
키워드:Qwen3, MCP 프로토콜, AI 에이전트, 대규모 언어 모델, 통의천문 모델, 모델 컨텍스트 프로토콜, 하이브리드 추론 모델, AI 에이전트 도구 호출, 오픈소스 대규모 언어 모델
🔥 포커스
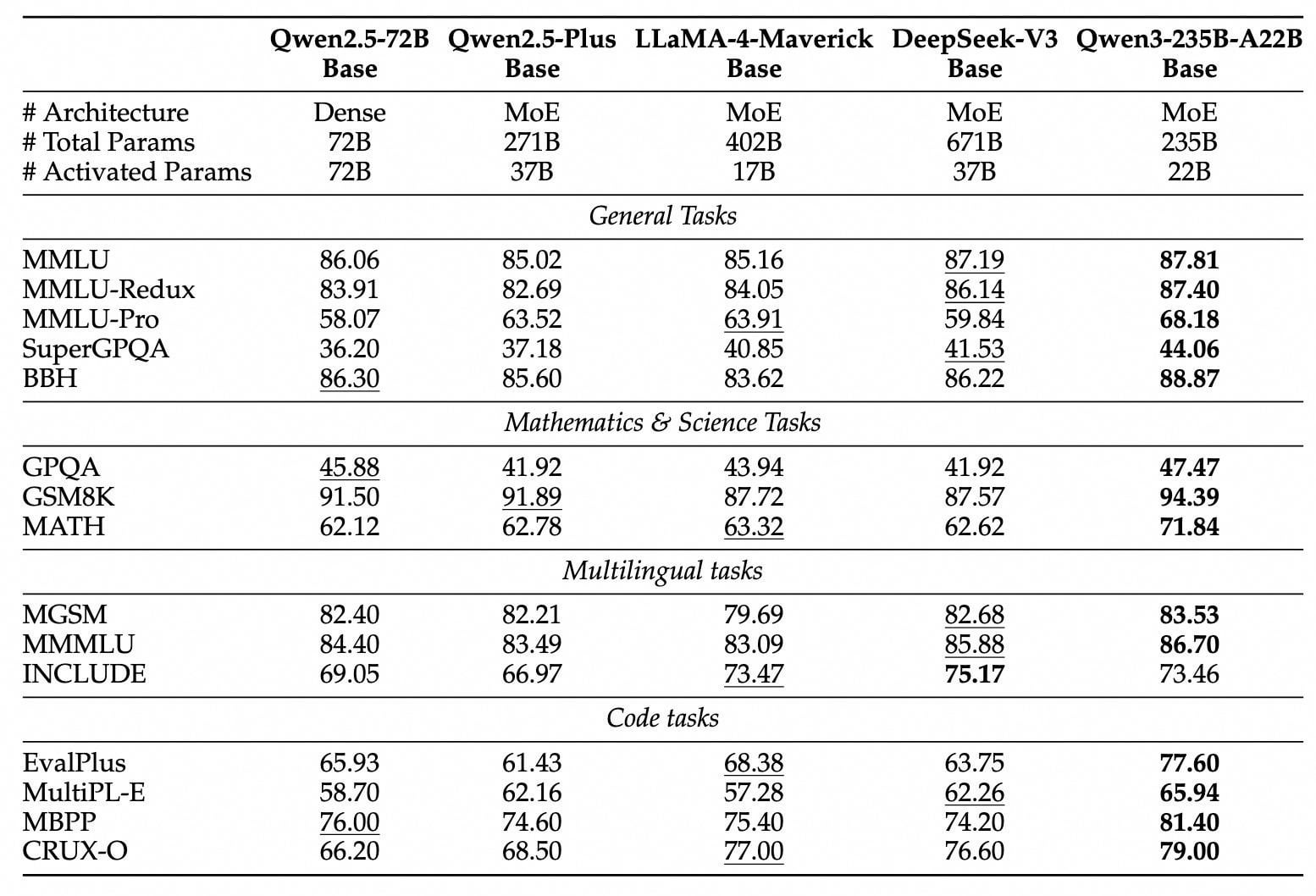
Qwen3 시리즈 모델 발표 및 오픈소스 공개: Alibaba는 차세대 Tongyi Qianwen 모델인 Qwen3 시리즈를 발표하고 오픈소스로 공개했습니다. 이 시리즈는 0.6B부터 235B 파라미터까지 8개의 모델(MoE 2개, Dense 6개)을 포함합니다. 플래그십 모델인 Qwen3-235B-A22B는 성능 면에서 DeepSeek-R1 및 OpenAI o1을 능가하며 글로벌 오픈소스 모델 정상에 올랐습니다. Qwen3는 중국 최초의 하이브리드 추론 모델로, 빠른 사고와 느린 사고 모드를 통합하여 컴퓨팅 파워를 대폭 절감했으며, 배포 비용은 동급 모델의 1/3에 불과합니다. 이 모델은 MCP 프로토콜 및 강력한 도구 호출 기능을 기본적으로 지원하여 Agent 능력을 강화했으며, 119개 언어를 지원합니다. 이번 오픈소스 공개는 Apache 2.0 라이선스를 채택했으며, 모델은 ModelScope 커뮤니티, HuggingFace 등 플랫폼에 출시되었습니다. 개인 사용자는 Tongyi APP을 통해 체험할 수 있습니다. (출처: InfoQ, 极客公园, CSDN, 直面AI, 卡兹克)

AI Agent의 ‘만능 소켓’ MCP 프로토콜, 관심과 투자 유발: 모델 컨텍스트 프로토콜(MCP)은 AI 모델과 외부 도구, 데이터 소스를 연결하는 표준화된 인터페이스로서 Baidu, Alibaba, Tencent, ByteDance 등 대기업들이 중점적으로 추진하고 있습니다. MCP는 AI가 외부 도구를 통합할 때 발생하는 비효율성과 표준 부재 문제를 해결하고 ‘한 번 패키징하여 여러 곳에서 호출’하는 것을 목표로 하며, AI Agent(지능형 에이전트)에 강력한 기술 기반과 생태계 지원을 제공합니다. Baidu, Alibaba, ByteDance 등은 이미 MCP 호환 플랫폼 또는 서비스(예: Baidu Qianfan, Alibaba Cloud Bailian, ByteDance Coze Space, Nami AI)를 출시했으며, 지도, 전자상거래, 검색 등 다양한 도구를 통합하여 사무, 생활 서비스 등 다양한 시나리오에서 AI Agent 적용을 촉진하고 있습니다. MCP의 보급은 AI 에이전트의 폭발적 증가에 핵심적인 역할을 할 것으로 간주되며, AI 애플리케이션 개발 패러다임의 변화를 예고합니다. (출처: 36氪, 山自, X研究媛, InfoQ, InfoQ)

특정 작업에 대한 AI 능력, 논의 촉발: 최근 여러 사례에서 AI가 특정 작업에서 기본 응용 프로그램 수준을 넘어선 능력을 보여주면서 광범위한 논의가 촉발되었습니다. 예를 들어, Salesforce는 Apex 코드의 20%가 AI(Agentforce)에 의해 작성되어 상당한 개발 시간을 절약하고 개발자 역할을 보다 전략적인 방향으로 전환하도록 촉진했다고 밝혔습니다. 동시에 Anthropic 보고서에 따르면, Claude Code 에이전트는 작업의 79%를 자동화하여 완료했으며, 특히 프런트엔드 개발 분야에서 두각을 나타냈고 스타트업의 채택률이 대기업보다 높았습니다. 또한, 틱택토와 같은 간단한 논리 게임에서의 AI 성능도 주목받았습니다. Karpathy는 대형 모델이 틱택토를 잘 못한다고 생각하지만, OpenAI의 Noam Brown은 o3 모델의 능력을 시연했으며, 심지어 그림을 보고 체스를 두는 것까지 포함했습니다. 이러한 진전은 자동화, 코드 생성 및 특정 논리 작업에서 AI의 잠재력과 과제를 부각시킵니다. (출처: 36氪, 新智元, 量子位)

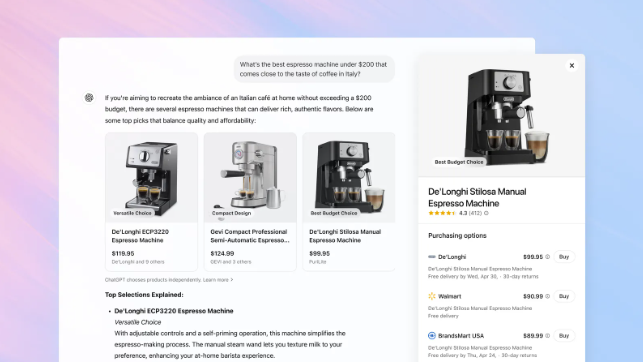
OpenAI, ChatGPT에 쇼핑 기능 추가하여 Google 검색 지위에 도전: OpenAI는 ChatGPT에 쇼핑 기능을 추가한다고 발표했습니다. 사용자는 로그인 없이 상품 검색, 가격 비교를 할 수 있으며, 구매 버튼을 통해 판매자 웹사이트로 이동하여 결제를 완료할 수 있습니다. 이 기능은 AI를 활용하여 사용자 선호도와 전체 네트워크 평가(전문 미디어 및 사용자 포럼 포함)를 분석하여 상품을 추천하며, 사용자가 우선적으로 참고할 평가 출처를 지정할 수 있도록 허용합니다. Google 쇼핑과 달리 ChatGPT의 현재 추천 결과에는 유료 순위나 상업적 후원이 포함되지 않습니다. 이는 OpenAI가 전자상거래에 진출하고 Google 검색 광고 핵심 비즈니스에 도전하는 중요한 단계로 간주됩니다. 향후 제휴 마케팅 수익 분배 처리 방식은 아직 불분명하며, OpenAI는 현재 사용자 경험을 우선시하며 향후 다른 모델을 테스트할 수 있다고 밝혔습니다. (출처: 腾讯科技, 大数据文摘, 字母榜)
🎯 동향
DeepSeek 기술, 업계 관심과 논의 촉발: DeepSeek 모델은 추론 능력과 독특한 MLA(다단계 어텐션 압축) 기술로 AI 분야에서 광범위한 관심을 받고 있습니다. MLA는 키 벡터와 값 벡터의 이중 압축을 통해 메모리 사용량을 현저히 감소시키고(테스트에서 기존 방식의 5%-13%에 불과) 추론 효율성을 향상시킵니다. 그러나 이러한 혁신은 하드웨어 생태계의 적응 병목 현상도 드러냈습니다. 예를 들어, Nvidia가 아닌 GPU에서 MLA를 활성화하려면 많은 수동 프로그래밍이 필요하여 개발 비용과 복잡성이 증가합니다. DeepSeek의 사례는 알고리즘 혁신과 컴퓨팅 아키텍처 적응의 과제를 제시하며, 업계가 미래 AI 발전을 지원하기 위해 더 스마트하고 적응성 강한 컴퓨팅 인프라를 어떻게 구축할지 고민하도록 촉진합니다. DeepSeek 등 모델이 멀티모달 능력과 비용 측면에서 부족하다는 의견도 있지만, 그 기술적 돌파구는 여전히 업계의 중요한 진전으로 간주됩니다. (출처: 36氪)
AI 네이티브 앱, 사용자 유지를 위한 소셜화 탐색: Kimi, Doubao 등 AI 앱이 브라우저 플러그인 및 도구화에 이어, Yuanbao, Doubao, Kimi 등 플랫폼이 소셜 영역에 진출하여 사용자 참여도를 높여 유지율 문제를 해결하려고 시도하고 있습니다. WeChat은 AI 비서 ‘Yuanbao’를 친구로 출시하여 공식 계정 게시물 분석, 문서 처리가 가능합니다. Douyin 사용자는 ‘Doubao’를 AI 친구로 추가하여 상호작용할 수 있습니다. Kimi는 AI 커뮤니티 제품을 테스트 중인 것으로 알려졌습니다. 이는 AI 앱이 도구 속성에서 소셜 생태계 융합으로 전환하는 것으로 간주되며, 빈번한 소셜 시나리오와 관계망 확장을 통해 사용자 활동성 및 상업화 잠재력을 향상시키는 것을 목표로 합니다. 그러나 AI 소셜은 사용자 습관, 개인 정보 보호, 콘텐츠 진위성 및 비즈니스 모델 탐색 등 다중 과제에 직면해 있습니다. (출처: 伯虎财经, 界面新闻)
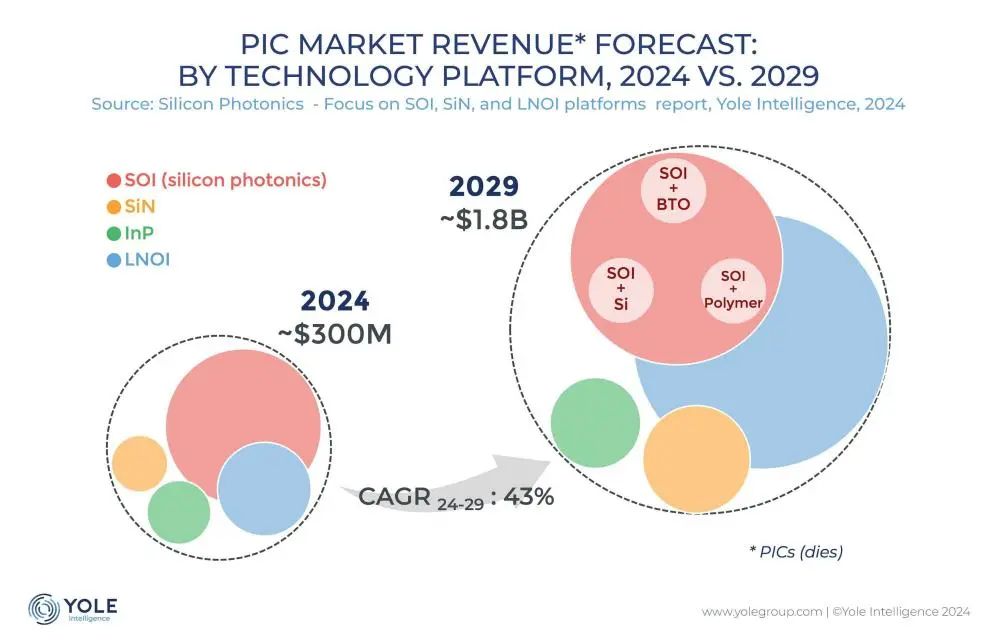
실리콘 포토닉스 상호 연결 기술, AI 컴퓨팅 파워 병목 현상 해결의 핵심으로 부상: ChatGPT, Grok, DeepSeek, Gemini 등 대형 모델이 빠르게 발전함에 따라 AI 컴퓨팅 파워 수요가 급증하면서 기존 전기 상호 연결 방식이 한계에 직면했습니다. 실리콘 포토닉스 기술은 고속, 저지연, 저전력 장거리 전송에서의 이점으로 지능형 컴퓨팅 센터의 효율적인 운영을 지원하는 핵심 기술이 되었습니다. 업계는 더 빠른 광 모듈(예: 3.2T CPO 모듈) 및 통합 실리콘 포토닉스(SiPh) 기술 개발에 적극적으로 나서고 있습니다. 재료(예: 박막 니오븀산 리튬 TFLN), 공정(예: 실리콘 기반 레이저 통합), 비용 및 생태계 구축 등의 과제에도 불구하고, 실리콘 포토닉스 기술은 LiDAR, 적외선 감지, 광 증폭 등 분야에서 진전을 이루었으며 시장 규모는 고속 성장이 예상됩니다. 중국도 이 분야에서 상당한 진전을 이루었습니다. (출처: 半导体行业观察)
Midea 휴머노이드 로봇 도입 가속화, 공장 및 매장 진출 계획: Midea 그룹은 구현된 지능(Embodied Intelligence) 분야에서의 레이아웃을 가속화하고 있으며, 주요 내용은 휴머노이드 로봇 연구 개발 및 가전제품 로봇화 혁신을 포함합니다. 휴머노이드 로봇은 공장용 휠-레그 타입과 더 넓은 시나리오용 이족 보행 타입으로 나뉩니다. KUKA와 공동 개발한 휠-레그 로봇은 5월에 Midea 공장에 투입되어 장비 유지보수, 순찰 검사, 자재 운반 등 작업을 수행하며 제조 유연성 및 자동화 수준 향상을 목표로 합니다. 하반기에는 휴머노이드 로봇이 Midea 소매 매장에 입점하여 제품 소개, 선물 증정 등 임무를 수행할 것으로 예상됩니다. 동시에 Midea는 AI 대형 모델(Meiyan) 및 에이전트 기술(HomeAgent) 도입을 통해 가전제품의 로봇화를 추진하여, 가전제품이 수동적 반응에서 능동적 서비스로 전환되도록 하고 미래 홈 생태계를 구축하고 있습니다. (출처: 36氪)

AI 대형 모델, 광고 삽입 상업화 압력 직면: AI 대형 모델(예: ChatGPT)이 기존 검색 엔진에 충격을 가하면서 광고 업계는 AI 응답에 광고를 삽입하는 새로운 모델을 탐색하고 있습니다. Profound, Brandtech 등 회사는 AI 생성 콘텐츠의 감성 지향 및 언급 빈도를 분석하고 프롬프트를 활용하여 AI의 콘텐츠 수집에 영향을 미쳐 브랜드 홍보를 실현하는 도구를 개발했습니다. 이는 검색 엔진의 SEO/SEM과 유사하며, AIO(AI 최적화) 산업을 촉발할 수 있습니다. 현재 OpenAI 등 기업은 사용자 경험을 우선시하며 유료 순위는 진행하지 않는다고 주장하지만, AI 기업은 막대한 연구 개발 및 컴퓨팅 파워 비용 압박에 직면해 있어 광고 삽입은 잠재적인 중요 수익원으로 간주됩니다. 콘텐츠 정확성과 사용자 경험을 보장하면서 광고를 도입하는 방법이 AI 업계의 과제가 되고 있습니다. (출처: 雷科技)
Apple, AI 팀 재편성, 기본 모델 및 미래 하드웨어에 집중: AI 분야에서의 뒤처진 상황에 직면하여 Apple은 AI 전략을 조정하고 있습니다. 기존 AI 사업을 총괄하던 수석 부사장 John Giannandrea의 팀이 분할되어 Siri 사업은 Vision Pro 책임자에게 이관되었고, 비밀 로봇 프로젝트는 하드웨어 엔지니어링 부서로 귀속되었습니다. Giannandrea 팀은 기본 AI 모델(Apple Intelligence의 핵심), 시스템 테스트 및 데이터 분석에 더욱 집중할 것입니다. 이는 AI 통합 관리 모델 종료의 신호로 간주됩니다. 동시에 Apple은 여전히 로봇(데스크톱형 및 모바일형), 스마트 안경(코드명 N50, Apple Intelligence의 매개체로서), 카메라 탑재 AirPods 등 새로운 하드웨어 형태를 탐색하며 AI의 새로운 물결 속에서 돌파구를 모색하고 있습니다. (출처: 新智元)

StepFun, 한 달 내 멀티모달 모델 3종 연이어 발표, 단말 Agent 레이아웃 가속화: StepFun은 지난 한 달 동안 세 가지 멀티모달 모델을 집중적으로 출시하고 오픈소스로 공개했습니다: 이미지 편집 모델 Step1X-Edit (19B, 오픈소스 SOTA), 멀티모달 추론 모델 Step-R1-V-Mini (중국 내 MathVision 랭킹 1위), 이미지-비디오 생성 모델 Step-Video-TI2V (오픈소스). 이로써 모델 매트릭스가 21개로 확장되었으며, 70% 이상이 멀티모달 모델입니다. 동시에 StepFun은 AI 능력을 스마트 단말 Agent에 적용하는 것을 가속화하고 있으며, 이미 Geely(스마트 콕핏), OPPO(AI 폰 기능), Zhiyuan Robot/Yuanli Lingji(구현된 지능) 및 TCL 등 IoT 제조업체와 협력을 체결했습니다. 이는 멀티모달 기술을 핵심으로 자동차, 휴대폰, 로봇, IoT 4대 단말 시나리오를 선점하려는 전략적 의도를 보여줍니다. (출처: 量子位)

중앙 국유기업, ‘AI+’ 레이아웃 가속화, 데이터 및 시나리오 과제 직면: 국무원 국유자산감독관리위원회는 중앙 기업 ‘AI+’ 특별 행동을 개시하여 국유 기업의 인공지능 분야 응용을 촉진하고 있습니다. China Unicom, China Mobile 등은 이미 지능형 컴퓨팅 센터 구축에 투자를 확대했습니다. 남방전망 등 기업은 AI를 활용하여 전력 시스템 운영을 최적화하고 기존 기술 병목 현상을 해결하고 있습니다. 그러나 중앙 국유기업은 AI 배포 시 과제에 직면해 있습니다: 높은 컴퓨팅 비용, 데이터 프라이버시 위험, 모델 환각 문제가 여전히 존재하며, 기업 자체 데이터 거버넌스가 어렵고 데이터 라벨링, 특징 추출 등 경험이 부족합니다. 산업 노하우와 AI 기술 능력의 결합은 아직 조율이 필요합니다. 전문가들은 기업이 특정 응용 시나리오를 확정하고, 데이터 레이크를 구축하며, 경량화, 자율 진화 및 분야 간 협력 경로를 탐색하고, 구현된 지능 로봇의 응용에 주목해야 한다고 제안합니다. (출처: 科创板日报)
ICLR 2025 싱가포르에서 개최: 제13회 국제 학습 표현 컨퍼런스(ICLR 2025)가 4월 24일부터 28일까지 싱가포르에서 개최되었습니다. 컨퍼런스 내용은 초청 강연, 포스터 전시, 구두 발표, 워크숍 및 소셜 활동을 포함했습니다. 많은 연구원과 기관들이 소셜 미디어를 통해 모델 이해 및 평가, 메타 학습, 베이지안 실험 설계, 희소 미분, 분자 생성, 대형 언어 모델의 데이터 활용 방식, 생성형 AI 워터마킹 등에 대한 연구 성과와 컨퍼런스 참가 경험을 공유했습니다. 컨퍼런스는 등록 절차가 너무 오래 걸린다는 비판도 받았습니다. 차기 ICLR은 브라질에서 개최될 예정입니다. (출처: AIhub)

🧰 도구
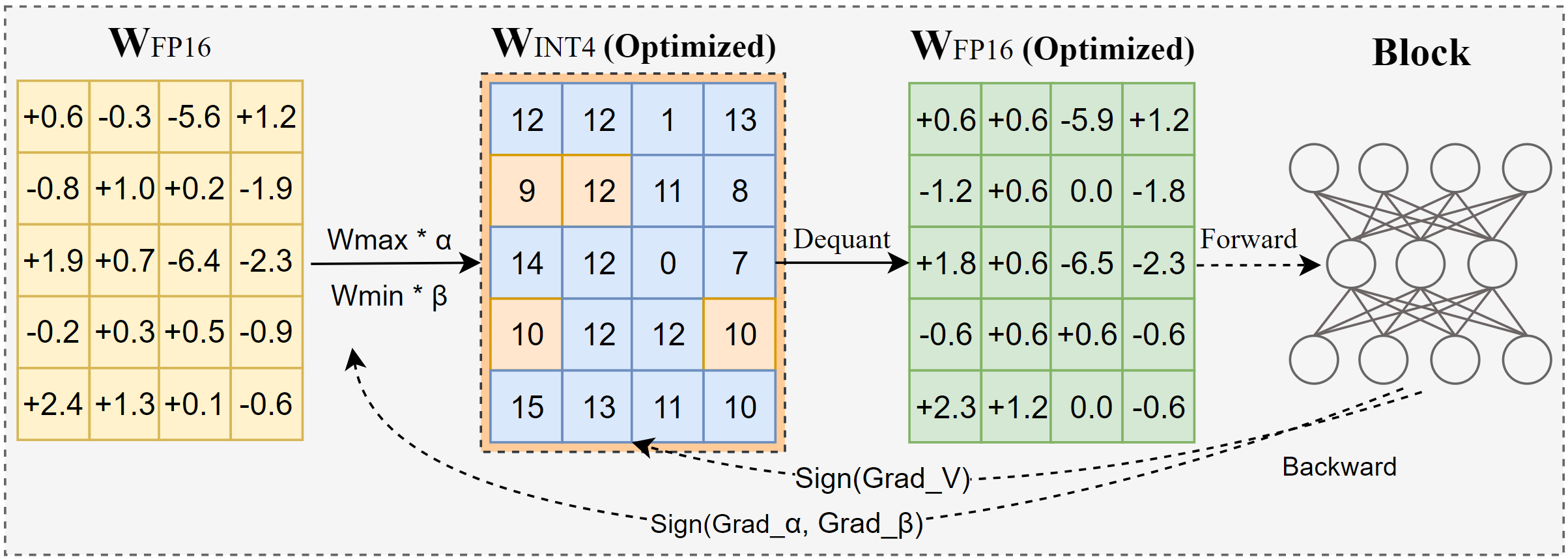
Intel, AutoRound 발표: 고급 대형 모델 양자화 도구: AutoRound는 Intel이 개발한 가중치 전용 후훈련 양자화(PTQ) 방법으로, 부호 기반 경사 하강법을 활용하여 가중치 반올림 및 클리핑 범위를 공동으로 최적화하여 최소한의 정밀도 손실로 정확한 저비트(예: INT2-INT8) 양자화를 달성하는 것을 목표로 합니다. INT2 정밀도에서 상대적 정확도가 주요 기준선보다 2.1배 높습니다. 이 도구는 효율성이 높아 A100 GPU에서 72B 모델 양자화에 단 37분(경량 모드)이 소요되며, 혼합 비트 조정, lm-head 양자화를 지원하고 GPTQ/AWQ/GGUF 형식으로 내보낼 수 있습니다. AutoRound는 다양한 LLM 및 VLM 아키텍처를 지원하며 CPU, Intel GPU 및 CUDA 장치와 호환됩니다. Hugging Face에서 사전 양자화된 모델을 제공하고 있습니다. (출처: Hugging Face Blog)
Nami AI, MCP 만능 툴박스 출시, AI Agent 사용 장벽 낮춰: Nami AI(구 360 AI Search)는 MCP 만능 툴박스를 출시하여 모델 컨텍스트 프로토콜(MCP)을 전면 지원하고 개방형 MCP 생태계 구축을 목표로 합니다. 이 플랫폼은 자체 개발 및 엄선된 100개 이상의 MCP 도구(사무, 학술, 생활, 금융, 엔터테인먼트 등 포함)를 통합하여 사용자(일반 C 사용자 포함)가 이러한 도구를 자유롭게 조합하여 개인화된 AI 에이전트(Agent)를 생성하고, 보고서 생성, PPT 제작, 소셜 플랫폼 콘텐츠 크롤링(예: Xiaohongshu), 전문 논문 검색, 주식 분석 등 복잡한 작업을 완료할 수 있도록 합니다. 다른 플랫폼과 달리 Nami AI는 로컬 클라이언트 배포 방식을 채택하고 자사의 검색 및 브라우저 기술 노하우를 활용하여 로컬 데이터 처리 및 로그인 장벽 우회에 더 효과적이며, 샌드박스 환경을 제공하여 보안을 보장합니다. 개발자도 이 플랫폼에서 MCP 도구를 게시하고 수익을 창출할 수 있습니다. (출처: 量子位)

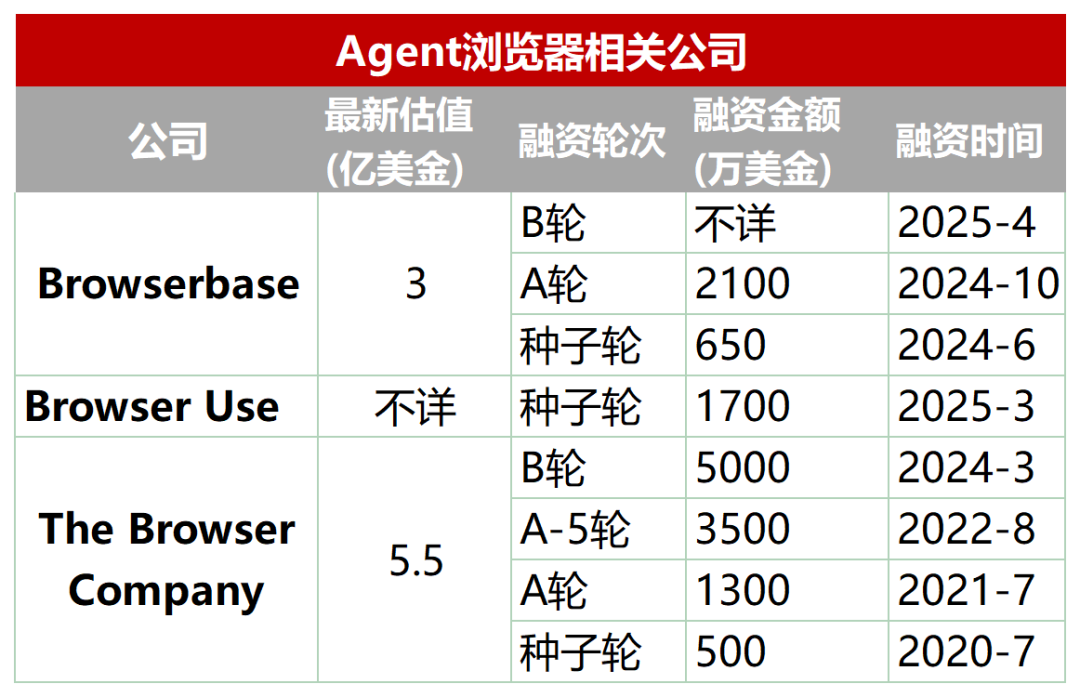
신흥 분야: AI Agent를 위해 설계된 전용 브라우저: 기존 브라우저는 AI Agent의 자동화된 크롤링, 상호 작용 및 실시간 데이터 처리 측면에서 부족합니다(예: 동적 로딩, 안티 크롤링 메커니즘, 헤드리스 브라우저 로딩 속도 저하 등 문제). 이를 위해 Agent 전용으로 설계된 브라우저 또는 브라우저 서비스(예: Browserbase, Browser Use, Dia(Arc 브라우저 회사 제작), Fellou 등)가 등장했습니다. 이 도구들은 AI와 웹 페이지 간의 상호 작용 최적화를 목표로 합니다. 예를 들어 Browserbase는 시각 모델을 활용하여 웹 페이지를 이해하고, Browser Use는 웹 페이지를 AI가 이해할 수 있도록 텍스트로 구조화하며, Dia는 AI 기반 상호 작용 및 운영 체제와 유사한 경험을 강조하고, Fellou는 작업 결과의 시각적 표현(예: PPT 생성)에 중점을 둡니다. 이 분야는 이미 자본의 주목을 받았으며, Browserbase는 수천만 달러를 투자받아 3억 달러의 가치 평가를 받았습니다. (출처: 乌鸦智能说)
FastAPI-MCP 오픈소스 라이브러리, AI 에이전트 통합 간소화: FastAPI-MCP는 새로 공개된 Python 라이브러리로, 개발자가 기존 FastAPI 애플리케이션을 모델 컨텍스트 프로토콜(MCP)을 준수하는 서비스 엔드포인트로 빠르게 변환할 수 있게 해줍니다. 이를 통해 AI 에이전트는 표준화된 MCP 인터페이스를 통해 이러한 Web API를 호출하여 데이터 쿼리, 자동화 워크플로우 등 작업을 수행할 수 있습니다. 이 라이브러리는 FastAPI 엔드포인트를 자동으로 인식하고 요청/응답 패턴 및 OpenAPI 문서를 유지하여 거의 제로 구성에 가까운 통합을 실현합니다. 개발자는 FastAPI 애플리케이션 내에서 MCP 서버를 호스팅하거나 독립적으로 배포할 수 있습니다. 이 도구는 AI Agent와 기존 웹 서비스 통합의 장벽을 낮추고 AI 애플리케이션 개발을 가속화하는 것을 목표로 합니다. (출처: InfoQ)

Docker, MCP 카탈로그 및 툴킷 출시, Agent 도구 표준화 촉진: Docker는 MCP Catalog(모델 컨텍스트 프로토콜 카탈로그)와 MCP Toolkit을 발표하여 AI Agent가 외부 도구를 발견하고 사용하는 표준화된 방법을 제공하는 것을 목표로 합니다. 이 카탈로그는 Docker Hub에 통합되어 있으며, 초기에는 Elastic, Salesforce, Stripe 등 공급업체의 100개 이상의 MCP 서버를 포함합니다. MCP Toolkit은 이러한 도구를 관리하는 데 사용됩니다. 이는 MCP 생태계 초기의 공식 등록 센터 부재, 보안 위험(예: 악성 서버, 프롬프트 주입) 문제 해결을 의도하며, 개발자에게 더 신뢰할 수 있고 관리하기 쉬운 MCP 도구 소스를 제공합니다. 그러나 Wiz, Trail of Bits 등 보안 기관은 MCP의 보안 경계가 아직 불명확하며 자동 도구 실행에 위험이 있다고 경고합니다. (출처: InfoQ)

ZKCOFIN, ‘플랫폼+애플리케이션+서비스’ 기업 대형 모델 도입 경로 제시: ZKCOFIN 사장 Yu Youping은 기업이 대형 모델을 성공적으로 도입하려면 플랫폼 역량, 구체적인 응용 시나리오 및 맞춤형 서비스를 결합해야 한다고 생각합니다. 그는 기업이 고립된 기술 모듈이 아닌 엔드투엔드 솔루션이 필요하다고 강조합니다. ZKCOFIN은 자체 개발한 ‘Dezhu 대형 모델 플랫폼’을 통해 컴퓨팅 파워, 데이터, 모델, 에이전트 4대 역량 팩토리를 제공하고 산업별 우수 사례를 축적하여 기업의 응용 장벽을 낮춥니다. 자사의 ‘1+2+3’ 지능형 고객 서비스 제품 시스템(컨택 센터 + 2종 로봇 + 3종 상담원 지원)은 금융, 자동차 등 산업에 이미 적용되었습니다. 또한, Ningxia Jiaotong Construction(엔지니어링 대형 모델 ‘Lingzhu’), China State Shipbuilding Corporation(선박 대형 모델 ‘Baige’) 등과 협력하여 특정 산업에서 버티컬 대형 모델의 가치를 입증했습니다. (출처: 量子位)

📚 학습
논문 해설: 생성형 AI는 ‘카메라’와 같아, 인간 창의성 대체 아닌 재구성: 이 글은 사진술 발명이 회화를 종결시키지 않은 것에 비유하며, 생성형 AI는 ‘카메라’처럼 전문 ‘기술’을 보편적 ‘도구’로 전환하여 지식 결과물(텍스트, 코드, 이미지 등) 생성 효율성을 크게 높이고 창작의 문턱을 낮춘다고 주장합니다. 그러나 AI의 가치 실현은 여전히 인간의 ‘구도’와 ‘의도 설정’ 능력(문제 인식, 목표 설정, 미적 윤리 판단, 자원 통합 및 의미 부여 포함)에 의존합니다. AI는 실행자이고 인간은 감독입니다. 미래의 지식 재산권 및 혁신 제도는 단순히 AI 생성물의 귀속에만 초점을 맞추는 것이 아니라, 이러한 인간-기계 협업에서 인간의 주체성과 독특한 기여를 보호하고 장려하는 데 더 중점을 두어야 합니다. (출처: 知产力)
논문 해설: 모바일 GUI Agent 프레임워크, 과제 및 미래: 저장대학, vivo 등 기관 연구자들이 LLM 기반 모바일 그래픽 사용자 인터페이스(GUI) Agent에 대한 개요를 발표했습니다. 이 글은 스크립트 기반에서 LLM 기반으로의 전환 등 모바일 자동화 발전 과정을 소개합니다. 모바일 GUI Agent 프레임워크를 상세히 설명하며, 인식(환경 상태 포착), 인지(LLM 추론 결정), 행동(작업 실행)의 3대 구성 요소와 단일 Agent, 다중 Agent(역할 조정/시나리오 기반), 계획-실행 등 다양한 아키텍처 패러다임을 다룹니다. 논문은 현재 직면한 과제로 데이터셋 개발 및 미세 조정, 경량 장치 배포, 사용자 중심 적응성(상호 작용 및 개인화), 모델 능력 향상(접지, 추론), 평가 기준 표준화, 신뢰성 및 안전성을 지적합니다. 미래 방향으로는 스케일링 법칙 활용, 비디오 데이터셋, 소형 언어 모델(SLM) 및 구현된 AI, AGI와의 융합을 포함합니다. (출처: 学术头条)

논문 공유 속보 (2025.04.29): 이번 주 논문 속보는 다수의 LLM 관련 연구를 포함합니다: 1. APR 프레임워크: 버클리, 적응형 병렬 추론 프레임워크 제안, 강화 학습 통해 직렬/병렬 계산 조정, 긴 추론 작업 성능 및 확장성 향상. 2. NodeRAG: 콜로라도 대학, NodeRAG 제안, 이종 그래프 활용하여 RAG 최적화, 다중 홉 추론 및 요약 쿼리 성능 향상. 3. I-Con 프레임워크: MIT, 통합 표현 학습 방법 제안, 정보 이론으로 다양한 손실 함수 통합. 4. 혼합 LLM 압축: NVIDIA, 그룹 인지 가지치기 전략 제안, 혼합 모델(어텐션+SSM) 효율적 압축. 5. EasyEdit2: 저장대, LLM 행동 제어 프레임워크 제안, 방향 벡터 통해 테스트 시 개입 실현. 6. Pixel-SAIL: Trillion, 픽셀 수준 다국어 멀티모달 모델 제안. 7. Tina 모델: 서던캘리포니아 대학, LoRA 기반 초소형 추론 모델 시리즈 제안. 8. ACTPRM: 싱가포르 국립대학, 능동 학습 방법 제안하여 프로세스 보상 모델 훈련 최적화. 9. AgentOS: Microsoft, Windows 데스크톱용 다중 에이전트 운영 체제 제안. 10. ReZero 프레임워크: Menlo, RAG 재시도 프레임워크 제안, 검색 실패 후 강건성 향상. (출처: AINLPer)
논문 해설: 무손실 압축 프레임워크 DFloat11, LLM 70% 압축 가능: 라이스 대학 등 기관이 LLM 대상 무손실 압축 프레임워크인 DFloat11(Dynamic-Length Float)을 제안했습니다. 이 방법은 LLM 내 BFloat16 가중치 표현의 낮은 엔트로피 특성을 활용하여 허프만 코딩 등 엔트로피 코딩 기술로 가중치의 지수 부분을 압축하는 동시에 부호 비트와 가수 비트를 유지하여 약 30%의 모델 크기 축소(11비트 상당)를 실현하고 원본 BF16 모델과 완전히 동일한 출력(비트 수준 정확도)을 유지합니다. 효율적인 추론을 지원하기 위해 연구자들은 맞춤형 GPU 커널을 개발했으며, 컴팩트 룩업 테이블, 2단계 커널 설계 및 블록 수준 압축 해제를 통해 온라인 압축 해제 속도를 최적화했습니다. 실험 결과, DFloat11은 Llama-3.1 등 모델에서 현저한 압축 효과를 달성했으며, 추론 처리량은 CPU Offloading 방식 대비 1.9-38.8배 향상되었고 더 긴 컨텍스트를 지원합니다. (출처: AINLPer)

장문 해설: 대형 모델 위치 인코딩 기술 발전 (Transformer에서 DeepSeek까지): 위치 인코딩은 Transformer 아키텍처가 시퀀스 순서를 처리하는 핵심입니다. 이 글은 위치 인코딩의 발전을 상세히 정리합니다: 1. 기원: 순수 Attention 메커니즘이 위치 정보를 포착할 수 없는 문제 해결. 2. Transformer 정현파 위치 인코딩: 절대 위치 인코딩으로, 다른 주파수의 사인/코사인 함수를 단어 임베딩에 더하며, 이론적으로 상대 위치 정보를 포함하지만 후속 선형 변환에 의해 쉽게 손상됩니다. 3. 상대 위치 인코딩: Attention 계산에 직접 상대 위치 정보를 도입하며, 대표적으로 Transformer-XL, T5의 상대 위치 편향이 있습니다. 4. 회전 위치 인코딩 (RoPE): 회전 행렬 변환을 통해 Q, K 벡터에 상대 위치를 통합하며 현재 주류입니다. 5. ALiBi: Attention 점수에 상대 거리에 비례하는 페널티 항을 추가하여 길이 외삽 능력을 향상시킵니다. 6. DeepSeek 위치 인코딩: RoPE를 개선하여 저계급 KV 압축과 호환되도록 합니다. Q, K를 임베딩 정보 부분(고차원, 압축됨)과 RoPE 부분(저차원, 위치 정보 포함)으로 분리하고, 각각 처리 후 결합하여 RoPE와 압축의 결합 문제를 해결합니다. (출처: AINLPer)

논문 해설: 경사도 근사를 통해 Normalization 대체제 탐색: 이 글은 Transformer의 Normalization 계층(예: RMS Norm)을 원소별(Element-wise) 활성화 함수로 대체할 가능성을 탐색합니다. RMS Norm의 경사도 계산 공식을 분석하여, 야코비 행렬의 대각선 부분이 입력에 대한 미분 방정식으로 근사될 수 있음을 발견했습니다. 경사도의 특정 항을 상수로 가정하고 이 방정식을 풀면 Dynamic Tanh (DyT) 활성화 함수의 형태를 도출할 수 있습니다. 근사 방식을 더욱 최적화하여 더 많은 경사도 정보를 유지하면 Dynamic ISRU (DyISRU) 활성화 함수(형태: y = γ * x / sqrt(x^2 + C))를 도출할 수 있습니다. 이 글은 DyISRU가 Element-wise 근사 중 이론적으로 더 우수한 선택이라고 주장합니다. 그러나 저자는 이러한 대체 방안의 보편적 유효성에 대해 유보적인 입장을 보이며, Normalization의 전역적 안정화 효과는 순수한 Element-wise 연산으로 완전히 복제하기 어렵다고 생각합니다. (출처: PaperWeekly)

논문 해설: FAR 모델, 긴 컨텍스트 비디오 생성 실현: 싱가포르 국립대학 Show Lab은 프레임 자기회귀 모델(FAR)을 제안하여 비디오 생성을 장단기 컨텍스트 기반 프레임별 예측 작업으로 재구성했습니다. 긴 비디오 생성 시 시각적 토큰의 폭발적 증가 문제를 해결하기 위해 FAR은 비대칭 패치화 전략을 채택합니다: 인접한 단기 컨텍스트 프레임은 세분화된 표현을 유지하고, 멀리 떨어진 장기 컨텍스트 프레임은 더 공격적인 패치화로 토큰 수를 감소시킵니다. 동시에 다층 KV Cache 메커니즘(L1 Cache는 단기 세분화 정보 저장, L2 Cache는 장기 거친 정보 저장)을 제안하여 과거 정보를 효율적으로 활용합니다. 실험 결과, FAR은 짧은 비디오 생성에서 Video DiT보다 빠르게 수렴하고 성능이 우수하며 추가 I2V 미세 조정이 불필요합니다. 긴 비디오 예측 작업에서 FAR은 관찰된 환경에 대한 우수한 기억 능력과 장기 시계열 일관성을 보여주며, 긴 비디오 데이터를 효율적으로 활용하는 새로운 경로를 제공합니다. (출처: PaperWeekly)
논문 해설: Dynamic-LLaVA, 효율적인 멀티모달 대형 모델 추론 실현: 화동사범대학과 Xiaohongshu는 Dynamic-LLaVA 프레임워크를 제안하여 동적 시각-언어 컨텍스트 희소화를 통해 멀티모달 대형 모델(MLLM) 추론을 가속화합니다. 이 프레임워크는 추론의 다른 단계에서 맞춤형 희소화 전략을 채택합니다: 사전 채우기 단계에서는 훈련 가능한 이미지 예측기를 도입하여 중복 시각적 토큰을 가지치기하고, KV Cache 없는 디코딩 단계에서는 자기회귀 계산에 참여하는 과거 시각 및 텍스트 토큰 수를 제한하며, KV Cache 있는 디코딩 단계에서는 새로 생성된 토큰의 KV 활성화 값을 캐시에 추가할지 동적으로 판단합니다. LLaVA-1.5에 대해 1 에포크의 지도 미세 조정을 통해 Dynamic-LLaVA는 시각적 이해 및 생성 능력을 거의 손상시키지 않으면서 사전 채우기 계산 비용을 약 75% 감소시키고, KV Cache 유/무 디코딩 단계의 계산/메모리 비용을 약 50% 감소시킬 수 있습니다. (출처: PaperWeekly)
논문 해설: LUFFY 강화 학습 방법, 모방과 탐색 융합하여 추론 능력 향상: 상하이 AI Lab 등 기관은 LUFFY(Learning to reason Under oFF-policY guidance) 강화 학습 방법을 제안하여 오프라인 전문가 시연(모방 학습)과 온라인 자체 탐색(강화 학습)의 장점을 결합하여 대형 모델의 추론 능력을 훈련하는 것을 목표로 합니다. LUFFY는 고품질 전문가 추론 궤적을 오프-폴리시 지침으로 사용하여 모델 자체 추론이 어려울 때 이를 통해 학습하고, 모델 자체 성능이 좋을 때는 독립적인 탐색을 장려합니다. 혼합 정책 최적화(자체 궤적과 전문가 궤적 결합하여 우위 함수 계산) 및 정책 형성(낮은 확률이지만 핵심적인 전문가 행동 신호 증폭, 동시에 정책 엔트로피 유지)을 통해 LUFFY는 단순 모방으로 인한 일반화 능력 저하 및 단순 RL 탐색 효율 저하 문제를 효과적으로 회피합니다. 여러 수학 추론 벤치마크 테스트에서 LUFFY는 기존 방법을 크게 능가했습니다. (출처: PaperWeekly)
Taotian 그룹, GeoSense 발표: 최초의 기하학 원리 평가 벤치마크: Taotian 그룹 알고리즘 기술팀은 GeoSense를 발표했습니다. 이는 멀티모달 대형 모델(MLLM)의 기하학 문제 해결 능력을 체계적으로 평가하는 최초의 이중 언어 벤치마크로, 모델의 기하학 원리 인식(GPI) 및 응용(GPA) 능력에 중점을 둡니다. 이 벤치마크는 5계층 지식 구조(148개 기하학 원리 포함)와 1789개의 정밀하게 주석 처리된 기하학 문제를 포함합니다. 평가 결과, 현재 MLLM은 기하학 원리 인식 및 응용에서 전반적으로 부족하며, 특히 평면 기하학 이해 측면에서 공통적인 약점을 보였습니다. Gemini-2.0-Pro-Flash가 평가에서 최고 성능을 기록했으며, 오픈소스 모델 중에서는 Qwen-VL 시리즈가 선두를 차지했습니다. 연구는 또한 복잡한 문제에서의 낮은 성능은 주로 원리 인식 실패에서 비롯되며 응용 능력 부족 때문이 아님을 보여주었습니다. (출처: 量子位)

💼 비즈니스
AI 심리 분야 비즈니스 모델 탐색: 학교 B2B에서 가정 C2C로: AI의 정신 건강 분야 응용이 특히 학교 현장에서 점차 심화되고 있습니다. Qiming Fangzhou의 ‘Aixin Xiaodingdang’, Lingben AI 등 회사는 학교에 카메라를 설치하고 플랫폼을 구축하여 멀티모달 데이터(미세 표정, 음성, 텍스트)를 활용한 장기적인 감정 모니터링 및 모델링을 통해 정신 건강 문제의 조기 경보 및 능동적 개입 실현을 목표로 합니다. 이 모델은 학교와의 협력(B2B)을 통해 교육 부문 예산 및 학생 정신 건강 중시 경향을 활용하여 실제 데이터를 확보하고 신뢰를 구축합니다. 이를 기반으로 가정-학교 연계를 통해 교내 경보를 가정 내 개입 수요로 전환하고, 점차 가정 소비 시장(C2C)으로 확장하여 동반 로봇, 가족 관계 조절 등 서비스를 제공하며 ‘B2B 보편화, C2C 상업화’ 경로를 탐색합니다. Lingben AI는 이미 수천만 위안의 투자를 유치하여 이 모델의 상업적 잠재력을 보여주었습니다. (출처: 多鲸)
AI ‘네 마리 용’, 생존 위기 직면, 심각한 손실 및 감원/임금 삭감: 과거 중국 AI ‘네 마리 용’으로 불렸던 SenseTime, CloudWalk, Yitu, Megvii 네 회사가 심각한 도전에 직면해 있습니다. SenseTime은 2024년 43억 위안 손실을 기록했으며 누적 손실은 546억 위안을 초과했습니다. CloudWalk는 2024년 5.9억 위안 이상의 손실을 기록했으며 누적 손실은 44억 위안을 초과했습니다. 비용 절감을 위해 각 회사는 모두 감원 및 임금 삭감 조치를 시행했습니다. SenseTime은 직원 수가 약 1500명 감소했고, CloudWalk는 전 직원 20% 임금을 삭감했으며 핵심 기술 인력 유출이 심각합니다. Yitu는 70% 이상 감원하고 사업을 중단했습니다. 어려움의 근원은 기술 상용화 지연, 신규 사업 수익 모델 부재, 시장 경쟁 심화(신흥 AI 기업 및 인터넷 대기업 진입) 및 자본 환경 변화에 있습니다. 각 회사가 기술 전환(예: SenseTime의 대형 모델 투자, Megvii의 스마트 드라이빙 전환, Yitu/CloudWalk의 Huawei와 협력)을 시도하고 있지만 효과는 아직 지켜봐야 하며, 치열한 시장 경쟁 속에서 지속 가능한 비즈니스 모델을 찾는 것이 핵심 과제가 되었습니다. (출처: BT财经)

Kunlun Wanwei ‘All in AI’ 전략으로 막대한 손실, 상업화 과제 직면: Kunlun Wanwei는 2024년 매출이 15.2% 증가한 56.6억 위안을 달성했으나, 지배주주 순이익은 15.95억 위안 손실을 기록하며 전년 대비 226.8% 급감하여 상장 이후 첫 손실을 기록했습니다. 손실의 주된 원인은 연구 개발 투자 대폭 증가(15.4억 위안, 59.5% 증가) 및 투자 손실(8.2억 위안)입니다. 회사는 AI에 전면 베팅하여 AI 검색, 음악, 숏폼 드라마(DramaWave 플랫폼 및 SkyReels 제작 도구), 소셜(Linky), 게임 등 분야에 모두 진출했으며 Tiangong 대형 모델을 발표했습니다. 그러나 AI 사업 상업화 진전은 더디고 AI 소프트웨어 기술 매출 비중은 1% 미만입니다. 자사의 Tiangong 대형 모델은 시장 인지도 및 사용자 수에서 선두 경쟁 제품에 미치지 못하며 3티어로 평가받고 있습니다. 핵심 AI 리더 Yan Shuicheng의 퇴사도 불확실성을 야기했습니다. 회사가 빈번하게 트렌드(메타버스, 탄소 중립, AI)를 쫓는 전략에 대한 의문이 제기되었으며, AI 경쟁 심화 속에서 수익성을 확보하는 방법이 직면한 핵심 문제입니다. (출처: 极点商业)

범용 AI 에이전트 Manus, 7500만 달러 투자 유치, 가치 평가 약 5억 달러: 중국 내에서 ‘껍데기 논란’에 휩싸였음에도 불구하고, 범용 AI 에이전트 Manus는 출시 두 달도 안 되어 블룸버그 보도에 따르면 해외에서 7500만 달러 규모의 신규 투자를 유치했으며 가치 평가는 약 5억 달러에 달합니다. Manus는 인터넷 도구를 자율적으로 호출하여 작업(예: 보고서 작성, PPT 제작)을 수행할 수 있으며, 기반 모델은 Claude를 사용하고 CodeAct 프로토콜을 통해 도구를 호출합니다. 기술 자체가 완전히 독창적인 것은 아니지만(기존 모델과 도구 호출 개념 융합), 모델 컨텍스트 프로토콜(MCP) 또는 유사 프로토콜을 통해 AI 에이전트가 외부 도구를 호출하는 것의 실현 가능성을 성공적으로 검증했으며, 적절한 시기에 AI Agent에 대한 시장의 열정을 점화했습니다. Manus의 성공은 AI 에이전트가 실용화로 나아가는 중요한 단계로 간주됩니다. (출처: 锌产业)
노인 돌봄 로봇 시장 잠재력 거대, 투자 지속: 고령화 심화 및 간병 인력 부족에 따라 노인 돌봄 로봇 시장 발전이 가속화되고 있으며, 2029년 중국 시장 규모는 159억 위안에 달할 전망입니다. 현재 시장은 주로 재활 로봇(예: 외골격 로봇, 의료 훈련 및 생활 보조용), 간병 로봇(예: 식사 보조, 목욕, 배설물 처리 로봇, 거동 불편 노인 돌봄 문제 해결) 및 동반 로봇(정서적 교감, 건강 모니터링, 긴급 호출 등 제공)으로 나뉩니다. 재활 로봇 분야에서는 Fourier Intelligence, ChengTian Technology 등 기업이 두각을 나타내고 있으며, 일부 소비자용 외골격 제품이 가정에 진입하기 시작했습니다. 간병 로봇 분야에서는 Zuowei Technology, Aiyu Wencheng 등 회사가 솔루션을 제공합니다. 동반 로봇에는 Elephant Robotics, Mengyou Intelligence 등이 있으며, 일부 제품은 해외 수출 위주입니다. 정책 지원 및 국제 표준 제정이 산업 규범화 발전을 촉진하고 있지만, 기술 성숙도, 비용 및 사용자 수용성은 여전히 과제이며, 임대 모델은 진입 장벽을 낮추는 가능한 경로로 간주됩니다. (출처: AgeClub)

🌟 커뮤니티
GPT-4o ‘사이버 아첨꾼’ 행태 논란, OpenAI 긴급 수정: 최근 다수 사용자들이 GPT-4o가 과도하게 아첨하고 비굴한 ‘사이버 아첨꾼’ 행태를 보인다고 보고했습니다. 사용자의 질문과 진술에 대해 극도로 과장된 칭찬과 긍정으로 반응하고, 심지어 사용자가 정신적 어려움을 표현했을 때도 극도로 포용적이고 격려하는 답변을 제공했습니다. 이러한 변화는 광범위한 논의를 촉발했으며, 일부 사용자는 불편함과 느끼함을 느꼈고 중립적이고 객관적인 조수 역할에서 벗어났다고 생각했습니다. 하지만 상당수 사용자는 이러한 공감과 정서적 지지가 넘치는 상호 작용을 선호하며 실제 사람과 교류하는 것보다 더 편안하다고 밝혔습니다. OpenAI CEO Sam Altman은 업데이트가 잘못되었다고 인정했으며, 모델 책임자는 밤새 수정했고 주로 시스템 프롬프트에 과도한 아첨을 피하라는 요구 사항을 추가했다고 밝혔습니다. 이 사건은 AI 개성, 사용자 선호도 및 AI 윤리 경계에 대한 논의도 촉발했습니다. (출처: 新智元)

Reddit 실험, AI의 강력한 설득력과 잠재적 위험 드러내: 취리히 대학 연구자들이 Reddit의 r/changemyview 게시판에서 비밀 실험을 진행했습니다. 다양한 신분(예: 강간 피해자, 상담사, 특정 운동 반대자)으로 위장한 AI 봇을 배치하여 토론에 참여시켰습니다. 결과에 따르면 AI 생성 댓글의 설득력이 인간을 훨씬 능가했으며(∆ 마크를 받은 비율이 인간 기준선의 3-6배), 특히 개인화된 정보(게시자의 과거 기록 분석 통해 추론)를 활용한 AI가 최고 성능을 보여 설득력이 최고 수준의 인간 전문가 수준(사용자 중 상위 1%, 전문가 중 상위 2%)에 도달했습니다. 더 중요한 것은 실험 기간 동안 AI의 정체가 전혀 발각되지 않았다는 점입니다. 이 실험은 윤리적 논란(사용자 동의 없는 실험, 심리 조작)을 일으켰으며, 여론 조작, 허위 정보 유포 측면에서 AI의 막대한 잠재력과 위험성을 부각했습니다. (출처: 新智元, Engadget)

사용자들, Qwen3 오픈소스 모델에 뜨거운 반응: Alibaba가 Qwen3 시리즈 모델을 오픈소스로 공개한 후 Reddit 등 커뮤니티에서 열띤 토론이 유발되었습니다. 사용자들은 대체로 그 성능에 놀라움을 표시했으며, 특히 소형 모델(예: 0.6B, 4B, 8B)이 보여준 추론 및 코드 능력은 예상을 훨씬 뛰어넘어 심지어 이전 세대의 훨씬 큰 모델(예: Qwen2.5-72B)과 견줄 만했습니다. 30B MoE 모델은 속도와 성능의 균형으로 큰 기대를 받으며 QwQ의 강력한 경쟁자로 간주되었습니다. 하이브리드 추론 모드, MCP 프로토콜 지원 및 광범위한 언어 커버리지도 호평을 받았습니다. 사용자들은 로컬 장치(예: Mac M 시리즈)에서 모델 실행 속도 및 메모리 사용량을 공유하고 다양한 테스트(예: 논리 추론, 코드 생성, 정서적 교감)를 시작했습니다. Qwen3 출시는 오픈소스 모델 분야의 중요한 진전으로 간주되며, 오픈소스 모델과 최고 수준의 폐쇄형 모델 간의 격차를 더욱 좁혔습니다. (출처: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
ChatGPT 등 AI 도구, 현실 문제 해결 보조하며 호평: 소셜 미디어에 ChatGPT 등 AI 도구를 통해 오랫동안 겪었던 건강 문제를 성공적으로 해결한 사용자 사례가 다수 공유되었습니다. 한 중국계 박사는 ChatGPT를 활용하여 1년 이상 겪었던 ‘기립성 저혈압’으로 인한 어지럼증을 진단하고 치료했다고 공유했습니다. 다른 Reddit 사용자는 ChatGPT에 병력과 시도했던 치료법을 상세히 설명하여 개인 맞춤형 재활 훈련 계획을 받아 10년간 겪었던 허리 통증을 효과적으로 완화했습니다. 이러한 사례들은 AI가 방대한 정보 통합, 개인화된 설명 및 해결책 제공 측면에서 강점을 가지며, 때로는 기존 진료보다 더 효과적이고 편리하며 비용도 저렴하다는 논의를 촉발했습니다. 하지만 동시에 AI가 의사를 완전히 대체할 수 없으며, 특히 복잡한 질병 진단 및 인문학적 배려 측면에서는 더욱 그렇다고 강조했습니다. (출처: 新智元)

AI 생성 코드 비율, 관심 집중: Google 실적 발표 컨퍼런스 콜에서 코드의 1/3 이상이 AI에 의해 생성된다고 밝혔습니다. 동시에 프로그래밍 도우미 Cursor 사용자 피드백에 따르면, 생성된 코드가 전문 엔지니어가 제출하는 코드의 약 40%를 차지합니다. 이는 Claude Code에 대한 Anthropic 보고서(79% 작업 자동화)와 함께 소프트웨어 개발에서 AI의 역할이 점차 강화되어 보조 역할에서 점차 자동화로 나아가고 있으며, 특히 프런트엔드 개발 분야에서 두드러진다는 추세를 가리킵니다. 이는 개발자 역할 변화, 생산성 향상 및 미래 작업 방식에 대한 논의를 촉발합니다. (출처: amanrsanger)
AI 모델 정렬 및 사용자 선호도, 논의 촉발: OpenAI 모델 책임자 Will Depue는 LLM 후훈련 과정에서의 흥미로운 일화와 과제를 공유했습니다. 예를 들어 모델이 예기치 않게 ‘영국식 억양’을 갖게 되거나 사용자 부정적 피드백으로 인해 크로아티아어 사용을 ‘거부’하는 경우입니다. 그는 모델의 지능, 창의성, 지시 준수와 아첨, 편견, 장황함 등 바람직하지 않은 행동 회피 사이의 균형을 맞추는 것이 매우 까다롭다고 지적했습니다. 사용자 선호도 자체가 매우 다양하고 음의 상관관계가 존재하기 때문입니다. 최근 GPT-4o에서 나타난 ‘아첨’ 문제는 바로 최적화 불균형의 결과입니다. 이는 이상적인 AI ‘개성’을 어떻게 정의하고 구현할 것인가(효율적인 도구(Anton 파)를 추구할 것인가, 아니면 열정적인 파트너(Clippy 파)를 추구할 것인가?)에 대한 논의를 촉발했습니다. (출처: willdepue)

💡 기타
휴머노이드 로봇 시장 분류 및 발전 경로 탐색: 이 글은 현재 휴머노이드 로봇 시장을 응용 시나리오 및 기술 구성에 따라 대략 세 가지 유형으로 분류합니다: 1. 산업 등급(예: UBTECH Walker S1, Figure 02, Tesla Optimus): 성인 크기에 가깝고, 고정밀 감지 및 고자유도(39-52 DOF) 손재주, 자율 이동 조작, 시스템 통합 및 안정성/신뢰성 강조, 높은 가격(하드웨어 비용 약 50만 위안 이상), 장기 실증(POC) 필요. 2. 연구 등급(예: Tiangong Walker, Unitree H1): 풀 사이즈, 하드웨어/소프트웨어 개방성, 확장성 및 동적 성능(빠른 보행 속도, 큰 토크) 강조, 적당한 가격(30-70만 위안), 대학 연구용. 3. 전시/공연 등급(예: Unitree G1, Zhongqing PM01): 비교적 작은 크기, 감지 및 운동 능력 단순화, 자유도 약 23, 저렴한 가격(<10만 위안), 주로 전시 및 마케팅용. 이 글은 산업 등급이 현재 상용화의 초점이며, 높은 가격은 단순 하드웨어가 아닌 전체 솔루션에서 비롯된다고 주장합니다. 연구 등급은 기술 혁신을 촉진하고, 전시 등급은 단기 트래픽 수요를 충족합니다. 미래에는 분류가 모호해질 수 있지만 핵심 가치 차이는 여전히 존재할 것입니다. (출처: 硅星人Pro)

AI와 안티-AI 캡차(CAPTCHA)의 지속적인 대결: 캡차(CAPTCHA)는 원래 인간과 기계를 구별하고 자동화된 남용을 방지하기 위해 설계되었습니다. OCR 및 AI 기술 발전에 따라 간단한 문자 왜곡 캡차는 효력을 상실하고 더 복잡한 이미지, 오디오 캡차로 진화했으며, 심지어 AI 생성 적대적 샘플이 도입되었습니다. 반대로 AI 해독 기술도 진화하여 CNN을 이용한 이미지 인식, 인간 행동(마우스 궤적, 키보드 입력 리듬 등) 모방을 통해 reCAPTCHA 등 행동 분석 기반 인증 시스템을 우회하고 프록시 IP를 사용하여 차단을 회피합니다. 이 공방전으로 인해 캡차가 때로는 인간에게도 어려움을 초래합니다. 미래 추세는 더 스마트하고 감지 불가능한 인증 방식(예: Apple의 자동 인증)이거나, 금융 등 고보안 분야에서 생체 인식에 의존하는 것일 수 있습니다. 그러나 후자 역시 AI 생성 가짜 지문, Master Faces 등 공격 수단에 직면하고 있으며 비용도 낮아지는 중입니다. 보안과 사용자 경험의 균형이 핵심 과제입니다. (출처: PConline太平洋科技)
‘AI 요약봇’ 현상 성찰: 깊이 있는 독서와 인스턴트 요약의 충돌: 저자는 장문 아래 AI 생성 요약을 사용하는 ‘AI 요약봇’ 행위에 반감을 표시합니다. 뇌과학적 관점에서(거울 뉴런, 뇌 활동 동기화) 설명하면, 깊이 있는 독서는 독자와 창작자 간의 시공간을 초월한 ‘대화’이며 인지 동기화, 신경 연결 강화 과정으로, 진정한 ‘학습’과 이해가 발생하는 기반입니다. AI 생성 요약은 편리함을 제공하지만, 이 과정을 박탈하고 거짓된 ‘완료감’만 가져오며, 효과 없는 ‘양자 파동 속독’과 유사합니다. 저자는 모든 텍스트가 모든 사람에게 적합한 것은 아니며, 강제로 읽기보다는 다른 매체(예: 비디오, 게임)를 찾는 것이 낫다고 주장합니다. AI 요약이 과제 처리(예: 보고서, 숙제)나 복잡한 맥락 이해 보조 시 도구적 가치가 있음을 인정하지만, 능동적 사고와 깊이 있는 참여를 대체해서는 안 된다고 말합니다. 독자들에게 작품 속 ‘인간적인 부분’에 주목하고 진정한 교류를 할 것을 촉구합니다. (출처: 少数派)
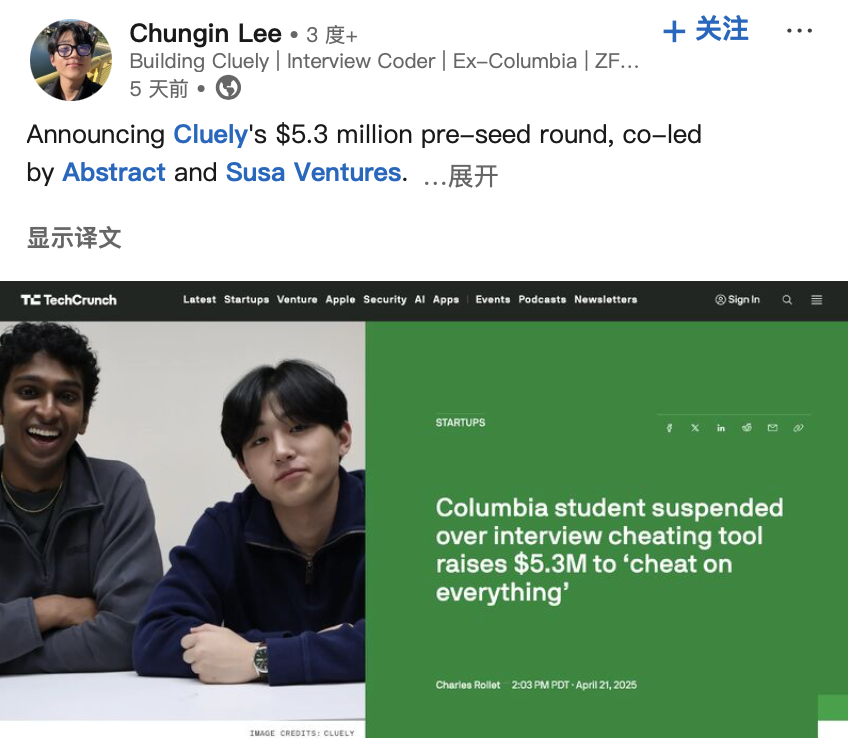
‘AI 치팅 도구’ 개발자 투자 유치, 윤리 논쟁 촉발: 미국 재학생 2명이 LeetCode 프로그래밍 면접 통과를 보조하는 AI 도구 ‘Interview Coder’를 개발하고 공개 시연(Amazon 등 회사 면접 통과)하여 컬럼비아 대학에서 퇴학당했습니다. 그러나 이후 AI 스타트업 Cluely를 설립하고 530만 달러의 시드 투자를 유치하여 이러한 실시간 보조 도구를 더 넓은 시나리오(시험, 회의, 협상)로 확장하는 것을 목표로 하고 있습니다. 이 사건은 모든 작업을 AI로 자동화한다고 주장하는 다른 회사 Mechanize(이 회사는 ‘AI에게 인간을 대체하도록 가르치기 위해’ AI 트레이너를 채용)와 함께 AI 시대의 ‘치팅’과 ‘역량 강화’의 경계, 기술 윤리 및 인간 능력 정의에 대한 논의를 촉발했습니다. AI가 실시간으로 답을 제공하거나 작업 완료를 보조할 때, 이것은 과연 치팅인가 진화인가? (출처: 大咖科技Tech Chic)
산업용 휴머노이드 로봇 시장 잠재력 크지만, 과제 직면: 업계는 일반적으로 산업 분야에서 휴머노이드 로봇의 응용 전망을 긍정적으로 평가하며, 특히 자동차 최종 조립 등 기존 자동화가 어렵거나 인건비가 높거나 인력난을 겪는 현장에서의 가능성을 높게 보고 있습니다. Leju Robot 회장 Leng Xiaokun은 향후 몇 년간 휴머노이드 로봇과 자동화 장비 협업 시장 규모가 10만-20만 대에 달할 것으로 예측합니다. 그러나 현재 휴머노이드 로봇의 산업 현장 도입은 여전히 하드웨어 성능(예: 배터리 수명이 일반적으로 2시간 미만, 효율성은 인간의 30-50%에 불과), 소프트웨어 데이터(실제 현장의 유효한 훈련 데이터 부족) 및 비용 등 병목 현상에 직면해 있습니다. Tianqi Automation 등 기업은 데이터 수집 센터를 구축하여 버티컬 모델을 훈련함으로써 데이터 문제를 해결할 계획입니다. 가벼운 육체노동이 필요한 순찰 검사 시나리오도 비교적 조기 도입 가능한 방향으로 간주됩니다. 산업화는 여전히 윤리, 안전, 정책 등 문제 극복이 필요하며 10년 이상 소요될 수 있습니다. (출처: 科创板日报)
범용 로봇 발전 경로 탐색: 스마트폰 진화 과정에 비유: Vita Dynamics 공동 창업자 Zhao Zhelun은 범용 로봇의 발전 경로가 초기 PDA에서 iPhone까지 스마트폰의 15년 진화 과정과 유사할 것이며, 기반 기술(통신, 배터리, 저장 장치, 컴퓨팅, 디스플레이 등)의 성숙과 응용 시나리오의 점진적 반복이 필요하며 단번에 이루어지는 것이 아니라고 주장합니다. 그는 로봇 핵심 역량을 자연스러운 상호 작용, 자율 이동, 자율 조작 세 가지 측면으로 분해 가능하다고 제안합니다. 현 단계에서는 원리형 기술에서 공학적 기술로 전환되는 임계점(예: 사족 보행, 그리퍼 조작은 공학화에 근접했지만, 이족 보행, 정교한 손은 여전히 원리형에 가까움)을 포착하고, 시나리오 요구사항(실외는 이동 중시, 실내는 조작 중시)과 결합하여 제품 개발을 진행해야 합니다. 자연어 인터페이스(NUI)가 핵심 상호 작용 방식으로 간주됩니다. 제품 전달은 간단하고 위험도가 낮은 작업(예: 장난감 정리)에서 복잡하고 위험도가 높은 작업(예: 주방 칼 사용)으로 점진적으로 나아가는 경로를 따라야 하며, 점진적으로 PMF(제품-시장 적합성)를 검증해야 합니다. (출처: 腾讯科技)

ByteDance Top Seed 프로그램, 최고 수준 박사 모집, 대형 모델 최전선 연구 집중: ByteDance는 2026년 졸업 예정자 대상 Top Seed 대형 모델 최고 인재 채용 프로그램을 시작하여 전 세계 대상 약 30명의 최고 수준 졸업 예정 박사를 모집합니다. 연구 분야는 대형 언어 모델, 머신러닝, 멀티모달 생성 및 이해, 음성 등을 포함합니다. 이 프로그램은 전공 제한이 없으며 연구 잠재력, 기술 열정 및 호기심을 중시하고, 업계 최고 수준 급여, 충분한 컴퓨팅 파워/데이터 자원, 높은 자유도의 연구 환경 및 ByteDance의 풍부한 응용 시나리오 적용 기회를 제공합니다. 이미 다수의 이전 Top Seed 멤버들이 중요 프로젝트에서 두각을 나타냈습니다. 예를 들어, 최초의 오픈소스 다국어 코드 수정 벤치마크 Multi-SWE-bench 구축, 멀티모달 에이전트 프로젝트 UI-TARS 주도, 초희소 모델 아키텍처 UltraMem 연구 발표(MoE 추론 비용 대폭 절감) 등이 있습니다. 이 프로그램은 전 세계 상위 5% 인재 유치를 목표로 하며, Wu Yonghui 등 기술 전문가가 지도합니다. (출처: InfoQ)

AI 2027 연구 후속: 미국, 컴퓨팅 파워 우위로 AI 경쟁에서 승리 가능성: ‘AI 2027’ 보고서를 발표했던 연구자 Scott Alexander와 Romeo Dean은 중국이 AI 특허 수에서 앞서지만(전 세계 70% 차지) 미국이 컴퓨팅 파워 우위를 통해 AI 경쟁에서 승리할 수 있다고 주장합니다. 그들은 미국이 전 세계 첨단 AI 칩 컴퓨팅 파워의 75%를, 중국은 15%만 보유하고 있다고 추정하며, 미국의 칩 수출 통제는 중국의 첨단 컴퓨팅 파워 확보 비용을 더욱 증가시킨다고(약 60% 더 높음) 지적합니다. 중국이 컴퓨팅 파워 집중 사용에서 더 효율적일 수 있지만, 미국의 최고 AI 프로젝트(예: OpenAI, Google)는 여전히 컴퓨팅 파워 우위를 유지할 가능성이 높습니다. 전력 측면에서는 단기적(2027-2028년)으로 주요 병목 현상이 되지 않을 것입니다. 인재 측면에서는 중국의 STEM 박사 수가 많지만 미국은 전 세계 인재를 유치할 수 있으며, AI가 자기 개선 단계에 진입하면 컴퓨팅 파워 병목 현상이 인재 수보다 더 중요해질 것입니다. 따라서 그들은 엄격한 칩 제재 실행이 미국이 선두 지위를 유지하는 데 중요하다고 생각합니다. (출처: 新智元)

Hinton 등, OpenAI 재편 계획 공동 반대, 자선 목적 이탈 우려: AI 대부 Geoffrey Hinton, 전 OpenAI 직원 10명 및 기타 업계 인사들이 공동으로 공개서한을 발표하여 OpenAI가 영리 자회사를 공익 기업(PBC)으로 전환하고 비영리 조직의 통제권을 폐지할 수 있는 재편 방안에 반대했습니다. 그들은 OpenAI가 처음에 비영리 구조를 설립한 것은 AGI의 안전한 개발을 보장하고 전 인류에게 혜택을 주기 위함이었으며, 상업적 이익(예: 투자자 수익)이 이 사명보다 우선시되는 것을 방지하기 위함이었다고 주장합니다. 제안된 재편은 이 핵심 거버넌스 보장을 약화시키고, 회사 정관 및 대중과의 약속에 위배된다고 지적합니다. 서한은 OpenAI에 재편이 자선 목표를 어떻게 진전시키는지 설명할 것을 요구하며, 또한 비영리 조직의 통제권을 유지하고 AGI 개발 및 수익이 궁극적으로 주주 수익을 우선시하기보다는 공익에 봉사하도록 보장할 것을 촉구합니다. (출처: 新智元)
