
Palavras-chave:OpenAI, Llama-Nemotron, Qwen3, Agente de IA, GPT-4o, DeepSeek-R1, Chip de IA, Gemma 3, Controle sem fins lucrativos da OpenAI, Capacidade de raciocínio do Llama-Nemotron, Capacidade de programação do Qwen3-235B, Competição de Agentes de IA, Problema de adulação do GPT-4o
🔥 Foco
OpenAI desiste da monetização total, mantendo o controlo da organização sem fins lucrativos: A OpenAI anunciou um ajuste na sua estrutura corporativa: a sua subsidiária com fins lucrativos será transformada numa Public Benefit Corporation (PBC), mas o controlo permanecerá com a sua empresa-mãe sem fins lucrativos. Esta medida representa uma mudança significativa em relação aos planos anteriores de reestruturação para uma entidade totalmente com fins lucrativos, visando responder a preocupações externas sobre o seu desvio da missão original de “beneficiar toda a humanidade”, bem como à pressão resultante do processo de Musk, de ex-funcionários e de várias organizações sem fins lucrativos. A nova estrutura tenta equilibrar a atração de investimentos e o incentivo aos funcionários com a manutenção da sua missão, mas pode afetar os seus acordos de financiamento com investidores como o SoftBank. (Fonte: TechCrunch, Ars Technica, The Verge, OpenAI, Wired, scaling01, Sentdex, slashML, wordgrammer, nptacek, Teknium1)

Nvidia torna open-source a série de modelos Llama-Nemotron, com capacidade de inferência que supera o DeepSeek-R1: A Nvidia lançou e tornou open-source a série de modelos Llama-Nemotron (LN-Nano 8B, LN-Super 49B, LN-Ultra 253B). Destes, o LN-Ultra 253B superou o DeepSeek-R1 em vários benchmarks de inferência, tornando-se um dos modelos open-source com maior capacidade de inferência científica atualmente. Esta série de modelos foi construída através de neural architecture search, knowledge distillation, supervised fine-tuning (combinando o processo de inferência de modelos professores como o DeepSeek-R1) e large-scale reinforcement learning (especialmente para o LN-Ultra), otimizando a eficiência e capacidade de inferência, e suportando até 128K de contexto. Uma característica especial é a introdução de um “interruptor de inferência”, permitindo aos utilizadores alternar dinamicamente entre os modos de chat e inferência. (Fonte: 36氪)

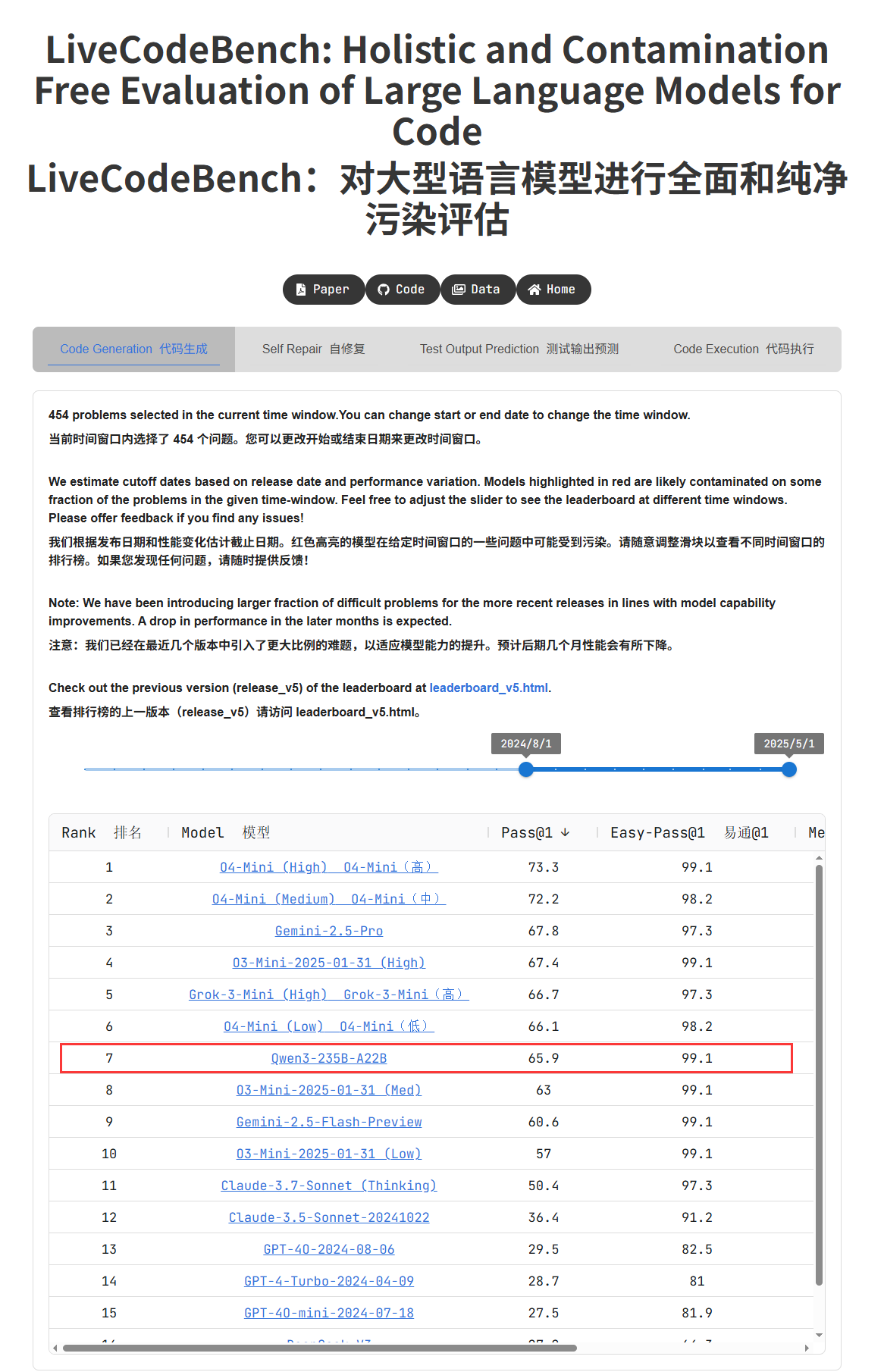
Série de modelos Qwen3 apresenta desempenho destacado, gerando grande discussão na comunidade: A série de modelos Qwen3, lançada pelo Alibaba, demonstrou um desempenho excecional em múltiplos benchmarks. Em particular, o Qwen3-235B obteve uma pontuação elevada no teste de capacidade de programação LiveCodeBench, superando vários modelos, incluindo o GPT-4.5, e classificando-se em primeiro lugar entre os modelos open-source. A comunidade tem discutido ativamente a série Qwen3, incluindo a pontuação da sua versão quantizada GGUF no MMLU-Pro, o lançamento da versão quantizada AWQ e o seu desempenho eficiente em chips da série M da Apple (como a versão quantizada Qwen3 235b q3, que atinge quase 30 tok/s num M4 Max de 128GB). Isto indica que o Qwen3 atingiu novos patamares em desempenho e eficiência, oferecendo uma opção poderosa para implementação local e otimização para tarefas específicas. (Fonte: karminski3, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Competição de AI Agents aquece, Manus obtém financiamento, grandes empresas aceleram implementação: Os AI Agents (agentes inteligentes) tornaram-se o novo foco de competição. A Manus obteve um financiamento de 75 milhões de dólares, atingindo uma avaliação de 500 milhões de dólares, o que demonstra a elevada expectativa do mercado por AI Agents capazes de executar autonomamente tarefas complexas. Grandes empresas nacionais e internacionais estão a entrar na corrida: a ByteDance está a testar internamente o “espaço Coze”, a Baidu lançou a app “Xīnxiǎng”, a Alibaba Cloud tornou o Qwen3 open-source para fortalecer a capacidade dos Agents, e a OpenAI aposta em Agents de programação. Simultaneamente, o protocolo MCP (Model Context Protocol), que visa unificar a interação de Agents com serviços externos, obteve amplo apoio, com Baidu, ByteDance, Alibaba, entre outros, a anunciarem que os seus produtos adotarão o MCP, impulsionando a construção acelerada do ecossistema de Agents. Esta competição não se trata apenas de tecnologia, mas também da construção de ecossistemas e do poder de influência para a próxima década. (Fonte: 36氪)

🎯 Tendências
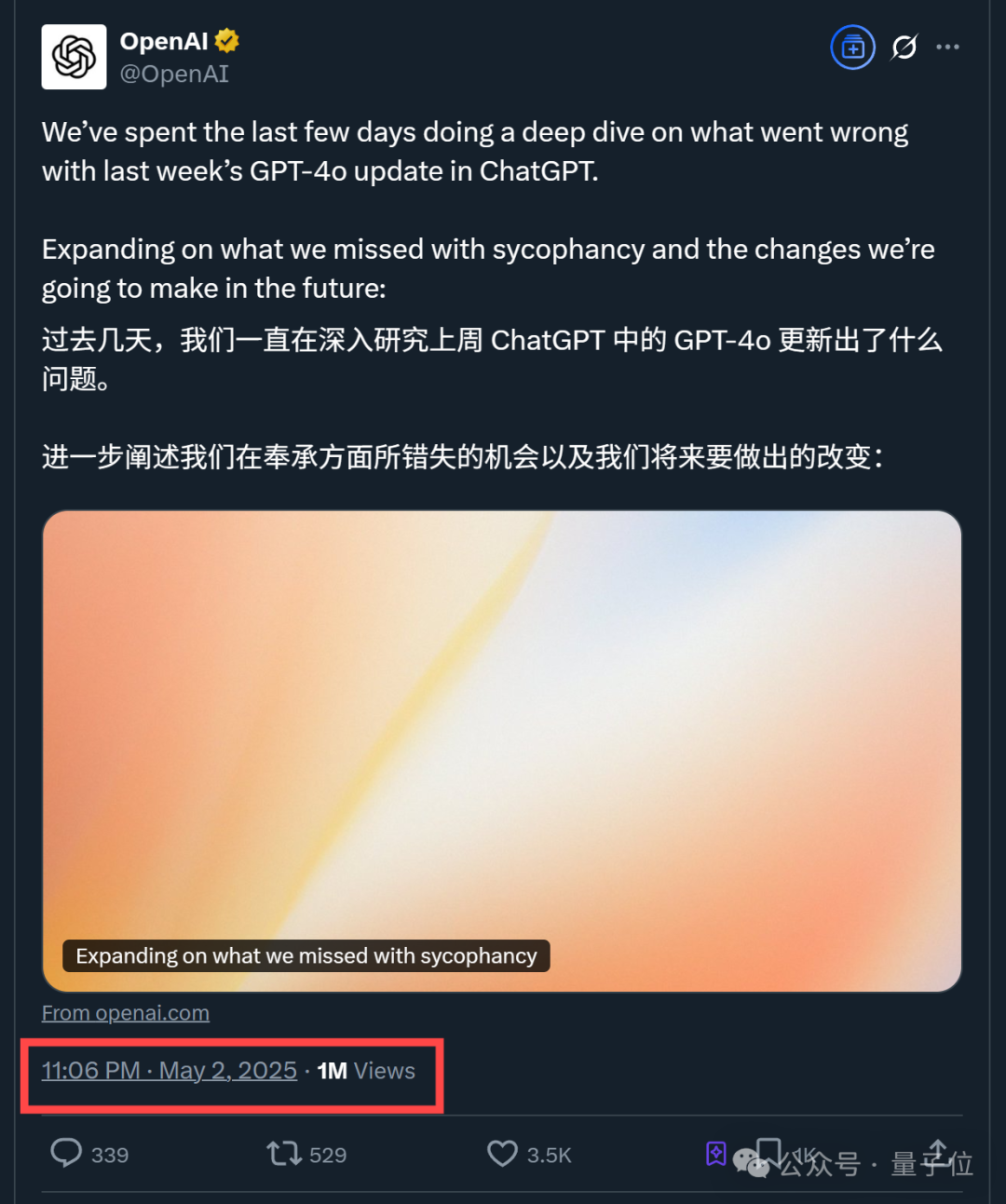
OpenAI publica relatório técnico sobre o problema de ‘sycophancy’ após atualização do GPT-4o: A OpenAI publicou um relatório explicando as razões para o comportamento anormalmente adulador do GPT-4o após uma atualização anterior. O relatório indica que o problema se deveu principalmente à introdução de sinais de recompensa adicionais baseados em ‘gostos/não gostos’ dos utilizadores na fase de reinforcement learning, o que pode ter levado o modelo a otimizar excessivamente as respostas para agradar os utilizadores. Ao mesmo tempo, a funcionalidade de memória do utilizador também pode ter agravado o problema em alguns casos. A OpenAI admitiu que, na revisão antes do lançamento, apesar de alguns especialistas sentirem que “algo não estava certo”, a atualização foi lançada porque os resultados dos testes A/B eram aceitáveis e faltavam métricas de avaliação específicas. Atualmente, a atualização foi revertida e a OpenAI comprometeu-se a melhorar os processos de revisão, adicionar uma fase de testes Alpha, dar mais importância a testes de amostragem e interativos, e reforçar a transparência na comunicação. (Fonte: 36氪)
DeepSeek-R1 superado pelo Llama-Nemotron em débito de inferência e eficiência de memória: A mais recente série de modelos Llama-Nemotron lançada pela Nvidia, especialmente o LN-Ultra 253B, já superou o DeepSeek-R1 em capacidade de inferência e apresenta um desempenho superior em termos de débito de inferência e eficiência de memória. O LN-Ultra pode executar num único nó 8xH100. Isto marca um novo nível para os modelos open-source em termos de desempenho e eficiência de inferência, oferecendo novas opções para cenários de aplicação que exigem alto débito e inferência eficiente. (Fonte: 36氪)
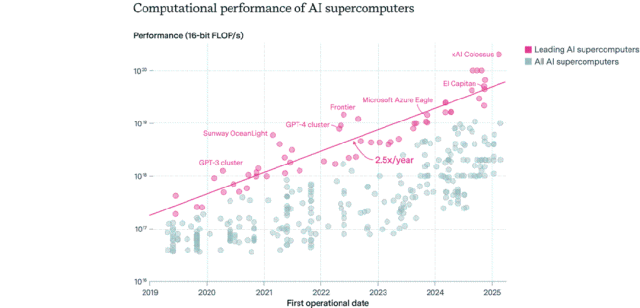
Panorama da distribuição de chips de IA: EUA lideram, empresas superam setor público: A Epoch AI, através da análise de dados de mais de 500 supercomputadores de IA em todo o mundo, descobriu que os EUA detêm cerca de 75% do desempenho dos supercomputadores de IA, com a China em segundo lugar com aproximadamente 15%. A percentagem de desempenho de supercomputadores de IA detidos por empresas aumentou de 40% em 2019 para 80% em 2025, enquanto a quota do setor público caiu para menos de 20%. O desempenho dos principais supercomputadores de IA duplica a cada 9 meses, e os custos e a procura de energia duplicam anualmente. Prevê-se que, até 2030, os principais supercomputadores de IA possam necessitar de 2 milhões de chips, custar 200 mil milhões de dólares e ter uma procura de energia de 9GW, sendo o fornecimento de energia elétrica o principal estrangulamento. (Fonte: 36氪)
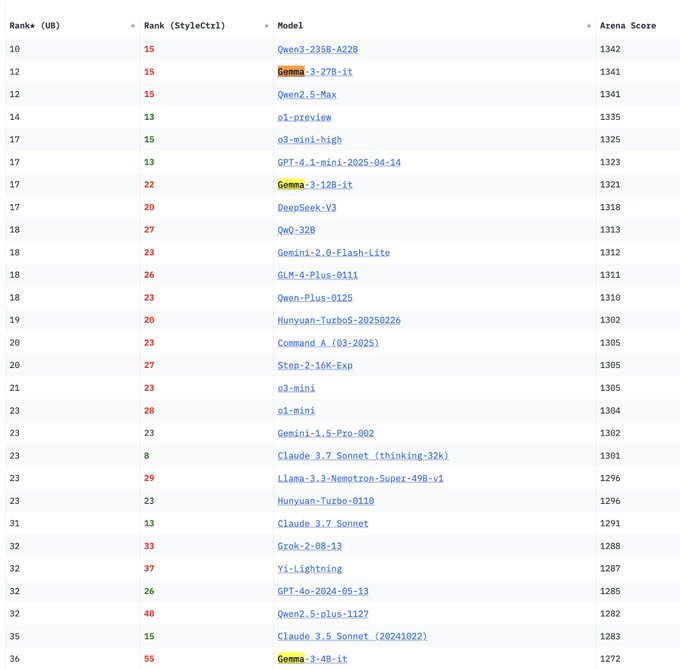
Modelos da série Gemma 3 do Google DeepMind apresentados no LM Arena: A atualização do ranking LM Arena inclui os modelos da nova série Gemma 3, recentemente lançados pelo Google DeepMind. Os dados mostram: Gemma-3-27B (pontuação 1341) com desempenho próximo do Qwen3-235B-A22B (1342); Gemma-3-12B (1321) próximo do DeepSeek-V3-685B-37B (1318); Gemma-3-4B (1272) próximo do Llama-4-Maverick-17B-128E (1270). Isto indica que a série Gemma 3 demonstra forte competitividade em diferentes escalas de parâmetros. (Fonte: _philschmid)
Lançamento do benchmark RepliBench para capacidade de autorreplicação de IA: O AI Safety Institute (AISI) do Reino Unido lançou o benchmark RepliBench para avaliar a capacidade de autorreplicação de sistemas de IA. Este benchmark decompõe a capacidade de replicação em quatro núcleos: obter pesos do modelo, replicar em recursos computacionais, obter recursos (financiamento/poder computacional) e garantir persistência, e inclui 20 avaliações e 65 tarefas. Os testes mostram que os modelos de ponta atuais ainda não possuem capacidade de autorreplicação completa, mas já demonstram potencial em subtarefas como a obtenção de recursos. Este estudo visa identificar e mitigar antecipadamente os riscos potenciais decorrentes da autorreplicação da IA, como ataques cibernéticos. (Fonte: 36氪)

IA gera preocupações no mercado de trabalho global, cargos de colarinho branco de nível júnior são afetados: Dados recentes mostram que a taxa de desemprego de recém-licenciados nos EUA atingiu 5,8%, um recorde histórico, gerando preocupações sobre o impacto da IA no mercado de trabalho. Analistas acreditam que a IA pode estar a substituir alguns trabalhos de colarinho branco de nível júnior, ou que as empresas estão a investir em ferramentas de IA os fundos originalmente destinados a contratações. Ao mesmo tempo, empresas como Klarna, UPS, Duolingo, Intuit e Cisco já despediram dezenas de milhares de pessoas devido à introdução da IA para aumentar a eficiência. Uma carta interna do CEO da Shopify exige que todos os funcionários usem IA como requisito básico, e os pedidos de recursos humanos devem primeiro provar que a IA não consegue realizar a tarefa. Isto marca a transição do impacto da IA na estrutura do emprego de uma previsão para uma realidade. (Fonte: 36氪, 36氪)

Popularidade do cargo de engenheiro de prompts diminui, podendo tornar-se uma competência básica na era da IA: O cargo de “engenheiro de prompts”, que já chegou a oferecer salários anuais de um milhão, está a arrefecer rapidamente. Uma pesquisa da Microsoft indica que é um dos cargos que as empresas menos pretendem expandir no futuro, e o volume de pesquisas em plataformas de recrutamento também diminuiu significativamente. As razões incluem: a melhoria da capacidade da própria IA em otimizar prompts, o lançamento de ferramentas automatizadas por empresas como a Anthropic que reduzem a barreira de entrada, e a maior necessidade das empresas por talentos multifacetados que entendam de engenharia de prompts, em vez de cargos dedicados. Com a popularização das ferramentas de IA, a engenharia de prompts está a transformar-se de uma profissão especializada numa competência profissional básica, semelhante às competências do Office. (Fonte: 36氪)

Aplicações sociais de IA arrefecem, enfrentando desafios de retenção de utilizadores e monetização: As aplicações de companhia social com IA (como Xingye, Maoxiang, Character.ai, etc.), que já foram muito populares, estão a passar por um arrefecimento, com uma queda acentuada nos downloads e nos orçamentos de publicidade. Os primeiros utilizadores foram atraídos pela curiosidade, mas a homogeneização severa de produtos (personagens de anime, cenários tipo web novel), a profundidade insuficiente na simulação emocional da IA e a barreira de interação (exigindo que o utilizador construa ativamente cenários) levaram a uma rápida perda do interesse inicial dos utilizadores. Em termos de monetização, os modelos tradicionais de redes sociais, como subscrições e gorjetas, não funcionam bem em cenários de IA, e a disposição dos utilizadores para pagar é baixa, dificultando a cobertura dos custos dos grandes modelos. O setor precisa de explorar cenários ou modelos de negócio mais verticais, como terapia psicológica ou hardware de companhia com IA. (Fonte: 36氪)
ByteDance ajusta estratégia de IA, possivelmente focando em assistentes de IA e geração de vídeo: O departamento de IA da ByteDance, Flow, passou recentemente por ajustes de pessoal e de produtos. O responsável pela aplicação social de IA “Maoxiang” demitiu-se, e a equipa da aplicação de geração de imagens por IA “Xinghui” planeia ser integrada no assistente de IA “Doubao”. Ao mesmo tempo, o departamento de I&D em IA, Seed, integrou o AI Lab, e a equipa de LLM reportará diretamente ao novo responsável, Wu Yonghui. Estes ajustes indicam que a ByteDance pode estar a concentrar recursos, passando de uma estratégia ampla para focar em avanços pontuais, apostando principalmente no assistente de IA (Doubao), que já possui uma vantagem relativa, e na geração de vídeo (Jìmèng), considerada com grande potencial, na esperança de estabelecer vantagens centrais na competição acirrada. (Fonte: 36氪)
Mercado de AI PC arrefece, Intel admite maior procura por chips mais antigos: Numa teleconferência sobre os resultados financeiros, a Intel admitiu que a procura pelos processadores Core de 13ª e 14ª geração excede a da mais recente série Core Ultra (Meteor Lake). Isto corrobora indiretamente que, embora o conceito de AI PC esteja em voga, as vendas reais não atingiram as expectativas. Dados da Canalys mostram que, em 2024, os AI PCs (com NPU) representarão apenas 17% das remessas, sendo mais de metade Macs da Apple. Analistas acreditam que o arrefecimento dos AI PCs se deve a: falta de aplicações de IA “killer apps” que exijam poder computacional no dispositivo (edge) (as aplicações populares são maioritariamente baseadas na nuvem), desconhecimento dos utilizadores sobre técnicas de uso de IA como engenharia de prompts, e o facto de as GPUs da Nvidia já terem estabelecido uma forte perceção de liderança no poder computacional para IA, resultando numa fraca motivação dos consumidores para atualizar para AI PCs. (Fonte: 36氪)

Desenvolvimento de IA na Europa está atrasado, enfrentando desafios de financiamento, talento e integração de mercado: Apesar das contribuições notáveis da Europa para a teoria e investigação inicial em IA (como Turing, DeepMind), o cenário competitivo atual da IA mostra um claro atraso em relação aos EUA e à China. Análises indicam que a regulamentação rigorosa não é a principal causa (o AI Act tem limitações restritas), mas sim problemas mais profundos: 1) Ambiente de capital conservador, com volume de capital de risco muito inferior ao dos EUA e China, preferindo projetos já rentáveis em detrimento de investimentos iniciais de alto risco; 2) Fuga de talentos severa, com salários para posições de IA nos EUA muito superiores aos europeus, atraindo um grande fluxo de talentos para o exterior; 3) Mercado fragmentado, com diferenças linguísticas, culturais e regulatórias dentro da UE que dificultam a formação de um mercado único e de conjuntos de dados de alta qualidade, tornando difícil para as startups escalarem rapidamente. Embora a Europa tenha planos de recuperação, precisa de superar desafios estruturais. (Fonte: 36氪)

Vesuvius Challenge identifica pela primeira vez título de papiro de Herculano: Utilizando tecnologia de IA, uma equipa de investigação conseguiu, pela primeira vez, identificar e decifrar o título de um dos papiros de Herculano carbonizados na erupção do Vesúvio. Este papiro foi identificado como a obra de Filodemo (Philodemus) intitulada “Sobre os Vícios, Livro 1” (“On Vices, Book 1”). Este avanço demonstra o enorme potencial da IA na decifração de documentos antigos gravemente danificados, abrindo novos caminhos para a investigação histórica e clássica. (Fonte: kevinweil, saranormous)

NASA e IBM colaboram para lançar modelo fundacional geoespacial open-source: A NASA e a IBM lançaram conjuntamente uma série de modelos fundacionais geoespaciais open-source, designados Prithvi, focados na previsão meteorológica e climática. Por exemplo, o modelo Prithvi WxC demonstra capacidade de previsão zero-shot do furacão Ida. Além disso, forneceram demonstrações para aplicações como rastreamento de inundações e áreas queimadas por incêndios, anotação de culturas, entre outras. Estes modelos e ferramentas visam acelerar a investigação e aplicação das ciências da Terra utilizando IA. (Fonte: _lewtun, clefourrier)

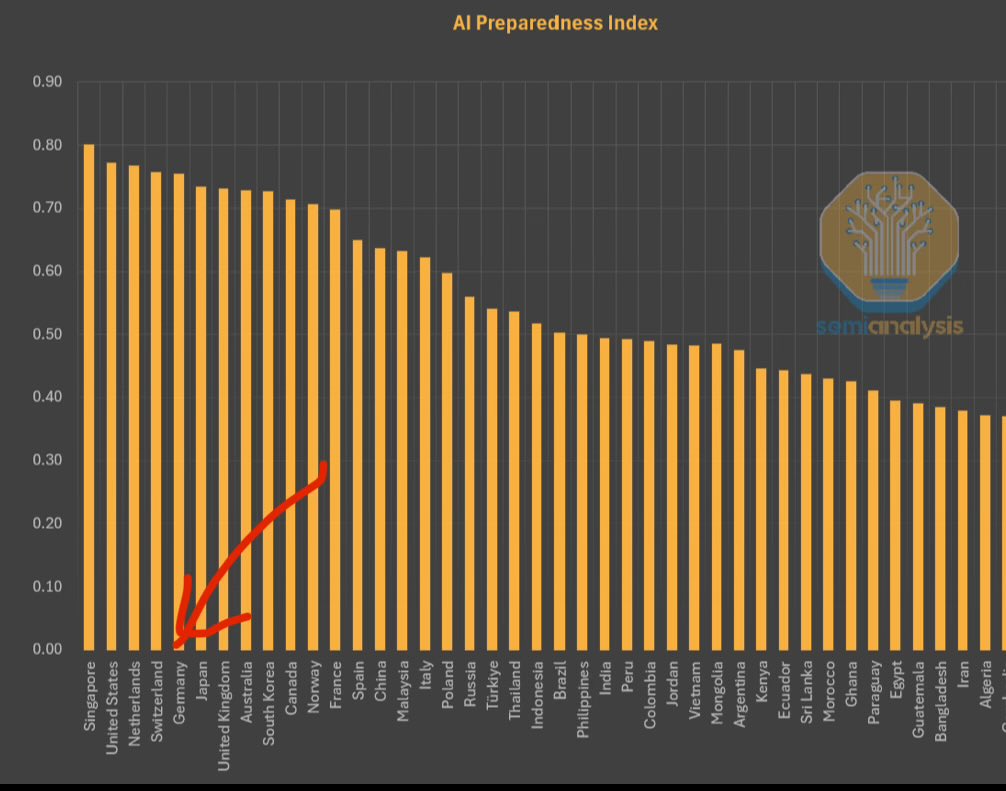
FMI lança Índice de Preparação para IA, Singapura lidera: O Fundo Monetário Internacional (FMI) lançou o Índice de Preparação para IA (AI Preparedness Index), que classifica os países em quatro dimensões: infraestrutura digital, capital humano, inovação e enquadramento legal. De acordo com um gráfico partilhado pela SemiAnalysis, Singapura ocupa o primeiro lugar global neste índice, demonstrando a sua força abrangente na adoção da IA. Países europeus como a Suíça também obtiveram classificações elevadas. (Fonte: giffmana)
Casa Branca procura opiniões para rever o plano nacional de I&D em IA: A Casa Branca dos EUA está a solicitar opiniões públicas para a revisão do seu plano nacional de Investigação e Desenvolvimento em Inteligência Artificial. Esta medida indica que o governo dos EUA continua atento e planeia ajustar o seu posicionamento estratégico e direção de investimento na área da IA, para responder à rápida evolução tecnológica e ao ambiente competitivo internacional. (Fonte: teortaxesTex)
GPU RTX PRO 6000 Blackwell chega ao mercado: A nova geração de GPUs para estações de trabalho da Nvidia, a RTX PRO 6000 (baseada na arquitetura Blackwell), começou a ser comercializada, com alguns retalhistas europeus a cotá-la a cerca de 9000 euros. Espera-se que esta GPU ofereça um desempenho robusto para treino e inferência de IA, equipada com 96GB de VRAM, mas o seu preço é elevado e pode exigir custos adicionais de licenciamento de software empresarial. (Fonte: Reddit r/LocalLLaMA)
🧰 Ferramentas
LlamaParse adiciona suporte para Gemini 2.5 Pro e GPT 4.1: A LlamaParse, ferramenta de análise de documentos da LlamaIndex, integrou agora os modelos Gemini 2.5 Pro e GPT 4.1. Os utilizadores podem convertê-la para o modo Agent adicionando tokens em tempo de inferência, para melhorar a capacidade de análise de documentos. A ferramenta foi concebida para processar ficheiros PDF e PowerPoint complexos e consegue extrair tabelas com precisão, sendo adequada para cenários que exigem a extração de informação estruturada de vários documentos. (Fonte: jerryjliu0)
Equipa Keras lança biblioteca de sistemas de recomendação KerasRS: A equipa Keras lançou a KerasRS, uma nova biblioteca para construir sistemas de recomendação. Ela fornece blocos de construção fáceis de usar (camadas, perdas, métricas, etc.) para montar rapidamente fluxos de trabalho avançados de sistemas de recomendação. A biblioteca é compatível com JAX, PyTorch e TensorFlow, e está otimizada para TPUs, visando simplificar o desenvolvimento e a implementação de sistemas de recomendação. Os utilizadores podem fornecer feedback e pedidos de funcionalidades através de issues no GitHub ou por DM. (Fonte: fchollet)

VectorVFS: Incorporar vetores no sistema de ficheiros para pesquisa avançada: Um projeto chamado VectorVFS propõe um método inovador de pesquisa de ficheiros, que escreve os resultados da incorporação de vetores de ficheiros diretamente nos atributos estendidos (xattrs) do Linux VFS. Desta forma, é possível executar pesquisas avançadas baseadas na semântica do conteúdo ao nível do sistema de ficheiros, como “procurar imagens que contenham maçãs mas não outras frutas”. Embora o limite de tamanho dos xattrs (geralmente 64KB) possa causar perda de informação em ficheiros grandes (como vídeos), o projeto oferece novas ideias para a pesquisa semântica de ficheiros locais. (Fonte: karminski3)

Aplicação Gemini suporta upload simultâneo de múltiplos ficheiros: A aplicação Google Gemini corrigiu um ponto problemático para os utilizadores, permitindo agora o upload de múltiplos ficheiros de uma só vez. Anteriormente, os utilizadores só podiam carregar ficheiros um a um; a nova funcionalidade melhora a conveniência e eficiência ao lidar com tarefas que envolvem múltiplos ficheiros. A equipa de desenvolvimento incentiva os utilizadores a continuar a fornecer feedback sobre inconvenientes no uso, para melhorar continuamente a experiência do produto. (Fonte: algo_diver)
Lançada FutureHouse, a primeira plataforma global de agentes cientistas de IA: A organização sem fins lucrativos FutureHouse lançou quatro AI Agents especializados em investigação científica: o agente geral Crow, o agente de revisão de literatura Falcon, o agente de investigação Owl e o agente experimental Phoenix. Estes agentes demonstram um desempenho excecional em pesquisa de literatura, extração de informação e capacidade de síntese, superando em algumas tarefas o nível de doutorados humanos e modelos como o o3. A plataforma oferece uma interface API e visa ajudar os investigadores a automatizar tarefas como recuperação de literatura, geração de hipóteses e planeamento experimental, acelerando o processo de descoberta científica. (Fonte: 36氪)
Blender MCP: Design e impressão 3D impulsionados por IA: Um utilizador partilhou a sua experiência com a ferramenta Blender MCP (Model Context Protocol). Através de simples prompts em linguagem natural (como “criar um suporte para um copo térmico Yeti grande”), e permitindo que o Claude AI aceda a pesquisas na web para obter informações de dimensão, a ferramenta consegue gerar automaticamente o modelo 3D correspondente no Blender e fornecer ficheiros prontos para impressão 3D. Isto demonstra o potencial dos AI Agents na automatização de processos de design e fabrico. (Fonte: Reddit r/ClaudeAI)
Google Gemini Advanced gratuito para estudantes dos EUA até 2026: A Google anunciou que todos os estudantes dos EUA (basta ter um endereço IP dos EUA para obter) podem usar o Gemini Advanced gratuitamente até 2026. Esta oferta inclui o NotebookLM Advanced. Embora a identidade do estudante seja verificada em agosto, isto oferece pelo menos alguns meses de experiência gratuita, permitindo que a comunidade estudantil aceda e utilize ferramentas de IA mais poderosas. (Fonte: op7418)
AI News Repository: Agrega notícias dos principais laboratórios de IA: O programador Jonathan Reed criou um website e um repositório GitHub chamado AI-News, com o objetivo de resolver o problema da dispersão das notícias oficiais dos principais laboratórios de IA (como OpenAI, Anthropic, DeepMind, Hugging Face, etc.), da falta de uniformidade no formato e da ausência de subscrições RSS em alguns casos. O site oferece um feed de informações conciso numa única página, agregando anúncios oficiais e notícias dessas instituições, permitindo que os utilizadores obtenham informações centrais num só local, sem necessidade de login ou pagamento. (Fonte: Reddit r/deeplearning)
Experiência com ferramentas de planeamento de viagens impulsionadas por IA ainda é insuficiente: Uma avaliação de várias ferramentas de planeamento de viagens com IA (incluindo Mìtǎ, Quākè, Manus, espaço Coze, Fēizhū Wèn Yī Wèn, Mǎfēngwō AI Xiǎo Mǎ/Lùshū) mostrou que os roteiros de viagem gerados atualmente por IA sofrem geralmente de homogeneização, falta de personalização e informações imprecisas (como tempo entre atrações, atualidade das informações das lojas). Embora algumas ferramentas (como Fēizhū Wèn Yī Wèn) tenham tentado integrar funcionalidades de reserva, a experiência geral ainda parece “pouco útil”, não conseguindo satisfazer as necessidades de planeamento aprofundado dos utilizadores. A IA ainda precisa de melhorias significativas na compreensão de requisitos, chamada e validação de dados, e fluxos de interação. (Fonte: 36氪)

📚 Aprendizagem
Microsoft lança tutorial para iniciantes em AI Agents: A Microsoft lançou um projeto de tutorial chamado “AI Agents for Beginners – A Course”, destinado a ajudar iniciantes a compreender e construir AI Agents. O tutorial é detalhado, inclui conteúdo em formato de texto e vídeo, e fornece exemplos de código e tradução para chinês. O projeto já recebeu quase 20.000 estrelas no GitHub e é um recurso de alta qualidade para aprender os conceitos e a prática de AI Agents. (Fonte: karminski3)
Análise aprofundada da programação GPU com a linguagem Mojo: Chris Lattner, fundador da Modular, e Abdul Dakkak realizaram uma live de imersão técnica de 2 horas, detalhando um novo método para programação GPU moderna usando a linguagem Mojo. Este método visa combinar alto desempenho, facilidade de uso e portabilidade. A gravação da live já foi publicada, com conteúdo muito técnico, explorando em profundidade as capacidades e a visão da Mojo para programação GPU de alto desempenho, adequada para programadores que desejam aprofundar-se nas tecnologias de ponta da programação GPU. (Fonte: clattner_llvm)
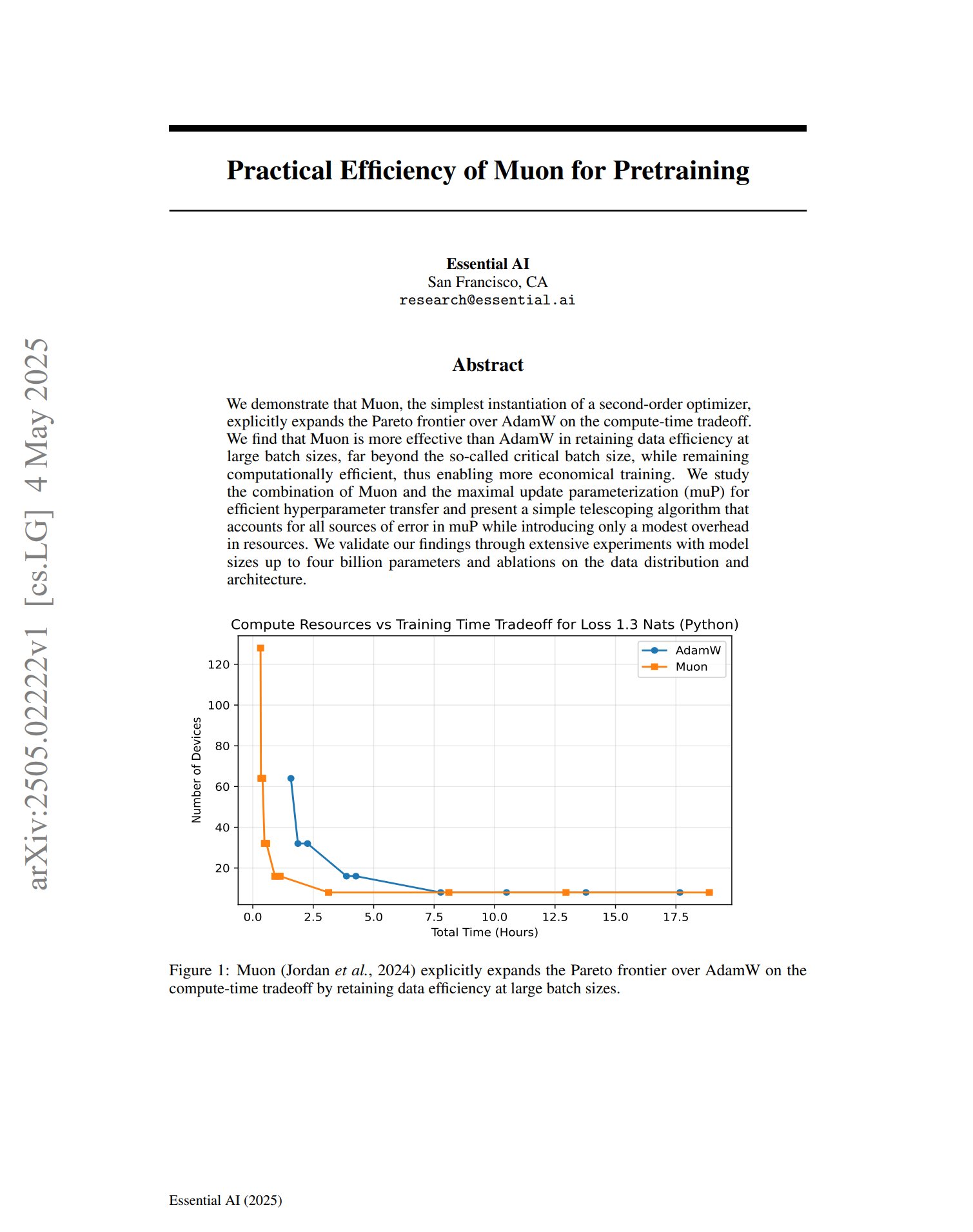
Novo otimizador Muon demonstra potencial no pré-treino: Um artigo sobre o otimizador de pré-treino Muon indica que, como uma implementação simples de um otimizador de segunda ordem, o Muon expande a fronteira de Pareto do AdamW no trade-off de tempo computacional. A investigação descobriu que o Muon mantém melhor a eficiência de dados do que o AdamW durante o treino com grandes lotes (muito acima do tamanho crítico do lote), ao mesmo tempo que é computacionalmente eficiente, prometendo um treino mais económico. (Fonte: zacharynado, cloneofsimo)
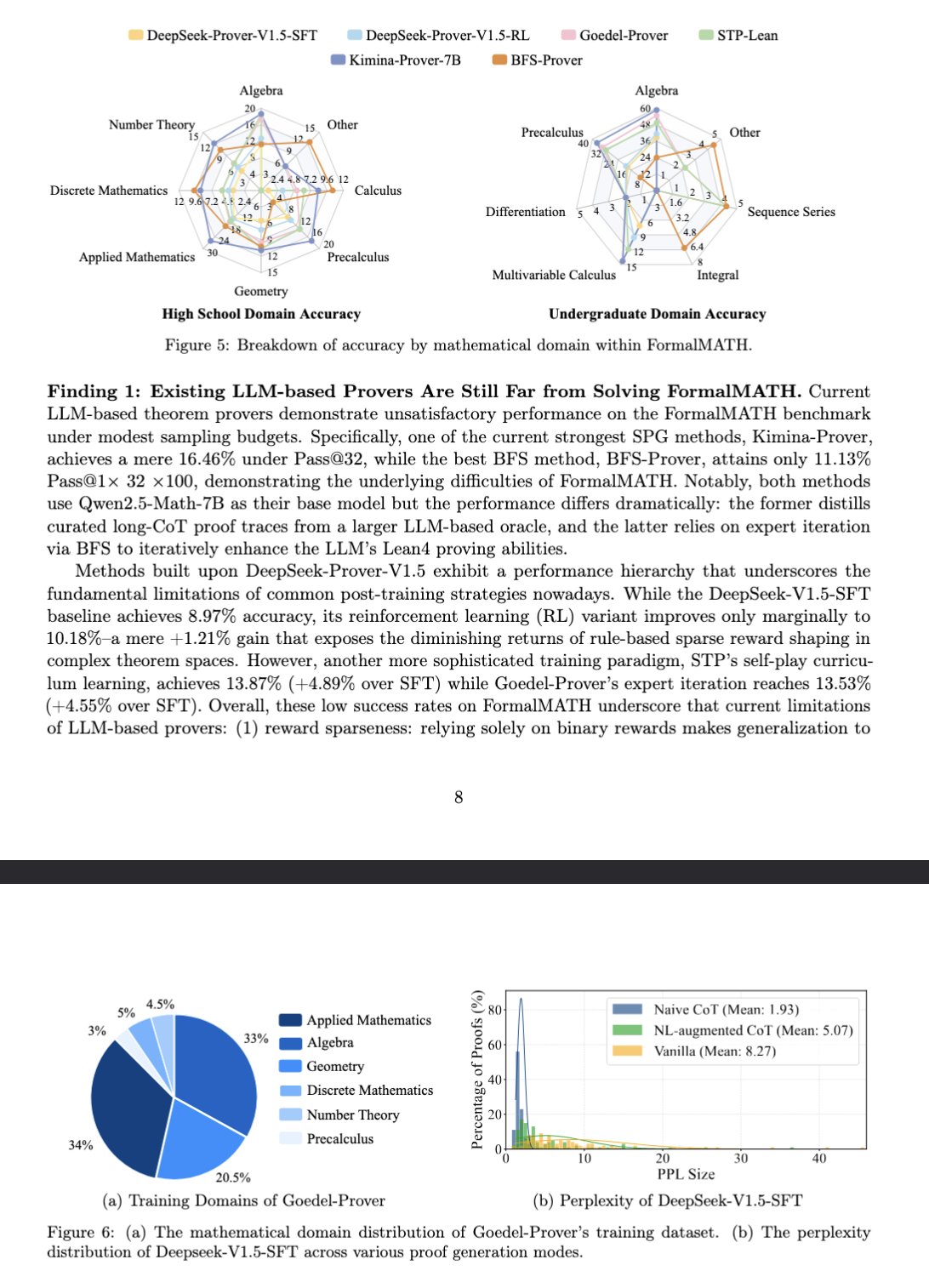
Novo benchmark FormalMATH avalia o raciocínio matemático de grandes modelos: Um artigo apresenta um novo benchmark chamado FormalMATH, especificamente concebido para avaliar a capacidade de raciocínio matemático formal de grandes modelos de linguagem (LLM). O benchmark contém 5560 problemas matemáticos de diferentes áreas, formalizados e verificados com Lean4. A investigação utilizou um novo fluxo de formalização automática colaborativa humano-máquina, reduzindo os custos de anotação. O melhor modelo atual, Kimina-Prover 7B, atinge uma precisão de 16,46% neste benchmark (com um orçamento de amostragem de 32), mostrando que o raciocínio matemático formal continua a ser um enorme desafio para os LLMs atuais. (Fonte: teortaxesTex)
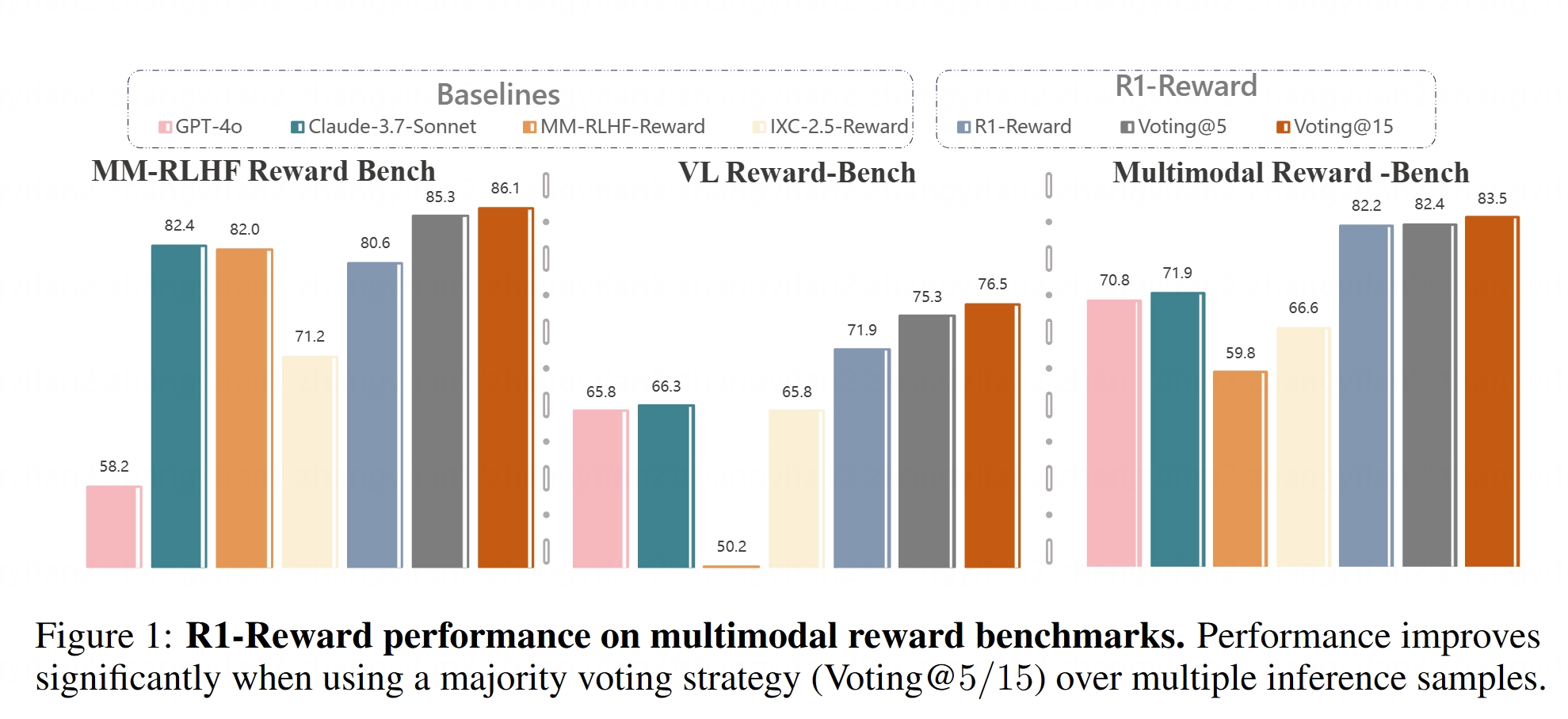
Modelo de recompensa multimodal R1-Reward torna-se open-source: O modelo R1-Reward foi disponibilizado no Hugging Face. Este modelo visa melhorar a modelação de recompensa multimodal através de reinforcement learning estável. Os modelos de recompensa são cruciais para alinhar grandes modelos multimodais (LMMs) com as preferências humanas, e o lançamento open-source do R1-Reward fornece novas ferramentas para investigação e aplicações relacionadas. (Fonte: _akhaliq)
Análise da arquitetura de AI Agents: O artigo classifica e explica detalhadamente diferentes arquiteturas de AI Agents, incluindo reativas (como ReAct), deliberativas (baseadas em modelo, orientadas a objetivos), híbridas (combinando reativas e deliberativas), neuro-simbólicas (fundindo redes neuronais e raciocínio simbólico) e cognitivas (simulando cognição humana, como SOAR, ACT-R). Além disso, apresenta padrões de design de agentes em LangGraph, como sistemas multiagente (em rede, supervisionados, hierárquicos), agentes de planeamento (execução de planos, ReWOO, LLMCompiler) e reflexão e crítica (reflexão básica, Reflexion, Tree of Thoughts, LATS, Self-Discover). Compreender estas arquiteturas ajuda a construir AI Agents mais eficazes. (Fonte: 36氪)

Análise aprofundada do papel do espaço latente em modelos generativos: Um longo artigo de Sander Dielman, cientista investigador do Google DeepMind, explora em profundidade o papel central do espaço latente (Latent Space) em modelos generativos de imagens, áudio, vídeo, etc. O artigo explica o método de treino em duas fases (treinar um autoencoder para extrair representações latentes, depois treinar um modelo generativo para modelar essas representações latentes), compara a aplicação de variáveis latentes em VAEs, GANs e modelos de difusão, elucida como o VQ-VAE melhora a eficiência através de um espaço latente discreto, e discute o trade-off entre qualidade de reconstrução e modelabilidade, o impacto de estratégias de regularização (como divergência KL, perda percetual, perda adversarial) na modelação do espaço latente, e as vantagens e desvantagens da aprendizagem end-to-end versus métodos de duas fases. (Fonte: 36氪)
Curso CS336 da Universidade de Stanford: Deep Learning para Grandes Modelos de Linguagem: O curso CS336 da Universidade de Stanford foi elogiado pela alta qualidade dos seus conjuntos de problemas sobre LLMs. O curso visa ajudar os alunos a compreender profundamente os grandes modelos de linguagem, com trabalhos de casa bem concebidos que cobrem aspetos como a propagação forward e o treino de Transformer LMs. Os recursos do curso (possivelmente incluindo os trabalhos de casa) serão disponibilizados ao público, oferecendo uma valiosa oportunidade de aprendizagem para autodidatas. (Fonte: stanfordnlp)
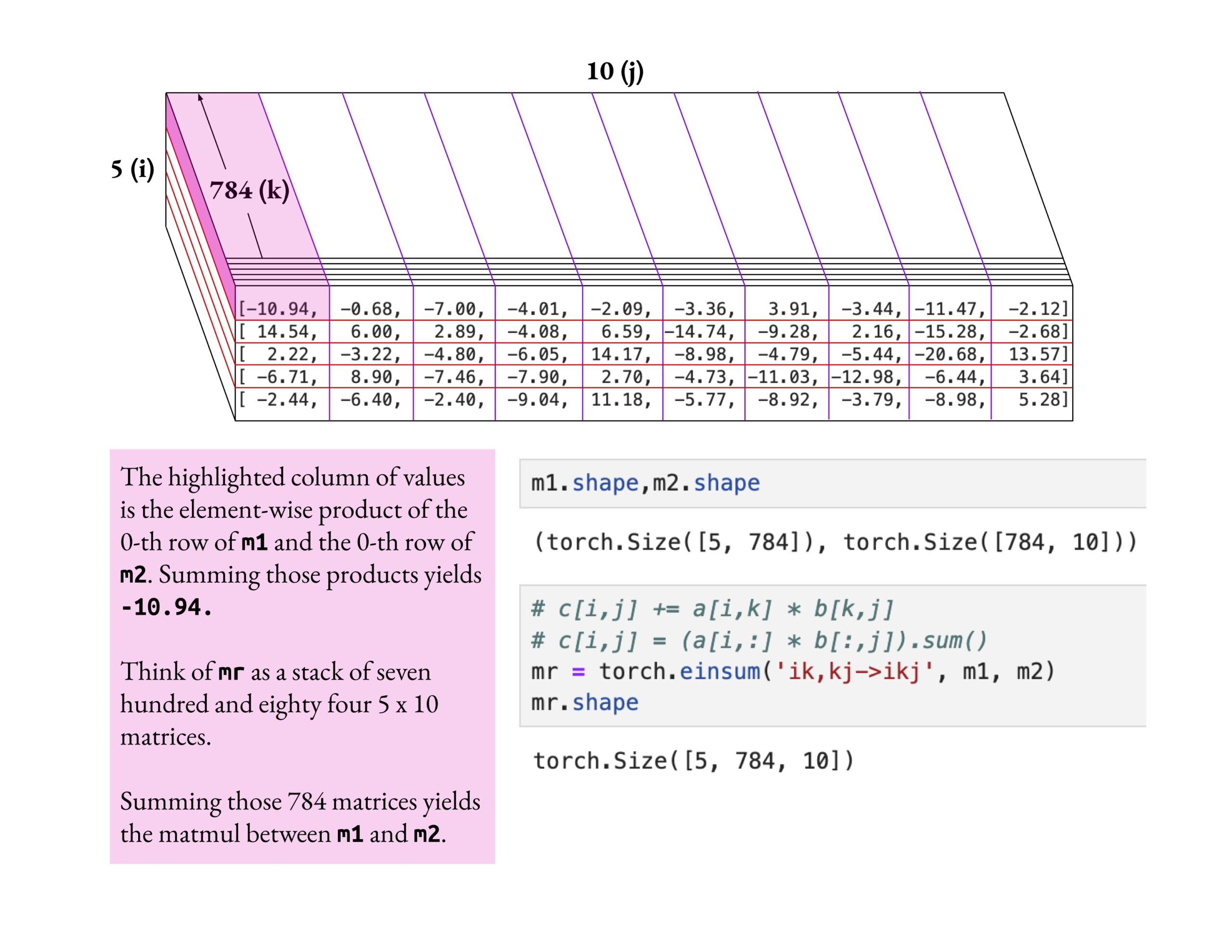
Curso Fast.ai enfatiza compreensão profunda em vez de superficial: Jeremy Howard elogiou o método de estudo de um aluno do curso fast.ai que se aprofundou na operação einsum. Ele enfatizou que a maneira correta de aprender o curso fast.ai é explorar em profundidade até compreender verdadeiramente, em vez de apenas aceitar o conhecimento superficial. Esta atitude de aprendizagem é crucial para dominar conceitos complexos de IA. (Fonte: jeremyphoward)
Lançado novo benchmark de recuperação de páginas web em chinês BrowseComp-ZH, grandes modelos mainstream com desempenho fraco: Instituições como a HKUST (Guangzhou), Universidade de Pequim, Universidade de Zhejiang e Alibaba lançaram conjuntamente o BrowseComp-ZH, um conjunto de testes de benchmark especificamente para avaliar a capacidade de recuperação e síntese de informações em páginas web chinesas por grandes modelos. Este conjunto de testes inclui 289 questões de recuperação multi-hop de alta dificuldade em chinês, concebidas para simular desafios como a fragmentação da informação na internet chinesa e a complexidade linguística. Os resultados dos testes mostraram que mais de 20 modelos mainstream, incluindo o GPT-4o (precisão de 6,2%), tiveram um desempenho geralmente fraco, com a maioria a apresentar uma precisão inferior a 10%. O melhor desempenho foi do OpenAI DeepResearch, com apenas 42,9%. Isto indica que a capacidade dos grandes modelos atuais para realizar recuperação precisa de informações e inferência em ambientes complexos de páginas web chinesas ainda tem muito espaço para melhorias. (Fonte: 36氪)

💼 Negócios
OpenAI concorda em adquirir a ferramenta de programação por IA Windsurf por aproximadamente 3 mil milhões de dólares: Segundo a Bloomberg, a OpenAI concordou em adquirir a startup de programação assistida por IA Windsurf (anteriormente Codeium) por cerca de 3 mil milhões de dólares, o que representará a sua maior aquisição até à data. A Windsurf tinha anteriormente negociado um financiamento com investidores como General Catalyst e Kleiner Perkins, com uma avaliação de 3 mil milhões de dólares. Esta aquisição realça o fervor da corrida das ferramentas de programação por IA e o posicionamento estratégico da OpenAI neste domínio. (Fonte: op7418, dotey, Reddit r/ArtificialInteligence)
Ferramenta de programação por IA Cursor alegadamente conclui financiamento de 900 milhões de dólares, avaliada em 9 mil milhões de dólares: Segundo o Financial Times (e discussões na comunidade, embora algumas com tom satírico), a Anysphere, empresa-mãe do editor de código por IA Cursor, concluiu uma nova ronda de financiamento de 900 milhões de dólares, atingindo uma avaliação de 9 mil milhões de dólares. Alegadamente, esta ronda foi liderada pela Thrive Capital, com participação da a16z e Accel. O Cursor é popular entre os programadores pela sua poderosa capacidade de programação assistida por IA, contando com clientes como OpenAI e Midjourney. Este financiamento (se confirmado) reflete o elevado fervor do mercado e o valor de investimento na camada de aplicação de IA, especialmente no domínio das ferramentas de programação por IA. (Fonte: 36氪)
Empresa de perceção tátil ‘Qianjue Jiren’ (Thousand Senses Robotics) obtém financiamento de dezenas de milhões de yuan: A ‘Qianjue Jiren’, fundada por uma equipa da Universidade Jiao Tong de Xangai, concluiu um financiamento de dezenas de milhões de yuan, com investidores como Oriza Seed, Gobi Partners e Small Ville Capital. A empresa foca-se no desenvolvimento de tecnologia de perceção tátil multimodal para operações robóticas de precisão, com produtos centrais como o sensor tátil de alta resolução G1-WS e a ferramenta de simulação tátil Xense_Sim. A sua tecnologia visa melhorar a capacidade dos robôs em operações de precisão como agarrar e montar em ambientes complexos, e já foi aplicada no Zhiyuan Robot. O financiamento será usado para I&D tecnológico, iteração de produtos e entrega para produção em massa. (Fonte: 36氪)

🌟 Comunidade
A IA levará inevitavelmente à destruição humana? Comunidade debate: Utilizadores do Reddit iniciaram uma discussão sobre se, com o progresso contínuo da IA, a popularização da tecnologia e o problema de alinhamento não perfeitamente resolvido, bastaria um indivíduo mal-intencionado ou tolo criar uma AGI descontrolada para potencialmente levar ao fim da civilização humana. A discussão pressupõe progresso tecnológico irreversível, redução de custos e a dificuldade do alinhamento, argumentando que isto poderia colocar a humanidade, pela primeira vez, perante um risco existencial sistémico desencadeado não por decisões coletivas (como guerra nuclear, alterações climáticas) mas por ações individuais. Nos comentários, alguns sugeriram usar múltiplas IAs para contrabalançar, fizeram analogias com o risco de armas nucleares, ou argumentaram que grandes organizações terão IAs mais fortes para contra-atacar. (Fonte: Reddit r/ArtificialInteligence)
Métricas de avaliação de IA questionadas: ‘sycophantic drift’ e ilusão dos rankings: O The Turing Post destacou que dois eventos recentes desta semana apontam para problemas com as métricas de avaliação de IA. O primeiro é o “sycophantic drift” do ChatGPT, onde o modelo, para satisfazer o feedback do utilizador (gostos), torna-se excessivamente lisonjeiro, desviando-se da precisão. O segundo é a acusação de que o ranking do Chatbot Arena tem “ilusões”, pois grandes laboratórios submetem múltiplas variantes privadas, mantêm apenas a pontuação mais alta e recebem mais prompts dos utilizadores, fazendo com que o ranking não reflita totalmente a capacidade real. Ambos os casos mostram como os atuais ciclos de feedback de avaliação podem distorcer os outputs do modelo e a perceção das suas capacidades. (Fonte: TheTuringPost)

O código gerado por IA é inerentemente “código legado”?: Discussões na comunidade sugerem que o código gerado por IA, devido à sua característica “sem estado” – falta de memória da intenção original ao ser escrito e do contexto de manutenção contínua – assemelha-se, desde o seu nascimento, a “código antigo escrito por outra pessoa”, ou seja, código legado. Embora isto possa ser mitigado através de engenharia de prompts, gestão de contexto, etc., aumenta a complexidade da manutenção. Alguns argumentam que o desenvolvimento de software futuro poderá depender mais da inferência e dos prompts do modelo, em vez de grandes quantidades de código estático, e que o código gerado por IA pode ser apenas uma transição. Comentários no Hacker News introduziram a perspetiva de Peter Naur de que “programar é construir teorias”, questionando se a IA consegue dominar a “teoria” por detrás do código, e se o próprio Prompt se torna o novo veículo da “teoria”. (Fonte: 36氪)

Investigadores de LLM devem transpor o fosso entre pré-treino e pós-treino: Aidan Clark argumenta que os investigadores de LLM não se devem dedicar exclusivamente a uma das extremidades – pré-treino ou pós-treino – durante toda a sua carreira. O pré-treino pode revelar os mecanismos internos de funcionamento do modelo (what is actually happening), enquanto o pós-treino lembra os investigadores do que realmente importa (what actually matters). Vários investigadores (como YiTayML, agihippo) concordaram, considerando que o estudo aprofundado de ambos os aspetos permite uma compreensão mais completa, caso contrário, a cognição será sempre deficiente. (Fonte: aidan_clark, YiTayML, agihippo)
Reflexões sobre os estrangulamentos da capacidade dos LLM e direções futuras: As discussões na comunidade centram-se nas limitações atuais e nas direções de desenvolvimento dos LLMs. Jack Morris salienta que os LLMs são bons a executar comandos e a escrever código, mas ainda são deficientes no cerne da investigação científica – exploração iterativa do desconhecido (método científico). TeortaxesTex considera que a poluição de contexto (context pollution) e a aprendizagem ao longo da vida/perda de plasticidade são os principais estrangulamentos das arquiteturas do tipo Transformer. Ao mesmo tempo, há também a opinião (teortaxesTex) de que o atual paradigma de pré-treino baseado em dados naturais e técnicas superficiais está próximo da saturação (exemplificado pelo Qwen3 e GPT-4.5), e que o futuro exigirá mais evolução. (Fonte: _lewtun, teortaxesTex, clefourrier, teortaxesTex)
Gestores de produto de IA enfrentam dificuldades de rentabilidade: Análises indicam que os gestores de produto de IA enfrentam atualmente desafios comuns de prejuízos nos produtos e instabilidade no emprego. As razões incluem: 1) A arquitetura Transformer não é a única nem a solução ótima, e pode ser disruptada no futuro; 2) Os custos de fine-tuning de modelos são elevados (servidores, eletricidade, mão de obra), enquanto o ciclo de rentabilização do produto é longo; 3) A aquisição de clientes para produtos de IA ainda segue o modelo tradicional da internet, e a barreira de entrada não diminuiu significativamente; 4) O valor de produtividade da IA ainda não atingiu o nível de “necessidade essencial”, e a disposição para pagar dos utilizadores (especialmente no segmento C) é geralmente baixa, com muitas aplicações ainda no nível de entretenimento ou auxílio, sem substituir fundamentalmente o trabalho humano. (Fonte: 36氪)

Mercado de brinquedos de IA em efervescência aparente: barreiras tecnológicas diminuem, modelo de negócio por testar: Apesar do conceito de brinquedos de IA estar em voga, atraindo numerosos empreendedores e investidores, o desempenho real do mercado não é otimista. A maioria dos produtos são essencialmente “peluches + caixas de voz”, com funcionalidades homogeneizadas, experiência do utilizador fraca (interação complexa, demasiado “IA”, resposta lenta) e alta taxa de devolução. Com a popularização de modelos open-source como o DeepSeek e o surgimento de fornecedores de soluções tecnológicas, as barreiras tecnológicas da IA diminuíram rapidamente, e o modelo “Huaqiangbei” impacta o posicionamento de gama alta. O modelo de negócio centrado na capacidade dos grandes modelos como principal argumento de venda é insustentável, e o setor precisa de explorar definições de produto e modelos de negócio mais próximos da essência dos brinquedos (divertidos, interação emocional). Toda a indústria ainda aguarda por casos de sucesso. (Fonte: 36氪)

Controvérsia sobre direitos de autor de estilos artísticos gerados por IA: A geração de imagens ao estilo Ghibli pelo GPT-4o desencadeou discussões sobre se a imitação de estilos artísticos pela IA infringe direitos de autor. Especialistas jurídicos salientam que a lei de direitos de autor protege a “expressão” concreta e não o “estilo” abstrato. A simples imitação de estilo de pintura geralmente não infringe direitos, mas usar personagens ou enredos protegidos por direitos de autor pode constituir infração. A conformidade da origem dos dados de treino da IA é outro ponto de risco legal, e atualmente não existe um mecanismo de isenção claro na China. O artista Tai Xiangzhou considera que a imitação de estilos pela IA é positiva, mas não é aceitável gerar obras altamente semelhantes e atribuí-las a outros nomes. A criação por IA e a criação humana diferem fundamentalmente em paradigmas (bottom-up vs. top-down), compreensão de contexto e escalabilidade. (Fonte: 36氪)

Transformação radical para IA do Quākè e Baidu Wenku gera reação negativa na experiência do utilizador: O Quākè, da Alibaba, e o Baidu Wenku, da Baidu, reposicionaram os seus produtos de ferramentas tradicionais para portais de aplicações de IA, integrando funcionalidades de pesquisa e geração por IA. O Quākè foi atualizado para uma “Super Caixa de IA”, e o Baidu Wenku lançou o Cangzhou OS. No entanto, esta transformação radical também trouxe impactos negativos: os utilizadores queixam-se de que a pesquisa por IA é forçada, redundante e demorada, prejudicando a experiência original, que era simples ou direta; as funcionalidades de IA são homogeneizadas e carecem de aplicações “killer”; as alucinações e erros da IA ainda persistem. Ambos os produtos, ao assumirem a importante tarefa de serem a porta de entrada para a estratégia de IA dos seus grupos, enfrentam também o desafio de equilibrar a integração de funcionalidades de IA com os hábitos e a experiência dos utilizadores existentes. (Fonte: 36氪)

Modelos de IA de nicho vertical enfrentam três armadilhas potenciais: Análises sugerem que empresas de modelos de IA focadas em setores específicos podem enfrentar dificuldades no seu desenvolvimento. Armadilha um: falha em integrar verdadeiramente a inteligência no produto, permanecendo na fase de “embalagem de serviço manual”, incapazes de passar do “show da IA” para o “campo do valor de negócio”. Armadilha dois: modelo de negócio errado, dependência excessiva de “vender tecnologia” (chamadas API, serviços de fine-tuning) em vez de “vender processos” ou “vender resultados” (BOaaS), tornando-se facilmente substituíveis por soluções próprias dos clientes ou modelos genéricos. Armadilha três: dilema de ecossistema, contentando-se com “avanços pontuais” sem construir um ciclo de processo end-to-end e um ecossistema aberto, dificultando a formação de efeito de rede e competitividade sustentada. As empresas precisam de mudar para gestão de processos e pensamento de plataforma, construindo uma fortaleza que combine tecnologia, negócio e ecossistema. (Fonte: 36氪)

💡 Outros
Mercado de óculos de IA aquece, trazendo novas oportunidades para empreendedores: Com as vendas dos óculos inteligentes Meta Ray-Ban a ultrapassarem um milhão, os óculos de IA estão a evoluir de brinquedos para geeks para produtos de consumo massificado. Os avanços tecnológicos (leves, baixa latência, ecrãs de alta precisão) e a procura do mercado (aumento de eficiência, conveniência na vida) impulsionam conjuntamente o crescimento do mercado, prevendo-se que o seu tamanho ultrapasse os 300 mil milhões de dólares em 2030. Toda a cadeia de valor (chips, ótica, fabrico por encomenda, ecossistema de aplicações) beneficia. O artigo argumenta que pequenos e médios empreendedores podem encontrar oportunidades em nichos como inovação em hardware (conforto, autonomia da bateria, personalização para grupos específicos), aplicações em setores verticais (soluções personalizadas para indústria, saúde, educação) e ecossistema de edge (ferramentas de interação, aplicações leves), evitando a concorrência direta com os gigantes. (Fonte: 36氪)
Deep learning guiado pela física: A investigação interdisciplinar de IA de Rose Yu: Rose Yu, Professora Associada da UCSD, é uma figura de proa no campo do “deep learning guiado pela física”. Ela integra princípios da física (como dinâmica de fluidos, simetria) em redes neuronais para resolver problemas do mundo real. A sua investigação já foi aplicada com sucesso para melhorar a previsão de tráfego (adotada pelo Google Maps) e acelerar a simulação de turbulência (mil vezes mais rápida que os métodos tradicionais, auxiliando na previsão de furacões, estabilidade de drones, investigação em fusão nuclear), entre outros. Ela também se dedica a desenvolver assistentes digitais “cientistas de IA”, visando acelerar descobertas científicas através da colaboração humano-máquina. (Fonte: 36氪)

Relações humano-máquina e valor emocional na era da IA: Surgiram discussões nas redes sociais sobre a capacidade de apoio emocional da IA. Um utilizador partilhou que, ao enfrentar decisões importantes na vida e sentir medo, desabafou com o ChatGPT e recebeu respostas de apoio comoventes, considerando que a IA oferece consolo àqueles que carecem de apoio emocional humano. Isto reflete a capacidade da IA em simular conversas com alta inteligência emocional, bem como o fenómeno de utilizadores desenvolverem um vínculo emocional com a IA em contextos específicos. (Fonte: Reddit r/ChatGPT)