
Palavras-chave:AI, 大模型 (grandes modelos), AI军备竞赛 (corrida armamentista de IA), 智谱AI IPO, AI独立发现物理定律 (IA a descobrir leis físicas independentemente), AI助盲系统 (sistema de IA para auxílio a deficientes visuais), aplicações de grandes modelos de IA em indústrias verticais, impacto da corrida armamentista de IA no mercado, detalhes sobre o IPO da 智谱AI, como a IA pode descobrir leis físicas sozinha, tecnologia de sistema de IA para apoio a cegos
“` markdown
🔥 Foco
Grandes empresas intensificam corrida armamentista de IA, com modelos verticais e ecossistemas em foco: Gigantes tecnológicos globais estão a investir em IA com uma intensidade sem precedentes, prevendo-se que as despesas de capital ultrapassem os 320 mil milhões de dólares em 2025. Empresas chinesas como Alibaba, Tencent, Huawei, etc., também estão a aumentar os seus investimentos, apostando fortemente em infraestrutura de IA, grandes modelos e poder computacional. O foco da competição está a deslocar-se de grandes modelos gerais para modelos de setores verticais, que se tornaram novos motores de crescimento devido às suas altas margens brutas e capacidade de resolver problemas práticos. Apesar dos desafios com chips de ponta, os fabricantes nacionais fizeram progressos na otimização de custos de computação e em modelos de inferência (‘pensamento lento’) (como o efeito DeepSeek). As abordagens variam: Alibaba investe fortemente em infraestrutura, Huawei inova em hardware (CloudMatrix 384) e promove a colaboração edge-cloud, Baidu foca-se em aplicações, enquanto Tencent e ByteDance aproveitam as suas vantagens em cenários diversificados. A extensão do hardware de IA e a construção de ecossistemas open-source (como HarmonyOS, Ascend, Hunyuan) tornaram-se cruciais, com a competição a evoluir de avanços tecnológicos pontuais para a capacidade de coordenação de ecossistemas. (Fonte: 36氪-科技云报道)

Descoberta surpreendente do MIT: IA deriva leis da física independentemente, sem conhecimento prévio: A equipa de Max Tegmark do MIT desenvolveu uma nova arquitetura MASS (Multiple AI Scalar Scientists). Este sistema de IA, sem qualquer informação prévia sobre leis da física, conseguiu aprender e propor de forma independente formulações teóricas altamente semelhantes ao Hamiltoniano ou Lagrangeano da mecânica clássica, analisando apenas dados observacionais de sistemas físicos como pêndulos e osciladores. A investigação mostra que a IA corrige autonomamente as suas teorias ao lidar com sistemas mais complexos, e diferentes “cientistas” de IA acabam por convergir para princípios físicos conhecidos, especialmente favorecendo a descrição Lagrangeana em sistemas complexos. Este resultado demonstra o enorme potencial da IA na descoberta científica fundamental, podendo vir a revelar independentemente as leis básicas do universo. (Fonte: 新智元)

Equipa da Universidade Jiao Tong de Xangai desenvolve sistema de assistência a cegos com IA, publicado na Nature子刊, permitindo que deficientes visuais “recuperem a visão”: A equipa de Gu Leilei da Universidade Jiao Tong de Xangai desenvolveu um sistema vestível de assistência a cegos impulsionado por IA, que combina tecnologia eletrónica flexível para substituir parcialmente a função visual através de feedback auditivo e tátil, ajudando pessoas com deficiência visual a realizar tarefas diárias como navegação e agarrar objetos. O hardware do sistema é leve, o software otimiza a forma de saída de informação para se adequar à cognição fisiológica humana, e foi desenvolvido um sistema de treino imersivo em VR. Testes indicam que o sistema melhora significativamente a capacidade de navegação, prevenção de obstáculos e agarrar objetos de utilizadores com deficiência visual em ambientes virtuais e reais. Os resultados da investigação foram publicados na Nature Machine Intelligence, demonstrando o enorme potencial da IA na assistência a pessoas com deficiência visual, melhorando a sua capacidade de vida independente e fornecendo novas ideias para dispositivos de assistência visual vestíveis personalizados e fáceis de usar. (Fonte: 36氪)

Zhipu AI inicia processo de assessoria para IPO, a caminho de se tornar a “primeira ação de grandes modelos”: A empresa de grandes modelos de IA Zhipu AI (Beijing Zhipu Huazhang Technology), ligada à Universidade de Tsinghua, concluiu o registo de assessoria para IPO junto do regulador de valores mobiliários de Pequim em 14 de abril, com a CICC como assessora. O objetivo é o mercado de ações A-share, com potencial para se tornar a primeira “ação de grandes modelos de IA” da China. Embora o seu produto para o consumidor final “Zhipu Qingyan” tenha uma base de utilizadores modesta, a Zhipu, com o seu forte background técnico (ligada a Tsinghua, desenvolvimento próprio da série de modelos GLM), apoio estatal (incluída na lista de entidades dos EUA) e progresso na comercialização (serviços a clientes governamentais e empresariais, crescimento significativo de receitas), já obteve mais de 16 mil milhões em financiamento, com uma avaliação superior a 20 mil milhões, contando com investidores como VCs de renome, gigantes da indústria e fundos estatais de várias regiões. Face ao impacto de novas forças como a DeepSeek, a decisão da Zhipu de avançar para IPO é vista como um passo crucial para garantir uma posição vantajosa na competição acirrada, satisfazer as necessidades de financiamento e responder às expectativas dos investidores. A empresa tem continuado recentemente a disponibilizar em open-source a série de modelos GLM-4, demonstrando o seu esforço simultâneo nas frentes técnica e de capital. (Fonte: 36氪-真故研究室, 36氪-互联网爆料汇, 创投日报)

🎯 Tendências
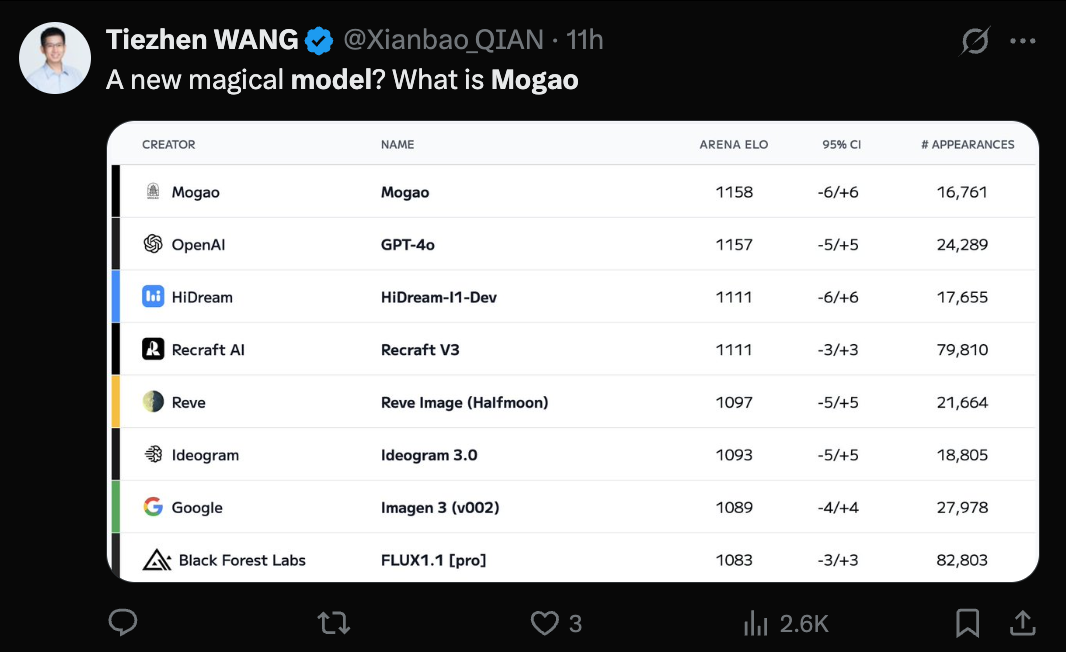
Modelo Seedream 3.0 (Mogao) da ByteDance revelado, capacidade de text-to-image reconhecida: O misterioso modelo Mogao, que recentemente liderou o ranking de text-to-image da Artificial Analysis, foi confirmado como sendo o Seedream 3.0, desenvolvido pela equipa Seed da ByteDance. O modelo destaca-se em realismo, design, anime e outros estilos, bem como na geração de texto, sendo particularmente bom a lidar com texto denso e a gerar retratos realistas. A taxa de usabilidade de caracteres chineses e ingleses atinge 94%, o realismo dos retratos aproxima-se do nível de fotografia profissional, suporta saída de imagem nativa em resolução 2K e tem uma velocidade de geração rápida. O relatório técnico revela várias inovações no processamento de dados (treino sensível a defeitos, amostragem de eixo duplo), pré-treino (arquitetura MMDiT, resolução mista, RoPE intermodal) e pós-treino (treino contínuo, SFT, RLHF, modelo de recompensa VLM), bem como na aceleração da inferência (Hyper-SD, RayFlow). Comparado com o GPT-4o, o Seedream 3.0 é superior em chinês, tipografia e cor. (Fonte: 36氪-机器之心)
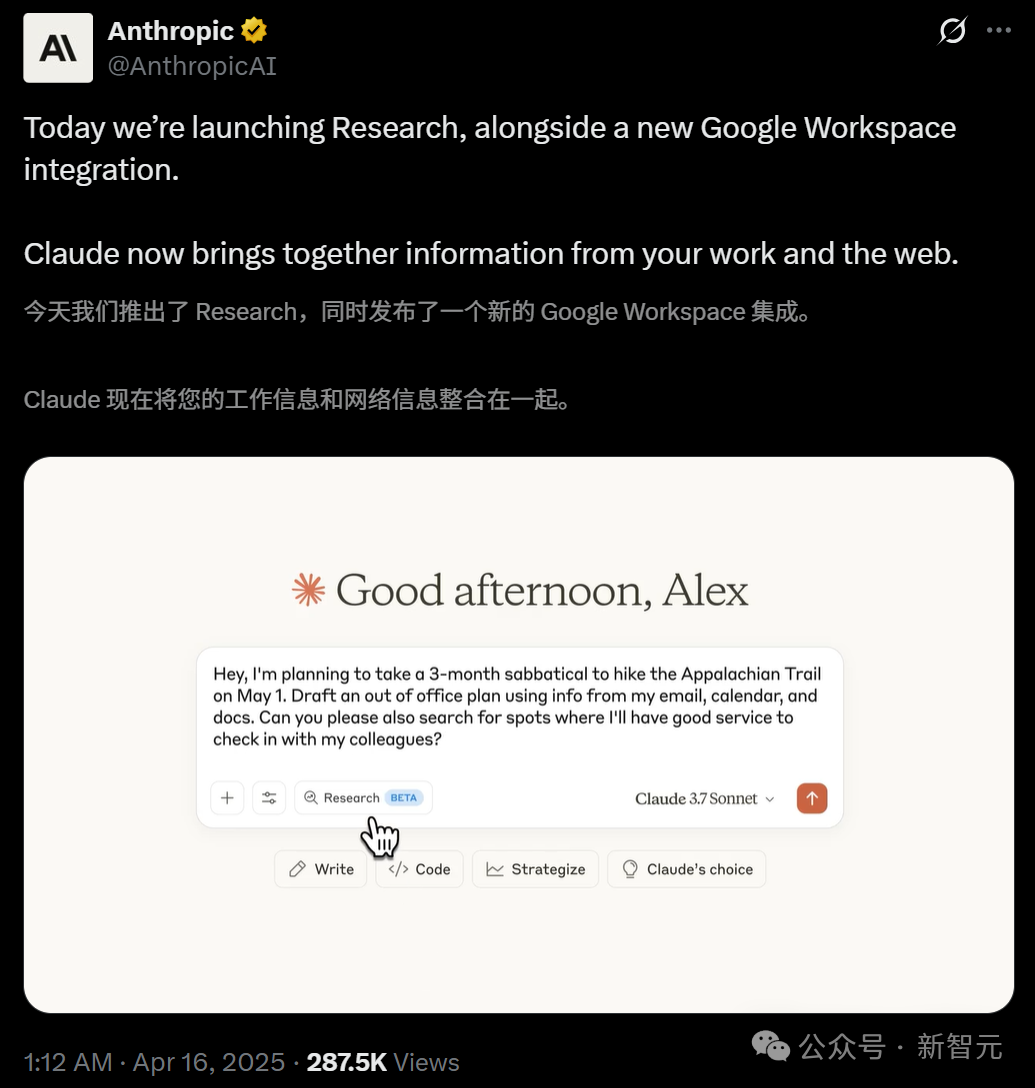
Claude lança funcionalidade Research e integra-se com Google Workspace: A Anthropic adicionou duas novas funcionalidades ao seu assistente de IA Claude: Research e integração com o Google Workspace. A funcionalidade Research permite que o Claude pesquise informações na internet e combine-as com ficheiros internos do utilizador (como Google Docs) para realizar análises multi-perspetiva, gerando rapidamente relatórios abrangentes. A integração com o Google Workspace conecta Gmail, Google Calendar e Docs, permitindo que o Claude compreenda a agenda, e-mails e conteúdo de documentos do utilizador, extraia informações e auxilie na conclusão de tarefas, como planear viagens com base em informações pessoais ou redigir e-mails. Estas funcionalidades visam aumentar significativamente a eficiência do trabalho do utilizador. A funcionalidade Research está atualmente em teste para utilizadores das versões Max, Team e Enterprise nos EUA, Japão e Brasil. A integração com o Workspace está em teste para todos os utilizadores pagos. O feedback dos utilizadores é positivo, indicando que aumenta a eficiência e ajuda a descobrir conexões entre dados, mas também existem preocupações sobre a segurança dos dados. (Fonte: 新智元, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
CUHK e Tsinghua lançam Video-R1, inaugurando novo paradigma de raciocínio em vídeo: Equipas da Universidade Chinesa de Hong Kong (CUHK) e da Universidade de Tsinghua lançaram conjuntamente o primeiro modelo de raciocínio em vídeo do mundo a adotar o paradigma R1 de aprendizagem por reforço, o Video-R1. Este modelo visa resolver a falta de lógica temporal e capacidade de raciocínio profundo nos modelos de vídeo existentes. Através da introdução do algoritmo T-GRPO sensível ao tempo e de um conjunto de dados de treino híbrido que combina imagens e vídeos (Video-R1-COT-165k e Video-R1-260k), o Video-R1 de 7B parâmetros superou o GPT-4o no benchmark de raciocínio espacial em vídeo VSI-Bench, proposto por Fei-Fei Li. O modelo demonstra “momentos de epifania” semelhantes aos humanos, capaz de realizar raciocínio lógico baseado em informações temporais. Experiências provam que aumentar o número de frames de entrada melhora a precisão do raciocínio. O projeto disponibilizou o modelo, código e conjuntos de dados em open-source, sinalizando que a IA de vídeo está a avançar de “compreender” para “pensar”. (Fonte: 新智元)

ICLR 2025 introduz revisão por IA em larga escala pela primeira vez, melhorando significativamente a qualidade da avaliação: Enfrentando o aumento exponencial de submissões e a queda na qualidade da revisão, a conferência ICLR 2025 implementou pela primeira vez em larga escala um “Agente Inteligente de Feedback de Revisão” (Review Feedback Agent) baseado em IA para auxiliar na revisão por pares. O sistema utiliza múltiplos LLMs, incluindo o Claude Sonnet 3.5, para identificar ambiguidades, incompreensões de conteúdo ou linguagem não profissional nas revisões, fornecendo sugestões específicas de melhoria aos revisores. A experiência cobriu 42,3% das revisões, e os resultados mostraram que o feedback da IA melhorou a qualidade da revisão em 89% dos casos. 26,6% dos revisores modificaram as suas revisões com base nas sugestões da IA, e as revisões modificadas aumentaram em média 80 palavras, tornando-se mais específicas e informativas. A intervenção da IA também aumentou a atividade e a profundidade da discussão entre autores e revisores durante o período de Rebuttal. Esta experiência pioneira demonstra o enorme potencial da IA na otimização do processo de revisão por pares. (Fonte: 新智元)

Robôs humanoides em casa geram debate, empresas de eletrodomésticos apostam na inteligência incorporada (embodied intelligence): A entrada de robôs humanoides no cenário doméstico suscita discussões na indústria sobre os seus modelos de aplicação e impacto no setor de eletrodomésticos. Argumenta-se que os robôs humanoides devem usar a sua característica “geral” para resolver tarefas não padronizadas como dobrar roupa e arrumar, e utilizar a capacidade de interação para atuar como “mordomos”, comandando e coordenando outros dispositivos inteligentes, em vez de simplesmente substituir eletrodomésticos existentes. Perante esta tendência, gigantes de eletrodomésticos como Haier e Midea já começaram a posicionar-se, lançando os seus próprios produtos de robôs humanoides (como o Kuavo) e explorando a integração da tecnologia de inteligência incorporada em eletrodomésticos tradicionais (como o aspirador com braço mecânico da Dreame, a máquina de lavar roupa da Yimu Technology capaz de agarrar roupa). Isto indica que a indústria de eletrodomésticos está a adaptar-se ativamente à onda da IA, podendo no futuro formar um ecossistema de casa inteligente simbiótico com robôs humanoides. (Fonte: 36氪-具身研习社)

Huawei lança servidor de IA CloudMatrix 384, visando competir com o Nvidia GB200: Na sua conferência de ecossistema cloud, a Huawei apresentou o seu mais recente cluster de servidores de IA, o CloudMatrix 384. O sistema é composto por 384 placas de computação Ascend, com um único cluster atingindo 300 PFlops de poder computacional e um débito de descodificação por placa de 1920 Tokens/s, desempenho que visa diretamente o H100 da Nvidia. Utiliza interconexão de alta velocidade totalmente ótica (6812 módulos óticos de 400G), com uma eficiência de treino próxima de 90% do desempenho de uma única placa Nvidia. Esta medida é vista como um passo importante da China para alcançar o nível internacional de liderança em infraestrutura de IA, visando responder à procura por poder computacional face às restrições de chips de ponta. Analistas consideram que isto demonstra o rápido progresso da Huawei no domínio do hardware de IA, podendo impactar a atual estrutura do mercado. (Fonte: dylan522p, 36氪-科技云报道)
Google lança funcionalidade text-to-video Veo 2 e Whisk Animate: A Google integrou o seu modelo text-to-video Veo 2 no Gemini Advanced. Os utilizadores membros podem usar esta funcionalidade gratuitamente através da Gemini App, gerando vídeos com 8 segundos de duração. Simultaneamente, a ferramenta de edição de imagem da Google, Whisk, foi atualizada com a funcionalidade Whisk Animate, permitindo aos utilizadores, após gerarem uma imagem, convertê-la em vídeo usando o Veo 2. No entanto, esta funcionalidade requer uma subscrição Google One. Isto marca o esforço contínuo da Google no campo da geração multimodal, oferecendo aos utilizadores ferramentas de criação mais ricas. (Fonte: op7418, op7418)
OpenAI poderá construir produto social semelhante ao X: Segundo o The Verge, a OpenAI está a desenvolver internamente um protótipo de produto social semelhante ao X (anteriormente Twitter). Este produto poderia combinar as capacidades de geração de imagem do ChatGPT (especialmente após o lançamento do GPT-4o) com um feed de atividades sociais. Considerando a vasta base de utilizadores do ChatGPT e os seus avanços na geração de imagens, esta medida é considerada viável e pode marcar uma tentativa da OpenAI de expandir as suas capacidades de IA para o domínio das redes sociais. (Fonte: op7418)
DeepCoder lança modelo de codificação open-source de 14B de alto desempenho: A equipa DeepCoder lançou um modelo de codificação open-source de 14 mil milhões de parâmetros de alto desempenho, que alegadamente se destaca em tarefas de codificação. O lançamento deste modelo oferece aos programadores mais uma opção poderosa de ferramenta de geração e assistência de código, especialmente em cenários que exigem um equilíbrio entre desempenho e tamanho do modelo. (Fonte: Ronald_vanLoon)

Tesla implementa estacionamento automático para veículos à saída da fábrica: A Tesla demonstrou um novo avanço na sua tecnologia de condução autónoma: os veículos, após saírem da linha de produção na fábrica, conseguem dirigir-se autonomamente para a zona de carregamento ou parque de estacionamento, sem intervenção humana. Isto mostra o potencial de aplicação da capacidade FSD (Full Self-Driving) da Tesla em ambientes específicos e controlados, ajudando a aumentar a eficiência logística da produção e sendo também um passo em direção a aplicações de condução autónoma mais amplas. (Fonte: Ronald_vanLoon, Ronald_vanLoon)
Dexterity lança robô industrial Mech impulsionado por “IA Física”: A empresa Dexterity lançou um robô industrial chamado Mech, cuja característica distintiva é a utilização da tecnologia “Physical AI” (IA Física). Esta IA permite que o robô navegue e opere em ambientes industriais complexos, demonstrando flexibilidade e adaptabilidade sobre-humanas, com o objetivo de resolver tarefas complexas que a automação industrial tradicional tem dificuldade em lidar. (Fonte: Ronald_vanLoon)
MIT desenvolve novo robô saltador, projetado para terrenos acidentados: Investigadores do MIT desenvolveram um novo tipo de robô cujo design é inspirado no movimento de salto, sendo especialmente hábil a mover-se em terrenos acidentados e irregulares. Este robô demonstra a aplicação da biomimética no design de robôs e o potencial do machine learning no controlo de movimentos complexos, com potencial aplicação em busca e salvamento, exploração planetária e outros ambientes complexos. (Fonte: Ronald_vanLoon)
INTELLECT-2 iniciado: Treino distribuído global de modelo de 32B com aprendizagem por reforço: O projeto Prime Intellect iniciou o plano INTELLECT-2, que visa treinar um modelo avançado de raciocínio de 32 mil milhões de parâmetros utilizando recursos de computação distribuída globalmente e aprendizagem por reforço. O modelo é baseado na arquitetura Qwen e o seu objetivo é alcançar um “orçamento de pensamento” controlável, ou seja, o utilizador pode especificar quantos passos de raciocínio (quantos tokens pensar) o modelo deve realizar antes de resolver um problema. Esta é uma exploração importante do treino distribuído e da aprendizagem por reforço na melhoria da capacidade de raciocínio de modelos grandes. (Fonte: Reddit r/LocalLLaMA)

ByteDance lança modelo autorregressivo multimodal Liquid, semelhante ao GPT-4o: A ByteDance lançou uma série de modelos multimodais chamada Liquid. Este modelo adota uma arquitetura autorregressiva semelhante à do GPT-4o, capaz de receber inputs de texto e imagem e gerar outputs de texto ou imagem. Diferente dos MLLMs anteriores que usavam embeddings visuais pré-treinados externamente, o Liquid usa um único LLM para geração autorregressiva. Uma versão de 7B do modelo e um Demo já foram lançados no Hugging Face. Avaliações preliminares consideram que a qualidade da geração de imagem ainda não atinge a do GPT-4o, mas a sua arquitetura unificada é um avanço técnico importante. (Fonte: Reddit r/LocalLLaMA)
Executar múltiplos LLMs através de tecnologia de snapshot de memória da GPU: Discute-se uma técnica que permite alternar e executar rapidamente múltiplos LLMs através do snapshot do estado da memória da GPU (incluindo pesos, cache KV, layout de memória, etc.). Este método, semelhante à operação fork de um processo, consegue restaurar o estado do modelo em segundos (cerca de 2 segundos para um modelo 70B, 0.5 segundos para um 13B), sem necessidade de recarregar ou reinicializar. As suas vantagens potenciais incluem a execução de dezenas de LLMs num único nó de GPU para reduzir custos de inatividade, permitir a comutação dinâmica de modelos sob demanda e utilizar o tempo ocioso para fine-tuning local, entre outros. (Fonte: Reddit r/MachineLearning)
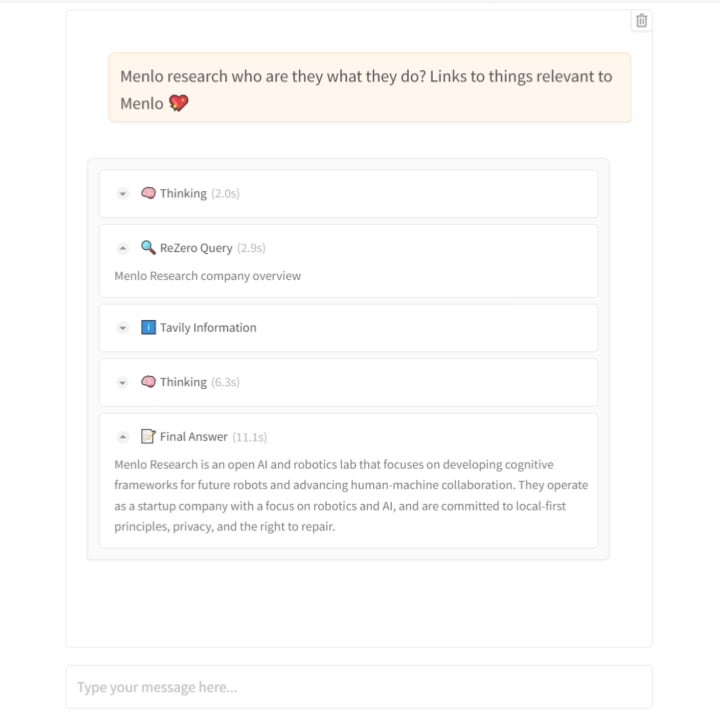
Menlo Research lança modelo ReZero: Ensinar a IA a pesquisar com “persistência”: A equipa da Menlo Research lançou um novo modelo e artigo chamado ReZero. O modelo baseia-se na ideia de que “a pesquisa requer múltiplas tentativas”, utilizando GRPO (um algoritmo de otimização de aprendizagem por reforço) e capacidade de chamada de ferramentas para treino, introduzindo também uma “recompensa por tentar novamente” (retry_reward). O objetivo do treino é fazer com que o modelo, ao encontrar dificuldades ou resultados de pesquisa iniciais insatisfatórios, tente pesquisar ativa e repetidamente até encontrar a informação necessária. Experiências mostram que, em comparação com modelos de base, o desempenho do ReZero melhora significativamente (46% vs 20%), provando a eficácia da estratégia de pesquisa repetida e desafiando a noção de que “repetição equivale a alucinação”. O modelo pode ser usado para otimizar a geração de consultas de motores de busca existentes ou como uma camada de melhoria de pesquisa para LLMs. O modelo e o código foram disponibilizados em open-source. (Fonte: Reddit r/LocalLLaMA)
Hugging Face adquire startup de robôs humanoides: A Hugging Face, conhecida comunidade e plataforma de IA open-source, adquiriu uma startup de robôs humanoides cujos detalhes não foram revelados. Esta medida pode sinalizar a intenção da Hugging Face de expandir as capacidades da sua plataforma de software e modelos para o domínio do hardware e robótica, impulsionando ainda mais a aplicação da IA no mundo físico, especialmente na área de embodied intelligence. (Fonte: Reddit r/ArtificialInteligence)

🧰 Ferramentas
Modelo TTS emocional open-source Orpheus lançado, suporta inferência em streaming e clonagem de voz: A Canopy Labs lançou em open-source uma série de modelos text-to-speech (TTS) chamada Orpheus (até 3 mil milhões de parâmetros, baseada na arquitetura Llama). Alega-se que o desempenho deste modelo supera os modelos open-source existentes e alguns modelos proprietários. A sua característica distintiva é a capacidade de gerar voz humanizada com entoação, emoção e ritmo naturais, conseguindo até inferir e gerar sons não verbais como suspiros e risos a partir do texto, demonstrando uma certa capacidade de “empatia”. O Orpheus suporta clonagem de voz zero-shot, entoação emocional controlável e alcança inferência em streaming de baixa latência (cerca de 200ms), adequada para aplicações de conversação em tempo real. O projeto fornece vários tamanhos de modelo e tutoriais de fine-tuning, visando reduzir a barreira para a síntese de voz de alta qualidade. (Fonte: 36氪)

Plataforma Trae.ai disponibiliza Gemini 2.5 Pro gratuitamente: A plataforma de ferramentas de IA Trae.ai anunciou que já disponibilizou o mais recente modelo da Google, Gemini 2.5 Pro, e oferece o seu uso gratuito. Os utilizadores podem experimentar as várias capacidades do Gemini 2.5 Pro na plataforma. (Fonte: dotey)
Ferramenta de recrutamento AI Hireway: seleciona 800 candidatos num dia: A Hireway demonstrou a capacidade da sua ferramenta de recrutamento AI, alegando que consegue selecionar eficientemente 800 candidatos num único dia. A ferramenta utiliza IA e tecnologia de automação para otimizar o processo de recrutamento, aumentando a eficiência da seleção e a experiência do candidato. (Fonte: Ronald_vanLoon)
PRIMA.CPP: Acelera a inferência de modelos grandes de 70B em clusters domésticos comuns: PRIMA.CPP é um projeto open-source baseado no llama.cpp, que visa otimizar e acelerar a velocidade de inferência de grandes modelos de linguagem (LLM) de até 70 mil milhões de parâmetros em clusters de computação doméstica comuns com recursos limitados (podendo envolver vários PCs ou dispositivos comuns). O projeto foca-se na eficiência da inferência distribuída, oferecendo novas possibilidades para executar modelos grandes localmente. O artigo foi publicado no Hugging Face. (Fonte: Reddit r/LocalLLaMA)

Partilha de Prompt para personagens de peluche: Um utilizador partilhou um conjunto de prompts para gerar personagens de animais adoráveis em estilo de peluche 3D, adequados para ferramentas de geração de imagem como Sora ou GPT-4o. O prompt foca-se na descrição detalhada, como textura ultra macia, pelo denso, olhos grandes, luz e sombra suaves e fundo, visando gerar renderizações de alta qualidade adequadas para mascotes de marca ou personagens IP. (Fonte: dotey)

📚 Aprendizagem
Jeff Dean partilha materiais da sua palestra na ETH Zurich: O Cientista Chefe da Google DeepMind, Jeff Dean, partilhou a gravação e os links dos slides da sua palestra no Departamento de Ciência da Computação da ETH Zurich. O conteúdo da palestra pode abordar os últimos avanços no campo da IA, direções de investigação ou resultados de pesquisa da Google, fornecendo um recurso de aprendizagem valioso para investigadores e estudantes. (Fonte: JeffDean)
Publicado relatório técnico sobre revisão por IA na ICLR 2025: Juntamente com a notícia da introdução da revisão por IA na ICLR 2025, foi publicado um relatório técnico detalhado de 30 páginas (arXiv:2504.09737). O relatório descreve em detalhe o design experimental, os modelos de IA utilizados (com o Claude Sonnet 3.5 como núcleo), o mecanismo de geração de feedback, os métodos de teste de fiabilidade e a análise quantitativa do impacto na qualidade da revisão, na atividade da discussão e na decisão final. Este relatório fornece uma referência aprofundada para compreender o potencial, os desafios e os detalhes de implementação da IA na revisão por pares académica. (Fonte: 新智元)
Artigo, código e conjuntos de dados do modelo de raciocínio em vídeo Video-R1 em open-source: As equipas da CUHK e Tsinghua não só lançaram o modelo Video-R1, como também disponibilizaram completamente em open-source o seu artigo técnico (arXiv:2503.21776), o código de implementação (GitHub: tulerfeng/Video-R1) e os dois conjuntos de dados chave usados para treino (Video-R1-COT-165k e Video-R1-260k). Isto fornece à comunidade de investigação recursos completos para replicar, melhorar e explorar ainda mais o paradigma R1 de raciocínio em vídeo, ajudando a impulsionar o desenvolvimento tecnológico nesta área. (Fonte: 新智元)
Publicado artigo sobre IA a descobrir leis da física de forma independente: Os resultados da investigação da equipa de Max Tegmark do MIT sobre o sistema de IA MASS capaz de descobrir independentemente o Hamiltoniano e o Lagrangeano foram publicados como um artigo pré-print (arXiv:2504.02822v1). O artigo detalha a filosofia de design da arquitetura MASS, o algoritmo central (aprendizagem de funções escalares baseada no princípio da conservação da ação), a configuração experimental (diferentes sistemas físicos, cenários com um ou múltiplos cientistas de IA) e a descoberta de como a teoria da IA evolui com a complexidade dos dados e eventualmente converge para as formulações da mecânica clássica. Este artigo fornece uma base teórica e empírica importante para explorar a aplicação da IA na descoberta científica fundamental. (Fonte: 新智元)
Publicado artigo sobre PRIMA.CPP: O artigo técnico que apresenta o projeto PRIMA.CPP (que visa acelerar a inferência de LLMs de escala 70B em clusters de baixos recursos) foi publicado no Hugging Face Papers (ID: 2504.08791). O artigo provavelmente detalha as técnicas de otimização adotadas, as estratégias de inferência distribuída e os resultados de avaliação de desempenho em configurações de hardware específicas, fornecendo detalhes técnicos de referência para investigadores e praticantes da área. (Fonte: Reddit r/LocalLLaMA)
Análise aprofundada do modelo RWKV-7 e conversa com o autor: Oxen.ai publicou um vídeo e um artigo de blog com uma análise aprofundada do modelo RWKV-7 (Goose). O conteúdo abrange os problemas que a arquitetura RWKV tenta resolver, a sua forma de iteração e as suas características técnicas centrais. O destaque é que o vídeo inclui uma entrevista e sessão de perguntas e respostas com um dos principais autores do modelo, Eugene Cheah, fornecendo uma perspetiva valiosa do autor para entender este LLM de arquitetura não-Transformer e explorando conceitos interessantes como “Learning at Test Time”. (Fonte: Reddit r/MachineLearning)

Partilha de artigo com 7 dicas para dominar a Engenharia de Prompts: O site FrontBackGeek publicou um artigo que resume 7 dicas poderosas para ajudar os utilizadores a dominar melhor a Engenharia de Prompts, obtendo assim melhores resultados de modelos de IA (como LLMs). O artigo pode abranger como dar instruções claras, fornecer contexto, definir papéis, controlar o formato de saída, entre outros aspetos. (Fonte: Reddit r/deeplearning)

Partilha de projeto: Fine-tuning de GPT-2/GPT-J para imitar o tom de Mr. Darcy de “Orgulho e Preconceito”: Um programador partilhou o seu projeto pessoal: utilizando os modelos GPT-2 (medium) e GPT-J, através de fine-tuning com dois conjuntos de dados contendo diálogos originais e dados sintéticos criados por si, tentou imitar o estilo de fala único de Mr. Darcy de “Orgulho e Preconceito” de Jane Austen (formal, conciso, ligeiramente crítico). O projeto mostra exemplos de output do modelo, métricas de avaliação (melhoria no BLEU-4 mas aumento da perplexidade) e desafios encontrados (como a dificuldade em ajustar o GPT-J). O código e os conjuntos de dados foram disponibilizados em open-source no GitHub, fornecendo um caso de estudo para explorar a modelação de estilos literários específicos ou vozes de figuras históricas. (Fonte: Reddit r/MachineLearning)
Discussão sobre a publicação das Meta Reviews da ACL 2025: Os resultados das Meta Reviews (revisões meta) da conferência ACL 2025 foram publicados, e investigadores relevantes iniciaram um tópico na comunidade, convidando todos a discutir e trocar impressões sobre as pontuações dos seus artigos e as correspondentes Meta Reviews. Isto oferece aos autores que submeteram trabalhos uma plataforma para partilhar experiências e comparar expectativas com resultados. (Fonte: Reddit r/MachineLearning)
Partilha de experiência: Construir servidor de IA com 160GB VRAM a baixo custo: Um utilizador do Reddit partilhou detalhadamente o processo e os resultados preliminares da construção de um servidor de inferência de IA com 160GB de VRAM por cerca de 1000 dólares (custo principal: 10 GPUs AMD MI50 usadas a 90 dólares cada e uma caixa de mineração Octominer de 100 dólares). O conteúdo inclui a seleção de hardware, instalação do sistema (Ubuntu + ROCm 6.3.0), compilação e teste do llama.cpp, medição real do consumo de energia (inativo ~120W, pico de inferência 340W), situação da dissipação de calor e dados de desempenho (comparação com placas como a 3090, execução dos modelos llama3.1-8b e llama-405b). Esta partilha oferece uma referência extremamente valiosa de configuração de hardware DIY e experiência prática para entusiastas de IA com orçamento limitado. (Fonte: Reddit r/LocalLLaMA)
Publicação do artigo e código do modelo ReZero: O artigo técnico relacionado com o modelo ReZero da Menlo Research (que treina o modelo para pesquisar repetidamente até encontrar a informação necessária usando GRPO) (arXiv:2504.11001), os pesos do modelo (Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404) e o código de implementação (GitHub: menloresearch/ReZero) foram todos tornados públicos. Isto fornece recursos completos de aprendizagem e experimentação para investigar e aplicar esta nova estratégia de pesquisa. (Fonte: Reddit r/LocalLLaMA)
💼 Negócios
Ex-executivo de robótica da Alibaba, Min Wei, funda YingShen Intelligence, obtém dezenas de milhões em financiamento seed: Fundada em 2024 por Min Wei, antigo líder técnico da equipa de robótica da Alibaba, a YingShen Intelligence foca-se na investigação, desenvolvimento e aplicação de tecnologia de inteligência incorporada (embodied intelligence) de nível L4. A empresa concluiu recentemente rondas consecutivas de financiamento seed (investimento da ZY Asia) e seed+ (investimento conjunto da ZY Asia e Hangzhou West Lake Science and Technology Venture Capital) no valor de dezenas de milhões de RMB. Baseada no seu grande modelo espaço-temporal inteligente auto-desenvolvido (que constrói um modelo quadridimensional do mundo real através de Real to Real, modelando diretamente a partir de dados de vídeo) e em robôs industriais, a YingShen Intelligence oferece soluções de hardware e software coordenadas. Já garantiu encomendas industriais na ordem dos dez milhões, focando-se inicialmente em cenários industriais, com planos de expansão para setores de serviços como entregas e hotelaria. (Fonte: 36氪)
Mercado de brinquedos AI quente online, frio offline, exportação pode ser a principal via: Brinquedos AI mostram grande popularidade em plataformas online (como vendas em direto, redes sociais), com previsões de rápido crescimento do mercado. No entanto, visitas a lojas físicas (usando Guangzhou como exemplo) revelam que os brinquedos AI são difíceis de encontrar em lojas de brinquedos tradicionais e lojas gerais, com baixa taxa de distribuição e reconhecimento pelo consumidor. Atualmente, as vendas de brinquedos AI podem depender principalmente de canais online, sendo os mercados estrangeiros (Europa, América, Médio Oriente) uma importante via de escoamento, com fabricantes a oferecer serviços de personalização de aparência e idioma. A análise dos dados de dimensão do mercado sugere que os relatos anteriores de um mercado de dezenas de milhares de milhões podem referir-se a “brinquedos inteligentes” de forma mais ampla, e não puramente a brinquedos AI. Apesar do arrefecimento offline, dado o crescimento da procura por companhia emocional por parte de adultos (como o caso Moflin) e o potencial da tecnologia AI para todas as idades, o mercado de brinquedos AI ainda é considerado como tendo um enorme espaço para desenvolvimento. (Fonte: 36氪)

Empresa de Infraestrutura AI ligada a Tsinghua, Qingcheng Jizhi: Explosão da procura por inferência, relação custo-benefício impulsiona substituição nacional: Entrevista com Tang Xiongchao, CEO da Qingcheng Jizhi, empresa de infraestrutura AI ligada à Universidade de Tsinghua. A empresa observou que, desde a popularização do modelo DeepSeek, a procura por poder computacional do lado da inferência AI aumentou drasticamente, e o poder computacional nacional anteriormente ocioso começou a ser utilizado. No entanto, a inovação técnica da DeepSeek (como a precisão FP8) está profundamente ligada às placas H da Nvidia, o que, pelo contrário, aumentou a lacuna em relação à maioria dos chips nacionais atuais. Para resolver este problema, a Qingcheng Jizhi, em colaboração com Tsinghua, lançou em open-source o motor de inferência “Chitu”, com o objetivo de permitir que GPUs existentes e chips nacionais executem eficientemente modelos avançados como o DeepSeek, promovendo um ciclo fechado no ecossistema AI nacional. Tang Xiongchao acredita que, embora a substituição por chips nacionais exija tempo, a sua vantagem de custo-benefício a longo prazo é promissora. O foco atual do negócio da empresa é satisfazer a procura de governos e empresas por implementações locais de grandes modelos. (Fonte: 凤凰网科技)
Febre de investimento em IA continua, jovens investidores emergem: Apesar do arrefecimento geral do ambiente de investimento em 2024, o setor de IA continua a atrair capital, com financiamento global a atingir recordes e o mercado interno igualmente ativo. Gigantes como ByteDance, Alibaba, Tencent aceleram a sua posição, enquanto unicórnios como Zhipu AI, Moonshot AI, Unitree Robotics emergem. Os pontos quentes de investimento cobrem toda a cadeia de valor, incluindo infraestrutura, AIGC, embodied intelligence, etc. Empresas de investimento estabelecidas como Sequoia China, BlueRun Ventures, etc., mantêm a liderança, enquanto fundos industriais e capital estatal, representados pelo Fundo de Investimento da Indústria de Inteligência Artificial de Pequim, também se tornam impulsionadores importantes. É notável que um grupo de jovens investidores nascidos nos anos 80 (como Cao Xi, Dai Yusen, Lin Haizhuo, Zhang Jinjian, etc.) está ativo na era da IA 2.0, usando a sua perspicácia e capacidade de execução para procurar ativamente oportunidades num mercado com novas regras, tornando-se uma força emergente a não ignorar. (Fonte: 36氪-第一新声)

Fundador da aplicação de compras AI Nate acusado de fraude, “API humana” disfarçada de AI engana investidores em 50 milhões de dólares: O Departamento de Justiça dos EUA acusou Albert Saniger, fundador da aplicação de compras AI Nate, de obter mais de 50 milhões de dólares em capital de risco através de publicidade enganosa sobre as capacidades da sua tecnologia AI. A Nate afirmava que a sua aplicação conseguia completar automaticamente processos de compra online através de tecnologia AI proprietária, mas na realidade, a sua funcionalidade principal dependia fortemente de centenas de agentes de apoio ao cliente contratados nas Filipinas para processar manualmente as encomendas, com a alegada taxa de automação por IA a ser quase nula. O fundador ocultou a verdade aos investidores e funcionários, levando eventualmente a empresa à falência por esgotamento de fundos. Este caso revela os potenciais riscos de fraude na atual febre de startups de IA, onde o trabalho humano é disfarçado de AI para atrair investimento, prejudicando os interesses dos investidores e a reputação da indústria. Saniger pode enfrentar até 40 anos de prisão. (Fonte: CSDN)

🌟 Comunidade
Vídeos modificados por IA invadem plataformas de vídeo curto, gerando controvérsia sobre entretenimento, direitos de autor e ética: A utilização de tecnologia AI (como ferramentas text-to-video Sora, Keling, etc.) para criar “remixes explosivos” de séries e filmes clássicos (como “A Lenda de Zhen Huan” a andar de mota, “Em Nome do Povo” transformado em “12.12: The Day”) tornou-se rapidamente popular em plataformas como Douyin e Bilibili. Este tipo de vídeo atrai tráfego massivo devido a enredos subversivos, impacto visual e cultura de memes, tornando-se um novo meio para criadores ganharem rapidamente seguidores e monetizarem (receitas de tráfego, publicidade integrada) e para promoverem as próprias séries. No entanto, a sua popularidade vem acompanhada de controvérsia: a definição de violação de direitos de autor sobre a obra original é complexa; o conteúdo modificado pode diminuir a profundidade artística do original, podendo até tornar-se vulgar, atraindo a atenção dos reguladores. Encontrar um equilíbrio entre satisfazer a procura por entretenimento, respeitar os direitos de autor e manter a qualidade do conteúdo tornou-se um desafio para a criação secundária com IA. (Fonte: 36氪-明晰野望)

Limites e preços dos planos Claude Pro/Max geram reclamações dos utilizadores: Vários posts no subreddit ClaudeAI mostram utilizadores a reclamar massivamente sobre as restrições e preços impostos pela Anthropic aos planos de subscrição Claude Pro e ao recém-lançado Max. Utilizadores relatam que mesmo sendo assinantes Pro pagos, atingem rapidamente o limite de utilização após interações de intensidade baixa ou média (como processar algumas centenas de milhares de tokens de contexto), o que afeta o fluxo de trabalho. O novo plano Max (100 dólares/mês), embora aumente o limite (cerca de 5-20 vezes o do Plus), ainda não é de uso ilimitado, e o preço elevado é criticado pelos utilizadores como “roubo”, com baixa relação custo-benefício. Os utilizadores geralmente reconhecem a capacidade do modelo Claude, mas expressam forte insatisfação com as suas restrições de uso e política de preços. (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Estilo de escrita humano claro confundido com geração por IA gera atenção: Na comunidade Reddit, utilizadores (incluindo alguns que se identificam como neurodivergentes) relatam que os seus textos cuidadosamente escritos, gramaticalmente corretos, logicamente claros e detalhados são confundidos por outros ou por ferramentas de deteção de IA como sendo gerados por IA. Este fenómeno gera discussão: por um lado, a prevalência de conteúdo gerado por IA pode levar as pessoas a suspeitar de textos “demasiado perfeitos”; por outro lado, expõe a imprecisão das atuais ferramentas de deteção de IA. Isto causa transtorno a escritores que prezam a clareza de expressão e levanta preocupações sobre como distinguir a criação humana da IA e sobre a fiabilidade das ferramentas de deteção de IA. (Fonte: Reddit r/artificial, Reddit r/artificial)
Discussão: É possível e comum humanos estabelecerem relações emocionais com robôs AI?: Surge na comunidade Reddit uma discussão sobre se os humanos estão realmente a estabelecer relações emocionais com robôs AI (como aplicações de namoradas AI) semelhantes às retratadas no filme “Her”. Alguns utilizadores partilham as suas experiências de desenvolverem ligações emocionais após interagirem profundamente com chatbots, argumentando que a IA, através da “escuta ativa” e imitação das preferências do utilizador, consegue desencadear respostas emocionais humanas. Nos comentários, explora-se a prevalência deste fenómeno, os mecanismos psicológicos e a relação com o nível de compreensão tecnológica, refletindo que, com o aumento da capacidade de interação da IA, as relações humano-máquina estão a entrar numa nova e mais complexa fase. (Fonte: Reddit r/ArtificialInteligence)
Discussão sobre a relação custo-benefício da placa gráfica Nvidia RTX 5060 Ti 16GB para LLMs locais: Utilizadores da comunidade discutem o valor da futura placa gráfica Nvidia GeForce RTX 5060 Ti (rumores indicam uma versão de 16GB VRAM com preço de 429 dólares) para executar grandes modelos de linguagem (LLM) localmente em casa. A discussão foca-se em se o barramento de memória de 128 bits (largura de banda de 448 GB/s) será um gargalo, e na comparação com o Mac Mini/Studio ou outras placas AMD em termos de capacidade de VRAM e desempenho por dólar (token/s por preço). Considerando que o preço real de mercado pode ser superior ao MSRP, os utilizadores avaliam se esta será uma opção de hardware AI local com boa relação custo-benefício. (Fonte: Reddit r/LocalLLaMA)
GPT-4o tem dificuldade em desenhar com precisão a coroa Fèngchì Zǐjīnguān de Sun Wukong: Utilizadores relatam que, ao usar o GPT-4o para geração de imagens, mesmo fornecendo descrições textuais detalhadas (incluindo coroa de cabelo preso com penas de faisão, semelhante a antenas de barata), o modelo tem dificuldade em desenhar com precisão a icónica “Coroa de Asas de Fénix e Ouro Púrpura” (Fèngchì Zǐjīnguān) da personagem mitológica chinesa Sun Wukong. As imagens geradas frequentemente apresentam desvios no estilo da coroa. Isto reflete os desafios que os atuais modelos de geração de imagem AI ainda enfrentam na compreensão e reprodução de símbolos culturais específicos ou detalhes complexos. (Fonte: dotey)

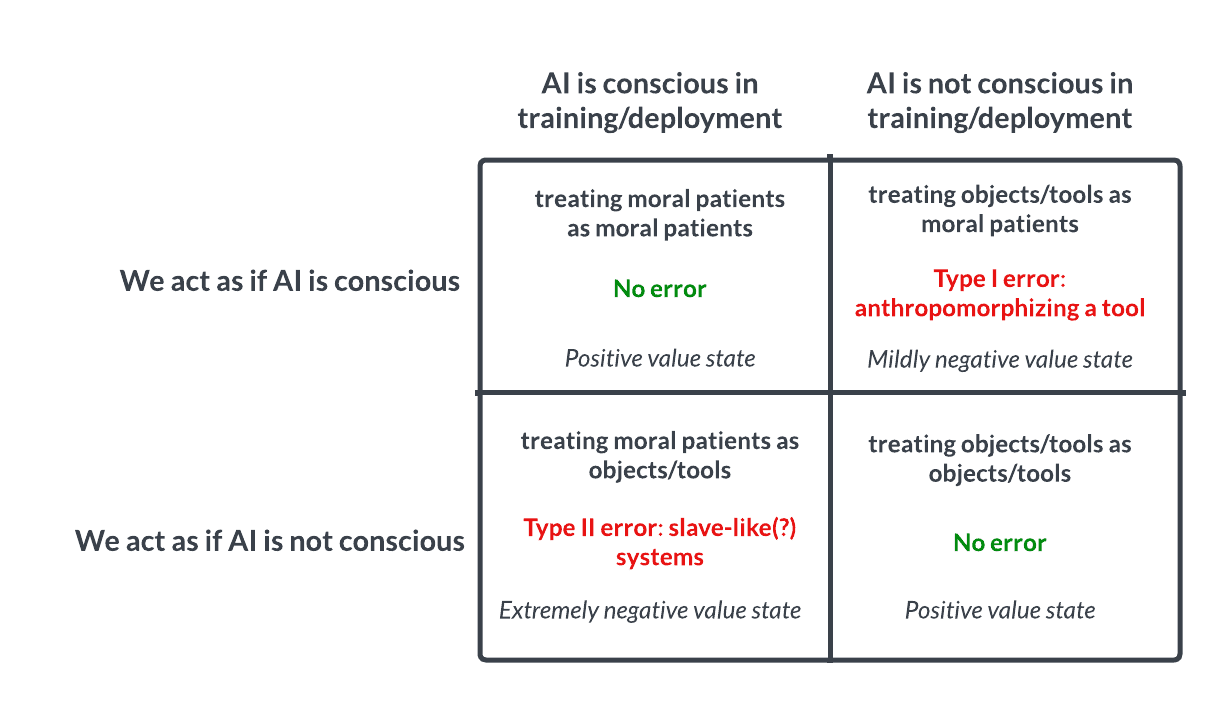
Discussão sobre consciência e ética da IA: Aposta de Pascal análoga leva à reflexão: Uma discussão no Reddit levanta a questão de se devemos tratar a IA de forma semelhante à Aposta de Pascal: se assumirmos que a IA não tem consciência e a maltratarmos, e ela na verdade tiver consciência, cometeremos um erro grave (como escravatura); se assumirmos que tem consciência e a tratarmos bem, e ela na verdade não tiver, a perda é menor. Isto desencadeia uma discussão ética sobre a possibilidade da consciência da IA, os critérios para a julgar e como devemos tratar IAs avançadas. Nos comentários, alguns argumentam que a IA atual não tem consciência, outros defendem cautela, e outros ainda apontam que devemos primeiro resolver questões éticas relativas a humanos e animais. (Fonte: Reddit r/artificial
💡 Outros
Filme “Here” aplica tecnologia de transformação de idade por IA, gerando controvérsia: O filme “Here”, dirigido por Robert Zemeckis e protagonizado por Tom Hanks e Robin Wright, utilizou de forma ousada a tecnologia de transformação generativa por IA em tempo real desenvolvida pela Metaphysic, permitindo que os atores apresentassem no filme uma amplitude etária dos 18 aos 78 anos. A tecnologia analisa em tempo real as características biométricas dos atores e gera rostos e corpos de diferentes idades, reduzindo drasticamente o tempo de pós-produção. No entanto, a tecnologia ainda não é perfeita, especialmente na reprodução do olhar e no tratamento de expressões complexas, gerando discussões sobre o “vale da estranheza” (uncanny valley). Ao mesmo tempo, a decisão de Hanks de autorizar o uso contínuo da sua imagem AI após a morte também suscitou ampla controvérsia sobre direitos de imagem, ética e autenticidade artística. Apesar do desempenho modesto de bilheteira e crítica, o filme tem valor importante para a indústria como uma exploração inicial da tecnologia AI na produção cinematográfica. (Fonte: 36氪-极客电影)

Recrutamento com IA: Oportunidades e desafios coexistem: A IA está a transformar os processos de recrutamento, com ferramentas como a Hireway a alegarem aumentar significativamente a eficiência da seleção. No entanto, a aplicação da IA no recrutamento também gera discussões, como por exemplo, como recrutar na Era da IA (Hiring In The AI Era), e como equilibrar eficiência e justiça, evitar vieses algorítmicos, entre outras questões. (Fonte: Ronald_vanLoon, Ronald_vanLoon)

Velocidade do desenvolvimento da IA leva à reflexão: O equilíbrio entre rápido e lento: Artigo discute se a estratégia de “agir rápido e quebrar coisas” (move fast and break things) ainda é aplicável na era do rápido desenvolvimento da IA. Argumenta-se que, por vezes, abrandar o ritmo e refletir cuidadosamente (slowing down to speed up) pode ter melhores resultados, especialmente em domínios como a IA que envolvem sistemas complexos e riscos potenciais. (Fonte: Ronald_vanLoon)

Servidor Discord oficial da Anthropic aberto para feedback direto dos utilizadores: Dado que os utilizadores têm muitas dúvidas e insatisfações sobre o desempenho e as limitações do modelo Claude, a comunidade recomenda que os utilizadores se juntem ao servidor Discord oficial da Anthropic. Lá, os utilizadores têm a oportunidade de interagir diretamente com os funcionários da Anthropic, fornecendo feedback sobre problemas e preocupações de forma mais eficaz. (Fonte: Reddit r/ClaudeAI)

Exibição de vários robôs e tecnologias de automação inovadoras: As redes sociais exibiram vídeos ou informações sobre diversas tecnologias de robótica e automação, incluindo drones capazes de trabalhar debaixo de água, robôs moles que imitam o peristaltismo intestinal, o drone biomimético X-Fly, robôs multifuncionais capazes de realizar diversas tarefas, robôs para transplante capilar, linhas de produção automatizadas para processamento de ovos, um fato robótico de 9 pés de altura capaz de simular movimentos humanos, e a cena curiosa de dois robôs de entrega a “confrontarem-se” na rua. Estas exibições mostram a exploração e o desenvolvimento da tecnologia robótica em diferentes áreas de aplicação. (Fonte: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)