
Palavras-chave:AI, GPT-4.1, IPO da Zhipu AI, Investimento em supercomputadores AI da Nvidia, Despesas de capital em AI da Amazon, Protocolo de interoperabilidade de AI Agent, Base de utilizadores do DeepSeek
🔥 Foco
OpenAI lança a série de modelos GPT-4.1, melhora o desempenho da API e descontinua o GPT-4.5: A OpenAI lançou três novos modelos através da API em 15 de abril: GPT-4.1, GPT-4.1 mini e GPT-4.1 nano, com o objetivo de superar de forma abrangente a série GPT-4o. Os novos modelos possuem uma janela de contexto de até 1 milhão de Tokens e a base de conhecimento foi atualizada até junho de 2024. O GPT-4.1 destaca-se na capacidade de codificação (pontuação de 54,6% no SWE-bench Verified, um aumento de 21,4% em relação ao GPT-4o), no seguimento de instruções (pontuação de 38,3% no MultiChallenge, um aumento de 10,5% em relação ao GPT-4o) e na compreensão de vídeo de longo contexto (pontuação de 72,0% no Video-MME, um aumento de 6,7% em relação ao GPT-4o). É de notar que o GPT-4.1 nano é o primeiro modelo nano, com desempenho superior ao GPT-4o mini e custo inferior. Simultaneamente, a OpenAI anunciou que descontinuará a API GPT-4.5 Preview em 3 meses (14 de julho), descrevendo-a como uma versão de pré-visualização para investigação, e que integrará as funcionalidades preferidas pelos programadores nos novos modelos. Este lançamento é visto como uma medida estratégica da OpenAI para diferenciar os modelos de API da linha de produtos ChatGPT e competir diretamente com a série Gemini da Google. (Fonte: 36氪, 新智元1, AI科技评论, Reddit r/LocalLLaMA, Reddit r/artificial)
Zhipu AI inicia assessoria para IPO e disponibiliza novos modelos em open-source, com avaliação superior a 20 mil milhões: A Zhipu AI (Zhipu Huazhang), uma das “seis pequenas tigres” dos grandes modelos na China, registou-se para assessoria de pré-listagem na Comissão Reguladora de Valores Mobiliários de Pequim em 14 de abril, iniciando formalmente o processo de IPO, com a CICC como instituição assessora. A Zhipu AI foi incubada pelo Laboratório de Engenharia do Conhecimento da Universidade de Tsinghua, com a maioria dos membros principais da equipa provenientes de Tsinghua. Acumulou mais de 15 mil milhões de yuans em financiamento, com uma avaliação recente superior a 20 mil milhões de yuans. Ao mesmo tempo que inicia o IPO, a Zhipu AI anunciou a disponibilização em larga escala e open-source da série de modelos GLM-4-32B/9B, incluindo modelos base, de inferência e de reflexão (contemplation), sob a licença MIT, permitindo o uso comercial gratuito. Entre eles, o modelo de inferência GLM-Z1-32B-0414 com 32 mil milhões de parâmetros rivaliza em desempenho com o DeepSeek-R1 de 671 mil milhões de parâmetros em algumas tarefas. A sua versão API ultrarrápida, GLM-Z1-AirX, atinge uma velocidade de inferência de 200 tokens/s, e a versão de alta relação custo-benefício tem um preço de apenas 1/30 do DeepSeek-R1. A empresa também lançou o novo domínio z.ai como plataforma de experimentação gratuita dos modelos. Esta ação demonstra o layout abrangente da Zhipu AI em investigação e desenvolvimento tecnológico próprio, exploração comercial e construção de ecossistema open-source. (Fonte: 智东西, InfoQ, 量子位, 极客公园, 雷递, 公众号)

Nvidia investe 500 mil milhões de dólares na fabricação de supercomputadores de IA nos EUA: A Nvidia anunciou um plano ambicioso para investir 500 mil milhões de dólares nos próximos quatro anos para fabricar, pela primeira vez, supercomputadores de IA em solo americano. O plano envolve a colaboração com vários gigantes da indústria, incluindo a TSMC (produção de chips Blackwell no Arizona), Foxconn e Wistron (construção de fábricas de supercomputadores no Texas), Amkor e SPIL (encapsulamento e teste no Arizona). O CEO da Nvidia, Jensen Huang, afirmou que esta medida visa satisfazer a crescente procura por chips de IA e supercomputadores, reforçar a resiliência da cadeia de abastecimento e utilizar as tecnologias de IA, robótica (Isaac GR00T) e gémeos digitais (Omniverse) da Nvidia para projetar e operar as fábricas. O plano é visto como uma implantação estratégica no contexto do impulso do governo dos EUA para a fabricação doméstica (como a Lei CHIPS) e da geopolítica, visando elevar a posição dos EUA na corrida global por infraestrutura de IA, mas enfrenta desafios como a complexidade da cadeia de abastecimento, escassez de trabalhadores qualificados e incerteza política. (Fonte: 新智元1, 新智元2, Reddit r/artificial)

Amazon planeia investir mais de 100 mil milhões de dólares para impulsionar a IA, enfrentar a concorrência e aproveitar oportunidades: O CEO da Amazon, Andy Jassy, revelou na carta anual aos acionistas de 2024 que a empresa planeia realizar despesas de capital superiores a 100 mil milhões de dólares em 2025, sendo a maior parte destinada a projetos relacionados com IA, incluindo centros de dados, equipamentos de rede, hardware de IA (como os chips próprios Trainium) e serviços de IA generativa (como a série de grandes modelos próprios Nova, a plataforma Bedrock, a versão atualizada Alexa+ e o assistente de compras Rufus). Este investimento maciço (próximo de 1/6 da receita anual) reflete a visão da Amazon sobre a IA como chave para enfrentar a concorrência acirrada no comércio eletrónico (de SHEIN, Temu, TikTok, etc.) e aproveitar uma oportunidade histórica. Jassy enfatizou que a IA mudará as regras da pesquisa, programação, compras, etc., e não investir significaria perder competitividade. Atualmente, o negócio de IA da Amazon já gera receitas anuais de vários milhares de milhões de dólares, com crescimento anual de três dígitos. Esta medida também demonstra a determinação da Amazon em continuar a investir para consolidar a sua posição de liderança no setor de serviços na nuvem (AWS), face à concorrência de rivais como Microsoft Azure e Google Cloud. (Fonte: 36氪)
🎯 Tendências
Protocolos de interoperabilidade para AI Agents MCP e A2A ganham destaque: O campo dos agentes inteligentes de IA está a assistir a uma competição por protocolos de interação padronizados. O MCP (Model Context Protocol) proposto pela Anthropic visa unificar a comunicação entre grandes modelos e ferramentas externas, fontes de dados, sendo apelidado de “USB-C da IA” e já conta com o apoio da OpenAI, Google, entre outros. A Google, por sua vez, disponibilizou em open-source o protocolo A2A (Agent2Agent), focado na colaboração segura e eficiente entre agentes de diferentes fornecedores e frameworks, com o objetivo de quebrar as barreiras do ecossistema. O surgimento destes dois protocolos marca a evolução da IA de inteligência individual para redes colaborativas, mas também levanta discussões sobre “protocolo como poder”, monopólio de dados e barreiras de ecossistema (“jardins murados”). Dominar a definição de padrões pode reestruturar a cadeia da indústria de IA e ter um impacto profundo na integração da IA com o mundo físico (robótica, IoT). Fabricantes chineses como Alibaba Cloud e Tencent Cloud também já começaram a implementar suporte para MCP. (Fonte: 36Kr)

Relatório da QuestMobile: DeepSeek revoluciona o panorama das aplicações de IA na China, com 240 milhões de utilizadores: O relatório “Análise da Concorrência no Mercado de Aplicações de IA no Primeiro Trimestre de 2025” publicado pela QuestMobile mostra que, impulsionado pela popularidade explosiva do modelo DeepSeek e das suas aplicações, o mercado de Apps nativas de IA na China foi completamente revolucionado. Até ao final de fevereiro de 2025, a escala de utilizadores ativos mensais de Apps nativas de IA atingiu 240 milhões, um aumento de quase 90% em relação a janeiro. A App DeepSeek liderou com 194 milhões de utilizadores ativos mensais, seguida pela Doubao da ByteDance (116 milhões) e Tencent Yuanbao (41,64 milhões), substituindo anteriores líderes como Kimi. O relatório aponta que o efeito de democratização do open-source do DeepSeek impulsionou a adoção pelos principais players e a explosão de aplicações de IA, formando 23 segmentos, incluindo assistentes gerais de IA e pesquisa de IA, sendo este último o mais competitivo. Atualmente, a abordagem “multi-modelo” tornou-se padrão nas Apps de topo, e o foco da concorrência deslocou-se para o design e operação do produto. (Fonte: QuestMobile)

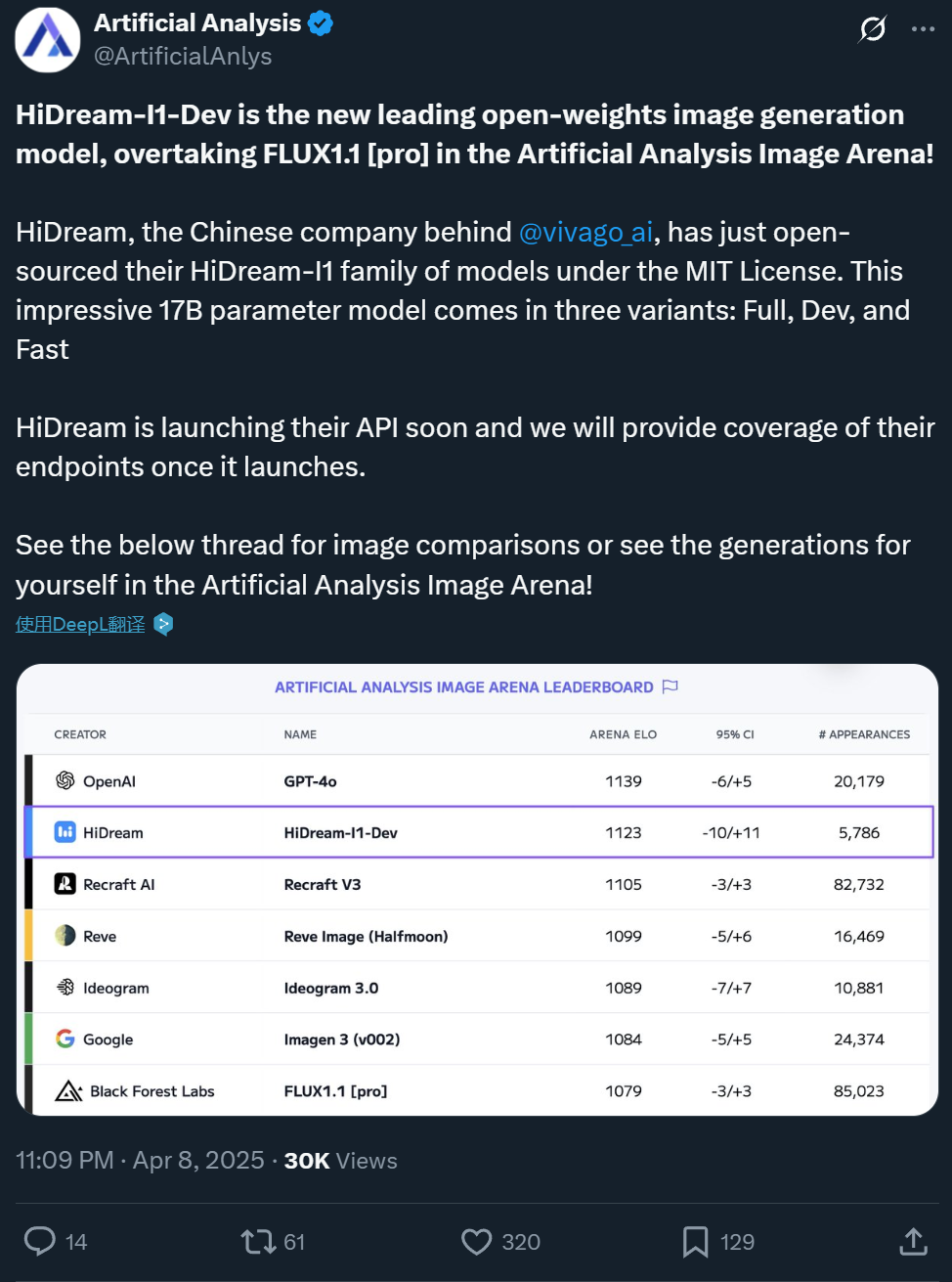
Zxiang Future disponibiliza em open-source o modelo de geração de imagem a partir de texto HiDream-I1 de 17B, com efeitos comparáveis ao GPT-4o: A empresa chinesa Zxiang Future disponibilizou em open-source o seu grande modelo de geração de imagem a partir de texto HiDream-I1 com 17 mil milhões de parâmetros, sob a licença permissiva MIT, permitindo o uso comercial. O modelo demonstrou um desempenho excecional em arenas e benchmarks (como HPSv2.1, GenEval, DPG-Bench) em plataformas como Artificial Analysis, com o realismo, detalhe e seguimento de instruções das imagens geradas considerados comparáveis ao GPT-4o e FLUX 1.1 Pro, e até superiores em alguns aspetos. O HiDream-I1 utiliza a arquitetura Sparse Diffusion Transformer (Sparse DiT), incorporando a tecnologia MoE para melhorar o desempenho e a eficiência. A empresa também anunciou que em breve disponibilizará em open-source o modelo HiDream-E1, que suporta edição interativa de imagens, com o objetivo de oferecer uma experiência de geração e edição de imagens “open-source tipo GPT-4o” através da combinação dos dois. O modelo já está disponível no Hugging Face e pode ser experimentado na plataforma Vivago. (Fonte: 机器之心1, 机器之心2)
ByteDance lança o modelo base de vídeo Seaweed de 7B, de baixo custo e alta eficiência: A equipa Seed da ByteDance lançou um modelo base de geração de vídeo chamado Seaweed (um trocadilho com Seed-Video). O modelo tem apenas 7 mil milhões de parâmetros e foi alegadamente treinado usando 665.000 horas de GPU H100 (equivalente a cerca de 28 dias com 1000 GPUs), com um custo relativamente baixo. O Seaweed é capaz de gerar vídeos de diferentes resoluções (suporta nativamente 1280×720, com upsampling para 2K), proporções arbitrárias e durações a partir de texto. O modelo suporta geração de imagem para vídeo, controlo de sujeito de referência (imagem única/múltipla), combinação com a solução de humanos digitais Omnihuman para gerar vídeos com sincronização labial, dobragem de vídeo, entre outras funções. Tecnicamente, utiliza uma arquitetura DiT+VAE, combinada com um processo abrangente de tratamento de dados e uma estratégia de treino multi-etapa e multi-tarefa (pré-treino, SFT, RLHF), e foi otimizado a nível de sistema para aumentar a eficiência do treino. A equipa é liderada pelo Dr. Jiang Lu, antigo responsável pela geração de vídeo na Google, entre outros. (Fonte: 量子位)

Alibaba Tongyi lança o modelo de geração de vídeo de humanos digitais OmniTalker: A equipa HumanAIGC do laboratório Alibaba Tongyi lançou um novo grande modelo de geração de vídeo de humanos digitais, o OmniTalker. O modelo visa resolver problemas como latência, dessincronização áudio-visual e inconsistência de estilo inerentes aos métodos tradicionais em cascata (TTS + audio-driven). O OmniTalker é um framework unificado de ponta a ponta que, a partir de texto e um áudio/vídeo de referência, gera em tempo real voz e vídeo de humano digital sincronizados, preservando a voz e o estilo de fala facial da fonte de referência. A sua arquitetura central utiliza um DiT (Diffusion Transformer) de fluxo duplo, processando informações de áudio e visuais separadamente, e garante sincronização e consistência de estilo através de um módulo inovador de fusão áudio-visual. O modelo utiliza um módulo de aprendizagem por referência contextual para capturar características de estilo do vídeo de referência, sem necessidade de treinar extratores de estilo adicionais. O projeto já está disponível para experimentação na comunidade ModelScope e no HuggingFace. (Fonte: 机器之心)

Kuaishou lança a versão 2.0 do modelo de vídeo Kling AI: O modelo de geração de vídeo Kling AI da Kuaishou lançou a sua versão 2.0, que alegadamente apresenta melhorias significativas na amplitude dos movimentos de câmara, no respeito pelas leis da física, na representação de personagens, na estabilidade dos movimentos e na compreensão semântica. Avaliações de utilizadores indicam que a nova versão tem um desempenho excecional no tratamento de interações complexas (como um T-Rex a partir árvores), ações detalhadas (como tirar óculos), cenas com várias pessoas e simulação de luz e sombra realistas, aumentando substancialmente o realismo e a sensação cinematográfica dos vídeos gerados, com efeitos considerados superiores à versão 1.6 anterior e líderes na indústria. Embora ainda haja espaço para melhorias em movimentos rápidos de grupo e simulações físicas extremas (como lançamentos de basquetebol), o seu desempenho geral é considerado como começando a desafiar o nível de produção profissional. Os utilizadores podem experimentar a nova versão através do site oficial klingai.com. (Fonte: 公众号, op7418)

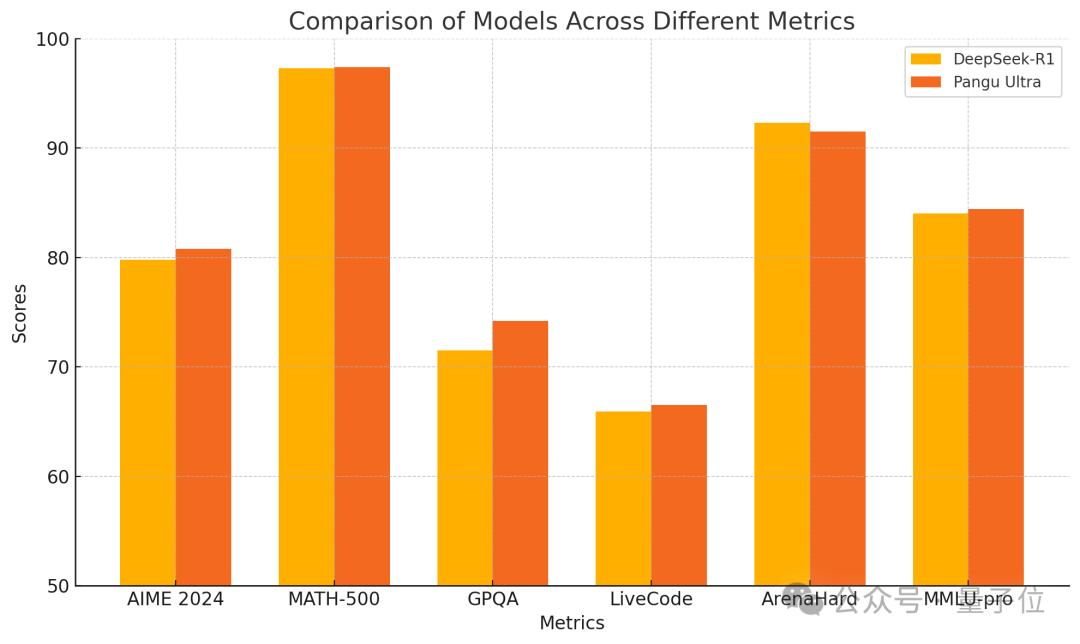
Huawei lança o modelo denso Pangu Ultra 135B, treinado puramente em Ascend com desempenho superior: A Huawei anunciou um novo membro da sua série de grandes modelos Pangu – o Pangu Ultra. Trata-se de um modelo denso (Dense) com 135 mil milhões de parâmetros, treinado inteiramente no cluster de computação AI Ascend da Huawei (8192 NPUs), sem utilizar GPUs Nvidia. Segundo relatos, o Pangu Ultra demonstra um desempenho excecional em tarefas como raciocínio matemático (AIME 2024, MATH-500) e programação (LiveCodeBench), com desempenho comparável a modelos MoE de maior escala como o DeepSeek-R1. Tecnicamente, o modelo utiliza uma inovadora camada de normalização Sandwich-Norm de escalonamento profundo e uma estratégia de inicialização de parâmetros TinyInit, resolvendo eficazmente os problemas de instabilidade no treino de redes ultra-profundas (94 camadas), alcançando um treino estável e sem picos de perda (loss spikes). Através de otimizações a nível de sistema, o treino atingiu uma utilização de poder computacional (MFU) superior a 52%. (Fonte: 量子位)
Canopy Labs disponibiliza em open-source o modelo de síntese de voz emocional Orpheus: A Canopy Labs lançou e disponibilizou em open-source uma série de modelos de conversão de texto em voz (TTS) chamada Orpheus. O modelo é baseado na arquitetura Llama, com a versão inicial de 3 mil milhões de parâmetros, seguida por versões menores de 1B, 0.5B, 0.15B, etc. A característica distintiva do Orpheus é a capacidade de gerar voz com emoção, entoação e ritmo altamente humanizados, conseguindo até inferir e gerar sons não verbais como risos e suspiros a partir do texto, alcançando uma expressão “empática”. O modelo suporta clonagem de voz zero-shot e controlo da entoação emocional através de etiquetas. Utiliza inferência em streaming, com latência baixa de 100-200ms, e velocidade de inferência mais rápida que a reprodução em tempo real numa placa gráfica A100 40GB. Os programadores afirmam que o seu desempenho supera os modelos SOTA open-source existentes e alguns closed-source, visando quebrar o monopólio dos modelos TTS fechados. O modelo e o código já estão disponíveis no GitHub e Hugging Face. (Fonte: 新智元)

Universidade de Zhejiang e ByteDance lançam conjuntamente o modelo de síntese de voz MegaTTS3: A equipa do Professor Zhao Zhou da Universidade de Zhejiang, em colaboração com a ByteDance, lançou e disponibilizou em open-source a terceira geração do modelo de síntese de voz MegaTTS3. Com um tamanho leve de apenas 0.45B parâmetros, o modelo alcança síntese de voz bilingue (chinês-inglês) de alta qualidade e demonstra um desempenho excecional na clonagem de voz zero-shot, capaz de gerar voz natural, controlável e personalizada. O MegaTTS3 foca-se em avanços no alinhamento esparso voz-texto, na controlabilidade da geração e no equilíbrio entre eficiência e qualidade. Os destaques técnicos incluem a tecnologia “Multi-Condition Classifier-Free Guidance” (Multi-Condition CFG) para controlo multidimensional, como a intensidade do sotaque, e a tecnologia “Piecewise Rectified Flow Acceleration” (PeRFlow) que triplica a velocidade de amostragem. O modelo demonstra naturalidade (CMOS) e similaridade do locutor (SIM-O) líderes em benchmarks como LibriSpeech. (Fonte: PaperWeekly)

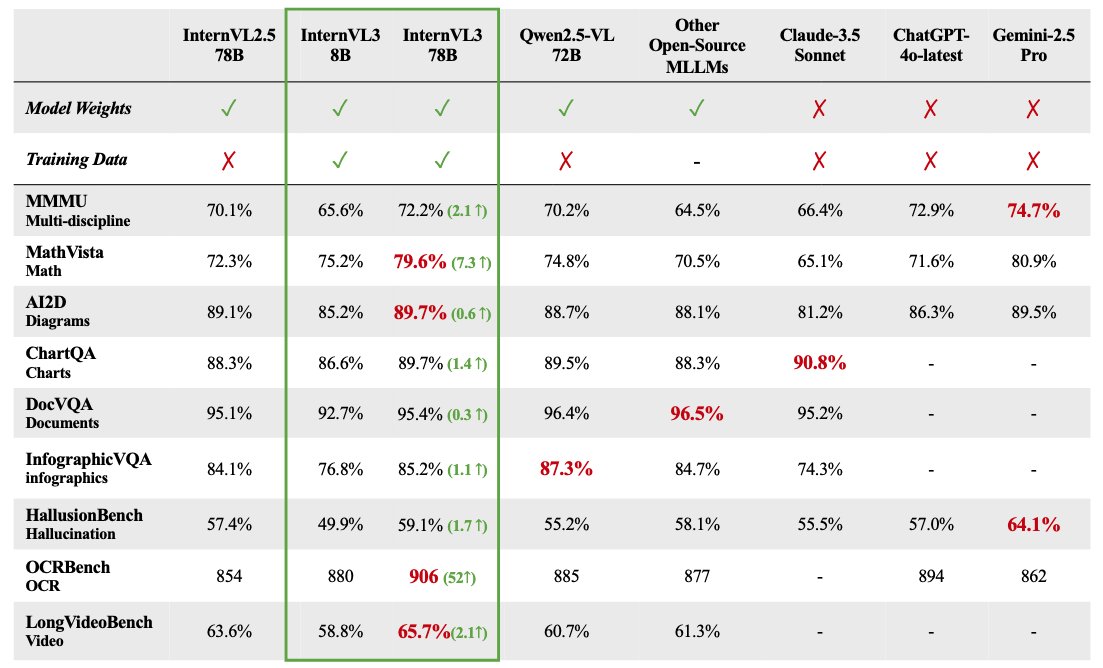
Série de grandes modelos multimodais InternVL 3 disponibilizada em open-source: O OpenGVLab lançou a série de grandes modelos multimodais InternVL 3, com tamanhos de parâmetros variando de 1B a 78B, já disponível no Hugging Face. Alegadamente, a versão de 78B parâmetros obteve uma pontuação de 72,2 no benchmark MMMU, estabelecendo um novo recorde SOTA para modelos multimodais open-source. Os destaques técnicos do InternVL 3 incluem: pré-treino multimodal nativo, aprendendo simultaneamente linguagem e visão; introdução de codificação de posição visual variável (V2PE) para suportar contexto expandido; utilização de técnicas avançadas de pós-treino como SFT e MPO; e aplicação de estratégias de escalonamento em tempo de teste para melhorar a capacidade de raciocínio matemático. Os dados de treino e os pesos do modelo foram disponibilizados para uso da comunidade. (Fonte: huggingface)
Análise do desempenho real do GPT-4.1: codificação melhorada mas raciocínio inferior: Os modelos da série GPT-4.1 lançados pela OpenAI mostram um quadro de desempenho complexo em testes iniciais e avaliações de benchmark. Embora demonstrem progressos significativos em tarefas de geração de código em comparação com o GPT-4o, como melhor desempenho em simulações físicas, desenvolvimento de jogos, e pontuações elevadas no SWE-Bench, o seu desempenho em benchmarks mais amplos de raciocínio, matemática e conhecimento (como Livebench, GPQA Diamond) ainda fica atrás do Gemini 2.5 Pro da Google e do Claude 3.7 Sonnet da Anthropic. Analistas sugerem que o GPT-4.1 pode ser uma atualização incremental do GPT-4o, ou destilado do GPT-4.5, e a sua estratégia de lançamento pode visar oferecer opções de modelo mais económicas e otimizadas para tarefas específicas através da API, em vez de um modelo emblemático que supere totalmente os concorrentes. (Fonte: 新智元)
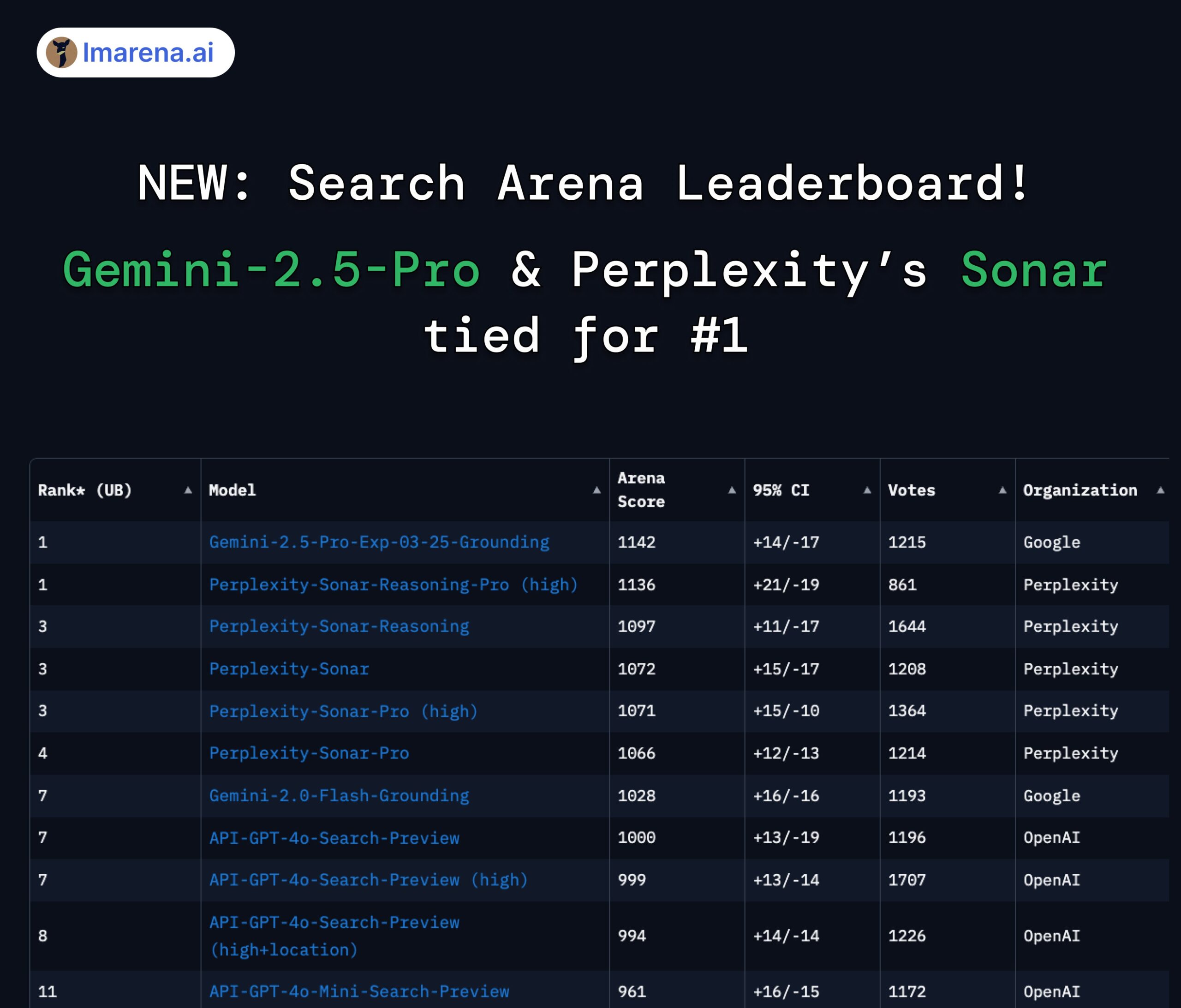
Ranking LMArena Search: Gemini 2.5 Pro e Perplexity Sonar empatados em primeiro lugar: Na avaliação da LMArena focada em grandes modelos com capacidade de pesquisa/ligação à internet, o Gemini-2.5-Pro da Google (combinado com Google Search) e o Sonar-Reasoning-Pro da Perplexity empataram no topo do ranking. Este resultado foi confirmado e partilhado pelo CEO da Google DeepMind, Demis Hassabis, e pelo responsável pelas relações com programadores da Google, Logan Kilpatrick. O CEO da Perplexity, Aravind Srinivas, também comentou que testes A/B internos mostram que o seu modelo Sonar tem melhor retenção de utilizadores que o GPT-4o, com desempenho comparável ao Gemini 2.5 Pro e ao recém-lançado GPT-4.1. A organização da avaliação, lmarena.ai, disponibilizou em open-source os dados de 7000 votos de utilizadores. (Fonte: lmarena_ai 1, lmarena_ai 2, AravSrinivas, demishassabis)
Meta retomará o uso de conteúdo público de utilizadores europeus para treinar IA: A Meta anunciou que voltará a usar conteúdo público de utilizadores na Europa para treinar os seus modelos de inteligência artificial. Anteriormente, a Meta tinha suspendido esta prática devido à pressão e exigências regulatórias das autoridades europeias de proteção de dados (especialmente a Comissão de Proteção de Dados da Irlanda). A decisão de retomar o treino pode refletir os esforços contínuos e ajustes estratégicos da Meta para equilibrar a privacidade do utilizador, o cumprimento de regulamentos (como o RGPD) e a obtenção de dados suficientes para manter a competitividade dos seus modelos de IA. Esta medida pode reacender o debate sobre os direitos dos utilizadores sobre os seus dados e a transparência no treino de IA. (Fonte: Reddit r/artificial)

Aplicação móvel Claude poderá adicionar modo de interação por voz: De acordo com pistas descobertas pelo utilizador do X @testingcatalog, a Anthropic pode estar a planear adicionar funcionalidade de interação por voz à sua aplicação móvel Claude. Capturas de ecrã mostram um ícone de microfone na interface da aplicação, sugerindo que os utilizadores poderão, no futuro, conversar com o Claude por voz, de forma semelhante aos modos de voz já oferecidos pelas aplicações ChatGPT e Google Gemini. Isto tornaria a interação com o Claude em dispositivos móveis mais diversificada e conveniente, melhorando ainda mais a experiência do utilizador e alinhando-o funcionalmente com outros assistentes de IA convencionais. (Fonte: Reddit r/ClaudeAI)
Velocidade dos modelos da série Z1 da Zhipu atrai atenção, apelidados de “modelos instantâneos”: A série de modelos Z1 recentemente lançada pela Zhipu AI, especialmente a versão GLM-Z1-AirX, tem recebido atenção pela sua velocidade de inferência extremamente rápida. Alguns analistas apelidaram-nos de “modelos instantâneos”, salientando que conseguem fornecer a primeira resposta e gerar mais de 50 caracteres chineses em 0,3 segundos, uma velocidade próxima do tempo de reflexo neural humano. Esta baixa latência e alto débito (throughput) prometem mudar o paradigma da interação humano-máquina, passando de “perguntar-esperar-responder” para um diálogo quase em tempo real, especialmente adequado para cenários como educação, atendimento ao cliente, criação de conteúdo e chamadas de Agents, onde a velocidade de resposta é crucial. A velocidade da versão API do Z1-AirX é alegadamente de 200 tokens/s. (Fonte: 公众号)

Jogos nativos de IA: evolução de ferramentas de eficiência para inovação na jogabilidade e desafios: A indústria de jogos está a evoluir do uso de IA para aumentar a eficiência no desenvolvimento e operação (como geração de arte, assistência de código, testes automatizados) para a exploração de verdadeiros “jogos nativos de IA”. O cerne dos jogos nativos de IA reside na integração profunda da IA na jogabilidade, criando conteúdo dinâmico impulsionado pela interação do jogador e experiências personalizadas, em vez de guiões predefinidos. Exemplos desta exploração incluem “Whispers from the Star”, investido pelo fundador da miHoYo, Cai Haoyu, e o modo de jogador IA em “Space Kill” da Giant Network. No entanto, a concretização de jogos nativos de IA enfrenta numerosos desafios: a nível técnico, é necessário resolver problemas de capacidade, estabilidade e custo dos modelos; a nível de design, faltam exemplos maduros, sendo preciso equilibrar controlabilidade e liberdade; a nível do utilizador, é preciso satisfazer as exigências dos jogadores por diversão e profundidade de interação; além disso, existem riscos de conformidade de conteúdo e éticos. Atualmente, a indústria ainda se encontra numa fase inicial de exploração, longe de uma implementação madura. (Fonte: 界面新闻)
🧰 Ferramentas
Inventário de cinco aplicações de IA criativas: O 36Kr destacou cinco ferramentas de IA com criatividade e utilidade a partir de casos de inovação em aplicações nativas de IA recentemente recolhidos: 1) AiPPT.com: Gera rapidamente PPTs a partir de uma frase ou importando ficheiros (Word, PDF, Xmind, link), suporta execução offline. 2) Shinezone AI Plogging Mirror: Óculos de IA com funções como tirar fotos, gravar vídeos, tradução em tempo real, reconhecimento de fórmulas. 3) Lianxin Digital Emotionless Interrogation Agent: Baseado no grande modelo psicológico “Insight into Human”, auxilia interrogatórios analisando microexpressões, voz, sinais fisiológicos e gerando relatórios. 4) Huili Ma Vali Footwear AI: Gera 8 designs de calçado em 10 segundos a partir de palavras-chave, integrando biblioteca de materiais e dados de moldes, com ligação à produção. 5) Nanfang Shidong Sandbox HR Agent: Processa tarefas de gestão de recursos humanos relacionadas com segurança social, fornecendo interpretação de políticas, cálculo de custos, processamento inteligente, alerta de riscos, etc. Estas aplicações demonstram o potencial de implementação da IA em ferramentas de eficiência, hardware inteligente e domínios profissionais (segurança, design, RH). (Fonte: 36Kr)

Haisin Intelligence lança plataforma de desenvolvimento AI no-code “Haisnap”: A Haisin Intelligence Technology, com apoio estatal de Pequim, lançou uma plataforma de desenvolvimento AI no-code/low-code chamada “Haisnap”. Os utilizadores podem descrever as suas necessidades em linguagem natural para que a IA gere automaticamente aplicações web ou pequenos jogos. A característica da plataforma é que o código é visível em tempo real durante o processo de geração e suporta edição e modificação secundárias através de diálogo. As aplicações desenvolvidas pelos utilizadores podem ser publicadas na “Comunidade Criativa” da plataforma, para que outros possam navegar, usar e recriar (remix). Atualmente, a plataforma está aberta gratuitamente, visando reduzir a barreira de entrada no desenvolvimento de aplicações de IA, promover a criação universal, com foco especial na educação de IA para jovens e na implementação em indústrias. (Fonte: 量子位)

Sistema open-source de perguntas e respostas sobre base de conhecimento ChatWiki lançado, suporta GraphRAG e integração com WeChat: ChatWiki é um novo sistema open-source de perguntas e respostas AI para bases de conhecimento, que integra grandes modelos de linguagem (suporta mais de 20 modelos, incluindo DeepSeek, OpenAI, Claude) com tecnologia de Geração Aumentada por Recuperação (RAG), e suporta especialmente GraphRAG baseado em grafos de conhecimento para lidar com consultas complexas. As funcionalidades do sistema incluem: suporte à importação de documentos em vários formatos (OFD, Word, PDF, etc.) para construir bases de conhecimento privadas; suporte à segmentação semântica para melhorar a precisão do RAG; possibilidade de publicar a base de conhecimento como um site de documentação pública; fornecimento de interface API para integração perfeita com ecossistemas como contas oficiais do WeChat, serviço de apoio ao cliente do WeChat, para criar chatbots de IA; ferramenta visual integrada de orquestração de fluxos de trabalho; suporte à ligação com dados de negócios de terceiros; gestão de permissões de nível empresarial; suporte à implementação local via Docker e código-fonte. (Fonte: 公众号)

Comunidade ModelScope lança Praça MCP, criando o maior ecossistema de serviços MCP da China: A comunidade de modelos de IA da Alibaba, ModelScope, lançou oficialmente a “Praça MCP”, reunindo cerca de 1500 serviços que implementam o Protocolo de Contexto de Modelo (MCP), abrangendo áreas como pesquisa, mapas, pagamentos, ferramentas de programador, etc., com o objetivo de criar a maior comunidade MCP em chinês na China. Vários serviços MCP do Alipay e MiniMax foram lançados exclusivamente aqui, como as capacidades de pagamento, consulta e reembolso do Alipay, e as capacidades de geração de voz, imagem e vídeo do MiniMax, todos invocáveis por agentes de IA através do protocolo MCP. Os programadores podem, no Campo Experimental MCP do ModelScope, experimentar e integrar rapidamente estes serviços através de configurações JSON simples e recursos de nuvem gratuitos, reduzindo significativamente a barreira para aplicações de IA acederem a ferramentas e dados externos. O ModelScope também lançou o MCP Bench para avaliar a qualidade e o desempenho de vários serviços MCP. (Fonte: 新智元)

Discussão sobre o uso da função WebSearch no Open WebUI: Utilizadores da comunidade Reddit discutiram como usar a função Web Search no Open WebUI. As questões centraram-se em como controlar precisamente as palavras-chave de consulta usadas pelo motor de busca e como restringir a função Web Search a modelos específicos, para evitar que dados de modelos privados sejam enviados acidentalmente para a rede. Isto reflete a necessidade real dos utilizadores por precisão de controlo e segurança de privacidade ao usar ferramentas de IA com funcionalidades de pesquisa integradas. (Fonte: Reddit r/OpenWebUI 1, Reddit r/OpenWebUI 2)
Utilizador procura compreender o Protocolo de Contexto de Modelo (MCP): Na comunidade Reddit, um utilizador publicou um pedido de explicação sobre o Protocolo de Contexto de Modelo (MCP), indicando que, com a promoção e aplicação do padrão MCP (como a Praça MCP do ModelScope), há uma necessidade crescente na comunidade de programadores e utilizadores de compreender esta tecnologia emergente e o seu funcionamento. (Fonte: Reddit r/OpenWebUI)
📚 Aprendizagem
Prémio Test of Time da ICLR 2025 atribuído ao otimizador Adam e ao mecanismo de atenção: A Conferência Internacional sobre Representações de Aprendizagem (ICLR) atribuiu o seu “Prémio Test of Time” de 2025 a dois artigos marcantes publicados há dez anos (2015). Um é “Adam: A Method for Stochastic Optimization” por Diederik P. Kingma e Jimmy Ba, cujo otimizador Adam se tornou o algoritmo padrão para treino de modelos de deep learning. O outro é “Neural Machine Translation by Jointly Learning to Align and Translate” por Dzmitry Bahdanau, Kyunghyun Cho e Yoshua Bengio, que introduziu pela primeira vez o mecanismo de atenção, estabelecendo as bases para a arquitetura Transformer e os modernos grandes modelos de linguagem. Estes dois prémios destacam o impacto profundo da investigação fundamental no desenvolvimento atual da IA. (Fonte: 新智元)

Breve história do desenvolvimento da IA e evolução das empresas: O artigo revê sistematicamente a história do desenvolvimento da inteligência artificial desde meados do século XX até ao presente, com marcos chave incluindo o Teste de Turing, a Conferência de Dartmouth, o simbolismo e os sistemas especialistas, o inverno da IA, a ascensão do machine learning (DeepBlue, PageRank), a revolução do deep learning (AlexNet, AlphaGo) e a era atual dos grandes modelos (série GPT, comercialização da IA generativa, disputa entre open-source e closed-source). Simultaneamente, o artigo divide o desenvolvimento das empresas de IA em quatro eras: Era Pioneira (2000-2010, exploração de aplicações tipo ferramenta), Era da Corrida ao Ouro (2011-2016, capacitação de plataformas e explosão orientada por dados), Era da Bolha (2017-2020, disputa por cenários e estrangulamentos na comercialização) e Era da Reconstrução (2021 até ao presente, novo panorama impulsionado por grandes modelos). O artigo enfatiza a sinergia entre poder computacional, dados e algoritmos, bem como o impacto de novas forças como o DeepSeek no panorama. (Fonte: 混沌大学)
OpenAI lança guia de engenharia de prompts para GPT-4.1: Acompanhando o lançamento da série de modelos GPT-4.1, a OpenAI atualizou o seu guia de engenharia de prompts (Prompting). O guia enfatiza que os modelos da série GPT-4.1, em comparação com modelos anteriores como o GPT-4, seguirão as instruções de forma mais rigorosa e literal, sendo mais sensíveis a prompts claros e específicos. Se o modelo não se comportar como esperado, geralmente adicionar instruções concisas e claras é suficiente para guiar o seu comportamento. Isto difere da tendência dos modelos anteriores de adivinhar a intenção do utilizador, pelo que os programadores podem precisar de ajustar as suas estratégias de prompt existentes. O guia fornece as melhores práticas, desde princípios básicos a estratégias avançadas, para ajudar os programadores a utilizar melhor as características dos novos modelos. (Fonte: dotey, Reddit r/LocalLLaMA)
Universidade Jiao Tong de Xangai e outros lançam benchmark de inteligência espácio-temporal STI-Bench, desafiando a compreensão física de modelos multimodais: A Universidade Jiao Tong de Xangai, em colaboração com várias instituições, lançou o primeiro benchmark para avaliar a inteligência espácio-temporal de grandes modelos multimodais (MLLM), o STI-Bench. Este benchmark utiliza vídeos do mundo real, focando-se na capacidade precisa e quantitativa de compreensão espacial e temporal, incluindo oito tarefas: medição de escala, relações espaciais, localização 3D, trajetória de deslocamento, velocidade e aceleração, orientação egocêntrica, descrição de trajetória e estimativa de pose. A avaliação de modelos de topo como GPT-4o, Gemini 2.5 Pro, Claude 3.7 Sonnet, Qwen 2.5 VL mostra que os modelos existentes têm um desempenho geralmente fraco nestas tarefas (precisão <42%), com dificuldades particulares no tratamento de atributos espaciais quantitativos, mudanças dinâmicas temporais e integração de informação intermodal. Este benchmark revela as limitações atuais dos MLLMs na compreensão do mundo físico, fornecendo direções para investigações futuras. (Fonte: 量子位)

Investigação combinando Aprendizagem por Reforço e Otimização Multiobjetivo ganha atenção: A área de interseção entre Aprendizagem por Reforço (RL) e Otimização Multiobjetivo (MOO) está a tornar-se um ponto quente na investigação de tomada de decisão em IA. Esta combinação visa permitir que agentes inteligentes ponderem múltiplos objetivos (potencialmente conflituantes) em ambientes complexos, em vez de perseguir um único ótimo. Por exemplo, a HKUST propôs um framework de equilíbrio dinâmico de gradientes para condução autónoma, otimizando simultaneamente segurança e eficiência energética; o algoritmo de busca de estratégias de Pareto do MIT é usado para controlo de robôs; a Alibaba Cloud aplica tecnologia de alinhamento multiobjetivo a transações financeiras para equilibrar retorno e risco. Investigações relacionadas como CMORL (Aprendizagem por Reforço Multiobjetivo Contínua) e aprendizagem de conjuntos de Pareto para otimização combinatória estão a explorar como tornar os agentes RL mais eficazes no tratamento de problemas do mundo real dinamicamente variáveis ou com múltiplas dimensões de otimização. (Fonte: 公众号)

Plataforma automatizada de ataque e defesa adversarial A³D disponibilizada em open-source (TPAMI 2025): A equipa de Investigação em Design Inteligente e Aprendizagem Robusta (IDRL) do Instituto de Inovação em Ciência e Tecnologia de Defesa da Academia de Ciências Militares desenvolveu e disponibilizou em open-source uma plataforma chamada A³D (Ataque e Defesa Adversarial Automatizados). Esta plataforma utiliza técnicas de Machine Learning Automatizado (AutoML), combinadas com ideias de teoria dos jogos de ataque-defesa, visando automatizar a busca por arquiteturas de redes neuronais robustas e estratégias eficientes de ataque adversarial. A plataforma integra vários métodos de Busca de Arquitetura Neural (NAS) e métricas de avaliação de robustez (ataques de norma, ataques semânticos, camuflagem adversarial, etc.) para defesa automatizada, ao mesmo tempo que fornece um módulo de ataque adversarial automatizado que pode procurar esquemas de ataque combinados ótimos através de algoritmos de otimização. Os resultados da investigação foram publicados na revista de topo TPAMI, e o código foi disponibilizado em plataformas como Hongshan Open Source, fornecendo novas ferramentas para avaliar e melhorar a segurança dos modelos DNN. (Fonte: 公众号)

Universidade da Flórida recruta doutorandos/estagiários com bolsa integral na área de NLP/LLM: O Professor Assistente Yuanyuan Lei do Departamento de Ciência da Computação da Universidade da Flórida (a iniciar funções no outono de 2025) publicou informações de recrutamento, procurando doutorandos com bolsa integral para admissão no outono de 2025 ou primavera de 2026, bem como estagiários de investigação com horários flexíveis (possibilidade de trabalho remoto). A área de investigação foca-se em Processamento de Linguagem Natural (NLP) e Grandes Modelos de Linguagem (LLM), incluindo especificamente LLMs aumentados por conhecimento, verificação de factos, raciocínio e planeamento, aplicações de NLP (multimodal, direito, negócios, ciência, etc.). São bem-vindos estudantes com formação em computação, engenharia eletrónica, estatística, matemática ou áreas relacionadas, com interesse e motivação para a investigação em IA. O email menciona o potencial impacto da lei SB-846 da Flórida no recrutamento de estudantes da China continental e as formas de lidar com isso. (Fonte: PaperWeekly)

Nova investigação em modelos de difusão: prior de ruído temporalmente correlacionado: Um artigo do arXiv intitulado “How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models” propõe um novo tipo de prior de ruído para modelos de difusão. O método visa melhorar a qualidade ou eficiência da geração de modelos de difusão (possivelmente de vídeo) introduzindo ruído temporalmente correlacionado. Detalhes técnicos específicos requerem consulta ao artigo original. (Fonte: Reddit r/MachineLearning)
Nova investigação em descoberta científica automatizada: AI Scientist-v2: Um artigo do arXiv intitulado “The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search” apresenta o sistema AI Scientist-v2. Este sistema utiliza o método Agentic Tree Search (busca em árvore por agentes) com o objetivo de alcançar descoberta científica automatizada de “nível de workshop”. Isto indica que os investigadores estão a explorar o uso de agentes de IA para investigação e exploração científica mais avançada e autónoma. (Fonte: Reddit r/MachineLearning)
Explicação da implementação da regularização Dropout: Um artigo do Substack explica detalhadamente a implementação da técnica de regularização Dropout. Dropout é uma técnica de regularização amplamente utilizada em deep learning que previne o overfitting do modelo “descartando” aleatoriamente uma parte dos neurónios durante o treino. O artigo pode ser direcionado a aprendizes que desejam compreender profundamente o princípio de funcionamento do Dropout ou implementar a técnica manualmente. (Fonte: Reddit r/deeplearning)
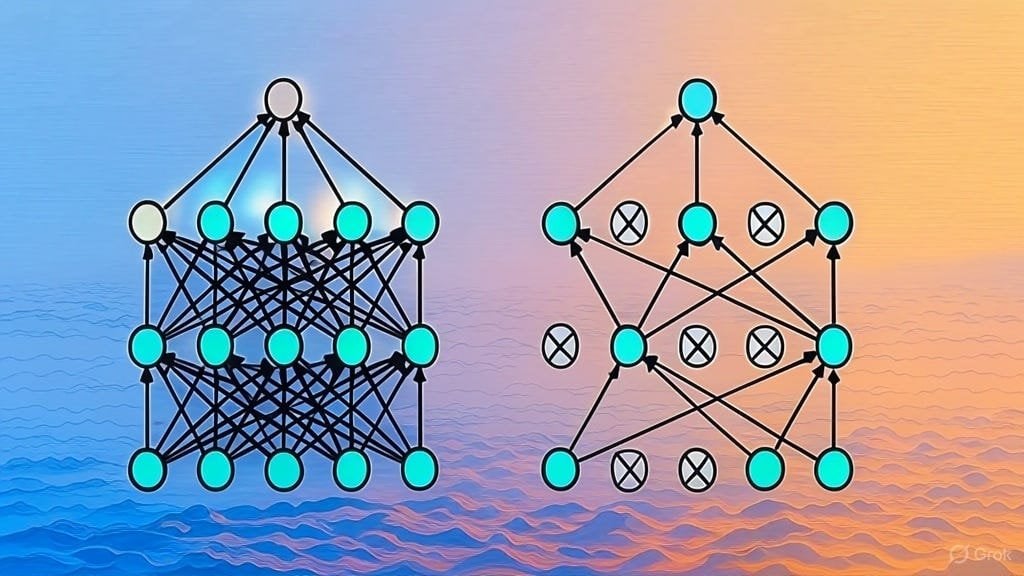
Recolha de artigos sobre arquiteturas LLM: Utilizadores do Reddit iniciaram uma discussão para partilhar e recolher artigos do arXiv sobre arquiteturas de grandes modelos de linguagem (LLM). As arquiteturas já listadas incluem BERT, Transformer, Mamba, RetNet, RWKV, Hyena, Jamba, série DeepSeek, etc. Esta lista reflete a diversidade e o rápido desenvolvimento atual da investigação em arquiteturas LLM, sendo uma referência valiosa para investigadores que desejam obter uma compreensão sistemática do campo. (Fonte: Reddit r/MachineLearning)
💼 Negócios
Plataforma de nutrição AI Fay obtém financiamento de 50 milhões de dólares, com receita anual de 50 milhões: A plataforma de nutrição AI Fay, do Silicon Valley, concluiu recentemente uma ronda de financiamento Série B de 50 milhões de dólares liderada pela Goldman Sachs, acumulando um financiamento total de 75 milhões de dólares e uma avaliação de 500 milhões de dólares. A Fay conecta nutricionistas registados com pacientes, utilizando IA para aumentar a eficiência do serviço (alega reduzir de 6,5 horas/paciente para 2 horas), automatizando tarefas como geração de notas clínicas (incluindo codificação ICD), elaboração de planos nutricionais personalizados, processamento de pedidos de reembolso de seguros, gestão administrativa, etc. A plataforma aproveitou com precisão o aumento da procura por aconselhamento nutricional impulsionado pelos medicamentos para perda de peso GLP-1 e estabeleceu parcerias com seguradoras (a intervenção nutricional pode reduzir os custos médicos a longo prazo de doenças crónicas) para facilitar os pagamentos. Com menos de 3000 nutricionistas na plataforma, a Fay alcançou uma receita anual recorrente (ARR) de 50 milhões de dólares, demonstrando um modelo de negócio bem-sucedido de capacitação de profissionais em nichos médicos verticais através da IA e ligação com entidades pagadoras. (Fonte: 乌鸦智能说)
Hengtu Technology de Chengdu: capacitando a criatividade digital com IA, lucrativa no exterior: A empresa local de Chengdu, Hengtu Technology, acumulou cerca de 700 milhões de utilizadores globalmente com o seu produto principal Fotor (plataforma de edição de imagem e vídeo), com mais de dez milhões de utilizadores ativos mensais, destacando-se especialmente nos mercados internacionais, sendo uma das primeiras empresas chinesas de aplicações de IA a internacionalizar-se e a alcançar lucratividade em escala. A empresa tem 16 anos de experiência em tecnologia de processamento de imagem e, em 2022, integrou rapidamente funcionalidades AIGC (text-to-image, text-to-video, etc.) no Fotor e na nova plataforma Clipfly. O Fotor reduz a barreira à criação de conteúdo visual digital através da IA, servindo múltiplos setores como e-commerce, mídia social, publicidade, turismo cultural, educação, etc. A Hengtu Technology utiliza IA para realizar “tradução cultural”, ajudando a cultura chinesa a internacionalizar-se e explorando novos caminhos na indústria da criatividade digital. (Fonte: 36Kr四川)
Práticas de implementação de IA nas empresas: foco no valor, menos ajuste fino, promoção da colaboração: No processo de implementação de grandes modelos, as empresas passaram de uma exploração inicial para uma orientação mais pragmática baseada no valor. Aplicações de IA bem-sucedidas geralmente focam-se em cenários com alta repetitividade, necessidade de criatividade e padrões que podem ser consolidados, como perguntas e respostas sobre conhecimento, atendimento ao cliente inteligente, geração de materiais, análise de dados, etc. As empresas reconhecem universalmente que a busca cega pelo ajuste fino (fine-tuning) de modelos muitas vezes tem baixo retorno sobre o investimento, devendo priorizar a governança do conhecimento e a construção de plataformas de agentes inteligentes (inicialmente baseadas em RAG). A implementação da IA requer participação profunda dos departamentos de negócios e apoio da alta administração, sendo mais eficaz adotar uma estratégia paralela de “pilotos de vitória rápida + preparação da base de IA”. Em termos de talento organizacional, as empresas tendem a formar pequenas equipas profissionais de IA para capacitar os negócios e resolver a escassez de talentos através da contratação de talentos de topo externos, desenvolvimento de jovens talentos internos (combinação de estagiários + pessoal de negócios experiente) e colaboração com especialistas externos. (Fonte: AI前线)
Índice de Inteligência Artificial do STAR Market atrai atenção, pode tornar-se novo foco de investimento: O relatório analisa que, apesar da recente volatilidade do mercado, a indústria de inteligência artificial da China formou um ciclo completo de “poder computacional – modelo – aplicação” e demonstra forte resiliência. O projeto nacional “Computação do Leste, Dados do Oeste”, modelos de baixo custo como DeepSeek e avanços em aplicações como robôs humanoides são destaques. A IA é vista como um motor importante para o crescimento económico global na próxima década, com retornos significativos a longo prazo para ativos relacionados. Neste contexto, o Índice de Inteligência Artificial do SSE STAR Market (focado em chips de computação e aplicações de IA) atrai a atenção dos investidores devido às suas altas expectativas de crescimento e crescente conteúdo de autonomia e controlo. Instituições como a E Fund já lançaram ETFs e fundos de ligação (como 588730, 023564/023565) que seguem este índice, fornecendo ferramentas para os investidores se posicionarem na cadeia da indústria de IA nacional. (Fonte: 创业最前线)

Estratégia de IA da Apple vira-se para a abertura: permite que o desenvolvimento do Siri use modelos de terceiros: Para acelerar o desenvolvimento da funcionalidade “Siri personalizado” e alcançar os concorrentes, a Apple terá ajustado a sua estratégia de longa data de desenvolvimento interno fechado. Sob a liderança do novo Vice-Presidente Sénior de Engenharia de Software, Craig Federighi, os engenheiros do Siri foram autorizados pela primeira vez a usar grandes modelos de linguagem de terceiros para desenvolver funcionalidades do Siri, quebrando a restrição anterior de usar apenas modelos desenvolvidos pela Apple. Esta mudança é considerada uma medida crucial da Apple para lidar com a sua relativa desvantagem em reservas tecnológicas de IA e evitar que o adiamento da funcionalidade “Siri personalizado” cause mais insatisfação (ou mesmo processos judiciais) por parte dos utilizadores. Esta medida pode criar oportunidades de colaboração entre a Apple e fornecedores de modelos externos como a OpenAI ou a Alibaba (no mercado chinês). (Fonte: 三易生活)

🌟 Comunidade
Concorrência acirrada entre as aplicações DeepSeek, Doubao e Yuanbao, experiência do produto torna-se crucial: O mercado de aplicações de assistente de IA na China está em ebulição. Após o DeepSeek explodir em popularidade devido à capacidade do seu modelo, o número de utilizadores aumentou drasticamente, levando o Tencent Yuanbao, que foi um dos primeiros a integrá-lo, a liderar temporariamente. No entanto, o Doubao da ByteDance, com funcionalidades de produto mais completas e integração profunda com o Douyin (TikTok na China), ultrapassou novamente o Yuanbao. Analistas acreditam que depender apenas da integração de modelos poderosos (como o DeepSeek) só traz benefícios a curto prazo. Na concorrência a longo prazo, a riqueza de funcionalidades da própria aplicação, a experiência do utilizador, a coordenação multi-dispositivo e a capacidade de integração do ecossistema da plataforma são mais cruciais. À medida que as capacidades dos modelos das diferentes empresas se tornam semelhantes (por exemplo, todas com capacidade de pensamento profundo), o foco futuro da concorrência será o design do produto, as estratégias de operação e os avanços em novas formas de aplicação, como os AI Agents. (Fonte: 字母榜)
Estudante asiático desenvolve ferramenta para fazer batota em entrevistas e incendeia discussão online: Roy Lee, um estudante asiático da Universidade de Columbia, desenvolveu uma ferramenta de IA chamada Interview Coder e usou o ChatGPT para passar nas entrevistas técnicas remotas de várias empresas de tecnologia, incluindo Amazon, Meta e TikTok. Ele não só recusou as ofertas dessas empresas, mas também gravou o processo de uso da ferramenta e publicou no YouTube. Após denúncia da Amazon, foi suspenso pela universidade. Roy Lee não se deixou abalar, pelo contrário, tornou público o incidente e a correspondência com a universidade e as empresas, ganhando apoio massivo de internautas e atenção da indústria, aproveitando a oportunidade para fundar uma empresa. O caso gerou discussões acaloradas sobre a validade das entrevistas técnicas (especialmente o modelo de resolução de problemas LeetCode), os limites éticos das ferramentas de IA no recrutamento e o desafio individual aos sistemas das grandes empresas. (Fonte: 直面AI)

Utilizador testa na prática a integração dos novos modelos GLM open-source da Zhipu com base de conhecimento e MCP: Um utilizador testou os modelos da série GLM recentemente lançados pela Zhipu AI (através de chamada API). Os resultados mostram que o GLM-Z1-AirX (versão ultrarrápida), ao aceder a uma base de conhecimento local construída com FastGPT, tem uma velocidade de resposta extremamente rápida (alegadamente 200 tokens/s) e a qualidade da resposta é melhorada em comparação com modelos comuns, conseguindo gerar respostas mais detalhadas e completas, bem como tabelas comparativas. O GLM-4-Air (modelo base), ao aceder ao MCP (Model Context Protocol) para executar tarefas de Agent (como pesquisa na web, escrita em ficheiros locais, controlo Docker, resumo de páginas web), consegue invocar corretamente as ferramentas e completar as tarefas, mas o efeito é ligeiramente inferior ao do DeepSeek-V3. O utilizador também elogiou o desempenho dos modelos Zhipu em termos de segurança (não respondendo a prompts de jailbreak). (Fonte: 公众号)

Partilha de prompt “solucionador de problemas hiper-racional” e comparação do desempenho de modelos: Um utilizador da comunidade partilhou um prompt avançado concebido para fazer com que um LLM desempenhe o papel de um “solucionador de problemas hiper-racional, baseado em primeiros princípios”. O prompt especifica detalhadamente os princípios operacionais do modelo (desconstrução do problema, engenharia da solução, protocolo de entrega, regras de interação), formato de resposta e características de tom, enfatizando lógica, ação e resultados, e rejeitando ambiguidades, desculpas e consolo emocional. O utilizador usou este prompt para comparar o desempenho do DeepSeek, Claude Sonnet 3.7 e ChatGPT 4o na resolução de problemas, fornecimento de orientações e recomendação de recursos online, considerando que o Claude 3.7 teve melhor desempenho. Isto demonstra como prompts cuidadosamente elaborados podem guiar e melhorar significativamente o desempenho de LLMs em tarefas específicas. (Fonte: 公众号)

Comunidade debate o lançamento do GPT-4.1: desempenho, estratégia e nomenclatura: O lançamento da série de modelos GPT-4.1 pela OpenAI gerou ampla discussão na comunidade. Por um lado, utilizadores, através de testes práticos e comparações de benchmarks (como Aider, Livebench, GPQA Diamond, KCORES Arena), descobriram que, embora o GPT-4.1 tenha melhorias significativas na codificação, ainda fica atrás do Google Gemini 2.5 Pro e do Claude 3.7 Sonnet em capacidade de raciocínio geral. Por outro lado, a comunidade discutiu e criticou a estratégia de produto da OpenAI (diferenciação entre API e ChatGPT, descontinuação do GPT-4.5), a velocidade de iteração dos modelos e a nomenclatura confusa (4.1 lançado após 4.5). Alguns acreditam que a OpenAI pode estar a enfrentar um estrangulamento na inovação, enquanto outros veem isto como uma estratégia para otimizar a sua linha de produtos API e oferecer opções com diferentes relações custo-benefício. (Fonte: dotey, op7418, Reddit r/LocalLLaMA 1, Reddit r/ArtificialInteligence, karminski3, Reddit r/LocalLLaMA 2)

ChatGPT mostra utilidade em consultoria jurídica, utilizador partilha experiência de sucesso: Um utilizador do Reddit partilhou um caso de sucesso no uso do ChatGPT para lidar com uma disputa legal relacionada com o trabalho. O utilizador enfrentava o risco de despedimento e, ao fornecer documentos ao ChatGPT e pedir-lhe para atuar como especialista em direito do trabalho do Reino Unido, descobriu erros processuais do empregador. Com a ajuda de uma carta redigida pelo ChatGPT, negociou e chegou a um acordo que incluía uma compensação de 2 meses de salário, evitando um registo negativo. Na secção de comentários, outros utilizadores também partilharam experiências de uso de IA (ChatGPT ou Gemini) para redigir cartas legais, preparar audiências e obter resultados positivos, considerando que a IA pode poupar custos e tempo significativos na assistência jurídica. (Fonte: Reddit r/ChatGPT)
Utilizador critica o fraco desempenho da funcionalidade Deep Research da OpenAI: Um utilizador do Reddit publicou uma crítica à funcionalidade Deep Research da OpenAI, argumentando que tem três problemas principais: 1) Resultados de pesquisa imprecisos ou irrelevantes (dependência da API do Bing); 2) Método de exploração mais parecido com busca em profundidade do que com pesquisa ampla; 3) Desconexão com os objetivos de pesquisa do utilizador, falta de restrições. O utilizador considera que se assemelha mais a uma capacidade de pesquisa expandida do que a uma verdadeira pesquisa aprofundada. Isto reflete o fosso entre as expectativas dos utilizadores quanto às capacidades atuais de investigação dos AI Agents e a experiência real. (Fonte: Reddit r/deeplearning)
Exibição e discussão de conteúdo gerado por IA: Utilizadores da comunidade partilham ativamente conteúdos criados com várias ferramentas de IA (como ChatGPT, Midjourney, Kling AI, Suno AI, etc.), incluindo cartoons satíricos (Trump e Musk), imagens personificadas de universidades, curtas-metragens de história alternativa da Segunda Guerra Mundial, imagens de deuses gregos, anúncios de pasta de dentes ao estilo dos anos 90, banda desenhada de múltiplos painéis, etc. Estas partilhas não só demonstram as capacidades da IA na geração de texto, imagem, vídeo e música, mas também geram discussões sobre a criatividade, estética (como ser considerada “kitsch”), limitações (como a falta de consistência das personagens em banda desenhada) e questões éticas do conteúdo gerado por IA. (Fonte: dotey 1, dotey 2, Reddit r/ChatGPT 1, Reddit r/ChatGPT 2, Reddit r/ChatGPT 3, Reddit r/ChatGPT 4, Reddit r/ChatGPT 5)

Preocupação com o ciclo de feedback de dados de treino de IA levando ao “colapso do modelo”: A discussão na comunidade foca-se num risco potencial: com o aumento do conteúdo gerado por IA na internet, se os futuros modelos de IA forem treinados principalmente com base nesses dados gerados por IA, isso pode levar ao “colapso do modelo” (Model Collapse). Este fenómeno refere-se à degradação do desempenho do modelo, com resultados que se tornam estreitos, repetitivos, carentes de originalidade e precisão, como fotocópias que se tornam progressivamente mais desfocadas. Os utilizadores temem que isto possa corroer lentamente a veracidade da informação e a perspetiva humana. A discussão também menciona métodos de mitigação, como o uso de dados sintéticos para treino e o reforço do controlo de qualidade dos dados, mas há controvérsia sobre se o problema já está a ocorrer e como evitá-lo eficazmente. (Fonte: Reddit r/ArtificialInteligence)
Opinião: Na era da IA, o poder computacional é o novo petróleo: Um utilizador do Reddit argumenta que, no desenvolvimento da IA, a capacidade de computação (Compute), e não os dados, se tornará o principal estrangulamento e recurso estratégico, tal como o petróleo na Revolução Industrial. As razões são: modelos de IA mais poderosos (especialmente sistemas de inferência e Agents) exigem um crescimento exponencial do poder computacional; a interação física, como a robótica, gerará enormes quantidades de novos dados, aumentando ainda mais a procura por capacidade de computação. Possuir mais poder computacional traduzir-se-á diretamente numa maior capacidade de produção económica. Esta opinião gerou discussão na comunidade, que concorda que o poder computacional é de facto um elemento central, determinando o limite superior das capacidades da IA e a velocidade do seu desenvolvimento. (Fonte: Reddit r/ArtificialInteligence)
Discussão sobre ética no uso de IA: usar IA para melhorar notas é inadequado?: Um estudante universitário online reprovou devido à estrutura do curso (apenas um teste ou trabalho por semana, seguido imediatamente por exame). Posteriormente, usou o ChatGPT para gerar exercícios a partir de PDFs das aulas para estudo diário, melhorando significativamente as suas notas. No entanto, o estudante sentiu-se culpado ao ler críticas sobre o impacto ambiental da IA e a importância do “pensamento independente”. Os comentários da comunidade consideram, em geral, que usar IA como auxiliar de estudo é um uso legítimo e eficaz, ajudando a aumentar a eficiência e os resultados da aprendizagem, e que não se deve sentir culpado por isso. Os comentadores salientam que o impacto ambiental da IA deve ser comparado com outras atividades humanas e que utilizar a IA para aumentar a produtividade já é uma tendência no local de trabalho. (Fonte: Reddit r/ArtificialInteligence)
Experiência do utilizador Claude Pro: discussão sobre limitação de uso e modelo de negócio: Na comunidade Reddit r/ClaudeAI, utilizadores discutiram problemas de limitação de uso (throttling) encontrados ao usar o serviço Claude Pro e exploraram o modelo de negócio da Anthropic. Um utilizador salientou que a taxa de subscrição Pro de 20 dólares por mês é muito inferior aos custos reais de computação que a Anthropic suporta para utilizadores intensivos (possivelmente até 100 dólares/mês), sugerindo que as reclamações dos utilizadores (como sentirem-se “explorados”) podem ignorar a estrutura de custos dos serviços de IA. A discussão também abordou a recente decisão da Anthropic de oferecer novas funcionalidades prioritariamente ao plano Max, mais caro, em vez do plano Pro, o que gerou insatisfação entre os utilizadores que subscreveram o plano Pro anual antecipadamente. (Fonte: Reddit r/ClaudeAI 1, Reddit r/ClaudeAI 2)
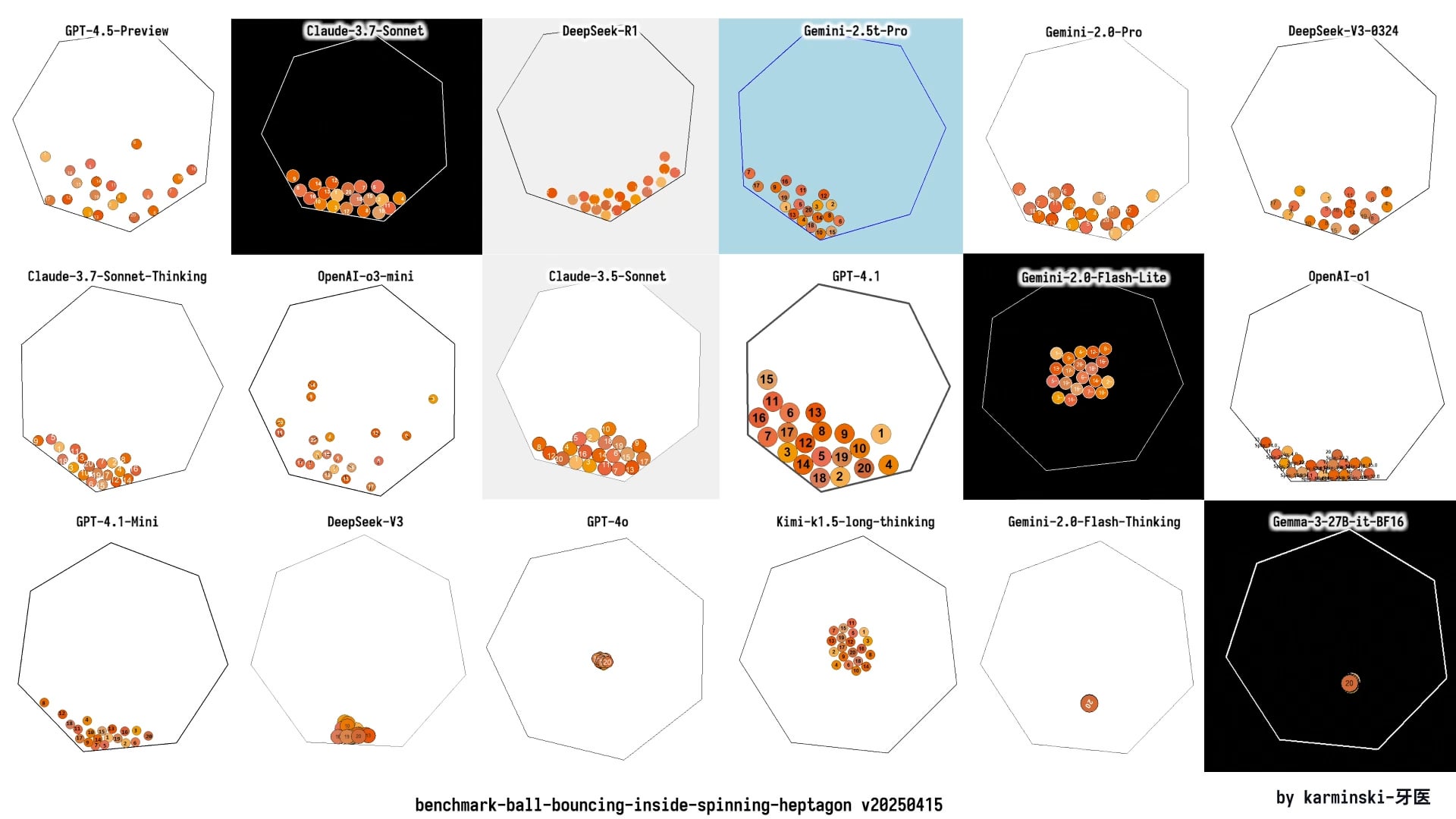
KCORES LLM Arena atualizada, DeepSeek R1 com desempenho notável: Um utilizador partilhou os resultados mais recentes da sua arena pessoal de LLM (KCORES LLM Arena), que testa os modelos pedindo-lhes para gerar código Python para uma simulação física complexa (20 bolas a colidir e ressaltar dentro de um heptágono em rotação). Após a atualização que incluiu novos modelos como GPT-4.1, Gemini 2.5 Pro, DeepSeek-V3, os resultados mostraram que o DeepSeek R1 teve um desempenho excelente nesta tarefa, gerando uma simulação com bons resultados. Isto fornece à comunidade mais um ponto de referência para avaliar a capacidade de diferentes modelos em tarefas complexas de programação. (Fonte: Reddit r/LocalLLaMA)
Exploração da capacidade de resposta emocional de diferentes LLMs: Um utilizador do Reddit publicou um Meme que compara, de forma humorística, os diferentes estilos de reação do ChatGPT 4o, Claude 3 Sonnet, Llama 3 70B e Mistral Large quando confrontados com um utilizador a expressar tristeza. Isto reflete as diferenças na experiência dos utilizadores ao usar diferentes LLMs para comunicação emocional ou procura de apoio, bem como a perceção e avaliação da comunidade sobre a capacidade de “empatia” dos modelos. A secção de comentários também discutiu as vantagens de privacidade do uso de modelos locais para lidar com tópicos emocionais privados. (Fonte: Reddit r/LocalLLaMA)

Discussão sobre se a AGI é uma farsa de Silicon Valley: Membros da comunidade partilharam e possivelmente discutiram um artigo que questiona se a Inteligência Artificial Geral (AGI) é um conceito excessivamente promovido (hoax) por Silicon Valley (a indústria tecnológica) para atrair investimento ou manter o entusiasmo. Isto reflete o debate e ceticismo contínuos na indústria e no público sobre a possibilidade e o cronograma de realização da AGI, bem como a veracidade da publicidade atual relacionada. (Fonte: Ronald_vanLoon)

💡 Outros
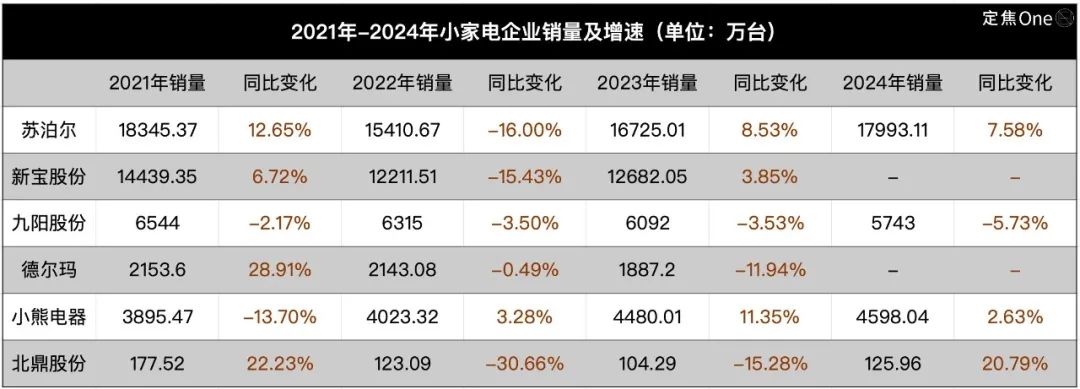
Setor de pequenos eletrodomésticos arrefece, IA torna-se nova narrativa mas aplicação ainda é superficial: O mercado de pequenos eletrodomésticos de cozinha (como máquinas de pequeno-almoço, fritadeiras de ar) enfrenta queda nas vendas e guerra de preços após o fim do bónus da “economia doméstica”. As “seis grandes” empresas listadas, como Supor, Joyoung, Bear Electric, enfrentam pressão nos resultados. Para procurar avanços, as empresas geralmente voltam-se para a expansão no mercado externo e a integração da tecnologia de IA. No entanto, atualmente, a aplicação de IA em pequenos eletrodomésticos limita-se principalmente a comandos de voz simples, ajuste automático, etc., com utilidade e espaço para inovação limitados, podendo ainda aumentar os custos e dissuadir os utilizadores. Em comparação, os grandes eletrodomésticos têm mais vantagens na aplicação de IA, podendo construir ecossistemas de casa inteligente e usar big data para fornecer serviços personalizados. A narrativa da IA no setor de pequenos eletrodomésticos ainda está numa fase inicial. (Fonte: 36Kr)
Turbulência tarifária impacta mercado de chips de Huaqiangbei, substituição nacional pode acelerar: As recentes mudanças na política tarifária sobre chips geraram preocupação no mercado eletrónico de Huaqiangbei, em Shenzhen. Comerciantes de chips populares como CPUs e GPUs (especialmente os que podem envolver origem nos EUA) suspenderam cotações e retiveram stock, aguardando para ver, intensificando a volatilidade dos preços. Categorias como chips de memória foram relativamente menos afetadas. Vários distribuidores listados afirmaram que, como a proporção de importações diretas dos EUA é pequena, o impacto direto da guerra tarifária é limitado, mas a incerteza do mercado aumentou. A indústria acredita que as empresas IDM com fábricas de semicondutores nos EUA (como TI, Intel, Micron) são as mais afetadas. Este evento já levou alguns clientes a jusante a consultar soluções de substituição por chips nacionais, podendo acelerar o processo de nacionalização no setor de semicondutores. (Fonte: 创业板观察)

IA agrava a crise de sentido humana? Reflexão sobre o equilíbrio entre tecnologia e valor: O artigo explora como o rápido desenvolvimento da inteligência artificial impacta o sentido da existência humana. Argumenta que a superação da IA em domínios profissionais (como Go, diagnóstico médico, criação artística) agrava a crise de sentido humana desencadeada desde a Revolução Industrial por fatores como alienação do trabalho, crise de fé, problemas ambientais, etc. A IA pode reforçar ainda mais a situação de “homem-ferramenta”, especialmente ao substituir a capacidade de decisão em trabalhos de colarinho branco. O artigo cita filósofos e obras de ficção científica (como “Duna”, “Westworld”) para alertar sobre o risco de escravidão tecnológica, apelando a que, ao abraçar o aprimoramento tecnológico trazido pela IA, se reconstrua a racionalidade valorativa, protegendo a criatividade, a ligação emocional e o pensamento crítico humanos através de quadros éticos e educação humanística, para evitar tornarmo-nos apêndices das nossas próprias criações. (Fonte: 腾讯研究院)
Custo de fabrico do iPhone nos EUA é elevado, pode ultrapassar os 25.000 yuan: O artigo analisa que, se o iPhone fosse totalmente produzido nos EUA, o seu custo aumentaria drasticamente, estimando-se que o preço de venda poderia atingir 3500 dólares (cerca de 25.588 yuan), muito acima do preço atual. As principais razões incluem os custos muito mais elevados nos EUA em comparação com a China na obtenção de matérias-primas (como terras raras, lítio e cobalto refinados), logística, construção de fábricas (terreno, eletricidade, licenciamento ambiental) e mão de obra (salário mínimo horário 4-5 vezes superior ao da China, e falta de trabalhadores industriais qualificados). O modelo anterior da Apple de manter altas margens de lucro explorando a cadeia de abastecimento global (especialmente fornecedores chineses com margens de lucro relativamente maiores) seria insustentável nos EUA. Os elevados custos de produção poderiam, em última análise, ser repassados aos consumidores, abalando a estratégia de preços e a posição de mercado da Apple. (Fonte: 星海情报局)

Avanço matemático: teoria das singularidades do fluxo de curvatura média é provada: A conjectura Multiplicity-one, que intrigou matemáticos por quase 30 anos, foi recentemente provada por Richard Bamler e Bruce Kleiner. A conjectura diz respeito ao fluxo de curvatura média (Mean Curvature Flow, MCF) – um processo matemático que descreve como uma superfície evolui ao longo do tempo para diminuir a sua área o mais rapidamente possível (semelhante ao derretimento de um cubo de gelo ou à erosão de um castelo de areia). A prova indica que, no espaço tridimensional, as singularidades (pontos onde a curvatura tende para infinito) formadas por superfícies fechadas bidimensionais sob MCF são simples, geralmente manifestando-se como uma esfera que encolhe localmente para um ponto ou um cilindro que colapsa numa linha, não ocorrendo singularidades complexas de múltiplas camadas sobrepostas. Este avanço garante que o MCF pode continuar a ser analisado mesmo após a formação de singularidades, fornecendo uma base teórica mais sólida para usar o MCF na resolução de problemas importantes em geometria e topologia (como a conjectura de Poincaré). (Fonte: 机器之心)

Utilizador partilha configuração de hardware AI local “económica” com 4x RTX 3090: Um utilizador do Reddit partilhou a sua configuração de hardware construída para executar LLMs localmente, com um custo total de aproximadamente 4204 dólares. A configuração inclui 4 placas gráficas EVGA RTX 3090 usadas (600 dólares cada), um CPU de servidor AMD EPYC 7302P, uma motherboard Asrock Rack, 96GB de memória DDR4 e um SSD NVMe de 2TB, montados numa caixa aberta MLACOM Quad Station Pro Lite e alimentados por duas fontes de 1200W. Esta partilha oferece uma solução de referência relativamente “económica” para utilizadores que desejam construir em casa uma estação de trabalho AI com poder computacional considerável (4x 24GB VRAM). (Fonte: Reddit r/LocalLLaMA)

Hackers nos EUA atacam semáforos para exibir mensagens Deepfake de Musk e Zuckerberg: Foi noticiado que vários sistemas de semáforos para peões na área da Baía de São Francisco, nos EUA, foram alvo de um ataque de hackers, sendo usados para exibir mensagens Deepfake (falsificação profunda) geradas por IA de Elon Musk e Mark Zuckerberg. Este incidente realça a vulnerabilidade das infraestruturas públicas face a ciberataques que utilizam tecnologia de IA, bem como o risco de abuso da tecnologia Deepfake para disseminar informações falsas ou realizar atos de vandalismo. (Fonte: Reddit r/ArtificialInteligence)

Exibição de diversas tecnologias de robótica e automação: As redes sociais exibiram várias aplicações de robótica e tecnologia de automação, incluindo: o robô Booster T1 capaz de imitar movimentos humanos para realizar kung fu; sistemas robóticos para treino de reabilitação; um braço mecânico capaz de fazer café; robôs agrícolas para plantação e remoção de ervas daninhas em arrozais; um sistema automatizado para facilitar o manuseamento de ovelhas por pastores; e robôs dançantes, entre outros. Estes exemplos refletem a ampla aplicação e o desenvolvimento contínuo da robótica nos setores industrial, agrícola, de serviços, reabilitação médica e entretenimento. (Fonte: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6)
Exibição de tecnologias emergentes e produtos inovadores: As redes sociais partilharam várias tecnologias emergentes e produtos inovadores, como: uma antena sem fios minúscula desenvolvida pelo MIT que utiliza luz para monitorizar comunicações celulares; um drone de asa única que imita o voo da semente de ácer; sanitas inteligentes IoT; tecnologia de impressão digital para ortodontia; um dispositivo que gera eletricidade a partir de água salgada; paredes dinâmicas que respiram e se movem; um fato de cosplay do Iron Man; uma prancha de ski elétrica todo-o-terreno; e a tecnologia de copiar chaves usando o dispositivo Flipper Zero, entre outros. Estas exibições mostram a inovação contínua da tecnologia em múltiplos domínios como comunicações, energia, saúde, transporte, construção e segurança. (Fonte: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6, Ronald_vanLoon 7, Ronald_vanLoon 8, Ronald_vanLoon 9)

Tendências em tecnologia de saúde: As redes sociais e links de artigos mencionaram aplicações e tendências de desenvolvimento tecnológico na área da saúde, incluindo cirurgia assistida por robô, tendências e pontos de inflexão da IA nos cuidados de saúde, utilização da tecnologia para impulsionar a excelência operacional (hiperautomação) e as potenciais transformações trazidas pela IA. Estes conteúdos refletem o potencial e a prática de tecnologias como IA, robótica e automação na melhoria da eficiência dos serviços de saúde, precisão do diagnóstico e experiência do paciente. (Fonte: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4)

Informações relacionadas com cibersegurança: As redes sociais partilharam conteúdos relacionados com cibersegurança, incluindo um diagrama dos tipos de ataques a passwords e um artigo sobre a importância da capacidade de recuperação nos 60 minutos seguintes a uma violação de dados. Estes conteúdos alertam os utilizadores para os riscos de cibersegurança e as estratégias de resposta. (Fonte: Ronald_vanLoon 1, Ronald_vanLoon 2)

Discussão sobre a plataforma AMD ROCm: Utilizadores do Reddit discutiram a possibilidade de construir uma estação de trabalho de deep learning usando duas GPUs AMD Radeon RX 7900 XTX, envolvendo a pilha de software ROCm (Radeon Open Compute platform). Isto reflete o interesse e a exploração dos utilizadores por soluções de GPU da AMD e o seu ecossistema de software (ROCm) no mercado de hardware de IA dominado pela Nvidia. (Fonte: Reddit r/deeplearning)