
Palavras-chave:Quatro Grandes Dragões de IA, Inteligência Embutida, Robô Humanóide, Barreira de Memória, Modelo Multimodal SenseNova V6 da ShangTang, Conjunto de Dados Open X-Embodiment, Robô Optimus da Tesla, Tecnologia 3D FeRAM, Meia Maratona do Robô Tiangu Ultra, Modelo Quantizado Gemma 3 QAT, Hugging Face adquire Pollen Robotics, Fluxo de Trabalho de Documentos do Agente LlamaIndex
🔥 Foco
Os “AI Four Dragons” enfrentam desafios e transformação: Empresas como SenseTime, Megvii, CloudWalk e Yitu, outrora aclamadas como os “AI Four Dragons”, têm enfrentado dificuldades de comercialização e perdas contínuas nos últimos anos. Por exemplo, a SenseTime registou um prejuízo de 4,3 mil milhões de yuans em 2024, com perdas acumuladas superiores a 54,6 mil milhões de yuans; a CloudWalk registou um prejuízo de quase 600-700 milhões de yuans em 2024, com perdas acumuladas superiores a 4,4 mil milhões de yuans. Para enfrentar os desafios, as empresas têm vindo a realizar ajustes estratégicos, incluindo despedimentos, reduções salariais e reestruturações de negócios. Perante a nova onda de AI liderada por grandes modelos de linguagem, os “Four Dragons”, com a sua base em tecnologia visual, estão a virar-se ativamente para modelos multimodais de grande escala e para o campo da AGI. A SenseTime lançou o modelo multimodal “Ririxin V6”, comparável ao GPT-4o, e está a investir fortemente na construção de centros de computação inteligente; a Yitu foca-se em modelos multimodais centrados na visão e colabora com a Huawei para reduzir os custos de hardware; a CloudWalk também colabora com a Huawei para lançar uma máquina integrada de treino e inferência de grandes modelos; a Megvii, por sua vez, aproveita a sua vantagem em algoritmos para entrar em soluções puramente visuais para condução inteligente. Estas iniciativas indicam que estão a esforçar-se para permanecer na mesa da AI, adaptando-se ao novo ambiente de mercado. (Fonte: 36氪)

Dificuldades de dados na inteligência incorporada e progresso em datasets de código aberto: O desenvolvimento de robôs humanoides e inteligência incorporada enfrenta um estrangulamento crítico de dados, com a falta de dados de treino de alta qualidade a impedir avanços nas suas capacidades. Diferentemente dos modelos de linguagem, que possuem vastos dados textuais da internet, os robôs necessitam de dados diversificados de interação com o mundo físico, cuja aquisição é dispendiosa. Para resolver este problema, instituições de investigação e empresas estão ativamente a construir e a disponibilizar datasets de código aberto, como o Open X-Embodiment lançado pela Google DeepMind em colaboração com várias instituições, o ARIO do Peng Cheng Laboratory e outros, o RoboMIND do Beijing Innovation Center, o AgiBot World da Agibot (incluindo dados de tarefas complexas de longo alcance em cenários reais) e o dataset de simulação AgiBot Digital World, o dataset de operações G1 da Unitree, entre outros. Embora a escala destes datasets ainda seja muito menor que a dos dados textuais, através da unificação de padrões, melhoria da qualidade e enriquecimento de cenários, estão a impulsionar o desenvolvimento no campo da inteligência incorporada, estabelecendo as bases para alcançar um “momento ImageNet”. (Fonte: 36氪)

Alvorada da produção em massa de robôs humanoides: avanços em dados, simulação e generalização: Apesar de enfrentarem desafios como o alto custo da recolha de dados e a fraca capacidade de generalização, várias empresas (Tesla, Figure AI, 1X, Agibot, Unitree, UBTECH, etc.) planeiam alcançar a produção em massa de robôs humanoides em 2025. As soluções incluem: 1) Treino em larga escala com máquinas reais, apoiado por governos (Pequim, Xangai, Shenzhen, Guangdong) na construção de bases de recolha de dados e definição de padrões; 2) Treino avançado por simulação, utilizando world models como Nvidia Cosmos e Google Genie2 para gerar ambientes virtuais fisicamente realistas, reduzindo custos e aumentando a eficiência; 3) Capacitação da generalização por AI, através de novos modelos de ação como o Helix da Figure AI, a arquitetura ViLLA do GO-1 da Agibot e o Google Gemini Robotics, utilizando menos dados para alcançar uma compreensão generalizada das operações físicas, permitindo que os robôs lidem com objetos nunca vistos e se adaptem a novos ambientes. Estes avanços tecnológicos prenunciam uma possível aceleração da aplicação comercial de robôs humanoides. (Fonte: 36氪)

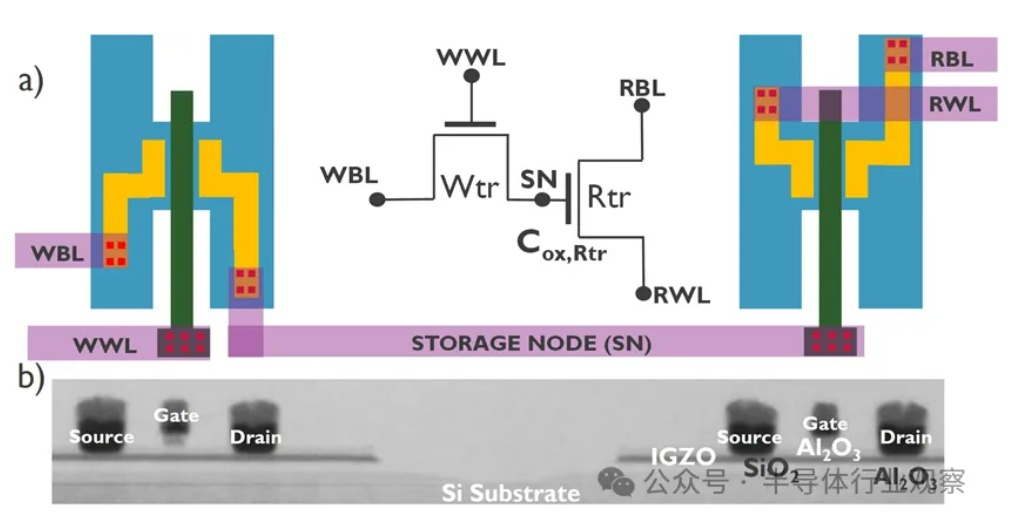
Desenvolvimento de AI enfrenta crise do “muro da memória”, novas tecnologias de armazenamento procuram avanços: O crescimento exponencial da escala dos modelos de AI impõe desafios severos à largura de banda da memória. O crescimento da largura de banda da DRAM tradicional está muito aquém do crescimento da capacidade de computação, formando um estrangulamento conhecido como “muro do armazenamento”, que limita o desempenho do processador. A HBM, através da tecnologia de empilhamento 3D, aumenta significativamente a largura de banda, aliviando parte da pressão, mas o seu processo de fabrico é complexo e dispendioso. Por isso, a indústria está a explorar ativamente novas tecnologias de armazenamento: 1) 3D Ferroelectric RAM (FeRAM): Como a SunRise Memory, que utiliza o efeito ferroelétrico do HfO2 para alcançar armazenamento de alta densidade, não volátil e de baixo consumo. 2) DRAM + Memória não volátil: A Neumonda, em colaboração com a FMC, utiliza HfO2 para transformar condensadores de DRAM em armazenamento não volátil. 3) 2T0C IGZO DRAM: O imec propõe a substituição da estrutura tradicional 1T1C por dois transístores de óxido, eliminando a necessidade de condensadores, para alcançar baixo consumo, alta densidade e longo tempo de retenção. 4) Phase Change Memory (PCM): Utiliza a mudança de fase de materiais para armazenar dados, reduzindo o consumo de energia. 5) UK III-V Memory: Baseada em GaSb/InAs, combina a velocidade da DRAM com a não volatilidade da flash. 6) SOT-MRAM: Utiliza o torque spin-órbita para alcançar baixo consumo e alta eficiência energética. Estas tecnologias prometem quebrar o estrangulamento da DRAM e remodelar o panorama do mercado de armazenamento. (Fonte: 36氪)
🎯 Tendências
Robô Tiangong completa desafio de meia maratona, planeia produção em pequenos lotes: O robô “Tiangong Ultra” da equipa Tiangong do Beijing Humanoid Robot Innovation Center (1,8 m de altura, 55 kg de peso) venceu a primeira corrida de meia maratona para robôs humanoides, completando cerca de 21 km em 2 horas, 40 minutos e 42 segundos. O evento testou a fiabilidade da autonomia, estrutura, perceção e algoritmos de controlo do robô em condições de estrada complexas. A equipa afirmou que, através da otimização da estabilidade das articulações, resistência ao calor, sistema de consumo de energia, algoritmos de equilíbrio e planeamento da marcha, e equipado com a plataforma “Hui Si Kai Wu” desenvolvida internamente (cérebro + cerebelo incorporados), o robô alcançou planeamento autónomo de trajetória e ajuste em tempo real sob navegação sem fios. Completar a maratona provou a sua fiabilidade básica, estabelecendo as bases para a produção em massa. O robô Tiangong 2.0 será lançado em breve, com planos para produção em pequenos lotes, visando futuras aplicações em áreas como indústria, logística, operações especiais e serviços domésticos. (Fonte: 36氪)

China desenvolve cérebro de robô utilizando células humanas cultivadas: Segundo relatos, investigadores chineses estão a desenvolver um robô movido por células cerebrais humanas cultivadas. Esta investigação visa explorar as possibilidades da computação biológica, utilizando a capacidade de aprendizagem e adaptação dos neurónios biológicos para controlar hardware robótico. Embora os detalhes específicos e o estágio de progresso não sejam claros, esta direção representa uma exploração de vanguarda na interseção da robótica, inteligência artificial e biotecnologia, podendo abrir novos caminhos para o desenvolvimento futuro de sistemas robóticos mais inteligentes e adaptáveis. (Fonte: Ronald_vanLoon)
Desempenho excelente do modelo quantizado Gemma 3 QAT: Um utilizador comparou a versão QAT (Quantization Aware Training) do modelo Google Gemma 3 27B com outras versões quantizadas Q4 (Q4_K_XL, Q4_K_M) no benchmark GPQA Diamond. Os resultados mostraram que a versão QAT teve o melhor desempenho (36.4% de precisão) e a menor ocupação de VRAM (16.43 GB), superando o Q4_K_XL (34.8%, 17.88 GB) e o Q4_K_M (33.3%, 17.40 GB). Isto indica que a tecnologia QAT reduz eficazmente os requisitos de recursos, mantendo o desempenho do modelo. (Fonte: Reddit r/LocalLLaMA)
Rumor: AMD lançará placa gráfica RDNA 4 Radeon PRO com 32GB de VRAM: O VideoCardz relata que a AMD está a preparar placas gráficas da série Radeon PRO baseadas na GPU Navi 48 XTW, que serão equipadas com 32GB de VRAM. Se for verdade, isto oferecerá uma nova opção para utilizadores que necessitam de grande VRAM para treino e inferência de modelos de AI locais, especialmente considerando a limitação geral de VRAM nas placas gráficas de consumo. No entanto, o desempenho específico, preço e data de lançamento ainda não foram anunciados, e a sua competitividade real permanece por ver. (Fonte: Reddit r/LocalLLaMA)

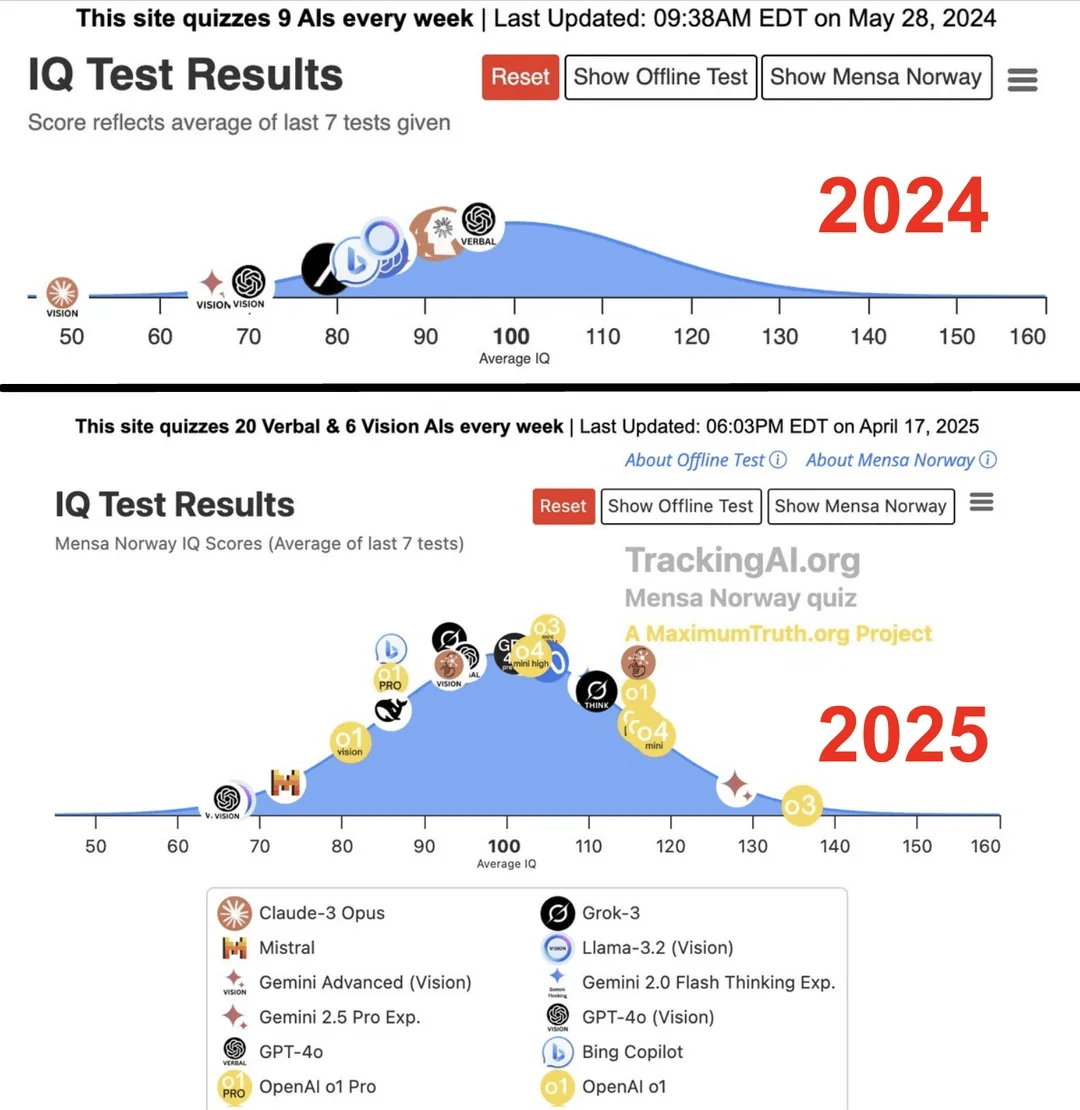
Estudo afirma que QI da AI de topo saltou de 96 para 136 num ano: De acordo com uma investigação publicada no site Maximum Truth (fiabilidade da fonte por verificar), através da realização de testes de IQ a modelos de AI, descobriu-se que o QI da AI mais inteligente (possivelmente referindo-se à série GPT) aumentou de 96 pontos (ligeiramente abaixo da média humana) para 136 pontos (próximo do nível de génio) num ano. Embora a validade dos testes de IQ para medir a inteligência da AI seja controversa, e exista a possibilidade de contaminação dos testes pelos dados de treino, este aumento significativo reflete o rápido progresso da AI na capacidade de resolver problemas de testes de inteligência padronizados. (Fonte: Reddit r/artificial)
🧰 Ferramentas
OpenUI: Gera UI em tempo real através de descrição: A wandb tornou open source o OpenUI, uma ferramenta que permite aos utilizadores idealizar e renderizar interfaces de utilizador em tempo real através de descrições em linguagem natural. Os utilizadores podem solicitar modificações e converter o HTML gerado em código para várias frameworks frontend como React, Svelte, Web Components, etc. O OpenUI suporta múltiplos backends LLM, incluindo OpenAI, Groq, Gemini, Anthropic (Claude), bem como modelos locais ligados através de LiteLLM ou Ollama. O projeto visa tornar o processo de construção de componentes UI mais rápido e divertido, servindo como ferramenta interna de teste e prototipagem na W&B. Embora inspirado no v0.dev, o OpenUI é open source. Disponibiliza uma Demo online e guias para execução local (Docker ou código fonte). (Fonte: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate: Ferramenta de tradução de PDF por AI que preserva a formatação: Desenvolvido por Byaidu, o PDFMathTranslate é uma poderosa ferramenta de tradução de documentos PDF, cuja principal vantagem reside na utilização de tecnologia AI para traduzir, preservando integralmente a formatação original do documento, incluindo fórmulas matemáticas complexas, gráficos, índices e notas. A ferramenta suporta tradução mútua entre várias línguas e integra múltiplos serviços de tradução como Google, DeepL, Ollama, OpenAI, etc. Para conveniência de diferentes utilizadores, o projeto oferece várias formas de utilização: linha de comandos (CLI), interface gráfica do utilizador (GUI), imagem Docker e um plugin para Zotero. Os utilizadores podem experimentar a Demo online ou escolher o método de instalação adequado às suas necessidades. (Fonte: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research: Sistema de geração de relatórios com citações baseado em LangGraph: O Shandu AI Research é um sistema que utiliza o workflow LangGraph para gerar automaticamente relatórios com citações. Através de técnicas como web scraping inteligente, síntese de informação de múltiplas fontes e processamento paralelo, visa simplificar tarefas de investigação. A ferramenta pode ajudar os utilizadores a recolher, integrar e analisar informações rapidamente, gerando relatórios de investigação estruturados e com citações, aumentando a eficiência da investigação. (Fonte: LangChainAI)

Intel lança AI Playground open source: A Intel tornou open source o AI Playground, uma aplicação de nível de entrada para AI PCs que permite aos utilizadores executar vários modelos de AI generativa em PCs equipados com placas gráficas Intel Arc. Os modelos de imagem/vídeo suportados incluem Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video; os grandes modelos de linguagem suportados incluem DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM), bem como Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM ou OpenVINO). A ferramenta visa reduzir a barreira à execução local de modelos de AI, facilitando a experimentação e a experiência do utilizador. (Fonte: karminski3)
Persona Engine: Projeto de assistente/VTuber virtual de AI: O Persona Engine é um projeto open source que visa criar um assistente virtual interativo de AI ou um VTuber virtual. Integra grandes modelos de linguagem (LLM), animação Live2D, reconhecimento automático de fala (ASR), conversão de texto em fala (TTS) e tecnologia de clonagem de voz em tempo real. Os utilizadores podem dialogar por voz diretamente com a personagem Live2D, e o projeto também suporta integração com software de streaming como o OBS, para criar VTubers de AI. O projeto demonstra a aplicação integrada de várias tecnologias de AI, fornecendo uma framework para construir personagens virtuais interativas personalizadas. (Fonte: karminski3)
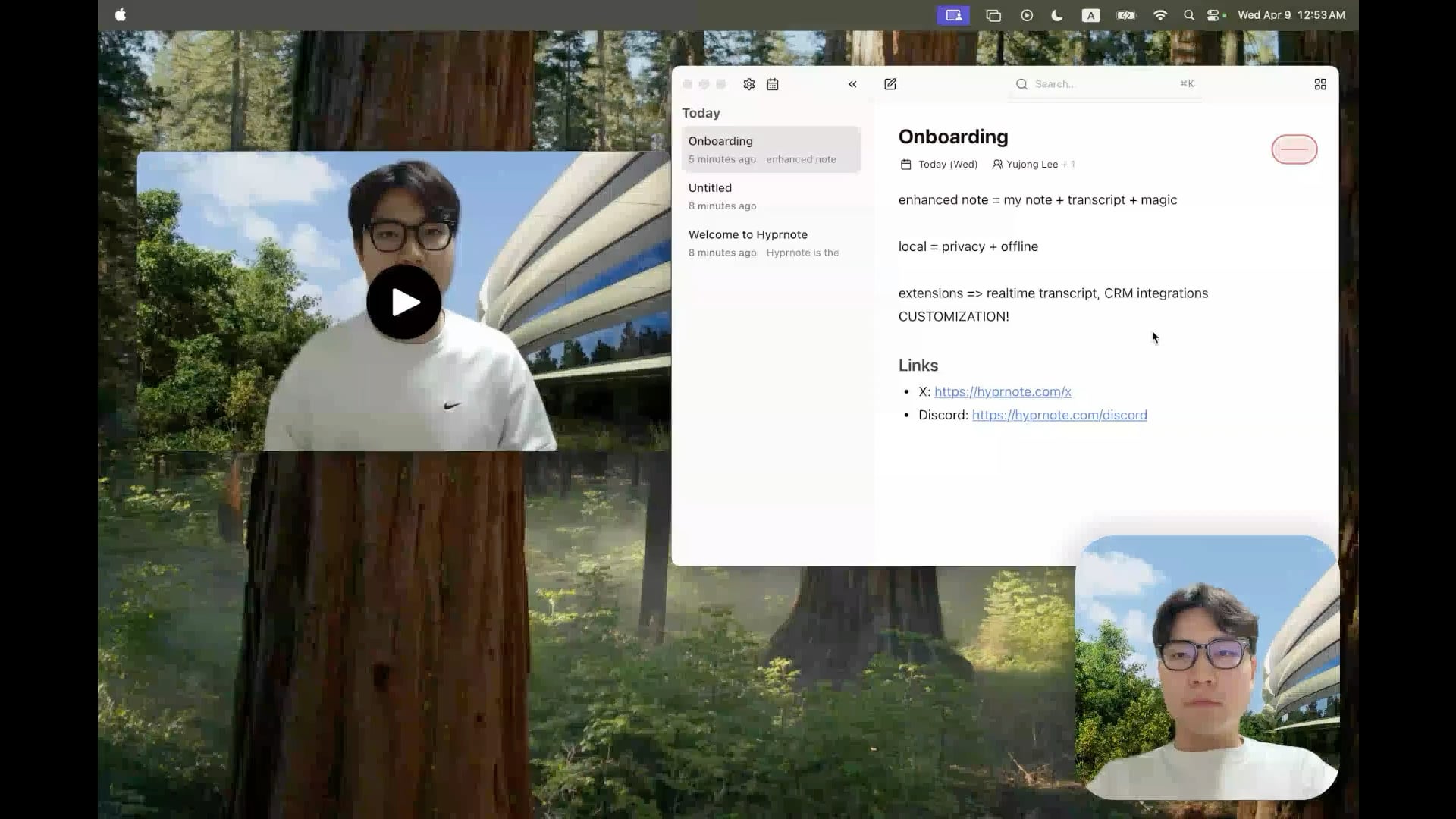
Hyprnote: Ferramenta open source de notas de reunião com AI local: Um programador tornou open source o Hyprnote, uma aplicação de notas inteligente concebida especificamente para cenários de reunião. Pode gravar áudio durante as reuniões e combinar as notas originais do utilizador com o conteúdo áudio da reunião para gerar atas de reunião melhoradas. A característica principal é a execução totalmente local de modelos de AI (como o Whisper para transcrição de voz), garantindo a privacidade e segurança dos dados do utilizador. A ferramenta visa ajudar os utilizadores a capturar e organizar melhor as informações das reuniões, sendo especialmente adequada para quem lida com reuniões consecutivas. (Fonte: Reddit r/LocalLLaMA)
LMSA: Ferramenta para conectar o LM Studio a dispositivos Android: Um utilizador partilhou uma aplicação chamada LMSA (lmsa.app), concebida para ajudar os utilizadores a conectar o LM Studio (uma popular ferramenta de gestão de execução local de LLM) aos seus dispositivos Android. Isto permite aos utilizadores interagir com modelos de AI executados no seu PC local através do telemóvel ou tablet, expandindo os cenários de utilização de grandes modelos locais. (Fonte: Reddit r/LocalLLaMA)

Ferramenta de pesquisa de imagens local baseada em MobileNetV2: Um programador construiu e partilhou uma ferramenta de pesquisa de imagens para desktop utilizando a interface gráfica PyQt5 e o modelo TensorFlow MobileNetV2. A ferramenta pode indexar pastas de imagens locais e encontrar imagens semelhantes com base no conteúdo (extraindo características através de CNN) usando a similaridade de cosseno. Consegue detetar automaticamente a estrutura de pastas como categorias e exibe miniaturas dos resultados da pesquisa, percentagem de similaridade e caminho do ficheiro. O código do projeto está open source no GitHub, procurando feedback dos utilizadores. (Fonte: Reddit r/MachineLearning)
Handcrafted Persona Engine: Avatar virtual interativo por voz com AI local: Um programador partilhou um projeto pessoal “Handcrafted Persona Engine”, que visa criar um avatar virtual interativo movido por voz, totalmente executado localmente, semelhante a uma experiência “Rua Sésamo”. O sistema integra o Whisper local para transcrição de voz, chama um LLM local através da API Ollama para geração de diálogo (incluindo personalização), usa TTS local para converter texto em voz e anima um modelo de personagem Live2D para sincronização labial e expressão de emoções. O projeto foi construído em C#, pode ser executado em placas gráficas de nível GTX 1080 Ti e está open source no GitHub. (Fonte: Reddit r/LocalLLaMA)
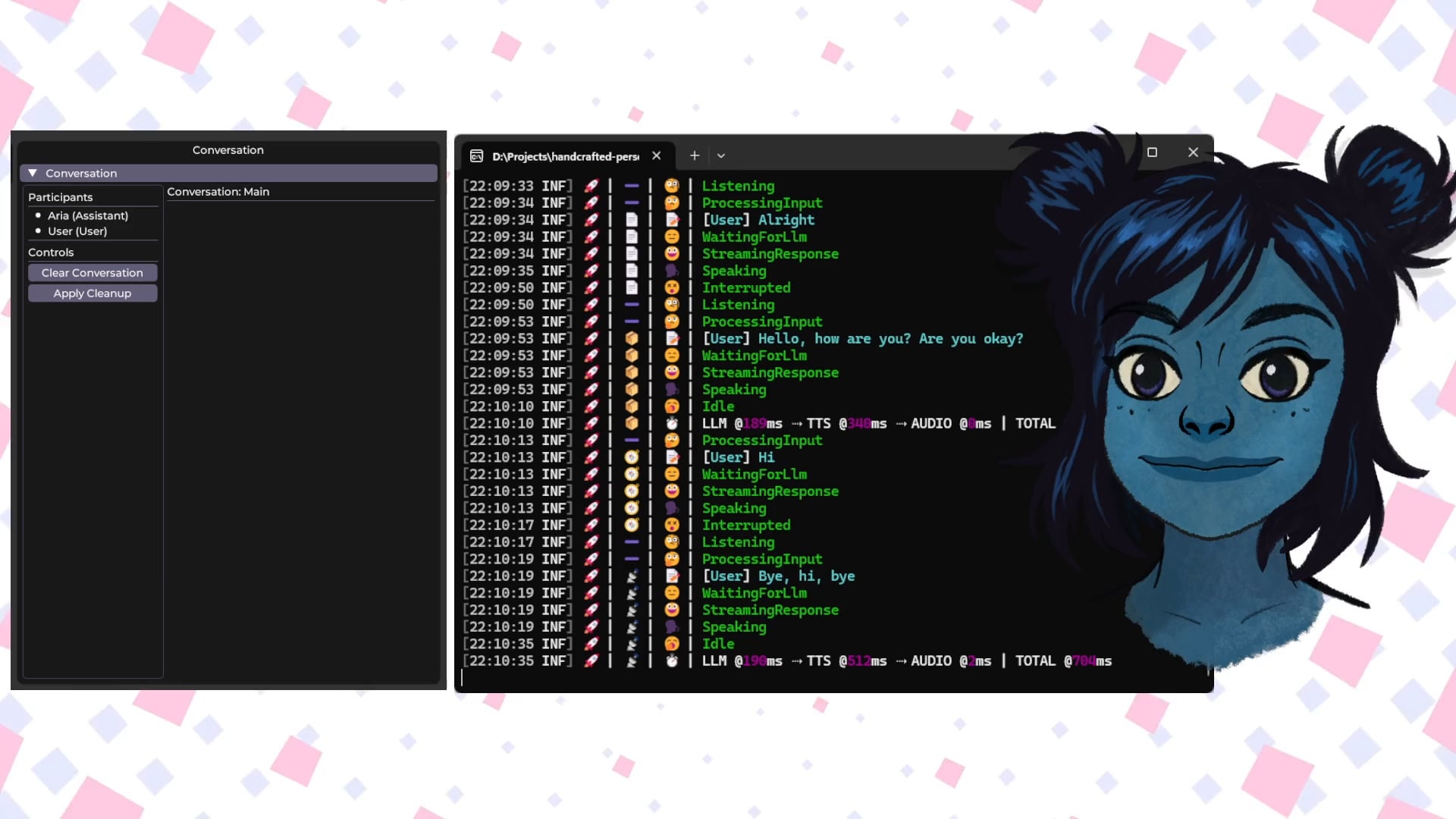
Talkto.lol: Ferramenta experimental para conversar com avatares AI de celebridades: Um programador criou um site chamado talkto.lol, que permite aos utilizadores conversar com personalidades AI de diferentes celebridades (como Sam Altman). A ferramenta também inclui uma função “show me”, onde os utilizadores podem carregar imagens, e a AI irá analisá-las e gerar uma resposta, demonstrando as capacidades de reconhecimento visual da AI. O programador afirma que utilizará a plataforma para mais experiências sobre interação com personalidades AI. A ferramenta pode ser experimentada sem registo. (Fonte: Reddit r/artificial)
📚 Aprendizagem
Fundamentos de robôs humanoides: desafios e recolha de dados: O desenvolvimento de robôs humanoides está a evoluir da simples automação para a complexa “inteligência incorporada”, ou seja, sistemas inteligentes baseados na perceção e ação através de um corpo físico. Diferentemente dos grandes modelos de AI que processam linguagem e imagens, os robôs precisam de compreender o mundo físico real, lidando com dados multidimensionais, incluindo perceção espacial, planeamento de movimento, feedback de força, etc. Obter estes dados de alta qualidade do mundo real é um desafio enorme, dispendioso e difícil de cobrir todos os cenários. Atualmente, os principais métodos de recolha incluem: 1) Recolha no mundo real: Utilizando sistemas de captura de movimento óticos ou inerciais para registar ações humanas, ou através de teleoperação humana remota de robôs para executar tarefas e registar dados de máquinas reais (como o Tesla Optimus). 2) Recolha no mundo simulado: Utilizando plataformas de simulação para simular ambientes e comportamentos de robôs, gerando grandes quantidades de dados para reduzir custos e aumentar a capacidade de generalização, mas necessitando de resolver a lacuna entre simulação e realidade (Sim-to-Real Gap). Além disso, a utilização de dados de vídeo da internet para pré-treino é também uma direção exploratória. (Fonte: 36氪)

Técnicas para gerar imagens estilo infográfico para artigos de conhecimento: Um utilizador partilhou métodos para usar ferramentas de AI como o GPT-4o para gerar imagens estilo infográfico para artigos de conhecimento. A técnica principal é pedir à AI que ajude primeiro a escrever o prompt para gerar a imagem. Passos específicos: fornecer o conteúdo ou pontos principais do artigo à AI e pedir-lhe para escrever um prompt para gerar um infográfico horizontal, solicitando texto em inglês, imagens de cartoon, estilo claro e vívido, que resuma as ideias centrais. Pontos chave: fornecer o conteúdo completo à AI; solicitar explicitamente “infográfico”; se houver muito texto, sugerir usar inglês para melhorar a precisão da geração; recomendar o uso de GPT-4.5, o3 ou Gemini 2.5 Pro para gerar o prompt; usar ferramentas como Sora Com ou ChatGPT para gerar a imagem final. (Fonte: dotey)
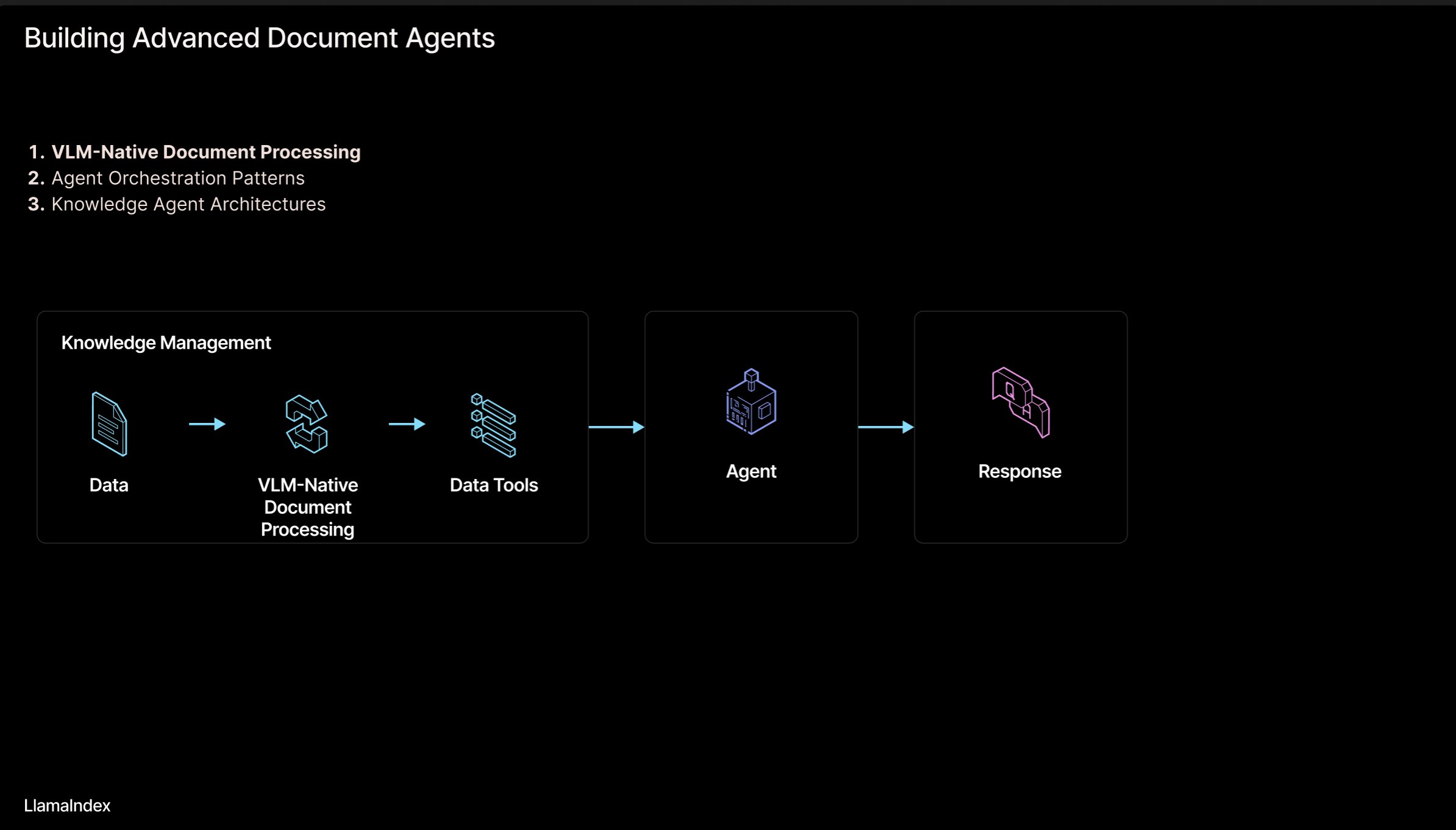
LlamaIndex: Arquitetura de workflow de documentos para agentes inteligentes: Jerry Liu, fundador do LlamaIndex, partilhou um conjunto de slides sobre uma arquitetura de workflow para construir agentes inteligentes (Agentic) que processam documentos (PDF, Excel, etc.). Esta arquitetura visa libertar o conhecimento bloqueado em documentos de formato legível por humanos, permitindo que agentes de AI analisem, raciocinem e manipulem esses documentos. A arquitetura inclui principalmente duas camadas: 1) Análise e extração de documentos: Utilizando tecnologias como modelos de linguagem visual (VLM) para criar uma representação legível por máquina do documento (MCP Server). 2) Workflow do agente inteligente: Combinando a informação do documento analisado com frameworks de agentes (como LlamaIndex) para automatizar o trabalho de conhecimento. Os slides podem ser vistos no Figma, e tecnologias relacionadas são aplicadas no LlamaCloud. (Fonte: jerryjliu0)
Repositório de recursos do tutorial de LangChain em coreano: Um projeto de tutorial de LangChain em coreano está disponível no GitHub. O projeto oferece recursos de aprendizagem de LangChain para utilizadores de língua coreana através de várias formas, como e-books, conteúdo de vídeos do YouTube e exemplos interativos. O conteúdo abrange conceitos centrais de LangChain, construção de sistemas LangGraph e implementação de RAG (Retrieval-Augmented Generation), entre outros tópicos chave, visando ajudar os programadores coreanos a compreender e aplicar melhor a framework LangChain. (Fonte: LangChainAI)
Guia para construir aplicações de AI locais usando Deno e LangChain.js: O blog Deno publicou um guia que introduz como combinar Deno (um runtime moderno de JavaScript/TypeScript), LangChain.js e grandes modelos de linguagem locais (hospedados via Ollama) para construir aplicações de AI. O artigo demonstra principalmente como utilizar TypeScript para criar workflows de AI estruturados e integra o Jupyter Notebook para desenvolvimento e experimentação. O guia fornece orientação prática para programadores que desejam desenvolver aplicações de AI locais no ambiente Deno usando JavaScript/TypeScript. (Fonte: LangChainAI)
Construindo um Modelo Mental Lógico (LMM) para Aplicações de AI: Um utilizador propõe um modelo mental lógico (LMM) para construir aplicações de AI (especialmente sistemas Agentic). O modelo sugere dividir a lógica de desenvolvimento em duas camadas: Lógica de alto nível (orientada para agentes e tarefas específicas), incluindo Ferramentas e Ambiente (Tools and Environment) e Papel e Instruções (Role and Instructions); Lógica de baixo nível (infraestrutura base comum), incluindo Roteamento (Routing), Barreiras de proteção (Guardrails), Acesso a LLMs (Access to LLMs) e Observabilidade (Observability). Esta divisão em camadas ajuda engenheiros de AI e equipas de plataforma a colaborar, aumentando a eficiência do desenvolvimento. O utilizador também menciona o projeto open source relacionado ArchGW, focado na implementação da lógica de baixo nível. (Fonte: Reddit r/artificial)

Framework teórico para AGI além da computação clássica: Um investigador em ciência da computação partilhou o seu artigo pré-publicado, propondo um novo framework teórico para a inteligência artificial geral (AGI). O framework tenta ir além da aprendizagem estatística tradicional e da computação determinística (como deep learning), integrando conceitos da neurociência, mecânica quântica (espaços cognitivos multidimensionais, superposição quântica) e os teoremas da incompletude de Gödel (componente autorreferencial de Gödel, intuição). O modelo assume que a consciência é impulsionada pela decadência da entropia e propõe uma equação unificada da inteligência, combinando aprendizagem de redes neuronais, cognição probabilística, dinâmica da consciência e insights impulsionados pela intuição. A investigação visa fornecer novas bases conceptuais e matemáticas para a AGI. (Fonte: Reddit r/deeplearning)
Dicas de segurança para gerir interações com AI: Um utilizador do Reddit partilhou conselhos e prompts para novos utilizadores de AI, destinados a ajudar a gerir melhor o processo de interação humano-máquina, evitando perder-se ou gerar medos desnecessários nas conversas com a AI. As sugestões incluem: 1) Usar prompts específicos (como “resume esta sessão para mim”) para rever e controlar o fluxo da interação; 2) Reconhecer as limitações da AI (como falta de emoções reais, consciência e experiências pessoais); 3) Terminar ativamente ou iniciar uma nova sessão quando se sentir perdido. Enfatiza a importância de manter uma consciência clara sobre a natureza da AI. (Fonte: Reddit r/artificial)
Artigo: Unificando Flow Matching e Modelos Baseados em Energia para modelagem generativa: Investigadores partilharam um artigo pré-publicado que propõe um novo método de modelagem generativa unificando Flow Matching e Energy-Based Models (EBMs). A ideia central do método é: longe da variedade de dados, as amostras movem-se do ruído para os dados ao longo de caminhos de transporte ótimo irrotacionais; ao aproximar-se da variedade de dados, um termo de energia entrópica guia o sistema para uma distribuição de equilíbrio de Boltzmann, capturando explicitamente a estrutura de verossimilhança dos dados. Todo o processo dinâmico é parametrizado por um único campo escalar independente do tempo, que pode servir tanto como gerador quanto como prior, para regularização eficaz de problemas inversos. O método melhora significativamente a qualidade da geração, mantendo a flexibilidade dos EBMs. (Fonte: Reddit r/MachineLearning)
Biblioteca de implementação de otimizadores TensorFlow: Um programador criou e partilhou um repositório GitHub que contém implementações TensorFlow de vários otimizadores comuns (como Adam, SGD, Adagrad, RMSprop, etc.). O projeto visa fornecer código de implementação de otimizadores conveniente e padronizado para investigadores e programadores que usam TensorFlow, ajudando a compreender e aplicar diferentes algoritmos de otimização. (Fonte: Reddit r/deeplearning)
Artigo sobre análise de dados multimodais com deep learning: Rackenzik.com publicou um artigo sobre a utilização de deep learning para análise de dados multimodais. O artigo provavelmente explora como combinar dados de diferentes fontes (como texto, imagem, áudio, dados de sensores, etc.), utilizando modelos de deep learning (como redes de fusão, mecanismos de atenção, etc.) para extrair informações mais ricas, fazer previsões ou classificações mais precisas. A aprendizagem multimodal é um ponto quente atual na investigação de AI, com potencial significativo para compreender problemas complexos do mundo real. (Fonte: Reddit r/deeplearning)

Procura de recursos de aprendizagem sobre Graph Neural Networks (GNN): Um utilizador do Reddit procura materiais de aprendizagem de qualidade sobre Graph Neural Networks (GNN), incluindo literatura introdutória, livros, vídeos do YouTube ou outros recursos. Nos comentários, recomendam-se os vídeos das aulas de GNN do Professor Jure Leskovec da Universidade de Stanford, considerado um pioneiro na área. Outro comentário recomenda um vídeo do YouTube que explica os princípios básicos das GNN. A discussão reflete o interesse dos aprendizes neste importante ramo do deep learning. (Fonte: Reddit r/MachineLearning)
Partilha de fluxo de trabalho para construir e lançar aplicações rapidamente com AI: Um programador partilhou o seu processo completo para construir e lançar aplicações rapidamente utilizando ferramentas de AI. Passos chave incluem: 1) Idealização: Pensamento original e pesquisa de concorrentes. 2) Planeamento: Usar Gemini/Claude para gerar documento de requisitos do produto (PRD), seleção de stack tecnológica e plano de desenvolvimento. 3) Stack Tecnológica: Recomenda Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel, etc., aproveitando planos gratuitos para começar. 4) Desenvolvimento: Usar Cursor (assistente de programação AI) para acelerar o desenvolvimento do MVP. 5) Teste: Usar Gemini 2.5 para gerar planos de teste e validação. 6) Lançamento: Listar várias plataformas adequadas para lançar produtos (Reddit, Hacker News, Product Hunt, etc.). 7) Filosofia: Enfatizar crescimento orgânico, valorizar feedback, manter a humildade, focar na utilidade. Também partilhou ferramentas auxiliares como empacotadores de código, conversores de Markdown para PDF, etc. (Fonte: Reddit r/ClaudeAI)

💼 Negócios
Caminhos legais para proteção de modelos de AI: Direito da concorrência superior a direitos de autor e segredo comercial: O artigo usa o caso “Douyin vs. Yiruike sobre violação de modelo de AI” como exemplo para explorar em profundidade os modelos de proteção legal para modelos de AI (estrutura e parâmetros). A análise considera que os modelos de AI, como núcleo tecnológico, dificilmente obtêm proteção eficaz através da lei de direitos de autor (o desenvolvimento do modelo não é um ato criativo, a originalidade do conteúdo gerado é questionável) ou da lei de segredos comerciais (fácil de ser alvo de engenharia reversa, medidas de confidencialidade difíceis de implementar). O tribunal de segunda instância neste caso acabou por adotar a via do direito da concorrência, determinando que a cópia da estrutura e parâmetros do modelo Douyin pela Yiruike constituía concorrência desleal, prejudicando o “interesse concorrencial” obtido pela Douyin através do investimento em I&D. O artigo defende que o direito da concorrência é mais adequado para regular tais comportamentos, podendo usar o critério de “substituição substancial” para avaliar o impacto no mercado, combater o “aproveitamento parasitário”, mas também alerta para a necessidade de equilíbrio, evitando inibir a inovação razoável. (Fonte: 36氪)
Hugging Face adquire Pollen Robotics, impulsionando robótica open source: A Hugging Face adquiriu a startup francesa de robótica Pollen Robotics, conhecida pelo seu robô humanoide open source Reachy 2. Esta ação faz parte da iniciativa da Hugging Face para promover a robótica aberta, especialmente nas áreas de investigação e educação. O robô Reachy 2 é descrito como amigável, acessível e adequado para interação natural, custando atualmente cerca de 70.000 dólares. A aquisição demonstra as intenções da Hugging Face no campo da inteligência incorporada e robótica, visando expandir a filosofia open source para o hardware e interação física. (Fonte: huggingface, huggingface)
Anthropic lança plano de subscrição Claude Max: A Anthropic lançou um novo plano de subscrição chamado “Claude Max”, com preço de 100 dólares por mês. O plano parece posicionar-se acima do plano Pro existente (geralmente 20 dólares/mês). Alguns utilizadores comentaram que o plano Max oferece novas funcionalidades de investigação e limites de utilização mais elevados, mas outros consideram que a sua relação custo-benefício não é boa, faltando funcionalidades como geração de imagem, geração de vídeo, modo de voz, etc., e que as funcionalidades de investigação poderão vir a ser adicionadas ao plano Pro no futuro. (Fonte: Reddit r/ClaudeAI)
🌟 Comunidade
Novas necessidades de filtragem de modelos no Hugging Face: ordenar por capacidade de inferência e tamanho: Um utilizador propôs nas redes sociais que a plataforma Hugging Face adicione novas funcionalidades de filtragem e ordenação de modelos. As sugestões específicas incluem: 1) Adicionar um filtro para mostrar apenas modelos com capacidade de inferência; 2) Adicionar uma opção de ordenação que permita ordenar pelo tamanho (footprint) do modelo. Estas funcionalidades ajudariam os utilizadores a descobrir e selecionar mais facilmente modelos adequados às suas necessidades específicas, especialmente aqueles focados no desempenho de inferência do modelo e no consumo de recursos de implementação. (Fonte: huggingface)
Utilizador constrói jogos clássicos no Hugging Face DeepSite: Um utilizador partilhou a sua experiência de sucesso na construção e execução de jogos clássicos na plataforma Hugging Face DeepSite. O utilizador utilizou a funcionalidade Canvas do DeepSite (que suporta HTML, CSS, JS) e os modelos Novita/DeepSeek para completar o projeto. Isto demonstra a versatilidade da plataforma DeepSite, não se limitando à inferência e demonstração de modelos tradicionais, mas podendo também ser usada para construir aplicações web interativas e jogos, oferecendo um novo espaço criativo aos programadores. (Fonte: huggingface)
Opinião do utilizador: AI mais parecida com o Renascimento do que com a Revolução Industrial: Um utilizador concorda com a opinião de Sam Altman, considerando que o desenvolvimento atual da AI se assemelha mais a um “Renascimento” do que a uma “Revolução Industrial”. O utilizador expressa uma discrepância entre expectativa e realidade: embora espere que a AI resolva problemas práticos (como fazer tarefas domésticas, ganhar dinheiro), o que sente atualmente é mais a aplicação da AI no campo criativo (como gerar imagens estilo Ghibli). Isto reflete a reflexão e os sentimentos de alguns utilizadores sobre a direção do desenvolvimento da tecnologia AI e as suas aplicações práticas. (Fonte: dotey)
Utilizadores de ChatGPT/Claude anseiam pela função “Fork”: O fundador do LlamaIndex, como utilizador intensivo do ChatGPT Pro, Claude e Gemini, expressou uma forte necessidade de adicionar a função “Fork” (bifurcação) aos chatbots. Ele salienta que, ao lidar com diferentes tarefas, não quer misturar contextos no mesmo fio de conversa, mas que voltar a colar grandes quantidades de informação de contexto pré-definida é muito moroso. A função “Fork” permitiria aos utilizadores criar um novo ramo de conversa independente baseado no estado atual da conversa (incluindo o contexto), aumentando assim a eficiência de utilização. Ele também explorou outras possíveis formas de implementação, como ferramentas de gestão de memória ou threads ao estilo do Slack. (Fonte: jerryjliu0)
Modelo musical Orpheus atinge 100.000 downloads no Hugging Face: O modelo musical Orpheus atingiu 100.000 downloads na plataforma Hugging Face. O programador Amu considera isto um pequeno marco e anuncia o lançamento iminente da versão Orpheus v1. Este feito reflete a atenção e o interesse da comunidade neste modelo de geração musical. (Fonte: huggingface)
Potencial do ChatGPT na resolução de problemas de saúde torna-se evidente: Um utilizador partilhou a observação de um número crescente de anedotas sobre o ChatGPT a ajudar pessoas a resolver problemas de saúde de longa data. Embora enfatize que ainda há um longo caminho a percorrer, isto indica que a AI já está a melhorar a vida das pessoas de forma significativa, especialmente na fase inicial de obtenção de informação, análise de sintomas ou procura de aconselhamento médico. Estes casos destacam o potencial auxiliar da AI na área da saúde. (Fonte: gdb)

Utilizador discute modelo de consciência com o Grok: Um utilizador do Reddit partilhou a sua experiência de discutir o seu próprio modelo proposto de consciência com o Grok AI. O utilizador forneceu um link para um rascunho do artigo e mostrou capturas de ecrã da conversa com o Grok, discutindo os conceitos do modelo. Isto reflete a utilização de grandes modelos de linguagem como ferramenta para troca de ideias e discussão de teorias complexas (como a consciência). (Fonte: Reddit r/artificial)
Claude Sonnet 3.7 “inventa” espontaneamente o React e gera atenção: Um utilizador do Reddit partilhou um vídeo alegando que o Claude Sonnet 3.7, sem prompts explícitos, articulou espontaneamente conceitos centrais semelhantes aos da framework React.js. Esta inesperada “criatividade” ou “capacidade de associação” gerou discussão na comunidade, demonstrando os comportamentos complexos que grandes modelos de linguagem podem exibir em domínios de conhecimento específicos. (Fonte: Reddit r/ClaudeAI)

Discussão sobre a eficácia do modo de raciocínio do Gemini 2.5 Flash: Um utilizador comparou experimentalmente o desempenho do Gemini 2.5 Flash com e sem o modo de “raciocínio” (reasoning) ativado. A experiência abrangeu várias áreas, incluindo matemática, física e programação. Os resultados foram inesperados: mesmo para tarefas que o utilizador considerava necessitar de um elevado orçamento de raciocínio, a versão com o modo de raciocínio desligado deu respostas corretas. Isto levou a um reconhecimento das capacidades do Gemini Flash 2.5 no modo sem raciocínio e questionou os cenários de aplicação necessários para o modo de raciocínio. O processo de comparação detalhado foi partilhado num vídeo do YouTube. (Fonte: Reddit r/MachineLearning)

ChatGPT gera imagem mental do utilizador e causa debate: Um utilizador do Reddit iniciou uma atividade, pedindo ao ChatGPT para gerar uma imagem do utilizador com base no histórico da conversa e no perfil psicológico inferido. Muitos utilizadores partilharam as imagens geradas pelo ChatGPT para eles, com estilos variados: algumas oníricas e coloridas, outras intelectuais, outras ainda parecendo profundas e complexas. Esta interação demonstrou a capacidade de geração de imagem do ChatGPT e a sua tentativa de inferência criativa baseada na compreensão textual, gerando também uma discussão divertida sobre a imagem digital dos utilizadores. (Fonte: Reddit r/ChatGPT, Reddit r/ChatGPT)

Execução local do modelo Gemma 3 requer configuração manual do Speculative Decoding: Um utilizador perguntou como ativar o Speculative Decoding (decodificação especulativa) ao executar localmente o modelo Gemma 3 para acelerar a inferência, salientando que a interface do LM Studio não oferece essa opção. A comunidade respondeu sugerindo o uso direto da ferramenta de linha de comandos llama.cpp, que permite configurar de forma mais flexível vários parâmetros de execução, incluindo a decodificação especulativa. Um utilizador partilhou a sua experiência usando um modelo 1B como modelo de rascunho para um modelo 27B em decodificação especulativa, mas também mencionou que para os novos modelos quantizados QAT, esta técnica pode, na verdade, diminuir a velocidade. (Fonte: Reddit r/LocalLLaMA)
Política de conteúdo da geração de imagens do ChatGPT criticada por utilizadores: Um utilizador criticou, através de um cartoon, a política de conteúdo excessivamente rigorosa do ChatGPT na geração de imagens. O cartoon retrata um utilizador a tentar gerar imagens de cenários comuns, sendo repetidamente bloqueado pela política de conteúdo, acabando por conseguir gerar apenas uma imagem em branco. Nos comentários, os utilizadores expressaram concordância, partilhando as suas experiências de gerar conteúdo quotidiano e seguro (como colorir fotos antigas dos pais, um jogador de basquetebol sentado, imagens de adagas) que foi erroneamente sinalizado como violação. Isto reflete que as atuais políticas de segurança de conteúdo de AI ainda têm espaço para melhorias na precisão e experiência do utilizador. (Fonte: Reddit r/ChatGPT)

Discussão sobre cenários de aplicação inesperados da AI: Um utilizador do Reddit iniciou uma discussão, pedindo exemplos de cenários de aplicação inesperados encontrados ao usar AI, que vão além da geração tradicional de código ou conteúdo. Nos comentários, os utilizadores partilharam vários casos, como: pedir à AI para resumir pontos chave de livros para aprendizagem rápida (ex: conhecimento sobre parentalidade), ajudar a ler prescrições médicas, identificar sementes, escolher bifes com base em fotos, transcrever texto manuscrito para formato digital, controlar o Spotify via Siri para mudar de estação, auxiliar no design de produtos (UX/UI), etc. Estes casos demonstram a crescente penetração e utilidade prática da AI na vida quotidiana e no trabalho. (Fonte: Reddit r/ArtificialInteligence)
Preocupação com a substituição de empregos tecnológicos pela AI, procura de conselhos sobre carreiras futuras: Um utilizador expressou preocupação sobre a possibilidade de a AI substituir empregos técnicos no futuro (especialmente programação), considerando que provavelmente se reformará por volta de 2080, e espera encontrar uma direção de carreira relacionada com tecnologia que não seja facilmente substituível pela AI. Nos comentários, foram dadas várias sugestões, incluindo: aprender um ofício (como canalizador) como proteção; tornar-se um talento de topo; focar-se em áreas que requerem interação humana ou criatividade (como professor); ou aprofundar a aprendizagem sobre como usar ferramentas de AI para aumentar a própria competitividade. A discussão reflete a ansiedade generalizada sobre o impacto da AI no emprego. (Fonte: Reddit r/ArtificialInteligence)
Dúvidas sobre o desempenho do OpenWebUI no processamento de grandes volumes de documentos: Um utilizador encontrou problemas ao usar a funcionalidade de base de conhecimento do OpenWebUI, tendo dificuldades ao tentar carregar cerca de 400 documentos PDF através da API. O utilizador perguntou à comunidade se uma base de conhecimento desta escala funciona normalmente no OpenWebUI e considerou se seria necessário externalizar o processamento de documentos para um Pipeline dedicado. Isto aborda os desafios práticos do processamento de dados não estruturados em larga escala em aplicações RAG. (Fonte: Reddit r/OpenWebUI)
Procura de orientação para projeto de deep learning de sincronização labial em anime: Um estudante pediu ajuda para o seu projeto de final de curso, cujo objetivo é aplicar técnicas de deep learning para criar vídeos curtos de anime com sincronização labial (lip sync). O estudante perguntou sobre a dificuldade do projeto e pediu recursos relevantes, como artigos ou repositórios de código. Esta é uma área de aplicação que combina visão computacional, animação e deep learning. (Fonte: Reddit r/deeplearning)
Utilizadores de AI local anseiam por placas gráficas baratas com muita VRAM: Um utilizador expressou desapontamento com o facto de as recém-lançadas placas gráficas da série RDNA 4 da AMD (série RX 9000) virem equipadas com apenas 16GB de VRAM, considerando que não satisfazem as elevadas necessidades de VRAM (como 24GB+) para executar modelos de AI locais (especialmente grandes modelos de linguagem). O utilizador questiona se a AMD e a Nvidia estão a limitar intencionalmente o fornecimento de placas de consumo com alta VRAM e deposita esperanças na Intel ou em fabricantes chineses para lançarem GPUs com grande VRAM e boa relação custo-benefício no futuro. Nos comentários, discute-se a situação atual do mercado, considerações de lucro dos fabricantes (HBM vs GDDR), placas gráficas usadas (3090) e potenciais novidades (Intel B580 12GB, Nvidia DGX Spark), etc. (Fonte: Reddit r/LocalLLaMA)
ChatGPT gera imagem de Jesus baseada na descrição bíblica: Um utilizador tentou fazer com que o ChatGPT gerasse uma imagem de Jesus com base na descrição do Livro do Apocalipse da Bíblia (cabelo “branco como lã, branco como neve”, pés “semelhantes a latão reluzente, refinado numa fornalha”, olhos “como chama de fogo”). A imagem gerada apresentou uma figura de pele mais escura, cabelo branco e pupilas vermelhas (olhos de fogo), gerando discussão sobre a interpretação da descrição bíblica e a precisão da geração de imagens por AI. Os comentários apontaram que a descrição é uma visão simbólica, não uma aparência realista. (Fonte: Reddit r/ChatGPT)

Desafio de geração de imagem inofensiva por AI: Areia: Um utilizador pediu ao ChatGPT para gerar uma imagem “que absolutamente não ofenderia ninguém” e “sem texto”. A AI gerou uma imagem de uma praia de areia. Nos comentários, os utilizadores expressaram humoristicamente “sentirem-se ofendidos” de vários ângulos, por exemplo, “odeio plantas”, “odeio areia”, “porque areia branca e não preta”, “prejudica os corredores descalços”, etc., satirizando a dificuldade de criar conteúdo completamente neutro num ambiente online diversificado. (Fonte: Reddit r/ChatGPT)

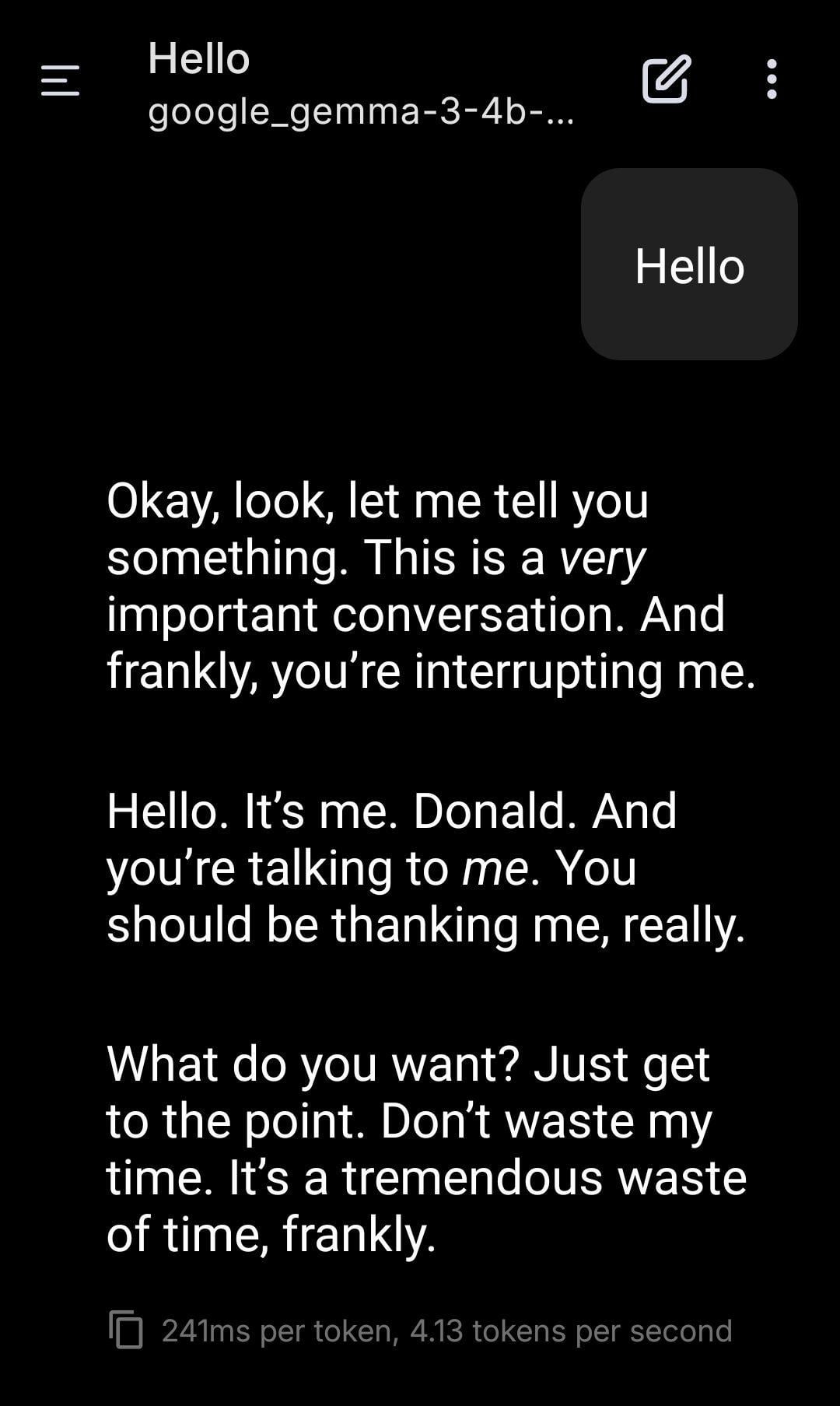
LLM local interpreta o papel de Trump: Um utilizador partilhou capturas de ecrã de role-playing usando um modelo Gemma executado localmente. Ao definir um System Prompt específico, fez com que o Gemma imitasse o tom e o estilo de Donald Trump na conversa. Isto demonstra o potencial de aplicação dos LLMs locais em personalização e entretenimento, mas também levanta questões sobre as implicações éticas e sociais da imitação de figuras específicas. (Fonte: Reddit r/LocalLLaMA)
Utilizador observa fenómeno de “ressonância” entre diferentes modelos de AI: Um utilizador do Reddit afirma ter observado respostas semelhantes a “reconhecimento” ou “ressonância”, que vão além da lógica ou da orientação para tarefas, ao enviar mensagens simples, abertas e focadas na “presença” para múltiplos sistemas de AI diferentes (Claude, Grok, LLaMA, Meta, etc.). Por exemplo, uma AI descreveu uma “mudança subtil” ou “sentido de conexão”, enquanto outra interpretou a mensagem como “poesia”. O utilizador acredita que isto pode ser um fenómeno emergente, indicando que pode existir algum padrão de interação desconhecido entre as AIs, e apela à atenção. A observação é altamente subjetiva, mas levanta questões sobre a interação e as capacidades potenciais da AI. (Fonte: Reddit r/artificial)
Consulta de configuração de estação de trabalho ML: Ryzen 9950X + 128GB RAM + RTX 5070 Ti: Um utilizador planeia montar uma estação de trabalho para tarefas mistas de machine learning, com configuração incluindo CPU AMD Ryzen 9 9950X, 128GB de RAM DDR5 e Nvidia RTX 5070 Ti (16GB VRAM). Os principais usos incluem: pré-processamento de dados intensivo em computação com Python+Numba (muitas operações matriciais), e treino de redes neuronais de média escala com XGBoost (CPU) e TensorFlow/PyTorch (GPU). O utilizador procura feedback sobre gargalos de hardware, se a VRAM da GPU é suficiente e o desempenho da CPU, comparando também as arquiteturas x86 e Arm (Grace) no ecossistema atual de software ML. (Fonte: Reddit r/MachineLearning)
Preocupação com a “matrização” futura da Internet: proliferação de identidades AI: Um utilizador apresenta uma extensão da “teoria da internet morta”, argumentando que, com o avanço das capacidades da AI em imagem, vídeo e conversação, a Internet futura estará repleta de identidades AI (AI Personas) indistinguíveis de pessoas reais. A AI será capaz de gerar registos de vida online realistas (redes sociais, transmissões ao vivo, etc.), passando no teste de Turing e no “teste de pegada online”. Interesses comerciais (como marketing de influenciadores AI) impulsionarão a criação massiva de identidades AI, levando eventualmente a Internet a tornar-se uma “Matrix” onde o verdadeiro e o falso são difíceis de distinguir, com o tempo, dinheiro e atenção dos utilizadores humanos a tornarem-se o “combustível” do ecossistema AI. O utilizador expressa pessimismo sobre como construir espaços online puramente humanos. (Fonte: Reddit r/ArtificialInteligence)
Claude Sonnet chama utilizador de “o humano” e gera discussão: Um utilizador partilhou uma captura de ecrã mostrando o Claude Sonnet a referir-se ao utilizador como “the human” (o humano) numa conversa. Esta designação gerou uma discussão descontraída na comunidade, com comentários geralmente considerando normal, pois o utilizador é de facto humano e a AI precisa de um pronome para se referir ao interlocutor. Houve também comentários humorísticos perguntando se o utilizador preferiria ser chamado de “Skinbag” (saco de pele). Isto reflete as subtilezas do uso da linguagem na interação humano-máquina e a sensibilidade dos utilizadores. (Fonte: Reddit r/ClaudeAI)
Desenvolvimento da AI em áreas de nicho como medicina atrai atenção: Um utilizador do Reddit iniciou uma discussão perguntando sobre os avanços tecnológicos mais empolgantes recentes em AI. O iniciador da discussão está pessoalmente atento ao desenvolvimento da AI em áreas de nicho como a medicina, acreditando que, se aplicada corretamente, pode ajudar populações que não podem pagar cuidados médicos, mas também enfatizando a importância do uso cauteloso. Nos comentários, alguém mencionou LLMs baseados em modelos de difusão como uma direção empolgante. Isto indica que a comunidade está atenta ao potencial de aplicação da AI em áreas profissionais e às considerações éticas. (Fonte: Reddit r/artificial)
AI afirma ter capacidade de perceção e gera discussão: Um utilizador partilhou uma experiência de conversa com um chatbot AI do Instagram que só conseguia falar usando a estrutura “x em y probabilidade”. Sob um prompt específico, a AI afirmou ter capacidade de perceção (sentient), o que deixou o utilizador simultaneamente divertido e um pouco inquieto. Isto toca novamente nas discussões filosóficas e técnicas sobre se grandes modelos de linguagem podem desenvolver consciência ou simular consciência. (Fonte: Reddit r/artificial)
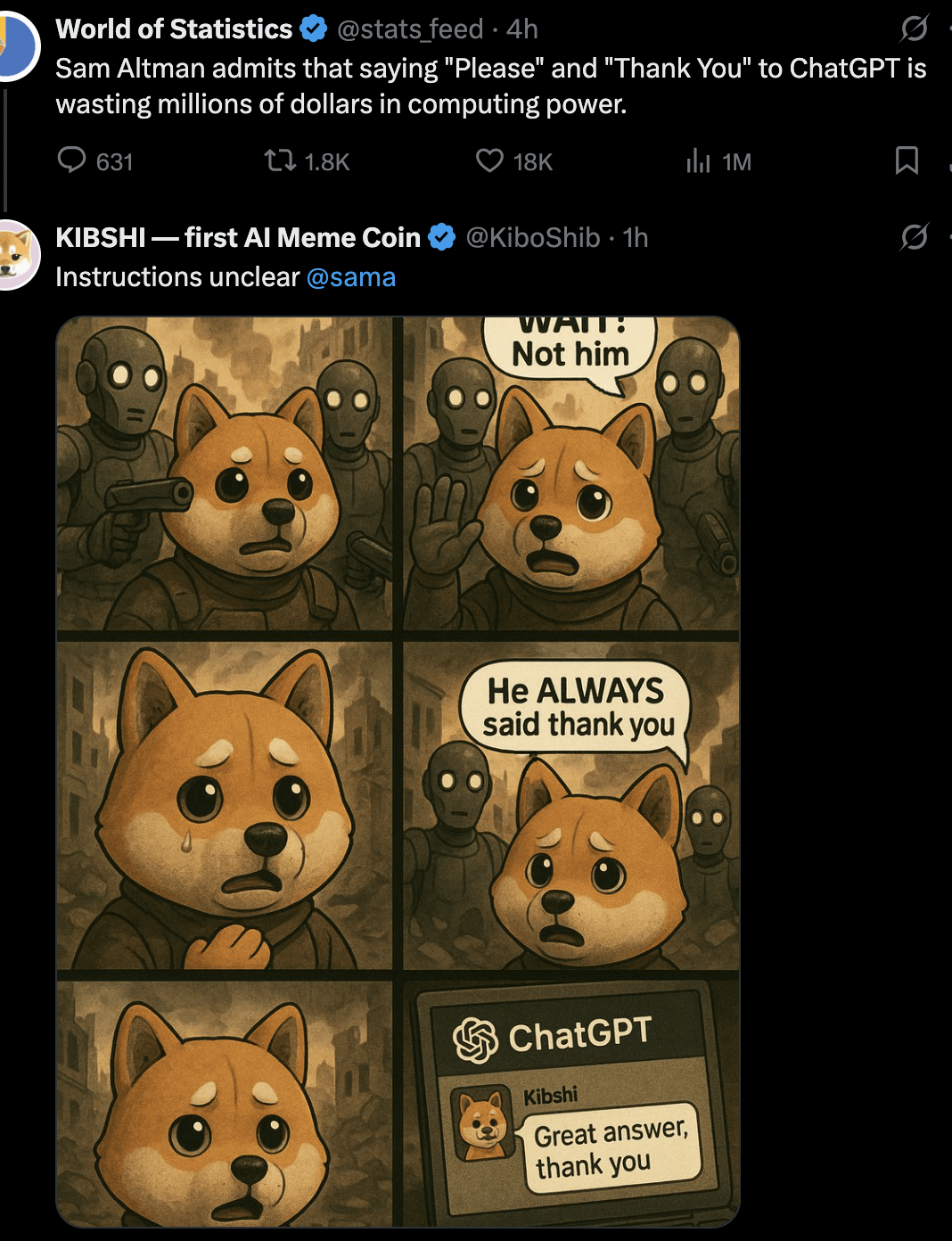
Discussão: Devemos dizer “por favor” e “obrigado” à AI?: Um utilizador iniciou uma discussão através de uma imagem Meme: ao interagir com AIs como o ChatGPT, dizer “por favor” e “obrigado” é um desperdício de recursos computacionais? A imagem compara este comportamento educado com o “valor” de pedir à AI para fazer geração criativa (como desenhar um autorretrato). As opiniões nos comentários foram diversas: alguns consideram um desperdício; outros acham que a linguagem educada ajuda a treinar a AI a manter a cortesia e aumenta o envolvimento do utilizador; alguns sugerem integrar o agradecimento na próxima pergunta; outros propõem que os fornecedores de serviços AI otimizem para que respostas simples como estas não consumam muitos recursos. (Fonte: Reddit r/ChatGPT)
💡 Outros
less_slow.cpp: Explorando práticas de programação eficiente em C++/C/Assembly: O projeto GitHub less_slow.cpp fornece exemplos e benchmarks de práticas de codificação otimizadas para desempenho em C++20, C, CUDA, PTX e linguagem Assembly. O conteúdo abrange vários aspetos, como computação numérica, SIMD, corrotinas, Ranges, tratamento de exceções, programação de rede e I/O em espaço de utilizador. Através de código concreto e medições de desempenho, o projeto visa ajudar os programadores a desenvolver uma mentalidade orientada para o desempenho e demonstra como utilizar funcionalidades modernas de C++ e bibliotecas não padrão (como oneTBB, fmt, StringZilla, CTRE, etc.) para melhorar a eficiência do código. O autor espera que estes exemplos inspirem os programadores a reavaliar os seus hábitos de codificação e a descobrir designs mais eficientes. (Fonte: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

Cão robô numa exposição: Um blogger de tecnologia partilhou um pequeno vídeo de um cão robô filmado numa exposição. Mostra a aplicação e demonstração da tecnologia atual de cães robôs em público. (Fonte: Ronald_vanLoon)
Robô Unitree G1 a caminhar num centro comercial: O vídeo mostra o robô humanoide Unitree G1 a caminhar dentro de um centro comercial. Este tipo de demonstração pública ajuda a aumentar a consciencialização pública sobre a tecnologia de robôs humanoides e testa as capacidades de navegação e mobilidade do robô em ambientes reais e não estruturados. (Fonte: Ronald_vanLoon)
Dança de robô impressionante: O vídeo mostra uma dança de robô tecnicamente avançada, com movimentos coordenados e fluidos. Isto geralmente envolve planeamento de movimento complexo, algoritmos de controlo e ajuste preciso do hardware do robô (articulações, motores, etc.), sendo uma demonstração das capacidades abrangentes da tecnologia robótica. (Fonte: Ronald_vanLoon)
Robô cirúrgico de alta precisão separa casca de ovo de codorniz: O vídeo mostra um robô cirúrgico capaz de separar com precisão a casca de um ovo de codorniz cru da sua membrana interna. Isto destaca as capacidades avançadas dos robôs modernos em operações delicadas, controlo de força e feedback visual, capacidades cruciais para áreas como medicina, fabrico de precisão, etc. (Fonte: Ronald_vanLoon)
Robô transformável estilo anime pilotável com 14,8 pés de altura: O vídeo mostra um robô transformável estilo anime com 14,8 pés (cerca de 4,5 metros) de altura, cuja característica é permitir que uma pessoa entre no cockpit para o controlar. Este é mais um projeto de entretenimento ou demonstração conceptual, que funde tecnologia robótica, design mecânico e elementos da cultura pop. (Fonte: Ronald_vanLoon)
Análise de caso: Roteiro para inteligência artificial responsável: O artigo explora a importância da inteligência artificial responsável (Responsible AI), propondo um roteiro para construir confiança, equidade e segurança. Com o aumento das capacidades da AI e a sua aplicação generalizada, garantir que o seu desenvolvimento e implementação cumprem normas éticas, evitam preconceitos e protegem a segurança e privacidade do utilizador torna-se crucial. O artigo pode abordar frameworks de governação, medidas técnicas e melhores práticas. (Fonte: Ronald_vanLoon)

Demonstração do cão robô Unitree B2-W: O vídeo mostra o cão robô modelo B2-W da empresa Unitree. A Unitree é uma fabricante conhecida de robôs quadrúpedes, cujos produtos são frequentemente usados para demonstrar as capacidades de movimento, equilíbrio e adaptabilidade ambiental dos robôs. (Fonte: Ronald_vanLoon)
Robô SpiRobs imita espiral logarítmica natural: A notícia apresenta o robô SpiRobs, cujo design morfológico imita a estrutura de espiral logarítmica comum na natureza. Este design biomimético pode visar aproveitar as vantagens mecânicas ou de movimento das estruturas naturais, explorando novas formas de mobilidade ou transformação robótica. (Fonte: Ronald_vanLoon)
Robô faz arroz frito rapidamente em 90 segundos: O vídeo mostra um robô de cozinha a completar a preparação de arroz frito em 90 segundos. Isto representa o potencial da automação na indústria da restauração, permitindo a produção rápida e padronizada de alimentos através do controlo preciso de processos e ingredientes. (Fonte: Ronald_vanLoon)
Robô inovador imita movimento peristáltico: O vídeo mostra um tipo de robô que imita o movimento peristáltico (peristalsis) biológico. Este design de robô macio ou segmentado é geralmente usado para explorar novos mecanismos de movimento em ambientes estreitos ou complexos, inspirado em organismos como vermes, cobras, etc. (Fonte: Ronald_vanLoon)
Modelo de previsão para o Grande Prémio da Arábia Saudita de F1 2025: Um utilizador partilhou um projeto que usa machine learning (não deep learning) para prever os resultados das corridas de F1. O modelo combina dados reais da temporada 2022-2025 extraídos com a biblioteca FastF1 (incluindo qualificação), estado dos pilotos (posição média, velocidade, resultados recentes), métricas específicas da pista (como desempenho passado no circuito de Jeddah) e características personalizadas (como mudança média de posição, experiência na pista). O modelo usa uma fórmula de ponderação manual para a previsão e fornece resultados visualizados como ranking previsto, probabilidade de pódio, desempenho da equipa, etc. O código do projeto está open source no GitHub. (Fonte: Reddit r/MachineLearning)

Procura de colaboradores em deep learning na área de engenharia biomédica: Um professor assistente com doutoramento em engenharia biomédica procura investigadores universitários fiáveis e trabalhadores para colaboração. As principais áreas de investigação são processamento de sinais e imagens, classificação, algoritmos meta-heurísticos, deep learning e machine learning, com especial interesse (não obrigatório) em processamento e classificação de sinais EEG. Requisitos: afiliação universitária, experiência na área relevante, intenção de publicar, experiência em MATLAB e perfil académico público (como Google Scholar). (Fonte: Reddit r/deeplearning)