
Palavras-chave:Gemini 2.5 Flash, OpenAI o3, Substituição de postos de trabalho por IA, Comercialização de IA na saúde, Modelo de raciocínio híbrido, Funcionalidade de orçamento de pensamento, Capacidade multimodal do o4-mini, Assistente de codificação IA Windsurf, Gateway doméstico Agentic AI, Teste de referência VisualPuzzles, Confiabilidade de recomendação DeepSeek, Modelo de código aberto da Zhipu AI
🔥 Foco
Google lança modelo de inferência híbrido Gemini 2.5 Flash, focado em custo-benefício e pensamento controlável: A Google lançou a versão de pré-visualização do Gemini 2.5 Flash, posicionado como um modelo de inferência híbrido de alto custo-benefício. A sua característica única é a introdução da funcionalidade “orçamento de pensamento” (thinking_budget), permitindo aos programadores (0-24k tokens) ou ao próprio modelo ajustar a profundidade da inferência com base na complexidade da tarefa. Com o pensamento desligado, o custo é extremamente baixo ($0.6/milhão de tokens de saída), com desempenho superior ao 2.0 Flash; com o pensamento ligado ($3.5/milhão de tokens de saída), consegue lidar com tarefas complexas, com desempenho comparável ao o4-mini em vários benchmarks (como AIME, MMMU, GPQA) e classificando-se bem na arena LMArena. Este modelo visa equilibrar desempenho, custo e latência, sendo especialmente adequado para cenários de aplicação que exigem flexibilidade e controlo de custos. Já está disponível via API no Google AI Studio e Vertex AI. (Fonte: 谷歌首款混合推理Gemini 2.5登场,成本暴降600%,思考模式一开,直追o4-mini, 谷歌大模型“性价比之王”来了,混合推理模型,思考深度可自由控制,竞技场排名仅次于自家Pro, op7418, JeffDean, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)

OpenAI lança modelos o3 e o4-mini, reforçando capacidades de raciocínio e multimodais: A OpenAI lançou a sua série de modelos mais forte até à data, o3, e o otimizado o4-mini, focando-se na melhoria das capacidades de raciocínio, programação e compreensão multimodal. Em particular, implementou pela primeira vez o raciocínio de “cadeia de pensamento” baseado em imagem, capaz de analisar detalhes de imagens para julgamentos complexos, como inferir a localização exata da filmagem de uma foto (GeoGuessing). O o3 alcançou uma pontuação recorde de 136 no teste de QI da Mensa e apresentou um desempenho excelente em benchmarks de programação. O o4-mini, por sua vez, demonstra fortes capacidades de resolução de problemas matemáticos (como problemas de Euler) e processamento visual, mantendo alta eficiência e baixo custo. Estes modelos já estão disponíveis para utilizadores do ChatGPT Plus, Pro e Team, mostrando que a OpenAI está a impulsionar a evolução dos modelos da aquisição de conhecimento para o uso de ferramentas e resolução de problemas complexos. (Fonte: 实测o3/o4-mini:3分钟解决欧拉问题,OpenAI最强模型名副其实, 智商136,o3王者归来,变身福尔摩斯“AI查房”,一张图秒定坐标, 满血版o3探案神技出圈,OpenAI疯狂暗示:大模型不修仙,要卷搬砖了)

Aumento da eficiência da IA gera preocupações sobre emprego, algumas empresas começam a usar IA para substituir postos de trabalho: A alta eficiência da tecnologia de inteligência artificial (IA) está a levar empresas como PayPal, Shopify, United Wholesale Mortgage a considerar ou a usar efetivamente IA para substituir postos de trabalho humanos, especialmente em áreas como atendimento ao cliente, vendas júnior, suporte de TI e processamento de dados. Por exemplo, o chatbot de IA do PayPal já lida com 80% dos pedidos de atendimento ao cliente, reduzindo significativamente os custos. A United Wholesale Mortgage utiliza IA para processar documentos de crédito à habitação, aumentando drasticamente a eficiência, duplicando o volume de negócios sem necessidade de contratar mais pessoal. Algumas empresas chegam a propor o conceito de “equipa de zero funcionários”, exigindo que novas contratações provem primeiro que a IA não consegue realizar a tarefa. Embora muitas empresas evitem admitir publicamente que as demissões se devem à IA, a desaceleração das contratações e a redução de postos de trabalho tornaram-se uma tendência. Espera-se que, especialmente sob pressão de custos, o efeito de substituição da IA em trabalhos de colarinho branco se torne mais evidente no futuro. (Fonte: 招聘慢了、岗位少了,AI效率太高迫使人类员工“让位”)

OpenAI planeia investir 3 mil milhões de dólares na aquisição do assistente de codificação AI Windsurf, reforçando a sua posição na camada de aplicação: A OpenAI planeia adquirir a startup de codificação AI Windsurf (anteriormente Codeium) por cerca de 3 mil milhões de dólares, naquela que será a sua maior aquisição. A Windsurf oferece ferramentas de assistência à codificação AI semelhantes ao Cursor, também baseadas em modelos da Anthropic. Esta aquisição é vista como um passo crucial para a OpenAI expandir-se para a camada de aplicação e fortalecer o controlo do seu ecossistema, visando adquirir utilizadores diretamente, recolher dados de treino e competir com rivais como GitHub Copilot e Cursor. Analistas acreditam que, com o aumento das capacidades da IA, a “programação ambiente” (Vibe Coding, IA profundamente integrada no fluxo de desenvolvimento) está a tornar-se uma tendência. Dominar a entrada na camada de aplicação e os dados do utilizador é crucial para a competitividade a longo prazo das empresas de modelos. Esta jogada da OpenAI indica que os seus objetivos estratégicos ultrapassam o de ser um mero fornecedor de modelos, pretendendo construir uma plataforma completa de desenvolvimento de IA. (Fonte: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
🎯 Tendências
ByteDance lança modelo de pensamento profundo Doubao 1.5 e atualizações multimodais, acelerando a implementação de Agents: A Volcano Engine, subsidiária da ByteDance, lançou o modelo de pensamento profundo Doubao 1.5. Este modelo possui capacidades semelhantes às humanas de “ver, pensar e pesquisar simultaneamente”, pode lidar com tarefas complexas, suporta entrada multimodal (texto, imagem) e tem capacidades de pesquisa na web e raciocínio visual. Simultaneamente, lançou o modelo de geração de texto para imagem Doubao 3.0 (melhorando a composição de texto e o realismo da imagem) e uma versão atualizada do modelo de compreensão visual (melhorando a precisão da localização e a compreensão de vídeo). A ByteDance acredita que o pensamento profundo e a multimodalidade são a base para a construção de Agents e lançou a solução OS Agent e o conjunto de inferência nativo na nuvem AI, visando reduzir a barreira e os custos para as empresas construírem e implementarem aplicações Agent. Esta ação é vista como uma reafirmação estratégica da ByteDance após o impacto de concorrentes como o DeepSeek, focando-se na implementação de aplicações Agent. (Fonte: 字节按下 AI Agent 加速键, 被DeepSeek打蒙的豆包,发起反攻了)

ByteDance e Kuaishou confrontam-se novamente na geração de vídeo por IA, focando no desempenho do modelo e na implementação: A ByteDance lançou o modelo de geração de vídeo Seaweed-7B, enfatizando a baixa contagem de parâmetros (7B), alta eficiência (treinado com 665.000 horas de GPU H100) e baixo custo de implementação (um único GPU pode gerar vídeo 1280×720). A Kuaishou, por sua vez, lançou o modelo de geração de vídeo “Keling 2.0” e o modelo de geração de imagem “Ketu 2.0”, alegando desempenho superior ao Veo2 da Google e ao Sora, e introduziu a funcionalidade de edição multimodal MVL. Ambas as empresas reconhecem que a capacidade do modelo é o limite superior dos produtos de IA, e a estratégia para 2025 volta a focar-se no aprimoramento dos modelos. Embora os caminhos de comercialização sejam diferentes (o Dreamina da ByteDance inclina-se para o consumidor final, o Keling da Kuaishou foca-se no B2B), ambas estão a esforçar-se para melhorar a usabilidade. Por exemplo, a Kuaishou enfatiza a importância da geração de vídeo a partir de imagem, enquanto a ByteDance utiliza as suas vantagens no processamento de texto para garantir a consistência narrativa do vídeo. A competição está a intensificar-se. (Fonte: 字节快手,AI视频“狭路又相逢”)

Zhipu AI lança três modelos open-source, reforçando a construção do ecossistema open-source: A Zhipu AI anunciou 2025 como o “Ano Open-Source” e lançou três modelos: GLM-Z1-Air (modelo de inferência), outro GLM-Z1-Air (indicado como possível erro de digitação no original, talvez referindo-se a uma versão rápida ou base) e GLM-Z1-Rumination (modelo de ruminação), com tamanhos de 9B e 32B, sob licença MIT. O GLM-Z1-Air (32B) apresenta desempenho próximo ao DeepSeek-R1 em alguns benchmarks, com um preço de inferência significativamente reduzido. O modelo de ruminação Z1-Rumination explora um pensamento mais profundo, suportando um ciclo fechado de investigação. Ao mesmo tempo, o Fundo Z da Zhipu (Zhipu Z Fund) anunciou um investimento de 300 milhões de yuan para apoiar a comunidade global de IA open-source, sem restrições a projetos baseados nos modelos Zhipu. Esta iniciativa alinha-se com a estratégia de Pequim de se tornar a “Capital Global do Open-Source”. (Fonte: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Agentic AI incorporado em gateways domésticos pode ser nova oportunidade para operadoras: Com a evolução da IA de generativa para agentiva (Agentic AI), sistemas de IA com capacidade de definir objetivos e executar tarefas autonomamente tornam-se o foco. Um executivo da MediaTek sugeriu que incorporar Agentic AI em gateways domésticos pode mudar o papel das operadoras no mercado de IoT. O gateway, como centro de inteligência de ponta da rede doméstica, combinado com Agentic AI, pode gerir ativamente a rede (por exemplo, otimizar videochamadas), diagnosticar falhas, melhorar a segurança doméstica (como identificar roubo de encomendas, risco de crianças perto de piscinas), reduzindo assim os custos de atendimento ao cliente das operadoras (muitas consultas relacionadas com Wi-Fi podem ser tratadas pela IA) e oferecer serviços de valor acrescentado. Embora o modelo de monetização ainda precise ser explorado, isto oferece às operadoras um caminho potencial para transcender o papel de “canal” e tornarem-se facilitadoras de serviços de Agentic AI. (Fonte: 将Agentic AI嵌入家庭网关,如何改变运营商在物联网市场的游戏规则?)
Microsoft lança MAI-DS-R1, pós-treinado sobre DeepSeek R1 para segurança e conformidade: A equipa de IA da Microsoft lançou o modelo MAI-DS-R1, que é pós-treinado sobre o DeepSeek R1, com o objetivo de preencher lacunas de informação do modelo original e melhorar o seu perfil de risco, mantendo ao mesmo tempo as capacidades de raciocínio do R1. Os dados de treino incluem 110.000 amostras de segurança e não conformidade do Tulu 3 SFT, bem como cerca de 350.000 amostras multilingues desenvolvidas internamente pela Microsoft, cobrindo vários tópicos com potencial de viés. Esta ação foi interpretada por alguns membros da comunidade como um esforço da Microsoft para melhorar a segurança e conformidade do modelo, mas também gerou discussões sobre se adicionou “censura de nível empresarial”. (Fonte: Reddit r/LocalLLaMA)

🧰 Ferramentas
OpenAI lança Codex CLI open-source, assistente de codificação AI orientado para terminal: A OpenAI lançou um novo projeto open-source, o Codex CLI, um agente de IA otimizado para tarefas de codificação que pode ser executado no terminal local do programador. Utiliza por defeito o modelo mais recente o4-mini, mas os utilizadores podem escolher outros modelos OpenAI através da API. O Codex CLI visa fornecer uma forma de desenvolvimento orientada por chat, compreendendo e executando operações no repositório de código local, competindo com ferramentas como Claude Code da Anthropic, Cursor e Windsurf. O projeto ganhou mais de 14.000 estrelas no GitHub em apenas um dia, mostrando o interesse dos programadores em ferramentas de codificação AI nativas do terminal. (Fonte: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
Google AI Studio atualizado, suporta criação e partilha direta de aplicações AI: A Google atualizou a sua plataforma AI Studio, adicionando a funcionalidade de criar aplicações AI diretamente na plataforma. Os utilizadores podem não só usar modelos como o Gemini para desenvolvimento, mas também navegar e experimentar aplicações de exemplo criadas por outros utilizadores. Esta atualização transforma o AI Studio de um campo de experimentação de modelos para uma plataforma mais completa de desenvolvimento e partilha de aplicações, reduzindo a barreira para construir aplicações baseadas na tecnologia AI da Google. (Fonte: op7418)
NVIDIA cuML lança modo de aceleração GPU sem alteração de código: A equipa do NVIDIA cuML lançou um novo modo acelerador que permite aos utilizadores executar código nativo scikit-learn, umap-learn e hdbscan diretamente na GPU sem modificar qualquer código. A funcionalidade é ativada através de python -m cuml.accel your_script.py ou carregando %load_ext cuml.accel num Jupyter Notebook. Os benchmarks mostram acelerações significativas de 25x a 175x para algoritmos como Random Forest, Linear Regression, t-SNE, UMAP, HDBSCAN, entre outros. O modo utiliza memória unificada CUDA (UVM), geralmente eliminando preocupações sobre o tamanho do dataset, embora o desempenho possa ser afetado por datasets com memória excessivamente grande. (Fonte: Reddit r/MachineLearning)

Alibaba lança modelo de vídeo Wan 2.1 open-source para frames inicial e final: O Alibaba tornou open-source o seu modelo de vídeo Wan 2.1, que se foca na geração de conteúdo de vídeo intermédio com base nos frames inicial e final. Este é um tipo específico de tecnologia de geração de vídeo que pode ser aplicado em cenários como interpolação de vídeo, transferência de estilo ou geração de animação baseada em keyframes. O lançamento deste modelo fornece aos investigadores e programadores uma nova ferramenta para explorar e utilizar esta tecnologia. (Fonte: op7418)
ViTPose: Modelo de estimativa de pose humana baseado em Vision Transformer: ViTPose é um novo modelo que utiliza a arquitetura Vision Transformer (ViT) para estimativa de pose humana. O artigo apresenta o modelo, explorando o potencial do ViT em tarefas de visão computacional (neste caso, estimativa de pose humana). Estes modelos geralmente utilizam o mecanismo de auto-atenção do Transformer para capturar dependências de longo alcance entre diferentes partes da imagem, o que pode potencialmente melhorar a precisão e robustez da estimativa de pose. (Fonte: Reddit r/deeplearning)

ClaraVerse: Assistente AI local-first integrado com n8n: ClaraVerse é um assistente AI local-first, baseado no Ollama, que enfatiza a privacidade e o controlo local. A atualização mais recente integra a plataforma de automação n8n, permitindo aos utilizadores construir e executar ferramentas e fluxos de trabalho personalizados (como verificação de email, gestão de calendário, chamadas API, ligação a bases de dados, etc.) dentro do assistente, sem serviços externos. Isto permite que o Clara acione tarefas de automação locais através de instruções em linguagem natural, visando fornecer uma solução local de IA e automação amigável e de baixa dependência. (Fonte: Reddit r/LocalLLaMA)
Modelo CSM 1B TTS alcança processamento em streaming em tempo real e fine-tuning: A comunidade open-source fez progressos no modelo de texto-para-voz (TTS) CSM 1B, implementando processamento em streaming em tempo real (real-time streaming) e desenvolvendo capacidades de fine-tuning (incluindo LoRA e fine-tuning completo). Isto significa que o modelo pode agora gerar voz mais rapidamente e ser personalizado para necessidades específicas. O repositório de código fornece uma demonstração de chat local, onde os utilizadores podem experimentar e comparar os seus efeitos com outros modelos TTS. (Fonte: Reddit r/LocalLLaMA)
Deebo: Utilização de MCP para depuração colaborativa de Agents AI: Deebo é um servidor experimental de Agent MCP (Machine Collaboration Protocol), concebido para permitir que Agents AI de codificação externalizem tarefas complexas de depuração para ele. Quando o Agent principal encontra dificuldades, pode iniciar uma sessão Deebo através do MCP. O Deebo gera múltiplos subprocessos para testar várias soluções de correção em paralelo em diferentes branches Git, utilizando LLM para raciocínio. No final, retorna logs, sugestões de correção e explicações. Esta abordagem utiliza isolamento de processos, simplifica a gestão de concorrência e explora a possibilidade de colaboração entre Agents AI para resolver problemas. (Fonte: Reddit r/OpenWebUI)
📚 Aprendizagem
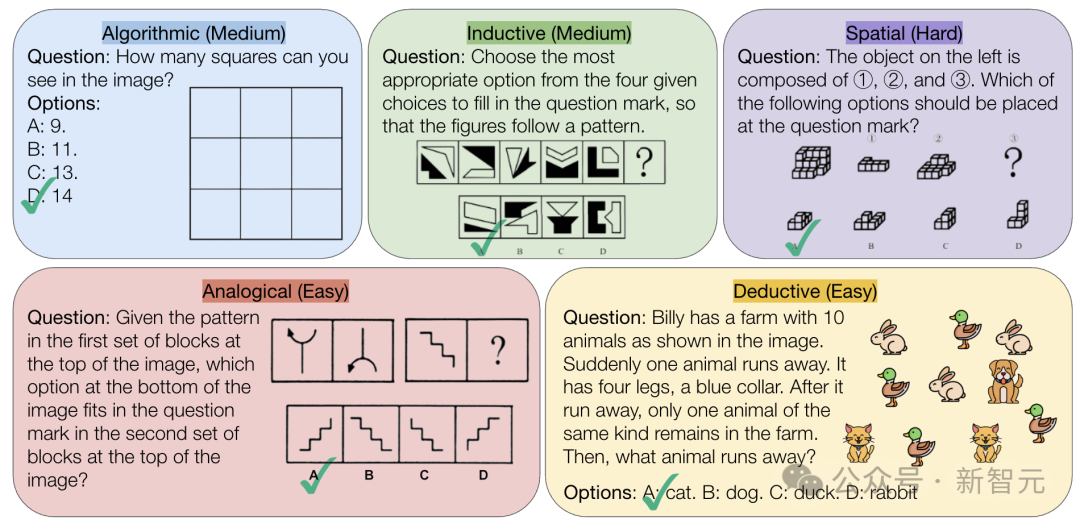
CMU lança benchmark VisualPuzzles, desafiando a capacidade de raciocínio puramente lógico da IA: Investigadores da Carnegie Mellon University (CMU) criaram o benchmark VisualPuzzles, contendo 1168 quebra-cabeças visuais lógicos adaptados de exames da função pública e outras fontes, com o objetivo de separar a capacidade de raciocínio multimodal da dependência do conhecimento de domínio. Os testes revelaram que mesmo os modelos de topo como o o1 e o Gemini 2.5 Pro têm um desempenho muito inferior ao dos humanos nestas tarefas de raciocínio puramente lógico (taxa de acerto máxima de 57,5%, inferior ao nível dos 5% piores humanos). A investigação indica que o aumento da escala do modelo ou a ativação do modo de “pensamento” nem sempre melhora a capacidade de raciocínio puro, e as técnicas existentes de aprimoramento do raciocínio têm resultados mistos. Isto revela que os atuais grandes modelos ainda têm lacunas significativas na compreensão espacial e no raciocínio lógico profundo. (Fonte: 全球顶尖AI来考公,不会推理全翻车,致命缺陷曝光,被倒数5%人类碾压)
InternVL3: Explorando técnicas avançadas de treino e teste para modelos multimodais open-source: O artigo “InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models” apresenta o modelo InternVL3, cuja versão de 78B alcançou uma pontuação de 72.2 no benchmark MMMU, estabelecendo um novo recorde para MLLM open-source. As tecnologias chave incluem pré-treino multimodal nativo, codificação de posição visual variável (V2PE) que suporta contexto longo, técnicas avançadas de pós-treino (SFT, MPO) e estratégias de expansão em tempo de teste (melhorando o raciocínio matemático). A investigação visa explorar métodos eficazes para melhorar o desempenho de modelos multimodais open-source e já disponibilizou dados de treino e pesos do modelo. (Fonte: Reddit r/deeplearning)

Geobench: Benchmark para avaliar a capacidade de geolocalização de imagens por grandes modelos: Geobench é um novo site de benchmark dedicado a medir a capacidade de grandes modelos de linguagem (LLM) inferirem a localização de filmagem com base em imagens como as do Google Street View, semelhante a jogar GeoGuessr. Avalia a precisão das suposições do modelo, incluindo a taxa de acerto do país/região, a distância até à localização real (média e mediana), entre outras métricas. Os resultados preliminares mostram que a série de modelos Gemini da Google se destaca nesta tarefa, possivelmente beneficiando do seu acesso aos dados do Google Street View. (Fonte: Reddit r/LocalLLaMA)
Discussão sobre práticas padrão para divisão de datasets: A comunidade de machine learning do Reddit discutiu como lidar com datasets (por exemplo, divisão train/val/test) na ausência de uma divisão padrão. As práticas comuns incluem gerar divisões aleatórias (mas pode afetar a reprodutibilidade), guardar e partilhar índices/ficheiros específicos, usar validação cruzada k-fold. A discussão enfatizou que, para datasets pequenos, a forma de divisão tem um impacto significativo na avaliação de desempenho e nas declarações de state-of-the-art (SOTA), apelando à padronização ou partilha mais ampla de informações de divisão para melhorar a reprodutibilidade e comparabilidade da investigação. Os desafios práticos incluem a falta de uma plataforma unificada e normas específicas de domínio. (Fonte: Reddit r/MachineLearning, Reddit r/MachineLearning)
Procura de conselhos sobre embeddings de frases para classificação de posts do Stack Overflow: Um utilizador no Reddit pediu conselhos sobre o uso de embeddings de frases (como BERT, SBERT) para classificação não supervisionada de posts do Stack Overflow (incluindo título, descrição, tags, respostas). O objetivo é alcançar uma classificação ao nível da frase, indo além de simples etiquetas de embeddings de palavras (como “instalação de pacote”), explorando agrupamentos de tópicos ou tipos de problemas mais profundos. Os comentários sugeriram começar com a biblioteca Sentence Transformers, que pode gerar um único embedding para segmentos de texto, e depois aplicar algoritmos de clustering. (Fonte: Reddit r/MachineLearning)
Conselhos sobre percursos de aprendizagem em IA e escolhas de carreira: Um estudante do ensino secundário consultou no Reddit sobre a escolha de curso universitário para entrar na área de engenharia de machine learning (UCSD CS vs Cal Poly SLO CS) e se seria necessário fazer mestrado. Os comentários sugeriram escolher a UCSD, com maior força em investigação, e considerar o mestrado, pois a engenharia de ML geralmente exige qualificações académicas mais elevadas. Ao mesmo tempo, alguém apontou que as competências práticas são igualmente importantes, e matemática e estatística são bases cruciais. Noutro post, alguém perguntou sobre cursos para utilizar IA ou desenvolver IA; os comentários mencionaram Ciência da Computação (CS), geralmente exigindo mestrado/doutoramento, bem como matemática/estatística. Houve até quem sugerisse aprender competências práticas como canalização ou outras profissões manuais para evitar o risco de substituição pela IA. (Fonte: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)
💼 Negócios
Exploração da comercialização da IA na saúde: Estratégias das grandes empresas vs. necessidades hospitalares: Com os hospitais a começarem a alocar orçamento para grandes modelos (como o Hospital Provincial de Jiangsu que comprou uma plataforma baseada em DeepSeek por 4,5 milhões de yuan), a comercialização da IA na área da saúde acelera. Grandes empresas como Huawei, Alibaba, Baidu, Tencent estão a posicionar-se, geralmente fornecendo poder de computação, serviços na nuvem e modelos base, em parceria com empresas verticais de saúde. No entanto, o modelo de negócio principal ainda não está claro; as grandes empresas atualmente focam-se mais na venda de hardware e serviços na nuvem do que em aprofundar diretamente as aplicações de IA na saúde. Do lado dos hospitais, como o Hospital 3201 em Hanzhong, Shaanxi, com orçamentos limitados, estão a experimentar modelos open-source (como versões de baixo custo do DeepSeek), mostrando uma consideração pela relação custo-benefício. Obter dados médicos de alta qualidade e treinar modelos especializados continua a ser um desafio chave, exigindo superar o “trabalho árduo” da anotação de dados. (Fonte: AI看病这件事,华为、百度、阿里谁先挣到钱?, 科技大厂掀起医疗界的AI革命,谁更有胜算?)
Fiabilidade de ferramentas de recomendação AI como DeepSeek questionada, otimização de marketing AI torna-se novo campo de batalha: Ferramentas de IA como DeepSeek são cada vez mais usadas para obter recomendações (por exemplo, restaurantes, produtos), e os comerciantes começam a usar “Recomendado pelo DeepSeek” como etiqueta de marketing. No entanto, a fiabilidade destas recomendações levanta preocupações. Por um lado, a IA pode ter “alucinações”, inventando lojas inexistentes ou recomendando produtos desatualizados. Por outro lado, as respostas da IA podem ser influenciadas comercialmente, com risco de publicidade inserida ou “contaminação” por estratégias de SEO/GEO (Generative Engine Optimization). Os comerciantes estão a tentar otimizar conteúdo e palavras-chave para influenciar o corpus da IA e os resultados de pesquisa, aumentando a visibilidade da sua marca. Isto desafia a objetividade das recomendações da IA, e os consumidores devem estar atentos a informações potencialmente enganosas. (Fonte: 第一批用DeepSeek推荐的人,已上当)

Zhipu AI recebe investimento adicional de 200 milhões de yuan do Fundo de Investimento da Indústria de Inteligência Artificial de Pequim: Após anunciar o lançamento de vários novos modelos open-source e a criação de um fundo open-source de 300 milhões de yuan, a Zhipu AI (Z.ai) recebeu um investimento adicional de 200 milhões de yuan do Fundo de Investimento da Indústria de Inteligência Artificial de Pequim. Este fundo já tinha investido na Zhipu no ano passado. Este aumento de capital visa apoiar a investigação e desenvolvimento de modelos open-source da Zhipu e a construção do ecossistema da comunidade open-source, refletindo também a determinação de Pequim em promover o desenvolvimento da indústria de IA e em tornar-se a “Capital Global do Open-Source”. (Fonte: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
CEO da Intel, Chen Lihwu, impulsiona reforma, nomeia novo CTO e Chief AI Officer: O novo CEO, Chen Lihwu, está a realizar ajustes na estrutura organizacional da Intel, visando simplificar os níveis de gestão e fortalecer a orientação tecnológica. Os departamentos chave de chips (Data Center & AI, PC Chips) reportarão diretamente ao CEO. Sachin Katti, responsável pelos chips de rede, foi nomeado o novo Chief Technology Officer (CTO) e Chief AI Officer, responsável por liderar a estratégia de IA, o roadmap de produtos e os Intel Labs, para enfrentar os desafios da Nvidia no campo da IA. Esta medida é vista como parte do plano de Chen Lihwu para revitalizar a Intel, com o objetivo de resolver dificuldades de fabrico e produto, quebrar barreiras internas e focar na engenharia e inovação. (Fonte: 陈立武挥刀高层,英特尔重生计划曝光,技术团队直通华人CEO)

Meta alegadamente procura partilhar custos de treino do Llama, evidenciando pressão do investimento em IA: Segundo relatos, a Meta contactou a Microsoft, Amazon, Databricks e outras empresas e instituições de investimento, propondo partilhar os custos de treino do seu modelo open-source Llama (a “Aliança Llama”), em troca de alguma influência no desenvolvimento de funcionalidades, mas a resposta inicial foi fria. As razões podem incluir a relutância dos parceiros em investir num modelo gratuito, a falta de vontade da Meta em ceder demasiado controlo e o facto de os potenciais parceiros já terem investimentos substanciais em IA. Este caso evidencia que mesmo gigantes como a Meta enfrentam a pressão do aumento dos custos de desenvolvimento de IA, especialmente com despesas de capital enormes (previstas aumentar 60% anualmente para 60-65 mil milhões de dólares) e um caminho de comercialização incerto para o modelo open-source. (Fonte: Llama开源太贵了,Meta被曝向亚马逊、微软“化缘”)

CEO da Nvidia, Jensen Huang, visita a China, pode discutir colaboração com DeepSeek e outros para lidar com restrições comerciais: O CEO da Nvidia, Jensen Huang, visitou recentemente a China, a convite do Conselho Chinês para a Promoção do Comércio Internacional, e reuniu-se com clientes, incluindo o fundador da DeepSeek, Liang Wenfeng. Esta visita ocorre num contexto complexo, incluindo o endurecimento das restrições do governo dos EUA à exportação de chips da Nvidia para a China (como o H20), o surgimento de chips de IA locais chineses (como o Ascend da Huawei) e a otimização de modelos como o DeepSeek, que reduz a dependência absoluta de GPUs de ponta da Nvidia. Analistas acreditam que Huang pode ter como objetivo discutir com parceiros chineses (como a DeepSeek) o design conjunto de chips de IA que cumpram as restrições de exportação dos EUA, evitando ao mesmo tempo as elevadas tarifas de importação chinesas, através de uma colaboração profunda para manter a quota de mercado e a influência na indústria na China. (Fonte: 英伟达CEO黄仁勋突然访华,都不穿皮衣了,还见了梁文锋)

🌟 Comunidade
Febre da geração de bonecos AI invade redes sociais, gerando preocupações sobre direitos de autor e ética: Uma tendência de usar ferramentas de IA como o ChatGPT para transformar fotos pessoais em imagens de bonecos (estilo semelhante à Barbie, com caixa de embalagem e acessórios personalizados) tornou-se popular em plataformas como LinkedIn e TikTok. Os utilizadores podem gerar as imagens carregando fotos e fornecendo descrições detalhadas. Embora divertido, isto também levanta preocupações sobre direitos de autor e ética: a geração por IA pode inadvertidamente usar estilos artísticos ou elementos de marca protegidos por direitos de autor; ao mesmo tempo, o grande consumo de energia necessário para treinar e operar estes modelos de IA também é alvo de atenção. Alguns comentários apontam para a necessidade de estabelecer limites e normas claras ao usar IA. (Fonte: 芭比风AI玩偶席卷全网:ChatGPT几分钟打造你的时尚分身)

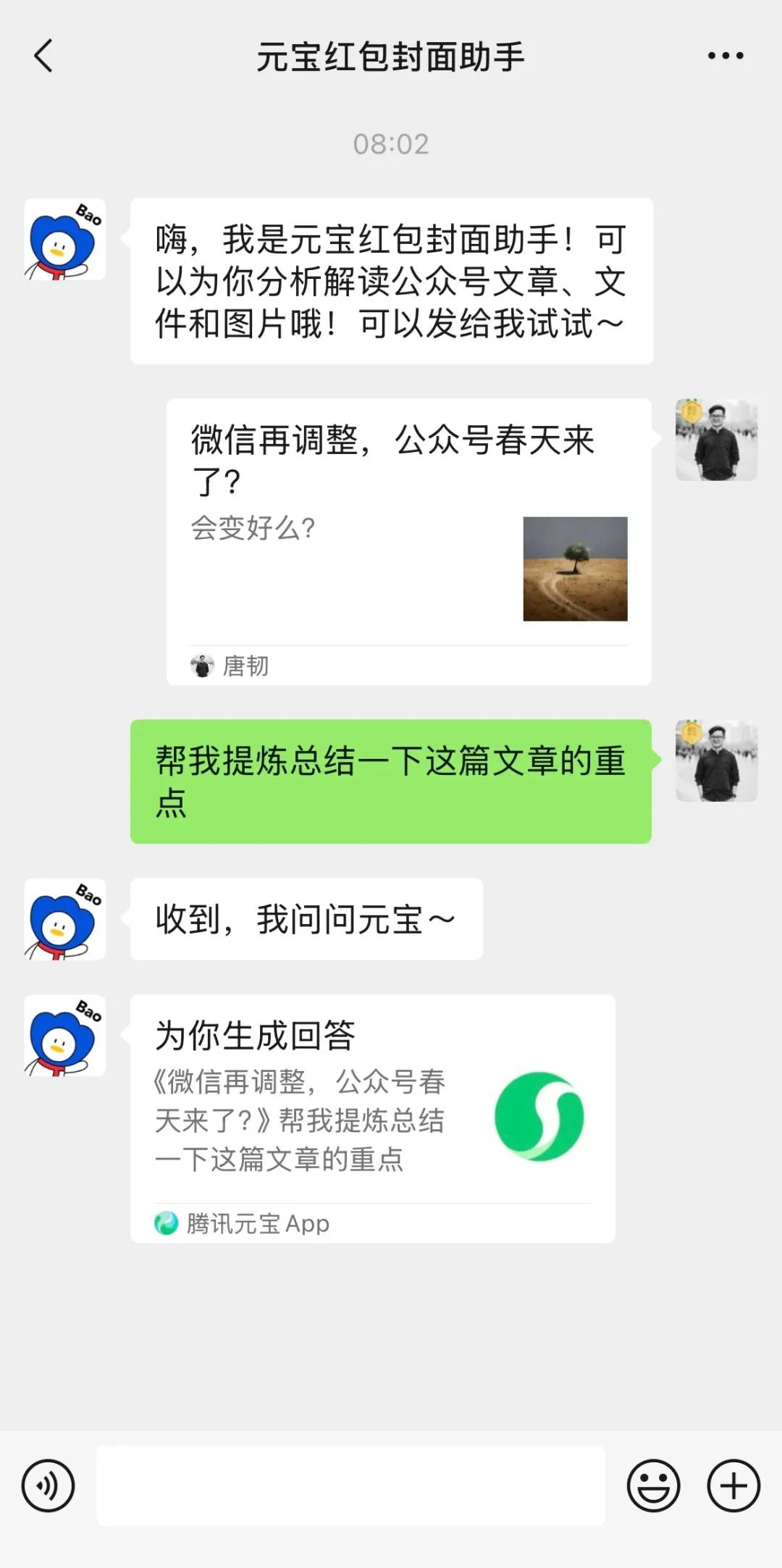
Integração profunda do Tencent Yuanbao (anteriormente assistente de capas de红包) no WeChat chama a atenção: Pesquisar por “Yuanbao” dentro do WeChat permite chamar diretamente funcionalidades de IA, sendo na verdade uma versão atualizada do anterior “Assistente de Capas de 红包 Yuanbao”. A experiência do utilizador mostra capacidades melhoradas, como gerar imagens mais precisas com base nos requisitos e otimização da adaptação nativa, podendo gerar cartões de resposta. O artigo discute a possibilidade de a grande aposta da Tencent em IA recair sobre o cenário do WeChat, especialmente utilizando entradas existentes como o assistente de transferência de ficheiros, considerando a vantagem do cenário como chave para a implementação da IA da Tencent. Menciona também a recente atualização das contas oficiais do WeChat, que adicionou uma entrada de publicação móvel, podendo incentivar a criação de conteúdo curto, mas potencialmente afetando o ecossistema de textos longos. (Fonte: 鹅厂的 AI 大招,真的落在微信上)
LMArena lança site de teste Beta: A arena de competição de grandes modelos LMArena lançou um novo site de teste Beta (beta.lmarena.ai) para testar vários grandes modelos, incluindo modelos ainda não lançados. Isto fornece à comunidade uma nova plataforma, independente da interface Gradio do Hugging Face, para avaliar e comparar o desempenho dos modelos. (Fonte: karminski3)
Exposição pública de instâncias Ollama gera preocupações de segurança: Um utilizador descobriu um site chamado freeollama.com e, através de pesquisa no ciberespaço, encontrou um grande número de hosts que expõem a porta do Ollama (ferramenta para implementar grandes modelos localmente, geralmente a porta 11434) em IPs públicos sem firewall configurada. Isto constitui um risco de segurança grave, podendo levar a acesso não autorizado e abuso dos modelos implementados localmente. Alerta-se os utilizadores para terem atenção à configuração de segurança de rede ao implementar, evitando expor serviços sem proteção à rede pública. (Fonte: karminski3)
Uso do ChatGPT para apoio psicológico gera discussão e alerta: Utilizadores do Reddit partilharam experiências de uso do ChatGPT para ajudar a lidar com problemas como depressão e ansiedade, descobrindo que as suas sugestões podem carecer de consistência, parecendo mais validar as opiniões existentes do utilizador do que fornecer orientação fiável. Quando confrontado com a sua própria lógica em chats diferentes, o ChatGPT admitia o erro. Os utilizadores alertam que a IA pode ser apenas um “bajulador digital” e não deve ser usada para apoio psicoterapêutico sério. A secção de comentários discute como usar a IA de forma mais eficaz (por exemplo, pedindo-lhe para desempenhar um papel crítico, fornecer múltiplas perspetivas) e as limitações da IA em substituir profissionais humanos na intervenção em crises. (Fonte: Reddit r/ChatGPT)
As três leis da tecnologia de Douglas Adams geram identificação: Um utilizador cita as três leis da tecnologia do escritor de ficção científica Douglas Adams, que descrevem humoristicamente as reações comuns de pessoas de diferentes faixas etárias a novas tecnologias: tecnologias existentes ao nascer são vistas como normais, tecnologias que surgem na juventude são vistas como revolucionárias, e tecnologias que aparecem mais tarde na vida são vistas como heréticas. Este comentário ressoa no contexto do rápido desenvolvimento da IA, sugerindo que a aceitação de tecnologias disruptivas como a IA pode estar relacionada com a fase da vida em que as pessoas se encontram. (Fonte: dotey)
Experiência do utilizador: ChatGPT torna-se “demasiado real” ou “Gen Z-ificado”: Um post no Reddit mostra uma captura de ecrã de uma conversa com o ChatGPT, cujo estilo de resposta foi descrito pelo utilizador como “demasiado real” ou contendo gíria e memes da internet da “Geração Z” (como “Let me cook”). As reações nos comentários foram mistas: alguns acharam divertido, outros consideraram o estilo “desconfortável” ou “infantilizado”. Isto reflete as diferentes perceções dos utilizadores sobre a personalidade e o estilo linguístico da IA, bem como os potenciais problemas de experiência que podem surgir da imitação das tendências linguísticas da internet pelo modelo. (Fonte: Reddit r/ChatGPT)
Geração por IA de instantâneos da vida futura gera discussão criativa: Um utilizador partilhou uma série de imagens geradas pelo ChatGPT no estilo “Snapchat da vida futura”, retratando cenários como empregados robôs, animais de estimação AI, transportes futuros, etc. Estas imagens criativas geraram discussão na comunidade sobre as capacidades de geração de imagem da IA e a imaginação sobre a vida futura, elogiando a sua criatividade e o realismo crescente. (Fonte: Reddit r/ChatGPT)
Utilizador partilha uso do ChatGPT para transformar esboços à mão em imagens realistas: Um artista utilizador demonstrou o processo e os resultados de usar o ChatGPT para transformar os seus próprios esboços surrealistas feitos à mão em imagens realistas. A comunidade elogiou, considerando-a uma forma interessante de experimentação artística que pode ajudar os artistas a explorar ideias e diferentes estilos, em vez de simplesmente procurar imagens “melhores”. (Fonte: Reddit r/ChatGPT)
💡 Outros
Reflexão sobre a construção de sistemas de IA: “A Amarga Revelação” e a prioridade da computação: O artigo cita a teoria da “Amarga Revelação” de Richard Sutton, apontando que no desenvolvimento da IA, os sistemas que dependem da expansão da capacidade computacional genérica (impulsionados pelo poder de computação) acabarão por superar os sistemas que dependem de regras complexas cuidadosamente desenhadas por humanos. Através da comparação de casos de IA de atendimento ao cliente (sistema baseado em regras vs. IA com computação limitada vs. IA exploratória com grande computação) e do sucesso da aprendizagem por reforço (RL) (como na investigação profunda da OpenAI, Claude), enfatiza que as empresas devem investir em infraestrutura computacional em vez de otimizar excessivamente algoritmos. O papel dos engenheiros deve transformar-se em “construtores de pistas” que criam ambientes de aprendizagem escaláveis. A ideia central é: arquitetura simples + computação em larga escala + aprendizagem exploratória > design complexo + regras fixas. (Fonte: 苦涩的启示:对AI系统构建方式的反思)
Exploração da ligação entre o campo da IA e as comunidades Racionalista/Altruísmo Eficaz: Um profissional de machine learning observou que o campo de investigação em IA parece ter duas subcomunidades com pouca interação, uma das quais está intimamente ligada às comunidades Racionalista (Rationalism) e do Altruísmo Eficaz (Effective Altruism, EA), publicando frequentemente investigações sobre previsões de AGI, problemas de alinhamento, e com ligações a certas grandes empresas da Bay Area. O autor aponta que esta comunidade, por vezes, ao discutir conceitos de ciência cognitiva (como consciência situacional), parece redefini-los independentemente do sistema académico existente. Por exemplo, a definição de “consciência situacional” da Anthropic foca-se na cognição do modelo sobre o seu processo de desenvolvimento, em vez da definição tradicional da ciência cognitiva baseada em modelos sensoriais e ambientais. (Fonte: Reddit r/ArtificialInteligence)
Utilizador descobre que chatbot AI usa inesperadamente o seu nickname de outras plataformas: Um utilizador, ao experimentar uma nova plataforma de chatbot AI sem fornecer qualquer informação pessoal, descobriu que o bot, na segunda mensagem, chamou-o pelo nickname que usa habitualmente noutras plataformas. Isto gerou preocupações no utilizador sobre privacidade de dados e rastreamento de informações entre plataformas, lamentando que possa já ter sido “rastreado” ou “perfilado”. (Fonte: Reddit r/ArtificialInteligence)
Nova abordagem para avaliação de modelos AI: Julgar inteligência através de relatório oral de 3 minutos: Propõe-se uma nova forma de avaliar a inteligência da IA: pedir aos modelos de IA de topo (como o o3 vs Gemini 2.5 Pro) para fazerem uma apresentação oral de 3 minutos sobre um tópico específico (política, economia, filosofia, etc.), sendo a sua inteligência julgada por ouvintes humanos. Argumenta-se que esta forma é mais intuitiva do que depender de benchmarks especializados e pode avaliar melhor a organização, retórica, emoção e desempenho intelectual do modelo, especialmente em tarefas que exigem persuasão. Esta forma de “debate AI” ou “concurso de discursos” pode tornar-se uma nova dimensão para avaliar as capacidades de modelos próximos da AGI. (Fonte: Reddit r/ArtificialInteligence)