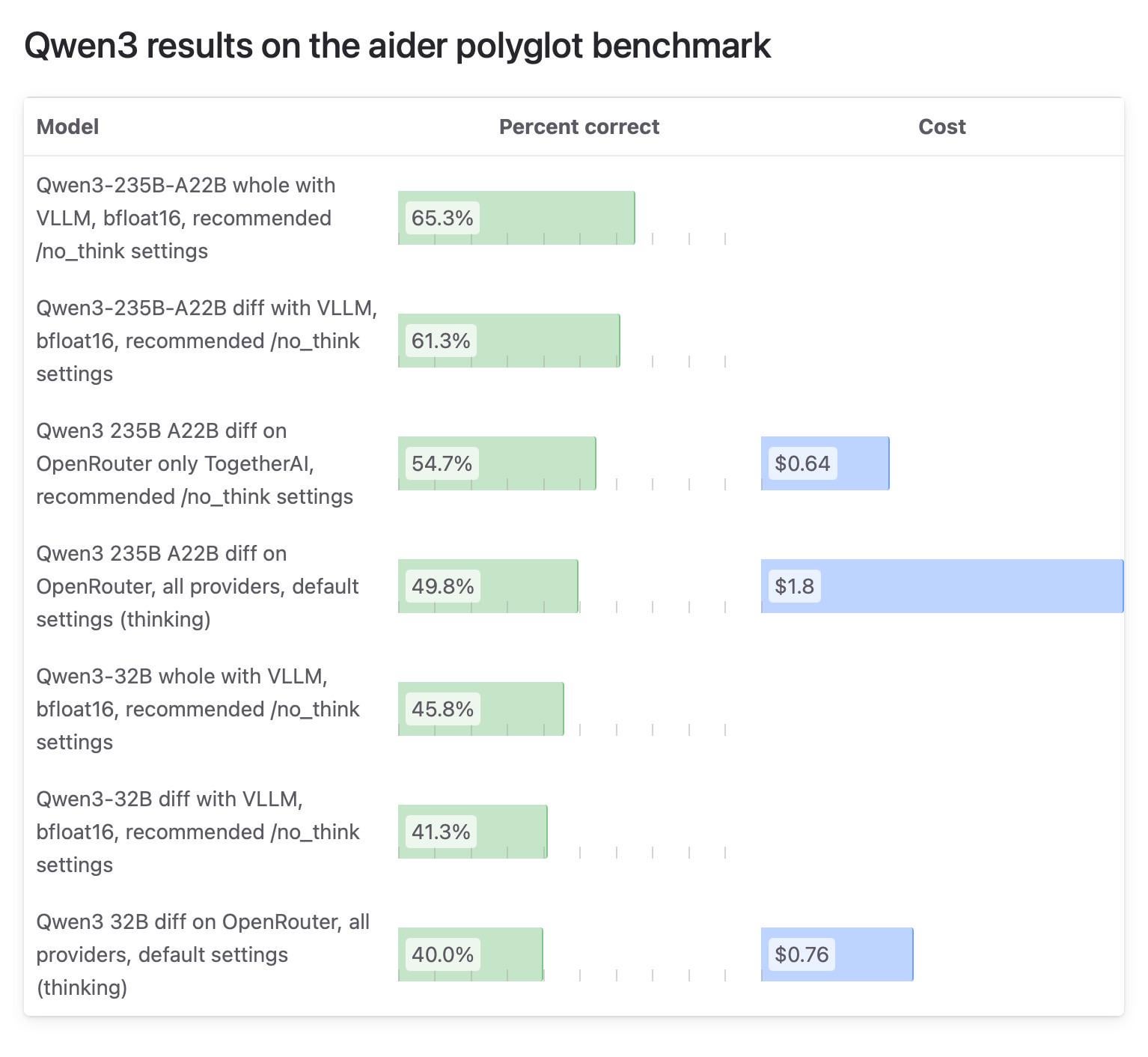
Resultados de testes do modelo Qwen3 na comunidade Aider geram atenção, testes do OpenRouter questionados: O blog Aider publicou um relatório de testes sobre o modelo Qwen3, apontando que o modelo apresenta grandes diferenças de pontuação dependendo da forma como é executado. O foco da discussão da comunidade está na fiabilidade de usar o OpenRouter para testar modelos, pois a maioria dos utilizadores provavelmente usa modelos através do OpenRouter, mas o seu mecanismo de roteamento pode levar a resultados inconsistentes. Alguns utilizadores acreditam que os modelos open source devem ser testados em ambientes padronizados e auto-hospedados (como vLLM) para garantir a reprodutibilidade, e apelam aos fornecedores de API para aumentarem a transparência, especificando a versão de quantização e o motor de inferência utilizados. (Fonte: Reddit r/LocalLLaMA)
Utilizadores partilham razões pessoais para pagar pelo ChatGPT, abrangendo assistência diária, aprendizagem, criação, etc.: Na comunidade Reddit r/ChatGPT, muitos utilizadores partilharam os seus usos pessoais para a subscrição paga do ChatGPT Plus/Pro. Estes incluem: ajudar utilizadores com deficiência visual a descrever imagens, ler embalagens de alimentos e sinais de trânsito; preparação para entrevistas; aprofundar o conhecimento sobre enredos de jogos como Elden Ring; analisar planos de treino de corrida, personalizar receitas; auxiliar na aprendizagem de novas habilidades como cerâmica; como companheiro pessoal; planear jardins, fazer ervas medicinais; e criação de personagens de D&D e escrita de fanfiction, entre outros. Estes casos demonstram o vasto valor de aplicação do ChatGPT na vida quotidiana e nos interesses pessoais. (Fonte: Reddit r/ChatGPT)
Testes comparativos de modelos quantizados GGUF geram discussão sobre “guerras de quantização”, enfatizando que diferentes esquemas de quantização têm os seus méritos: O utilizador do Reddit ubergarm publicou uma comparação detalhada de benchmarks para diferentes versões quantizadas GGUF de modelos como o Qwen3-30B-A3B, incluindo esquemas de quantização de diferentes fornecedores como bartowski e unsloth. Os testes cobriram múltiplas dimensões, incluindo perplexidade, divergência KLD, velocidade de inferência, etc. O artigo salienta que, com o surgimento de novos tipos de quantização como a quantização por matriz de importância (imatrix), IQ4_XS, e a introdução de métodos como o GGUF dinâmico da unsloth, a quantização GGUF já não é “tamanho único”. O autor enfatiza que não existe um esquema de quantização absolutamente ideal, e os utilizadores precisam de escolher com base no seu hardware e caso de uso específico, mas, no geral, os principais esquemas apresentam um bom desempenho. (Fonte: Reddit r/LocalLLaMA)

💡 Outros
Daimon Robotics apresenta robô Sparky 1 com destreza mental e manual: A Daimon Robotics demonstrou o seu produto inovador em tecnologia de robôs ágeis, o Sparky 1. Este robô é descrito como possuindo capacidades “Mind-Dexterous”, sugerindo que atingiu um novo nível em perceção, tomada de decisão e operação fina, possivelmente integrando IA avançada e tecnologias de machine learning. (Fonte: Ronald_vanLoon)
MIT desenvolve microrrobô do tamanho de um grão de arroz, capaz de entrar no cérebro para tratar tumores inoperáveis: Investigadores do MIT desenvolveram um microrrobô do tamanho de um grão de arroz com potencial para entrar no cérebro de forma minimamente invasiva, para tratar tumores anteriormente difíceis de remover cirurgicamente. Este tipo de tecnologia combina microrrobótica com navegação ou controlo por IA, oferecendo novas possibilidades para a neurocirurgia e o tratamento do cancro. (Fonte: Ronald_vanLoon)

Ulsan National Institute of Science and Technology (UNIST) conclui duas rondas de financiamento, impulsionando produção em massa de robôs exoesqueleto de consumo e fusão com tecnologia de IA: A empresa de plataforma tecnológica de robôs exoesqueleto Ulsan National Institute of Science and Technology (UNIST) anunciou a conclusão consecutiva de duas rondas de financiamento, lideradas pela Bin Fu Capital, com o antigo acionista Guoyi Capital a acompanhar. Os fundos serão usados para a produção em massa de robôs exoesqueleto de consumo e para promover a fusão de hardware de exoesqueleto com tecnologia de IA. Os produtos da empresa já são aplicados em cenários industriais e começaram a explorar o mercado de assistência ao ar livre (como auxílio em caminhadas em áreas cénicas) e o mercado de cuidados a idosos em casa, planeando lançar produtos de consumo abaixo dos dez mil yuan. O seu produto mais recente já está equipado com capacidade de treino de modelos de grande escala de IA e está a pré-investigar a tecnologia de interface cérebro-máquina. (Fonte: 36氪)