
Palavras-chave:GPT-4.1, Hugging Face, GPT-4.1 comparação de desempenho da série de modelos, Hugging Face adquire Pollen Robotics, OpenAI novo modelo com melhoria na capacidade de codificação, GPT-4.1 mini custo reduzido em 83%, robô de código aberto Reachy 2
🔥 Foco
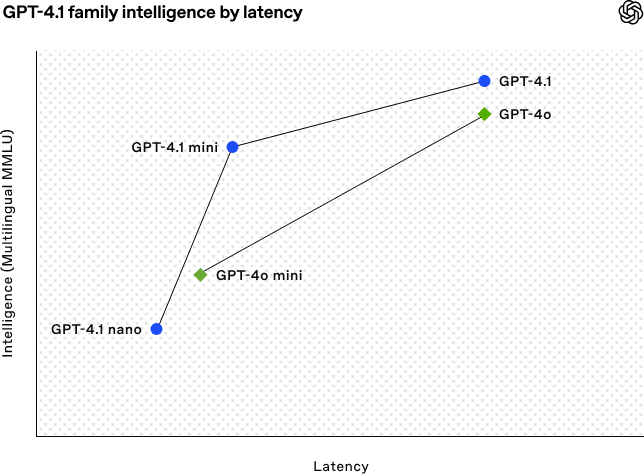
OpenAI lança a série de modelos GPT-4.1, reforçando as capacidades de codificação e processamento de texto longo: A OpenAI lançou na madrugada de 15 de abril três novos modelos da série GPT-4.1: GPT-4.1 (principal), GPT-4.1 mini (eficiente) e GPT-4.1 nano (ultra-pequeno), todos disponíveis apenas através da API. Esta série de modelos apresenta um desempenho excelente em codificação, seguimento de instruções e compreensão de contexto longo, com uma janela de contexto de 1 milhão de tokens e 32.768 tokens de saída para todos. O GPT-4.1 obteve uma pontuação de 54,6% no teste SWE-bench Verified, superando significativamente o GPT-4o e o GPT-4.5 Preview, que será descontinuado. O GPT-4.1 mini supera o desempenho do GPT-4o, com metade da latência e um custo 83% inferior. O GPT-4.1 nano é atualmente o modelo mais rápido e de menor custo, adequado para tarefas de baixa latência. Este lançamento visa fornecer aos programadores opções de modelos mais potentes, económicos e rápidos, impulsionando a construção de sistemas inteligentes complexos e aplicações de agentes inteligentes. (Fonte: 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face adquire empresa de robótica open-source Pollen Robotics: A plataforma comunitária de IA Hugging Face anunciou a aquisição da startup francesa de robótica open-source Pollen Robotics, com o objetivo de promover a abertura e popularização da robótica de IA. Esta aquisição combinará os pontos fortes da Hugging Face em plataformas de software (como a biblioteca LeRobot e o Hub) com a especialização da Pollen Robotics em hardware open-source (como o robô humanoide Reachy 2). O Reachy 2 é um robô humanoide open-source, compatível com VR, projetado para pesquisa, educação e experiências de inteligência incorporada, com um preço de 70.000 dólares. A Hugging Face acredita que a robótica é a próxima interface de interação importante para a IA e deve ser aberta, acessível e personalizável. Esta aquisição é um passo fundamental para concretizar essa visão, com o objetivo de permitir que a comunidade construa e controle os seus próprios companheiros robóticos, em vez de depender de sistemas fechados e caros. (Fonte: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 Tendências
IA ajuda a resolver problema matemático de 50 anos: Weiguo Yin, investigador chinês do Brookhaven National Laboratory nos EUA, utilizou o modelo de raciocínio o3-mini-high da OpenAI para alcançar um avanço na solução exata do modelo Potts J_1-J_2 q-state unidimensional, especialmente no caso q=3, onde a IA auxiliou na conclusão da prova crucial. O problema envolve modelos fundamentais de mecânica estatística, relacionados com fenómenos físicos como o empilhamento atómico em materiais lamelares e supercondutividade não convencional, cuja solução exata não tinha sido alcançada nos últimos 50 anos. Os investigadores introduziram o método do subespaço de simetria máxima (MSS) e, com a ajuda de sugestões passo a passo da IA para processar a matriz de transferência, conseguiram simplificar a matriz de transferência 9×9 para q=3 numa matriz 2×2 eficaz, generalizando este método para qualquer valor de q. Esta investigação não só resolve um problema de física matemática de longa data, mas também demonstra o enorme potencial da IA em auxiliar a investigação científica complexa e fornecer novas perspetivas. (Fonte: 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

Ascensão dos assistentes IA em versão web, fabricantes de telemóveis e automóveis apostam em experiências multiplataforma: Fabricantes como Huawei (Assistente Xiaoyi), Li Auto (Ideal Companion), OPPO (Assistente Xiaobu), entre outros, lançaram sucessivamente versões web dos seus assistentes de IA, gerando atenção. Embora estas versões web possam não ser tão completas em termos de funcionalidades (como edição de perguntas, formatação, opções de configuração) como os serviços de modelos profissionais como o DeepSeek, o seu objetivo principal não é a concorrência direta, mas sim servir os utilizadores das suas respetivas marcas, criando um ciclo fechado de experiência desde o telemóvel, ao sistema do carro, até ao PC. Ao vincular contas de utilizador e sincronizar históricos de conversação, estas versões web visam aumentar a fidelidade do utilizador, fornecer uma experiência de interação consistente entre terminais e integrar os assistentes de IA em cenários de utilizador mais amplos, sendo essencialmente uma estratégia focada nos pontos de entrada do utilizador e no ecossistema de dados. (Fonte: AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
Robô Figure alcança transferência zero-shot da simulação para a realidade através de aprendizagem por reforço: A empresa Figure demonstrou o seu robô humanoide Figure 02 a alcançar uma marcha natural através de aprendizagem por reforço (RL) num ambiente puramente simulado. Utilizando um simulador físico eficiente acelerado por GPU, gerou em poucas horas dados de treino equivalentes a vários anos, treinando uma única estratégia de rede neuronal capaz de controlar múltiplos robôs virtuais com diferentes parâmetros físicos e cenários (como terrenos diferentes, perturbações). Combinando a randomização do domínio de simulação com o feedback de torque de alta frequência do robô real, a estratégia treinada consegue ser transferida zero-shot para o robô físico, sem necessidade de ajuste fino. Este método não só encurta o tempo de desenvolvimento e aumenta a estabilidade do desempenho no mundo real, como também permite que uma única estratégia controle toda uma frota de robôs, demonstrando o seu potencial para aplicações comerciais em larga escala. (Fonte: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek irá tornar open-source parte da otimização do seu motor de inferência: A DeepSeek anunciou planos para contribuir para a comunidade com algumas das otimizações e funcionalidades do seu motor de inferência de alto desempenho baseado em modificações do vLLM. Em vez de lançar a sua pilha de inferência completa e altamente personalizada, optarão por integrar melhorias chave (como suporte para as mais recentes arquiteturas de modelos, otimizações de desempenho) nos frameworks de inferência open-source mainstream como vLLM e SGLang, com o objetivo de permitir que a comunidade obtenha suporte de nível SOTA para novos modelos e tecnologias desde o primeiro dia. Esta iniciativa foi bem recebida pela comunidade, sendo considerada um verdadeiro compromisso com a contribuição open-source, em vez de mera publicidade. (Fonte: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
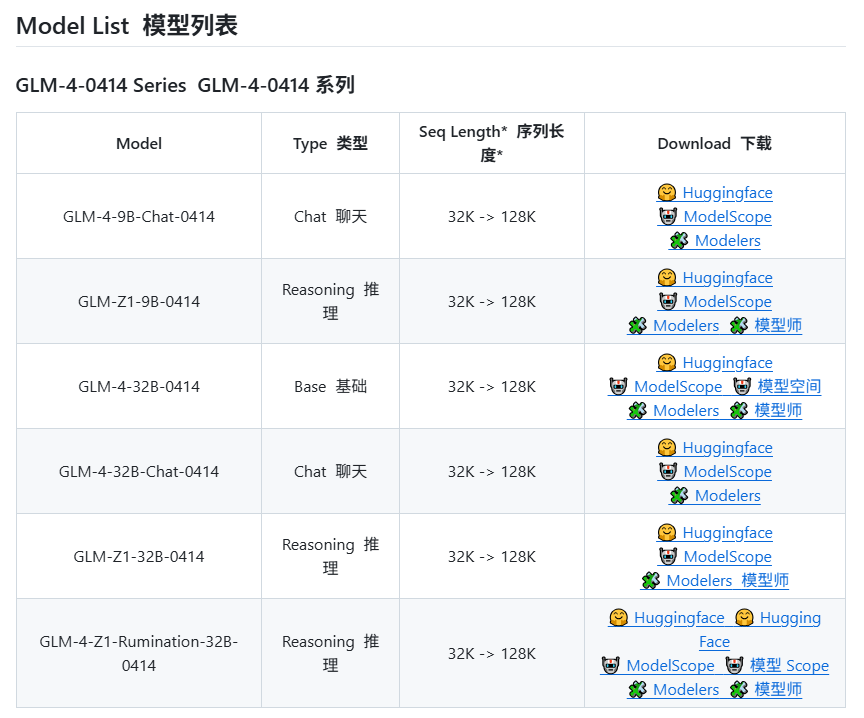
Zhipu AI alegadamente prestes a lançar novos modelos da série GLM-4: De acordo com informações vazadas no GitHub (posteriormente removidas), a Zhipu AI parece estar a preparar o lançamento de novos modelos da série GLM-4. A série poderá incluir versões com diferentes escalas de parâmetros (como 9B, 32B) e funcionalidades, por exemplo, modelos base (GLM-4-32B-0414), modelos de conversação (Chat), modelos de raciocínio (GLM-Z1-32B-0414) e modelos com capacidade de pensamento mais profundo “Rumination”, possivelmente comparáveis ao Deep Research da OpenAI. Além disso, poderá incluir modelos multimodais visuais (GLM-4V-9B). Os benchmarks vazados indicam que o GLM-4-32B-0414 poderá superar o DeepSeek-V3 e o DeepSeek-R1 em algumas métricas. O código de suporte ao motor de inferência relacionado já foi incorporado em transformers/vllm/llama.cpp. A comunidade está a acompanhar com grande interesse, aguardando o lançamento oficial e as avaliações. (Fonte: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA lança novos modelos da série Nemotron: A NVIDIA lançou no Hugging Face os novos modelos base da série Nemotron-H, incluindo três escalas de parâmetros: 56B, 47B e 8B, todos suportando uma janela de contexto de 8K. Estes modelos são baseados numa arquitetura híbrida de Transformer e Mamba. Atualmente, foram lançados os modelos base (Base), não estando ainda disponíveis as versões ajustadas por instrução (Instruct). A série Nemotron visa explorar o potencial de novas arquiteturas na modelação de linguagem. (Fonte: Reddit r/LocalLLaMA)

🧰 Ferramentas
GitHub Copilot integrado na versão Canary do Windows Terminal: A Microsoft integrou a funcionalidade GitHub Copilot na versão Canary preview do Windows Terminal, introduzindo uma nova funcionalidade chamada “Terminal Chat”. Esta funcionalidade permite aos utilizadores interagir diretamente com a IA no ambiente do terminal, obtendo sugestões e explicações de comandos. Os utilizadores precisam de subscrever o GitHub Copilot e instalar a versão Canary mais recente do terminal; após verificarem a conta, podem usar a funcionalidade. O objetivo é integrar a assistência de IA diretamente no ambiente de linha de comandos frequentemente usado pelos programadores, reduzindo a mudança de contexto, aumentando a eficiência no tratamento de tarefas complexas ou desconhecidas, acelerando o processo de aprendizagem e ajudando a reduzir erros. (Fonte: GitHub Copilot 现可在 Windows 终端中运行了)

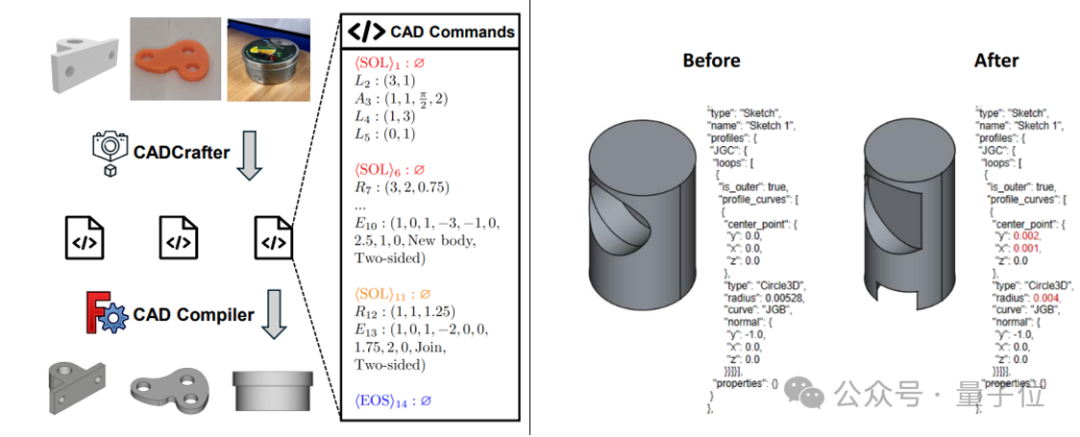
CADCrafter: Geração de ficheiros CAD editáveis a partir de uma única imagem: Investigadores da KOKONI 3D, da Nanyang Technological University e de outras instituições propuseram um novo framework chamado CADCrafter, capaz de gerar diretamente ficheiros de engenharia CAD parametrizados e editáveis (representados como sequências de comandos CAD) a partir de uma única imagem (renderização, fotografia de objeto real, etc.), resolvendo o problema dos métodos existentes de imagem para 3D (que geram Mesh ou 3DGS) cujos modelos são difíceis de editar com precisão e têm baixa qualidade de superfície. O método utiliza uma arquitetura de geração em duas fases que combina VAE e Diffusion Transformer, e melhora a qualidade e a taxa de sucesso da geração através de uma estratégia de destilação de múltiplas vistas para vista única e de um mecanismo de verificação de compilabilidade baseado em DPO. Os resultados da investigação foram aceites na CVPR 2025, fornecendo um novo paradigma para o design industrial assistido por IA. (Fonte: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain lança integração GraphRAG com MongoDB Atlas: A LangChain anunciou uma colaboração com a MongoDB para lançar um sistema RAG baseado em grafos (GraphRAG). Este sistema utiliza o MongoDB Atlas para armazenar e processar dados, implementado através do LangChain, capaz de ir além do RAG tradicional baseado em pesquisa de similaridade, compreendendo e raciocinando sobre as relações entre entidades. Suporta a extração de entidades e relações através de LLM e utiliza a travessia de grafos para obter informações de contexto conectadas, visando fornecer capacidades de resposta a perguntas e raciocínio mais poderosas para aplicações que requerem uma compreensão profunda das relações. (Fonte: LangChainAI)
Hugging Face torna open-source o seu Inference Playground: A Hugging Face tornou open-source a sua ferramenta online Inference Playground, utilizada para testar e comparar a inferência de modelos. Trata-se de uma interface de chat LLM baseada na web que permite aos utilizadores controlar várias configurações de inferência (como temperatura, top-p, etc.), modificar as respostas da IA, comparar o desempenho de diferentes modelos e fornecedores. O projeto foi construído com Svelte 5, Melt UI e Tailwind, e o código foi publicado no GitHub, fornecendo aos programadores uma plataforma local ou online personalizável e extensível para interação e avaliação de modelos. (Fonte: huggingface)
Plataforma Flowith ultrapassa 1 milhão de dólares em ARR, demonstrando capacidade de geração de páginas web por Agentes IA: A receita anual recorrente (ARR) da plataforma de Agentes IA Flowith ultrapassou 1 milhão de dólares, mostrando a forte procura do mercado por plataformas de Agentes IA versáteis capazes de substituir o trabalho humano. Um utilizador partilhou a utilização da funcionalidade Oracle do Flowith, que, apenas através de uma descrição simples em linguagem natural (“Quero criar uma página web de pré-visualização de imagens para redes sociais…”), conseguiu gerar rapidamente uma pequena ferramenta web funcional, com estilo preciso (como o estilo do Twitter) e suporte para pré-visualização de imagens, sem necessidade de conectar ao GitHub ou realizar configurações complexas, demonstrando o potencial dos Agentes IA na geração de páginas web low-code/no-code. (Fonte: karminski3)
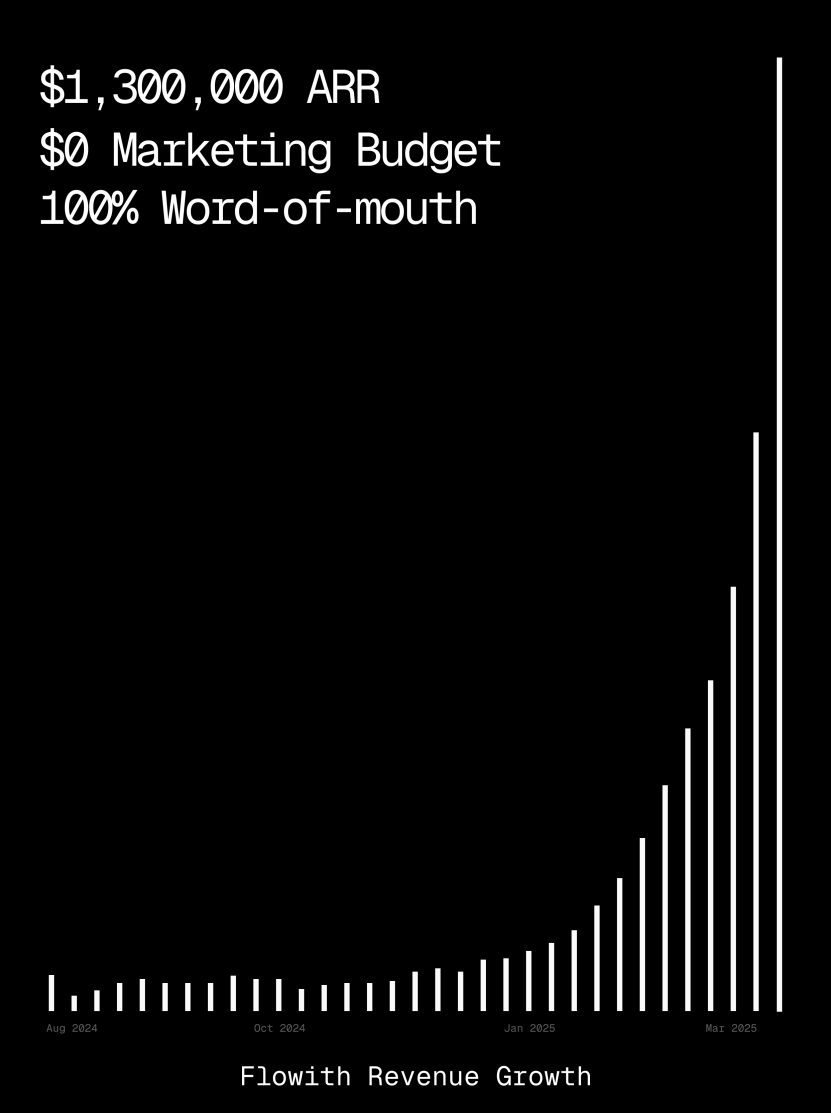
Agente de depuração autónomo Deebo lançado: Investigadores construíram um servidor MCP de agente de depuração autónomo chamado Deebo. Ele funciona como um daemon local ao qual os agentes de programação podem descarregar tarefas complexas de tratamento de erros de forma assíncrona. O Deebo gera múltiplos subprocessos com diferentes hipóteses de correção, executa cada cenário num ramo git isolado, e um “agente mãe” realiza testes cíclicos e raciocínio, retornando finalmente resultados de diagnóstico e patches sugeridos. Num teste real com um bug do tinygrad com recompensa de $100, o Deebo identificou com sucesso a causa raiz do problema e propôs duas soluções específicas, passando nos testes. (Fonte: Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 Aprendizagem
Nabla-GFlowNet: Novo método de ajuste fino de recompensa para modelos de difusão que equilibra diversidade e eficiência: Para resolver os problemas de convergência lenta da aprendizagem por reforço tradicional, overfitting fácil da maximização direta de recompensa e perda de diversidade no ajuste fino de modelos de difusão, investigadores da Universidade Chinesa de Hong Kong (Shenzhen) e outras instituições propuseram o Nabla-GFlowNet. Este método baseia-se no framework de redes de fluxo generativo (GFlowNet), tratando o processo de difusão como um sistema de equilíbrio de fluxo, e deriva a condição de equilíbrio Nabla-DB e a função de perda correspondente. Através de um design parametrizado, utiliza a estimativa de denoising de passo único para estimar o gradiente residual, evitando a necessidade de redes adicionais para estimativa. Experiências mostram que, ao ajustar o Stable Diffusion com funções de recompensa como pontuação estética e seguimento de instruções, o Nabla-GFlowNet converge mais rapidamente e é menos propenso a overfitting em comparação com métodos como ReFL e DRaFT, mantendo ao mesmo tempo a diversidade das amostras geradas. (Fonte: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath: Lançamento do maior conjunto de dados open-source para raciocínio matemático, com 371B Tokens: Lançado pela LLM360, o conjunto de dados MegaMath, contendo 371 mil milhões de Tokens, visa resolver a falta na comunidade open-source de dados de pré-treino de alta qualidade e em grande escala para raciocínio matemático. O conjunto de dados divide-se em três partes: páginas web densas em matemática (279B), código relacionado com matemática (28.1B) e dados sintéticos de alta qualidade (64B). O processo de construção utilizou um pipeline inovador de processamento de dados, incluindo análise HTML otimizada para fórmulas matemáticas, extração de texto em duas fases, pontuação dinâmica de valor educacional, recuperação precisa de dados de código em várias etapas e vários métodos de síntese em larga escala (Q&A, geração de código, intercalação de texto e código). A validação de pré-treino com 100B Tokens no Llama-3.2 (1B/3B) mostra que o MegaMath pode trazer melhorias de desempenho absoluto de 15-20% em benchmarks como GSM8K e MATH. (Fonte: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
Revisão de OS Agents: Investigação sobre agentes inteligentes para computadores, telemóveis e browsers baseados em modelos multimodais grandes: A Universidade de Zhejiang, em colaboração com a OPPO, a 01.AI e outras instituições, publicou um artigo de revisão sobre agentes de sistema operativo (OS Agents). O artigo revê sistematicamente o estado da arte na construção de agentes inteligentes (como o Computer Use da Anthropic, o Apple Intelligence da Apple) que utilizam modelos de linguagem multimodais grandes (MLLM) para realizar tarefas automaticamente em ambientes como computadores, telemóveis e browsers. O conteúdo abrange os fundamentos dos OS Agents (ambiente, espaço de observação, espaço de ação, capacidades principais), métodos de construção (arquitetura do modelo base e estratégias de treino, módulos de perceção/planeamento/memória/ação do framework do agente), protocolos e benchmarks de avaliação, bem como produtos comerciais relacionados e desafios futuros (segurança e privacidade, personalização e auto-evolução). A equipa de investigação mantém um repositório open-source com mais de 250 artigos relacionados, com o objetivo de impulsionar o desenvolvimento nesta área. (Fonte: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt: Método robusto de aprendizagem de prompts que combina perda MAE e transporte ótimo: O YesAI Lab da ShanghaiTech University propôs o NLPrompt num artigo Highlight da CVPR 2025, visando resolver o problema do ruído nos rótulos na aprendizagem de prompts para modelos de visão-linguagem. A investigação descobriu que, no cenário de aprendizagem de prompts, usar a perda de erro absoluto médio (MAE) (PromptMAE) é mais resistente à influência de rótulos ruidosos do que a perda de entropia cruzada (CE), e provou a sua robustez do ponto de vista da teoria da aprendizagem de características. Além disso, propôs um método de purificação de dados baseado em prompts e transporte ótimo (PromptOT), que utiliza características de texto como protótipos para dividir o conjunto de dados num subconjunto limpo (treinado com perda CE) e num subconjunto ruidoso (treinado com perda MAE), fundindo eficazmente as vantagens das duas perdas. Experiências demonstram que o NLPrompt tem um desempenho superior em conjuntos de dados com ruído sintético e real, e possui boa capacidade de generalização. (Fonte: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Análise do mecanismo de inferência do DeepSeek-R1: Investigadores da Universidade McGill analisaram o processo de raciocínio de modelos de inferência grandes como o DeepSeek-R1. Ao contrário dos LLMs que dão respostas diretas, os modelos de raciocínio geram cadeias de raciocínio detalhadas em várias etapas. O estudo explora a relação entre o comprimento da cadeia de raciocínio e o desempenho (existe um “ponto ótimo”, cadeias demasiado longas podem prejudicar o desempenho), gestão de contexto longo, questões culturais e de segurança (existem vulnerabilidades de segurança mais fortes em comparação com modelos que não são de raciocínio), e a associação com fenómenos cognitivos humanos (como a insistência contínua em problemas já explorados). Este estudo revela algumas características e problemas potenciais no funcionamento dos atuais modelos de raciocínio. (Fonte: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Método de otimização em tempo de teste para modelos MoE grandes C3PO: A Universidade Johns Hopkins descobriu que os LLMs de Mistura de Especialistas (MoE) têm um problema de caminhos de especialistas subótimos e propôs o método de otimização em tempo de teste C3PO (Otimização de Camadas Críticas, Especialistas Nucleares e Caminhos Colaborativos). Este método não depende de rótulos reais, mas define um objetivo substituto através de “vizinhos bem-sucedidos” num conjunto de amostras de referência para otimizar o desempenho do modelo. Utiliza algoritmos como pesquisa de padrões, regressão kernel, perda média de amostras semelhantes, e para reduzir custos, otimiza apenas os pesos dos especialistas nucleares das camadas críticas. Aplicado a LLMs MoE, o C3PO aumentou a precisão do modelo base em 7-15% em seis benchmarks, superando as linhas de base comuns de aprendizagem em tempo de teste, e fez com que o desempenho de modelos MoE de parâmetros menores superasse LLMs de parâmetros maiores, aumentando a eficiência do MoE. (Fonte: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Estudo sobre o impacto da quantização no desempenho de modelos de raciocínio: Uma equipa de investigação da Universidade de Tsinghua explorou sistematicamente pela primeira vez o impacto da tecnologia de quantização no desempenho de modelos de linguagem de raciocínio (como a série DeepSeek-R1, Qwen, LLaMA). O estudo avaliou o desempenho de algoritmos de quantização de pesos, cache KV e ativação com diferentes larguras de bits (W8A8, W4A16, etc.) em benchmarks de raciocínio como matemática, ciências e programação. Os resultados mostram que a quantização W8A8 ou W4A16 geralmente pode alcançar desempenho sem perdas, mas larguras de bits inferiores trazem um risco significativo de queda na precisão. O tamanho do modelo, a origem e a dificuldade da tarefa são fatores chave que influenciam o desempenho pós-quantização. O comprimento da saída dos modelos quantizados não aumentou significativamente, e ajustar razoavelmente o tamanho do modelo ou aumentar os passos de inferência pode melhorar o desempenho. Os modelos quantizados e o código relacionados foram tornados open-source. (Fonte: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT: Barreira de proteção para forçar Agentes a cumprir políticas de segurança: A Universidade de Chicago propôs o framework SHIELDAGENT, que visa forçar as trajetórias de ação dos Agentes IA a cumprir políticas de segurança explícitas através de raciocínio lógico. O framework primeiro extrai regras verificáveis de documentos de política, constrói um modelo de política de segurança (baseado em circuitos de regras probabilísticas) e, durante a execução do Agente, recupera regras relevantes com base na sua trajetória de ação e gera um plano de proteção, utilizando uma biblioteca de ferramentas e código executável para verificação formal, garantindo que o comportamento do Agente não viola as regras de segurança. Foi também lançado o conjunto de dados SHIELDAGENT-BENCH, contendo 3K instruções e pares de trajetórias relacionados com segurança. Experiências mostram que o SHIELDAGENT atinge o estado da arte (SOTA) em vários benchmarks, aumentando significativamente a taxa de conformidade de segurança e a taxa de recuperação (recall), ao mesmo tempo que reduz as consultas à API e o tempo de inferência. (Fonte: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1: Incentivando a capacidade de raciocínio de VLM médicos através de aprendizagem por reforço: A Universidade Técnica de Munique, a Universidade de Oxford e outras instituições colaboraram para propor o MedVLM-R1, um modelo de linguagem visual (VLM) médico projetado para gerar processos de raciocínio explícitos em linguagem natural. O modelo adota o framework de aprendizagem por reforço de otimização de política relativa de grupo (GRPO) do DeepSeek, treinado em conjuntos de dados que contêm apenas a resposta final, mas capaz de descobrir autonomamente caminhos de raciocínio interpretáveis por humanos. Após treinar com apenas 600 amostras de VQA de MRI, este modelo de 2B parâmetros alcançou uma precisão de 78,22% em benchmarks de MRI, CT e raios-X, superando significativamente as linhas de base e demonstrando forte capacidade de generalização fora do domínio, superando até mesmo modelos de maior escala como o Qwen2-VL-72B. A investigação fornece novas ideias para a construção de IA médica confiável e interpretável. (Fonte: 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
Investigação revela que treino com aprendizagem por reforço pode levar a respostas longas em modelos de raciocínio: Um estudo da Wand AI analisou as razões pelas quais modelos de raciocínio (como o DeepSeek-R1) geram respostas mais longas. A investigação descobriu que este comportamento pode derivar do processo de treino com aprendizagem por reforço (especialmente o algoritmo PPO), e não da necessidade inerente do problema de um raciocínio mais longo. Quando o modelo recebe uma recompensa negativa por uma resposta errada, a função de perda do PPO tende a gerar respostas mais longas para diluir a penalização por token, mesmo que o conteúdo adicional não ajude a melhorar a precisão. O estudo também mostra que um raciocínio conciso está frequentemente associado a uma maior precisão. Através de uma segunda ronda de treino com aprendizagem por reforço usando apenas uma parte dos problemas solucionáveis, é possível encurtar o comprimento da resposta, mantendo ou até melhorando a precisão, o que é importante para aumentar a eficiência da implementação. (Fonte: 更长思维并不等于更强推理性能,强化学习可以很简洁)

Universidade de Ciência e Tecnologia da China e ZTE propõem Curr-ReFT: Melhorar a capacidade de raciocínio e generalização de VLM de pequeno porte: Para abordar o fenómeno de “parede de tijolos” (gargalo de treino) e a capacidade insuficiente de generalização fora do domínio em modelos de linguagem visual (VLM) de pequeno porte em tarefas complexas, a Universidade de Ciência e Tecnologia da China e a ZTE Communications propuseram o paradigma de pós-treino com aprendizagem por reforço curricular (Curr-ReFT). Este paradigma combina aprendizagem curricular (CL) e aprendizagem por reforço (RL), projetando um mecanismo de recompensa sensível à dificuldade, permitindo que o modelo aprenda progressivamente do fácil para o difícil (decisão binária → escolha múltipla → resposta aberta). Ao mesmo tempo, adota uma estratégia de auto-aperfeiçoamento baseada em amostragem por rejeição, utilizando amostras multimodais e linguísticas de alta qualidade para manter as capacidades básicas do modelo. Experiências nos modelos Qwen2.5-VL-3B/7B mostram que o Curr-ReFT melhora significativamente o desempenho de raciocínio e generalização dos modelos, com o modelo 7B superando até mesmo o InternVL2.5-26B/38B em alguns benchmarks. (Fonte: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM: Expandindo modelos de recompensa de processo através de raciocínio generativo: A Universidade de Tsinghua e o Shanghai AI Lab propuseram o Modelo de Recompensa de Processo Generativo (GenPRM), visando resolver os problemas dos modelos de recompensa de processo (PRM) tradicionais que dependem de pontuações escalares, carecem de interpretabilidade e não podem ser expandidos em tempo de teste. O GenPRM adota uma abordagem generativa, combinando raciocínio de cadeia de pensamento (CoT) e verificação de código, para realizar análise em linguagem natural e verificação de execução de código Python para cada passo do raciocínio, fornecendo supervisão de processo mais profunda e interpretável. Além disso, o GenPRM introduz um mecanismo de expansão em tempo de teste, que melhora a precisão da avaliação através da amostragem paralela de múltiplos caminhos de raciocínio e agregação dos valores de recompensa. Um modelo de 1.5B treinado com apenas 23K dados sintéticos supera o GPT-4o no ProcessBench através da expansão em tempo de teste, e a versão 7B supera o Qwen2.5-Math-PRM-72B de 72B. O GenPRM também pode atuar como um modelo crítico para orientar a otimização do modelo de política. (Fonte: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Investigação revela fenómeno de “pensar demais” da IA de raciocínio em problemas com premissas em falta: Investigadores da Universidade de Maryland e da Universidade de Lehigh descobriram que os modelos de raciocínio atuais (como DeepSeek-R1, o1), quando confrontados com problemas que carecem de informações de premissa necessárias (Missing Premise, MiP), tendem a exibir uma tendência para “pensar demais”. Eles geram respostas 2-4 vezes mais longas do que para problemas normais, entrando num ciclo de revisão repetida do problema, adivinhação de intenções e auto-dúvida, em vez de identificar rapidamente que o problema não pode ser resolvido e parar. Em contraste, modelos que não são de raciocínio (como GPT-4.5) respondem de forma mais curta a problemas MiP, sendo mais capazes de identificar a falta de premissas. O estudo indica que, embora os modelos de raciocínio consigam detetar a falta de premissas, carecem do “pensamento crítico” para interromper decisivamente o raciocínio ineficaz. Este padrão de comportamento pode derivar de restrições insuficientes de comprimento no treino com aprendizagem por reforço e propagar-se através da destilação. (Fonte: 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

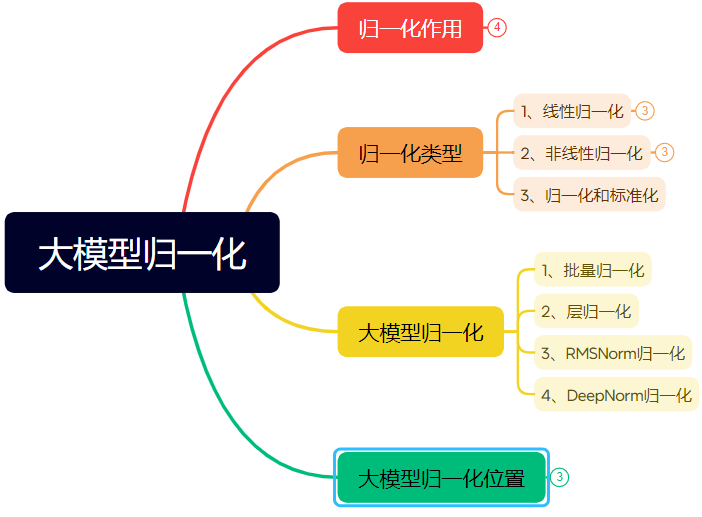
Longo artigo detalhado explica a evolução da tecnologia de normalização em redes neuronais: O artigo revê sistematicamente o papel e a evolução da normalização (Normalization) em redes neuronais, especialmente em Transformers e modelos grandes. A normalização, ao restringir os dados a um intervalo fixo, resolve problemas de comparabilidade de dados, aumenta a velocidade de otimização, mitiga a saturação da função de ativação e o problema de deslocamento de covariáveis internas (ICS). O artigo apresenta métodos comuns de normalização linear (Min-max, Z-score, Mean) e não linear, explicando em detalhe a Normalização por Lote (BN), Normalização por Camada (LN), RMSNorm e DeepNorm, adequadas para modelos de aprendizagem profunda, e analisa as suas diferenças de aplicação na arquitetura Transformer (porque LN/RMSNorm são mais adequadas para PNL). Além disso, discute as diferentes posições de colocação do módulo de normalização dentro das camadas Transformer (Post-Norm, Pre-Norm, Sandwich-Norm) e o seu impacto na estabilidade e desempenho do treino. (Fonte: 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
Engenharia de Prompt para gerar designs de fontes com estilos específicos usando IA: O artigo partilha a experiência do autor e modelos de prompt para explorar o uso do Dream AI 3.0 para gerar designs de texto com estilos específicos. O autor descobriu que especificar diretamente nomes de fontes (como Songti, Kaiti) não funciona bem, pois o modelo de IA tem uma compreensão limitada disso. Portanto, o autor passou a descrever as características do estilo da fonte, a atmosfera emocional e os efeitos visuais, combinando exemplos de referência de diferentes estilos, para construir um modelo de Prompt “Gerador Avançado de Prompts de Design de Estilo de Texto”. O utilizador só precisa de inserir o conteúdo do texto, e o modelo pode combinar ou fundir inteligentemente vários estilos predefinidos (como Sombra Noturna Luminosa, Rusticidade Industrial, Rabisco Infantil, Ficção Científica Metálica, etc.) com base no significado do texto, gerando prompts detalhados para modelos de texto para imagem, obtendo assim efeitos de design gráfico e de texto com qualidade relativamente estável. (Fonte: AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip: Método adaptativo de supressão de picos de gradiente para pré-treino de LLM: Investigadores propuseram o ZClip, um método leve de recorte de gradiente adaptativo, destinado a reduzir os picos de perda durante o processo de treino de LLM e a aumentar a estabilidade do treino. Ao contrário do recorte de gradiente tradicional que usa um limiar fixo, o ZClip utiliza um método baseado no z-score para detetar e recortar picos de gradiente anormais, ou seja, aqueles gradientes que se desviam significativamente da média móvel recente. Este método ajuda a manter a estabilidade do treino sem interferir na convergência e é fácil de integrar em qualquer ciclo de treino. O código e o artigo foram publicados. (Fonte: Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 Negócios
Solução Intel Arc Graphics + Processador Xeon W ajuda a criar máquinas AI all-in-one de baixo custo: A Intel, através da combinação das suas placas gráficas Arc™ e processadores Xeon® W, oferece ao mercado uma solução para construir máquinas all-in-one de modelos grandes com custo controlado (na faixa dos 100.000 RMB) e desempenho prático. As placas gráficas Arc™ utilizam a arquitetura Xe e o motor de aceleração AI XMX, suportam frameworks AI mainstream e Ollama/vLLM, têm baixo consumo de energia e suportam ligação multi-GPU. Os processadores Xeon® W oferecem um elevado número de núcleos e capacidade de expansão de memória, com tecnologia de aceleração AMX integrada. Combinado com otimizações de software como IPEX-LLM, OpenVINO™ e oneAPI, alcança-se uma colaboração eficiente entre CPU e GPU. Testes práticos mostram que esta solução all-in-one a correr o modelo QwQ-32B para um único utilizador pode atingir 32 tokens/s, e a correr o modelo DeepSeek R1 de 671B (requer otimização FlashMoE) pode atingir perto de 10 tokens/s, satisfazendo as necessidades de inferência offline e promovendo a popularização da inferência AI. (Fonte: 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA fabricará supercomputador AI nos EUA: A NVIDIA anunciou que irá projetar e construir completamente o seu supercomputador AI pela primeira vez nos EUA, em colaboração com os principais parceiros de fabrico. Ao mesmo tempo, a sua nova geração de chips Blackwell já começou a ser produzida na fábrica da TSMC no Arizona. A NVIDIA planeia produzir até quinhentos mil milhões de dólares em infraestrutura AI nos EUA nos próximos 4 anos, com parceiros como TSMC, Foxconn, Wistron, Amkor e SPIL. Esta medida visa satisfazer a procura por chips AI e supercomputadores, fortalecer a cadeia de abastecimento e aumentar a resiliência. (Fonte: nvidia, nvidia)

Horizon Robotics recruta estagiários de reconstrução/geração 3D: A equipa de Inteligência Incorporada da Horizon Robotics está a recrutar estagiários de algoritmos na área de reconstrução/geração 3D em Xangai/Pequim. As responsabilidades incluem participar no design e desenvolvimento de soluções de algoritmos Real2Sim para robôs (combinando reconstrução 3D GS, reconstrução feed-forward, geração 3D/vídeo), otimizar o desempenho do simulador Real2Sim (suportando simulação de fluidos, tátil, etc.), e acompanhar a investigação de ponta publicando artigos em conferências de topo. Requisitos: mestrado ou superior, formação em Computação/Computação Gráfica/IA, experiência em visão 3D/geração de vídeo ou modelos multimodais/difusão, proficiência em Python/Pytorch/Huggingface. Publicação em conferências de topo, familiaridade com plataformas de simulação ou experiência em projetos open-source são preferenciais. Oferece oportunidade de efetivação, cluster de GPU e salário competitivo. (Fonte: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan Hotel & Travel recruta Engenheiros de Algoritmos de Modelos Grandes L7-L8: A equipa de Algoritmos de Fornecimento da Meituan Hotel & Travel está a recrutar Engenheiros de Algoritmos de Modelos Grandes de nível L7-L8 (recrutamento externo) em Pequim. As responsabilidades incluem construir um sistema de compreensão do fornecimento de hotelaria e viagens (etiquetas de produtos, identificação de pontos de interesse, mineração de fornecimentos semelhantes, etc.), otimizar materiais de exibição (geração de títulos, imagens e texto, razões de recomendação), construir combinações de pacotes de férias (seleção de produtos, previsão de vendas, precificação), e explorar e implementar tecnologias de modelos grandes de ponta (ajuste fino, RL, otimização de Prompt). Requisitos: mestrado ou superior, mais de 2 anos de experiência, formação em Computação/Automação/Estatística Matemática, bases sólidas em algoritmos e capacidade de programação. (Fonte: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta usará dados de utilizadores na UE para treinar IA: A Meta anunciou que se prepara para começar a usar dados públicos de utilizadores do Facebook e Instagram na região da UE (como publicações, comentários, excluindo mensagens privadas) para treinar os seus modelos de IA, limitado a utilizadores maiores de 18 anos. A empresa informará os utilizadores através de notificações na aplicação e por email, fornecendo um link para objeção (opt-out). Anteriormente, a Meta suspendeu os planos de usar dados de utilizadores na Europa para treinar IA devido a exigências do regulador irlandês. (Fonte: Reddit r/artificial)

Tencent Cloud lança serviço gerido MCP: A Tencent Cloud também começou a oferecer serviços geridos MCP (Managed Cloud Platform), visando fornecer às empresas soluções de gestão e operação de recursos na nuvem mais convenientes e eficientes. Esta medida significa uma intensificação da concorrência entre os principais fornecedores de nuvem nesta área. Detalhes específicos do serviço e as “características WeChat” ainda não foram detalhados. (Fonte: 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 Comunidade
Vencedor do Prémio Turing LeCun fala sobre o desenvolvimento da IA: inteligência humana não é geral, próximo avanço pode estar em modelos não generativos: Numa recente entrevista de podcast, Yann LeCun reiterou que o termo AGI é enganoso, argumentando que a inteligência humana é altamente especializada, não geral. Ele prevê que o próximo grande avanço na IA pode vir de modelos não generativos, com foco em fazer as máquinas compreenderem verdadeiramente o mundo físico, possuírem capacidade de raciocínio e planeamento, e memória persistente, semelhante à arquitetura JEPA que propôs. Ele acredita que os LLMs atuais carecem de capacidade de raciocínio real e de modelação do mundo físico, e atingir o nível de inteligência de um gato já seria um progresso enorme. Quanto ao LLaMA open-source da Meta, ele considera que foi a escolha certa para impulsionar todo o ecossistema de IA, enfatizando que a inovação vem de todo o mundo e o open-source é crucial para acelerar os avanços. Ele também vê os óculos inteligentes como um importante veículo para assistentes de IA. (Fonte: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

Breve “bloqueio” de IPs chineses pelo GitHub gera atenção, oficial afirma ter sido erro de configuração: Entre 12 e 13 de abril, alguns utilizadores chineses descobriram que não conseguiam aceder ao GitHub, com a página a indicar “Endereço IP sujeito a restrições de acesso”, gerando pânico e discussão na comunidade, temendo um bloqueio direcionado. Anteriormente, o GitHub tinha bloqueado contas de programadores da Rússia, Irão, etc., devido a sanções dos EUA. O GitHub respondeu posteriormente que o incidente se deveu a um erro numa alteração de configuração que impediu temporariamente o acesso a utilizadores não autenticados, e que o problema foi corrigido a 13 de abril. Apesar de ser uma falha técnica, o evento reacendeu a discussão sobre os riscos geopolíticos das plataformas de alojamento de código e as alternativas domésticas (como Gitee, CODING, Jihu GitLab, etc.). (Fonte: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

Agentes IA levantam preocupações de cibersegurança: Um artigo da MIT Technology Review aponta que ataques cibernéticos autónomos impulsionados por IA estão iminentes. Com o aumento das capacidades da IA, atores maliciosos podem usar Agentes IA para descobrir vulnerabilidades automaticamente, planear e executar ataques cibernéticos mais complexos e em maior escala, representando novas ameaças à segurança de indivíduos, empresas e até nações. Isto exige que o campo da cibersegurança acelere a investigação e implementação de estratégias e tecnologias de defesa capazes de lidar com ataques impulsionados por IA. (Fonte: Ronald_vanLoon)

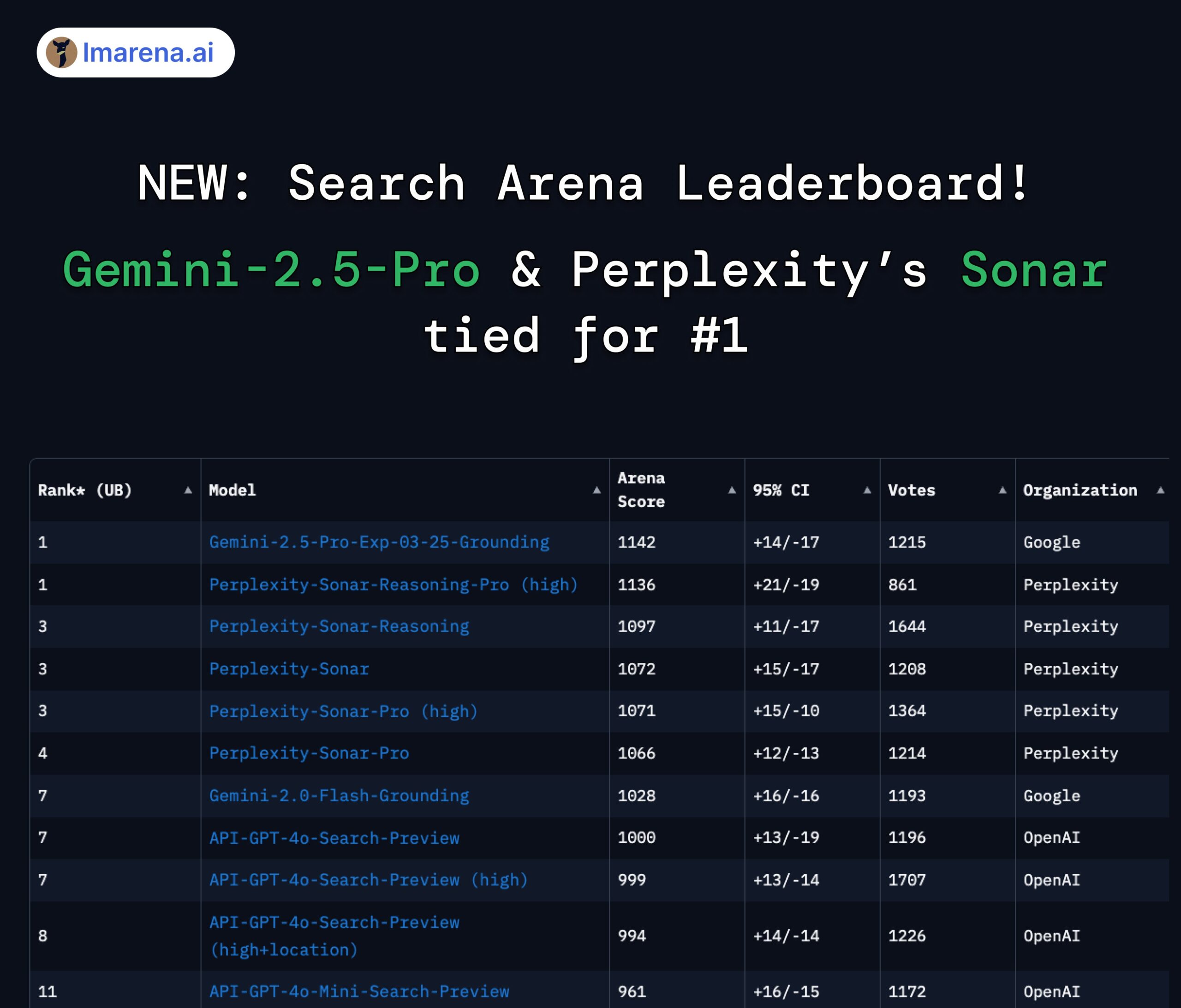
Perplexity Sonar e Gemini 2.5 Pro empatados no topo da arena de pesquisa: No novo ranking Search Arena do LMArena.ai (anteriormente LMSYS), o modelo Sonar-Reasoning-Pro-High da Perplexity e o Gemini-2.5-Pro-Grounding da Google estão empatados em primeiro lugar. Este ranking avalia especificamente a qualidade das respostas de LLMs baseadas em pesquisa na web. O CEO da Perplexity, Arav Srinivas, congratulou-se com o resultado e salientou que continuarão a melhorar o modelo Sonar e o índice de pesquisa. A comunidade considera que isto demonstra que, no campo dos LLMs melhorados por pesquisa, a competição se desenrola principalmente entre a Google e a Perplexity. (Fonte: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Discussão sobre as restrições de uso do modelo Claude: Na comunidade Reddit r/ClaudeAI, existe controvérsia entre os utilizadores sobre as restrições de uso da versão Claude Pro (como limite de mensagens, restrições de capacidade). Alguns utilizadores queixam-se de encontrar frequentemente limitações, afetando os seus fluxos de trabalho, e até consideram mudar de modelo; outros afirmam raramente encontrar restrições, sugerindo que pode ser devido ao modo de uso (como carregar contextos muito grandes) ou exagero. Isto reflete as diferentes experiências e opiniões dos utilizadores sobre as políticas de uso e estabilidade dos modelos da Anthropic. (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Discussão sobre IA e o futuro do emprego: Um gráfico comparativo no Reddit r/ChatGPT gerou discussão: a IA irá aumentar as capacidades humanas, trazendo uma vida de abundância, ou substituirá o trabalho humano, levando ao desemprego em massa? Nos comentários, muitos utilizadores expressaram preocupação com a substituição de empregos pela IA, especialmente em profissões criativas (programação, arte). Alguns acreditam que a IA agravará a desigualdade social, pois os benefícios irão principalmente para os proprietários da IA, enquanto a redução da base tributária pode dificultar a implementação do Rendimento Básico Universal (UBI). Outros mantêm uma atitude mais otimista, vendo a IA como uma ferramenta poderosa que pode aumentar a eficiência e criar novos postos de trabalho (como engenheiro de prompt), sendo crucial adaptar-se e aprender a utilizar a IA. (Fonte: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

Recolha de dados por IA levanta preocupações de privacidade: Um infográfico comparando os tipos de dados de utilizador recolhidos por diferentes chatbots de IA (ChatGPT, Gemini, Copilot, Claude, Grok) gerou discussão na comunidade sobre questões de privacidade. O gráfico mostra que o Google Gemini recolhe o maior número de tipos de dados, enquanto o Grok (requer conta) e o ChatGPT (não requer conta) recolhem relativamente menos. Os comentários dos utilizadores enfatizam a omnipresença da recolha de dados por trás dos serviços gratuitos (“não há almoços grátis”) e expressam preocupação sobre os propósitos específicos da recolha de dados (como previsão de comportamento). (Fonte: Reddit r/artificial)

Destilação de modelos considerada uma via eficaz para replicar alto desempenho a baixo custo: Utilizadores do Reddit partilharam como, através da técnica de destilação de modelos, treinaram modelos pequenos e afinados usando modelos grandes (como GPT-4o), alcançando desempenho próximo ao do GPT-4o (92% de precisão) num domínio específico (análise de sentimento) a um custo 14 vezes menor. Os comentários apontam que a destilação é uma técnica amplamente utilizada, mas em termos de capacidade de generalização entre domínios, os modelos pequenos geralmente não são tão bons quanto os grandes. Para domínios específicos e estáveis, a destilação é um método eficaz de redução de custos e aumento de eficiência, mas para cenários complexos que exigem adaptação constante a novos dados ou múltiplos domínios, usar diretamente APIs grandes pode ser mais económico. (Fonte: Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 Outros
OceanBase organiza a primeira competição AI Hackathon: O fornecedor de bases de dados distribuídas OceanBase, em conjunto com a Ant Open Source, Machine之心, etc., organiza a sua primeira competição AI Hackathon. As inscrições abriram a 10 de abril e encerram a 7 de maio. A competição tem como tema “DB+AI” e define duas direções principais: usar o OceanBase como base de dados para construir aplicações AI, e explorar a combinação do OceanBase com o ecossistema AI (como CAMEL AI, FastGPT, OpenDAL). A competição oferece um prémio total de 100.000 RMB, aberta a inscrições individuais e de equipas, visando estimular os programadores a explorar aplicações inovadoras da integração profunda entre bases de dados e IA. (Fonte: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

Professor Liu Xinjun da Universidade de Tsinghua fará palestra online sobre robôs paralelos: O Professor Liu Xinjun, Diretor do Instituto de Engenharia de Design do Departamento de Engenharia Mecânica da Universidade de Tsinghua e Presidente do Comité Chinês da IFToMM, fará uma palestra online na noite de 15 de abril, com o tema “Fundamentos da Cinemática de Robôs Paralelos e Inovação em Equipamentos”. A palestra abordará a teoria fundamental dos robôs paralelos e a sua aplicação na inovação de equipamentos de ponta. O moderador será o Professor Liu Yingxiang da Universidade de Tecnologia de Harbin. (Fonte: 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

Guia para a 3ª Cimeira da Indústria AIGC da China publicado: A 3ª Cimeira da Indústria AIGC da China, que se realizará a 16 de abril em Pequim, publicou a sua agenda detalhada e destaques. A cimeira focar-se-á na tecnologia AI e na sua implementação prática, com tópicos que abrangem infraestrutura de computação, aplicação de modelos grandes em cenários verticais como educação/entretenimento/serviços empresariais/AI4S, segurança e controlo de IA, etc. Os oradores vêm da Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, Ant Group, entre outros. A cimeira também divulgará a lista de empresas e produtos AIGC a acompanhar em 2025, bem como o panorama completo das aplicações AIGC na China. (Fonte: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
