
Palavras-chave:Modelo Gemini, Mistral AI, NVIDIA NeMo, LTX-Video, Navegador Safari, RTX 5060, Agente de IA, Ajuste fino de aprendizagem por reforço, Geração nativa de imagens Gemini, Desempenho de programação Mistral Medium 3, Estrutura modular NeMo 2.0, Geração de vídeo em tempo real DiT, Reformulação de busca orientada por IA
🔥 Foco
Funcionalidade nativa de geração de imagem do Google Gemini é atualizada, melhorando a qualidade visual e a precisão da renderização de texto: O Google anunciou uma atualização importante para a funcionalidade nativa de geração de imagem do seu modelo Gemini. A nova versão, “gemini-2.0-flash-preview-image-generation”, está disponível no Google AI Studio e na Vertex AI. Esta atualização melhora significativamente a qualidade visual das imagens e a precisão da renderização de texto, além de reduzir a latência. As novas funcionalidades incluem fusão de elementos de imagem, edição em tempo real (como adicionar objetos, modificar conteúdo local) e, em combinação com o Gemini 2.0 Flash, permite que a IA conceba autonomamente e gere imagens. Os usuários podem experimentar gratuitamente no Google AI Studio, e o preço da chamada de API é de US$ 0,039 por imagem. Apesar dos avanços significativos, alguns usuários consideram que o efeito geral ainda é ligeiramente inferior ao GPT-4o. (Fonte: 量子位)

Mistral AI lança Mistral Medium 3, com foco em programação e multimodalidade, e custo drasticamente reduzido: A startup francesa de IA, Mistral AI, lançou seu mais recente modelo multimodal, o Mistral Medium 3. Este modelo se destaca em tarefas de programação e STEM, alegadamente atingindo ou superando o desempenho do Claude Sonnet 3.7 em 90% em vários benchmarks, com um custo de apenas 1/8 (US$ 0,4/milhão de tokens para entrada, US$ 2/milhão de tokens para saída). O Mistral Medium 3 possui capacidades de nível empresarial, como implantação híbrida, pós-treinamento personalizado e integração com ferramentas corporativas, e já está disponível na Mistral La Plateforme e no Amazon Sagemaker, com planos de lançamento em mais plataformas de nuvem no futuro. Simultaneamente, a Mistral AI também lançou o Le Chat Enterprise, um serviço de chatbot para empresas. (Fonte: 量子位)

NVIDIA NeMo framework 2.0 lançado, com modularidade e usabilidade aprimoradas, suporte para modelos Hugging Face e GPUs Blackwell: O NVIDIA NeMo framework foi atualizado para a versão 2.0. As principais melhorias incluem a adoção de configuração Python em vez de YAML, aumentando a flexibilidade; simplificação da experimentação e personalização através da abstração modular do PyTorch Lightning; e expansão contínua de experimentos em larga escala usando a ferramenta NeMo-Run. A nova versão adiciona suporte para pré-treinamento e fine-tuning de modelos Hugging Face AutoModelForCausalLM e já oferece suporte preliminar para as GPUs NVIDIA Blackwell B200. Além disso, o NeMo framework integra suporte para a plataforma de modelos de fundação do mundo NVIDIA Cosmos, para acelerar o desenvolvimento de modelos do mundo para sistemas de IA física, incluindo a biblioteca de processamento de vídeo NeMo Curator e o tokenizer Cosmos. (Fonte: GitHub Trending)

Lightricks lança LTX-Video: modelo de geração de vídeo DiT em tempo real: A Lightricks tornou open-source o LTX-Video, anunciado como o primeiro modelo de geração de vídeo em tempo real baseado em Diffusion Transformer (DiT). O modelo é capaz de gerar vídeos de alta qualidade com resolução de 1216×704 a 30FPS, suportando múltiplas funcionalidades como texto para imagem, imagem para vídeo, animação de keyframes, extensão de vídeo e conversão de vídeo para vídeo. A versão mais recente, 13B v0.9.7, melhorou a aderência aos prompts e a capacidade de compreensão física, e introduziu um pipeline de vídeo multiescala para renderização rápida e de alta qualidade. O modelo está disponível no Hugging Face e possui integrações com ComfyUI e Diffusers. (Fonte: GitHub Trending)

Apple considera grande reformulação do navegador Safari, podendo migrar para pesquisa orientada por IA, relação de parceria com Google em foco: Eddy Cue, vice-presidente sênior da Apple, testemunhou no caso antitruste do Departamento de Justiça dos EUA contra o Google, revelando que a Apple está considerando ativamente uma reformulação do navegador Safari, com foco principal em um motor de busca orientado por IA. Ele destacou que o volume de buscas no Safari caiu pela primeira vez, em parte devido à migração de usuários para ferramentas de IA como OpenAI e Perplexity AI. A Apple já teve discussões com a Perplexity AI e pode introduzir mais opções de pesquisa de IA no Safari. Essa medida pode afetar o acordo de motor de busca padrão da Apple com o Google, avaliado em cerca de US$ 20 bilhões anuais, e impactar o preço das ações de ambas as empresas. A Apple já integrou o ChatGPT na Siri e planeja adicionar o Google Gemini. (Fonte: 36氪)

🎯 Tendências
Placa de vídeo desktop NVIDIA RTX 5060 será lançada em 20 de maio, com preço na China de 2499 yuans: A NVIDIA anunciou que a placa de vídeo desktop RTX 5060 será lançada em 20 de maio, horário de Pequim, com preço na China de 2499 yuans. A placa utiliza a arquitetura Blackwell RTX, possui 3840 núcleos CUDA, 8GB de memória GDDR7 e um consumo total de energia de 145W. Oficialmente, em jogos que suportam a tecnologia de geração multi-frame DLSS 4, seu desempenho é o dobro da RTX 4060, com o objetivo de permitir que os usuários rodem jogos a mais de 100 FPS. O embargo de reviews e as vendas ocorrerão no mesmo dia. (Fonte: 量子位)

Google Gemini API lança funcionalidade de cache implícito, podendo economizar 75% dos custos: O Google anunciou o lançamento da funcionalidade de cache implícito para sua Gemini API. Quando a solicitação de um usuário atinge o cache, o custo de uso do modelo Gemini 2.5 pode ser automaticamente reduzido em 75%. Ao mesmo tempo, o número mínimo de tokens necessários para acionar o cache também foi reduzido, com o Gemini 2.5 Flash caindo para 1K tokens e o Gemini 2.5 Pro para 2K tokens. Esta funcionalidade visa reduzir os custos para os desenvolvedores que utilizam a Gemini API, sem a necessidade de criar caches explicitamente. (Fonte: matvelloso, demishassabis, algo_diver, jeremyphoward)
Meta FAIR nomeia Rob Fergus como novo líder, com foco em Inteligência Artificial Geral (AGI): A Meta anunciou que Rob Fergus assumirá a liderança de sua equipe de pesquisa fundamental em IA (FAIR). Yann LeCun afirmou que o FAIR se concentrará novamente na inteligência artificial avançada, comumente referida como IA de nível humano ou AGI. Esta notícia foi amplamente recebida e parabenizada pela comunidade de pesquisa em IA. (Fonte: ylecun, Ar_Douillard, soumithchintala, aaron_defazio, sainingxie)
OpenAI lança funcionalidade de fine-tuning por reforço (RFT) para o modelo o4-mini: A OpenAI anunciou que seu modelo o4-mini agora suporta fine-tuning por reforço (RFT). Esta tecnologia, em desenvolvimento desde dezembro do ano passado, utiliza raciocínio de cadeia de pensamento (chain-of-thought) e pontuação específica da tarefa para melhorar o desempenho do modelo, especialmente em domínios complexos. A empresa Ambience usou um modelo ajustado com RFT que superou médicos especialistas em 27% na precisão da codificação ICD-10. A empresa Harvey também treinou modelos com RFT para melhorar a precisão das citações em tarefas jurídicas. Ao mesmo tempo, o modelo 4.1-nano, o menor e mais rápido da OpenAI, também foi disponibilizado para fine-tuning. (Fonte: stevenheidel, aidan_mclau, andrwpng, teortaxesTex, OpenAIDevs, OpenAIDevs)
Universidade Tsinghua propõe Absolute Zero Reasoner: IA autogera dados de treinamento para alcançar raciocínio excepcional: Uma equipe da Universidade Tsinghua desenvolveu um modelo de IA chamado Absolute Zero Reasoner, que pode gerar completamente tarefas de treinamento através de auto-jogo (self-play) e aprender com elas, sem necessidade de dados externos. Em domínios como matemática e codificação, seu desempenho já superou modelos que dependem de dados curados por especialistas humanos. Este avanço pode significar que o problema de gargalo de dados no desenvolvimento da IA será aliviado, abrindo novos caminhos para a AGI. (Fonte: corbtt)

Meta e NVIDIA colaboram para aprimorar o desempenho da busca vetorial em GPU do Faiss com cuVS: A Meta e a NVIDIA anunciaram uma colaboração para integrar o cuVS (CUDA Vector Search) da NVIDIA na biblioteca de busca por similaridade de código aberto da Meta, Faiss v1.10, para melhorar significativamente o desempenho da busca vetorial em GPUs. Esta integração resultou em uma melhoria de até 4,7 vezes no tempo de construção de índices IVF e uma redução na latência de busca de até 8,1 vezes; em termos de índices de grafo, o tempo de construção do CUDA ANN Graph (CAGRA) é 12,3 vezes mais rápido que o HNSW em CPU, com uma redução na latência de busca de 4,7 vezes. (Fonte: AIatMeta)
Google AI Studio e Firebase Studio integram Gemini 2.5 Pro: O Google anunciou a integração do modelo Gemini 2.5 Pro no Gemini Code Assist (versão pessoal) e no Firebase Studio. Isso proporcionará aos desenvolvedores mais conveniência e funcionalidades poderosas ao usar modelos de codificação de ponta nessas plataformas, com o objetivo de aumentar a eficiência e a experiência de codificação. (Fonte: algo_diver)
Microsoft Copilot lança funcionalidade Pages, com suporte para edição em linha e destaque de texto: O Microsoft Copilot adicionou a funcionalidade “Pages”, permitindo aos usuários editar diretamente as respostas geradas pela IA na interface do Copilot. É possível destacar texto e solicitar modificações específicas. Esta funcionalidade visa ajudar os usuários a transformar perguntas e resultados de pesquisa em documentos utilizáveis de forma mais rápida e inteligente, aumentando a eficiência do trabalho. (Fonte: yusuf_i_mehdi)
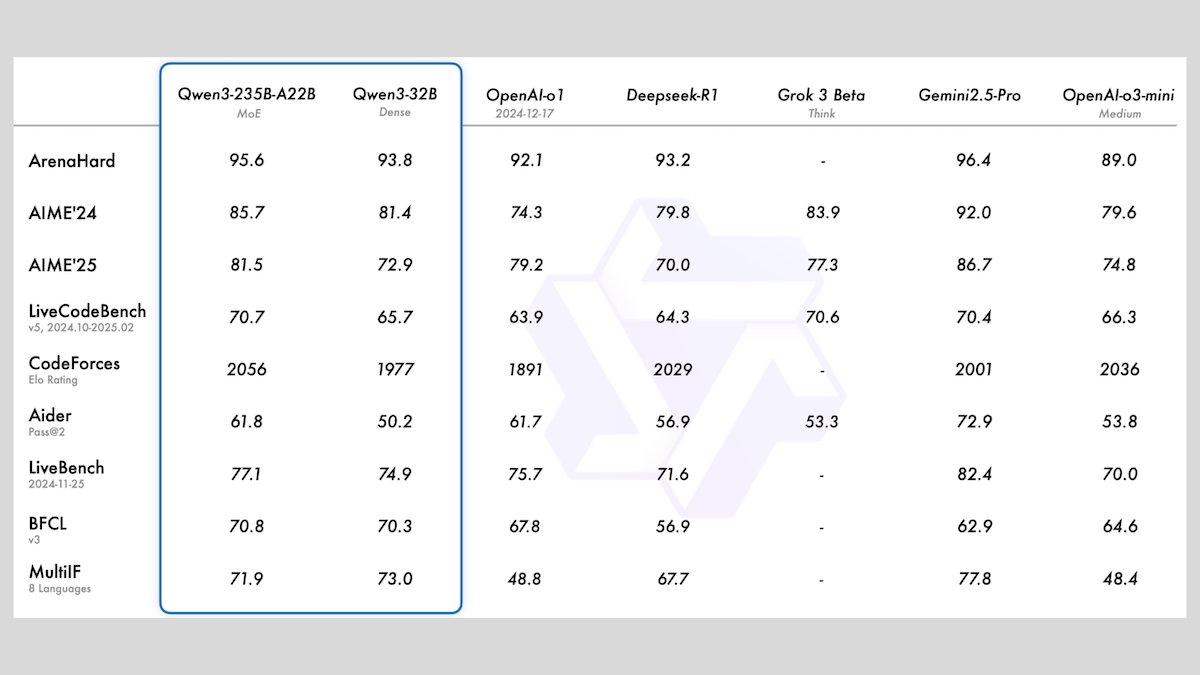
Alibaba lança série de modelos Qwen3, incluindo 8 modelos de linguagem grandes de código aberto: O Alibaba lançou a série Qwen3, que inclui 8 modelos de linguagem grandes de código aberto, sendo 2 modelos de Mistura de Especialistas (MoE) e 6 modelos densos com parâmetros variando de 0.6B a 32B. Todos os modelos suportam modos de inferência opcionais e capacidades multilíngues em 119 idiomas. O Qwen3-235B-A22B e o Qwen3-30B-A3B apresentam excelente desempenho em tarefas de raciocínio, codificação e chamada de função, comparáveis aos principais modelos como os da OpenAI. Em particular, o Qwen3-30B-A3B tem chamado a atenção por seu forte desempenho e capacidade de execução local. (Fonte: DeepLearningAI)
Meta lança modelo Meta Locate 3D para localização precisa de objetos em ambientes 3D: A Meta AI lançou o Meta Locate 3D, um modelo projetado especificamente para a localização precisa de objetos em ambientes 3D. O modelo visa ajudar robôs a entenderem com mais precisão o ambiente ao seu redor e a interagirem de forma mais natural com humanos. A Meta disponibilizou o modelo, o conjunto de dados, o artigo de pesquisa e uma demonstração para uso e experimentação pública. (Fonte: AIatMeta)
Google divulga novo relatório sobre como utiliza IA para combater fraudes online: O Google publicou um novo relatório detalhando como utiliza tecnologia de inteligência artificial para combater fraudes online em seu motor de busca, navegador Chrome e sistema Android. O relatório descreve os esforços de mais de uma década do Google e os progressos mais recentes no uso de IA para proteger os usuários contra fraudes online, enfatizando o papel crucial da IA na identificação e bloqueio de atividades fraudulentas. (Fonte: Google)
Cohere lança modelo de embedding Embed 4, fortalecendo capacidades de pesquisa e recuperação de IA: A Cohere lançou seu mais recente modelo de embedding, o Embed 4, projetado para revolucionar a forma como as empresas acessam e utilizam dados. O Embed 4, o modelo de embedding mais poderoso da Cohere até o momento, foca em melhorar a precisão e eficiência da pesquisa e recuperação de IA, ajudando organizações a desbloquear valor oculto em seus dados. (Fonte: cohere)

Google anuncia que a conferência Google I/O será realizada em 20 de maio: O Google anunciou oficialmente que sua conferência anual de desenvolvedores, Google I/O, será realizada em 20 de maio, e as inscrições já estão abertas. Haverá apresentações principais, lançamento de novos produtos e anúncios de tecnologia, com a expectativa de que a IA seja um dos temas centrais. (Fonte: Google)
Modelo Parakeet da NVIDIA estabelece novo recorde de transcrição de áudio: 60 minutos de áudio transcritos em 1 segundo: O modelo Parakeet da NVIDIA alcançou um avanço na transcrição de áudio, conseguindo transcrever até 60 minutos de áudio em apenas 1 segundo, e lidera os rankings relevantes no Hugging Face. Esta conquista demonstra a liderança da NVIDIA na tecnologia de reconhecimento de voz e oferece aos desenvolvedores ferramentas eficientes de processamento de áudio. (Fonte: huggingface)

🧰 Ferramentas
LlamaParse adiciona suporte para GPT 4.1 e Gemini 2.5 Pro, fortalecendo a capacidade de análise de documentos: O LlamaParse passou por uma série de atualizações de funcionalidades recentemente, incluindo a introdução de novos modelos de análise, GPT 4.1 e Gemini 2.5 Pro, para aumentar a precisão. Além disso, a nova versão adicionou funcionalidade de detecção automática de orientação e inclinação, garantindo uma análise perfeitamente alinhada; fornece pontuações de confiança para avaliar a qualidade da análise; e permite que os usuários personalizem a tolerância a erros e a forma de lidar com páginas com falha. O LlamaParse oferece uma cota gratuita de 10.000 páginas por mês. (Fonte: jerryjliu0)

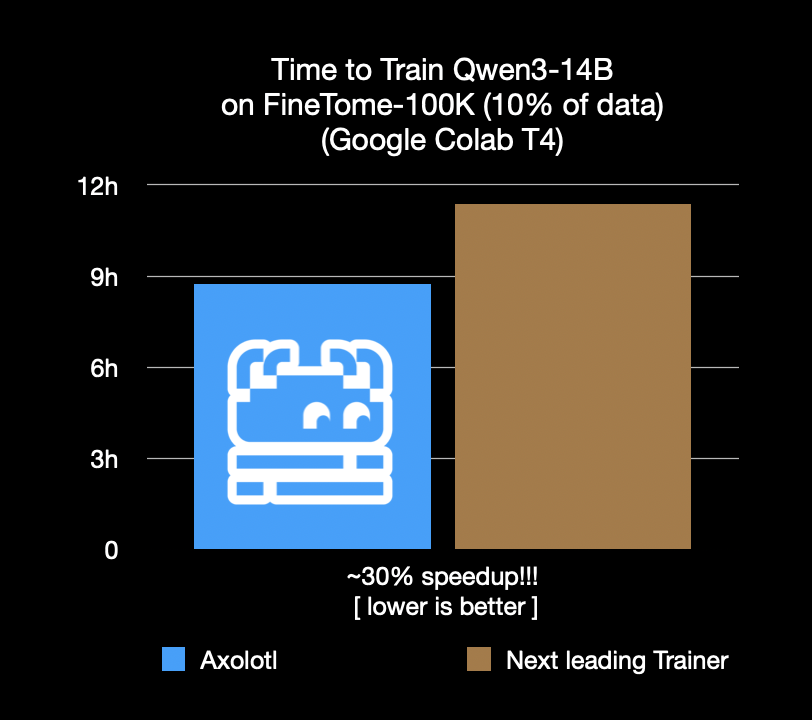
Framework de fine-tuning Axolotl acelera em 30%, economizando custos e tempo: O framework de fine-tuning Axolotl anunciou que, em cargas de trabalho reais como FineTome-100k, sua velocidade é 30% mais rápida que o segundo melhor framework. Para equipes de machine learning de médio a grande porte, isso significa uma economia de milhares de dólares por mês em custos. A otimização do framework visa ajudar os usuários a realizar o fine-tuning de modelos de forma mais eficiente e econômica. (Fonte: Teknium1, winglian, maximelabonne)
Runway lança episódio piloto de animação “Mars & Siv: No Vacancy”, demonstrando capacidades do modelo Gen-4: O estúdio de IA da Runway lançou o episódio piloto de animação “Mars & Siv: No Vacancy”, criado por Jeremy Higgins e Britton Korbel. A obra demonstra a aplicação do modelo Gen-4 da Runway em várias etapas do processo de produção de animação, do conceito ao produto final, destacando o potencial da IA na geração de conteúdo criativo. (Fonte: c_valenzuelab, c_valenzuelab)
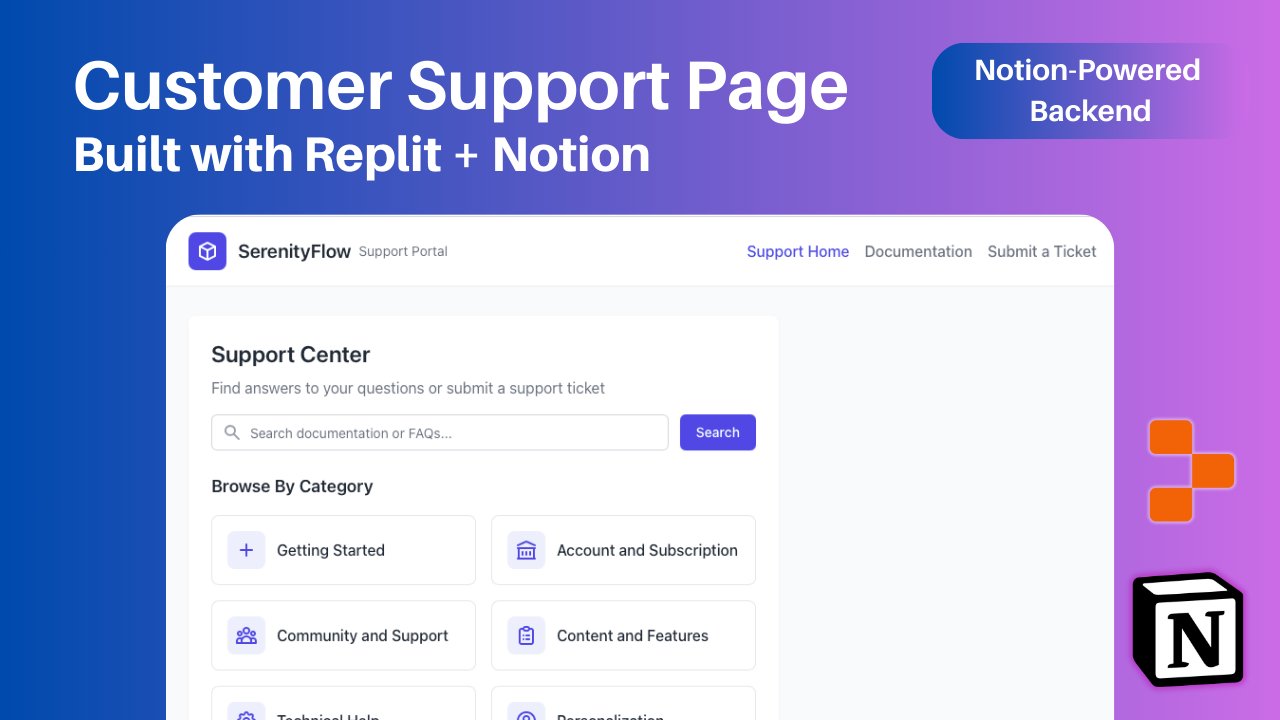
Replit adiciona integração com Notion, permitindo usar conteúdo do Notion como backend de aplicativos: O Replit anunciou uma nova parceria de integração com o Notion, permitindo que desenvolvedores usem o Notion como backend para seus aplicativos. Os usuários podem conectar bancos de dados do Notion a projetos do Replit para exibir FAQs, alimentar chatbots de IA personalizados baseados em documentos e registrar tickets de suporte de volta no Notion. O objetivo é combinar as capacidades de organização de backend do Notion com a flexibilidade de criação de frontend do Replit. (Fonte: amasad, amasad, pirroh)
Langchain-huggingface v0.2 lançado, com suporte para HF Inference Providers: Langchain-huggingface lançou a versão v0.2, que adiciona suporte para Hugging Face Inference Providers. Esta atualização tornará mais conveniente o uso de serviços de inferência fornecidos pelo Hugging Face dentro do ecossistema LangChain. (Fonte: LangChainAI, huggingface, ClementDelangue, hwchase17, Hacubu)
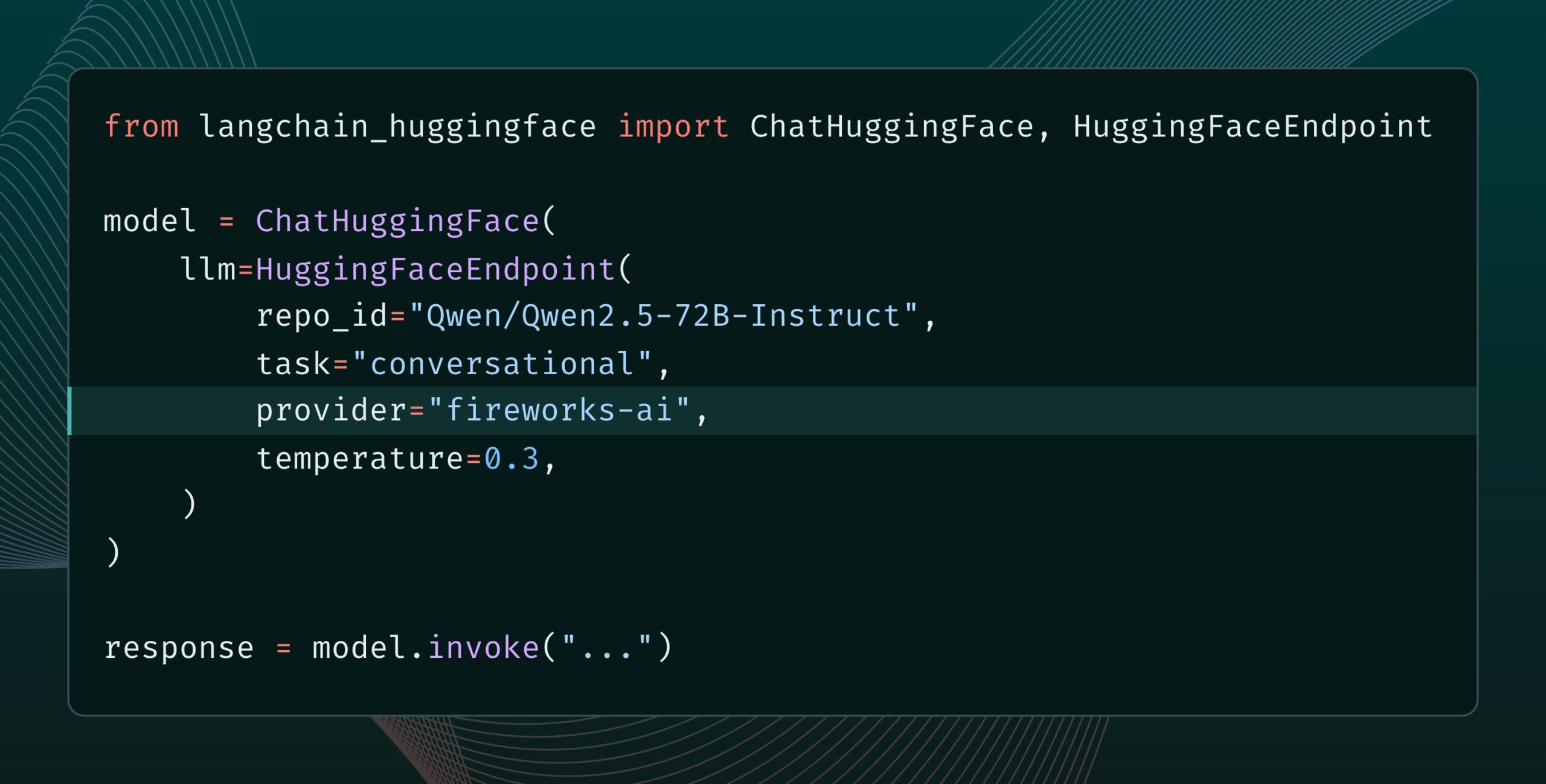
smolagents 1.15 lançado, adicionando funcionalidade de saídas em stream: O framework de agentes de IA smolagents lançou a versão 1.15, introduzindo a funcionalidade de saídas em stream (streaming outputs). Os usuários podem habilitá-la definindo stream_outputs=True ao inicializar o CodeAgent, o que tornará todas as interações mais fluidas. (Fonte: huggingface, AymericRoucher, ClementDelangue)
Projeto Better-Qwen3: Fazendo o modelo Qwen3 alternar automaticamente o modo de pensamento: Um projeto do GitHub chamado Better-Qwen3 ganhou atenção. O projeto visa permitir que o modelo Qwen3 controle automaticamente se deve ativar o “modo de pensamento” com base na complexidade da pergunta do usuário. Para perguntas simples, o modelo responderá diretamente; para perguntas complexas, ele entrará automaticamente no modo de pensamento para fornecer respostas mais aprofundadas. Endereço do projeto: http://github.com/AaronFeng753/Better-Qwen3 (Fonte: karminski3, Reddit r/LocalLLaMA)
MLX-Audio: Biblioteca TTS/STT/STS baseada no framework Apple MLX: MLX-Audio é uma biblioteca de conversão de texto para fala (TTS), fala para texto (STT) e fala para fala (STS) criada especificamente para chips Apple Silicon, desenvolvida com base no framework MLX da Apple, com o objetivo de fornecer capacidades eficientes de processamento de voz. A biblioteca suporta vários idiomas, personalização de voz, controle de velocidade da fala e oferece uma interface web interativa e API REST. (Fonte: GitHub Trending)
Modelo References da Runway agora suporta funcionalidade de expansão de imagem (Outpainting): O modelo References da Runway agora suporta a funcionalidade de expansão de imagem (outpainting). Os usuários precisam apenas colocar uma imagem no References, selecionar o formato de saída desejado, deixar o prompt em branco e clicar em gerar para expandir a imagem original. Esta funcionalidade aprimora ainda mais as capacidades da Runway na edição e criação de imagens. (Fonte: c_valenzuelab)

Docker2exe: Converte imagens Docker em arquivos executáveis: Docker2exe é uma ferramenta que pode converter imagens Docker em arquivos executáveis independentes, facilitando o compartilhamento e a execução pelos usuários. Ele suporta um modo de incorporação, onde o tarball da imagem Docker é empacotado diretamente no arquivo executável. Ao ser executado no dispositivo de destino, se a imagem Docker correspondente não existir localmente, ele carregará automaticamente a imagem incorporada ou a baixará da rede. (Fonte: GitHub Trending)
Smoothie Qwen: Suaviza as probabilidades de token do modelo Qwen para equilibrar a geração multilíngue: Smoothie Qwen é uma ferramenta de ajuste leve que, ao suavizar as probabilidades de token no modelo Qwen, visa aprimorar o equilíbrio do modelo na geração multilíngue, reduzindo vieses inesperados para idiomas específicos (como o chinês), enquanto mantém o desempenho central. A ferramenta utiliza intervalos Unicode para identificar tokens, realiza análise de N-gramas e ajusta os pesos dos tokens no lm_head. Modelos pré-ajustados estão disponíveis no Hugging Face. (Fonte: Reddit r/LocalLLaMA)

ComfyGPT: Sistema multiagente auto-otimizável para geração abrangente de fluxos de trabalho ComfyUI: Um artigo intitulado “ComfyGPT: A Self-Optimizing Multi-Agent System for Comprehensive ComfyUI Workflow Generation” foi submetido ao arXiv, apresentando um sistema chamado ComfyGPT. Este sistema utiliza uma abordagem multiagente auto-otimizável com o objetivo de gerar de forma abrangente fluxos de trabalho para o ComfyUI, simplificando a construção de processos complexos de geração de imagem. (Fonte: Reddit r/LocalLLaMA)
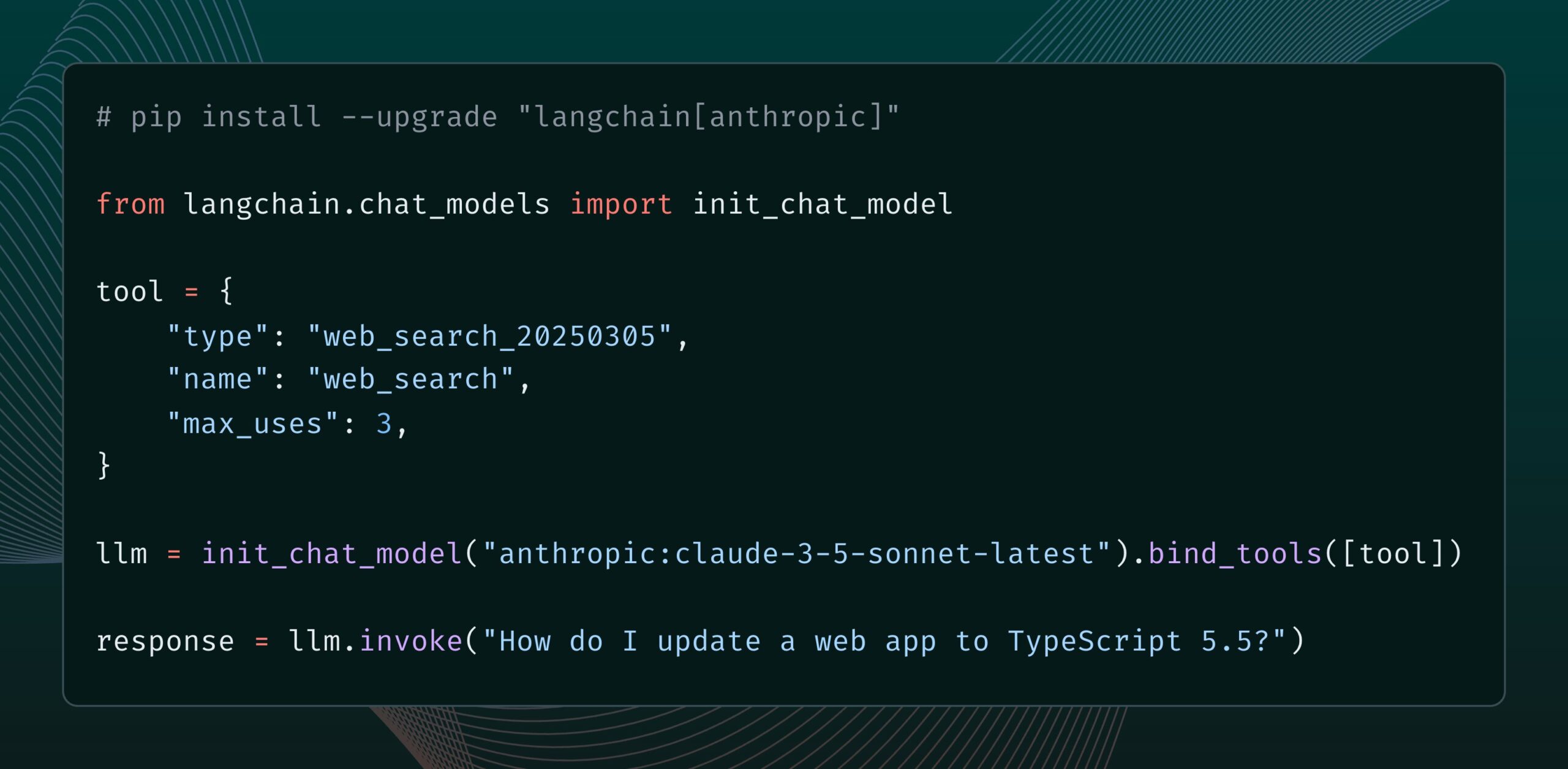
Modelo Claude da Anthropic adiciona nova ferramenta de pesquisa na web: A Anthropic lançou uma nova ferramenta de pesquisa na web para seu modelo Claude. A ferramenta permite que o Claude realize pesquisas na web ao gerar respostas e use os resultados da pesquisa como base, fornecendo respostas com citações. Esta funcionalidade foi integrada à biblioteca langchain-anthropic, aprimorando a capacidade do Claude de obter e utilizar informações em tempo real. (Fonte: LangChainAI, hwchase17)
Glass Health lança funcionalidade Workspace, utilizando IA para auxiliar no diagnóstico clínico e planejamento de tratamento: A Glass Health lançou a nova funcionalidade Workspace, que permite aos clínicos usar IA para concluir com mais eficiência fluxos de trabalho complexos de raciocínio diagnóstico, planejamento de tratamento e documentação. O objetivo é aumentar a eficiência e a qualidade do trabalho médico por meio da tecnologia de IA. (Fonte: GlassHealthHQ)
OpenWebUI adiciona funcionalidades de anotações aprimoradas por IA e gravação de reuniões: A versão mais recente do OpenWebUI adicionou funcionalidades de anotações aprimoradas por IA. Os usuários podem criar anotações, anexar áudio de reuniões ou voz, e permitir que a IA use a transcrição de áudio para aprimorar, resumir ou otimizar instantaneamente as anotações. Além disso, suporta gravação e importação de áudio de reuniões, facilitando a revisão e extração de informações importantes de discussões. (Fonte: Reddit r/OpenWebUI)
📚 Aprendizado
Nações Unidas publicam relatório de 200 páginas sobre IA e Desenvolvimento Humano Global: O Programa das Nações Unidas para o Desenvolvimento (PNUD) publicou um relatório de 200 páginas que examina a inteligência artificial sob a perspectiva do desenvolvimento humano global. O relatório explora o impacto da IA nos Objetivos de Desenvolvimento Sustentável, desigualdade, governança e o futuro do trabalho, entre outros aspectos, e propõe recomendações de políticas. O relatório chamou a atenção por suas opiniões contundentes. (Fonte: random_walker)
The Turing Post publica artigo de análise aprofundada sobre o protocolo Agent2Agent (A2A): Dado o grande interesse da comunidade em protocolos de comunicação entre Agentes de IA, o The Turing Post publicou gratuitamente no Hugging Face seu artigo de análise aprofundada sobre o protocolo A2A do Google. O artigo explora a importância do protocolo A2A (que visa quebrar os silos dos Agentes de IA e permitir a colaboração), aplicações potenciais (como colaboração de equipes de Agentes especializados, fluxos de trabalho interempresariais, padronização da colaboração homem-máquina, diretórios de Agentes pesquisáveis), bem como seu princípio de funcionamento e métodos de introdução. (Fonte: TheTuringPost, TheTuringPost, TheTuringPost, dl_weekly)

Engenheiro de prompts compartilha: Como escrever facilmente bons modelos de prompt: O engenheiro de prompts dotey compartilhou um método de três etapas para criar modelos de prompt eficientes: 1. Coletar prompts do mesmo estilo, mas com temas diferentes; 2. Identificar pontos em comum e diferenças (pode-se usar IA para ajudar); 3. Testar e otimizar repetidamente. Ele enfatizou que bons modelos são como funções em programas, onde pequenas modificações nas variáveis podem gerar resultados diferentes. Ele também compartilhou um modelo de instrução para gerar rapidamente novos prompts usando IA e observou que nem todos os estilos são adequados para modelagem, temas com detalhes complexos ainda requerem otimização personalizada. (Fonte: dotey)

Pesquisador John Jumper da DeepMind e sua equipe estão contratando para expandir descobertas científicas baseadas em LLM: John Jumper, pesquisador do Google DeepMind, anunciou que sua equipe está contratando para várias posições para expandir o trabalho em descobertas científicas baseadas em modelos de linguagem grandes (LLM). As posições abertas incluem Cientista de Pesquisa (RS) e Engenheiro de Pesquisa (RE), com o objetivo de impulsionar o futuro da IA científica em linguagem natural. (Fonte: demishassabis, NandoDF)
Blog Ragas compartilha dois anos de experiência em melhoria de aplicações de IA: Shahules786 publicou um artigo no blog Ragas resumindo as lições aprendidas nos últimos dois anos trabalhando em estreita colaboração com equipes de IA, entregando ciclos de avaliação e melhorando sistemas LLM. O artigo visa fornecer orientação prática e insights para profissionais que constroem e otimizam aplicações de IA. (Fonte: Shahules786)

Kyunghyun Cho discute métodos de ensino para cursos de pós-graduação em machine learning na era dos LLMs: O professor Kyunghyun Cho, da Universidade de Nova York, compartilhou suas reflexões e experimentos sobre o conteúdo de ensino para cursos de pós-graduação em machine learning do primeiro ano na era atual dos LLMs e da computação em larga escala. Ele propôs ensinar todo o conteúdo que aceita SGD (descida de gradiente estocástico) e não é LLM, e orientar os alunos a ler artigos clássicos. (Fonte: ylecun, sainingxie)

Ranking de Processamento Inteligente de Documentos (IDP) lançado, unificando a avaliação da capacidade de compreensão de documentos por VLMs: Um novo ranking de Processamento Inteligente de Documentos (IDP) foi lançado, com o objetivo de fornecer um benchmark unificado para diversas tarefas de compreensão de documentos, como OCR, KIE, VQA e extração de tabelas. O ranking abrange 6 tarefas centrais de IDP, 16 conjuntos de dados e 9229 documentos. Resultados preliminares mostram que o Gemini 2.5 Flash lidera no geral, mas todos os modelos apresentam baixo desempenho na compreensão de documentos longos, e a extração de tabelas continua sendo um gargalo. O desempenho da versão mais recente do GPT-4o até diminuiu. (Fonte: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
LangGraph lança funcionalidade Cron Jobs, permitindo acionar agentes de IA em horários programados: A plataforma LangGraph da LangChain adicionou a funcionalidade Cron Jobs, permitindo aos usuários configurar tarefas agendadas para acionar automaticamente a execução de agentes de IA. Esta funcionalidade permite que agentes de IA executem tarefas de acordo com um cronograma predefinido, adequado para cenários que exigem processamento ou monitoramento periódico. (Fonte: hwchase17)
💼 Negócios
Ferramenta de depuração de software de IA Lightrun recebe US$ 70 milhões em rodada Série B, liderada por Accel e Insight Partners: A Lightrun, desenvolvedora de ferramentas de observabilidade e depuração de software de IA, anunciou a conclusão de uma rodada de financiamento Série B de US$ 70 milhões, liderada pela Accel e Insight Partners, com participação do Citigroup e outros, elevando o financiamento total para US$ 110 milhões. Seu principal produto, Runtime Autonomous AI Debugger, pode localizar com precisão o código problemático no IDE e fornecer sugestões de correção, com o objetivo de reduzir o tempo de depuração de horas para minutos. A receita da empresa cresceu 4,5 vezes em 2024, com clientes incluindo empresas da Fortune 500 como Citigroup e Microsoft. (Fonte: 36氪)

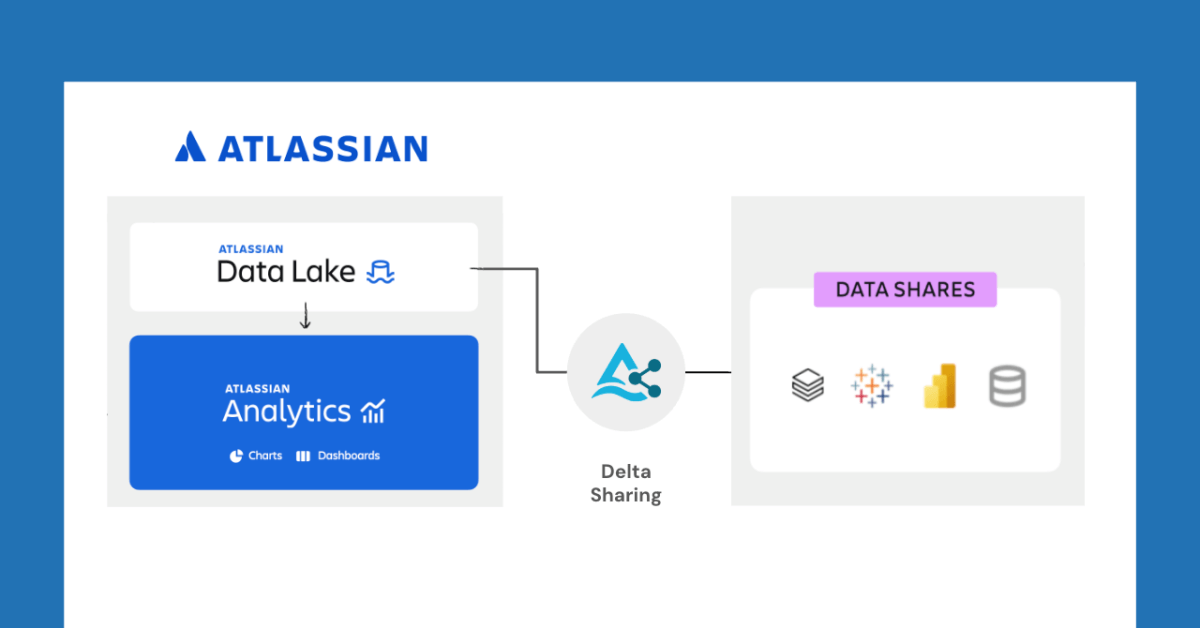
Databricks e Atlassian colaboram para desbloquear novas funcionalidades de compartilhamento de dados através do Delta Sharing: A Databricks anunciou uma colaboração com a Atlassian para trazer novas capacidades de compartilhamento de dados para o Atlassian Analytics. Através do protocolo aberto do Delta Sharing, os clientes da Atlassian podem acessar e analisar com segurança seus dados no Atlassian Data Lake usando as ferramentas de sua escolha. Esta funcionalidade suporta integração com BI, fluxos de trabalho de dados personalizados, colaboração entre equipes e outros casos de uso. (Fonte: matei_zaharia)
Fastino recebe US$ 17,5 milhões em financiamento, com foco em modelos de linguagem específicos para tarefas (TLM): A startup Fastino anunciou ter recebido US$ 17,5 milhões (totalizando US$ 25 milhões na rodada pré-seed) em financiamento liderado pela Khosla Ventures, para desenvolver seus inovadores modelos de linguagem específicos para tarefas (TLM). A Fastino afirma que sua arquitetura TLM é compacta e otimizada para tarefas específicas, podendo ser treinada em GPUs de jogos de baixo custo, com alta eficiência de custo. Os TLMs eliminam a redundância de parâmetros e a ineficiência da arquitetura através da especialização de tarefas nos níveis de arquitetura, pré-treinamento e pós-treinamento, visando aumentar a precisão em tarefas específicas e podendo ser incorporados em aplicações sensíveis à latência e ao custo. (Fonte: Reddit r/MachineLearning)

🌟 Comunidade
Ferramentas de busca de emprego assistidas por IA levantam preocupações sobre fraudes, empresas reforçam contramedidas: Recentemente, o uso de ferramentas de IA para auxiliar em entrevistas online e testes escritos aumentou. Esses “artefatos de entrevista de IA” podem personalizar respostas com base no currículo do usuário, ajudando os candidatos a obter vantagem na busca por emprego. O acesso a esses softwares é fácil, e alguns até oferecem pacotes pagos de vários níveis e orientação remota. Essa tendência remonta ao surgimento de ferramentas de fraude de IA anteriores, como o “Interview Coder”. As empresas já começaram a tomar contramedidas, como prestar atenção a comportamentos anormais dos candidatos durante as entrevistas, considerar a introdução de detecção de tela ou retomar as entrevistas presenciais. Advogados apontam que o uso de IA para fraudar viola o princípio da boa-fé, pode levar à rescisão do contrato de trabalho e apresenta riscos de vazamento de privacidade. (Fonte: 36氪)

CEO da LangChain, Harrison Chase, propõe os conceitos de “Agentes Ambientais” e “Caixa de Entrada de Agentes”: Harrison Chase, CEO da LangChain, compartilhou sua visão sobre o futuro desenvolvimento de agentes de IA no evento AI Ascent da Sequoia, propondo os conceitos de “Agentes Ambientais” (Ambient Agents) e “Caixa de Entrada de Agentes” (Agent Inbox). Agentes Ambientais referem-se a sistemas de IA que podem operar continuamente em segundo plano, respondendo a eventos em vez de comandos humanos diretos, enquanto a Caixa de Entrada de Agentes é uma nova interface de interação homem-máquina para gerenciar e supervisionar as atividades desses agentes. (Fonte: hwchase17, hwchase17, hwchase17)

Jim Fan propõe o “Teste de Turing Físico” como a nova Estrela Polar da IA: O cientista da NVIDIA, Jim Fan, no evento AI Ascent da Sequoia, propôs o conceito de “Teste de Turing Físico”, considerando-o a próxima “Estrela Polar” no campo da IA. O teste imagina um cenário: após um hackathon de domingo, a casa está uma bagunça; na segunda-feira à noite, ao voltar para casa, a sala de estar está impecável e um jantar à luz de velas está preparado, e você não consegue distinguir se foi feito por um humano ou uma máquina. Ele acredita que este é o objetivo da robótica geral e compartilhou os princípios fundamentais para resolver este problema, incluindo estratégia de dados e leis de escala. (Fonte: DrJimFan, killerstorm)
Avaliação de modelos de IA enfrenta crise, coalizão EvalEval pede melhorias: Em resposta às deficiências atuais nos métodos de avaliação de modelos de IA, como saturação de benchmarks e falta de rigor científico, a coalizão EvalEval foi mencionada, visando unir pessoas preocupadas com o estado atual da avaliação para trabalhar em conjunto na melhoria dos relatórios de avaliação, resolução do problema de saturação, aumento do rigor científico da avaliação e infraestrutura, etc. Discussões relacionadas consideram que se deve dar mais atenção à validade da avaliação. (Fonte: ClementDelangue)

Debate no Reddit: Observações e experiências na construção de fluxos de trabalho LLM: Um desenvolvedor compartilhou no Reddit um resumo de suas experiências no último ano construindo fluxos de trabalho LLM complexos. Pontos-chave incluem: decompor tarefas em etapas mínimas e encadear chamadas de prompts é melhor do que um único prompt complexo; usar tags XML para construir a estrutura do prompt funciona melhor; é preciso informar explicitamente ao LLM que seu papel é apenas análise e transformação semântica, não devendo introduzir seu próprio conhecimento; usar bibliotecas NLP tradicionais como NLTK para validar a saída do LLM; classificadores do tipo BERT ajustados para tarefas pequenas geralmente superam os LLMs; LLMs como árbitros ou para pontuação de confiança não são confiáveis, especialmente na ausência de critérios de pontuação claros; em ciclos agênticos, definir as condições para o LLM decidir sair do ciclo é um desafio; o desempenho geralmente cai após a janela de contexto de entrada exceder 4K Tokens; modelos de 32B são suficientes para tarefas estruturadas; CoT estruturado é superior ao não estruturado; CoT escrito pelo próprio usuário é melhor do que depender de modelos de raciocínio; o objetivo de longo prazo é ajustar todos os componentes e prestar atenção à construção de conjuntos de dados de ajuste fino equilibrados. (Fonte: Reddit r/LocalLLaMA)
Usuários do Reddit discutem configurações de prompt de sistema do Claude Sonnet 3.7: Usuários da comunidade r/ClaudeAI do Reddit relataram instabilidade no modelo Claude Sonnet 3.7 em seguir instruções, corrigir código e memória de contexto, e solicitaram prompts de sistema eficazes. Alguns usuários compartilharam prompts que imitam o comportamento do Sonnet 3.5, bem como instruções detalhadas que enfatizam soluções eficientes e práticas, e o seguimento de princípios fundamentais da ciência da computação (como DRY, KISS, SRP). Outros usuários sugeriram melhorar os resultados fazendo o Claude reescrever e otimizar seus próprios prompts de sistema, ou usando instruções de uma linha concisas e claras. (Fonte: Reddit r/ClaudeAI)
Discussão sobre o número de Epochs necessários para o fine-tuning de LLMs: No Reddit r/MachineLearning, um usuário levantou dúvidas sobre o artigo Deepseek R1, que usou apenas 2 Epochs para o fine-tuning do modelo Deepseek-V3-Base (aproximadamente 800.000 amostras), explorando métricas além da função de perda que determinam o número de Epochs para fine-tuning, como o desempenho dos dados de avaliação e a qualidade dos dados. (Fonte: Reddit r/MachineLearning)
💡 Outros
François Chollet: Construir modelos mentais sólidos é um pré-requisito para resolver problemas difíceis: O pensador de IA François Chollet enfatiza que estabelecer modelos mentais claros e autoconsistentes é um pré-requisito para resolver problemas de forma criativa (em vez de depender da sorte), o que é diferente da capacidade de resolver rapidamente problemas simples. Ele acredita que a elegância é a combinação de expressividade e concisão, intimamente relacionada à compressão. (Fonte: fchollet, teortaxesTex, fchollet, pmddomingos)

CEO da Replit, Amjad Masad: Agentes de IA serão a nova onda da programação: Amjad Masad, CEO e cofundador da Replit, afirmou em entrevista ao The Turing Post que sempre acreditou que os Agentes de IA liderarão a próxima onda da programação. Ele compartilhou a transição de pensamento de ensinar programação para construir Agentes que podem programar automaticamente. Ele mencionou que os Agentes de software já estão produzindo resultados em negócios reais, por exemplo, ajudando empresas imobiliárias a otimizar algoritmos de distribuição de leads, aumentando a taxa de conversão em 10%. Ele acredita que futuras startups de bilhões de dólares podem ser construídas por fundadores independentes aprimorados por IA e discutiu as condições necessárias para realizar essa visão, o estado atual e futuro da programação, a evolução da visão da Replit e a importância da AGI e do código aberto. (Fonte: TheTuringPost, TheTuringPost)
LazyVim: Configuração do Neovim para “preguiçosos”: LazyVim é uma solução de configuração para o Neovim baseada no lazy.nvim, projetada para permitir que os usuários personalizem e estendam facilmente seu ambiente Neovim. Ele oferece uma experiência pré-configurada, rica em funcionalidades, semelhante a um IDE, mantendo ao mesmo tempo alta flexibilidade, permitindo que os usuários façam ajustes conforme necessário. (Fonte: GitHub Trending)
