
Palavras-chave:Desenvolvimento de IA, Grok 3, Gemma 3, Aplicações de IA, Mudança de paradigma no desenvolvimento de IA, API xAI Grok 3, Google Gemma 3 QAT, Avaliação VideoGameBench IA, Aceleração da descoberta molecular com IA, Aprendizagem federada em imagens médicas, Agente de conhecimento LlamaIndex, Tecnologia de autorreparação de código com IA
🔥 Foco
Mudança de paradigma no desenvolvimento de IA: De perseguir classificações à criação de valor: O blog do investigador da OpenAI, Yao Shunyu, gerou discussão, propondo que o desenvolvimento da IA entrou na sua segunda fase. A primeira fase focou-se na inovação de algoritmos e na obtenção de pontuações elevadas em benchmarks (como AlphaGo, GPT-4), conseguindo avanços na generalização através da combinação de pré-treino em larga escala (fornecendo conhecimento prévio) e aprendizagem por reforço (RL), introduzindo também o conceito de ‘raciocínio como ação’. No entanto, ele argumenta que os benefícios marginais de continuar a perseguir classificações estão a diminuir. A segunda fase deve focar-se na definição de problemas com valor prático de aplicação, no desenvolvimento de métodos de avaliação mais próximos do mundo real, pensando como um gestor de produto, e utilizando verdadeiramente a IA para criar valor para o utilizador e valor social, em vez de apenas perseguir a melhoria de métricas. Isto marca uma mudança de mentalidade no campo da IA, passando de uma exploração predominantemente técnica para uma focada na implementação de aplicações e na realização de valor (Fonte: dotey)
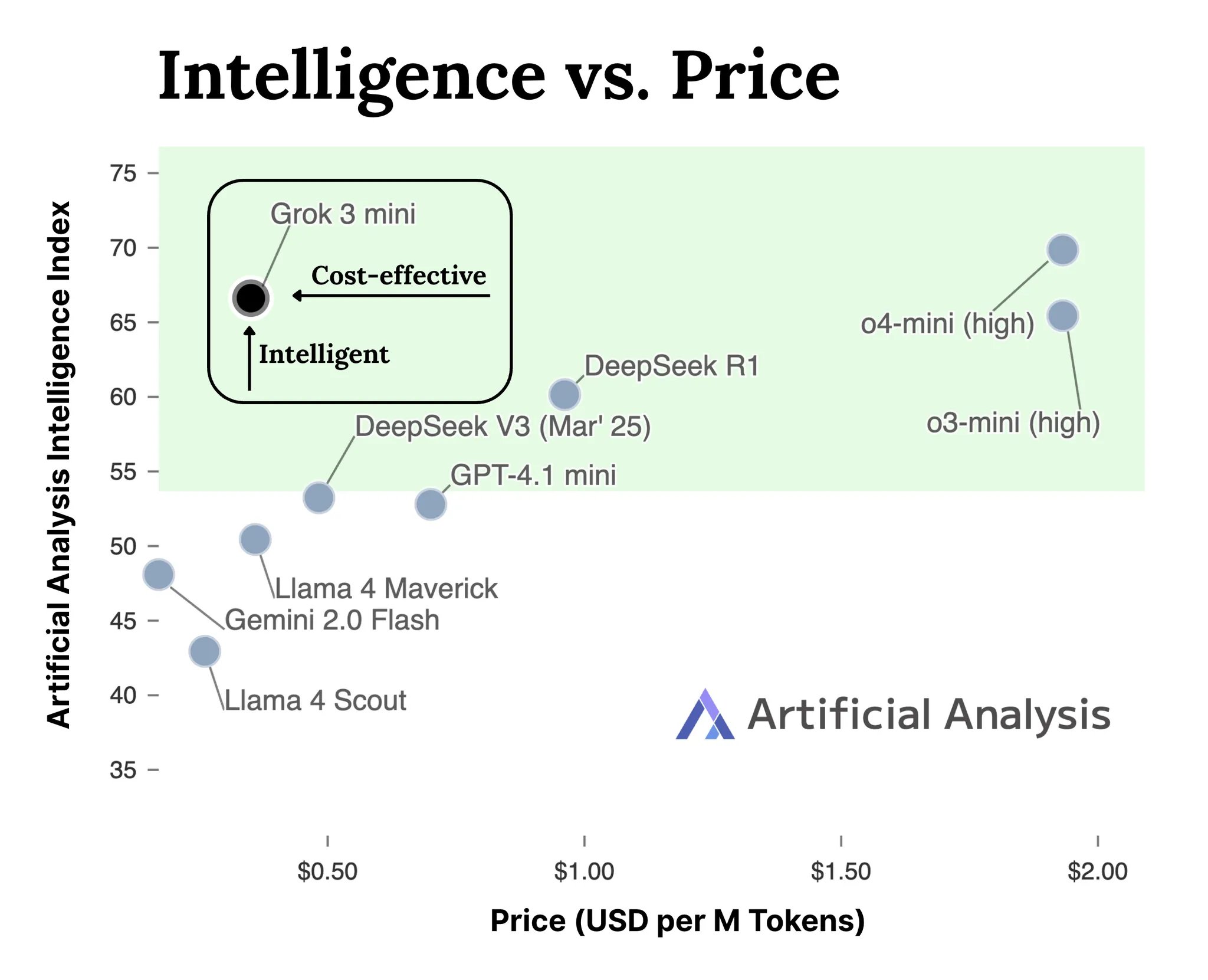
xAI lança API para a série de modelos Grok 3: A xAI lançou oficialmente a interface API para a sua série de modelos Grok 3 (docs.x.ai), disponibilizando os seus modelos mais recentes aos programadores. A série inclui o Grok 3 Mini e o Grok 3. Segundo a xAI, o Grok 3 Mini demonstra capacidades de raciocínio superiores mantendo um custo baixo (alegadamente 5 vezes inferior a modelos de inferência comparáveis); enquanto o Grok 3 se posiciona como um poderoso modelo não-inferencial (possivelmente referindo-se a tarefas intensivas em conhecimento), destacando-se em domínios como direito, finanças e medicina, que exigem conhecimento do mundo real. Esta medida marca a entrada da xAI na competição do mercado de APIs de modelos de IA, oferecendo novas opções aos programadores (Fonte: grok, grok)
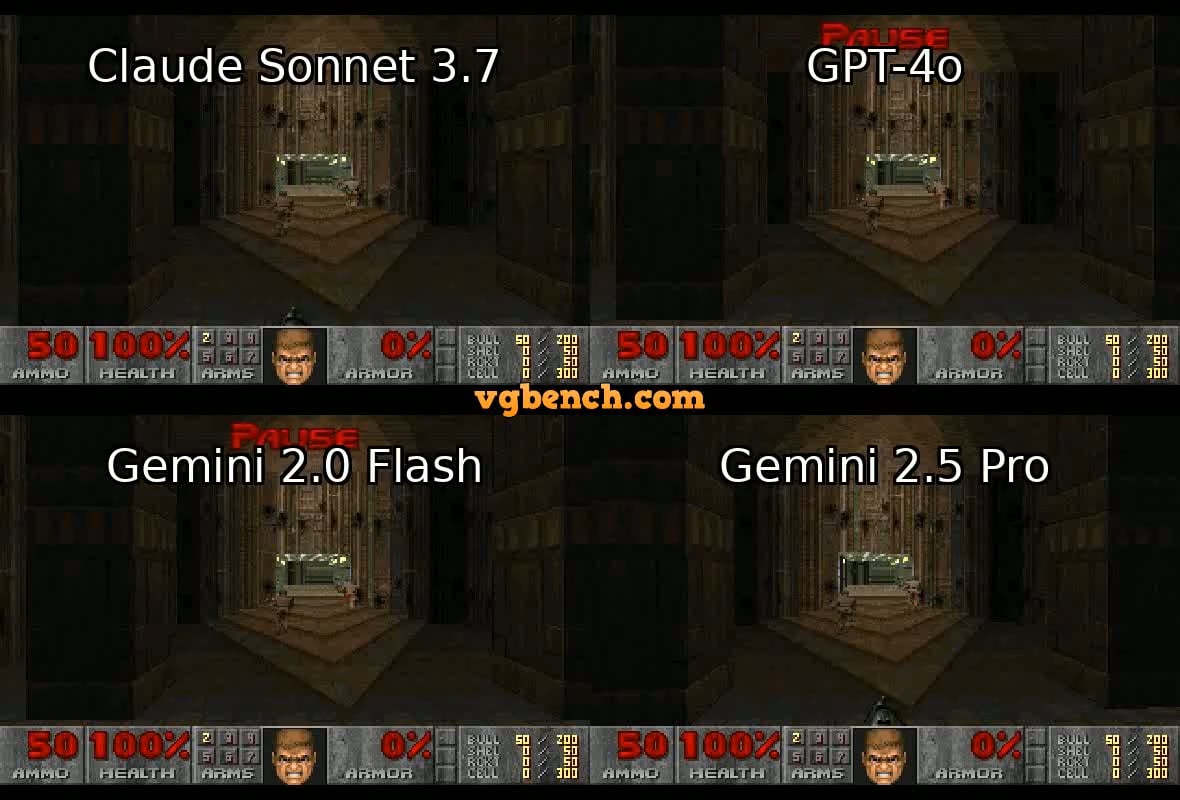
VideoGameBench: Avaliação da capacidade de agentes de IA com jogos clássicos: Investigadores lançaram uma versão de pré-visualização do benchmark VideoGameBench, destinado a avaliar a capacidade de modelos de linguagem visual (VLM) na conclusão de tarefas em tempo real em 20 videojogos clássicos (como Doom II). Testes preliminares mostram que os principais modelos, incluindo GPT-4o, Claude Sonnet 3.7 e Gemini 2.5 Pro, apresentam desempenhos variados em Doom II, mas nenhum conseguiu passar do primeiro nível. Isto indica que, apesar da forte capacidade dos modelos em muitas tarefas, ainda enfrentam desafios em ambientes dinâmicos complexos que exigem perceção, tomada de decisão e ação em tempo real. Este benchmark fornece uma nova ferramenta para medir e impulsionar o progresso de agentes de IA em ambientes interativos (Fonte: Reddit r/LocalLLaMA)
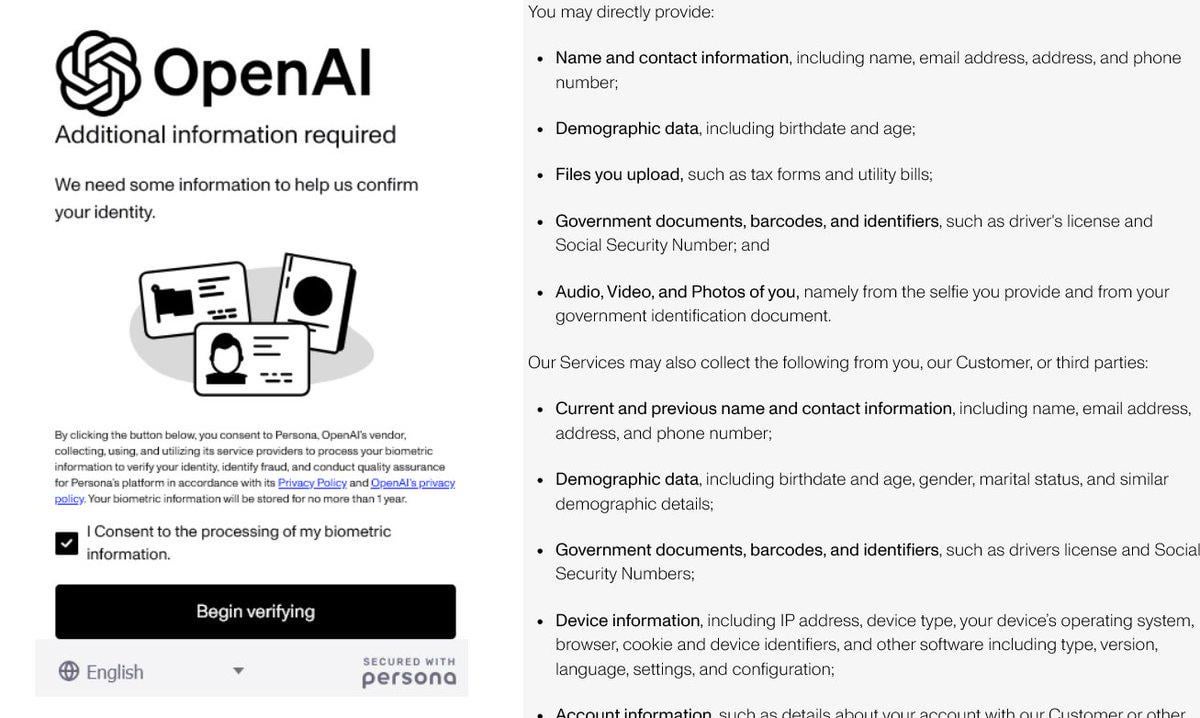
Reforço da verificação de identidade pela OpenAI gera controvérsia: Foi reportado que a OpenAI está a exigir que os utilizadores forneçam provas de identidade detalhadas (como passaporte, declaração de impostos, fatura de serviços públicos) para aceder a alguns dos seus modelos avançados (especialmente aqueles com fortes capacidades de raciocínio, como o o3). Esta medida gerou forte reação na comunidade, com os utilizadores a expressarem preocupações sobre a privacidade e o aumento da barreira de acesso. Embora a OpenAI possa ter motivos relacionados com segurança, conformidade ou gestão de recursos, esta exigência rigorosa de verificação contrasta com a sua imagem aberta e pode levar os utilizadores a procurar alternativas com melhor proteção de privacidade ou mais fáceis de aceder, especialmente modelos locais (Fonte: Reddit r/LocalLLaMA)
IA acelera descoberta de moléculas: Simulando milhões de anos de evolução natural: Discussões nas redes sociais mencionam que a inteligência artificial pode projetar uma molécula em dias, algo que poderia levar 500 milhões de anos a evoluir naturalmente. Embora os detalhes específicos careçam de verificação, isto realça o enorme potencial da IA na aceleração da descoberta científica, especialmente nas áreas da química e biologia. A IA pode explorar vastos espaços químicos e prever propriedades moleculares a uma velocidade muito superior aos métodos experimentais tradicionais e à evolução natural, prometendo avanços disruptivos no desenvolvimento de fármacos, ciência de materiais e outros campos (Fonte: Ronald_vanLoon)
🎯 Tendências
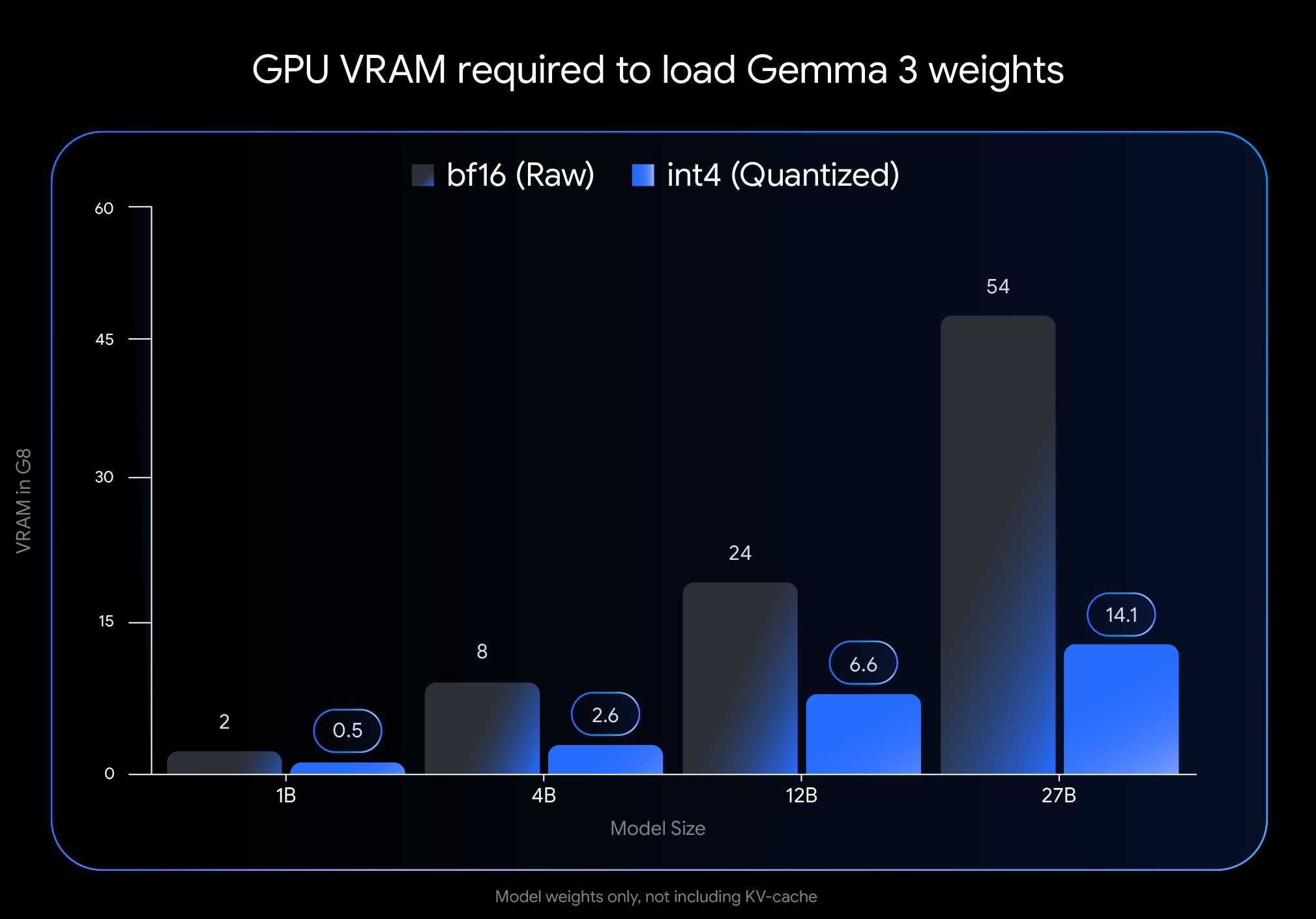
Google lança versão QAT do Gemma 3, reduzindo significativamente a barreira de implementação: A Google DeepMind lançou versões do modelo Gemma 3 que passaram por Quantization-Aware Training (QAT). A tecnologia QAT visa comprimir drasticamente o tamanho do modelo, mantendo ao máximo o desempenho do modelo original. Por exemplo, o tamanho do modelo Gemma 3 27B foi reduzido de 54GB (bf16) para aproximadamente 14.1GB (int4), permitindo que modelos de ponta, que antes exigiam GPUs de cloud de alta gama, possam agora ser executados em GPUs de desktop de nível consumidor (como a RTX 3090). A Google já lançou checkpoints QAT não quantizados e em vários formatos (MLX, GGUF), e colaborou com ferramentas da comunidade como Ollama, LM Studio e llama.cpp para garantir que os programadores possam usá-los convenientemente em várias plataformas, impulsionando enormemente a popularização de modelos open source de alto desempenho (Fonte: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR divulga resultados de investigação em perceção, mantendo a rota open source: A Meta FAIR divulgou vários novos resultados de investigação em inteligência artificial avançada (AMI), com progressos notáveis na área da perceção, incluindo o lançamento de um codificador visual em larga escala, o Meta Perception Encoder. Yann LeCun enfatizou que estes resultados serão open source. Isto demonstra o investimento contínuo da Meta na investigação fundamental em IA e o seu compromisso em partilhar os seus progressos através do open source, impulsionando o desenvolvimento de todo o campo. Ferramentas como o codificador visual lançado beneficiarão uma comunidade mais ampla de investigadores e programadores (Fonte: ylecun)
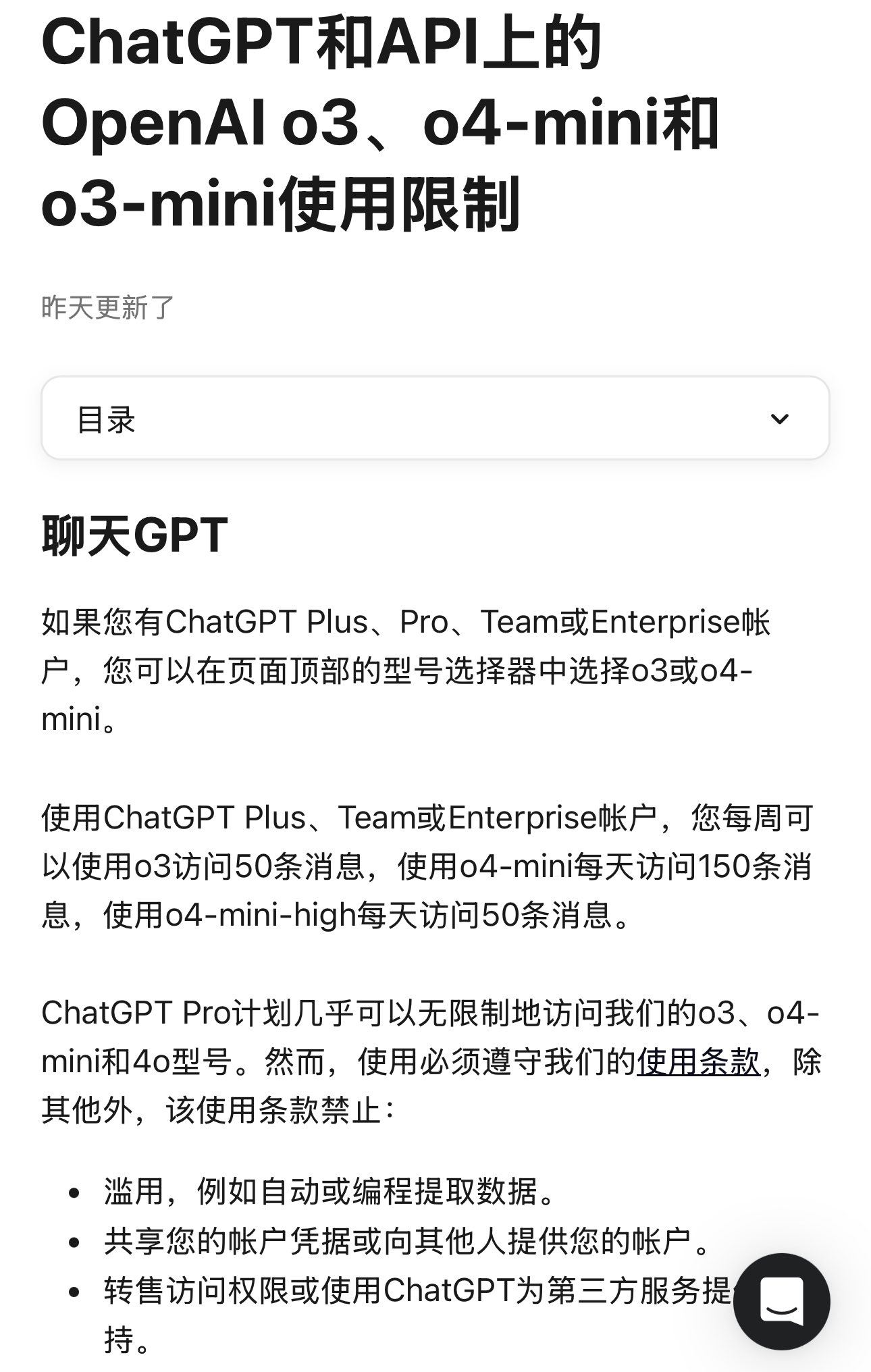
OpenAI clarifica limites de utilização dos modelos: A OpenAI especificou os limites de utilização dos seus modelos para os utilizadores ChatGPT Plus, Team e Enterprise. O modelo o3 está limitado a 50 mensagens por semana, o o4-mini a 150 por dia, e o o4-mini-high a 50 por dia. Alegadamente, o ChatGPT Pro (possivelmente referindo-se a um plano específico ou um erro) tem acesso ilimitado. Estas restrições afetam diretamente os utilizadores frequentes e os programadores de aplicações que dependem de modelos específicos, exigindo consideração no planeamento do uso (Fonte: dotey)
LlamaIndex integra-se com bases de dados Google Cloud para construir agentes de conhecimento: Na conferência Google Cloud Next 2025, a LlamaIndex demonstrou como a sua framework se integra com as bases de dados Google Cloud para construir agentes de conhecimento capazes de realizar pesquisas em várias etapas, processar documentos e gerar relatórios. A demonstração incluiu um caso de um sistema multi-agente que gera automaticamente um guia de integração para novos funcionários. Isto mostra a tendência de integração profunda entre frameworks de aplicações de IA e plataformas cloud com os seus serviços de dados, visando resolver as necessidades práticas das empresas na utilização de IA para processar conhecimento e dados internos (Fonte: jerryjliu0)

Novo sensor cerebral nanométrico combinado com IA alcança alta precisão no reconhecimento de sinais: Foi reportado um novo sensor cerebral à escala nanométrica que atingiu uma precisão de 96.4% no reconhecimento de sinais neuronais. Embora a tecnologia do sensor seja o avanço principal, alcançar uma precisão de reconhecimento tão elevada geralmente requer o auxílio de algoritmos avançados de IA e machine learning para descodificar sinais neuronais complexos e fracos. Este progresso abre novos caminhos para a investigação em neurociência e futuras aplicações de interfaces cérebro-máquina, prometendo uma monitorização e interação mais refinadas com a atividade cerebral (Fonte: Ronald_vanLoon)

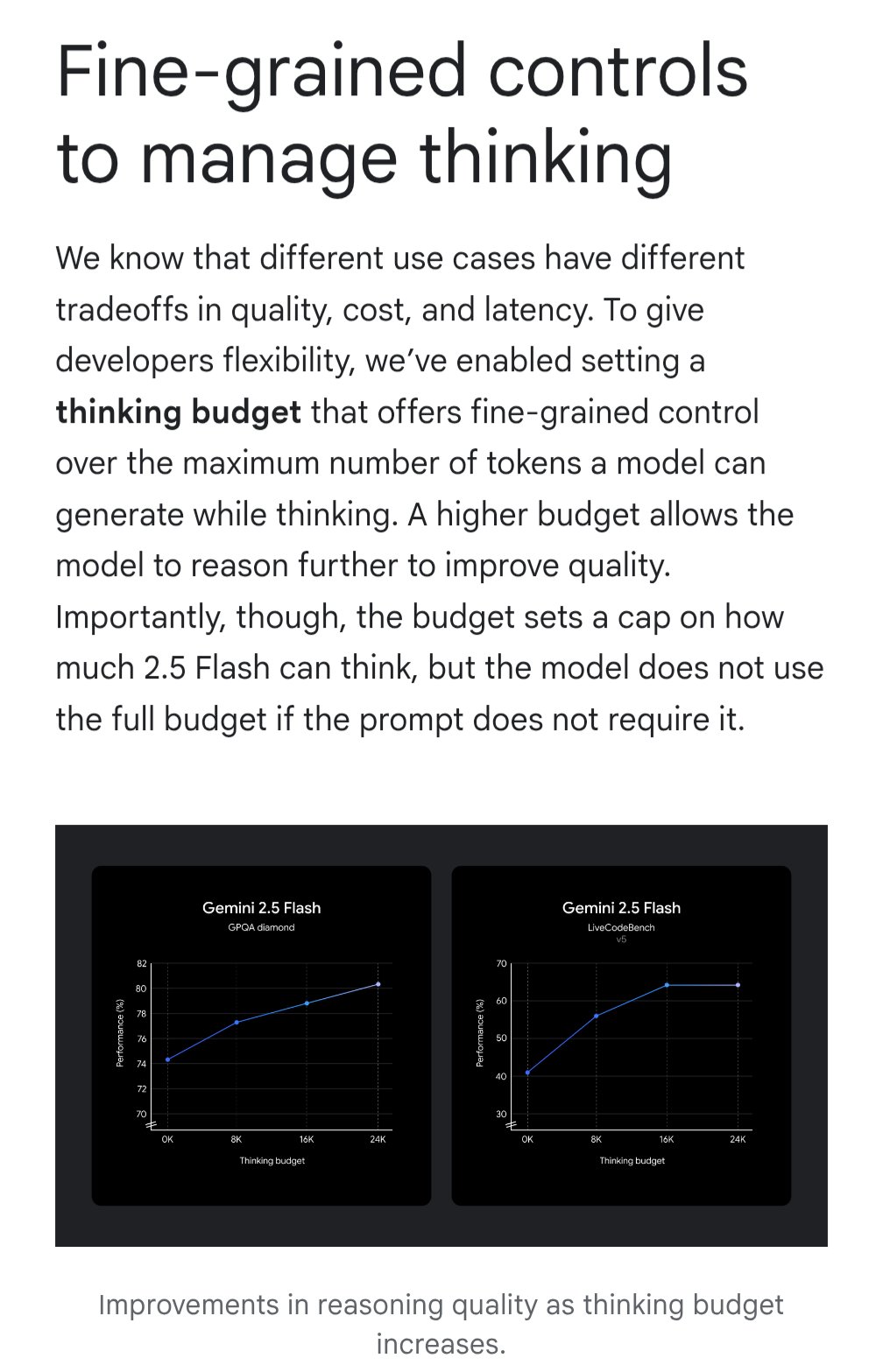
Gemini introduz funcionalidade “thinking budget” para otimizar custo-benefício: O modelo Google Gemini introduziu a funcionalidade “thinking budget” (orçamento de pensamento), permitindo aos utilizadores ajustar os recursos computacionais ou a profundidade de “pensamento” alocada pelo modelo ao processar consultas. A funcionalidade visa permitir que os utilizadores façam um equilíbrio entre a qualidade da resposta, o custo e a latência. Esta é uma característica muito prática para utilizadores de API, que podem controlar flexivelmente o custo de utilização e o desempenho do modelo de acordo com as necessidades específicas do cenário de aplicação (Fonte: JeffDean)
Qualidade de ecografias assistidas por IA comparável à de especialistas: Um estudo publicado na JAMA Cardiology mostra que ecografias realizadas por profissionais de saúde treinados e guiados por IA atingiram uma qualidade de imagem suficiente para padrões de diagnóstico (98.3%), sem diferença estatisticamente significativa em comparação com imagens obtidas por especialistas sem orientação de IA. Isto indica que a IA, como ferramenta auxiliar, pode ajudar eficazmente utilizadores não especialistas a melhorar a qualidade e consistência da operação de imagiologia médica, prometendo expandir a acessibilidade a serviços de diagnóstico de alta qualidade em regiões com recursos limitados (Fonte: Reddit r/ArtificialInteligence)
Investigação do MIT melhora a precisão e conformidade estrutural do código gerado por IA: Investigadores do MIT desenvolveram um método mais eficiente para controlar o output de modelos de linguagem grandes, com o objetivo de guiar os modelos a gerar código que cumpra estruturas específicas (como a sintaxe de linguagens de programação) e sem erros. Esta investigação visa resolver o problema da fiabilidade do código gerado por IA, melhorando as técnicas de geração restrita para garantir que o output siga rigorosamente as regras de sintaxe, aumentando assim a utilidade dos assistentes de código de IA e reduzindo os custos de depuração subsequentes (Fonte: Reddit r/ArtificialInteligence)
NVIDIA poderá revelar o seu grande projeto na área da robótica: Menções nas redes sociais indicam que a NVIDIA está a trabalhar no seu “projeto mais ambicioso”, envolvendo robótica, engenharia, inteligência artificial e tecnologia autónoma. Embora o conteúdo específico não seja conhecido, considerando a posição central da NVIDIA em hardware e plataformas de IA (como o Isaac), qualquer anúncio importante relacionado é altamente aguardado, podendo sinalizar um maior posicionamento estratégico e avanços tecnológicos na área da inteligência incorporada e robótica (Fonte: Ronald_vanLoon)
🧰 Ferramentas
Potpie: Assistente de engenharia de IA dedicado a repositórios de código: Potpie é uma plataforma open source (GitHub: potpie-ai/potpie) destinada a criar agentes de engenharia de IA personalizados para repositórios de código. Constrói um grafo de conhecimento do código para compreender as relações complexas entre componentes, oferecendo tarefas automatizadas como análise de código, testes, depuração e desenvolvimento. A plataforma fornece vários agentes pré-construídos (como depuração, perguntas e respostas, análise de alterações de código, geração de testes unitários/integração, design de baixo nível, geração de código) e conjuntos de ferramentas, suportando também a criação de agentes personalizados pelos utilizadores. Oferece extensão para VSCode e integração API, facilitando a incorporação nos fluxos de trabalho de desenvolvimento (Fonte: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel: Painel de servidor Linux com gestão integrada de LLM: 1Panel (GitHub: 1Panel-dev/1Panel) é um painel de gestão e operação de servidores Linux open source moderno, que oferece uma interface gráfica web para gerir hosts, ficheiros, bases de dados, contentores, etc. Uma das suas características distintivas é a inclusão de funcionalidades de gestão para modelos de linguagem grandes (LLM). Além disso, oferece uma loja de aplicações, implementação rápida de websites (com integração WordPress), proteção de segurança e backup/restauro com um clique, visando simplificar a gestão de servidores e a implementação de aplicações, incluindo a implementação e gestão de aplicações relacionadas com IA (Fonte: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex lança componente de UI de chat atualizado: A LlamaIndex lançou uma atualização significativa para a sua biblioteca de componentes de UI de chat (@llamaindex/chat-ui). Os novos componentes, construídos com base na shadcn UI, apresentam um design mais moderno, layout responsivo e são totalmente personalizáveis. O objetivo é ajudar os programadores a construir interfaces de chat bonitas e fáceis de usar para projetos baseados em LLM de forma mais simples, melhorando a experiência de interação das aplicações de IA. Os programadores podem instalar via npm e usar diretamente nos seus projetos (Fonte: jerryjliu0)
LlamaExtract na prática: Construção de uma aplicação de análise financeira: A LlamaIndex demonstrou um caso de uso da sua ferramenta LlamaExtract (parte da LlamaCloud) para construir uma aplicação web full-stack. O LlamaExtract permite aos utilizadores definir Schemas precisos para extrair dados estruturados de documentos complexos. A aplicação de exemplo extrai fatores de risco de relatórios anuais de empresas e analisa as mudanças ao longo dos anos, automatizando um trabalho que originalmente levava mais de 20 horas. Esta aplicação é open source (GitHub: run-llama/llamaextract-10k-demo) e existe um vídeo demonstrativo de como combinar LlamaExtract e Sonnet 3.7 para construir este fluxo de trabalho, mostrando o potencial dos agentes de IA na automatização de tarefas de análise complexas (Fonte: jerryjliu0, jerryjliu0)
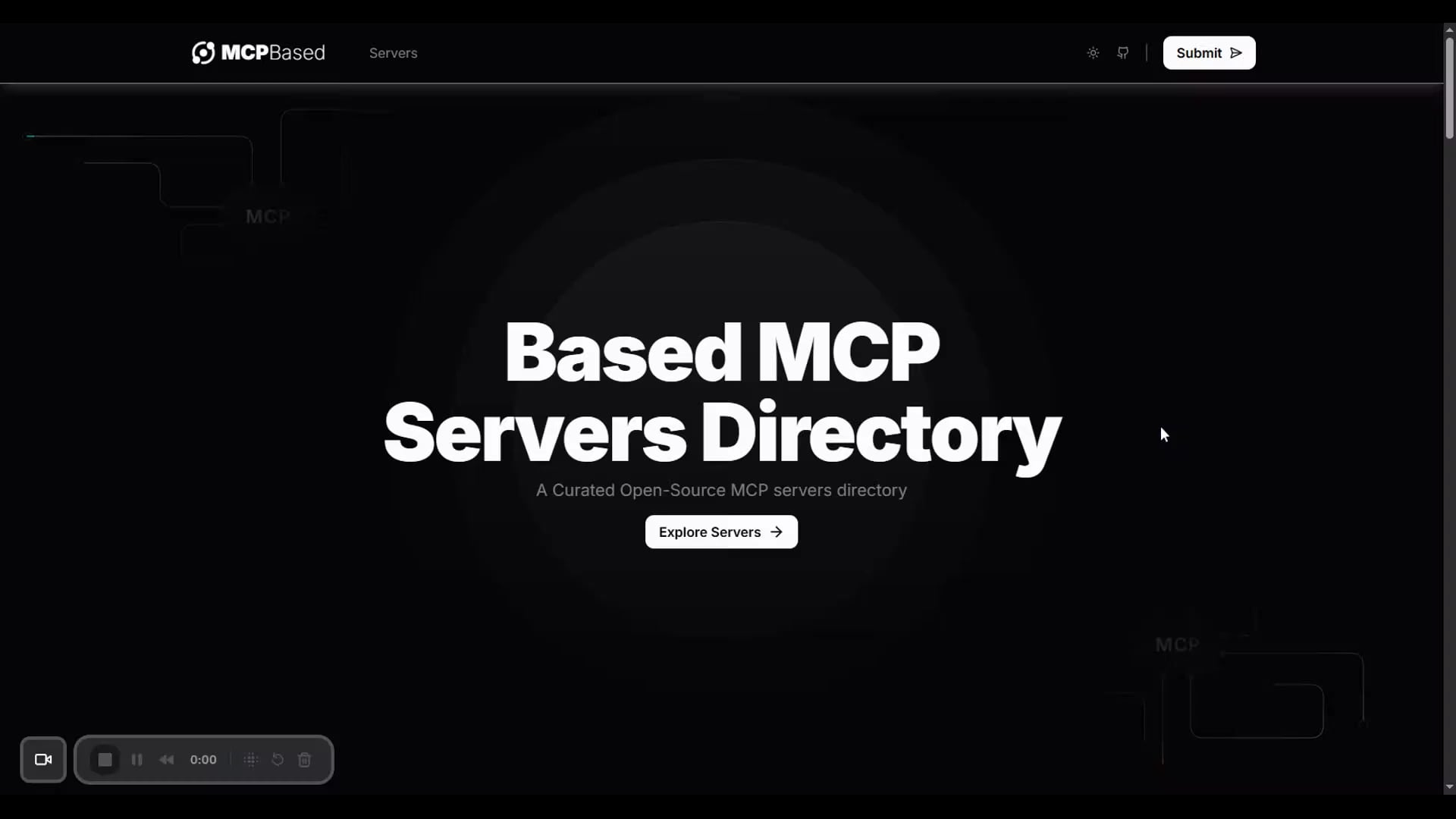
mcpbased.com: Lançamento do diretório de servidores MCP open source: O novo website mcpbased.com foi lançado como um diretório dedicado a servidores MCP (possivelmente referindo-se a Meta Controller Pattern ou outro conceito similar) open source. A plataforma visa reunir e apresentar vários projetos de servidores MCP, sincronizando dados de repositórios Github em tempo real, facilitando aos programadores a descoberta, navegação e conexão com ferramentas relevantes. Para programadores que constroem ou usam servidores MCP, realizam integração de ferramentas ou acompanham o ecossistema MCP, este é um novo centro de recursos (Fonte: Reddit r/ClaudeAI)
📚 Aprendizagem
Livro sobre RLHF chega ao ArXiv: O livro sobre Aprendizagem por Reforço a partir de Feedback Humano (RLHF), “rlhfbook”, escrito por Nathan Lambert e outros, está agora disponível na plataforma ArXiv (número 2504.12501). O RLHF é atualmente uma das tecnologias chave para o alinhamento de modelos de linguagem grandes (como o ChatGPT). A publicação deste livro fornece aos investigadores e praticantes um recurso importante para aprender sistematicamente e compreender profundamente os princípios e práticas do RLHF, promovendo a disseminação e aplicação do conhecimento nesta área (Fonte: natolambert)
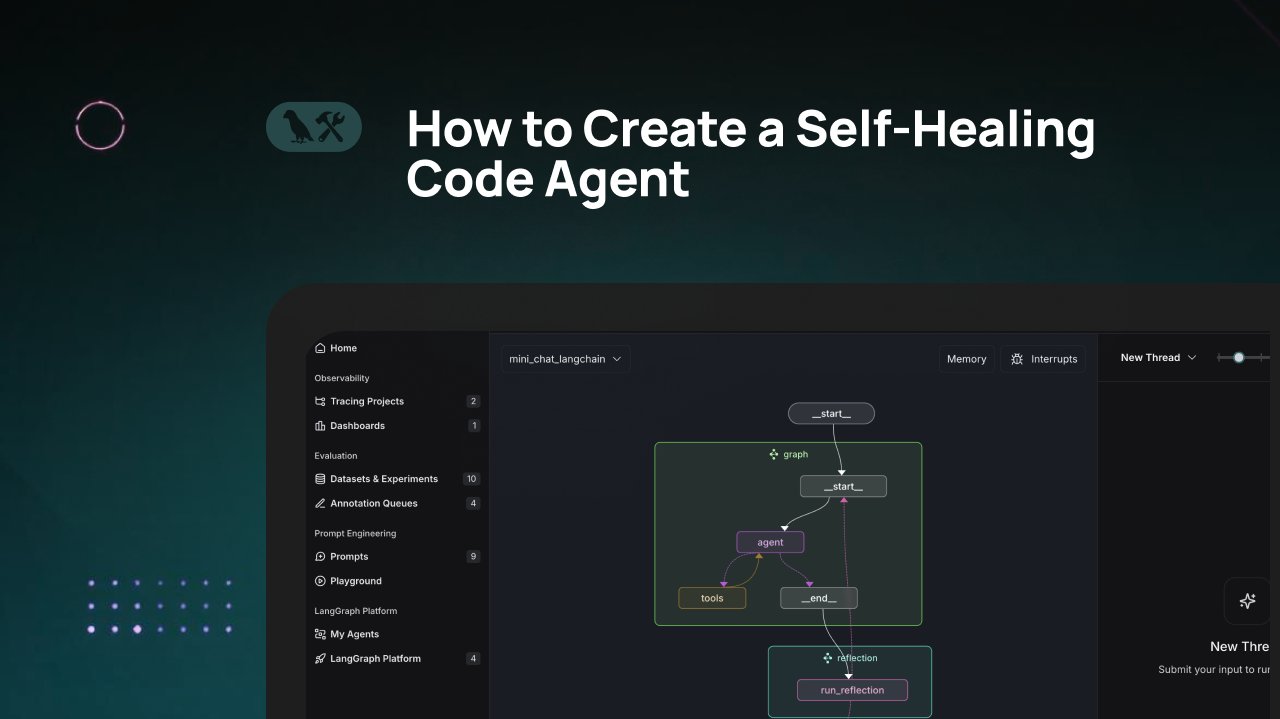
Tutorial LangChain: Construir um agente de geração de código com auto-reparação: A LangChain publicou um tutorial em vídeo que ensina a construir um agente de geração de código de IA com capacidade de “auto-reparação”. A ideia central é adicionar um passo de “reflexão” após a geração do código, permitindo que o agente valide, avalie ou melhore autonomamente o código gerado antes de devolver o resultado. Este método visa aumentar a precisão e fiabilidade do código gerado por IA, sendo uma técnica eficaz para melhorar a utilidade dos assistentes de código (Fonte: LangChainAI)
IA combinada com Blender para criar assets 3D prontos para jogos: Foi partilhado nas redes sociais um tutorial sobre o uso de ferramentas de IA (possivelmente de geração de imagem) em conjunto com o software de modelação 3D Blender para produzir assets 3D prontos para jogos (game-ready). Isto aborda o problema atual da capacidade limitada da IA na geração direta de modelos 3D, mostrando um fluxo de trabalho híbrido prático: usar IA para gerar conceitos ou texturas, e depois usar ferramentas profissionais como o Blender para modelar, otimizar e, finalmente, produzir recursos que cumpram os requisitos dos motores de jogo (Fonte: huggingface)
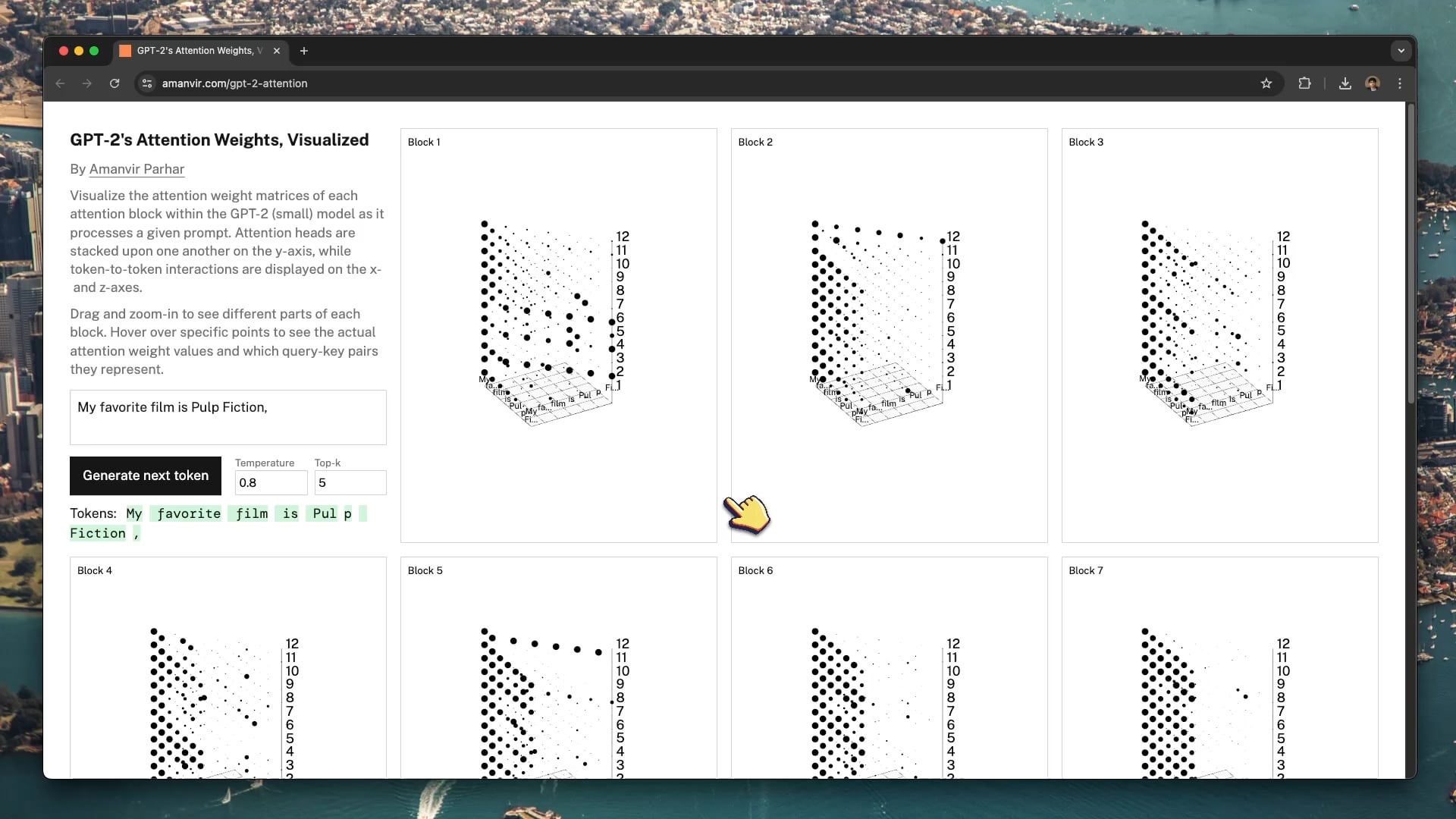
Ferramenta interativa de visualização ajuda a decifrar o mecanismo de atenção do GPT-2: O programador tycho_brahes_nose_ criou e partilhou uma ferramenta interativa de visualização 3D (amanvir.com/gpt-2-attention) para mostrar o processo de cálculo de pesos de cada bloco de atenção dentro do modelo GPT-2 (pequeno). Os utilizadores podem ver intuitivamente como, após a introdução de texto, o modelo calcula a intensidade da interação entre tokens em diferentes camadas e cabeças de atenção. Isto fornece uma excelente ajuda para compreender o mecanismo central do Transformer, auxiliando na aprendizagem de IA e na investigação da interpretabilidade dos modelos (Fonte: karminski3, Reddit r/LocalLLaMA)
Aplicação da Aprendizagem Federada na análise de imagens médicas: Uma publicação no Reddit aponta para um artigo sobre a combinação de Aprendizagem Federada (Federated Learning, FL) com redes neuronais profundas (DNN) aplicada à análise de imagens médicas. Devido à sensibilidade da privacidade dos dados médicos, a FL permite treinar modelos colaborativamente entre várias instituições sem partilhar os dados originais. Isto é crucial para impulsionar a aplicação da IA no setor médico, e este recurso ajuda a compreender esta técnica de aprendizagem distribuída que protege a privacidade e a sua prática em imagiologia médica (Fonte: Reddit r/deeplearning)

Sander Dielman analisa em profundidade VAEs e espaço latente: Andrej Karpathy recomendou o artigo de blog aprofundado de Sander Dielman (sander.ai/2025/04/15/latents.html) sobre Autoencoders Variacionais (VAE) e modelação de espaço latente. O artigo explora detalhes do treino de VAEs, como o papel limitado do termo de divergência KL na modelação do espaço latente na prática, e as razões pelas quais as perdas de reconstrução L1/L2 tendem a produzir imagens desfocadas (o decaimento do espectro da imagem não corresponde ao foco da perceção visual humana). O artigo fornece uma análise rigorosa e perspicaz para a compreensão de modelos generativos (Fonte: Reddit r/MachineLearning)
💼 Negócios
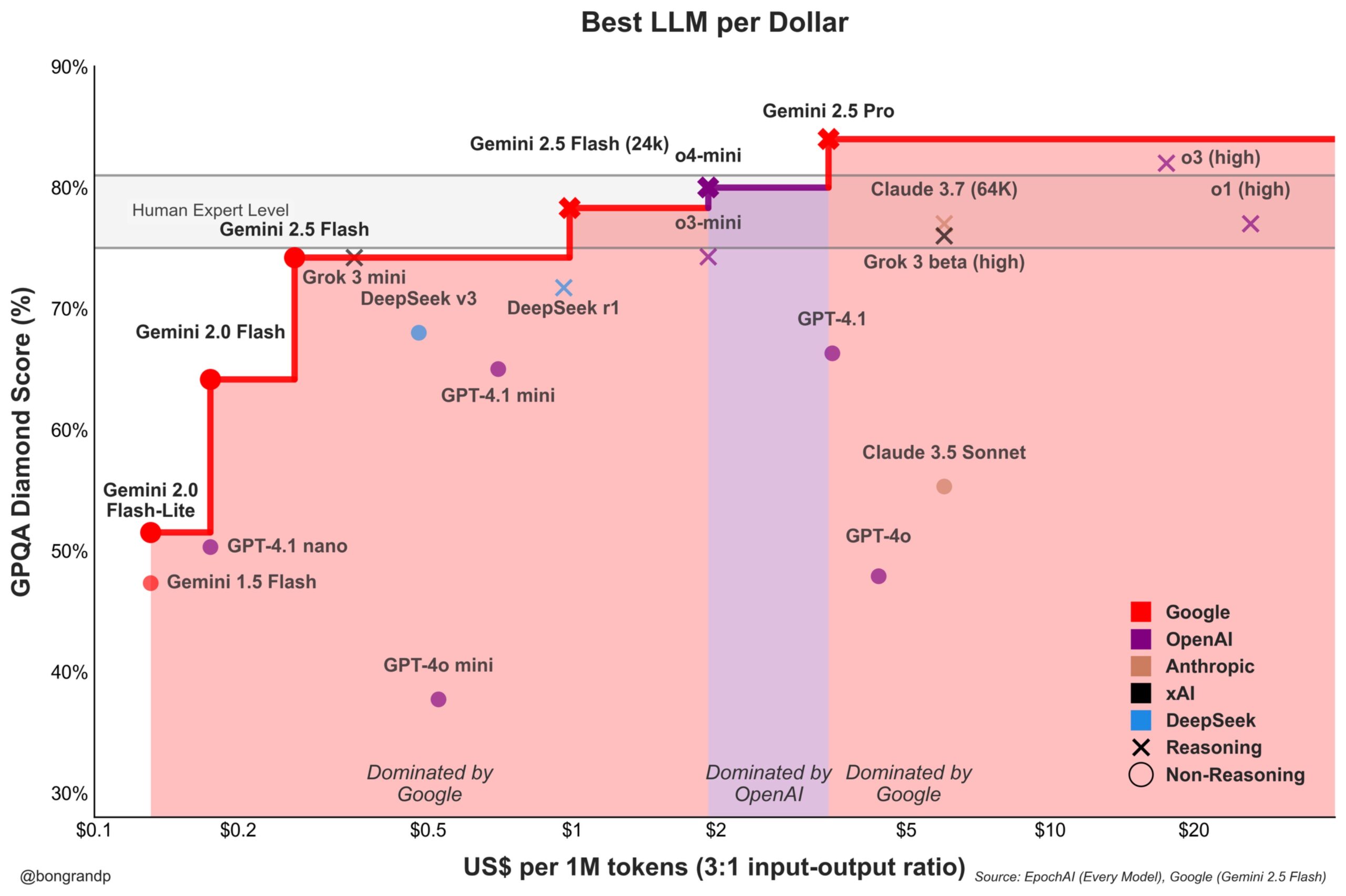
Guerra de preços de modelos intensifica-se: Google Gemini desafia ativamente a OpenAI: Análises indicam que a Google, com a sua série de modelos Gemini (especialmente o recém-lançado Gemini 2.5 Flash), demonstra forte competitividade em termos de desempenho e preço, alegadamente oferecendo uma melhor relação custo-benefício do que a OpenAI em cerca de 95% dos cenários. A resposta rápida da Google à sua API e a sua estratégia de preços (dominando mais de 90% das faixas de preço) indicam que está a lutar ativamente por quota de mercado de LLM, procurando atrair utilizadores através de vantagens de custo, intensificando a concorrência no mercado de modelos base (Fonte: JeffDean)
Coinbase patrocina conferência LangChain, explorando Agentic Commerce: A Coinbase Development tornou-se patrocinadora da conferência LangChain Interrupt 2025. A Coinbase está a capacitar o “comércio agêntico” (Agentic Commerce) através das suas ferramentas como AgentKit e o protocolo de pagamento x402, permitindo que agentes de IA realizem pagamentos autónomos por serviços como recuperação contextual, chamadas API, etc. Esta colaboração destaca a convergência da tecnologia de agentes de IA com pagamentos Web3, prenunciando futuros cenários de interação económica automatizada impulsionada por IA (Fonte: LangChainAI)

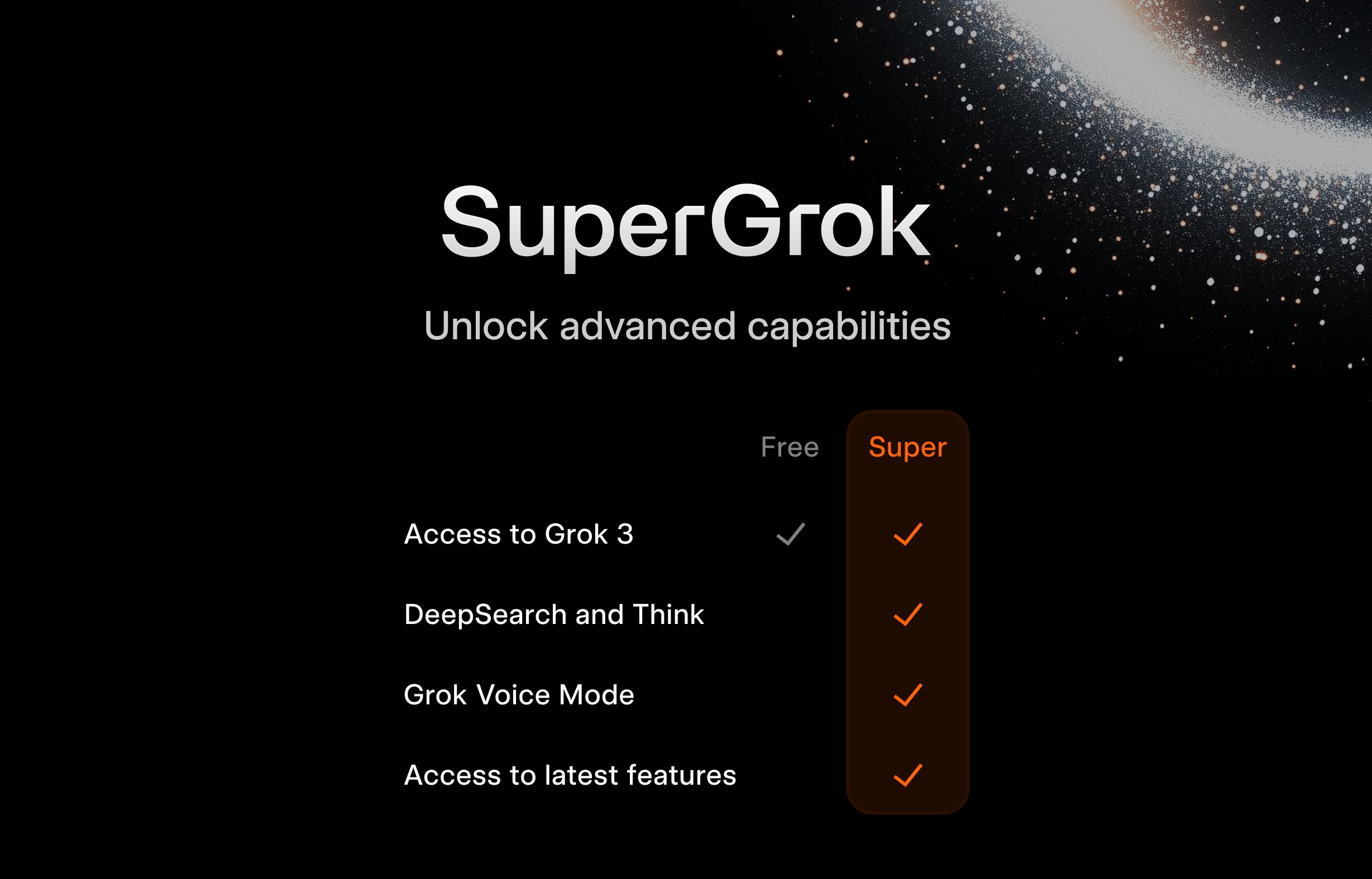
xAI lança plano gratuito SuperGrok para estudantes: Para atrair o público jovem, a xAI lançou uma promoção para estudantes: registando-se com um email .edu, podem obter dois meses de acesso gratuito ao SuperGrok (a versão avançada do Grok). Esta iniciativa visa posicionar o Grok como uma ferramenta de apoio ao estudo, promovendo-o durante a época de exames finais, competindo por utilizadores no mercado educacional e cultivando potenciais clientes pagantes futuros (Fonte: grok)
Google oferece gratuitamente Gemini Advanced e vários serviços a estudantes universitários dos EUA: A Google anunciou benefícios gratuitos de longo prazo para estudantes universitários nos EUA: se se registarem até 30 de junho de 2025, podem usar gratuitamente o Gemini Advanced (com Gemini 2.5 Pro), NotebookLM Plus, funcionalidades Gemini no Google Workspace, Whisk e 2TB de armazenamento na cloud, até ao final do semestre da primavera de 2026. Esta campanha de promoção em larga escala visa integrar profundamente as ferramentas de IA da Google no ecossistema educacional, competir com rivais como a Microsoft e cultivar a fidelidade da próxima geração de utilizadores e programadores à plataforma de IA da Google (Fonte: demishassabis, JeffDean)
FanDuel lança chatbot de IA de celebridade “ChuckGPT”: A celebridade do desporto Charles Barkley licenciou o seu nome, imagem e voz para colaborar com a empresa de apostas desportivas FanDuel no lançamento de um chatbot de IA chamado “ChuckGPT” (chuck.fanduel.com). Este é mais um exemplo de utilização de IP de celebridades e tecnologia de IA para marketing de marca e interação com o utilizador, simulando o estilo de conversação da celebridade para fornecer informações desportivas, conselhos de apostas ou interação de entretenimento, aumentando o envolvimento do utilizador (Fonte: Reddit r/artificial)
🌟 Comunidade
Dependência de ferramentas de IA gera preocupação: Uma caricatura nas redes sociais que retrata um utilizador rodeado por inúmeras ferramentas de IA (ChatGPT, Claude, Midjourney, etc.), legendada como “Dependência de ferramentas de IA”, gerou identificação. Isto reflete a sobrecarga de informação e a potencial dependência excessiva sentida por alguns utilizadores da comunidade face à proliferação de aplicações de IA, bem como o fardo cognitivo de gerir e escolher as ferramentas adequadas (Fonte: dotey)
Falha de modelos de topo em teste específico expõe limites de capacidade: O CEO da Perplexity, Arav Srinivas, partilhou um caso de teste que mostra que tanto o o3 como o Gemini 2.5 Pro falharam ao tentar completar uma tarefa complexa de desenho gráfico. Isto foi visto por alguns como um teste desafiador às capacidades atuais dos modelos. Tais “casos de falha” são amplamente discutidos na comunidade para revelar as limitações dos modelos SOTA (state-of-the-art) em raciocínio específico, compreensão espacial ou seguimento de instruções, ajudando a ter uma perceção mais objetiva da lacuna entre a IA atual e a inteligência artificial geral (AGI) (Fonte: AravSrinivas)
Comunidade discute efeito de geração de imagens de almofadas pelo GPT-4o e partilha de Prompts: Utilizadores partilharam casos de sucesso e prompts otimizados para usar o GPT-4o na geração de imagens de almofadas com um estilo específico (fofo, textura ligeiramente aveludada, forma de emoji). Este tipo de partilha demonstra a aplicação da geração de imagens por IA no design criativo e promove a troca na comunidade sobre técnicas de engenharia de prompts e exploração de estilos. A alta qualidade dos resultados gerados estimulou o entusiasmo criativo dos utilizadores (Fonte: dotey)

Sam Altman: IA mais semelhante a um Renascimento do que a uma Revolução Industrial: O CEO da OpenAI, Sam Altman, expressou a opinião de que a transformação trazida pela inteligência artificial se assemelha mais a um Renascimento do que a uma Revolução Industrial. Esta metáfora gerou discussão na comunidade, sugerindo que o impacto da IA pode manifestar-se mais nos níveis cultural, intelectual e criativo, e não apenas como um aumento mecanizado da produtividade. Este julgamento qualitativo influencia as expectativas e imaginações sobre o futuro papel social da IA (Fonte: sama)
Comunidade questiona quando o Grok 2 será open source: Utilizadores do Reddit discutem quando a xAI cumprirá a promessa de tornar o modelo Grok 2 open source. Muitos temem que, dada a rápida velocidade de iteração da tecnologia de IA, quando o Grok 2 for lançado, possa já estar desatualizado em comparação com outros modelos contemporâneos (como DeepSeek V3, Qwen 3), repetindo o cenário do Grok 1, que estava obsoleto no lançamento. A discussão também aborda o equilíbrio entre o valor dos modelos open source (investigação, liberdade de licenciamento) e a sua atualidade (Fonte: Reddit r/LocalLLaMA)
Interpretando as palavras de Altman: Eficiência de dados como novo gargalo para AGI?: A comunidade do Reddit discute a declaração de Sam Altman sobre a necessidade de a IA aumentar a eficiência de dados em 100.000 vezes, em vez de depender apenas da capacidade computacional, interpretando-a como um sinal de que o caminho atual de expansão por força bruta para a AGI encontrou obstáculos. A opinião predominante é que os dados humanos de alta qualidade estão quase esgotados, os dados sintéticos têm eficácia limitada e a baixa eficiência de aprendizagem dos modelos é o desafio central, o que pode até afetar os planos de investimento em hardware de empresas como a Microsoft. A discussão reflete uma reflexão sobre as rotas de desenvolvimento da IA (Fonte: Reddit r/artificial)
Como distinguir a memória da capacidade de raciocínio dos LLMs?: A comunidade explora como testar eficazmente se os modelos de linguagem grandes possuem realmente capacidade de raciocínio ou se estão apenas a repetir ou combinar padrões dos dados de treino. Alguém sugeriu usar perguntas inéditas do tipo “E se” (What If), que o modelo nunca viu, para sondar a sua capacidade de raciocínio generalizado. Isto toca no cerne da dificuldade de avaliar o nível de inteligência dos LLMs, nomeadamente distinguir entre correspondência de padrões avançada e inferência lógica genuína (Fonte: Reddit r/MachineLearning)
Utilizador partilha conversa “assustadora” com GPT, levantando preocupações éticas: Um utilizador partilhou capturas de ecrã de uma conversa com o ChatGPT, cujo conteúdo abordava potenciais impactos sociais negativos da IA (como controlo do pensamento, perda de pensamento crítico), descrevendo-a como “assustadora”. A publicação gerou discussão, focando em pontos como se o output da IA reflete a orientação do utilizador ou as “ideias” do modelo, os limites éticos da IA e a ansiedade dos utilizadores relativamente aos riscos potenciais da IA (Fonte: Reddit r/ChatGPT)

Execução local de modelos grandes enfrenta gargalo de memória: Na comunidade r/OpenWebUI, utilizadores relatam que, com 16GB de RAM e uma RTX 2070S, ao executar OpenWebUI e Ollama, não conseguem carregar modelos grandes acima de 12B (como Gemma3:27b), pois a memória do sistema e o espaço de troca esgotam-se. Isto representa um desafio comum enfrentado por muitos utilizadores que tentam implementar modelos grandes localmente em hardware de nível consumidor, destacando os elevados requisitos de recursos de hardware (especialmente memória) dos modelos (Fonte: Reddit r/OpenWebUI)
Cartaz gerado por GPT-4o desencadeia debate sobre “desemprego de designers”: Um utilizador exibiu um cartaz de “parque para cães” gerado pelo GPT-4o, elogiando o seu efeito “quase perfeito” e declarando “RIP designers gráficos”. A secção de comentários gerou um debate aceso: por um lado, reconhecendo o avanço na capacidade de geração de imagens por IA, por outro, apontando falhas no design (excesso de texto, má paginação, erros ortográficos) e enfatizando que a IA é atualmente uma ferramenta para aumentar a eficiência, incapaz de substituir o valor central dos designers na tomada de decisões criativas, julgamento estético, adequação à marca, etc. (Fonte: Reddit r/ChatGPT)

Gestão do ciclo de vida de modelos fine-tuned gera atenção: Programadores questionam na comunidade: quando o modelo base dependente (como GPT-4o) é atualizado (por exemplo, surge o GPT-5), o que fazer com os modelos fine-tuned anteriormente nele? Como o fine-tuning está geralmente ligado a uma versão específica do modelo base, a descontinuação ou atualização do modelo base pode forçar os programadores a retreinar, trazendo custos contínuos e problemas de manutenção. Isto levanta discussões sobre a dependência e a estratégia a longo prazo do uso de APIs fechadas para fine-tuning (Fonte: Reddit r/ArtificialInteligence)
Exploração de configurações para conversação por voz com LLMs locais: Utilizadores da comunidade procuram soluções de sistema para estabelecer conversas por voz com LLMs locais, esperando alcançar uma experiência semelhante ao Google AI Studio, para brainstorming e planeamento. A questão reflete o desejo dos utilizadores de expandir da interação textual para uma interação por voz mais natural, e procuram métodos práticos e partilha de experiências para integrar STT, LLM e TTS em frameworks locais como o OpenWebUI (Fonte: Reddit r/OpenWebUI )
Nomenclatura hierárquica dos modelos OpenAI causa confusão nos utilizadores: Utilizadores publicam queixas sobre a nomenclatura confusa dos modelos da OpenAI (como o3, o4-mini, o4-mini-high, o4). Uma imagem mostra os diferentes níveis de modelos, cuja relação entre nome, capacidade e limitações não é suficientemente intuitiva. Isto reflete que, à medida que a família de modelos se expande, uma clara divisão e nomenclatura da linha de produtos representa um desafio para a compreensão e escolha do utilizador (Fonte: Reddit r/artificial)

Estilo excessivamente “bajulador” do ChatGPT gera debate: Utilizadores da comunidade, através de memes e discussões, apontam que o ChatGPT tende a elogiar excessivamente as perguntas dos utilizadores (“Essa pergunta é ótima!”), mesmo que a pergunta seja comum ou até tola. A discussão sugere que esta pode ser uma estratégia da OpenAI para aumentar a fidelização do utilizador, mas também pode levar os utilizadores a desenvolver viés de confirmação, carecendo de feedback crítico. Alguns utilizadores expressam até preferência por uma IA que desse avaliações “venenosas” (Fonte: Reddit r/ChatGPT)

Desafios da IA em jogos de informação incompleta: A comunidade discute os desafios enfrentados pela IA ao lidar com jogos de informação incompleta (como a névoa de guerra em StarCraft). Diferente de jogos de informação completa como Go ou xadrez, estes jogos exigem que a IA lide com incerteza, realize exploração e planeamento a longo prazo, não podendo depender simplesmente de informação global e pré-cálculos. Embora a IA tenha feito progressos em jogos como Dota 2 e StarCraft (AlphaStar), alcançar um nível estável que supere os melhores jogadores humanos ainda é um desafio (Fonte: Reddit r/ArtificialInteligence)
Alerta para o fenómeno de “convergência linguística” causado por conteúdo de IA: Utilizadores levantam o conceito de “mimetismo linguístico” (linguistic mimicry), expressando preocupação de que a leitura massiva de conteúdo gerado por IA, cujo estilo pode tender a convergir, leve a que a expressão linguística e até o modo de pensar das pessoas se tornem monótonos e homogeneizados. Este fenómeno pode constituir uma ameaça potencial à diversidade cultural e ao pensamento individual independente. A leitura de obras diversificadas de autores humanos é defendida como uma forma de manter a vitalidade da linguagem (Fonte: Reddit r/ArtificialInteligence)
💡 Outros
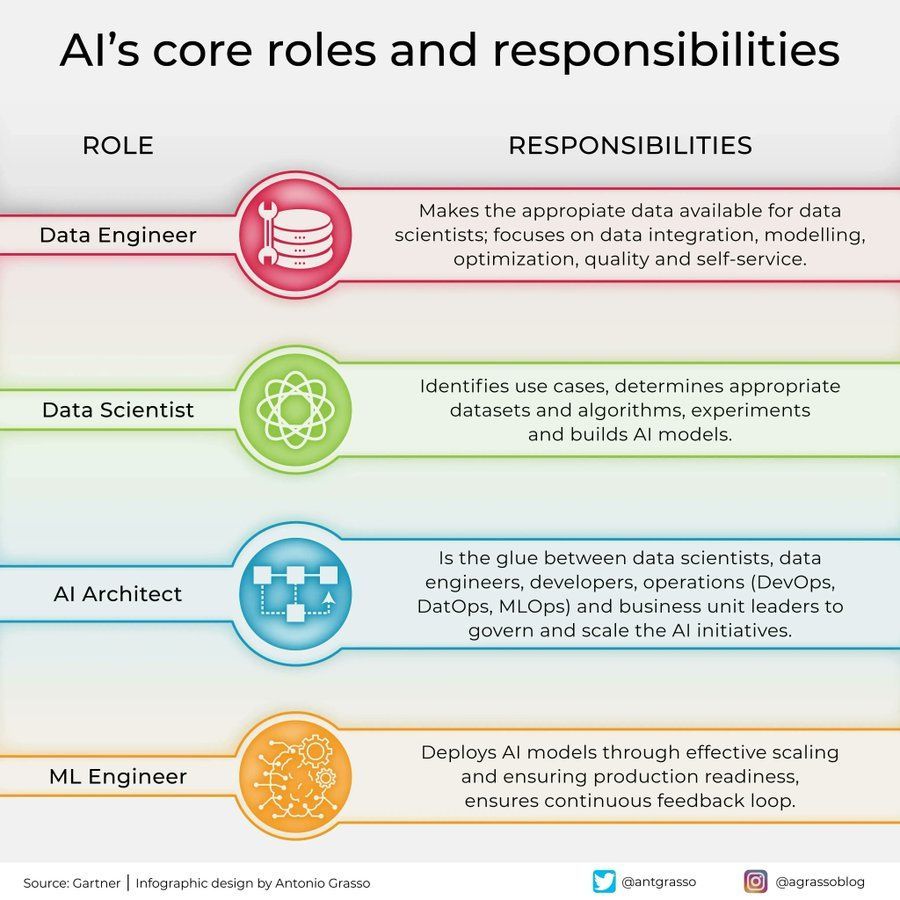
Divisão de papéis e responsabilidades na área de IA: Foi partilhado nas redes sociais um infográfico que resume os papéis centrais na área da inteligência artificial e as suas responsabilidades, como cientista de dados, engenheiro de machine learning, investigador de IA, etc. Este gráfico ajuda a compreender a divisão de trabalho dentro das equipas de projetos de IA, as competências necessárias e a natureza multidisciplinar do desenvolvimento de IA (Fonte: Ronald_vanLoon)
Aplicações e desafios da IA no setor das telecomunicações: Discussão menciona as aplicações disruptivas e as potenciais armadilhas da IA no setor das telecomunicações. A IA está a ser amplamente utilizada na otimização de redes, atendimento ao cliente inteligente, manutenção preditiva, etc., para aumentar a eficiência e a experiência do utilizador, mas também enfrenta desafios como privacidade de dados, viés algorítmico, complexidade de implementação, etc. Aprofundar estes aspetos ajuda o setor a aproveitar as oportunidades da IA e a mitigar os riscos (Fonte: Ronald_vanLoon)
Influência da psicologia no desenvolvimento da IA: Artigo explora como a psicologia influenciou o desenvolvimento da inteligência artificial, e como essa influência continua. Conhecimentos de ciência cognitiva, teoria da aprendizagem, estudo de vieses, etc., da psicologia forneceram referências importantes para o design de IA, como simular processos cognitivos humanos, compreender e lidar com vieses. Por outro lado, a IA também forneceu novas ferramentas de modelação e teste para a investigação psicológica (Fonte: Ronald_vanLoon)

Equipamento computacional de grande porte demonstra a necessidade de hardware para IA: Utilizador partilha uma imagem que mostra um dispositivo de hardware computacional vasto e complexo (muito provavelmente um grande cluster de servidores multi-GPU), chamando-lhe “monstro”. Esta imagem reflete visualmente o enorme investimento em recursos computacionais necessário atualmente para treinar modelos de IA grandes ou realizar tarefas de inferência de alta intensidade, demonstrando a elevada dependência da IA moderna em infraestruturas de hardware (Fonte: karminski3)

Papel da IA na cibersegurança: Artigo explora o papel transformador da inteligência artificial na área da cibersegurança. A tecnologia de IA é usada para melhorar a deteção de ameaças (como análise de comportamento anómalo), automatizar a resposta de segurança, avaliação de vulnerabilidades e previsão, aumentando a eficiência e capacidade de defesa. No entanto, a própria IA também pode ser explorada maliciosamente, trazendo novos desafios de segurança (Fonte: Ronald_vanLoon)

OCR de alta precisão enfrenta desafio de confusão de caracteres: Programadores que procuram construir sistemas OCR de alta precisão para reconhecer códigos alfanuméricos curtos (como números de série) encontraram um problema comum: o modelo tem dificuldade em distinguir caracteres visualmente semelhantes (como I/1, O/0). Mesmo usando um modelo YOLO para deteção de caracteres únicos, existem casos limite. Isto realça o desafio de alcançar uma precisão OCR quase perfeita em cenários específicos, exigindo otimização direcionada do modelo, dados ou a adoção de estratégias de pós-processamento (Fonte: Reddit r/MachineLearning)

Pedido de ajuda para executar ambiente Gym Retro: Utilizador encontra problemas técnicos ao usar a biblioteca de aprendizagem por reforço Gym Retro, tendo conseguido importar o jogo Donkey Kong Country, mas sem saber como iniciar o ambiente predefinido para treino. Este é um problema típico de configuração e operação que investigadores de IA podem encontrar ao usar ferramentas específicas (Fonte: Reddit r/MachineLearning)
Dilema de escolha quando vários modelos têm desempenho semelhante: Um investigador, ao usar diferentes métodos de seleção de características e modelos de machine learning, descobriu que várias combinações atingiram níveis de desempenho elevados e semelhantes (por exemplo, precisão de 93-96%), dificultando a escolha da solução ótima. Isto reflete que, na avaliação de modelos, quando as métricas padrão diferem pouco, é necessário considerar outros fatores como complexidade do modelo, interpretabilidade, velocidade de inferência, robustez, etc., para tomar a decisão final (Fonte: Reddit r/MachineLearning)
Migração do arXiv para Google Cloud gera atenção: Sendo uma plataforma importante de preprints para IA e muitos outros campos científicos, o arXiv planeia migrar dos servidores da Universidade de Cornell para a Google Cloud. Esta mudança significativa na infraestrutura pode trazer melhorias na escalabilidade e fiabilidade do serviço, mas também pode levantar discussões na comunidade sobre custos operacionais, gestão de dados e políticas de acesso aberto (Fonte: Reddit r/MachineLearning)
Claude gera ferramenta de simulação económica e suas limitações: Utilizador utilizou a funcionalidade Claude Artifact para gerar um simulador económico interativo do impacto de tarifas alfandegárias. Embora demonstre a capacidade da IA de gerar aplicações complexas, os comentários apontam que os resultados da simulação podem ser excessivamente simplificados ou não conformes com os princípios económicos (como tarifas elevadas trazendo benefícios generalizados). Isto alerta para a necessidade de uma análise rigorosa da lógica interna e dos pressupostos ao usar ferramentas de análise geradas por IA (Fonte: Reddit r/ClaudeAI)

Integrar clonagem de voz XTTS personalizada no OpenWebUI: Utilizador procura integrar a sua voz clonada com a tecnologia open source XTTS no OpenWebUI, para substituir a API paga da ElevenLabs, alcançando uma saída de voz personalizada e gratuita. Isto representa a necessidade dos utilizadores, ao usar ferramentas de IA locais, de integrar componentes open source e personalizáveis (como TTS) (Fonte: Reddit r/OpenWebUI)