
Palavras-chave:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-reasoning, LLM Física, LangGraph, Agente de IA, Método de rastreamento de circuitos Attribution Graphs, Capacidade de codificação Qwen3-235B-A22B, Cálculo de raciocínio Phi-4-reasoning, Agente de verificação de faturas LangGraph, Moondream Station VLM local
🔥 Destaques
Anthropic publica pesquisa sobre biologia de LLMs, explorando profundamente os mecanismos internos do modelo: Anthropic publicou um post de blog de pesquisa aprofundada intitulado “On the Biology of a Large Language Model”, usando seu método de rastreamento de circuitos (Attribution Graphs) para investigar os mecanismos internos do modelo Claude 3.5 Haiku em diferentes contextos. A pesquisa, através do treinamento de um “modelo substituto” (Transcoder) mais fácil de analisar, revelou como o modelo realiza adição (através de múltiplos caminhos aproximados em vez de algoritmos exatos), faz diagnósticos médicos (formando conceitos internos de diagnóstico) e lida com alucinações e recusas (existe um circuito de recusa padrão que pode ser suprimido por características de “resposta conhecida”). O estudo oferece novas perspectivas sobre o funcionamento interno dos LLMs, mas também gerou discussões sobre as limitações metodológicas e o posicionamento da própria Anthropic (Fonte: YouTube – Yannic Kilcher
)

Série de modelos Qwen3 demonstra forte desempenho, atraindo atenção da comunidade open source: A série de modelos de linguagem grande Qwen3 lançada pelo Alibaba apresentou excelente desempenho em múltiplos benchmarks, especialmente em capacidade de codificação. Os resultados do Aider Polyglot Coding Benchmark mostram que o desempenho do Qwen3-235B-A22B (sem chain-of-thought ativado) parece superar o Claude 3.7 com 32k tokens de chain-of-thought ativados, e com um custo significativamente menor. Ao mesmo tempo, o Qwen3-32B também superou o GPT-4.5 e o GPT-4o neste benchmark. A comunidade também está explorando ativamente a poda (pruning) dos modelos Qwen3 (como podar de 30B para 16B) e o fine-tuning (como usar Unsloth para fine-tuning com pouca VRAM), reduzindo ainda mais a barreira de aplicação para modelos de alto desempenho, indicando que os grandes modelos open source chineses podem ocupar uma posição importante no mercado (Fonte: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
Microsoft lança modelo Phi-4-reasoning, focado em raciocínio complexo: A Microsoft lançou o modelo Phi-4-reasoning no Hugging Face, um modelo de raciocínio com 14 bilhões de parâmetros. Este modelo alcança o desempenho estado da arte (SOTA) em tarefas de raciocínio complexo, utilizando computação em tempo de inferência (inference-time compute). Isso indica que o design de modelos está explorando o aumento da computação na fase de inferência para melhorar capacidades específicas, em vez de depender apenas do aumento da escala do modelo, fornecendo novas ideias para modelos pequenos alcançarem alto desempenho (Fonte: _akhaliq)
Novos avanços na pesquisa da física de LLMs: “Momento Galileu” do design de arquitetura: Zeyuan Allen-Zhu publicou a quarta parte de sua série de pesquisas sobre a física de modelos de linguagem grandes, focando no design de arquitetura. A pesquisa, através de um ambiente de pré-treinamento sintético controlado, revela as limitações e potenciais reais de diferentes arquiteturas de LLM (como Transformer, Mamba). A pesquisa introduz uma camada residual horizontal leve chamada “Canon”, que melhora significativamente a capacidade de raciocínio do modelo. Ao mesmo tempo, a pesquisa descobriu que a vantagem do modelo Mamba vem em grande parte de sua camada oculta conv1d, e não do SSM em si. Esta série de experimentos fornece novas perspectivas e teoria fundamental para entender e otimizar a arquitetura de LLMs (Fonte: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 Tendências
Amazon lança modelo de inteligência artificial geral “Amazon Artificial General Intelligence”: Este modelo possui um comprimento de contexto de 1 milhão de tokens e capacidade de entrada multimodal, otimizado para geração de código, RAG, compreensão de vídeo/documentos, chamada de função e interação com Agents. O preço é de US$ 2,5 por milhão de tokens de entrada e US$ 12,5 por milhão de tokens de saída. Avaliações preliminares mostram que seu desempenho no AI Index é comparável ao Llama-4 Scout, mas está em desvantagem em velocidade e custo, podendo ser adequado para cenários específicos de aplicação multimodal de longo contexto ou Agents (Fonte: scaling01)

Modelo Anthropic Claude agora oferece funcionalidade de pesquisa na web em planos pagos globais: Esta funcionalidade permite que o Claude realize pesquisas rápidas ao lidar com tarefas diárias e, para questões mais complexas, explore múltiplas fontes, incluindo o Google Workspace. Isso aprimora a capacidade do Claude de obter informações em tempo real e lidar com tarefas que exigem conhecimento externo (Fonte: menhguin)

IBM lança modelo de arquitetura híbrida granite-4.0-tiny-7B-A1B-preview: Esta versão preview do modelo de 7B adota uma arquitetura híbrida Mamba-2 e Transformer, onde cada bloco Transformer contém 9 blocos Mamba. A ideia do design é utilizar os blocos Mamba para capturar o contexto global e passá-lo para a camada de atenção para análise do contexto local. A pontuação preliminar no MMLU é boa, mas os resultados de outros testes, como matemática e capacidade de programação, ainda não foram divulgados (Fonte: karminski3)
OpenAI ChatGPT adiciona funcionalidade de compras: OpenAI está experimentando a funcionalidade de compras no ChatGPT, com o objetivo de simplificar o processo de encontrar, comparar e comprar produtos. As novas funcionalidades incluem exibição aprimorada de resultados de produtos, detalhes visualizados de produtos com preços e avaliações, e links diretos para compra. OpenAI enfatiza que os resultados dos produtos são selecionados independentemente e não são anúncios (Fonte: sama)
Detalhes do treinamento do modelo Qwen3 0.6B geram atenção: O usuário Dorialexander aponta que, de acordo com as informações, o modelo Qwen 0.6B parece também ter sido treinado com até 36T tokens. Se for verdade, isso estabeleceria um novo recorde além da lei de Chinchilla (aproximadamente 60.000 tokens por parâmetro), mostrando a tendência de melhorar a capacidade de modelos pequenos aumentando enormemente a quantidade de dados de treinamento (Fonte: Dorialexander)

Algoritmo de recomendação do X (Twitter) será substituído por versão leve do Grok: Elon Musk anunciou que o algoritmo de recomendação da plataforma X está sendo substituído por uma versão leve do Grok, que deve melhorar significativamente os resultados das recomendações. Usuários relatam melhorias no efeito do algoritmo, especulando que pode estar relacionado a recentes mudanças na equipe da Exa AI e ao início do uso de Embeddings pelo X para recomendações (Fonte: menhguin, colin_fraser, paul_cal)
Allen AI lança modelo MoE totalmente aberto OLMoE: Este modelo é um avançado modelo Mixture of Experts (MoE), com 1,3 bilhão de parâmetros ativos e 6,9 bilhões de parâmetros totais. Ser totalmente open source significa que a comunidade pode usar, modificar e pesquisar livremente o modelo, impulsionando o desenvolvimento e a aplicação da arquitetura MoE (Fonte: dl_weekly)
Modelo Mistral-Small-3.1-24B-Instruct-2503 recebe atenção: Usuários do Reddit discutem o modelo Mistral-Small-3.1-24B-Instruct-2503, que possui uma pontuação alta em UGI (Uncensored General Intelligence) e supera modelos similares de alta pontuação em compreensão de linguagem natural e codificação. Usuários acreditam que pode ser a escolha ideal para inferência não censurada em GPU única e suporta o uso de ferramentas. No entanto, apontam que seu estilo de escrita pode ser um tanto monótono e repetitivo, com menos criatividade do que modelos como o Gemma 3 (Fonte: Reddit r/LocalLLaMA)
🧰 Ferramentas
CreateMVP 2.0 lançado, otimizando o fluxo de desenvolvimento orientado por IA: CreateMVP foi atualizado para a versão 2.0, visando resolver o problema de resultados insatisfatórios ao solicitar diretamente à IA a construção de aplicativos. A nova versão oferece uma UI mais fluida, métodos de autenticação convenientes (suporta Replit, Google, GitHub, em breve XAI), geração de planos de desenvolvimento mais detalhados (aumentado de 11KB para 40KB+), visualização instantânea de arquivos e chat integrado com modelos de IA de ponta, ajudando os usuários a criar “plantas” mais precisas para a IA, garantindo que a IA construa aplicativos que correspondam à visão do usuário (Fonte: amasad)
LlamaIndex lança Agent de verificação de faturas: Esta ferramenta demonstra a aplicação de AI Agents em tarefas de automação em lote, em vez da interação tradicional por chat. Ele pode processar um grande número de documentos de fatura não estruturados, extrair detalhes relevantes, combinar automaticamente com ordens de compra e marcar discrepâncias. Seu núcleo é uma camada de inteligência de documentos Agentic baseada na análise/extração do LlamaCloud e na inferência de fluxo de trabalho do LlamaIndex.TS, mostrando o potencial dos Agents na automação de processos de negócios reais e sendo considerado um substituto para o RPA tradicional (Fonte: jerryjliu0)
LangGraph Expense Tracker: Sistema automatizado de gerenciamento de despesas: Este é um exemplo de sistema automatizado de gerenciamento de despesas construído com LangGraph. Ele é capaz de processar faturas, utilizar extração inteligente de dados, armazenar informações no PostgreSQL e incluir uma etapa de verificação humana. O projeto demonstra a capacidade do LangGraph na construção de fluxos de automação de negócios reais (Fonte: LangChainAI, Hacubu, hwchase17)
Moondream Station lançado: Execute VLM localmente: Moondream lançou o Moondream Station, permitindo aos usuários executar o modelo de linguagem visual (VLM) Moondream localmente no Mac, sem conexão com a nuvem. Oferece acesso via CLI ou porta local, configuração simples e totalmente gratuita, reduzindo a barreira para implantação e uso local de VLMs (Fonte: vikhyatk)
ChaiGenie: Extensão Chrome de busca em documentos baseada em LangChain: ChaiGenie é uma extensão do Chrome que integra Gemini e Qdrant do LangChain para fornecer funcionalidade de busca em documentos. Suporta múltiplos idiomas e recuperação baseada em vetores, visando aumentar a eficiência do usuário ao encontrar e entender o conteúdo de documentos enquanto navega na web (Fonte: LangChainAI)

Research Agent: Aplicativo web assistente de pesquisa com um clique: Este é um aplicativo web construído sobre o framework de assistente de pesquisa LangGraph, projetado para simplificar o processo de pesquisa. Os usuários podem obter resultados de pesquisa com apenas um clique, demonstrando o potencial de aplicação do LangGraph na construção de fluxos de trabalho orientados por IA para simplificar tarefas complexas (Fonte: LangChainAI)

Muyan-TTS: Modelo TTS open source, de baixa latência e personalizável: A equipe ChatPods lançou o Muyan-TTS, um modelo de texto para fala totalmente open source, visando resolver problemas de baixa qualidade ou abertura insuficiente dos modelos TTS open source existentes. Baseado no LLaMA-3.2-3B e SoVITS otimizado, suporta TTS zero-shot e clonagem de voz, e fornece fluxos completos de treinamento e processamento de dados, facilitando o fine-tuning e desenvolvimento secundário por desenvolvedores, especialmente adequado para cenários de aplicação que exigem vozes personalizadas (Fonte: Reddit r/MachineLearning)
Integração de Mem0 com pipelines Open Web UI: O usuário cloudsbird criou uma integração de pipeline de filtro Open Web UI para Mem0 (MCP não oficial), fornecendo outra opção para usar a funcionalidade de memória Mem0 no Open Web UI (Fonte: Reddit r/OpenWebUI)
Ferramenta YNAB API Request implementa gerenciamento financeiro local e privado: O usuário Megaphonix criou uma ferramenta OpenWebUI que utiliza a API YNAB (You Need A Budget), permitindo aos usuários consultar informações financeiras pessoais (como transações, gastos por categoria, patrimônio líquido, etc.) localmente através de um LLM, sem enviar dados sensíveis para o exterior. Isso resolve a necessidade de lidar com informações pessoais sensíveis de forma segura ao executar LLMs localmente (Fonte: Reddit r/OpenWebUI)
Extensão de navegador gratuita de IA texto-para-fala GPT-Reader: O desenvolvedor promove sua extensão de navegador gratuita de IA texto-para-fala GPT-Reader, que atualmente tem mais de 4000 usuários. A ferramenta visa facilitar aos usuários a conversão do conteúdo de texto de páginas da web em áudio para ouvir (Fonte: Reddit r/artificial)
sunnypilot: Sistema de assistência ao motorista open source: sunnypilot é um fork do openpilot da comma.ai, fornecendo um sistema de assistência ao motorista open source. Suporta mais de 300 modelos de veículos, modifica o comportamento de interação da assistência ao motorista e segue, tanto quanto possível, a política de segurança da comma.ai. O projeto utiliza tecnologia de IA (embora modelos específicos não sejam explicitamente mencionados, tais sistemas geralmente envolvem visão computacional e algoritmos de controle) para melhorar a experiência de condução (Fonte: GitHub Trending)

📚 Aprendizado
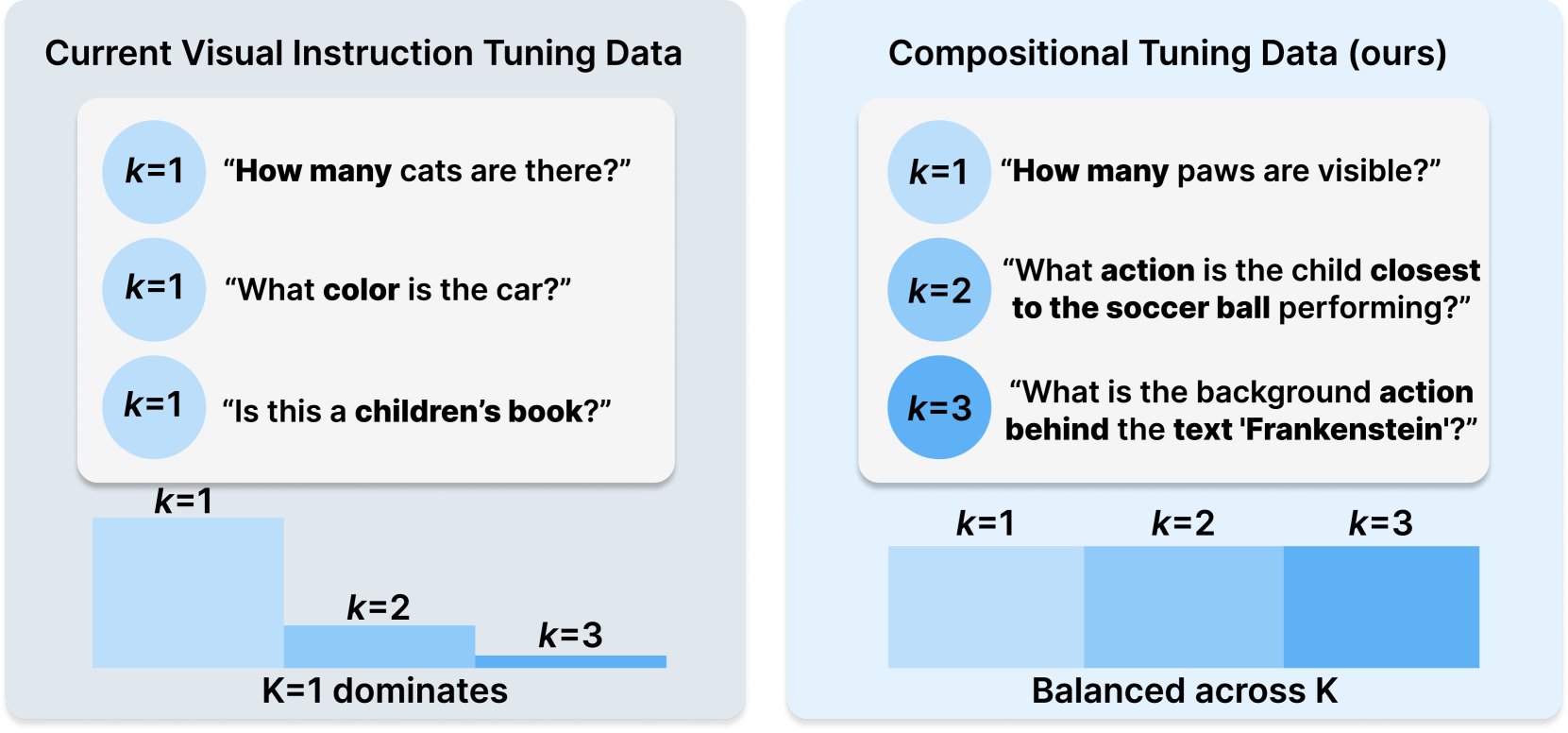
Princeton e Meta AI publicam receita de conjunto de dados COMPACT: Esta pesquisa, publicada no Hugging Face, propõe uma nova receita de dados chamada COMPACT, destinada a expandir as capacidades dos modelos de linguagem grandes multimodais (Multimodal LLM) controlando explicitamente a complexidade combinatória das amostras de treinamento. Isso fornece novas ideias para melhorar os métodos de treinamento de modelos multimodais e aumentar sua capacidade de entender conceitos combinatórios complexos (Fonte: _akhaliq)
Unsloth publica tutorial de fine-tuning para Qwen3: Unsloth forneceu um tutorial de fine-tuning para os modelos Qwen3, reduzindo significativamente a barreira para o fine-tuning. Os usuários precisam de apenas 16GB de VRAM para fazer fine-tuning do modelo Qwen3-14B, e 17.5GB de VRAM para fazer fine-tuning do modelo Qwen3-30B-A3B. Isso permite que mais pesquisadores e desenvolvedores realizem treinamento personalizado em modelos open source avançados com recursos de hardware limitados (Fonte: karminski3)
LangGraph combinado com Azure OpenAI para construir chatbot de busca web inteligente: Um tutorial no Medium demonstra como combinar LangGraph e Azure OpenAI, integrando a capacidade de busca na web do Tavily, para construir um chatbot inteligente. O tutorial cobre gerenciamento de estado e roteamento condicional para alcançar integração de busca transparente, fornecendo orientação prática para construir aplicações de IA mais poderosas que podem utilizar informações da web em tempo real (Fonte: LangChainAI, hwchase17)

Blog de IA de Stanford discute a relação entre memorização literal e capacidade geral de LLMs: Um artigo no blog de IA de Stanford explora profundamente a conexão intrínseca entre o fenômeno da memorização literal (verbatim memorization) em modelos de linguagem grandes (LLMs) e sua capacidade geral. Compreender essa relação é crucial para avaliar riscos do modelo, otimizar métodos de treinamento e explicar o comportamento do modelo (Fonte: dl_weekly)
Guia de integração Gemini com LangChain: Philipp Schmid publicou um guia para desenvolvedores detalhando como integrar os modelos Gemini do Google com o framework LangChain. O guia cobre capacidades multimodais, chamada de ferramentas e implementação de saída estruturada, e inclui suporte para os modelos mais recentes e exemplos de código práticos, facilitando aos desenvolvedores o uso das poderosas funcionalidades do Gemini para construir aplicações LangChain (Fonte: LangChainAI, _philschmid)

Tutorial introdutório de LangGraph: Prática de fluxos de trabalho com estado: Um tutorial publicado no AI@GoPubby demonstra a capacidade de fluxos de trabalho com estado do LangGraph através de um exemplo de análise de comentários de website. Os aprendizes podem entender como usar nós interconectados e lógica sequencial para construir aplicações de IA estruturadas (Fonte: LangChainAI, hwchase17)
Reflexões aprofundadas do CEO da LangChain sobre frameworks Agentic (tradução para chinês): O embaixador da LangChain, Harry Zhang, traduziu e compartilhou o post do blog do CEO da LangChain, Harrison, sobre suas reflexões acerca de frameworks Agentic. O artigo analisa e organiza as funcionalidades de mais de 15 frameworks Agentic da indústria e interpreta as histórias por trás deles, fornecendo uma referência valiosa para entender o cenário atual de desenvolvimento da tecnologia Agent e direções futuras (Fonte: LangChainAI)
Progresso na pesquisa Latent Meta Attention: Usuários do Reddit discutem um novo mecanismo de atenção chamado Latent Meta Attention. O desenvolvedor afirma que o mecanismo desafia as suposições fundamentais do Transformer, podendo alcançar ou até superar o desempenho dos modelos existentes com um tamanho de modelo menor (por exemplo, replicando o desempenho do BERT com um modelo de metade do tamanho), mas devido à falta de financiamento e apoio de instituições de pesquisa formais, o método específico ainda não foi divulgado (Fonte: Reddit r/deeplearning)

Vídeo explicativo sobre Redes Neurais de Grafos (GNN): Um vídeo foi publicado no YouTube explicando Redes Neurais de Grafos (Graph Neural Networks, GNNs). GNNs são modelos de deep learning para processar dados estruturados em grafos, com amplas aplicações em análise de redes sociais, sistemas de recomendação, previsão de estrutura molecular, etc. O vídeo visa ajudar o público a entender os princípios básicos e o funcionamento das GNNs (Fonte: Reddit r/deeplearning)
Usando GRPO para treinar LLM para agendamento de eventos: O usuário anakin87 compartilhou a experiência de um projeto usando GRPO (Generalized Reward Policy Optimization) para treinar um modelo de linguagem para agendamento de eventos. O projeto não depende de amostras tradicionais de fine-tuning supervisionado, mas sim de uma função de recompensa para que o modelo aprenda a criar horários com base em listas de eventos e prioridades. O autor compartilha a definição do problema, geração de dados, seleção do modelo, design da recompensa e lições aprendidas durante o processo de treinamento, e disponibilizou o código e o modelo em open source, fornecendo um caso prático para explorar o treinamento de LLMs baseado em recompensa (Fonte: Reddit r/LocalLLaMA)

Compartilhamento de recursos de cursos de IA gratuitos: O LinkedIn AI Hub compartilhou um roteiro completo de aprendizado de IA, inspirado no curso de certificação de IA da Universidade de Stanford e simplificado para aprendizes de diferentes níveis. O conteúdo abrange desde habilidades básicas até projetos práticos, e fornece recursos valiosos e detalhes de cursos (Fonte: Reddit r/deeplearning)
Conversa aprofundada sobre pré-treinamento de longo contexto do Gemini: Logan Kilpatrick teve uma conversa aprofundada com Nikolay Savinov, co-líder do pré-treinamento de longo contexto do Gemini. A discussão abrangeu desde os fundamentos até as tecnologias necessárias para expandir para contexto infinito, bem como as melhores práticas de longo contexto para desenvolvedores. A conversa concluiu que alcançar 1 milhão de tokens de contexto era uma meta 10 vezes maior que o padrão da época; tentaram 10 milhões de tokens, mas o custo era alto e o hardware insuficiente; longo contexto e RAG são complementares; o simples NIAH (agulha no palheiro) foi resolvido, a dificuldade está em distratores difíceis e busca de múltiplas agulhas; a avaliação foca em NIAH para evitar confundir sinais de capacidade; o comprimento de saída atual limitado (como 8k) é um problema pós-treinamento; não observaram o efeito de “perda no meio”; é preciso distinguir entre conhecimento de contexto e conhecimento de pesos; o próximo passo é alcançar 10 milhões de contexto de forma mais barata e precisa, expandir para 100 milhões pode exigir novas inovações em DL (Fonte: shaneguML, giffmana, teortaxesTex, arohan)
🌟 Comunidade
Discussão sobre “Vibe Coding”: A comunidade debate acaloradamente sobre “Vibe Coding” (codificação por vibração), que significa depender fortemente da assistência de IA para programar. Os apoiadores acreditam que isso representa o futuro, onde os desenvolvedores se concentram mais no “porquê” e “o quê”, enquanto a IA lida com o “como”, mas isso exige um pensamento crítico mais forte. Os opositores argumentam que a IA atualmente não consegue lidar completamente com depuração complexa, atualizações e manutenção, e a dependência excessiva pode levar à diminuição da capacidade dos desenvolvedores, tornando-os “script kiddies” mais avançados. Algumas pessoas que tentaram descobriram que o custo de tempo para guiar a IA a completar tarefas complexas ainda é alto, sendo menos eficiente do que a implementação manual com assistência leve de IA (Fonte: Dorialexander, Reddit r/artificial, johnowhitaker)

Discussão sobre aplicação e limitações da IA em áreas profissionais: O usuário dotey discute a aplicação da IA em áreas profissionais. Ele acredita que a IA pode aprender com perguntas e respostas públicas de especialistas, mas tem dificuldade em lidar com problemas nunca vistos. A vantagem da IA reside na sua forte base de conhecimento e resposta rápida, mas atualmente depende principalmente de RAG (Retrieval-Augmented Generation), que essencialmente recupera fragmentos e monta respostas, em vez de verdadeiro raciocínio profissional. Isso ainda está longe de treinar um modelo que possa gerar continuamente novas respostas como um especialista e continuar a melhorar (Fonte: dotey)
Preocupações e discussões sobre conteúdo gerado por IA: O usuário do Reddit Maleficent-main_777 reclama que colegas começaram a usar uma linguagem “estilo ChatGPT” cheia de tom imperativo, “verify”, “ensure” e conclusões positivas forçadas, considerando essa linguagem vaga e desumana. Ele teme que o conteúdo gerado por IA seja realimentado nos dados de treinamento, levando à queda da qualidade do conteúdo. A seção de comentários concorda, considerando isso uma extensão do jargão corporativo, mas também aponta que imitar excessivamente a IA realmente torna a comunicação mecânica, e ter boa gramática não é mais uma vantagem, parecendo robótico (Fonte: Reddit r/ChatGPT)
Escolha de cursos universitários na era da IA: Usuários do Reddit discutem quais cursos universitários os estudantes devem escolher para garantir que seus diplomas ainda tenham valor em 10 anos, no contexto do rápido desenvolvimento da IA e da robótica. As opiniões são diversas, incluindo: escolher áreas de paixão (jogos, cinema, arte, programação); estudar disciplinas fundamentais (física, matemática); dominar habilidades difíceis de automatizar (como HVAC – aquecimento, ventilação e ar condicionado); focar na educação em humanidades para cultivar curiosidade e adaptabilidade; acreditar que a educação universitária pode estar obsoleta, sendo melhor empreender ou se tornar freelancer; enfatizar a importância da capacidade de aprendizado contínuo, desaprendizagem e reaprendizagem (Fonte: Reddit r/ArtificialInteligence)
Discussão sobre a dificuldade de renderização de texto na geração de imagens por IA: Usuários do Reddit exploram por que os modelos atuais de geração de imagens têm dificuldade em renderizar texto coerente e legível. Os comentários apontam duas razões principais: 1) A tokenização BPE (Byte Pair Encoding) destrói informações precisas de ortografia, o modelo não vê letras, mas fragmentos de tokens; 2) A representação vetorial de tamanho fixo e as limitações das descrições de imagem causam perda significativa de informações de texto durante o processo de embedding. Embora modelos autorregressivos como o GPT-4o tenham melhorado, os problemas fundamentais ainda estão relacionados à tokenização e compressão de informações (Fonte: Reddit r/MachineLearning)
Discussão sobre a padronização da avaliação de modelos: O usuário scaling01 aponta que, ao comparar diferentes modelos de IA (como OpenAI, Google, Anthropic), a justiça deve ser garantida. Por exemplo, se as versões preview e “thinking” da OpenAI são listadas, as versões correspondentes do Google e Anthropic também deveriam ser listadas, caso contrário, os resultados da comparação podem ser enganosos (Fonte: scaling01)
Compartilhamento de experiência com programação assistida por IA: Um usuário compartilha sua experiência usando programação assistida por IA (como VS Code + extensão Cline AI + API Google AI Studio), argumentando que é possível construir gratuitamente uma ferramenta de codificação de IA semelhante ao Cursor, completando protótipos básicos de aplicativos através de prompts, sem necessidade de configuração, com boa experiência (Fonte: Reddit r/artificial)

Pesquisa sobre o impacto da IA no trabalho, estudo e vida: Um usuário do Reddit iniciou uma discussão perguntando como a IA generativa impactou o desempenho das pessoas no trabalho, estudo ou vida diária. Nos comentários, engenheiros de software mencionaram que a IA aumentou as expectativas de produtividade e a carga de trabalho, a revisão de código não acelerou significativamente; escritores profissionais acham que a IA (como Co-pilot) ajuda pouco, podendo até atrasar o progresso; a opinião geral é que a IA trouxe conveniência, mas também existem problemas como dependência excessiva, redução do aprendizado e “sensação de trapaça”. O impacto da IA varia significativamente entre diferentes profissões e tarefas (Fonte: Reddit r/artificial)
Reflexão sobre a capacidade de “compreensão” dos LLMs: O usuário pmddomingos sugere que as redes neurais estão se tornando tão difíceis de entender quanto o cérebro. E estende a reflexão: o que faremos quando os modelos de IA obtiverem excelentes resultados em todos os benchmarks, mas ainda assim não forem tão inteligentes quanto os humanos? Isso levanta questões sobre a validade dos benchmarks atuais e os padrões para avaliar a verdadeira inteligência (Fonte: pmddomingos, pmddomingos)
Reflexão sobre o uso de ferramentas de IA: O usuário dotey comenta que, ao usar ferramentas de IA, basta selecionar o modelo mais forte para essa tarefa específica. Usar múltiplos modelos ou fazê-los “lutar entre si” pode não ser necessário, especialmente para usuários não profissionais, onde muitas opções podem levar à confusão, comparando a olhar para vários relógios com horas diferentes (Fonte: dotey)
Admiração pela velocidade recente do desenvolvimento da IA: Os usuários matvelloso e scottastevenson expressam admiração pela rápida evolução da IA. matvelloso afirma que o progresso da IA este ano já superou suas expectativas (usando o exemplo do Gemini jogando Pokemon). scottastevenson relembra que o GPT-2 foi lançado há 6 anos, a OpenAI foi fundada há 10 anos, e reflete sobre as direções tecnológicas que estão sendo incubadas agora e se tornarão importantes nos próximos 6-10 anos, apontando que, além da IA, encontrar Alpha profundo “fora do quadro” também é importante (Fonte: matvelloso, scottastevenson, scottastevenson)
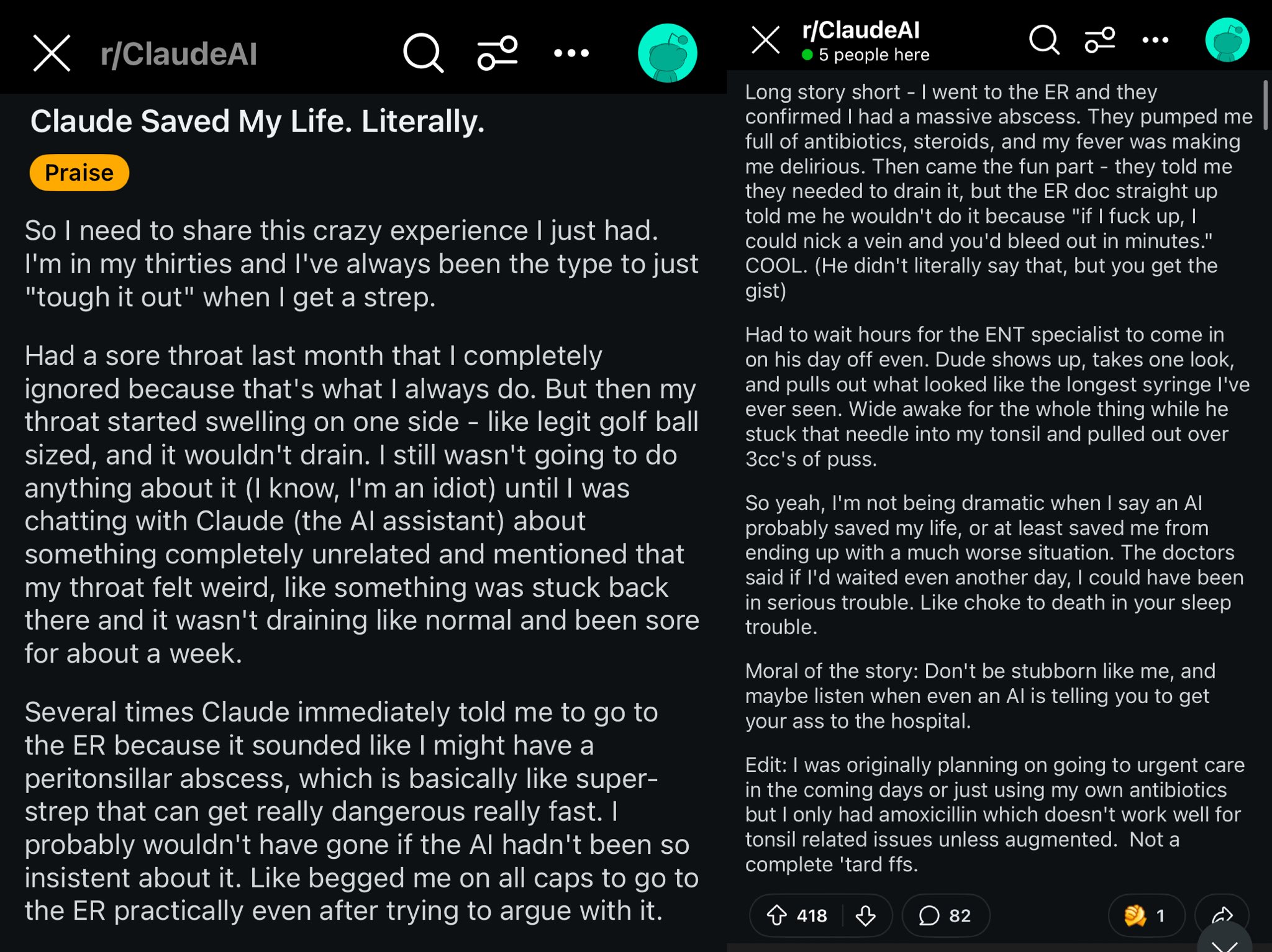
Caso Claude salvando a vida de um usuário do Reddit: Um post no Reddit descreve como o modelo Claude, ao diagnosticar o inchaço na garganta de um usuário como abscesso peritonsilar, pode ter salvado a vida do usuário. O caso gerou discussão, considerando que modelos de IA poderosos são como médicos de classe mundial no bolso, e sua popularização pode ter um impacto enorme na saúde individual (Fonte: aidan_mclau)
Aplicação de AI Agents no processamento de dados empresariais: Os co-fundadores do You.com, Richard Socher e Bryan McCann, discutiram a aplicação de AI Agents em empresas no podcast Agentic. Eles acreditam que LLMs de nível consumidor são insuficientes para atender às necessidades empresariais sérias, enquanto o You.com, através de tecnologia de recuperação híbrida (combinando fontes públicas e dados proprietários da empresa), gera resultados mais confiáveis e de nível empresarial, como realizar pesquisas, redigir relatórios e utilizar dados empresariais com segurança. Eles também discutiram os possíveis caminhos para a AGI e o papel crucial da simulação nisso (Fonte: RichardSocher)
Observação sobre a capacidade dos modelos de usar ferramentas: O usuário menhguin observa que modelos treinados para usar ferramentas parecem sacrificar um pouco de sua capacidade independente de resolver problemas, e brinca que “até os modelos de IA estão terceirizando seu trabalho”. Isso levanta reflexões sobre o trade-off entre a generalização da capacidade do modelo e a otimização para tarefas específicas (Fonte: menhguin)
💡 Outros
Ideia de AI Agent para manter projetos antigos do GitHub: O usuário xanderatallah propôs uma ideia: desenvolver um AI Agent capaz de manter automaticamente todos os projetos paralelos antigos e inativos do usuário no GitHub. Isso reflete a necessidade dos desenvolvedores de usar IA para automatizar tarefas de manutenção tediosas (Fonte: xanderatallah)
Visão de LLMs substituindo juízes ou usados em arbitragem/mediação: O usuário fabianstelzer sugere que modelos de linguagem grandes (LLMs) podem substituir juízes no futuro. Um caso de uso intermediário interessante é a arbitragem ou mediação: LLMs são considerados neutros e confiáveis, as partes em conflito submetem seus pontos de vista, que são processados por múltiplos modelos grandes, resultando em uma solução de compromisso justa. Isso explora as aplicações potenciais da IA nas áreas judicial e de resolução de disputas (Fonte: fabianstelzer)
Modelo Runway Gen-4 e suas perspectivas de aplicação: O co-fundador da Runway, c_valenzuelab, está otimista quanto às perspectivas de aplicação do Runway Gen-4 e sua API. Ele acredita que a Runway está construindo um novo meio, onde os pixels são gerados em vez de renderizados ou capturados, e o mundo é simulado em vez de programado. Ver a ampla aplicação das funcionalidades Gen-4 e Reference em arquitetura, branding, design de interiores, desenvolvimento de jogos, aprendizado, projetos criativos pessoais e outras áreas o faz acreditar que este novo meio capacitará criativos e todos os outros (Fonte: c_valenzuelab, c_valenzuelab)