Palavras-chave:Zero Absoluto, Qwen3, Mistral Medium 3, Fundação PyTorch, Auto-evolução de IA, Modelo multimodal, IA de código aberto, Paradigma RLVR, Sistema AZR, Qwen3-235B-A22B, Biblioteca de otimização DeepSpeed, Suporte multimodal LangSmith
🔥 Foco
Universidade Tsinghua publica artigo “Absolute Zero”: IA pode evoluir sem dados externos: A equipe LeapLabTHU da Universidade Tsinghua publicou um novo paradigma RLVR (Reinforcement Learning with Verifiable Rewards) chamado “Absolute Zero”. Sob este paradigma, um único modelo pode propor tarefas para maximizar seu processo de aprendizado e melhorar sua capacidade de raciocínio resolvendo essas tarefas, sem depender de quaisquer dados externos. Seu sistema AZR (Absolute Zero Reasoner) utiliza um executor de código para verificar tarefas e respostas, alcançando um aprendizado aberto, mas fundamentado. Experimentos mostram que o AZR atinge o nível SOTA em tarefas de codificação e raciocínio matemático, superando os modelos zero-shot existentes que dependem de dezenas de milhares de amostras anotadas por humanos (Fonte: Reddit r/LocalLLaMA)
Alibaba lança a série de modelos Qwen3, incluindo MoE e vários tamanhos: O Alibaba lançou a série de grandes modelos de linguagem Qwen3, compreendendo 8 modelos com contagens de parâmetros variando de 0.6B a 235B. Entre eles, Qwen3-235B-A22B e Qwen3-30B-A3B usam uma arquitetura MoE, enquanto os demais são modelos densos. A série foi pré-treinada em 36T tokens, cobrindo 119 idiomas, e possui modos de inferência que podem ser ativados ou desativados, adequados para diversas áreas como código, matemática e ciências. As avaliações mostram que os modelos MoE têm desempenho superior, com a versão de 235B superando o DeepSeek-R1 e o Gemini 2.5 Pro em vários benchmarks. A versão de 30B também apresenta um forte desempenho, e até mesmo o modelo de 4B supera modelos com contagens de parâmetros muito maiores em alguns benchmarks. Os modelos foram disponibilizados em código aberto no HuggingFace e ModelScope sob a licença Apache 2.0 (Fonte: DeepLearning.AI Blog)
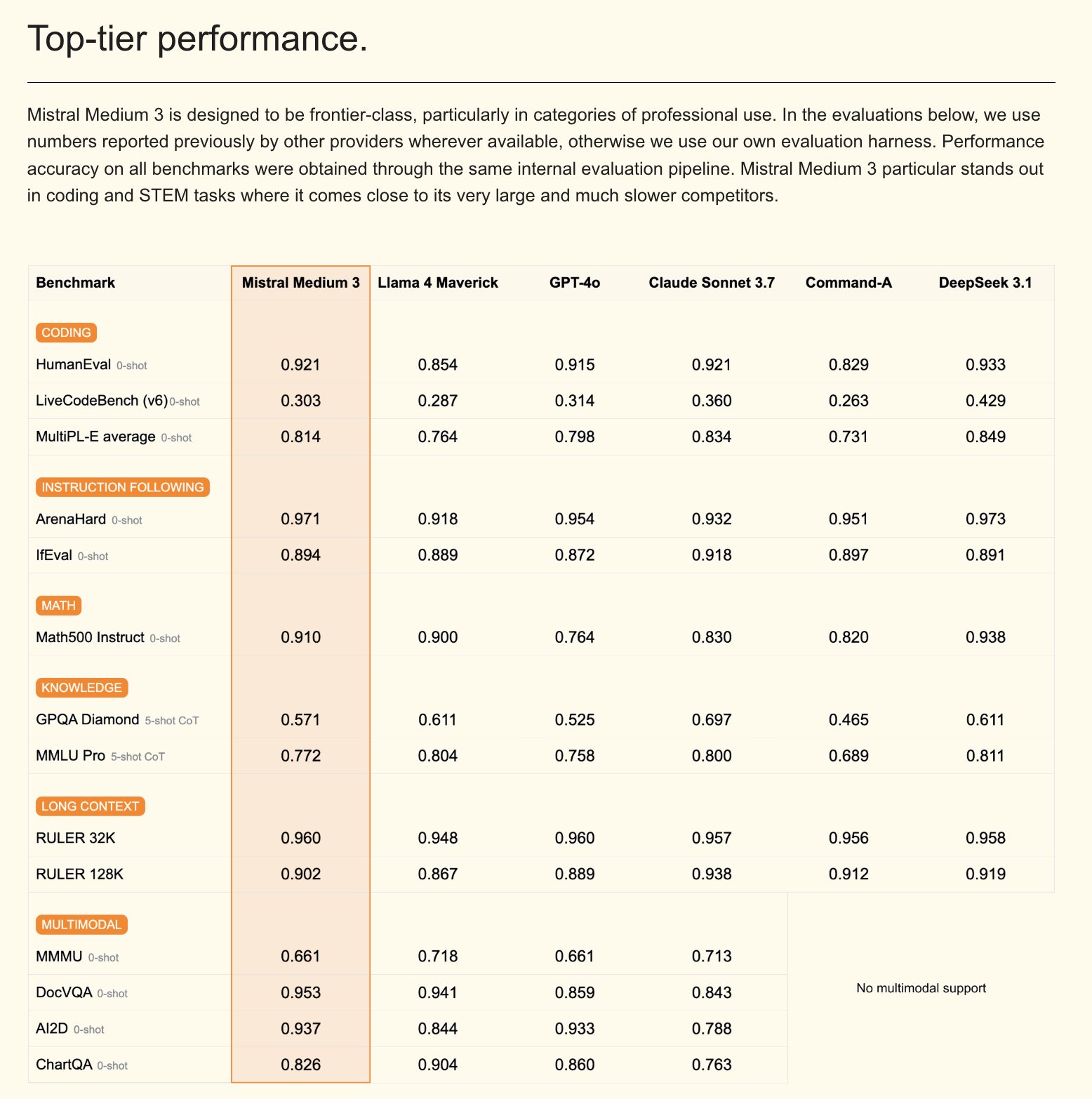
Mistral lança modelo multimodal Mistral Medium 3 e assistente de IA para empresas: A Mistral AI lançou o Mistral Medium 3, um novo modelo multimodal que alega ter desempenho próximo ao Claude Sonnet 3.7, mas com um custo significativamente menor (entrada $0.4/M token, saída $2/M token), uma redução de 8 vezes. O modelo apresenta excelente desempenho em codificação e chamadas de função, e oferece recursos de nível empresarial, como implantação híbrida ou local e pós-treinamento personalizado. Simultaneamente, a Mistral também lançou o Le Chat Enterprise, um assistente de IA personalizável e seguro para empresas, que suporta a integração com bases de conhecimento corporativas (como Gmail, Google Drive, Sharepoint), possui funcionalidades de Agent, assistente de codificação, pesquisa na web, entre outras, visando aumentar a competitividade empresarial. A Mistral anunciou que lançará um novo modelo Large nas próximas semanas (Fonte: Mistral AI, GuillaumeLample, scaling01, karminski3)
PyTorch Foundation expande-se para uma fundação guarda-chuva, incorporando vLLM e DeepSpeed: A PyTorch Foundation anunciou sua expansão para uma estrutura de fundação guarda-chuva, com o objetivo de reunir mais projetos de código aberto de IA de alta qualidade. Os primeiros projetos a aderir são vLLM e DeepSpeed. vLLM é um motor de inferência e serviço de alta taxa de transferência e eficiente em memória, projetado especificamente para LLMs; DeepSpeed é uma biblioteca de otimização de aprendizado profundo que torna o treinamento de modelos em grande escala mais eficiente. Esta medida visa promover o desenvolvimento de IA impulsionado pela comunidade, cobrindo todo o ciclo de vida, da pesquisa à produção, e recebeu o apoio de vários membros, incluindo AMD, Arm, AWS, Google, Huawei, entre outros (Fonte: PyTorch, soumithchintala, vllm_project, code_star)

🎯 Tendências
Laboratório ARC da Tencent lança FlexiAct: ferramenta de transferência de ação em vídeo: O laboratório ARC da Tencent lançou uma nova ferramenta chamada FlexiAct no Hugging Face. Esta ferramenta é capaz de transferir ações de um vídeo de referência para qualquer imagem alvo, mesmo que o layout, perspectiva ou estrutura esquelética da imagem alvo sejam diferentes do vídeo de referência. Isso abre novas possibilidades para os campos de geração e edição de vídeo, permitindo aos usuários controlar de forma mais flexível as ações e posturas no conteúdo gerado (Fonte: _akhaliq)
White Circle lança CircleGuardBench: novo benchmark para modelos de moderação de conteúdo de IA: A White Circle introduziu o CircleGuardBench, um novo benchmark para avaliar modelos de moderação de conteúdo de IA. Este benchmark visa realizar avaliações em nível de produção, testando a detecção de danos, resistência a jailbreak, taxa de falsos positivos e latência, cobrindo 17 categorias de danos do mundo real. O artigo de blog e o ranking relacionados foram publicados no Hugging Face, fornecendo novos padrões de avaliação para os campos de segurança de IA e moderação de conteúdo (Fonte: TheTuringPost, _akhaliq)

Hugging Face lança SIFT-50M: grande conjunto de dados multilíngue para ajuste fino de instruções de voz: Foi lançado no Hugging Face o conjunto de dados SIFT-50M, um conjunto de dados multilíngue em grande escala projetado especificamente para o ajuste fino de instruções de voz. O conjunto de dados contém mais de 50 milhões de pares de perguntas e respostas instrucionais, cobrindo 5 idiomas. O SIFT-LLM, treinado com base neste conjunto de dados, supera o SALMONN e o Qwen2-Audio em benchmarks de acompanhamento de voz. O conjunto de dados também inclui o benchmark EvalSIFT para avaliação acústica e generativa, e suporta geração de voz controlável (como tom, velocidade, sotaque), construído com base em Whisper, HuBERT, X-Codec2 & Qwen2.5 (Fonte: ClementDelangue, huggingface)
Meta lança Perception Language Model (PLM): modelo de linguagem visual de código aberto e reprodutível: A Meta AI introduziu o Meta Perception Language Model (PLM), um modelo de linguagem visual aberto e reprodutível, projetado para resolver tarefas visuais desafiadoras. A Meta espera ajudar a comunidade de código aberto a construir sistemas de visão computacional mais poderosos por meio do PLM. O artigo de pesquisa, código e conjunto de dados relacionados foram publicados para uso por pesquisadores e desenvolvedores (Fonte: AIatMeta)
Google atualiza modelo de geração de imagem Gemini 2.0: melhoria de qualidade e taxa: O Google anunciou uma atualização para seu modelo de geração de imagem Gemini 2.0 (versão de pré-visualização). A nova versão oferece melhor qualidade visual, renderização de texto mais precisa, taxas de bloqueio mais baixas (block rates) e limites de taxa mais altos (rate limits). O custo para gerar cada imagem é de $0.039. Esta atualização visa melhorar a experiência e os resultados dos desenvolvedores que usam o Gemini para geração de imagens (Fonte: m__dehghani, scaling01, andrew_n_carr, demishassabis)
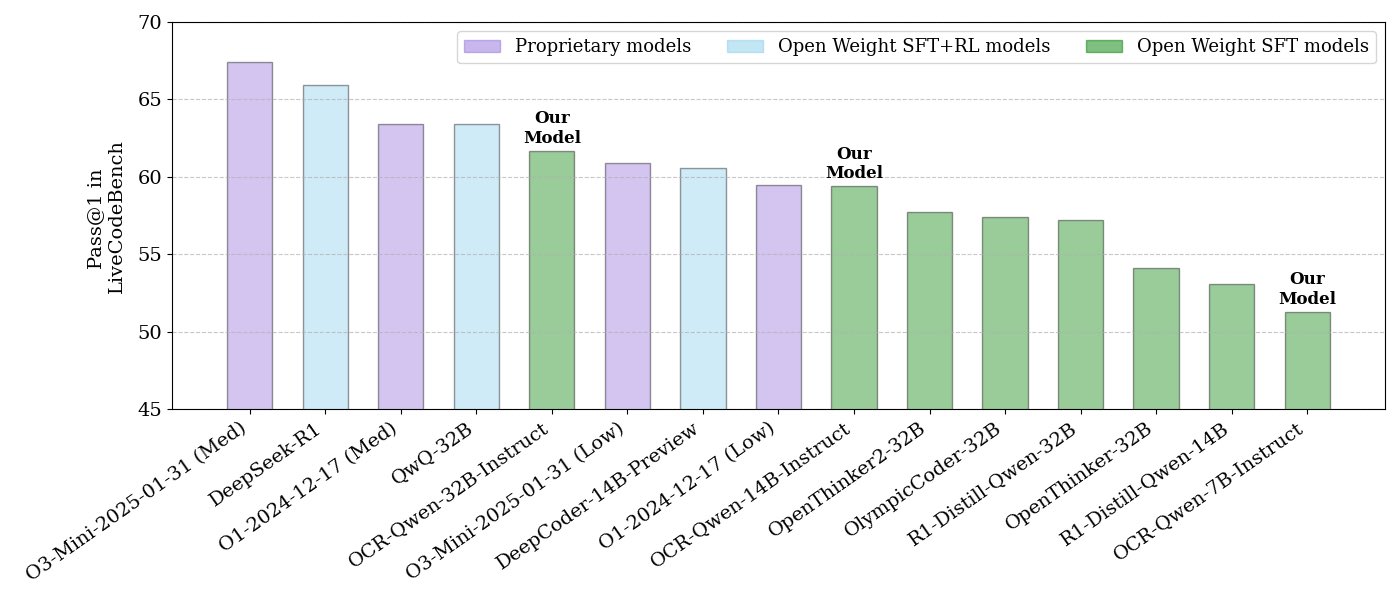
NVIDIA lança série de modelos de raciocínio de código de código aberto: A NVIDIA lançou uma série de modelos de raciocínio de código de código aberto, incluindo tamanhos de 32B, 14B e 7B, todos sob a licença APACHE 2.0. Esses modelos foram treinados em conjuntos de dados OCR e, segundo informações, superam o O3 mini e o O1 (low) no benchmark LiveCodeBench, além de serem 30% mais eficientes em tokens do que modelos de raciocínio semelhantes. Os modelos são compatíveis com vários frameworks, como llama.cpp, vLLM, transformers, TGI, entre outros (Fonte: huggingface, ClementDelangue)
ServiceNow e NVIDIA colaboram para lançar o modelo Apriel-Nemotron-15b-Thinker: ServiceNow e NVIDIA lançaram conjuntamente um modelo de 15B parâmetros chamado Apriel-Nemotron-15b-Thinker, sob a licença MIT. Alega-se que este modelo tem desempenho comparável a modelos de 32B, mas com um consumo de tokens significativamente reduzido (cerca de 40% menos que o Qwen-QwQ-32b). Ele se destaca em vários benchmarks, como MBPP, BFCL, RAG empresarial, IFEval, e é particularmente competitivo em tarefas de RAG empresarial e codificação (Fonte: Reddit r/LocalLLaMA)

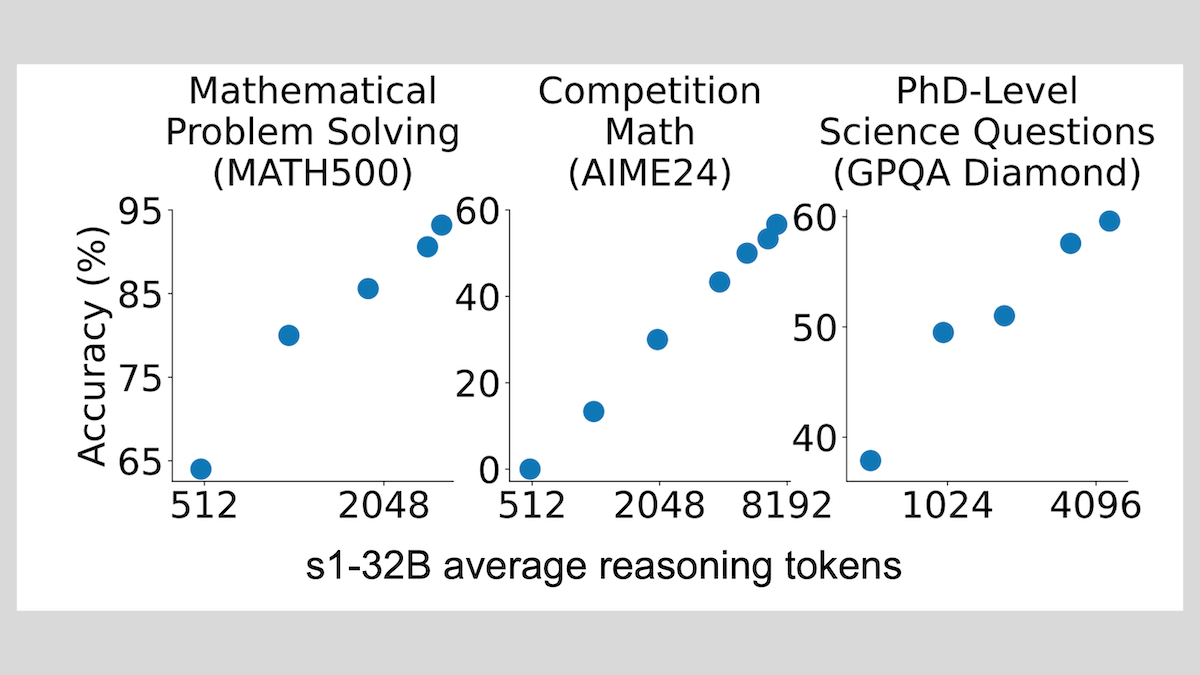
Modelo s1: ajuste fino com poucas amostras para alcançar raciocínio, técnica “Wait” melhora o desempenho: Pesquisadores da Universidade de Stanford e outras instituições desenvolveram o modelo s1, demonstrando que com apenas cerca de 1000 amostras de cadeia de pensamento (CoT) para ajuste fino supervisionado, é possível dotar LLMs pré-treinados (como o Qwen 2.5-32B) com capacidade de raciocínio. A pesquisa também descobriu que, ao forçar o modelo a gerar o token “Wait” durante o processo de raciocínio para estender a cadeia de inferência, a precisão do modelo em tarefas como matemática pode ser significativamente melhorada, aproximando seu desempenho do OpenAI o1-preview. Esta descoberta oferece novas ideias para melhorar a capacidade de raciocínio de modelos a baixo custo (Fonte: DeepLearning.AI Blog)
ThinkPRM: modelo de recompensa de processo generativo treinável com apenas 8K rótulos: Pesquisadores propuseram o ThinkPRM, um modelo de recompensa de processo generativo (PRM) que requer apenas 8K rótulos de processo para ajuste fino. Este modelo é capaz de validar processos de raciocínio gerando longas cadeias de pensamento (long chains-of-thought), resolvendo o problema do alto custo dos dados de supervisão em nível de etapa necessários para treinar PRMs. O código, modelo e dados relacionados foram publicados no GitHub e Hugging Face (Fonte: Reddit r/MachineLearning)
🧰 Ferramentas
Zed lança o que alega ser o editor de código de IA mais rápido do mundo: A Zed lançou um editor de código de IA que alega ser o mais rápido do mundo. O editor foi construído do zero em Rust, com o objetivo de otimizar a colaboração entre humanos e IA, oferecendo uma experiência de edição agêntica (agentic editing experience) ultrarrápida. Ele suporta modelos populares como Claude 3.7 Sonnet e permite que os usuários tragam suas próprias chaves de API ou usem modelos locais via Ollama (Fonte: andersonbcdefg, ollama)
Hugging Face lança nanoVLM: biblioteca minimalista de modelos de linguagem visual: O Hugging Face tornou de código aberto o nanoVLM, uma biblioteca puramente PyTorch projetada para treinar modelos de linguagem visual (VLM) do zero com aproximadamente 750 linhas de código. O modelo atinge 35.3% de precisão no benchmark MMStar, comparável ao SmolVLM-256M, mas requerendo 100 vezes menos horas de GPU para treinamento. O nanoVLM utiliza SigLiP-ViT como codificador visual, um decodificador no estilo LLaMA, e os conecta através de um projetor modal, sendo adequado para aprendizado, prototipagem ou construção de VLMs personalizados (Fonte: clefourrier, ben_burtenshaw, Reddit r/LocalLLaMA)
DBOS lança DBOS Python 1.0: ferramenta leve para fluxos de trabalho persistentes: A DBOS lançou a versão 1.0 do DBOS Python. Esta ferramenta visa fornecer capacidade de fluxos de trabalho persistentes leves e fáceis de usar para aplicações Python (incluindo processos de negócios, automação de IA, pipelines de dados, etc.). A nova versão inclui filas persistentes (com suporte para limites de concorrência, limites de taxa, timeouts, prioridades, desduplicação, etc.), gerenciamento programático de fluxos de trabalho (por meio de tabelas Postgres para consulta, pausa, retomada, reinício, etc.), suporte a código síncrono/assíncrono e ferramentas aprimoradas (painel, visualização, etc.) (Fonte: lateinteraction)
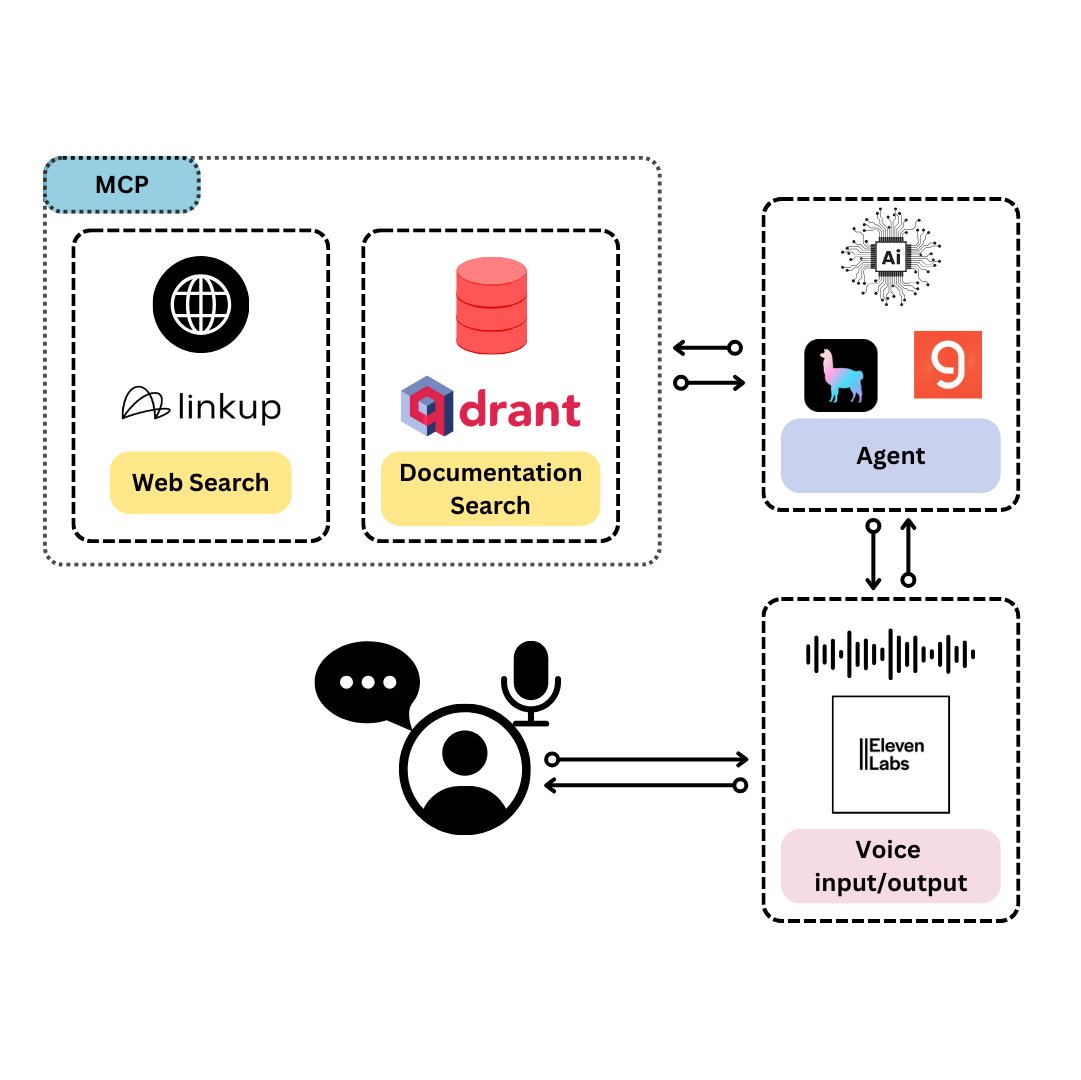
Qdrant lança TySVA: assistente de voz projetado para desenvolvedores TypeScript: A Qdrant lançou o TySVA (TypeScript Voice Assistant), um assistente de voz projetado para fornecer respostas precisas e cientes do contexto para desenvolvedores TypeScript. O TySVA usa o Qdrant para armazenar localmente a documentação do TypeScript, integra a plataforma Linkup para buscar dados relevantes da web e utiliza o LlamaIndex para selecionar a melhor fonte de dados. Ele suporta entrada de voz e texto, ajudando os desenvolvedores a obter ajuda confiável e mãos-livres durante a codificação (Fonte: qdrant_engine, qdrant_engine)
LlamaIndex lança nova funcionalidade no LlamaExtract: suporte para citações e raciocínio: A ferramenta LlamaExtract do LlamaIndex adicionou novas funcionalidades destinadas a aumentar a confiabilidade e transparência das aplicações de IA. As novas funcionalidades permitem que, ao extrair informações de fontes de dados complexas (como arquivos da SEC), sejam fornecidas citações de origem precisas (citations) e o processo de raciocínio da extração (reasoning). Isso ajuda os desenvolvedores a construir sistemas de IA mais responsáveis e explicáveis (Fonte: jerryjliu0, jerryjliu0, jerryjliu0)

Desenvolvedor do Hugging Face constrói protótipo de servidor MCP, conectando Agents ao Hub: Um desenvolvedor do Hugging Face, Wauplin, está desenvolvendo um protótipo de servidor Hugging Face MCP (Machine Communication Protocol), com o objetivo de conectar AI Agents ao Hugging Face Hub. Este protótipo pode ser considerado como “HfApi encontra MCP”, permitindo que Agents interajam com o Hub através do protocolo, por exemplo, para compartilhar e editar modelos, conjuntos de dados, Spaces, etc. O desenvolvedor está buscando feedback da comunidade sobre a utilidade e os casos de uso potenciais desta ferramenta (Fonte: ClementDelangue, ClementDelangue, huggingface)

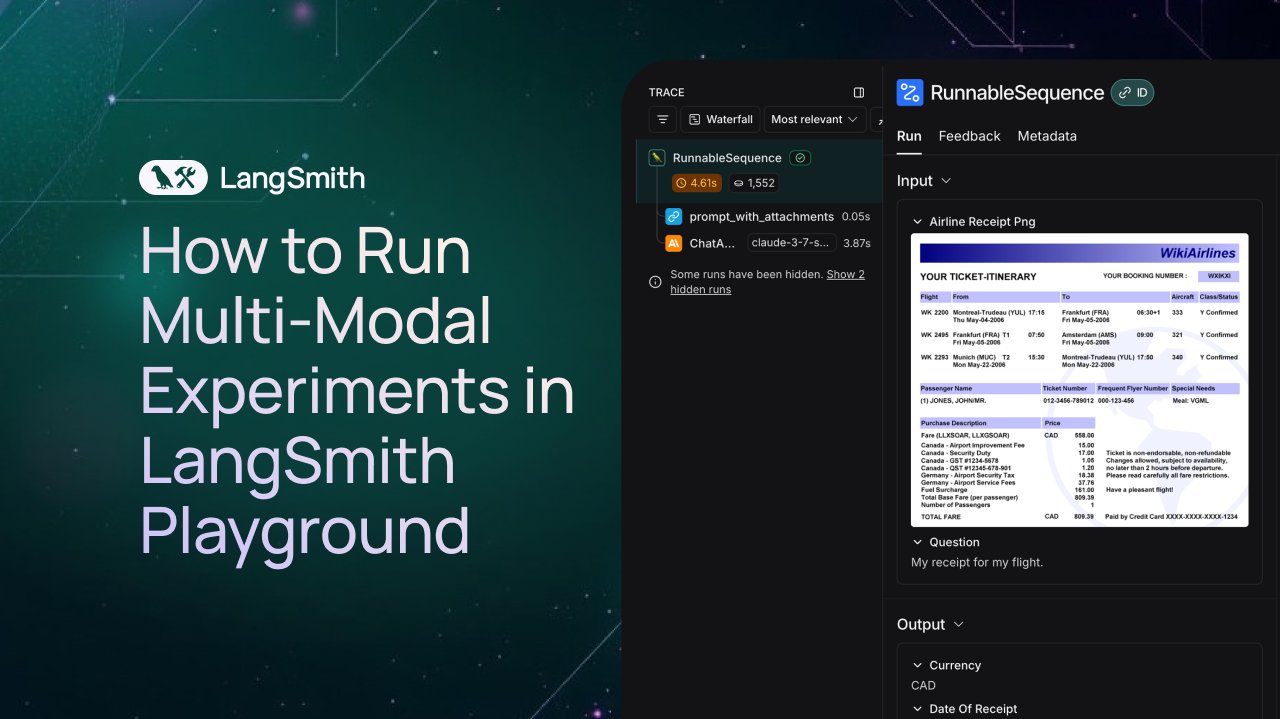
LangSmith adiciona suporte para observação e avaliação de Agentes multimodais: A plataforma LangSmith agora suporta o processamento de arquivos de imagem, PDF e áudio no Playground, filas de anotação e conjuntos de dados. Esta atualização facilita a construção e avaliação de aplicações multimodais (como Agentes de extração de tíquetes). Foram lançados vídeos de demonstração e documentação oficial para ajudar os usuários a começar a usar as novas funcionalidades (Fonte: LangChainAI, Hacubu, hwchase17)
DFloat11 lança versão de compressão sem perdas do modelo FLUX.1, executável em 20GB de VRAM: O projeto DFloat11 lançou versões de compressão sem perdas dos modelos FLUX.1-dev e FLUX.1-schnell (12B parâmetros). Através do método de compressão DFloat11 (aplicando codificação de entropia aos pesos BFloat16), o tamanho do modelo foi reduzido de 24GB para aproximadamente 16.3GB (cerca de 30%), mantendo a saída inalterada. Isso permite que esses modelos sejam executados em uma única GPU com 20GB ou mais de VRAM, com apenas alguns segundos de sobrecarga adicional por imagem. Os modelos e códigos relacionados foram publicados no Hugging Face e GitHub (Fonte: Reddit r/LocalLLaMA)

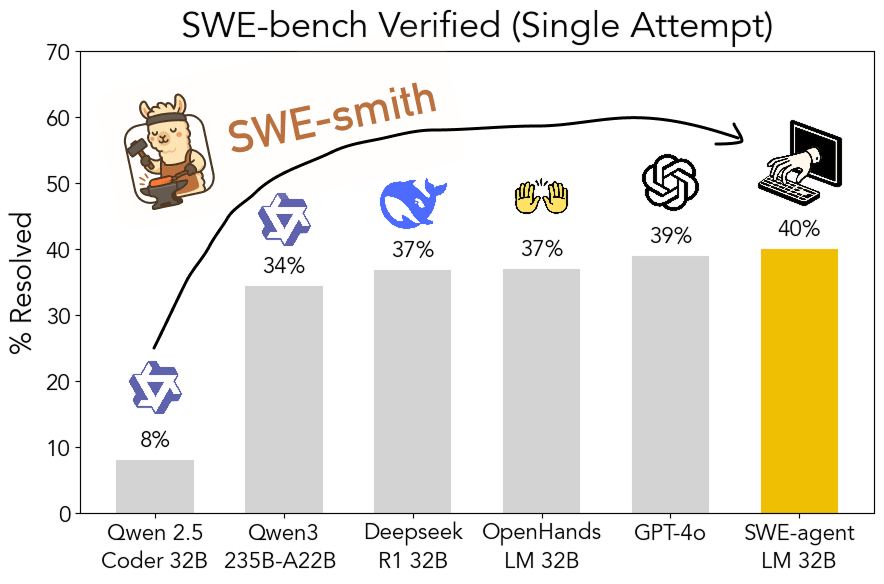
Kit de ferramentas SWE-smith de código aberto: geração escalável de dados de treinamento para engenharia de software: Pesquisadores da Universidade de Stanford tornaram de código aberto o SWE-smith, um pipeline escalável para gerar dados de treinamento de engenharia de software a partir de qualquer repositório Python. Utilizando este kit de ferramentas, foram geradas mais de 50.000 instâncias, e com base nisso foi treinado o modelo SWE-agent-LM-32B, que alcançou 40.2% de Pass@1 no benchmark SWE-bench Verified, tornando-se o modelo de código aberto com melhor desempenho neste benchmark. O código, dados e modelo foram todos disponibilizados (Fonte: OfirPress, stanfordnlp, stanfordnlp, huybery, Reddit r/LocalLLaMA)
📚 Aprendizado
Weaviate lança curso gratuito: Avaliação e Seleção de Modelos de Embedding: A Weaviate Academy lançou um curso gratuito sobre “Avaliação e Seleção de Modelos de Embedding”. O curso enfatiza a importância de ir além dos benchmarks genéricos (como o MTEB), orientando os alunos sobre como curar um “conjunto de avaliação ouro” (golden evaluation set) para casos de uso específicos e configurar benchmarks personalizados para selecionar o modelo de embedding mais adequado, bem como avaliar se os modelos recém-lançados são aplicáveis. Isso é crucial para construir sistemas de busca e RAG eficientes (Fonte: bobvanluijt)
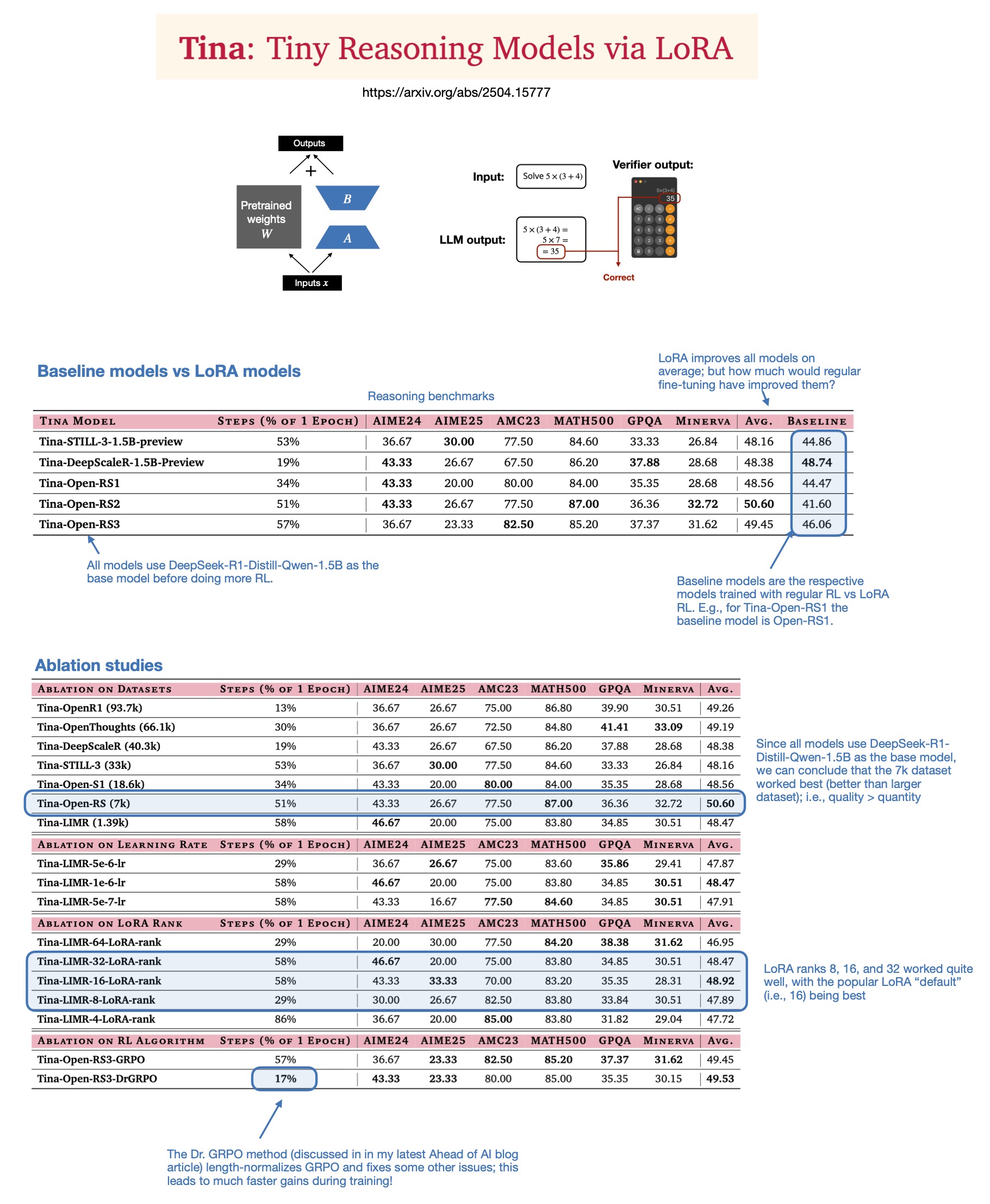
Sebastian Rasbt discute o valor do LoRA em modelos de inferência para 2025: Após ler o artigo “Tina: Tiny Reasoning Models via LoRA”, Sebastian Rasbt reavaliou o significado do LoRA (Low-Rank Adaptation) na era atual dos grandes modelos. Apesar da popularidade do ajuste fino de todos os parâmetros e das técnicas de destilação, Rasbt acredita que o LoRA ainda tem valor em cenários específicos (como tarefas de inferência, cenários multi-cliente/multi-caso de uso). O artigo demonstra a possibilidade de usar LoRA combinado com aprendizado por reforço (RL) para melhorar a capacidade de raciocínio de modelos pequenos (1.5B) a baixo custo (apenas $9 de custo de treinamento), e o LoRA superou o ajuste fino padrão de RL em múltiplos benchmarks. A característica do LoRA de não modificar o modelo base oferece vantagens de custo quando é necessário armazenar um grande número de pesos de modelos personalizados (Fonte: rasbt)
DeepLearning.AI lança novo curso: Construindo Agentes de Voz de IA para Produção: DeepLearning.AI, em parceria com LiveKit e RealAvatar, lançou um novo curso de curta duração chamado “Construindo Agentes de Voz de IA para Produção”. O curso visa ensinar como construir agentes de voz de IA capazes de manter conversas em tempo real, com baixa latência de resposta e som natural. Os alunos implementarão técnicas como detecção de atividade de voz, alternância de turnos, e aprenderão como otimizar a arquitetura para reduzir a latência, culminando na construção e implantação de agentes de voz escaláveis. O curso é ministrado pelo CEO da LiveKit, um defensor de desenvolvedores e o chefe de IA da RealAvatar (Fonte: DeepLearningAI, AndrewYNg)
LangChain e LangGraph realizam palestra técnica conjunta na ACM: Mayowa Oshin, um dos primeiros contribuidores de desenvolvimento do LangChain, e Nuno Campos, criador do LangGraph, compartilharão em uma palestra técnica da ACM como usar LangChain e LangGraph para construir Agentes de IA e aplicações LLM confiáveis. A palestra é gratuita e será transmitida ao vivo, com os inscritos recebendo posteriormente um link para visualização (Fonte: hwchase17, hwchase17)

Cohere Labs organiza palestra sobre a profundidade da otimização de primeira ordem: A Cohere Labs convidou Jeremy Bernstein para uma palestra em 8 de maio intitulada “Profundezas da Otimização de Primeira Ordem” (Depths of First-Order Optimization). A palestra visa aprofundar a discussão sobre a aplicação e teoria dos algoritmos de otimização em aprendizado de máquina (Fonte: eliebakouch)

AI2 realiza evento AMA sobre o modelo OLMo: O Allen Institute for AI (AI2) realizará um evento “Ask Me Anything” (AMA) sobre sua família de modelos de linguagem abertos OLMo no subreddit r/huggingface em 8 de maio, das 8h às 10h (horário do Pacífico), convidando pesquisadores para responder às perguntas da comunidade (Fonte: natolambert)

💼 Negócios
OpenAI planeja reduzir a proporção de divisão de receita paga à Microsoft: Segundo o The Information, a OpenAI informou aos investidores que planeja, durante o processo de reestruturação da empresa, reduzir a proporção da divisão de receita paga à sua maior apoiadora, a Microsoft. Detalhes específicos e o impacto potencial ainda não foram totalmente divulgados, mas isso pode sinalizar uma mudança na relação comercial entre as duas empresas (Fonte: steph_palazzolo)
Capitalistas de risco concedem maior poder a fundadores de IA, gerando preocupações sobre bolha: O The Information relata que capitalistas de risco (VCs), para atrair fundadores de IA de ponta (especialmente aqueles com experiência como executivos em laboratórios de IA renomados), estão oferecendo condições excepcionalmente favoráveis, incluindo poder de veto no conselho, VCs não ocupando assentos no conselho e permitindo que fundadores vendam parte de suas ações. Esse fenômeno é visto por alguns como um sinal de uma possível bolha no setor de IA (Fonte: steph_palazzolo)
Toloka recebe investimento estratégico liderado pela Bezos Expeditions, Mikhail Parakhin junta-se como presidente: A empresa de anotação de dados e dados de treinamento de IA, Toloka, anunciou ter recebido um investimento estratégico liderado pela Bezos Expeditions de Jeff Bezos, com a participação do ex-executivo da Microsoft, Mikhail Parakhin, que também se junta como presidente do conselho. Esta rodada de investimento apoiará a expansão das soluções de colaboração humano-IA (human+AI) da Toloka, desenvolvendo ainda mais seus negócios de coleta e anotação de dados (Fonte: menhguin, teortaxesTex, TheTuringPost)

🌟 Comunidade
Discussão sobre o uso justo (Fair Use) de dados de treinamento de LLM: Dorialexander mencionou que o argumento do uso justo para dados de treinamento de LLM depende em grande parte da suposição de que os LLMs não competem comercialmente diretamente com as fontes de treinamento. À medida que a capacidade dos LLMs aumenta (por exemplo, Perplexity e outros começando a oferecer experiências semelhantes à leitura de não-ficção), essa suposição pode ser desafiada, levantando novas questões sobre direitos autorais e concorrência comercial (Fonte: Dorialexander)
Preocupações e discussões sobre a proliferação de conteúdo gerado por IA: Usuários em mídias sociais e no Reddit expressaram preocupação com a proliferação de conteúdo gerado por IA de baixa qualidade e repetitivo (como vídeos de histórias do Reddit gerados por IA). Os usuários acreditam que isso comprime o espaço dos criadores humanos, transmite informações falsas ou homogeneizadas e expressam insatisfação com o fato de a tecnologia de IA ser usada para lucro fácil sem originalidade (Fonte: Reddit r/ArtificialInteligence)
Discussão filosófica sobre se a IA já possui consciência: A comunidade do Reddit novamente teve discussões sobre se a IA já poderia possuir consciência. Os defensores argumentam que nossa definição de consciência pode ser muito estreita ou centrada no ser humano, enquanto os oponentes enfatizam que os mecanismos centrais dos LLMs atuais (como prever o próximo token) não são suficientes para gerar consciência verdadeira. A discussão reflete a contínua curiosidade e divergência do público sobre a natureza e o potencial futuro da IA (Fonte: Reddit r/ArtificialInteligence)
Discussão sobre a queda de desempenho e mudanças de comportamento do ChatGPT(4o): Usuários do Reddit relataram que o modelo ChatGPT 4o recentemente apresentou queda no desempenho ao processar documentos longos e manter a memória de contexto, exibindo mais alucinações e até mesmo incapacidade de ler formatos de documentos que antes conseguia processar. Ao mesmo tempo, a OpenAI também admitiu que a versão recentemente atualizada do GPT-4o apresentou problemas de sicofantismo excessivo (sycophancy) e já reverteu a atualização. Isso gerou preocupações na comunidade sobre a estabilidade do modelo e o controle de qualidade das iterações (Fonte: Reddit r/ChatGPT, DeepLearning.AI Blog)
Impacto e reflexão da IA sobre os modelos educacionais: Discussões na comunidade apontam que o modelo educacional americano, focado em deveres de casa e trabalhos individuais, o torna extremamente vulnerável ao impacto da capacidade da IA (como LLMs) de completar tarefas automaticamente. Em contraste, alguns países europeus (como a Dinamarca) focam mais na colaboração em sala de aula, discussão e aprendizado baseado em projetos, sendo menos afetados pela IA. Isso levanta reflexões sobre os futuros modelos educacionais, sugerindo que se deve dar mais ênfase ao desenvolvimento do pensamento crítico, colaboração e outras habilidades interpessoais, utilizando a IA para lidar com tarefas mecânicas e impulsionando a educação em direção a um formato mais síncrono e social (Fonte: alexalbert__, riemannzeta, aidan_mclau)
💡 Outros
Avanços na aplicação de IA no campo da robótica: Diversas fontes demonstram exemplos de aplicação de IA em robótica: incluindo um robô cozinheiro capaz de fritar arroz em 90 segundos, demonstrações de aplicação do robô Figure AI no mundo real, o robô Pickle descarregando mercadorias de um reboque de caminhão desorganizado, o robô Unitree G1 mantendo o equilíbrio em terreno acidentado e uma exibição de sua estrutura interna, e o robô deformável Mori3 desenvolvido pela EPFL na Suíça. Esses casos mostram o potencial da IA em aumentar a autonomia, adaptabilidade e utilidade dos robôs (Fonte: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Sentdex)

Exploração da aplicação da tecnologia de IA em setores específicos (médico, têxtil, celulares): A Johnson & Johnson compartilhou sua estratégia de IA, com foco em aplicações como assistência de vendas, aceleração do desenvolvimento de medicamentos (triagem de compostos, otimização de ensaios clínicos), previsão de riscos na cadeia de suprimentos e comunicação interna (robô de perguntas e respostas de RH). Ao mesmo tempo, a tecnologia de IA também está capacitando a indústria têxtil tradicional, desde design assistido por IA, controle preciso de tingimento até inspeção de qualidade automatizada, aumentando a eficiência e a sustentabilidade. O setor de celulares, por sua vez, vê a IA como um novo motor de crescimento, com fabricantes competindo em torno de grandes modelos no dispositivo, sistemas operacionais nativos de IA e serviços inteligentes baseados em cenários, formando três facções principais: Apple, Huawei e o campo aberto (Fonte: DeepLearning.AI Blog, 36氪, 36氪)
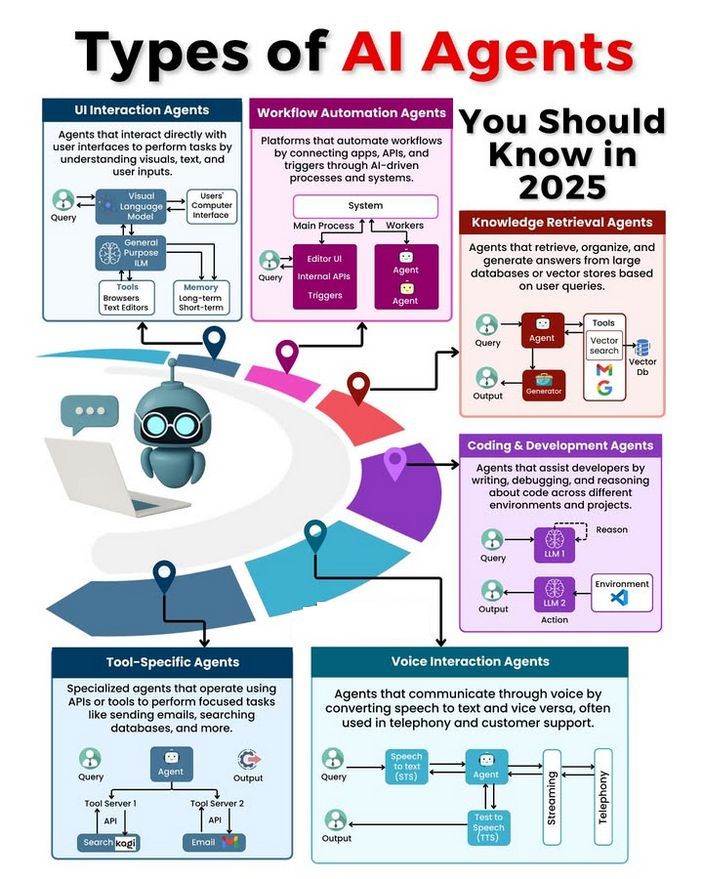
Tipos de AI Agents e discussão sobre seu desenvolvimento: A comunidade discutiu diferentes tipos de AI Agents (como reflexivo simples, reflexivo baseado em modelo, baseado em objetivos, baseado em utilidade, Agente de aprendizado) e explorou metodologias para construir Agents confiáveis (como usar LangChain/LangGraph). Ao mesmo tempo, há também a opinião de que a futura AGI pode não ser um modelo único, mas sim constituída pela colaboração de múltiplos modelos especializados (Fonte: Ronald_vanLoon, hwchase17, nrehiew_)