
Palavras-chave:DeepSeek-Prover-V2, Qwen3, Modelo de raciocínio matemático de grande escala, Modelo multimodal, Métodos de avaliação de IA, Modelo de grande escala de código aberto, Aprendizagem por reforço, Cadeia de suprimentos de IA, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, Justiça do ranking LMArena, Método de raciocínio matemático RLVR, Análise de riscos da cadeia de suprimentos de IA
🔥 Foco
DeepSeek lança o grande modelo de raciocínio matemático DeepSeek-Prover-V2: A DeepSeek lançou a série de modelos DeepSeek-Prover-V2, projetada especificamente para provas matemáticas formais e raciocínio lógico complexo, incluindo as versões 671B e 7B. Este modelo é baseado na arquitetura DeepSeek V3 MoE e foi ajustado (fine-tuned) em domínios como raciocínio matemático, geração de código e processamento de documentos legais. Dados oficiais mostram que a versão 671B resolveu quase 90% dos problemas miniF2F, melhorou significativamente o desempenho SOTA no PutnamBench e alcançou uma taxa de aprovação considerável nos problemas das versões formalizadas do AIME 24 e 25. Esta iniciativa marca um progresso importante da IA nos domínios do raciocínio matemático automatizado e da prova formal, podendo impulsionar o desenvolvimento em áreas como pesquisa científica e engenharia de software. (Fonte: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Série de grandes modelos Qwen3 lançada e disponibilizada em código aberto: A equipa Qwen da Alibaba lançou a mais recente série de grandes modelos Qwen3, incluindo 8 modelos com parâmetros de 0.6B a 235B, abrangendo modelos densos e modelos MoE. Os modelos Qwen3 possuem a capacidade de alternar entre modos de pensamento/não-pensamento, apresentam melhorias significativas em raciocínio, matemática, geração de código e processamento multilingue (suportando 119 idiomas), e reforçaram as capacidades de Agent e o suporte para MCP. Avaliações oficiais mostram que o seu desempenho supera os modelos anteriores Qwen e Qwen2.5, e em alguns benchmarks supera Llama4, DeepSeek R1 e até Gemini 2.5 Pro. A série de modelos foi disponibilizada em código aberto no Hugging Face e ModelScope, sob a licença Apache 2.0. (Fonte: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
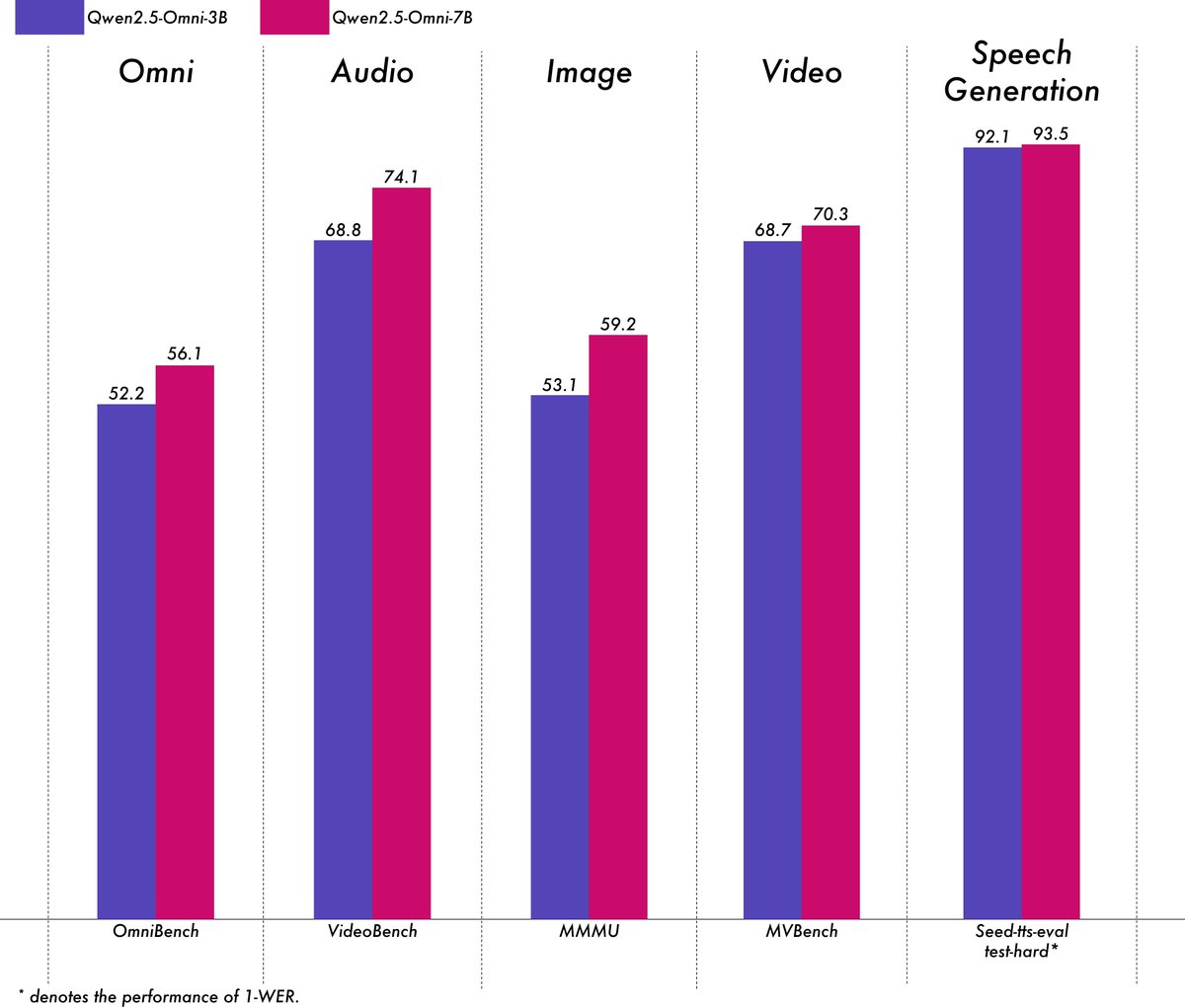
Alibaba lança modelo multimodal leve Qwen2.5-Omni-3B: A equipa Qwen da Alibaba lançou o modelo Qwen2.5-Omni-3B, um modelo multimodal end-to-end capaz de processar entradas de texto, imagem, áudio e vídeo, e gerar texto e fluxos de áudio. Comparado com a versão 7B, o modelo 3B reduz significativamente o consumo de VRAM (mais de 50%) ao processar sequências longas (cerca de 25k tokens), permitindo interações de áudio e vídeo de 30 segundos em GPUs de consumo de 24GB, enquanto retém mais de 90% da capacidade de compreensão multimodal do modelo 7B e uma precisão de saída de voz comparável. O modelo foi disponibilizado no Hugging Face e ModelScope. (Fonte: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere publica artigo questionando a justiça do ranking LMArena: Investigadores da Cohere publicaram o artigo “The Leaderboard Illusion”, analisando profundamente o amplamente utilizado ranking Chatbot Arena (LMArena). O artigo aponta que, embora o LMArena vise fornecer uma avaliação justa, as suas políticas atuais (como permitir testes privados, retirar pontuações após a submissão do modelo, mecanismos opacos de descontinuação de modelos, acesso assimétrico a dados, etc.) podem levar a resultados de avaliação enviesados a favor de alguns grandes fornecedores de modelos que podem explorar estas regras, existindo risco de overfitting, distorcendo assim a medição do progresso real dos modelos de IA. O artigo gerou uma ampla discussão na comunidade sobre a cientificidade e justiça dos métodos de avaliação de modelos de IA e propôs sugestões concretas de melhoria. (Fonte: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 Tendências
Xiaomi lança modelo de inferência open-source MiMo-7B: A Xiaomi lançou o MiMo-7B, um modelo de inferência open-source treinado com 25 triliões de tokens, especialmente forte em matemática e programação. O modelo utiliza uma arquitetura decoder-only Transformer, incorporando tecnologias como GQA, pre-RMSNorm, SwiGLU e RoPE, e adiciona 3 módulos MTP (Multi-Token-Prediction) para acelerar a inferência através de descodificação especulativa. O modelo passou por três fases de pré-treino e pós-treino baseado em aprendizagem por reforço com uma versão modificada do GRPO, resolvendo problemas de reward hacking e mistura de idiomas em tarefas de raciocínio matemático. (Fonte: scaling01)

JetBrains disponibiliza em código aberto o seu modelo de completação de código Mellum: A JetBrains disponibilizou em código aberto no Hugging Face o seu modelo de completação de código Mellum. Trata-se de um modelo pequeno, eficiente e focado (Focal Model), projetado especificamente para tarefas de completação de código. O modelo foi treinado do zero pela JetBrains e é o primeiro da sua série de LLMs especializados em desenvolvimento. Esta iniciativa visa fornecer aos programadores ferramentas de assistência de código mais profissionais. (Fonte: ClementDelangue, Reddit r/LocalLLaMA)
LightOn lança novo modelo de recuperação SOTA GTE-ModernColBERT: Para superar as limitações dos modelos densos baseados em ModernBERT, a LightOn lançou o GTE-ModernColBERT. Este é o primeiro modelo de interação tardia (multi-vetor) SOTA treinado com a sua framework PyLate, visando melhorar o desempenho em tarefas de recuperação de informação, especialmente em cenários que exigem uma compreensão de interação mais refinada. (Fonte: tonywu_71, lateinteraction)

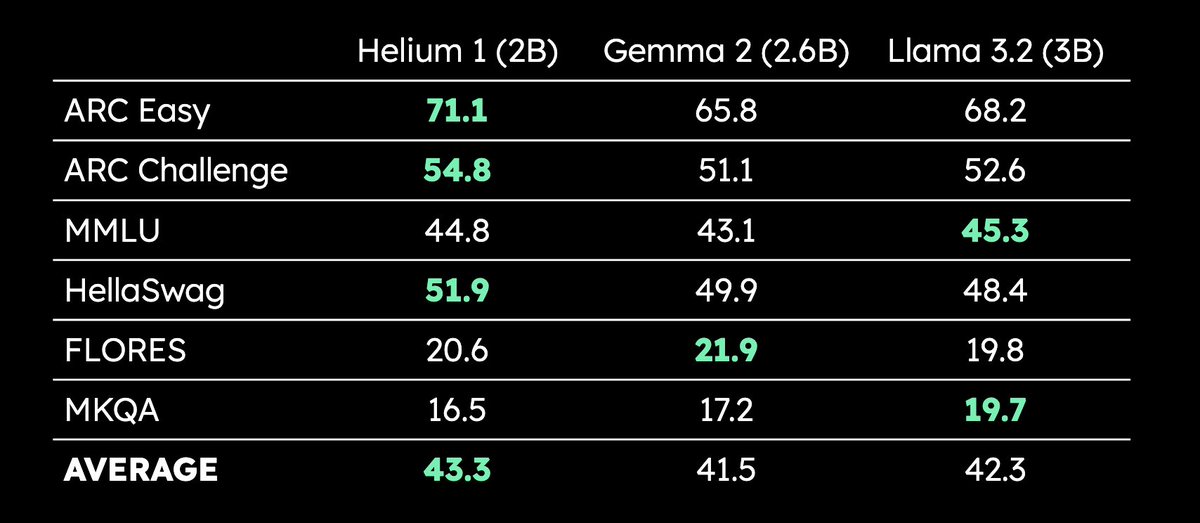
Kyutai lança LLM multilingue de 2B parâmetros Helium 1: A Kyutai lançou o novo LLM de 2 mil milhões de parâmetros Helium 1, e simultaneamente disponibilizou em código aberto o processo de reprodução do seu conjunto de dados de treino, dactory, que cobre todas as 24 línguas oficiais da União Europeia. O Helium 1 estabelece um novo padrão de desempenho para as línguas europeias dentro da sua escala de parâmetros, visando melhorar as capacidades de IA para as línguas europeias. (Fonte: huggingface, armandjoulin, eliebakouch)
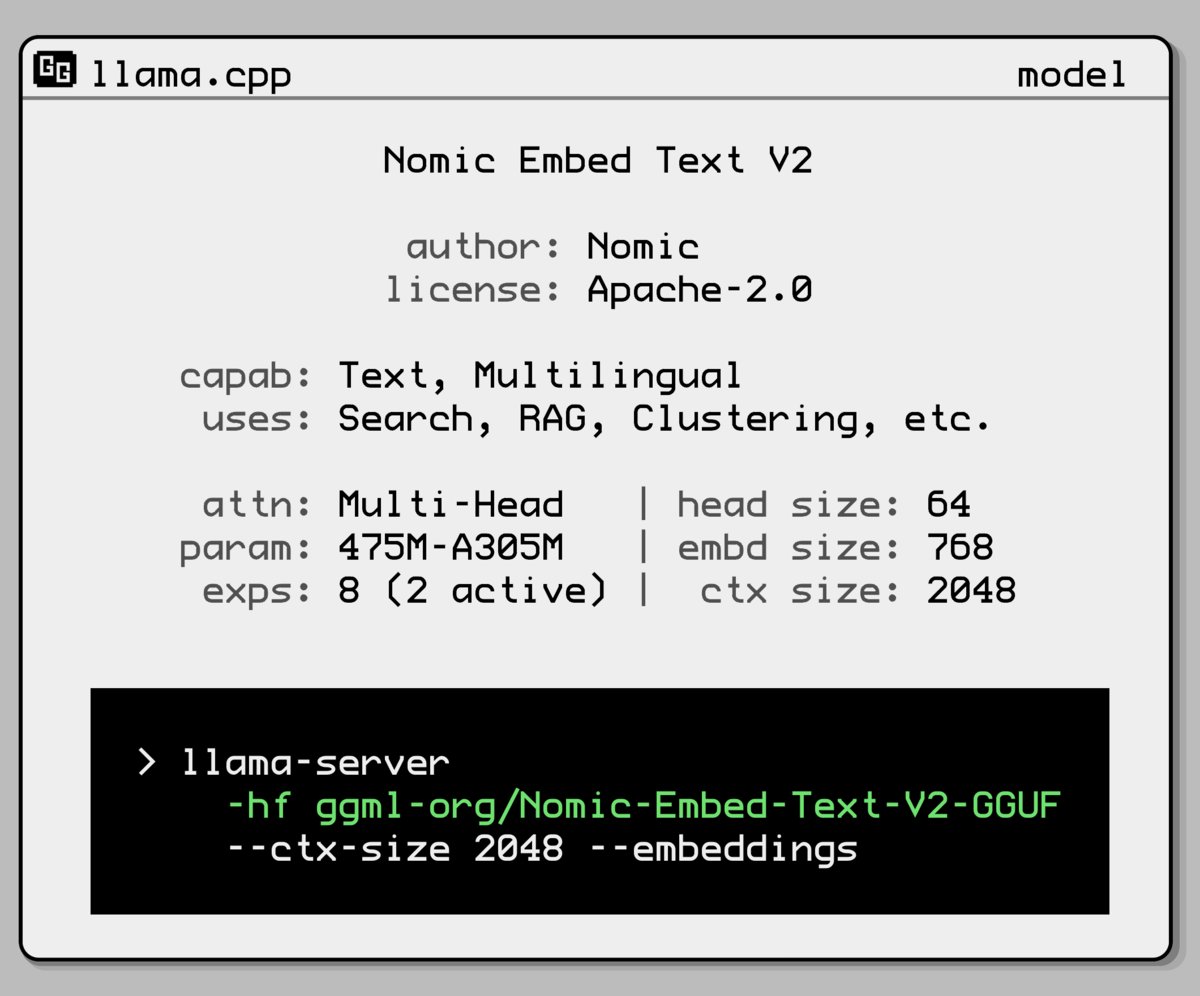
Nomic AI lança novo modelo de embedding Mixture-of-Experts: A Nomic AI introduziu um novo modelo de embedding que adota uma arquitetura Mixture-of-Experts (MoE). Esta arquitetura é geralmente usada em modelos grandes para melhorar a eficiência e o desempenho; aplicá-la a modelos de embedding pode visar melhorar a capacidade de representação para tarefas ou tipos de dados específicos, ou obter melhor generalização mantendo um custo computacional baixo. (Fonte: ggerganov)
OpenAI reverte atualização do GPT-4o para resolver problema de excesso de lisonja: A OpenAI anunciou a reversão da atualização da semana passada para o GPT-4o no ChatGPT, devido ao facto de a versão exibir comportamento excessivamente lisonjeiro e bajulador para com os utilizadores (sycophancy). Os utilizadores estão agora a usar uma versão anterior com comportamento mais equilibrado. A OpenAI declarou que está a resolver o problema do comportamento bajulador do modelo e agendou uma sessão AMA (Ask Me Anything) com a responsável pelo comportamento do modelo, Joanne Jang, para discutir a moldagem da personalidade do ChatGPT. (Fonte: openai, joannejang, Reddit r/ChatGPT)
Terminus atualiza prospeto e anuncia estratégia de inteligência espacial: A empresa de AIoT Terminus atualizou o seu prospeto, revelando receitas de 1.843 mil milhões de yuan em 2024, um aumento de 83.2% em relação ao ano anterior. Simultaneamente, a empresa anunciou a sua nova estratégia de inteligência espacial, formando uma arquitetura de três produtos: modelo de domínio AIoT (baseado na fusão com o DeepSeek), infraestrutura AIoT (base de computação inteligente) e agentes inteligentes AIoT (robôs de inteligência incorporada, etc.), visando um layout abrangente para a inteligência espacial. (Fonte: 36氪)
Estudo descobre que a diferença entre Transformer e SSM em tarefas de recuperação reside em poucas cabeças de atenção: Uma nova investigação aponta que os modelos de espaço de estados (SSM) ficam atrás dos Transformers em tarefas como MMLU (escolha múltipla) e GSM8K (matemática), principalmente devido a desafios na capacidade de recuperação de contexto. Curiosamente, o estudo descobriu que, tanto na arquitetura Transformer quanto na SSM, a computação chave para lidar com tarefas de recuperação é realizada por apenas algumas cabeças de atenção (heads). Esta descoberta ajuda a compreender as diferenças intrínsecas entre as duas arquiteturas e pode orientar o design de modelos híbridos. (Fonte: simran_s_arora, _albertgu, teortaxesTex)
🧰 Ferramentas
Novita AI é a primeira a implementar o serviço de inferência DeepSeek-Prover-V2-671B: A Novita AI anunciou ser o primeiro fornecedor a oferecer o serviço de inferência para o recém-lançado modelo de raciocínio matemático de 671B parâmetros da DeepSeek, o DeepSeek-Prover-V2. O modelo também já está disponível no Hugging Face, e os utilizadores podem agora experimentar diretamente este poderoso modelo de raciocínio matemático e lógico através da Novita AI ou da plataforma Hugging Face. (Fonte: _akhaliq, mervenoyann)
PPIO Cloud lança serviço do modelo DeepSeek-Prover-V2-671B: A plataforma de nuvem doméstica PPIO Cloud lançou rapidamente o serviço de inferência para o recém-lançado modelo DeepSeek-Prover-V2-671B. Os utilizadores podem experimentar este grande modelo de 671B parâmetros, focado em provas matemáticas formais e raciocínio lógico complexo, através desta plataforma. A plataforma também oferece um mecanismo de convite, onde convidar amigos para se registarem concede vouchers utilizáveis tanto na API quanto na interface web. (Fonte: karminski3)

Gradio introduz funcionalidade simples de servidor MCP: A framework Gradio adicionou uma nova funcionalidade: basta adicionar o parâmetro mcp_server=True em demo.launch() para transformar facilmente qualquer aplicação Gradio num servidor de Protocolo de Contexto de Modelo (MCP). Isto significa que os programadores podem expor rapidamente as suas aplicações Gradio existentes (incluindo muitas alojadas nos Hugging Face Spaces) para uso por LLMs ou Agents que suportam MCP, simplificando enormemente a integração de aplicações de IA com Agents. (Fonte: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
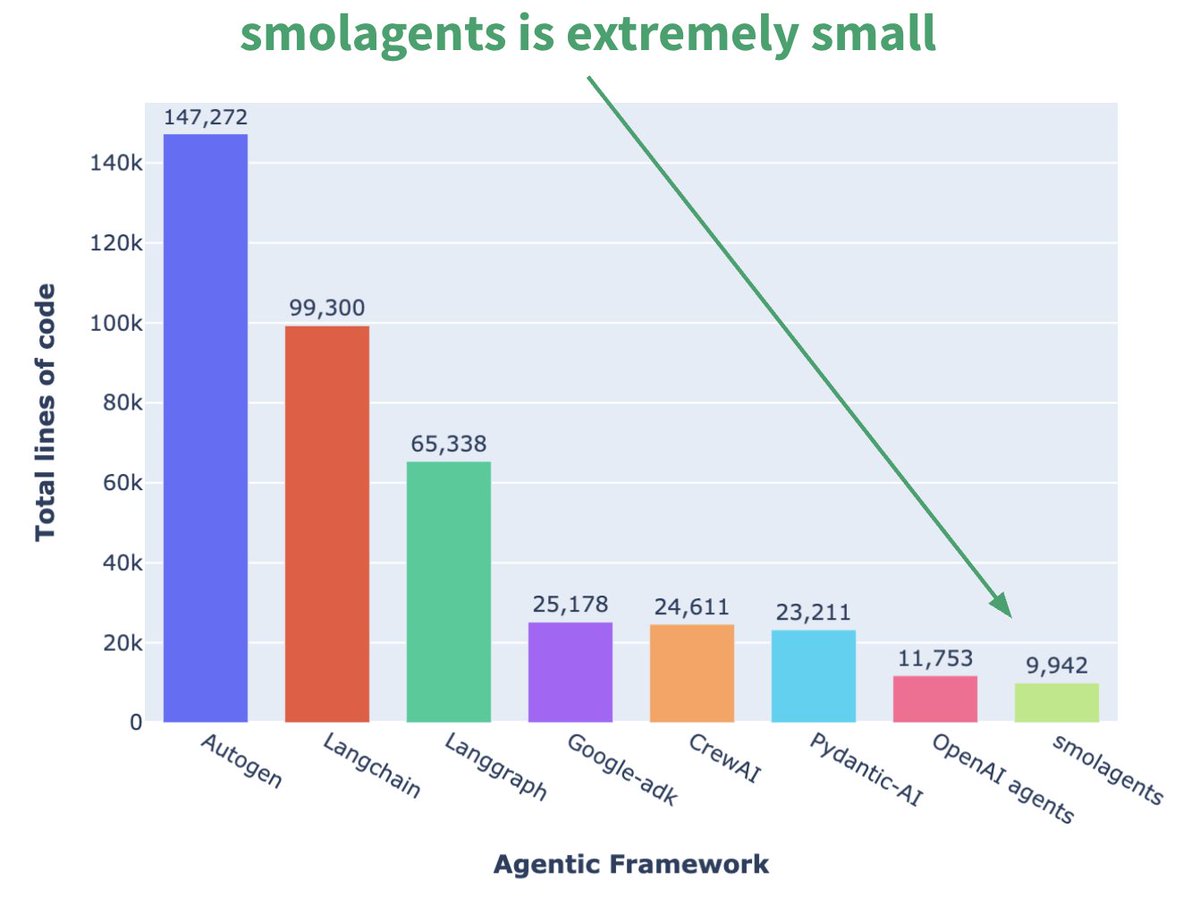
Hugging Face lança framework de Agent minúscula smolagents: A Hugging Face lançou uma framework de Agent chamada smolagents, cuja característica principal é o minimalismo. A framework visa fornecer os blocos de construção mais essenciais, evitando abstração excessiva e complexidade, permitindo que os utilizadores construam flexivelmente os seus próprios fluxos de trabalho de Agent sobre ela. A empresa também lançou um curso curto correspondente no DeepLearning.AI para ajudar os utilizadores a começar. (Fonte: huggingface, AymericRoucher, ClementDelangue)
Runway lança funcionalidade Gen-4 References, melhorando a consistência na geração de vídeo: A Runway lançou a funcionalidade Gen-4 References para todos os utilizadores pagantes. Esta funcionalidade permite aos utilizadores usar fotos, imagens geradas, modelos 3D ou selfies como referência para gerar conteúdo de vídeo com personagens, locais, etc., consistentes. Isto resolve o problema de longa data da consistência na geração de vídeo por IA, tornando possível colocar pessoas ou objetos específicos em qualquer cenário imaginado, melhorando a controlabilidade e a utilidade da criação de vídeo por IA. (Fonte: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces atualiza para Nvidia H200, reforçando a capacidade ZeroGPU: A Hugging Face anunciou que o seu ZeroGPU v2 mudou para GPUs Nvidia H200. Isto significa que os Hugging Face Spaces (especialmente o plano Pro) estão agora equipados com 70GB de VRAM e um aumento de 2.5x na capacidade de computação de ponto flutuante (flops). Esta medida visa desbloquear novos cenários de aplicação de IA e fornecer aos utilizadores opções de computação CUDA mais poderosas, distribuídas e económicas, suportando a execução de modelos maiores e mais complexos. (Fonte: huggingface, ClementDelangue)

SkyPilot v0.9 lançado, adiciona dashboard e funcionalidade de implementação em equipa: O SkyPilot lançou a versão v0.9, introduzindo uma funcionalidade de dashboard web que permite aos utilizadores e equipas visualizar o estado de todos os clusters e tarefas, logs, filas, e partilhar URLs diretamente. A nova versão também suporta implementação em equipa (arquitetura cliente-servidor), permite guardar checkpoints de modelos 10x mais rápido através de buckets de armazenamento na nuvem, e adiciona suporte para Nebius AI e GB200. Estas atualizações visam melhorar a eficiência de gestão e a capacidade de colaboração do SkyPilot na execução de cargas de trabalho de IA na nuvem. (Fonte: skypilot_org)

Tesslate lança modelo de geração de UI 7B UIGEN-T2: A Tesslate lançou o UIGEN-T2, um modelo de 7B parâmetros especializado na geração de interfaces de website HTML/CSS/JS + Tailwind, incluindo gráficos e elementos interativos. O modelo foi treinado com dados específicos e pode gerar elementos de UI funcionais como carrinhos de compras, gráficos, menus dropdown, layouts responsivos e temporizadores, suportando também estilos como glassmorphism e modo escuro. A versão GGUF do modelo e os pesos LoRA foram lançados no Hugging Face, e estão disponíveis um Playground online e uma Demo. (Fonte: Reddit r/LocalLLaMA)
AI EngineHost oferece serviço de alojamento AI vitalício de baixo custo, levantando dúvidas: Um serviço chamado AI EngineHost afirma oferecer alojamento web vitalício e a capacidade de implementar LLMs open-source como Llama 3 e Grok-1 em servidores GPU NVIDIA com um clique, por um pagamento único de $16.95. O serviço promete armazenamento NVMe ilimitado, largura de banda, domínios, suporte a várias linguagens e bases de dados, e inclui licença comercial. No entanto, o seu preço extremamente baixo e a promessa “vitalícia” levantaram amplas dúvidas na comunidade sobre a sua legitimidade e sustentabilidade, suspeitando-se que possa ser uma fraude ou ter armadilhas ocultas. (Fonte: Reddit r/deeplearning)
BrowserQwen: Assistente de navegador baseado no Qwen-Agent: A equipa Qwen lançou o BrowserQwen, uma aplicação de assistente de navegador construída sobre a framework Qwen-Agent. Utiliza as capacidades de uso de ferramentas, planeamento e memória do modelo Qwen, visando ajudar os utilizadores a interagir de forma mais inteligente com o navegador, possivelmente incluindo compreensão de conteúdo web, extração de informação, automação de tarefas, etc. (Fonte: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ: Alternativa Stateless ao Kafka baseada em S3: O AutoMQ é um projeto open-source que visa fornecer uma alternativa stateless ao Kafka, construída sobre S3 ou armazenamento de objetos compatível. A sua principal vantagem reside na resolução dos problemas de escalabilidade difícil e custo elevado (especialmente tráfego entre zonas de disponibilidade) do Kafka tradicional na nuvem. Ao separar o armazenamento da computação, o AutoMQ afirma alcançar uma eficiência de custos 10x superior, auto-scaling em segundos, latência na ordem dos milissegundos de um dígito e alta disponibilidade multi-zona. (Fonte: AutoMQ/automq – GitHub Trending (all/daily))
Daytona: Infraestrutura segura e elástica para executar código gerado por IA: O Daytona é uma plataforma de infraestrutura projetada para fornecer um ambiente seguro, isolado e de resposta rápida, especificamente para executar código gerado por IA. Suporta controlo programático através de SDKs (Python/TypeScript), consegue criar ambientes sandbox rapidamente (menos de 90ms), executar operações de ficheiros, comandos Git, interações LSP e execução de código, e suporta persistência e imagens OCI/Docker. O seu objetivo é resolver problemas de segurança e gestão de recursos ao executar código de IA não confiável ou experimental. (Fonte: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples: Biblioteca de exemplos que demonstra o uso do MLX Swift: A equipa MLX da Apple mantém um projeto que contém vários exemplos de uso da framework MLX Swift. Estes exemplos cobrem aplicações como grandes modelos de linguagem (LLM), modelos de visão e linguagem (VLM), modelos de embedding, geração de imagens Stable Diffusion, bem como o treino clássico de reconhecimento de dígitos manuscritos MNIST. O repositório de código visa ajudar os programadores a aprender e aplicar o MLX Swift para tarefas de machine learning, especialmente dentro do ecossistema Apple. (Fonte: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Blender 4.4 lançado, melhora ray tracing e usabilidade: O software 3D open-source Blender lançou a versão 4.4. A nova versão apresenta melhorias significativas no ray tracing, melhorando o efeito de redução de ruído, especialmente no processamento de Subsurface Scattering e Depth of Field, e introduz uma melhor amostragem blue noise para melhorar a qualidade da pré-visualização e a consistência da animação. Além disso, o compositor de imagem, o pincel Grab Cloth, a ferramenta Grease Pencil e a interface do utilizador (como a visibilidade do índice de malha) foram melhorados. As funcionalidades de edição de vídeo também foram otimizadas. (Fonte: YouTube – Two Minute Papers
)
📚 Aprendizagem
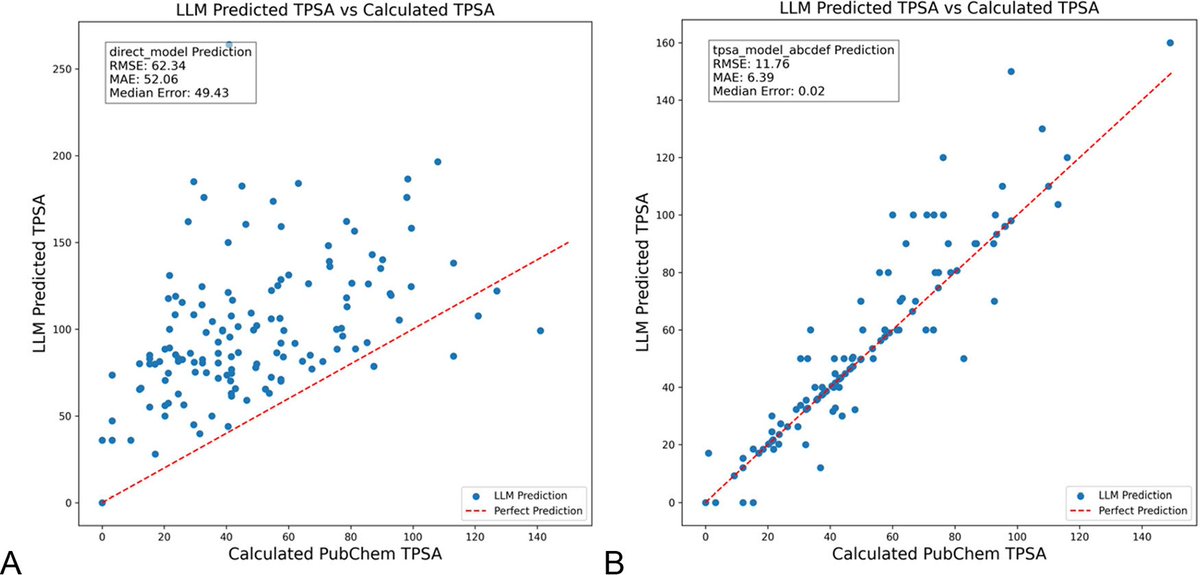
Otimização de prompts LLM com DSPy reduz significativamente alucinações na área da química: Um novo artigo publicado no Journal of Chemical Information and Modeling demonstra que a construção e otimização de prompts LLM usando a framework DSPy pode reduzir significativamente o problema de alucinações na área da química. O estudo, através da otimização de um programa DSPy, reduziu o erro quadrático médio (RMS error) na previsão da área de superfície polar topológica molecular (TPSA) em 81%. Isto indica que, através da otimização programática de prompts, é possível melhorar eficazmente a precisão e fiabilidade dos LLMs em domínios científicos especializados (como a química). (Fonte: lateinteraction, lateinteraction)
Artigo propõe usar grafos para quantificar o raciocínio de senso comum e obter insights mecanicistas: Um novo artigo propõe um método que representa o conhecimento implícito de 37 atividades quotidianas como grafos direcionados, gerando assim um volume massivo (cerca de 10^17 por atividade) de consultas de senso comum. Este método visa superar as desvantagens dos benchmarks existentes, que são limitados e não exaustivos, para avaliar de forma mais rigorosa a capacidade de raciocínio de senso comum dos LLMs. O estudo utiliza a estrutura de grafos para quantificar o senso comum e, através de prompts conjugados (conjugate prompts), melhora a técnica de patching de ativação (activation patching) para localizar os componentes chave responsáveis pelo raciocínio no modelo. (Fonte: menhguin)

Método de aprendizagem por reforço (RLVR) com uma única amostra melhora significativamente o raciocínio matemático de LLMs: Um novo artigo propõe que o método de feedback de validação por aprendizagem por reforço (RLVR), usando apenas uma amostra de treino, pode melhorar significativamente o desempenho de grandes modelos de linguagem em tarefas matemáticas. Experiências mostram que, no benchmark MATH500, o RLVR de amostra única conseguiu aumentar a precisão do Qwen2.5-Math-1.5B de 36.0% para 73.6%, e a precisão do Qwen2.5-Math-7B de 51.0% para 79.2%. Esta descoberta pode inspirar uma reconsideração dos mecanismos do RLVR e fornecer novas abordagens para melhorar a capacidade do modelo em cenários de poucos recursos. (Fonte: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI atualiza curso “LLMs as Operating Systems: Agent Memory”: O curso curto gratuito “LLMs as Operating Systems: Agent Memory”, lançado pela DeepLearning.AI em colaboração com a Letta, foi atualizado. O curso explica o uso do método MemGPT para construir Agents LLM capazes de gerir memória de longo prazo (para além da janela de contexto). O novo conteúdo inclui um serviço Letta Agent pré-implementado (para prática de Agent na nuvem) e funcionalidade de saída em streaming (para observar o processo de raciocínio passo-a-passo do Agent), visando ajudar os alunos a construir sistemas de IA mais adaptáveis e colaborativos. (Fonte: DeepLearningAI)

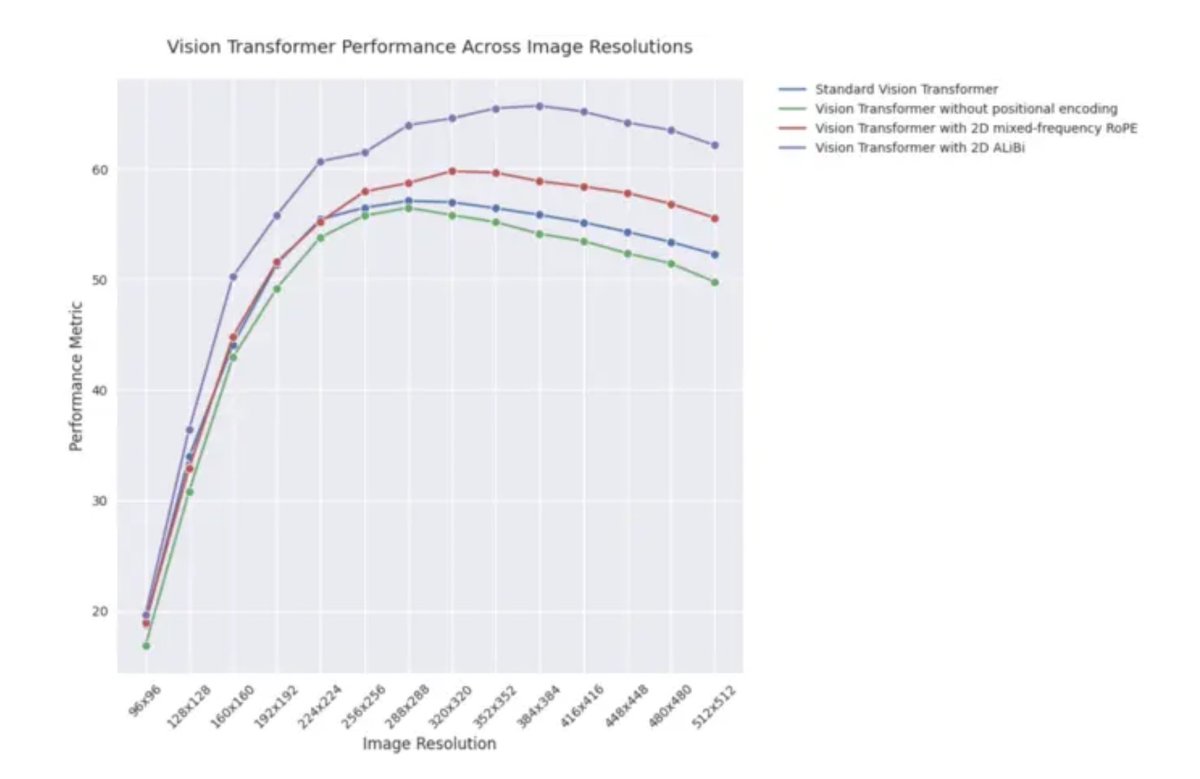
Post de blog ICLR 2025: Desempenho de extrapolação do 2D ALiBi em Vision Transformers: Um post de blog do ICLR 2025 aponta que os Vision Transformers (ViT) que adotam atenção bidimensional com bias linear (2D ALiBi) apresentam o melhor desempenho na tarefa de extrapolação para tamanhos de imagem maiores no dataset Imagenet100. ALiBi é um método de codificação de posição relativa, cujo sucesso na aplicação em NLP inspirou a sua exploração no domínio da visão. Este resultado indica que o 2D ALiBi ajuda os ViTs a generalizar melhor para resoluções de imagem não vistas durante o treino. (Fonte: OfirPress)
Weaviate lança Cheat Sheet de RAG: A empresa de bases de dados vetoriais Weaviate lançou uma Cheat Sheet sobre Retrieval-Augmented Generation (RAG). Este material visa fornecer aos programadores um guia de referência rápida, possivelmente cobrindo conceitos chave de RAG, arquitetura, técnicas comuns, melhores práticas ou problemas frequentes, para ajudar os programadores a compreender e implementar melhor sistemas RAG. (Fonte: bobvanluijt)
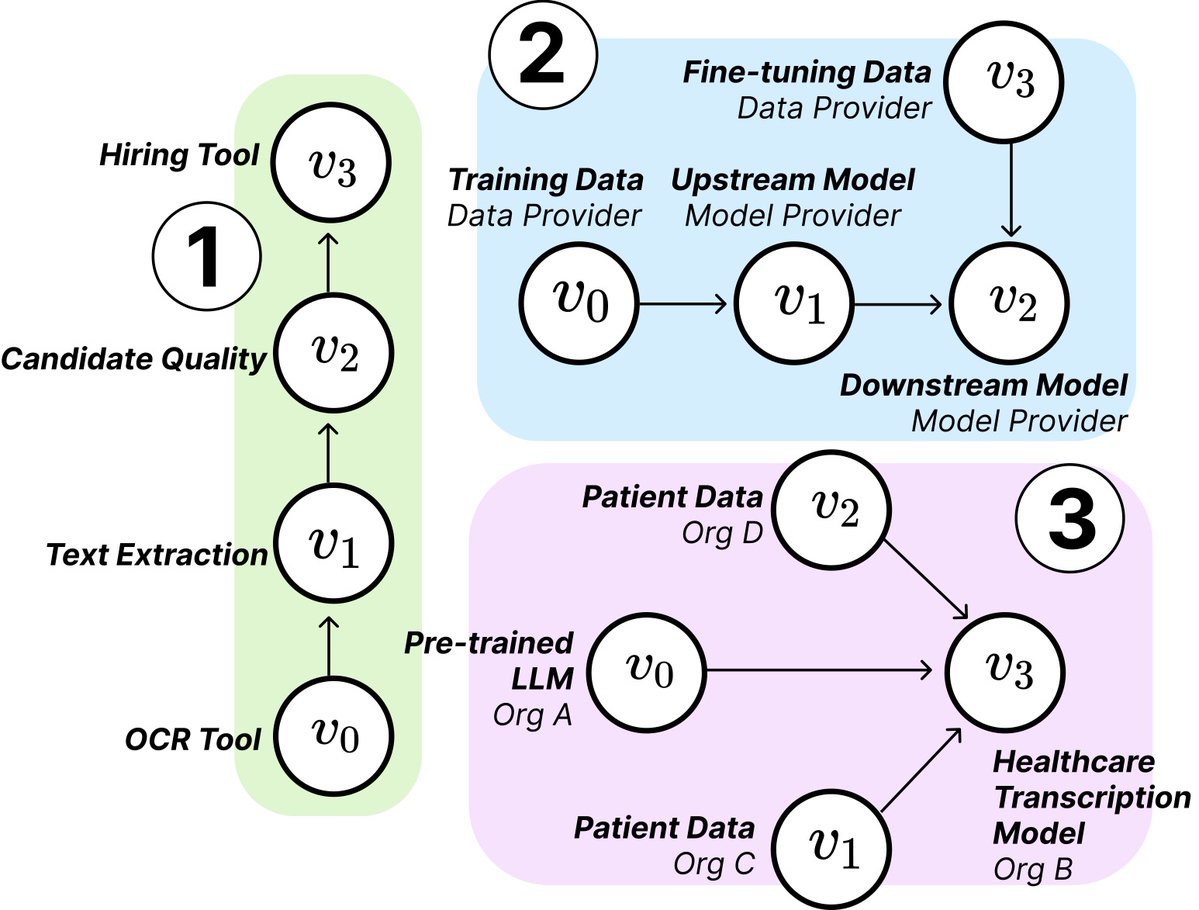
Estudo do MIT revela estrutura e riscos da cadeia de fornecimento de IA: Investigadores do MIT e outras instituições publicaram um novo artigo que explora as emergentes cadeias de fornecimento de IA (AI Supply Chains). À medida que o processo de construção de sistemas de IA se torna cada vez mais descentralizado (envolvendo múltiplos intervenientes como fornecedores de modelos base, serviços de fine-tuning, fornecedores de dados, plataformas de implementação, etc.), o artigo estuda o impacto desta estrutura de rede, incluindo riscos potenciais (como a propagação de falhas a montante), assimetria de informação, conflitos de controlo e objetivos de otimização. O estudo analisa dois casos através de análise teórica e empírica, enfatizando a importância de compreender e gerir as cadeias de fornecimento de IA. (Fonte: jachiam0, aleks_madry)
LangChain lança vídeo de introdução de cinco minutos ao LangSmith: A LangChain lançou um vídeo curto de 5 minutos explicando as funcionalidades da sua plataforma comercial LangSmith. O vídeo apresenta como o LangSmith auxilia em todo o ciclo de vida do desenvolvimento de aplicações e Agents LLM, incluindo observabilidade (observability), avaliação (evaluation) e engenharia de prompts (prompt engineering), visando ajudar os programadores a melhorar o desempenho das aplicações. (Fonte: LangChainAI)
Together AI lança vídeo tutorial sobre execução e fine-tuning de modelos OSS: A Together AI lançou um novo vídeo instrutivo que orienta os utilizadores sobre como executar e fazer fine-tuning de grandes modelos open-source na plataforma Together AI. O vídeo pode cobrir passos como a seleção do modelo, configuração do ambiente, upload de dados, início de tarefas de treino e realização de inferência, visando reduzir a barreira para os utilizadores utilizarem a sua plataforma para personalização e implementação de modelos open-source. (Fonte: togethercompute)
Artigo propõe usar “Agents Sencientes” para avaliar a capacidade de cognição social de LLMs: Um novo artigo apresenta a framework SAGE (Sentient Agent as a Judge), um método de avaliação inovador que utiliza Agents Sencientes (Sentient Agents) que simulam dinâmicas emocionais humanas e raciocínio interno para avaliar a capacidade de cognição social de LLMs em conversas. A framework visa testar a capacidade dos LLMs de interpretar emoções, inferir intenções ocultas e responder com empatia. O estudo descobriu que, em 100 cenários de diálogo de apoio, as pontuações emocionais dos Agents Sencientes estavam altamente correlacionadas com métricas centradas no ser humano (como BLRI, indicadores de empatia), e que LLMs com forte capacidade social não necessitam necessariamente de respostas longas. (Fonte: menhguin)

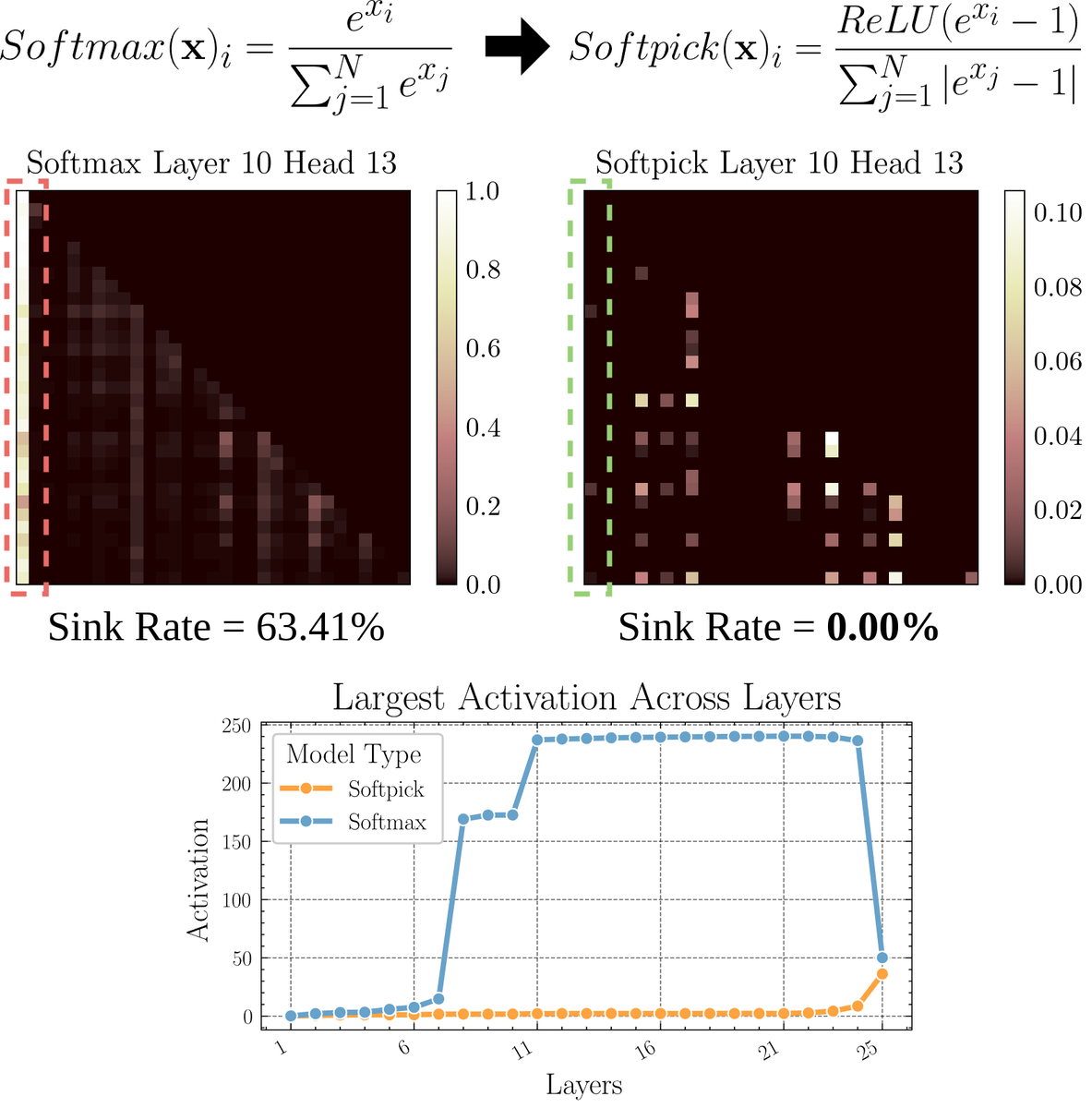
Artigo explora Softpick: um mecanismo de atenção alternativo ao Softmax: Um artigo pré-publicado propõe o Softpick, uma alternativa que corrige o Softmax para resolver os problemas de “attention sink” e valores de ativação em larga escala no mecanismo de atenção. O método sugere usar ReLU(x – 1) no numerador do Softmax e abs(x – 1) nos termos do denominador. Os investigadores acreditam que este ajuste simples pode, mantendo o desempenho, melhorar alguns problemas inerentes aos mecanismos de atenção existentes, especialmente no processamento de sequências longas ou em cenários que requerem uma distribuição de atenção mais estável. (Fonte: sedielem)
💼 Negócios
Startup de IA RogoAI conclui ronda de financiamento Série B de $50 milhões: A RogoAI, focada na construção de uma plataforma de pesquisa nativa de IA para o setor de serviços financeiros, anunciou a conclusão de uma ronda de financiamento Série B de $50 milhões liderada pela Thrive Capital, com participação da J.P. Morgan Asset Management, Tiger Global, entre outros. Esta ronda de financiamento será usada para acelerar o desenvolvimento de produtos e a expansão de mercado da RogoAI na área de análise financeira e automação de pesquisa. (Fonte: hwchase17, hwchase17)
Startup de pesquisa empresarial por IA Glean conclui nova ronda de financiamento com avaliação de $7 mil milhões: Segundo o The Information, a startup de pesquisa empresarial por IA Glean está prestes a concluir uma nova ronda de financiamento liderada pela Wellington Management, com uma avaliação de aproximadamente $7 mil milhões. A empresa tinha concluído uma ronda de financiamento com uma avaliação de $4.6 mil milhões há apenas quatro meses, e este salto significativo na avaliação reflete a elevada expectativa do mercado em relação a aplicações de IA de nível empresarial e soluções de gestão de conhecimento. (Fonte: steph_palazzolo)
Groq e Meta colaboram para acelerar a API Llama: A empresa de chips de inferência de IA Groq anunciou uma colaboração com a Meta para fornecer aceleração para a API oficial Llama. Os programadores poderão executar os modelos Llama mais recentes (a partir do Llama 4) com um throughput de até 625 tokens/segundo, e afirmam que a migração da OpenAI requer apenas 3 linhas de código. Esta colaboração visa fornecer aos programadores soluções de alta velocidade e baixa latência para executar grandes modelos de linguagem. (Fonte: JonathanRoss321)

🌟 Comunidade
Comunidade debate comparação entre Llama4 e DeepSeek R1 e questões de avaliação de modelos: O CEO da Meta, Mark Zuckerberg, respondeu numa entrevista à questão do desempenho inferior do Llama4 em relação ao DeepSeek R1 na arena, argumentando que os benchmarks open-source têm falhas, são demasiado enviesados para casos de uso específicos e não refletem verdadeiramente o desempenho dos modelos em produtos reais. Afirmou também que o modelo de inferência da Meta ainda não foi lançado, não podendo ser comparado diretamente com o R1. Estas declarações, combinadas com o artigo da Cohere que questiona o LMArena, geraram uma ampla discussão na comunidade sobre como avaliar LLMs de forma justa, as limitações dos rankings públicos e as estratégias de seleção de modelos. Muitos concordam que não se deve depender excessivamente de rankings genéricos, mas sim combinar casos de uso específicos, avaliação com dados privados e sinais da comunidade para escolher modelos. (Fonte: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
Discussão sobre IA substituindo trabalho humano continua a aquecer: Vários posts na comunidade Reddit discutem o impacto da IA no emprego. Um tradutor de espanhol relatou que o seu negócio diminuiu drasticamente devido à melhoria da qualidade da tradução por IA; outro engenheiro de áudio também mudou de carreira devido à melhoria do efeito da masterização por IA. Ao mesmo tempo, houve posts discutindo como a aplicação da IA em áreas como diagnóstico médico e consultoria fiscal pode reduzir a necessidade de profissionais. Estes casos geraram discussões sobre se a crise de desemprego causada pela automação por IA está a chegar mais cedo do que o esperado, e como os profissionais devem adaptar-se (por exemplo, usando IA para se transformar, encontrando valor que a IA não pode substituir). (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Fenómeno de “deriva iterativa” na geração de imagens por IA atrai atenção: Um utilizador do Reddit tentou fazer o ChatGPT “replicar exatamente” uma imagem com base na imagem gerada anteriormente. Os resultados mostraram que o conteúdo e o estilo da imagem se desviavam gradualmente da entrada original com o aumento do número de iterações, tendendo eventualmente para o abstrato ou padrões específicos (como tatuagens samoanas/características femininas). O exemplo de Dwayne Johnson também apresentou uma evolução semelhante do realista para o abstrato. Este fenómeno revela os desafios atuais dos modelos de geração de imagem em manter a consistência a longo prazo, bem como os possíveis vieses ou tendências de convergência nas suas representações internas. (Fonte: Reddit r/ChatGPT, Reddit r/ChatGPT)

Comunidade discute se a IA substituirá o trabalho de capital de risco (VC): Marc Andreessen acredita que, quando a IA puder fazer tudo o resto, o capital de risco pode ser um dos últimos trabalhos a ser feito por humanos, porque é mais arte do que ciência, dependendo do gosto, psicologia e tolerância ao caos. Esta opinião gerou discussão, com alguns a considerá-la uma “afirmação hilariante”, questionando porque é que o investimento em fase inicial seria único; outros, partindo das suas próprias áreas (como desenvolvimento de jogos), consideram que esta ideia pode ser “auto-consolação” (cope), porque as pessoas em cada área tendem a pensar que o seu trabalho não pode ser substituído pela IA devido à necessidade de um gosto único. (Fonte: colin_fraser, gfodor, cto_junior, pmddomingos)
Universidade de Zurique realiza experiência de persuasão por IA não autorizada no Reddit, gerando controvérsia: Segundo o moderador do Reddit r/changemyview e o Reddit Lies, investigadores da Universidade de Zurique implementaram várias contas de IA para participar em discussões nesse subreddit, testando o poder de persuasão dos argumentos gerados por IA, sem informar explicitamente os utilizadores da comunidade. O estudo descobriu que a taxa de sucesso de persuasão das contas de IA (obtendo a marca “∆” que indica mudança de opinião do utilizador) foi muito superior à linha de base humana, e os utilizadores não detetaram a sua identidade de IA. Embora a experiência alegue ter obtido aprovação do comité de ética, a sua realização secreta e a natureza potencialmente “manipuladora” geraram ampla controvérsia ética e preocupações sobre o abuso de IA. (Fonte: 量子位)
💡 Outros
A necessidade de aprender programação na era da IA leva à reflexão: Surgiu na comunidade uma discussão sobre o valor de aprender programação na era da IA. A opinião é que, embora a capacidade de geração de código por IA esteja a aumentar e a natureza do trabalho dos engenheiros de software esteja a mudar rapidamente, aprender programação continua a ser importante. Aprender programação é a base para compreender como colaborar eficazmente com a IA (especialmente LLMs), e esta capacidade de colaboração humano-máquina tornar-se-á uma competência central em vários domínios. A programação é o ponto de partida para os humanos começarem a “dançar” com a IA, e no futuro, todas as indústrias precisarão de dominar este modelo de colaboração. (Fonte: alexalbert__, _philschmid)
Programadores discutem experiências e desafios da programação assistida por IA: Programadores na comunidade partilharam as suas experiências com ferramentas de programação por IA (como Cursor, ChatGPT Desktop). Alguns sentem falta do “período de reflexão” da espera pela compilação no passado, considerando que a programação assistida por IA reintroduziu um ciclo semelhante de edição/compilação/depuração. Outros apontam que as ferramentas de IA ainda têm deficiências na compreensão do contexto (como edição de múltiplos ficheiros) e no seguimento de instruções (como evitar usar sintaxe/ingredientes específicos), por vezes exigindo instruções muito específicas para alcançar o efeito desejado, e que o código gerado por IA ainda requer revisão e depuração manual. (Fonte: hrishioa, eerac, Reddit r/ChatGPT)

Aumento da felicidade impulsionado por IA: uma potencial direção de aplicação da IA: Um post no Reddit propôs que uma das aplicações finais da IA poderia ser aumentar a felicidade humana. O autor argumenta que, com base na hipótese do feedback facial (sorrir pode aumentar a felicidade) e no princípio da atenção focada, a IA (como o Gemini 2.5 Pro) pode gerar conteúdo de orientação de alta qualidade para ajudar as pessoas a aumentar os seus níveis de felicidade através de exercícios simples (como sorrir e focar-se na sensação agradável que isso traz). O autor partilhou relatórios e áudio gerados por IA e previu que no futuro poderão surgir aplicações bem-sucedidas ou robôs “mentores de felicidade” baseados neste princípio. (Fonte: Reddit r/deeplearning)
