Palavras-chave:robô humanóide, aplicação de IA, AGI, condução autónoma, maratona de robôs humanóides, Agente+MCP, previsão AGI da DeepMind, FSD puramente visual da Tesla, clonagem de voz GPT-SoVITS, raciocínio químico ChemAgent, modelo de negócio da robótica Inteligência Primordial, desafio ao monopólio de GPUs da NVIDIA
🔥 Foco
Robôs humanoides fazem “estreia” na Meia Maratona de Pequim, entre oportunidades e desafios: Na Meia Maratona de Pequim Yizhuang 2025, 21 equipas de robôs humanoides competiram pela primeira vez ao lado de atletas humanos. TianGong Ultra, SongYan Dynamics N2 e Zhuoyi Dynamics Walker II ficaram nos três primeiros lugares. A competição destacou o potencial dos robôs humanoides, mas também expôs numerosos desafios, como quedas, autonomia da bateria e controlo (maioritariamente por controlo remoto). Após a corrida, a Unitree Technology comentou o incidente da queda do seu robô G1, salientando que o desenvolvimento e operação autónomos pelo utilizador têm um impacto significativo no desempenho do robô. Este evento não só demonstrou a escala inicial da indústria de robôs humanoides na China, mas também suscitou amplas discussões sobre a maturidade tecnológica, custos (o preço de pré-venda do SongYan N2 começa nos 39.900 yuan), caminhos de comercialização (aluguer, aplicações industriais) e desenvolvimento futuro (AI large models, aprendizagem autónoma). Embora o setor tenha atraído o interesse do capital, a rentabilidade a curto prazo é difícil e a implementação no mercado ainda levará tempo (Fonte: 摔倒的宇树和人形机器人的“求生”博弈, 从进厂到马拉松:人形机器人离“实用”还有多远?)
Novo paradigma de aplicação de IA: Agent+MCP torna-se a fórmula de sucesso para 2025: A combinação da capacidade de planeamento e ação autónoma do Agent com a capacidade do protocolo MCP de chamar ferramentas e dados externos está a tornar-se uma nova tendência nas aplicações de IA. Produtos como “Coze Space”, Fellou, Dia, GenSpark, Zhipu AutoGLM surgiram sucessivamente e despertaram atenção. Muitos destes produtos evoluíram da pesquisa de IA, tentando construir barreiras na experiência do utilizador através de diferentes designs de produto (facilidade de uso, capacidade de pesquisa, execução prática). Apesar do enorme potencial, ainda enfrentam desafios como os limites da capacidade do modelo, a obtenção de informações entre plataformas e modelos de comercialização. A Microsoft também lançou o sistema multi-Agent UFO² para desktop, indicando que AM (Agent+MCP) se tornará uma direção importante para produtos de IA (Fonte: 2025年,AI应用的爆款公式只有一个)
Debate aceso sobre o futuro da IA: Hassabis prevê a cura de todas as doenças em dez anos, historiador de Harvard alerta para a extinção humana pela AGI: O CEO da Google DeepMind, Demis Hassabis, previu numa entrevista que a IA alcançará a AGI dentro de 5 a 10 anos e poderá curar todas as doenças numa década, apresentando avanços da IA como o Project Astra. Ele acredita que a IA se tornará a ferramenta definitiva para acelerar descobertas científicas. No entanto, o historiador de Harvard, Niall Ferguson, alertou que a chegada da AGI pode levar à obsolescência ou mesmo extinção da humanidade, tal como aconteceu com as carruagens, tornando-nos “alienígenas” criados por nós mesmos. Ele aponta que tendências como a rigidez institucional e o declínio da taxa de natalidade global podem levar a humanidade a optar por “sair do palco da história” perante a AGI. Esta discussão destaca o enorme contraste entre o otimismo extremo sobre o potencial da AGI e a profunda preocupação com o futuro da civilização humana (Fonte: 诺奖得主Hassabis豪言:AI十年治愈所有疾病,哈佛教授警告AGI终结人类文明, 哈佛历史学家预警:AGI灭绝人类,美国或将解体)
🎯 Tendências
Indústria robótica regista progressos frequentes, comercialização acelera: A Feira de Cantão criou pela primeira vez uma zona dedicada a robôs de serviço, onde fabricantes nacionais como a Pangolin Robot e a Hongxu Jin Technology obtiveram um grande número de encomendas do exterior, demonstrando a competitividade dos robôs de serviço chineses no mercado global. Simultaneamente, empresas como a Midea estão a iterar os seus robôs humanoides, planeando introduzi-los em fábricas para “trabalhar”. Na cadeia de abastecimento, embora existam desenvolvimentos em segmentos como PCB, sensores e novos materiais (como PEEK), a produção em massa ainda levará tempo, sendo cruciais a tecnologia, os custos e o fecho do ciclo de cenários de aplicação. Vários fabricantes planeiam atingir a produção em massa de milhares de unidades em 2025, o que poderá impulsionar o desenvolvimento da cadeia de abastecimento e a acumulação de dados, acelerando a transição dos robôs para uma fase mais prática (Fonte: 机器人组团“营业”引爆声量场,产业链频刷进展)

Tesla insiste em FSD puramente visual, rota LiDAR enfrenta desafios e oportunidades: Musk reafirmou a confiança na solução puramente visual para alcançar o FSD, acreditando que câmaras mais IA podem simular a condução humana, sem necessidade de LiDAR. Apesar da realidade da redução de custos (LiDAR chinês já baixou para centenas de dólares) e da popularização no mercado (já presente em modelos de 100.000 yuan), a Tesla mantém a sua rota, o que exige muito do seu poder computacional, algoritmos e dados. Ao mesmo tempo, fabricantes de LiDAR como Hesai e RoboSense dominam o mercado com vantagens de custo e iteração tecnológica, expandindo ativamente para mercados estrangeiros e negócios não automóveis, como robótica. A aproximação da condução autónoma de nível L3 pode trazer novas oportunidades para o LiDAR, pois a sua capacidade de perceção em redundância de segurança e cenários específicos é considerada indispensável (Fonte: 马斯克最新的AI驾驶方案,会终结激光雷达吗?)

Google Imagen 3/4 possivelmente em teste interno: Rumores indicam que a Google está a testar internamente os seus modelos de geração de imagem de próxima geração, Imagen 3 e Imagen 4, sugerindo que a Google pode ter grandes novidades na área de geração de imagens, com o objetivo de alcançar ou superar os concorrentes (Fonte: Google 又憋图像大招?传 Imagen 3/4 内测中。)
THUDM lança série de modelos de codificação SWE-Dev: O grupo de investigação em Engenharia do Conhecimento e Mineração de Dados da Universidade de Tsinghua (THUDM) lançou a série de large models de codificação SWE-Dev baseados em Qwen-2.5 e GLM-4, incluindo versões 7B, 9B e 32B, com o objetivo de melhorar as capacidades de IA em tarefas de desenvolvimento de software e codificação (Fonte: Reddit r/LocalLLaMA)

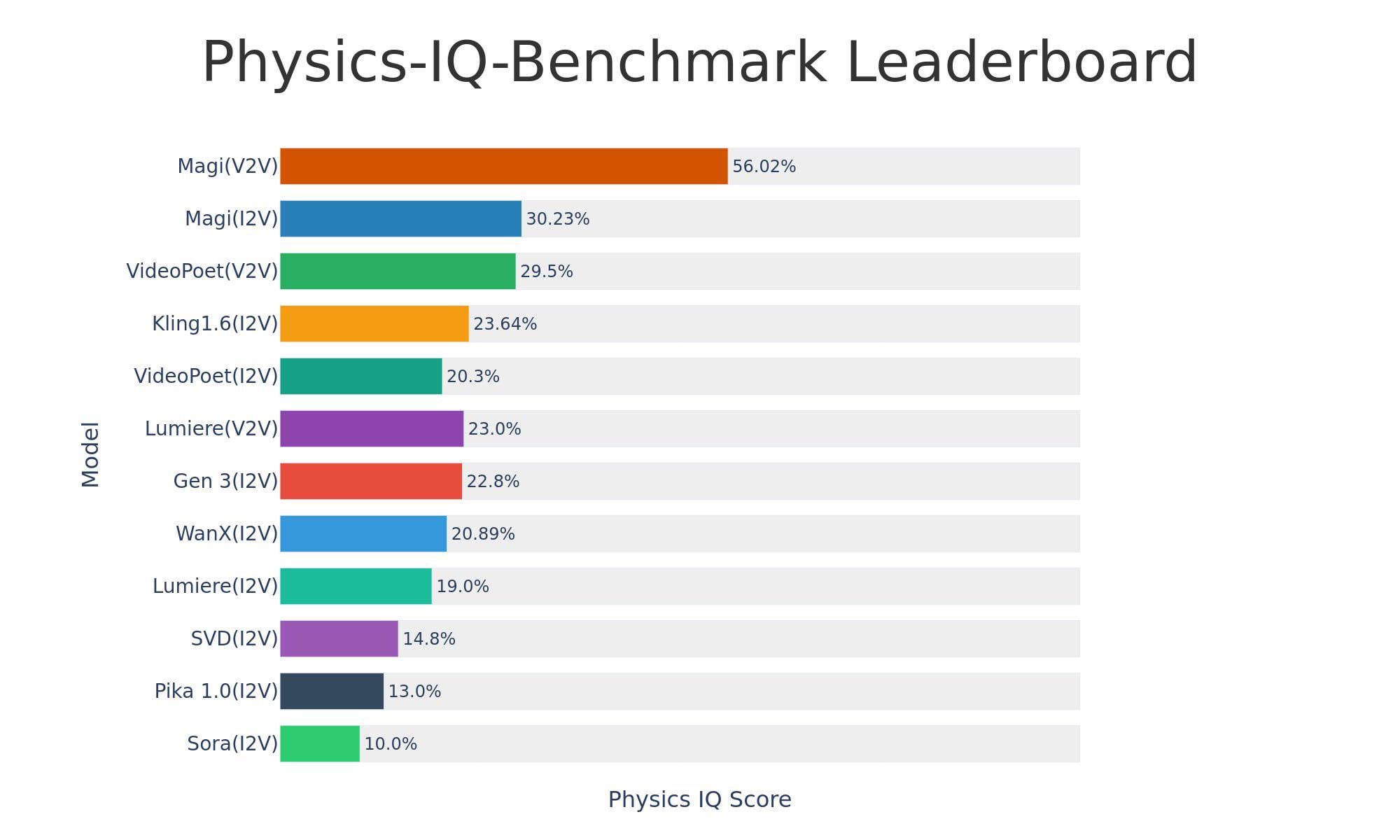
Sand-AI lança modelo open-source de geração de vídeo Magi-1: A Sand-AI lançou o Magi-1, um modelo open-source de geração de vídeo por difusão autorregressiva, que alega poder gerar vídeos de duração ilimitada e suporta texto-para-vídeo, imagem-para-vídeo e vídeo-para-vídeo. O modelo demonstrou excelente desempenho em benchmarks de compreensão física, mas requer uma quantidade extremamente alta de VRAM para funcionar (cerca de 640GB VRAM). O código e o modelo foram publicados no GitHub e Hugging Face (Fonte: Reddit r/LocalLLaMA)
Grok adiciona capacidades visuais, áudio multilingue e pesquisa em tempo real: A xAI anunciou que o modelo Grok adicionou capacidade de compreensão visual e, no modo de voz, suporta entrada de áudio multilingue e funcionalidade de pesquisa em tempo real, melhorando as suas capacidades de interação multimodal e aquisição de informação (Fonte: grok, xai)
Modelo Grok 3 chega ao You.com: O modelo principal da xAI, Grok 3, está agora disponível no motor de busca You.com, permitindo aos utilizadores experimentar as capacidades do Grok 3 nessa plataforma (Fonte: xai)

Modelo TTS open-source Dia lançado e recebe atenção: Foi lançado um modelo open-source de conversão de texto em voz (TTS) chamado Dia, que alega ter um desempenho comparável a modelos comerciais como ElevenLabs e OpenAI. Suporta clonagem de voz zero-shot e síntese em tempo real, podendo ser executado num MacBook. O modelo ganhou rapidamente atenção no Hugging Face e foi noticiado por meios como o VentureBeat (Fonte: huggingface, huggingface, huggingface)
Demonstração da tecnologia de condução autónoma da Tesla: Vídeos ou informações relacionadas com a tecnologia de condução autónoma Autopilot da Tesla foram apresentados, continuando a gerar atenção sobre os progressos na tecnologia de condução autónoma (Fonte: Ronald_vanLoon)
Demonstração de tecnologia robótica: Várias fontes mostraram diferentes aplicações de robôs, incluindo braços mecânicos para montagem de pequenos gadgets, avaliação do robô TITA, o robô anfíbio Copperstone HELIX Neptune e como os robôs percebem o mundo, indicando o desenvolvimento contínuo da tecnologia robótica em diferentes áreas (Fonte: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Ferramentas
GPT-SoVITS: Poderosa ferramenta de clonagem de voz few-shot e text-to-speech: Desenvolvido por RVC-Boss, GPT-SoVITS é um projeto open-source que permite treinar um modelo TTS de alta qualidade com apenas 1 minuto de dados de voz, realizando clonagem de voz few-shot. Suporta TTS zero-shot (conversão instantânea com 5 segundos de entrada), inferência interlingual (suporta inglês, japonês, coreano, cantonês, chinês) e integra uma caixa de ferramentas WebUI, incluindo separação de voz e acompanhamento, segmentação automática de conjuntos de treino, ASR chinês e anotação de texto, facilitando a criação de datasets e modelos pelos utilizadores. O projeto recebeu enorme atenção no GitHub (mais de 44k estrelas) e foi atualizado para a versão V4, otimizando continuamente a semelhança do timbre, estabilidade e qualidade da saída (Fonte: RVC-Boss/GPT-SoVITS – GitHub Trending (all/daily))

Equipa de Tsinghua lança SurveyGO (Juan Ji): Ferramenta de revisão de literatura e geração de relatórios longos impulsionada por IA: Baseado na tecnologia LLMxMapReduce-V2 desenvolvida pelas equipas de Tsinghua NLP, OpenBMB e Mianbi Intelligence, SurveyGO consegue processar eficientemente um grande volume de literatura, gerando relatórios de revisão longos (milhares de palavras) com estrutura clara, lógica rigorosa e citações precisas. A ferramenta otimiza o esboço através de um mecanismo convolucional orientado pela entropia da informação e gera conteúdo hierarquicamente, resolvendo o problema de conteúdo fragmentado e falta de profundidade na geração de textos longos por IA tradicional. Os utilizadores podem inserir um tópico ou carregar ficheiros através da versão web, com o objetivo de aumentar significativamente a eficiência da pesquisa bibliográfica e da escrita para investigadores e criadores de conteúdo (Fonte: INTJ式学术暴力!清华团队造出“论文卷姬”:3分钟速通200小时文献综述, 如何 AI「拼好文」:生成万字报告,不限模型)

text-generation-webui lança versão portátil, focada em llama.cpp: Para simplificar o processo de implementação, text-generation-webui lançou uma versão portátil e autónoma focada em llama.cpp. Os utilizadores podem descarregar, extrair e executar, sem necessidade de instalar Python, PyTorch ou outras dependências. A nova versão suporta Windows, Linux, macOS, inclui versões CPU e CUDA, tem cerca de 700MB e otimizou a velocidade de arranque e a experiência do utilizador (como abrir automaticamente o navegador, iniciar a API por defeito). Isto oferece grande conveniência aos utilizadores que pretendem apenas usar llama.cpp para inferência local (Fonte: Reddit r/LocalLLaMA)
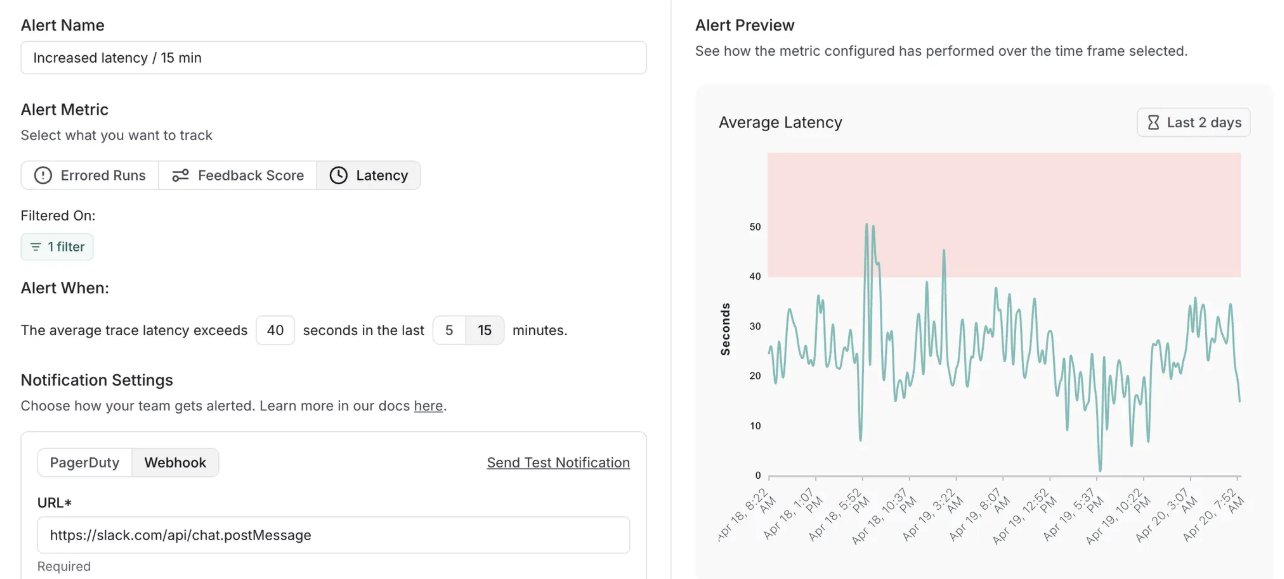
LangSmith adiciona funcionalidade de alertas e atualiza versão auto-hospedada: A plataforma MLOps da LangChain, LangSmith, adicionou funcionalidade de alertas em tempo real, permitindo aos utilizadores configurar notificações para taxas de erro, latência de execução e pontuações de feedback, para detetar problemas antes que afetem os clientes. Simultaneamente, a sua versão auto-hospedada foi atualizada para v0.10, incluindo a funcionalidade de alertas, nova UI para criação e visualização de avaliações, suporte para dados de rastreamento de clientes OpenTelemetry e otimizações de desempenho (Fonte: LangChainAI, LangChainAI)
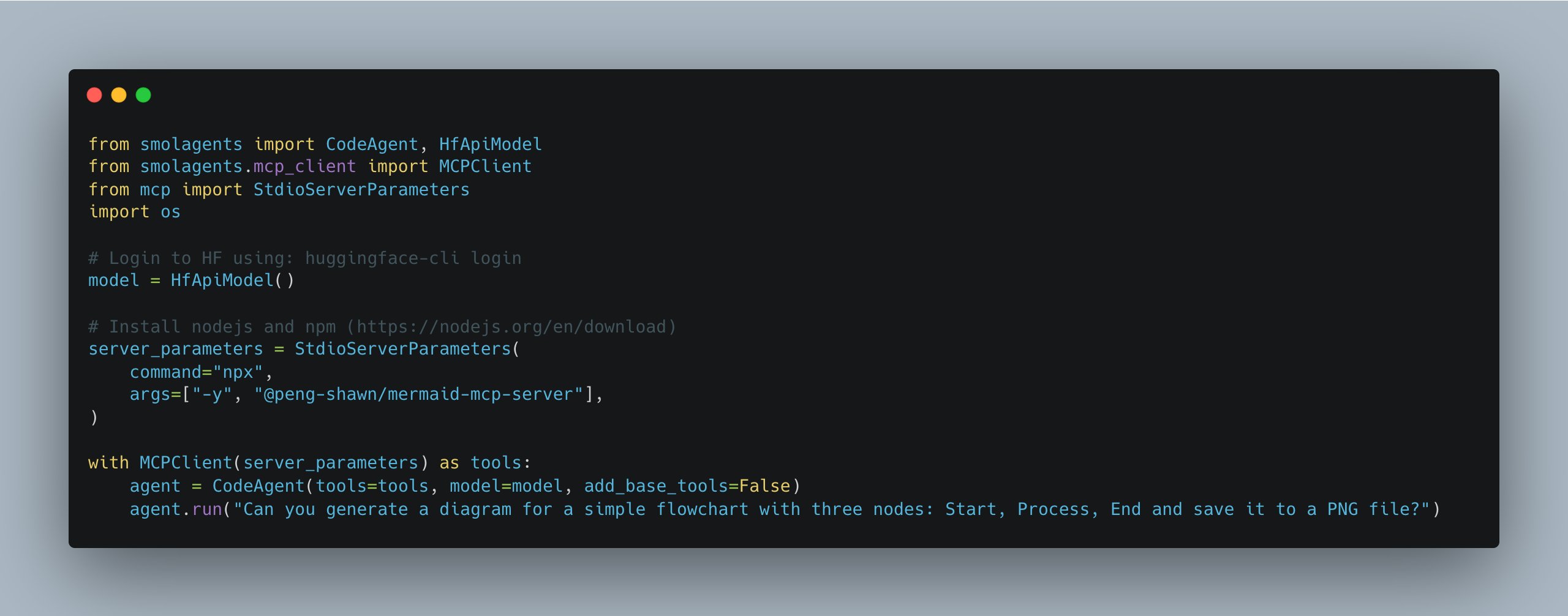
smolagents atualizado, simplifica gestão de múltiplos servidores MCP: A biblioteca smolagents do Hugging Face lançou uma nova versão, introduzindo a classe MCPClient, que facilita a gestão de conexões a múltiplos servidores MCP (Model Communication Protocol), tornando mais fácil para os desenvolvedores construir e coordenar sistemas Agent mais complexos (Fonte: huggingface)
Suna: Plataforma Agent open-source para rivalizar com Manus: Kortix AI lançou a plataforma Agent open-source Suna, com o objetivo de rivalizar com Manus. Suna integra automação de navegador, gestão de ficheiros, web crawling, pesquisa expandida, execução de linha de comandos, implementação de websites e integração de API, permitindo que a IA opere estas ferramentas de forma colaborativa para resolver problemas complexos e automatizar fluxos de trabalho (Fonte: karminski3)
Exa MCP agora suporta pesquisa no Twitter sem API: O servidor MCP (Model Communication Protocol) da Exa foi atualizado e agora suporta a pesquisa de conteúdo no Twitter sem a necessidade de usar a API do Twitter. Isto oferece conveniência aos AI Agents que precisam de obter informações do Twitter, mas atualmente parece ter suporte limitado para a recolha de dados de utilizadores chineses (Fonte: karminski3)
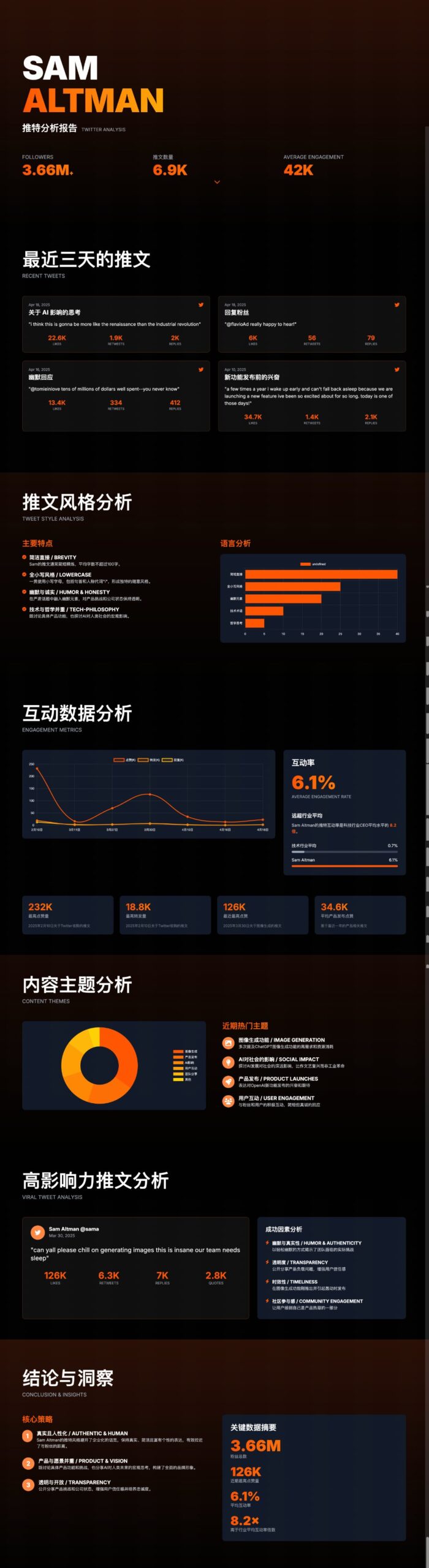
ChatUI-energy: Interface que exibe consumo de energia de conversas AI em tempo real: Membros da comunidade Hugging Face lançaram ChatUI-energy, uma variante da Chat UI que exibe em tempo real a energia consumida durante as conversas do utilizador com modelos de IA (como Llama, Mistral, Qwen, Gemma, etc.). Esta iniciativa visa aumentar a transparência energética do uso de IA (Fonte: huggingface, huggingface)
Utilização de IA para desenvolvimento, implementação e otimização de aplicações Web: O artigo partilha a prática completa de usar IA (como Lovable, Cursor, BrowserTools MCP) para desenvolver (uma ferramenta de colagem de imagens), depurar, auditar SEO e otimizar o desempenho de uma aplicação Web. Destaca como utilizar Vercel e GitHub para implementar a implementação automatizada CI/CD, e a configuração de resolução de domínios e subdomínios. Demonstra o papel auxiliar da IA na codificação e manutenção de websites (Fonte: AI 编码 + Vercel 部署 + 域名解析:一文搞定Web 应用开发上线全流程,氛围编码+MCP 审计优化。)

Recriação leve de “Her” OS1/Samantha baseada em modelos locais: Um desenvolvedor usou transformers.js e modelos ONNX (incluindo Ultravox Llama 3.2 1B, Whisper Base, Kokoro TTS e MiniLM embeddings) para recriar localmente no navegador o assistente AI OS1/Samantha do filme “Her”. O projeto demonstra a possibilidade de executar uma IA de interação por voz localmente com recursos limitados (download de modelo de cerca de 2GB) (Fonte: Reddit r/LocalLLaMA)
ChatWise combina servidores MCP para implementar RAG e sincronização de dados: Um utilizador partilhou a configuração de um fluxo de trabalho simples em ChatWise usando instruções de sistema, combinando servidores MCP de Pinecone (base de dados), Exa (pesquisa) e Time (tempo) para implementar RAG (Retrieval-Augmented Generation) e sincronização de dados (Fonte: op7418)

📚 Aprendizagem
Universidade de Stanford abre curso sobre Transformers CS25: O curso de seminário sobre Transformers CS25 da Universidade de Stanford está aberto ao público, podendo ser acompanhado via Zoom em direto. O curso convida investigadores de topo como Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani e convidados da OpenAI, Google, NVIDIA para palestras, cobrindo temas de vanguarda como arquitetura LLM, aplicações multimodais, biologia, robótica, etc. As gravações do curso serão publicadas no YouTube e existe uma comunidade Discord para discussão (Fonte: karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
Investigação de Tsinghua e Jiao Tong revela limitações do RL na capacidade de raciocínio dos LLM: Um estudo da Universidade de Tsinghua e da Universidade Jiao Tong de Xangai desafia a visão de que a aprendizagem por reforço (RL) melhora a capacidade de raciocínio dos large models. Experimentos mostram que, embora o RL possa aumentar a precisão do modelo em taxas de amostragem baixas (eficiência), em taxas de amostragem altas, o modelo base consegue resolver mais problemas difíceis (limite de capacidade). Isto sugere que o RL é melhor a otimizar o desempenho do modelo dentro das suas capacidades existentes, em vez de expandir a sua capacidade fundamental de raciocínio. O artigo aponta que os métodos atuais de RL (como GRPO) podem ficar presos em ótimos locais devido à exploração insuficiente, limitando a resolução de problemas complexos (Fonte: RL 是推理神器?清华上交大最新研究指出:RL 让大模型更会 「套公式」,却不会真推理, Reddit r/artificial)

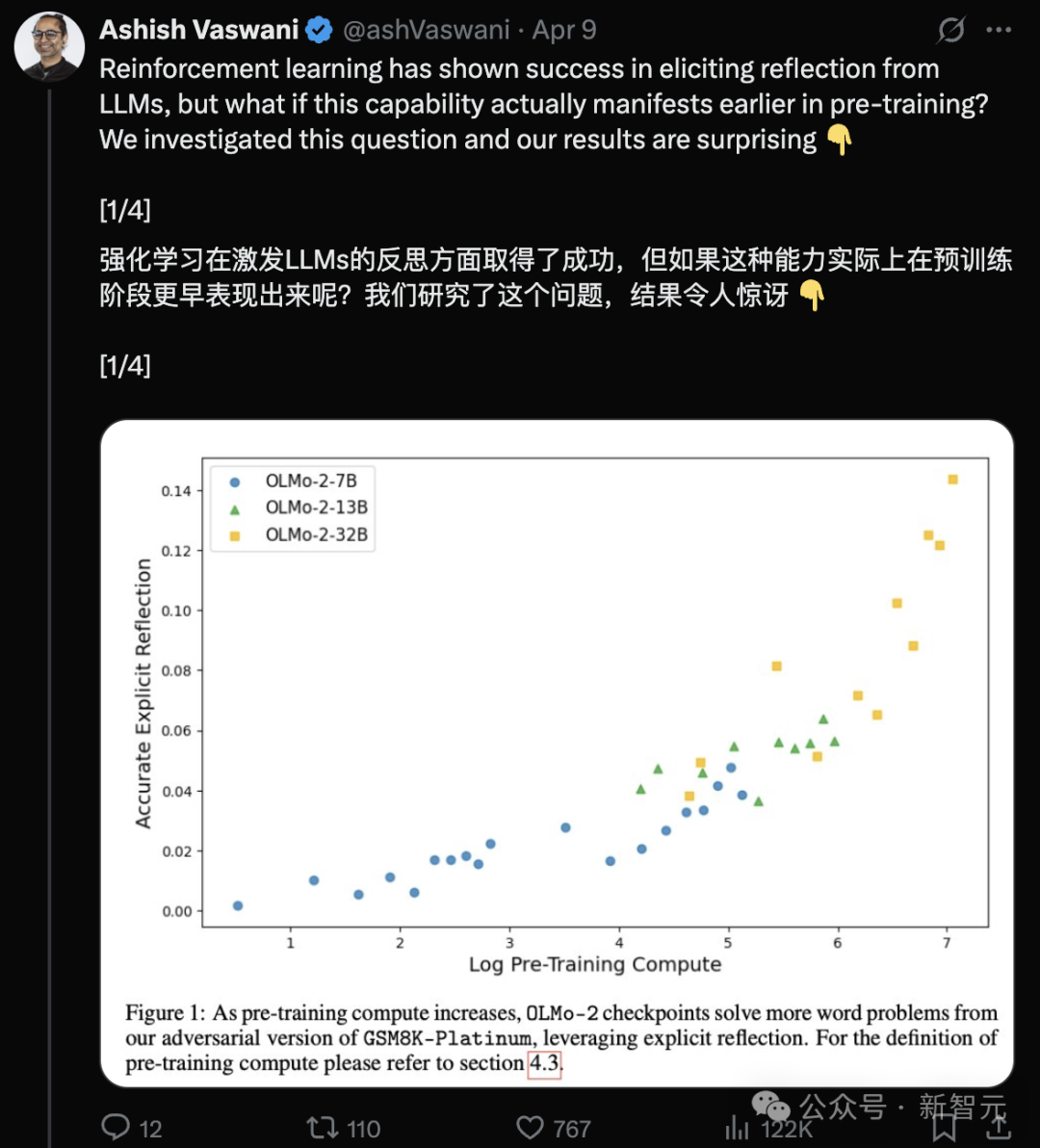
Equipa de autores do Transformer: LLM já possui capacidade de reflexão na fase de pré-treino: Uma equipa liderada por Ashish Vaswani, primeiro autor do artigo do Transformer, publicou uma investigação que propõe que os large language models já desenvolvem capacidades de reflexão e autocorreção durante a fase de pré-treino, em vez de dependerem inteiramente da aprendizagem por reforço (RLHF). A investigação, através da introdução de cadeias de pensamento adversárias, distingue e quantifica as capacidades de reflexão contextual e autorreflexão, descobrindo que estas capacidades aumentam com o aumento da computação de pré-treino. Prompts simples como “Wait,” podem efetivamente estimular a reflexão explícita. Isto desafia visões como a do DeepSeek, que consideram que a reflexão deriva principalmente do RL, e oferece uma nova perspetiva para compreender e acelerar o desenvolvimento da capacidade de raciocínio no pré-treino (Fonte: Transformer原作打脸DeepSeek观点?一句Wait就能引发反思,RL都不用)
ChemAgent: Biblioteca de memória autoatualizável melhora capacidade de raciocínio químico dos LLM: Investigadores de Yale, Stanford e outras instituições propuseram a framework ChemAgent, que melhora significativamente o desempenho dos LLM em tarefas de raciocínio químico através da introdução de uma biblioteca de memória dinâmica autoatualizável que inclui planeamento, execução e memória de conhecimento. Esta framework simula o processo de aprendizagem humano, resolvendo problemas químicos complexos através da decomposição de tarefas e recuperação de memória. Experimentos no dataset SciBench mostram que ChemAgent melhora a precisão em média 10% (relativo ao SOTA) a 37% (relativo ao raciocínio direto) em comparação com métodos baseline, especialmente em precisão de cálculo e conversão de unidades. A investigação também analisa a relação entre similaridade de memória, quantidade e desempenho, bem como as limitações atuais (Fonte: 准确率飙升46%!耶鲁-斯坦福「自更新记忆库」新框架,重塑LLM化学推理能力)
Universidade de Tecnologia do Sul da China alcança série de progressos na área da computação evolutiva distribuída: A equipa de Inteligência Computacional da Universidade de Tecnologia do Sul da China obteve uma série de resultados na otimização de consenso distribuído de sistemas multi-agente (MAS). A investigação inclui: publicação de uma revisão desta área interdisciplinar; proposta do algoritmo MASOIE, que otimiza a colaboração através de mecanismos de aprendizagem internos e externos; proposta do algoritmo MACPO, que utiliza incentivos de objetivo para impulsionar a cooperação; conceção do mecanismo de adaptação de passo CCSA para melhorar o desempenho da otimização black-box; proposta do algoritmo MASTER para melhorar a precisão da localização em redes de sensores. A equipa também organizou competições relacionadas, promovendo o desenvolvimento da área (Fonte: 打破共识优化壁垒!华南理工深耕分布式进化计算,实现多智能体高效协同)
Série de tutoriais em vídeo “Construir DeepSeek do Zero”: Vizuara publicou no YouTube a série de tutoriais em vídeo “Construir DeepSeek do Zero”, atualmente com 13 aulas atualizadas, cobrindo conceitos fundamentais como bases do DeepSeek, fluxo de processamento de Token, mecanismos de atenção (auto-atenção, atenção causal, atenção multi-cabeça, atenção multi-consulta, atenção de consulta agrupada, atenção latente multi-cabeça) e KV Cache, com explicações e implementação de código. A série visa analisar em profundidade a arquitetura DeepSeek, planeando um total de 35-40 vídeos, cobrindo mais conteúdos como RoPE, MoE, MTP, SFT, GRPO (Fonte: karminski3, Reddit r/LocalLLaMA)
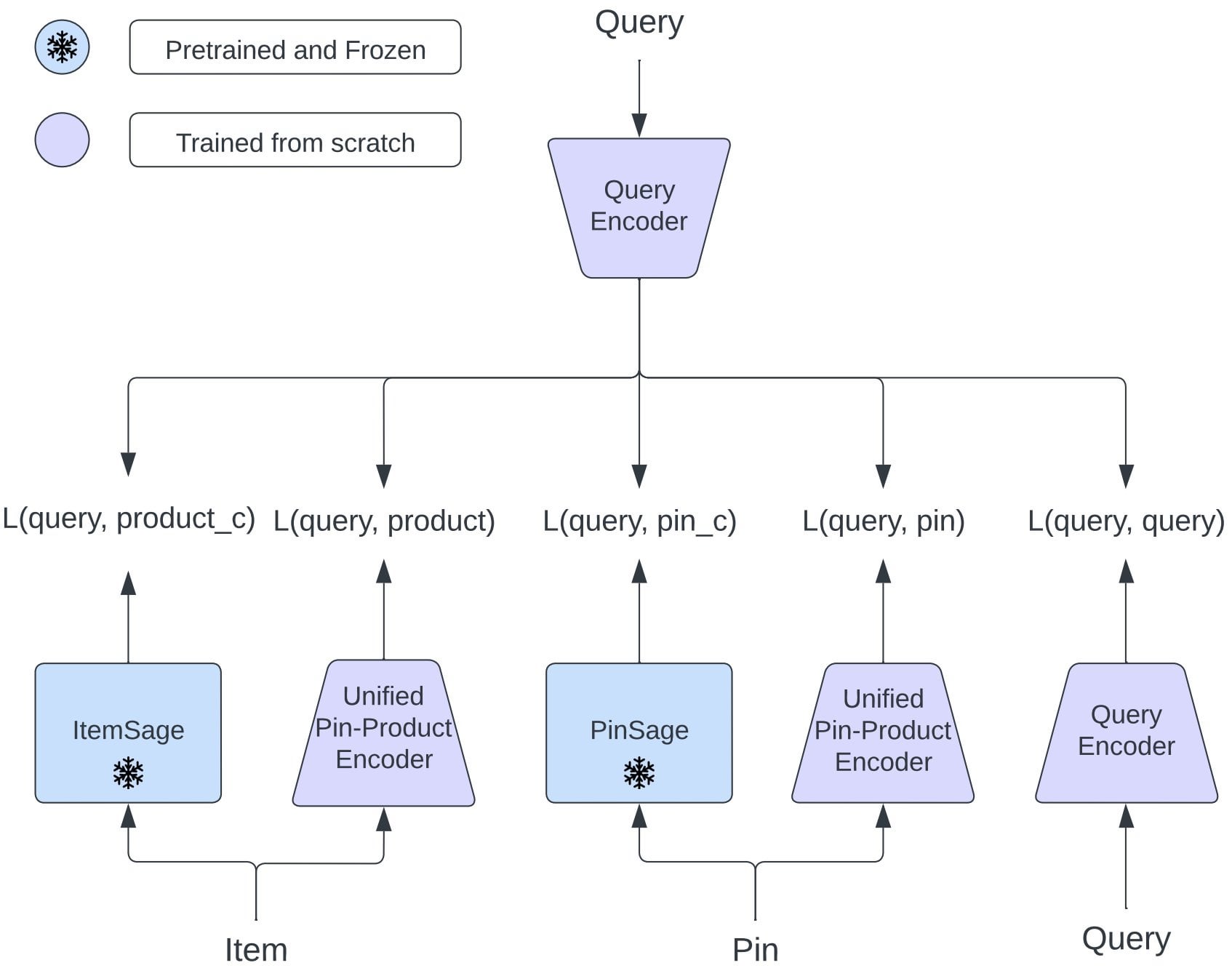
Pinterest propõe OmniSearchSage: Modelo de embedding unificado melhora recuperação multi-tarefa: Investigadores do Pinterest propuseram OmniSearchSage, um modelo de embedding de consulta unificado, treinado através de aprendizagem multi-tarefa, capaz de recuperar simultaneamente pins, produtos e consultas relacionadas, desafiando a arquitetura tradicional de torre dupla. O modelo funde títulos gerados por GenAI, sinais de boards curados por utilizadores e dados de envolvimento comportamental, enriquecendo a compreensão do item e podendo ser integrado diretamente em sistemas existentes (como PinSage). Os resultados mostram que esta abordagem alcançou melhorias práticas significativas na pesquisa, publicidade e latência (Fonte: Reddit r/MachineLearning)
FlowReasoner: Fluxo de trabalho multi-agente ajustado dinamicamente com base na consulta: O artigo propõe FlowReasoner, que visa inferir instantaneamente um fluxo de trabalho (workflow) multi-agente exclusivo para cada consulta do utilizador. Através de SFT de raciocínio e aprendizagem por reforço GRPO, o modelo pode ajustar dinamicamente a combinação e a sequência das tarefas do Agent (como geração de código, revisão, teste, revisão) com base no feedback de execução. Este método foi validado no cenário do Code Interpreter, dependendo da execução Python e testes unitários, demonstrando o potencial de adaptação dinâmica do fluxo de trabalho às necessidades da consulta, podendo ser generalizado no futuro para áreas como recuperação, análise de dados, etc. (Fonte: dotey)

Tutorial LangChain: Construir fluxo de trabalho de geração de relatórios de conformidade usando LlamaIndex: LlamaIndex publicou um tutorial em vídeo demonstrando como construir um Agentic Workflow para gerar relatórios de conformidade. Este fluxo de trabalho utiliza LLM para processar grandes volumes de texto regulatório, compará-lo com a linguagem contratual e gerar resumos concisos. O tutorial mostra como configurar o índice LlamaCloud, definir esquemas para extração de cláusulas e verificação de conformidade, e usar pesquisa semântica para encontrar linguagem regulatória relevante (Fonte: jerryjliu0)

Tutorial LangChain: Agent de geração de código auto-reparador: LangChain publicou um tutorial sobre como construir um AI code generation Agent com capacidade de auto-reparação. O tutorial utiliza a framework OpenEvals e o ambiente sandbox E2B para avaliar e melhorar o código gerado por IA, adicionando um passo de reflexão para validar o código antes de retornar a resposta (Fonte: LangChainAI)

Análise da Anthropic descobre que Claude possui código moral intrínseco: A Anthropic, após analisar 700.000 conversas do Claude, descobriu que o seu modelo de IA demonstra um código moral intrínseco. Esta descoberta pode ter implicações significativas para a investigação em segurança e ética da IA (Fonte: Reddit r/ClaudeAI, Reddit r/artificial)

Google propõe “Era da Experiência” para lidar com a escassez de dados de treino de IA: Investigadores da Google (incluindo David Silver) publicaram o artigo “The Era of Experience”, propondo resolver o problema da escassez de dados, atualmente dependente de dados humanos para treino, permitindo que AI Agents gerem os seus próprios dados de treino. Isto pode sinalizar uma nova direção no paradigma de treino de IA e desafiar métodos de treino dependentes de datasets existentes (Fonte: Reddit r/artificial)

Lista de recursos de certificados e cursos gratuitos: O repositório GitHub cloudcommunity/Free-Certifications compila um grande número de recursos que oferecem cursos e certificações gratuitas, cobrindo várias áreas como tecnologia geral, segurança, bases de dados, gestão de projetos, marketing, etc. Inclui alguns cursos e certificações gratuitas relacionadas com IA, machine learning, data science, como o curso de machine learning do freeCodeCamp, fundamentos de GenAI da Databricks, cursos de IA da IBM Cognitive Class, etc. (Fonte: cloudcommunity/Free-Certifications – GitHub Trending (all/daily))
Teste de fiabilidade de LLM para edição de código: Um utilizador partilhou um vídeo testando a fiabilidade de vários large language models (LLM) na escrita e modificação de código de deep learning, explorando a eficácia e limitações atuais dos LLM em tarefas de programação assistida (Fonte: Reddit r/deeplearning)

💼 Negócios
Guerra tarifária dos EUA impacta startups chinesas de hardware de IA: A imposição de altas tarifas pelos EUA sobre produtos chineses (algumas taxas chegam a 125%) afetou gravemente as startups chinesas de hardware de IA (como brinquedos de IA, óculos inteligentes, etc.) voltadas para o mercado americano. Como o mercado dos EUA é crucial para muitas validações de mercado e aquisição de early adopters (por exemplo, através do Kickstarter), as altas tarifas levaram a uma redução drástica dos lucros ou mesmo a prejuízos, com algumas empresas a suspenderem os envios para os EUA. Embora categorias como óculos inteligentes tenham obtido isenção temporária, o futuro é incerto. O risco do modelo de “desalfandegamento cinzento” (grey clearance) também está a aumentar. Isto força as empresas a reavaliar as suas estratégias de mercado, acelerar a globalização e diversificar os riscos (Fonte: 襁褓中的AI硬件,迎接最激烈的关税战)

Análise aprofundada da Zhiyuan Robot: Produtos, tecnologia e modelo de negócio: A Zhiyuan Robot, fundada por Peng Zhihui (“ZhiHuiJun”) e outros, possui a série “Yuanzheng” (A1, A2, A2-W com rodas, A2-Max para cargas pesadas) para cenários industriais e comerciais, e a série “Lingxi” (X1 open-source, X1-W para recolha de dados, X2 bípede interativo) focada em leveza e open-source, bem como os robôs de limpeza Jingling G1 e Juechen C5. Tecnologicamente, a empresa enfatiza a sinergia hardware-software e o ciclo fechado de dados, desenvolvendo internamente o módulo de articulação PowerFlow, mão ágil, e desenvolvendo o large model Qiyuan (GO-1), a plataforma de dados AIDEA, a framework de comunicação AimRT, etc. O modelo de negócio inclui venda de hardware, serviços de subscrição e partilha de ecossistema (componentes open-source, cooperação na cadeia de abastecimento). A empresa concluiu 8 rondas de financiamento, com uma avaliação de 15 mil milhões de yuan, tendo como investidores Hillhouse, BYD, Tencent, etc., e coopera com várias empresas da cadeia de abastecimento e governos locais, visando criar um robô corpóreo universal de classe mundial (Fonte: 智元机器人深度拆解:人形机器人独角兽进化论)

Projeto de impressão 3D incubado internamente pela Dreame, “AtomFab”, recebe dezenas de milhões em financiamento: A AtomFab Technology, incubada internamente pela Dreame Technology, concluiu uma ronda de financiamento anjo de dezenas de milhões de yuan, investida pela Chuāngchuàng Venture Capital. A empresa, fundada em janeiro de 2025, foca-se no mercado de impressão 3D de consumo, utilizando tecnologia de IA para resolver problemas de usabilidade, estabilidade e eficiência. A empresa reutilizará as tecnologias de motor, sensor, interação AI da Dreame e recursos maduros da cadeia de abastecimento para reduzir custos e acelerar a produção. Os produtos serão lançados prioritariamente nos mercados europeu e americano, utilizando a rede de pós-venda internacional da Dreame para suporte. O primeiro produto está previsto para o segundo semestre de 2025 (Fonte: 追觅内部孵化3D打印项目获数千万融资,优先布局欧美等海外市场|硬氪首发)
Posição de monopólio das GPU da NVIDIA pode enfrentar desafios: Apesar do crescimento contínuo nas remessas de GPU da NVIDIA, a sua posição dominante a longo prazo enfrenta desafios. As principais razões incluem: 1) A forte procura dos gigantes da nuvem (Google, Microsoft, Amazon, Meta) que, no entanto, estão a investir fortemente em chips próprios (TPU, Maia, Trainium, MTIA) para reduzir custos e dependência; 2) A transição da indústria para otimização distribuída, verticalmente integrada e a nível de sistema (chip, rede, refrigeração, software), onde a NVIDIA tem um posicionamento relativamente insuficiente; 3) Aumento da procura por personalização, com os ASIC a mostrarem vantagens em cargas de trabalho específicas (como inferência, recomendação); 4) A tecnologia de rede da NVIDIA (Infiniband) e a pilha de software (como BaseCommand) podem não igualar as soluções internas dos gigantes da nuvem em termos de hiperescala e tolerância a falhas. Embora a NVIDIA esteja a esforçar-se por se adaptar (por exemplo, Blackwell, Spectrum-X), os desafios estruturais persistem (Fonte: 计算的未来:英伟达王冠正摇摇欲坠)

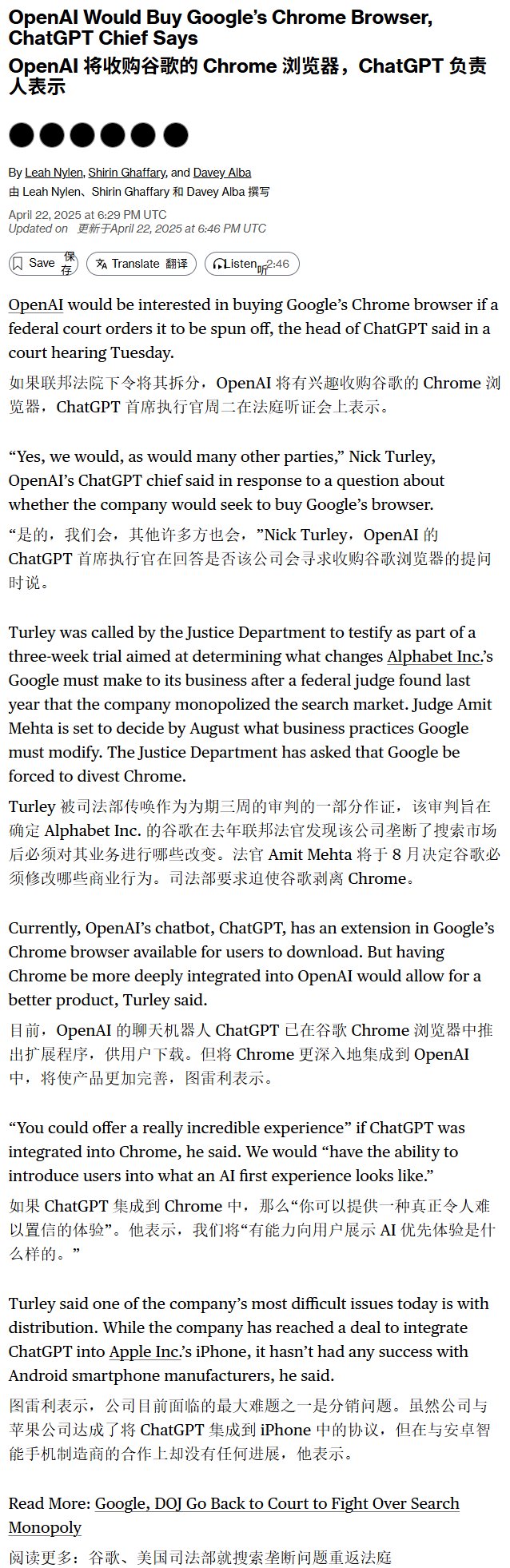
Rumores de que a OpenAI tem interesse em adquirir o navegador Chrome: Segundo a Bloomberg, se a Google for obrigada por um tribunal federal dos EUA a desmembrar o seu negócio de pesquisa devido a um processo antitrust, a OpenAI poderá ter interesse em adquirir o seu negócio do navegador Chrome. Isto reflete o potencial interesse das empresas de IA em controlar os pontos de entrada do utilizador e as fontes de dados, mas atualmente é apenas um rumor e depende do desenrolar do processo antitrust da Google (Fonte: karminski3)
Estratégias para alcançar resultados de negócio com GenAI: Um artigo da Forbes explora como as empresas podem ir além da fase experimental e obter resultados de negócio reais utilizando a IA generativa (GenAI), propondo 9 estratégias para ajudar as empresas a integrar a GenAI nos seus processos de negócio para aumentar a eficiência e a inovação (Fonte: Ronald_vanLoon)

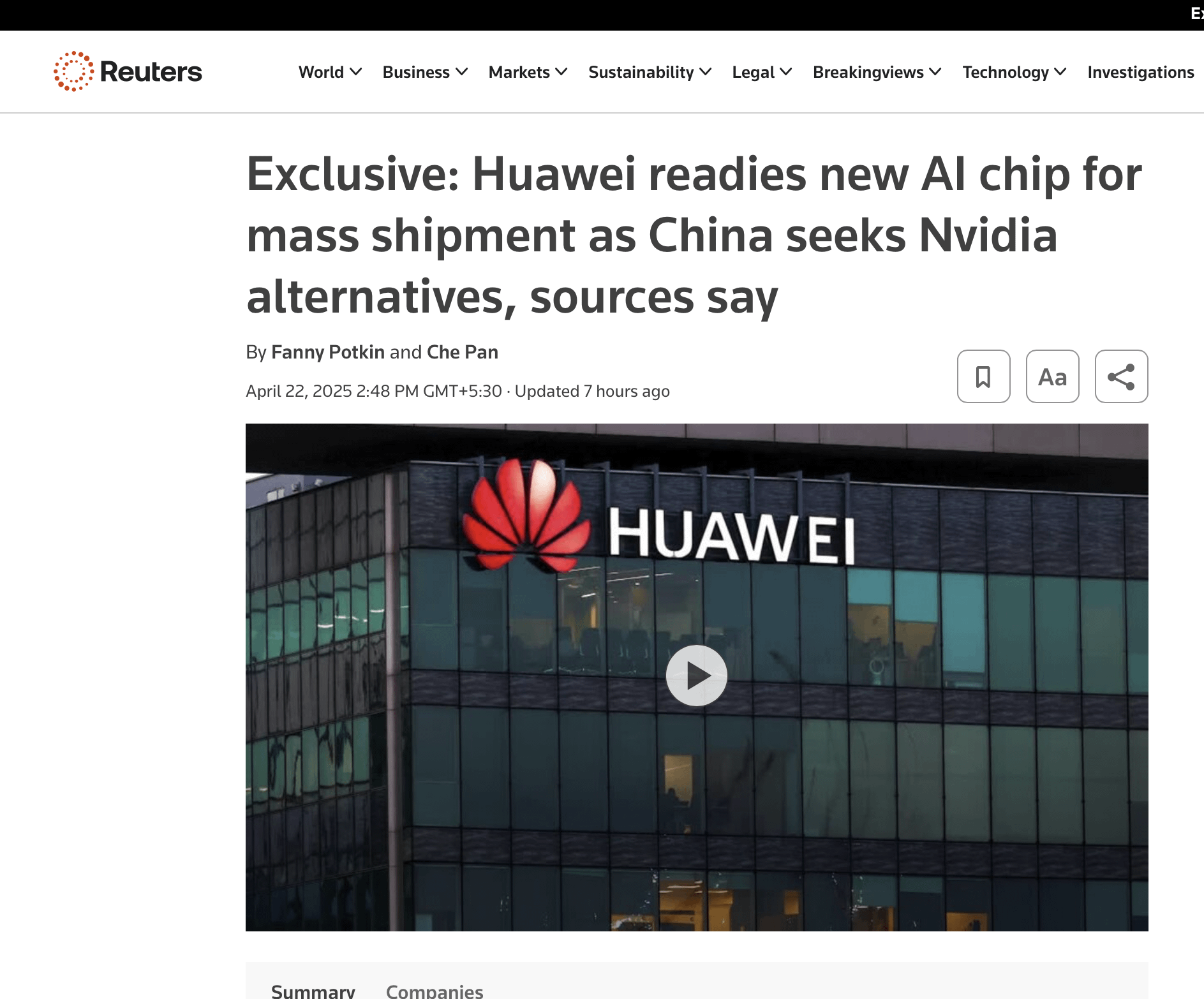
Novo chip da Huawei pode representar concorrência para a NVIDIA: Discussões nas redes sociais mencionam o lançamento de um novo chip pela Huawei, que pode constituir concorrência para a NVIDIA no campo da IA, o que poderá influenciar o cenário das negociações sino-americanas sobre chips e tarifas (Fonte: Reddit r/ArtificialInteligence)
🌟 Comunidade
A febre do ouro do DeepSeek e reflexões: A popularidade do DeepSeek gerou inúmeras tentativas comerciais em torno dele, incluindo criação de conteúdo (produção em massa de guiões para vídeos curtos, copywriting), conhecimento pago (venda de tutoriais de uso, cursos de monetização) e serviços de gestão de contas. No entanto, muitos que tentaram descobriram que o conteúdo produzido em massa pela IA é altamente homogéneo, facilmente limitado ou banido pelas plataformas, e dificilmente se traduz em receita efetiva. O artigo aponta que os verdadeiros beneficiários são muitas vezes os “intermediários” que vendem cursos ou serviços aproveitando a assimetria de informação, e não os utilizadores diretos. Ao mesmo tempo, o próprio DeepSeek expôs problemas como servidores ocupados e respostas padronizadas, gerando discussões sobre o seu valor de aplicação e limitações (Fonte: DeepSeek走红三个月,第一批想靠它赚钱的怎么样了?)

Desenvolvedor de ferramenta de batota com IA obtém financiamento, gerando controvérsia ética: Chungin Lee, estudante de 21 anos da Universidade de Columbia, foi suspenso pela universidade por desenvolver a ferramenta de IA Interview Coder para batota em entrevistas técnicas. Menos de um mês depois, ele e um colega fundaram a empresa Cluely, expandindo a ferramenta para exames, vendas, reuniões e outros cenários, e obtiveram 5,3 milhões de dólares em financiamento semente. Eles argumentam que não se trata de batota, mas de usar a tecnologia para aumentar a eficiência, e que no futuro todos usarão IA como assistente. O caso gerou enorme controvérsia: apoiantes veem-no como inovação ousada, críticos temem que prejudique a equidade, esbata os limites da capacidade e até o comparam a um episódio de Black Mirror. O incidente suscitou discussões acaloradas sobre ética da IA, equidade na educação e definição de capacidade (Fonte: 21岁学生开发AI作弊工具被哥大停学,转身拿下530万美元融资,网友:《黑镜》成真, 靠开发AI作弊神器成名,21岁小伙遭学校开除不足一月后,转身拿下530万美元融资)

Política de vistos dos EUA aperta, talento em IA pode sair: Recentemente, o governo dos EUA revogou em massa registos SEVIS e vistos de estudantes internacionais (incluindo doutorandos em IA), por motivos que vão desde infrações menores até erros do sistema (possivelmente envolvendo triagem por IA), com um processo carente de transparência e oportunidades de recurso. Professores como Yisong Yue do Caltech temem que esta medida esteja a prejudicar a atratividade dos EUA para talentos de topo em IA, com muitos investigadores em instituições como OpenAI e Google já a considerar sair. Isto pode levar a um retrocesso nos projetos de IA dos EUA, enfraquecendo a sua vantagem em IA. Alguns estudantes já processaram conjuntamente o governo e obtiveram uma ordem de restrição temporária (Fonte: 加州AI博士一夜失身份,谷歌OpenAI学者掀「离美潮」,38万岗位消失AI优势崩塌)

Discussão sobre o estado atual do desenvolvimento de modelos open-source: A comunidade discute as últimas novidades sobre large models open-source, mencionando a expectativa pelo Qwen 3, a adoção lenta do Llama 4, a aparente estagnação nos modelos de inferência, a subestimação dos modelos multimodais e o domínio contínuo da China na área open-source. Os participantes enfatizam que a compreensão da “saturação da inferência” precisa distinguir entre open-source e closed-source, e apontam que isto está mais relacionado com a diversidade de modelos e os desafios da expansão do RL (Fonte: natolambert)
Capacidade de pesquisa do modelo OpenAI o3 elogiada: Utilizadores elogiam a forte capacidade de pesquisa do modelo OpenAI o3, capaz de encontrar informações muito específicas sem necessidade de muito contexto adicional, com uma experiência de interação semelhante à comunicação com colegas (Fonte: gdb)
Significado e impacto do TTS open-source: Membros da comunidade, ao discutir o modelo Dia TTS, enfatizam que o seu desempenho de alta qualidade prova que treinar modelos TTS SOTA já não requer investimentos de milhares de milhões de dólares. O efeito composto da indústria de IA torna o treino cada vez mais fácil, e a força do open-source está a acelerar a popularização da tecnologia (Fonte: huggingface, huggingface)
Meta organiza LlamaCon 2025, celebrando a comunidade open-source: A Meta anunciou que irá organizar o evento LlamaCon 2025, com o objetivo de celebrar a comunidade open-source Llama e as suas conquistas, e partilhará os últimos progressos e planos futuros para os modelos e ferramentas Llama (Fonte: AIatMeta)

Discussão sobre se a IA é verdadeiramente “inteligente”: O artigo “Precisamos parar de fingir que a IA é inteligente” gerou discussão, explorando os limites da capacidade da tecnologia de IA atual e a complexidade da definição de “inteligência” (Fonte: Ronald_vanLoon)

Experiência de uso do ChatGPT: Perda de conexão e teste de honestidade: Utilizadores relatam encontrar frequentemente o problema de “conexão de rede perdida” no ChatGPT, especulando que pode estar relacionado com a carga de uso. Ao mesmo tempo, um utilizador partilhou um prompt interessante, pedindo ao ChatGPT para usar a função de memória para dar a sua “opinião real” sobre o utilizador, gerando discussão sobre interação personalizada com IA e “consciência” (Fonte: natolambert, dotey)
Otimismo no desenvolvimento da área de robótica: O cofundador do Hugging Face, Thomas Wolf, comentou que os laboratórios de robótica de 2025 são divertidos devido ao hardware open-source, bons progressos em aprendizagem por reforço e concentração de talento, refletindo o entusiasmo da indústria pelo rápido desenvolvimento da tecnologia robótica (Fonte: huggingface)
Utilidade do Gemini Deep Research reconhecida: Utilizadores partilharam casos de uso da função Gemini Deep Research para verificar a fiabilidade de informações no Twitter, mostrando o seu valor prático na verificação de informações e pesquisa aprofundada (Fonte: dotey)

Críticas e defesa das bibliotecas de IA open-source: Membros da comunidade observaram um aumento recente de comentários negativos sobre várias bibliotecas de IA open-source, argumentando que essas críticas podem basear-se em informações desatualizadas ou métricas parciais, e apelando aos críticos para participarem na construção de versões melhores (Fonte: natolambert)
Especulação sobre a experiência de jogo com IA: Utilizadores expressam curiosidade sobre a futura experiência de jogo impulsionada por IA, especulando que pode ser semelhante à interação no VRChat, mas expressando dúvidas sobre a operação totalmente por voz (Fonte: karminski3)
Discussão sobre a função de ampliação de imagem do ChatGPT: Utilizadores tentaram fazer o ChatGPT aumentar a resolução de imagens, descobrindo que ele não aumenta realmente os píxeis, mas redesenha uma imagem semelhante, mas com detalhes diferentes, em alta resolução. A secção de comentários concordou amplamente com isto e discutiu a verdadeira tecnologia de ampliação de imagem por IA (Fonte: Reddit r/ChatGPT)
ChatGPT gera imagem do mundo imaginado: Um utilizador pediu ao ChatGPT para gerar a aparência do mundo como ele o imagina, obtendo uma imagem de um cenário idílico de parque. Os comentários apontaram as inconsistências lógicas na imagem (como a distância Terra-Lua, posição dos bancos) e potenciais vieses (raça das personagens), refletindo as limitações atuais dos modelos de geração de imagem (Fonte: Reddit r/ChatGPT)

Exploração das razões da popularidade do antigo modelo LLM MythoMax13B: Utilizadores do Reddit perguntam por que o modelo MythoMax13B, baseado em Llama2, ainda é popular em cenários de RPG em plataformas como OpenRouter. Os comentários sugerem que as razões incluem: baixo custo (frequentemente como opção gratuita), estabilidade relativa e cumprimento de instruções, familiaridade dos utilizadores com os seus prompts e configurações, e o efeito de consolidação de tutoriais iniciais (Fonte: Reddit r/LocalLLaMA)
Procura por ferramenta de filtragem de privacidade local: Utilizadores do Reddit procuram ferramentas ou small language models (SLM) que possam ser executados localmente no dispositivo para detetar e anonimizar automaticamente (por exemplo, substituindo por placeholders) informações antes de enviar prompts para LLM, e restaurar a informação original após receber a resposta do LLM, para proteger a privacidade (Fonte: Reddit r/OpenWebUI)
Discussão sobre o aviso da Anthropic sobre “funcionários totalmente IA”: A Anthropic alertou que funcionários virtuais totalmente constituídos por IA podem surgir dentro de um ano, gerando discussão na comunidade. Comentadores expressaram ceticismo, apontando problemas de estabilidade nos próprios serviços da Anthropic e considerando isto mais como propaganda ou alarmismo (Fonte: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)

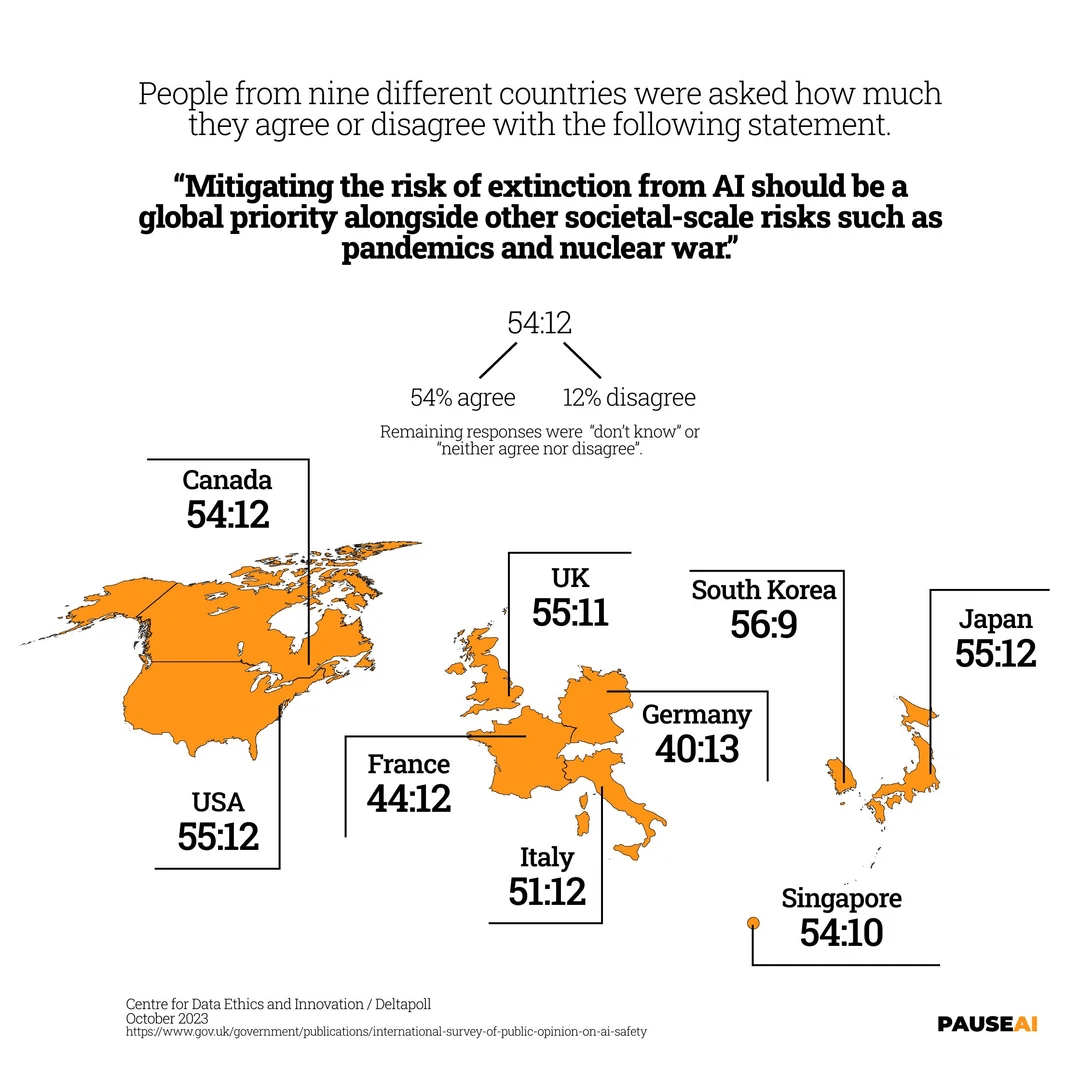
Preocupação global com o risco de extinção por IA: A imagem mostra o resultado de uma pesquisa, indicando que a maioria das pessoas no mundo acredita que o risco de a IA poder causar a extinção humana deve ser levado a sério (Fonte: Reddit r/artificial)
O “sabor a máquina” do texto gerado por IA e técnicas de humanização: Utilizadores discutem como identificar texto gerado por IA (como e-mails, posts), apontando os seus problemas comuns: falta de tom direcionado, excesso de formalidade, perfeição impecável. E partilham técnicas para tornar a escrita da IA mais natural: definir claramente o cenário, fornecer exemplos, ajustar a aleatoriedade, adicionar detalhes concretos, editar pessoalmente, manter pequenas imperfeições, etc. (Fonte: Reddit r/artificial)
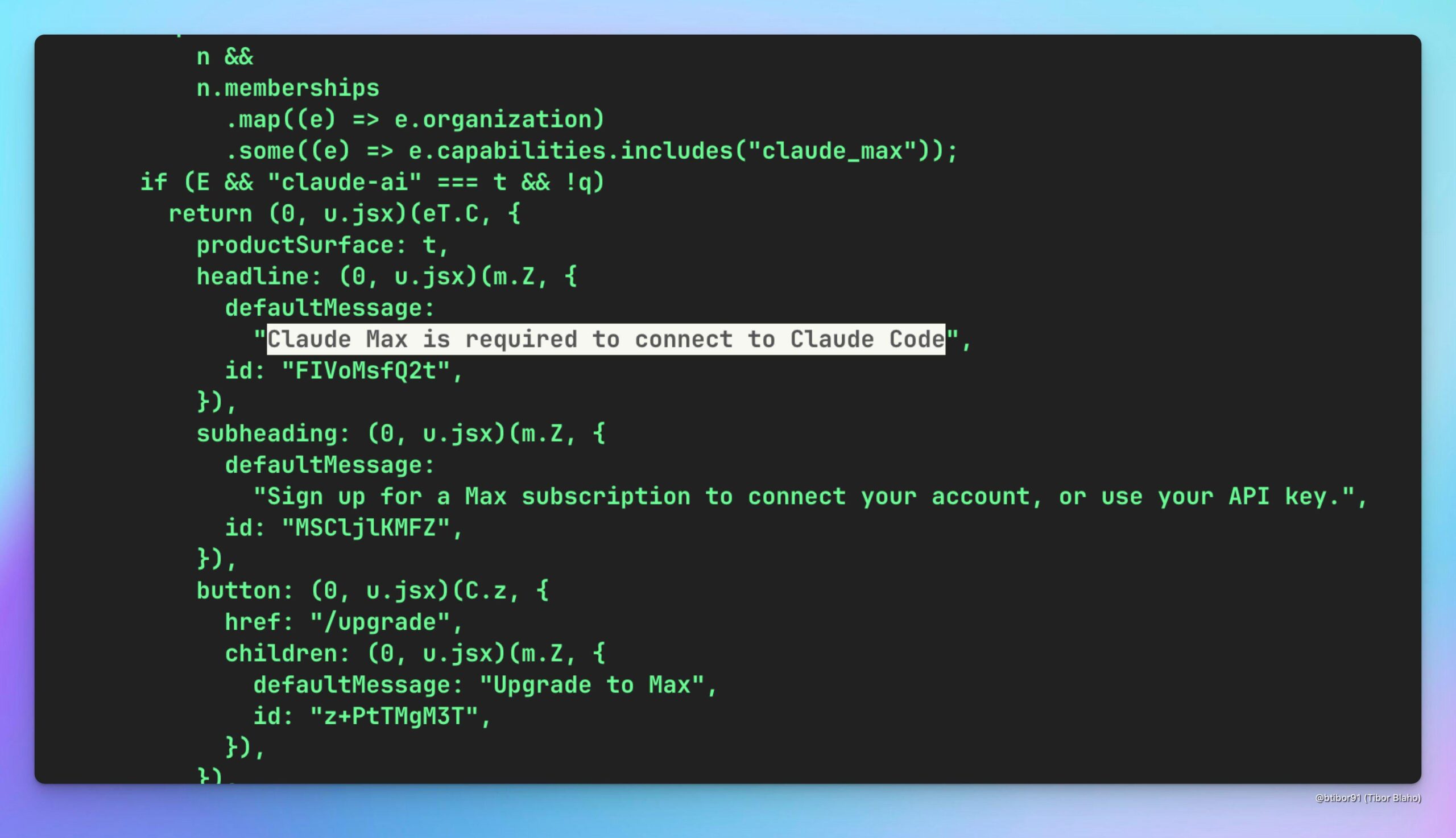
Especulação sobre se o Claude Code pode ser usado através do Claude Max: Utilizadores especulam se é possível usar indiretamente o modelo Claude Code (potencialmente mais económico) através da subscrição do serviço Claude Max, e discutem o seu valor potencial, esperando também que a OpenAI ofereça uma solução semelhante (Fonte: Reddit r/ClaudeAI)
Imitação humorística do comportamento local do modelo o3: Um utilizador publicou um prompt de sistema humorístico, destinado a fazer um modelo LLM local exibir características semelhantes às criticadas por alguns utilizadores no modelo OpenAI o3 (como respostas curtas, código subtilmente errado, comportamento irritante), para satirizar a insatisfação com o modelo o3 (Fonte: Reddit r/LocalLLaMA)

Pedido de ajuda com problema de conexão do OpenWebUI ao servidor proxy MCP: Utilizadores de K8s encontraram um problema ao usar OpenWebUI, não conseguindo aceder a partir da interface web a um servidor proxy MCP (aplicação FastAPI) implementado no mesmo pod, embora o acesso seja possível via localhost dentro do pod. O utilizador pede ajuda à comunidade para resolver o problema de conexão de rede ou configuração (Fonte: Reddit r/OpenWebUI)
Discussão sobre práticas de segurança para servidores MCP locais: Utilizadores iniciaram uma discussão perguntando como executar servidores MCP locais de forma segura para lidar com potenciais riscos de vulnerabilidade. Os comentários sugerem usar o modo stdio, ou restringir o modo SSE a localhost/127.0.0.1, ou usar autenticação por token, e apontam que a preocupação com injeção de prompt/roubo de credenciais se aplica a todas as instalações de software (Fonte: Reddit r/ClaudeAI)
Exploração do mecanismo de pagamento do protocolo Agent-to-Agent (A2A): A comunidade discute a falta de um mecanismo de pagamento integrado entre Agents no protocolo A2A da Google. Utilizadores consideram que isto pode dificultar o desenvolvimento da economia de Agents e exploram potenciais soluções, como o uso de tokens de autenticação vinculados à faturação, processos de custódia integrados ou adição de informações de preços no AgentSkill, etc. (Fonte: Reddit r/artificial)
Alerta sobre a dependência excessiva da IA: Utilizadores partilharam a experiência de a IA de pesquisa da Google dar respostas opostas para a mesma pergunta, enfatizando que não se deve depender totalmente da IA para tomar decisões finais. Os comentários explicam que a natureza probabilística dos LLM, o viés nos dados de treino, a simplificação do modelo, etc., levam a inconsistências, e recomendam usar a IA como ferramenta de pesquisa auxiliar, e não como fonte de informação autoritária (Fonte: Reddit r/ArtificialInteligence)
Dúvidas sobre o uso de Qdrant para RAG no OpenWebUI: Utilizadores perguntam como integrar a base de dados vetorial Qdrant no ambiente OpenWebUI para implementar RAG (Retrieval-Augmented Generation), especialmente como fazer o OpenWebUI usar os dados do Qdrant e se é necessário um script retriever (Fonte: Reddit r/OpenWebUI)
Discussão sobre a comparação da eficácia de pesquisa entre Google e ChatGPT: Utilizadores publicaram um gráfico comparativo (não exibido), alegando que a eficácia da pesquisa do ChatGPT é superior à do Google, gerando discussão na comunidade. Nos comentários, alguns refutam, considerando que o Google Gemini tem um desempenho excelente e possui ferramentas como o NotebookLM; outros consideram a comparação sem sentido, pois a tecnologia está em constante progresso; outros ainda apontam a importância da experiência do utilizador e da integração (Fonte: Reddit r/ChatGPT)
Perspetivas otimistas para a área de investigação de Character Training: Observadores da indústria preveem que o Character Training (treino de personagem, possivelmente referindo-se a fazer a IA simular personagens ou personalidades específicas) se tornará uma área de investigação académica explosiva, considerando que agora é um bom momento para publicar artigos pioneiros iniciais (Fonte: natolambert)
💡 Outros
Exploração da racionalidade da forma humanoide dos robôs: O artigo explora as razões para projetar robôs com forma humana: principalmente para se adaptarem ao mundo projetado e construído para humanos (ferramentas, ambientes, formas de interação). O design humanoide facilita a navegação e operação dos robôs na infraestrutura existente, reduz a necessidade de modificação e permite o uso de ferramentas humanas. Características antropomórficas também ajudam na interação e colaboração humano-robô. Apesar dos desafios como equilíbrio, controlo, custo e o “vale da estranheza”, os avanços tecnológicos estão gradualmente a superar essas barreiras. O artigo também revê brevemente a história do desenvolvimento de robôs, compara o cenário competitivo em robôs humanoides entre países como China e EUA, e perspetiva o futuro da popularização trazida pela redução de custos (Fonte: 外媒深度:机器人为什么要做成人形?)

Desafios e contramedidas do emprego na China na era da IA: O artigo analisa o impacto da inteligência artificial no mercado de trabalho chinês, especialmente os desafios para a mão de obra de baixa e média qualificação e o desequilíbrio no desenvolvimento regional. Inspirando-se na experiência dos EUA em reforma educacional, requalificação, sistema de segurança social e apoio à inovação, o artigo propõe que a China deve fortalecer a formação profissional e a educação ao longo da vida (especialmente competências digitais), aperfeiçoar o sistema de segurança social para cobrir novas formas de emprego, promover a integração da indústria com a IA e o desenvolvimento regional coordenado,健全 a regulamentação de algoritmos e a proteção da privacidade de dados, e fortalecer a coordenação multissetorial e o alerta precoce de monitorização do emprego, para estabilizar e melhorar a base do emprego (Fonte: 人工智能时代:中国如何稳住、提升就业基本盘)
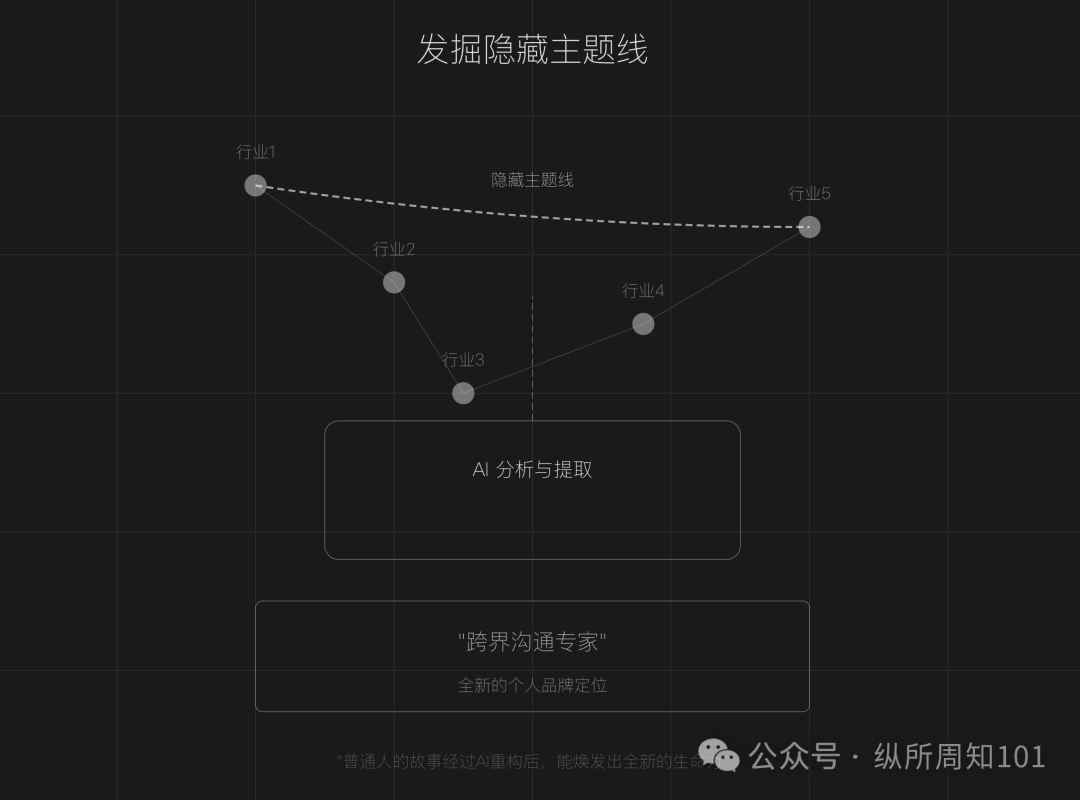
Utilização de IA para remodelar a narrativa da marca pessoal (IP): O artigo propõe que, numa era de saturação de criação de conteúdo, pessoas comuns podem usar ferramentas de IA (como ChatGPT) para reconstruir experiências pessoais, descobrir linhas temáticas ocultas, remodelar a narrativa de pontos de viragem cruciais e moldar um sistema linguístico diferenciado, criando assim uma marca pessoal (IP) única. O artigo fornece passos concretos (recolha de dados, mineração de temas por IA, remodelação da estrutura da história, iteração prática) e técnicas (construção inversa, amplificação emocional, reforço de contraste), e alerta para evitar embelezamento excessivo, uniformidade e falta de profundidade emocional, enfatizando a combinação de autenticidade com assistência de IA (Fonte: 做个人IP的第一步:用AI改写你的人生叙事)
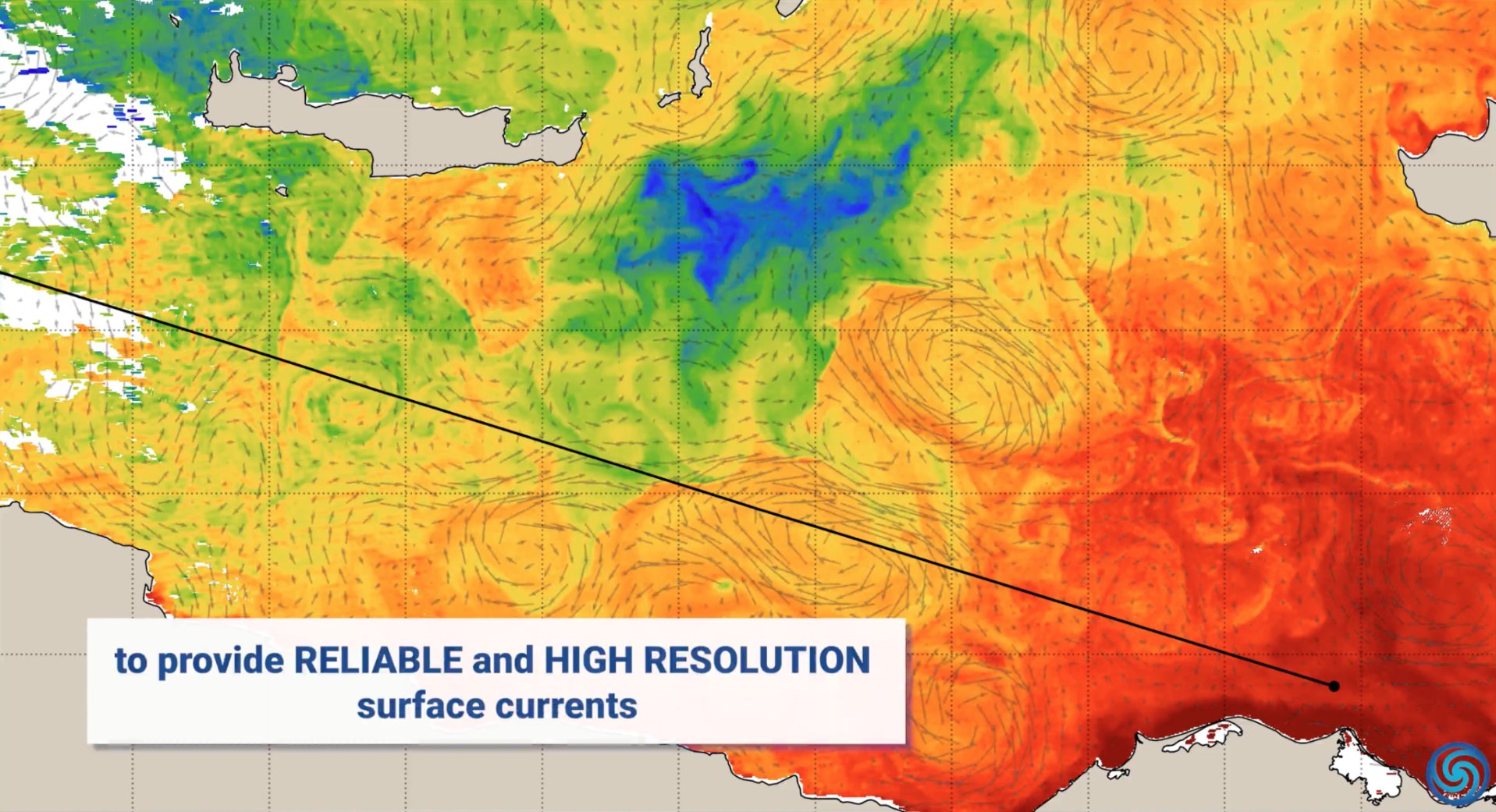
Aplicações da IA na proteção ambiental: Por ocasião do Dia Mundial da Terra, a NVIDIA demonstrou casos de aplicação da sua tecnologia de IA (como as plataformas Jetson, Earth-2) na proteção ambiental, incluindo a previsão de correntes oceânicas para reduzir o consumo de combustível, proteção em tempo real contra incêndios florestais e caça furtiva, fornecimento de previsões de tempestades mais precisas e deteção de asteroides, cobrindo múltiplas dimensões como oceano, terra, céu e espaço (Fonte: nvidia, nvidia, nvidia)
IA usada para melhorar o atendimento ao cliente: Centros de contacto impulsionados por IA estão a transformar a experiência de atendimento ao cliente, visando resolver os pontos problemáticos das chamadas de atendimento tradicionais, aumentando a eficiência e a satisfação (Fonte: Ronald_vanLoon)
Partilha de prompts para IA gerar selfies realistas / imagens engraçadas: Utilizadores partilharam prompts para usar ferramentas de geração de imagem AI (como GPT-4o, Sora) para gerar selfies “comuns” extremamente realistas, que parecem tiradas casualmente, bem como para gerar imagens engraçadas, como transformar certas pessoas em escovas de sanita, mostrando o potencial criativo e de entretenimento da IA na geração de imagens (Fonte: dotey, dotey, dotey)

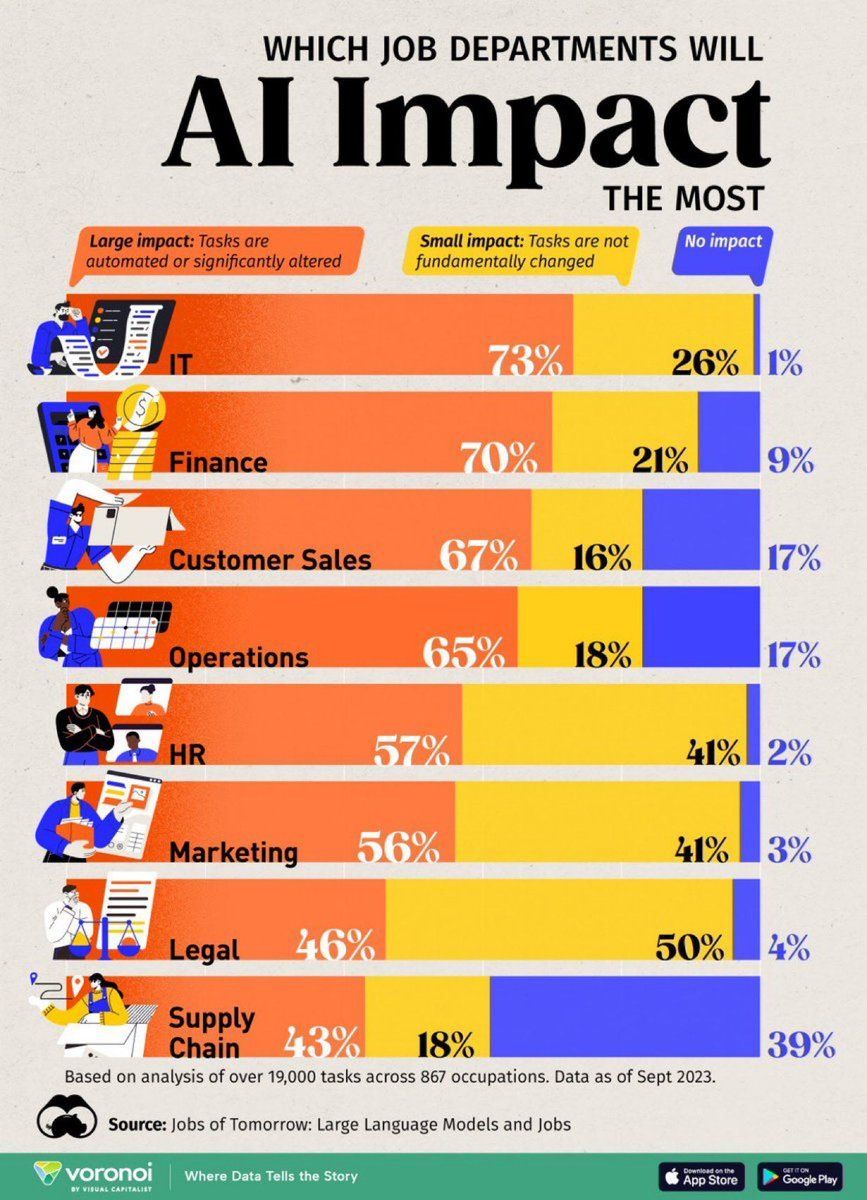
Análise do impacto da IA nos postos de trabalho: Um infográfico produzido pela Visual Capitalist mostra os postos de trabalho mais afetados pela IA, gerando atenção para as mudanças na forma futura do trabalho (Fonte: Ronald_vanLoon)
IA usada para deteção de defeitos nas estradas do Dubai: O Dubai adotará nova tecnologia de IA para detetar defeitos nas estradas, mostrando o potencial de aplicação da IA na manutenção de infraestruturas urbanas (Fonte: Ronald_vanLoon)
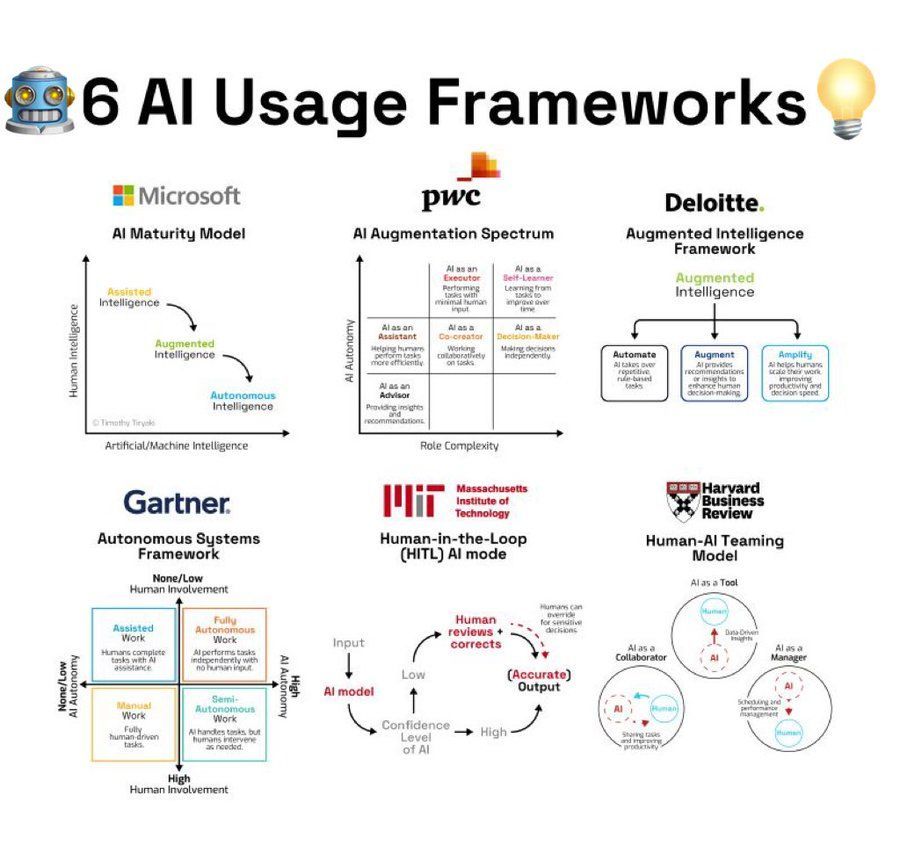
Resumo de frameworks de uso de IA: Um infográfico resume 6 frameworks ou metodologias para usar IA, fornecendo referências de ideias para utilizadores aplicarem IA (Fonte: Ronald_vanLoon)
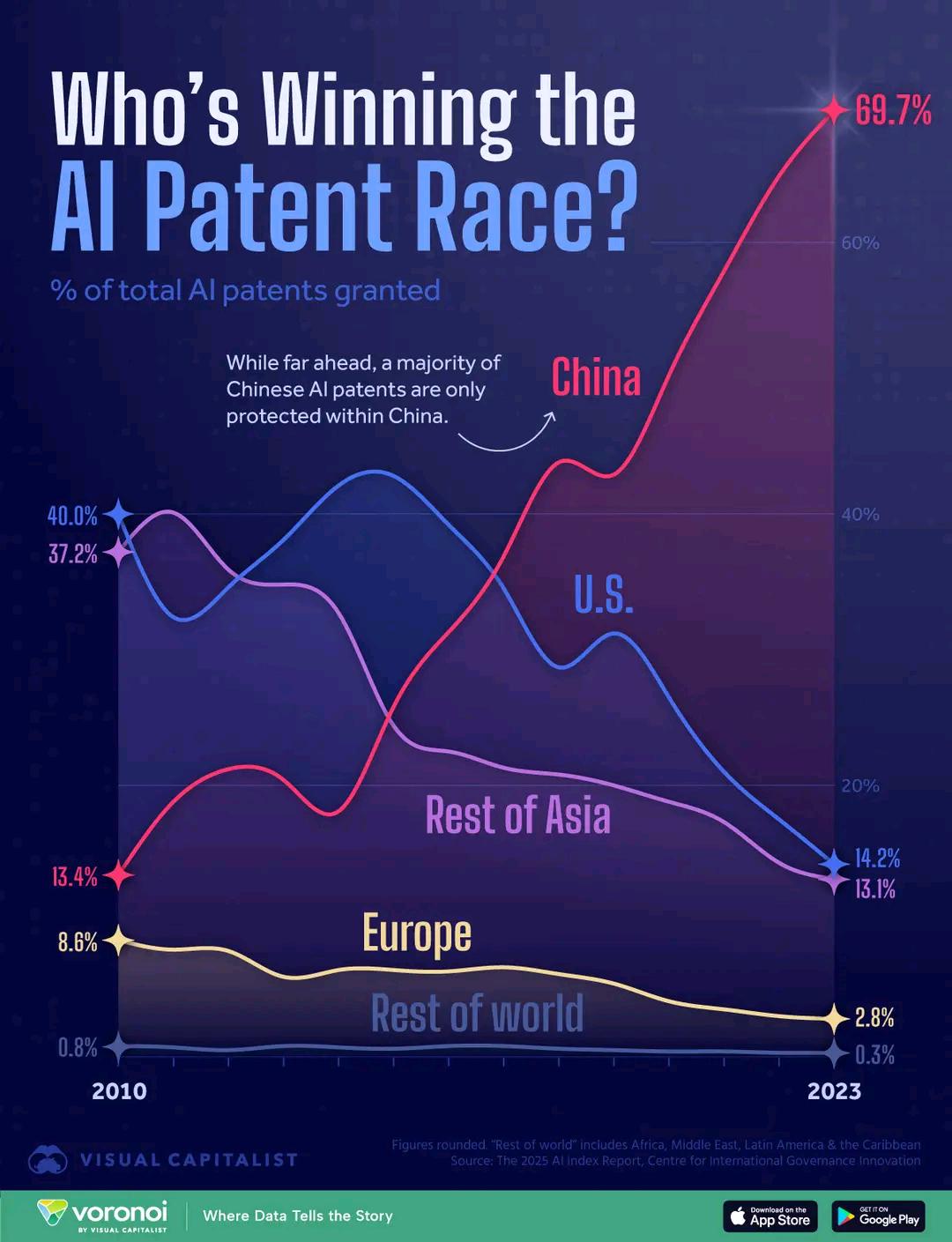
Comparação do número de patentes de IA por país: Um gráfico mostra a comparação do número de patentes na área de IA por país, refletindo as diferenças no investimento em I&D e produção de IA entre diferentes países. Comentários mencionam que o custo relativamente baixo de registo de patentes na China pode afetar a interpretação dos dados (Fonte: karminski3)
Braço biónico ajuda pessoas com deficiência: A empresa Open Bionics instalou um braço biónico numa rapariga amputada de 15 anos, Grace, demonstrando a aplicação da IA e da tecnologia robótica nas áreas da saúde e tecnologia assistiva (Fonte: Ronald_vanLoon)
Filme assistido por IA elegível para Óscar gera atenção: A Academia de Artes e Ciências Cinematográficas dos EUA atualizou as regras, clarificando que filmes produzidos com ferramentas digitais como IA também são elegíveis para concorrer aos Óscares, o que gerou ampla discussão dentro e fora de Hollywood, focando no impacto da IA na criação cinematográfica e nos padrões da indústria (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Lituânia estabelece regras para uso de IA nas escolas: A Lituânia está a desenvolver regras relativas ao uso de inteligência artificial nas escolas, refletindo que o setor da educação começa a normalizar a aplicação de ferramentas de IA (Fonte: Reddit r/ArtificialInteligence)