키워드:휴머노이드 로봇, AI 응용, AGI, 자율주행, 휴머노이드 로봇 마라톤, 에이전트+MCP, 딥마인드 AGI 예측, 테슬라 순수 비전 FSD, GPT-SoVITS 음성 복제, ChemAgent 화학 추론, 지원 로봇 비즈니스 모델, 엔비디아 GPU 독점 도전
🔥 포커스
베이징 하프 마라톤에서 ‘첫선’ 보인 휴머노이드 로봇, 기회와 도전 공존: 2025 베이징 이좡 하프 마라톤에서 21개 휴머노이드 로봇 팀이 처음으로 인간 선수와 함께 경쟁했습니다. 天工 Ultra, 松延动力 N2, 卓益得 行者 2호가 각각 1, 2, 3위를 차지했습니다. 이번 경기는 휴머노이드 로봇의 잠재력을 보여주었지만, 넘어짐, 배터리 수명, 제어(대부분 원격 조종) 등 많은 과제도 드러냈습니다. 경기 후 宇树科技는 자사의 G1 로봇 넘어짐 사건에 대해 사용자의 자체 개발 및 조작이 로봇 성능에 큰 영향을 미친다고 해명했습니다. 이번 대회는 중국 휴머노이드 로봇 산업의 초기 규모를 보여줬을 뿐만 아니라, 기술 성숙도, 비용(松延 N2 예약 판매가 3.99만 위안부터), 상업화 경로(임대, 산업 응용) 및 미래 발전(AI 대형 모델, 자율 학습)에 대한 광범위한 논의를 촉발했습니다. 업계는 자본의 주목을 받고 있지만 단기적인 수익 창출은 어렵고 시장화 정착까지는 시간이 걸릴 것으로 보입니다 (출처: 넘어진 宇树와 휴머노이드 로봇의 ‘생존’ 게임, 공장 진출부터 마라톤까지: 휴머노이드 로봇은 ‘실용’까지 얼마나 남았나?)
AI 응용의 새로운 패러다임: Agent+MCP, 2025년 히트 공식으로 부상: Agent의 자율 계획 및 행동 능력과 MCP 프로토콜의 외부 도구 및 데이터 호출 능력을 결합하는 것이 AI 응용의 새로운 트렌드가 되고 있습니다. ‘扣子空间’, Fellou, Dia, GenSpark, 智谱 AutoGLM 등 제품이 잇달아 등장하며 주목받고 있습니다. 이들 제품은 대부분 AI 검색에서 전환된 것으로, 다양한 제품 디자인(사용 편의성, 연구 능력, 실행력)을 통해 사용자 경험 장벽을 구축하려고 시도합니다. 잠재력은 크지만 현재 모델 능력의 한계, 플랫폼 간 정보 획득, 상업화 모델 등의 과제에 직면해 있습니다. Microsoft도 데스크톱용 다중 Agent 시스템 UFO²를 출시하며 AM(Agent+MCP)이 AI 제품의 중요한 방향이 될 것임을 예고했습니다 (출처: 2025년, AI 응용의 히트 공식은 단 하나)
AI 미래 격론: Hassabis는 10년 내 모든 질병 치료 예언, 하버드 역사학자는 AGI 인류 멸종 경고: Google DeepMind CEO Demis Hassabis는 인터뷰에서 AI가 5~10년 내에 AGI를 실현하고 10년 안에 모든 질병을 치료할 수 있을 것으로 예측하며 Project Astra 등 AI 진전을 선보였습니다. 그는 AI가 과학적 발견을 가속하는 궁극적인 도구가 될 것이라고 믿습니다. 그러나 하버드 역사학자 Niall Ferguson은 AGI의 도래가 인류를 마차처럼 도태시키거나 심지어 멸종시켜 인류가 스스로 창조한 ‘외계인’이 될 수 있다고 경고했습니다. 그는 제도적 경직성과 전 세계 출산율 하락 등의 추세가 인류가 AGI 앞에서 ‘역사의 무대에서 퇴장’하도록 만들 수 있다고 지적했습니다. 이 논의는 AGI 잠재력에 대한 극단적인 낙관론과 인류 문명의 미래에 대한 깊은 우려 사이의 큰 대조를 부각합니다 (출처: 노벨상 수상자 Hassabis 호언: AI 10년 내 모든 질병 치료, 하버드 교수 AGI 인류 문명 종결 경고, 하버드 역사학자 경고: AGI 인류 멸종, 미국 해체 가능성)
🎯 동향
로봇 산업 진전 빈번, 상업화 정착 가속: 광저우 교역회에 처음으로 서비스 로봇 전문 구역이 설치되었으며, 穿山甲 로봇, 鸿绪锦科技 등 중국 업체들이 대량의 해외 주문을 확보하여 글로벌 시장에서 중국 서비스 로봇의 경쟁력을 보여주었습니다. 동시에 美的 등 기업의 휴머노이드 로봇은 반복적인 개선을 거쳐 공장 ‘취업’을 계획하고 있습니다. 산업 체인에서는 PCB, 센서, 신소재(예: PEEK) 등 분야에 투자가 이루어지고 있지만, 대규모 양산까지는 시간이 필요하며 기술, 비용, 응용 시나리오의 선순환 구조 구축이 핵심입니다. 여러 제조업체가 2025년에 천 대 규모의 양산을 계획하고 있으며, 이는 산업 체인 발전과 데이터 축적을 촉진하여 로봇이 더욱 실용적인 단계로 나아가는 것을 가속할 것으로 기대됩니다 (출처: 로봇 그룹 ‘영업’으로 화제 집중, 산업 체인 진전 잇따라)

Tesla, 순수 비전 FSD 고수, 라이다 노선은 도전과 기회 직면: 머스크는 FSD 실현에 대한 순수 비전 솔루션의 자신감을 재차 강조하며, 카메라와 AI만으로 인간의 운전을 모방할 수 있어 라이다가 필요 없다고 주장했습니다. 비용 하락(중국산 라이다는 이미 수백 달러로 하락)과 시장 보급(이미 10만 위안대 차량에 탑재)이라는 현실에도 불구하고 Tesla는 이 노선을 고수하고 있으며, 이는 연산 능력, 알고리즘, 데이터에 매우 높은 요구 사항을 제기합니다. 동시에 禾赛, 速腾聚创 등 라이다 제조업체는 비용 우위와 기술 반복을 통해 시장 주도권을 확보하고 해외 시장 및 로봇 등 비차량 사업을 적극적으로 확장하고 있습니다. L3 수준 자율 주행의 도래는 라이다에 새로운 기회를 가져올 수 있는데, 이는 안전 중복성과 특정 시나리오에서의 감지 능력 때문에 필수 불가결하다고 여겨지기 때문입니다 (출처: 머스크의 최신 AI 주행 솔루션, 라이다를 종결시킬까?)

Google Imagen 3/4, 내부 테스트 중일 가능성: Google이 차세대 이미지 생성 모델인 Imagen 3과 Imagen 4를 내부적으로 테스트하고 있다는 소문이 돌고 있습니다. 이는 Google이 이미지 생성 분야에서 경쟁사를 따라잡거나 능가하기 위한 새로운 큰 움직임을 보일 수 있음을 시사합니다 (출처: Google, 또 이미지 대작 준비 중? Imagen 3/4 내부 테스트 소문.)
THUDM, SWE-Dev 시리즈 코딩 모델 발표: 칭화대학교 지식 공학 및 데이터 마이닝 연구 그룹(THUDM)은 Qwen-2.5 및 GLM-4 기반의 SWE-Dev 시리즈 코딩 대형 모델(7B, 9B, 32B 버전 포함)을 발표했습니다. 이는 소프트웨어 개발 및 코딩 작업의 AI 능력을 향상시키는 것을 목표로 합니다 (출처: Reddit r/LocalLLaMA)

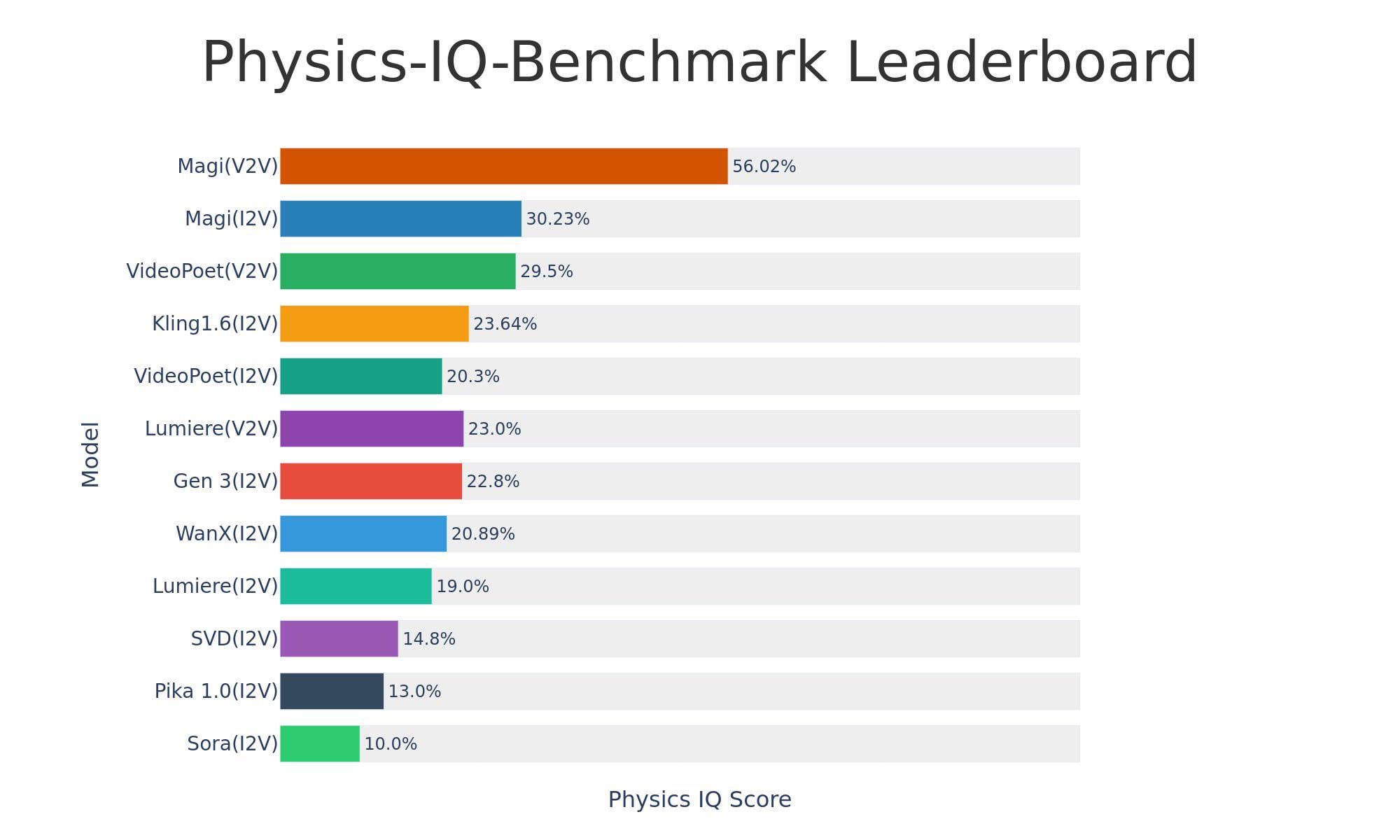
Sand-AI, 오픈소스 비디오 생성 모델 Magi-1 발표: Sand-AI는 오픈소스 자가회귀 확산 비디오 생성 모델인 Magi-1을 발표했습니다. 무한 길이의 비디오를 생성할 수 있다고 주장하며, 텍스트-비디오, 이미지-비디오, 비디오-비디오 생성을 지원합니다. 이 모델은 물리적 이해 벤치마크 테스트에서 우수한 성능을 보였지만, 실행에는 매우 높은 VRAM(약 640GB)이 필요합니다. 코드와 모델은 GitHub와 Hugging Face에 공개되었습니다 (출처: Reddit r/LocalLLaMA)
Grok, 시각, 다국어 오디오 및 실시간 검색 기능 추가: xAI는 Grok 모델에 시각 이해 능력을 추가하고, 음성 모드에서 다국어 오디오 입력과 실시간 검색 기능을 지원한다고 발표했습니다. 이는 다중 모드 상호 작용 및 정보 획득 능력을 향상시킵니다 (출처: grok, xai)
Grok 3 모델, You.com에 출시: xAI의 플래그십 모델인 Grok 3가 검색 엔진 You.com에 출시되었습니다. 사용자는 해당 플랫폼에서 Grok 3의 능력을 경험할 수 있습니다 (출처: xai)

오픈소스 TTS 모델 Dia 발표 및 주목: Dia라는 이름의 오픈소스 텍스트 음성 변환(TTS) 모델이 발표되었습니다. ElevenLabs, OpenAI 등 상업용 모델에 필적하는 효과를 자랑하며, 제로샷 음성 복제 및 실시간 합성을 지원하고 MacBook에서도 실행 가능합니다. 이 모델은 Hugging Face에서 빠르게 주목받았으며 VentureBeat 등 미디어에도 보도되었습니다 (출처: huggingface, huggingface, huggingface)
Tesla 자율 주행 기술 시연: Tesla Autopilot 자율 주행 기술 관련 비디오 또는 정보가 공개되어 자율 주행 기술 진전에 대한 지속적인 관심을 불러일으키고 있습니다 (출처: Ronald_vanLoon)
로봇 기술 시연: 여러 출처에서 다양한 로봇 응용 사례를 보여주었습니다. 소형 기기 조립용 로봇 팔, TITA 로봇 평가, 수륙 양용 로봇 Copperstone HELIX Neptune, 로봇이 세상을 인식하는 방식 등이 포함되어 로봇 기술이 다양한 분야에서 지속적으로 발전하고 있음을 보여줍니다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 도구
GPT-SoVITS: 강력한 소량 샘플 음성 복제 및 텍스트 음성 변환 도구: RVC-Boss가 개발한 GPT-SoVITS는 오픈소스 프로젝트(GitHub 44k+ 스타)로, 단 1분의 음성 데이터만으로 고품질 TTS 모델을 훈련하여 소량 샘플 음성 복제를 실현합니다. 제로샷 TTS(5초 입력 즉시 변환), 다국어 추론(영어, 일본어, 한국어, 광둥어, 중국어 지원)을 지원하며, WebUI 툴박스(보컬/반주 분리, 자동 훈련 세트 분할, 중국어 ASR 및 텍스트 주석 등)를 통합하여 사용자가 데이터 세트와 모델을 쉽게 만들 수 있도록 합니다. 이 프로젝트는 V4 버전으로 업데이트되어 음색 유사성, 안정성 및 출력 품질을 지속적으로 최적화하고 있습니다 (출처: RVC-Boss/GPT-SoVITS – GitHub Trending (all/daily))

칭화대 팀, SurveyGO(卷姬) 출시: AI 기반 문헌 검토 및 장문 보고서 생성 도구: 칭화대 NLP, OpenBMB 및 面壁智能 팀이 개발한 LLMxMapReduce-V2 기술 기반의 SurveyGO는 방대한 문헌(온라인 검색 또는 파일 업로드)을 효율적으로 처리하여 구조가 명확하고 논리가 정연하며 인용이 정확한 만 자 분량의 장문 검토 보고서를 생성할 수 있습니다. 이 도구는 정보 엔트로피 기반의 컨볼루션 메커니즘을 통해 개요를 최적화하고 계층적으로 내용을 생성하여 기존 AI의 장문 생성 시 내용 짜깁기 및 깊이 부족 문제를 해결합니다. 사용자는 웹 버전을 통해 주제를 입력하거나 파일을 업로드하여 사용할 수 있으며, 연구자와 콘텐츠 제작자의 문헌 조사 및 글쓰기 효율성을 대폭 향상시키는 것을 목표로 합니다. 사용자는 웹 버전으로 체험할 수 있습니다 (출처: INTJ식 학문 폭력! 칭화대 팀 ‘논문 卷姬’ 개발: 3분 만에 200시간 문헌 검토 완료, AI로 ‘좋은 글 조합’하는 법: 만 자 보고서 생성, 모델 제한 없음)

text-generation-webui, llama.cpp에 집중한 포터블 버전 출시: 배포를 간소화하기 위해 text-generation-webui는 llama.cpp를 위한 포터블, 자체 포함 버전(약 700MB)을 출시했습니다. 사용자는 다운로드 후 압축을 풀기만 하면 Python, PyTorch 등 의존성 설치 없이 실행할 수 있습니다. 새 버전은 Win/Linux/macOS(CPU/CUDA 버전 포함)를 지원하며, 시작 속도와 사용자 경험(예: 브라우저 자동 열기, API 기본 시작)을 최적화하여 llama.cpp 로컬 추론만 사용하려는 사용자에게 큰 편의를 제공합니다 (출처: Reddit r/LocalLLaMA)
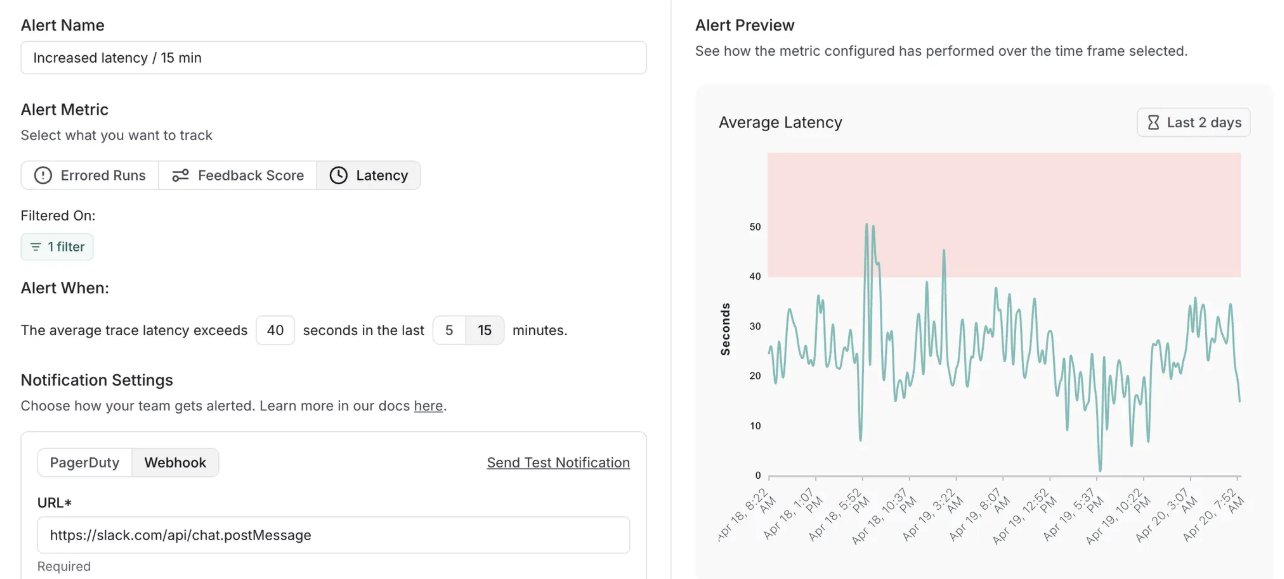
LangSmith, 알림 기능 추가 및 자체 호스팅 버전 업데이트: LangChain의 MLOps 플랫폼 LangSmith에 실시간 알림 기능이 새로 추가되어 사용자는 오류율, 실행 지연 시간 및 피드백 점수에 대한 알림을 설정하여 문제가 고객에게 영향을 미치기 전에 신속하게 발견할 수 있습니다. 동시에 자체 호스팅 버전이 v0.10으로 업데이트되어 알림 기능, 새로운 평가 생성 및 보기 UI, OpenTelemetry 클라이언트 추적 데이터 지원 및 성능 최적화가 포함되었습니다 (출처: LangChainAI, LangChainAI)
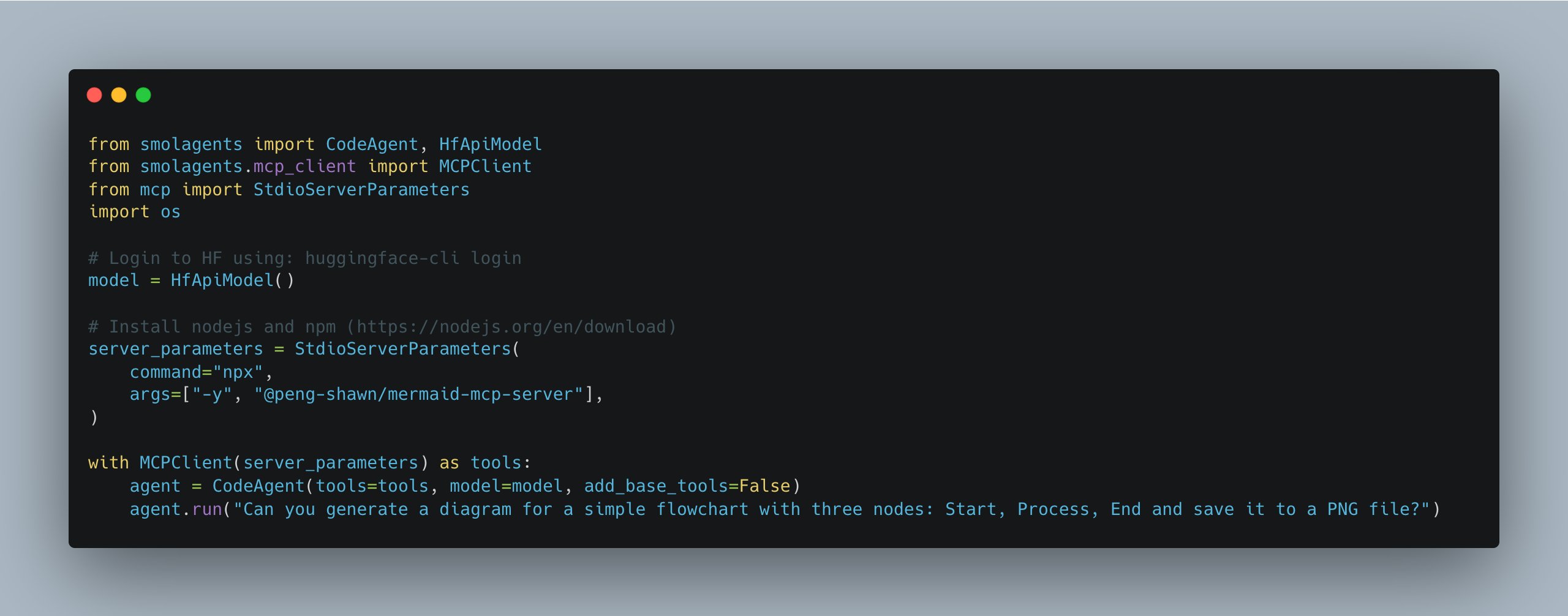
smolagents 업데이트, 다중 MCP 서버 관리 간소화: Hugging Face의 smolagents 라이브러리가 새 버전을 출시하여 MCPClient 클래스를 도입했습니다. 이를 통해 여러 MCP(모델 통신 프로토콜) 서버에 대한 연결 관리가 더욱 쉬워져 개발자가 더 복잡한 Agent 시스템을 구축하고 조정하는 데 편리해졌습니다 (출처: huggingface)
Suna: Manus에 대항하는 오픈소스 Agent 플랫폼: Kortix AI가 Manus를 대체할 목적으로 오픈소스 Agent 플랫폼 Suna를 출시했습니다. Suna는 브라우저 자동화, 파일 관리, 웹 크롤링, 확장 검색, 명령줄 실행, 웹사이트 배포 및 API 통합 등의 기능을 통합하여 AI가 이러한 도구들을 협력적으로 조작하여 대화를 통해 복잡한 문제를 해결하고 워크플로우를 자동화할 수 있도록 합니다 (출처: karminski3)
Exa MCP, 이제 API 없이 트위터 검색 지원: Exa의 MCP 서버가 업데이트되어 이제 트위터 API 없이도 트위터 콘텐츠를 검색할 수 있습니다. 이는 트위터에서 정보를 얻어야 하는 AI Agent에게 편의를 제공하지만, 현재 중국어 사용자 데이터 크롤링 지원은 미흡한 것으로 보입니다 (출처: karminski3)
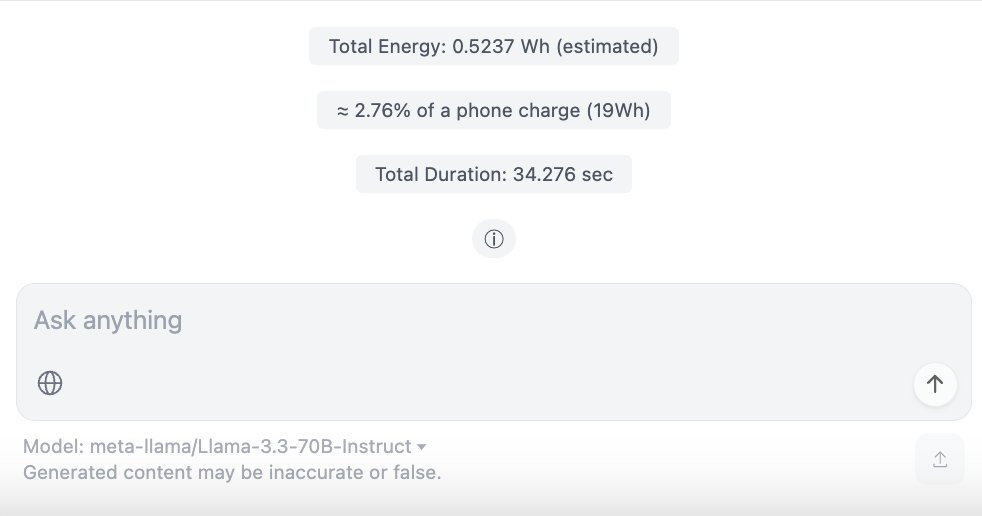
ChatUI-energy: AI 대화 에너지 소비 실시간 표시 인터페이스: Hugging Face 커뮤니티 멤버가 ChatUI-energy를 출시했습니다. 이는 사용자가 AI 모델(예: Llama, Mistral, Qwen, Gemma 등)과 대화할 때 소비되는 에너지를 실시간으로 표시하는 Chat UI의 변형입니다. 이 조치는 AI 사용의 에너지 투명성을 높이는 것을 목표로 합니다 (출처: huggingface, huggingface)
AI를 활용한 웹 애플리케이션 개발, 배포 및 최적화: 이 글은 AI(예: Lovable, Cursor, BrowserTools MCP)를 사용하여 웹 애플리케이션(이미지 스티칭 도구)을 개발, 디버깅, SEO 감사 및 성능 최적화하는 전체 과정을 공유합니다. Vercel과 GitHub를 활용한 CI/CD 자동 배포 구현 방법과 도메인 및 하위 도메인 분석 구성에 대해 중점적으로 설명합니다. 코딩 및 웹사이트 운영에서 AI의 보조 역할을 보여줍니다 (출처: AI 코딩 + Vercel 배포 + 도메인 분석: 웹 애플리케이션 개발 및 출시 전체 과정 마스터하기, 분위기 코딩+MCP 감사 최적화.)

로컬 모델 기반 “Her” OS1/Samantha 경량 복제: 한 개발자가 transformers.js와 ONNX 모델(Ultravox Llama 3.2 1B, Whisper Base, Kokoro TTS, MiniLM embeddings 포함)을 사용하여 브라우저에서 로컬로 영화 ‘Her’의 AI 비서 OS1/Samantha를 복제했습니다. 이 프로젝트는 제한된 리소스(약 2GB 모델 다운로드) 하에서 로컬 실행 음성 상호 작용 AI의 가능성을 보여줍니다 (출처: Reddit r/LocalLLaMA)
ChatWise, MCP 서버와 결합하여 RAG 및 데이터 동기화 구현: 사용자가 ChatWise에서 시스템 명령어를 사용하여 Pinecone(데이터베이스), Exa(검색), Time(시간)의 MCP 서버를 결합하여 간단한 RAG(검색 증강 생성) 및 데이터 동기화 워크플로우를 구성한 사례를 공유했습니다 (출처: op7418)

📚 학습
스탠포드 대학교, Transformer 과정 CS25 공개: 스탠포드 대학교에서 개설한 Transformer 관련 세미나 과정 CS25가 일반 대중에게 공개되어 Zoom 라이브 스트리밍을 통해 참여할 수 있습니다. 이 과정에는 Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani 등 최고 연구자들과 OpenAI, Google, NVIDIA의 게스트들이 초청되어 LLM 아키텍처, 다중 모드 응용, 생물학, 로봇 공학 등 최첨단 주제에 대해 강의합니다. 강의 영상은 YouTube에 게시될 예정이며, 토론을 위한 Discord 커뮤니티도 운영됩니다 (출처: karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
칭화대-상하이교통대 연구, LLM 추론 능력에 대한 RL의 한계 밝혀: 칭화대학교와 상하이교통대학교의 한 연구는 강화 학습(RL)이 대형 모델의 추론 능력을 향상시킨다는 관점에 도전합니다. 실험 결과, RL은 낮은 샘플링 속도에서 모델의 정확성(효율성)을 높일 수 있지만, 높은 샘플링 속도에서는 기본 모델이 더 많은 어려운 문제(능력 경계)를 해결할 수 있음을 보여주었습니다. 이는 RL이 모델의 근본적인 추론 능력을 확장하기보다는 기존 능력 범위 내에서의 성능 최적화에 더 능숙하다는 것을 시사합니다. 논문은 현재 RL 방법(예: GRPO)이 탐색 부족으로 인해 국소 최적점에 빠져 복잡한 문제 해결을 제한할 수 있다고 지적합니다 (출처: RL은 추론의 신기? 칭화대-상하이교통대 최신 연구: RL은 대형 모델이 ‘공식 적용’은 더 잘하게 하지만, 진정한 추론은 못하게 한다, Reddit r/artificial)

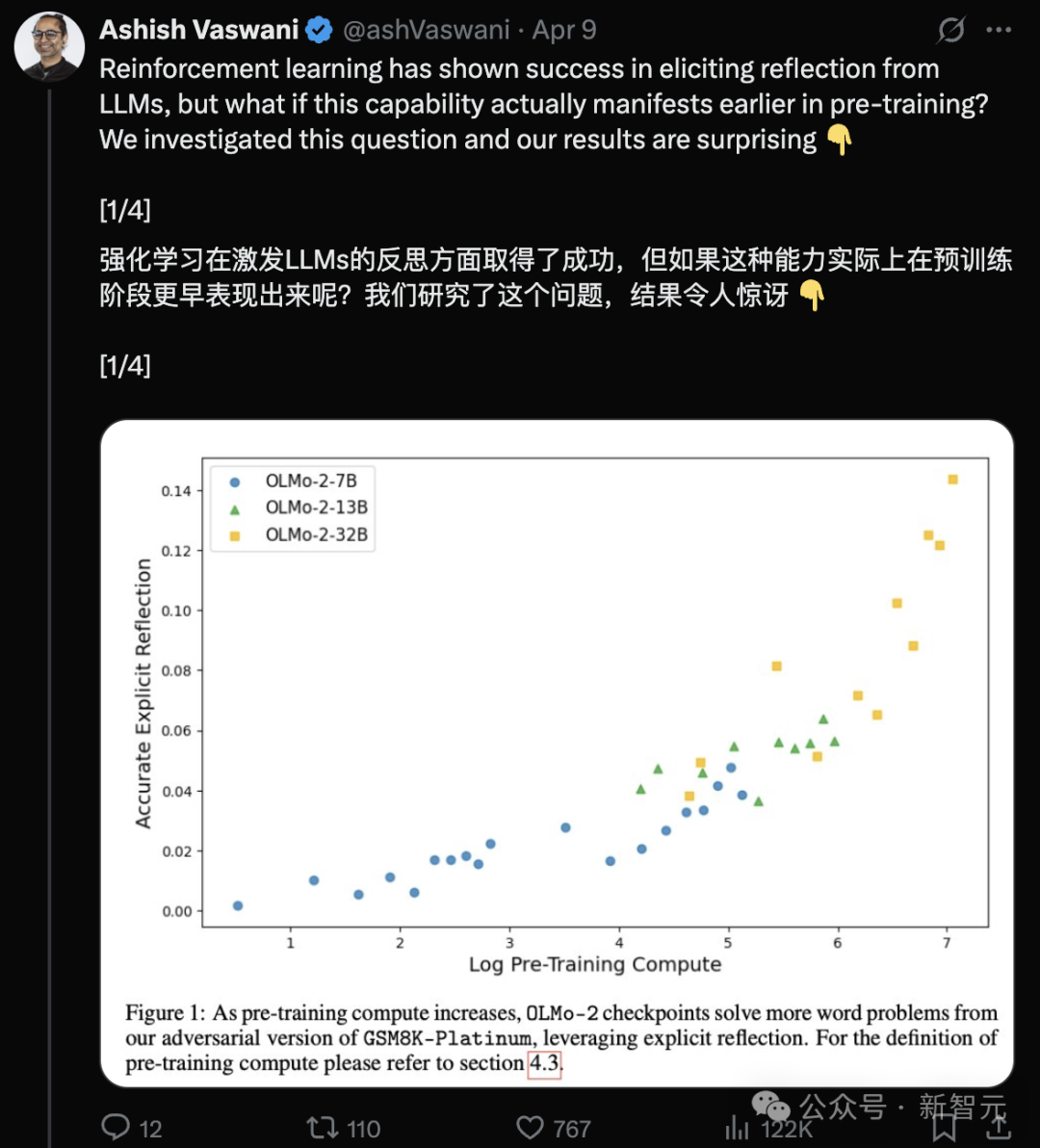
Transformer 저자 팀: LLM은 사전 훈련 단계에서 이미 성찰 능력 갖춰: Transformer 논문 제1 저자인 Ashish Vaswani가 이끄는 팀은 대형 언어 모델이 강화 학습(RLHF)에 전적으로 의존하는 것이 아니라 사전 훈련 단계에서 이미 성찰 및 자기 교정 능력이 발현된다는 연구 결과를 발표했습니다. 연구는 대립적 사고 사슬을 도입하여 상황적 성찰과 자기 성찰 능력을 구분하고 정량화했으며, 이러한 능력이 사전 훈련 계산량 증가에 따라 향상된다는 것을 발견했습니다. ‘Wait,’와 같은 간단한 프롬프트가 명시적 성찰을 효과적으로 유발할 수 있습니다. 이는 성찰이 주로 RL에서 비롯된다는 DeepSeek 등의 견해에 도전하며, 사전 훈련 중 추론 능력 발전을 이해하고 가속화하는 새로운 시각을 제공합니다 (출처: Transformer 원작자, DeepSeek 견해 반박? ‘Wait’ 한 마디로 성찰 유발, RL 필요 없어)
ChemAgent: 자체 업데이트 메모리 뱅크로 LLM 화학 추론 능력 향상: 예일, 스탠포드 등 기관의 연구자들이 ChemAgent 프레임워크를 제안했습니다. 계획, 실행, 지식 기억을 포함하는 동적 자체 업데이트 메모리 뱅크를 도입하여 화학 추론 작업에서 LLM의 성능을 크게 향상시켰습니다. 이 프레임워크는 인간의 학습 과정을 모방하여 작업 분해 및 메모리 검색을 통해 복잡한 화학 문제를 해결합니다. SciBench 데이터 세트에서의 실험 결과, ChemAgent는 기준 방법 대비 정확도가 평균 10%(상대적 SOTA 대비)에서 37%(직접 추론 대비)까지 향상되었으며, 특히 계산 및 단위 변환 정확도에서 눈에 띄는 개선을 보였습니다. 연구는 또한 메모리 유사성, 수량과 성능 간의 관계 및 현재의 한계점을 분석했습니다 (출처: 정확도 46% 급증! 예일-스탠포드 ‘자체 업데이트 메모리 뱅크’ 새 프레임워크, LLM 화학 추론 능력 재구성)
화남이공대학교, 분산 진화 연산 분야에서 연속적인 진전 이뤄: 화남이공대학교 계산 지능 팀은 다중 에이전트 시스템(MAS)의 분산 합의 최적화 분야에서 일련의 성과를 거두었습니다. 연구에는 다음이 포함됩니다: 해당 교차 분야에 대한 리뷰 논문 발표; 내부 및 외부 학습 메커니즘을 통해 협업을 최적화하는 MASOIE 알고리즘 제안; 목표 인센티브를 활용하여 협력을 유도하는 MACPO 알고리즘 제안; 블랙박스 최적화 성능을 향상시키는 CCSA 스텝 사이즈 자체 적응 메커니즘 설계; 센서 네트워크 위치 정확도를 향상시키는 MASTER 알고리즘 제안. 팀은 또한 관련 경진 대회를 조직하여 분야 발전을 촉진했습니다 (출처: 합의 최적화 장벽 돌파! 화남이공대, 분산 진화 연산 심층 연구로 다중 에이전트 효율적 협력 실현)
처음부터 DeepSeek 구축하기 비디오 튜토리얼 시리즈: Vizuara는 YouTube에 ‘처음부터 DeepSeek 구축하기’ 시리즈 비디오 튜토리얼을 게시했으며, 현재 13강까지 업데이트되었습니다. 내용은 DeepSeek 기본 사항, 토큰 처리 과정, 어텐션 메커니즘(셀프 어텐션, 인과적 어텐션, 멀티 헤드 어텐션, 멀티 쿼리 어텐션, 그룹 쿼리 어텐션, 멀티 헤드 잠재 어텐션) 및 KV Cache 등 핵심 개념 설명과 코드 구현을 다룹니다. 이 시리즈는 DeepSeek 아키텍처를 심층적으로 분석하는 것을 목표로 하며, 총 35~40개의 비디오를 게시하여 RoPE, MoE, MTP, SFT, GRPO 등 더 많은 내용을 다룰 계획입니다 (출처: karminski3, Reddit r/LocalLLaMA)
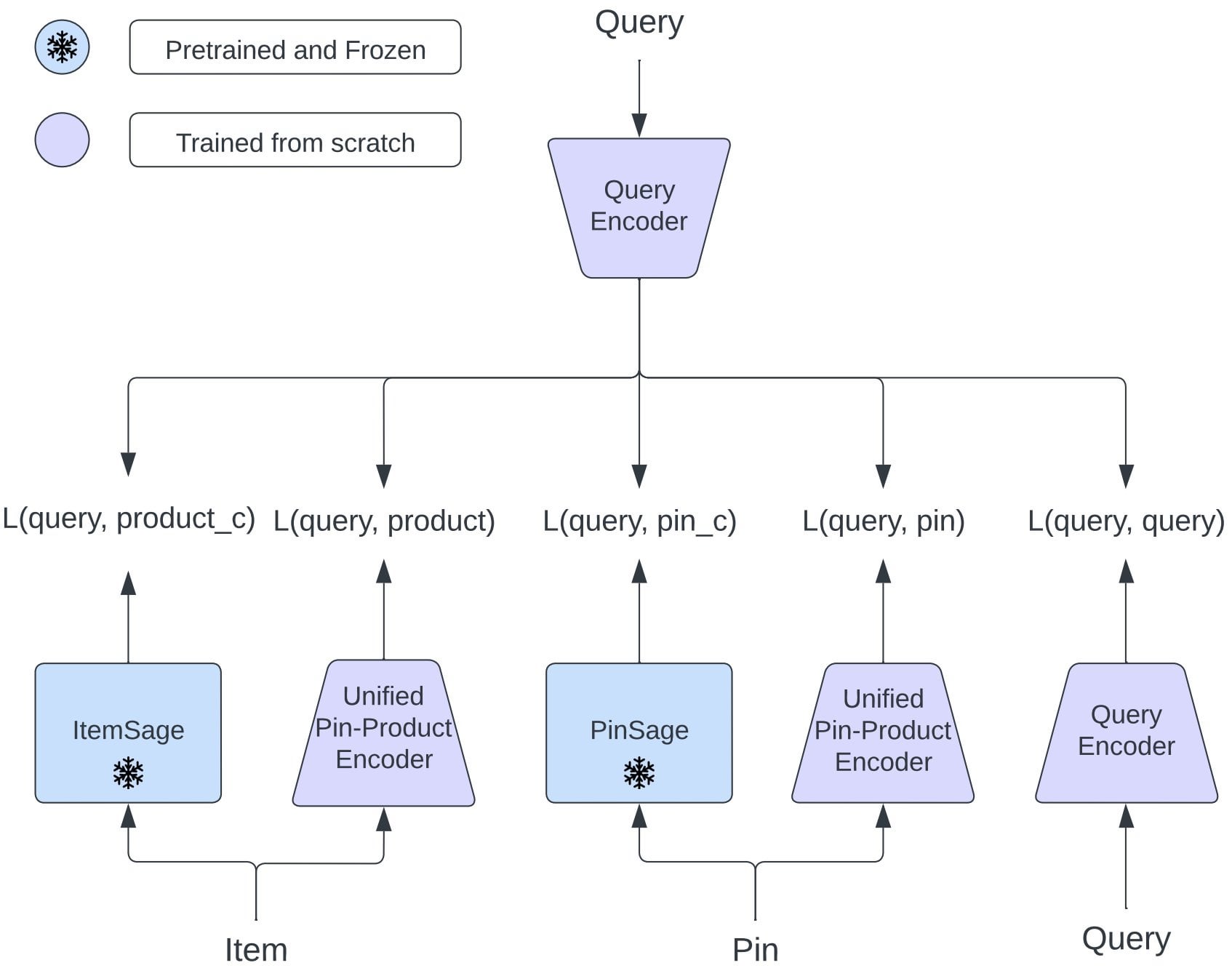
Pinterest, 다중 작업 검색 향상을 위한 통합 임베딩 모델 OmniSearchSage 제안: Pinterest 연구자들은 다중 작업 학습을 통해 훈련된 통합 쿼리 임베딩 모델인 OmniSearchSage를 제안했습니다. 이 모델은 핀, 제품 및 관련 쿼리를 동시에 검색할 수 있어 기존의 이중 타워 아키텍처에 도전합니다. 이 모델은 GenAI 생성 제목, 사용자가 큐레이션한 보드 신호 및 행동 참여 데이터를 통합하여 항목 이해를 풍부하게 하고, 기존 시스템(예: PinSage)에 직접 통합될 수 있습니다. 결과적으로 이 방법은 검색, 광고 및 지연 시간 측면에서 상당한 실제 개선을 달성했음을 보여줍니다 (출처: Reddit r/MachineLearning)
FlowReasoner: 쿼리 기반 동적 조정 다중 에이전트 워크플로우: 논문은 각 사용자 쿼리에 대해 즉시 전용 다중 에이전트 워크플로우를 추론하는 것을 목표로 하는 FlowReasoner를 제안합니다. 추론 SFT 및 GRPO 강화 학습을 통해 모델은 실행 피드백에 따라 Agent 작업(예: 코드 생성, 검토, 테스트, 수정)의 조합과 순서를 동적으로 조정할 수 있습니다. 이 방법은 Code Interpreter 시나리오에서 검증되었으며, Python 실행 및 단위 테스트에 의존합니다. 이는 워크플로우가 쿼리 요구 사항에 동적으로 적응할 수 있는 잠재력을 보여주며, 향후 검색, 데이터 분석 등 영역으로 일반화될 수 있습니다 (출처: dotey)

LangChain 튜토리얼: LlamaIndex를 사용하여 규정 준수 보고서 생성 워크플로우 구축: LlamaIndex는 규정 준수 보고서를 생성하는 Agentic Workflow를 구축하는 방법을 시연하는 비디오 튜토리얼을 게시했습니다. 이 워크플로우는 LLM을 활용하여 방대한 규정 텍스트를 처리하고, 계약 언어와 비교하며, 간결한 요약을 생성합니다. 튜토리얼은 LlamaCloud 인덱스 설정, 조항 추출 및 규정 준수 검사를 위한 스키마 정의, 관련 규정 언어 검색을 위한 시맨틱 검색 사용 방법을 보여줍니다 (출처: jerryjliu0)

LangChain 튜토리얼: 자가 치유 코드 생성 Agent: LangChain은 자가 치유 능력을 갖춘 AI 코드 생성 Agent를 구축하는 방법을 소개하는 튜토리얼을 게시했습니다. 이 튜토리얼은 OpenEvals 프레임워크와 E2B 샌드박스 환경을 활용하여 AI 생성 코드를 평가하고 개선하며, 코드를 검증하는 성찰 단계를 추가한 후 응답을 반환합니다 (출처: LangChainAI)

Anthropic 분석 결과, Claude는 내재적 도덕 규범 보여: Anthropic이 70만 건의 Claude 대화를 분석한 결과, 자사의 AI 모델이 내재적인 도덕 규범을 나타낸다는 것을 발견했습니다. 이 발견은 AI 안전 및 윤리 연구에 중요한 의미를 가질 수 있습니다 (출처: Reddit r/ClaudeAI, Reddit r/artificial)

Google, AI 훈련 데이터 부족 대응 위해 ‘경험의 시대’ 제안: Google 연구원들(David Silver 포함)은 ‘The Era of Experience’라는 논문을 발표하여, 현재 인간 데이터에 의존하는 훈련 방식이 직면한 데이터 부족 문제를 해결하기 위해 AI Agent가 자체 훈련 데이터를 생성하도록 하는 방안을 제안했습니다. 이는 AI 훈련 패러다임의 새로운 방향을 예고하며, 기존 데이터 세트에 의존하는 훈련 방법에 도전할 수 있습니다 (출처: Reddit r/artificial)

무료 자격증 및 과정 리소스 목록: GitHub 저장소 cloudcommunity/Free-Certifications는 무료 과정 및 인증을 제공하는 수많은 리소스를 수집 및 정리했습니다. 일반 기술, 보안, 데이터베이스, 프로젝트 관리, 마케팅 등 다양한 분야를 포괄하며, 일부 AI, 머신러닝, 데이터 과학 관련 무료 과정 및 인증(예: freeCodeCamp의 머신러닝 과정, Databricks의 GenAI 기초, IBM Cognitive Class의 AI 과정 등)도 포함되어 있습니다 (출처: cloudcommunity/Free-Certifications – GitHub Trending (all/daily))
코드 편집에 대한 LLM의 신뢰성 테스트: 사용자가 딥러닝 코드 작성 및 수정 측면에서 여러 대형 언어 모델(LLM)의 신뢰성을 테스트하는 비디오를 공유하며, 현재 LLM이 보조 프로그래밍 작업에서 실제 효과와 한계를 논의했습니다 (출처: Reddit r/deeplearning)

💼 비즈니스
미국 관세 전쟁, 중국 AI 하드웨어 스타트업에 충격: 미국이 중국 상품에 고율 관세(일부 세율 125% 도달)를 부과하면서 미국 시장을 겨냥한 중국 AI 하드웨어 스타트업(예: AI 장난감, 스마트 안경 등)에 심각한 영향을 미치고 있습니다. 미국 시장은 많은 AI 하드웨어 제품이 시장 검증 및 초기 사용자 확보(예: Kickstarter 통해)를 위한 핵심 거점이기 때문에, 고율 관세는 이익을 대폭 축소시키거나 손실을 초래하여 일부 기업은 이미 대미 발송을 중단했습니다. 스마트 안경 등 품목은 일시적으로 면제되었지만 전망은 불투명합니다. 업계가 의존하는 ‘회색 통관’ 방식의 위험도 증가하고 있습니다. 이는 기업들이 시장 전략을 재평가하고 글로벌화 레이아웃을 가속화하여 위험을 분산하도록 압박하고 있습니다 (출처: 갓 태어난 AI 하드웨어, 가장 격렬한 관세 전쟁 맞이하다)

智元 로봇 심층 분석: 제품, 기술 및 비즈니스 모델: 智元 로봇은 ‘稚晖君’ 彭志辉 등이 설립했으며, 산업 및 상업용 ‘远征’ 시리즈(A1, A2, A2-W 휠형, A2-Max 중량형)와 경량화 및 오픈소스에 초점을 맞춘 ‘灵犀’ 시리즈(X1 오픈소스, X1-W 데이터 수집, X2 이족 보행 상호작용) 로봇, 그리고 精灵 G1, 绝尘 C5 청소 로봇 등을 보유하고 있습니다. 기술적으로는 하드웨어-소프트웨어 협력과 데이터 폐쇄 루프를 강조하며, 자체 개발한 PowerFlow 관절 모듈, 민첩한 손, 그리고 启元 대형 모델(GO-1), AIDEA 데이터 플랫폼, AimRT 통신 프레임워크 등 소프트웨어를 개발했습니다. 비즈니스 모델에는 하드웨어 판매, 구독 서비스 및 생태계 수익 분배(오픈소스 부품, 공급망 협력)가 포함됩니다. 회사는 이미 8차례 투자를 유치했으며, 기업 가치는 150억 위안에 달합니다. 투자자로는 高瓴, 比亚迪, 腾讯 등이 있으며, 여러 공급망 기업 및 지방 정부와 협력하여 세계적인 범용 의인화 로봇을 만드는 것을 목표로 합니다 (출처: 智元 로봇 심층 분석: 휴머노이드 로봇 유니콘 진화론)

追觅 내부 인큐베이팅 3D 프린팅 프로젝트 ‘原子重塑’, 수천만 위안 투자 유치: 追觅科技(Dreame) 내부에서 인큐베이팅된 原子重塑科技(AtomFab)가 수천만 위안 규모의 엔젤 투자를 유치했으며, 追创创投가 투자했습니다. 이 회사는 2025년 1월에 설립되어 소비자용 3D 프린팅 시장에 집중하며, AI 기술을 활용하여 사용 편의성, 안정성 및 효율성 등의 문제점을 해결합니다. 회사는 追觅의 모터, 센서, AI 상호작용 등 기술 및 성숙한 공급망 자원을 재활용하여 비용을 절감하고 제품화를 가속할 것입니다. 제품은 우선 유럽 및 미국 시장에 진출하며, 追觅의 해외 애프터서비스 네트워크를 활용하여 지원을 제공할 예정입니다. 첫 제품은 2025년 하반기에 출시될 것으로 예상됩니다 (출처: 追觅 내부 인큐베이팅 3D 프린팅 프로젝트, 수천만 위안 투자 유치, 유럽·미국 등 해외 시장 우선 공략|하드웨어 크립톤 단독 보도)
NVIDIA GPU 독점 지위, 도전 직면 가능성: NVIDIA GPU 출하량이 지속적으로 증가하고 있음에도 불구하고, 장기적인 주도적 지위는 도전에 직면해 있습니다. 주요 원인은 다음과 같습니다: 1) 클라우드 거대 기업(Google, Microsoft, Amazon, Meta)의 수요는 강력하지만 비용 절감 및 의존도 감소를 위해 자체 개발 칩(TPU, Maia, Trainium, MTIA)에 대대적으로 투자하고 있습니다; 2) 업계가 분산형, 수직 통합 및 시스템 수준 협력 최적화(칩, 네트워크, 냉각, 소프트웨어)로 전환하고 있으며, NVIDIA는 이 분야에서 상대적으로 부족한 투자를 하고 있습니다; 3) 맞춤형 수요 증가로 특정 워크로드(예: 추론, 추천)에서 ASIC이 우위를 보이고 있습니다; 4) NVIDIA의 네트워크 기술(Infiniband) 및 소프트웨어 스택(예: BaseCommand)은 초거대 규모 및 내결함성 측면에서 클라우드 거대 기업의 내부 솔루션에 미치지 못할 수 있습니다. NVIDIA는 (Blackwell, Spectrum-X 등으로) 적응하려 노력하고 있지만 구조적인 도전은 여전히 존재합니다 (출처: 컴퓨팅의 미래: NVIDIA 왕관이 흔들리고 있다)

OpenAI, Chrome 브라우저 인수 관심 소문: Bloomberg 보도에 따르면, 만약 Google이 반독점 소송으로 인해 미국 연방 법원으로부터 검색 사업 분할 명령을 받는다면, OpenAI는 Chrome 브라우저 사업 인수에 관심을 가질 수 있습니다. 이는 AI 기업이 사용자 접점과 데이터 소스를 장악하려는 잠재적 관심을 반영하지만, 현재로서는 소문일 뿐이며 Google 반독점 소송의 진행 상황에 따라 달라질 것입니다 (출처: karminski3)
GenAI를 활용한 비즈니스 성과 달성 전략: Forbes 기사는 기업이 실험 단계를 넘어 생성형 AI(GenAI)를 활용하여 실제 비즈니스 성과를 얻는 방법을 탐구하며, 기업이 GenAI를 비즈니스 프로세스에 통합하여 효율성과 혁신을 향상시키는 데 도움이 되는 9가지 전략적 제안을 제시합니다 (출처: Ronald_vanLoon)

화웨이 신규 칩, NVIDIA에 경쟁 위협 가능성: 소셜 미디어에서는 화웨이가 발표한 신규 칩이 AI 분야에서 NVIDIA에 경쟁 위협이 될 수 있으며, 이는 칩 및 관세 관련 미중 협상 구도에 영향을 미칠 수 있다는 논의가 있었습니다 (출처: Reddit r/ArtificialInteligence)
🌟 커뮤니티
DeepSeek이 일으킨 골드러시와 성찰: DeepSeek의 인기는 콘텐츠 제작(단편 비디오 스크립트, 광고 문구 대량 생산), 지식 유료화(사용 튜토리얼, 수익화 강좌 판매) 및 대행 서비스 등 이를 둘러싼 수많은 상업적 시도를 낳았습니다. 그러나 많은 시도자들은 AI를 이용해 대량 생산된 콘텐츠가 동질성이 심각하고 플랫폼에 의해 트래픽이 제한되거나 차단되기 쉬우며, 실제 효과적인 수익으로 전환하기 어렵다는 것을 발견했습니다. 이 글은 진정한 수혜자는 종종 직접 사용자가 아니라 정보 격차를 이용해 강좌나 서비스를 판매하는 ‘중개상’이라고 지적합니다. 동시에 DeepSeek 자체도 서버 과부하, 답변 패턴화 등의 문제를 드러내며 그 응용 가치와 한계에 대한 논의를 불러일으켰습니다 (출처: DeepSeek 인기 3개월, 그것으로 돈 벌려던 첫 번째 그룹은 어떻게 되었나?)

AI 부정행위 도구 개발자 투자 유치, 윤리 논란 촉발: 21세 컬럼비아대 학생 Chungin Lee는 기술 면접 부정행위에 사용되는 AI 도구 Interview Coder를 개발하여 학교로부터 정학 처분을 받았습니다. 한 달도 채 되지 않아 그는 동료들과 함께 Cluely라는 회사를 설립하고 이 도구를 시험, 영업, 회의 등 다양한 시나리오로 확장하여 530만 달러의 시드 투자를 유치했습니다. 그들은 이것이 부정행위가 아니라 기술을 활용하여 효율성을 높이는 것이며, 미래에는 누구나 AI 보조를 사용할 것이라고 주장합니다. 이 사건은 격렬한 논쟁을 불러일으켰습니다. 지지자들은 이를 대담한 혁신으로 보는 반면, 비판자들은 공정성을 해치고 능력의 경계를 모호하게 하며 심지어 ‘블랙 미러’의 에피소드에 비유하기도 합니다. 이 사건은 AI 윤리, 교육 공정성 및 능력 정의에 대한 격렬한 논의를 촉발했습니다 (출처: 21세 학생, AI 부정행위 도구 개발로 컬럼비아대 정학 후 530만 달러 투자 유치, 네티즌: ‘블랙 미러’ 현실화, AI 부정행위 도구 개발로 유명해진 21세 청년, 학교 퇴학 한 달도 안 돼 530만 달러 투자 유치)

미국 비자 정책 강화, AI 인재 유출 가능성: 최근 미국 정부는 경미한 위반이나 심지어 시스템 오판(AI 심사 관련 가능성) 등 다양한 이유로 국제 학생(AI 박사 과정 학생 포함)의 SEVIS 기록과 비자를 대규모로 취소했으며, 그 과정에서 투명성과 항소 기회가 부족했습니다. 캘리포니아 공과대학 교수 Yisong Yue 등은 이러한 조치가 최고 수준의 AI 인재에 대한 미국의 매력을 손상시키고 있으며, OpenAI, Google 등 기관의 많은 연구자들이 이미 미국을 떠나는 것을 고려하고 있다고 우려합니다. 이는 미국 AI 프로젝트의 후퇴를 초래하고 AI 우위를 약화시킬 수 있습니다. 이미 학생들이 정부를 상대로 공동 소송을 제기하여 임시 금지 명령을 받았습니다 (출처: 캘리포니아 AI 박사, 하룻밤 사이 신분 상실, Google OpenAI 학자들 ‘탈미국’ 물결, 38만 개 일자리 사라지며 AI 우위 붕괴)

오픈소스 모델 발전 현황 논의: 커뮤니티에서는 오픈소스 대형 모델의 최신 동향에 대해 논의하며, Qwen 3에 대한 기대, Llama 4의 느린 채택, 추론 모델의 병목 현상 가능성, 다중 모드 모델의 저평가, 그리고 오픈소스 분야에서 중국의 지속적인 주도적 위치를 언급했습니다. 토론자들은 ‘추론 포화’에 대한 이해는 오픈소스와 폐쇄 소스를 구분해야 하며, 이는 모델 다양성 및 RL 확장 문제와 더 관련이 있다고 강조했습니다 (출처: natolambert)
OpenAI o3 모델 검색 능력 호평: 사용자는 OpenAI o3 모델의 검색 능력이 강력하여 매우 틈새 정보도 많은 추가 컨텍스트 없이 찾을 수 있으며, 상호 작용 경험이 동료와 대화하는 것과 유사하다고 칭찬했습니다 (출처: gdb)
오픈소스 TTS의 의미와 영향: 커뮤니티 멤버들은 Dia TTS 모델을 논의하면서, 그 고품질 성능이 SOTA TTS 모델 훈련이 더 이상 수십억 달러 투자가 필요한 일이 아님을 증명한다고 강조했습니다. AI 산업의 복합 효과로 인해 훈련이 점점 쉬워지고 있으며, 오픈소스의 힘이 기술 보급을 가속화하고 있습니다 (출처: huggingface, huggingface)
Meta, LlamaCon 2025 개최, 오픈소스 커뮤니티 축하: Meta는 Llama 오픈소스 커뮤니티와 그 성과를 축하하기 위해 LlamaCon 2025 행사를 개최한다고 발표했으며, Llama 모델 및 도구의 최신 진전과 향후 계획을 공유할 예정입니다 (출처: AIatMeta)

AI가 진정으로 ‘지능적’인가에 대한 논의: ‘우리는 AI가 지능적이라고 가장하는 것을 멈춰야 한다’는 제목의 기사가 논의를 촉발하며, 현재 AI 기술의 능력 경계와 ‘지능’ 정의의 복잡성에 대해 탐구합니다 (출처: Ronald_vanLoon)

ChatGPT 사용 경험: 연결 끊김 및 정직성 테스트: 사용자는 ChatGPT ‘네트워크 연결 끊김’ 문제를 자주 겪는다고 불평하며, 사용 부하와 관련이 있을 수 있다고 추측했습니다. 동시에, 한 사용자는 ChatGPT가 메모리 기능을 활용하여 사용자에 대한 ‘진짜 생각’을 제시하도록 하는 흥미로운 프롬프트를 공유하며, AI 개인화 상호 작용 및 ‘의식’에 대한 논의를 유발했습니다 (출처: natolambert, dotey)
로봇 분야 발전 낙관론: Hugging Face 공동 창립자 Thomas Wolf는 오픈소스 하드웨어, 양호한 강화 학습 진전 및 인재 집결 덕분에 2025년 로봇 연구실이 즐거움으로 가득 차 있다고 평하며, 업계 내 로봇 기술의 빠른 발전에 대한 흥분을 반영했습니다 (출처: huggingface)
Gemini Deep Research 실용성 긍정 평가: 사용자는 Gemini Deep Research 기능을 사용하여 트윗 정보의 신뢰성을 검증한 사례를 공유하며, 정보 확인 및 심층 연구 측면에서의 실용적 가치를 보여주었습니다 (출처: dotey)

오픈소스 AI 라이브러리에 대한 비판과 옹호: 커뮤니티 멤버들은 최근 다양한 오픈소스 AI 라이브러리에 대한 부정적인 댓글이 많다는 점을 관찰하며, 이러한 비판이 오래된 정보나 편향된 지표에 기반할 수 있다고 지적하고 비판자들에게 더 나은 버전을 구축하는 데 참여할 것을 촉구했습니다 (출처: natolambert)
AI 게임 경험 추측: 사용자는 미래의 AI 기반 게임 경험에 대해 궁금증을 표하며, VRChat의 상호 작용 방식과 유사할 수 있다고 추측했지만, 완전히 입으로만 조작하는 것에 대해서는 의문을 제기했습니다 (출처: karminski3)
ChatGPT 이미지 확대 기능 논의: 사용자가 ChatGPT에 이미지 해상도 확대를 시도한 결과, 실제 픽셀을 확대하는 것이 아니라 유사하지만 세부 사항이 다른 고해상도 이미지를 다시 그리는 것을 발견했습니다. 댓글 섹션에서는 이 점에 대해 보편적으로 동의하며 실제 AI 이미지 확대 기술에 대해 논의했습니다 (출처: Reddit r/ChatGPT)
ChatGPT가 생성한 세계 상상도: 사용자가 ChatGPT에 자신이 상상하는 세계의 모습을 생성하도록 요청하자, 목가적인 공원 풍경 이미지를 얻었습니다. 댓글 섹션 사용자들은 이미지의 논리적 불합리성(예: 달과 지구의 거리, 벤치 위치)과 잠재적 편견(인물 인종)을 지적하며 현재 이미지 생성 모델의 한계를 반영했습니다 (출처: Reddit r/ChatGPT)

구형 LLM 모델 MythoMax13B 인기 원인 탐구: Reddit 사용자는 Llama2 기반의 MythoMax13B 모델이 OpenRouter 등 플랫폼의 RPG 시나리오에서 여전히 인기가 많은 이유를 질문했습니다. 댓글에서는 저렴한 비용(종종 무료 옵션으로 제공됨), 상대적으로 안정적이고 지시를 잘 따름, 사용자가 프롬프트와 설정에 익숙함, 초기 튜토리얼의 고착 효과 등을 원인으로 꼽았습니다 (출처: Reddit r/LocalLLaMA)
로컬 개인 정보 필터링 도구 요청: Reddit 사용자는 프롬프트를 LLM에 보내기 전에 자동으로 개인 정보를 감지하고 익명 처리(예: 자리 표시자로 대체)하고, LLM 응답을 받은 후 원래 정보를 복원하여 개인 정보를 보호할 수 있는 로컬 장치에서 실행되는 도구 또는 소형 언어 모델(SLM)을 찾고 있습니다 (출처: Reddit r/OpenWebUI)
Anthropic의 ‘완전 AI 직원’ 경고에 대한 논의: Anthropic이 완전히 AI로 구성된 가상 직원이 1년 안에 나타날 수 있다고 경고한 것이 커뮤니티 논의를 촉발했습니다. 댓글 작성자들은 이에 대해 회의적인 반응을 보이며 Anthropic 자체 서비스의 안정성 문제를 지적하고, 이것이 홍보나 과장된 경고에 가깝다고 생각합니다 (출처: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)

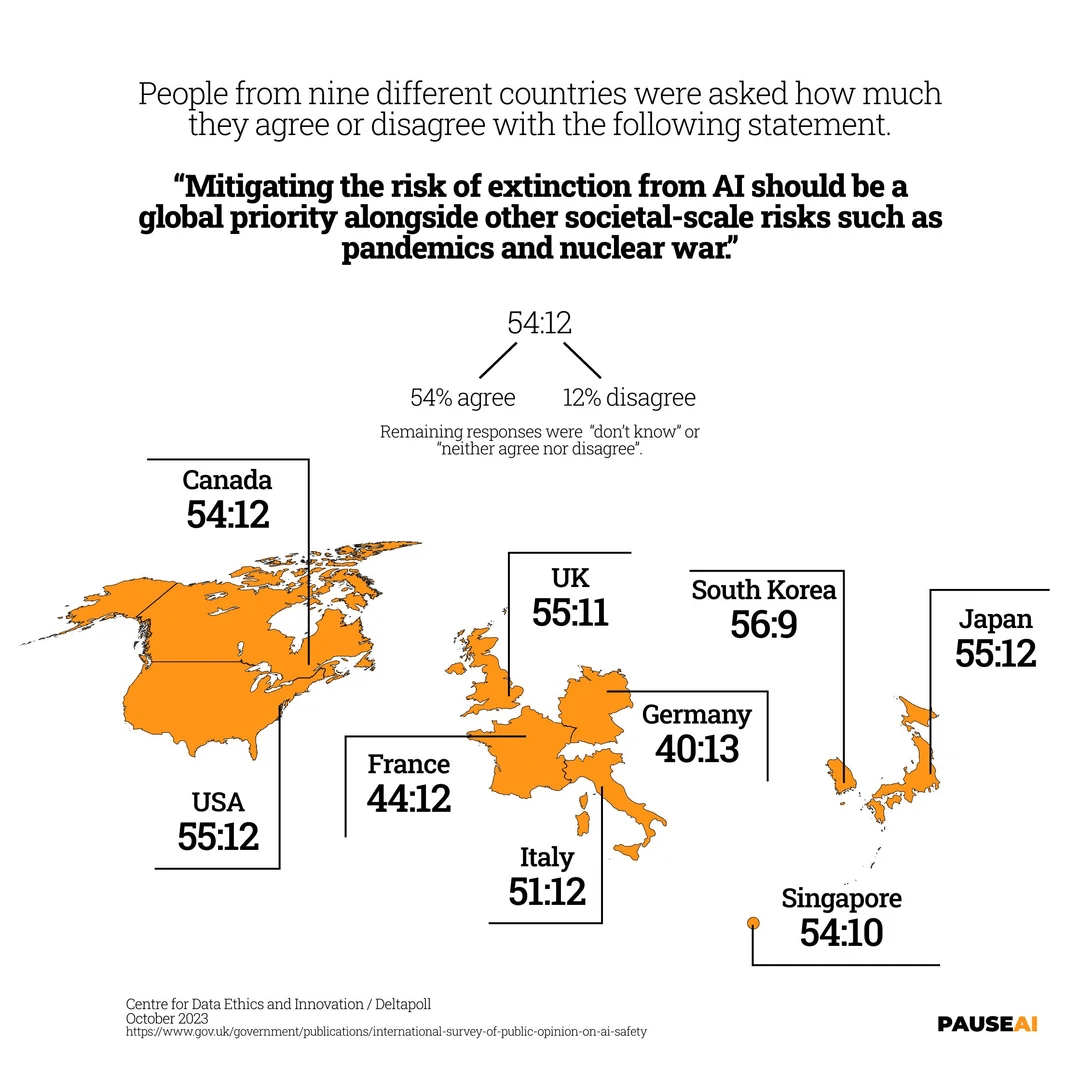
AI 멸종 위험에 대한 전 세계적 우려: 이미지는 AI가 인류 멸종을 초래할 수 있는 위험을 심각하게 받아들여야 한다는 데 세계 대부분의 사람들이 동의한다는 조사 결과를 보여줍니다 (출처: Reddit r/artificial)
AI 생성 텍스트의 ‘기계적인 느낌’과 인간적인 글쓰기 기법: 사용자는 AI가 생성한 텍스트(예: 이메일, 게시물)를 식별하는 방법을 논의하며, 일반적인 문제점으로 대상에 맞는 어조 부족, 지나치게 형식적임, 완벽함 등을 지적했습니다. 그리고 AI 글쓰기를 더 자연스럽게 만드는 기법으로 장면 명확화, 예시 제공, 무작위성 조정, 구체적인 세부 정보 추가, 직접 편집, 미세한 결함 남기기 등을 공유했습니다 (출처: Reddit r/artificial)
Claude Code를 Claude Max를 통해 사용할 수 있는지에 대한 추측: 사용자는 Claude Max 서비스를 구독하여 (아마도 비용 효율적인) Claude Code 모델을 간접적으로 사용할 수 있는지 추측하고 그 잠재적 가치를 논의하며, OpenAI도 유사한 방안을 제공하기를 희망했습니다 (출처: Reddit r/ClaudeAI)
o3 모델의 로컬 동작 유머러스하게 모방: 사용자는 로컬 LLM 모델이 일부 사용자들이 비판하는 OpenAI o3 모델의 특징(예: 짧은 답변, 미묘하게 잘못된 코드, 짜증나는 행동)과 유사하게 작동하도록 하는 유머러스한 시스템 프롬프트를 공유하여 o3 모델에 대한 불만을 풍자했습니다 (출처: Reddit r/LocalLLaMA)

OpenWebUI에서 MCP 프록시 서버 연결 문제 도움 요청: K8s 사용자가 OpenWebUI를 사용할 때 웹 인터페이스에서 동일한 pod 내에 배포된 MCP 프록시 서버(FastAPI 애플리케이션)에 액세스할 수 없는 문제에 직면했습니다(pod 내부에서는 localhost를 통해 액세스 가능). 사용자는 네트워크 연결 또는 구성 문제 해결을 위해 커뮤니티에 도움을 요청했습니다 (출처: Reddit r/OpenWebUI)
로컬 MCP 서버 보안 실천 방안 논의: 사용자는 잠재적인 취약점 위험에 대비하여 로컬 MCP 서버를 안전하게 실행하는 방법에 대한 논의를 시작했습니다. 댓글에서는 stdio 모드 사용, SSE 모드를 localhost/127.0.0.1로 제한, 토큰 인증 사용 등을 제안했으며, 프롬프트 주입/자격 증명 도용에 대한 우려는 모든 소프트웨어 설치에 적용된다고 지적했습니다 (출처: Reddit r/ClaudeAI)
Agent-to-Agent (A2A) 프로토콜 결제 메커니즘 탐구: 커뮤니티에서는 Google의 A2A 프로토콜에 내장된 Agent 간 결제 메커니즘이 부족하다는 문제를 논의했습니다. 사용자들은 이것이 Agent 경제 발전을 저해할 수 있다고 생각하며, 청구서와 연동된 인증 토큰 사용, 내장된 에스크로 프로세스 또는 AgentSkill에 가격 정보 추가 등 잠재적인 해결책을 탐구했습니다 (출처: Reddit r/artificial)
AI 과잉 의존 경고: 사용자는 Google 검색 AI가 동일한 질문에 대해 상반된 답변을 제공한 경험을 공유하며, 최종 결정을 내릴 때 AI에 전적으로 의존해서는 안 된다고 강조했습니다. 댓글에서는 LLM의 확률성, 훈련 데이터 편향, 모델 단순화 등으로 인한 불일치 원인을 설명하고, AI를 권위 있는 정보원이 아닌 보조 연구 도구로 사용할 것을 제안했습니다 (출처: Reddit r/ArtificialInteligence)
OpenWebUI에서 Qdrant를 사용한 RAG 관련 질문: 사용자는 OpenWebUI 환경에서 Qdrant 벡터 데이터베이스를 통합하여 RAG(검색 증강 생성)를 구현하는 방법, 특히 OpenWebUI가 Qdrant의 데이터를 사용하도록 하는 방법과 retriever 스크립트가 필요한지 여부에 대해 질문했습니다 (출처: Reddit r/OpenWebUI)
Google과 ChatGPT 검색 효과 비교 논의: 사용자가 ChatGPT 검색 효과가 Google보다 우수하다고 주장하는 비교 차트(표시되지 않음)를 게시하여 커뮤니티 논의를 촉발했습니다. 댓글 중 일부는 Google Gemini가 우수한 성능을 보이며 NotebookLM과 같은 도구를 보유하고 있다고 반박했습니다. 다른 일부는 이러한 비교가 무의미하며 기술은 계속 발전한다고 주장했습니다. 또한 사용자 경험과 통합의 중요성을 지적하는 의견도 있었습니다 (출처: Reddit r/ChatGPT)
Character Training 연구 방향 유망: 업계 관찰자는 Character Training(AI가 특정 캐릭터나 개성을 모방하도록 훈련하는 것)이 폭발적인 학술 연구 분야가 될 것으로 예측하며, 지금이 초기 선구적인 논문을 발표하기 좋은 시기라고 생각합니다 (출처: natolambert)
💡 기타
휴머노이드 로봇 형태의 합리성 탐구: 이 글은 로봇을 인간 형태로 설계하는 이유를 탐구합니다: 주된 이유는 인간을 위해 설계되고 건설된 세계(도구, 환경, 상호 작용 방식)에 적응하기 위해서입니다. 인간 형태 디자인은 기계가 기존 인프라 내에서 탐색하고 조작하는 데 편리하며, 개조 요구를 줄이고 인간 도구를 활용할 수 있게 합니다. 의인화된 특징은 또한 인간-기계 상호 작용 및 협업에 도움이 됩니다. 균형, 제어, 비용 및 ‘불쾌한 골짜기’와 같은 과제가 존재하지만, 기술 발전이 점차 이러한 장애물을 극복하고 있습니다. 이 글은 또한 로봇 발전 약사를 검토하고, 휴머노이드 로봇 분야에서 미국과 중국 등 국가 간의 경쟁 구도를 비교하며, 비용 하락으로 인한 보급 전망을 제시합니다 (출처: 외신 심층 분석: 로봇은 왜 인간 형태로 만들어지는가?)

AI 시대 중국의 고용 도전과 대책: 이 글은 인공지능이 중국 고용 시장에 미치는 영향, 특히 중저 숙련 노동력 및 지역 발전 불균형에 미치는 도전을 분석합니다. 교육 개혁, 재교육, 사회 보장 시스템 및 혁신 지원 분야에서 미국의 경험을 참고하여, 중국은 직업 훈련 및 평생 교육(특히 디지털 기술) 강화, 새로운 산업 형태를 포괄하는 사회 보장 시스템 개선, 산업과 AI 융합 및 지역 균형 발전 촉진, 알고리즘 규제 및 데이터 프라이버시 보호 강화, 다부처 협력 및 고용 모니터링 경보 시스템 강화를 통해 고용 기반을 안정시키고 향상시켜야 한다고 제안합니다 (출처: 인공지능 시대: 중국은 어떻게 고용 기반을 안정시키고 향상시킬 것인가)
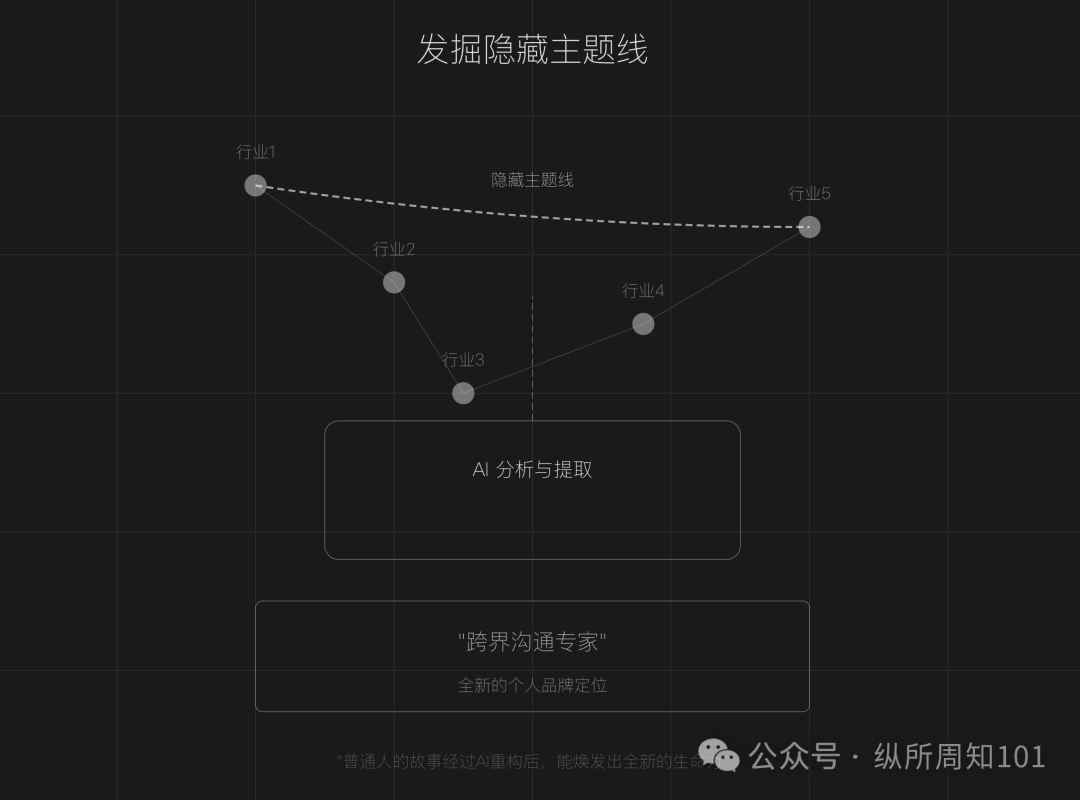
AI를 활용한 개인 IP 서사 재구성: 이 글은 콘텐츠 제작이 포화된 시대에 일반인이 AI 도구(예: ChatGPT)를 통해 개인 경험을 재구성하고, 숨겨진 주제 라인을 발굴하며, 핵심 전환점 서사를 재구성하고, 차별화된 언어 체계를 형성하여 독특한 개인 IP를 구축할 수 있다고 제안합니다. 구체적인 단계(데이터 수집, AI 주제 발굴, 스토리 구조 재구성, 실천 반복)와 기법(역방향 구축, 감정 증폭, 대비 강화)을 제공하며, 과도한 미화, 천편일률, 감정적 깊이 부족의 함정을 피하고 진정성과 AI 보조의 결합을 강조합니다 (출처: 개인 IP 구축의 첫걸음: AI로 당신의 인생 서사 다시 쓰기)
환경 보호 분야에서의 AI 응용: 세계 지구의 날을 맞아 NVIDIA는 자사의 AI 기술(예: Jetson, Earth-2 플랫폼)이 환경 보호에 활용되는 사례를 선보였습니다. 해류 예측을 통한 연료 소비 감소, 산불 및 밀렵 실시간 방지, 더 정확한 폭풍 예보 제공, 소행성 탐지 등이 포함되며, 해양, 육지, 하늘, 우주 등 여러 차원을 포괄합니다 (출처: nvidia, nvidia, nvidia)
고객 서비스 개선을 위한 AI 활용: AI 기반 컨택 센터는 전통적인 고객 서비스 전화의 문제점을 해결하고 효율성과 만족도를 높여 고객 서비스 경험을 혁신하고 있습니다 (출처: Ronald_vanLoon)
AI 생성 현실적인 셀카/우스꽝스러운 이미지 프롬프트 공유: 사용자는 AI 이미지 생성 도구(예: GPT-4o, Sora)를 사용하여 매우 현실적이고 마치 아무렇게나 찍은 듯한 ‘평범한’ 셀카를 생성하는 프롬프트와 특정 인물을 변기 솔 등으로 디자인하는 우스꽝스러운 이미지를 생성하는 프롬프트를 공유하며, 이미지 생성 분야에서 AI의 창의성과 엔터테인먼트 잠재력을 보여주었습니다 (출처: dotey, dotey, dotey)

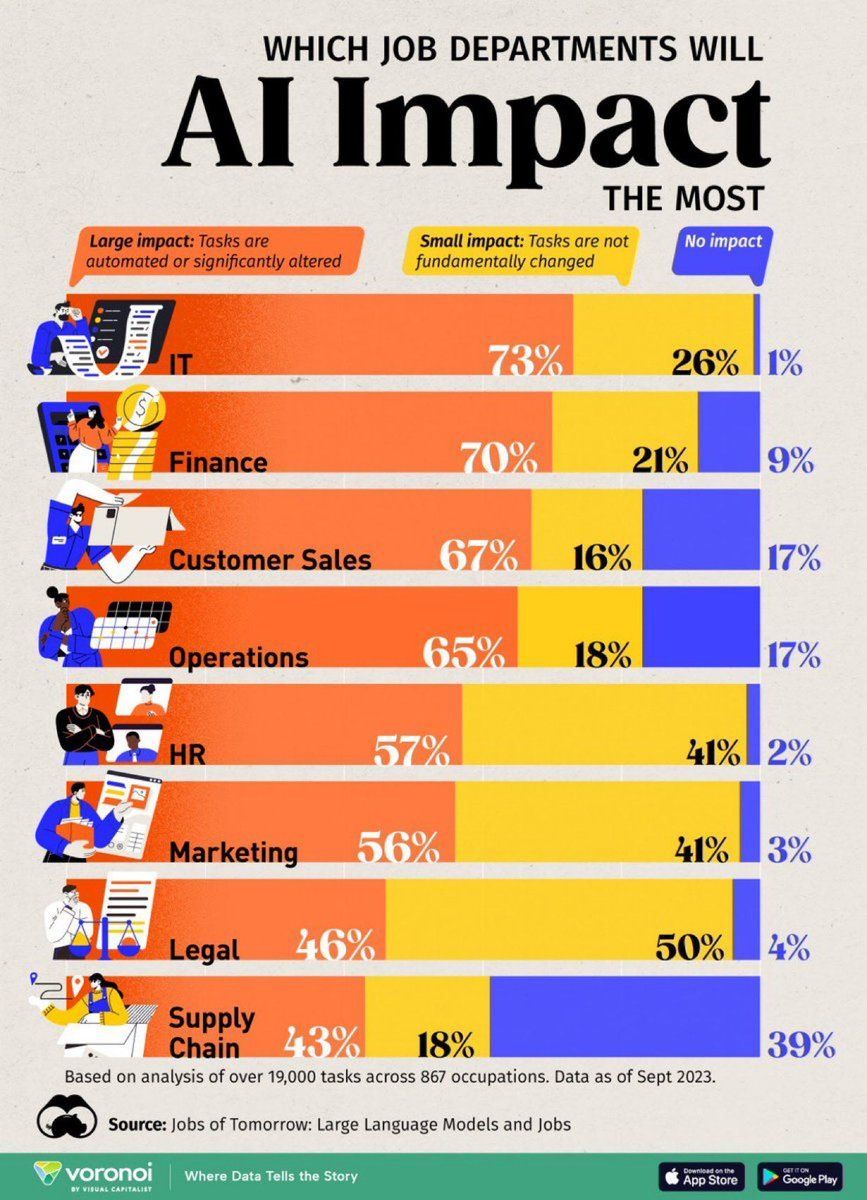
AI가 고용 직위에 미치는 영향 분석: Visual Capitalist가 제작한 인포그래픽은 AI의 영향을 가장 많이 받는 직업들을 보여주며, 미래의 일자리 형태 변화에 대한 관심을 불러일으킵니다 (출처: Ronald_vanLoon)
두바이 도로 결함 감지에 AI 활용: 두바이는 도로 결함을 감지하기 위해 새로운 AI 기술을 채택할 예정이며, 이는 도시 인프라 유지 관리에서 AI의 응용 잠재력을 보여줍니다 (출처: Ronald_vanLoon)
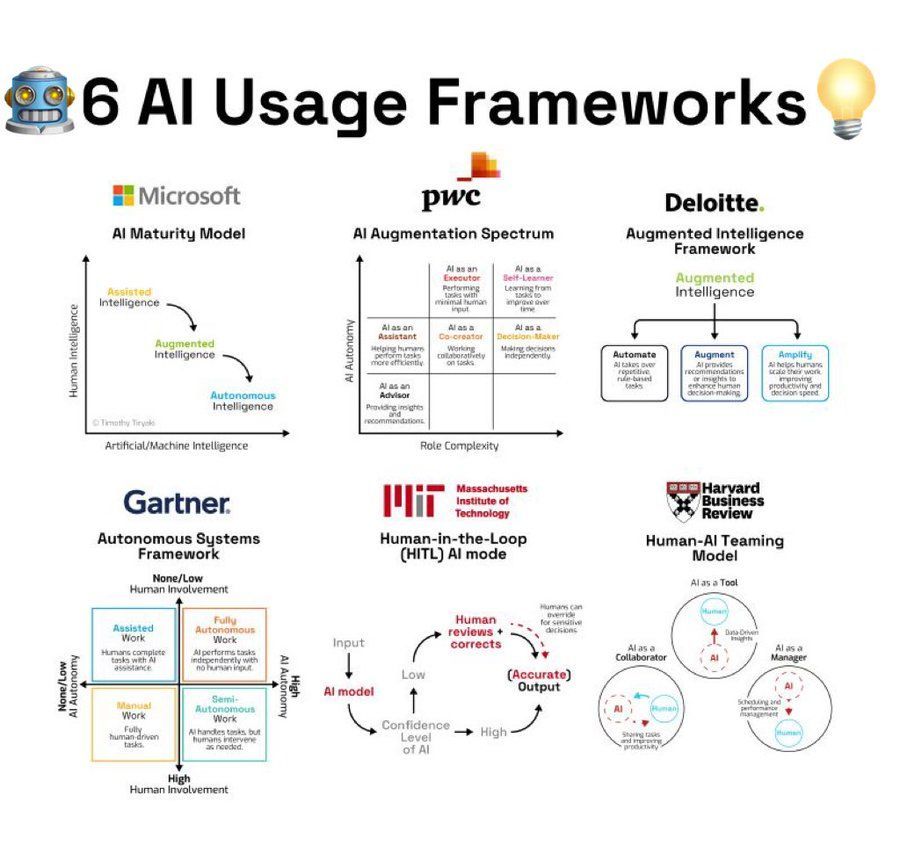
AI 사용 프레임워크 요약: 인포그래픽은 AI를 사용하는 6가지 프레임워크 또는 방법론을 요약하여 사용자에게 AI 응용에 대한 아이디어 참고 자료를 제공합니다 (출처: Ronald_vanLoon)
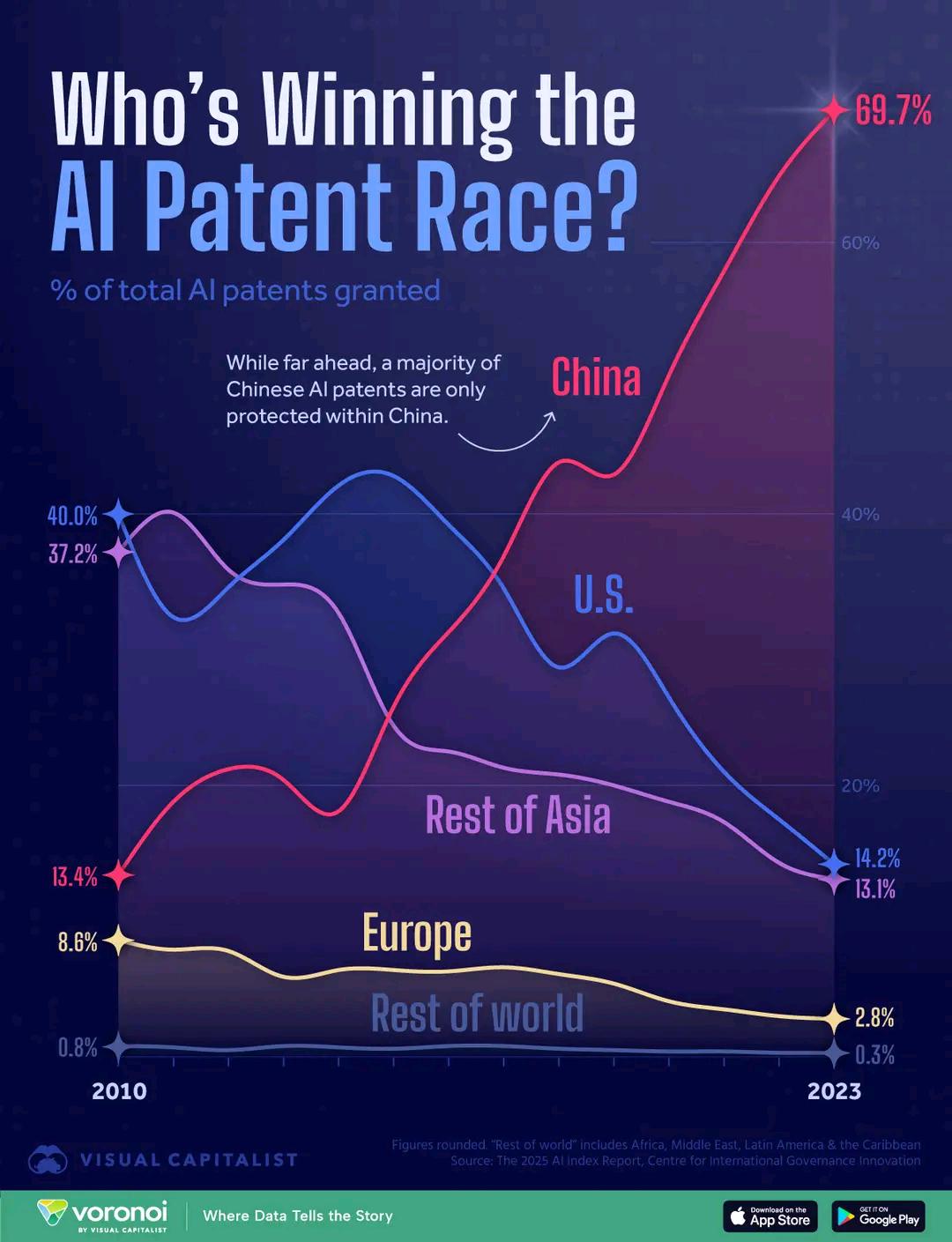
AI 특허 수 국가 비교: 차트는 각국의 AI 분야 특허 수를 비교하여 보여주며, AI 연구 개발 투자 및 성과에서 국가 간 차이를 반영합니다. 댓글에서는 중국의 특허 출원 비용이 상대적으로 저렴하다는 점이 데이터 해석에 영향을 미칠 수 있다고 언급되었습니다 (출처: karminski3)
생체 공학 팔, 장애인 지원: Open Bionics 회사가 15세 절단 장애 소녀 Grace에게 생체 공학 팔을 설치하여, AI 및 로봇 기술이 의료 건강 및 보조 기술 분야에서 활용되는 사례를 보여주었습니다 (출처: Ronald_vanLoon)
AI 보조 영화, 오스카 자격 획득 주목: 미국 영화 예술 과학 아카데미는 규칙을 업데이트하여 AI 등 디지털 도구를 사용하여 제작된 영화도 오스카상 후보 자격이 있음을 명확히 했습니다. 이는 할리우드 안팎에서 AI가 영화 제작 및 산업 표준에 미치는 영향에 대한 광범위한 논의를 촉발했습니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

리투아니아, 학교 AI 사용 규칙 제정: 리투아니아는 학교에서 인공지능 사용 관련 규칙을 제정 중이며, 이는 교육 분야에서 AI 도구 사용을 규범화하기 시작했음을 반영합니다 (출처: Reddit r/ArtificialInteligence)