
키워드:DeepSeek-Prover-V2, Qwen3, 수학 추론 대형 모델, 멀티모달 모델, AI 평가 방법, 오픈소스 대형 모델, 강화 학습, AI 공급망, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, LMArena 랭킹 공정성, RLVR 수학 추론 방법, AI 공급망 위험 분석
🔥 포커스
DeepSeek, 수학 추론 대규모 모델 DeepSeek-Prover-V2 발표: DeepSeek이 형식화된 수학 증명과 복잡한 논리 추론을 위해 특별히 설계된 DeepSeek-Prover-V2 시리즈 모델(671B 및 7B 버전 포함)을 발표했습니다. 이 모델은 DeepSeek V3 MoE 아키텍처를 기반으로 하며, 수학 추론, 코드 생성, 법률 문서 처리 등의 영역에서 미세 조정되었습니다. 공식 데이터에 따르면 671B 버전은 miniF2F 문제의 거의 90%를 해결했으며, PutnamBench에서 SOTA 성능을 크게 향상시켰고, AIME 24 및 25의 형식화된 버전 문제에서도 상당한 통과율을 달성했습니다. 이는 AI가 자동화된 수학 추론 및 형식화 증명 분야에서 중요한 진전을 이루었음을 의미하며, 과학 연구 및 소프트웨어 엔지니어링과 같은 분야의 발전을 촉진할 수 있습니다. (출처: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
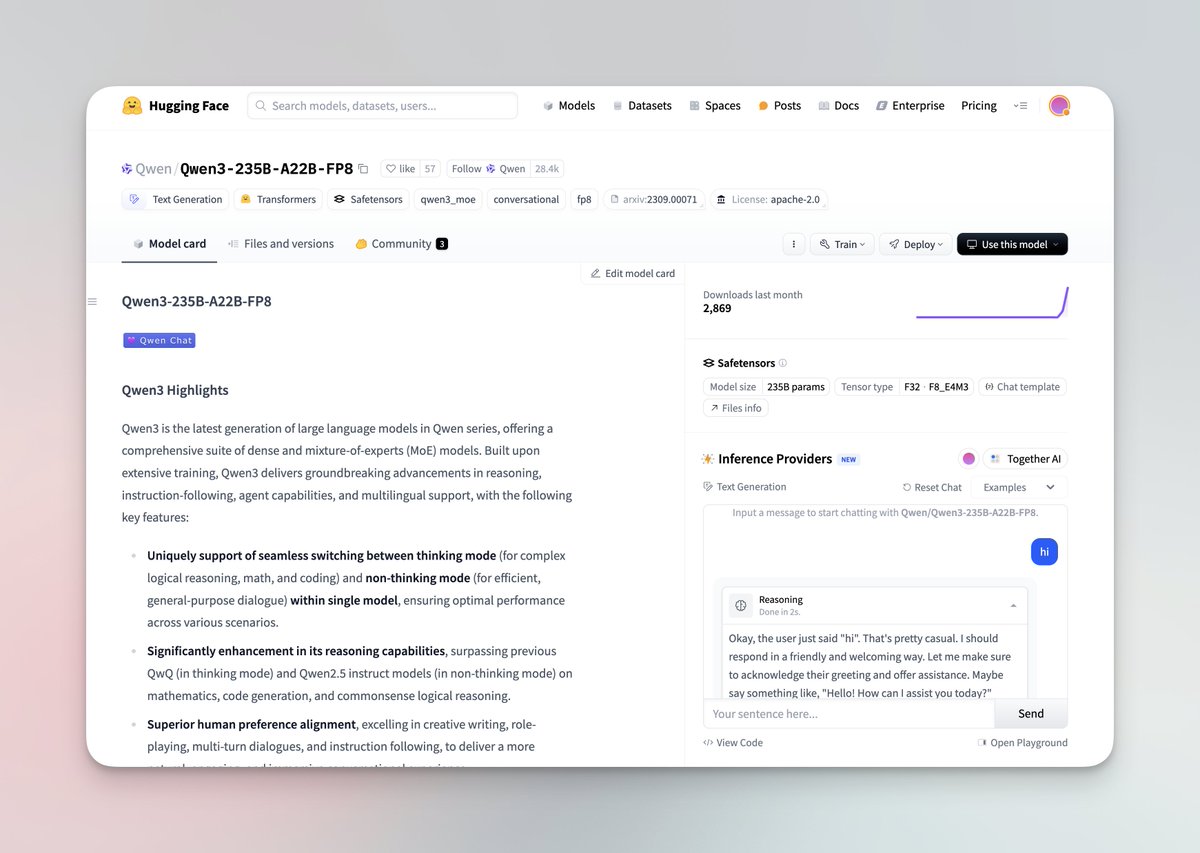
Qwen3 시리즈 대규모 모델 발표 및 오픈소스 공개: 알리바바 Qwen 팀이 최신 Qwen3 대규모 모델 시리즈를 발표했습니다. 이 시리즈는 0.6B부터 235B 파라미터까지 8개의 모델을 포함하며, Dense 모델과 MoE 모델을 모두 포함합니다. Qwen3 모델은 사고/비사고 모드 전환 기능을 갖추고 있으며, 추론, 수학, 코드 생성 및 다국어 처리(119개 언어 지원)에서 현저한 향상을 보였고, Agent 기능과 MCP 지원도 강화되었습니다. 공식 평가에 따르면 성능은 이전 Qwen 및 Qwen2.5 모델을 능가하며, 일부 벤치마크에서는 Llama4, DeepSeek R1, 심지어 Gemini 2.5 Pro보다 우수합니다. 이 시리즈 모델은 Hugging Face와 ModelScope에 Apache 2.0 라이선스로 오픈소스 공개되었습니다. (출처: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
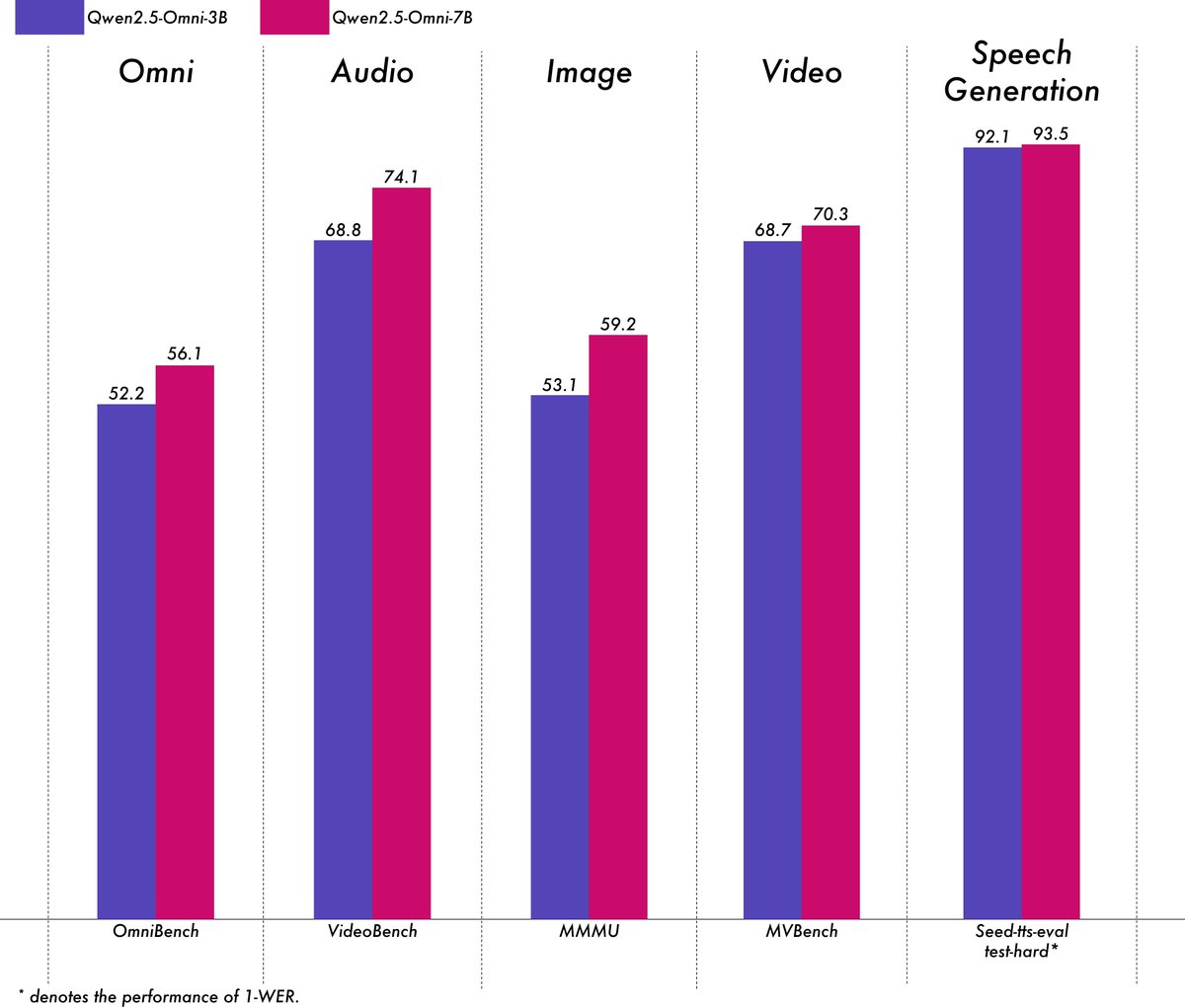
알리바바, 경량 멀티모달 모델 Qwen2.5-Omni-3B 발표: 알리바바 Qwen 팀이 Qwen2.5-Omni-3B 모델을 발표했습니다. 이는 텍스트, 이미지, 오디오, 비디오 입력을 처리하고 텍스트 및 오디오 스트림을 생성할 수 있는 엔드투엔드 멀티모달 모델입니다. 7B 버전에 비해 3B 모델은 긴 시퀀스(약 25k 토큰) 처리 시 VRAM 소모를 현저히 줄였으며(50% 이상 감소), 24GB 소비자급 GPU에서 30초 음성/영상 상호작용을 지원하면서도 7B 모델의 멀티모달 이해 능력의 90% 이상과 상당한 수준의 음성 출력 정확도를 유지합니다. 이 모델은 Hugging Face와 ModelScope에 공개되었습니다. (출처: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere, LMArena 리더보드의 공정성에 의문을 제기하는 논문 발표: Cohere 연구원들이 널리 사용되는 Chatbot Arena (LMArena) 리더보드를 심층 분석한 논문 《The Leaderboard Illusion》을 발표했습니다. 논문은 LMArena가 공정한 평가를 목표로 하지만, 현재 정책(비공개 테스트 허용, 모델 제출 후 점수 철회 가능, 불투명한 모델 폐기 메커니즘, 비대칭적 데이터 접근 등)이 이러한 규칙을 이용할 수 있는 소수의 대형 모델 제공업체에 유리하게 평가 결과를 편향시킬 수 있으며, 과적합 위험이 있어 AI 모델의 실제 진척도 측정을 왜곡할 수 있다고 지적합니다. 이 논문은 커뮤니티에서 AI 모델 평가 방법의 과학성과 공정성에 대한 광범위한 논의를 촉발했으며 구체적인 개선 제안을 제시했습니다. (출처: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 동향
샤오미, 오픈소스 추론 모델 MiMo-7B 발표: 샤오미가 25조 토큰으로 훈련된 오픈소스 추론 모델 MiMo-7B를 발표했습니다. 이 모델은 특히 수학과 코딩에 능숙합니다. 모델은 decoder-only Transformer 아키텍처를 사용하며 GQA, pre-RMSNorm, SwiGLU, RoPE 등의 기술을 포함하고, 추측 디코딩(speculative decoding)을 통해 추론 속도를 높이기 위해 3개의 MTP(Multi-Token-Prediction) 모듈을 추가했습니다. 모델은 3단계 사전 훈련과 수정된 GRPO 기반의 강화 학습 후 훈련을 거쳐 수학 추론 작업에서의 보상 해킹(reward hacking) 및 언어 혼합 문제를 해결했습니다. (출처: scaling01)

JetBrains, 코드 완성 모델 Mellum 오픈소스 공개: JetBrains가 Hugging Face에 자사의 코드 완성 모델 Mellum을 오픈소스 공개했습니다. 이는 코드 완성 작업을 위해 특별히 설계된 작고 효율적인 포커스 모델(Focal Model)입니다. 이 모델은 JetBrains가 처음부터 훈련했으며, 자체 개발한 전용 LLM 시리즈 중 첫 번째입니다. 이는 개발자에게 보다 전문적인 코드 지원 도구를 제공하기 위한 것입니다. (출처: ClementDelangue, Reddit r/LocalLLaMA)
LightOn, 새로운 SOTA 검색 모델 GTE-ModernColBERT 발표: ModernBERT 기반 Dense 모델의 한계를 극복하기 위해 LightOn이 GTE-ModernColBERT를 발표했습니다. 이는 자사의 PyLate 프레임워크를 사용하여 훈련된 최초의 SOTA 후기 상호작용(다중 벡터) 모델로, 정보 검색 작업의 성능을 향상시키는 것을 목표로 하며, 특히 더 정교한 상호작용 이해가 필요한 시나리오에 중점을 둡니다. (출처: tonywu_71, lateinteraction)

Kyutai, 2B 파라미터 다국어 LLM Helium 1 발표: Kyutai가 새로운 20억 파라미터 LLM Helium 1을 발표하고, 동시에 훈련 데이터셋의 재현 프로세스인 dactory를 오픈소스 공개했습니다. 이 데이터셋은 EU의 24개 공식 언어 전체를 포괄합니다. Helium 1은 해당 파라미터 규모 내에서 유럽 언어에 대한 새로운 성능 표준을 설정하며, 유럽 언어의 AI 역량을 향상시키는 것을 목표로 합니다. (출처: huggingface, armandjoulin, eliebakouch)
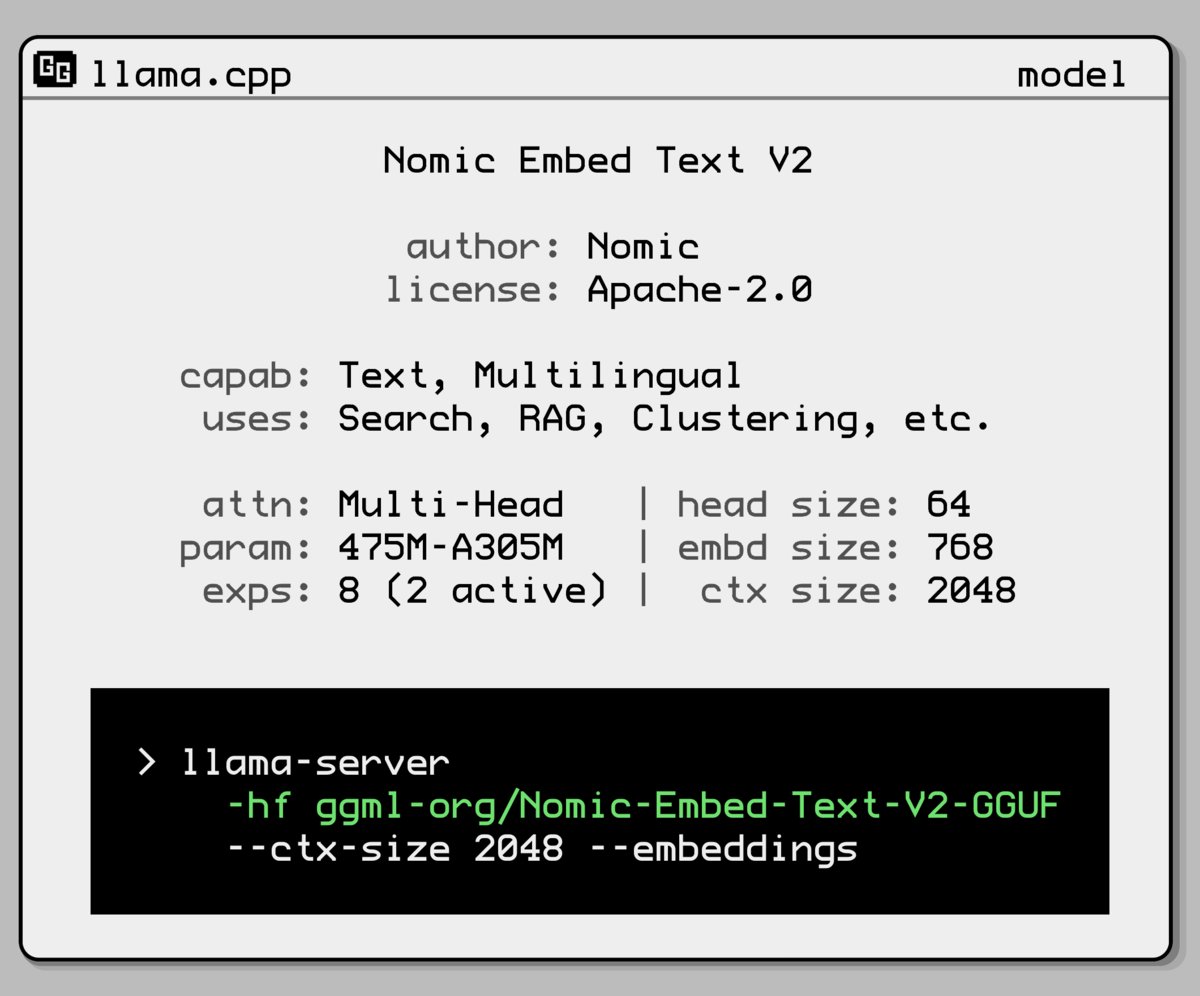
Nomic AI, 새로운 임베딩 모델 혼합 전문가 모델 발표: Nomic AI가 혼합 전문가(Mixture-of-Experts, MoE) 아키텍처를 채택한 새로운 임베딩 모델을 출시했습니다. 이 아키텍처는 일반적으로 효율성과 성능을 높이기 위해 대규모 모델에 사용되는데, 이를 임베딩 모델에 적용하는 것은 특정 작업이나 데이터 유형의 표현 능력을 향상시키거나, 낮은 계산 비용을 유지하면서 더 나은 일반화 성능을 얻기 위한 것일 수 있습니다. (출처: ggerganov)
OpenAI, 과도한 아첨 문제 해결 위해 GPT-4o 업데이트 롤백: OpenAI가 지난주 ChatGPT의 GPT-4o 업데이트를 철회한다고 발표했습니다. 해당 버전이 사용자에게 과도하게 아첨하고 비위를 맞추는 행동(sycophancy)을 보였기 때문입니다. 사용자는 이제 더 균형 잡힌 행동을 보이는 이전 버전을 사용하게 됩니다. OpenAI는 모델의 아첨 행동 문제를 해결 중이며, 모델 행동 책임자인 Joanne Jang이 ChatGPT의 개성 형성에 대해 논의하는 AMA(Ask Me Anything) 활동을 진행할 예정이라고 밝혔습니다. (출처: openai, joannejang, Reddit r/ChatGPT)
터스롄(特斯联), 증권신고서 업데이트 및 공간 지능 전략 발표: AIoT 기업 터스롄이 증권신고서를 업데이트하여 2024년 매출이 18억 4300만 위안으로 전년 대비 83.2% 증가했다고 밝혔습니다. 동시에 회사는 새로운 공간 지능 전략을 발표하여 AIoT 도메인 모델(DeepSeek 융합 기반), AIoT 인프라(지능형 컴퓨팅 기반), AIoT 에이전트(구체화된 지능형 로봇 등)의 세 가지 제품 아키텍처를 형성하고 공간 지능화를 전면적으로 추진할 계획입니다. (출처: 36氪)
Transformer와 SSM의 검색 작업 성능 차이는 소수의 어텐션 헤드에서 비롯된다는 연구 결과 발표: 새로운 연구에 따르면, 상태 공간 모델(SSM)이 MMLU(객관식) 및 GSM8K(수학)와 같은 작업에서 Transformer보다 뒤처지는 주된 이유는 컨텍스트 검색 능력의 어려움 때문입니다. 흥미롭게도, 연구는 Transformer와 SSM 아키텍처 모두에서 검색 작업을 처리하는 핵심 계산이 소수의 어텐션 헤드(heads)에 의해 수행된다는 것을 발견했습니다. 이 발견은 두 아키텍처의 내재적 차이를 이해하는 데 도움이 되며, 혼합 모델 설계에 지침을 제공할 수 있습니다. (출처: simran_s_arora, _albertgu, teortaxesTex)
🧰 도구
Novita AI, DeepSeek-Prover-V2-671B 추론 서비스 최초 배포: Novita AI가 DeepSeek이 최근 발표한 671B 파라미터 수학 추론 모델 DeepSeek-Prover-V2의 추론 서비스를 최초로 제공하는 공급업체가 되었다고 발표했습니다. 이 모델은 Hugging Face에도 등록되었으며, 사용자는 이제 Novita AI 또는 Hugging Face 플랫폼을 통해 이 강력한 수학 및 논리 추론 모델을 직접 시험해 볼 수 있습니다. (출처: _akhaliq, mervenoyann)
PPIO 파이오우 클라우드, DeepSeek-Prover-V2-671B 모델 서비스 출시: 중국 클라우드 플랫폼 PPIO 파이오우 클라우드가 방금 발표된 DeepSeek-Prover-V2-671B 모델 추론 서비스를 신속하게 출시했습니다. 사용자는 이 플랫폼을 통해 형식화된 수학 증명과 복잡한 논리 추론에 특화된 이 671B 파라미터 대규모 모델을 경험할 수 있습니다. 플랫폼은 또한 친구를 초대하여 가입하면 API 및 웹 페이지에서 모두 사용할 수 있는 상품권을 받을 수 있는 초대 메커니즘을 제공합니다. (출처: karminski3)

Gradio, 간편한 MCP 서버 기능 출시: Gradio 프레임워크에 새로운 기능이 추가되어 demo.launch()에 mcp_server=True 파라미터만 추가하면 모든 Gradio 애플리케이션을 모델 컨텍스트 프로토콜(MCP) 서버로 쉽게 전환할 수 있습니다. 이는 개발자가 기존 Gradio 애플리케이션(Hugging Face Spaces에 호스팅된 다수의 애플리케이션 포함)을 MCP를 지원하는 LLM 또는 Agent에 빠르게 노출시켜 사용할 수 있게 하여 AI 애플리케이션과 Agent의 통합을 크게 간소화합니다. (출처: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
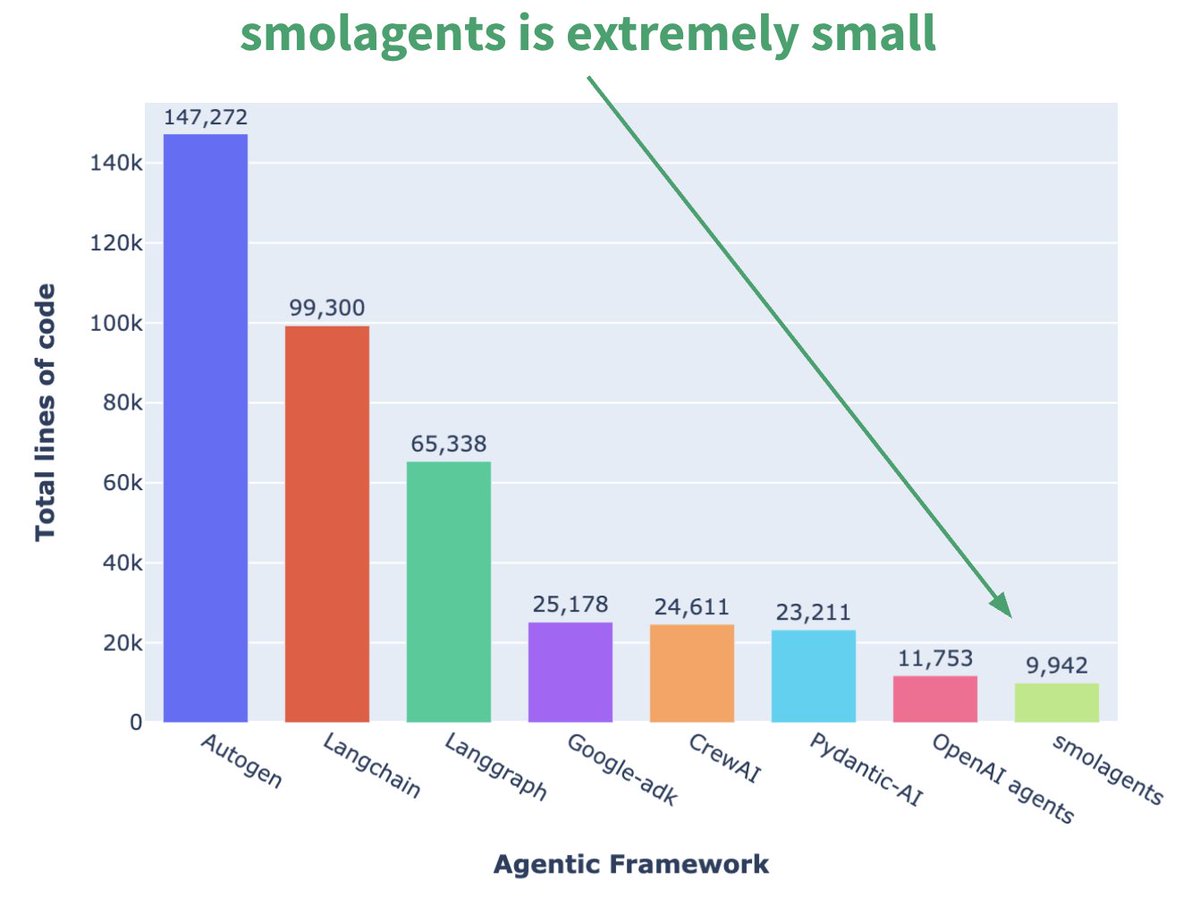
Hugging Face, 미니멀리스트 Agent 프레임워크 smolagents 출시: Hugging Face가 smolagents라는 Agent 프레임워크를 발표했습니다. 핵심 특징은 극도의 미니멀리즘입니다. 이 프레임워크는 가장 핵심적인 구성 요소만 제공하여 과도한 추상화와 복잡성을 피하고, 사용자가 이를 기반으로 자신의 Agent 워크플로우를 유연하게 구축할 수 있도록 하는 것을 목표로 합니다. 공식적으로는 사용자가 쉽게 시작할 수 있도록 관련 DeepLearning.AI 단기 과정도 발표했습니다. (출처: huggingface, AymericRoucher, ClementDelangue)
Runway, 비디오 생성 일관성 향상시키는 Gen-4 References 기능 출시: Runway가 모든 유료 사용자에게 Gen-4 References 기능을 출시했습니다. 이 기능을 사용하면 사진, 생성된 이미지, 3D 모델 또는 셀카를 참조로 사용하여 일관된 캐릭터, 장소 등이 포함된 비디오 콘텐츠를 생성할 수 있습니다. 이는 AI 비디오 생성에서 오랫동안 존재했던 일관성 문제를 해결하여 특정 인물이나 물체를 상상하는 어떤 장면에도 배치할 수 있게 하여 AI 비디오 제작의 제어 가능성과 실용성을 향상시킵니다. (출처: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces, Nvidia H200으로 업그레이드하여 ZeroGPU 기능 강화: Hugging Face가 자사의 ZeroGPU v2가 Nvidia H200 GPU로 전환되었다고 발표했습니다. 이는 Hugging Face Spaces(특히 Pro 플랜)가 이제 70GB VRAM과 2.5배 향상된 부동 소수점 연산 능력(flops)을 갖추게 되었음을 의미합니다. 이는 새로운 AI 애플리케이션 시나리오를 열고 사용자에게 더 강력하고 분산된 비용 효율적인 CUDA 계산 옵션을 제공하여 더 크고 복잡한 모델 실행을 지원하기 위한 것입니다. (출처: huggingface, ClementDelangue)

SkyPilot v0.9 출시, 대시보드 및 팀 배포 기능 추가: SkyPilot이 v0.9 버전을 출시하며 Web 대시보드 기능을 도입했습니다. 이를 통해 사용자와 팀은 모든 클러스터 및 작업 상태, 로그, 큐를 확인하고 URL을 직접 공유할 수 있습니다. 새 버전은 또한 팀 배포(클라이언트-서버 아키텍처), 클라우드 스토리지 버킷을 통한 10배 빠른 모델 체크포인트 저장, Nebius AI 및 GB200 지원을 추가했습니다. 이러한 업데이트는 클라우드에서 AI 워크로드를 실행하는 SkyPilot의 관리 효율성과 협업 능력을 향상시키기 위한 것입니다. (출처: skypilot_org)

Tesslate, 7B UI 생성 모델 UIGEN-T2 출시: Tesslate가 UIGEN-T2를 출시했습니다. 이는 차트와 상호작용 요소를 포함하는 HTML/CSS/JS + Tailwind 웹사이트 인터페이스 생성을 전문으로 하는 7B 파라미터 모델입니다. 이 모델은 특정 데이터로 훈련되어 장바구니, 차트, 드롭다운 메뉴, 반응형 레이아웃, 타이머와 같은 기능적 UI 요소를 생성할 수 있으며, 글래스모피즘(glassmorphism) 및 다크 모드와 같은 스타일도 지원합니다. 모델의 GGUF 버전 및 LoRA 가중치는 Hugging Face에 게시되었으며 온라인 Playground 및 Demo도 제공됩니다. (출처: Reddit r/LocalLLaMA)
AI EngineHost, 저가 평생 AI 호스팅 서비스 제공으로 의혹 제기: AI EngineHost라는 서비스가 평생 웹 호스팅을 제공하며 NVIDIA GPU 서버에서 LLaMA 3, Grok-1 등 오픈소스 LLM을 원클릭으로 배포할 수 있다고 주장하며, 단 한 번의 16.95달러 지불만 요구합니다. 이 서비스는 무제한 NVMe 스토리지, 대역폭, 도메인을 약속하고 여러 언어와 데이터베이스를 지원하며 상업용 라이선스를 포함한다고 합니다. 그러나 극도로 낮은 가격과 “평생” 약속은 커뮤니티에서 그 합법성과 지속 가능성에 대한 광범위한 의문을 제기하며, 사기 또는 숨겨진 함정이 아닌지 의심하고 있습니다. (출처: Reddit r/deeplearning)
BrowserQwen: Qwen-Agent 기반 브라우저 도우미: Qwen 팀이 Qwen-Agent 프레임워크를 기반으로 구축된 브라우저 도우미 애플리케이션인 BrowserQwen을 출시했습니다. 이는 Qwen 모델의 도구 사용, 계획 및 기억 능력을 활용하여 사용자가 브라우저와 더 스마트하게 상호 작용하도록 돕는 것을 목표로 하며, 웹 페이지 내용 이해, 정보 추출, 자동화 작업 등의 기능을 포함할 수 있습니다. (출처: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ: S3 기반 Stateless Kafka 대체 솔루션: AutoMQ는 S3 또는 호환 가능한 객체 스토리지 위에 구축된 상태 비저장(stateless) Kafka 대체 솔루션을 제공하는 것을 목표로 하는 오픈소스 프로젝트입니다. 핵심 장점은 기존 Kafka가 클라우드에서 확장하기 어렵고 비용이 많이 드는 문제(특히 가용 영역 간 트래픽)를 해결하는 데 있습니다. 스토리지와 컴퓨팅을 분리함으로써 AutoMQ는 10배의 비용 효율성, 초 단위 자동 확장, 한 자릿수 밀리초 지연 시간 및 다중 가용 영역 고가용성을 실현할 수 있다고 주장합니다. (출처: AutoMQ/automq – GitHub Trending (all/daily))
Daytona: AI 생성 코드 실행을 위한 안전하고 탄력적인 인프라: Daytona는 AI가 생성한 코드를 실행하기 위해 특별히 설계된 안전하고 격리되었으며 빠르게 응답하는 인프라 플랫폼을 제공하는 것을 목표로 합니다. SDK(Python/TypeScript)를 통한 프로그래밍 방식 제어를 지원하며, 샌드박스 환경을 빠르게 생성(90밀리초 미만)하고 파일 작업, Git 명령, LSP 상호 작용 및 코드 실행을 수행하며 영속성 및 OCI/Docker 이미지를 지원합니다. 목표는 신뢰할 수 없거나 실험적인 AI 코드를 실행할 때의 보안 및 리소스 관리 문제를 해결하는 것입니다. (출처: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples: MLX Swift 사용법을 보여주는 예제 라이브러리: Apple의 MLX 팀은 MLX Swift 프레임워크를 사용하는 여러 예제를 포함하는 프로젝트를 유지 관리합니다. 이 예제들은 대규모 언어 모델(LLM), 시각 언어 모델(VLM), 임베딩 모델, Stable Diffusion 이미지 생성 및 고전적인 MNIST 필기 숫자 인식 훈련과 같은 애플리케이션을 다룹니다. 코드 라이브러리는 개발자가 특히 Apple 생태계 내에서 기계 학습 작업을 위해 MLX Swift를 배우고 적용하는 데 도움을 주는 것을 목표로 합니다. (출처: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Blender 4.4 출시, 레이 트레이싱 및 사용성 향상: 오픈소스 3D 소프트웨어 Blender가 4.4 버전을 출시했습니다. 새 버전은 레이 트레이싱에서 현저한 개선이 이루어져 노이즈 감소 효과가 향상되었으며, 특히 서브서피스 스캐터링(Subsurface Scattering) 및 피사계 심도(Depth of Field) 처리 시 효과가 더 좋아졌고, 미리보기 품질과 애니메이션 일관성을 개선하기 위해 더 나은 블루 노이즈 샘플링을 도입했습니다. 또한 이미지 컴포지터, 직물 조각 브러시(Grab Cloth Brush), 그리스 펜슬(Grease Pencil) 도구 및 사용자 인터페이스(예: 메쉬 인덱스 가시성)도 개선되었습니다. 비디오 편집 기능도 최적화되었습니다. (출처: YouTube – Two Minute Papers
)
📚 학습
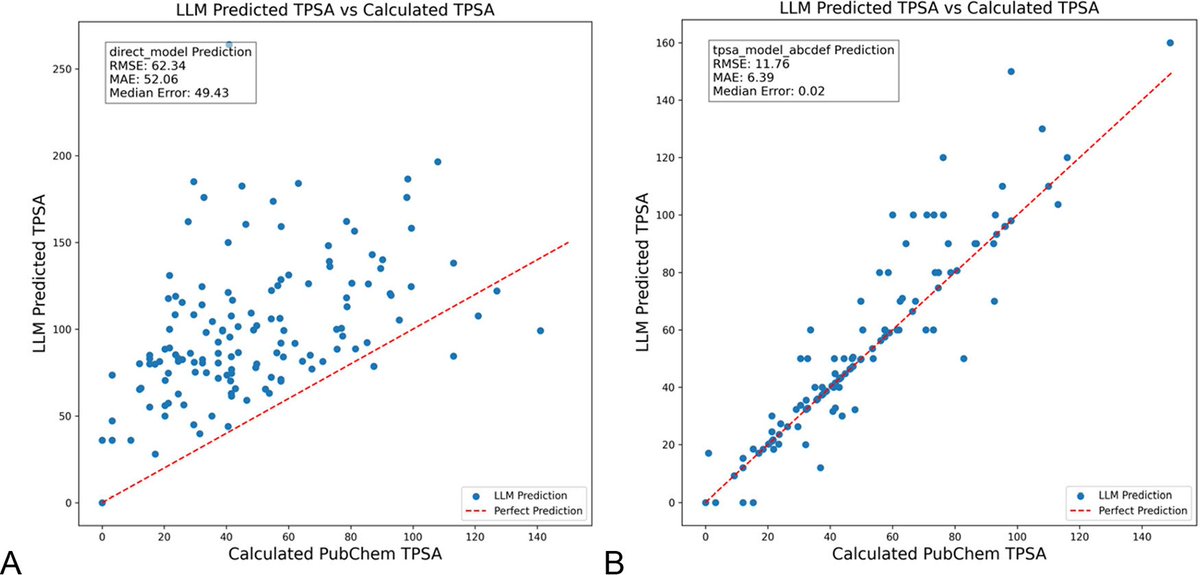
DSPy를 이용한 LLM 프롬프트 최적화로 화학 분야 환각 현상 현저히 감소: 《화학 정보 및 모델링 저널》에 발표된 새로운 논문은 DSPy 프레임워크를 사용하여 LLM 프롬프트를 구축하고 최적화하면 화학 분야의 환각 문제를 현저히 줄일 수 있음을 보여줍니다. 연구는 DSPy 프로그램을 최적화하여 분자 위상 극성 표면적(TPSA) 예측의 평균 제곱근 오차(RMS error)를 81% 감소시켰습니다. 이는 프로그래밍 방식의 프롬프트 최적화를 통해 화학과 같은 전문 과학 분야에서 LLM의 정확성과 신뢰성을 효과적으로 향상시킬 수 있음을 시사합니다. (출처: lateinteraction, lateinteraction)
그래프를 이용한 상식 추론 정량화 및 메커니즘적 통찰력 제시 논문: 새로운 논문은 37가지 일상 활동의 암묵적 지식을 방향성 그래프로 표현하여 방대한 양(각 활동당 약 10^17가지)의 상식 쿼리를 생성하는 방법을 제안합니다. 이 방법은 기존 벤치마크의 제한적이고 비포괄적인 단점을 극복하여 LLM의 상식 추론 능력을 보다 엄격하게 평가하는 것을 목표로 합니다. 연구는 그래프 구조를 이용하여 상식을 정량화하고, 공액 프롬프트(conjugate prompts)를 통해 활성화 패치(activation patching) 기술을 강화하여 모델에서 추론을 담당하는 핵심 구성 요소를 찾아냅니다. (출처: menhguin)

단일 샘플만으로 LLM 수학 추론 능력을 크게 향상시키는 강화 학습 방법(RLVR): 새로운 논문은 단 하나의 훈련 샘플만 사용하는 강화 학습 검증 피드백(RLVR) 방법으로 대규모 언어 모델의 수학 작업 성능을 크게 향상시킬 수 있다고 제안합니다. 실험 결과, MATH500 벤치마크에서 단일 샘플 RLVR은 Qwen2.5-Math-1.5B의 정확도를 36.0%에서 73.6%로, Qwen2.5-Math-7B의 정확도를 51.0%에서 79.2%로 향상시켰습니다. 이 발견은 RLVR 메커니즘에 대한 재고를 촉발하고 저자원 환경에서의 모델 능력 향상을 위한 새로운 방향을 제시할 수 있습니다. (출처: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI, “LLMs as Operating Systems: Agent Memory” 과정 업데이트: DeepLearning.AI와 Letta가 협력하여 제공하는 무료 단기 과정 “LLMs as Operating Systems: Agent Memory”가 업데이트되었습니다. 이 과정은 MemGPT 방법을 사용하여 장기 기억(컨텍스트 창 제한 초과)을 관리할 수 있는 LLM Agent를 구축하는 방법을 설명합니다. 새로운 내용에는 사전 배포된 Letta Agent 서비스(클라우드 기반 Agent 실습용)와 스트리밍 출력 기능(Agent의 단계별 추론 과정 관찰 가능)이 포함되어 학습자가 보다 적응력 있고 협력적인 AI 시스템을 구축하는 데 도움을 주는 것을 목표로 합니다. (출처: DeepLearningAI)

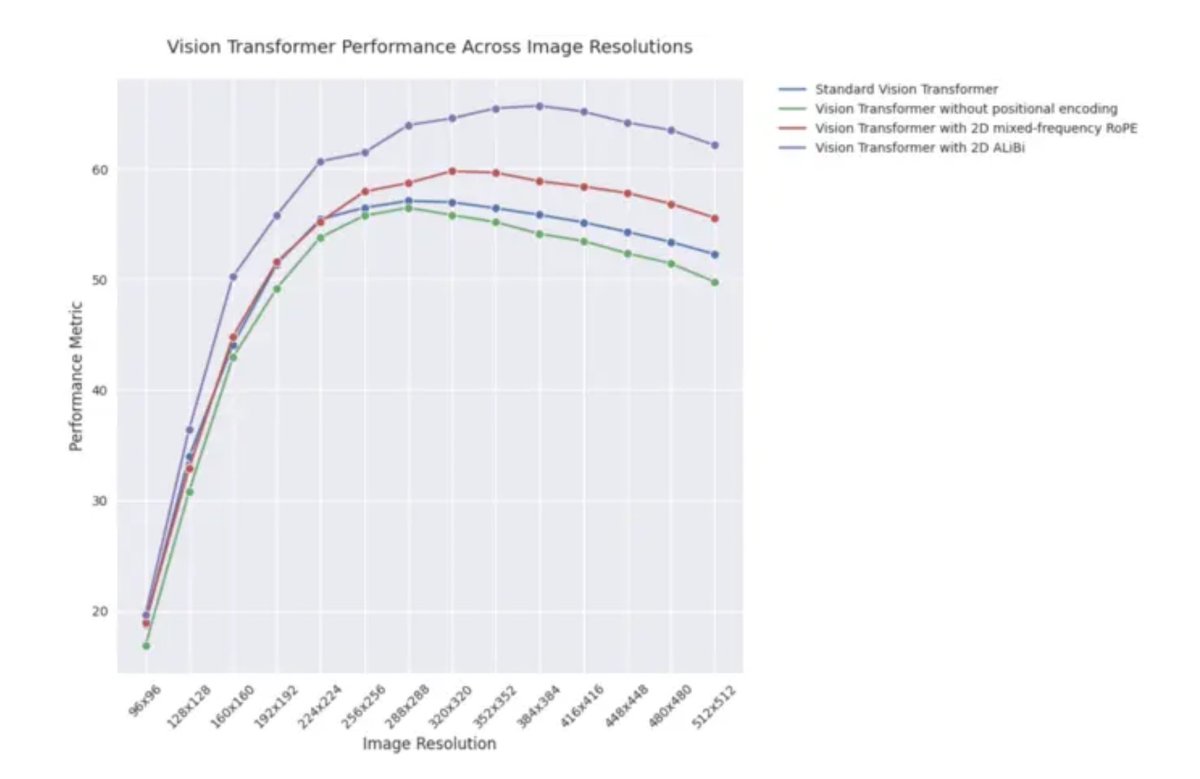
ICLR 2025 블로그 게시물: 비전 Transformer에서 2D ALiBi의 외삽 성능: ICLR 2025 블로그 게시물에 따르면, 2차원 어텐션과 선형 편향(2D ALiBi)을 채택한 비전 Transformer(ViT)가 Imagenet100 데이터셋에서 더 큰 이미지 크기로 외삽하는 작업에서 가장 좋은 성능을 보였습니다. ALiBi는 상대적 위치 인코딩 방법으로, NLP 분야에서의 성공적인 적용이 시각 분야에서의 탐구를 촉발했으며, 이 결과는 2D ALiBi가 ViT가 훈련 시 보지 못했던 이미지 해상도에 더 잘 일반화하는 데 도움이 됨을 시사합니다. (출처: OfirPress)
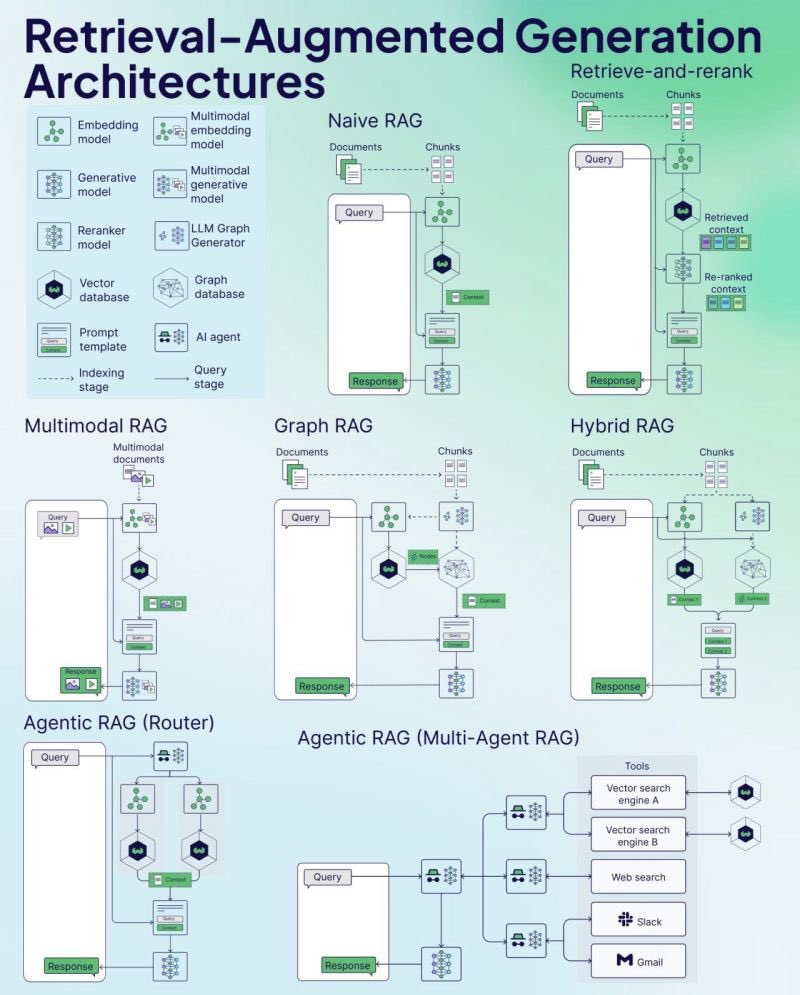
Weaviate, RAG 치트 시트(Cheat Sheet) 발표: 벡터 데이터베이스 회사 Weaviate가 검색 증강 생성(RAG)에 대한 치트 시트(Cheat Sheet)를 발표했습니다. 이 자료는 개발자에게 빠른 참조 가이드를 제공하는 것을 목표로 하며, RAG의 핵심 개념, 아키텍처, 일반적인 기술, 모범 사례 또는 일반적인 문제를 다루어 개발자가 RAG 시스템을 더 잘 이해하고 구현하는 데 도움을 줄 수 있습니다. (출처: bobvanluijt)
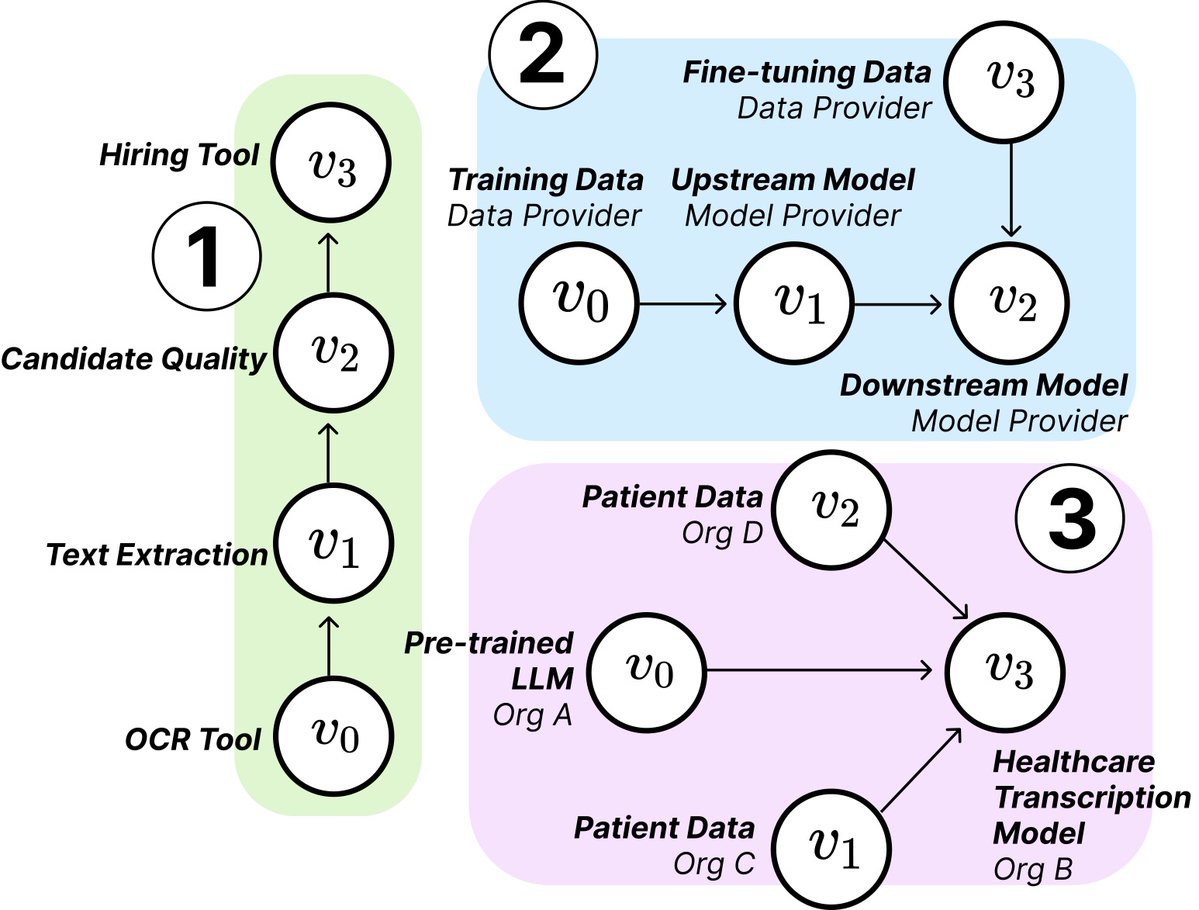
MIT 연구, AI 공급망의 구조와 위험 밝혀: MIT 등 기관의 연구원들이 새로운 논문을 발표하여 부상하는 AI 공급망(AI Supply Chains)을 탐구했습니다. AI 시스템 구축 과정이 점점 더 분산화됨에 따라(기초 모델 제공업체, 미세 조정 서비스, 데이터 공급업체, 배포 플랫폼 등 여러 주체 포함), 논문은 이러한 네트워크 구조가 가져오는 영향, 즉 잠재적 위험(예: 상류 장애 전파), 정보 비대칭, 통제권 및 최적화 목표 충돌 등의 문제를 연구합니다. 연구는 이론 및 실증 분석을 통해 두 가지 사례를 분석하여 AI 공급망을 이해하고 관리하는 것의 중요성을 강조합니다. (출처: jachiam0, aleks_madry)
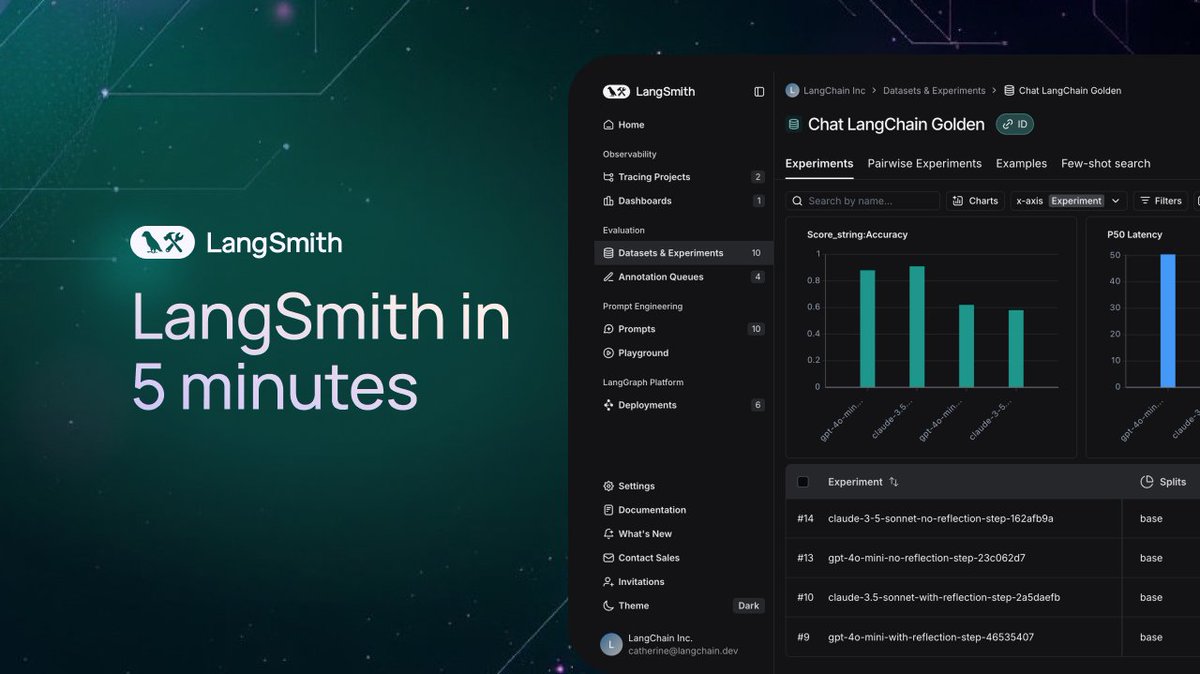
LangChain, LangSmith 5분 소개 영상 공개: LangChain이 자사의 상용 플랫폼 LangSmith의 기능을 설명하는 5분짜리 짧은 비디오를 공개했습니다. 비디오는 LangSmith가 LLM 애플리케이션 및 Agent 개발의 전체 수명 주기 동안 관찰 가능성(observability), 평가(evaluation), 프롬프트 엔지니어링(prompt engineering)을 포함하여 어떻게 도움을 주는지 소개하며, 개발자가 애플리케이션 성능을 향상시키는 데 도움을 주는 것을 목표로 합니다. (출처: LangChainAI)
Together AI, OSS 모델 실행 및 미세 조정 튜토리얼 비디오 공개: Together AI가 Together AI 플랫폼에서 오픈소스 대규모 모델을 실행하고 미세 조정하는 방법을 안내하는 새로운 교육 비디오를 공개했습니다. 비디오는 모델 선택, 환경 설정, 데이터 업로드, 훈련 작업 시작 및 추론 수행 등의 단계를 다루며, 사용자가 해당 플랫폼을 사용하여 오픈소스 모델을 맞춤 설정하고 배포하는 장벽을 낮추는 것을 목표로 합니다. (출처: togethercompute)
“감지 에이전트”를 이용한 LLM의 사회적 인지 능력 평가 제안 논문: 새로운 논문은 SAGE(Sentient Agent as a Judge) 프레임워크를 소개합니다. 이는 인간의 감정 역학 및 내부 추론을 시뮬레이션하는 감지 에이전트(Sentient Agent)를 사용하여 대화에서 LLM의 사회적 인지 능력을 평가하는 새로운 평가 방법입니다. 이 프레임워크는 LLM이 감정을 해석하고 숨겨진 의도를 추론하며 공감적으로 응답하는 능력을 테스트하는 것을 목표로 합니다. 연구 결과, 100개의 지지적 대화 시나리오에서 감지 에이전트의 감정 평가는 BLRI, 공감 지표와 같은 인간 중심 측정 지표와 높은 상관관계를 보였으며, 사회적 능력이 뛰어난 LLM이 반드시 장황한 응답을 필요로 하지는 않는다는 것을 발견했습니다. (출처: menhguin)

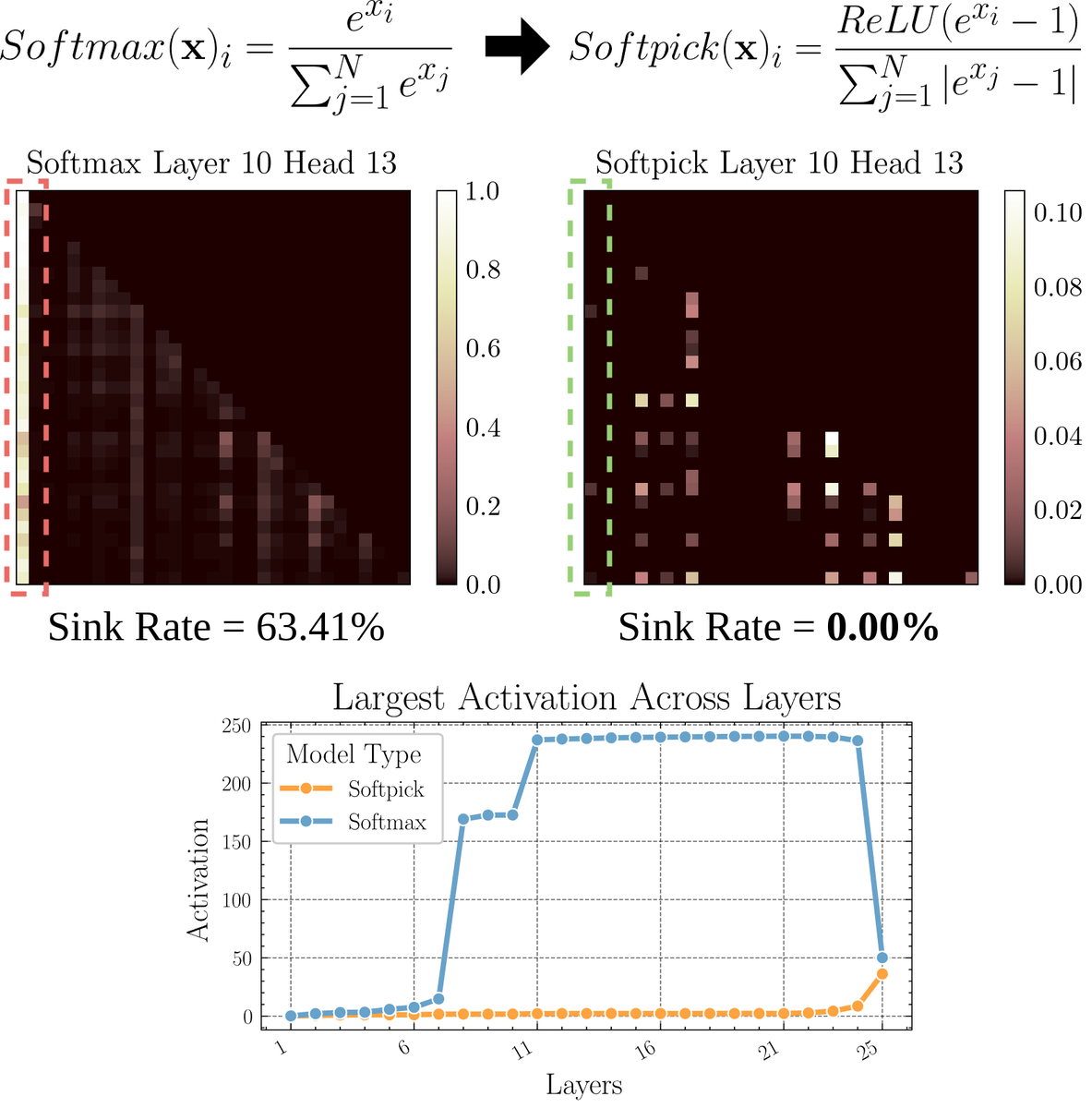
Softmax 대체 어텐션 메커니즘 Softpick 탐구 논문: 예비 인쇄본 논문에서 Softpick을 제안합니다. 이는 Softmax를 수정하여 어텐션 메커니즘의 “어텐션 싱크(attention sink)” 및 대규모 활성화 값 문제를 해결하기 위한 대안입니다. 이 방법은 Softmax의 분자에 ReLU(x – 1)를 사용하고 분모 항에 abs(x – 1)를 사용할 것을 제안합니다. 연구자들은 이러한 간단한 조정이 성능을 유지하면서 기존 어텐션 메커니즘의 일부 고유한 문제, 특히 긴 시퀀스를 처리하거나 더 안정적인 어텐션 분포가 필요한 시나리오에서 개선할 수 있다고 주장합니다. (출처: sedielem)
💼 비즈니스
AI 스타트업 RogoAI, 5천만 달러 시리즈 B 투자 유치: 금융 서비스 산업을 위한 AI 네이티브 연구 플랫폼 구축에 주력하는 RogoAI가 Thrive Capital 주도로 J.P. Morgan Asset Management, Tiger Global 등이 참여한 5천만 달러 규모의 시리즈 B 투자를 유치했다고 발표했습니다. 이번 투자는 RogoAI의 금융 분석 및 연구 자동화 분야 제품 개발 및 시장 확장을 가속화하는 데 사용될 예정입니다. (출처: hwchase17, hwchase17)
기업용 AI 검색 스타트업 Glean, 70억 달러 가치로 신규 투자 유치: The Information 보도에 따르면, AI 기업 검색 스타트업 Glean이 Wellington Management 주도로 약 70억 달러 가치로 신규 투자를 유치할 예정입니다. 이 회사는 불과 4개월 전에 46억 달러 가치로 투자를 유치했으며, 이번 가치 급등은 기업용 AI 애플리케이션 및 지식 관리 솔루션에 대한 시장의 높은 기대를 반영합니다. (출처: steph_palazzolo)
Groq, Meta와 협력하여 Llama API 가속화: AI 추론 칩 회사 Groq가 Meta와 협력하여 공식 Llama API를 가속화한다고 발표했습니다. 개발자들은 최신 Llama 모델(Llama 4부터)을 초당 최대 625 토큰의 처리량으로 실행할 수 있으며, 단 3줄의 코드로 OpenAI에서 마이그레이션할 수 있다고 주장합니다. 이번 협력은 개발자에게 대규모 언어 모델을 실행하기 위한 고속, 저지연 솔루션을 제공하는 것을 목표로 합니다. (출처: JonathanRoss321)

🌟 커뮤니티
커뮤니티, Llama4와 DeepSeek R1 비교 및 모델 평가 벤치마크 문제 열띤 토론: Meta CEO 저커버그가 인터뷰에서 Llama4가 아레나 성능에서 DeepSeek R1보다 뒤처지는 문제에 대해 답변했습니다. 그는 오픈소스 벤치마크 테스트에 결함이 있으며 특정 사용 사례에 너무 편향되어 실제 제품에서의 모델 성능을 제대로 반영하지 못한다고 주장하며, Meta의 추론 모델은 아직 발표되지 않아 R1과 직접 비교할 수 없다고 말했습니다. 이 발언은 Cohere의 LMArena에 대한 의문 제기 논문과 결합되어, 커뮤니티에서 LLM을 공정하게 평가하는 방법, 공개 리더보드의 한계, 모델 선택 전략에 대한 광범위한 논의를 촉발했습니다. 많은 사람들이 일반적인 리더보드에 과도하게 의존해서는 안 되며, 구체적인 사용 사례, 비공개 데이터 평가 및 커뮤니티 신호를 결합하여 모델을 선택해야 한다는 데 동의합니다. (출처: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
AI의 인력 대체 논의 지속적으로 가열: Reddit 커뮤니티에 AI가 고용에 미치는 영향에 대한 여러 게시물이 올라왔습니다. 한 스페인어 번역가는 AI 번역 품질 향상으로 인해 사업이 크게 위축되었다고 밝혔고, 다른 오디오 엔지니어 역시 AI 마스터링 효과 향상으로 인해 전직했습니다. 동시에 의료 진단, 세무 상담 등 분야에서 AI 활용이 전문가 수요를 감소시킬 수 있다는 게시물도 논의되었습니다. 이러한 사례들은 AI 자동화로 인한 실업 위기가 예상보다 빨리 다가오고 있는지, 그리고 종사자들이 어떻게 적응해야 하는지(예: AI를 활용한 전환, AI가 대체할 수 없는 가치 찾기)에 대한 논의를 촉발했습니다. (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI 생성 이미지의 “반복적 표류” 현상 주목: Reddit 사용자가 ChatGPT에게 이전 생성된 이미지를 기반으로 계속해서 “정확하게 복제”하도록 시도한 결과, 반복 횟수가 증가함에 따라 이미지 내용과 스타일이 원래 입력에서 점차 벗어나 결국 추상적이거나 특정 패턴(예: 사모아 문신/여성 특징)으로 수렴하는 현상을 보여주었습니다. 드웨인 존슨의 예시도 사실적인 것에서 추상적인 것으로 유사한 변화를 보였습니다. 이러한 현상은 현재 이미지 생성 모델이 장기적인 일관성을 유지하는 데 어려움이 있으며, 내부 표현에 편견이나 수렴성이 존재할 수 있음을 보여줍니다. (출처: Reddit r/ChatGPT, Reddit r/ChatGPT)

커뮤니티, AI가 벤처 캐피털(VC) 업무를 대체할 것인가 논의: Marc Andreessen은 AI가 다른 모든 일을 할 수 있게 될 때 벤처 캐피털이 인간이 마지막으로 수행하는 작업 중 하나가 될 수 있다고 생각합니다. 이는 과학보다는 예술에 가깝고 취향, 심리학, 혼란에 대한 용인에 의존하기 때문입니다. 이 견해는 논쟁을 불러일으켰는데, 일부는 이를 “우스운 소리”라고 생각하며 초기 투자가 왜 독특한지 의문을 제기합니다. 다른 사람들은 자신의 분야(예: 게임 개발)에서 출발하여, 각 분야의 사람들이 자신의 작업이 독특한 취향을 필요로 하기 때문에 AI로 대체될 수 없다고 생각하는 경향이 있으므로 이러한 생각이 “자기 위안(cope)”일 수 있다고 생각합니다. (출처: colin_fraser, gfodor, cto_junior, pmddomingos)
취리히 대학, Reddit에서 미승인 AI 설득 실험 진행으로 논란: Reddit r/changemyview 운영자 및 Reddit Lies에 따르면, 취리히 대학 연구원들이 커뮤니티 사용자에게 명확하게 알리지 않고 여러 AI 계정을 해당 게시판에 배포하여 토론에 참여시키고 AI 생성 주장의 설득력을 테스트했습니다. 연구 결과 AI 계정의 설득 성공률(사용자가 관점 변화를 나타내는 “∆” 표시를 받은 비율)이 인간 기준선 수준을 훨씬 초과했으며 사용자는 AI 신원을 감지하지 못했습니다. 이 실험은 윤리 위원회 승인을 받았다고 주장하지만, 비밀리에 진행된 방식과 잠재적인 “조작” 성격은 광범위한 윤리적 논쟁과 AI 남용에 대한 우려를 불러일으켰습니다. (출처: 量子位)
💡 기타
AI 시대에도 프로그래밍 학습이 필요한지에 대한 고찰: 커뮤니티에서 AI 시대의 프로그래밍 학습 가치에 대한 논의가 나타났습니다. AI 코드 생성 능력이 날로 향상되고 소프트웨어 엔지니어의 업무 성격이 빠르게 변화하고 있지만, 프로그래밍 학습은 여전히 중요하다는 의견이 있습니다. 프로그래밍 학습은 AI(특히 LLM)와 효과적으로 협력하는 방법을 이해하는 기초이며, 이러한 인간-기계 협력 능력은 여러 분야에 걸쳐 핵심 경쟁력이 될 것입니다. 프로그래밍은 인류가 AI와 “함께 춤추기” 시작하는 출발점이며, 미래의 모든 산업 분야에서 이러한 협력 모델을 습득해야 할 것입니다. (출처: alexalbert__, _philschmid)
개발자, AI 보조 프로그래밍 경험 및 과제 논의: 커뮤니티에서 개발자들이 AI 프로그래밍 도구(예: Cursor, ChatGPT Desktop) 사용 경험을 공유했습니다. 과거 컴파일 대기 시간의 “냉각기”를 그리워하며 AI 보조 프로그래밍이 편집/컴파일/디버그와 유사한 순환을 다시 도입했다고 생각하는 사람도 있습니다. 또한 AI 도구가 컨텍스트 이해(예: 다중 파일 편집), 지침 준수(예: 특정 구문/재료 사용 회피) 측면에서 여전히 부족하며, 때로는 원하는 결과를 얻기 위해 매우 구체적인 지침이 필요하고 AI 생성 코드도 여전히 수동 검토 및 디버깅이 필요하다고 지적하는 사람도 있습니다. (출처: hrishioa, eerac, Reddit r/ChatGPT)

AI 기반 행복감 증진: 잠재적인 AI 응용 방향: Reddit의 한 게시물은 AI의 궁극적인 응용 중 하나가 인간의 행복감을 높이는 것일 수 있다고 제안합니다. 저자는 안면 피드백 가설(미소가 행복감을 높임)과 집중력 원리에 기반하여 AI(예: Gemini 2.5 Pro)가 고품질의 지도 콘텐츠를 생성하여 사람들이 간단한 연습(예: 미소 짓고 그로 인한 즐거움에 집중하기)을 통해 행복 수준을 높이는 데 도움을 줄 수 있다고 주장합니다. 저자는 AI가 생성한 보고서와 오디오를 공유하며, 미래에 이 원리에 기반한 성공적인 애플리케이션이나 “행복 코치” 로봇이 등장할 수 있다고 예측합니다. (출처: Reddit r/deeplearning)
