
키워드:AI, LLM, AI 인덱스 보고서, AI 음악 생성, Llama 4 모델, DeepSeek 현상, AI 에이전트
🔥 포커스
스탠포드, 2025년 AI 인덱스 보고서 발표, 업계 주요 트렌드 공개: 스탠포드 대학 인간 중심 인공지능 연구소(HAI)가 8번째 연례 AI 인덱스 보고서(456페이지)를 발표하여 2024년 글로벌 AI 발전을 종합적으로 추적했습니다. 보고서에는 AI 하드웨어, 추론 비용, 기업의 책임감 있는 AI 관행, 과학/의학 분야 AI 응용 등의 내용이 새로 추가되었습니다. 핵심 트렌드는 다음과 같습니다: 1) MMMU 등 고난도 벤치마크에서 AI 성능 현저히 향상; 2) 의료, 교통 등 일상생활에 AI 통합 심화; 3) 기업 투자 및 도입률 사상 최고치 기록, 미국 투자가 중국을 크게 앞서지만 중국 모델 성능 격차 빠르게 축소 (미중 최고 모델 MMLU 등 벤치마크 격차 0.3%-1.7%로 축소); 4) DeepSeek 등 오픈소스/소형 모델 성능이 클로즈드 소스/대형 모델에 근접, 추론 비용 대폭 하락 (2년간 280배 감소); 5) 글로벌 AI 규제 강화, 투자 확대; 6) AI 교육 보급 가속화되나 자원 불균형; 7) AI 보안 사건 급증, 책임감 있는 AI 관행 불균형; 8) AI에 대한 글로벌 낙관론 상승하나 지역별 격차 큼. 보고서는 AI의 변혁적 잠재력과 그 발전을 유도할 필요성을 강조합니다. (출처: 36氪, 新智元, 元宇宙之心MetaverseHub, 机器之心)

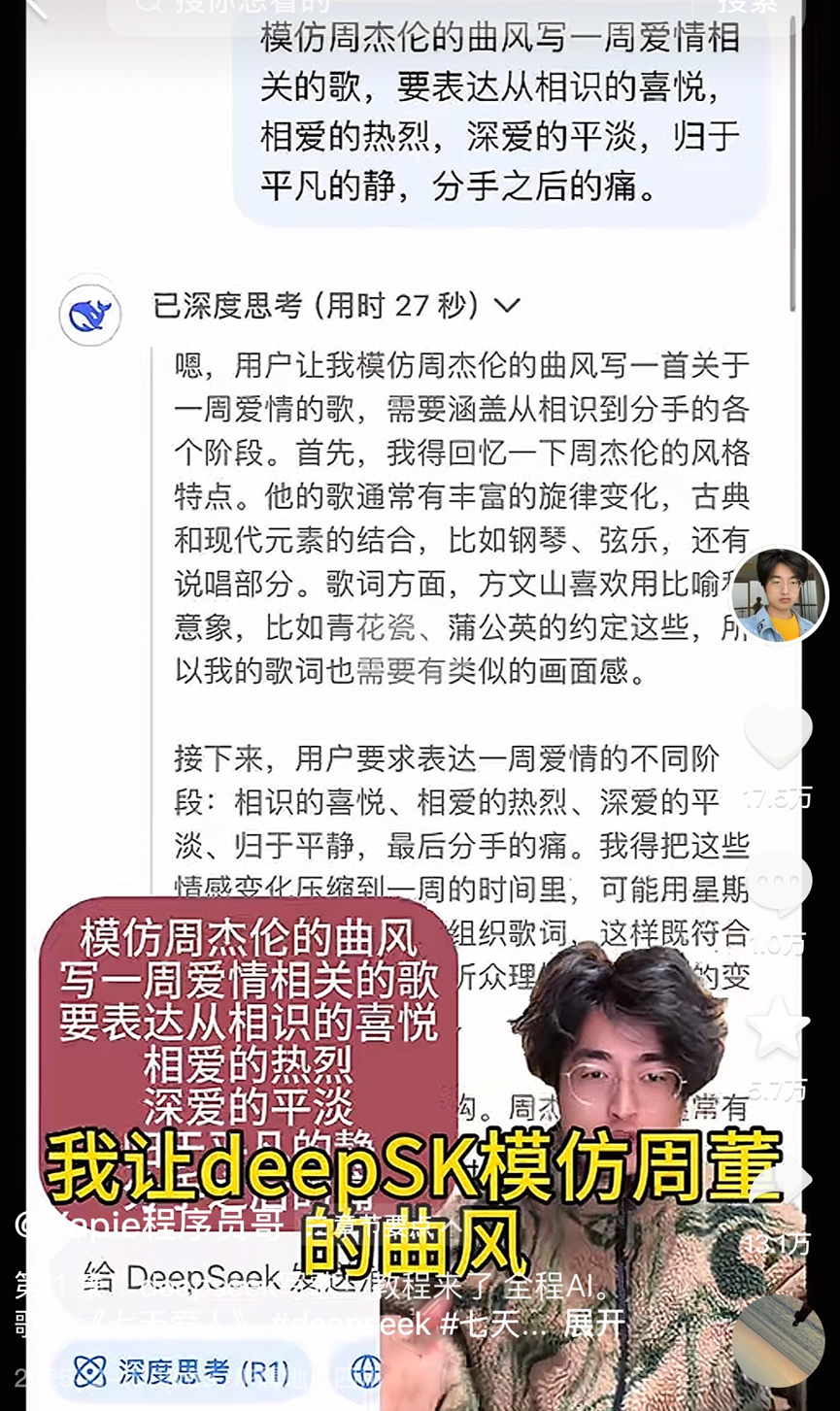
AI 음악 창작 열풍 속 논란, 《七天爱人》 현상으로 본 업계 거품과 과제: AI가 생성한 노래 《七天爱人》이 주걸륜 스타일을 모방하여 예기치 않게 인기를 얻으며 실시간 검색어와 음악 차트에 오르고 빠르게 저작권이 판매되어 AI 음악 창작 열풍을 일으켰습니다. 수많은 아마추어 애호가들이 플랫폼에 몰려들어 AI 도구를 이용해 노래를 “양산”하고 있으며, 일부 플랫폼도 관련 활동을 출시했습니다. 그러나 번영 이면에는 문제가 산적해 있습니다: 대량의 AI 노래 품질이 들쑥날쑥하여 “음악 쓰레기”라는 비판을 받고 있으며, 모방과 짜깁기에 의존하여 진정한 혁신이 부족합니다. 저작권 귀속이 모호하며, 미국은 이미 AI 창작물이 저작권 보호를 받지 못한다고 명확히 했고, Tencent Music 등 플랫폼 역시 법적 위험을 지적했습니다. 상업적 수익화는 난관에 부딪혀, 일부 히트 사례를 제외하고 대부분의 AI 노래 수익은 미미하며 플랫폼 심사는 엄격해지는 추세입니다. 업계 관계자들은 AI가 초급 음악가들의 일자리를 위협할 수 있다고 우려하며, “과정 생략” 창작이 인간의 사고 나태와 심미적 퇴보를 초래할 것을 더욱 걱정하고 있습니다. (출처: 36氪)
Llama 4 모델 발표 후 ‘조작’ 논란, 아레나 순위와 실제 성능 차이 논쟁: Meta가 최근 발표한 오픈소스 모델 Llama 4가 Chatbot Arena에서 높은 점수를 받아 DeepSeek-V3를 제치고 오픈소스 1위에 올랐습니다. 그러나 다수의 사용자들이 실제 테스트 결과 프로그래밍, 추론, 창의적 글쓰기 등에서 성능이 기대에 미치지 못하고 아레나 순위와 큰 차이가 있다고 피드백했습니다. 이후 대형 모델 아레나(LMArena) 측은 Meta가 아레나 테스트에 제공한 버전이 인간 선호도 최적화를 위해 맞춤 제작된 실험 버전(Llama-4-Maverick-03-26-Experimental)이며, Hugging Face에 공개된 표준 버전이 아니고 Meta가 이 차이를 명확히 밝히지 않았다고 지적했습니다. LMArena는 2000여 건의 대결 기록을 공개하며 해당 실험 버전의 응답 스타일(예: 더 친근함, 이모티콘 사용)이 순위에 영향을 미친 중요 요인일 수 있다고 밝혔으며, HF 버전 Llama 4를 다시 평가할 예정입니다. Meta Gen AI 책임자는 테스트 세트로 훈련했다는 사실을 부인하며 성능 차이는 배포 안정성 문제 때문이라고 주장했습니다. 이 사건은 Llama 4 성능, Meta의 투명성, LMArena 평가 방법의 신뢰성에 대한 커뮤니티의 광범위한 논의와 의문을 불러일으켰습니다. (출처: 量子位, 机器之心, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

DeepSeek 현상, 업계 주목 속 중국 생성형 AI 컨퍼런스에서 새로운 기회 논의: DeepSeek의 부상은 중국 및 글로벌 생성형 AI 산업의 중요한 변곡점으로 간주되며, 고효율, 저비용의 오픈소스 모델은 추론 모델, AI Infra 연구 개발 붐을 촉진하고 엣지 AI 및 국산 컴퓨팅 파워 구현에 새로운 동력을 불어넣었습니다. 2025 중국 생성형 AI 컨퍼런스에서는 50여 명의 산학연 전문가들이 DeepSeek이 촉발한 변화, 심층 추론, 멀티모달, 월드 모델, AI Infra, AIGC 응용, Agents 및 체화 지능 등의 주제를 논의했습니다. 참가자들은 DeepSeek이 기업의 배포 비용을 현저히 낮추고(일부 응용은 전환 후 비용 90% 절감) 중국의 오픈소스 커뮤니티 활동성과 빠른 구현 능력을 보여주었다고 평가했습니다. 컨퍼런스에서는 AI 응용 폭발에 필요한 새로운 단말기, Agent 구현 과제, 국산 컴퓨팅 클러스터 돌파, 물리적 지능 발전, AI 상업화 경로 등의 의제도 다루며 글로벌 AI 구도에서 중국의 역할이 점점 더 중요해지고 있음을 강조했습니다. (출처: 36氪, Ronald_vanLoon)

🎯 동향
Agentic AI, 차세대 주요 혁신으로 주목: Agentic AI(지능형 에이전트 AI)가 비즈니스 및 기술 분야 전환의 핵심 동력으로 부상하고 있습니다. 특정 작업을 수행하는 기존 AI와 달리, Agentic AI는 자율적으로 목표를 설정하고 계획을 수립하며 복잡한 다단계 작업을 실행할 수 있어 자율적인 디지털 직원과 더 유사합니다. 다양한 도구와 데이터 소스를 통합하여 추론하고 의사결정을 내릴 수 있으며, 고객 서비스, 데이터 분석, 소프트웨어 개발 등 분야에서 혁신적인 변화를 가져올 것으로 기대됩니다. 기술 발전에 따라 Agentic AI는 기업 운영 모델과 인간-기계 상호작용 방식의 심오한 변화를 주도할 것입니다. (출처: Ronald_vanLoon)

Nvidia, Llama-Nemotron-Ultra 253B 모델 발표, 가중치 및 데이터 오픈소스 공개: Nvidia가 Llama-Nemotron-Ultra를 출시했습니다. 이는 Llama-3.1-405B를 기반으로 NAS 가지치기 및 추론 최적화를 통해 훈련된 253B 파라미터의 밀집 모델입니다. 이 모델은 추론 능력 향상에 중점을 두었으며, SFT 및 RL 후훈련(FP8 정밀도)을 채택하고 가중치와 후훈련 데이터를 오픈소스로 공개했습니다. Nvidia의 오픈소스 후훈련 작업에 대한 지속적인 기여는 커뮤니티로부터 환영받고 있습니다. (출처: natolambert)

Qwen3 시리즈 모델 출시 가능성 제기, 8B 및 15B MoE 버전 포함 추정: vLLM 코드 저장소에 병합된 PR 정보를 바탕으로 Alibaba가 곧 Qwen3 시리즈의 새로운 모델을 출시할 것으로 추측됩니다. 현재 알려진 바로는 Qwen3-8B와 Qwen3-MoE-15B-A2B 두 가지 버전이 포함될 가능성이 있습니다. 커뮤니티에서는 8B 버전이 멀티모달 모델일 수 있으며, 15B 버전은 텍스트에 특화된 MoE(Mixture of Experts) 모델일 것으로 추측하고 있습니다. 사용자들은 새로운 모델이 성능 면에서 돌파구를 마련하기를 기대하며, 만약 15B MoE가 Qwen2.5-Max 수준에 도달한다면 상당한 성공으로 간주될 것입니다. (출처: karminski3)

Runway, Gen-4 Turbo 출시, 비디오 생성 속도 대폭 향상: Runway가 최신 비디오 생성 모델인 Gen-4 Turbo를 발표했습니다. 새 모델의 주요 특징은 생성 속도로, 10초 분량의 비디오를 30초 안에 생성할 수 있다고 주장하며 이전 버전에 비해 속도가 크게 향상되었습니다. 이로 인해 Gen-4 Turbo는 빠른 반복 작업과 창의적인 탐색이 필요한 응용 시나리오에 특히 적합합니다. 이 업데이트는 모든 사용자 플랜에 적용될 예정입니다. (출처: op7418)
Google Gemini Live 출시, 시각 및 음성 실시간 상호작용 구현: Google이 Gemini Live 기능의 정식 출시를 발표했습니다. Pixel 9 및 Samsung Galaxy S25 기기에 먼저 탑재되며, Android의 Gemini Advanced 사용자에게도 개방됩니다. 이 기능은 사용자가 카메라를 통해 화면 내용이나 실시간 화면을 공유하고 Gemini와 음성 대화를 나누며 시각적 콘텐츠 이해, 상호작용적 질문, 문제 해결, 브레인스토밍 등을 가능하게 합니다. 이는 Google의 멀티모달 AI 상호작용 경험에서의 중요한 진전을 의미하며, Project Astra의 비전을 더욱 구체화합니다. (출처: op7418, JeffDean, demishassabis)
HiDream, 17B 파라미터 오픈소스 이미지 모델 HiDream-I1 발표: HiDream AI 팀이 17B 파라미터의 이미지 생성 모델 HiDream-I1을 발표하고 오픈소스로 공개했습니다. 초기 공개된 이미지를 보면 해당 모델이 생성한 이미지 품질은 양호한 수준입니다. 모델 코드는 GitHub에 공개되어 개발자와 연구자들이 사용하고 탐색할 수 있습니다. (출처: op7418)

대형 모델 오픈소스 물결 가속화, 비즈니스 모델 탐색 ‘2.0’: 2025년, DeepSeek을 필두로 한 오픈소스 모델의 부상은 Meta, Alibaba, Tencent 등의 오픈소스 행보를 가속화했으며, 심지어 OpenAI, Baidu 등 기존 ‘클로즈드 소스파’도 전환하기 시작했습니다. 오픈소스의 동력으로는 엣지 인텔리전스 수요, 산업 맞춤형 수요, 생태계 분업 가속화 및 기술 임계점 돌파 등이 있습니다. 오픈소스는 개발자와 중소기업의 진입 장벽을 낮추고 기술 보급과 혁신을 촉진합니다. 그러나 오픈소스가 무료를 의미하는 것은 아니며 유지보수 및 현지화에는 여전히 비용이 듭니다. 선도 기업들은 ‘오픈소스 기반 모델 + 상업용 API 부가 서비스'(예: DeepSeek, Zhipu AI), ‘오픈소스 커뮤니티 버전 + 기업 전용 버전'(예: Alibaba Cloud Qwen), ‘모델 오픈소스 + 클라우드 플랫폼 수익화'(예: Meta Llama)와 같은 상업화 2.0 모델을 모색하고 있습니다. 핵심은 ‘오픈소스로 유인하고 서비스로 수익화’하는 것으로, 생태계, 맞춤화, 클라우드 서비스를 통해 수익을 창출합니다. (출처: 第一新声)

🧰 도구
Augment Code: 복잡한 프로젝트를 위한 AI 코딩 플랫폼: Augment Code가 출시되었습니다. 대규모 복잡 코드베이스를 깊이 이해하고 팀 협업을 위해 특별히 설계된 최초의 AI 코딩 플랫폼으로 포지셔닝합니다. 최대 200K 컨텍스트 토큰 처리 능력, 영구 메모리(코드 스타일, 리팩토링 이력, 팀 규범 학습) 및 심층 도구 통합(VS Code, JetBrains, Vim, GitHub, Linear, Notion 등)을 제공합니다. 핵심 Agent는 코드 작성뿐만 아니라 터미널 명령 실행, 완전한 PR 생성, 컨텍스트 인식 문서 및 테스트 케이스 생성도 가능합니다. Augment는 SWE-bench Verified 순위에서 1위(Claude Sonnet 3.7 및 o1 결합)를 차지했으며 Webflow, Kong 등 기업에서 이미 사용 중입니다. 플랫폼은 현재 무료이며, 개발자들이 대규모 레거시 코드베이스를 처리할 때 겪는 어려움을 해결하는 것을 목표로 합니다. (출처: AI进修生)
Cloudflare, AutoRAG 서비스 출시, RAG 애플리케이션 구축 간소화: Cloudflare가 검색 증강 생성(RAG) 애플리케이션 개발을 간소화하기 위한 서비스인 AutoRAG를 발표했습니다. 개발자는 이 서비스를 통해 데이터 소스(예: 문서, 웹사이트)를 대형 모델이 쿼리할 수 있는 지식 베이스로 자동 변환할 수 있으며, 데이터 인덱싱 및 검색 로직을 수동으로 처리할 필요가 없습니다. 공개 베타 기간 동안 AutoRAG는 무료로 사용할 수 있으며, 계정당 10개의 인스턴스로 제한되고 각 인스턴스는 최대 10만 개의 파일을 처리할 수 있습니다. 이는 특정 지식 기반 AI 애플리케이션 구축의 진입 장벽을 낮춥니다. (출처: karminski3)

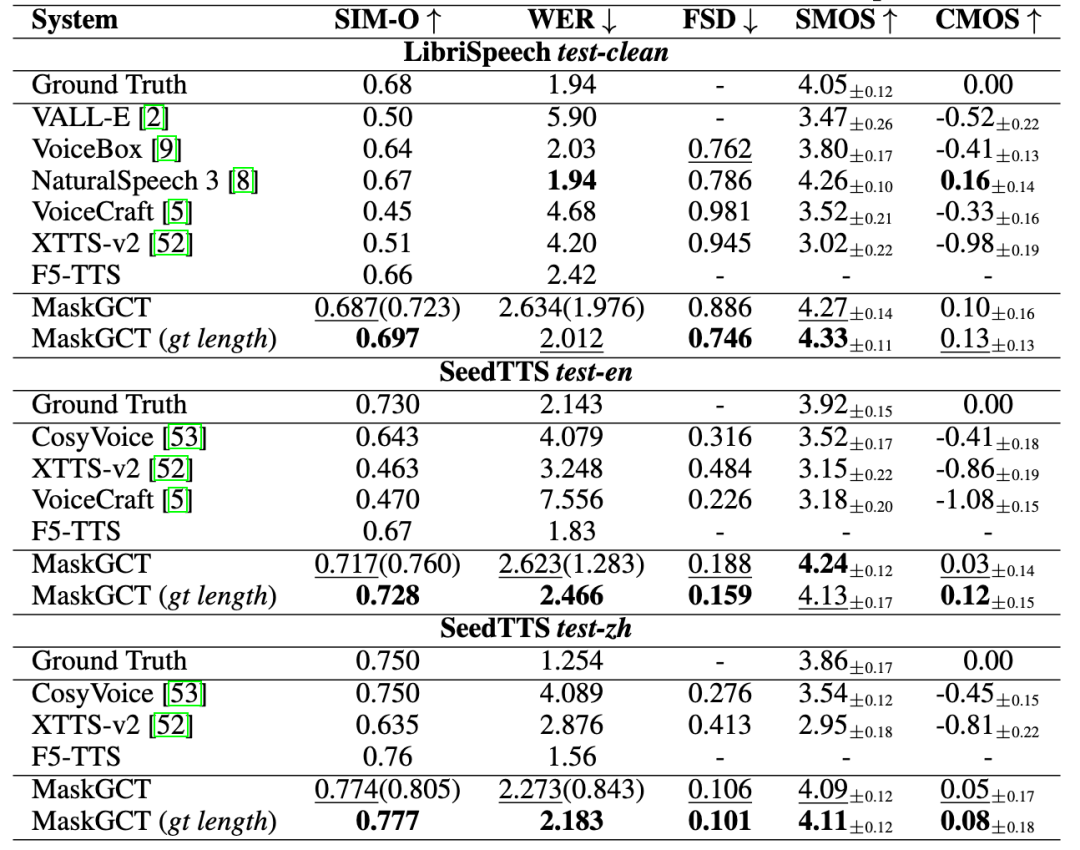
취완과기, ‘취완천음’ 출시, AI 음성 전체 프로세스 솔루션 제공: 취완과기(趣丸科技)가 홍콩중문대(선전)와 공동 개발한 MaskGCT 모델 기반의 AI 음성 제품 ‘취완천음(All Voice Lab)’을 발표했습니다. 이 제품은 텍스트 음성 변환, 비디오 번역, 다국어 합성, 자막 제거 등의 기능을 통합했으며, 비디오 번역 전체 프로세스 자동화를 구현하여 일일 처리량 1000분 이상, 효율 10배 향상이 특징입니다. 음성 생성 효과는 감정이 풍부하고 실제 사람과 유사합니다. 취완천음은 산업화 역량을 통해 언어 간 전파의 규모화 수요를 해결하는 것을 목표로 하며, 이미 숏폼 드라마 해외 진출(비용 절감, 사용자 증가), 뉴스, 문화 관광, 오디오북 등 분야에 적용되었고 ‘글로벌 콘텐츠 인프라’로 포지셔닝합니다. (출처: 36氪)
Exa: AI Agent를 위한 전용 검색 엔진: Exa는 “LLM 시대의 Bing API”로 포지셔닝하며, AI Agent가 인터넷 정보에 효율적으로 접근하고 이해할 수 있도록 설계된 전용 검색 엔진입니다. 인간 검색과 달리 Exa는 더 복잡한 자연어 쿼리를 처리하고 더 포괄적인 결과를 제공하며, 높은 처리량과 낮은 지연 시간의 요청을 지원합니다. 핵심 API에는 빠른 검색, 콘텐츠 가져오기(크롤러), 유사 링크 찾기 등이 포함됩니다. Exa는 또한 사용자가 자연어 필터링 조건을 사용하여 인터넷 정보를 구조화할 수 있는 Websets 기능을 제공합니다. 이 회사는 Lightspeed, Nvidia 등으로부터 투자를 유치했으며 ARR은 천만 달러를 초과하고 주요 경쟁 상대는 Brave Search입니다. (출처: AI探索者)
AI 도구로 WeChat 채팅 기록 시각화 요약 구현: AI 도구 조합을 사용하여 WeChat 그룹 채팅 또는 개인 채팅 기록을 내보내고 시각화 보고서를 생성할 수 있습니다. 단계는 다음과 같습니다: 1) 타사 도구(예: 留痕MemoTrace)를 사용하여 WeChat 채팅 기록을 TXT 파일로 내보냅니다(데이터 보안 위험 주의). 2) TXT 파일과 특정 Prompt 템플릿(스타일 코드 포함)을 긴 텍스트 처리를 지원하는 대형 모델(예: Gemini 2.5 Pro in AI Studio)에 입력하여 HTML 코드를 생성합니다. 3) 생성된 HTML 코드를 온라인 서비스(예: yourware.so)를 통해 공유 가능한 웹 페이지 링크로 변환하거나 온라인 도구(예: cloudconvert.com)를 사용하여 직접 이미지로 변환합니다. 이 방법은 장황한 채팅 정보를 구조가 명확하고 일일 명언과 워드 클라우드가 포함된 보고서로 변환하여 검토 및 공유를 용이하게 합니다. (출처: 卡兹克)
즉몽 AI 3.0 이미지 모델 전체 출시: 즉몽 AI(即梦AI)가 3.0 버전 이미지 생성 모델의 테스트를 완료하고 전체 출시했다고 발표했습니다. 새 버전은 이미지 품질, 스타일 다양성, 의미 이해 등에서 향상될 것으로 예상됩니다. 이미 사용자(예: 歸藏)가 3.0 모델을 사용하여 다양한 분야 디자인(예: AI 운영 이미지)에 대한 상세 테스트 및 프롬프트 모음을 공유하며 생성 효과를 보여주었습니다. (출처: op7418)

VIBE Chat: 무작위 배경의 재미있는 채팅 웹사이트: VIBE Chat이라는 웹사이트는 새로운 채팅 경험을 제공하며, 대화마다 다른 배경 이미지가 무작위로 생성됩니다. 이 웹사이트는 Gemini 2.0 Flash 모델을 기반으로 하며, 사용자는 이를 사용하여 프로그래밍 등의 작업을 할 수 있고 코드나 내용은 채팅 인터페이스에 직접 표시됩니다. 테스트 결과 Flappy Bird나 테트리스와 같은 간단한 게임 코드를 생성할 수 있는 것으로 나타났습니다. (출처: karminski3)
개발자, Suno AI 전용 GPT 어시스턴트 제작: 한 개발자가 Suno AI 음악 창작 과정을 보조하기 위한 “Hook & Harmony Studio”라는 맞춤형 GPT를 만들었습니다. 이 도구는 사용자가 입력한 노래 콘셉트를 기반으로 독특한 제목, 구조화된 가사(악기 및 보컬 지침 포함), Suno 스타일 태그에 맞는 제안, 진부한 표현 필터링을 생성하고, 선택적으로 노래의 시각적 효과를 위한 프롬프트를 생성할 수 있습니다. 가사 창작과 스타일 탐색을 간소화하고 Suno 프로젝트 모드에서 사용하기 쉽도록 자동으로 형식을 지정하는 것을 목표로 합니다. (출처: Reddit r/SunoAI)
Code to Prompt Generator: 코드에서 LLM 프롬프트 생성을 간소화하는 도구: 개발자가 코드 저장소에서 LLM 프롬프트를 만드는 과정을 간소화하기 위해 “Code to Prompt Generator”라는 작은 도구를 오픈소스로 공개했습니다. 이 도구는 프로젝트 폴더를 자동으로 스캔하여 파일 트리를 생성하고(관련 없는 파일 제외), 사용자가 파일/디렉토리를 선택적으로 포함할 수 있게 하며, 실시간으로 토큰 수를 표시하고, 지침(Meta Prompts)을 저장 및 재사용하며, 최종 프롬프트를 한 번의 클릭으로 복사할 수 있습니다. 이 도구는 Next.js 프론트엔드와 Flask 백엔드를 사용하며 여러 플랫폼에서 실행할 수 있습니다. (출처: Reddit r/ClaudeAI)
Llama 4 GGUF 버전 출시, 로컬 실행 지원: llama.cpp가 Llama 4(현재 텍스트만) 지원을 병합함에 따라 커뮤니티 개발자(예: bartowski, unsloth, lmstudio-community)들이 Llama 4 Scout 모델의 GGUF 양자화 버전을 빠르게 출시했습니다. 이 버전들은 imatrix와 같은 최적화된 양자화 전략을 채택하여 모델 크기와 성능의 균형을 맞추고 사용자가 로컬 하드웨어에서 Llama 4를 실행할 수 있도록 합니다. 다양한 비트 폭(예: IQ1_S 1.78bit, Q4_K_XL 4.5bit)의 버전을 선택할 수 있어 다양한 하드웨어 구성 요구를 충족합니다. 사용자는 Hugging Face에서 이러한 GGUF 파일을 찾을 수 있습니다. (출처: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

📚 학습
Microsoft와 홍콩중문대, ImageGen-CoT 제안, AI 그림의 컨텍스트 이해 능력 향상: AI 그림 모델이 복잡한 텍스트 설명과 컨텍스트 연관성(예: “가죽 사과”에서 “가죽 상자”로의 재질 이전)을 이해하는 데 부족한 점을 해결하기 위해 Microsoft Research Asia와 홍콩중문대 연구진이 ImageGen-CoT 프레임워크를 제안했습니다. 이 방법은 이미지 생성 전에 사고의 연쇄(Chain-of-Thought, CoT) 추론 단계를 도입하여 모델이 먼저 핵심 정보를 생각하고 논리를 정리한 후 창작하도록 합니다. 고품질 ImageGen-CoT 데이터셋을 구축하고 미세 조정을 통해 모델(예: SEED-X)의 T2I-ICL 작업 성능이 현저히 향상되었습니다(CoBSAT 89% 향상, DreamBench++ 114% 향상). 이 프레임워크는 2단계 추론을 채택하고 다양한 테스트 시 확장 전략(단일 CoT, 다중 CoT, 혼합 확장)을 탐색했으며, 그중 혼합 확장이 가장 효과적이었습니다. (출처: 36氪, 新智元)

논문, 라우팅 LLM 새로운 패러다임 및 RouterEval 벤치마크 제안: 대형 모델 연구가 직면한 컴퓨팅 파워 독점, 높은 비용, 단일 기술 경로 문제를 해결하기 위해 연구자들은 라우팅 LLM(Routing LLM) 패러다임을 제안했습니다. 지능형 라우터(Router)를 통해 작업을 여러 (오픈소스) 소형 모델에 동적으로 할당하여 협력 처리합니다. 이 연구를 지원하기 위해 논문은 8500개 이상의 LLM이 12개 주요 벤치마크에서 기록한 2억 건의 성능 기록을 포함하는 포괄적인 RouterEval 벤치마크를 오픈소스로 공개했습니다. 이 벤치마크는 라우팅 문제를 표준 분류 작업으로 변환하여 단일 GPU 카드나 노트북에서도 연구를 수행할 수 있게 합니다. 연구 결과, 지능형 라우팅(후보 모델이 3~10개만 있어도)을 통해 여러 약한 모델의 조합 성능이 최고 수준의 단일 모델(예: GPT-4)을 능가할 수 있음을 발견하여 “Model-level Scaling Up” 효과를 보여주었습니다. 이 연구는 저비용으로 고성능 AI를 구현하는 새로운 방향을 제시합니다. (출처: 新智元)
UIUC 한가위, 손기맹 팀, DeepRetrieval 오픈소스 공개, RL로 검색 엔진 쿼리 최적화: 사용자의 원본 쿼리 품질이 낮아 정보 검색 효과가 떨어지는 문제를 해결하기 위해 UIUC 팀이 DeepRetrieval 프레임워크를 제안했습니다. 이 시스템은 강화 학습(RL)을 이용하여 LLM이 사용자의 원본 쿼리(자연어, 부울 표현식 또는 SQL)를 특정 검색 엔진(예: PubMed, BM25, SQL 데이터베이스)의 특성에 더 잘 맞도록 최적화하여 기존 검색 시스템을 변경하지 않고 검색 효과를 극대화합니다. 실험 결과, DeepRetrieval(3B 모델만 사용)은 검색 성능을 현저히 향상시키고(문헌 검색 10배 향상, Evidence-Seeking 작업에서 GPT-4o 능가, SQL 실행 정확도 향상), SFT 기반 방법보다 훨씬 뛰어난 효과를 보였습니다. 연구는 RL의 탐색 능력이 SFT의 모방 학습보다 우수하여 더 나은 쿼리 전략을 발견할 수 있음을 강조합니다. (출처: 机器之心)
중국과학원 자동화연구소 등, Vision-R1 제안, 강화 학습으로 VLM 시각적 위치 파악 능력 향상: 비전-언어 모델(VLM)이 객체 탐지, 시각적 위치 파악 작업에서 겪는 형식 오류, 낮은 재현율, 부족한 정밀도 등의 문제를 해결하기 위해 중국과학원 자동화연구소와 중커쯔둥타이추(中科紫东太初) 팀이 Vision-R1 프레임워크를 제안했습니다. 이 방법은 언어 모델 R1의 성공 경험을 바탕으로 규칙 기반 강화 학습(Rule-Based RL)을 시각적 위치 파악 작업에 도입했습니다. 시각적 평가 지표(형식 정확성, 재현율, IoU 정밀도) 기반의 작업 수준 보상 함수를 설계하고 점진적 규칙 조정 전략(차등 보상, 단계적 점진적 임계값)을 채택하여 인공 선호도 데이터나 보상 모델 없이도 Qwen2.5-VL 등 모델의 COCO, ODINW 등 데이터셋에서의 객체 탐지 성능을 현저히 향상시켰으며(최대 50% 향상), 일반적인 질의응답 능력에는 거의 영향을 미치지 않았습니다. 코드와 모델은 오픈소스로 공개되었습니다. (출처: 机器之心)
CalibQuant: 1비트 KV Cache 양자화 방안으로 멀티모달 모델 처리량 향상: 멀티모달 대형 모델(MLLM)이 대규모 시각 입력을 처리할 때 KV Cache 메모리 점유율이 과도하게 높아 처리량을 제한하는 문제를 해결하기 위해 연구자들이 CalibQuant 방안을 제안했습니다. 이 방안은 극단적인 1비트 KV Cache 양자화를 구현하며, 시각 KV Cache의 중복 특성을 고려하여 설계된 후-스케일링(Post-Scaling) 및 보정(Calibration) 기술을 결합합니다. 후-스케일링은 역양자화 계산 순서를 최적화하여 효율성을 높이고, 보정은 1비트 양자화로 인한 극단값 왜곡을 완화하기 위해 어텐션 점수를 조정합니다. 실험 결과, CalibQuant는 LLaVA, InternVL-2.5 등 모델에서 메모리 및 계산 비용을 현저히 줄여 최대 10배의 처리량 향상을 달성하면서도 모델 성능 손실은 거의 없음을 보여주었습니다. 이 방법은 플러그 앤 플레이 방식으로 원본 모델 수정 없이 사용할 수 있습니다. (출처: PaperWeekly)
CVPR 2025 | SeqAfford: 순차적 3D 어포던스 추론 구현: 기존 AI가 여러 객체, 여러 단계의 복잡한 지시를 이해하고 실행하기 어려운 문제를 해결하기 위해 연구자들이 SeqAfford 프레임워크를 제안했습니다. 이 프레임워크는 처음으로 3D 비전과 멀티모달 대형 언어 모델(MLLM)을 결합하여 순차적 3D 어포던스(Affordance) 추론에 사용합니다. 18만 쌍 이상의 지시-포인트 클라우드 데이터를 포함하는 최초의 Sequential 3D Affordance 데이터셋을 구축하여 미세 조정하고, 분할 어휘(
GitHub, MCP 서버 리소스 모음 공개: awesome-mcp-servers라는 GitHub 저장소가 AI Agent를 위한 300개 이상의 MCP(Model Capability Protocol) 서버를 정리하여 오픈소스로 공개했습니다. 이 서버들은 프로덕션 수준 및 실험적 프로젝트를 포괄하며, 개발자에게 풍부한 도구와 인터페이스를 제공하여 AI Agent가 외부 서비스 및 데이터 소스와 상호작용하는 것을 용이하게 하고 Agent 생태계 발전을 더욱 촉진합니다. (출처: Reddit r/ClaudeAI)

에모리 대학교 류페이 교수, 대형 모델/NLP/GenAI 박사과정생 및 인턴 모집: 미국 에모리 대학교 컴퓨터 과학과 부교수 류페이(刘菲)가 2025년 가을 학기 입학 전액 장학금 박사과정생을 모집합니다. 연구 방향은 지능형 에이전트로서의 대형 언어 모델(LLM)의 추론, 계획 및 의사결정 능력, 그리고 교육, 의료 등 분야에서의 AI 응용입니다. 관련 분야에 관심 있는 학생들의 원격 인턴십 또는 협력 신청도 환영합니다. 지원자는 컴퓨터 또는 관련 전공 배경, 우수한 프로그래밍 능력, 연구 성과 또는 강력한 수학적 기초를 가진 자를 우대합니다. (출처: AI求职)
AI Agent 구축 가이드 발표: SuccessTech Services가 대형 언어 모델(LLM) 지능형 에이전트(Agent) 구축 방법을 소개하는 단계별 가이드를 발표했습니다. 이 가이드는 Agent의 기본 개념, 아키텍처 설계, 도구 선택, 개발 프로세스 및 실제 응용 사례를 다루며, 자율 AI 애플리케이션 개발을 희망하는 개발자에게 입문 지침을 제공할 수 있습니다. (출처: Reddit r/OpenWebUI)

홍콩과기대, Diffusion 모델 추론에 특화된 Dream 7B 코드 공개: 홍콩과기대 NLP 팀이 이전에 발표한 Diffusion 모델 추론 모델 Dream 7B의 GitHub 코드 저장소를 공개했습니다. 이 모델은 LLM이 Diffusion 모델과 관련된 지시를 이해하고 실행하도록 하는 것을 목표로 합니다. 코드 공개로 연구자들은 해당 모델을 재현하고 추가 연구를 진행할 수 있게 되었습니다. (출처: Reddit r/LocalLLaMA)

💼 비즈니스
링신차오서우, 억대 시드 투자 유치, 세계 최고 자유도 링커 핸드 개발: 체화 지능 회사 ‘링신차오서우(灵心巧手)’가 1억 위안 이상의 시드 투자를 유치했으며, Sequoia Seed Fund 등이 주도했습니다. 이 회사는 “링커 핸드 + 클라우드 지능” 플랫폼에 집중하고 있으며, 자체 개발한 Linker Hand 시리즈 링커 핸드는 산업용 버전 자유도가 25-30, 연구용 버전은 42(세계 최고, Shadow Hand의 24와 Optimus의 22 초과)에 달하며 고정밀 감지(다중 센서 융합) 및 조작 능력을 갖추고 있습니다. 회사는 연동 막대와 건-로프 두 가지 구조를 채택하여 양산을 실현했으며, 클라우드 지능(대규모 데이터셋 DexSkill-Net 기반 훈련)과 결합하여 학습 및 제어를 수행합니다. 제품은 비용(약 5만 위안, Shadow Hand의 150만 위안보다 훨씬 저렴)과 내구성 면에서 우위를 가지며, 베이징대, 칭화대 등 최고 대학에서 구매했으며 의료, 산업 등 분야에 응용되고 있습니다. (출처: 36氪)

구글, AI 직원에게 고액 ‘가드닝 리브’ 지급하며 경쟁사 이직 막았다는 보도: 보도에 따르면 구글은 핵심 AI 인재가 OpenAI 등 경쟁사로 유출되는 것을 막기 위해 일부 퇴사 직원에게 최대 1년간의 고액 급여(수십만 달러에 달할 수 있음)를 지급했으며, 이는 해당 기간 동안 경쟁사에 합류하지 않는 조건이었습니다. 이러한 관행은 ‘가드닝 리브(gardening leave)’라고 불리며 금융 등 업계에서는 흔하지만, 기술 업계, 특히 비임원급 AI 연구원 및 엔지니어를 대상으로 하는 경우는 드뭅니다. 이는 최고 수준 AI 인재의 극심한 부족과 기술 대기업 간의 치열한 인재 쟁탈전을 반영합니다. (출처: Reddit r/ArtificialInteligence)

Shopify CEO, 직원의 효과적인 AI 활용 강조: Shopify CEO Tobias Lütke는 직원들에게 팀 인원 증원을 고려하기 전에 먼저 AI 도구를 활용하여 효율성을 높이고 문제를 해결하는 방법을 생각해야 한다고 요구했습니다. 그는 AI가 생산성 향상의 핵심 레버리지이며 직원들이 적극적으로 배우고 일상 업무 프로세스에 통합해야 한다고 생각합니다. 이러한 입장은 기업계가 AI를 통한 업무 효율성 향상에 높은 중요성을 부여하고 있으며, 직원들이 AI 시대의 새로운 요구 사항에 적응하기를 기대한다는 것을 반영합니다. (출처: bushaicave.com)
36Kr, ‘2025 AI 파트너 혁신 대상’ 공모 시작: AI 분야의 혁신적인 제품, 솔루션 및 기업을 발굴하고 장려하며 AI의 각 산업 분야 적용을 촉진하기 위해 36Kr이 ‘2025 AI 파트너 혁신 대상’ 선정 활동을 시작했습니다. 공모 범위는 일반 혁신(사무, 기업 서비스, 데이터 분석 등), 산업 혁신(금융, 의료, 교육, 산업 등), 단말 혁신(스마트 하드웨어, 자동차, 로봇 등) 세 가지 범주의 비응용 소프트웨어 제품/솔루션을 포함합니다. 선정은 기술 혁신, 응용 효과, 사용자 경험, 사회적 가치 네 가지 차원에서 전문가 심사단의 평가로 진행됩니다. 신청 기간은 3월 13일부터 4월 7일까지이며, 결과는 4월 18일에 발표될 예정입니다. (출처: 36氪)

전국 최초 AI 대형 모델 프라이빗 배포 표준 제정 착수: 기업이 AI 대형 모델을 프라이빗하게 배포할 때 직면하는 기술 불일치, 비표준 프로세스, 평가 시스템 부재 등의 문제를 해결하기 위해 즈허표준센터(智合标准中心)가 공안부 제3연구소 등 기관과 협력하여 《인공지능 대형 모델 프라이빗 배포 기술 구현 및 평가 가이드라인》 단체 표준 제정 작업에 착수했습니다. 이 표준은 모델 선정, 자원 계획, 배포 구현, 품질 평가부터 지속적인 최적화까지 전 과정을 포괄하며 기술, 보안, 평가 및 사례를 융합하고 모델 응용 측, 기술 서비스 측, 품질 평가 측이 공동으로 제정하는 것을 목표로 합니다. 표준은 AI 대형 모델 기업, 기술 서비스 제공업체, 하드웨어 제공업체, 클라우드 컴퓨팅 기업, 보안 서비스 제공업체, 데이터 서비스 제공업체, 산업 응용 기업, 테스트 평가 기관, 규정 준수 법률 기관 및 지속 가능한 발전 기관 등을 대상으로 편찬 참여 단위를 모집합니다. (출처: 智合标准化建设)
🌟 커뮤니티
AI 생성 콘텐츠, ‘환각’ 및 정보 신뢰성 우려 야기: 다수의 사용자와 미디어가 DeepSeek을 포함한 대형 언어 모델이 “진지하게 헛소리하는” 현상, 즉 AI 환각(hallucination)이 존재한다고 지적했습니다. AI는 존재하지 않는 사실을 꾸며내거나 잘못된 출처(예: 시 출처, 법 조항, 문화재 정보)를 인용하고, 심지어 데이터(예: “80년대생 사망률”)를 조작할 수도 있습니다. 이러한 현상은 훈련 데이터의 노후화, 오류 또는 편견, 모델의 지식 사각지대, 실시간 검증 능력 부족에서 비롯됩니다. 사용자는 AI 생성 콘텐츠의 정확성에 주의하고 교차 검증 및 인공 검토를 수행해야 하며, 특히 학술, 업무 등 진지한 상황에서는 더욱 그렇습니다. 과도한 의존은 잘못된 정보 확산을 초래하고 “탈진실 시대”의 도전을 심화시킬 수 있습니다. Vectara HHEM 환각 테스트에서도 DeepSeek-R1의 높은 환각률이 나타났습니다. (출처: 锌刻度)
AI 예술 생성 논란 재점화: 지브리 스타일 열풍을 중심으로: OpenAI의 GPT 새로운 이미지 기능이 생성한 지브리 스타일 이미지가 큰 인기를 얻으며 CEO Sam Altman까지 해당 스타일로 프로필 사진을 변경했고, 이는 ChatGPT 다운로드 수와 수입 증가로 이어졌습니다. 그러나 이는 AI 생성 예술의 윤리 및 저작권 논란을 다시 불러일으켰습니다. 미야자키 하야오 본인은 기계가 생성한 화면에 명확히 반대 의사를 표명한 바 있습니다. 할리우드 종사자들(예: 《그래비티 폴즈》 제작자 Alex Hirsch, Robin Williams의 딸 Zelda Williams)은 이에 강한 불만을 표하며 예술가의 창작 성과를 도용한 것이며 영혼이 없다고 비판했습니다. Altman은 이것이 “창작의 민주화”이며 사회의 거대한 승리라고 응수했습니다. 기사는 AI가 화풍을 모방할 수는 있지만 지브리 작품에 담긴 복잡한 서사, 미학 시스템, 인문학적 관심을 복제하기는 어렵다고 주장합니다. 대부분의 AI 생성 콘텐츠는 고전이 되기 어렵지만, 일부 인간-기계 공동 창작 또는 보조 도구는 성공할 것입니다. (출처: APPSO, Reddit r/artificial)

관점: 인간의 인지 구조가 AI 시대의 핵심 경쟁력: 기사는 AI 도구 보급이 창작자 가치 하락을 초래한다는 관점에 반박하며, 표현과 창작 자체가 인간의 내재적 요구이자 “소비 행위”이며 그 가치는 결과뿐 아니라 과정에 있다고 주장합니다. AI는 도구일 뿐, 인간의 독특한 인지와 감정을 대체할 수 없습니다. 수억 년 진화를 거쳐 형성된 인간 뇌의 “인지 구조”가 핵심이며, AI 발전 역시 데이터 중심에서 인지 중심(인간 인지 과정 모방)으로 전환되고 있습니다. 따라서 미래 핵심 경쟁력은 “일하는 것”이 아니라 AI와 상호작용하는 “인지 구조” 또는 “앵커 포인트”, 즉 독특한 관점, 깊은 경험, 타인과 구축한 진정한 연결입니다. 창작자는 자신의 독특한 부분을 연마하는 데 집중하여 정보 홍수 속에서 안정적인 참조물이 되고, 자신과 타인에게 방향감과 가치감을 제공하며 AI가 초래할 수 있는 “엔트로피 증가”에 맞서야 합니다. (출처: 王智远)
관점: AI 응용에는 관계와 신뢰 기반의 새로운 장벽 존재: 주샤오후(朱啸虎)의 “AI 응용에는 장벽이 없다”는 발언에 대해 기사는 반박하며, AI 시대 응용 장벽이 전통적인 기술 장벽에서 관계와 신뢰 기반의 새로운 장벽으로 전환되었다고 주장합니다. AI 응용은 더 이상 사용자 규모만 추구하는 것이 아니라 개인화된 경험 제공을 통해 수직 시장에서 수익을 창출할 수 있습니다. “껍데기” 응용이라도 사용자와의 깊은 연결(AI는 사용할수록 사용자를 더 잘 이해함), 창작자 IP와 사용자의 신뢰 유대, 데이터 폐쇄 루프를 통한 지속적인 최적화(산업 데이터 + 개인 데이터 훈련)를 통해 해자를 구축할 수 있습니다. 창업자들에게는 수직 분야에 집중하고 독특한 경험을 만들며 데이터 폐쇄 루프를 구축하고 감정적 연결을 구축할 것을 제안합니다. (출처: 周知)
AI ‘속성반’ 사기, 노인 연금 노려: “AI 속성 수익화”, “월 수입 만 위안 이상”을 내세운 온라인 강의가 숏폼 비디오 플랫폼을 통해 노인들에게 정밀하게 푸시되고 있습니다. 이러한 강의는 종종 무료 교육을 미끼로 디지털 휴먼 비디오, 가짜 “전문가” 신분, 노후 불안감 또는 창업 신화 조장 등의 수단을 사용하여 노인들을 그룹 채팅방으로 유인합니다. 이후 세뇌식 마케팅(예: 수익 인증샷 게시, 마감 임박 분위기 조성)을 통해 노인들에게 고액의 수강료(수천 ~ 수만 위안) 지불을 유도합니다. 강의 내용은 종종 기본적인 소셜 미디어 운영 지식을 포장한 것이며, 약속된 AI 기술 교육, 일감 연결 후 현금 지급, 일대일 지도 등은 대부분 허위 광고이고 사후 서비스는 부재하며 환불은 어렵습니다. 많은 젊은이들이 이미 소셜 미디어에서 가족이 사기를 당할 뻔했거나 당한 경험을 공유하며 이러한 사기에 대한 경계를 촉구하고 있습니다. (출처: 豹变)

Karpathy: LLM, 전통적 기술 확산 경로 뒤집고 개인에게 힘 실어줘: Andrej Karpathy는 대형 언어 모델(LLM)의 기술 확산 모델이 역사적인 변혁적 기술(보통 하향식: 정부->기업->개인)과 완전히 다르다고 지적했습니다. LLM은 거의 하룻밤 사이에 저렴한 비용(심지어 무료)과 빠른 속도로 모든 사람의 기기에 보급되어 일반 개인에게 불균형적으로 큰 혜택을 가져다주었지만, 기업과 정부에 미치는 영향은 상대적으로 뒤처졌습니다. 이는 LLM이 광범위한 분야에서 준전문가 수준의 지식을 제공하여 개인의 지식 영역 한계를 보완하기 때문입니다. 반면, 조직 기관은 고유한 장점과 LLM 능력의 불일치, 문제의 복잡성, 내부 관성 등의 요인으로 인해 혜택 정도가 제한적입니다. 그는 현재 AI의 미래 분포가 놀랍도록 균형 잡혀 있으며 진정한 “인민의 힘”이라고 생각합니다. 그러나 미래에 돈으로 현저히 더 나은 AI를 살 수 있게 된다면 구도는 다시 바뀔 수 있습니다. (출처: op7418)
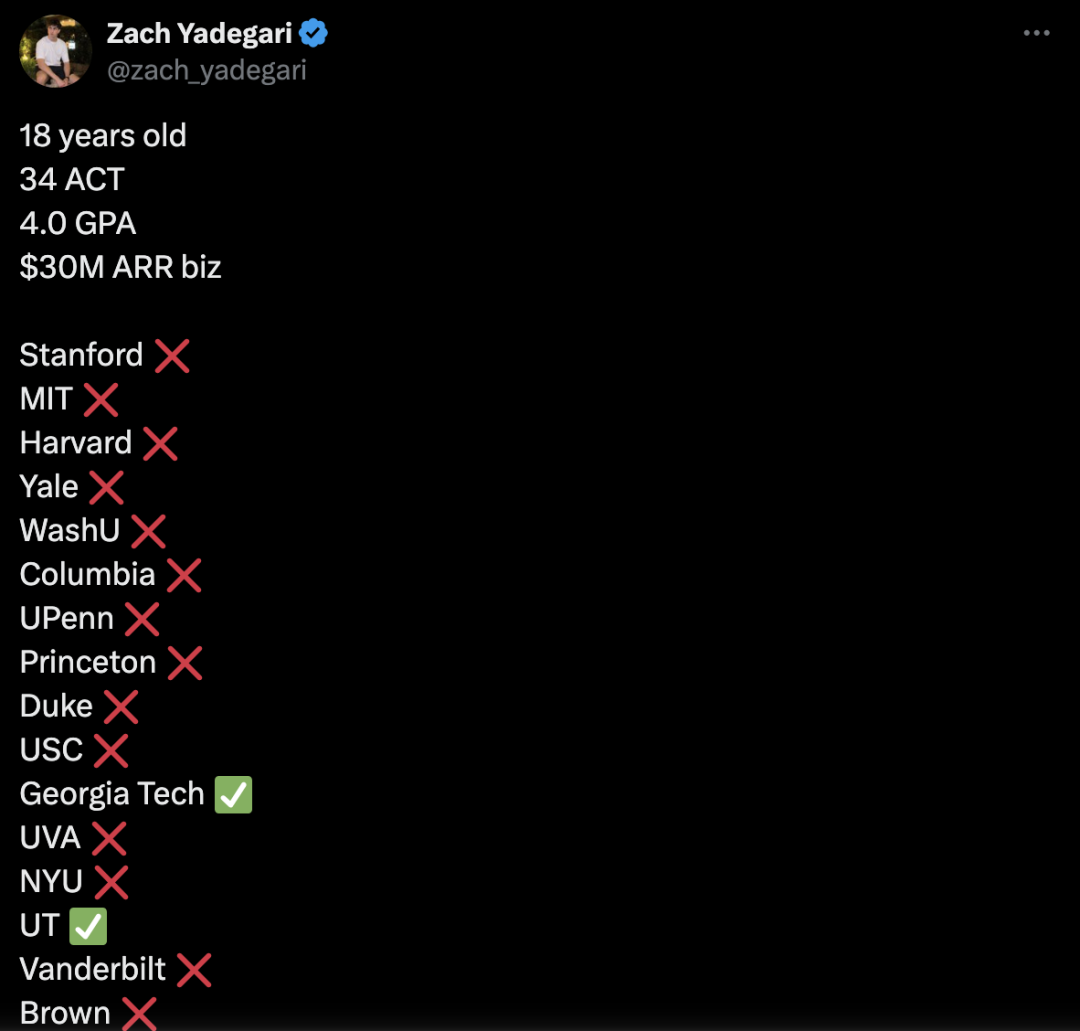
18세 AI 앱 CEO, 다수 명문대 불합격 소식에 논란: 18세 Zach Yadegari는 고등학교 재학 중 AI 칼로리 추적 앱 Cal AI를 공동 창업했으며, 이 앱은 다운로드 300만 회 이상, 연 수입 수백만 달러를 기록했습니다. 그는 4.0 GPA와 높은 ACT 점수, 눈에 띄는 창업 경력에도 불구하고 하버드, 스탠포드, MIT 등을 포함한 18개 명문 대학에 지원하여 15곳에서 불합격했습니다. 이 사건은 소셜 미디어에서 광범위한 관심과 논의를 불러일으켰습니다. Yadegari가 공개한 입학 에세이에는 원래 대학에 갈 생각이 없었으나 대학 생활의 가치를 깨닫고 생각을 바꿨다는 내용이 담겨 있습니다. 불합격 사유에 대한 추측이 분분하며, 일부는 에세이가 “오만해” 보이거나 중퇴 위험이 높음을 암시하여 명문대가 중시하는 졸업률 지표에 영향을 미쳤다고 보고, 다른 일부는 대학 입학 시스템의 문제나 아시아계 지원자에 대한 차별(Stanley Zhong 사례와 유사)을 비판합니다. Yadegari 본인은 진정성 있게 봐주기를 바란다고 밝혔습니다. (출처: 36氪, AI前线)
커뮤니티 논쟁: AI는 축복인가 재앙인가?: Reddit 커뮤니티에서 AI 기술의 장단점에 대한 논의가 있었습니다. 한 사용자는 AI가 기술의 축복이며 창의적인 아이디어(예: 특정 장면 이미지 생성)를 빠르게 실현할 수 있다고 생각하며, 왜 일부 사람들(특히 비창작자)이 이에 적대감을 갖는지 이해하지 못한다고 말했습니다. 이 관점은 AI가 개인의 즉각적이고 저렴한 창작 요구를 충족시키는 가치를 강조합니다. 이는 커뮤니티 내에서 AI 도구가 개인의 창의력을 강화하는 긍정적인 시각을 반영하는 동시에, 사회적으로 AI 기술에 대한 보편적인 논쟁과 다양한 태도가 존재함을 보여줍니다. (출처: Reddit r/artificial)
커뮤니티 논쟁: MCP 프로토콜이 AI Agent의 ‘인터넷’이 될 것인가?: MCP(Model Capability Protocol)의 발전과 함께 커뮤니티는 그 잠재력에 대해 논의하기 시작했습니다. MCP가 표준화된 인터페이스를 제공하여 LLM이 외부 도구 및 데이터 소스와 상호작용하게 함으로써, 다양한 AI Agent와 서비스를 연결하는 기반 시설이 될 수 있으며, 이는 인터넷이 다른 컴퓨터와 웹사이트를 연결한 것과 유사하다는 관점이 있습니다. 이는 미래 AI Agent 생태계가 MCP를 기반으로 상호 운용성과 협업을 실현할 수 있음을 예고합니다. (출처: Reddit r/ClaudeAI)

💡 기타
Microsoft 삼 거두, AI Copilot과 50년 및 미래에 대해 대화: Microsoft 창립 50주년을 맞아 빌 게이츠, 스티브 발머, 사티아 나델라 3대 CEO가 AI 비서 Copilot과 대화를 나눴습니다. 게이츠는 초기 소프트웨어 가치와 컴퓨팅 비용 하락에 대한 예견을 회고하며 정부와의 관계를 더 일찍 처리했어야 했다고 반성했습니다. 발머와 나델라는 모두 AI의 중요성을 강조했으며, 발머는 핵심 AI 기술을 중심으로 비즈니스를 심화해야 한다고 생각했고, 나델라는 AI가 보편적인 “소비재” 지능형 도구가 될 것이라고 예언했습니다. 대화 중 Copilot은 세 거물을 유머러스하게 “디스”하기도 했는데, 예를 들어 게이츠의 “사색하는 표정”이 AI를 “블루 스크린” 상태로 만들 수 있다는 식이었습니다. 이 대화는 Microsoft 리더십의 역사에 대한 반성과 AI 주도 미래에 대한 공감대를 보여줍니다. (출처: 腾讯科技)

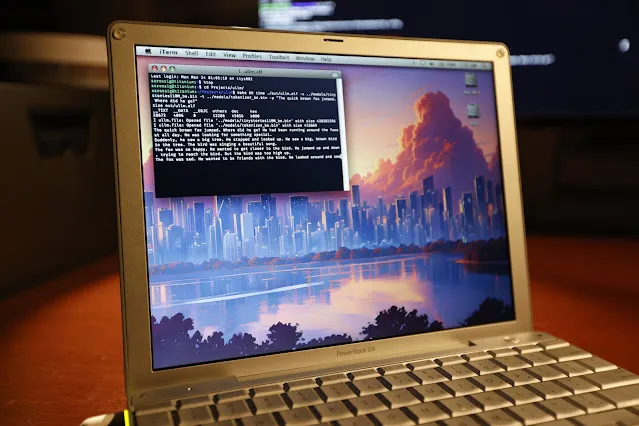
20년 된 PowerBook G4에서 LLM 추론 성공적으로 실행: 소프트웨어 엔지니어 Andrew Rossignol이 20년 된 Apple PowerBook G4 노트북(1.5 GHz PowerPC G4 프로세서, 1GB 메모리)에서 Meta의 Llama 2 대형 모델(TinyStories 110M 버전) 추론 작업을 성공적으로 실행했습니다. 그는 오픈소스 프로젝트 llama2.c를 이식하고 PowerPC 아키텍처(빅 엔디안 처리, 메모리 정렬)에 맞게 수정했으며, AltiVec 벡터 확장(융합 곱셈-덧셈 연산)을 활용하여 추론 속도를 약 10% 향상시켰습니다(0.77 token/s에서 0.88 token/s로). 속도는 현대 CPU의 약 1/8에 불과하지만, 매우 오래되고 자원이 제한된 하드웨어에서도 현대 AI 모델을 실행하는 것이 가능하다는 것을 증명했습니다. (출처: 36氪, AI前线)
탐구: 왜 월드 모델이 필요한가?: 기사는 월드 모델(World Models)의 필요성을 탐구하며, 이것이 현재 대형 언어 모델(LLM)의 한계(예: 물리적 세계 이해 부족, 영구 기억 부재, 추론 및 계획 능력 부족)를 극복하는 핵심이라고 주장합니다. 월드 모델은 AI가 사람처럼 환경에 대한 내부 시뮬레이션을 구축하고 물리 법칙(예: 중력, 충돌)과 인과 관계를 이해하여 예측하고 의사결정을 내리도록 하는 것을 목표로 합니다. 기사는 월드 모델이 인지 과학 개념에서 계산 모델링(RL/DL 결합, 예: DeepMind의 《World Models》 논문)을 거쳐 대형 모델 시대(Transformer 및 멀티모달 결합, 예: Genie, PaLM-E)로 발전해 온 과정을 되짚어 봅니다. 월드 모델의 핵심 장점은 인과적 예측 및 반사실적 추론 능력, 그리고 작업 간 일반화 능력이며, 이는 LLM이 대규모 텍스트 연관 확률 기반 예측을 하는 본질과 다릅니다. 월드 모델의 전망은 밝지만, 컴퓨팅 파워, 일반화 능력, 데이터 측면에서 여전히 과제를 안고 있습니다. (출처: 脑极体)

AI 위험 탐지 새로운 돌파구: Holmes-VAU, 다층적 장편 비디오 이상 이해 실현: 기존 비디오 이상 이해(VAU) 방법이 장편 비디오 및 복잡한 시계열 이상 처리에서 부족한 점을 해결하기 위해 화중과기대 등 기관이 Holmes-VAU 모델 및 HIVAU-70k 데이터셋을 제안했습니다. 이 데이터셋은 7만 개 이상의 다중 시계열 척도(video-level, event-level, clip-level) 지시 데이터를 포함하며, 반자동 데이터 엔진을 통해 구축되어 모델이 장단편 비디오 이상을 종합적으로 이해하도록 촉진합니다. 동시에 제안된 Anomaly-focused Temporal Sampler (ATS)는 이상 점수에 따라 동적으로 핵심 프레임을 희소 샘플링하여 중복 정보를 효과적으로 줄이고 장편 비디오 이상 분석의 정확성과 효율성을 향상시킵니다. 실험 결과, Holmes-VAU는 다양한 시계열 단위의 비디오 이상 이해 작업에서 일반적인 멀티모달 대형 모델보다 현저히 우수한 성능을 보였습니다. (출처: 量子位)
AI와 지속 가능성: 탄소 발자국 문제 주목: AI 모델의 규모와 훈련 계산량이 기하급수적으로 증가함에 따라 에너지 소비 및 탄소 배출 문제가 점점 더 부각되고 있습니다. 스탠포드 AI 인덱스 보고서는 하드웨어 에너지 효율이 향상되었음에도 불구하고 전체 에너지 소비는 계속 증가하고 있다고 지적합니다. 예를 들어, Meta의 Llama 3.1 모델 훈련은 약 9000톤의 이산화탄소를 발생시키는 것으로 추정됩니다. DeepSeek과 같은 모델이 에너지 효율 면에서 돌파구를 마련했지만, AI 산업 전체의 탄소 발자국은 여전히 심각한 과제입니다. 이는 AI 기업들이 핵에너지와 같은 제로 탄소 에너지 솔루션을 모색하게 하고 AI 발전의 지속 가능성에 대한 논의를 촉발합니다. (출처: Ronald_vanLoon, 机器之心)
