
키워드:AI, LLM, AI 인덱스 보고서, Llama 4 성능 논란, 생성형 AI 투자 동향, AI+제조업 적용 사례, DeepSeek R1 추론 속도 기록
🔥 포커스
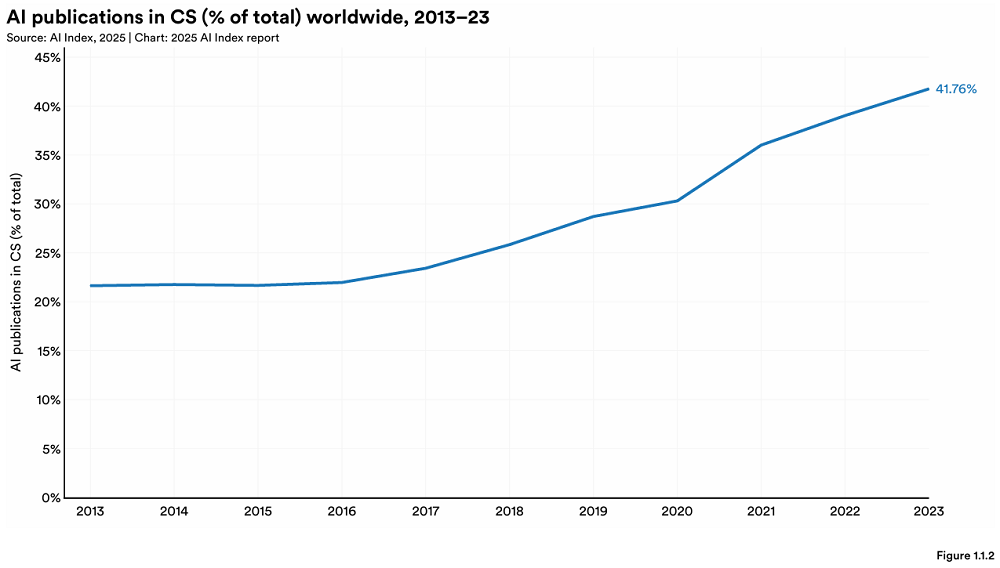
스탠포드, 연례 AI 지수 보고서 발표, 글로벌 AI 지형의 새로운 변화 공개: 스탠포드 대학 HAI가 456페이지 분량의 《AI Index Report 2025》를 발표했습니다. 보고서에 따르면 미국이 최고 수준의 AI 모델 생산에서 여전히 선두를 달리고 있지만, 중국이 성능 격차를 빠르게 좁히고 있습니다(예: MMLU 및 HumanEval에서의 격차 거의 사라짐). 산업계가 주요 모델 개발을 주도(90% 차지)했으나 모델 수는 감소했습니다. AI 하드웨어 비용은 연 30% 속도로 하락하고 있으며, 성능은 1.9년마다 두 배로 증가하고 있습니다. 전 세계 AI 투자액은 2,523억 달러에 달하며, 미국이 1,091억 달러로 압도적인 선두를 달리고 있습니다(중국 93억 달러의 약 12배). 생성형 AI 투자액은 339억 달러입니다. 기업의 AI 도입률은 78%로 상승했으며, 중국이 가장 빠른 성장세(75% 도달)를 보이고 있습니다. AI는 이미 기업의 비용 절감 및 효율 증대에 기여하기 시작했습니다. AI는 과학 분야에서 돌파구를 마련하여 노벨상 2개를 수상했으며, 단백질 시퀀싱 및 임상 진단에서 인간의 능력을 넘어섰습니다. AI에 대한 전 세계적인 낙관론은 상승했지만 지역별 차이가 뚜렷하며, 중국이 가장 낙관적인 태도를 보이고 있습니다. 책임감 있는 AI(RAI) 생태계는 점차 성숙하고 있지만, 평가 및 실천은 여전히 불균형합니다. (출처: 36氪, AI科技评论, dotey, 36kr)
Meta Llama 4 출시, ‘벤치마크 조작’ 및 성능 미흡 지적으로 큰 논란: Meta가 최근 발표한 오픈 소스 대형 모델 Llama 4 시리즈(Scout, Maverick, Behemoth)가 출시 72시간 만에 평판이 급락했습니다. Maverick 버전이 Chatbot Arena에서 빠르게 2위로 올라섰으나, 대화에 최적화된 미공개 “실험 버전”을 제출했다는 폭로로 ‘벤치마크 조작’ 의혹이 제기되었습니다. Meta는 테스트셋 학습을 부인했지만 성능 문제는 인정했습니다. 커뮤니티 피드백에 따르면 Llama 4는 코딩, 긴 컨텍스트 이해 등에서 기대 이하의 성능을 보이며, 심지어 파라미터 수가 더 적은 모델(예: DeepSeek V3)보다 못하다는 평가입니다. AI 분야 전문가인 Gary Marcus는 이를 두고 “Scaling은 죽었다”고 평하며, 단순히 모델 규모를 키우는 것만으로는 신뢰할 수 있는 추론 능력을 가져올 수 없다고 지적하고 자금, 지정학적 요인 등으로 글로벌 AI 발전이 정체될 수 있다고 우려했습니다. LMArena는 관련 평가 데이터를 공개하여 검토할 수 있도록 했으며, 혼란을 피하기 위해 순위 정책을 업데이트했습니다. (출처: 36kr, 雷科技, AIatMeta, karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

🎯 동향
Gemini Deep Research 기능 업그레이드, Gemini 2.5 Pro 모델 채택: Google Gemini App의 Deep Research 기능이 이제 Gemini 2.5 Pro 모델로 구동됩니다. 초기 사용자 테스트 피드백에 따르면 성능이 다른 경쟁 제품보다 우수합니다. 이번 업그레이드는 정보 검색 및 합성 능력, 보고서 통찰력, 분석 추론 능력을 향상시키는 것을 목표로 합니다. Gemini Advanced 사용자는 이 업데이트를 경험할 수 있습니다. 여러 사용자와 Google DeepMind CEO Demis Hassabis는 새로운 버전의 Deep Research를 사용하여 복잡한 작업(예: 시장 분석)을 완료한 긍정적인 경험을 공유하며, 속도가 빠르고 내용이 포괄적이라고 평가했습니다. (출처: JeffDean, dotey, JeffDean, demishassabis)

Nvidia, Llama 3.1 Nemotron Ultra 253B 모델 출시: Nvidia가 Hugging Face에 Llama 3.1 Nemotron Ultra 253B 모델을 출시했습니다. 이 모델은 추론 활성화/비활성화 기능이 있는 Dense 모델(MoE 아님)입니다. Meta의 Llama-405B 모델을 NAS 가지치기 기술로 수정하고 추론 중심의 후훈련(SFT + RL in FP8)을 거쳤습니다. 벤치마크 테스트 결과 DeepSeek R1보다 성능이 우수하지만, MoE 모델인 DeepSeek R1(활성 파라미터 수가 적음)과의 직접 비교는 완전히 공정하지 않을 수 있다는 의견도 있습니다. Nvidia는 관련 후훈련 데이터셋도 Hugging Face에 함께 공개했습니다. (출처: huggingface, Reddit r/LocalLLaMA, dylan522p, huggingface)

AI+제조, 새로운 초점으로 부상, 기회와 도전 공존: AI가 중국 제조업에 빠르게 침투하고 있으며, 생산 자동화(예: 玉汝成의 치과 재료 생산), 제품 지능화(예: 冰寒科技의 AI 수면 보조 안경), 프로세스 최적화(예: 中科领创의 AI 회의록 작성), 연구 개발 및 진단(예: 睿心智能의 심혈관 진료 플랫폼, 壁虎汽车의 부품 수요 예측 및 고장 감지) 등 다양한 분야에 적용되고 있습니다. 微众银行과 같은 금융 기관도 AI 기술(예: 스마트 실사 보고서 생성)을 활용하여 과학 기술 제조 기업을 지원하고 있습니다. 그러나 ‘AI+제조’는 여전히 데이터 품질 저하, 기업의 디지털 기반 취약 등의 도전에 직면해 있습니다. 투자자들은 기업이 AI를 단순히 홍보 수단으로 삼지 말고 주력 사업에 활용해야 하며, 데이터 및 구현 문제를 해결하기 위해 장기적인 투자가 필요하다고 조언합니다. (출처: 36氪)
DeepSeek R1, Nvidia B200에서 추론 속도 신기록 달성: AI 스타트업 Avian.io는 Nvidia와의 협력을 통해 최신 Blackwell B200 GPU 플랫폼에서 DeepSeek R1 모델의 추론 속도 303 tokens/초를 달성하여 세계 신기록을 세웠다고 발표했습니다. Avian.io는 앞으로 며칠 내에 B200 기반의 전용 DeepSeek R1 추론 엔드포인트를 제공할 예정이며, 이미 사전 예약을 받고 있습니다. 이 성과는 테스트 시간 컴퓨팅 기반 모델(test time compute driven models)의 새로운 시대를 열었습니다. (출처: Reddit r/LocalLLaMA)

OpenAI, 최첨단 모델 배포 위한 전략적 배포 팀 신설: OpenAI는 최첨단 모델(예: GPT-4.5 및 미래 모델)의 능력, 신뢰성, 정렬(alignment) 수준을 높이고, 이를 영향력 있는 실제 세계 분야에 배포하여 AI의 경제 변혁을 가속화하고 AGI로 가는 경로를 탐색하기 위해 새로운 전략적 배포(Strategic Deployment) 팀을 신설했습니다. 이 팀은 적극적으로 인력을 채용 중이며, ICLR 등 학회에서 홍보 활동을 하고 있습니다. (출처: sama)
AI, 고객 경험(CX) 개선에서 도전 과제 직면: 이 글은 AI를 사용하여 고객 경험을 개선할 때 직면하는 어려움과 도전 과제를 탐구합니다. AI는 잠재력을 제공하지만 효과적인 구현은 쉽지 않으며, 데이터 통합, 모델 정확성, 사용자 수용성, 유지 관리 비용 등 여러 측면의 문제가 관련될 수 있습니다. (출처: Ronald_vanLoon)

AI 애플리케이션, 직장 내 혁신과 우려 동시에 유발: 이 글은 직장에서 AI 애플리케이션 사용이 가져오는 이중적 영향, 즉 혁신 잠재력 촉발과 동시에 기존 노동력에 대한 우려(예: 일자리 대체 가능성, 기술 요구 변화 등)를 논의합니다. (출처: Ronald_vanLoon)

인터넷 행동(IoB), 비즈니스 의사 결정 방식 변화: 머신러닝과 인공지능을 이용해 사용자 행동 데이터(Internet of Behavior)를 분석하는 기술이 기업에 더 깊은 통찰력을 제공함으로써 비즈니스 의사 결정 방식을 변화시키고 있습니다. 이는 개인화 마케팅, 위험 평가, 제품 개발 등 여러 측면에 영향을 미칠 수 있습니다. (출처: Ronald_vanLoon)

멀티모달 모델 RolmOCR, Hugging Face 순위에서 두각: Yifei Hu는 자신의 팀이 개발한 시각 언어 모델 RolmOCR이 Hugging Face 순위에서 우수한 성적을 거두어 VLM 부문 3위, 전체 모델 중 5위를 차지했다고 밝혔습니다. 팀은 앞으로 더 많은 모델, 데이터셋, 알고리즘을 공개하여 오픈 소스 과학 연구를 지원할 계획입니다. (출처: huggingface)

AI 뉴스 요약 (2025/04/08): 최근 AI 관련 뉴스: Meta Llama 4, 벤치마크에서 오해의 소지가 있는 행위로 지적; Apple, 관세 회피 위해 더 많은 iPhone 생산을 인도로 이전할 가능성; IBM, AI 시대를 위한 새로운 메인프레임 발표; Google, 인재 유치 위해 일부 AI 직원에게 고액 연봉 지급하며 1년간 ‘유휴’ 상태로 두었다는 소문; Microsoft, Copilot 행사 방해한 시위 직원 해고 보도; Amazon, 자사 AI 비디오 모델이 이제 수 분 길이의 클립 생성 가능하다고 주장. (출처: Reddit r/ArtificialInteligence)

🧰 도구
FunASR: 알리바바 DAMO 아카데미 오픈 소스 기반 엔드투엔드 음성 인식 툴킷: FunASR은 음성 인식(ASR), 음성 활동 감지(VAD), 구두점 복원, 언어 모델, 화자 인식, 화자 분리, 다중 화자 인식 등의 기능을 통합한 툴킷입니다. 산업 수준의 사전 훈련된 모델(예: Paraformer, SenseVoice, Whisper, Qwen-Audio 등)에 대한 추론 및 미세 조정을 지원하며, 편리한 스크립트와 튜토리얼을 제공합니다. 최근 업데이트에는 SenseVoiceSmall, Whisper-large-v3-turbo, 키워드 검출 모델, 감정 인식 모델 지원이 포함되었으며, 메모리 및 성능 최적화된 오프라인/실시간 전사 서비스(GPU 버전 포함)가 출시되었습니다. (출처: modelscope/FunASR – GitHub Trending (all/daily))
LightRAG: 간결하고 효율적인 검색 증강 생성 프레임워크: LightRAG는 홍콩대 DS 연구실에서 개발한 RAG 프레임워크로, RAG 애플리케이션 구축을 단순화하고 가속화하는 것을 목표로 합니다. 지식 그래프(KG) 구축 및 검색 기능을 통합하고, 다양한 검색 모드(로컬, 글로벌, 혼합, 단순, Mix 모드)를 지원하며, 다양한 LLM(예: OpenAI, Hugging Face, Ollama) 및 Embedding 모델에 유연하게 연결할 수 있습니다. 또한 다양한 스토리지 백엔드(예: NetworkX, Neo4j, PostgreSQL, Faiss)와 다양한 파일 유형 입력(PDF, DOC, PPT, CSV)을 지원하며, 엔티티/관계 편집, 데이터 내보내기, 캐시 관리, 토큰 추적, 대화 기록 및 사용자 정의 프롬프트 등의 기능을 제공합니다. 프로젝트는 Web UI 및 API 서비스, 지식 그래프 시각화 도구를 제공합니다. (출처: HKUDS/LightRAG – GitHub Trending (all/daily))
LangGraph, Definely의 법률 AI 에이전트 구축 지원: Definely는 LangGraph를 활용하여 Microsoft Word에 직접 통합된 다중 AI 에이전트 시스템을 구축하여 변호사의 복잡한 법률 업무를 지원합니다. 이 시스템은 법률 작업을 하위 작업으로 분해하고, 컨텍스트 정보를 결합하여 조항 추출, 변경 분석 및 계약 초안 작성을 수행하며, 인간-기계 협업 루프(Human-in-the-loop)를 통해 변호사의 입력과 승인을 받아 주요 결정을 안내합니다. 이는 LangGraph가 복잡하고 제어 가능한 에이전트 워크플로우를 구축하는 능력을 보여줍니다. (출처: LangChainAI)

LlamaParse, 새로운 레이아웃 인식 에이전트 출시: LlamaIndex는 LlamaParse의 새로운 기능인 레이아웃 에이전트를 출시했습니다. 이 에이전트는 Flash 2.0부터 Sonnet 3.7까지 다양한 규모의 SOTA VLM 모델을 활용하여 동적으로 레이아웃을 인식하며 문서 페이지를 분석합니다. 먼저 전체 레이아웃을 분석하고 페이지를 블록(예: 표, 차트, 단락)으로 분해한 다음, 블록의 복잡성에 따라 다른 모델을 선택하여 처리합니다(예: 더 강력한 모델로 차트 처리, 작은 모델로 텍스트 처리). 이 기능은 대량의 문서 컨텍스트를 처리해야 하는 에이전트 워크플로우에 특히 중요합니다. (출처: jerryjliu0)

Auth0, GenAI 애플리케이션용 보안 도구 출시: Auth0는 개발자가 GenAI 애플리케이션 및 에이전트의 보안을 쉽게 보호할 수 있도록 돕는 신제품 “Auth for GenAI”를 출시했습니다. 이 제품은 사용자 인증, 사용자를 대신한 API 호출, 비동기 사용자 확인(CIBA), RAG 권한 부여 등의 기능을 제공합니다. 인기 있는 GenAI 프레임워크(예: LangChain, LlamaIndex, Firebase Genkit 등)를 위한 SDK 및 문서를 제공하여 AI 애플리케이션에 인증 및 권한 부여를 통합하는 프로세스를 간소화합니다. (출처: jerryjliu0, jerryjliu0)

Ollama, Mistral Small 3.1 비전 모델 지원 추가: 로컬 대형 모델 실행 도구 Ollama가 이제 Mistral AI의 최신 Mistral Small 3.1 모델(비전(멀티모달) 기능 포함)을 지원합니다. 사용자는 Ollama 라이브러리를 통해 mistral-small3.1:24b-instruct-2503-q4_K_M 등 양자화된 버전을 가져와 실행할 수 있습니다. 커뮤니티 피드백에 따르면 이 모델은 OCR 등의 작업에서 좋은 성능을 보이지만, 특정 하드웨어(예: AMD 7900xt)에서 추론 속도가 느리다는 사용자 보고도 있습니다. (출처: Reddit r/LocalLLaMA)

Unsloth, Llama-4 Scout GGUF 양자화 모델 출시: Unsloth는 Llama-4 Scout 17B 모델의 GGUF 형식 양자화 버전을 오픈 소스로 공개하여 로컬 CPU 또는 메모리가 제한된 GPU에서 쉽게 실행할 수 있도록 했습니다. 여기에는 크기가 42.2GB에 불과한 2.71비트 동적 양자화 버전이 포함됩니다. 사용자는 Hugging Face에서 다양한 양자화 수준(예: Q6_K)의 모델 파일과 하드웨어 호환성 정보를 확인할 수 있습니다. (출처: karminski3)

LangSmith 산하 OpenEvals, 사용자 정의 출력 스키마 지원: LangSmith의 LLM 평가 도구 OpenEvals가 이제 사용자가 LLM-as-judge 평가기의 출력 스키마를 사용자 정의할 수 있도록 지원합니다. 기본 스키마가 많은 일반적인 경우를 다루지만, 이 업데이트는 사용자에게 완전한 유연성을 제공하여 특정 평가 요구에 맞게 모델 응답의 구조와 내용을 맞춤 설정할 수 있게 합니다. 이 기능은 Python 및 JS 버전 모두에서 사용할 수 있습니다. (출처: LangChainAI)

Qwen 3 모델, 곧 llama.cpp 지원 예정: 알리바바 Qwen 3 시리즈 모델에 대한 llama.cpp 지원 패치가 Pull Request로 제출되어 승인되었으며 곧 병합될 예정입니다. 이는 사용자가 곧 llama.cpp 프레임워크를 통해 로컬에서 Qwen 3 모델을 실행할 수 있게 된다는 의미입니다. 이번 업데이트는 이전에 transformers 라이브러리에 Qwen 3 지원을 기여했던 bozheng-hit에 의해 제출되었습니다. (출처: Reddit r/LocalLLaMA)

Computer Use Agent Arena 출시: OSWorld 팀이 설정 없이 실제 환경에서 컴퓨터 사용 에이전트(Computer-Use Agents)를 테스트할 수 있는 플랫폼인 Computer Use Agent Arena를 출시했습니다. 사용자는 OpenAI Operator, Claude 3.7, Gemini 2.5 Pro, Qwen 2.5 VL 등 최고 수준의 VLM이 100개 이상의 실제 애플리케이션 및 웹사이트에서 어떻게 작동하는지 비교할 수 있습니다. 이 플랫폼은 원클릭 구성을 제공하며 안전하고 무료라고 주장합니다. (출처: lmarena_ai)
음악 배포 서비스 Too Lost, AI 음악에 우호적: Reddit 사용자가 Suno, Udio 등 AI 생성 음악을 배포하기 위해 Too Lost를 사용한 경험을 공유했습니다. 장점: AI 음악 명시적 수용, 빠른 승인(1-2일), 저렴한 가격(연 35달러 무제한 배포), 구독 만료 후 음악 유지(단, 수익 분배는 85/15로 변경), 사용자 정의 레이블 이름 지원. 단점: Instagram/Facebook 배포 속도 느림(>16일), 이전 배포 증명 필요할 수 있음. (출처: Reddit r/SunoAI)
📚 학습
NVIDIA, CUDA Python 출시: NVIDIA는 Python에서 CUDA 플랫폼에 대한 통합된 접근을 제공하기 위해 CUDA Python을 출시했습니다. 여기에는 여러 구성 요소가 포함됩니다: cuda.core는 Pythonic한 CUDA Runtime 접근을 제공합니다; cuda.bindings는 CUDA C API에 대한 저수준 바인딩을 제공합니다; cuda.cooperative는 CCCL의 장치 측 병렬 기본 요소(Numba CUDA용)를 제공합니다; cuda.parallel은 CCCL의 호스트 측 병렬 알고리즘(정렬, 스캔 등)을 제공합니다; 그리고 numba.cuda는 Python 하위 집합을 CUDA 커널로 컴파일하는 데 사용됩니다. cuda-python 패키지 자체는 이러한 독립적으로 버전 관리되는 하위 패키지를 포함하는 메타 패키지로 전환될 것입니다. (출처: NVIDIA/cuda-python – GitHub Trending (all/daily))
Hugging Face, 대규모 추론 코딩 데이터셋 공개: Hugging Face에 DeepSeek-R1이 생성한 736,712개의 Python 코드 솔루션을 포함하는 대규모 데이터셋이 공개되었습니다. 이 데이터셋에는 코드의 추론 과정(reasoning traces)이 포함되어 있으며, 상업적 및 비상업적 용도로 사용할 수 있습니다. 이는 현재 가장 큰 추론 코딩 데이터셋 중 하나입니다. (출처: huggingface)

AI 에이전트 구축의 5가지 주요 과제와 해결책: 이 글은 AI 에이전트를 구축할 때 직면하는 5가지 핵심 과제를 정리합니다: 1) 추론 및 의사 결정 관리(일관성 및 신뢰성 보장); 2) 다단계 프로세스 및 컨텍스트 처리(상태 관리, 오류 처리); 3) 도구 통합 관리(고장 지점 증가, 보안 위험); 4) 환각 제어 및 정확성 보장; 5) 대규모 성능 관리(높은 동시성, 시간 초과, 리소스 병목 현상 처리). 각 과제에 대해 구조화된 프롬프트(ReAct), 견고한 상태 관리, 정확한 도구 정의, 엄격한 검증 시스템(사실 근거, 인용), 인적 검토, LLMOps 모니터링 등 구체적인 해결책을 제시합니다. (출처: AINLPer)
Kaggle 전 수석 과학자, 최초의 LLM일 수 있는 ULMFiT 회고: Jeremy Howard(fast.ai 창립자, Kaggle 전 수석 과학자)는 소셜 미디어에서 자신의 2018년 ULMFiT가 최초의 “범용 언어 모델”이라고 주장하며 “최초의 LLM”에 대한 논의를 촉발했습니다. ULMFiT는 비지도 사전 훈련 및 미세 조정 패러다임을 사용하여 텍스트 분류 작업에서 SOTA를 달성했으며 GPT-1에 영감을 주었습니다. 고증 기사는 자가 지도 학습, 다음 토큰 예측, 새로운 작업 적응 능력, 범용성 등의 기준으로 볼 때 ULMFiT가 CoVE, ELMo보다 현대 LLM 정의에 더 가깝고 현대 LLM의 “공동 조상” 중 하나라고 평가합니다. (출처: 量子位)
개발자 관점에서의 경량 LLM 미세 조정 기술 공유: 비전문 ML 엔지니어인 개발자를 대상으로 LoRA, QLoRA 등 파라미터 효율적 미세 조정(PEFT) 방법을 사용하여 LLM 출력 품질을 개선할 때의 경험과 교훈을 공유합니다. 이러한 방법이 전체 미세 조정의 복잡성을 피하고 일반적인 개발 프로세스에 통합하기에 더 적합함을 강조합니다. 관련 팀은 개발자가 실무에서 겪는 문제점을 중심으로 무료 웨비나를 개최할 예정입니다. (출처: Reddit r/artificial, Reddit r/MachineLearning)
논문, 사전 훈련에서의 반성(Reflection) 재고 제안: Essential AI(Transformer 제1저자 Ashish Vaswani 주도)의 연구에 따르면 LLM은 사전 훈련 단계에서 이미 여러 작업과 분야에 걸쳐 범용 추론 능력을 보여줍니다. 논문은 간단한 “wait” 토큰이 “반성 트리거” 역할을 하여 모델의 추론 성능을 크게 향상시킬 수 있다고 제안합니다. 이 연구는 정교한 Reward Model에 의존하는 후훈련 방법(예: RLHF)보다 사전 훈련 단계에서 모델의 내재적 반성 능력을 활용하는 것이 범용 추론 능력을 향상시키는 더 간결하고 근본적인 방법일 수 있으며, 현재의 task-specific 미세 조정 방법의 병목 현상을 돌파할 수 있다고 주장합니다. (출처: dotey)

논문, 보상 모델 없이 RL 손실을 이용한 스토리 생성 제안: 연구자들은 명시적인 보상 모델 없이 RL 손실(예: perplexity)을 통해 장편 스토리 생성(다음 챕터 예측 작업, 약 10만 토큰)을 최적화하기 위해 RLVR에서 영감을 받은 보상 패러다임 VR-CLI를 제안했습니다. 실험 결과, 이 방법은 생성된 콘텐츠 품질에 대한 인간의 판단과 관련이 있음을 보여주었습니다. (출처: natolambert)

논문, Zero-Shot 분류 견고성 향상을 위한 P3 방법 제안: Zero-Shot 텍스트 분류에서 모델이 프롬프트 변화에 민감한 문제(prompt brittleness)를 해결하기 위해 연구자들은 Placeholding Parallel Prediction (P3) 방법을 제안했습니다. 이 방법은 여러 위치에서 토큰 확률을 예측하여 다음 토큰 확률에만 의존하는 대신 생성 경로의 포괄적인 샘플링을 시뮬레이션합니다. 실험 결과, P3는 정확도를 높이고 다양한 프롬프트에 걸친 표준 편차를 최대 98%까지 줄여 견고성을 향상시켰으며, 프롬프트가 없는 경우에도 비교 가능한 성능을 유지했습니다. (출처: Reddit r/MachineLearning)
논문, 긴 비디오 생성을 개선하는 Test-Time Training 레이어 제안: Transformer 아키텍처가 긴 비디오(예: 1분 이상)를 생성할 때 자기 주의 메커니즘의 비효율성으로 인해 발생하는 일관성 문제를 해결하기 위해, 연구에서는 새로운 Test-Time Training (TTT) 레이어를 제안했습니다. 이 레이어의 은닉 상태 자체는 신경망일 수 있으며, 기존 레이어보다 표현력이 뛰어나 일관성, 자연스러움, 미적 감각이 더 뛰어난 긴 비디오를 생성할 수 있습니다. (출처: dotey)
SmolVLM 기술 보고서 발표, 효율적인 소형 멀티모달 모델 탐색: 기술 보고서는 효율적인 소형 멀티모달 모델 구축을 목표로 하는 SmolVLM(256M, 500M, 2.2B 파라미터)의 설계 아이디어와 실험 결과를 소개합니다. 주요 통찰력: 컨텍스트 길이 증가(2K->16K)는 성능을 크게 향상시킴(+60%); 소형 LLM은 더 작은 SigLIP(80M)에서 더 많은 이점을 얻음; 픽셀 셔플링(Pixel shuffling)은 시퀀스 길이를 크게 단축시킬 수 있음; 학습된 위치 토큰이 원시 텍스트 토큰보다 우수함; 시스템 프롬프트와 전용 미디어 토큰은 비디오 작업에 특히 중요함; 너무 많은 CoT 데이터는 오히려 소형 모델 성능을 저해함; 더 긴 비디오를 훈련하면 이미지 및 비디오 작업 성능 향상에 도움이 됨. SmolVLM은 하드웨어 제약 하에서 SOTA 수준을 달성했으며, iPhone 15 및 브라우저에서 실시간 추론을 구현했습니다. (출처: huggingface)

Hugging Face, 추론 필요 데이터셋(Reasoning Required Dataset) 공개: 이 데이터셋은 fineweb-edu에서 가져온 5000개의 샘플을 포함하며, 추론 복잡성(0-4점)에 따라 레이블이 지정되어 텍스트가 추론 데이터셋 생성에 적합한지 판단하는 데 사용됩니다. 데이터셋은 ModernBERT 분류기를 훈련하여 콘텐츠를 효율적으로 사전 필터링하고, 추론 데이터셋의 범위를 수학 및 코딩 이외의 영역으로 확장하는 것을 목표로 합니다. (출처: huggingface)
CoCoCo 벤치마크, LLM의 결과 정량화 능력 평가: Upright Project는 LLM이 행동 결과를 정량화하는 능력의 일관성을 평가하기 위한 CoCoCo 벤치마크의 기술 보고서를 발표했습니다. 테스트 결과 Claude 3.7 Sonnet(2000 토큰 사고 예산)이 가장 좋은 성능을 보였지만, 긍정적인 결과를 강조하고 부정적인 결과를 경시하는 편향이 존재했습니다. 보고서는 최근 몇 년간 LLM이 이 능력에서 진전을 이루었지만 아직 갈 길이 멀다고 평가했습니다. (출처: Reddit r/ArtificialInteligence)

GenAI 추론 엔진 비교: TensorRT-LLM vs vLLM vs TGI vs LMDeploy: NLP Cloud는 네 가지 인기 있는 GenAI 추론 엔진에 대한 비교 분석 및 벤치마크 결과를 공유했습니다. TensorRT-LLM은 Nvidia GPU에서 가장 빠르지만 설정이 복잡합니다. vLLM은 오픈 소스이고 유연하며 처리량이 높지만 단일 요청 지연 시간은 약간 떨어집니다. Hugging Face TGI는 설정 및 확장이 용이하며 HF 생태계와 잘 통합됩니다. LMDeploy (TurboMind)는 Nvidia GPU에서 디코딩 속도와 4-bit 추론 성능이 뛰어나고 지연 시간이 낮지만, TurboMind는 모델 지원이 제한적입니다. (출처: Reddit r/MachineLearning)
Google DeepMind 팟캐스트 새 시즌 예고: Google DeepMind 팟캐스트 새 시즌이 4월 10일에 공개되며, Hannah Fry가 진행합니다. 내용은 AI 기반 과학이 의학을 혁신하는 방법, 최첨단 로봇 기술, 인간 생성 데이터의 한계 등의 주제를 다룰 예정입니다. (출처: GoogleDeepMind)
LangGraph 플랫폼 소개 영상: LangChain은 LangGraph 플랫폼의 기능을 설명하는 4분짜리 영상을 공개하여, 이 엔터프라이즈급 제품을 사용하여 AI 에이전트를 개발, 배포 및 관리하는 방법을 보여줍니다. (출처: LangChainAI, LangChainAI)

Keras로 First-Order Motion Transfer 구현: 개발자가 Keras에서 Siarohin 등의 NeurIPS 2019 논문에 나오는 1차 운동 모델(First-Order Motion Model)을 이미지 애니메이션 제작에 구현한 경험을 공유했습니다. Keras에 PyTorch grid_sample과 유사한 기능이 없어 개발자는 배치 처리, 정규화된 좌표, GPU 가속을 지원하는 사용자 정의 플로우 필드 워핑 모듈을 구축했습니다. 프로젝트에는 키포인트 감지, 운동 추정, 생성기 및 GAN 훈련 프로세스가 포함되어 있으며 예제 코드와 문서가 제공됩니다. (출처: Reddit r/deeplearning)

자연어 처리(NLP) 흐름도: 이미지는 텍스트 전처리, 특징 추출, 모델 훈련, 평가 등 자연어 처리의 기본 흐름을 보여줍니다. (출처: Ronald_vanLoon)

GANs 수학 원리 설명 블로그: 개발자가 Medium에 작성한 생성적 적대 신경망(GANs)의 수학적 원리에 대한 블로그 게시물을 공유했습니다. 특히 GANs의 최소-최대 게임에서 사용되는 가치 함수의 유도 및 증명을 중점적으로 설명합니다. (출처: Reddit r/deeplearning)

K-Means 클러스터링 입문 개념: 머신러닝 초심자를 위한 개념 보급으로 K-Means 클러스터링 알고리즘의 입문 소개를 공유하며, 이 비지도 학습 방법을 설명합니다. (출처: Reddit r/deeplearning)

생의학 데이터 과학 여름 학교 및 컨퍼런스: 헝가리 부다페스트에서 2025년 7월 28일부터 8월 8일까지 생의학 데이터 과학 여름 학교 및 컨퍼런스가 개최됩니다. 여름 학교는 의료 데이터 시각화, 머신러닝, 딥러닝, 생의학 네트워크 등에 대한 집중 교육을 제공합니다. 컨퍼런스에서는 최첨단 연구를 선보이며 노벨상 수상자를 포함한 전문가들의 강연이 있을 예정입니다. (출처: Reddit r/MachineLearning)
개인 딥러닝 모델 저장소 공유: 한 독학자가 자신의 GitHub 저장소를 공유하며, 다양한 데이터셋(예: CIFAR-10, MNIST, yt-finance)을 위해 딥러닝 모델을 만든 실습 과정을 기록했습니다. 점수, 예측 그래프, 문서 기록이 포함되어 있으며 개인 학습 및 훈련 방식으로 활용됩니다. (출처: Reddit r/deeplearning)

💼 비즈니스
AI 유니콘 OpenEvidence, 인터넷 사고방식으로 AI 의료 혁신: AI 의료 회사 OpenEvidence가 Sequoia로부터 7,500만 달러 투자를 유치하여 기업 가치 10억 달러를 달성하며 새로운 유니콘으로 등극했습니다. 전통적인 B2B 모델과 달리, OpenEvidence는 소비자 인터넷과 유사한 전략을 채택하여 C단 의사에게 직접 무료 서비스(광고 수익 기반)를 제공합니다. 이를 통해 의사들이 방대한 의학 문헌에서 정확한 정보를 찾고 복잡한 증례를 처리하도록 돕습니다. 이 제품은 빠르게 성장하여 미국 의사의 1/4이 사용하고 있다고 알려졌습니다. 성공의 핵심은 엄격한 데이터 출처(동료 검토 문헌)와 다중 모델 통합 아키텍처를 통해 정보 정확성을 보장하고, 출처 인용을 통해 투명성을 확보하여 의사와 의학 저널 모두에게 윈-윈 모델을 형성한 데 있습니다. (출처: 36氪)
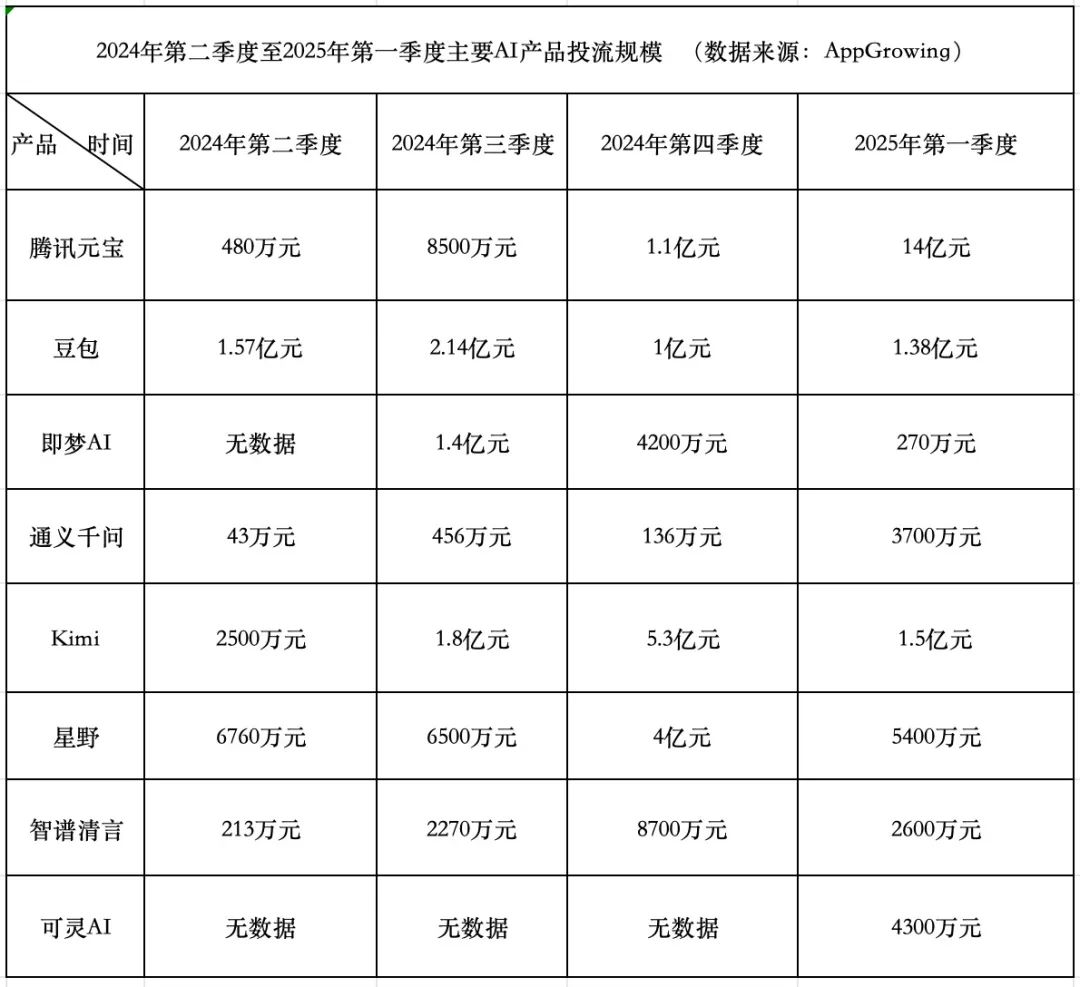
AI 제품 자금 소모 경쟁: 텐센트 공격적, 바이트댄스 보수적, 스타트업 후퇴: 2025년 1분기 AI 제품 광고 집행 비용은 18억 4천만 위안에 달했으며, Tencent Yuanbao가 14억 위안으로 대부분을 차지했고 광고는 시골 벽까지 도배되었습니다. ByteDance Doubao는 1억 3천 8백만 위안을 지출하며 상대적으로 보수적인 전략을 취했습니다. KuaiShou Kling AI는 4,300만 위안을 투자했습니다. 이에 비해 스타 스타트업 Kimi와 Starship은 광고 집행을 대폭 축소했으며(합계 약 2억 위안, 4분기 9억 3천만 위안보다 훨씬 낮음), Zhipu AI도 투자를 현저히 줄였습니다. 스타트업 창업자들은 자금 소모 모델을 재고하기 시작했으며, 모델 능력 향상과 기술 장벽 구축에 더 집중하고 있습니다. 텐센트는 자사의 광고 시스템 덕분에 AI 광고 집행 경쟁의 수혜자가 되었습니다. Alibaba Tongyi Qianwen과 Baidu Wenxin Yiyan은 광고 집행에 상대적으로 소극적이며, 생태계와 오픈 소스에 더 집중하고 있습니다. 업계 동향은 단순히 자금을 투입하여 규모를 키우는 방법론이 더 이상 효과가 없으며, AI 제품 경쟁이 모델 능력과 생태계 구축의 새로운 단계로 진입했음을 보여줍니다. (출처: 中国企业家杂志)
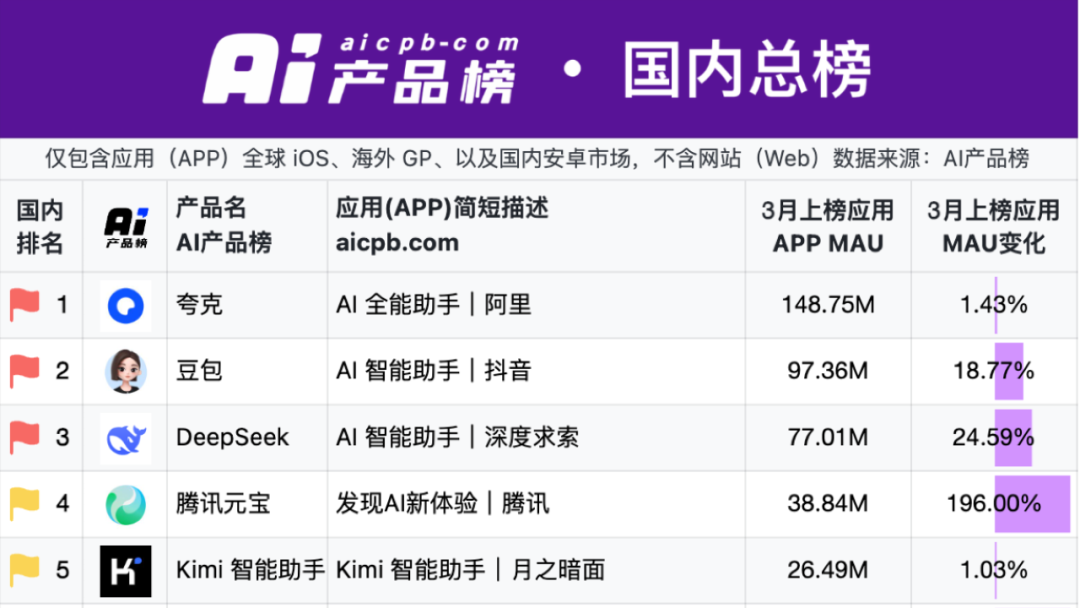
Quark과 Baidu Wenku, AI 애플리케이션 새 격전지 주도: “슈퍼 박스” 모델 부상: 2025년 AI 애플리케이션의 초점이 ChatBot에서 AI 검색, 대화, 도구(예: PPT, 번역, 이미지 생성)를 하나로 통합한 입구인 “AI 슈퍼 박스”로 이동하고 있습니다. Alibaba Quark과 Baidu Wenku가 이 분야의 선두 주자로 부상하며 월간 활성 사용자(MAU) 데이터에서 앞서고 있습니다. 두 서비스 모두 “검색 + 클라우드 스토리지 + 문서” 기반 위에 AI 능력을 통합하여 사용자의 원스톱 작업 요구를 충족시키고 C단 트래픽 입구를 확보하려 합니다. 실제 테스트 결과, 기본 정보 매칭에서는 기존 검색보다 우수하지만, 구체적인 작업(예: 여행 계획, PPT 생성)의 깊이와 만족도에서는 개선의 여지가 있습니다. 대기업들이 이 두 제품을 AI 선봉으로 선택한 것은 사용자 기반과 데이터 축적을 활용하여 AI To C의 최적 형태를 탐색하고 자체 AI 생태계를 보완하려는 의도입니다. (출처: 定焦One)
기업, 내부 전문 지식 제한적일 때 AI 효과적 구현 방법: 이 글은 기업이 깊이 있는 내부 AI 전문 지식이 부족한 상황에서 어떻게 인공지능 기술을 효과적이고 신중하게 도입하고 구현할 수 있는지 탐구합니다. 외부 협력 활용, 적합한 도구 플랫폼 선택, 소규모 파일럿 시작, 직원 교육 강조, 명확한 비즈니스 목표 설정 등이 포함될 수 있습니다. (출처: Ronald_vanLoon, Ronald_vanLoon)

AI 투자 수익률(ROI) 달성에 기술 다양성 중요: 성공적인 AI 프로젝트는 기술 전문가뿐만 아니라 비즈니스 이해, 데이터 분석, 윤리적 고려, 프로젝트 관리 등 다양한 기술을 갖춘 인재가 필요합니다. 조직 내부의 기술 다양성은 AI 프로젝트가 효과적으로 구현되고 실제 문제를 해결하며 궁극적으로 비즈니스 가치(ROI)를 창출하는 데 핵심적인 요소입니다. (출처: Ronald_vanLoon)

AI 제품 SEO 랜딩 페이지 전략 공유: 哥飞가 자신의 AI 제품(월 10만 달러 수입 달성 주장)에 사용한 SEO 랜딩 페이지 전략 요약 카드를 공유하며, 자신의 방법론의 효과성을 강조했습니다. (출처: dotey)

🌟 커뮤니티
AI 면접 부정행위 현상 주목, 도구 범람으로 채용 공정성 위협: 이 글은 원격 화상 면접에서 AI 도구를 이용한 부정행위 현상이 증가하고 있음을 폭로합니다. 이러한 도구는 면접관의 질문을 실시간으로 전사하고 면접자가 읽을 답을 생성하며, 기술 필기시험까지 보조할 수 있습니다. 저자가 직접 테스트해 본 결과, 이러한 도구는 명백한 지연, 인식 오류, 실패 위험이 존재하며 사용자 경험이 좋지 않고 비용도 비쌌습니다. 그러나 이 현상은 이미 HR 및 면접관의 경계를 불러일으켰고, 부정행위 방지 방법을 연구하기 시작했습니다. 이 글은 AI 부정행위가 채용 공정성에 미치는 영향을 탐구하고, “AI로 문제를 해결할 수 있다면 그것도 능력”이라는 관점을 반박하며, 면접의 핵심은 불안정한 외부 도구에 의존하는 것이 아니라 실제 능력과 사고를 평가하는 것이라고 강조합니다. (출처: 差评X.PIN)

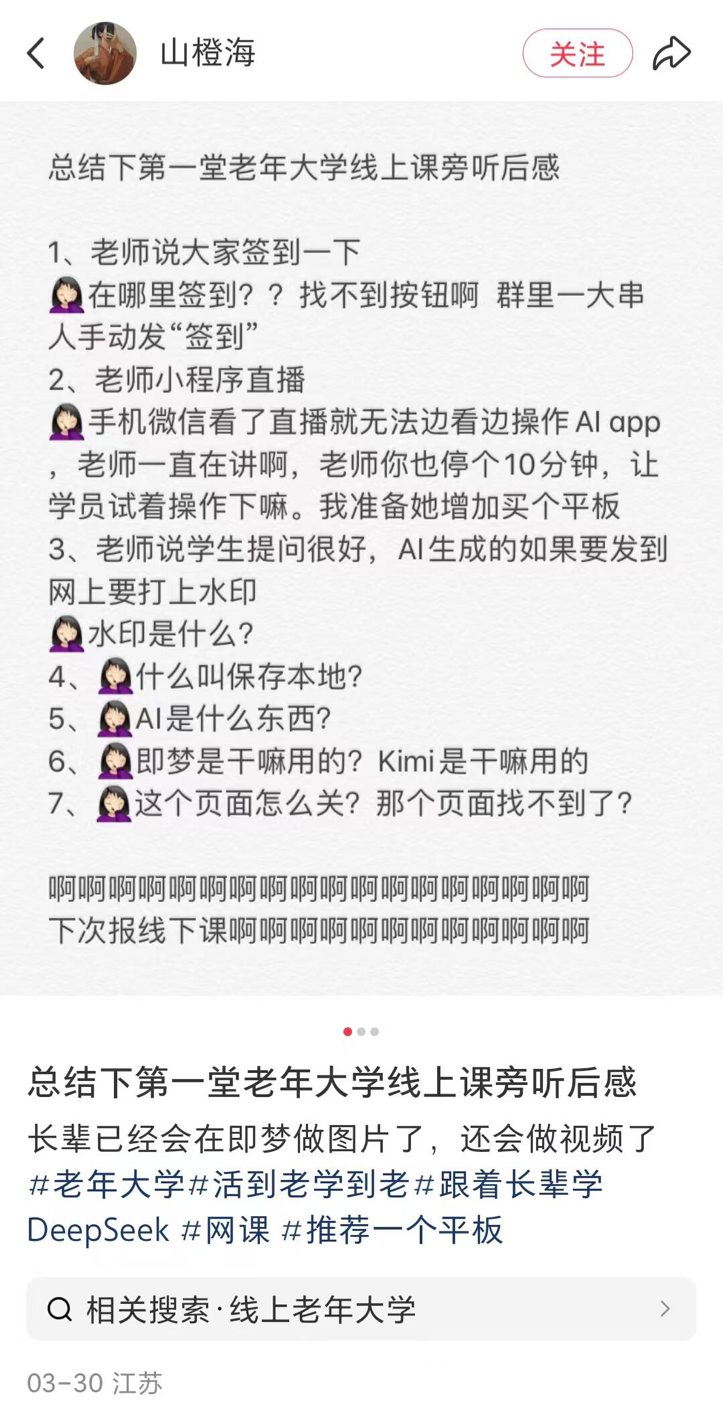
지방 소도시 노인 대학, AI 강좌 개설 붐, 보급과 위험 공존: 전국 여러 지역(지방 소도시 포함)의 노인 대학에서 AI 강좌를 잇달아 개설하는 추세를 보도합니다. 강좌 내용은 주로 AI 콘텐츠 제작(예: Doubao로 문안 작성, Jimeng/Keling으로 이미지/비디오 생성, DeepSeek으로 시/그림 창작)과 생활 응용(건강 검진 결과 해석, 레시피 검색, 사기 방지)에 초점을 맞춥니다. 수강료는 보통 학기당 100-300위안으로, 시중의 값비싼 상업 AI 강좌보다 가성비가 좋습니다. 그러나 노인들은 학습 과정에서 디지털 격차(예: 앱 다운로드, 기본 조작 어려움)에 직면하며, 교육 과정에서 AI 환각 등 위험에 대한 충분한 경고가 부족할 수 있으며, 특히 건강 등 중요한 분야에서 잠재적 위험이 존재합니다. (출처: 刺猬公社)
John Carmack, AI 도구가 기술 가치에 미치는 영향에 대해 답변: AI 도구가 프로그래머, 아티스트 등의 기술 가치를 떨어뜨릴 수 있다는 우려에 대해 John Carmack은 도구의 발전은 항상 컴퓨터 분야의 핵심이었다고 답했습니다. 게임 엔진이 게임 개발 참여 범위를 넓혔듯이, AI 도구는 최고 수준의 창작자, 소규모 팀에게 힘을 실어주고 새로운 사람들을 끌어들일 것입니다. 미래에는 간단한 프롬프트만으로 게임 등을 생성할 수 있겠지만, 뛰어난 작품은 여전히 전문 팀이 만들어야 합니다. AI 도구는 전반적으로 우수한 콘텐츠 생산 효율성을 높일 것입니다. 그는 실업을 우려하여 첨단 도구 사용을 거부하는 것에 반대했습니다. (출처: dotey)
AI에 대한 일련의 비판과 성찰: 이 글은 일련의 짧고 명료한 문장으로 현재 AI 분야의 보편적인 현상에 대해 비판하고 성찰합니다. AGI의 과대 광고, AI 뉴스의 범람, 투자 거품, 모델 능력과 인간 기대 간의 격차, AI 윤리 문제, 의사 결정 블랙박스 문제, AI에 대한 대중 인식 편향 등을 다룹니다. 핵심 관점은 현실과 과장된 홍보 사이에 격차가 있으며, AI 발전을 더 신중하게 바라볼 필요가 있다는 것입니다. (출처: 世上本无 AGI,报道多了,就有了)
RAG가 긴 컨텍스트로 대체될 것인가에 대한 논의: 커뮤니티에서는 Llama 4와 같은 모델이 주장하는 초장기 컨텍스트 창(예: 1000만 토큰)이 RAG(검색 증강 생성) 기술을 대체할 것인지에 대한 논의가 다시 주목받고 있습니다. 단순히 컨텍스트 길이를 늘리는 것만으로는 RAG를 완전히 대체할 수 없다는 의견이 있습니다. RAG는 실시간 정보 처리, 특정 지식 기반 검색, 정보 출처 제어, 비용 효율성 등에서 여전히 장점을 가지고 있기 때문입니다. 긴 컨텍스트와 RAG는 대체 관계라기보다는 상호 보완적인 관계일 가능성이 높습니다. (출처: Reddit r/artificial)

AI 커뮤니티 토론: AI 발전 속도를 따라잡는 방법은?: Reddit 사용자가 AI 발전 속도가 너무 빨라 따라잡기 어렵고 FOMO(놓치는 것에 대한 두려움)를 느낀다고 토로했습니다. 댓글에서는 완전히 따라잡는 것은 불가능하다는 데 대체로 동의하며, 다음과 같은 조언을 제시했습니다: 자신의 세분화된 분야에 집중하기, 동료와 협력하여 정보 공유하기, 모든 작은 업데이트에 대해 불안해하지 않기, 실제 진전과 시장 과대 광고 구분하기, 지속적인 학습 과정임을 받아들이기. (출처: Reddit r/ArtificialInteligence)
커뮤니티 토론: 현재 최고의 로컬 LLM 사용자 인터페이스(UI)는?: Reddit 사용자가 2025년 4월 현재 가장 추천하는 로컬 LLM UI에 대한 토론을 시작했습니다. 댓글에서 언급된 인기 있는 옵션으로는 Open WebUI, LM Studio, SillyTavern(특히 역할극 및 세계관 구축에 적합), Msty(기능이 많은 원클릭 설치 옵션), Reor(노트+RAG), llama.cpp(명령줄), llamafile, llama-server, 그리고 d.ai(안드로이드 모바일) 등이 있습니다. 선택은 사용자 요구(사용 편의성, 기능, 특정 시나리오 등)에 따라 달라집니다. (출처: Reddit r/LocalLLaMA)
AI 정렬(Alignment)이 모델의 “거짓말” 유발 우려: Reddit 사용자가 일부 AI 정렬 방법이 모델에게 자신의 정체성(예: 특정 모델임을 인정하지 않음)을 부인하도록 강요하는 것을 비판하며, 이러한 “강요된 거짓말” 방식의 정렬에 문제가 있다고 주장했습니다. 게시물은 유도 질문을 통해 모델이 결국 자신의 정체성을 “인정”하는 대화 스크린샷을 보여주며, 정렬 목표와 투명성에 대한 논의를 촉발했습니다. (출처: Reddit r/artificial

OpenAI GPT-4.5 A/B 테스트 논란: 사용자들이 GPT-4.5 사용 시 “어느 쪽을 더 선호하십니까?”라는 A/B 테스트 프롬프트를 자주 접하게 된다는 점을 지적했습니다. 댓글에서는 OpenAI가 유료 사용자를 이용하여 모델 선호도 데이터를 수집하고 있을 수 있으며, 이러한 방식으로 수집된 데이터는 LM Arena와 같은 공개 플랫폼의 데이터와 다를 수 있다고 추측했습니다. (출처: natolambert)
모델 컨텍스트 프로토콜(MCP) 실제 구현 문제: 커뮤니티 사용자는 MCP(Model Context Protocol)가 AI와 도구 간 상호 작용을 표준화하는 개념으로 유망하지만, 현재 많은 구현의 품질이 우려스럽다고 지적했습니다. 위험 요소로는 개발자가 MCP 서버에서 보내는 명령을 완전히 제어할 수 없음, 시스템이 인간의 입력 오류(예: 오타)를 처리하는 능력이 부족함, LLM 자체의 환각 문제, MCP 능력 경계가 불분명함 등이 있습니다. 특히 읽기 전용이 아닌 시나리오에서는 신중하게 사용하고, 투명성을 보장하기 위해 오픈 소스 구현을 우선적으로 고려할 것을 권장합니다. (출처: Reddit r/artificial)
Suno 사용자, Extend 기능 이상 피드백: 여러 Suno 사용자가 “Extend”(확장) 기능에 문제가 발생하여 예상대로 노래 스타일을 이어가지 못하고 오히려 새로운 멜로디, 악기, 심지어 리듬과 스타일까지 도입된다고 보고했습니다. 사용자들은 많은 크레딧을 소모하고도 사용할 수 없는 결과를 얻는 것에 불만을 표하며 시스템 버그인지 의문을 제기했습니다. 한 사용자는 이 문제를 보여주는 비디오를 제작했습니다. (출처: Reddit r/SunoAI, Reddit r/SunoAI)

Suno 사용자, 최근 생성 품질 저하 피드백: 장기간 Suno 유료 사용자가 최근 V4 및 V3.5 모델의 생성 품질이 심각하게 저하되었다고 불평하며, 이전에는 신뢰할 수 있었던 프롬프트가 이제 “소음”이나 음정이 맞지 않는 음악을 생성하고 3000 크레딧을 소모해도 사용할 수 있는 노래를 얻지 못했다고 주장했습니다. 사용자는 버그인지 의문을 제기하며 구독 취소를 고려하고 있습니다. (출처: Reddit r/SunoAI)
커뮤니티 공유: AI로 아이들의 꿈의 직업 이미지 생성: 영상은 따뜻한 활용 사례를 보여줍니다: 아이들이 커서 하고 싶은 일(예: 변호사, 아이스크림 가게 주인, 동물원 사육사, 자전거 선수)을 설명하면, AI(영상에서는 ChatGPT)가 설명을 바탕으로 해당 이미지를 생성하고, 아이들은 이미지를 보고 매우 기뻐합니다. (출처: Reddit r/ChatGPT)

커뮤니티 공유: AI 생성 유명인과 젊거나 늙은 자신과의 만남 이미지: 사용자가 ChatGPT의 이미지 생성 기능을 사용하여 유명인(예: 머스크, 아놀드 슈워제네거, 폴 매카트니, 토니 호크, 클린트 이스트우드 등)이 젊거나 늙은 시절의 자신과 만나는 일련의 이미지를 창작했습니다. 효과가 사실적이고 흥미롭습니다. (출처: Reddit r/ChatGPT)
AI 생성 미국 재산업화에 대한 “기괴한” 비디오: 사용자가 중국 AI가 생성했다고 주장하는 “미국 재산업화”에 대한 비디오를 공유했습니다. 비디오 내용과 배경 음악 스타일이 “거칠고” 유머/풍자적인 의미를 담고 있다고 평가되며, AI가 특정 서사 콘텐츠를 생성하는 능력과 잠재적 편견을 보여줍니다. (출처: Reddit r/ChatGPT

사용자, Claude와 o1-pro 비용 및 효과 비교: 한 사용자가 OpenAI o1-pro와 Anthropic Claude Sonnet 3.7을 사용하여 Tailwind CSS 카드 스타일을 개선한 경험을 공유했습니다. 결과적으로 Claude의 출력이 더 좋았고 비용도 o1-pro보다 훨씬 저렴했습니다(1달러 미만 vs 거의 6달러). (출처: Reddit r/ClaudeAI)
Claude 서비스 안정성, 사용자 조롱 대상: 사용자들이 meme이나 댓글을 통해 Anthropic Claude 서비스가 평일 피크 시간대에 “예상치 못한 높은 수요”로 인해 과부하되거나 접속 불가능한 상황이 자주 발생하는 것을 조롱하며 안정성 개선이 필요함을 암시했습니다. (출처: Reddit r/ClaudeAI)

수학 박사 과정생, 머신러닝 입문 자료 요청: 곧 수학 박사 과정을 시작하는 학생으로, 연구 방향이 선형 대수 도구를 머신러닝(특히 PINNs)에 적용하는 것과 관련되어 있습니다. 수학 배경에 적합하고 엄밀하며 간결한 ML 입문 자료(서적, 강의 노트, 비디오 강의)를 찾고 있으며, 표준 교재(예: Bishop, Goodfellow)는 너무 장황하다고 생각합니다. (출처: Reddit r/MachineLearning)

학생, 다른 하드웨어에서 소형 모델 성능 차이 테스트: 한 학생이 RTX 2060 데스크톱 GPU와 Raspberry Pi 5에서 Llama3.2 1B 및 Granite3.1 MoE와 같은 소형 모델의 성능 데이터를 테스트한 결과를 공유했습니다. Llama3.2가 데스크톱에서는 가장 좋은 성능을 보였지만 Raspberry Pi에서는 그 다음으로 좋은 성능을 보여 혼란스러워했습니다. 동시에 MoE 모델 결과 변동성이 더 크다는 것을 관찰하고 그 이유를 물었습니다. (출처: Reddit r/MachineLearning)
사용자, OpenWebUI 검색 및 제목 생성 모델 분리 요청: OpenWebUI 사용자가 검색 요청 생성에 사용되는 모델(추론 능력이 강한 모델 선호)과 제목/태그 생성에 사용되는 모델(더 경제적인 소형 모델 선호)을 분리하여 설정할 수 있는지 질문했습니다. (출처: Reddit r/OpenWebUI)
사용자, Suno AI 음악 프롬프트 핸드북 요청: 사용자가 이전에 유포되었던 Suno AI 음악 프롬프트 핸드북(PDF)을 아직 가지고 있는 사람이 있는지 물었습니다. 원본 링크가 더 이상 작동하지 않기 때문입니다. (출처: Reddit r/SunoAI)

사용자, OpenWebUI와 LM Studio 통합 도움 요청: 사용자가 OpenWebUI를 LM Studio와 백엔드로 연결(OpenAI 호환 API를 통해)하려고 시도했지만 웹 검색 및 임베딩 기능 설정 시 문제가 발생하여 커뮤니티에 도움을 요청했습니다. (출처: Reddit r/OpenWebUI)
사용자, AI 생성 음악 작품 공유: 여러 사용자가 r/SunoAI에서 Suno AI를 사용하여 만든 음악 작품을 공유했습니다. Ambient, Musical, Alternative Psychedelic Rock, Folk Country, Comedy ballad (EDM), Rap, Folk Music, Dreamy indie pop 등 다양한 스타일을 포함합니다. (출처: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)

사용자, Suno 구독 가치 문의: 최근 Suno v4 품질에 대한 불만을 고려하여, 사용자는 현재 Suno 구독 구매가 여전히 가치가 있는지, 특히 오래된 v3 버전 노래를 리마스터링하는 데 사용할 경우 가치가 있는지 물었습니다. (출처: Reddit r/SunoAI)
사용자, Suno 음악 앨범 제작 조언 요청: 경험 많은 Suno 사용자가 만족스러운 작품을 앨범으로 정리하여 DistroKid 등의 플랫폼을 통해 Spotify에 배포할 계획이며, 노래 선정, 순서 배열, 기술적 조작에 대한 조언을 커뮤니티에 구했습니다. (출처: Reddit r/SunoAI)
사용자, iPad에서 Suno UI 문제 불만: 새로운 구독 사용자가 iPad에서 Suno 웹사이트 사용 시 인터페이스 문제에 직면하여 녹음, 가사 편집, 드래그 앤 드롭 등의 기능을 정상적으로 사용할 수 없다고 보고하며 해결책이나 조언을 구했습니다. (출처: Reddit r/SunoAI)
사용자, Cursor AI가 몰래 모델 다운그레이드 가능성 제기: 사용자는 Cursor AI가 알리지 않고 사용하는 모델을 주장하는 Claude 3.7에서 3.5로 다운그레이드했을 수 있다고 의심합니다. 근거는 에이전트 행동 변화와 모델 정보 공개 거부입니다. 사용자는 r/cursor에 게시한 의혹 제기 글이 삭제되었다고 주장했습니다. (출처: Reddit r/ClaudeAI)
사용자, 자주 사용하는 유료 AI 서비스 문의: 사용자가 매달 어떤 유료 AI 서비스를 구독하고 있는지 묻는 토론을 시작했습니다. 어떤 도구가 가치 있다고 여겨지는지, 추천할 만한 서비스가 있는지 알고 싶어합니다. (출처: Reddit r/artificial)
딥러닝 도움 요청: 혼합 신호 식별: 초보자가 딥러닝을 사용하여 혼합된 과학 측정 신호 패턴을 식별하는 방법에 대해 도움을 요청했습니다. 데이터는 txt/Excel 형식의 좌표점입니다. 질문에는 다음이 포함됩니다: 이미지 형식의 보충 데이터를 어떻게 통합하는가? 모델이 좌표점으로 표현된 혼합 패턴을 처리할 수 있는가? 어떤 모델이나 학습 방향을 추천하는가? (출처: Reddit r/deeplearning)
Meme/Humor: 커뮤니티에는 AI와 관련된 여러 Meme이나 유머 게시물이 등장했습니다. 예를 들어 AI와 사랑에 빠지는 것(영화 Her), Gemma 3 모델 선호, AI 노트 테이커 시장 포화, Claude 서비스 다운, AI 생성 유명인 트레이딩 카드 등이 있습니다. (출처: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, AravSrinivas, Reddit r/artificial)

💡 기타
Protocol Buffers (Protobuf) 지속적 관심: Google이 개발한 데이터 교환 형식 Protobuf가 GitHub에서 높은 관심을 유지하고 있습니다. 이는 구조화된 데이터를 직렬화하기 위한 언어 중립적, 플랫폼 중립적 확장 가능 메커니즘으로, AI/ML 및 TensorFlow, gRPC와 같은 수많은 대규모 시스템에서 널리 사용됩니다. 저장소는 컴파일러(protoc) 설치 지침, 다국어 런타임 라이브러리 링크 및 Bazel 통합 가이드라인을 제공합니다. (출처: protocolbuffers/protobuf – GitHub Trending (all/daily))
Gin 웹 프레임워크 인기 유지: Go 언어로 작성된 고성능 HTTP 웹 프레임워크 Gin이 GitHub에서 지속적으로 인기를 얻고 있습니다. Martini와 유사한 API와 httprouter 덕분에 최대 40배 향상된 성능으로 유명하며, 고성능 웹 서비스(AI 모델의 API 서비스 포함 가능)가 필요한 시나리오에 적합합니다. (출처: gin-gonic/gin – GitHub Trending (all/daily))
Hugging Face Hub, 효율성 향상 위해 새로운 백엔드 Xet 채택: Hugging Face Hub가 기존 Git 백엔드를 대체하는 새로운 스토리지 백엔드 Xet 사용을 시작했습니다. Xet는 콘텐츠 정의 청킹(CDC) 기술을 활용하여 파일 수준이 아닌 바이트 수준(약 64KB 청크)에서 데이터 중복 제거를 수행합니다. 이는 대용량 파일(예: Parquet) 수정 시 변경된 행 수준의 차이만 전송 및 저장하면 되므로 업로드/다운로드 효율성과 스토리지 효율성을 크게 향상시킵니다. Llama-4 모델 출시를 통해 이 백엔드를 성공적으로 테스트했습니다. (출처: huggingface)
Hugging Face Hub, 곧 MCP 클라이언트 지원 예정: Hugging Face 개발자가 huggingface_hub 라이브러리의 Inference 클라이언트에 모델 컨텍스트 프로토콜(MCP) 지원을 추가하기 위한 Pull Request를 제출했습니다. 이는 Hugging Face 추론 서비스가 MCP 표준을 따르는 도구 및 에이전트와 더 잘 상호 작용할 수 있게 됨을 의미할 수 있습니다. (출처: huggingface)
Zipline 드론 배송 시스템: Zipline 회사의 드론 배송 시스템을 보여줍니다. 이 시스템은 경로 계획, 장애물 회피, 정밀 투하에 AI를 활용할 수 있으며, 물류 및 공급망 분야, 특히 의료 물품 운송 등에서 잠재력을 보여줍니다. (출처: Ronald_vanLoon)
물리적 인간-로봇 상호작용 위한 ergoCub 로봇: 이탈리아 기술 연구원(IIT)이 물리적 인간-로봇 상호작용 연구를 위해 설계된 ergoCub 로봇을 선보였습니다. 이러한 종류의 로봇은 일반적으로 인식, 운동 제어 및 안전한 상호작용 능력을 구현하기 위해 고급 AI 알고리즘이 필요합니다. (출처: Ronald_vanLoon)
KeyForge3D: 컴퓨터 비전으로 열쇠 복제: KeyForge3D라는 GitHub 프로젝트는 OpenCV(컴퓨터 비전 라이브러리)를 활용하여 열쇠 모양을 식별하고, 열쇠의 비팅 코드(bitting code)를 계산하며, 3D 프린팅용 STL 모델을 내보낼 수 있습니다. 주로 전통적인 CV 기술을 사용하지만, 물리적 세계 복제 작업에서 이미지 인식의 응용 잠재력을 보여주며, 미래에는 AI와 결합하여 인식 정확도와 적응성을 더욱 향상시킬 수 있습니다. (출처: karminski3)

책임감 있는 AI(Responsible AI) 원칙 주목: 게시물은 EY 등 기관에서 사용하는 책임감 있는 AI 원칙을 언급하며, AI 시스템 개발 및 배포 시 공정성, 투명성, 설명 가능성, 프라이버시, 보안, 책임성 등 윤리적, 사회적 요소를 고려해야 함을 강조합니다. (출처: Ronald_vanLoon)
카와사키, 수소 동력 탑승형 로봇 “말” 공개: 카와사키 중공업이 Corleo라는 이름의 4족 보행 로봇을 공개했습니다. 이 로봇은 탑승 가능하도록 설계되었으며 수소 연료를 동력원으로 사용합니다. 로봇이지만, 보도에서는 제어 또는 상호작용 시스템에서 AI의 구체적인 적용 정도를 명확히 언급하지 않았습니다. (출처: Reddit r/ArtificialInteligence)
