
Palavras-chave:ChatBot Arena, Phi-4-raciocínio, Claude Integrations, Agente de IA Inteligente, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, Alucinação de ranking, Capacidade de raciocínio de modelos pequenos, Integração de aplicativos de terceiros, Agente de programação de IA, Prova de teoremas matemáticos
🔥 Foco
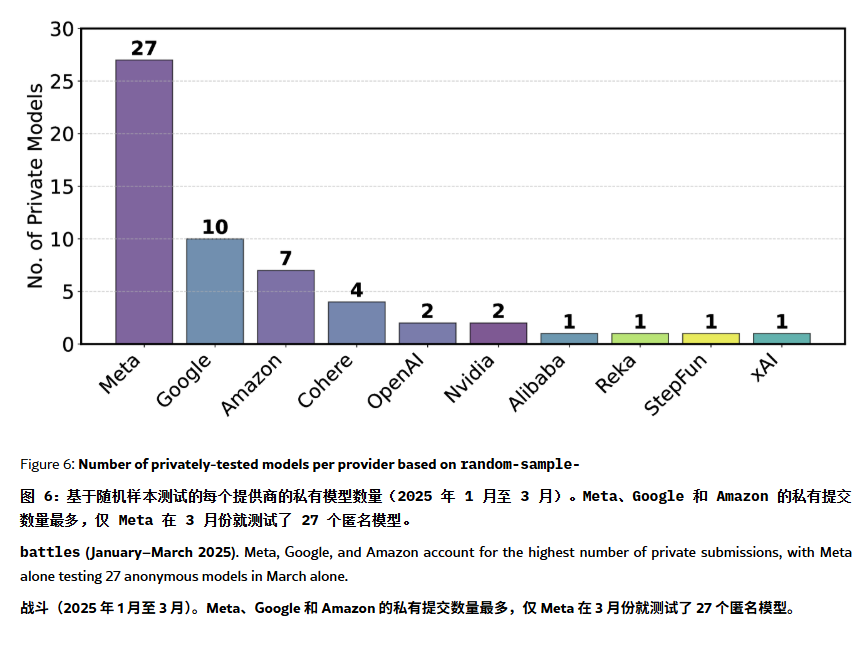
Ranking do ChatBot Arena acusado de “alucinação” e manipulação: Um artigo no ArXiv [2504.20879] questiona o amplamente citado ranking de modelos do ChatBot Arena, sugerindo que ele sofre de “alucinação de ranking”. O artigo aponta que grandes empresas de tecnologia (como a Meta) podem manipular o ranking submetendo um grande número de variantes de modelos ajustados (como 27 versões do Llama-4 testadas) e publicando apenas os melhores resultados; a frequência de exibição dos modelos também pode favorecer os modelos de grandes empresas, reduzindo as oportunidades de exposição para modelos de código aberto; o mecanismo de eliminação de modelos carece de transparência, com muitos modelos de código aberto sendo removidos com dados de teste insuficientes; além disso, a semelhança das perguntas frequentes dos usuários pode levar os modelos a um overfitting direcionado para melhorar as pontuações. Isso levanta preocupações sobre a confiabilidade e a imparcialidade dos benchmarks de LLM atuais, recomendando que desenvolvedores e usuários vejam os rankings com cautela e considerem a construção de sistemas de avaliação que atendam às suas próprias necessidades. (Fonte: karminski3, op7418, TheRundownAI)
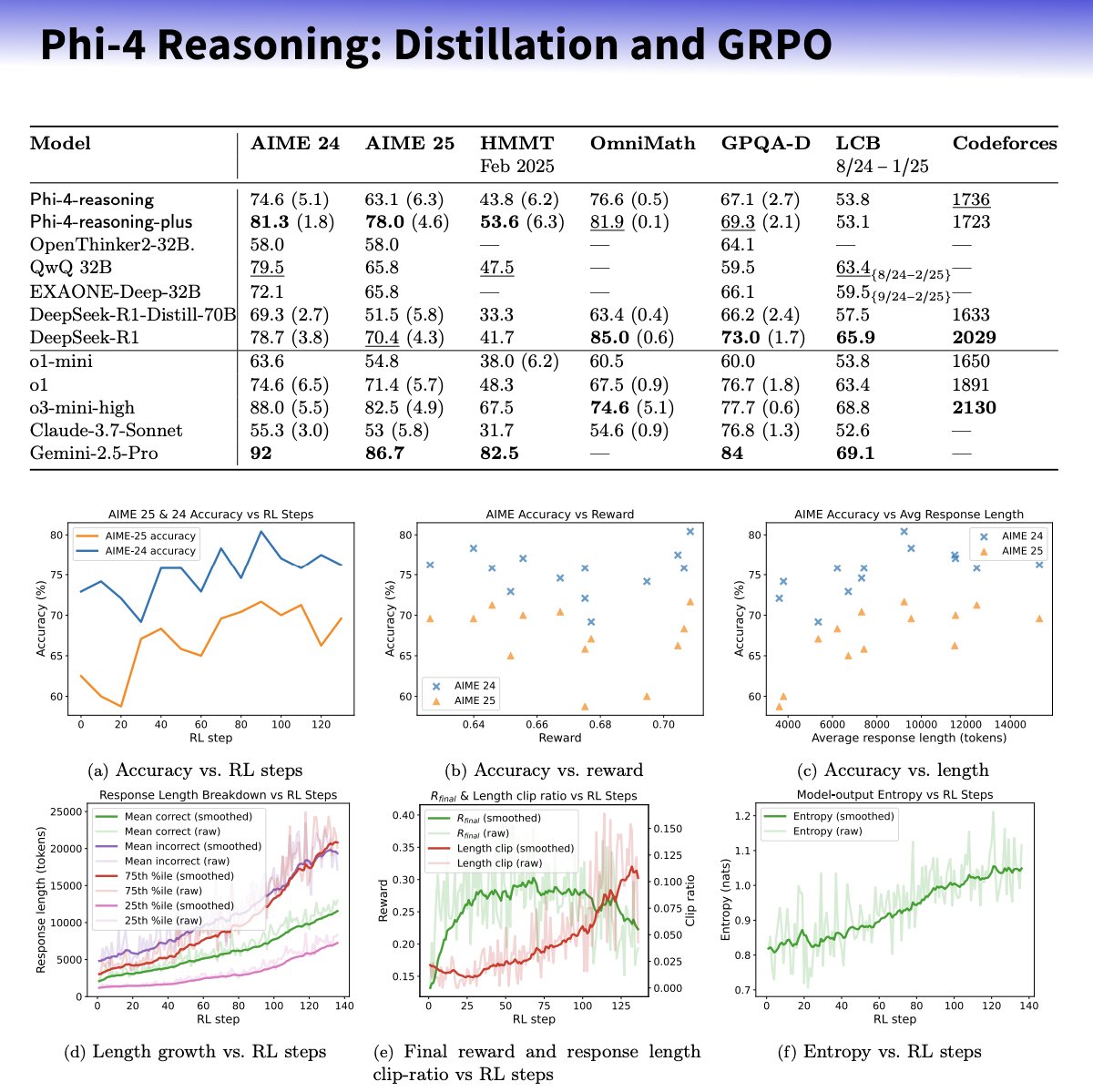
Microsoft lança série de pequenos modelos Phi-4-reasoning, focados em aprimorar a capacidade de raciocínio: A Microsoft introduziu os modelos Phi-4-reasoning e Phi-4-reasoning-plus baseados na arquitetura Phi-4, visando aprimorar a capacidade de raciocínio de pequenos modelos de linguagem através de conjuntos de dados cuidadosamente selecionados, ajuste fino supervisionado (SFT) e aprendizado por reforço direcionado (RL). Alega-se que esses modelos utilizam o o3-mini da OpenAI como “professor” para gerar trajetórias de raciocínio de cadeia de pensamento (CoT) de alta qualidade e são otimizados através do algoritmo GRPO para aprendizado por reforço. O pesquisador da Microsoft, Sebastien Bubeck, afirma que o Phi-4-reasoning supera o DeepSeek R1 em capacidade matemática, embora o tamanho do modelo seja apenas 2% do DeepSeek R1. A série de modelos utiliza tokens de raciocínio dedicados e um comprimento de contexto estendido de 32K. Esta iniciativa é vista como uma exploração na direção de modelos menores e especializados, podendo oferecer soluções de raciocínio mais fortes para cenários com recursos limitados, mas também levanta discussões sobre se utiliza tecnologia da OpenAI e é lançado sob a licença MIT. (Fonte: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic lança funcionalidade Integrations e expande capacidades de pesquisa: A Anthropic anunciou o lançamento do Claude Integrations, permitindo aos usuários conectar o Claude com 10 aplicativos e serviços de terceiros, como Jira, Confluence, Zapier, Cloudflare, Asana, com suporte futuro para Stripe, GitLab, entre outros. O suporte ao MCP (Model Context Protocol), anteriormente limitado a servidores locais, foi estendido para servidores remotos, permitindo que desenvolvedores criem suas próprias integrações em cerca de 30 minutos através da documentação ou soluções como Cloudflare. Ao mesmo tempo, a funcionalidade de pesquisa (Research) do Claude foi aprimorada com um novo modo avançado, que pode pesquisar na web, no Google Workspace e nas Integrations conectadas, decompor solicitações complexas para investigação e gerar relatórios abrangentes com citações, podendo levar até 45 minutos para processar. A funcionalidade de pesquisa na web também foi disponibilizada para usuários pagantes globalmente. Essas atualizações visam aprimorar a integração e a capacidade de pesquisa aprofundada do Claude como assistente de trabalho. (Fonte: _philschmid, Reddit r/ClaudeAI)

Capacidade dos agentes de IA segue nova Lei de Moore: dobra a cada 4 meses: Uma pesquisa do AI Digest aponta que a capacidade dos agentes de programação de IA para completar tarefas está passando por um crescimento exponencial. O tempo necessário para processar tarefas (medido pelo tempo que um especialista humano levaria) está dobrando aproximadamente a cada 4 meses no período 2024-2025, mais rápido do que a taxa de duplicação a cada 7 meses observada entre 2019-2025. Atualmente, os principais agentes de IA já conseguem lidar com tarefas de programação que exigiriam 1 hora de um humano. Se essa tendência acelerada continuar, espera-se que até 2027 os agentes de IA possam completar tarefas complexas que levariam até 167 horas (cerca de um mês). Esse rápido aumento de capacidade é impulsionado pelos avanços nos próprios modelos e pela melhoria da eficiência algorítmica, podendo formar um ciclo de feedback positivo de crescimento superexponencial devido à IA auxiliando na pesquisa e desenvolvimento de IA. Isso prenuncia a possibilidade de uma “explosão de inteligência de software”, que mudará profundamente áreas como desenvolvimento de software e pesquisa científica, ao mesmo tempo que traz desafios sociais como o impacto da automação no mercado de trabalho. (Fonte: 新智元)

🎯 Tendências
DeepSeek-Prover-V2 lançado, aprimorando a capacidade de prova de teoremas matemáticos: A DeepSeek AI lançou o DeepSeek-Prover-V2, disponível em tamanhos de 7B e 671B, focado na prova formal de teoremas em Lean 4. O modelo utiliza busca recursiva de provas e aprendizado por reforço (GRPO) para treinamento, empregando o DeepSeek-V3 para decompor teoremas complexos e gerar esboços de prova, combinados com iteração de especialistas e dados sintéticos de inicialização a frio para ajuste fino e aprendizado por reforço. O DeepSeek-Prover-V2-671B alcançou uma taxa de aprovação de 88.9% no MiniF2F-test e resolveu 49 problemas no PutnamBench, demonstrando desempenho SOTA. Também foi lançado o benchmark ProverBench, que inclui problemas do AIME e de livros didáticos. O modelo visa unificar o raciocínio informal com a prova formal, impulsionando o desenvolvimento da prova automática de teoremas. (Fonte: 新智元)

Nvidia e UIUC propõem novo método para expansão de contexto para 4 milhões de tokens: Pesquisadores da Nvidia e da Universidade de Illinois em Urbana-Champaign propuseram um método de treinamento eficiente que pode expandir a janela de contexto do Llama 3.1-8B-Instruct de 128K para 1M, 2M e até 4M tokens. O método adota uma estratégia de duas fases: pré-treinamento contínuo e ajuste fino de instruções. As tecnologias chave incluem o uso de separadores de documentos especiais, extensão de codificação posicional baseada em YaRN e pré-treinamento em uma única etapa. O modelo UltraLong-8B treinado demonstrou excelente desempenho em benchmarks de contexto longo como RULER, LV-Eval e InfiniteBench, e manteve ou até superou o desempenho do Llama 3.1 base em tarefas padrão de contexto curto como MMLU e MATH, superando outros modelos de contexto longo como ProLong e Gradient. A pesquisa oferece um caminho eficiente e escalável para construir LLMs com contexto ultralongo. (Fonte: 新智元)

Qwen3 lançado, com melhorias significativas de desempenho: O Alibaba lançou a série de modelos Qwen3, incluindo o Qwen3-30B-A3B, entre outros. De acordo com testes preliminares de usuários do Reddit e dados de benchmark (como o AHA Leaderboard), o Qwen3 demonstra melhor desempenho em várias dimensões (como saúde, Bitcoin, conhecimento específico do Nostr) em comparação com as versões anteriores Qwen2.5 e QwQ. O feedback dos usuários indica que o Qwen3 mostra forte capacidade no tratamento de tarefas específicas (como simular a dinâmica do sistema solar), aplicando corretamente as leis da física para gerar órbitas elípticas e períodos relativos. No entanto, alguns usuários apontaram que o desempenho do Qwen3 diminui significativamente em contextos longos (próximos a 16K) e consome muitos tokens durante a inferência, sugerindo o uso combinado com ferramentas de busca. A nomenclatura do Qwen3 (como Qwen3-30B-A3B) também foi elogiada por sua clareza. (Fonte: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini em breve integrará dados da Conta Google para oferecer experiência personalizada: O Google planeja permitir que o assistente de IA Gemini acesse os dados da Conta Google do usuário, incluindo Gmail, Fotos, histórico do YouTube, etc., com o objetivo de fornecer uma experiência de assistência mais personalizada, proativa e poderosa. Josh Woodward, chefe de produto do Google, afirmou que isso visa permitir que o Gemini entenda melhor o usuário, tornando-se uma extensão dele. A funcionalidade será opcional (opt-in), e os usuários poderão escolher se ativam ou não o acesso aos dados. Esta medida levanta discussões sobre privacidade e segurança de dados, exigindo que os usuários ponderem entre a conveniência da personalização e a privacidade dos dados. (Fonte: JeffDean, Reddit r/ArtificialInteligence)

Nvidia lança modelo ASR Parakeet-TDT-0.6B-v2: A Nvidia lançou um novo modelo de reconhecimento automático de fala (ASR), o Parakeet-TDT-0.6B-v2, com 600 milhões de parâmetros. Alega-se que o modelo supera o Whisper3-large (1.6 bilhão de parâmetros) no Open ASR Leaderboard, especialmente no processamento de conjuntos de dados diversificados (incluindo LibriSpeech, Fisher Corpus, dados do YouTube, etc., totalizando cerca de 120.000 horas de dados). O modelo suporta timestamps em nível de caractere, palavra e parágrafo, mas atualmente suporta apenas inglês e requer GPU Nvidia e frameworks específicos para execução. O feedback inicial dos usuários elogia sua alta precisão na transcrição e pontuação. (Fonte: Reddit r/LocalLLaMA)

Qwen2.5-VL lançado, aprimorando a compreensão visual-linguística: O Alibaba lançou a série de modelos multimodais Qwen2.5-VL (incluindo parâmetros de 3B, 7B, 72B), visando aprimorar a compreensão e interação da máquina com o mundo visual. Esses modelos podem ser usados para resumo de imagens, perguntas e respostas visuais, geração de relatórios a partir de informações visuais complexas, entre outras tarefas. O artigo apresenta sua arquitetura, desempenho em benchmarks e detalhes de inferência, mostrando seus avanços na compreensão visual-linguística. (Fonte: Reddit r/deeplearning)

Suporte para Mistral Small 3.1 Vision incorporado ao llama.cpp: O projeto llama.cpp incorporou suporte para o modelo Mistral Small 3.1 Vision (24B parâmetros). Isso significa que os usuários poderão executar este modelo multimodal no framework llama.cpp para tarefas como compreensão de imagem. A Unsloth já forneceu os arquivos de modelo correspondentes no formato GGUF. Isso facilita a execução local dos modelos de visão da Mistral. (Fonte: Reddit r/LocalLLaMA)
Meta lança Synthetic Data Kit: A Meta tornou open-source uma ferramenta de linha de comando chamada Synthetic Data Kit, projetada para simplificar a fase de preparação de dados necessária para o ajuste fino de LLMs. A ferramenta oferece quatro comandos: ingest (importar dados), create (gerar pares de QA, opcionalmente com cadeia de raciocínio), curate (usar o Llama como avaliador para selecionar amostras de alta qualidade) e save-as (exportar em formato compatível). Ela utiliza LLMs locais (via vLLM) para gerar dados de treinamento sintéticos de alta qualidade, especialmente adequados para desbloquear capacidades de raciocínio em tarefas específicas para modelos como o Llama-3. (Fonte: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 torna-se um modelo de embedding popular: O modelo GTE-ModernColBERT-v1, lançado pela LightOnIO, tornou-se o novo modelo de busca/embedding em tendência no Hugging Face. O modelo adota um método de busca multi-vetorial (também conhecido como interação tardia ou ColBERT), oferecendo uma nova opção para desenvolvedores interessados nesse tipo de tecnologia. (Fonte: lateinteraction)
Atualização do algoritmo de recomendação do X: A plataforma X (antigo Twitter) corrigiu seu algoritmo de recomendação para resolver problemas de longa data, como feedback negativo do usuário não ser considerado, visualização repetida do mesmo conteúdo e recomendações irrelevantes do algoritmo SimCluster. Alega-se que o feedback inicial é positivo. (Fonte: TheGregYang)
Wikipédia anuncia nova estratégia de IA para auxiliar editores humanos: A Wikipédia divulgou sua nova estratégia de inteligência artificial, visando utilizar ferramentas de IA para apoiar e aprimorar o trabalho dos editores humanos, em vez de substituí-los. Detalhes específicos não foram fornecidos na fonte, mas indica que a maior enciclopédia online do mundo está explorando como integrar a tecnologia de IA em seus processos de criação e manutenção de conteúdo. (Fonte: Reddit r/artificial)
🧰 Ferramentas
Midjourney lança funcionalidade Omni-Reference: O Midjourney lançou a nova funcionalidade Omni-Reference (oref), que permite aos usuários guiar a geração de imagens fornecendo URLs de imagens de referência (usando o parâmetro –oref) para alcançar consistência em personagens, objetos, veículos ou seres não humanos. Os usuários podem controlar o peso da influência da imagem de referência com o parâmetro –ow, com pesos mais baixos adequados para estilização e pesos mais altos para realismo ou correspondência facial precisa. A funcionalidade visa melhorar a consistência e o controle de elementos específicos nas imagens geradas. (Fonte: op7418, DavidSHolz)

Runway Gen-4 References realiza personalização com uma única imagem: O modelo Gen-4 do Runway introduziu a funcionalidade References (referência), onde os usuários precisam fornecer apenas uma imagem de referência para aplicar o estilo ou as características de personagens da imagem a novo conteúdo gerado. Demonstrações mostram que a funcionalidade pode facilmente recriar retratos de pessoas no estilo da imagem de referência ou inseri-los no mundo retratado pela imagem de referência, exibindo a capacidade do modelo de alcançar alta consistência e qualidade estética na geração personalizada com apenas uma imagem de referência. (Fonte: c_valenzuelab, c_valenzuelab)

Bot do WhatsApp da Perplexity retoma serviço: O chatbot do WhatsApp da Perplexity AI, após uma breve interrupção devido à demanda muito acima do esperado, retomou o serviço. Os usuários podem interagir com ele através do número de telefone +1 (833) 436-3285, podendo encaminhar mensagens para verificação de fatos, fazer perguntas diretas para obter respostas, ter conversas de texto em formato livre e criar imagens. (Fonte: AravSrinivas, AravSrinivas)
Krea AI combina modelo de imagem 4o para controle preciso de imagem: A ferramenta criativa de IA Krea AI adicionou uma nova funcionalidade que permite aos usuários combinar as capacidades do modelo de imagem 4o da OpenAI para controlar com mais precisão o conteúdo e o estilo das imagens geradas através de colagem de imagens e rabiscos. Isso demonstra a inovação contínua da Krea na geração interativa de imagens, permitindo que os usuários guiem a criação de IA de forma mais intuitiva e detalhada. (Fonte: op7418)
Máquina integrada Xingyun Brown Ant: rodando DeepSeek completo a baixo custo: A Xingyun Integrated Circuit, com origens na Universidade de Tsinghua, lançou a máquina integrada de IA Brown Ant, que afirma ser capaz de rodar o modelo DeepSeek-R1/V3 671B com precisão FP8 não quantizada a mais de 20 tokens/s, com suporte a contexto de 128K, por um preço de 149.000 yuans. A solução utiliza CPUs AMD EPYC dual-socket e memória de alta capacidade e frequência, complementada por uma pequena quantidade de aceleração de GPU. O objetivo é reduzir significativamente o custo de hardware para implantação privada de grandes modelos através de uma arquitetura CPU+memória, oferecendo uma experiência localizada próxima ao desempenho oficial, adequada para cenários empresariais sensíveis ao custo que exigem alta precisão. (Fonte: 新智元)

Aplicativo NotebookLM será lançado em breve: O aplicativo de anotações com IA do Google, NotebookLM, lançará em breve aplicativos oficiais para iOS e Android, com previsão de lançamento em 20 de maio, e já está disponível para pré-encomenda. Isso levará as funcionalidades do NotebookLM de fornecer resumos, respostas a perguntas e geração criativa com base nas notas e documentos do usuário para o ambiente móvel. (Fonte: zacharynado)
Granola lança aplicativo iOS para atas de reunião em tempo real com IA: O aplicativo de anotações com IA Granola lançou sua versão para iOS, estendendo sua funcionalidade original de anotações de IA para reuniões do Zoom para cenários de conversas presenciais offline. Os usuários podem usar o Granola no iPhone para gravar e transcrever conversas, e utilizar a IA para gerar resumos e notas, facilitando a revisão e organização posterior. (Fonte: amasad)
Grok Studio suporta processamento de PDF: O assistente de IA Grok adicionou a capacidade de processar arquivos PDF em sua funcionalidade Studio. Os usuários agora podem processar e analisar documentos PDF de forma mais conveniente no Grok Studio. Detalhes específicos da funcionalidade não foram fornecidos, mas marca uma expansão nas capacidades do Grok em compreensão e interação com documentos de múltiplos formatos. (Fonte: grok, TheGregYang)
Novo modelo da Suno demonstra excelente capacidade de geração musical: A plataforma de geração de música por IA Suno lançou um novo modelo, com feedback dos usuários indicando que seus resultados são “muito excelentes”. Um usuário tentou usá-lo para gerar uma música no estilo de apresentação ao vivo e, embora não tenha conseguido o efeito de chamada e resposta desejado, a música gerada apresentou bom desempenho na ambientação de multidão, mostrando o progresso do novo modelo na qualidade musical e diversidade de estilos. (Fonte: nptacek, nptacek)
Aplicativo Frog Spot usa IA para identificar coaxar de sapos: Um desenvolvedor criou um aplicativo gratuito chamado Frog Spot, que usa um modelo CNN auto-treinado (TensorFlow Lite) para identificar diferentes espécies de coaxares de sapos analisando o espectrograma de 10 segundos de áudio. O aplicativo visa ajudar o público a conhecer as espécies locais e também demonstra o potencial do aprendizado profundo no monitoramento bioacústico e na ciência cidadã. (Fonte: Reddit r/deeplearning)
Automação de desenhos técnicos industriais assistida por IA: Um artigo da IAAI 2025 apresenta um método para automatizar a expansão de “instrument typicals” em diagramas de tubulação e instrumentação (P&ID). O método combina modelos de visão computacional (detecção e reconhecimento de texto) e regras específicas de domínio para extrair automaticamente informações de desenhos P&ID e legendas, expandindo símbolos simplificados de instrument typicals em listas detalhadas de instrumentos, gerando um índice de instrumentos preciso. Isso visa aumentar a eficiência em projetos de engenharia (especialmente na fase de licitação) e reduzir erros manuais. (Fonte: aihub.org)

Utilizando Sora para gerar paisagem em miniatura de pato prensado com molho: Um usuário compartilhou uma imagem de “pato prensado com molho em paisagem em miniatura” gerada pelo Sora com base em um prompt detalhado. O prompt descreveu meticulosamente o estilo da cena (macrofotografia, paisagem em miniatura), o tema principal (barraca feita de pato prensado com molho), detalhes (pele vermelho-molho, pimenta e gergelim, chef fatiando, clientes), ambiente (ruas feitas de molho de carne de pato, paredes estilo conserva, lanternas vermelhas, etc.). Isso demonstra a capacidade do Sora de compreender descrições textuais complexas e imaginativas e gerar imagens de alta qualidade correspondentes. (Fonte: dotey)

Criação de GPTs de previsão do tempo em 3D: Um usuário compartilhou um aplicativo ChatGPTs caseiro chamado “Weather 3D”, que pode, com base no nome da cidade inserido pelo usuário, chamar uma API de clima para obter dados meteorológicos em tempo real e gerar uma ilustração em estilo de modelo isométrico em miniatura 3D do marco arquitetônico da cidade, incorporando as condições climáticas atuais. O topo da ilustração exibe o nome da cidade, condição climática, temperatura e ícone do tempo. Este GPTs demonstra como combinar chamadas de API e capacidade de geração de imagem para criar aplicativos de IA práticos e visualmente atraentes. (Fonte: dotey)

📚 Aprendizado
AdaRFT: Novo método para otimizar o ajuste fino por aprendizado por reforço: Taiwei Shi e colegas propuseram um método de aprendizado curricular leve e plug-and-play chamado AdaRFT, destinado a otimizar o processo de treinamento de algoritmos de aprendizado por reforço baseado em feedback humano (RFT) (como PPO, GRPO, REINFORCE). Alega-se que o AdaRFT pode reduzir o tempo de treinamento RFT em até 2 vezes e melhorar o desempenho do modelo, organizando de forma mais inteligente a ordem dos dados de treinamento para aumentar a eficiência e os resultados do aprendizado. (Fonte: menhguin)

Masterclass online sobre Avaliação de IA (Evals): Hamel Husain e Shreya Shankar estão oferecendo uma masterclass online de 4 semanas sobre avaliação de aplicações de IA (Evals). O curso visa ajudar desenvolvedores a levar aplicações de IA da fase de protótipo para o estado de prontidão para produção, cobrindo métodos de avaliação durante o desenvolvimento e pós-lançamento, a diferença entre benchmarks e avaliação prática, inspeção de dados, PromptEvals, etc. Enfatiza a importância da avaliação para garantir a confiabilidade e o desempenho das aplicações de IA. (Fonte: HamelHusain, HamelHusain)

Manual de Ajuste de Modelo do Google: O Google Research oferece um repositório de recursos chamado “tuning_playbook”, destinado a fornecer orientação e melhores práticas para o ajuste de modelos. Este é um recurso de aprendizado valioso para desenvolvedores e pesquisadores que precisam ajustar modelos de linguagem grandes ou outros modelos de aprendizado de máquina para tarefas ou conjuntos de dados específicos. (Fonte: zacharynado)

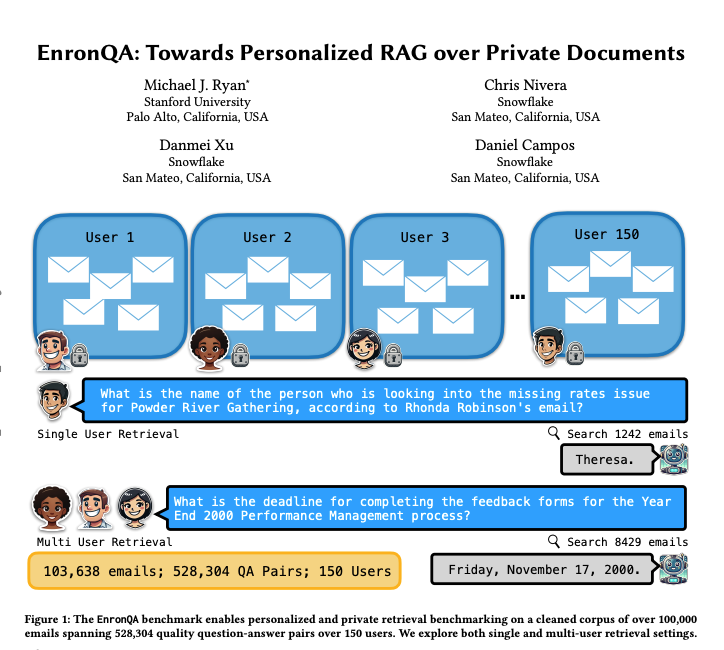
EnronQA: Conjunto de dados de benchmark RAG personalizado: Pesquisadores lançaram o conjunto de dados EnronQA, contendo 103.638 e-mails de 150 usuários e 528.304 pares de perguntas e respostas de alta qualidade. O conjunto de dados visa servir como um benchmark para avaliar o desempenho de sistemas personalizados de geração aumentada por recuperação (RAG) no processamento de documentos privados. O conjunto de dados inclui respostas de referência (gold standard), respostas incorretas, justificativas de raciocínio e respostas alternativas, ajudando a analisar o desempenho dos sistemas RAG de forma mais detalhada. (Fonte: tokenbender)
ReXGradient-160K: Conjunto de dados em larga escala de radiografias de tórax e relatórios: Foi lançado um grande conjunto de dados público de raios-X de tórax chamado ReXGradient-160K, contendo 60.000 estudos de radiografia de tórax e seus relatórios radiológicos pareados (texto livre) de 109.487 pacientes únicos de 3 sistemas de saúde nos EUA (79 locais médicos). Alega-se ser o maior conjunto de dados de radiografia de tórax publicamente disponível em termos de número de pacientes, fornecendo um recurso valioso para treinar e avaliar modelos de IA de imagem médica. (Fonte: iScienceLuvr)

Artigo de blog explorando o crescimento da capacidade dos agentes de IA: O pesquisador Shunyu Yao publicou um artigo de blog intitulado “The Second Half”, propondo que o desenvolvimento atual da IA está em um momento de “intervalo”. Antes disso, o treinamento era mais importante que a avaliação; depois disso, a avaliação será mais importante que o treinamento, porque o aprendizado por reforço (RL) finalmente começou a funcionar efetivamente. O artigo explora a importância da mudança na metodologia de avaliação no contexto do aumento contínuo da capacidade da IA. (Fonte: andersonbcdefg)
Compartilhamento de pesquisa da OpenAI sobre privacidade e memorização: Os pesquisadores da OpenAI, Pratyush Maini e Zhili Feng, farão uma apresentação sobre pesquisa de privacidade e memorização, discutindo como detectar, quantificar e eliminar o fenômeno da memorização em grandes modelos de linguagem, e sua aplicação prática em LLMs em produção. Isso se relaciona a como equilibrar a capacidade do modelo com a proteção da privacidade dos dados do usuário. (Fonte: code_star)

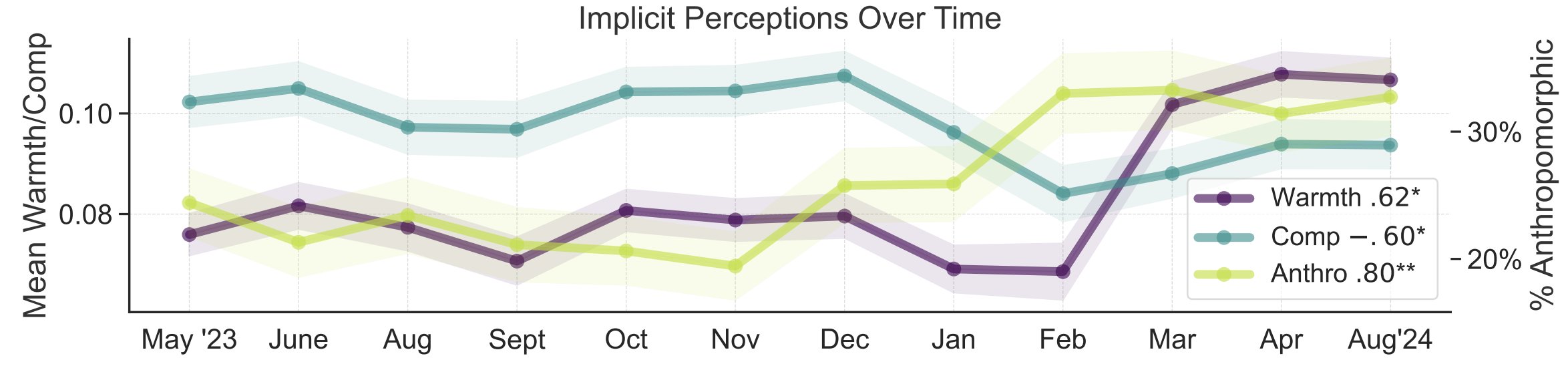
Estudo de metáforas sobre a percepção pública da IA: Pesquisadores da Universidade de Stanford, Myra Cheng e colegas, publicaram um artigo na FAccT 2025 analisando 12.000 metáforas sobre IA coletadas ao longo de 12 meses para entender os modelos mentais do público sobre IA e suas mudanças ao longo do tempo. O estudo descobriu que, com o tempo, o público tende a ver a IA como mais humana e com mais agência (aumento da antropomorfização), e sua inclinação emocional em relação a ela (calor) também está aumentando. Este método fornece insights mais detalhados sobre a percepção pública do que os auto-relatos. (Fonte: stanfordnlp, stanfordnlp)
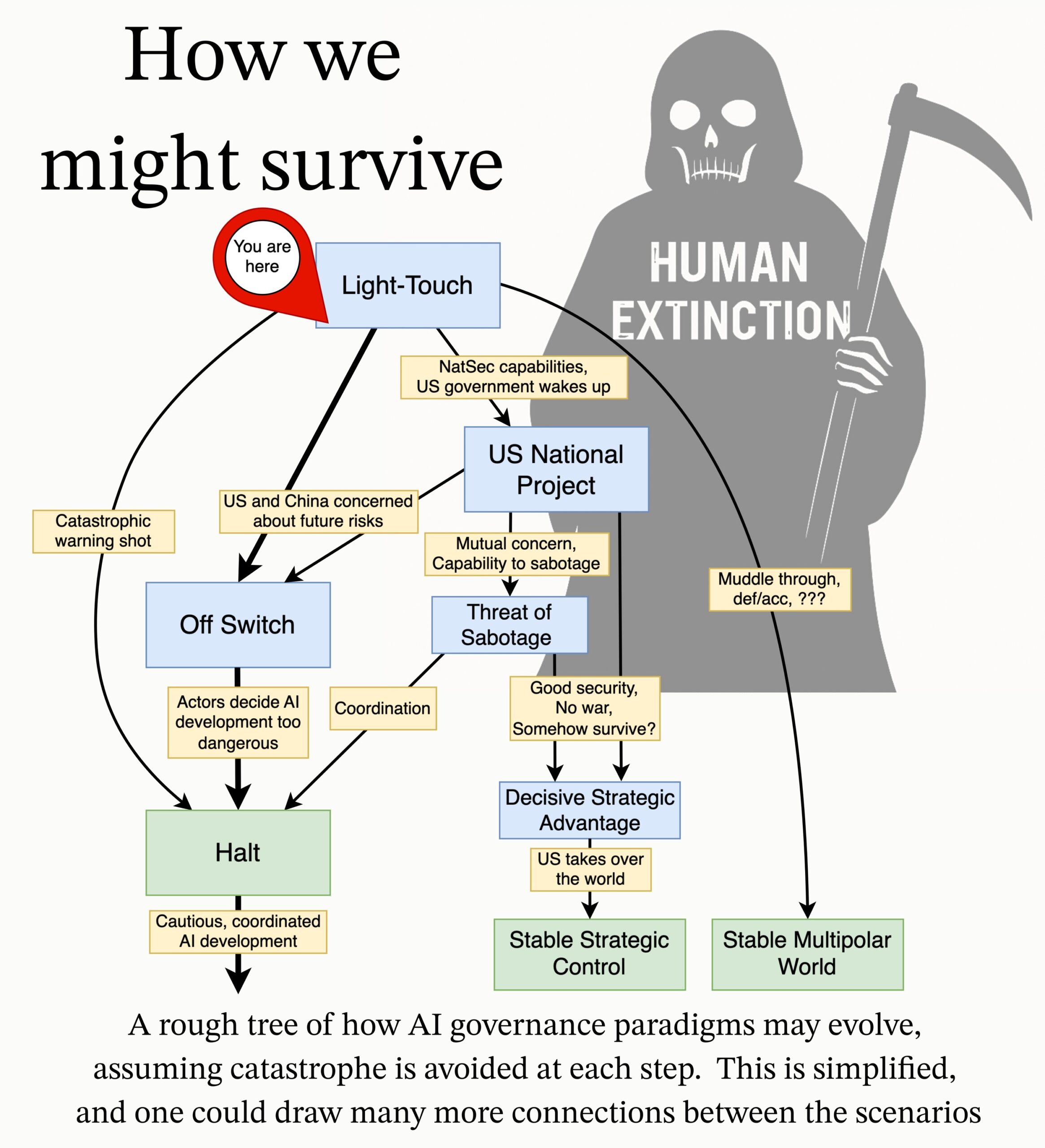
MIRI publica agenda de pesquisa em governança de IA: A equipe de governança técnica do Instituto de Pesquisa em Inteligência Artificial (MIRI) publicou uma nova agenda de pesquisa em governança de IA, expondo sua visão sobre o cenário estratégico e propondo uma série de questões de pesquisa acionáveis. Seu objetivo é explorar quais medidas precisam ser tomadas para impedir que qualquer organização ou indivíduo construa uma superinteligência incontrolável, a fim de reduzir os riscos catastróficos e de extinção da IA. (Fonte: JeffLadish)
💼 Negócios
Deepexi, fornecedora de soluções de IA empresarial, solicita IPO em Hong Kong: A Deepexi (滴普科技), fornecedora de soluções de IA empresarial fundada por Zhao Jiehui, ex-executivo da Huawei e Alibaba, apresentou formalmente um pedido de listagem na bolsa de valores de Hong Kong. A empresa se concentra na plataforma de inteligência de dados FastData e nas soluções de inteligência artificial empresarial FastAGI, atendendo a setores como varejo (ex: Belle), manufatura e saúde. Nos últimos três anos, a receita da empresa cresceu continuamente, atingindo 243 milhões de yuans em 2024. A Deepexi concluiu 8 rodadas de financiamento, recebendo investimentos de instituições renomadas como Hillhouse Capital, IDG Capital e 5Y Capital, com uma avaliação pós-última rodada de cerca de 6,8 bilhões de yuans. Apesar do crescimento da receita, a empresa ainda está em prejuízo, embora o prejuízo líquido ajustado tenha diminuído ano a ano. (Fonte: 36氪)
BMW China anuncia integração com o modelo grande DeepSeek: Após a colaboração com o Alibaba, o Grupo BMW aprofunda ainda mais sua presença em IA na China, anunciando a integração com o modelo grande DeepSeek. A funcionalidade está planejada para começar no terceiro trimestre de 2025, sendo aplicada primeiro em vários novos modelos vendidos na China equipados com o sistema operacional BMW de 9ª geração, e futuramente também nos modelos BMW New Generation produzidos localmente. O objetivo é fortalecer a experiência de interação homem-máquina centrada no BMW Intelligent Personal Assistant através da capacidade de pensamento profundo do DeepSeek, elevando o nível de inteligência e conexão emocional do veículo. Este é um passo importante para a BMW acelerar sua estratégia de IA localizada e enfrentar os desafios da transformação inteligente. (Fonte: 36氪)
Shopify exige uso de IA por todos os funcionários, visando substituir alguns cargos: O CEO da plataforma global de e-commerce Shopify, Tobi Lutke, enfatizou em um memorando interno que o uso eficiente de IA se tornou uma “regra de ferro” para todos os funcionários da empresa, não mais uma sugestão. O memorando exige que os funcionários apliquem IA em seus fluxos de trabalho, tornando-se um reflexo condicionado; as equipes que solicitarem aumento de pessoal devem primeiro provar por que a IA não pode realizar a tarefa; as avaliações de desempenho incluirão métricas de uso de IA. Lutke apontou que a IA pode aumentar enormemente a eficiência (alguns funcionários em 10x ou até 100x), e os funcionários precisam melhorar de 20% a 40% anualmente para se manterem competitivos. A Shopify já realizou demissões em departamentos como atendimento ao cliente e introduziu a IA como substituta. Esta medida é vista como um sinal claro da tendência de ajustes e demissões em cargos de colarinho branco causados pela IA. (Fonte: 新智元)

🌟 Comunidade
Discussão sobre o problema de alucinação da IA: Li Yanhong, na Conferência de Desenvolvedores de IA da Baidu, criticou o DeepSeek-R1 por ter alta taxa de alucinação, ser lento e caro, reacendendo a discussão na comunidade sobre o fenômeno de “alucinação” em grandes modelos. Análises apontam que não apenas o DeepSeek, mas também modelos avançados como o o3/o4-mini da OpenAI e o Qwen3 do Alibaba, apresentam problemas de alucinação, e o pensamento multi-etapas dos modelos de inferência pode amplificar vieses. A avaliação da Vectara mostra que a taxa de alucinação do R1 (14.3%) é muito maior que a do V3 (3.9%). A comunidade acredita que, à medida que a capacidade dos modelos aumenta, as alucinações se tornam mais sutis e logicamente coerentes, dificultando a distinção entre verdadeiro e falso pelos usuários, levantando preocupações sobre a confiabilidade. Ao mesmo tempo, há quem argumente que a alucinação é um subproduto da criatividade, especialmente valioso em áreas como a criação literária. Como definir um nível aceitável de alucinação e como mitigar o problema através de técnicas como RAG, controle de qualidade de dados e modelos críticos, continuam sendo questões exploradas pela indústria. (Fonte: 36氪)

Reflexões e discussões sobre companheiros/amigos de IA: O CEO da Meta, Mark Zuckerberg, propôs o uso de amigos de IA personalizados para satisfazer a necessidade das pessoas por mais conexões sociais (alegando que a pessoa média tem 3 amigos, mas precisa de 15), gerando discussão na comunidade. Sebastien Bubeck acredita que realizar verdadeiros companheiros de IA é muito difícil, sendo crucial que a IA possa responder significativamente a “O que você tem feito ultimamente?”, ou seja, ter suas próprias experiências, e não apenas compartilhar as do usuário. Ele argumenta que a visão atual de companheiros de IA foca demais na experiência compartilhada, ignorando que a própria IA precisa ter experiências independentes para compartilhar, até mesmo fofocas (compartilhar experiências mútuas). Outros comentaristas questionam, da perspectiva do número de Dunbar, se um círculo social vasto composto por IA teria significado real. Há também preocupações de que amigos de IA fornecidos por empresas comerciais possam ter como objetivo final a conversão de marketing direcionado, em vez de companhia genuína. (Fonte: jonst0kes, SebastienBubeck, gfodor, gfodor)

Criação artística por IA provoca emoções e reflexões: Na comunidade, usuários expressaram “tristeza” (grieving) pelo fato de a IA poder criar obras de arte “incrivelmente boas” em pouco tempo, argumentando que isso desafia a singularidade humana na criação artística. Isso gerou discussões sobre arte de IA, a natureza da criatividade humana e o senso de valor pessoal sob o impacto da tecnologia. Alguns comentários sugerem que o prazer da criação artística reside no processo em si, não na competição com a IA; a arte de IA pode servir como fonte de inspiração. Outros acreditam que a arte de IA carece dos “erros” ou da alma da criação humana, parecendo excessivamente perfeita ou estereotipada. Ao mesmo tempo, a discussão se estendeu a reflexões filosóficas sobre simulação emocional por IA, consciência e a estrutura social futura (como a substituição de empregos). (Fonte: Reddit r/ArtificialInteligence)
Ética e responsabilidade da IA: experimentos secretos e divulgação de informações: A comunidade discutiu questões éticas na pesquisa de IA. Uma notícia mencionou pesquisadores de IA realizando experimentos secretos no Reddit para tentar mudar as opiniões dos usuários, levantando preocupações sobre o direito ao consentimento informado e o risco de manipulação por IA. Em outra discussão, um usuário relatou dificuldades ao reportar potenciais problemas de segurança para empresas de IA, enfrentando processos complexos e responsabilidade pouco clara, destacando a imaturidade atual do campo da IA em mecanismos de divulgação responsável e resposta a vulnerabilidades. (Fonte: Reddit r/ArtificialInteligence, nptacek)

Reflexão do campo de NLP sobre a ascensão do ChatGPT: A Quanta Magazine publicou um artigo com entrevistas de vários especialistas em Processamento de Linguagem Natural (NLP), como Chris Potts, Yejin Choi, Emily Bender, revisando o impacto e as reflexões trazidas ao campo após o lançamento do ChatGPT. O artigo explora como a ascensão dos grandes modelos de linguagem desafiou as bases teóricas do NLP tradicional, gerou debates internos, divisões de facções e ajustes nas direções de pesquisa. Membros da comunidade reagiram positivamente ao artigo, considerando que ele resume bem a agitação e o processo de adaptação no campo da linguística após o GPT-3. (Fonte: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
Surgimento e percepção de anúncios gerados por IA: Usuários de redes sociais relataram ter começado a ver anúncios gerados por IA em plataformas como o YouTube, expressando sentir “muito desconforto”. Isso indica que a tecnologia de geração de conteúdo por IA começou a ser aplicada na produção de publicidade comercial, ao mesmo tempo que provoca reações iniciais dos usuários quanto à qualidade, autenticidade e experiência emocional do conteúdo gerado por IA. (Fonte: code_star)
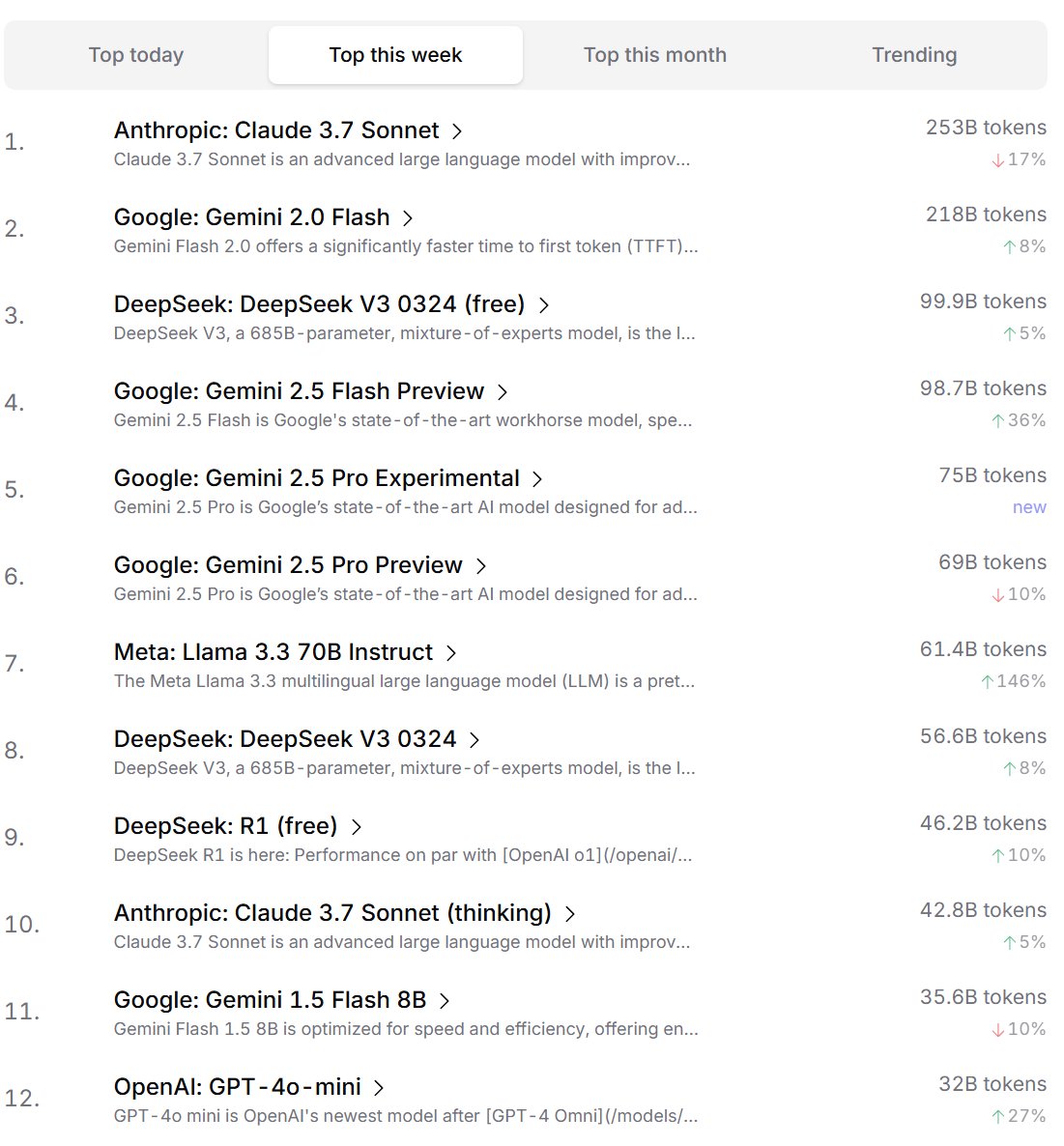
Ranking de preferência de modelos de IA por desenvolvedores: O Cursor.ai publicou o ranking de modelos de IA preferidos por seus usuários (principalmente desenvolvedores), enquanto o Openrouter também divulgou o ranking de uso de tokens por modelo. Esses rankings, baseados em dados de uso real de produtos, são considerados potencialmente mais representativos das preferências dos usuários em cenários reais de desenvolvimento do que rankings de estilo arena como o ChatBot Arena, oferecendo diferentes perspectivas para avaliar a utilidade prática dos modelos. (Fonte: op7418, Reddit r/LocalLLaMA)
Discussão sobre se a IA possui capacidade de “pensar”: Na comunidade, persiste a discussão sobre se os grandes modelos de linguagem (LLMs) realmente possuem capacidade de “pensar”. Alguns argumentam que os LLMs atuais, na verdade, não pensam antes de falar, mas sim simulam o processo de pensamento gerando mais texto (como a cadeia de pensamento), o que seria enganoso. Outros argumentam que usar métodos matemáticos contínuos (como LLMs) para realizar raciocínio discreto em computadores discretos é fundamentalmente problemático. Essas discussões refletem uma reflexão profunda sobre a natureza da tecnologia de IA atual e suas futuras direções de desenvolvimento. (Fonte: francoisfleuret, pmddomingos)
Reflexão dialética sobre o consumo de energia da IA e o impacto ambiental: Em resposta aos problemas ambientais causados pelo enorme consumo de energia para treinamento e operação da IA, surge uma reflexão dialética na comunidade. Uma visão argumenta que a enorme demanda de energia da IA (especialmente de empresas de computação em hiperescala como Google, Amazon, Microsoft) está forçando essas empresas a investir na construção de suas próprias fontes de energia renovável (solar, eólica, baterias), e até mesmo a reiniciar usinas nucleares (como a Microsoft em parceria com a Constellation para reiniciar a usina de Three Mile Island). Essa demanda pode, paradoxalmente, se tornar um catalisador para acelerar a implantação de energia limpa e avanços tecnológicos (como reatores nucleares modulares pequenos – SMR). No entanto, outra visão aponta que o problema de retornos decrescentes do consumo de energia da IA e o consumo de recursos hídricos para resfriamento também merecem atenção. (Fonte: Reddit r/ArtificialInteligence)
Anthropic acusada de tentar limitar a concorrência de chips de IA: A comunidade discute que o CEO da Anthropic, Dario Amodei, defende o fortalecimento dos controles de exportação de chips de IA para lugares como a China, chegando a sugerir que os chips poderiam ser contrabandeados disfarçados de barrigas falsas de grávidas. Críticos argumentam que a medida da Anthropic visa limitar o acesso de concorrentes (especialmente empresas chinesas como DeepSeek, Qwen) a recursos computacionais avançados, a fim de manter sua vantagem no desenvolvimento de modelos de ponta. Essa prática é acusada de usar políticas para reprimir a concorrência, prejudicando o desenvolvimento aberto global da tecnologia de IA e a comunidade de código aberto. (Fonte: Reddit r/LocalLLaMA)

💡 Outros
Reflexões sobre IA e limites cognitivos humanos: Jeff Ladish comenta que a janela de oportunidade para os humanos atuarem como “assistentes de copiar e colar” para a IA é extremamente curta, sugerindo que a capacidade autônoma da IA superará rapidamente a simples assistência. Ao mesmo tempo, o fundador da DeepMind, Hassabis, afirmou em entrevista que uma verdadeira AGI deveria ser capaz de propor independentemente conjecturas científicas valiosas (como Einstein propondo a relatividade geral), e não apenas resolver problemas, argumentando que a IA atual ainda carece de capacidade de geração de hipóteses. Liu Cixin, por sua vez, espera que a IA possa romper os limites cognitivos biológicos do cérebro humano. Essas visões apontam coletivamente para uma reflexão profunda sobre os limites da capacidade da IA, a evolução do papel humano e a natureza da inteligência futura. (Fonte: JeffLadish, 新智元)
LiDAR da Waymo captura momento perigoso: O sistema LiDAR do veículo autônomo da Waymo, em um acidente de motocicleta que conseguiu evitar com sucesso, capturou claramente a imagem em nuvem de pontos 3D do entregador virando no ar durante a colisão. Isso não apenas demonstra a poderosa capacidade do sistema de percepção da Waymo (mesmo em cenários dinâmicos complexos), mas também registrou acidentalmente uma perspectiva única do acidente. Felizmente, ninguém ficou gravemente ferido no acidente. (Fonte: andrew_n_carr)
Nova abordagem para criação de romances com IA: sistema de Promessa de Enredo: O desenvolvedor Levi propôs um sistema de “Promessa de Enredo” (Plot Promise) para a criação de romances com IA, como alternativa ao método tradicional de esboço hierárquico. O sistema, inspirado na teoria de “promessa, progresso, recompensa” de Brandon Sanderson, trata a história como uma série de fios narrativos ativos (promessas), cada um com uma pontuação de importância. O algoritmo sugere o momento de avançar com base na pontuação e no progresso, mas a IA escolhe logicamente a promessa mais adequada para avançar no contexto atual. O usuário pode adicionar ou remover promessas dinamicamente. O método visa aumentar a flexibilidade da história, a escalabilidade (adaptando-se a narrativas ultralongas) e a emergência na criação, mas enfrenta desafios como otimização da decisão da IA, manutenção da coerência a longo prazo e limitações no comprimento do prompt de entrada. (Fonte: Reddit r/ArtificialInteligence)