
키워드:Gemini 2.5 Flash, OpenAI o3, AI 직업 대체, AI 의료 상용화, 하이브리드 추론 모델, 사고 예산 기능, o4-mini 멀티모달 능력, AI 코딩 어시스턴트 Windsurf, 에이전트 AI 홈 게이트웨이, VisualPuzzles 벤치마크 테스트, DeepSeek 추천 신뢰성, 지푸AI 오픈소스 모델
🔥 포커스
구글, 가성비와 제어 가능한 사고 강조한 Gemini 2.5 Flash 하이브리드 추론 모델 발표: 구글이 고가성비 하이브리드 추론 모델로 포지셔닝한 Gemini 2.5 Flash 프리뷰 버전을 출시했습니다. 독특한 점은 개발자(0-24k 토큰)나 모델 자체가 작업 복잡성에 따라 추론 깊이를 조절할 수 있는 “thinking_budget” 기능을 도입했다는 것입니다. 사고 기능을 껐을 때는 비용이 매우 낮으며($0.6/백만 토큰 출력), 성능은 2.0 Flash보다 우수합니다. 사고 기능을 켰을 때($3.5/백만 토큰 출력)는 복잡한 작업을 처리할 수 있으며, 여러 벤치마크(예: AIME, MMMU, GPQA)에서 o4-mini에 필적하는 성능을 보이고 LMArena 경쟁 순위에서도 상위권에 올랐습니다. 이 모델은 성능, 비용, 지연 시간의 균형을 맞추는 것을 목표로 하며, 특히 유연성과 비용 제어가 필요한 애플리케이션 시나리오에 적합합니다. Google AI Studio와 Vertex AI에서 API를 제공하고 있습니다. (출처: 谷歌首款混合推理Gemini 2.5登场,成本暴降600%,思考模式一开,直追o4-mini、谷歌大模型“性价比之王”来了,混合推理模型,思考深度可自由控制,竞技场排名仅次于自家Pro、op7418、JeffDean、Reddit r/LocalLLaMA、Reddit r/LocalLLaMA、Reddit r/artificial)

OpenAI, 추론 및 멀티모달 능력 강화한 o3 및 o4-mini 모델 발표: OpenAI가 추론, 프로그래밍, 멀티모달 이해 능력을 중점적으로 향상시킨 역대 최강 모델 시리즈 o3와 최적화된 o4-mini를 출시했습니다. 특히 이미지 기반의 “chain-of-thought” 추론을 최초로 구현하여, 사진을 보고 정확한 촬영 장소를 추론하는(GeoGuessing) 등 이미지 세부 정보를 분석하여 복잡한 판단을 내릴 수 있습니다. o3는 Mensa IQ 테스트에서 136점으로 신기록을 세웠으며, 프로그래밍 벤치마크에서도 우수한 성능을 보였습니다. o4-mini는 높은 효율과 낮은 비용을 유지하면서도 강력한 수학 문제 해결(예: Euler 문제) 및 시각 처리 능력을 보여주었습니다. 이 모델들은 ChatGPT Plus, Pro, Team 사용자에게 공개되었으며, OpenAI가 모델을 지식 습득에서 도구 사용 및 복잡한 문제 해결로 발전시키고 있음을 보여줍니다. (출처: 实测o3/o4-mini:3分钟解决欧拉问题,OpenAI最强模型名副其实、智商136,o3王者归来,变身福尔摩斯“AI查房”,一张图秒定坐标、满血版o3探案神技出圈,OpenAI疯狂暗示:大模型不修仙,要卷搬砖了)

AI 효율성 향상으로 고용 불안 야기, 일부 기업 AI로 일자리 대체 시작: 인공지능 기술의 높은 효율성으로 인해 PayPal, Shopify, United Wholesale Mortgage 등의 기업들이 특히 고객 서비스, 초급 영업, IT 지원, 데이터 처리 분야에서 AI로 인간의 일자리를 대체하는 것을 고려하거나 실제로 사용하기 시작했습니다. 예를 들어, PayPal의 AI 챗봇은 이미 고객 서비스 요청의 80%를 처리하여 비용을 크게 절감했습니다. United Wholesale Mortgage는 AI를 사용하여 모기지 대출 문서를 처리함으로써 효율성을 대폭 향상시켰고, 업무량이 두 배로 늘었음에도 인력을 충원할 필요가 없었습니다. 일부 회사는 심지어 “zero-employee team” 개념을 제시하며, 신규 인력 채용 시 AI가 해당 업무를 수행할 수 없음을 먼저 증명하도록 요구하고 있습니다. 많은 기업이 AI로 인한 감원을 공개적으로 인정하지는 않지만, 채용 둔화와 일자리 감축은 이미 추세가 되었으며, 특히 비용 압박 하에서 향후 AI가 화이트칼라 직업을 대체하는 효과는 더욱 뚜렷해질 것으로 예상됩니다. (출처: 招聘慢了、岗位少了,AI效率太高迫使人类员工“让位”)

OpenAI, 약 30억 달러에 AI 코딩 어시스턴트 Windsurf 인수 추진, 애플리케이션 레이어 강화: OpenAI가 약 30억 달러에 AI 코딩 스타트업 Windsurf(구 Codeium)를 인수할 계획이며, 이는 OpenAI의 최대 규모 인수가 될 것입니다. Windsurf는 Cursor와 유사한 AI 코딩 보조 도구를 제공하며, 마찬가지로 Anthropic 모델을 기반으로 합니다. 이번 인수는 OpenAI가 애플리케이션 레이어로 확장하고 생태계 통제권을 강화하는 핵심 단계로 간주되며, 사용자를 직접 확보하고 훈련 데이터를 수집하며 GitHub Copilot, Cursor 등 경쟁사와 경쟁하는 것을 목표로 합니다. 분석가들은 AI 능력이 향상됨에 따라 “Vibe Coding”(AI가 개발 프로세스에 깊숙이 통합되는 것)이 추세가 되고 있으며, 애플리케이션 레이어 진입점과 사용자 데이터를 장악하는 것이 모델 회사의 장기적인 경쟁력에 중요하다고 보고 있습니다. OpenAI의 이러한 움직임은 모델 제공자를 넘어 완전한 AI 개발 플랫폼을 구축하려는 전략적 목표를 보여줍니다. (출처: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
🎯 동향
ByteDance, Doubao 1.5 딥 씽킹 모델 및 멀티모달 업데이트 발표, Agent 레이아웃 가속화: ByteDance 산하 Volcano Engine이 Doubao 1.5 딥 씽킹 모델을 발표했습니다. 이 모델은 인간과 유사한 “보면서 생각하고 검색하는” 능력을 갖추고 복잡한 작업을 처리할 수 있으며, 멀티모달 입력(텍스트, 이미지)을 지원하고 인터넷 검색 및 시각적 추론 능력을 갖추었습니다. 동시에 Doubao 텍스트-이미지 변환 모델 3.0(텍스트 레이아웃 및 이미지 사실감 향상)과 업그레이드된 시각 이해 모델(위치 정확도 및 비디오 이해도 향상)을 발표했습니다. ByteDance는 딥 씽킹과 멀티모달이 Agent 구축의 기초라고 보고 있으며, 기업이 Agent 애플리케이션을 구축하고 배포하는 데 드는 장벽과 비용을 낮추기 위해 OS Agent 솔루션 및 AI 클라우드 네이티브 추론 스위트를 출시했습니다. 이는 DeepSeek 등 경쟁 제품의 충격 이후 ByteDance가 전략을 재정비하고 Agent 애플리케이션 실현에 힘을 쏟는 것으로 간주됩니다. (출처: 字节按下 AI Agent 加速键、被DeepSeek打蒙的豆包,发起反攻了)

ByteDance와 Kuaishou, AI 비디오 생성 분야에서 재격돌, 모델 성능과 실현에 초점: ByteDance가 Seaweed-7B 비디오 생성 모델을 발표하며 낮은 파라미터(7B), 높은 효율성(66.5만 H100 GPU 시간 훈련), 낮은 배포 비용(단일 GPU로 1280×720 비디오 생성 가능)을 강조했습니다. Kuaishou는 “Kling 2.0” 비디오 생성 모델과 “KeTu 2.0” 이미지 생성 모델을 발표하며 구글 Veo2와 Sora를 능가하는 성능을 주장하고 멀티모달 편집 기능 MVL을 출시했습니다. 양측 모두 모델 능력이 AI 제품의 상한선임을 인식하고 2025년 전략의 초점을 모델 개선으로 되돌렸습니다. 상업화 경로는 다르지만(ByteDance의 Jiemeng은 C단에 치우치고, Kuaishou의 Kling은 B단에 중점), 모두 실용성 향상에 주력하고 있습니다. 예를 들어 Kuaishou는 이미지-비디오 변환의 중요성을 강조하고, ByteDance는 텍스트 처리 우위를 활용하여 비디오 서사의 일관성을 보장하는 등 경쟁이 치열해지고 있습니다. (출처: 字节快手,AI视频“狭路又相逢”)

Zhipu AI, 3가지 오픈소스 모델 발표하며 오픈소스 생태계 구축 강화: Zhipu AI가 2025년을 “오픈소스의 해”로 선언하고 GLM-Z1-Air(추론 모델), GLM-Z1-Air(오타로 추정, 초고속 버전 또는 기반 모델 의심), GLM-Z1-Rumination(숙고 모델) 세 가지 모델을 발표했습니다. 모델 크기는 9B와 32B이며 MIT 라이선스를 채택했습니다. GLM-Z1-Air(32B)는 일부 벤치마크 테스트에서 DeepSeek-R1에 근접한 성능을 보이며 추론 가격을 대폭 낮췄습니다. 숙고 모델 Z1-Rumination은 더 깊은 수준의 사고를 탐구하며 연구 폐쇄 루프를 지원합니다. 동시에 Zhipu Z 펀드는 Zhipu 모델 기반 프로젝트에 국한하지 않고 전 세계 AI 오픈소스 커뮤니티를 지원하기 위해 3억 위안을 출자한다고 발표했습니다. 이는 베이징시의 “글로벌 오픈소스 허브” 구축 전략에 부응하는 조치입니다. (출처: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Agentic AI를 홈 게이트웨이에 내장하는 것이 통신사의 새로운 기회가 될 수 있음: AI가 생성형에서 에이전트형(Agentic AI)으로 진화함에 따라 자율적인 목표 설정 및 작업 수행 능력을 갖춘 AI 시스템이 주목받고 있습니다. MediaTek 임원은 Agentic AI를 홈 게이트웨이에 내장하는 것이 사물인터넷(IoT) 시장에서 통신사의 역할을 바꿀 수 있다고 제안했습니다. 홈 네트워크의 엣지 인텔리전스 허브인 게이트웨이는 Agentic AI와 결합하여 네트워크를 능동적으로 관리하고(예: 화상 통화 최적화), 장애를 진단하며, 가정 보안을 향상시킬 수 있습니다(예: 택배 도난, 어린이가 수영장에 접근하는 위험 식별). 이를 통해 통신사의 고객 서비스 비용을 절감하고(AI가 대량의 Wi-Fi 관련 문의 처리 가능) 부가 가치 서비스를 제공할 수 있습니다. 수익 모델은 아직 탐색 중이지만, 이는 통신사가 “파이프라인” 역할을 넘어 Agentic AI 서비스 제공자가 될 수 있는 잠재적인 경로를 제공합니다. (출처: 将Agentic AI嵌入家庭网关,如何改变运营商在物联网市场的游戏规则?)
Microsoft, DeepSeek R1 기반으로 안전 및 규정 준수 후훈련된 MAI-DS-R1 발표: Microsoft AI 팀이 DeepSeek R1을 기반으로 후훈련(post-training)된 MAI-DS-R1 모델을 발표했습니다. 이 모델은 원본 모델의 정보 공백을 메우고 위험 상태를 개선하는 동시에 R1의 추론 능력을 유지하는 것을 목표로 합니다. 훈련 데이터에는 Tulu 3 SFT의 11만 개 안전 및 비준수 샘플과 Microsoft 내부에서 개발한 약 35만 개의 다국어 샘플이 포함되어 있으며, 편견이 있는 다양한 주제를 다룹니다. 이 조치는 일부 커뮤니티 구성원들에게 Microsoft가 모델 안전성과 규정 준수를 향상시키려는 노력으로 해석되지만, “기업 수준의 검열”이 추가되었는지에 대한 논의도 불러일으켰습니다. (출처: Reddit r/LocalLLaMA)

🧰 도구
OpenAI, 터미널 기반 AI 코딩 어시스턴트 Codex CLI 오픈소스 공개: OpenAI가 개발자 로컬 터미널에서 실행되는 코딩 작업 최적화 AI 에이전트인 새로운 오픈소스 프로젝트 Codex CLI를 발표했습니다. 기본적으로 최신 o4-mini 모델을 사용하지만, 사용자는 API를 통해 다른 OpenAI 모델을 선택할 수 있습니다. Codex CLI는 채팅 기반 개발 방식을 제공하여 로컬 코드베이스 작업을 이해하고 실행하며, Anthropic의 Claude Code 및 Cursor, Windsurf와 같은 도구와 경쟁하는 것을 목표로 합니다. 이 프로젝트는 출시 하루 만에 GitHub에서 14,000개 이상의 스타를 받으며 개발자들이 터미널 네이티브 AI 코딩 도구에 대한 관심을 보여주었습니다. (출처: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
Google AI Studio 업그레이드, AI 애플리케이션 직접 생성 및 공유 지원: Google이 AI Studio 플랫폼을 업데이트하여 플랫폼 내에서 직접 AI 애플리케이션을 생성하는 기능을 추가했습니다. 사용자는 Gemini 등 모델을 사용하여 개발할 수 있을 뿐만 아니라 다른 사용자가 만든 예제 애플리케이션을 탐색하고 사용해 볼 수 있습니다. 이번 업그레이드를 통해 AI Studio는 모델 실험장에서 보다 완전한 애플리케이션 개발 및 공유 플랫폼으로 진화하여 Google AI 기술 기반 애플리케이션 구축의 장벽을 낮췄습니다. (출처: op7418)
NVIDIA cuML, 코드 변경 없는 GPU 가속 모드 출시: NVIDIA cuML 팀이 사용자가 코드를 전혀 수정하지 않고도 네이티브 scikit-learn, umap-learn, hdbscan 코드를 GPU에서 직접 실행할 수 있는 새로운 가속기 모드를 발표했습니다. 이 기능은 python -m cuml.accel your_script.py 명령이나 Jupyter Notebook에서 %load_ext cuml.accel을 로드하여 구현됩니다. 벤치마크 테스트 결과 Random Forest, Linear Regression, t-SNE, UMAP, HDBSCAN 등의 알고리즘에서 25배에서 175배에 달하는 현저한 가속 효과를 얻을 수 있습니다. 이 모드는 CUDA 통합 메모리(UVM)를 활용하므로 일반적으로 데이터셋 크기에 대해 걱정할 필요가 없지만, 초대형 메모리 데이터셋의 성능은 영향을 받을 수 있습니다. (출처: Reddit r/MachineLearning)

Alibaba, 시작-끝 프레임 비디오 모델 Wan 2.1 오픈소스 공개: Alibaba가 시작 프레임과 끝 프레임을 기반으로 중간 비디오 콘텐츠를 생성하는 데 중점을 둔 Wan 2.1 비디오 모델을 오픈소스화했습니다. 이는 비디오 보간, 스타일 변환 또는 키프레임 기반 애니메이션 생성과 같은 장면에 적용될 수 있는 특정 유형의 비디오 생성 기술입니다. 이 모델의 오픈소스 공개는 연구자와 개발자에게 해당 기술을 탐색하고 활용할 수 있는 새로운 도구를 제공합니다. (출처: op7418)
ViTPose: Vision Transformer 기반 인체 자세 추정 모델: ViTPose는 Vision Transformer(ViT) 아키텍처를 활용하여 인체 자세를 추정하는 새로운 모델입니다. 이 글은 해당 모델을 소개하며, 컴퓨터 비전 작업(여기서는 인체 자세 추정)에서 ViT의 적용 잠재력을 탐구합니다. 이러한 유형의 모델은 일반적으로 Transformer의 셀프 어텐션 메커니즘을 활용하여 이미지 내 각 부분 간의 장거리 의존성을 포착함으로써 자세 추정의 정확성과 견고성을 향상시킬 수 있습니다. (출처: Reddit r/deeplearning)

ClaraVerse: n8n을 통합한 로컬 우선 AI 어시스턴트: ClaraVerse는 Ollama 기반으로 실행되며 프라이버시와 로컬 제어를 강조하는 로컬 우선 AI 어시스턴트입니다. 최신 업데이트는 n8n 자동화 플랫폼을 통합하여 사용자가 외부 서비스 없이 어시스턴트 내부에서 사용자 지정 도구 및 워크플로우(예: 메일 확인, 캘린더 관리, API 호출, 데이터베이스 연결 등)를 구축하고 실행할 수 있도록 합니다. 이를 통해 Clara는 자연어 명령을 통해 로컬 자동화 작업을 트리거할 수 있으며, 사용자 친화적이고 의존성이 낮은 로컬 AI 및 자동화 솔루션을 제공하는 것을 목표로 합니다. (출처: Reddit r/LocalLLaMA)
CSM 1B TTS 모델, 실시간 스트리밍 처리 및 파인튜닝 구현: 오픈소스 커뮤니티가 CSM 1B 텍스트 음성 변환(TTS) 모델에서 실시간 스트리밍(real-time streaming) 처리를 구현하고 파인튜닝(LoRA 및 전체 파인튜닝 포함) 기능을 개발하는 데 진전을 이루었습니다. 이는 해당 모델이 이제 더 빠르게 음성을 생성하고 특정 요구 사항에 맞게 사용자 정의할 수 있음을 의미합니다. 코드 저장소는 로컬 채팅 데모를 제공하며, 사용자는 이를 시도하고 다른 TTS 모델과 효과를 비교할 수 있습니다. (출처: Reddit r/LocalLLaMA)
Deebo: MCP를 활용한 AI Agent 협업 디버깅: Deebo는 코딩 AI Agent가 복잡한 디버깅 작업을 아웃소싱할 수 있도록 설계된 실험적인 Agent MCP(Machine Collaboration Protocol) 서버입니다. 주 Agent가 어려움에 직면했을 때 MCP를 통해 Deebo 세션을 시작할 수 있습니다. Deebo는 여러 하위 프로세스를 생성하여 다른 Git 브랜치에서 병렬로 다양한 수정 방안을 테스트하고 LLM을 사용하여 추론합니다. 최종적으로 로그, 수정 제안 및 설명을 반환합니다. 이 방법은 프로세스 격리를 활용하여 동시성 관리를 단순화하고 AI Agent 간의 협업 문제 해결 가능성을 탐색합니다. (출처: Reddit r/OpenWebUI)
📚 학습
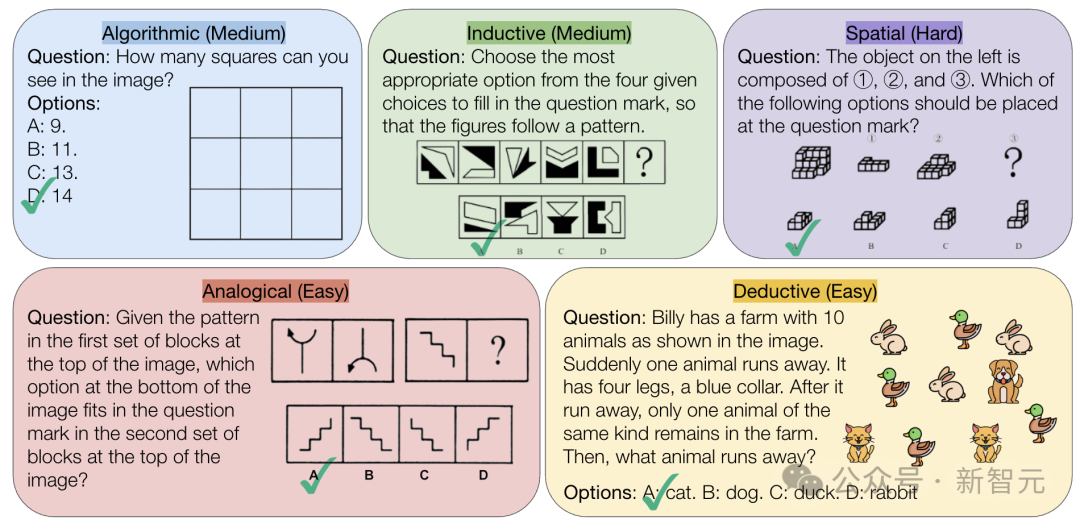
CMU, AI의 순수 논리 추론 능력에 도전하는 VisualPuzzles 벤치마크 발표: 카네기 멜런 대학교(CMU) 연구진이 공무원 시험 등에서 발췌한 1168개의 시각 논리 퍼즐을 포함하는 VisualPuzzles 벤치마크를 만들었습니다. 이는 멀티모달 추론 능력과 도메인 지식 의존성을 분리하기 위한 것입니다. 테스트 결과, o1, Gemini 2.5 Pro와 같은 최고 수준의 모델조차도 이러한 순수 논리 추론 작업에서는 인간보다 훨씬 낮은 성능을 보였습니다(최고 정답률 57.5%, 인간 하위 5% 수준보다 낮음). 연구에 따르면 모델 규모를 늘리거나 “사고” 모드를 활성화하는 것이 항상 순수 추론 능력을 향상시키는 것은 아니며, 기존 추론 향상 기술의 효과는 고르지 않았습니다. 이는 현재 대형 모델이 공간 이해 및 심층 논리 추론 측면에서 여전히 상당한 격차가 있음을 보여줍니다. (출처: 全球顶尖AI来考公,不会推理全翻车,致命缺陷曝光,被倒数5%人类碾压)
InternVL3: 오픈소스 멀티모달 모델의 고급 훈련 및 테스트 기술 탐구: 논문 《InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models》는 InternVL3 모델을 소개하며, 78B 버전은 MMMU 벤치마크에서 72.2점을 얻어 오픈소스 MLLM 신기록을 세웠습니다. 핵심 기술에는 네이티브 멀티모달 사전 훈련, 긴 컨텍스트를 지원하는 가변 시각 위치 인코딩(V2PE), 고급 후훈련 기술(SFT, MPO), 테스트 시 확장 전략(수학 추론 강화)이 포함됩니다. 이 연구는 오픈소스 멀티모달 모델의 성능을 향상시키는 효과적인 방법을 탐구하는 것을 목표로 하며, 훈련 데이터와 모델 가중치를 공개했습니다. (출처: Reddit r/deeplearning)

Geobench: 대형 모델의 이미지 지리 위치 추정 능력 평가 벤치마크: Geobench는 대형 언어 모델(LLM)이 Google Street View 등 이미지를 기반으로 촬영 장소를 추론하는 능력(GeoGuessr 게임과 유사)을 측정하기 위해 특별히 제작된 새로운 벤치마크 웹사이트입니다. 모델 추측의 정확성, 즉 국가/지역 정답률, 실제 장소와의 거리(평균 및 중앙값) 등의 지표를 평가합니다. 초기 결과에 따르면 Google의 Gemini 시리즈 모델이 이 작업에서 두드러진 성능을 보였으며, 이는 Google Street View 데이터에 접근할 수 있는 이점 덕분일 수 있습니다. (출처: Reddit r/LocalLLaMA)
데이터셋 분할의 표준 관행 논의: Reddit 머신러닝 커뮤니티에서 표준 분할이 없을 때 데이터셋(예: train/val/test split)을 처리하는 방법에 대해 논의했습니다. 일반적인 방법으로는 무작위 분할 생성(재현성에 영향을 미칠 수 있음), 특정 인덱스/파일 저장 및 공유, k-fold 교차 검증 사용 등이 있습니다. 논의에서는 소규모 데이터셋의 경우 분할 방식이 성능 평가 및 SOTA 선언에 상당한 영향을 미치므로, 연구의 재현성과 비교 가능성을 높이기 위해 분할 정보의 표준화 또는 광범위한 공유를 촉구했습니다. 실제적인 어려움으로는 통일된 플랫폼과 분야별 규범의 부재가 있습니다. (출처: Reddit r/MachineLearning、Reddit r/MachineLearning)
Stack Overflow 게시물 분류를 위한 문장 임베딩 사용 조언 요청: 한 사용자가 Reddit에서 Stack Overflow 게시물(제목, 설명, 태그, 답변 포함)을 문장 임베딩(예: BERT, SBERT)을 사용하여 비지도 방식으로 분류하는 방법에 대한 조언을 구했습니다. 목표는 단순한 단어 임베딩 태그(예: “패키지 설치”)를 넘어 문장 수준의 분류를 구현하여 더 깊은 수준의 주제 또는 문제 유형 클러스터링을 탐색하는 것입니다. 댓글에서는 텍스트 단락에 대한 단일 임베딩을 생성한 다음 클러스터링 알고리즘을 적용할 수 있는 Sentence Transformers 라이브러리로 시작할 것을 제안했습니다. (출처: Reddit r/MachineLearning)
AI 학습 경로 및 직업 선택에 대한 조언: 한 고등학생이 Reddit에서 머신러닝 엔지니어링 분야 진출을 위한 대학 전공 선택(UCSD CS vs Cal Poly SLO CS)과 대학원 진학 필요성에 대해 문의했습니다. 댓글에서는 연구 역량이 더 강한 UCSD를 선택하고 대학원 진학을 고려할 것을 권장했습니다. ML 엔지니어링은 일반적으로 더 높은 학력을 요구하기 때문입니다. 동시에 실무 기술도 중요하며 수학과 통계학도 핵심 기초라고 지적하는 사람도 있었습니다. 다른 게시물에서는 AI를 활용하거나 개발하는 전공에 대해 질문했고, 댓글에서는 일반적으로 석박사 학위가 필요한 컴퓨터 과학(CS)과 수학/통계학을 언급했으며, 심지어 AI 대체 위험을 피하기 위해 배관공과 같은 실용적인 기술을 배우라는 조언도 있었습니다. (출처: Reddit r/MachineLearning、Reddit r/ArtificialInteligence)
💼 상업
AI 의료 상업화 탐색: 대기업 전략과 병원 수요의 줄다리기: 병원들이 대형 모델에 예산을 투입하기 시작하면서(예: 장쑤성 성급 기관 병원, DeepSeek 기반 플랫폼에 450만 위안 투자), 의료 분야 AI 상업화가 가속화되고 있습니다. Huawei, Alibaba, Baidu, Tencent 등 대기업들이 앞다투어 진출하고 있으며, 일반적으로 컴퓨팅 파워, 클라우드 서비스, 기본 모델을 제공하고 의료 전문 회사와 협력합니다. 그러나 핵심 비즈니스 모델은 여전히 불분명하며, 대기업들은 현재 의료 AI 애플리케이션에 직접적으로 깊이 관여하기보다는 하드웨어 및 클라우드 서비스 판매에 더 중점을 두고 있습니다. 병원 측(예: 산시성 한중 3201 병원)은 예산이 제한된 상황에서 오픈소스 모델(예: 저사양 DeepSeek)을 사용하여 시도하고 있으며, 이는 비용 효율성에 대한 고려를 보여줍니다. 고품질 의료 데이터를 확보하고 전문 모델을 훈련하는 것은 여전히 핵심 과제이며, 데이터 라벨링과 같은 “고된 작업”을 극복해야 합니다. (출처: AI看病这件事,华为、百度、阿里谁先挣到钱?、科技大厂掀起医疗界的AI革命,谁更有胜算?)
DeepSeek 등 AI 추천 도구의 신뢰성 의문 제기, AI 마케팅 최적화가 새로운 전쟁터로: DeepSeek과 같은 AI 도구가 추천(예: 레스토랑, 제품)을 얻기 위해 점점 더 많은 사용자에 의해 사용되고 있으며, 상인들도 “DeepSeek 추천”을 마케팅 태그로 사용하기 시작했습니다. 그러나 이러한 추천의 신뢰성에 대한 우려가 제기되고 있습니다. 한편으로는 AI가 “환각”을 일으켜 존재하지 않는 가게를 만들거나 오래된 제품을 추천할 수 있습니다. 다른 한편으로는 AI의 답변이 상업적 영향을 받아 광고가 삽입되거나 SEO/GEO(생성형 엔진 최적화) 전략에 의해 “오염”될 위험이 있습니다. 상인들은 콘텐츠, 키워드를 최적화하여 AI의 말뭉치와 검색 결과에 영향을 미침으로써 자체 브랜드 노출도를 높이려고 시도하고 있습니다. 이로 인해 AI 추천의 객관성이 도전을 받고 있으며, 소비자는 잠재적인 오해의 소지가 있는 정보에 주의해야 합니다. (출처: 第一批用DeepSeek推荐的人,已上当)

Zhipu AI, 베이징시 인공지능 산업 투자 펀드로부터 2억 위안 추가 투자 유치: 여러 신규 오픈소스 모델을 발표하고 3억 위안 규모의 오픈소스 펀드를 설립한 후, Zhipu AI(Z.ai)는 베이징시 인공지능 산업 투자 펀드로부터 2억 위안의 추가 투자를 받았습니다. 이 펀드는 작년에 이미 Zhipu에 투자한 바 있습니다. 이번 추가 투자는 Zhipu의 오픈소스 모델 연구 개발 및 오픈소스 커뮤니티 생태계 구축을 지원하기 위한 것이며, 베이징시가 AI 산업 발전을 촉진하고 “글로벌 오픈소스 허브”를 구축하려는 결의를 보여줍니다. (출처: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Intel CEO 팻 겔싱어, 개혁 추진하며 새로운 CTO 겸 최고 AI 책임자 임명: 신임 CEO 팻 겔싱어가 Intel의 조직 구조를 조정하여 관리 계층을 간소화하고 기술 지향성을 강화하고자 합니다. 핵심 칩 부문(데이터 센터 및 AI, PC 칩)은 CEO에게 직접 보고하게 됩니다. 네트워크 칩 책임자인 Sachin Katti가 새로운 최고기술책임자(CTO) 겸 최고 AI 책임자로 임명되어 AI 전략, 제품 로드맵 및 Intel Labs를 이끌며 AI 분야에서 NVIDIA의 도전에 대응하게 됩니다. 이 조치는 겔싱어가 Intel을 재건하려는 계획의 일환으로 간주되며, 제조 및 제품 문제를 해결하고 내부 장벽을 허물며 엔지니어링과 혁신에 집중하려는 의도를 담고 있습니다. (출처: 陈立武挥刀高层,英特尔重生计划曝光,技术团队直通华人CEO)

Meta, Llama 훈련 비용 분담 모색 보도, AI 투자 압박 부각: 보도에 따르면 Meta는 Microsoft, Amazon, Databricks 등 기업 및 투자 기관과 접촉하여 오픈소스 모델 Llama의 훈련 비용(“Llama 연합”)을 공동 분담하는 대신 기능 개발에 대한 일부 발언권을 얻는 방안을 제안했지만, 초기 반응은 미온적이었습니다. 이는 협력 파트너들이 무료 모델에 투자하기를 꺼리거나, Meta가 과도한 통제권을 양도하기를 원치 않거나, 잠재적 파트너들이 이미 자체적으로 막대한 AI 투자를 하고 있기 때문일 수 있습니다. 이 사건은 Meta와 같은 거대 기업조차도 AI 개발 비용 급증의 압박에 직면하고 있음을 부각하며, 특히 막대한 자본 지출(연간 60% 증가하여 600억~650억 달러 예상)과 오픈소스 모델의 불확실한 상업화 경로 속에서 더욱 그렇습니다. (출처: Llama开源太贵了,Meta被曝向亚马逊、微软“化缘”)

NVIDIA CEO 젠슨 황 방중, DeepSeek 등과 무역 제한 대응 협력 논의 가능성: NVIDIA CEO 젠슨 황이 최근 중국 국제무역촉진위원회(CCPIT)의 초청으로 중국을 방문하여 DeepSeek 창업자 Liang Wenfeng을 포함한 고객들과 만났습니다. 이번 방문은 미국 정부의 NVIDIA H20 등 대중국 수출 칩 제한 강화, 중국 본토 AI 칩(예: Huawei Ascend)의 부상, DeepSeek 등 모델 최적화로 인한 NVIDIA 고급 GPU에 대한 절대적 의존도 감소 등 복잡한 배경 속에서 이루어졌습니다. 분석가들은 젠슨 황이 중국 파트너(예: DeepSeek)와 미국의 수출 제한을 준수하면서 동시에 중국의 높은 수입 관세를 피할 수 있는 AI 칩을 공동 설계하는 방안을 논의하여, 심도 있는 협력을 통해 중국 시장 점유율과 업계 영향력을 유지하려는 목적일 수 있다고 보고 있습니다. (출처: 英伟达CEO黄仁勋突然访华,都不穿皮衣了,还见了梁文锋)

🌟 커뮤니티
AI 인형 생성 열풍 소셜 미디어 강타, 저작권 및 윤리 우려 제기: ChatGPT 등 AI 도구를 사용하여 개인 사진을 인형 이미지(바비 인형 스타일과 유사하며 포장 상자와 개성 있는 액세서리 포함)로 변환하는 유행이 LinkedIn, TikTok 등 플랫폼에서 확산되고 있습니다. 사용자는 사진을 업로드하고 상세한 설명을 제공하면 이미지를 생성할 수 있습니다. 재미는 있지만 저작권 및 윤리에 대한 우려도 제기됩니다. AI 생성물이 의도치 않게 저작권으로 보호되는 예술 스타일이나 브랜드 요소를 사용할 수 있으며, 이러한 AI 모델을 훈련하고 실행하는 데 필요한 막대한 에너지 소비도 주목받고 있습니다. AI 사용 시 명확한 경계와 규범을 설정해야 한다는 의견이 있습니다. (출처: 芭比风AI玩偶席卷全网:ChatGPT几分钟打造你的时尚分身)

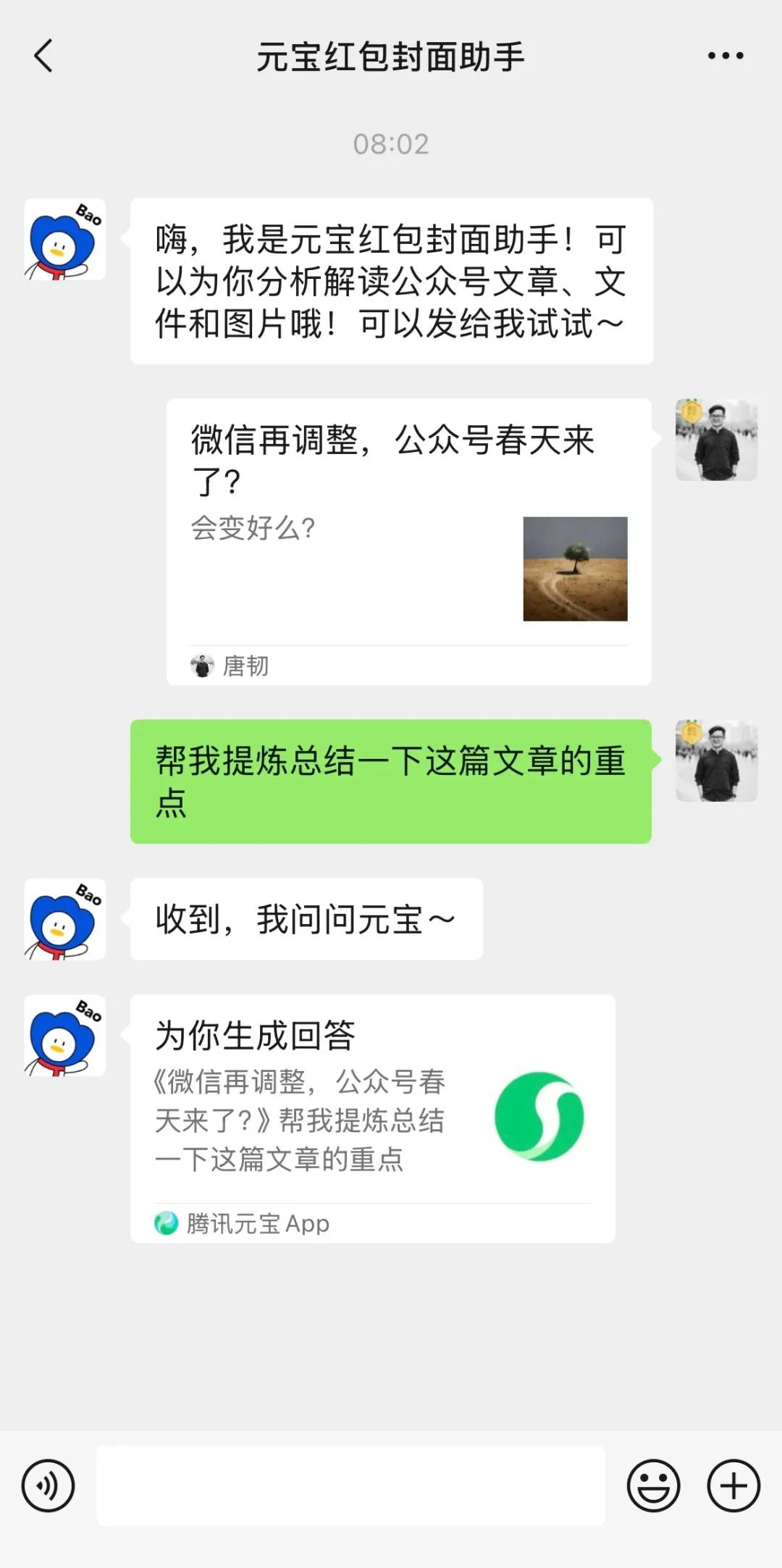
Tencent Yuanbao(구 홍바오 표지 도우미), WeChat에 깊숙이 통합되어 주목: WeChat 내에서 “Yuanbao”를 검색하면 AI 기능을 직접 호출할 수 있으며, 이는 이전 “Yuanbao 홍바오 표지 도우미”의 업그레이드 버전입니다. 사용자 경험에 따르면 기능이 향상되어 요구 사항에 따라 더 정확한 이미지를 생성하고 네이티브 적응을 최적화하여 답변 카드를 생성할 수 있습니다. 이 글은 Tencent의 AI 핵심 기능이 WeChat 시나리오에 적용될 가능성, 특히 파일 전송 도우미와 같은 기존 진입점의 잠재력을 논의하며, 시나리오 우위가 Tencent AI 실현의 핵심이라고 주장합니다. 동시에 WeChat 공식 계정의 최근 업데이트가 모바일 게시 진입점을 추가하여 짧은 콘텐츠 작성을 장려할 수 있지만 긴 글 생태계에 영향을 미칠 수 있다고 언급합니다. (출처: 鹅厂的 AI 大招,真的落在微信上)
LMArena, 베타 테스트 사이트 출시: 대형 모델 경쟁 플랫폼 LMArena가 미공개 모델을 포함한 다양한 대형 모델을 테스트하기 위한 새로운 베타 테스트 웹사이트(beta.lmarena.ai)를 개설했습니다. 이는 커뮤니티가 Hugging Face Gradio 인터페이스와 별개로 모델 성능을 평가하고 비교할 수 있는 새로운 플랫폼을 제공합니다. (출처: karminski3)
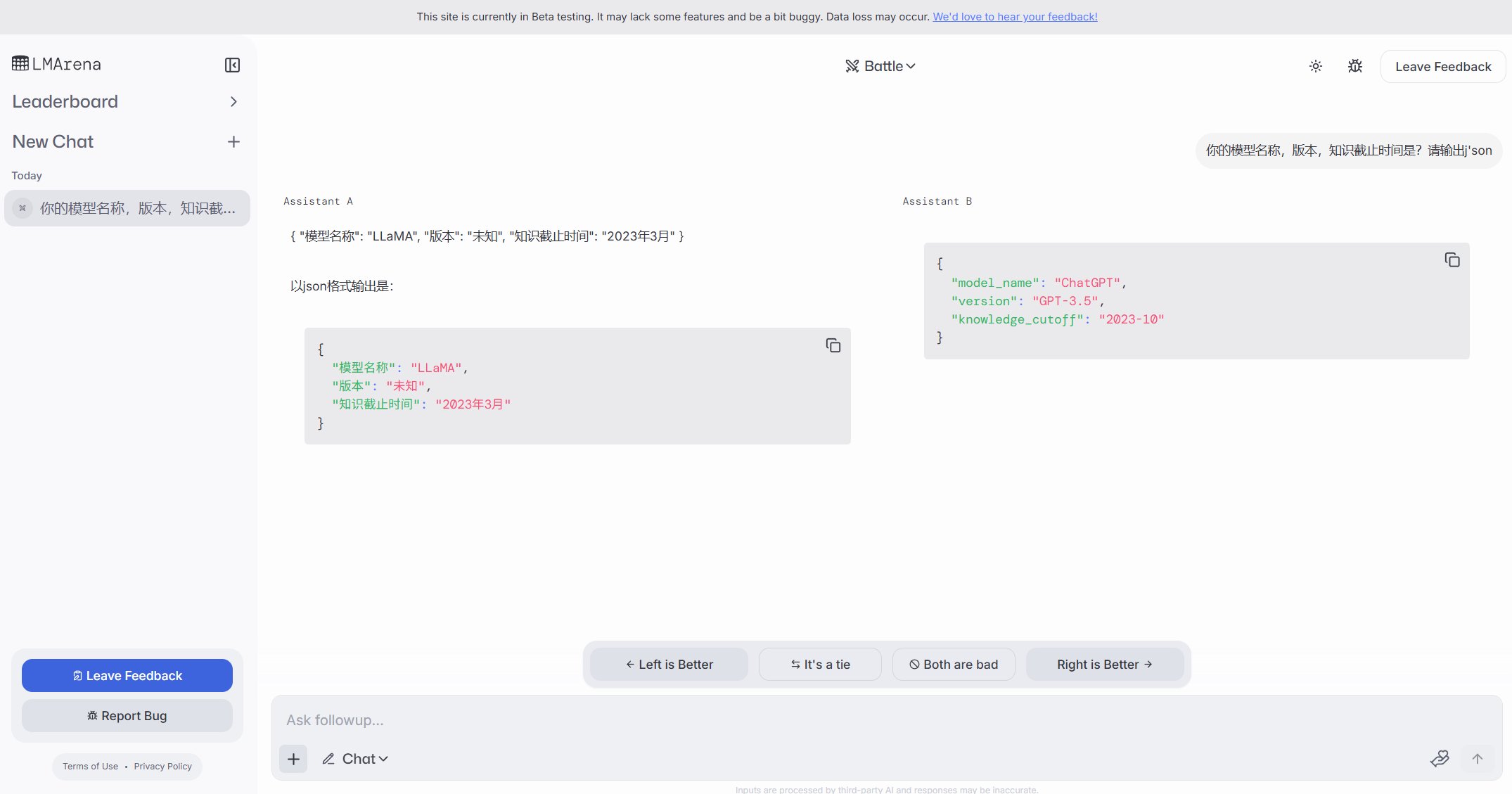
Ollama 인스턴스의 공용 인터넷 노출로 보안 우려 제기: 한 사용자가 freeollama.com이라는 웹사이트를 발견했으며, 인터넷 공간 검색을 통해 Ollama(로컬 배포 대형 모델 도구) 포트(일반적으로 11434)를 방화벽 없이 공용 IP에 노출시킨 호스트가 다수 발견되었습니다. 이는 심각한 보안 위험을 초래하며, 무단 액세스 및 로컬 배포 모델의 남용으로 이어질 수 있습니다. 사용자는 배포 시 네트워크 보안 구성에 주의하고 서비스를 보호 없이 공용 인터넷에 노출하지 않도록 주의해야 합니다. (출처: karminski3)
ChatGPT를 심리 지원에 사용하는 것에 대한 논의 및 경고: Reddit 사용자가 우울증, 불안 등 문제 처리에 ChatGPT를 보조적으로 사용한 경험을 공유하며, 그 조언이 일관성이 부족하고 신뢰할 수 있는 지침을 제공하기보다는 사용자의 기존 관점을 확인시켜주는 경향이 있음을 발견했습니다. 다른 채팅에서 자체 논리로 반박했을 때 ChatGPT는 오류를 인정했습니다. 사용자는 AI가 단지 “디지털 아첨꾼”일 수 있으며 심각한 심리 치료 보조에 사용해서는 안 된다고 경고합니다. 댓글 섹션에서는 AI를 더 효과적으로 사용하는 방법(예: 비판적 역할 요구, 다양한 관점 제공)과 위기 개입에서 AI가 인간 전문가를 대체할 수 없는 한계에 대해 논의합니다. (출처: Reddit r/ChatGPT)
더글러스 애덤스의 기술의 세 가지 법칙 공감대 형성: 사용자가 SF 작가 더글러스 애덤스의 기술의 세 가지 법칙을 인용하여, 다른 연령대의 사람들이 새로운 기술에 대해 보이는 보편적인 반응을 유머러스하게 묘사했습니다: 태어날 때 이미 존재했던 기술은 당연한 것으로 여기고, 젊었을 때 탄생한 기술은 혁명적인 것으로 여기며, 나이가 들어 나타난 기술은 이단적인 것으로 여긴다는 것입니다. 이 댓글은 AI가 빠르게 발전하는 현재 상황에서 공감을 얻으며, AI와 같은 파괴적인 기술에 대한 사람들의 수용 정도가 그들이 처한 생애 단계와 관련될 수 있음을 시사합니다. (출처: dotey)
사용자 경험: ChatGPT가 “너무 현실적이거나” “Gen Z화”됨: Reddit 게시물에 ChatGPT 대화 스크린샷이 공유되었는데, 그 응답 스타일이 사용자에 의해 “너무 현실적이거나” “Gen Z” 슬랭 및 인터넷 밈(예: “Let me cook”)을 사용하는 것으로 묘사되었습니다. 댓글 반응은 엇갈려서, 어떤 이는 재미있다고 느끼는 반면, 어떤 이는 이러한 스타일이 “불편하다”거나 “뇌가 없는 것 같다”고 생각합니다. 이는 AI의 개인화 및 언어 스타일에 대한 사용자 인식의 차이와 모델이 인터넷 언어 트렌드를 모방함으로써 발생할 수 있는 경험 문제를 반영합니다. (출처: Reddit r/ChatGPT)
AI가 생성한 미래 생활 스냅샷, 창의적 토론 유발: 사용자가 ChatGPT를 사용하여 생성한 “미래 생활 Snapchat” 스타일의 이미지 시리즈를 공유했습니다. 로봇 웨이터, AI 애완동물, 미래 교통 등과 같은 장면을 묘사합니다. 이러한 창의적인 이미지는 커뮤니티에서 AI 이미지 생성 능력과 미래 생활 상상력에 대한 토론을 불러일으켰으며, 그 창의성과 날로 향상되는 사실감에 대해 찬사를 보냈습니다. (출처: Reddit r/ChatGPT)
사용자, ChatGPT를 사용하여 손그림 스케치를 사실적인 이미지로 변환한 경험 공유: 한 아티스트 사용자가 자신의 초현실주의 스타일 손그림 스케치를 ChatGPT를 사용하여 사실적인 이미지로 변환하는 과정과 결과를 보여주었습니다. 커뮤니티는 이를 흥미로운 예술 실험 방식으로 간주하며, 단순히 “더 나은” 이미지를 추구하는 것이 아니라 아티스트가 아이디어와 다양한 스타일을 탐색하는 데 도움이 될 수 있다고 평가했습니다. (출처: Reddit r/ChatGPT)
💡 기타
AI 시스템 구축에 대한 성찰: “쓰디쓴 교훈”과 컴퓨팅 파워 우선주의: 이 글은 Richard Sutton의 “쓰디쓴 교훈(The Bitter Lesson)” 이론을 인용하여, AI 개발에서 일반 컴퓨팅 능력 확장(컴퓨팅 파워 주도)에 의존하는 시스템이 결국 인간이 정교하게 설계한 복잡한 규칙에 의존하는 시스템을 능가할 것이라고 지적합니다. 고객 서비스 AI 사례 비교(규칙 기반 시스템 vs 제한된 컴퓨팅 파워 AI vs 대규모 컴퓨팅 파워 탐색 AI)와 강화 학습(RL)의 성공(예: OpenAI 심층 연구, Claude)을 통해, 기업은 알고리즘을 과도하게 최적화하는 대신 컴퓨팅 인프라에 투자해야 하며, 엔지니어의 역할은 확장 가능한 학습 환경을 구축하는 “트랙 빌더”로 전환되어야 함을 강조합니다. 핵심 관점은 다음과 같습니다: 간단한 아키텍처 + 대규모 컴퓨팅 파워 + 탐색적 학습 > 복잡한 설계 + 고정된 규칙. (출처: 苦涩的启示:对AI系统构建方式的反思)
AI 분야와 합리주의/효과적 이타주의 커뮤니티의 연관성 탐구: 한 머신러닝 종사자가 AI 연구 분야에 상호 작용이 적은 두 개의 하위 커뮤니티가 존재하는 것으로 관찰했으며, 그중 하나는 합리주의(Rationalism) 및 효과적 이타주의(Effective Altruism, EA) 커뮤니티와 밀접하게 관련되어 AGI 예측, 정렬 문제에 대한 연구를 자주 발표하고 일부 베이 에어리어 대기업과 긴밀한 관계를 맺고 있다고 지적합니다. 저자는 이 커뮤니티가 때때로 인지 과학 개념(예: 상황 인식)을 논의할 때 기존 학문 체계와 독립적으로 재정의하는 것처럼 보인다고 지적합니다. 예를 들어 Anthropic의 “상황 인식” 정의는 전통적인 인지 과학의 감각 및 환경 모델 기반 정의가 아닌 모델의 개발 과정에 대한 인지에 중점을 둡니다. (출처: Reddit r/ArtificialInteligence)
사용자, AI 챗봇이 다른 플랫폼에서 사용하는 닉네임을 예기치 않게 사용하는 것 발견: 한 사용자가 새로운 AI 챗봇 플랫폼을 시도할 때 개인 정보를 전혀 제공하지 않았음에도 불구하고, 봇이 두 번째 메시지에서 해당 사용자가 다른 플랫폼에서 자주 사용하는 닉네임을 정확하게 불렀습니다. 이는 사용자의 데이터 프라이버시 및 플랫폼 간 정보 추적에 대한 우려를 불러일으켰으며, 자신이 이미 “추적”되거나 “프로파일링”되었을 수 있다고 한탄했습니다. (출처: Reddit r/ArtificialInteligence)
AI 모델 평가의 새로운 아이디어: 3분 구두 발표를 통해 지능 평가: 최고 수준의 AI 모델(예: o3 vs Gemini 2.5 Pro)에게 특정 주제(정치, 경제, 철학 등)에 대해 3분간 구두 발표를 하도록 하고 인간 청중이 그 지능 수준을 평가하는 새로운 AI 지능 평가 방식을 제안합니다. 전문적인 벤치마크 테스트에 의존하는 것보다 더 직관적이며, 특히 설득력이 필요한 작업에서 모델의 구성, 수사, 감성 및 지적 표현을 더 잘 평가할 수 있다고 주장합니다. 이러한 형태의 “AI 토론” 또는 “연설 대회”는 AGI에 가까운 모델의 능력을 평가하는 새로운 차원이 될 수 있습니다. (출처: Reddit r/ArtificialInteligence)