
Keywords:GPT-4.5, 华为盘古Ultra性能, GPT-4.5训练细节, RLHF对推理能力影响, 人类学习上限4GB研究, 开源数学数据集MegaMath, 大模型
🔥 Foco
OpenAI revela detalhes e desafios do treino do GPT-4.5: O CEO da OpenAI, Sam Altman, conversou com a equipa técnica principal do GPT-4.5, revelando detalhes do desenvolvimento do modelo. O projeto começou há dois anos, envolveu quase toda a equipa e demorou mais do que o esperado. Durante o treino, enfrentaram “problemas catastróficos”, como falhas no cluster de 100.000 GPUs e bugs ocultos, expondo gargalos na infraestrutura, mas também impulsionando a atualização da pilha tecnológica. Atualmente, apenas 5 a 10 pessoas são necessárias para replicar um modelo de nível GPT-4. A equipa acredita que a chave para o aumento futuro do desempenho reside na eficiência dos dados, e não na capacidade de computação, exigindo o desenvolvimento de novos algoritmos para aprender mais com a mesma quantidade de dados. A arquitetura do sistema está a mudar para multi-cluster, podendo envolver a colaboração de dezenas de milhões de GPUs no futuro, o que impõe requisitos mais elevados de tolerância a falhas. A conversa também abordou Scaling Law, design colaborativo de machine learning e sistemas, a essência da aprendizagem não supervisionada, entre outros, mostrando o pensamento e a prática da OpenAI na promoção da investigação de modelos de grande escala de ponta (Fonte: 36Kr)

Huawei lança modelo denso de grande escala Pangu Ultra de 135B nativo Ascend: A equipa Pangu da Huawei lançou o Pangu Ultra, um modelo de linguagem geral denso com 135 mil milhões de parâmetros, treinado com NPUs Ascend de fabrico nacional. O modelo utiliza uma estrutura Transformer de 94 camadas e introduz as tecnologias Depth-scaled sandwich-norm (DSSN) e TinyInit para resolver problemas de estabilidade no treino de modelos ultraprofundos, alcançando um treino estável sem picos de perda (loss spikes) em 13,2T de dados de alta qualidade. A nível de sistema, através de otimizações como paralelismo híbrido, fusão de operadores e divisão de subsequências, a taxa de utilização da capacidade de computação (MFU) no cluster Ascend de 8192 GPUs foi elevada para mais de 50%. As avaliações mostram que o Pangu Ultra supera modelos densos como Llama 405B e Mistral Large 2 em várias benchmarks, e consegue competir com modelos MoE de maior escala como o DeepSeek-R1, demonstrando a viabilidade do desenvolvimento de modelos de grande escala de topo baseados em capacidade de computação nacional (Fonte: Jiqizhixin)

Estudo questiona a significância do reinforcement learning na melhoria da capacidade de raciocínio dos LLMs: Investigadores da Universidade de Tübingen e da Universidade de Cambridge questionam as recentes alegações de que o reinforcement learning (RL) pode melhorar significativamente a capacidade de raciocínio dos modelos de linguagem. Através de uma investigação rigorosa de benchmarks de raciocínio comuns (como o AIME24), o estudo descobriu que os resultados apresentam alta instabilidade, com a simples alteração da semente aleatória (random seed) a poder causar grandes flutuações na pontuação. Sob avaliação padronizada, a melhoria de desempenho trazida pelo RL é muito menor do que a originalmente reportada, frequentemente não é estatisticamente significativa, sendo até inferior ao efeito do supervised fine-tuning (SFT), e a capacidade de generalização também é fraca. O estudo aponta que as diferenças na amostragem, configurações de descodificação, frameworks de avaliação e heterogeneidade de hardware são as principais causas da instabilidade, e apela à adoção de padrões de avaliação mais rigorosos e reprodutíveis para avaliar com mais calma e medir o progresso real na capacidade de raciocínio dos modelos (Fonte: Jiqizhixin)

Discurso de Altman na TED: Lançará modelo open-source poderoso, considera ChatGPT não ser AGI: O CEO da OpenAI, Sam Altman, afirmou na Conferência TED que está a desenvolver um modelo open-source poderoso, cujo desempenho superará todos os modelos open-source existentes, respondendo diretamente a concorrentes como o DeepSeek. Ele enfatizou que o número de utilizadores do ChatGPT continua a crescer exponencialmente e que a nova funcionalidade de memória melhorará a experiência personalizada. Ele acredita que a IA trará avanços nas áreas da descoberta científica e desenvolvimento de software (com enormes ganhos de eficiência), mas que os modelos atuais como o ChatGPT ainda não possuem capacidade de aprendizagem contínua autónoma e generalização entre domínios, não sendo AGI. Discutiu também as questões de direitos de autor e “direitos de estilo” levantadas pela capacidade criativa do GPT-4o, e reiterou a confiança da OpenAI na segurança dos modelos e nos seus mecanismos de controlo de risco (Fonte: AI Era)

Estudo afirma que limite de aprendizagem humana ao longo da vida é de cerca de 4GB, gerando debate sobre interfaces cérebro-máquina e desenvolvimento de IA: Um estudo publicado na revista Neuron, do grupo Cell, pelo Caltech, estima que a velocidade de processamento de informação do cérebro humano é de aproximadamente 10 bits por segundo, muito inferior à taxa de recolha de dados dos sistemas sensoriais, que é de 1 bilião de bits por segundo. Com base nisto, o estudo infere que o limite superior de acumulação de conhecimento ao longo da vida humana (assumindo 100 anos de aprendizagem contínua sem esquecimento) é de cerca de 4GB, muito menor que a capacidade de armazenamento de parâmetros de modelos de grande escala (por exemplo, um modelo 7B pode armazenar 14 mil milhões de bits). O estudo considera que este gargalo deriva do mecanismo de processamento em série do sistema nervoso central e prevê que a superação da inteligência humana pela máquina é apenas uma questão de tempo. O estudo também levanta questões sobre o Neuralink de Musk, argumentando que não consegue ultrapassar as limitações estruturais básicas do cérebro, sendo preferível otimizar os métodos de comunicação existentes. Este estudo gerou ampla discussão sobre os limites cognitivos humanos, o potencial de desenvolvimento da IA e a direção das interfaces cérebro-máquina (Fonte: QbitAI)

🎯 Tendências
GPT-4 prestes a ser retirado, GPT-4.1 e novo modelo misterioso podem surgir: A OpenAI anunciou que a partir de 30 de abril substituirá completamente o GPT-4, lançado há dois anos, pelo GPT-4o no ChatGPT, embora o primeiro continue disponível via API. Simultaneamente, fugas de informação na comunidade e no código indicam que a OpenAI poderá lançar em breve uma série de novos modelos, incluindo o GPT-4.1 (e as suas versões mini/nano), o modelo de inferência o3 “full-power” e a nova série o4 (como o o4-mini). Um modelo misterioso chamado Optimus Alpha já está online no OpenRouter, com desempenho excelente (especialmente em programação) e suporte para contexto de um milhão de tokens, sendo amplamente especulado como um dos novos modelos da OpenAI a serem lançados (possivelmente GPT-4.1 ou o4-mini), apresentando muitas semelhanças com os modelos da OpenAI (como bugs específicos). Isto sugere que a velocidade de iteração dos modelos da OpenAI está a acelerar, consolidando ativamente a sua liderança tecnológica (Fonte: source, source)

Modelo de grande escala Qwen3 da Alibaba prepara-se para lançamento: Fontes indicam que a Alibaba planeia lançar o modelo de grande escala Qwen3 em breve. A equipa de desenvolvimento confirmou que o modelo está na fase final de preparação, mas a data exata de lançamento não foi definida. Sabe-se que o Qwen3 é um produto de modelo importante da Alibaba para o primeiro semestre de 2025, cujo desenvolvimento começou após o Qwen2.5. Influenciada por modelos concorrentes como o DeepSeek-R1, a equipa de modelos de base da Alibaba Cloud está a inclinar ainda mais o foco estratégico para a melhoria da capacidade de raciocínio do modelo, mostrando um foco estratégico em capacidades específicas no panorama competitivo dos modelos de grande escala (Fonte: InfoQ)

Plataforma aberta Kimi reduz preços e lança modelo visual leve open-source: A plataforma aberta Kimi, da Moonshot AI, anunciou uma redução nos preços dos serviços de inferência de modelos e cache de contexto, visando reduzir os custos para os utilizadores através da otimização tecnológica. Simultaneamente, a Kimi lançou em open-source dois modelos de linguagem visual leves baseados na arquitetura MoE, Kimi-VL e Kimi-VL-Thinking, que suportam contexto de 128K e têm apenas cerca de 3 mil milhões de parâmetros ativos. Alegadamente, superam significativamente modelos de grande escala com 10 vezes mais parâmetros em capacidade de raciocínio multimodal, visando impulsionar o desenvolvimento e aplicação de modelos multimodais pequenos e eficientes (Fonte: InfoQ)
Google lança protocolo de interoperabilidade de agentes A2A e vários novos produtos de IA: Na conferência Google Cloud Next ’25, a Google, em conjunto com mais de 50 parceiros, lançou o protocolo aberto Agent2Agent (A2A), que visa permitir a interoperabilidade e colaboração entre agentes de IA desenvolvidos por diferentes empresas e plataformas. Lançou também vários modelos e aplicações de IA, incluindo Gemini 2.5 Flash (versão eficiente do modelo principal), Lyria (geração de música a partir de texto), Veo 2 (criação de vídeo), Imagen 3 (geração de imagem), Chirp 3 (voz personalizada), e apresentou o chip TPU de sétima geração, Ironwood, otimizado especificamente para inferência. Esta série de lançamentos reflete a aposta abrangente e a estratégia aberta da Google em infraestrutura, modelos, plataformas e agentes de IA (Fonte: InfoQ)
ByteDance lança modelo de inferência Seed-Thinking-v1.5 com 200B parâmetros: A equipa Doubao da ByteDance publicou um relatório técnico apresentando o seu modelo de inferência MoE Seed-Thinking-v1.5, com um total de 200 mil milhões de parâmetros. O modelo ativa 20 mil milhões de parâmetros por inferência e apresenta um desempenho excelente em vários testes de benchmark, alegadamente superando o DeepSeek-R1, que possui 671 mil milhões de parâmetros no total. A comunidade especula que este possa ser o modelo atualmente utilizado no modo “pensamento profundo” da App Doubao da ByteDance, mostrando o progresso da ByteDance no desenvolvimento de modelos de inferência eficientes (Fonte: InfoQ)
Midjourney lança modelo V7, melhorando qualidade de imagem e eficiência de geração: A ferramenta de geração de imagens por IA Midjourney lançou o seu novo modelo V7 (versão alfa). A nova versão melhora a coerência e consistência da geração de imagens, especialmente em mãos, partes do corpo e detalhes de objetos, e consegue gerar texturas mais realistas e ricas. O V7 introduz o Draft Mode, que permite uma velocidade de renderização dez vezes maior por metade do custo, ideal para iteração e exploração rápidas. Oferece também os modos turbo (mais rápido mas mais caro) e relax (mais lento mas mais barato), para satisfazer as diferentes necessidades dos utilizadores (Fonte: InfoQ)
Amazon lança modelo de voz AI Nova Sonic: A Amazon lançou o Nova Sonic, um modelo de IA generativa de nova geração que processa voz nativamente. Alegadamente, o modelo pode rivalizar com os modelos de voz de topo da OpenAI e da Google em métricas chave como velocidade, reconhecimento de voz e qualidade de conversação. O Nova Sonic é disponibilizado através da plataforma de desenvolvimento Amazon Bedrock, utiliza uma nova API de streaming bidirecional e tem um preço cerca de 80% inferior ao do GPT-4o, visando fornecer capacidade de interação por voz natural de alta relação custo-benefício para aplicações empresariais de IA (Fonte: InfoQ)
Funcionalidades de IA da Apple para iPhone na China podem chegar a meio do ano, integrando tecnologia da Baidu e Alibaba: Relatos indicam que a Apple planeia introduzir o serviço Apple Intelligence nos iPhones do mercado chinês antes de meados de 2025 (possivelmente no iOS 18.5). A funcionalidade utilizará o modelo de grande escala Wenxin da Baidu para fornecer capacidades inteligentes e integrará o motor de censura da Alibaba para cumprir os requisitos de regulamentação de conteúdo. A Apple não assinou acordos de exclusividade com a Baidu ou a Alibaba, mostrando a sua estratégia de colaboração localizada em mercados chave para implementar rapidamente funcionalidades de IA (Fonte: InfoQ)
🧰 Ferramentas
Volcano Engine lança agente de inteligência de dados empresarial Data Agent: A Volcano Engine lançou o Data Agent, um agente de inteligência de dados de nível empresarial. A ferramenta utiliza as capacidades de raciocínio, análise e chamada de ferramentas de modelos de grande escala, visando compreender profundamente as necessidades de negócio das empresas e automatizar a execução de tarefas complexas de análise e aplicação de dados, como a elaboração de relatórios de investigação aprofundados e o design de campanhas de marketing, aumentando a eficiência da utilização de dados e o nível de decisão das empresas (Fonte: InfoQ)
Novo estilo de geração de imagens do GPT-4o chama a atenção: Utilizadores das redes sociais têm demonstrado novos estilos criados com a funcionalidade de geração de imagens do GPT-4o, por exemplo, combinando elementos da interface retro do Windows 2000 com imagens de personagens para gerar efeitos de colagem únicos. Os utilizadores partilharam dicas de prompts, como usar imagens de referência (墊圖) para guiar a geração e combinar descrições de estilo e conteúdo, despertando o interesse da comunidade na exploração do potencial criativo do GPT-4o (Fonte: source, source)

📚 Aprendizagem
Lançado o maior dataset open-source de pré-treino matemático MegaMath: O LLM360 lançou o MegaMath, um dataset open-source de pré-treino para raciocínio matemático contendo 371 mil milhões de tokens, superando em escala o DeepSeek-Math Corpus. O dataset abrange páginas web com conteúdo matemático intensivo (279B), código relacionado com matemática (28B) e dados sintéticos de alta qualidade (64B). A equipa utilizou um processo de tratamento de dados refinado, incluindo otimização da estrutura HTML, extração em duas fases, filtragem e refinamento assistidos por LLM, etc., para garantir a escala, qualidade e diversidade dos dados. A validação do pré-treino no modelo Llama-3.2 mostrou que o uso do MegaMath pode trazer um aumento absoluto de 15-20% em benchmarks como GSM8K e MATH, fornecendo à comunidade open-source uma base poderosa para treinar capacidades de raciocínio matemático (Fonte: Jiqizhixin)

Nabla-GFlowNet: Equilibrando diversidade e eficiência no fine-tuning de modelos de difusão: Investigadores da CUHK-Shenzhen e outras instituições propuseram o Nabla-GFlowNet, um novo método de fine-tuning de recompensa para modelos de difusão baseado em redes de fluxo generativo (GFlowNet). O método visa resolver os problemas da lenta convergência do fine-tuning tradicional por reinforcement learning e da fácil ocorrência de overfitting e perda de diversidade na otimização direta por recompensa. Através da derivação de uma nova condição de equilíbrio de fluxo (Nabla-DB) e do design de uma função de perda específica e parametrização do gradiente de fluxo logarítmico, o Nabla-GFlowNet consegue alinhar eficientemente o modelo com a função de recompensa (como pontuação estética, seguimento de instruções), mantendo ao mesmo tempo a diversidade das amostras geradas. Experiências no Stable Diffusion demonstraram as suas vantagens em comparação com métodos como DDPO, ReFL e DRaFT (Fonte: Jiqizhixin)
Llama.cpp corrige problemas relacionados com Llama 4: O projeto llama.cpp integrou duas correções para os modelos Llama 4, relacionadas com RoPE (Rotary Position Embeddings) e cálculo incorreto de normas (norms). Estas correções visam melhorar a qualidade do output do modelo, mas os utilizadores podem precisar de descarregar novamente os ficheiros de modelo GGUF gerados com as ferramentas de conversão atualizadas para que as correções tenham efeito (Fonte: source)
💼 Negócios
Nvidia conclui aquisição da Lepton AI: Segundo relatos, a Nvidia adquiriu a Lepton AI, uma startup de infraestrutura de IA fundada pelo ex-vice-presidente da Alibaba, Jia Yangqing, por um valor que pode atingir centenas de milhões de dólares. O principal negócio da Lepton AI é o aluguer de servidores GPU da Nvidia e o fornecimento de software para ajudar empresas a construir e gerir aplicações de IA. Jia Yangqing e o seu cofundador Bai Junjie, juntamente com cerca de 20 outros funcionários, juntaram-se à Nvidia. Esta medida é vista como uma implantação estratégica da Nvidia para expandir os seus serviços na nuvem e o mercado de software empresarial, respondendo à concorrência de chips desenvolvidos internamente pela AWS, Google Cloud, etc. (Fonte: InfoQ)
Setor tecnológico dos EUA tomado por ansiedade, IA impacta mercado de trabalho: Relatos indicam que o setor tecnológico dos EUA está a passar por dificuldades com redução de postos de trabalho, diminuição de salários e prolongamento dos ciclos de procura de emprego. Despedimentos em massa, empresas (como Salesforce, Meta, Google) a usar IA para substituir mão de obra ou a suspender contratações (especialmente para cargos de engenharia e de nível júnior) intensificam a ansiedade profissional dos trabalhadores. Os dados mostram um aumento na proporção de pessoas que relatam redução salarial e transição de cargos de gestão para contribuidor individual. A IA está a remodelar o mercado de trabalho, forçando os candidatos a alargar horizontes para setores não tecnológicos ou a virarem-se para o empreendedorismo. Especialistas aconselham a procurar oportunidades de emprego fora dos “Sete Gigantes” e a dominar ferramentas de IA para aumentar a competitividade (Fonte: InfoQ)

Rumor: OpenAI planeia adquirir empresa de hardware de IA de Altman e Jony Ive: Fontes indicam que a OpenAI está a discutir a aquisição da io Products, empresa de IA fundada pelo seu CEO Sam Altman em colaboração com o ex-diretor de design da Apple, Jony Ive, por um valor não inferior a 500 milhões de dólares. A empresa visa desenvolver dispositivos pessoais impulsionados por IA, possivelmente sob a forma de um “telemóvel” sem ecrã ou dispositivo doméstico. A io Products é composta por uma equipa de engenheiros que constrói os dispositivos, a OpenAI fornece a tecnologia, o estúdio de Ive é responsável pelo design e Altman está profundamente envolvido. Se a aquisição se concretizar, integrará esta equipa de hardware na OpenAI, acelerando os seus planos no domínio do hardware de IA (Fonte: InfoQ)
Startup da ex-CTO da OpenAI recruta novamente na antiga empresa: A empresa de IA “Thinking Machines Laboratory”, fundada pela ex-CTO da OpenAI, Mira Murati, atraiu duas figuras-chave da OpenAI para a sua equipa de consultores: o ex-Chief Research Officer Bob McGrew e o ex-investigador Alec Radford. Radford foi o autor principal dos artigos técnicos fundamentais da série GPT. Este recrutamento reforça ainda mais a capacidade técnica da startup e reflete a intensa competição por talento na área da IA (Fonte: InfoQ)
Baichuan Intelligence ajusta foco de negócio, concentra-se na área da saúde: O fundador da Baichuan Intelligence, Wang Xiaochuan, numa carta a todos os funcionários por ocasião do segundo aniversário da empresa, reiterou que a empresa se concentrará na área da saúde, desenvolvendo serviços de aplicação como Baixiaoying, pediatria por IA, clínica geral por IA e medicina de precisão. Ele enfatizou a necessidade de reduzir ações supérfluas e que a estrutura organizacional se tornará mais horizontal. Anteriormente, foi noticiado que a equipa B2B do setor financeiro da empresa foi desmantelada, o parceiro comercial Deng Jiang saiu, e vários outros cofundadores saíram ou estão prestes a sair, indicando que a empresa está a passar por um foco estratégico e ajuste organizacional (Fonte: InfoQ)
Alibaba Cloud lança plano “Flourishing Flowers” para parceiros do ecossistema de IA: A Alibaba Cloud lançou o plano “Flourishing Flowers” (繁花), que visa apoiar os parceiros do ecossistema de IA. O plano fornecerá recursos na nuvem, suporte de computação, empacotamento de produtos, planeamento de comercialização e serviços de ciclo de vida completo, com base na maturidade do produto do parceiro. Simultaneamente, a Alibaba Cloud lançou o Mercado de Aplicações e Serviços de IA, com o objetivo de construir um ecossistema de IA próspero e acelerar a implementação de tecnologias e aplicações de IA (Fonte: InfoQ)
Kugou Music e DeepSeek estabelecem parceria aprofundada: A Kugou Music anunciou uma parceria com a empresa de IA DeepSeek para lançar uma série de funcionalidades inovadoras de IA. Incluem a geração de relatórios de audição personalizados através de análise multimodal, recomendações diárias por IA, pesquisa inteligente, gestão de playlists por IA, geração de capas dinâmicas por IA e um “Comentador de IA” com persona definida, entre outros, visando melhorar a experiência musical do utilizador e a interação na comunidade através da tecnologia de IA (Fonte: InfoQ)
Rumor: Google usa acordos de não concorrência “agressivos” para reter talento em IA: Relatos indicam que a DeepMind, da Google, para impedir a fuga de talento para concorrentes, implementou acordos de não concorrência de um ano para alguns funcionários no Reino Unido. Durante este período, os funcionários não precisam de trabalhar mas continuam a receber salário (licença remunerada), mas isto faz com que alguns investigadores se sintam marginalizados, incapazes de participar no rápido desenvolvimento do setor. Esta medida poderia ser proibida pela FTC nos EUA, mas é aplicável na sede de Londres, gerando debate sobre a competição por talento e a restrição da inovação (Fonte: InfoQ)
Ex-funcionários da OpenAI apresentam documentos legais em apoio ao processo de Musk: 12 ex-funcionários da OpenAI apresentaram documentos legais apoiando o processo movido por Elon Musk contra a OpenAI. Eles argumentam que o plano de reestruturação da OpenAI (mudança para uma estrutura com fins lucrativos) pode violar fundamentalmente a missão original sem fins lucrativos da empresa, que foi um fator chave para os atrair. A OpenAI respondeu que, mesmo com a mudança estrutural, a sua missão não mudará (Fonte: InfoQ)
🌟 Comunidade
Estudo da Anthropic revela padrões de uso e desafios da IA no ensino superior: A Anthropic analisou milhões de conversas anónimas de estudantes na plataforma Claude.ai, descobrindo que estudantes de ciências e engenharia (especialmente de informática) são os primeiros a adotar a IA. Os padrões de interação estudante-IA incluem quatro tipos, com proporções semelhantes: resolução direta de problemas, geração direta de conteúdo, resolução colaborativa de problemas e geração colaborativa de conteúdo. A IA é usada principalmente para tarefas cognitivas de ordem superior, como criar (programar, escrever exercícios) e analisar (explicar conceitos). O estudo também revela potenciais comportamentos de má conduta académica (como obter respostas, contornar a deteção de plágio), levantando preocupações sobre integridade académica, desenvolvimento do pensamento crítico e métodos de avaliação (Fonte: AI Era)

Geração de imagens do GPT-4o lidera nova tendência: Do estilo Ghibli aos cartões de celebridades da IA: A poderosa capacidade de geração de imagens do GPT-4o continua a gerar uma onda de criação nas redes sociais. Após o sucesso viral dos “retratos de família estilo Ghibli” (impulsionados pelo ex-engenheiro da Amazon Grant Slatton), os utilizadores começaram a criar cartões estilo “Magic: The Gathering” de figuras proeminentes da área da IA (como Altman definido como “Senhor da AGI”), bem como cartas de Tarot personalizadas. Estes exemplos demonstram o potencial da IA na imitação de estilos artísticos e na geração criativa, mas também levantam discussões sobre originalidade, direitos de autor, valor estético e o impacto da IA na profissão de designer (Fonte: AI Era)

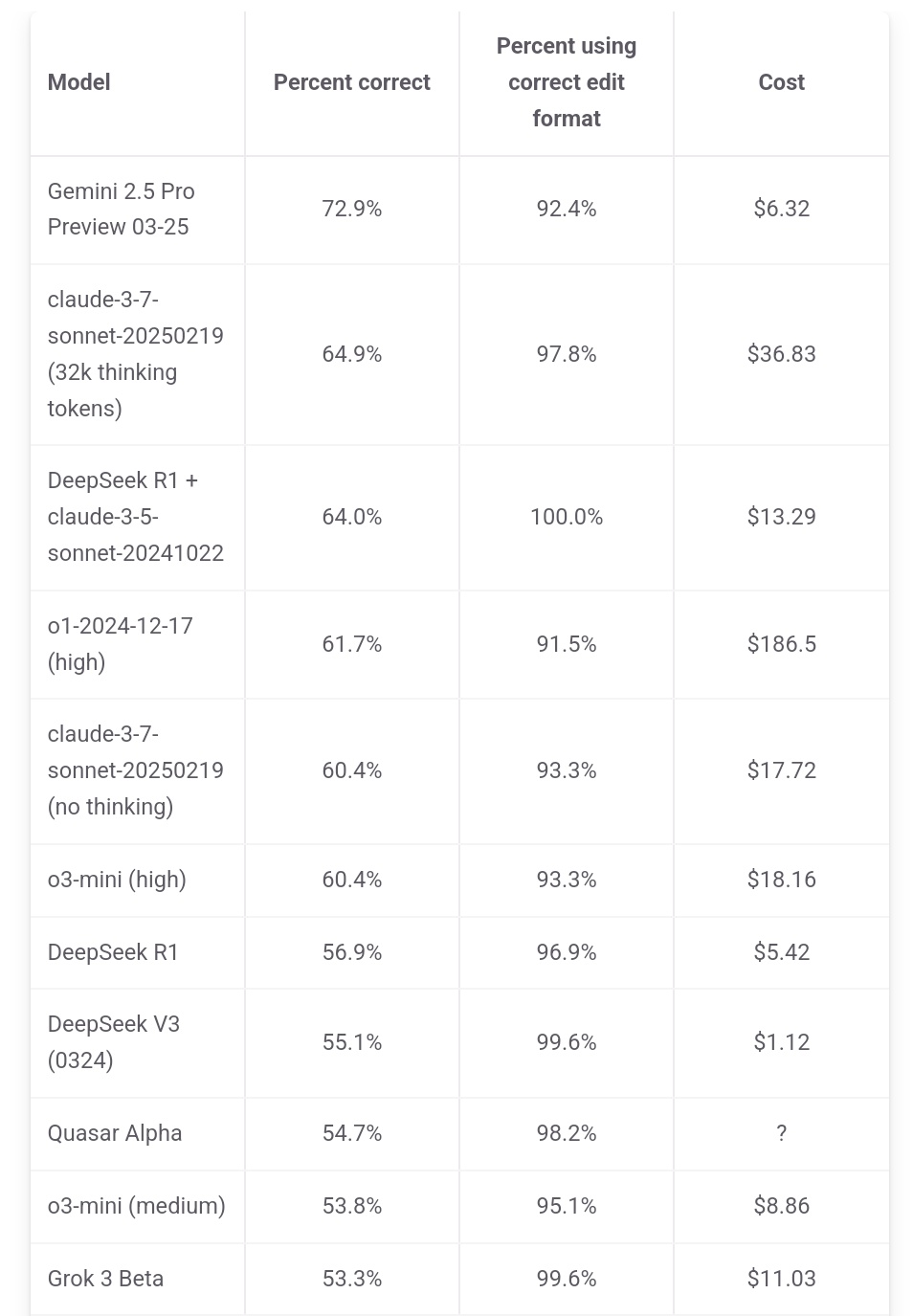
Jeff Dean enfatiza vantagem de custo do Gemini 2.5 Pro: O responsável pela IA da Google, Jeff Dean, partilhou dados do ranking do aider.chat, salientando que o Gemini 2.5 Pro não só lidera em desempenho no benchmark de programação Polyglot, mas também o seu custo (6 dólares) é significativamente inferior ao de outros modelos do Top 10, exceto o DeepSeek, enfatizando a sua vantagem de custo-benefício. Alguns modelos concorrentes custam 2x, 3x ou até 30x mais que o Gemini 2.5 Pro (Fonte: JeffDean)
Reddit debate impacto da IA no mercado de trabalho, especialmente em cargos de nível básico: Uma publicação no fórum Reddit gerou debate, com o autor (um estudante de mestrado em CIS) a expressar profunda preocupação com a substituição de trabalhos não manuais de nível básico pela IA (especialmente engenharia de software, análise de dados, suporte de TI), argumentando que a afirmação “a IA não vai roubar empregos” ignora a situação difícil dos recém-licenciados. Ele aponta que grandes empresas já estão a reduzir as contratações universitárias e teme um mercado de trabalho futuro sombrio. Os comentários mostram divergência: alguns concordam com a crise, outros veem como uma mudança tecnológica normal que exige adaptação a novos papéis (como gerir equipas de IA), e outros questionam a afirmação de “90% dos postos de trabalho desaparecerão”, considerando os ciclos económicos e as diferenças entre países, além das limitações atuais da IA (Fonte: source)
Utilizadores do Claude queixam-se de queda no desempenho e restrições mais apertadas: O subreddit ClaudeAI do Reddit viu uma discussão concentrada, com vários utilizadores (incluindo utilizadores Pro) a relatarem limites de uso (quota) mais rigorosos recentemente, atingindo o limite frequentemente mesmo com operações normais. Alguns utilizadores acreditam que a Anthropic está a apertar secretamente as quotas e expressam insatisfação, considerando que isso forçará os utilizadores a migrar para concorrentes. Além disso, alguns utilizadores relatam que a “personalidade” do Claude parece ter mudado, tornando-se mais “fria”, “mecânica”, perdendo o toque filosófico e poético das versões anteriores, levando alguns a cancelar as suas subscrições (Fonte: source, source, source, source)
Geração de imagens do ChatGPT gera diversão e discussão: Utilizadores do Reddit partilham várias tentativas e resultados usando a geração de imagens do ChatGPT. Alguém pediu para “transformar” um cão em humano, resultando em imagens semelhantes a “homens-fera/furries”, gerando discussão sobre a compreensão do prompt e potenciais vieses. Outro utilizador pediu para ser desenhado como um vitral de múltiplos universos, com resultados impressionantes. Outros pediram para gerar imagens metafóricas sobre IA ou perguntaram sobre os “pesadelos” da IA, mostrando o potencial e as limitações da geração de imagens por IA na expressão criativa e visualização de conceitos abstratos (Fonte: source, source, source, source, source)

Comunidade discute seleção de modelos LLM e estratégias de uso: No subreddit LocalLLaMA do Reddit, um utilizador propôs uma discussão mensal sobre o uso de modelos, partilhando os melhores modelos (open-source e proprietários) usados em diferentes cenários (codificação, escrita, investigação, etc.) e as razões. Nos comentários, os utilizadores partilharam as suas combinações de modelos atuais, como Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemo, etc., e mencionaram usos específicos (como chamada de ferramentas, classificação, role-playing), refletindo a tendência dos utilizadores de selecionar e combinar diferentes modelos de acordo com as necessidades da tarefa (Fonte: source)
💡 Outros
Cimeira da Indústria AIGC da China prestes a acontecer: A terceira Cimeira da Indústria AIGC da China será realizada em Pequim a 16 de abril. A cimeira reunirá mais de 20 líderes da indústria de empresas como Baidu, Huawei, Microsoft Research Asia, Amazon Web Services, ModelBest, ShengShu Technology, para discutir avanços tecnológicos em IA (computação, modelos de grande escala), aplicações setoriais (educação, entretenimento, investigação, serviços empresariais), construção de ecossistemas (segurança e controlo, desafios de implementação), entre outros tópicos. A cimeira também divulgará rankings de empresas/produtos AIGC e o mapa panorâmico completo das aplicações AIGC na China (Fonte: QbitAI)

Relatório de Stanford: Diferença de desempenho entre modelos de IA de topo da China e dos EUA reduzida para 0,3%: O relatório AI Index de 2025, publicado pela Universidade de Stanford, mostra que a diferença de desempenho entre os modelos de IA de topo da China e dos EUA diminuiu significativamente de 20% em 2023 para 0,3%. Embora os EUA ainda liderem em número de modelos notáveis (40 vs 15) e empresas dominantes na indústria, a velocidade de recuperação dos modelos chineses acelerou. O relatório também aponta que a diferença de desempenho entre os próprios modelos de topo está a diminuir, de 12% em 2024 para 5%, evidenciando um fenómeno de convergência (Fonte: InfoQ)