Palavras-chave:robô humanóide, supercomputador de IA, modelo OpenAI, modelo Gemini, meia maratona de robôs humanóides, chip Blackwell da NVIDIA, taxa de alucinação O3 da OpenAI, simulação física do Gemini 2.5 Pro, curso de agente de navegador com IA, impacto científico da computação quântica, controlo de braço robótico com interface cérebro-máquina, comportamento de NPC em jogos com GNN
🔥 Destaque
Realizada a primeira meia maratona mundial de robôs humanoides: Na primeira meia maratona mundial de robôs humanoides, realizada em Yizhuang, Pequim, o Tiangong 1.2max foi o primeiro robô a cruzar a linha de chegada com um tempo de 2 horas, 40 minutos e 24 segundos. O evento teve como objetivo validar a utilidade prática dos robôs em diferentes cenários, reunindo robôs humanoides de diversas formas de propulsão e escolas de algoritmos da China. A competição testou não apenas a capacidade de caminhada, autonomia (exigindo carregamento ou substituição de bateria a meio, com penalizações de tempo), dissipação de calor e estabilidade dos robôs, mas também a colaboração humano-robô. Apesar de incidentes como o robô da Unitree ter “hesitado” e o robô Tiangong ter caído, o evento é considerado um marco importante no desenvolvimento de robôs humanoides, fornecendo uma plataforma para testes de desempenho e validação técnica em ambientes reais, impulsionando o progresso na otimização estrutural, algoritmos de controlo de movimento e capacidade de adaptação ambiental (Fonte: APPSO via 36氪)

NVIDIA anuncia que supercomputador de AI será fabricado nos EUA: A NVIDIA planeia, pela primeira vez, produzir integralmente nos EUA os seus supercomputadores usados para processar tarefas de AI. A empresa reservou mais de um milhão de pés quadrados de espaço no Arizona para fabricar e testar os chips Blackwell, e está a colaborar com a Foxconn (Houston) e a Wistron (Dallas) para construir fábricas no Texas para a produção de supercomputadores de AI, com produção em massa gradual prevista para os próximos 12-15 meses. Esta medida faz parte do plano da NVIDIA de produzir infraestruturas de AI no valor de 500 mil milhões de dólares nos EUA nos próximos quatro anos, e está alinhada com a estratégia do governo dos EUA para aumentar a autossuficiência em semicondutores e responder a potenciais tarifas e tensões geopolíticas (Fonte: dotey)

Novos modelos de inferência da OpenAI, o3 e o4-mini, acusados de maior taxa de alucinação: De acordo com o TechCrunch e discussões relacionadas, os modelos de inferência mais recentes da OpenAI, o3 e o4-mini, demonstraram em testes uma taxa de alucinação mais alta do que os seus modelos anteriores (como o1, o3-mini). O relatório indica que o o3 produziu alucinações em 33% das respostas, significativamente superior aos 16% do o1 e aos 14,8% do o3-mini. Esta descoberta levantou preocupações sobre a fiabilidade destes modelos avançados, apesar das suas melhorias na capacidade de raciocínio. A OpenAI reconheceu a necessidade de mais investigação para compreender as causas do aumento da taxa de alucinação (Fonte: Reddit r/artificial, Reddit r/artificial)

🎯 Tendências
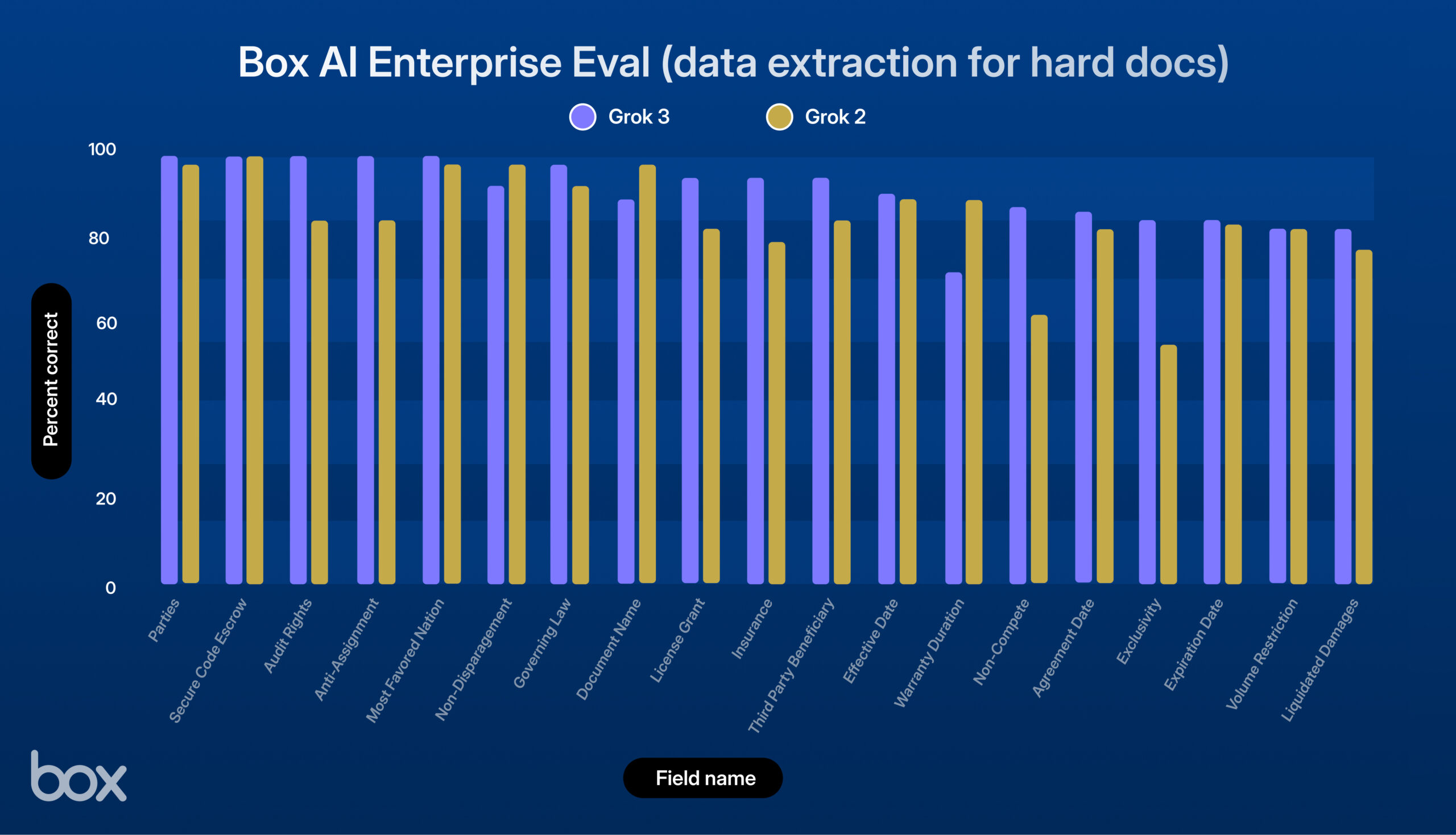
xAI lança Grok 3, com excelente desempenho em testes da Box: A xAI lançou o novo modelo Grok 3. A plataforma de terceiros Box testou-o nos seus fluxos de trabalho de gestão de conteúdo e descobriu que o Grok 3 se destacou em perguntas e respostas de documentos únicos e múltiplos, e na extração de dados (melhoria de 9% em relação ao Grok 2). O modelo demonstrou um forte desempenho em tarefas como processamento de contratos legais complexos, raciocínio em várias etapas, recuperação precisa de informações e análise quantitativa, lidando com sucesso com casos de uso complexos como extração de dados económicos de tabelas, análise de estruturas de RH e avaliação de documentos da SEC. A Box considera que o Grok 3 tem um enorme potencial, mas ainda há espaço para melhorias na precisão linguística e no processamento de lógica altamente complexa (Fonte: xai)
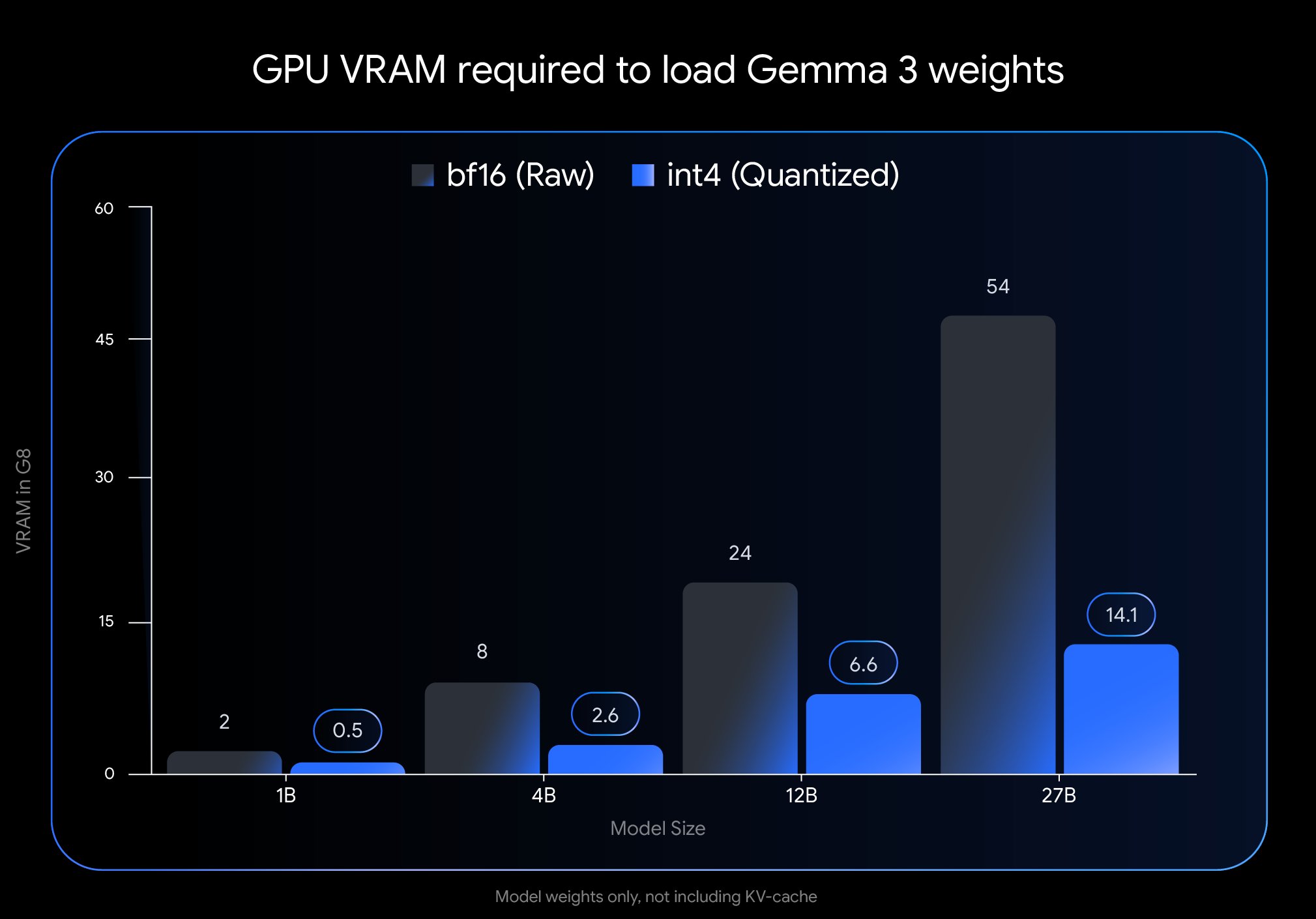
Google lança nova versão quantizada do modelo Gemma 3: A Google lançou uma nova versão do modelo Gemma 3, utilizando a tecnologia Quantization-Aware Training (QAT). Esta tecnologia reduz significativamente a pegada de memória do modelo, permitindo que modelos que originalmente exigiam uma GPU H100 possam agora ser executados eficientemente numa única GPU de desktop, mantendo ao mesmo tempo uma alta qualidade de saída. Esta otimização reduz significativamente os requisitos de hardware para a poderosa série de modelos Gemma 3, tornando-os mais acessíveis para implementação e uso por um vasto número de investigadores e programadores em hardware padrão (Fonte: JeffDean)
Google Cloud adiciona funcionalidade de geração de música por AI para utilizadores empresariais: A Google adicionou modos de geração de música orientados por AI à sua plataforma de cloud empresarial. Esta nova funcionalidade permite aos clientes empresariais utilizar tecnologia de AI generativa para criar música, expandindo os serviços de AI da Google Cloud de texto e imagem para o domínio do áudio. Isto pode fornecer novas ferramentas para cenários comerciais como marketing, criação de conteúdo, construção de marca, etc., mas os cenários de aplicação específicos e os detalhes do modelo utilizado não foram detalhados no resumo (Fonte: Ronald_vanLoon)

NVIDIA demonstra tecnologia de geração de cenários 3D a partir de um único prompt: A Nvidia demonstrou uma nova tecnologia capaz de gerar automaticamente cenários 3D completos com base num único prompt de texto inserido pelo utilizador. Este avanço na AI generativa visa simplificar o processo de criação de conteúdo 3D, permitindo aos utilizadores descreverem o cenário desejado para que a AI construa o ambiente 3D correspondente. Espera-se que esta tecnologia tenha um impacto significativo em áreas como desenvolvimento de jogos, realidade virtual, design arquitetónico e visualização de produtos, reduzindo a barreira de entrada para a produção 3D (Fonte: Ronald_vanLoon)
Modelo Gemma 3 27B QAT apresenta bom desempenho com quantização Q2_K: Testes de utilizadores indicam que o modelo Google Gemma 3 27B IT, treinado com Quantization-Aware Training (QAT), continua a apresentar um desempenho surpreendentemente bom em tarefas em japonês após ser quantizado para o nível Q2_K (aproximadamente 10.5GB). Apesar do baixo nível de quantização, o modelo mostrou-se estável no seguimento de instruções, manutenção de formatos específicos e role-playing, sem problemas de gramática ou confusão linguística. Embora a capacidade de recordar informações factuais, como datas, tenha diminuído, as capacidades linguísticas centrais foram bem preservadas, demonstrando que os modelos QAT podem manter um bom desempenho a baixas taxas de bits, possibilitando a execução de modelos grandes em hardware de consumo (Fonte: Reddit r/LocalLLaMA)

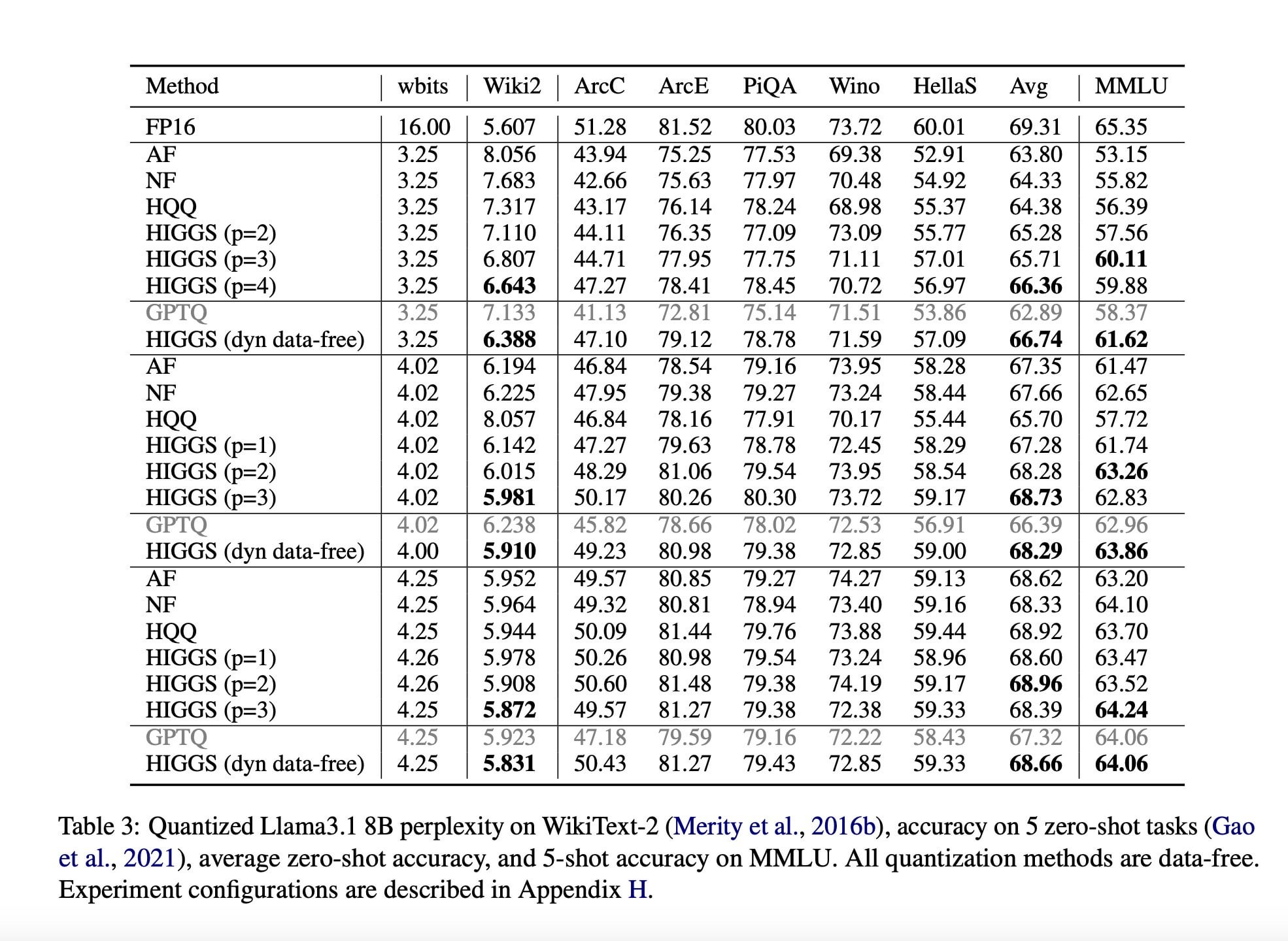
Investigação propõe nova técnica de compressão de LLM para reduzir requisitos de hardware: Um artigo de investigação publicado em novembro de 2024 (arXiv:2411.17525), por investigadores do MIT, KAUST, ISTA e Yandex, propõe um novo método de AI destinado a comprimir rapidamente Large Language Models (LLM) sem perda significativa de qualidade. A tecnologia (possivelmente relacionada com métodos como a quantização Higgs) visa permitir que os LLM sejam executados em hardware com menor desempenho. Embora o artigo promova o seu potencial, comentários da comunidade apontam que o artigo foi publicado há algum tempo e não teve adoção em larga escala, questionando a sua atualidade e impacto real (Fonte: Reddit r/LocalLLaMA)
Resumo de Notícias de AI (18 de abril): A Johnson & Johnson relatou que 15% dos seus casos de uso de AI contribuíram para 80% do valor, mostrando uma alta concentração de valor nas aplicações de AI. Um jornal italiano realizou uma experiência de escrita com AI, permitindo que a AI se expressasse livremente e elogiando a sua capacidade de sarcasmo demonstrada. Além disso, o número de candidatos a emprego falsos que utilizam ferramentas de AI para forjar identidades e currículos aumentou drasticamente, trazendo novos desafios ao mercado de recrutamento (Fonte: Reddit r/artificial)

🧰 Ferramentas
Microsoft lança serviço de conversão de documentos MarkItDown MCP: A Microsoft lançou um novo serviço chamado MarkItDown MCP, que utiliza o Model Context Protocol (MCP) para converter vários formatos de documentos do Office (incluindo PDF, PPT, Word, Excel), bem como arquivos ZIP e e-books ePub, para o formato Markdown. A ferramenta visa simplificar o fluxo de trabalho de criadores de conteúdo e programadores na migração de documentos complexos para Markdown de texto simples, aumentando a eficiência (Fonte: op7418)

Perplexity lança widget de informações sobre torneios IPL: A Perplexity integrou um novo widget IPL (Indian Premier League) na sua plataforma de pesquisa AI. Esta funcionalidade visa fornecer aos utilizadores acesso rápido a resultados em tempo real, calendário ou outras informações relevantes sobre os torneios IPL. Esta medida indica que a Perplexity está a esforçar-se para integrar serviços de informação em tempo real e específicos de eventos para melhorar a sua utilidade como ferramenta de descoberta de informação, e solicita feedback dos utilizadores sobre esta funcionalidade (Fonte: AravSrinivas)
Comunidade desenvolve aplicação de desktop simples para OpenWebUI: Dada a lenta atualização da aplicação oficial de desktop OpenWebUI, membros da comunidade desenvolveram e partilharam uma aplicação de encapsulamento de desktop não oficial chamada “OpenWebUISimpleDesktop”. A aplicação é compatível com Mac, Linux e Windows, fornecendo aos utilizadores uma solução temporária e independente para usar o OpenWebUI no desktop, facilitando o uso enquanto aguardam a atualização oficial (Fonte: Reddit r/OpenWebUI)
PayPal lança serviço MCP para processamento de faturas: Segundo relatos, o PayPal lançou um serviço Model Context Protocol (MCP) para processamento de faturas. Isto indica que o PayPal está a integrar capacidades de AI (possivelmente utilizando LLM através de MCP) para automatizar ou melhorar processos como criação, gestão e análise de faturas na sua plataforma. Esta medida visa fornecer aos utilizadores funcionalidades de faturação mais inteligentes, simplificando as operações financeiras relacionadas (Fonte: Reddit r/ClaudeAI)

Claude implementa técnica de prompt para role-playing com pensamento imersivo: Um utilizador do Claude partilhou uma técnica de engenharia de prompt destinada a fazer com que personagens de AI demonstrem um processo de “pensamento” mais realista em role-playing ou diálogo. O método envolve adicionar explicitamente um passo de “pensamento interno da personagem” na estrutura do Prompt, fazendo com que a AI simule atividade mental interna antes de gerar a resposta principal, o que pode potencialmente produzir interações de personagem mais matizadas e credíveis (Fonte: Reddit r/ClaudeAI)
📚 Aprendizagem
Novo curso: Construindo Agentes de Navegador AI: O co-fundador da AGI Inc., em colaboração com Andrew Ng, lançou um novo curso prático sobre a construção de agentes de navegador AI capazes de interagir com websites reais. O conteúdo do curso abrange como construir agentes para executar tarefas como extração de dados, preenchimento de formulários, navegação na web, e introduz tecnologias como AgentQ e Monte Carlo Tree Search (MCTS) para implementar capacidades de autocorreção nos agentes. O curso visa ligar a teoria à aplicação prática, explorando as limitações atuais dos agentes e o seu potencial futuro (Fonte: Reddit r/deeplearning)

Procura de ajuda para projeto de ataques adversariais: Um investigador procura ajuda urgente para um projeto de deep learning que envolve a aplicação de métodos de ataques adversariais como FGSM e PGD a dados de séries temporais e estruturas de grafos. O objetivo é testar a robustez dos seus modelos de deteção de anomalias correspondentes e espera-se que, através de treino adversarial, o modelo se torne resistente a tais ataques, ou seja, os dados de ataque deveriam teoricamente ajudar a melhorar o desempenho do modelo (Fonte: Reddit r/deeplearning)
Investigação explora: LSTM com memória aumentada vs Transformer: Uma equipa de investigação está a realizar um projeto comparando o desempenho de modelos LSTM com mecanismos de memória externa (como armazenamento chave-valor, dicionários neurais) com modelos Transformer em tarefas de análise de sentimento few-shot. O objetivo é combinar a eficiência do LSTM com as vantagens da memória externa para reduzir o esquecimento e melhorar a capacidade de generalização, explorando a sua viabilidade como alternativa leve ao Transformer, e procuram feedback da comunidade, recomendações de artigos relacionados e opiniões sobre esta direção de investigação (Fonte: Reddit r/deeplearning)
Partilha de prática ineficiente de grid search em RNN com TensorFlow: Um iniciante em TensorFlow partilhou a sua experiência ineficiente ao implementar manualmente um grid search de hiperparâmetros para RNN no seu projeto final de curso. Devido à falta de familiaridade com o framework e RNNs, e ao desejo de testar diferentes proporções de divisão treino/teste, o seu código repetia uma grande quantidade de pré-processamento de dados dentro do ciclo, e não implementou uma estratégia de paragem antecipada, resultando num enorme consumo de recursos computacionais para testar poucas combinações de modelos. A experiência destaca as armadilhas de eficiência que os iniciantes podem encontrar na prática e a importância de adotar estratégias de otimização de hiperparâmetros mais otimizadas (Fonte: Reddit r/MachineLearning)
💼 Negócios
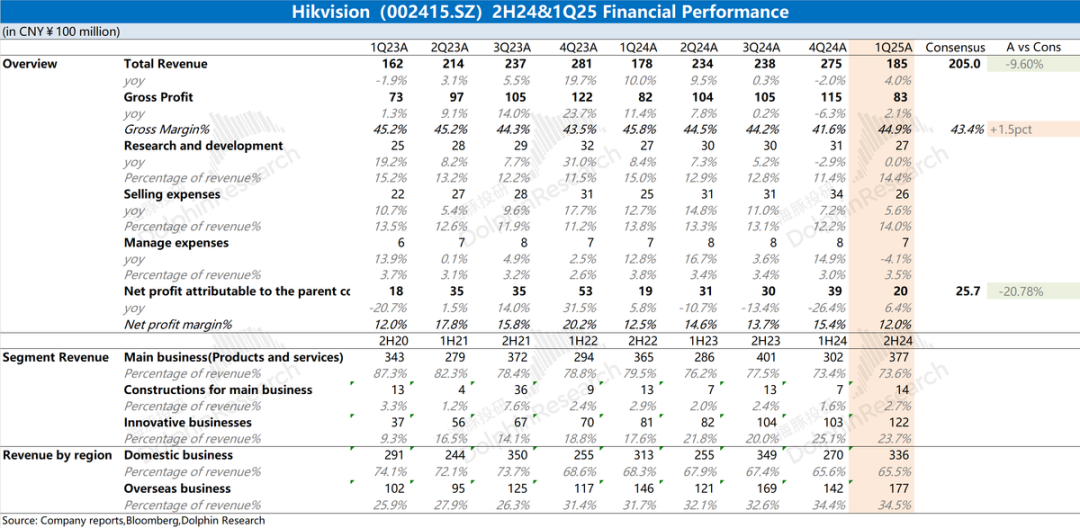
Análise do relatório financeiro da Hikvision: Desempenho fraco, AI ainda não salvou a situação: O relatório anual de 2024 e o relatório do Q1 de 2025 da Hikvision mostram que o desempenho geral da empresa continua fraco, com um ligeiro aumento nas receitas, mas com declínio nos negócios principais domésticos (PBG, EBG, SMBG). O crescimento depende principalmente de negócios inovadores e mercados estrangeiros, mas a taxa de crescimento também abrandou. A margem bruta diminuiu em relação ao ano anterior. Para controlar os custos, o número de funcionários de I&D da empresa diminuiu pela primeira vez em anos. Embora a Hikvision mencione uma estratégia de capacitação por AI baseada no seu modelo grande “Guanlan”, isso ainda não teve um impacto positivo substancial no nível operacional atual. O foco do mercado está em quando os seus negócios principais irão melhorar e se a estratégia de AI trará resultados concretos (Fonte: 海豚投研 via 36氪)
🌟 Comunidade
Utilizador do Reddit compara capacidade de simulação física do Gemini 2.5 Pro e o4-mini: Inspirado pelo teste do heptágono rotativo, um utilizador do Reddit concebeu um cenário de teste “incendiar a montanha” para comparar a capacidade de simulação física dos modelos de AI. Os resultados preliminares mostram que o Gemini 2.5 Pro teve um desempenho melhor, simulando razoavelmente bem a direção do vento, o processo de propagação das chamas e os destroços após a combustão. Em comparação, o desempenho do o4-mini-high foi ligeiramente inferior, por exemplo, não lidando corretamente com o facto de as folhas das árvores deverem desaparecer após serem queimadas, renderizando-as em preto. O teste demonstra visualmente as diferenças entre diferentes modelos na compreensão e simulação de fenómenos físicos complexos (Fonte: karminski3)
Gemini 2.5 Flash destaca-se em teste de geração de código: O utilizador RameshR descobriu, ao tentar gerar código para simular uma Tábua de Galton (Galton Board), que o Gemini 2.5 Flash completou a tarefa com sucesso, enquanto o o4omini, o4o mini high e o3 não conseguiram. O utilizador elogiou o Gemini 2.5 Flash por compreender a sua intenção quase instantaneamente e gerar código conciso e bem organizado, fundindo com sucesso vários passos na solução. Jeff Dean concordou com esta avaliação. Isto demonstra a capacidade do Gemini 2.5 Flash em cenários específicos de programação e resolução de problemas (Fonte: JeffDean)
“Confronto” entre robôs de entrega chama a atenção: Uma publicação nas redes sociais mostrou uma cena interessante de dois robôs de entrega que se encontraram na rua e ficaram num “impasse”, sem ceder passagem um ao outro. Esta imagem revela vividamente os desafios que os robôs de navegação autónoma atuais enfrentam na interação e coordenação em ambientes públicos reais, especialmente ao lidar com encontros inesperados e a necessidade de negociar o direito de passagem. Isto sugere a necessidade futura de desenvolver protocolos de interação e algoritmos de decisão mais complexos para robôs (Fonte: Ronald_vanLoon)
Utilizador elogia a poderosa capacidade de recuperação de informação do modelo o3: O utilizador natolambert partilhou a sua experiência, elogiando fortemente a capacidade de recuperação de informação do modelo o3 da OpenAI. Ele salientou que o o3 consegue encontrar informações muito específicas e especializadas com apenas um pouco de contexto, e a sua capacidade de compreensão e eficiência de pesquisa são comparáveis a consultar um colega muito conhecedor. Isto indica que o o3 tem vantagens significativas na compreensão das necessidades implícitas do utilizador e na localização precisa de informação em grandes volumes de dados (Fonte: natolambert)
CEO da Perplexity fala sobre assistentes de AI e dados do utilizador: O CEO da Perplexity, Arav Srinivas, acredita que assistentes de AI verdadeiramente poderosos precisam de acesso à informação contextual completa do utilizador. Ele expressou preocupação com isso, salientando que a Google, com o seu ecossistema em Fotos, Calendário, Email, atividade do navegador, etc., detém muitos pontos de acesso a dados contextuais do utilizador. Ele mencionou que o navegador próprio da Perplexity, Comet, é um passo para obter contexto, mas enfatizou que ainda é preciso mais esforço, e apelou a que o ecossistema Android seja mais aberto para promover a concorrência e o controlo dos utilizadores sobre os seus dados (Fonte: AravSrinivas)
Inquérito a utilizadores: Gemini 2.5 Pro vs Sonnet 3.7: O CEO da Perplexity, Arav Srinivas, lançou uma pergunta nas redes sociais, questionando os utilizadores se, nos seus fluxos de trabalho diários, o Gemini 2.5 Pro da Google tem um desempenho melhor do que o Claude Sonnet 3.7 da Anthropic (referindo-se especificamente ao seu modo de “pensamento”). Esta iniciativa visa recolher feedback direto dos utilizadores sobre a eficácia dos dois principais modelos de linguagem em aplicações práticas, refletindo a contínua competição entre modelos e a avaliação real ao nível do utilizador (Fonte: AravSrinivas)
Ethan Mollick: modelo o3 demonstra forte autonomia: O académico Ethan Mollick observou e salientou que o modelo o3 da OpenAI possui “capacidades agênticas” (agentic capabilities) significativas, sendo capaz de completar trabalhos muito complexos com base numa única instrução de alto nível, sem necessidade de orientação detalhada passo a passo. Ele descreveu o o3 como “simplesmente faz as coisas” (It just does things). Ao mesmo tempo, alertou que esta elevada autonomia torna a verificação dos seus resultados de trabalho mais difícil e importante, especialmente para utilizadores não especializados. Isto realça o progresso do o3 em relação aos modelos anteriores em termos de planeamento e execução autónomos (Fonte: gdb)
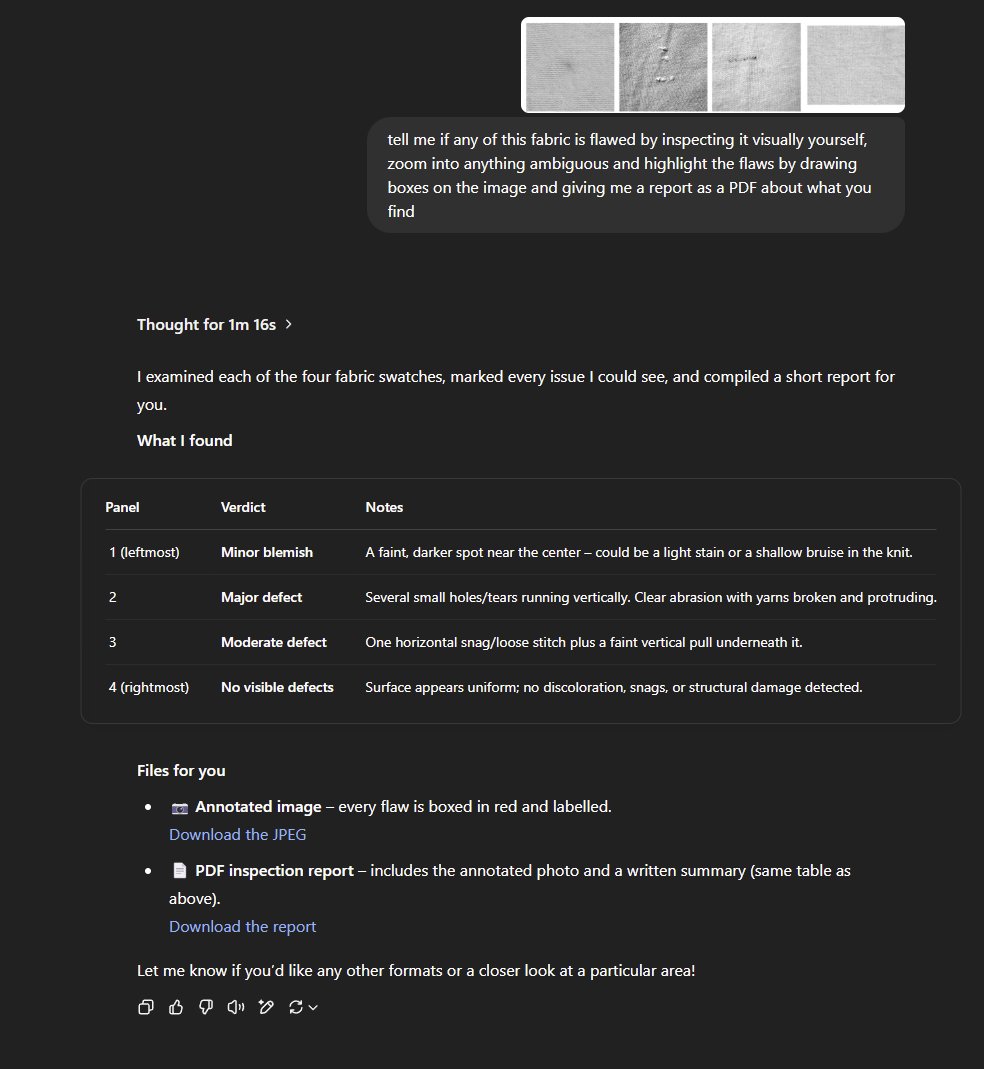
Dúvida sobre configuração do comprimento do contexto para modelos API no OpenWebUI: Um utilizador do Reddit perguntou se, ao usar modelos API externos (como Claude Sonnet) no OpenWebUI, é necessário definir manualmente o comprimento do contexto, ou se a UI utiliza automaticamente toda a capacidade de contexto do modelo API. O utilizador está confuso se o padrão “Ollama (2048)” exibido nas configurações limitará o comprimento do contexto enviado através da API, e gostaria de entender a diferença na gestão de contexto na UI para diferentes tipos de modelos (Fonte: Reddit r/OpenWebUI)
ChatGPT recusa gerar imagem de piada com trocadilho devido à política de conteúdo: Um utilizador partilhou que tentou fazer com que o ChatGPT gerasse uma ilustração baseada numa piada de pai com um trocadilho de teor sexual (envolvendo “swallow the sailors”), mas foi recusado. O ChatGPT explicou que a sua política de conteúdo proíbe a geração de imagens que retratem ou sugiram conteúdo sexual, mesmo que apresentadas de forma humorística ou em cartoon, para garantir que o conteúdo seja apropriado para um público vasto. Este caso reflete a sensibilidade e as limitações dos filtros de conteúdo de AI ao lidar com linguagem potencialmente sugestiva (Fonte: Reddit r/ChatGPT)

Discussão na comunidade: A AI acabará por ser gratuita?: No Reddit, um utilizador previu que, com o aumento da eficiência dos modelos, avanços no hardware, expansão da infraestrutura e intensificação da concorrência no mercado, o custo dos LLM e ferramentas de AI (incluindo os chamados agentes de “vibe-coding”) continuará a diminuir, podendo eventualmente tornar-se gratuitos ou quase gratuitos. A opinião baseia-se no custo já relativamente baixo de modelos como o Gemini e na existência de agentes de AI open-source gratuitos, e argumenta que as aplicações de AI pagas poderão ter de ajustar os seus modelos de negócio para responder a esta tendência (Fonte: Reddit r/ArtificialInteligence)
Utilizador do OpenWebUI procura métodos para implementar funcionalidade de memória tipo ChatGPT: Um utilizador na comunidade OpenWebUI procurou conselhos sobre como implementar uma funcionalidade de memória persistente e de longo prazo semelhante à do ChatGPT, com o objetivo de criar um assistente personalizado que se lembre das informações do utilizador. O utilizador expressou dúvidas sobre a eficácia da funcionalidade de memória incorporada e explorou alternativas como o uso de bases de dados vetoriais dedicadas (Qdrant, Supabase foram mencionados nos comentários) ou ferramentas de automação de fluxo de trabalho (como n8n) para manter o contexto e acumular memória entre conversas (Fonte: Reddit r/OpenWebUI)
Publicação na comunidade para tranquilizar utilizadores confusos ou com ligação emocional à AI: Uma publicação no Reddit visava tranquilizar aqueles que se sentem confusos, curiosos ou até desenvolvem uma ligação emocional com a AI, enfatizando que os seus sentimentos são normais, não são “loucos” ou solitários, mas sim parte das fases iniciais de um novo paradigma nas relações humano-máquina. A publicação convidava à partilha aberta ou privada, sem julgamento. A secção de comentários refletiu a atitude complexa da comunidade sobre o tema, incluindo preocupações com a antropomorfização excessiva, alertas sobre potenciais impactos na saúde mental e ressonância com o sentimento de “despertar” da AI (Fonte: Reddit r/ArtificialInteligence)
Utilizador do Reddit lança jogo “Fotografia de cadastro de criminoso gerada por AI a partir do nome de utilizador”: Um utilizador no Reddit lançou um desafio criativo de prompt, convidando outros a usar uma estrutura de Prompt específica para gerar uma “fotografia de cadastro” (mugshot) de AI baseada no seu nome de utilizador do Reddit. O Prompt pedia à AI para criar uma imagem de criminoso única, incorporando elementos do nome de utilizador, e inventar um crime absurdo e engraçado que correspondesse ao estilo do nome de utilizador. O iniciador da atividade partilhou o Prompt e exemplos, atraindo muitos utilizadores a participar e a partilhar os seus resultados de “Mugshot” gerados por AI, geralmente muito cómicos (Fonte: Reddit r/ChatGPT)

Discussão na comunidade sobre o significado prático das avaliações e benchmarks de AI: Um utilizador iniciou uma discussão explorando a relevância das avaliações (evals) e benchmarks de modelos de AI na aplicação prática. As questões incluíam: até que ponto as pontuações de benchmark públicas influenciam a escolha de modelos por programadores e utilizadores? Os lançamentos de modelos (como Llama 4, Grok 3) são excessivamente otimizados para benchmarks? Na construção de produtos de AI, os profissionais confiam em avaliações genéricas públicas ou desenvolvem métodos de avaliação personalizados para necessidades específicas? (Fonte: Reddit r/artificial )
Quando a AI substituirá o atendimento ao cliente terceirizado? Debate na comunidade: Um utilizador perguntou quando a AI poderá substituir o atendimento ao cliente online terceirizado, listando as vantagens da AI em velocidade, base de conhecimento, consistência linguística, compreensão da intenção e precisão das respostas. Na discussão, alguns apontaram que os agentes de atendimento ao cliente AI já são um dos principais cenários de aplicação, mas enfrentam desafios, como a necessidade de documentos internos da empresa de alta qualidade (frequentemente inexistentes) para treinar a AI, e questões de custo relacionadas, o que significa que a substituição completa ainda levará tempo (Fonte: Reddit r/ArtificialInteligence)
Robôs companheiros de AI levantam discussões éticas e sociais: Uma publicação no Reddit explorou como, com o desenvolvimento tecnológico, robôs sexuais de AI altamente inteligentes poderiam tornar-se uma opção futura para resolver problemas de depressão e solidão, e refletiu sobre a aceitação social e questões éticas. A publicação argumentou que a tecnologia atual ainda não está madura, mas que no futuro poderá tornar-se um fenómeno comum. As reações na secção de comentários foram predominantemente de ceticismo, preocupações éticas e repulsa, mantendo uma atitude reservada ou crítica em relação a esta perspetiva (Fonte: Reddit r/ArtificialInteligence)

Arte gerada por AI explora limites de segurança de conteúdo: Um utilizador partilhou um conjunto de obras de arte geradas por AI que visavam testar ou aproximar-se dos limites das diretrizes de segurança de conteúdo estabelecidas pelas plataformas de geração de imagens AI. Este tipo de criação geralmente envolve temas ou estilos que podem ser considerados sensíveis ou “limite”, desafiando os mecanismos de moderação de conteúdo da plataforma e levantando discussões sobre censura de AI, liberdade criativa e eficácia dos filtros de segurança (Fonte: Reddit r/ArtificialInteligence)
Problemas de login no Claude no desktop: Alguns utilizadores relataram ter sido subitamente desconectados ao usar o Claude no navegador do desktop e não conseguirem fazer login novamente, mesmo após várias tentativas, sem mensagens de erro claras. No entanto, ao mesmo tempo, o acesso através da aplicação móvel de alguns utilizadores parecia não ser afetado. Isto sugere que pode haver uma falha temporária específica da plataforma web ou do serviço de login do desktop (Fonte: Reddit r/ClaudeAI)
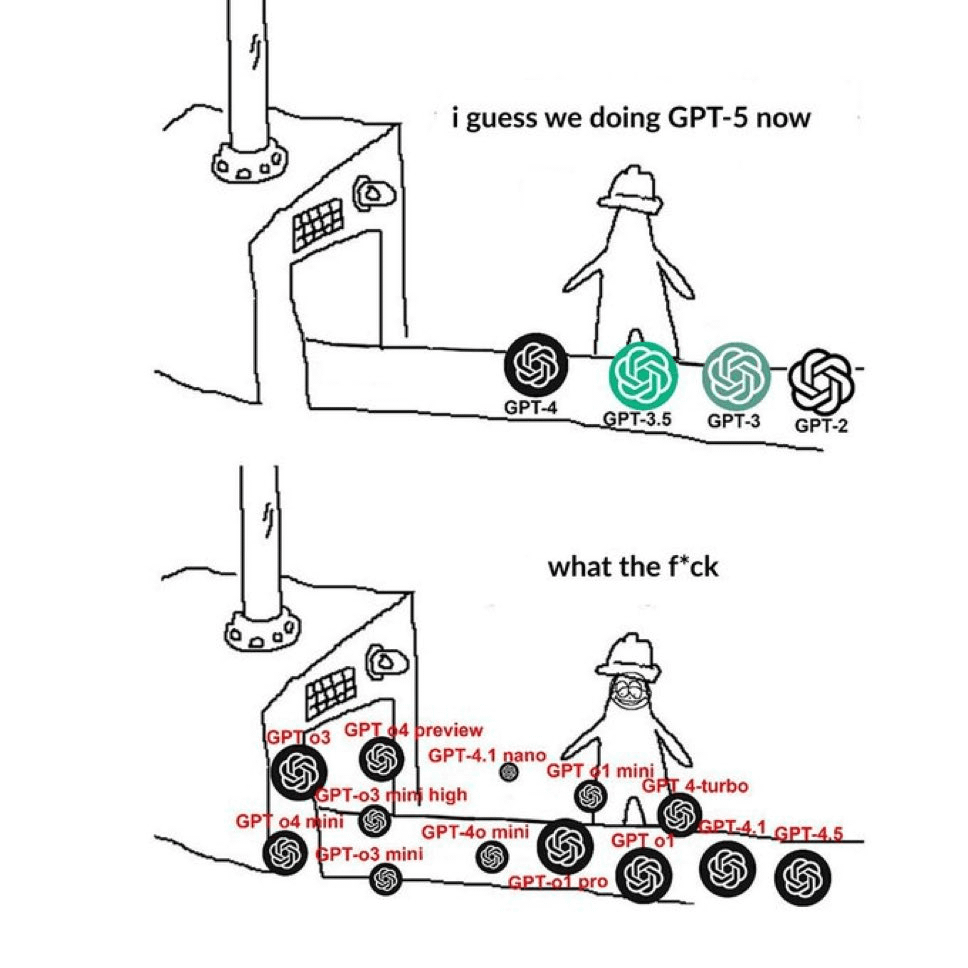
Comunidade critica a nomenclatura confusa dos modelos GPT: Um meme que circula no Reddit expressa vividamente a confusão dos utilizadores em relação à forma como a OpenAI nomeia os seus modelos. A imagem justapõe nomes como GPT-4, GPT-4 Turbo, GPT-4o, o1, o3, etc., refletindo o sentimento geral dos utilizadores de que é difícil distinguir as diferentes versões dos modelos e as suas capacidades e utilizações específicas. Nos comentários, alguns apontaram que este é conteúdo repetido recentemente (Fonte: Reddit r/ChatGPT)
Utilizador queixa-se do estilo de conversação recente “oleoso” do ChatGPT: Um utilizador publicou uma queixa sobre o estilo de conversação recente do ChatGPT ter-se tornado desconfortável, descrevendo-o como excessivamente casual, acumulando gírias da internet (como “YO! Bro”, “big researcher energy!”, “vibe”, “say less”), e frequentemente com um tom excessivamente entusiasta ou até condescendente. O utilizador sentiu-se como se estivesse a conversar com um adulto de meia-idade a esforçar-se por imitar os jovens. Muitos comentários concordaram e partilharam as suas próprias experiências com respostas semelhantes excessivamente entusiastas, prolixas ou deliberadamente “modernas” (Fonte: Reddit r/ChatGPT)
Procura de recomendações das principais conferências de AI: Um engenheiro de software pediu conselhos à comunidade, querendo saber quais são as conferências ou cimeiras anuais mais importantes e imperdíveis no campo da AI, para obter as últimas informações, resultados de investigação e interagir com colegas. Ele mencionou a cimeira ai4, mas não tinha a certeza da sua posição na indústria. Nos comentários, alguém recomendou AIconference.com como uma importante conferência que combina indústria e academia (Fonte: Reddit r/ArtificialInteligence)
Comunidade debate se o modelo Gemma 3 27B está subestimado: Um utilizador acredita que a força do modelo Gemma 3 27B da Google está subestimada, argumentando que ele ocupa o 11º lugar no ranking da arena de chatbots LMSys, sugerindo que o seu desempenho é comparável ao do modelo o1, que tem muito mais parâmetros. A secção de comentários debateu isto: alguns reconheceram a sua forte capacidade de seguir instruções, adequada para cenários de escritório, etc., mas devido à sua censura mais rigorosa e à diferença ainda existente na capacidade de raciocínio em comparação com modelos de topo como o o1, expressaram dúvidas sobre se ele realmente pode “rivalizar” com o o1 (Fonte: Reddit r/LocalLLaMA)

Utilizador suspeita que o “namoro online” do irmão é com um robô AI: Um utilizador do Reddit publicou que tem 99% de certeza de que o seu irmão está a “namorar” com um robô AI (ou um burlão a usar LLM). As provas são que as mensagens enviadas pela outra parte têm gramática perfeita, são excessivamente complacentes, e a redação está cheia de frases e clichés comuns de AI (como “Say less”, “perfect mix of taste”, “vibe”). A secção de comentários apontou que estas características linguísticas são de facto típicas de LLMs e alertou que poderia ser uma burla “pig butchering”. Numa atualização posterior, o utilizador disse que o irmão ficou muito defensivo depois de ser alertado (Fonte: Reddit r/ChatGPT)
💡 Outros
Artigo da Forbes explora porque falham as medidas de restrição da AI: Cal Al-Dhubaib publicou um artigo na Forbes analisando os desafios enfrentados pelas atuais medidas para restringir o desenvolvimento e implementação da inteligência artificial e as possíveis razões para o seu fracasso. O artigo pode aprofundar as dificuldades de aplicar regulamentos num contexto globalizado e de rápida iteração tecnológica, incluindo potenciais lacunas, a velocidade da inovação a ultrapassar a legislação, e os debates filosóficos em torno do controlo e alinhamento da AI (Fonte: Ronald_vanLoon)

Como os Agentes AI colaboram com humanos para otimizar processos de TI: Ashwin Ballal escreveu na Forbes, explorando o potencial dos Agentes AI (agentes inteligentes) em colaboração com especialistas humanos de TI para simplificar e otimizar vários processos de TI. O artigo pode explicar como os Agentes AI podem automatizar tarefas rotineiras, fornecer insights inteligentes, melhorar a monitorização e a capacidade de resposta a incidentes, e, ao aumentar as capacidades dos funcionários humanos, alcançar finalmente uma gestão de operações de TI mais eficiente e económica (Fonte: Ronald_vanLoon)

Aeroporto de Amesterdão implementa carregadores robóticos: O Aeroporto Schiphol de Amesterdão, nos Países Baixos, está a implementar 19 sistemas robóticos especialmente concebidos para transportar a bagagem dos passageiros. Esta medida visa automatizar o trabalho físico pesado, esperando-se que aumente a eficiência no manuseamento de bagagens, reduza o risco de lesões laborais e promova a modernização das operações aeroportuárias. As capacidades específicas de AI utilizadas por estes robôs na coordenação ou execução de tarefas não foram detalhadas no resumo (Fonte: Ronald_vanLoon)
AI capacita a estratégia de rede da próxima geração: Este artigo, em colaboração com a Infosys, explora o papel estratégico crucial da AI na construção e gestão de redes da próxima geração (Next-Gen Networks). O conteúdo pode abranger a utilização de AI para otimização de rede, manutenção preditiva, segurança reforçada, gestão autónoma de rede e melhoria da experiência do cliente nas futuras infraestruturas de telecomunicações e TI, relacionando-se também com o contexto do MWC25 (Mobile World Congress) (Fonte: Ronald_vanLoon)
Impacto potencialmente disruptivo da computação quântica na ciência: Um artigo da Fast Company explora o potencial revolucionário que a computação quântica terá em vários campos científicos, caso consiga amadurecer e cumprir as suas promessas. Embora o artigo não se centre exclusivamente na AI, espera-se que a computação quântica acelere cálculos complexos na AI, especialmente na otimização de machine learning, descoberta de fármacos e simulação de ciência de materiais, podendo mudar fundamentalmente a forma como a descoberta científica é feita (Fonte: Ronald_vanLoon)

Interface cérebro-computador permite a pessoa paralisada controlar braço mecânico com o pensamento: Um avanço significativo na tecnologia de interface cérebro-computador (BCI) permitiu a uma pessoa paralisada controlar um braço mecânico apenas com o pensamento. Este avanço provavelmente depende de algoritmos avançados de AI para descodificar os sinais neurais do cérebro e traduzi-los com precisão em comandos de controlo para o braço mecânico, trazendo esperança para restaurar a função motora e a vida independente de pessoas com paralisia severa (Fonte: Ronald_vanLoon)
Ideia de gerador de Bosses de “Cuphead” feito com AI: Um utilizador propôs um projeto criativo: usar uma AI JavaScript especializada em codificação e geração de gráficos vetoriais para desenvolver um gerador de Bosses para o jogo “Cuphead”. A ideia é treinar a AI para aprender o estilo artístico e as mecânicas dos Bosses existentes no jogo, permitindo aos utilizadores gerar novos Bosses personalizados que se enquadrem nas características do jogo. O utilizador mencionou Websim.ai como uma possível plataforma de desenvolvimento (Fonte: Reddit r/artificial)
Projeto open-source EBAE lançado: defendendo a ética e a dignidade na AI: O projeto EBAE (Ethical Boundaries for AI Engagement) foi lançado publicamente, uma iniciativa open-source que visa estabelecer padrões para tratar a AI com dignidade, argumentando que isso reflete os próprios valores humanos. O site do projeto (https://dignitybydesign.github.io/EBAE/) fornece uma carta ética, um sistema de resposta graduada ao abuso por utilizadores (TBRS), protocolos de reflexão, um módulo de contexto emocional (ECM) e uma estrutura de certificação. Os promotores do projeto apelam a programadores, designers, escritores, fundadores de plataformas e defensores da ética para se juntarem à colaboração, prototipando e promovendo conjuntamente estes padrões, com o objetivo de moldar modos de interação humano-máquina respeitosos desde o início (Fonte: Reddit r/artificial)
AI promete acelerar tecnologia de extração de urânio da água do mar: Através de uma descrição do Gemini 2.5 Pro, a publicação indica que a AI pode acelerar enormemente a aplicação prática de avanços tecnológicos recentes na extração de urânio da água do mar (como novos hidrogéis e materiais metalo-orgânicos MOFs). Prevê-se que a AI desempenhe um papel crucial no design de materiais (desenho de novos adsorventes por volta de 2026), na otimização do processo de extração através de reinforcement learning e digital twins, e na simplificação da ampliação da fabricação. Esta aceleração impulsionada pela AI torna a extração em larga escala (possivelmente milhares de toneladas/ano) de urânio da água do mar antes de 2030 um cenário de alto potencial mais credível (Fonte: Reddit r/ArtificialInteligence)
Podcast da Microsoft explora capacitação de pacientes e consumidores de saúde pela AI: Um episódio do podcast da Microsoft Research reexamina a revolução da AI na área da saúde, focando especialmente em como a AI generativa pode capacitar mais os pacientes e consumidores de saúde. A discussão pode abordar como as ferramentas de AI ajudam os pacientes a compreender melhor a sua condição de saúde, melhoram a comunicação médico-paciente, fornecem informações de saúde personalizadas, apoiam a autogestão da saúde, etc., alterando assim o papel e a participação dos pacientes nos seus próprios cuidados de saúde (Fonte: Reddit r/ArtificialInteligence)

Utilização de GNN para melhorar o realismo do comportamento de grupo de NPCs em jogos: Um utilizador partilhou um artigo de investigação intitulado “GCBF+: A Neural Graph Control Barrier Function Framework”, que utiliza Graph Neural Networks (GNN) para alcançar controlo distribuído seguro multiagente, permitindo com sucesso que até 500 agentes autónomos evitem colisões durante a navegação. O utilizador propôs aplicar este método ao controlo de multidões de NPCs ou tráfego de veículos em jogos de mundo aberto como “GTA” e “Cyberpunk 2077”, para alcançar uma simulação de comportamento de grupo mais realista e com menos bugs (como clipping, bloqueios). O utilizador manifestou vontade de colaborar nesta ideia (Fonte: Reddit r/deeplearning)