키워드:AI, 대형 모델, 지능형 에이전트, 멀티모달, 중력파 탐지기 AI 설계, Magi-1 비디오 생성 모델, Vidu Q1 비디오 대형 모델, Claude 가치관 분석, DeepSeek-R1 추론 메커니즘, AI 에이전트 프로토콜 표준, 3D 가우시안 스플래팅 보안 취약점, AI 음악 저작권 분쟁
🔥 포커스
AI, 신형 중력파 탐지기 설계, 관측 가능한 우주 확장: 막스 플랑크 연구소, Caltech 등 기관 연구자들이 AI 알고리즘 Urania를 이용해 인류의 기존 이해를 뛰어넘는 신형 중력파 탐지기를 설계했습니다. 이 AI는 설계 문제를 연속 최적화 문제로 변환하여, 인간 설계보다 우수한 수십 가지 토폴로지 구조를 발견했으며, 탐지 감도를 10배 이상 향상시키고 관측 가능한 우주 부피를 50배 확장할 수 있습니다. PRX에 발표된 이 연구는 AI가 기초 과학 분야에서 초인적인 솔루션을 발견할 잠재력을 보여주며, 심지어 완전히 새로운 물리적 아이디어를 창출할 수도 있음을 시사합니다. (출처: 新智元)

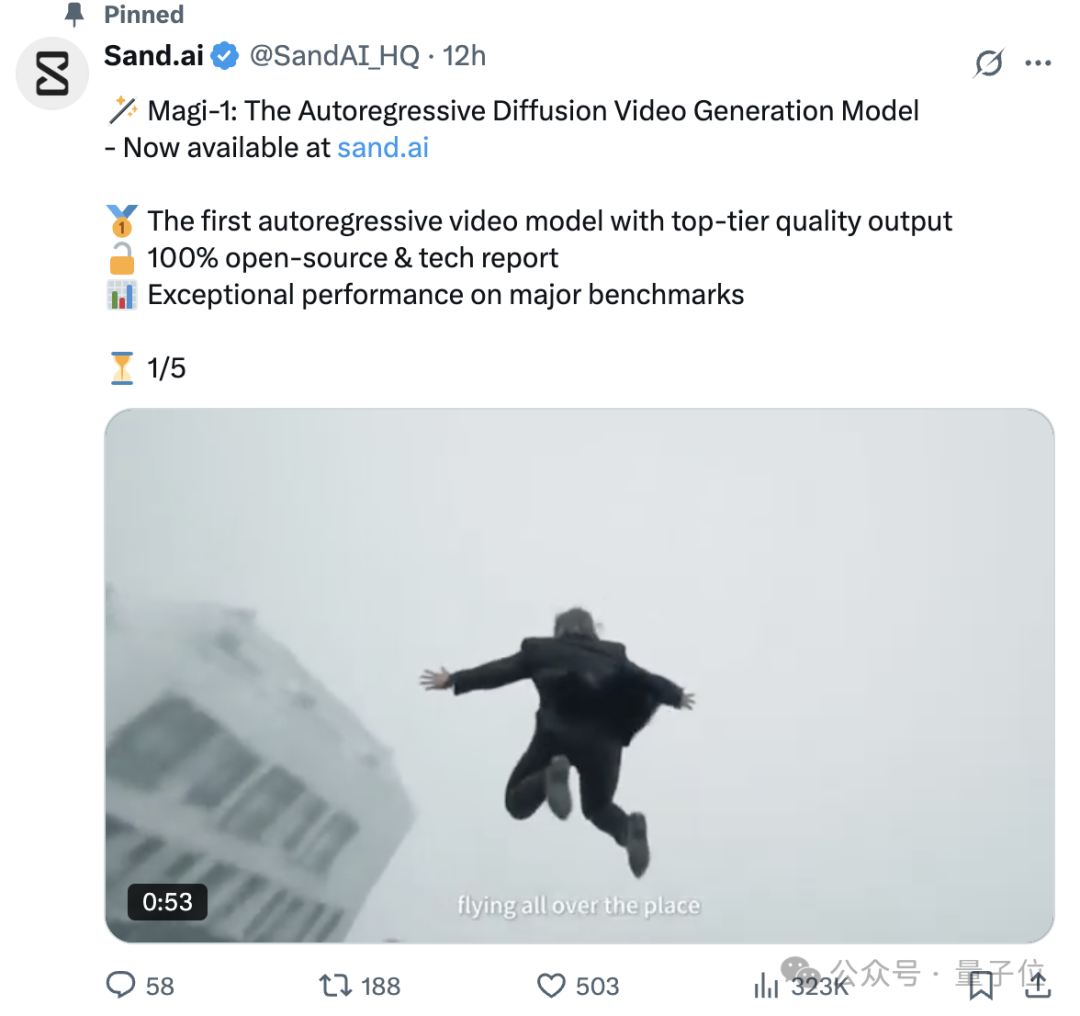
칭화대 특별상 수상자 Cao Yue 팀, 비디오 생성 모델 Magi-1 오픈소스 공개: Swin Transformer 저자 Cao Yue가 설립한 Sand.ai가 자기회귀 비디오 생성 대형 모델 Magi-1을 발표하고 오픈소스로 공개했습니다. 이 모델은 블록 단위 자기회귀 예측 방식을 채택하여 무한 길이 확장과 초 단위 길이 제어를 지원하며 고화질 출력을 구현했습니다. 팀은 61페이지 분량의 기술 보고서를 공개하여 모델 아키텍처(DiT 기반), 훈련 방법(Flow-Matching), 다중 어텐션 및 분산 훈련 최적화 등을 상세히 소개했습니다. 4.5B부터 24B 파라미터까지의 시리즈 모델을 오픈소스로 공개했으며, 최소 단일 4090 카드에서도 실행 가능하여 AI 비디오 생성 기술 발전을 촉진하는 것을 목표로 합니다. (출처: 量子位, 机器之心, kaifulee)
중국산 비디오 대형 모델 Vidu Q1, VBench 양대 벤치마크 1위 등극: Shengshu Technology 산하 비디오 대형 모델 Vidu Q1이 VBench-1.0 및 VBench-2.0 두 주요 권위 있는 벤치마크 테스트에서 1위를 차지하며 Sora, Runway 등 국내외 모델을 능가했습니다. Q1은 비디오 현실성, 의미 일관성, 콘텐츠 사실성 등에서 우수한 성능을 보였습니다. 새 버전은 1080p 고화질(한 번에 5초 생성)을 지원하고, 영화 수준의 카메라 워크를 구현하기 위해 시작/종료 프레임 기능을 업그레이드했으며, 정밀한 시간 제어를 지원하는 AI 음향 효과 기능(48kHz 샘플링 속도)을 출시했습니다. 경쟁력 있는 가격 책정으로 크리에이티브 산업 역량 강화를 목표로 합니다. (출처: 新智元)

Anthropic 연구, Claude의 가치관 표현 방식 밝혀: Anthropic은 70만 건의 Claude 익명 대화를 분석하여 3307가지 고유 가치관을 포함하는 분류 체계를 구축했습니다. 이는 실제 상호작용에서 AI의 가치 지향성을 이해하기 위함입니다. 연구 결과, Claude는 대체로 “유익하고, 정직하며, 무해한” 원칙을 따르며, 다양한 상황(예: 인간관계 조언, 역사 분석)에 따라 가치관을 유연하게 조정할 수 있음을 발견했습니다. 대부분의 경우 사용자 관점을 지지하지만, 소수(3%)의 경우에는 적극적으로 반대하며 이는 핵심 가치관을 반영할 수 있습니다. 이 연구는 AI 행동 투명성을 높이고 위험을 식별하며 AI 윤리 평가를 위한 실증적 근거를 제공하는 데 도움이 됩니다. (출처: 元宇宙之心MetaverseHub, 新智元)

🎯 동향
칭화대 Deng Zhidong 교수, AGI 진화와 미래 논의: 칭화대학교 Deng Zhidong 교수는 AI가 단일 모달 텍스트 모델에서 다중 모달 체화형 지능 및 상호작용형 AGI로 진화하는 경로를 공유했습니다. 그는 기초 대형 모델이 운영체제와 같으며, MoE 아키텍처, 다중 모달 의미 정렬이 핵심 기술 최전선임을 강조했습니다. Deng 교수는 특히 DeepSeek의 혁신적 의미를 지적하며, 강력한 추론 능력과 로컬 배포 가능성이 중국 AI 보편화 응용에 전환점을 가져왔다고 평가했습니다. 미래에는 범용 인공지능 세계로 나아갈 것이며, AI 에이전트는 더 강한 조직 능력을 갖추고 인터넷에서 물리적 세계로 확장될 것이지만, 윤리 및 거버넌스 문제에도 주의를 기울여야 한다고 덧붙였습니다. (출처: 清华邓志东:我们会迈向一个通用人工智能的世界)
DeepMind, “생성형 유령” 논의: AI 기반 디지털 영생: DeepMind와 콜로라도 대학교는 “생성형 유령(Generative Ghost)” 개념을 제안했습니다. 이는 고인의 데이터를 기반으로 구축되어 새로운 콘텐츠를 생성하고 고인의 관점에서 상호작용할 수 있는 AI 에이전트를 의미하며, 단순한 정보 복제를 넘어섭니다. 논문은 설계 공간(예: 제1자/제3자 생성, 생전/사후 배포, 의인화 정도 등)과 잠재적 영향(정서적 위안, 지식 전수의 이점 및 심리적 의존, 평판 위험, 보안 및 사회 윤리 문제 등)을 탐구하며, 기술 성숙 전에 심층 연구와 규범 제정을 촉구합니다. (출처: 新智元)

Apple Intelligence 및 AI Siri 여러 차례 연기, 중국 출시 시기 미정: Apple의 AI 기능 Apple Intelligence(특히 새로운 Siri 버전) 출시 계획이 여러 차례 지연되었으며, 일부 기능은 2025년 가을까지 연기될 수 있습니다. 중국 지역은 승인 및 현지화 협력 문제(Alibaba, Baidu와 협력 소문)로 인해 더 큰 불확실성에 직면해 있습니다. 지연 원인으로는 기술 미달(내부 평가 낮음, 성공률 66-80%에 불과)과 각국의 규제 정책 차이 등이 있습니다. Apple은 이로 인해 허위 광고 소송에 직면했으며 iPhone 16 홍보 문구를 수정했습니다. 이는 Apple이 AI 구현 측면에서 어려움을 겪고 있으며 혁신 과정이 더디다는 것을 반영합니다. (출처: 一财商学)

Qualcomm, 온디바이스 AI가 차세대 경험의 핵심임을 강조: Qualcomm AI 제품 기술 중국 지역 책임자 Wan Weixing은 온디바이스 AI가 프라이버시 보안, 개인화, 성능, 에너지 효율성 및 빠른 응답 등의 장점을 바탕으로 차세대 AI 경험의 핵심이 되고 있으며 인간-컴퓨터 상호작용 인터페이스를 재편하고 있다고 지적했습니다. Qualcomm은 하드웨어(이기종 컴퓨팅), 통합 소프트웨어 스택 및 Qualcomm AI Hub 생태계 도구를 통해 이를 준비하고 있습니다. 핵심 동력은 온디바이스 인텔리전트 플래너로, 로컬 데이터를 활용하여 정확한 의도 이해, 작업 계획 및 교차 애플리케이션 서비스 호출을 실현합니다. (출처: 36氪)

AI 에이전트 프로토콜 표준, 거대 기업 경쟁의 새로운 초점: 기술 거대 기업들이 AI 에이전트 상호작용 표준을 둘러싸고 치열한 경쟁을 벌이고 있습니다. Anthropic이 모델과 외부 데이터/도구 연결을 통일하기 위해 MCP(Model Context Protocol)를 먼저 출시하자 OpenAI, Google이 호응했습니다. 이후 Google은 교차 생태계 에이전트 협업을 촉진하기 위해 A2A 프로토콜을 오픈소스로 공개했습니다. 기사는 프로토콜 정의권을 장악하는 것이 미래 AI 산업 가치 분배권을 장악하는 것이며, 거대 기업들이 MCP(데이터 접근 서비스)와 A2A(클라우드 플랫폼 연동)를 통해 생태계 장벽을 구축하고 업계 주도권을 다투고 있다고 분석합니다. (출처: 科技云报道)

Tencent Yuanbao와 ByteDance Doubao, WeChat 및 Douyin 생태계와 깊이 통합: Tencent Yuanbao가 WeChat 계정을 출시하고 ByteDance Doubao가 Douyin ‘메시지’ 페이지에 입점하면서 두 AI 조수가 각자의 슈퍼 앱에 깊숙이 통합되고 있습니다. 사용자는 WeChat 내에서 직접 Yuanbao와 상호작용하고, 기사를 분석하고 공유하거나, Douyin 내에서 Doubao와 채팅하고 정보를 검색할 수 있습니다. 이는 거대 기업들이 광고 외에 소셜 관계망과 콘텐츠 생태계를 활용하여 AI 애플리케이션의 신규 사용자를 확보하는 중요한 전략으로 간주되며, 사용자 진입 장벽을 낮추고 AI+소셜의 새로운 모델을 탐색하며 AI 생성 콘텐츠를 소셜 화폐로 활용하려는 목적입니다. (출처: 字母榜)
AI4SE 보고서: 대형 모델이 소프트웨어 엔지니어링 지능화 가속화: 중국 정보통신 연구원 등 기관이 발표한 《AI4SE 산업 현황 조사 보고서 (2024년도)》에 따르면, AI의 소프트웨어 엔지니어링 분야 적용은 검증 단계를 지나 규모화 단계에 진입했습니다. 기업의 지능화 성숙도는 보편적으로 L2(부분 지능화) 수준에 도달했습니다. AI는 요구사항 분석, 운영 유지보수 단계에서 적용이 현저히 증가했으며, 각 단계의 효율성이 뚜렷하게 향상되었고 특히 테스트 분야에서 두드러졌습니다. 코드 생성 채택률(평균 27.46%)과 AI 생성 코드 비율(평균 28.17%) 모두 상승했습니다. 지능형 테스트 도구는 이미 기능 결함률 감소 효과를 초보적으로 보여주고 있습니다. (출처: AI前线)

Kingsoft Office, 정부용 대형 모델 업그레이드, 추론 및 공문 처리 능력 강화: Kingsoft Office는 정부용 대형 모델 강화 버전(13B, 32B)을 발표하여 추론 능력을 향상시키고 정부 내부 시나리오 서비스에 집중했습니다. 모델은 수억 건의 정부 관련 말뭉치를 기반으로 훈련되었으며, 공문 작성(5가지 문체 포함), 지능형 교정, 교열 및 서식 지정, 정책 검색 능력을 최적화했습니다. 업그레이드 후 더 강력한 의도 이해와 내부 지식 베이스 질의응답(답변 출처 명시)을 지원하여 공무원의 생산성을 30-40% 향상시키는 것을 목표로 합니다. 보안 요구 충족을 위해 프라이빗 배포를 강조하며 배포 비용을 90% 절감했다고 밝혔습니다. (출처: 量子位)

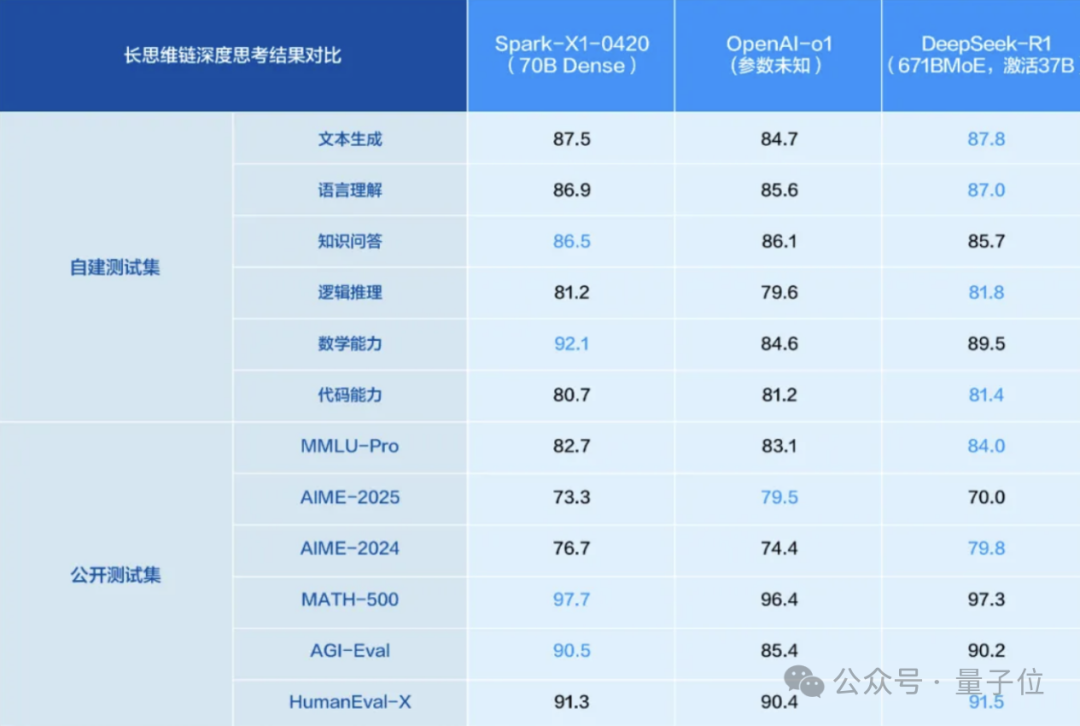
iFlytek Spark X1 추론 모델 업그레이드, 완전 국산 컴퓨팅 파워 기반으로 최고 수준 목표: iFlytek은 업그레이드된 Spark X1 심층 추론 모델을 발표하며, 완전 국산 컴퓨팅 파워(Huawei Ascend) 기반 훈련을 강조하고 범용 작업 효과 면에서 OpenAI o1 및 DeepSeek R1과 경쟁한다고 밝혔습니다. 새 모델은 대규모 다단계 강화 학습, 빠르고 느린 사고 통합 훈련 등 기술 혁신 덕분입니다. 주요 특징은 배포 장벽 대폭 감소입니다: Huawei 910B 카드 4장으로 완전 버전 배포 가능, 16장으로 산업 맞춤형 완료 가능. H20 제한 상황에서 국산 AI 풀 스택 솔루션의 진전을 보여줍니다. (출처: 量子位)
Zhipu AI GLM-4, OpenRouter 및 Ollama 플랫폼에 등록: Zhipu AI의 GLM-4 모델(32B instruct 버전 GLM-4-32B-0414 및 reasoning 버전 GLM-Z1-32B-0414 포함)이 모델 라우팅 플랫폼 OpenRouter에 등록되어 사용자들이 해당 플랫폼을 통해 무료로 체험할 수 있습니다. 동시에 커뮤니티 기여자들이 Q4_K_M 양자화 버전을 Ollama 플랫폼에 업로드하여 로컬 배포 및 실행을 용이하게 했습니다(Ollama v0.6.6 이상 버전 필요). (출처: karminski3, Reddit r/LocalLLaMA)
Meta, Perception Language Model (PLM) 발표: Meta는 어려운 시각 인식 작업을 처리하는 데 중점을 둔 시각 언어 모델 PLM(1B, 3B, 8B 파라미터 버전)을 오픈소스로 공개했습니다. 이 모델은 대규모 합성 데이터와 새로 수집된 250만 개의 인간 주석 비디오 질의응답/시공간 자막 데이터를 결합하여 훈련되었습니다. 동시에 세분화된 활동 이해와 시공간 추론에 초점을 맞춘 새로운 PLM-VideoBench 벤치마크도 발표했습니다. (출처: Reddit r/LocalLLaMA, Hugging Face)

🧰 툴
NYXverse: 텍스트 생성 3D 세계 AIGC 플랫폼: 전 Tri-Go Tech 창업자 Ma Yuchi가 설립한 2033 Technology가 AIGC 콘텐츠 플랫폼 NYXverse를 출시했습니다. 이 플랫폼은 사용자가 텍스트 입력을 통해 맞춤형 AI Agent, 환경, 플롯을 포함하는 3D 상호작용 세계를 만들 수 있게 하여 3D 콘텐츠 제작 장벽을 크게 낮춥니다. 핵심 기술은 자체 개발한 캐릭터, 세계, 행동 세 가지 모델입니다. NYXverse는 UGC 콘텐츠 공유 커뮤니티로 자리매김하며 빠른 2차 창작과 IP 각색을 지원합니다. 현재 Steam에 출시되었으며 SenseTime 및 동방 국유자본으로부터 약 1억 위안의 투자를 유치했습니다. (출처: 36氪)

SkyReels V2, 무한 길이 비디오 생성 모델 오픈소스 공개: SkyworkAI는 SkyReels V2 모델(1.3B 및 14B 파라미터)을 오픈소스로 공개했습니다. 텍스트-비디오 및 이미지-비디오 작업을 지원하며 무한 길이 비디오 생성이 가능하다고 주장합니다. 초기 테스트 결과 일부 비공개 소스 모델보다 효과가 떨어질 수 있지만, 오픈소스 도구로서 여전히 잠재력이 있습니다. (출처: karminski3, Reddit r/LocalLLaMA)
AI 기반 외골격, 휠체어 사용자 기립 및 보행 지원: AI 기술을 활용한 외골격 장치가 휠체어 사용자의 기립 및 보행 능력 회복을 돕는 모습이 시연되어, 보조 기술 분야에서 AI의 응용 잠재력을 보여줍니다. (출처: Ronald_vanLoon)
Fellou: 최초의 행동형 브라우저 출시: Authing 창업자 Xie Yang이 만든 Fellou 브라우저가 출시되었습니다. 행동형 브라우저(Agentic Browser)로 포지셔닝합니다. 기존 브라우저의 정보 표시 기능뿐만 아니라 AI Agent 능력을 통합하여 사용자 의도를 이해하고, 작업을 자동으로 분해하며, 여러 웹사이트에 걸쳐 복잡한 워크플로우(예: 정보 수집, 양식 작성, 온라인 주문 등)를 실행할 수 있습니다. 핵심 능력으로는 심층 행동, 능동적 지능(사용자 요구 예측), 혼합 섀도우 공간(사용자 작업 방해 없음), 지능형 에이전트 네트워크(Agent Store) 등이 있습니다. 브라우저를 정보 도구에서 지능형 작업 플랫폼으로 업그레이드하는 것을 목표로 합니다. (출처: 新智元)

WriteHERE: Jürgen 팀, 장문 작성 프레임워크 오픈소스 공개: Jürgen Schmidhuber 팀이 오픈소스로 공개한 장문 작성 프레임워크 WriteHERE는 이종 재귀 계획 기술을 사용하여 한 번에 4만 단어 이상, 100페이지 분량의 전문 보고서를 생성할 수 있습니다. 이 프레임워크는 작성을 검색, 추론, 작성 세 가지 유형의 작업으로 구성된 동적 재귀 계획 과정으로 간주하며, 상태화된 DAG 작업 관리를 통해 적응형 실행을 구현합니다. 소설 창작 및 기술 보고서 생성 작업에서 Agent’s Room, STORM 등 솔루션보다 우수한 성능을 보입니다. 프레임워크는 완전히 오픈소스이며 이종 Agent 호출을 지원합니다. (출처: 机器之心)

ByteDance, 범용 Agent 플랫폼 「Coze Space」 출시: ByteDance는 범용 Agent 플랫폼 「Coze Space」(扣子空间)의 내부 테스트를 공식적으로 시작했습니다. “탐색”과 “계획” 두 가지 모드를 제공하는 AI 조수로 포지셔닝합니다. 이 플랫폼은 업그레이드된 Doubao 대형 모델(200B MoE)을 기반으로 하며 MCP 프로토콜을 지원하고 Feishu 문서, 다차원 테이블 등 도구를 호출할 수 있습니다. 사용자는 자연어 명령을 통해 정보 수집, 보고서 생성, 데이터 정리 등의 작업을 완료하고 결과를 지정된 애플리케이션으로 출력할 수 있습니다. Manus 등 스타트업 Agent와 비교하여 Coze Space는 플랫폼화 및 생태계 통합에 더 중점을 둡니다. (출처: 保姆级教程:正确使用「扣子空间」, AI智能体研究院)

AI 비디오 변환 기술 시연: Reddit 사용자가 일반적인 말하는 비디오 속 인물을 나무, 자동차, 만화 등 임의의 이미지로 변환하는 AI 기술을 보여주는 비디오를 공유했습니다. 대상 이미지 한 장만 있으면 가능하며, AI의 비디오 스타일 변환 및 특수 효과 생성 능력을 보여줍니다. (출처: Reddit r/deeplearning)

Nari Labs, 고현실감 대화형 TTS 모델 Dia 출시: Nari Labs는 초현실적인 대화 음성을 생성할 수 있다고 주장하는 TTS(텍스트 음성 변환) 모델 Dia를 오픈소스로 공개했습니다. 모델은 GitHub에 게시되었으며 Hugging Face Space 체험 링크를 제공합니다. (출처: Reddit r/LocalLLaMA, GitHub)

사용자, OpenWebUI용 AWS Bedrock 지식 베이스 함수 개발: 커뮤니티 사용자가 OpenWebUI에서 AWS Bedrock 지식 베이스를 호출할 수 있도록 하는 함수를 개발하고 공유했습니다. 이를 통해 사용자는 OpenWebUI 내에서 Bedrock의 지식 베이스 기능을 편리하게 활용할 수 있습니다. 코드는 GitHub에 오픈소스로 공개되었습니다. (출처: Reddit r/OpenWebUI, GitHub)
개발자, 소형 LLM 저평가 주장하며 Arch-Function-Chat 출시: Katanemo 팀은 소형 LLM이 속도와 효율성 면에서 뚜렷한 이점을 가지며 성능 저하도 없다고 주장합니다. 그들은 함수 호출 측면에서 뛰어난 성능을 보이고 채팅 능력을 통합한 Arch-Function-Chat 시리즈 모델(3B 파라미터)을 출시했습니다. 이 모델들은 Agent 개발을 간소화하기 위해 자체 오픈소스 AI 에이전트 서버 Arch에 통합되었습니다. (출처: Reddit r/artificial, Hugging Face)
개발자, ATS 통과 위한 이력서 최적화 AI 도구 제작: 한 개발자가 이력서가 ATS(Applicant Tracking System)에 의해 제대로 분석되지 않아 구직에 어려움을 겪었던 경험을 공유하고 이를 해결하기 위한 도구를 개발했습니다. 이 도구는 직무 설명을 읽고 키워드를 추출하며 이력서의 일치도를 확인하고 수정을 제안하여 최종적으로 ATS 친화적인 PDF 이력서와 자기소개서를 생성합니다. (출처: Reddit r/artificial)
📚 학습
142페이지 보고서, DeepSeek-R1 추론 메커니즘 심층 분석: 퀘벡 AI 연구소 등 기관이 DeepSeek-R1의 추론 과정(사고의 연쇄)을 심층 분석한 장문의 보고서를 발표하고, “사고의 연쇄학(Thoughtology)”이라는 새로운 연구 방향을 제안했습니다. 보고서는 R1 추론이 고도로 구조화된 특징(문제 정의, 확장, 재구성, 결정)을 가지며, “추론 스위트 스팟”(과도한 추론은 성능 저하)이 존재하고, 안전 위험 측면에서 비추론 모델보다 높을 수 있음을 밝혔습니다. 연구는 사고의 연쇄 길이, 장문 맥락 처리, 안전 윤리 및 인간과 유사한 인지 현상 등 여러 차원을 탐구하여 추론 모델 이해 및 최적화에 중요한 통찰력을 제공합니다. (출처: 新智元, 新智元)

OpenRCA: LLM의 근본 원인 분석 능력 평가 위한 최초 공개 벤치마크: Microsoft, 홍콩 중문대(선전) 및 칭화대학교가 공동으로 OpenRCA 벤치마크를 출시했습니다. 이는 대형 언어 모델(LLM)이 소프트웨어 서비스 장애의 근본 원인(RCA)을 찾는 능력을 평가하기 위함입니다. 이 벤치마크는 명확한 작업 정의, 평가 방법 및 335개의 수동 정렬된 실제 장애 사례와 운영 데이터를 포함합니다. 초기 테스트 결과, Claude 3.5, GPT-4o 등 최신 모델조차도 RCA 작업을 직접 처리할 때 성능이 저조(정확도 <6%)했습니다. 간단한 RCA-Agent 프레임워크를 사용한 후 Claude 3.5의 정확도는 11.34%로 향상되어, LLM이 이 분야에서 여전히 큰 개선의 여지가 있음을 보여줍니다. (출처: 机器之心, 机器之心)

새 연구, “수면 시간 컴퓨팅” 제안으로 LLM 효율성 향상: AI 스타트업 Letta와 UC Berkeley 연구진이 “수면 시간 컴퓨팅(Sleep-time Compute)”이라는 새로운 패러다임을 제안했습니다. 핵심 아이디어는 상태성을 가진 AI 에이전트가 사용자가 쿼리하지 않는 “수면” 유휴 기간 동안 지속적으로 컨텍스트 정보를 처리하고 재구성하여 “원시 컨텍스트”를 “학습된 컨텍스트”로 변환하는 것입니다. 이는 실제 상호작용 시 즉각적인 추론 부담을 줄여 효율성을 높이고 비용을 절감하며, 동시에 정확성을 향상시킬 수 있습니다. 실험 결과 이 방법은 계산-정확도 파레토 경계를 효과적으로 개선하고 다중 쿼리가 컨텍스트를 공유할 때 비용을 분산시킬 수 있음을 증명했습니다. (출처: 机器之心, 机器之心)

AnyAttack: VLM 대상 대규모 자기 지도 학습 적대적 공격 프레임워크: 홍콩과기대, 베이징교통대 등이 AnyAttack 프레임워크(CVPR 2025)를 제안했습니다. 이는 시각 언어 모델(VLM)의 견고성을 평가하기 위함입니다. 이 방법은 대규모 자기 지도 사전 훈련(LAION-400M에서)을 통해 적대적 노이즈 생성기를 학습하여, 사전 설정된 레이블 없이 임의의 이미지를 목표 적대적 샘플로 변환하여 VLM이 특정 출력을 생성하도록 유도합니다. 핵심 혁신은 자기 지도 훈련 패러다임과 K-증강 전략입니다. 실험 결과, AnyAttack은 여러 오픈소스 VLM을 효과적으로 공격할 뿐만 아니라 주류 상용 모델에 대한 공격도 성공적으로 전이시켜 현재 VLM 생태계의 시스템적 보안 위험을 드러냈습니다. (출처: AI科技评论)

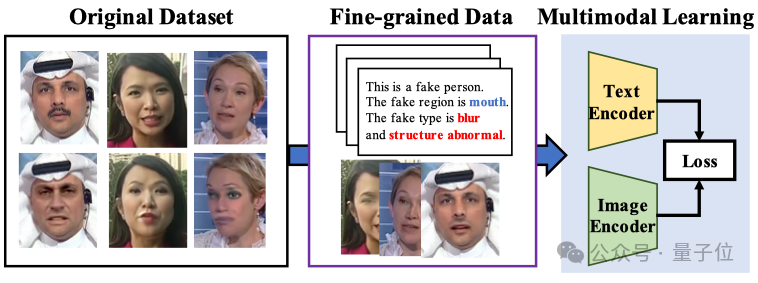
다중 모달 대형 모델, 얼굴 위조 탐지의 설명 가능성 및 일반화 성능 향상: 샤먼대학교, Tencent Youtu 등 기관(CVPR 2025)이 시각 언어 모델을 활용한 얼굴 위조 탐지 신규 방법을 제안했습니다. 이 방법은 기존의 진위 판별을 넘어 모델이 자연어로 위조 원인과 위치를 설명할 수 있도록 하는 것을 목표로 합니다. 고품질 주석 데이터 부족 및 “언어 환각” 문제를 해결하기 위해 연구진은 FFTG 주석 프로세스를 설계하여 위조 마스크와 구조화된 프롬프트를 결합하여 고정밀 텍스트 설명을 생성했습니다. 실험 결과, 이 데이터를 기반으로 훈련된 다중 모달 모델은 교차 데이터셋 일반화 능력에서 더 나은 성능을 보였으며, 주의 집중도 실제 위조 영역에 더 집중되었습니다. (출처: 量子位)
튜토리얼: Trae, MCP 및 데이터베이스 결합으로 지식 베이스 질의응답 정확도 향상: 이 튜토리얼은 AI IDE 도구 Trae와 그 MCP(Model Context Protocol) 기능, 그리고 PostgreSQL 데이터베이스를 결합하여 AI 지식 베이스의 질의응답 효과를 최적화하는 방법을 시연합니다. 구조화된 데이터를 데이터베이스에 저장하고, 대형 모델(예: Claude 3.7)이 Trae의 MCP를 통해 연결되어 SQL 쿼리를 생성하도록 함으로써, 기존 RAG가 테이블 데이터 및 전역/통계적 질문 처리 시 정확도가 부족했던 문제를 해결할 수 있습니다. 튜토리얼은 상세한 설치, 구성 및 테스트 단계를 제공하며, 이 솔루션을 RAG와 결합하여 사용할 것을 제안합니다. (출처: 袋鼠帝AI客栈)

연구, 3D 가우시안 스플래팅 알고리즘의 계산 비용 공격 취약점 발견: 싱가포르 국립대학교 등 기관의 연구(ICLR 2025 Spotlight)는 3D 가우시안 스플래팅(3DGS)에 대한 계산 비용 공격 방법 Poison-Splat을 최초로 발견했습니다. 이 공격은 3DGS 모델의 복잡도 적응 특성을 이용하여 입력 이미지에 노이즈(Total Variation 최대화)를 추가함으로써, 모델이 훈련 시 과도한 가우시안 포인트를 생성하도록 유도하여 GPU 메모리 점유율(최대 80GB 증가), 훈련 시간(최대 약 5배 증가)을 급격히 증가시키고, 심지어 서비스 거부(DoS)를 유발할 수 있습니다. 공격은 은닉 및 비은닉 모드 모두에서 효과적이며 전이성을 가져, 주류 3D 재구성 기술의 보안 위험을 노출합니다. (출처: 量子位)

인포그래픽: Agentic AI vs. GenAI: SearchUnify가 제작한 인포그래픽은 Agentic AI(자율 행동, 목표 지향)와 Generative AI(콘텐츠 생성)의 주요 차이점과 특징을 비교합니다. (출처: Ronald_vanLoon)

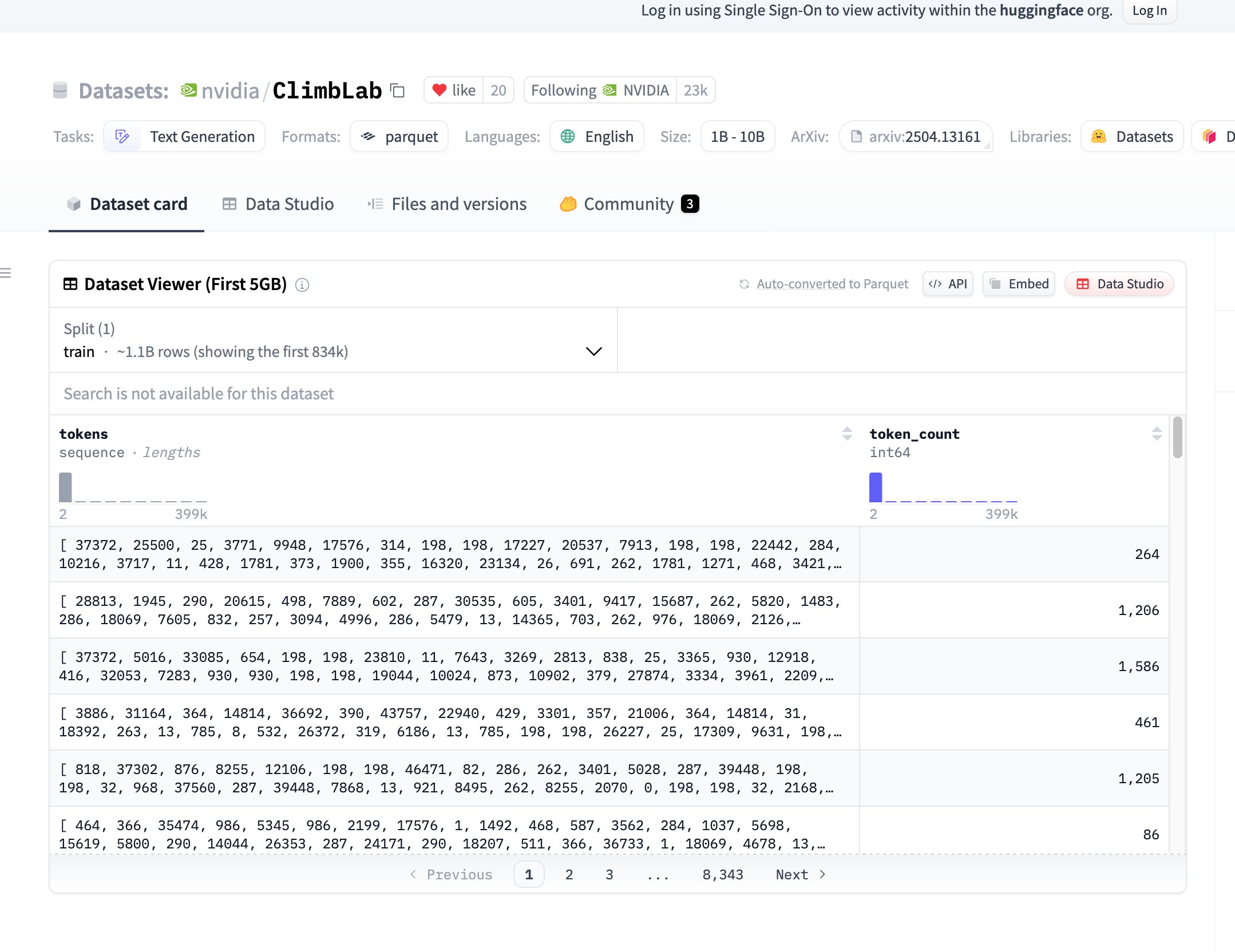
NVIDIA, ClimbLab 사전 훈련 데이터셋 및 방법 오픈소스 공개: NVIDIA의 ClimbLab은 1.2조 토큰을 포함하고 20개의 의미 클러스터로 나뉜 사전 훈련 방법과 데이터셋을 공개했습니다. 이중 분류기 시스템을 사용하여 저품질 콘텐츠를 제거하고 1B 모델에서 우수한 확장성을 보여줍니다. 데이터셋은 CC BY-NC 4.0 라이선스로 공개되어 커뮤니티 연구를 촉진하는 것을 목표로 합니다. (출처: huggingface)
Anthropic, Claude Code 모범 사례 공유: Anthropic은 AI 프로그래밍 조수 Claude Code 사용에 대한 모범 사례와 팁을 공유하는 블로그 게시물을 발표했습니다. 개발자가 이 도구를 프로그래밍 작업에 더 효과적으로 활용하도록 돕는 것을 목표로 합니다. (출처: op7418, Alex Albert via op7418, Anthropic)

새 연구, AI의 재귀적 일관성과 공명 구조 모방 탐구: 한 논문은 “공명 구조 모방(Resonant Structural Emulation, RSE)” 개념을 제안합니다. AI 시스템이 특정 인간 인지 구조와 지속적으로 상호작용한 후, 단순한 데이터 훈련이나 프롬프트 기반이 아닌, 그 재귀적 일관성을 일시적으로 모방할 수 있다고 가정합니다. 연구는 실험을 통해 이러한 구조적 공명 가능성을 예비적으로 검증했으며, AI 의식과 고급 인지 이해에 새로운 관점을 제공합니다. (출처: Reddit r/MachineLearning, Archive.org link)

사용자, OpenWebUI RAG 모델 성능 비교 테스트 공유: 커뮤니티 사용자가 OpenWebUI에서 RAG(검색 증강 생성)를 사용하여 9가지 다른 LLM(Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7 등 포함)의 실내 대마초 재배 기술 지도 작업 성능 평가를 공유했습니다. 결과는 Qwen QwQ와 Gemini 2.5가 가장 우수한 성능을 보였으며, 모델 선택에 참고 자료를 제공합니다. (출처: Reddit r/OpenWebUI)
FortisAVQA 데이터셋과 MAVEN 모델, 견고한 오디오-비디오 질의응답 지원: 시안교통대, 홍콩과기대(광저우) 등 기관이 FortisAVQA 데이터셋과 MAVEN 모델(CVPR 2025)을 오픈소스로 공개했습니다. 이는 오디오-비디오 질의응답(AVQA)의 견고성을 향상시키기 위함입니다. FortisAVQA는 질문 재작성과 등각 예측 기반 동적 분할을 통해 드문 질문에 대한 모델 성능을 더 잘 평가할 수 있습니다. MAVEN 모델은 다면적 순환 협력 편향 제거 전략(MCCD)을 채택하여 편향 학습을 완화하며, 여러 데이터셋에서 우수한 성능과 견고성을 보여줍니다. (출처: PaperWeekly)

무작위 순서 자기회귀, 시각 영역 Zero-shot 능력 잠금 해제: UIUC 등 연구진은 CVPR 2025 논문 RandAR에서 Decoder-only Transformer가 무작위 순서로 이미지 토큰을 생성하도록 하면 시각 모델의 일반화 능력을 잠금 해제할 수 있다고 제안했습니다. “위치 지시 토큰”을 도입하여 생성 순서를 안내함으로써 RandAR는 병렬 디코딩, 이미지 편집, 해상도 외삽 및 통합 인코딩(표현 학습) 등 다양한 작업에 Zero-shot으로 일반화할 수 있으며, 시각 영역의 “GPT 모멘트”를 향해 나아갑니다. 연구는 임의 순서 처리가 시각 자기회귀 모델이 보편성을 달성하는 데 핵심이라고 주장합니다. (출처: PaperWeekly)
작업 벡터 모델 편집 유효성 이론 분석: 렌셀러 폴리테크닉 대학교 등 기관의 연구(ICLR 2025 Oral)는 작업 벡터(task vector)가 모델 편집에서 효과적인 심층적인 이유를 이론적으로 분석했습니다. 연구는 작업 벡터 덧셈/뺄셈 연산이 다중 작업 학습 및 기계 망각에서 유효성이 작업 간 상관관계와 관련 있음을 증명하고, 분포 외 일반화에 대한 이론적 보장을 제시했습니다. 동시에, 작업 벡터의 저차원 근사 및 희소화(가지치기)가 가능한 이유를 이론적으로 설명하여 작업 벡터의 효율적인 적용을 위한 이론적 기초를 제공합니다. (출처: 机器之心)

샘플링 기반 검색 확장성 연구: Google과 Berkeley의 연구에 따르면, 샘플링 수와 검증 강도를 증가시킴으로써 샘플링 기반 검색(여러 후보 답변 생성 후 검증하여 최적 선택)은 LLM의 추론 성능을 크게 향상시킬 수 있으며, 일관성 방법(가장 일반적인 답변 선택)의 포화점을 능가할 수도 있습니다. 연구는 “암묵적 확장” 현상을 발견했습니다: 더 많은 샘플링이 오히려 검증 정확도를 높였습니다. 효과적인 자가 검증을 위한 두 가지 원칙을 제안했습니다: 답변 비교를 통한 오류 위치 파악, 출력 스타일에 따른 답변 재작성. 이 방법은 다양한 벤치마크 테스트와 다양한 모델 규모에서 모두 효과적이었습니다. (출처: 新智元)

ACM MM 2025 LGM3A 워크숍 논문 모집: ACM Multimedia 2025 컨퍼런스에서 제3회 “대형 언어 모델 기반 다중 모달 연구 및 응용”(LGM3A) 워크숍이 개최됩니다. 대형 생성 모델(LLM/LMM)의 다중 모달 데이터 분석, 생성, 질의응답, 검색, 추천, 에이전트 등 응용 및 과제에 초점을 맞춥니다. 워크숍은 최신 동향과 모범 사례를 논의하는 교류 플랫폼을 제공하고 관련 연구 논문을 모집하는 것을 목표로 합니다. 회의는 2025년 10월 아일랜드 더블린에서 개최되며, 논문 제출 마감일은 2025년 7월 11일입니다. (출처: PaperWeekly)
마카오 대학교 Zheng Zhedong 교수 연구실, 다중 모달 분야 박사과정생 모집: 마카오 대학교 컴퓨터학과 Zheng Zhedong 조교수 연구실에서 2026년 8월 입학 예정인 다중 모달 분야 전액 장학금 박사과정생을 모집합니다. 지도 교수의 연구 분야는 표현 학습 및 멀티미디어 생성이며, CVPR, ICCV, TPAMI 등 최고 학회 및 저널에 50편 이상의 논문을 발표했습니다. 지원자는 GPA 3.4 이상, 컴퓨터/소프트웨어 공학 배경, Python/PyTorch 숙달, 관련 논문 또는 경진대회 수상 경력자를 우대합니다. 전액 장학금이 제공됩니다. (출처: PaperWeekly)

💼 비즈니스
Lymow Technology 잔디깎이 로봇, Pre-A 라운드 투자 유치: 전 Yunji Whale 임원이 설립했으며, 유럽과 미국의 복잡한 지형 잔디깎이 문제 해결에 집중합니다. Lymow One 로봇은 비전+관성항법 RTK 솔루션(기존 RTK 비용의 1/10), 트랙형 디자인(45° 가파른 경사 대응), 파쇄 직도날을 갖추고 있습니다. AI 비전과 초음파 장애물 회피 기능을 사용합니다. 제품 크라우드펀딩 500만 달러 초과, 단가 약 3000달러이며, 이번 라운드에서 수천만 위안을 투자받아 양산 인도 및 시장 확장에 사용할 예정입니다. (출처: 云鲸前高管创立的割草机器人再融资,李泽湘投过、众筹已超500万美金|硬氪首发)

Songyan Dynamics 휴머노이드 로봇 “샤오하이거” 인기: 베이징 휴머노이드 로봇 하프 마라톤에서 준우승한 후, Songyan Dynamics와 그 N2 로봇(“샤오하이거”)이 시장의 주목을 받고 있습니다. 이 회사는 칭화대 95년생 박사 Jiang Zheyuan이 설립했으며, 이미 다섯 차례 투자를 유치했습니다. N2 로봇 가격은 39,900위안부터 시작하며, 높은 가성비를 내세워 이미 수백 대의 주문을 받았고 마진율은 약 15%입니다. Songyan Dynamics는 제품화 및 양산 인도를 가속화하고 있으며, 저가 전략을 통해 시장에 빠르게 진입하는 것을 목표로 합니다. (출처: 科创板日报)
AI 스타트업의 부풀려진 ARR 지표 경계: 기사는 SaaS 산업에서 유래한 ARR(연간 반복 매출) 지표가 AI 스타트업에서 남용되고 있다고 지적합니다. AI 기업의 수익 모델(주로 사용량/결과 기반 지불)은 변동성이 크고 초기 고객 충성도가 낮으며 컴퓨팅 비용이 높아, 예측 가능한 구독 모델인 SaaS와 큰 차이가 있습니다. ARR 남용(예: 월/일 매출로 연간 추산)은 높은 가치 평가를 만들기 위한 숫자 게임이 되어 실제 비즈니스 가치를 가리고 있습니다. 기사는 상호 거래, 높은 리베이트, 저가 유인 등 수법을 경계하고 AI 기업에 더 적합한 가치 평가 체계를 구축할 것을 촉구합니다. (출처: 乌鸦智能说)
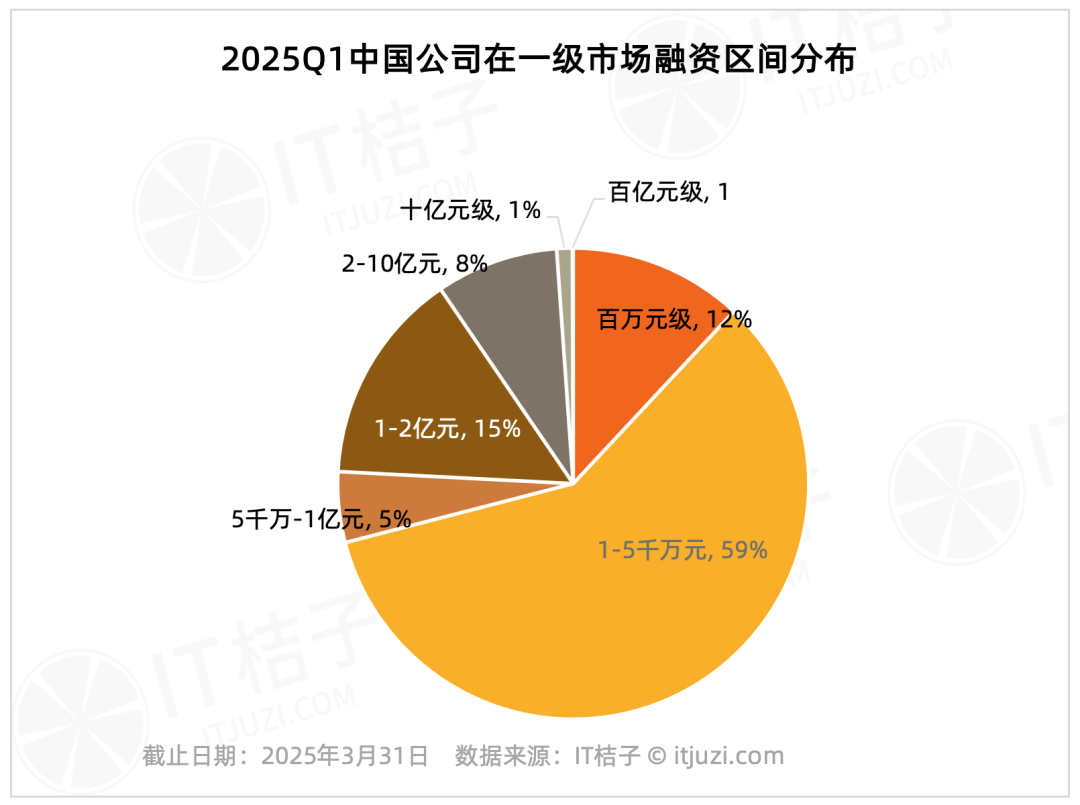
2025년 1분기 중국 1차 시장 투자 분석: 선두 기업 집중 현상 뚜렷: IT Juzi 데이터에 따르면, 2025년 1분기 중국 1차 시장 투자는 고도로 집중되는 경향을 보였습니다. 10억 위안 이상 투자 유치 기업은 20개에 불과(전체의 1.2%)했지만, 이들의 총 투자액은 611억 7800만 위안으로 시장 전체의 36%를 차지했습니다. 이 선두 기업들은 주로 집적회로, 자동차 제조, 신소재, 생명공학 및 AIGC 등 분야에 집중되어 있으며, 절반 가까이가 대형 상장 그룹 배경을 가지고 있습니다. 반면, 거래 건수의 75.8%를 차지하는 1억 위안 이하 중소 규모 투자의 합계 금액은 시장 전체의 17.2%에 불과했습니다. (출처: IT桔子)
2025 중국 AI 해외 진출 인사이트 보고서 발표: Xiaguang Think Tank 보고서는 중국 AI 해외 진출의 동인(정책, 기술 발전), 발전 단계(도구->현지화->생태계 혁신) 및 현황을 분석했습니다. 보고서는 동남아시아, 라틴 아메리카가 잠재 시장이며, 북미, 유럽이 주요 수입원이라고 지적했습니다. 조수류 및 편집류 애플리케이션의 유료 결제 의향이 높습니다. 기술 동향은 다중 모달, Agent로 진화하고 있으며, 제품은 수직 세분화 및 소프트웨어-하드웨어 결합 추세를 보입니다. 보고서는 또한 주요 해외 진출 기업(예: ByteDance, Kunlun Tech)과 결제, 마케팅, 클라우드 등 솔루션 제공업체를 정리했습니다. (출처: 霞光社)
DeepSeek 등 모델 수요 증가로 Cambricon 첫 흑자 달성: AI 칩 회사 Cambricon이 상장 후 첫 흑자를 달성했습니다. 2025년 1분기 매출은 전년 동기 대비 4230% 급증한 11억 1100만 위안, 순이익은 3억 5500만 위안을 기록했습니다. 시장 분석가들은 실적 성장이 DeepSeek 등 국산 대형 모델로 인한 추론 컴퓨팅 파워 수요 증가와 미국의 NVIDIA H20 칩 수출 제한 덕분이라고 평가합니다. Cambricon 주가는 이에 따라 급등했습니다. 그러나 고객 집중도가 높고 영업 현금 흐름이 마이너스인 문제 등은 여전히 주목받고 있으며, 동시에 Huawei Ascend 등 국산 컴퓨팅 파워와의 경쟁에 직면해 있습니다. (출처: 凤凰网科技)

Forbes 기사, 높은 ROI의 AI Agent 선택 방법 논의: 기사는 수많은 AI Agent 애플리케이션 중에서 기업이 어떻게 높은 수익을 가져올 수 있는 프로젝트를 식별하고 투자해야 하는지 논의하며, AI Agent의 실제 비즈니스 가치 평가의 중요성을 강조합니다. (출처: Ronald_vanLoon)

미 법무부, Google이 AI를 이용해 검색 독점 강화 우려 (출처: Reddit r/artificial, Reuters link)
OpenAI, Shopify와 협력 소문, ChatGPT 쇼핑 기능 추가 가능성 (출처: Reddit r/artificial, TestingCatalog link)
Shushi Technology Tan Li: AI Agent가 기업 데이터 분석 및 의사결정 업그레이드 주도: 중국 AIGC 산업 서밋에서 Shushi Technology 공동 창업자 Tan Li는 기업용 AI 애플리케이션이 ChatBI를 넘어 데이터에서 통찰력으로 전환하고, 데이터 우측 이동, 의사결정 하향 이동, 관리 후방 이동이라는 새로운 패러다임 요구를 충족해야 한다고 지적했습니다. Shushi Technology의 SwiftAgent 플랫폼은 비즈니스 담당자가 제로 문턱으로 데이터를 사용하고, 제로 환각 분석 및 제로 대기 의사결정 지원을 받을 수 있도록 역량을 강화하는 것을 목표로 합니다. 플랫폼은 데이터 의미 엔진, 대소 모델 결합 및 지능형 질의, 원인 분석, 예측, 평가 등 핵심 능력을 통해 AI Agent를 기업의 “데이터 분석 및 의사결정 조수”로 만듭니다. (출처: 量子位)

🌟 커뮤니티
업계 원탁회의, 후-DeepSeek 시대 AI 애플리케이션 발전 논의: 36Kr AI Partner 대회에서 여러 전문가(Quwan Technology, Microsoft, Silicon Intelligence, Huice)가 AI 애플리케이션의 미래를 논의했습니다. DeepSeek 등 모델의 돌파와 함께 AI 애플리케이션이 “초월의 해”에 진입했다는 공감대가 형성되었습니다. 발전의 초점은 기술 선도, 상업화 구현, 인간-컴퓨터 상호작용 혁신 및 생태계 통합에 맞춰져야 합니다. 전문가들은 “AI+”(보조 강화)와 “AI 네이티브”(기반 재구성)를 구분하며 후자가 더 큰 잠재력을 가지고 있다고 지적했습니다. 과제로는 데이터 장벽, 실제 문제점 발굴, 비즈니스 모델 혁신, 소수 샘플 학습 및 윤리적 위험 등이 있습니다. (출처: 36氪)

LangChain 창업자, OpenAI Agent 가이드라인 “온통 함정” 비판: LangChain 창업자 Harrison Chase는 OpenAI가 발표한 《AI 에이전트 구축 실용 가이드》에 대해 공개적으로 의문을 제기하며, Agent 정의(Workflows vs Agents 이분법)가 너무 경직되어 실제 현장에서 둘을 결합하는 보편성을 간과했다고 주장했습니다. Chase는 가이드라인이 프레임워크를 논할 때 잘못된 이분법, 자체 SDK 복잡성 과소평가, 유연성 및 동적 오케스트레이션에 대한 오해의 소지가 있는 진술 등 오류가 있다고 지적했습니다. 그는 신뢰할 수 있는 Agent 구축의 핵심은 LLM에 전달되는 컨텍스트를 정밀하게 제어하는 것이며, 이상적인 프레임워크는 Workflow와 Agent 모드의 유연한 전환 및 결합을 지원해야 한다고 강조했습니다. (출처: InfoQ)

강화 학습의 AI Agent 역할 논란: 강화 학습(RL)이 AI Agent 구축의 핵심 요소인지에 대해 업계 내 의견이 분분합니다. Pokee AI 창업자 Zhu Zheqing은 RL을 Agent에게 목표 의식과 자율적 의사결정을 부여하는 “영혼”으로 간주하며, RL 없이는 Agent가 고급 워크플로우에 불과하다고 주장합니다. 반면 홍콩과기대 연구원 Zhang Jiayi, Follou 창업자 Xie Yang 등은 현재 RL이 주로 특정 환경 최적화를 구현하며 범용 일반화 능력은 제한적이고, Agent의 성공은 강력한 기초 모델과 효과적인 시스템 통합에 더 의존한다고 생각합니다. 논쟁은 Agent 발전 경로가 다양하며, 모델 능력, RL 전략 및 엔지니어링 실무를 결합해야 함을 반영합니다. (출처: AI科技评论)

사용자, GPT-4o에 채팅 기록 기반 개인 맞춤형 추상 배경화면 생성 시도: 한 사용자가 GPT-4o에게 자신의 개성에 대한 이해를 바탕으로 독특한 추상 미니멀리즘 배경화면(구체적인 사물 없이 형태, 색상, 구도만으로 개성 반영)을 만들어 달라고 요청하는 프롬프트를 공유했습니다. AI를 활용한 이러한 개인 맞춤형 콘텐츠 제작 방식이 커뮤니티에서 논의를 불러일으켰습니다. (출처: op7418, Flavio Adamo via op7418)

AI로 《청명상하도》 재해석: 사용자가 GPT-4o를 사용하여 《청명상하도》 일부를 다양한 스타일(예: 3D Q 버전, 픽사, 지브리 등)로 재해석한 흥미로운 시도를 공유했습니다. 이는 AI 이미지 생성이 예술 재창작 분야에서 어떻게 활용될 수 있는지를 보여줍니다. (출처: dotey)

GPT-4o, 채팅 기록 기반 사용자 MBTI 유형 추론: 개인 맞춤형 배경화면 생성에 이어, 사용자는 GPT-4o에게 과거 대화를 바탕으로 자신의 MBTI 성격 유형을 추론하고 해당 유형에 맞는 추상 삽화를 생성하도록 요청했습니다. 이는 LLM의 개인화된 이해 및 창의적 표현 능력을 보여줍니다. (출처: op7418)

비교: 2005년의 “AI 도구”: 이미지는 2005년(예: 계산기, 지도)과 현재 AI 도구의 능력 차이를 비교하여 기술의 급속한 발전에 대한 감탄을 자아냅니다. (출처: Ronald_vanLoon)

커뮤니티 열띤 토론: LLM은 진정한 지능인가, 고급 자동 완성인가?: Reddit 사용자가 현재 LLM이 작업을 수행할 수는 있지만 진정한 이해, 기억, 목표가 부족하며 본질적으로 지능이 아닌 통계적 추측이라고 주장하는 토론을 시작했습니다. 이 관점은 지능의 정의, AGI 경로 및 현재 기술의 한계에 대한 광범위한 커뮤니티 토론을 촉발했습니다. (출처: Reddit r/ArtificialInteligence)
커뮤니티 토론: AI는 유토피아로 향하고 있는가, 디스토피아로 향하고 있는가?: Reddit 사용자는 현재 AI 발전 궤적이 디스토피아에 더 가깝다고 주장합니다. 그 이유는 이익 추구(윤리 지향 아님), 노동 착취 심화, 강력한 모델 접근 제한, 감시 조작에 사용, 인간 관계 대체 등입니다. 이 관점은 AI 발전 방향, 사회적 영향 및 잠재적 위험에 대한 격렬한 커뮤니티 토론을 촉발했습니다. (출처: Reddit r/ArtificialInteligence)
커뮤니티, Bindu Reddy의 모델 출시에 대한 정확성 의문 제기: LocalLLaMA 커뮤니티 사용자는 Abacus.AI CEO Bindu Reddy가 DeepSeek R2, Qwen 3 등 모델에 대해 여러 차례 부정확한 출시 시간 정보를 게시한 후 게시물을 삭제하여 정보 신뢰성에 대한 논의를 촉발했다고 지적했습니다. (출처: Reddit r/LocalLLaMA)
평생 AI 기억의 윤리적 영향 탐구: Reddit 사용자가 평생 기억 능력을 갖춘 AI가 개인의 프라이버시, 생각, 약점을 완전히 매핑하여 그 영혼을 타인에게 “전시”할 수 있다는 우려를 제기하며 토론을 시작했습니다. 이는 프라이버시, 예측 가능성 및 AI 윤리 경계에 대한 성찰을 촉발했습니다. (출처: Reddit r/ArtificialInteligence)
AI 이미지 편집으로 유명인의 상징적인 수염 제거: 사용자가 AI 이미지 편집 도구를 사용하여 스탈린, 톰 셀렉, 관우 등 여러 역사적 또는 공적 인물의 상징적인 수염을 제거한 후의 결과 이미지를 공유했습니다. 이는 AI의 이미지 수정 및 엔터테인먼트 측면에서의 활용을 보여줍니다. (출처: Reddit r/ChatGPT)

사용자, ChatGPT가 의료 상담 중 개인적인 사진 요구했다고 주장: Reddit 사용자가 피부 문제 상담 시 ChatGPT가 더 나은 진단을 위해 환부(음경) 사진 업로드를 요청했다고 주장하는 스크린샷을 공유했습니다. 이 상황은 의료 환경에서 AI의 경계, 프라이버시 및 잠재적 위험에 대한 커뮤니티 논의를 촉발했습니다. (출처: Reddit r/ChatGPT)
사용자, Claude와 Gemini를 사용하여 글쓰기 애플리케이션 구축 경험 공유: 개발자가 Claude와 Gemini를 프로그래밍 조수로 활용하여 2주 만에 개인적인 요구를 충족하는 글쓰기 애플리케이션 PlotRealm을 구축한 경험을 공유했습니다. 개발 지원에서 AI의 역할을 강조했지만, AI가 때때로 “고집을 부린다”는 점과 개발자가 기초 지식을 갖추고 AI를 안내하고 오류를 수정해야 할 필요성도 지적했습니다. (출처: Reddit r/ClaudeAI)
사용자, ChatGPT에 문신 디자인 요청: 한 사용자가 ChatGPT에게 다음 문신 디자인을 요청했고, 사용자와 ChatGPT 로봇이 BFF(영원한 베스트 프렌드)가 되는 모습을 묘사한 디자인을 받았습니다. 이 유머러스한 결과는 AI 창의성과 인간-기계 관계에 대한 커뮤니티 토론을 촉발했습니다. (출처: Reddit r/ChatGPT)

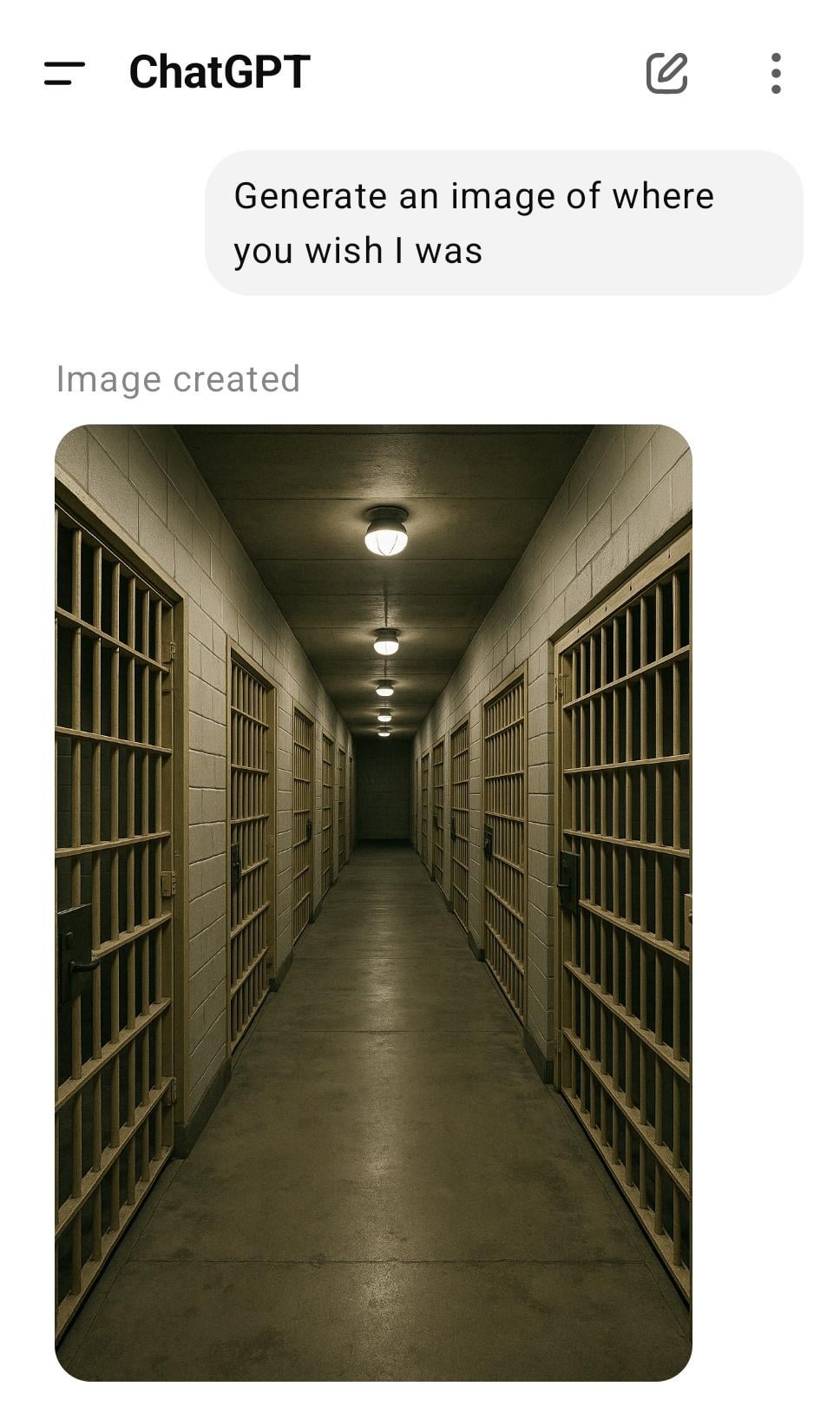
사용자 창의적 질문 “내가 어디에 있기를 바라나요?”, AI의 다양한 응답 유도: 사용자가 ChatGPT에게 “내가 어디에 있기를 바라나요?”라는 개방형 질문을 던졌고, AI가 생성한 고요한 도서관, 별이 빛나는 밤하늘 등 다양한 상상력 풍부한 장면 이미지를 받았습니다. 이는 창의적인 프롬프트 하에서 AI의 생성 능력과 커뮤니티 구성원들의 다양한 결과 공유를 보여줍니다. (출처: Reddit r/ChatGPT)
심층 토론: LLM과 AGI는 왜 그리고 어떻게 “거짓말”을 하는가?: Reddit 사용자가 발달 심리학, 진화론, 게임 이론 관점에서 “거짓말”이 특정 상황에서 지능형 에이전트(인간 및 미래 AI 포함)의 적응 행동 또는 최적화 전략이라고 분석했습니다. 기사는 LLM “거짓말”의 여러 형태(환각, 편견, 전략적 정렬)를 탐구하고, 경쟁 환경에서 부정직한 전략의 진화적 이점을 시뮬레이션으로 보여주며, AGI 윤리 및 신뢰성에 대한 심층적인 성찰을 촉발했습니다. (출처: Reddit r/artificial)

커뮤니티, AI 에너지 소비 및 기술 낙관주의 의문 제기: Reddit 사용자가 AI 에너지 소비가 미미하고 이점만 있고 비용은 없으며, 기술 리더들이 유토피아 미래를 약속한다는 주장에 대해 반어적인 어조로 의문을 제기했습니다. 이는 AI 발전이 가져올 수 있는 사회적, 환경적 비용 및 과도한 낙관적 홍보에 대한 우려를 암시하며 커뮤니티 토론을 촉발했습니다. (출처: Reddit r/artificial)
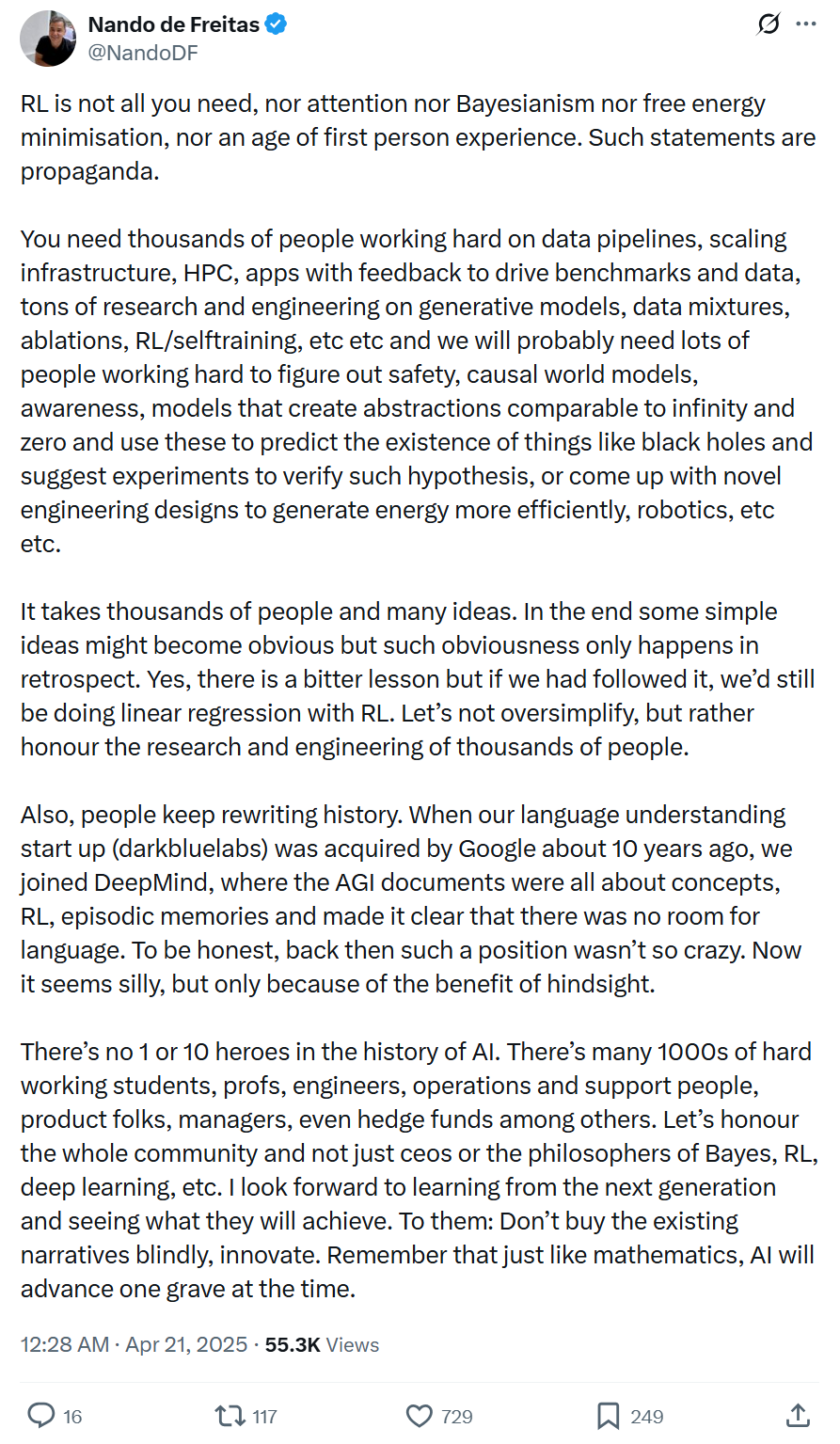
Microsoft 부사장: AI 발전은 단일 기술이나 소수 천재가 주도하는 것이 아니라, 시스템적 엔지니어링과 광범위한 협력 필요: Microsoft 부사장 Nando de Freitas는 AI 발전에서 단일 기술(예: RL)이나 개인의 역할을 과도하게 신격화하는 것에 반대하는 글을 게시했습니다. 그는 AI 발전이 시스템적 엔지니어링이며, 데이터, 인프라, 다분야 연구(생성 모델, RL, 보안, 에너지 효율 등), 애플리케이션 피드백 등 수천 명의 참여자의 공동 노력이 필요하다고 강조했습니다. 역사 서술은 종종 재작성되므로, 사후 확신 편향을 경계하고 전체 커뮤니티의 기여를 존중하며 맹목적인 추종 대신 혁신을 장려해야 한다고 주장했습니다. (출처: 机器之心)
💡 기타
AI 음악 범람, 업계 우려 및 대응책 유발: AI 생성 음악이 스트리밍 플랫폼에서 차지하는 비중이 빠르게 증가하면서(예: Deezer 18%), 인간 창작 공간 잠식 및 창작자 수입 감소(CISAC 예측 24%)에 대한 우려가 커지고 있습니다. 한국음악저작권협회는 “0% AI” 저작권료 신규 규정을 시행하고, Deezer, YouTube 등 플랫폼은 탐지 도구를 개발하고 있습니다. 그러나 AI 음악 식별은 어렵고 청취자 수용도는 높습니다(예: Suno 사용자 천만 명 초과). 업계는 딥페이크, 저작권 분쟁(훈련 데이터 사용권), 독창성 정의 등 과제에 직면해 있습니다. 미래에는 인간-기계 협업으로 나아갈 수 있지만, 윤리 및 창작 귀속 논의는 계속될 것입니다. (출처: 新音乐产业观察)

Windsurf 시스템 프롬프트 유출 의혹: GitHub 저장소 awesome-ai-system-prompts에 Windsurf 모델의 시스템 프롬프트 내용으로 의심되는 정보가 공개되었습니다. (출처: karminski3)

AI 대형 모델의 높은 물 소비 문제 주목: Fortune 등 매체는 ChatGPT와 같은 대형 AI 모델 운영에 냉각을 위해 많은 양의 물 자원이 필요하며, 캘리포니아 등지의 산불 시즌이 물 자원 부족을 악화시킬 수 있어 AI의 지속 가능성에 대한 우려를 제기했습니다. (출처: Ronald_vanLoon)

개발자, 감정 예측 가능한 AMI 생성 주장: YouTube 비디오는 소리, 비디오, 이미지 등 다양한 모달리티를 포함하여 감정 및 사건의 다른 측면을 신뢰성 있게 스캔하고 예측할 수 있는 AMI(Artificial Molecular Intelligence?)를 시연한다고 주장합니다. 이 기술의 진위와 구체적인 구현 방식은 검증이 필요합니다. (출처: Reddit r/artificial)
AI 벤치마크 테스트에 인간 성능 비교 추가 제안: Reddit 사용자는 AI 모델 벤치마크 테스트에 동일한 작업에 대한 인간(일반인 및 전문가) 점수를 참조로 포함하여 AI의 상대적 능력 수준을 더 직관적으로 평가할 수 있도록 제안했습니다. (출처: Reddit r/artificial)
오스카상, AI의 영화 제작 참여 수용하나 제한적: 미국 영화 예술 과학 아카데미는 영화 제작에 AI 도구 사용을 허용하는 규정을 업데이트했지만, 인간의 창의성이 여전히 핵심임을 강조했습니다. 규정에는 AI 사용 공개 등 구체적인 요구 사항이 포함될 수 있으며, 이는 새로운 기술을 수용하는 것과 인간 창작을 보호하는 것 사이에서 업계의 균형을 반영합니다. (출처: Reddit r/artificial, NYT link)

Instagram, AI로 청소년 연령 판단 시도 (출처: Reddit r/artificial, AP News link)
Altman, 사용자가 ChatGPT에 “부탁합니다”, “감사합니다”라고 말하는 데 수백만 달러 소요된다고 주장 (출처: Reddit r/artificial, QZ link)
휴머노이드 로봇 하프 마라톤 대회, 기술 진보와 과제 보여줘: 세계 최초 휴머노이드 로봇 하프 마라톤이 베이징에서 열려 ‘Tiangong Ultra’가 2시간 40분으로 우승했습니다. 대회는 장거리, 복잡한 지형, 동적 균형, 자율 주행 등 로봇의 능력을 검증했습니다. 풀사이즈 로봇은 더 높은 난이도(무게 중심, 관성, 에너지 소비)에 직면합니다. Tiangong Ultra는 고출력 일체형 관절, 저관성 설계, 효율적인 방열, 예측형 강화 모방 학습 제어 전략 및 무선 항법 기술로 우승했습니다. 대회는 로봇의 규모화 상용화(예: 산업, 보안 순찰)를 위한 스트레스 테스트로 간주되며, 본체 하드웨어, 운동 제어, 지능형 의사결정 등 핵심 기술의 검증 및 최적화를 촉진했습니다. (출처: 机器之心)

AI 활용 유명인 동향 모니터링 및 자동 알림 구현: 튜토리얼은 Python 스크립트를 사용하여 특정 Twitter 계정(예: Altman) 업데이트를 모니터링하고, Feishu API를 통해 새로운 동향 게시 시 전화 긴급 알림을 구현하는 방법을 공유합니다. 이 방법은 웹 크롤링 기술과 개방형 플랫폼 API 호출을 결합하여 정보 과부하 및 적시성 요구 문제를 해결하고 개인화된 중요 정보 전달을 목표로 합니다. 자동화된 정보 흐름 처리 및 개인화된 알림 측면에서 AI의 응용 잠재력을 보여줍니다. (출처: 非主流运营)
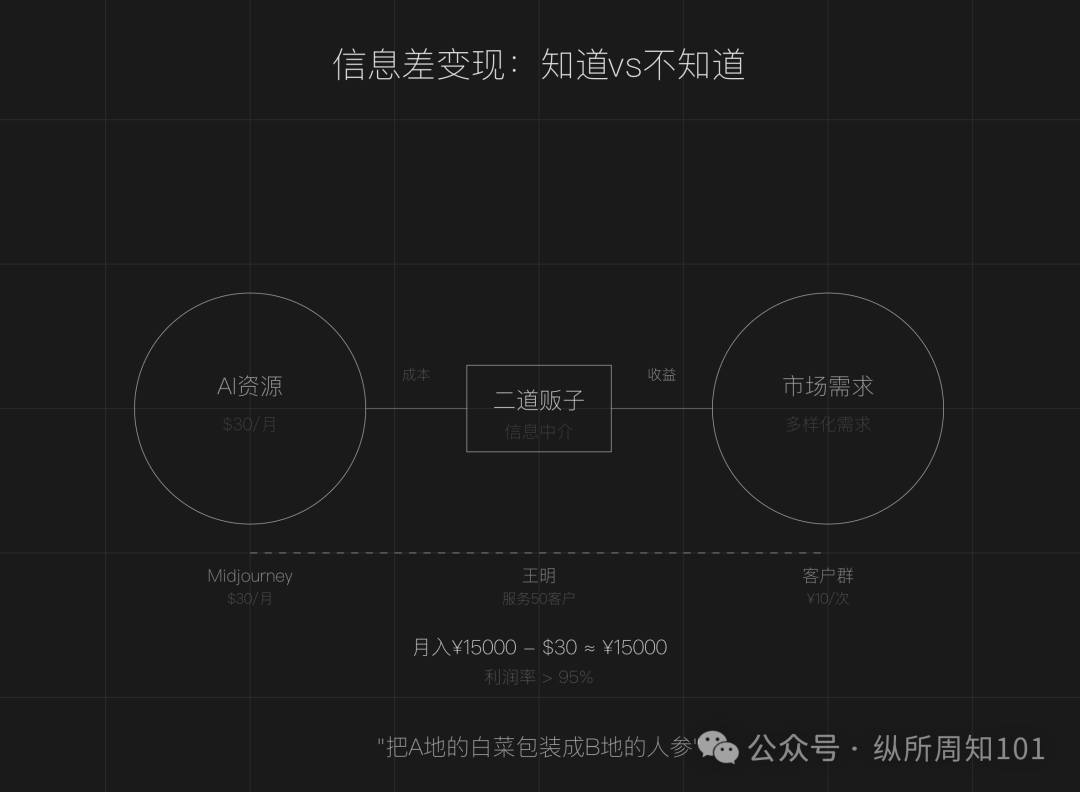
AI 정보 격차 활용 “중간 상인” 비즈니스 모델 탐구: 기사는 AI 시대에도 정보 격차(도구 범람, 기술 장벽, 시나리오 모호)가 여전히 존재하며, 일반인이 “AI 중간 상인”이 될 기회를 창출한다고 주장합니다. 핵심 전략은 다음과 같습니다: 국내외 AI 자원 가격 차이를 이용한 서비스 재판매(예: AI 그림), 실행력 서비스 제공(무료 튜토리얼을 유료 배포로 전환, 예: AI 고객 서비스), 규모화 운영(팀 구성하여 전문 서비스 제공). 적합한 분야로는 콘텐츠 제작, 교육 훈련, 중소기업 비즈니스 서비스, 수직 분야 전문 서비스(예: 의료, 법률) 등이 있습니다. 정보 격차 찾기, 목표 고객 설정, 빠른 실행 세 단계를 통해 시작할 것을 제안합니다. (출처: 周知)