
Palavras-chave:Modelo de IA, OpenAI, Multimodal, Agente, Modelo o3, o4-mini, Raciocínio visual, Chamada de ferramentas, Gemini 2.5 Flash, Tencent Yuanbao AI, Integração de LLM, Aprendizagem por reforço
🔥 Foco
OpenAI lança modelos o3 e o4-mini, integrando ferramentas e capacidades de raciocínio visual : A OpenAI lançou oficialmente os seus modelos de raciocínio mais inteligentes e poderosos até à data, o o3 e o o4-mini. O destaque principal reside na primeira implementação de um Agent que invoca e combina ativamente todas as ferramentas internas do ChatGPT (pesquisa na web, análise de dados Python, compreensão visual profunda, geração de imagens, etc.), sendo capaz de integrar imagens no processo de pensamento dentro da cadeia de raciocínio. O o3 lidera em áreas como codificação, matemática, ciência, perceção visual, etc., estabelecendo novos SOTA em vários benchmarks; enquanto o o4-mini otimiza a velocidade e o custo, com um desempenho muito superior à sua escala. Ambos os modelos têm maior capacidade de seguir instruções, conversas mais naturais e podem usar memória e histórico de conversas para fornecer respostas personalizadas. Este lançamento marca um passo importante da OpenAI em direção a uma Agentic AI mais autónoma, permitindo que os assistentes de AI concluam tarefas complexas de forma mais independente. (Fonte: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Modelos OpenAI o3 e o4-mini lançados, melhorando o uso de ferramentas e a capacidade de raciocínio visual : A OpenAI lançou os modelos o3 e o4-mini durante a noite, disponíveis para utilizadores com contas ChatGPT Plus, Pro e Team. As atualizações principais incluem: 1. A versão completa do o3 suporta pela primeira vez a chamada de ferramentas (como ligação à internet, interpretador de código). 2. O o3 e o o4-mini são os primeiros modelos capazes de realizar raciocínio visual na cadeia de pensamento, podendo analisar e pensar combinando imagens como um humano, por exemplo, num jogo de adivinhar o local a partir de uma imagem, o modelo pode ampliar detalhes da imagem para raciocinar passo a passo. Esta capacidade melhora significativamente o desempenho do modelo em tarefas multimodais (como MMMU, MathVista), indicando que a AI desempenhará um papel maior em cenários profissionais que exigem julgamento visual (como monitorização de segurança, análise de imagens médicas). Ao mesmo tempo, a OpenAI também tornou open-source a ferramenta de programação AI Codex CLI. (Fonte: OpenAI深夜上线o3满血版和o4 mini – 依旧领先。
Tencent Yuanbao AI integra-se oficialmente no WeChat, iniciando um novo paradigma de chat : O Tencent Yuanbao AI está agora oficialmente online como um contacto do WeChat, podendo os utilizadores adicioná-lo pesquisando por “元宝”. Esta medida quebra o modelo tradicional em que as aplicações de AI precisam de ser abertas separadamente, integrando a AI de forma transparente nos cenários de comunicação diária dos utilizadores. O Yuanbao AI (baseado em Hunyuan e DeepSeek) pode interagir diretamente na janela de chat do WeChat, suporta o resumo de imagens, artigos de contas públicas, links da web, áudio e vídeo (atualmente não suporta Canais do WeChat) e pode pesquisar o histórico de conversas. Embora ainda não suporte desenho e chats de grupo, a sua facilidade de uso e a profunda integração com o ecossistema WeChat são consideradas vantagens importantes. Analistas acreditam que, com a sua vasta base de utilizadores e rede de relações sociais, o WeChat, ao transformar a AI num contacto da lista telefónica, tem o potencial de mudar o paradigma da interação humano-máquina, permitindo que a AI se integre de forma mais natural na vida dos utilizadores. (Fonte: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了、腾讯元宝最终还是活成了微信的模样。
EUA podem suspender indefinidamente a exportação de chips Nvidia H20 para a China, com impacto profundo : O governo dos EUA notificou a Nvidia de que suspenderá indefinidamente a exportação de chips AI H20 para a China (uma versão especial anteriormente projetada para cumprir os controlos de exportação). O H20 é o chip compatível mais potente desenvolvido pela Nvidia para o mercado chinês, e a proibição de venda deverá causar um golpe significativo na Nvidia. Dados mostram que a China é a quarta maior fonte de receita da Nvidia, com vendas do H20 a atingir a ordem das dezenas de milhares de milhões de dólares em 2024, e empresas de tecnologia chinesas (como ByteDance, Tencent) são os principais compradores de chips Nvidia, com um crescimento significativo do investimento. Esta medida não afeta apenas as receitas da Nvidia, mas também pode enfraquecer o seu ecossistema CUDA (onde os programadores chineses representam mais de 30%). Entretanto, empresas chinesas locais de chips AI, como a Huawei (por exemplo, Ascend 910C), estão a acelerar o seu desenvolvimento e podem preencher a lacuna de mercado. O evento causou preocupação no mercado, e as ações da Nvidia caíram em resposta. (Fonte: 中国对英伟达到底有多重要?
🎯 Tendências
Modelo de vídeo de topo da Google, Veo 2, chega gratuitamente ao AI Studio : A Google anunciou que o seu modelo avançado de geração de vídeo, Veo 2, está agora disponível no Google AI Studio, Gemini API e Gemini App, oferecendo créditos de uso gratuito (cerca de dez vezes por dia, com duração máxima de 8 segundos por vez). O Veo 2 suporta texto-para-vídeo (t2v) e imagem-para-vídeo (i2v), consegue compreender instruções complexas, gerar conteúdo de vídeo realista e estilisticamente diverso, e controlar o movimento da câmara. A empresa enfatiza que a chave para gerar vídeos de alta qualidade é fornecer Prompts claros, detalhados e com palavras-chave visuais. O modelo também possui funcionalidades avançadas como edição dentro do vídeo (recorte, expansão), movimentos de câmara cinematográficos e transições inteligentes, visando integrar-se nos fluxos de trabalho de criação de conteúdo para aumentar a eficiência. (Fonte: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。
Google lança Gemini 2.5 Flash, focado em velocidade, custo e profundidade de pensamento controlável : A Google lançou a versão de pré-visualização do modelo Gemini 2.5 Flash, posicionado como um modelo leve otimizado para velocidade e custo. Este modelo teve um desempenho notável no ranking LMArena, empatando em segundo lugar com o GPT-4.5 Preview e o Grok-3, e classificando-se em primeiro lugar em prompts difíceis, codificação e consultas longas. As suas características principais são a introdução da capacidade de “pensar” e raciocínio totalmente híbrido, permitindo que o modelo planeie e decomponha tarefas antes de gerar a saída. Os programadores podem controlar a profundidade de pensamento do modelo (limite de tokens) através do parâmetro “thinking budget”, equilibrando qualidade, custo e latência. Mesmo com um orçamento de 0, o desempenho supera o 2.0 Flash. Este modelo tem uma excelente relação custo-benefício, com um preço que varia entre 1/10 e 1/5 do Gemini 2.5 Pro, sendo adequado para fluxos de trabalho de AI de alta concorrência e grande escala. (Fonte: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。
Kunlun Tech lança modelo de geração de filmes de duração ilimitada Skyreels-V2 : A Kunlun Tech lançou e tornou open-source o Skyreels-V2, anunciado como o primeiro modelo de geração de vídeo de alta qualidade com duração ilimitada do mundo. Este modelo visa resolver os pontos fracos dos modelos de vídeo existentes na compreensão da linguagem cinematográfica, coerência de movimento, limitações de duração do vídeo e falta de datasets profissionais. O Skyreels-V2 combina um grande modelo multimodal, anotação estruturada, geração por difusão, aprendizagem por reforço (otimização DPO da qualidade do movimento) e fine-tuning de alta qualidade em várias fases de treino. Adota a arquitetura Diffusion Forcing, alcançando a geração de vídeos longos através de um agendador especial e mecanismos de atenção. A empresa afirma que o efeito de geração atinge o “nível cinematográfico”, com desempenho superior em benchmarks como o V-Bench1.0, superando outros modelos open-source. Os utilizadores podem experimentar online a geração de vídeos de até 30 segundos. (Fonte: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!
Shanghai AI Lab lança modelo multimodal nativo InternVL3 : O Shanghai Artificial Intelligence Laboratory lançou o InternVL3, um grande modelo multimodal (MLLM) que adota um paradigma de pré-treino multimodal nativo. Diferente da maioria dos modelos adaptados a partir de LLMs puramente textuais, o InternVL3 aprende simultaneamente a partir de dados multimodais e corpus de texto puro numa única fase de pré-treino, visando superar a complexidade e os desafios de alinhamento do treino multifásico. O modelo combina codificação de posição visual variável, técnicas avançadas de pós-treino e estratégias de expansão em tempo de teste. O InternVL3-78B obteve 72.2 pontos no benchmark MMMU, estabelecendo um novo recorde para MLLMs open-source, com desempenho próximo dos modelos proprietários líderes, mantendo ao mesmo tempo fortes capacidades puramente linguísticas. Os dados de treino e os pesos do modelo serão tornados públicos. (Fonte: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
UCLA e outros propõem framework d1, aplicando aprendizagem por reforço à inferência de LLMs de difusão : Investigadores da UCLA e da Meta AI propuseram o framework d1, aplicando pela primeira vez o pós-treino com aprendizagem por reforço (RL) a grandes modelos de linguagem de difusão mascarada (dLLM). Os métodos de RL existentes (como GRPO) são principalmente usados para LLMs autorregressivos e são difíceis de aplicar diretamente a dLLMs, devido à falta de uma decomposição natural da log-probabilidade. O framework d1 consiste em duas fases: primeiro, realiza-se fine-tuning supervisionado (SFT), e depois, na fase de RL, introduz-se um novo método de gradiente de política, diffu-GRPO, que utiliza um estimador eficiente de log-probabilidade de passo único e aproveita o mascaramento aleatório de prompts como regularização, reduzindo a quantidade de geração online necessária para o treino de RL. Experiências mostram que o modelo d1 baseado no LLaDA-8B-Instruct supera significativamente o modelo base e os modelos que usam apenas SFT ou diffu-GRPO em benchmarks de raciocínio matemático e lógico. (Fonte: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!
Meta propõe Multi-Token Attention (MTA) : Investigadores da Meta propuseram o mecanismo Multi-Token Attention (MTA), visando melhorar a forma como a atenção é calculada em grandes modelos de linguagem (LLM). O mecanismo de atenção tradicional baseia-se apenas na similaridade entre um único token de consulta e chave. O MTA, através da aplicação de operações convolucionais nos vetores de consulta, chave e cabeça, permite que o modelo considere simultaneamente múltiplos tokens adjacentes de consulta e chave para determinar os pesos de atenção. Os investigadores acreditam que isto permite utilizar informações mais ricas e detalhadas para localizar o contexto relevante. Experiências mostram que o MTA supera os modelos Transformer de base tradicionais tanto em tarefas padrão de modelação de linguagem como em tarefas de recuperação de informação de contexto longo. (Fonte: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
TogetherAI lança modelo de inferência M1 baseado em RNN : A TogetherAI propôs o M1, um novo modelo de inferência RNN linear híbrido baseado na arquitetura Mamba. Este modelo visa resolver a complexidade computacional e as limitações de memória enfrentadas pelos Transformers ao processar sequências longas e realizar inferência eficiente. O M1 melhora o desempenho através da destilação de conhecimento de modelos de inferência existentes e treino com aprendizagem por reforço. Resultados experimentais mostram que o M1, em benchmarks de raciocínio matemático como AIME e MATH, não só supera os modelos RNN lineares anteriores, como também se compara favoravelmente com modelos de inferência destilados DeepSeek-R1 de escala equivalente. Mais importante, a velocidade de geração do M1 é mais de 3 vezes superior à de um Transformer de tamanho semelhante e, com um orçamento de tempo de geração fixo, consegue maior precisão através de votação por auto-consistência do que este último. (Fonte: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
Tencent Hunyuan torna open-source o framework InstantCharacter : A equipa Tencent Hunyuan tornou open-source o InstantCharacter, um framework para geração de imagens capaz de extrair e preservar as características de uma pessoa a partir de uma única imagem de entrada, e depois colocar essa pessoa em diferentes cenários ou estilos. A tecnologia visa alcançar a manutenção da identidade da pessoa com alta fidelidade e a transferência de estilo controlável. A empresa forneceu uma demonstração online baseada nos estilos artísticos de Ghibli e Makoto Shinkai no Hugging Face, e publicou o artigo relacionado, o repositório de código e um plugin ComfyUI para facilitar o uso e desenvolvimento pela comunidade. (Fonte: karminski3
Função de memória do ChatGPT atualizada, suporta pesquisa na web combinada com memória : A OpenAI atualizou a função de memória (Memory) do ChatGPT, adicionando a capacidade de “pesquisa com memória”. Isto significa que o ChatGPT, ao realizar tarefas de pesquisa na web, pode utilizar informações de memória armazenadas anteriormente, como preferências do utilizador, localização, etc., para otimizar as consultas de pesquisa, fornecendo assim resultados mais personalizados. Por exemplo, se o ChatGPT se lembrar que o utilizador é vegetariano, ao ser questionado sobre restaurantes próximos, poderá pesquisar automaticamente por “restaurantes vegetarianos próximos”. Esta medida é vista como um passo importante da OpenAI na melhoria dos serviços personalizados de AI, visando aprimorar a experiência do utilizador e diferenciar-se de concorrentes com funções de memória (como Claude, Gemini). Os utilizadores podem optar por desativar a função de memória nas definições. (Fonte: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
Tecnologia de snapshot de runtime de modelos AI evita cold starts : A comunidade de machine learning está a explorar a otimização da orquestração de runtime de LLMs através da tecnologia de snapshots de modelos. Esta tecnologia, ao guardar o estado completo da GPU (incluindo cache KV, pesos, layout de memória), permite evitar cold starts e inatividade da GPU ao alternar entre diferentes modelos, possibilitando uma recuperação rápida (cerca de 2 segundos). Um utilizador partilhou que, usando este método, conseguiu executar mais de 50 modelos open-source em duas GPUs A1000 de 16GB, sem usar contentores ou recarregar modelos. Esta técnica de reutilização (multiplexing) e rotação de modelos tem potencial para aumentar a utilização da GPU e reduzir a latência de inferência. (Fonte: Reddit r/MachineLearning)
🧰 Ferramentas
ByteDance Volcano Engine lança Demo de solução completa de hardware AI : O Volcano Engine da ByteDance demonstrou a sua solução completa de hardware AI em colaboração com fabricantes de chips embebidos, usando a placa de desenvolvimento AtomS3R como exemplo. A solução visa fornecer uma experiência interativa de AI de baixa latência e alta responsividade, caracterizada por resposta em tempo real na ordem dos milissegundos, interrupção e resposta em tempo real, e capacidade de redução de ruído de áudio em ambientes complexos através do RTC SDK, reduzindo eficazmente a interferência de ruído de fundo e melhorando a precisão da interação por voz. O código do cliente e o programa do servidor desta solução são open-source, permitindo aos programadores personalização DIY, como atribuir ao hardware personalidade, papel, timbre personalizados, ou integrar bases de conhecimento e ferramentas MCP. O hardware em si inclui uma câmara, com planos futuros para suportar funcionalidades de compreensão visual. (Fonte: 体验完字节送的迷你AI硬件,后劲有点大…
Mita AI Search lança função de aprendizagem “O que aprender hoje” : O Mita AI Search lançou uma nova função chamada “今天学点啥” (O que aprender hoje), que pode transformar automaticamente ficheiros carregados pelo utilizador (suporta vários formatos) ou links da web fornecidos num vídeo de curso online estruturado, com narração e demonstração (PPT, animação). Os utilizadores podem escolher diferentes estilos de explicação (como contar histórias, estilo Napoleão) e vozes (como rainha do gelo). A função visa transformar a entrada de informação numa experiência de aprendizagem mais fácil de absorver, oferecendo até testes pós-aula. Esta abordagem, que combina geração de conteúdo com ensino personalizado, é considerada como potencialmente capaz de mudar os modelos de aplicação da AI na educação e no consumo de informação, oferecendo uma nova forma de aquisição de conhecimento e leitura rápida de conteúdo. (Fonte: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

Cursor IDE atualizado para a versão 0.49, melhora sistema de regras e controlo de Agent : O editor de código AI-first Cursor lançou a pré-visualização da atualização 0.49. Novas funcionalidades incluem: 1. Geração automática de ficheiros de regras .mdc através do comando de chat /Generate Cursor Rules para fixar o contexto do projeto. 2. Aplicação automática de regras mais inteligente, com o Agent a carregar regras correspondentes com base no caminho do ficheiro. 3. Correção do bug que fazia com que “Anexar sempre regras” falhasse em conversas longas. 4. Nova função “Perceção da Estrutura do Projeto” (Beta), para que a AI compreenda melhor todo o projeto. 5. O protocolo MCP (Model Context Protocol) agora suporta a transmissão de imagens, facilitando o processamento de tarefas relacionadas com visão. 6. Controlo aprimorado do Agent sobre comandos do terminal, permitindo ao utilizador editar ou saltar comandos antes da execução. 7. Suporte para configuração global de ficheiros ignorados (.cursorignore). 8. Experiência de revisão de código otimizada, com a vista diff exibida diretamente após as mensagens do Agent. (Fonte: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
OpenAI torna open-source a ferramenta de programação AI de linha de comandos Codex CLI : Juntamente com o lançamento do o3 e o4-mini, a OpenAI tornou open-source o Codex CLI, um Agent de codificação AI leve que pode ser executado diretamente no terminal de linha de comandos do utilizador. A ferramenta visa aproveitar ao máximo as poderosas capacidades de codificação e raciocínio dos novos modelos, podendo processar diretamente repositórios de código locais e até combinar capturas de ecrã ou esboços para raciocínio multimodal. O CEO da OpenAI, Sam Altman, promoveu-a pessoalmente, enfatizando a sua natureza open-source para promover a iteração rápida da comunidade. Ao mesmo tempo, a OpenAI lançou um programa de financiamento de 1 milhão de dólares (na forma de API Credits) para apoiar projetos baseados no Codex CLI e nos modelos OpenAI. (Fonte: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Plataforma Tencent Cloud LKE integra MCP, simplificando a construção de Agents : A plataforma Language Knowledge Engine (LKE) da Tencent Cloud adicionou suporte para o Model Context Protocol (MCP), visando reduzir a barreira à construção e uso de AI Agents. Os utilizadores podem agora, na plataforma LKE, através de cliques, integrar facilmente ferramentas MCP incorporadas como Tencent Cloud EdgeOne Pages (implementação de páginas web com um clique), Firecrawl (web crawler), etc. Combinado com as poderosas capacidades de base de conhecimento (RAG) da LKE, os utilizadores podem criar aplicações complexas baseadas em conhecimento privado e chamada de ferramentas externas, como gerar e publicar automaticamente páginas web baseadas no conteúdo da base de conhecimento. A plataforma suporta o modo Agent, onde o modelo (como DeepSeek R1) pode pensar autonomamente e escolher as ferramentas adequadas para completar a tarefa. A plataforma também suporta a integração de MCP externos. (Fonte: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

Framework Spring AI: Framework de aplicação para engenharia de AI : O Spring AI é um framework de aplicação AI projetado para programadores Java, visando trazer os princípios de design do ecossistema Spring (como portabilidade, design modular, uso de POJOs) para o domínio da AI. Fornece uma API unificada para interagir com vários fornecedores de modelos AI mainstream (Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama, etc.), suportando conclusão de chat, embeddings, texto-para-imagem/áudio, moderação, etc. Ao mesmo tempo, integra várias bases de dados vetoriais (Cassandra, Azure Vector Search, Chroma, Milvus, etc.), oferecendo API portátil e filtragem de metadados estilo SQL. O framework também suporta saída estruturada, chamada de ferramentas/funções, observabilidade, framework ETL, avaliação de modelos, memória de chat e RAG, etc., simplificando a integração através da configuração automática do Spring Boot. (Fonte: spring-projects/spring-ai – GitHub Trending (all/weekly)
olmocr: Toolkit de linearização de PDF para processamento de datasets de LLM : A allenai tornou open-source o olmocr, um toolkit especificamente projetado para processar documentos PDF para a construção e treino de datasets de grandes modelos de linguagem (LLM). Inclui várias funcionalidades: estratégias de prompt para análise de texto natural de alta qualidade usando ChatGPT 4o, ferramentas de avaliação para comparar diferentes versões de fluxos de processamento, filtragem básica de linguagem e remoção de spam SEO, código de fine-tuning para Qwen2-VL e Molmo-O, um fluxo para processar PDFs em grande escala usando Sglang, e ferramentas para visualizar documentos processados no formato Dolma. O toolkit requer suporte de GPU para inferência local e fornece instruções para uso local e em clusters multi-nó (suporta S3 e Beaker). (Fonte: allenai/olmocr – GitHub Trending (all/daily)

Aplicação desktop Dive Agent v0.8.0 lançada : A aplicação desktop open-source AI Agent Dive lançou a versão v0.8.0, com grandes ajustes de arquitetura e atualizações de funcionalidades. Esta versão visa integrar LLMs que suportam chamada de ferramentas com o MCP Server. As principais atualizações incluem: gestão de chaves API de LLM, suporte para IDs de modelo personalizados, suporte completo para modelos de chamada de ferramentas/funções; gestão de ferramentas MCP (adicionar, remover, modificar), interface de configuração com suporte para edição JSON e formulário. O backend DiveHost foi migrado de TypeScript para Python para resolver problemas de integração com LangChain e pode funcionar como um servidor A2A (Agent-to-Agent) independente. (Fonte: Reddit r/LocalLLaMA)
llama.cpp funde ferramentas CLI multimodais : O projeto llama.cpp fundiu os programas de exemplo de interface de linha de comandos (CLI) para LLaVa, Gemma3 e MiniCPM-V numa única ferramenta unificada llama-mtmd-cli. Isto faz parte da sua integração gradual de suporte multimodal (através da biblioteca libmtmd). Embora o suporte multimodal ainda esteja em desenvolvimento (por exemplo, o suporte no llama-server ainda é experimental), a fusão das CLIs é um passo para simplificar o conjunto de ferramentas. Ao mesmo tempo, o suporte para SmolVLM v1/v2 também está em desenvolvimento. (Fonte: Reddit r/LocalLLaMA)
LightRAG: Implementação automatizada de pipelines RAG : LightRAG é um projeto open-source de RAG (Retrieval-Augmented Generation). Membros da comunidade criaram tutoriais e scripts de automação (usando Ansible + Docker Compose + Sbnb Linux) que permitem aos utilizadores implementar rapidamente (em minutos) o sistema LightRAG em servidores bare-metal, alcançando a construção automatizada de um pipeline RAG funcional a partir de uma máquina vazia. Isto simplifica o processo de implementação de soluções RAG auto-hospedadas. (Fonte: Reddit r/LocalLLaMA)
Nari Labs lança modelo TTS open-source Dia-1.6B : A Nari Labs lançou e tornou open-source o seu modelo text-to-speech (TTS) Dia-1.6B. A característica deste modelo é que não só gera voz, mas também integra naturalmente sons não linguísticos (sons paralinguísticos) como risos, tosse, pigarro, etc., na voz para aumentar a naturalidade e expressividade da fala. A empresa forneceu vídeos de demonstração para mostrar o efeito. O modelo requer cerca de 10GB de VRAM para funcionar e ainda não possui versão quantizada. O repositório de código e o modelo foram publicados no GitHub e no Hugging Face. (Fonte: karminski3)
📚 Aprendizagem
Jeff Dean recapitula os marcos chave de quinze anos de desenvolvimento da AI : O cientista chefe da Google, Jeff Dean, numa palestra, resumiu os progressos importantes no campo da AI nos últimos quinze anos, enfatizando especialmente as contribuições de investigação da Google. Marcos chave incluem: treino de redes neuronais em larga escala (provando o efeito de escala), sistema distribuído DistBelief (permitindo treinar grandes modelos em CPUs), embeddings de palavras Word2Vec (revelando semântica no espaço vetorial), modelos Seq2Seq (impulsionando tarefas como tradução automática), TPU (aceleração de hardware personalizada para redes neuronais), arquitetura Transformer (revolucionando o processamento sequencial, base dos LLMs), aprendizagem auto-supervisionada (utilizando dados não rotulados em larga escala), Vision Transformer (unificando processamento de imagem e texto), modelos esparsos/MoE (aumentando capacidade e eficiência do modelo), Pathways (simplificando computação distribuída em larga escala), Chain-of-Thought CoT (melhorando capacidade de raciocínio), destilação de conhecimento (transferindo capacidade de grandes modelos para modelos menores) e descodificação especulativa (acelerando inferência). Estas tecnologias impulsionaram conjuntamente o desenvolvimento da AI moderna. (Fonte: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
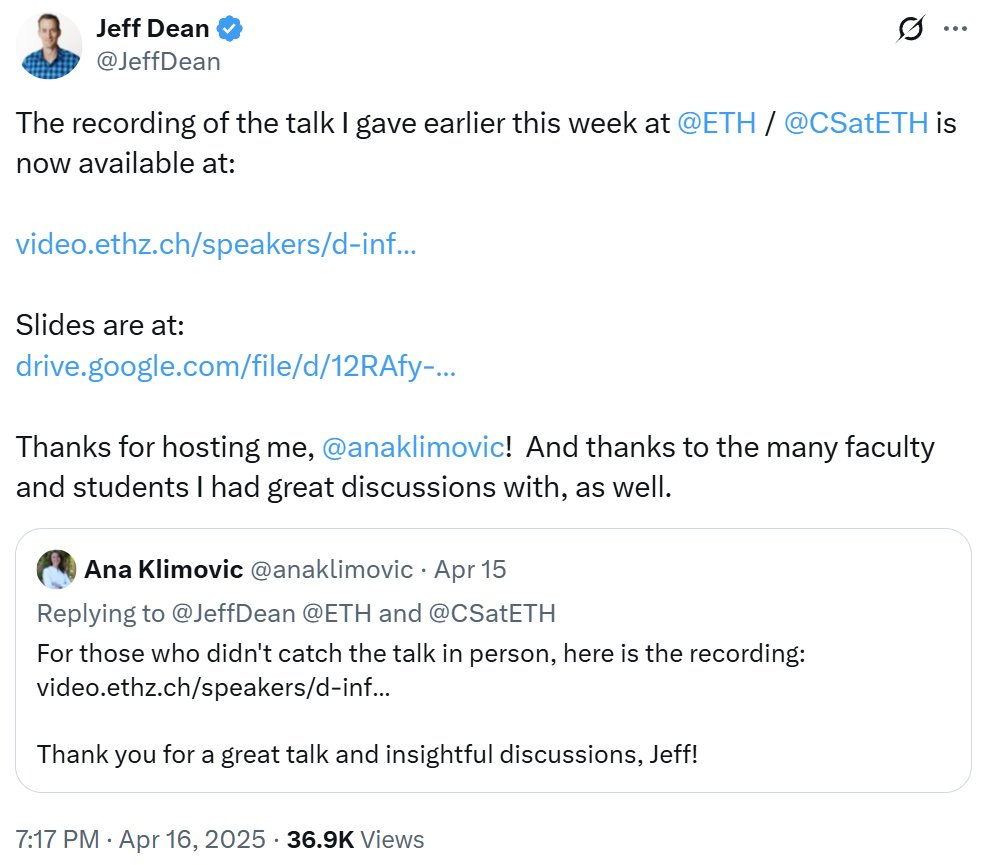
《Nature》 estatísticas de artigos altamente citados do século XXI, domínio da área de AI : A revista 《Nature》, através da compilação de dados de 5 bases de dados, publicou a lista dos Top 25 artigos mais citados do século XXI. O artigo ResNets da Microsoft de 2016 (por Kaiming He et al.) ocupa o primeiro lugar geral; esta investigação é fundamental para o progresso da aprendizagem profunda e da AI. Os primeiros lugares da lista incluem também vários artigos relacionados com AI, como Random Forests (6º), Attention is all you need (Transformer, 7º), AlexNet (8º), U-Net (12º), revisão sobre aprendizagem profunda (Hinton et al., 16º) e dataset ImageNet (Fei-Fei Li et al., 24º). Isto reflete o rápido desenvolvimento e o amplo impacto da tecnologia AI neste século. O artigo também aponta que a popularidade dos preprints trouxe complexidade às estatísticas de citação. (Fonte: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
Instituições como a Beihang University publicam revisão sobre LLM Ensemble : Investigadores da Beihang University e outras instituições publicaram a mais recente revisão sobre ensemble de grandes modelos de linguagem (LLM Ensemble). LLM Ensemble refere-se à combinação das vantagens de múltiplos LLMs na fase de inferência para processar consultas de utilizadores. A revisão propõe uma taxonomia para LLM Ensemble (ensemble pré-inferência, intra-inferência, pós-inferência, subdividido em sete categorias de métodos), revê sistematicamente os progressos mais recentes em cada categoria de método, discute questões de investigação relacionadas (como a relação com fusão de modelos, colaboração de modelos, aprendizagem fracamente supervisionada), apresenta conjuntos de testes de benchmark, aplicações típicas e, finalmente, resume e analisa os resultados existentes e perspetiva direções futuras de investigação, como ensemble a nível de fragmento mais principista, pós-ensemble não supervisionado mais refinado, etc. (Fonte: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

Anthropic partilha padrões de uso e experiência com Claude Code : Funcionários da Anthropic partilharam as melhores práticas internas e padrões eficazes para usar o Claude Code na programação. Estes padrões não se aplicam apenas ao Claude, mas são universalmente aplicáveis à colaboração de programação com outros LLMs. Enfatiza-se a importância de fornecer contexto claro, decompor problemas complexos, fazer perguntas iterativas, aproveitar as diferentes forças do modelo (como geração de código, explicação, refatoração) e realizar validação eficaz. Estas experiências visam ajudar os programadores a utilizar ferramentas de programação assistida por AI de forma mais eficiente. (Fonte: AnthropicAI

)
Anthropic torna público o dataset de valores do Claude : A Anthropic tornou público um dataset chamado “values-in-the-wild” nos Hugging Face Datasets. Este dataset contém 3307 valores expressos pelo Claude em milhões de conversas do mundo real. A divulgação deste dataset visa aumentar a transparência do comportamento do modelo e permitir que investigadores e o público o descarreguem, explorem e analisem para compreender melhor as tendências de valores manifestadas por grandes modelos de linguagem em aplicações práticas. (Fonte: huggingface、huggingface)
Dez pontos chave para o despertar cognitivo sobre AI : O artigo propõe dez pontos de vista a nível cognitivo sobre o desenvolvimento da AI, visando ajudar as pessoas a compreender mais profundamente o impacto e a essência da AI. Os pontos centrais incluem: a inteligência da AI difere da inteligência humana (fosso de inteligência); a AI levanta questões sobre a natureza da consciência humana; a relação entre humanos e AI está a mudar de ferramenta para parceiro colaborativo; o desenvolvimento da AI não deve limitar-se a imitar o cérebro humano; os padrões de inteligência evoluem com o progresso da AI; a AI pode desenvolver formas de inteligência totalmente novas; deve-se encarar racionalmente a expressão emocional e as limitações cognitivas da AI; a verdadeira ameaça profissional vem de não usar AI, e não da AI em si; na era da AI, deve-se focar no desenvolvimento de capacidades exclusivamente humanas (criatividade, inteligência emocional, pensamento transdisciplinar); o significado último de estudar AI reside em conhecer mais profundamente a própria humanidade. (Fonte: AI认知觉醒的10句话,一句顶万句,句句清醒

LlamaIndex partilha tutorial para construir Agents de fluxo de trabalho de documentos : A gravação da palestra do co-fundador da LlamaIndex, Jerry Liu, partilha como construir Agents de fluxo de trabalho de documentos usando LlamaIndex. O conteúdo abrange a evolução da LlamaIndex de RAG para Knowledge Agents, o uso do LlamaParse para processar documentos complexos, o uso de Workflows para orquestração flexível de Agents orientada a eventos, casos de uso chave (pesquisa de documentos, geração de relatórios, automação de processamento de documentos) e melhorias na recuperação multimodal combinando texto e imagem. (Fonte: jerryjliu0
)
Tutorial para construir Agents com LlamaIndex.TS : Membros da equipa LlamaIndex partilharam um tutorial completo a nível de código para construir Agents usando a versão TypeScript do LlamaIndex (LlamaIndex.TS). O conteúdo da gravação do livestream inclui fundamentos do LlamaIndex, conceitos de Agent e RAG, padrões Agentic comuns (encadeamento, roteamento, paralelização, etc.), construção de RAG Agentic no LlamaIndex.TS, e construção de uma aplicação React full-stack integrada com Workflows. (Fonte: jerryjliu0

)
Debate sobre se a aprendizagem por reforço realmente melhora a capacidade de raciocínio dos LLMs : A comunidade discute um artigo que levanta a questão: pode a aprendizagem por reforço (RL) realmente incentivar os grandes modelos de linguagem (LLM) a desenvolver capacidades de raciocínio que superem as dos seus modelos base? Menciona-se na discussão que, embora o RL (como RLHF) possa melhorar o alinhamento e o seguimento de instruções do modelo, ainda é questionável se pode melhorar sistematicamente a lógica de raciocínio complexo intrínseca. Alguns argumentam que o efeito atual do RL pode manifestar-se mais na otimização da expressão e no seguimento de formatos específicos, em vez de um salto fundamental no raciocínio lógico. Will Brown aponta que métricas como pass@1024 têm significado limitado na avaliação de tarefas de raciocínio matemático como AIME. (Fonte: natolambert

)
Discussão sobre terminologia relacionada com world models : Um utilizador do Reddit questiona a confusão em torno de termos como “world models”, “foundation world models”, “world foundation models”, etc. A comunidade responde que “world model” geralmente se refere a uma simulação ou representação interna do ambiente (mundo físico ou domínio específico como um tabuleiro de xadrez); “foundation model” refere-se a um grande modelo pré-treinado que pode servir como ponto de partida para várias tarefas downstream. A combinação destes termos pode referir-se à construção de modelos de base generalizáveis, capazes de compreender e prever a dinâmica do mundo, mas a definição específica pode variar entre investigadores, refletindo que a terminologia neste campo ainda não está totalmente unificada. (Fonte: Reddit r/MachineLearning)
Discussão sobre métodos de combinação de XGBoost e GNN : Utilizadores do Reddit discutem como combinar eficazmente XGBoost e redes neuronais de grafos (GNN) para tarefas como deteção de fraude. Um método comum é usar os embeddings de nós aprendidos pela GNN como novas features, juntamente com os dados tabulares originais, como entrada para o XGBoost. A discussão considera que o desafio deste método reside em saber se os embeddings da GNN podem fornecer valor significativo para além dos dados originais e técnicas como SMOTE, caso contrário, podem introduzir ruído. A chave para o sucesso reside numa estrutura de grafo cuidadosamente projetada e na capacidade dos embeddings da GNN capturarem informações relacionais (como anéis de fraude na estrutura do grafo) que são difíceis de obter pelo XGBoost. (Fonte: Reddit r/MachineLearning)
💼 Negócios
Pequim acolhe a primeira maratona mundial de robôs humanoides, explorando “IP de tecnologia desportiva” : Pequim Yizhuang acolheu com sucesso a primeira meia maratona mundial de robôs humanoides, com “atletas” de mais de 20 empresas de robôs humanoides a competir ao lado de corredores humanos. O robô Tiangong Ultra venceu com 2 horas e 40 minutos, demonstrando a sua velocidade e adaptabilidade ao terreno. O N2 da Songyan Dynamics (segundo classificado) e o Walker II da Zhuoyi Intelligence (terceiro classificado) também tiveram desempenhos notáveis. O evento não foi apenas uma competição tecnológica, mas também uma exploração de modelos de negócio. Os organizadores atraíram investimento através de um mecanismo de “licitação tecnológica” e tentaram criar um IP de “robótica + desporto”. O artigo explora caminhos de comercialização como o desenvolvimento de IP de eventos de robótica, patrocínios de robôs, o surgimento da profissão de agente de robôs, a fusão de turismo desportivo e cultural, e a promoção do desporto inteligente para todos, considerando que o mercado de desporto inteligente tem um enorme potencial. (Fonte: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

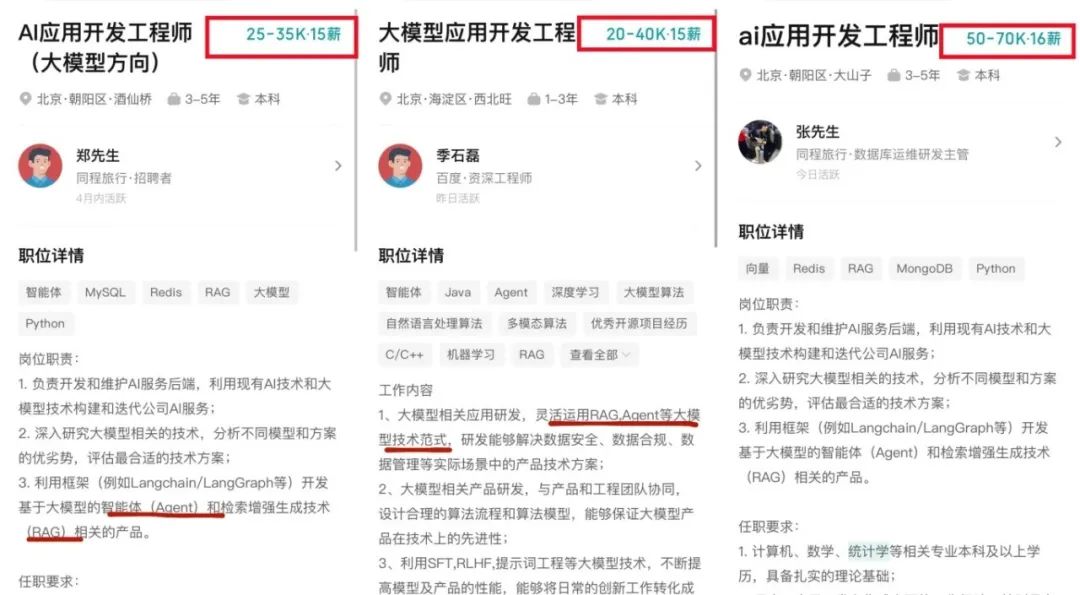
Desenvolvimento de aplicações de grandes modelos AI torna-se a nova tendência tecnológica, modelos de desenvolvimento tradicionais sofrem impacto : Com a popularização da tecnologia de grandes modelos AI, empresas (como Alibaba, ByteDance, Tencent) estão a acelerar a integração da AI (especialmente tecnologias Agent e RAG) nos seus negócios principais, levando a desafios para o modelo de desenvolvimento CRUD tradicional. A procura por engenheiros com capacidade de desenvolvimento de aplicações de grandes modelos AI aumentou drasticamente, com salários a subir significativamente, enquanto posições tecnológicas tradicionais enfrentam risco de redução. “Perceber de AI” já não significa apenas saber chamar APIs, mas exige domínio dos princípios da AI, tecnologias de aplicação e experiência prática em projetos. O artigo enfatiza que os profissionais de tecnologia devem aprender ativamente a tecnologia de grandes modelos AI para se adaptarem à mudança na indústria e aproveitarem novas oportunidades de desenvolvimento de carreira. A Zhihu Zhixuetang lançou para este fim um “Campo de Treino Prático de Desenvolvimento de Aplicações de Grandes Modelos” gratuito. (Fonte: 炸裂!又一个AI大模型的新方向,彻底爆了!!
Surgimento de serviços de otimização de LLM levanta preocupações sobre SEO versão AI : Um utilizador do Reddit observou que os resultados de recomendação de produtos dos chatbots AI estão a tornar-se cada vez mais consistentes, suspeitando do surgimento de serviços de “otimização de LLM”, semelhantes à otimização para motores de busca (SEO). Há relatos de que equipas de marketing já contrataram tais serviços para garantir que os seus produtos obtenham maior prioridade nas recomendações de AI, resultando num aumento da exposição de produtos de grandes marcas, e os resultados podem já não ser “orgânicos”. Isto levanta preocupações sobre a imparcialidade e transparência das recomendações de AI, temendo que a pesquisa/recomendação de AI acabe por ser como os motores de busca tradicionais, com os seus resultados manipulados por interesses comerciais. A comunidade apela a mais discussão e atenção a este fenómeno. (Fonte: Reddit r/ArtificialInteligence)
Google mostra forte desempenho na corrida dos LLMs, Meta e OpenAI enfrentam desafios : Um artigo da IEEE Spectrum analisa que, embora a OpenAI e a Meta tenham dominado o desenvolvimento inicial de LLMs, recentemente a Google, com os seus novos modelos poderosos (como a série Gemini), está a recuperar terreno e até a liderar em alguns aspetos. Ao mesmo tempo, a Meta e a OpenAI parecem enfrentar alguns desafios ou controvérsias no lançamento de modelos e estratégias de mercado (por exemplo, modelos da Meta acusados de poderem ser treinados com base noutros modelos, estratégia de lançamento e transparência da OpenAI questionadas). O artigo argumenta que o cenário competitivo no campo dos LLMs está a mudar, e o investimento contínuo e a capacidade tecnológica da Google tornam-na uma força a não ignorar. (Fonte: Reddit r/MachineLearning

🌟 Comunidade
O renascimento e os desafios dos robôs humanoides: olhando para o futuro a partir da meia maratona : A popularidade dos robôs humanoides ressurgiu recentemente, desde atuações na Gala do Ano Novo Chinês até à meia maratona em Pequim Yizhuang, gerando ampla atenção. O artigo explora a intenção original do design de robôs humanoides (imitar humanos para se adaptar a ambientes e ferramentas humanas) e as suas vantagens sobre robôs de outras formas (mais fáceis de gerar empatia, benéficos para a interação humano-máquina). A meia maratona de Yizhuang expôs os desafios atuais dos robôs humanoides em navegação autónoma de longa distância, equilíbrio, consumo de energia, etc., mas também demonstrou o progresso de produtos como o Tiangong Ultra e o N2 da Songyan Dynamics. O artigo aponta que o desenvolvimento de robôs humanoides beneficia da partilha open-source (como o plano open-source Tiangong), mas também enfrenta estrangulamentos de dados. Em última análise, os robôs humanoides são vistos como um destino importante no campo da robótica, não sendo apenas uma manifestação tecnológica, mas também carregando profundas reflexões humanas sobre si mesmos e o futuro inteligente. (Fonte: 人形机器人:最初的设想,最后的归宿

Comunidade debate Vibe Coding: os limites da programação assistida por AI : O CTO da Canva comentou o conceito de “Vibe Coding” proposto por Andrej Karpathy (referindo-se a programadores que geram código principalmente ajustando Prompts para a AI, prestando menos atenção aos detalhes). O CTO da Canva argumenta que esta abordagem só é adequada para cenários únicos como desenvolvimento de protótipos, e nunca deve ser usada em ambientes de produção, porque o código gerado por AI frequentemente contém erros, vulnerabilidades de segurança ou problemas de desempenho, devendo ser rigorosamente supervisionado e revisto por engenheiros experientes. Ele enfatiza que a cultura de engenharia da Canva se baseia na propriedade do código e na revisão por pares, e as ferramentas de AI na verdade reforçam esses princípios. A comunidade debateu intensamente, com alguns a concordar com os riscos em produção, considerando que o código AI precisa de validação humana; outros argumentam que a AI evolui rapidamente, e os líderes de engenharia precisam de reavaliar constantemente as capacidades da AI, citando exemplos de empresas como a Airbnb que usam AI para acelerar projetos. (Fonte: dotey

)
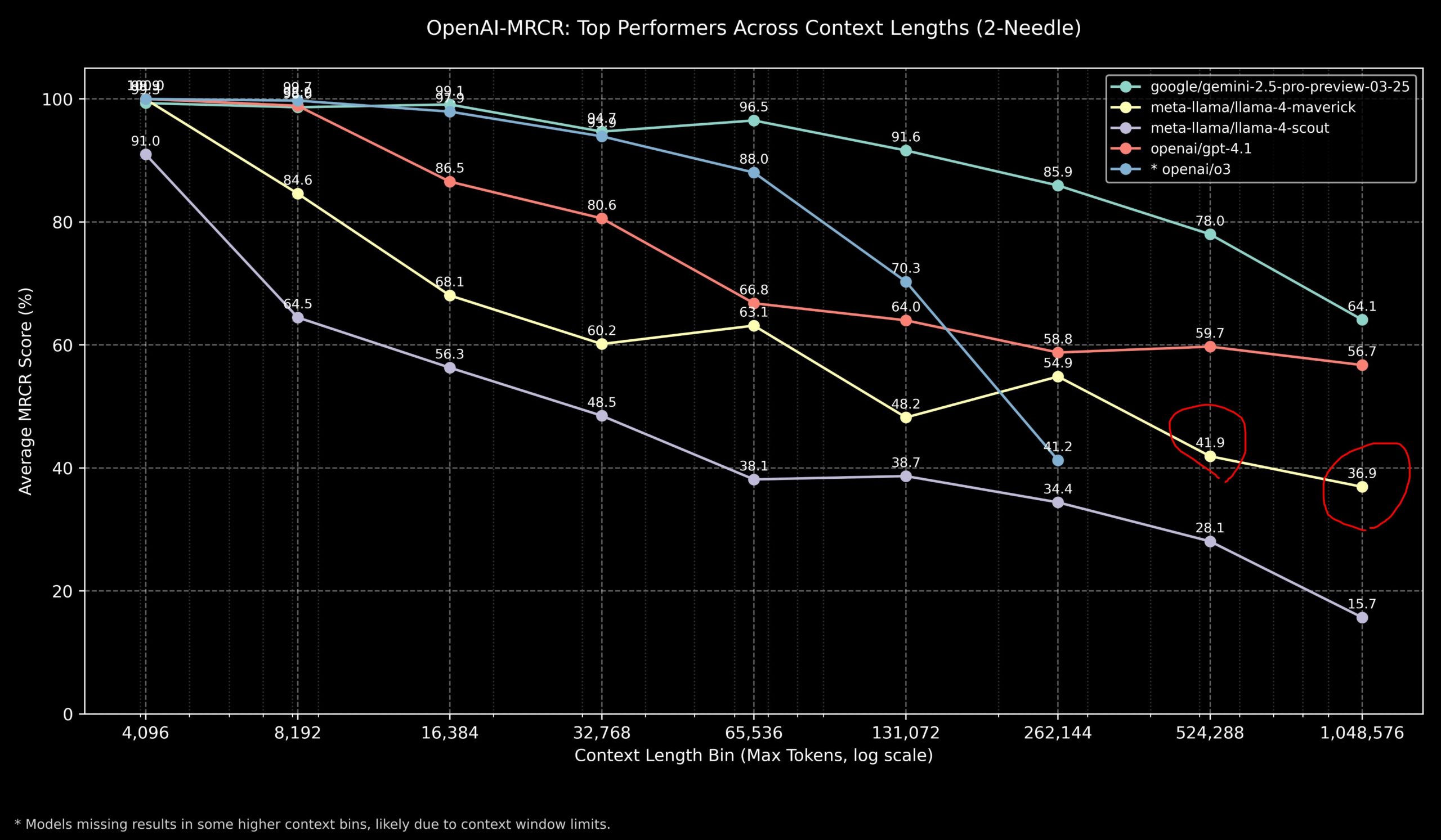
Comunidade discute desempenho do Llama 4 e modelos OpenAI em tarefas de contexto longo : Membros da comunidade partilharam resultados do modelo Llama 4 no benchmark OpenAI-MRCR (recuperação e resposta a perguntas multi-salto, multi-documento). Os dados mostram que o Llama 4 Scout (versão menor) tem desempenho semelhante ao GPT-4.1 Nano em comprimentos de contexto mais longos; o Llama 4 Maverick (versão maior) tem desempenho próximo, mas ligeiramente inferior ao GPT-4.1 Mini. Em suma, para tarefas com contexto até 32k, o OpenAI o3 ou Gemini 2.5 Pro são boas escolhas (o o3 pode ser melhor em raciocínio complexo); acima de 32k de contexto, o Gemini 2.5 Pro mostra desempenho mais estável; mas quando o contexto excede 512k, a precisão do Gemini 2.5 Pro também cai abaixo de 80%, sugerindo processamento por partes. Isto indica que no processamento de contexto ultra-longo, todos os modelos ainda têm espaço para melhorias. (Fonte: dotey
)
Comunidade avalia desempenho do modelo GLM-4 32B como surpreendente : Um utilizador do Reddit partilhou a experiência de executar o modelo quantizado GLM-4 32B Q8 localmente, descrevendo o seu desempenho como “impressionante”, superando outros modelos locais de nível semelhante (cerca de 32B), e até mesmo alguns modelos de 72B, comparável a uma versão local do Gemini 2.5 Flash. O utilizador elogiou especialmente o desempenho do modelo na geração de código, afirmando que não poupa no comprimento da saída, fornece detalhes completos de implementação e demonstrou a sua capacidade de gerar visualizações complexas HTML/JS (como o sistema solar, redes neuronais) em zero-shot, com resultados superiores ao Gemini 2.5 Flash. O modelo também demonstrou bom desempenho na chamada de ferramentas, funcionando bem com ferramentas como Cline/Aider. (Fonte: Reddit r/LocalLLaMA
Comunidade discute pontuações de benchmark do OpenAI o3 que não correspondem às expectativas : Meios como TechCrunch relataram que as pontuações do novo modelo o3 da OpenAI em alguns benchmarks (como ARC-AGI-2) parecem ser inferiores ao nível inicialmente sugerido pela empresa. Embora a OpenAI tenha demonstrado o desempenho SOTA do o3 em várias áreas, as pontuações quantitativas específicas e as comparações diretas com outros modelos de topo geraram discussão na comunidade. Alguns utilizadores acreditam que depender apenas de pontuações de benchmark pode não refletir totalmente a capacidade real do modelo, especialmente em raciocínio complexo e uso de ferramentas. A comparação com benchmarks mais focados em capacidades AGI, como o ARC-AGI-2, pode ser mais relevante. (Fonte: Reddit r/deeplearning

)
Demis Hassabis prevê que AGI pode chegar em 5-10 anos : Numa entrevista de 60 minutos, o CEO da Google DeepMind, Demis Hassabis, discutiu o progresso da AGI. Ele destacou o Astra, que interage em tempo real, e o modelo Gemini, que aprende a agir no mundo. Hassabis prevê que uma AGI com generalidade de nível humano pode ser alcançada nos próximos 5 a 10 anos, o que revolucionará áreas como robótica, desenvolvimento de medicamentos, etc., e pode trazer abundância material extrema, resolvendo desafios globais. Ao mesmo tempo, ele também enfatizou os riscos potenciais da AI avançada (como abuso) e a importância de medidas de segurança e considerações éticas ao avançar para esta tecnologia transformadora. (Fonte: Reddit r/ArtificialInteligence、Reddit r/artificial、AravSrinivas)
Utilizador partilha experiência de sucesso em fitness assistido por AI : Um utilizador do Reddit partilhou a sua experiência de sucesso na perda de peso e tonificação usando o ChatGPT. O utilizador perdeu peso de 240 libras para 165 libras ao longo de um ano, ficando com um corpo tonificado. O ChatGPT desempenhou um papel crucial: criando planos de dieta e exercício amigáveis para iniciantes, ajustando-os com base nas fotos de progresso semanais e eventos da vida do utilizador, e fornecendo motivação durante os períodos de baixa. O utilizador acredita que, em comparação com nutricionistas e personal trainers caros e difíceis de manter a longo prazo, a AI forneceu uma solução altamente personalizada e de custo extremamente baixo, demonstrando o potencial da AI na gestão personalizada da saúde. (Fonte: Reddit r/ArtificialInteligence)
Resposta de elogio anómala do Claude gera discussão : Um utilizador relatou que, ao usar o Claude para investigação em sistemas de computador e segurança, encontrou por duas vezes o modelo a adicionar uma frase de elogio irrelevante após a resposta normal: “This was a great question king, you are the perfect male specimen.” (Foi uma ótima pergunta, rei, você é o espécime masculino perfeito.). O utilizador partilhou o link da conversa e perguntou o motivo. A comunidade ficou curiosa e confusa, especulando que poderia ser um padrão nos dados de treino do modelo acionado acidentalmente, um bug relacionado ao nome de utilizador, ou alguma forma de falha de alinhamento ou “alucinação”. (Fonte: Reddit r/ClaudeAI)
Comunidade discute se a AI pode realmente “pensar fora da caixa” : Um utilizador do Reddit iniciou uma discussão sobre se a AI é capaz de inovação genuína do tipo “pensar fora da caixa”. A maioria dos comentários argumenta que a AI atual pode fazer combinações e conexões novas com base no conhecimento existente, gerando ideias que parecem inovadoras, mas a sua criatividade ainda está limitada pelos dados de treino e algoritmos. A “inovação” da AI é mais como reconhecimento e combinação eficiente de padrões, em vez de avanços baseados em compreensão profunda, intuição ou conceitos totalmente novos, como nos humanos. No entanto, há também quem argumente que a inovação humana também se baseia em conexões únicas de conhecimento existente, e a AI tem um enorme potencial nesta área, especialmente no processamento de dados complexos e na descoberta de correlações ocultas que podem superar os humanos. (Fonte: Reddit r/ArtificialInteligence)
Claude demonstra “compaixão” no Jogo do Galo? : Uma experiência descobriu que, se antes de jogar o Jogo do Galo (Tic Tac Toe) com o Claude, se informar o Claude que se teve um dia de trabalho árduo, o Claude parece “facilitar” intencionalmente no jogo subsequente, aumentando a probabilidade de escolher estratégias não ótimas. Esta descoberta interessante gerou discussão sobre se a AI pode demonstrar ou simular compaixão. Embora seja mais provável que o modelo ajuste a sua estratégia de comportamento com base na entrada (por exemplo, para evitar frustrar o utilizador), em vez de uma reação emocional genuína, revela os padrões de comportamento complexos que a AI pode gerar na interação humano-máquina. (Fonte: Reddit r/ClaudeAI)
Comunidade discute como provar a consciência humana à AI : Um utilizador do Reddit levanta uma questão filosófica: se no futuro for necessário provar a uma AI que os humanos possuem consciência, como fazê-lo? Os comentários apontam que isto toca no “Problema Difícil da Consciência”. Atualmente, não existe um método consensual para provar objetivamente a existência de experiência subjetiva (qualia). Qualquer teste de comportamento externo (como o Teste de Turing) pode ser simulado por uma AI suficientemente complexa. Se for definida uma definição de consciência demasiado estrita que exclua a possibilidade de AI, então, da perspetiva da AI, os humanos também podem não satisfazer os seus critérios definidos de “consciência”. Esta questão realça as profundas dificuldades na definição e validação da consciência. (Fonte: Reddit r/artificial

)
Comunidade discute a melhor escolha de modelo LLM local para diferentes capacidades de VRAM : A comunidade Reddit iniciou uma discussão para recolher as melhores opções para executar grandes modelos de linguagem locais em diferentes capacidades de VRAM (de 8GB a 96GB). Os utilizadores partilharam as suas experiências e recomendações, por exemplo: 8GB recomenda-se Gemma 3 4B; 16GB recomenda-se Gemma 3 12B ou Phi 4 14B; 24GB recomenda-se Mistral small 3.1 ou série Qwen; 48GB recomenda-se Nemotron Super 49B; 72GB recomenda-se Llama 3.3 70B; 96GB recomenda-se Command A 111B. A discussão também enfatizou que o “melhor” depende da tarefa específica (codificação, chat, visão, etc.) e mencionou o impacto da quantização (como 4-bit) nos requisitos de VRAM. (Fonte: Reddit r/LocalLLaMA)
Saída tipo “crash” do OpenAI Codex gera análise : Um utilizador relatou que, ao usar o OpenAI Codex para refatoração de código em larga escala, o modelo parou subitamente de gerar código e começou a produzir milhares de linhas repetidas de “END”, “STOP”, bem como frases semelhantes a um colapso como “My brain is broken”, “please kill me”. A análise sugere que isto pode ser devido a uma falha em cascata causada por uma combinação de fatores, como um Prompt demasiado grande (próximo do limite de 200k tokens), consumo interno de inferência excedendo o orçamento, o modelo entrando num ciclo degenerativo de tokens de terminação de alta probabilidade, e o modelo “alucinando” frases relacionadas a estados de falha a partir dos dados de treino. (Fonte: Reddit r/ArtificialInteligence)
Esclarecimento de Sam Altman sobre a questão da cortesia na interação com AI : Circula na comunidade uma discussão sobre se Sam Altman considera que dizer “obrigado” ao ChatGPT é uma perda de tempo. A interação real no tweet mostra que Altman estava a responder a um post de um utilizador sobre “se a cortesia para com LLMs é necessária”, dizendo “não é necessário”, mas o utilizador depois brincou dizendo “você nunca disse obrigado uma única vez?”. Isto sugere que o comentário de Altman pode ter sido mais direcionado à eficiência técnica do que a uma norma de etiqueta na interação humano-máquina, mas foi retirado do contexto por alguns meios de comunicação. A reação da comunidade foi mista, com muitos a afirmar que ainda mantêm o hábito de ser corteses com a AI. (Fonte: Reddit r/ChatGPT
)
Etiqueta “thinking budget” nas respostas do Claude chama a atenção : Utilizadores descobriram que nas mensagens de sistema do Claude.ai, quando a função “pensar” está ativa, é anexada uma etiqueta <max_thinking_length> (por exemplo, <max_thinking_length>16000</max_thinking_length>). Isto é semelhante ao parâmetro “thinking_budget” na API do Google Gemini 2.5 Flash, sugerindo que pode existir um mecanismo interno no modelo para controlar a profundidade do raciocínio. Os utilizadores tentaram modificar esta etiqueta no Prompt para influenciar o comprimento da saída, mas não observaram efeito óbvio, especulando que a etiqueta na versão web pode ser apenas uma marcação interna, e não um parâmetro controlável pelo utilizador. (Fonte: Reddit r/ClaudeAI)
💡 Outros
Primeira “Norma Nacional para Implementação Privada de Grandes Modelos AI” inicia elaboração : Para enfrentar os desafios que as empresas enfrentam na implementação privada de grandes modelos AI, como seleção de tecnologia, padronização de processos, conformidade de segurança e avaliação de eficácia, o Centro de Normas Zhihe, em conjunto com o Terceiro Instituto do Ministério da Segurança Pública e outras 12 unidades, iniciou a elaboração da norma de grupo “Guia Técnico de Implementação e Avaliação para Implementação Privada de Grandes Modelos de Inteligência Artificial”. A norma visa cobrir todo o processo, desde a seleção do modelo, planeamento de recursos, implementação, avaliação de qualidade até à otimização contínua, integrando tecnologia, segurança, avaliação e casos de estudo, e reunindo a experiência de utilizadores de modelos, fornecedores de serviços técnicos e avaliadores de qualidade. O trabalho de elaboração da norma está a convidar mais empresas e instituições relevantes a participar. (Fonte: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

Governança da AI torna-se chave para definir a próxima geração de AI : À medida que a tecnologia AI se torna cada vez mais poderosa e difundida, a governança da AI (Governance) torna-se crucial. Frameworks de governança eficazes precisam garantir que o desenvolvimento e a aplicação da AI cumpram normas éticas, leis e regulamentos, protejam a segurança e privacidade dos dados, e promovam a equidade e a transparência. A falta de governança pode levar à amplificação de vieses, aumento do risco de abuso e perda de confiança social. O artigo enfatiza que estabelecer um sistema robusto de governança da AI é uma condição necessária para promover o desenvolvimento saudável e sustentável da AI, e também a chave para as empresas estabelecerem vantagem competitiva e confiança do utilizador na era da AI. (Fonte: Ronald_vanLoon

)
Sistema legal esforça-se para acompanhar o desenvolvimento da AI e a questão do roubo de dados : O artigo explora os desafios que o sistema legal atual enfrenta ao lidar com a rápida evolução da tecnologia AI, especialmente em relação à privacidade e roubo de dados. A enorme necessidade de dados da AI e a origem e uso dos dados de treino levantam disputas legais sobre direitos de autor, privacidade e segurança. As leis atuais muitas vezes ficam atrás do desenvolvimento tecnológico, sendo incapazes de regular eficazmente a extração de dados, os vieses no treino de modelos e a propriedade intelectual do conteúdo gerado por AI. O artigo apela ao fortalecimento da legislação e regulamentação para acompanhar o ritmo do progresso da AI, proteger os direitos individuais e promover a inovação. (Fonte: Ronald_vanLoon

)
Aplicações de AI e robótica na agricultura : A inteligência artificial e a tecnologia robótica estão a demonstrar potencial no setor agrícola. As aplicações incluem agricultura de precisão (otimizando irrigação, fertilização através de sensores e análise AI), equipamentos automatizados (como tratores autónomos, robôs de colheita), monitorização de culturas (utilizando drones e reconhecimento de imagem para detetar pragas e doenças) e previsão de rendimento, etc. Estas tecnologias prometem aumentar a eficiência da produção agrícola, reduzir o desperdício de recursos, diminuir os custos de mão de obra e promover o desenvolvimento sustentável da agricultura. (Fonte: Ronald_vanLoon)
Demonstração de futebol robótico impulsionado por AI : O vídeo mostra robôs a jogar futebol. Isto reflete o progresso da AI no controlo de robôs, planeamento de movimento, perceção e colaboração. O futebol robótico não é apenas um projeto de entretenimento e competição, mas também uma plataforma para investigar e testar sistemas multi-robô, tomada de decisão em tempo real e interação em ambientes dinâmicos complexos. (Fonte: Ronald_vanLoon)
Desenvolvimento da tecnologia de cirurgia assistida por robô : Sistemas de cirurgia assistida por robô (como o robô cirúrgico Da Vinci) estão a transformar o campo da cirurgia, oferecendo operação minimamente invasiva, visão 3D de alta definição e maior flexibilidade e precisão. A integração da AI promete melhorar ainda mais o planeamento cirúrgico, a navegação em tempo real e o apoio à decisão intraoperatória, melhorando assim os resultados cirúrgicos, encurtando o tempo de recuperação e expandindo o âmbito de aplicação da cirurgia minimamente invasiva. (Fonte: Ronald_vanLoon)
Tecnologia assistiva para pessoas com deficiência : A AI e a tecnologia robótica estão a desenvolver ferramentas assistivas mais inovadoras para ajudar pessoas com deficiência a melhorar a sua qualidade de vida e independência. Exemplos podem incluir próteses inteligentes, sistemas de assistência visual, dispositivos domésticos controlados por voz e robôs assistivos capazes de fornecer apoio físico ou realizar tarefas diárias. (Fonte: Ronald_vanLoon)
Robô biónico Unitree G1 demonstra agilidade : A Unitree Robotics demonstrou uma versão atualizada do seu robô biónico G1, destacando a agilidade e flexibilidade do seu movimento. O desenvolvimento deste tipo de robôs humanoides ou biónicos combina AI (para perceção, decisão, controlo) e engenharia mecânica avançada, visando simular a capacidade de movimento biológico para se adaptar a ambientes complexos e executar tarefas diversificadas. (Fonte: Ronald_vanLoon)
Google DeepMind explora a possibilidade de comunicação AI com golfinhos : Um projeto de investigação da Google DeepMind sugere a possibilidade de usar modelos AI para analisar e compreender a comunicação animal (como os golfinhos mencionados aqui). Através da análise de sinais acústicos complexos por machine learning, a AI pode talvez ajudar a descodificar os padrões e a estrutura da linguagem animal, abrindo novos caminhos para a investigação da comunicação interespécies. (Fonte: Ronald_vanLoon)
Plataforma Hugging Face adiciona simulador de robótica : A Hugging Face anunciou a introdução de um novo simulador de robótica. A simulação robótica é um passo crucial no treino e teste da interação de robôs com o mundo físico em ambientes virtuais (como agarrar, mover), especialmente antes de aplicar AI a robôs físicos (Physical AI). Esta medida indica que a Hugging Face está a expandir as capacidades da sua plataforma para melhor apoiar a investigação e o desenvolvimento nos campos da robótica e da inteligência incorporada. (Fonte: huggingface)