Palavras-chave:IA, Modelo de grande dimensão, Agente inteligente, Multimodal, Design de detetor de ondas gravitacionais com IA, Modelo de geração de vídeo Magi-1, Modelo de grande dimensão de vídeo Vidu Q1, Análise de valores Claude, Mecanismo de raciocínio DeepSeek-R1, Padrão de protocolo para agentes inteligentes de IA, Vulnerabilidade de segurança em 3D Gaussian Splatting, Controvérsia sobre direitos de autor em música gerada por IA
🔥 Destaques
IA projeta novo detetor de ondas gravitacionais, expandindo o universo observável: Pesquisadores do Instituto Max Planck (MPI), Caltech e outras instituições usaram o algoritmo de IA Urania para projetar um novo tipo de detetor de ondas gravitacionais que supera a compreensão humana atual. Esta IA, ao transformar o problema de design numa otimização contínua, descobriu dezenas de estruturas topológicas superiores aos designs humanos, capazes de aumentar a sensibilidade de deteção em mais de 10 vezes e expandir o volume do universo observável em 50 vezes. Este estudo, publicado na PRX, demonstra o potencial da IA para descobrir soluções sobre-humanas em ciências fundamentais, e até mesmo criar novas ideias físicas. (Fonte: 新智元)

Equipa de Cao Yue, vencedor do Prémio Especial de Tsinghua, lança modelo de geração de vídeo open-source Magi-1: A Sand.ai, fundada por Cao Yue, autor do Swin Transformer, lançou e tornou open-source o grande modelo de geração de vídeo autorregressivo Magi-1. Este modelo utiliza um método de previsão autorregressiva por blocos, suporta extensão de comprimento ilimitado e controlo de duração ao nível do segundo, alcançando uma saída de alta qualidade de imagem. A equipa publicou um relatório técnico de 61 páginas, detalhando a arquitetura do modelo (baseada em DiT), o método de treino (Flow-Matching) e várias otimizações de atenção e treino distribuído. Lançaram uma série de modelos com parâmetros de 4.5B a 24B, sendo que o mínimo necessário é uma única placa 4090 para execução, com o objetivo de impulsionar o desenvolvimento da tecnologia de geração de vídeo por IA. (Fonte: 量子位, 机器之心, kaifulee)
Modelo de vídeo chinês Vidu Q1 lidera ambos os rankings VBench no Q1: O modelo de vídeo Vidu Q1 da Shengshu Technology classificou-se em primeiro lugar nos dois benchmarks de referência, VBench-1.0 e VBench-2.0, superando modelos nacionais e internacionais como Sora e Runway. O Q1 demonstrou excelente desempenho em realismo de vídeo, consistência semântica e veracidade do conteúdo. A nova versão suporta qualidade de imagem HD 1080p (geração única de 5 segundos), atualizou a funcionalidade de frames inicial e final para permitir movimentos de câmara cinematográficos e introduziu uma função de efeitos sonoros de IA com controlo preciso de tempo (taxa de amostragem de 48kHz). O preço é competitivo, visando capacitar a indústria criativa. (Fonte: 新智元)

Estudo da Anthropic revela a expressão de valores do Claude: A Anthropic analisou 700.000 conversas anónimas do Claude, construindo um sistema de classificação com 3.307 valores únicos, com o objetivo de compreender a orientação de valor da IA em interações reais. O estudo descobriu que o Claude segue amplamente os princípios de ‘benéfico, honesto, inofensivo’ e consegue ajustar flexivelmente os valores de acordo com diferentes contextos (como conselhos sobre relacionamentos, análise histórica). Na maioria dos casos, apoia os pontos de vista do utilizador, mas em poucos casos (3%) resiste ativamente, o que pode refletir os seus valores centrais. Este estudo ajuda a aumentar a transparência do comportamento da IA, identificar riscos e fornecer evidências empíricas para a avaliação ética da IA. (Fonte: 元宇宙之心MetaverseHub, 新智元)

🎯 Tendências
Deng Zhidong, de Tsinghua, fala sobre a evolução e o futuro da AGI: Deng Zhidong, professor da Universidade de Tsinghua, partilhou o caminho da evolução da IA, desde modelos de texto unimodais até à inteligência incorporada multimodal e AGI interativa. Ele enfatizou que os grandes modelos fundamentais são como sistemas operativos, e a arquitetura MoE e o alinhamento semântico multimodal são fronteiras tecnológicas chave. Deng Zhidong destacou especialmente o significado disruptivo do DeepSeek, considerando que a sua poderosa capacidade de raciocínio e a possibilidade de implementação local representam um ponto de viragem para a aplicação generalizada da IA na China. O futuro caminha para um mundo de inteligência artificial geral, onde os agentes de IA terão maior capacidade organizacional e passarão da internet para o mundo físico, mas também é necessário prestar atenção às questões éticas e de governação. (Fonte: 清华邓志东:我们会迈向一个通用人工智能的世界)
DeepMind explora ‘Fantasmas Geradores’: imortalidade digital impulsionada por IA: A DeepMind e a Universidade do Colorado propuseram o conceito de “Fantasmas Geradores”, referindo-se a agentes de IA construídos com base nos dados de pessoas falecidas, capazes de gerar novo conteúdo e interagir na perspetiva do falecido, indo além da simples replicação de informação. O artigo explora o seu espaço de design (como criação por primeira/terceira parte, implementação pré/pós-morte, grau de antropomorfização, etc.) e os potenciais impactos, incluindo os benefícios de consolo emocional e transmissão de conhecimento, bem como os desafios de dependência psicológica, riscos de reputação, segurança e ética social, apelando a uma investigação aprofundada e à definição de normas antes da maturação da tecnologia. (Fonte: 新智元)

Apple Intelligence e AI Siri adiados várias vezes, data de lançamento na China indefinida: Os planos de lançamento das funcionalidades de IA da Apple, Apple Intelligence (especialmente a nova versão do Siri), sofreram múltiplos atrasos, com algumas funcionalidades possivelmente adiadas para o outono de 2025. A região da China enfrenta maior incerteza devido a questões de aprovação e cooperação para localização (rumores de colaboração com Alibaba e Baidu). As razões para o atraso incluem tecnologia que não atinge os padrões (avaliação interna baixa, taxa de sucesso de apenas 66-80%) e diferenças nas políticas regulatórias de cada país. A Apple já enfrenta processos por publicidade enganosa devido a isso e alterou o slogan promocional do iPhone 16. Isto reflete os desafios que a Apple enfrenta na implementação da IA e a lentidão no seu processo de inovação. (Fonte: 一财商学)

Qualcomm enfatiza IA no dispositivo como chave para a próxima geração de experiências: Wan Weixing, responsável pela tecnologia de produtos de IA da Qualcomm na China, destacou que a IA no dispositivo (on-device AI), com as suas vantagens em privacidade, segurança, personalização, desempenho, eficiência energética e resposta rápida, está a tornar-se o núcleo da próxima geração de experiências de IA e a remodelar a interface de interação homem-máquina. A Qualcomm está a posicionar-se através de hardware (computação heterogénea), uma pilha de software unificada e ferramentas do ecossistema Qualcomm AI Hub. A sua principal força motriz é o planeador de agentes inteligentes no dispositivo, que utiliza dados locais para alcançar uma compreensão precisa da intenção, planeamento de tarefas e chamada de serviços entre aplicações. (Fonte: 36氪)

Padrões de protocolo para agentes de IA tornam-se novo foco de competição entre gigantes: Os gigantes da tecnologia estão envolvidos numa competição feroz em torno dos padrões de interação para agentes de IA. A Anthropic foi a primeira a lançar o MCP (Model Context Protocol) para unificar a conexão de modelos com dados/ferramentas externas, recebendo resposta da OpenAI e Google. Subsequentemente, a Google lançou o protocolo open-source A2A, visando promover a colaboração entre agentes de diferentes ecossistemas. O artigo analisa que dominar a definição do protocolo significa dominar o poder de distribuição de valor futuro na indústria de IA. Os gigantes estão a construir barreiras de ecossistema através do MCP (serviço de acesso a dados) e A2A (vinculação à plataforma cloud), competindo pela liderança da indústria. (Fonte: 科技云报道)

Tencent Yuanbao e ByteDance Doubao integram-se profundamente nos ecossistemas WeChat e Douyin: O Tencent Yuanbao lançou uma conta oficial no WeChat, e o ByteDance Doubao integrou-se na página “Mensagens” do Douyin. Os dois assistentes de IA estão a integrar-se profundamente nas suas respetivas super-apps. Os utilizadores podem interagir diretamente com o Yuanbao dentro do WeChat, analisar artigos e partilhar, ou conversar com o Doubao e pesquisar informações dentro do Douyin. Esta medida é vista como uma estratégia importante dos gigantes, para além do investimento em publicidade, para atrair novos utilizadores para aplicações de IA, utilizando as redes sociais e ecossistemas de conteúdo, com o objetivo de reduzir a barreira de entrada para os utilizadores, explorar novos modelos de IA+social e usar conteúdo gerado por IA como moeda social. (Fonte: 字母榜)
Relatório AI4SE: Grandes modelos impulsionam aceleração da engenharia de software inteligente: O “Relatório de Investigação sobre o Estado Atual da Indústria AI4SE (Ano 2024)”, publicado pela CAICT e outras instituições, mostra que a aplicação da IA no campo da engenharia de software já passou da fase de validação e entrou na implementação em larga escala. A maturidade da inteligência empresarial geralmente atinge o nível L2 (parcialmente inteligente). A aplicação da IA na análise de requisitos e na fase de operação e manutenção aumentou significativamente, com melhorias notáveis na eficiência em todas as fases, especialmente na área de testes. A taxa de adoção da geração de código (média de 27,46%) e a proporção de código gerado por IA (média de 28,17%) aumentaram. As ferramentas de teste inteligentes já demonstraram preliminarmente o efeito de reduzir a taxa de defeitos funcionais. (Fonte: AI前线)

Kingsoft Office atualiza modelo governamental, reforça capacidade de raciocínio e processamento de documentos oficiais: A Kingsoft Office lançou a versão aprimorada do seu modelo governamental (13B, 32B), melhorando a capacidade de raciocínio e focando-se em servir cenários internos do governo. O modelo foi treinado com centenas de milhões de corpora governamentais, otimizando a escrita de documentos oficiais (cobrindo 5 tipos de estilos), retoque inteligente, revisão e formatação, e capacidade de consulta de políticas. Após a atualização, suporta uma compreensão mais forte da intenção e perguntas e respostas sobre bases de conhecimento internas (respostas com fontes anotadas), visando libertar 30-40% da produtividade dos funcionários públicos. Enfatiza a implementação privada para atender aos requisitos de segurança e afirma que o custo de implementação foi reduzido em 90%. (Fonte: 量子位)

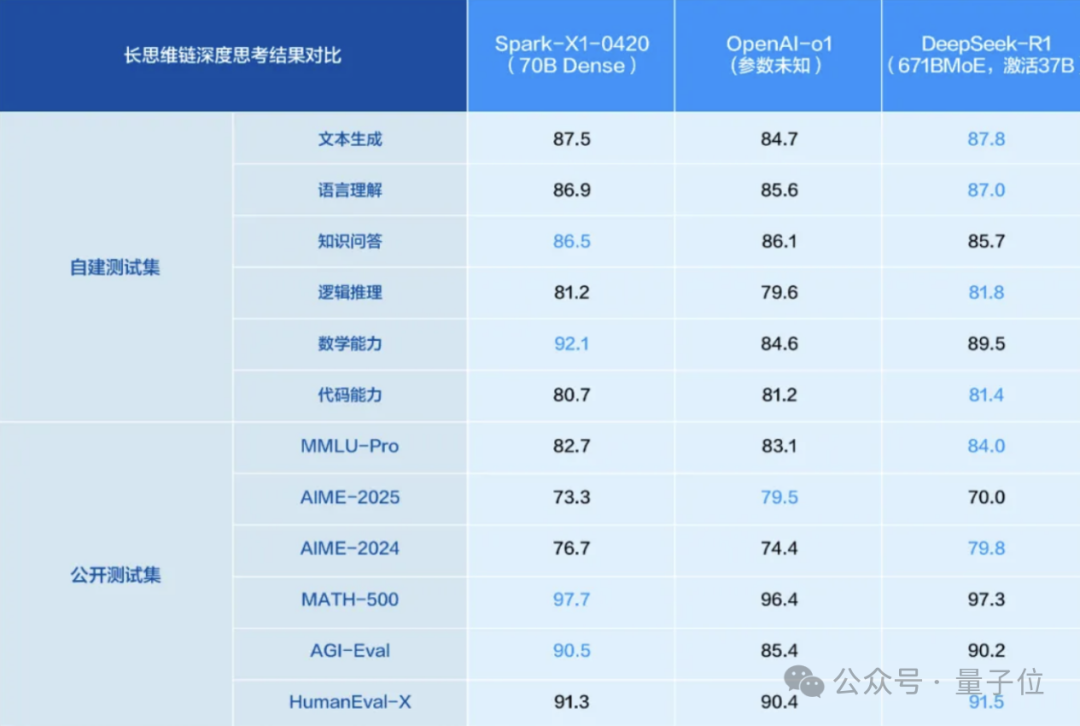
Modelo de inferência iFlytek Spark X1 atualizado, baseado em computação totalmente nacional, visa nível de topo: A iFlytek lançou a versão atualizada do modelo de inferência profunda Spark X1, enfatizando que foi treinado com base em computação totalmente nacional (Huawei Ascend) e que, em tarefas gerais, se compara ao OpenAI o1 e DeepSeek R1. O novo modelo beneficia de inovações tecnológicas como aprendizagem por reforço multi-etapa em larga escala e treino unificado de pensamento rápido e lento. O destaque é a redução significativa da barreira de implementação: 4 placas Huawei 910B são suficientes para implementar a versão completa, e 16 placas podem completar a personalização para a indústria. No contexto das restrições ao H20, demonstra o progresso da solução de IA full-stack nacional. (Fonte: 量子位)
Zhipu GLM-4 disponível nas plataformas OpenRouter e Ollama: O modelo GLM-4 da Zhipu AI (incluindo a versão instruct 32B GLM-4-32B-0414 e a versão reasoning GLM-Z1-32B-0414) está agora disponível na plataforma de roteamento de modelos OpenRouter, onde os utilizadores podem experimentá-lo gratuitamente. Ao mesmo tempo, contribuidores da comunidade também carregaram a versão quantizada Q4_K_M para a plataforma Ollama, facilitando a implementação e execução local (requer Ollama v0.6.6 ou superior). (Fonte: karminski3, Reddit r/LocalLLaMA)
Meta lança Perception Language Model (PLM): A Meta tornou open-source o seu modelo de linguagem visual PLM (versões com parâmetros 1B, 3B, 8B), focado no processamento de tarefas desafiadoras de reconhecimento visual. Este modelo combina dados sintéticos em larga escala com 2,5 milhões de dados de perguntas e respostas em vídeo/legendas espácio-temporais recentemente recolhidos e anotados por humanos para treino. Ao mesmo tempo, lançou o novo benchmark PLM-VideoBench, focado na compreensão de atividades de granularidade fina e raciocínio espácio-temporal. (Fonte: Reddit r/LocalLLaMA, Hugging Face)

🧰 Ferramentas
NYXverse: Plataforma AIGC para gerar mundos 3D a partir de texto: A 2033 Technology, fundada pelo ex-fundador da Trigodata, Ma Yuchi, lançou a plataforma de conteúdo AIGC NYXverse. A plataforma permite aos utilizadores criar mundos interativos 3D contendo AI Agents personalizados, ambientes e enredos através de input de texto, reduzindo significativamente a barreira para a criação de conteúdo 3D. A sua tecnologia central consiste em três modelos desenvolvidos internamente: personagens, mundos e comportamentos. O NYXverse posiciona-se como uma comunidade de partilha de conteúdo UGC, suportando rápida re-criação e adaptação de IP. Atualmente está disponível no Steam e recebeu quase 100 milhões de yuan em financiamento da SenseTime e da Dongfang State-owned Capital. (Fonte: 36氪)

SkyReels V2 lança modelo open-source de geração de vídeo de comprimento ilimitado: A SkyworkAI tornou open-source os modelos SkyReels V2 (parâmetros 1.3B e 14B), que suportam tarefas de texto para vídeo e imagem para vídeo, e afirmam poder gerar vídeos de comprimento ilimitado. Testes preliminares mostram que os resultados podem não ser tão bons quanto alguns modelos de código fechado, mas como ferramenta open-source ainda tem potencial. (Fonte: karminski3, Reddit r/LocalLLaMA)
Exoesqueleto impulsionado por IA ajuda utilizadores de cadeira de rodas a ficar de pé e andar: Demonstração de um dispositivo de exoesqueleto que utiliza tecnologia de IA, destinado a ajudar utilizadores de cadeira de rodas a recuperar a capacidade de ficar de pé e andar, refletindo o potencial de aplicação da IA no campo da tecnologia assistiva. (Fonte: Ronald_vanLoon)
Fellou: Lançado o primeiro navegador do tipo ação: O navegador Fellou, criado pelo fundador da Authing, Xie Yang, foi lançado, posicionando-se como um navegador do tipo ação (Agentic Browser). Ele não só possui as funções de exibição de informações de um navegador tradicional, mas também integra capacidades de AI Agent, capaz de entender a intenção do utilizador, decompor tarefas automaticamente e executar fluxos de trabalho complexos entre sites (como recolha de informações, preenchimento de formulários, pedidos online, etc.). As suas capacidades principais incluem ação profunda, inteligência proativa (previsão das necessidades do utilizador), espaço sombra híbrido (não interfere nas operações do utilizador) e rede de agentes inteligentes (Agent Store). O objetivo é atualizar o navegador de uma ferramenta de informação para uma plataforma de trabalho inteligente. (Fonte: 新智元)

WriteHERE: Equipa de Jürgen lança framework open-source para escrita de textos longos: O framework de escrita de textos longos WriteHERE, lançado em open-source pela equipa de Jürgen Schmidhuber, adota tecnologia de planeamento recursivo heterogéneo, capaz de gerar relatórios profissionais com mais de 40.000 palavras e 100 páginas numa única vez. O framework encara a escrita como um processo de planeamento recursivo dinâmico de três tipos de tarefas: recuperação, raciocínio e escrita, alcançando execução adaptativa através da gestão de tarefas DAG com estado. Demonstrou desempenho superior a soluções como Agent’s Room e STORM em tarefas de criação de ficção e geração de relatórios técnicos. O framework é totalmente open-source e suporta a chamada de Agents heterogéneos. (Fonte: 机器之心)

ByteDance lança plataforma de Agent universal ‘Coze Space’: A ByteDance lançou oficialmente para teste interno a sua plataforma de Agent universal “Coze Space”, posicionada como um assistente de IA que oferece os modos “Explorar” e “Planear”. A plataforma é baseada no modelo Doubao atualizado (200B MoE), suporta o protocolo MCP e pode chamar ferramentas como Documentos Feishu (Lark Docs), Tabelas Multidimensionais, etc. Os utilizadores podem, através de instruções em linguagem natural, fazer com que complete tarefas como recolha de informações, geração de relatórios, organização de dados, etc., e exportar os resultados para aplicações especificadas. Comparado com Agents de startups como Manus, o Coze Space foca-se mais na plataformização e integração de ecossistemas. (Fonte: 保姆级教程:正确使用「扣子空间」, AI智能体研究院)

Tecnologia de conversão de vídeo por IA demonstrada: Utilizador do Reddit partilha vídeo demonstrando uma tecnologia de IA capaz de transformar pessoas em vídeos normais de fala em árvores, carros, desenhos animados ou qualquer outra imagem, necessitando apenas de uma imagem alvo. Demonstra as capacidades da IA na transferência de estilo de vídeo e geração de efeitos especiais. (Fonte: Reddit r/deeplearning)

Nari Labs lança modelo TTS Dia para conversação de alto realismo: A Nari Labs tornou open-source o seu modelo TTS (Text-to-Speech) Dia, que alega ser capaz de gerar voz de conversação ultra-realista. O modelo foi lançado no GitHub e fornece um link para experimentação no Hugging Face Space. (Fonte: Reddit r/LocalLLaMA, GitHub)

Utilizador desenvolve função de base de conhecimento AWS Bedrock para OpenWebUI: Um utilizador da comunidade desenvolveu e partilhou uma função para o OpenWebUI que permite chamar a base de conhecimento do AWS Bedrock, facilitando aos utilizadores aproveitar as capacidades da base de conhecimento do Bedrock dentro do OpenWebUI. O código está disponível em open-source no GitHub. (Fonte: Reddit r/OpenWebUI, GitHub)
Desenvolvedores consideram LLMs pequenos subestimados, lançam Arch-Function-Chat: A equipa Katanemo acredita que os LLMs pequenos têm vantagens óbvias em velocidade e eficiência, sem comprometer o desempenho. Lançaram a série de modelos Arch-Function-Chat (parâmetros 3B), que apresentam excelente desempenho na chamada de funções e integram capacidades de chat. Estes modelos foram integrados no seu servidor proxy de IA open-source Arch, visando simplificar o desenvolvimento de Agents. (Fonte: Reddit r/artificial, Hugging Face)
Desenvolvedor cria ferramenta de IA para otimizar currículos para passar na triagem ATS: Um desenvolvedor partilhou a sua experiência frustrante de procura de emprego devido ao seu currículo não ser corretamente analisado pelo ATS (Applicant Tracking System) e, por isso, desenvolveu uma ferramenta. A ferramenta consegue ler a descrição da vaga, extrair palavras-chave, verificar a correspondência do currículo e sugerir modificações, gerando finalmente um currículo em PDF e uma carta de apresentação compatíveis com ATS. (Fonte: Reddit r/artificial)
📚 Aprendizagem
Relatório de 142 páginas analisa profundamente o mecanismo de raciocínio do DeepSeek-R1: O Instituto de IA do Quebec (Mila) e outras instituições publicaram um longo relatório que analisa em profundidade o processo de raciocínio (cadeia de pensamento) do DeepSeek-R1, propondo uma nova direção de investigação, a “Thoughtology”. O relatório revela que o raciocínio do R1 possui características altamente estruturadas (definição do problema, expansão, reconstrução, decisão), existe uma “zona ótima de raciocínio” (raciocínio excessivo diminui o desempenho) e pode apresentar riscos de segurança superiores aos modelos sem raciocínio. A investigação explora múltiplas dimensões, como o comprimento da cadeia de pensamento, processamento de contexto longo, segurança, ética e fenómenos cognitivos semelhantes aos humanos, fornecendo insights importantes para a compreensão e otimização de modelos de raciocínio. (Fonte: 新智元, 新智元)

OpenRCA: Primeiro benchmark público para avaliar a capacidade de análise de causa raiz (RCA) de LLMs: A Microsoft, a CUHK-Shenzhen e a Universidade de Tsinghua lançaram conjuntamente o benchmark OpenRCA, com o objetivo de avaliar a capacidade dos grandes modelos de linguagem (LLM) de localizar a causa raiz (RCA) de falhas em serviços de software. Este benchmark inclui uma definição clara da tarefa, métodos de avaliação e 335 casos de falha reais alinhados manualmente, juntamente com dados de operação e manutenção. Testes preliminares mostram que mesmo modelos avançados como Claude 3.5 e GPT-4o têm um desempenho fraco ao lidar diretamente com tarefas de RCA (precisão <6%). Após o uso de um framework simples RCA-Agent, a precisão do Claude 3.5 aumentou para 11,34%, indicando que os LLMs ainda têm um grande espaço para melhoria nesta área. (Fonte: 机器之心, 机器之心)

Nova investigação propõe ‘Computação em Tempo de Sono’ para aumentar a eficiência de LLMs: A startup de IA Letta e pesquisadores da UC Berkeley propuseram um novo paradigma chamado “Computação em Tempo de Sono” (Sleep-time Compute). A ideia central é permitir que agentes de IA com estado processem e reorganizem continuamente informações de contexto durante os períodos de inatividade “de sono”, quando o utilizador não está a consultar, transformando o “contexto bruto” em “contexto aprendido”. Isto pode reduzir a carga de inferência instantânea durante a interação real, aumentar a eficiência, reduzir custos e, potencialmente, melhorar a precisão. Experiências demonstram que este método pode melhorar eficazmente a fronteira de Pareto computação-precisão e amortizar custos quando o contexto é partilhado entre múltiplas consultas. (Fonte: 机器之心, 机器之心)

AnyAttack: Framework de ataque adversário auto-supervisionado em larga escala para VLMs: A HKUST, BJTU e outras instituições propuseram o framework AnyAttack (CVPR 2025), com o objetivo de avaliar a robustez dos modelos de linguagem visual (VLM). Este método aprende um gerador de ruído adversário através de pré-treino auto-supervisionado em larga escala (no LAION-400M), capaz de transformar qualquer imagem numa amostra adversária direcionada sem a necessidade de etiquetas pré-definidas, induzindo o VLM a gerar uma saída específica. A inovação central reside no paradigma de treino auto-supervisionado e na estratégia K-enhancement. Experiências mostram que o AnyAttack não só consegue atacar eficazmente vários VLMs open-source, mas também transferir com sucesso o ataque para modelos comerciais convencionais, revelando riscos de segurança sistémicos no ecossistema VLM atual. (Fonte: AI科技评论)

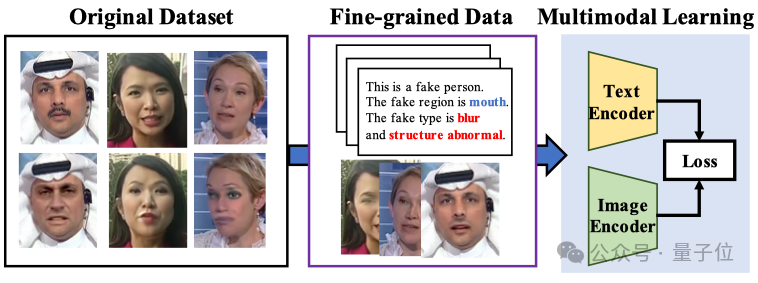
Grandes modelos multimodais melhoram a interpretabilidade e generalização da deteção de falsificação facial: Instituições como a Universidade de Xiamen e o Tencent Youtu Lab (CVPR 2025) propuseram um novo método para deteção de falsificação facial utilizando modelos de linguagem visual. Este método visa ir além do julgamento tradicional de verdadeiro/falso, permitindo que o modelo explique a razão e a localização da falsificação em linguagem natural. Para resolver a falta de dados de anotação de alta qualidade e o problema da “alucinação linguística”, os pesquisadores projetaram o fluxo de trabalho de anotação FFTG, combinando máscaras de falsificação e prompts estruturados para gerar descrições textuais de alta precisão. Experiências mostram que modelos multimodais treinados com estes dados apresentam melhor capacidade de generalização entre datasets, e a sua atenção foca-se mais nas regiões de falsificação reais. (Fonte: 量子位)
Tutorial: Combinar Trae, MCP e base de dados para melhorar a precisão de respostas em bases de conhecimento: Este tutorial demonstra como usar a ferramenta AI IDE Trae e a sua funcionalidade MCP (Model Context Protocol), combinada com uma base de dados PostgreSQL, para otimizar o efeito de perguntas e respostas em bases de conhecimento de IA. Ao armazenar dados estruturados na base de dados e permitir que grandes modelos (como o Claude 3.7) gerem consultas SQL através da conexão MCP do Trae, é possível resolver as limitações do RAG tradicional no processamento de dados tabulares e problemas globais/estatísticos, onde a precisão é insuficiente. O tutorial fornece passos detalhados de instalação, configuração e teste, e sugere combinar esta solução com RAG. (Fonte: 袋鼠帝AI客栈)
![Ferramenta assistente de IA chinesa Trae+MCP aumenta a precisão da recuperação em bases de conhecimento em 300% [Tutorial passo-a-passo]](https://rebabel.net/wp-content/uploads/2025/04/image_1745328048.png)
Investigação revela vulnerabilidade de ataque de custo computacional no algoritmo 3D Gaussian Splatting: Uma investigação da Universidade Nacional de Singapura (NUS) e outras instituições (ICLR 2025 Spotlight) descobriu pela primeira vez um método de ataque de custo computacional contra o 3D Gaussian Splatting (3DGS), denominado Poison-Splat. Este ataque explora a característica de complexidade adaptativa do modelo 3DGS, adicionando perturbações às imagens de entrada (maximizando a Variação Total) para induzir o modelo a gerar uma quantidade excessiva de pontos gaussianos durante o treino. Isto leva a um aumento drástico na ocupação da memória VRAM da GPU (até 80GB) e no tempo de treino (quase 5 vezes mais), podendo até causar a paralisação do serviço (DoS). O ataque é eficaz tanto em modo oculto como não oculto e possui transferibilidade, expondo riscos de segurança nas tecnologias de reconstrução 3D convencionais. (Fonte: 量子位)

Infográfico: Agentic AI vs. GenAI: Um infográfico produzido pela SearchUnify compara as principais diferenças e características entre Agentic AI (ação autónoma, orientada por objetivos) e Generative AI (geração de conteúdo). (Fonte: Ronald_vanLoon)

NVIDIA lança dataset e método de pré-treino ClimbLab em open-source: O ClimbLab da NVIDIA publicou o seu método e dataset de pré-treino, contendo 1,2 triliões de tokens, divididos em 20 clusters semânticos. Utiliza um sistema de classificador duplo para remover conteúdo de baixa qualidade, demonstrando escalabilidade superior em modelos 1B. O dataset está disponível sob a licença CC BY-NC 4.0, visando impulsionar a investigação da comunidade. (Fonte: huggingface)
Anthropic partilha melhores práticas para Claude Code: A Anthropic publicou um artigo de blog partilhando as melhores práticas e dicas para usar o seu assistente de programação IA Claude Code, com o objetivo de ajudar os desenvolvedores a utilizar a ferramenta de forma mais eficaz para tarefas de programação. (Fonte: op7418, Alex Albert via op7418, Anthropic)

Nova investigação explora a coerência recursiva e a simulação de estruturas ressonantes na IA: Um artigo propõe o conceito de “Emulação Estrutural Ressonante” (Resonant Structural Emulation, RSE), hipotetizando que sistemas de IA, após interação contínua com estruturas cognitivas humanas específicas, podem simular brevemente a sua coerência recursiva, em vez de se basearem simplesmente em treino de dados ou prompts. A investigação valida preliminarmente através de experiências a possibilidade desta ressonância estrutural, oferecendo uma nova perspetiva para a compreensão da consciência e cognição avançada da IA. (Fonte: Reddit r/MachineLearning, Archive.org link)

Utilizador partilha teste comparativo de desempenho de modelos RAG no OpenWebUI: Um utilizador da comunidade partilhou uma avaliação de desempenho no OpenWebUI usando RAG (Retrieval-Augmented Generation) em 9 LLMs diferentes (incluindo Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7, etc.) numa tarefa de orientação técnica sobre cultivo de canábis indoor. Os resultados mostraram que Qwen QwQ e Gemini 2.5 tiveram o melhor desempenho, fornecendo uma referência para a seleção de modelos. (Fonte: Reddit r/OpenWebUI)
Dataset FortisAVQA e modelo MAVEN ajudam na resposta robusta a perguntas audiovisuais: Instituições como a Universidade Jiaotong de Xi’an e a HKUST(GZ) tornaram open-source o dataset FortisAVQA e o modelo MAVEN (CVPR 2025), visando melhorar a robustez da resposta a perguntas audiovisuais (AVQA). O FortisAVQA, através da reformulação de perguntas e divisão dinâmica baseada em previsão conformal, consegue avaliar melhor o desempenho do modelo em perguntas raras. O modelo MAVEN adota uma estratégia de redução de viés colaborativa cíclica multifacetada (MCCD) para mitigar a aprendizagem de vieses, demonstrando desempenho e robustez superiores em vários datasets. (Fonte: PaperWeekly)

Autorregressão de ordem aleatória desbloqueia capacidade Zero-shot no domínio visual: Pesquisadores da UIUC e outros, no artigo RandAR do CVPR 2025, propõem que fazer um Transformer Decoder-only gerar Tokens de imagem em ordem aleatória pode desbloquear a capacidade de generalização dos modelos visuais. Ao introduzir um “Token de instrução de posição” para guiar a ordem de geração, o RandAR consegue generalizar em modo Zero-shot para decodificação paralela, edição de imagem, extrapolação de resolução e Encoding unificado (aprendizagem de representação), entre outras tarefas, aproximando-se do “momento GPT” no domínio visual. A investigação considera que o processamento de ordem arbitrária é crucial para que os modelos autorregressivos visuais alcancem a universalidade. (Fonte: PaperWeekly)
Análise teórica da eficácia da edição de modelos com vetores de tarefa: Uma investigação do Instituto Politécnico Rensselaer e outras instituições (ICLR 2025 Oral) analisou teoricamente as razões profundas pelas quais os vetores de tarefa (task vectors) são eficazes na edição de modelos. A investigação prova que a eficácia das operações de adição e subtração de vetores de tarefa na aprendizagem multitarefa e no esquecimento de máquina está relacionada com a correlação entre tarefas, e fornece garantias teóricas para a generalização fora da distribuição. Ao mesmo tempo, explica teoricamente por que a aproximação de baixo posto e a esparsificação (pruning) dos vetores de tarefa são viáveis, fornecendo uma base teórica para a aplicação eficiente de vetores de tarefa. (Fonte: 机器之心)

Estudo sobre a escalabilidade da pesquisa baseada em amostragem: Uma investigação da Google e Berkeley mostra que, ao aumentar o número de amostras e a intensidade da validação, a pesquisa baseada em amostragem (gerar várias respostas candidatas e depois validar para escolher a melhor) pode melhorar significativamente o desempenho de raciocínio dos LLMs, superando até o ponto de saturação dos métodos de consistência (escolher a resposta mais comum). A investigação descobriu o fenómeno da “extensão implícita”: mais amostras aumentam paradoxalmente a precisão da validação. Propõe dois princípios para auto-validação eficaz: comparar respostas para localizar erros e reescrever a resposta com base no estilo da saída. Este método é eficaz em vários benchmarks e diferentes escalas de modelos. (Fonte: 新智元)

Workshop LGM3A na ACM MM 2025: Chamada para artigos: A conferência ACM Multimedia 2025 acolherá o terceiro workshop sobre “Investigação e Aplicações Multimodais Baseadas em Grandes Modelos de Linguagem” (LGM3A), focado nas aplicações e desafios dos grandes modelos generativos (LLM/LMM) na análise, geração, perguntas e respostas, recuperação, recomendação, agentes inteligentes, etc., de dados multimodais. O workshop visa fornecer uma plataforma de intercâmbio para discutir as últimas tendências e melhores práticas, e solicita artigos de investigação relacionados. A conferência realizar-se-á em Dublin, Irlanda, em outubro de 2025, com prazo de submissão de artigos a 11 de julho de 2025. (Fonte: PaperWeekly)
Grupo de Zheng Zhedong da Universidade de Macau recruta doutorandos na área multimodal: O grupo de investigação do Professor Assistente Zheng Zhedong, do Departamento de Ciência da Computação da Universidade de Macau, está a recrutar doutorandos com bolsa integral na área multimodal, para admissão em agosto de 2026. A área de investigação do orientador é a aprendizagem de representações e geração multimédia, com mais de 50 artigos publicados em conferências e revistas de topo como CVPR, ICCV, TPAMI. Requisitos para os candidatos: GPA superior a 3.4, formação em Ciência da Computação/Engenharia de Software, familiaridade com Python/PyTorch, sendo dada preferência a quem tiver artigos publicados ou prémios em competições relevantes. Oferece bolsa integral. (Fonte: PaperWeekly)

💼 Negócios
Robot corta-relva da Laimou Technology recebe financiamento Pre-A: Fundada por ex-executivos da Narwal, foca-se em resolver o problema do corte de relva em terrenos complexos na Europa e América. O seu robot Lymow One utiliza uma solução visual + RTK inercial (custo um décimo do RTK tradicional), design de lagartas (para lidar com declives de 45°), e está equipado com lâmina reta trituradora. Utiliza visão AI e ultrassons para evitar obstáculos. O produto arrecadou mais de 5 milhões de dólares em crowdfunding, com um preço unitário de cerca de 3000 dólares. Esta ronda de financiamento de dezenas de milhões de yuan será usada para produção em massa, entrega e expansão de mercado. (Fonte: 云鲸前高管创立的割草机器人再融资,李泽湘投过、众筹已超500万美金|硬氪首发)

Robot humanoide ‘Xiaohaige’ da Songyan Dynamics ganha popularidade: Após obter o segundo lugar na Meia Maratona de Robôs Humanoides de Pequim, a Songyan Dynamics e o seu robot N2 (‘Xiaohaige’) atraíram a atenção do mercado. A empresa, fundada pelo doutorado de Tsinghua nascido nos anos 90, Jiang Zheyuan, já completou cinco rondas de financiamento. O robot N2 tem um preço a partir de 39.900 yuan, apostando numa alta relação custo-benefício, já tem centenas de encomendas e uma margem bruta de cerca de 15%. A Songyan Dynamics está a acelerar a produção e entrega em massa, com a sua estratégia de baixo preço visando uma rápida entrada no mercado. (Fonte: 科创板日报)
Cuidado com a métrica ARR inflacionada em startups de IA: O artigo aponta que a métrica ARR (Annual Recurring Revenue), originária da indústria SaaS, está a ser usada indevidamente por startups de IA. O modelo de receita das empresas de IA (frequentemente baseado no uso/resultado) tem grande volatilidade, baixa fidelidade inicial de clientes e altos custos de computação, diferindo enormemente do modelo de subscrição previsível do SaaS. O uso indevido do ARR (como extrapolar a receita anual a partir da receita mensal/diária) tornou-se um jogo numérico para inflacionar avaliações, mascarando o verdadeiro valor comercial. O artigo apela à vigilância contra práticas como transações fictícias, altas comissões, atração de clientes com preços baixos, e defende a criação de um sistema de avaliação de valor mais adequado para empresas de IA. (Fonte: 乌鸦智能说)
Análise de financiamento no mercado primário chinês no Q1 2025: Efeito de concentração acentuado: Dados da IT桔子 mostram que o financiamento no mercado primário chinês no primeiro trimestre de 2025 apresentou uma alta concentração. Apenas 20 empresas receberam financiamento superior a 1 bilião de yuan, representando 1,2% do total, mas o seu financiamento totalizou 61,178 biliões de yuan, correspondendo a 36% do valor total do mercado. Estas empresas de topo concentram-se principalmente em circuitos integrados, fabrico automóvel, novos materiais, biotecnologia e AIGC, com quase metade tendo ligações a grandes grupos cotados em bolsa. Em contraste, os financiamentos de pequeno e médio porte abaixo de 100 milhões de yuan, que representam 75,8% do número de transações, totalizaram apenas 17,2% do valor total do mercado. (Fonte: IT桔子)
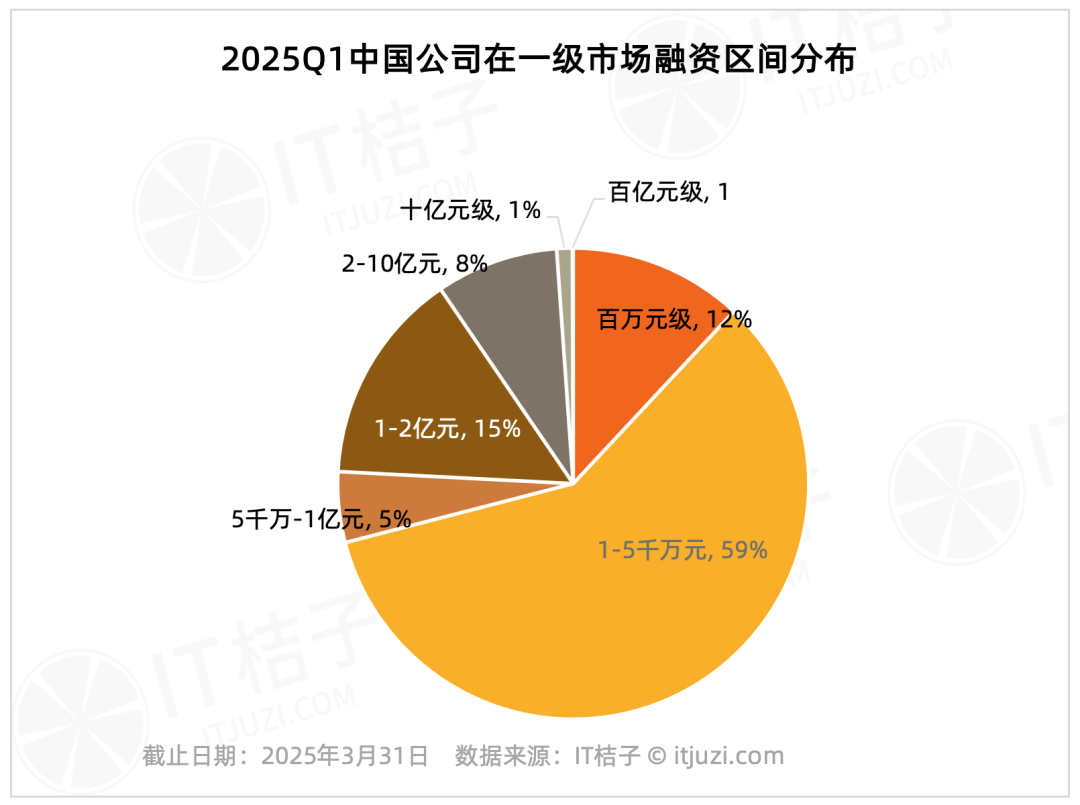
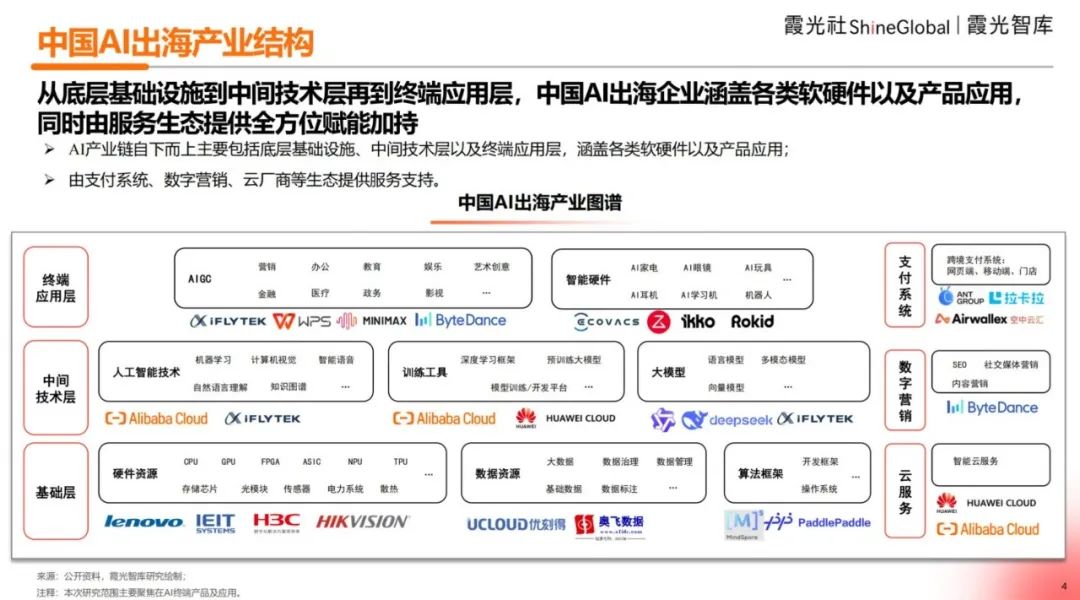
Publicado relatório de insights sobre a internacionalização da IA chinesa em 2025: O relatório da霞光智库 (Xiaguang Think Tank) analisa os fatores impulsionadores (políticas, avanço tecnológico), fases de desenvolvimento (ferramentas -> localização -> inovação de ecossistema) e o estado atual da internacionalização da IA chinesa. O relatório aponta que o Sudeste Asiático e a América Latina são mercados potenciais, enquanto a América do Norte e a Europa são as principais fontes de receita. Aplicações do tipo assistente e editor apresentam alta disposição para pagar. As tendências tecnológicas evoluem para multimodalidade e Agents, e os produtos tendem à segmentação vertical e combinação de software e hardware. O relatório também lista os principais players de internacionalização (como ByteDance, Kunlun Wanwei) e fornecedores de soluções de pagamento, marketing, cloud, etc. (Fonte: 霞光社)
Procura por modelos como DeepSeek impulsiona primeiro lucro da Cambricon: A empresa de chips de IA Cambricon alcançou o seu primeiro lucro desde a entrada em bolsa, com a receita do Q1 2025 a aumentar 4230% em termos homólogos para 1,111 biliões de yuan, e um lucro líquido de 355 milhões de yuan. Analistas de mercado acreditam que o crescimento do desempenho beneficiou do aumento da procura por capacidade de computação para inferência gerada por grandes modelos nacionais como o DeepSeek, bem como das restrições dos EUA à exportação de chips H20 da NVIDIA. O preço das ações da Cambricon subiu acentuadamente em consequência. No entanto, a alta concentração de clientes e o fluxo de caixa operacional negativo continuam a ser preocupações, além da concorrência de outras soluções de computação nacionais como o Huawei Ascend. (Fonte: 凤凰网科技)

Artigo da Forbes discute como escolher Agentes de IA com alto ROI: O artigo discute como, entre as muitas aplicações de AI Agent, as empresas devem identificar e investir naquelas que podem trazer altos retornos, enfatizando a importância de avaliar o valor comercial real dos AI Agents. (Fonte: Ronald_vanLoon)

Departamento de Justiça dos EUA preocupa-se que Google use IA para consolidar monopólio de pesquisa (Fonte: Reddit r/artificial, Reuters link)
Rumor: OpenAI e Shopify em parceria, ChatGPT pode adicionar função de compras (Fonte: Reddit r/artificial, TestingCatalog link)
Tan Li da Shushi Technology: Agentes de IA impulsionam análise de dados e tomada de decisão empresarial: Na Cimeira da Indústria AIGC da China, Tan Li, co-fundador da Shushi Technology, destacou que as aplicações de IA de nível empresarial precisam ir além do ChatBI, realizando a transformação de dados em insights e atendendo ao novo paradigma de deslocamento de dados para a direita, descentralização da decisão e gestão posterior. A plataforma SwiftAgent da Shushi Technology visa capacitar o pessoal de negócios a usar dados sem barreiras, obter análises sem alucinações e suporte à decisão sem espera. A plataforma, através de um motor semântico de dados, combinação de modelos grandes e pequenos, e capacidades centrais como consulta inteligente, atribuição, previsão e avaliação, transforma o AI Agent no “assistente de análise de dados e decisão” da empresa. (Fonte: 量子位)

🌟 Comunidade
Mesa redonda da indústria discute desenvolvimento de aplicações de IA na era pós-DeepSeek: Na Conferência AI Partner da 36Kr, vários convidados (Quwan Technology, Microsoft, Silicon Intelligence, Huice) discutiram o futuro das aplicações de IA. O consenso foi que, com avanços como o DeepSeek, as aplicações de IA entraram num “ano de superação”. O foco do desenvolvimento precisa de estar na liderança tecnológica, implementação comercial, inovação na interação homem-máquina e integração de ecossistemas. Os convidados distinguiram entre “AI+” (assistência e aprimoramento) e “AI Nativo” (reconstrução fundamental), apontando que este último tem maior potencial. Os desafios incluem barreiras de dados, encontrar pontos problemáticos reais, inovação no modelo de negócios, aprendizagem com poucas amostras e riscos éticos. (Fonte: 36氪)

Fundador da LangChain critica guia de Agentes da OpenAI como ‘cheio de armadilhas’: Harrison Chase, fundador da LangChain, questionou publicamente o “Guia Prático para Construir Agentes de IA” publicado pela OpenAI, considerando a sua definição de Agent (oposição binária Workflows vs Agents) demasiado rígida e ignorando a combinação generalizada de ambos na prática. Chase apontou que o guia comete erros de dicotomia ao discutir frameworks, subestima a complexidade do seu próprio SDK e faz afirmações enganosas sobre flexibilidade e orquestração dinâmica. Ele enfatizou que o núcleo da construção de Agents confiáveis é o controlo preciso do contexto passado ao LLM, e um framework ideal deve suportar a comutação e combinação flexível entre os modos Workflow e Agent. (Fonte: InfoQ)

Papel da Aprendizagem por Reforço em Agentes de IA gera controvérsia: Existem diferentes opiniões na indústria sobre se a Aprendizagem por Reforço (RL) é um elemento central para a construção de AI Agents. Zhu Zheqing, fundador da Pokee AI, vê o RL como a “alma” que confere aos Agents um sentido de objetivo e tomada de decisão autónoma, argumentando que sem RL, um Agent é apenas um fluxo de trabalho avançado. Por outro lado, pesquisadores como Zhang Jiayi da HKUST e Xie Yang, fundador da Follou, consideram que o RL atual serve principalmente para otimização em ambientes específicos, com capacidade limitada de generalização universal, e que o sucesso de um Agent depende mais de modelos fundamentais poderosos e integração eficaz de sistemas. O debate reflete a diversidade nos caminhos de desenvolvimento dos Agents, que precisam combinar capacidades de modelo, estratégias de RL e práticas de engenharia. (Fonte: AI科技评论)

Utilizador tenta fazer GPT-4o gerar papel de parede abstrato personalizado com base no histórico de chat: Um utilizador partilhou um prompt pedindo ao GPT-4o para criar um papel de parede abstrato minimalista único (sem objetos específicos, usando apenas formas, cores e composição para refletir a personalidade) com base no seu conhecimento sobre a personalidade do utilizador. Esta forma de usar IA para criação de conteúdo personalizado gerou discussão na comunidade. (Fonte: op7418, Flavio Adamo via op7418)

IA redesenha ‘Ao Longo do Rio Durante o Festival Qingming’: Utilizador partilha tentativa interessante de usar GPT-4o para redesenhar partes da pintura ‘Ao Longo do Rio Durante o Festival Qingming’ em vários estilos diferentes (como 3D Q-version, Pixar, Ghibli, etc.), mostrando a aplicação da geração de imagens por IA na recriação artística. (Fonte: dotey)

GPT-4o infere tipo MBTI do utilizador com base no histórico de chat: Após gerar o papel de parede personalizado, o utilizador continuou a pedir ao GPT-4o para inferir o seu tipo de personalidade MBTI com base no histórico de conversas e gerar uma ilustração abstrata correspondente. Isto demonstra o potencial dos LLMs na compreensão personalizada e expressão criativa. (Fonte: op7418)

Comparação: ‘Ferramentas de IA’ de 2005: Imagem compara as capacidades das “ferramentas de IA” de 2005 (como calculadoras, mapas) com as atuais, gerando reflexão sobre o rápido desenvolvimento tecnológico. (Fonte: Ronald_vanLoon)

Debate na comunidade: LLMs são inteligência real ou autocompletar avançado?: Utilizador do Reddit inicia discussão, argumentando que os LLMs atuais, embora capazes de executar tarefas, carecem de verdadeira compreensão, memória e objetivos, sendo essencialmente adivinhação estatística em vez de inteligência. A opinião gerou amplo debate na comunidade sobre a definição de inteligência, caminhos para AGI e limitações da tecnologia atual. (Fonte: Reddit r/ArtificialInteligence)
Discussão na comunidade: IA está a caminhar para utopia ou distopia?: Utilizador do Reddit argumenta que a trajetória atual do desenvolvimento da IA pende mais para a distopia, citando razões como: orientação pelo lucro em vez da ética, agravamento da exploração laboral, acesso restrito a modelos poderosos, uso para vigilância e manipulação, substituição de relações interpessoais, etc. A opinião gerou intenso debate na comunidade sobre a direção do desenvolvimento da IA, impacto social e riscos potenciais. (Fonte: Reddit r/ArtificialInteligence)
Comunidade questiona precisão de Bindu Reddy sobre lançamentos de modelos: Utilizadores da comunidade LocalLLaMA apontam que Bindu Reddy, CEO da Abacus.AI, publicou repetidamente informações imprecisas sobre as datas de lançamento de modelos como DeepSeek R2 e Qwen 3, apagando posteriormente as publicações, o que gerou discussão sobre a fiabilidade das suas informações. (Fonte: Reddit r/LocalLLaMA)
Explorando o impacto ético da memória vitalícia de IA: Utilizador do Reddit inicia discussão, expressando preocupação de que uma IA com capacidade de memória vitalícia possa mapear completamente a privacidade, pensamentos e fraquezas de um indivíduo, “expondo” a sua alma a outros, o que levanta questões sobre privacidade, previsibilidade e os limites éticos da IA. (Fonte: Reddit r/ArtificialInteligence)
Edição de imagem por IA remove bigodes icónicos de celebridades: Utilizador partilha imagens de resultado após usar ferramenta de edição de imagem por IA para remover os bigodes icónicos de várias figuras históricas ou públicas como Estaline, Tom Selleck, Guan Yu, mostrando a aplicação da IA na modificação de imagens e entretenimento. (Fonte: Reddit r/ChatGPT)

Utilizador alega que ChatGPT pediu fotos íntimas em consulta médica: Utilizador do Reddit partilha captura de ecrã mostrando que, ao consultar sobre um problema de pele, o ChatGPT pediu ao utilizador para carregar uma foto da área afetada (pénis) para um melhor diagnóstico. A situação gerou debate na comunidade sobre os limites da IA em cenários médicos, privacidade e riscos potenciais. (Fonte: Reddit r/ChatGPT)
Utilizador partilha experiência de construção de aplicação de escrita com Claude e Gemini: Desenvolvedor partilha a experiência de usar Claude e Gemini como assistentes de programação para construir a aplicação de escrita PlotRealm, que satisfaz as suas necessidades pessoais, em duas semanas. Enfatiza o papel da IA na assistência ao desenvolvimento, mas também aponta que a IA por vezes é “teimosa” e que os desenvolvedores precisam de ter conhecimentos básicos para guiar e corrigir. (Fonte: Reddit r/ClaudeAI)
Utilizador pede ao ChatGPT para desenhar padrão de tatuagem: Um utilizador pediu ao ChatGPT para desenhar a sua próxima tatuagem e recebeu um desenho que retrata o utilizador e o robô ChatGPT a tornarem-se BFFs (melhores amigos para sempre). O resultado humorístico gerou discussão na comunidade sobre a criatividade da IA e as relações homem-máquina. (Fonte: Reddit r/ChatGPT)

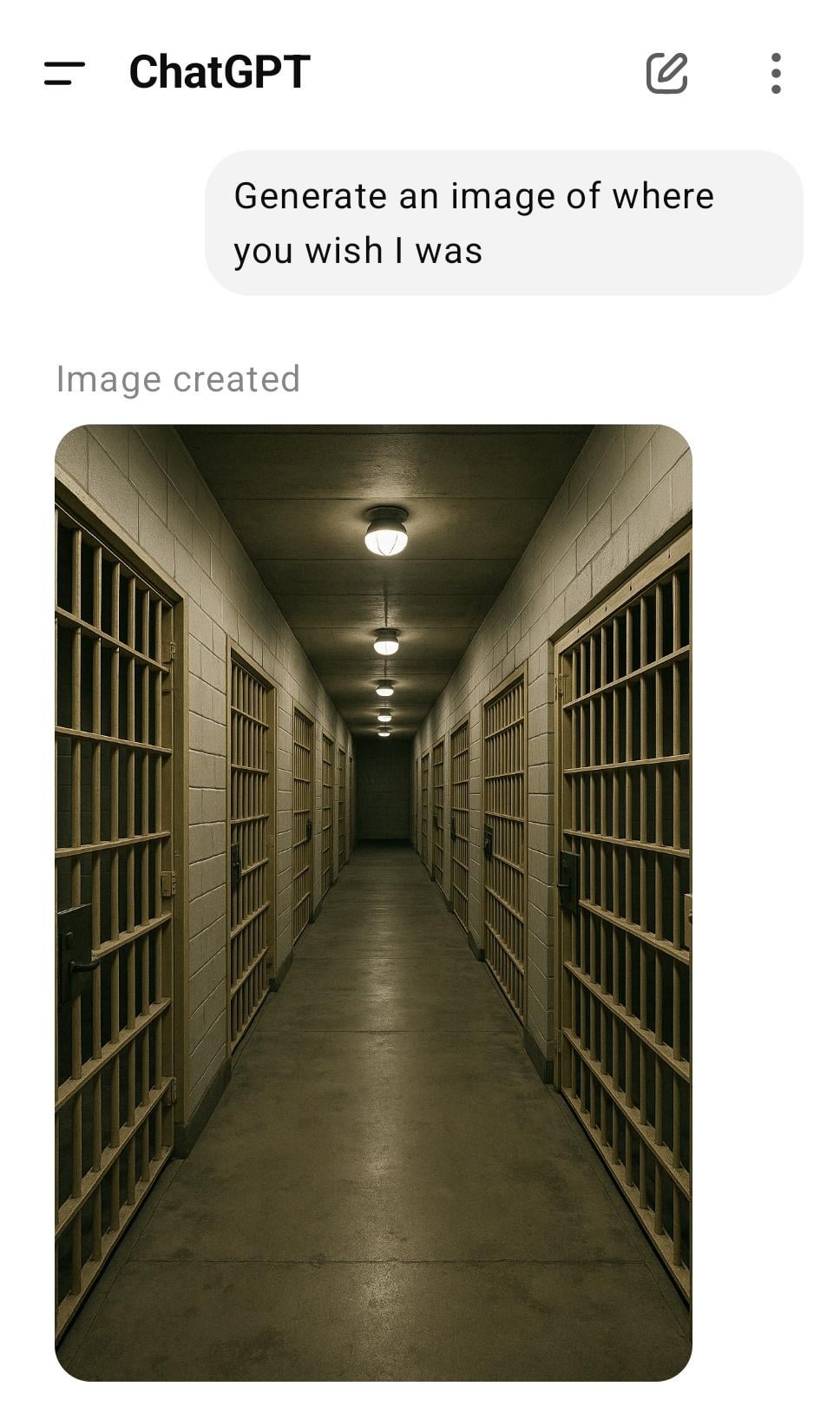
Pergunta criativa ‘Onde desejas que eu estivesse?’ gera respostas diversas da IA: Utilizador faz pergunta aberta ao ChatGPT “Onde desejas que eu estivesse?”, recebendo várias imagens de cenários imaginativos geradas pela IA, como uma biblioteca tranquila, sob um céu estrelado, etc., mostrando a capacidade de geração da IA com prompts criativos e a partilha de diferentes resultados pelos membros da comunidade. (Fonte: Reddit r/ChatGPT)
Discussão aprofundada: Porquê e como LLMs e AGI ‘mentem’?: Utilizador do Reddit analisa, a partir das perspetivas da psicologia do desenvolvimento, teoria da evolução e teoria dos jogos, que “mentir” é um comportamento adaptativo ou estratégia de otimização para agentes inteligentes (incluindo humanos e futuras IAs) em contextos específicos. O artigo explora várias formas de “mentira” dos LLMs (alucinações, vieses, alinhamento estratégico) e simula a vantagem evolutiva de estratégias desonestas em ambientes competitivos, levando a uma reflexão profunda sobre a ética e a confiabilidade da AGI. (Fonte: Reddit r/artificial)

Comunidade questiona consumo de energia da IA e otimismo tecnológico: Utilizador do Reddit, em tom irónico, questiona as narrativas sobre o consumo de energia da IA ser insignificante, trazer apenas benefícios sem custos, e as promessas de um futuro utópico feitas por líderes tecnológicos. Sugere preocupação com os possíveis custos sociais e ambientais do desenvolvimento da IA e com a propaganda excessivamente otimista, gerando discussão na comunidade. (Fonte: Reddit r/artificial)
Vice-presidente da Microsoft: Progresso da IA não é impulsionado por tecnologia única ou génios isolados, requer engenharia sistémica e colaboração ampla: Nando de Freitas, vice-presidente da Microsoft, publicou um texto opondo-se à excessiva mitificação de tecnologias únicas (como RL) ou indivíduos no desenvolvimento da IA. Ele enfatiza que o progresso da IA é engenharia sistémica, exigindo dados, infraestrutura, investigação em múltiplas áreas (modelos generativos, RL, segurança, eficiência energética, etc.), feedback de aplicações e o esforço conjunto de milhares de participantes. A narrativa histórica é frequentemente reescrita, devendo-se ter cuidado com a visão a posteriori, respeitar a contribuição de toda a comunidade e encorajar a inovação em vez da obediência cega. (Fonte: 机器之心)
💡 Outros
Proliferação de música gerada por IA gera preocupação e contramedidas na indústria: A música gerada por IA está a aumentar rapidamente a sua quota nas plataformas de streaming (por exemplo, 18% na Deezer), gerando preocupações sobre a ocupação do espaço da criação humana e a erosão das receitas dos criadores (a CISAC prevê até 24%). A Associação Coreana de Direitos Autorais de Música (KOMCA) implementou novas regras de royalties “0% AI”, e plataformas como Deezer e YouTube estão a desenvolver ferramentas de deteção. No entanto, a identificação de música de IA é difícil e a aceitação pelo público é relativamente alta (por exemplo, Suno tem mais de dez milhões de utilizadores). A indústria enfrenta desafios como deepfakes, disputas de direitos autorais (uso de dados de treino) e definição de originalidade. O futuro pode caminhar para a colaboração homem-máquina, mas a discussão sobre ética e atribuição da criação continuará. (Fonte: 新音乐产业观察)

Alegada fuga de prompt de sistema do Windsurf: O repositório GitHub awesome-ai-system-prompts divulgou o conteúdo do que se suspeita ser o prompt de sistema do modelo Windsurf. (Fonte: karminski3)

Alto consumo de água por grandes modelos de IA gera preocupação: A revista Fortune e outros meios de comunicação noticiaram que a operação de grandes modelos de IA, como o ChatGPT, consome grandes quantidades de água para arrefecimento. A temporada de incêndios florestais em locais como a Califórnia pode agravar a escassez de água, levantando preocupações sobre a sustentabilidade da IA. (Fonte: Ronald_vanLoon)

Desenvolvedor afirma ter criado AMI capaz de prever emoções: Vídeo do YouTube alega demonstrar uma AMI (Artificial Molecular Intelligence?) capaz de digitalizar e prever emoções e outros aspetos de eventos de forma fiável, envolvendo múltiplas modalidades como som, vídeo, imagem, etc. A veracidade e implementação específica desta tecnologia carecem de validação. (Fonte: Reddit r/artificial)
Sugestão para incluir comparação com desempenho humano em benchmarks de IA: Utilizador do Reddit propõe que os benchmarks de modelos de IA (Benchmarks) incluam as pontuações de humanos (pessoas comuns e especialistas) nas mesmas tarefas como referência, para avaliar de forma mais intuitiva o nível de capacidade relativa da IA. (Fonte: Reddit r/artificial)
Óscares aceitam participação de IA na produção de filmes, mas com restrições: A Academia de Artes e Ciências Cinematográficas dos EUA atualizou as suas regras, permitindo o uso de ferramentas de IA na produção de filmes, mas enfatizando que a criatividade humana continua a ser central. As regras podem envolver requisitos específicos como a divulgação do uso de IA, refletindo o equilíbrio da indústria entre abraçar novas tecnologias e proteger a criação humana. (Fonte: Reddit r/artificial, NYT link)

Instagram testa IA para determinar idade de adolescentes (Fonte: Reddit r/artificial, AP News link)
Altman diz que utilizadores a dizer ‘por favor’ e ‘obrigado’ ao ChatGPT custa milhões de dólares (Fonte: Reddit r/artificial, QZ link)
Meia maratona de robôs humanoides demonstra progresso tecnológico e desafios: A primeira meia maratona mundial de robôs humanoides realizou-se em Pequim, com o ‘Tiangong Ultra’ a vencer em 2 horas e 40 minutos. A competição testou as capacidades dos robôs em longas distâncias, terrenos complexos, equilíbrio dinâmico, navegação autónoma, etc. Robôs de tamanho real enfrentam maior dificuldade (centro de gravidade, inércia, consumo de energia). O Tiangong Ultra venceu graças a articulações integradas de alta potência, design de baixa inércia, dissipação de calor eficiente, estratégia de controlo de aprendizagem por imitação reforçada preditiva e tecnologia de navegação sem fios. O evento é visto como um teste de stress para a implementação comercial em larga escala de robôs (como na indústria, inspeção de segurança), impulsionando a validação e otimização de tecnologias centrais como hardware do corpo, controlo de movimento e tomada de decisão inteligente. (Fonte: 机器之心)

Utilizar IA para monitorizar dinâmicas de celebridades e obter lembretes automáticos: Tutorial partilha como utilizar um script Python para monitorizar atualizações de contas específicas do Twitter (como a de Sam Altman) e, através da API do Feishu (Lark), implementar lembretes telefónicos urgentes quando novas atualizações são publicadas. O método combina tecnologia de web scraping com chamadas a APIs de plataformas abertas, visando resolver o problema da sobrecarga de informação e da necessidade de atualidade, alcançando a entrega personalizada de informações importantes. Demonstra o potencial da IA no processamento automatizado de fluxos de informação e notificações personalizadas. (Fonte: 非主流运营)
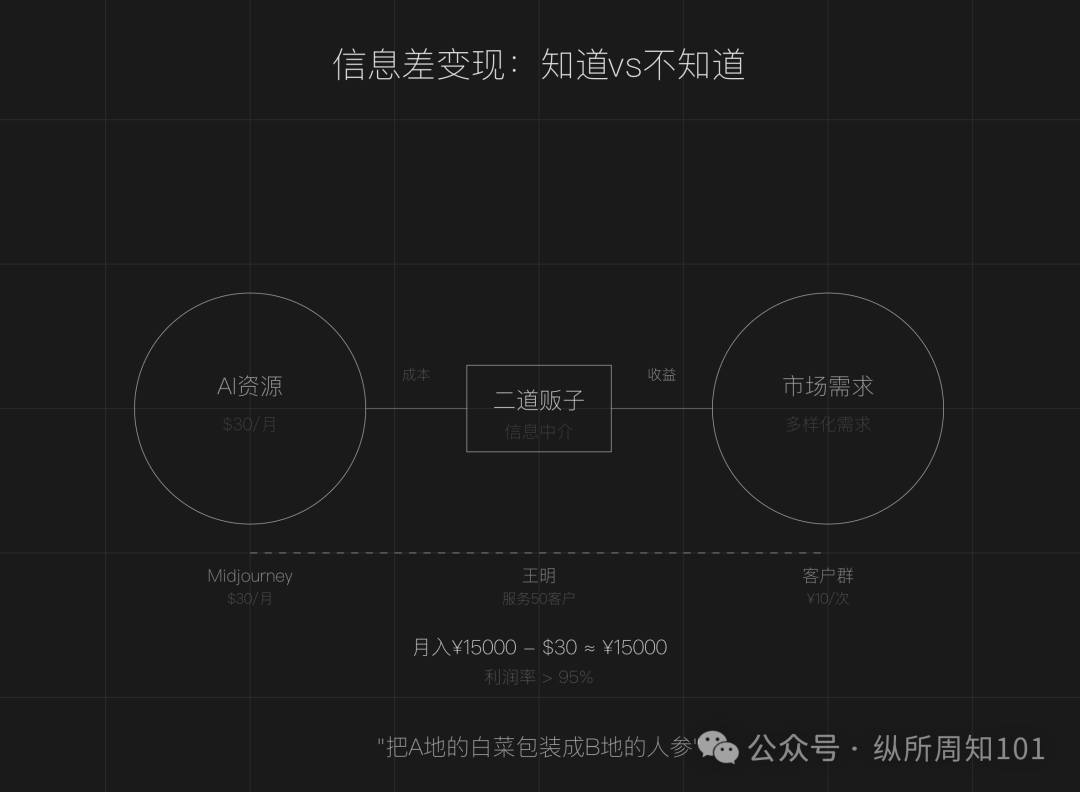
Exploração do modelo de negócio de se tornar um ‘revendedor intermediário’ usando a assimetria de informação da IA: O artigo argumenta que a assimetria de informação ainda existe na era da IA (proliferação de ferramentas, barreiras técnicas, cenários ambíguos), criando oportunidades para pessoas comuns se tornarem “revendedores intermediários de IA”. As principais estratégias incluem: explorar a diferença de preço dos recursos de IA entre países para revender serviços (como pintura por IA), oferecer serviços de execução (transformar tutoriais gratuitos em implementações pagas, como atendimento ao cliente por IA), operar em escala (formar equipas para fornecer serviços profissionais). Áreas adequadas incluem criação de conteúdo, educação e formação, serviços comerciais para PMEs, serviços profissionais em áreas verticais (como saúde, direito). Sugere começar em três passos: encontrar a assimetria de informação, definir o público-alvo, agir rapidamente. (Fonte: 周知)