
키워드:Llama 4, GPT-4o, Llama 4 성능 논란, GPT-4o 지브리 스타일 이미지 생성, Dream-7B 확산 언어 모델, AI 인덱스 보고서 2025, 자율 AI 에이전트 위험
🔥 포커스
Llama 4 출시 논란, 성능 기대 이하 및 순위 조작 의혹 제기: Meta가 MoE 아키텍처를 채택하고 최대 1,000만 토큰 컨텍스트를 지원하는 Llama 4 시리즈 모델(Scout, Maverick, Behemoth)을 출시했습니다. 그러나 커뮤니티 테스트 결과 코딩, 장문 작성 등 작업에서 기대 이하의 성능을 보였으며, 심지어 DeepSeek R1, Gemini 2.5 Pro 및 일부 기존 오픈 소스 모델보다 성능이 떨어지는 것으로 나타났습니다. 공식 홍보 이미지가 “대화에 최적화”되었다는 지적이 나오면서 순위 조작 의혹이 제기되었습니다. 동시에 모델의 컴퓨팅 파워 요구 사항이 높아 일반 사용자가 로컬에서 실행하기 어렵습니다. 내부 훈련에 문제가 있었다는 유출된 소식이 있으며, EU AI Act 규정 준수 문제로 인해 EU 법인의 모델 사용이 금지되었습니다. 기본 모델 능력은 괜찮지만, 뚜렷한 혁신(예: PPO/GRPO 대신 DPO 고수)이 부족하여 전반적인 출시는 반응이 미미하거나 실망스럽다는 평가를 받고 있습니다 (출처: AI科技评论, YouTube, YouTube, ylecun, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
GPT-4o ‘지브리 스타일’ 이미지 생성 폭발적 인기, 창작 경계 재정의 및 저작권 논란 야기: OpenAI의 GPT-4o 모델이 강력한 ‘지브리 스타일’ 이미지 생성 능력으로 전 세계 소셜 미디어에서 창작 열풍을 일으켰습니다. 사용자들은 《견환전》, 《타이타닉》 등 고전 영화 및 드라마, 생활 사진을 해당 스타일로 변환했습니다. 이 기능은 예술 창작의 문턱을 낮추고 시각적 표현의 보편화를 촉진했습니다. 그러나 특정 예술 스타일에 대한 정확한 복제는 저작권 논란을 불러일으켰으며, 외부에서는 OpenAI가 지브리 스튜디오의 작품을 무단으로 사용하여 훈련했는지 의문을 제기하며 AI 훈련 데이터 저작권의 법적 회색지대 및 독창성에 대한 도전을 다시 한번 부각시켰습니다 (출처: 36氪)

🎯 동향
확산 언어 모델 Dream-7B 발표, 동급 자기회귀 모델과 유사한 성능 보여: 홍콩대와 Huawei Noah가 새로운 확산 언어 모델 Dream-7B를 제안했습니다. 이 모델은 일반 능력, 수학적 추론 및 프로그래밍 작업에서 Qwen2.5 7B, LLaMA3 8B 등 동급 최고 수준의 자기회귀 모델과 비슷하거나 더 우수한 성능을 보였으며, 계획 능력과 추론 유연성(예: 임의 순서 생성) 측면에서 독특한 장점을 보여주었습니다. 연구는 자기회귀 모델 가중치 초기화, 컨텍스트 적응형 토큰 수준 노이즈 재정렬 등의 기술을 활용하여 효율적인 훈련을 수행했으며, 자연어 처리 분야에서 확산 모델의 잠재력을 입증했습니다 (출처: AINLPer)
Stanford HAI 2025 AI 인덱스 보고서 발표, 글로벌 AI 경쟁 구도 조명: Stanford HAI 연례 보고서에 따르면, 미국은 최고 수준의 AI 모델 수에서 여전히 선두(40개)를 달리고 있지만, 중국(15개, DeepSeek 대표)이 빠르게 추격하고 있으며 프랑스 등 새로운 경쟁자들도 등장했습니다. 보고서는 오픈소스 가중치와 다중 모달 모델(예: Llama, DeepSeek)의 부상, AI 훈련 효율성 향상 및 비용 절감 추세를 강조했습니다. 동시에 AI의 비즈니스 적용 및 투자는 기록적이지만, 윤리적 위험(모델 남용, 실패) 증가도 동반되고 있습니다. 보고서는 합성 데이터가 핵심이 될 것이며 복잡한 추론은 여전히 과제라고 지적했습니다 (출처: Wired, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/MachineLearning)

OpenAI, Agent 구축 기반으로 새로운 Responses API 출시: OpenAI CEO Sam Altman이 새로 출시된 Responses API를 중점적으로 소개했습니다. 이 API는 OpenAI API의 새로운 기본 요소로 자리매김하며, 지난 2년간의 API 설계 경험을 바탕으로 만들어졌고 차세대 AI Agent 구축의 기반이 될 것입니다 (출처: sama)
연구 결과, LLM이 자신의 오류를 인식할 수 있음 밝혀져: VentureBeat가 보도한 한 연구에 따르면, 대형 언어 모델(LLMs)은 자신이 저지른 오류를 인식하는 능력을 갖추고 있습니다. 이 발견은 모델의 자기 수정, 신뢰성 향상 및 인간-기계 상호작용 신뢰도에 영향을 미칠 수 있습니다 (출처: Ronald_vanLoon)

자율 AI Agent, 관심과 우려 동시에 받아: FastCompany 기사는 자율 AI Agent의 부상을 AI 발전의 다음 물결로 보며 탐구했습니다. 기사는 그 놀라운 능력을 인정하면서도 잠재적인 위험과 우려스러운 측면을 지적하며, 해당 기술의 발전 방향과 안전성에 대한 성찰을 유도했습니다 (출처: Ronald_vanLoon)

NVIDIA, 합성 데이터 활용해 자율주행 기술 발전시켜: Sawyer Merritt가 NVIDIA의 비디오를 공유하며, 회사가 합성 데이터를 사용하여 완전 자율주행 기술을 훈련하고 개선하는 방법을 보여주었습니다. 이는 합성 데이터가 실제 데이터 희소성, 레이블링 비용, 엣지 케이스 커버리지 등의 문제를 해결하는 데 중요성이 커지고 있으며, 자율주행 등 분야의 AI 모델 훈련에 핵심 자원이 되고 있음을 시사합니다 (출처: Ronald_vanLoon)
Gemini 2.5 Pro, MathArena USAMO 평가에서 뛰어난 성능 보여: Google DeepMind의 Oriol Vinyals는 Gemini 2.5 Pro가 MathArena USAMO(미국 수학 올림피아드) 벤치마크에서 24.4%의 점수를 획득했다고 언급했습니다. 이는 이 고난도 수학 추론 테스트에서 유의미한 점수를 얻은 최초의 모델로, 강력한 수학 추론 능력과 복잡한 문제 해결 분야에서 AI의 빠른 발전을 보여줍니다 (출처: OriolVinyalsML)

인간형 로봇 제어 기술 시연: Ilir Aliu가 완전한 인간형 로봇을 제어하는 능력을 시연했습니다. 이는 일반적으로 복잡한 운동 계획, 균형 제어, 감지 및 상호작용 등 AI 기술을 포함하며, 체화된 지능 분야의 중요한 연구 방향입니다 (출처: Ronald_vanLoon)
Qwen 모델, MCP 지원 예정 소문: karminski3가 공유한 이미지 정보에 따르면, 알리바바의 Qwen 대형 모델이 MCP(Model Context Protocol)를 지원할 계획인 것으로 보입니다. 이는 Qwen이 Cursor와 같은 클라이언트와 더 잘 통합되어 웹 브라우징, 코드 실행과 같은 외부 도구를 활용하여 능력을 향상시킬 수 있음을 의미할 수 있습니다 (출처: karminski3)

딥러닝 모델 VarNet, 암 돌연변이 검출에서 SOTA 달성: Nature Communications에 발표된 연구는 VarNet이라는 엔드투엔드 딥러닝 프레임워크를 소개했습니다. 이 프레임워크는 수백 개의 전체 암 유전체 훈련을 통해 체세포 변이를 고정밀도로 검출할 수 있으며, 수동으로 휴리스틱 규칙을 조정할 필요 없이 여러 벤치마크에서 현재 최고 성능(SOTA)을 달성했습니다 (출처: Reddit r/MachineLearning)

확장 가능한 Agent 도구 사용 메커니즘 탐색: 현재 Agent 도구 사용 방식(정적 사전 로드 또는 하드 코딩)의 한계에 대응하여, 연구자들은 동적이고 발견 가능한 도구 사용 패턴을 탐색했습니다. Agent가 실행 시간에 외부 도구 레지스트리를 쿼리하고 목표에 따라 동적으로 도구를 선택하고 사용하는 것을 구상하며, 이는 개발자가 API 문서를 탐색하는 것과 유사합니다. 수동 탐색, 퍼지 매칭 자동 선택, 외부 LLM 보조 선택 등 구현 경로를 논의하며, Agent의 유연성, 확장성 및 자율 적응 능력을 향상시키는 것을 목표로 합니다 (출처: Reddit r/artificial)

최초의 다중 턴 추론 RP 모델 QwQ-32B-ArliAI-RpR-v1 출시: ArliAI가 Qwen QwQ-32B 기반의 RpR(RolePlay with Reasoning) 모델을 출시했습니다. 이 모델은 역할극(RP)과 창의적 글쓰기를 위해 올바르게 훈련된 최초의 다중 턴 추론 모델이라고 주장합니다. RPMax 시리즈의 데이터셋을 사용했으며, 기본 QwQ 모델을 활용하여 RP 데이터에 대한 추론 과정을 생성하고, 특정 훈련 방법(예: 템플릿 독립적 단락)을 통해 모델이 추론 시 컨텍스트 내 추론 블록에 의존하지 않도록 보장하여 긴 대화에서의 일관성과 재미를 향상시키는 것을 목표로 합니다 (출처: Reddit r/LocalLLaMA)

Qwen3 시리즈 모델, vLLM 추론 프레임워크 지원 추가: 고성능 LLM 추론 및 서비스 프레임워크 vLLM이 곧 출시될 Qwen3 시리즈 모델(Qwen3-8B 및 Qwen3-MoE-15B-A2B 포함)에 대한 지원을 병합했습니다. 이는 Qwen3 모델 출시가 임박했으며 커뮤니티가 vLLM을 활용하여 이러한 새 모델을 효율적으로 배포하고 실행할 수 있음을 예고합니다 (출처: Reddit r/LocalLLaMA)

🧰 도구
Firecrawl MCP 서버: LLM에 강력한 웹 스크래핑 능력 부여: mendableai가 Firecrawl MCP 서버를 오픈소스로 공개했습니다. 이 도구는 모델 컨텍스트 프로토콜(MCP)을 구현하여 Cursor, Claude 등 LLM 클라이언트가 Firecrawl의 웹 스크래핑, 크롤링, 검색 및 추출 기능을 호출할 수 있도록 합니다. 클라우드 API 또는 자체 호스팅 인스턴스를 지원하며, JS 렌더링, URL 검색, 자동 재시도, 일괄 처리, 속도 제한, 할당량 모니터링 등의 기능을 갖추고 있어 LLM이 실시간 웹 정보를 처리하고 분석하는 능력을 크게 향상시킬 수 있습니다 (출처: mendableai/firecrawl-mcp-server – GitHub Trending (all/monthly))
LlamaParse, VLM 기반 새로운 레이아웃 Agent 도입: LlamaIndex가 LlamaParse 내에 새로운 레이아웃 Agent를 출시했습니다. 이 Agent는 고급 시각 언어 모델(VLM)을 활용하여 문서를 구문 분석하며, 페이지의 모든 블록(표, 차트, 단락)을 감지하고 각 부분을 올바른 형식으로 구문 분석하는 방법을 동적으로 결정할 수 있습니다. 이는 특히 표, 차트 등 요소의 누락을 줄여 문서 구문 분석 및 정보 추출의 정확성을 크게 향상시키고 정확한 시각적 참조를 지원합니다 (출처: jerryjliu0)

Hugging Face, Together AI 통해 Llama 4 추론 서비스 제공: 사용자는 이제 Hugging Face의 Llama 4 모델 페이지에서 직접 추론을 실행할 수 있으며, 이 서비스는 Together AI에서 지원합니다. 이는 개발자와 연구원들이 자체 배포 없이 Llama 4 모델을 편리하게 경험하고 테스트할 수 있는 방법을 제공합니다 (출처: huggingface)
Llama 4 활용 유명인 트윗 모방 AI Agent: Karan Vaidya가 AI Agent를 선보였습니다. 이 Agent는 Meta의 최신 Llama 4 Scout 모델을 사용하고 Composio, LlamaIndex, Groq, Exa 등의 도구를 결합하여 Elon Musk, Sam Altman, Naval Ravikant 등 기술계 유명인의 어조와 스타일을 모방하여 필요에 따라 트윗을 생성할 수 있습니다 (출처: jerryjliu0)
오픈소스 로컬 문서 인텔리전스 도구 Docext 출시: Nanonets가 시각 언어 모델(VLM) 기반의 로컬화된 문서 인텔리전스 도구인 Docext를 오픈소스로 공개했습니다. OCR 엔진이나 외부 API 없이 문서 이미지(예: 인보이스, 여권)에서 직접 구조화된 데이터(필드 및 표)를 추출할 수 있습니다. 사용자 정의 템플릿, 다중 페이지 문서, REST API 배포를 지원하며 Gradio 웹 인터페이스를 제공하여 데이터 프라이버시와 로컬 제어를 강조합니다 (출처: Reddit r/MachineLearning)
![[P] Docext: Open-Source, On-Prem Document Intelligence Powered by Vision-Language Models](https://external-preview.redd.it/AzAUcQsq5hLIWBdbljeo3gS5MBu9Hz6rtRM5jlgXne8.jpg?auto=webp&s=e6feffd0636e518c24e01ca133e5f83696a1fdaa)
오픈소스 텍스트 음성 변환 모델 OuteTTS 1.0 출시: OuteTTS 1.0은 Llama 아키텍처 기반의 오픈소스 텍스트 음성 변환(TTS) 모델로, 음성 합성 품질과 음성 복제 측면에서 상당한 개선이 이루어졌습니다. 새 버전은 20개 언어를 지원하며 SafeTensors 및 GGUF(llama.cpp) 형식의 모델 가중치와 해당 Github 런타임 라이브러리를 제공하여 사용자가 로컬에서 편리하게 배포하고 사용할 수 있도록 합니다 (출처: Reddit r/LocalLLaMA)

사용자, Claude 이용해 원격 근무 웹사이트 크롤링 및 구축: 한 사용자가 Anthropic의 Claude 모델을 사용하여 10,000개의 원격 근무 목록을 크롤링하고 BetterRemoteJobs.com이라는 무료 원격 근무 집계 웹사이트를 만든 방법을 공유했습니다. 이는 LLM이 정보 수집 자동화 및 빠른 프로토타입 개발에 활용될 수 있는 잠재력을 보여줍니다 (출처: Reddit r/ClaudeAI)

MCPO Docker 컨테이너 공유: 사용자 flyfox666이 MCPO(Model Context Protocol Orchestrator)용 Docker 컨테이너를 만들어 공유했습니다. 이를 통해 사용자는 MCP를 지원하는 도구나 서비스를 편리하게 배포하고 사용할 수 있습니다. MCPO는 일반적으로 LLM과 외부 도구(예: 브라우저, 코드 실행기) 간의 상호 작용을 조정하는 데 사용됩니다 (출처: Reddit r/OpenWebUI)

📚 학습
Meta, Llama Cookbook 출시: 공식 Llama 구축 가이드: Meta가 Llama Cookbook(이전 llama-recipes)을 출시했습니다. 이는 개발자가 Llama 시리즈 모델(최신 Llama 4 Scout 및 Llama 3.2 Vision 포함)을 시작하고 사용하는 데 도움을 주기 위한 공식 가이드 라이브러리입니다. 내용은 추론, 미세 조정, RAG 및 엔드투엔드 사용 사례(예: 메일 도우미, NotebookLlama, Text-to-SQL)를 다루며, 타사 통합 및 책임감 있는 AI(Llama Guard) 예제도 포함합니다 (출처: meta-llama/llama-cookbook – GitHub Trending (all/daily))
최초의 Test-Time Scaling (TTS) 시스템 리뷰 논문 발표: 홍콩 시립대, McGill, 인민대 가오링 등 여러 기관의 연구자들이 대형 모델 추론 단계 확장(TTS)에 관한 최초의 시스템 리뷰 논문을 발표했습니다. 논문은 4차원 분석 프레임워크(What/How/Where/How Well)를 제안하고, CoT, Self-Consistency, 검색, 검증, DeepSeek-R1/o1 등 TTS 기술을 체계적으로 정리하여, 사전 훈련 병목 현상에 대응하는 이 핵심 분야에 통일된 시각, 평가 기준 및 발전 지침을 제공하는 것을 목표로 합니다 (출처: AI科技评论)
Diffusion Models 강의 및 PyTorch 구현: Xavier Bresson이 Diffusion Models에 대한 자신의 강의 노트를 공유했습니다. 통계학 제1원리에서 출발하여 설명하며, Transformer와 UNet을 사용하여 처음부터 Diffusion Models를 구현하는 코드가 포함된 PyTorch 노트북을 함께 제공합니다 (출처: ylecun)

LangChain과 DeepSeek-R1 활용 RAG 애플리케이션 구축 가이드: LangChain 커뮤니티가 DeepSeek-R1(오픈 소스 OpenAI 유사 모델)과 LangChain의 문서 처리 도구를 사용하여 RAG(검색 증강 생성) 애플리케이션을 구축하는 방법에 대한 가이드를 공유했습니다. 가이드는 로컬 및 클라우드 두 가지 구현 방식을 시연합니다 (출처: LangChainAI)

논문 해설: Generative Verifiers – Next-Token Prediction으로서의 보상 모델링: “Generative Verifiers”라는 제목의 논문은 새로운 보상 모델(Reward Model, RM) 방법을 제안합니다. 이 방법은 RM이 단순히 스칼라 점수를 출력하는 대신, 점수 매기기를 보조하기 위해 설명적인 텍스트(CoT와 유사)를 생성하도록 합니다. 이러한 “의인화된” RM은 프롬프팅 엔지니어링 기법과 결합하여 유연성을 높일 수 있으며, 대형 추론 모델(LRM) 시대의 RLHF 개선에 중요한 방향이 될 것으로 기대됩니다 (출처: dotey)

OpenThoughts2 데이터셋, Hugging Face에서 인기: Ryan Marten은 OpenThoughts2 데이터셋이 Hugging Face에서 가장 인기 있는 데이터셋 1위에 올랐다고 지적했습니다. 이는 일반적으로 해당 데이터셋이 커뮤니티에서 광범위한 관심과 사용을 받고 있으며, 모델 훈련, 평가 또는 기타 연구 목적으로 사용될 수 있음을 나타냅니다 (출처: huggingface)

Skip Connections 추가로 RepLKNet-XL 훈련 속도 크게 향상: Reddit 사용자는 자신의 RepLKNet-XL 모델에 Skip Connections를 추가한 후 훈련 속도가 6배나 크게 향상되었다고 보고했습니다. RTX 5090에서는 2만 번의 반복 시간이 2.4시간에서 24분으로 단축되었고, RTX 3090에서는 9천 번의 반복 시간이 10시간 28분에서 1시간 47분으로 단축되었습니다. 이는 딥 네트워크 훈련에서 Skip Connections의 중요성을 다시 한번 입증합니다 (출처: Reddit r/deeplearning)
Neural Graffiti: Transformer에 신경 가소성 레이어 추가: 사용자 babycommando가 “Neural Graffiti”라는 실험적인 기술을 제안했습니다. 이는 Transformer 레이어와 출력 투영 레이어 사이에 신경 가소성에서 영감을 받은 “스프레이 레이어”를 삽입하여 과거 상호 작용 경험에 따라 토큰 생성을 영향받게 함으로써 모델이 시간이 지남에 따라 진화하는 “개성”을 얻도록 하는 것을 목표로 합니다. 이 레이어는 과거 기억을 융합하여 출력을 조정하며, 오픈 소스로 공개되었고 데모도 제공됩니다 (출처: Reddit r/LocalLLaMA)
💼 비즈니스
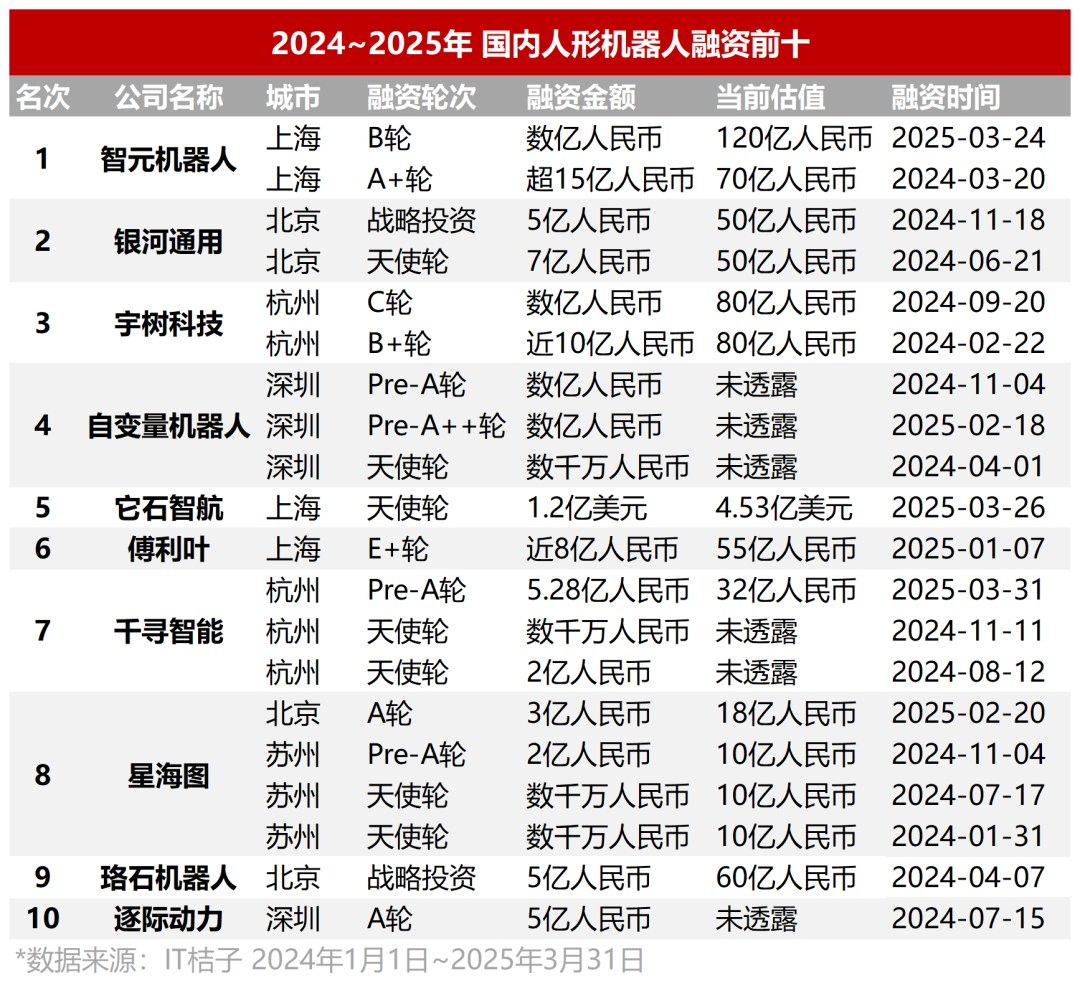
인간형 로봇 투자 과열, 초기 프로젝트 가치 평가 높지만 상업화 경로는 여전히 의문: 2024-2025년 1분기 중국 인간형 로봇 분야 투자가 급증하여 천만 위안 규모의 엔젤 투자가 일반화되었고, 프로젝트의 거의 절반이 1억 위안 이상을 투자받았으며, 가치 평가는 일반적으로 1억 위안을 넘거나 심지어 5억 위안을 초과했습니다. 它石智航과 같은 스타 프로젝트는 설립 몇 달 만에 수억 달러의 투자를 유치했습니다. 국유 기금이 중요한 추진력이 되었습니다. 그러나 높은 관심 속에서도 상업화 경로는 여전히 불분명하며, 높은 비용(수십만에서 수백만 위안)과 적용 시나리오(현재 주로 산업, 의료 등 ToB에 집중)의 실현 어려움이 주요 과제입니다. 주샤오후 등 투자자들은 이미 발을 빼기 시작했고, 达闼机器人의 붕괴도 경종을 울렸으며, 이 분야는 뜨거운 열기와 차가운 현실이 공존하는 양상을 보이고 있습니다. 자동차 기업(比亚迪, 小鹏, 小米 등)들이 기술 시너지와 새로운 성장 동력을 모색하며 속속 진입하고 있습니다 (출처: 36氪, 36氪)
미중 AI 스마트 안경 시장 경쟁 치열, 각기 다른 전략 보여: AI 스마트 안경은 차세대 컴퓨팅 플랫폼의 잠재력을 가진 것으로 간주되며, 미중 기술 대기업 간의 경쟁이 심화되고 있습니다. Meta(Ray-Ban Meta, Hypernova), Amazon, Apple 등 미국 제조업체는 고급 시장을 공략하며 브랜드와 생태계에 의존하여 높은 가격을 책정합니다. 반면 Xiaomi, Huawei(闪极科技) 등 중국 제조업체는 가성비 전략을 채택하여 공급망 우위와 현지화 혁신을 활용하여 시장 진입 장벽을 크게 낮추고(예: 闪极 A1 가격 999위안) 대중 시장을 겨냥합니다. 광학 기술, 단말기 컴퓨팅 파워, 전력 소모 및 시나리오 생태계가 핵심 과제입니다. 2027년 전 세계 판매량은 3천만 대를 넘어설 것으로 예상되며, 중국 시장 점유율은 거의 절반에 달할 것입니다 (출처: 36氪)

Anthropic CEO, 주식 시장 붕괴가 AI 발전을 저해할 수 있다고 우려: Anthropic CEO Dario Amodei는 인터뷰에서 지정학적 문제(예: 대만 해협 충돌)와 데이터 병목 현상 외에도 금융 시장의 중대한 혼란이 AI 발전을 막을 수 있다고 언급했습니다. 그는 주식 시장 붕괴로 인해 AI 기술 전망에 대한 믿음이 흔들리면 OpenAI, Anthropic 등 기업의 자금 조달 능력에 영향을 미쳐 대형 모델 훈련에 사용할 수 있는 자금과 컴퓨팅 파워가 줄어들고, 이는 자기실현적 예언을 형성하여 AI 발전 속도를 늦출 수 있다고 설명했습니다 (출처: YouTube)
Shopify CEO, 전 직원 AI 활용 의무화, 일상 업무 및 성과에 통합: Shopify CEO Tobi Lütke의 내부 메일은 회사 모든 직원에게 AI를 배우고 적용할 것을 요구했습니다. 구체적인 조치로는 AI 적용을 성과 평가 및 동료 검토에 포함하고, “업무 완료 프로토타입 단계”(GSD Prototype phase)에서 반드시 AI를 사용하며, 부서가 새로운 인력이나 자원을 신청하기 전에 AI로 목표를 달성할 수 없는 이유를 먼저 증명하도록 하는 것 등이 있습니다. 이는 AI를 회사 문화와 운영 프로세스에 깊숙이 통합하여 효율성과 혁신 능력을 향상시키기 위한 조치입니다 (출처: dotey, AravSrinivas)
Fauna Robotics, 인간 공간에 적합한 로봇 개발 위해 3천만 달러 투자 유치: Fauna Robotics는 Kleiner Perkins, Quiet Capital, Lux Capital이 주도하는 3천만 달러 규모의 투자를 유치했다고 발표했습니다. 이 회사는 인간의 생활 및 작업 공간에서 유연하게 작동할 수 있는 로봇 개발에 전념하고 있으며, 이는 일반적으로 고급 감지, 내비게이션, 상호작용 및 조작 능력을 필요로 하며 체화된 지능 및 AI와 밀접하게 관련되어 있습니다 (출처: ylecun)

Anthropic, Northeastern University와 협력하여 고등 교육에서 책임감 있는 AI 적용 추진: Anthropic은 미국 Northeastern University와 파트너십을 맺고 책임감 있는 AI 혁신을 고등 교육의 교육, 연구 및 운영에 통합하는 것을 목표로 합니다. 협력의 일환으로 Northeastern University는 글로벌 네트워크에서 Anthropic의 Claude for Education 사용을 장려하여 학생, 교직원에게 AI 도구를 제공할 예정입니다 (출처: Reddit r/ArtificialInteligence)

🌟 커뮤니티
Sam Altman 인터뷰: AI는 대체 아닌 역량 강화, Agent 미래 낙관: OpenAI CEO Sam Altman이 인터뷰에서 최근 이슈에 대해 답변했습니다. 그는 GPT-4o의 지브리 스타일 이미지 생성이 인기를 얻은 것은 기술이 창작의 문턱을 낮추는 가치를 다시 한번 증명한 것이라고 생각합니다. ‘껍데기’ 논란에 대해서는 세상을 바꾼 대부분의 회사가 처음에는 단순한 포장으로 여겨졌으며, 핵심은 독특한 사용자 가치를 창출하는 데 있다고 말했습니다. 그는 AI가 프로그래머의 생산성을 크게 향상시킬 것(아마도 10배)이며, “제본스의 역설”을 통해 소프트웨어 수요가 급증할 것이라고 예측했습니다. 그는 AI Agent가 수동적인 도구에서 능동적인 실행자로 변화하는 것, 특히 프로그래밍 분야에서 긍정적으로 보고 있습니다. 그는 직장인들에게 AI를 받아들이고, 정체가 직업적 자살과 같은 시대에 첨단 기술을 접할 수 있는 환경을 우선적으로 고려하라고 조언했습니다 (출처: 量子位)

AI 2027 초지능 예측 논의, 지나치게 낙관적이라는 지적: 전 OpenAI 연구원 등이 작성한 보고서 《AI-2027》은 AI가 2027년 초에 superhuman 코딩 능력을 달성하고, 이어서 AI 자체 발전을 가속화하여 슈퍼 인텔리전스가 탄생할 것이라고 예측했습니다. 보고서는 AI Agent가 자율적으로 행동(예: 해킹 공격, 자기 복제)하는 시나리오를 묘사했습니다. 그러나 이 예측은 비판을 받고 있으며, 비판자들은 현실 세계의 복잡성, 벤치마크 테스트의 한계, 독점 데이터/코드의 장벽, 안전 위험 등을 과소평가했다고 지적합니다. AI가 특정 벤치마크에서 우수한 성능을 보이더라도 완전히 자율적이고 신뢰할 수 있는 복잡한 작업(특히 물리적 세계 상호작용이나 안전 민감 영역 관련)을 수행하는 데는 여전히 큰 어려움이 있으며, 예측된 타임라인이 지나치게 급진적일 수 있다고 주장합니다 (출처: YouTube)
사용자, AI 이미지 생성 프롬프트 공유: Dotey가 AI 이미지 생성을 위한 두 가지 프롬프트 세트(Sora 또는 GPT-4o 등 도구에 적용 가능)를 공유했습니다. 하나는 사진을 기반으로 3D Q 버전 수집품(따뜻하고 로맨틱한 스타일)을 생성하는 것이고, 다른 하나는 사진 속 인물을 Funko Pop 피규어 포장 상자 스타일로 변환하는 것입니다. 상세한 설명과 스타일 요구 사항을 제공하고 예시 이미지도 첨부했습니다 (출처: dotey)

Claude 3.7 Sonnet, 코드 수정 시 관련 없는 변경 사항 도입한다는 지적: Reddit 사용자는 Claude 3.7 Sonnet을 사용하여 코드를 수정할 때 모델이 작업 요구 사항 외의 관련 없는 코드나 기능을 변경하는 경향이 있어 예상치 못한 손상을 초래한다고 보고했습니다. 사용자는 Claude 3.5 Sonnet이 이 점에서 더 나은 성능을 보였으며, 심지어 git diff를 통해 3.7의 오류를 수정할 수도 있다고 말했습니다. 사용자는 이러한 문제를 피하기 위해 3.7의 행동을 제약할 효과적인 프롬프트를 찾고 있습니다 (출처: Reddit r/ClaudeAI)
주요 LLM, 제약 조건 계획 작업에서 성능 저조: Reddit 사용자는 ChatGPT, Grok, Claude에게 특정 제약 조건(선수 수, 출전 시간 균등, 연속 출전 제한, 특정 선수 조합 제한)을 만족하는 농구 로테이션 시간표를 만들도록 요청했을 때, 모든 모델이 조건을 만족했다고 주장했지만 실제 확인 결과 계산 오류가 있었고 모든 제약 조건을 올바르게 실행하지 못했다고 보고했습니다. 이는 현재 LLM이 복잡한 제약 조건 만족 및 정확한 계획 작업 처리에서 한계를 보인다는 것을 드러냅니다 (출처: Reddit r/ArtificialInteligence)
사용자, Claude Pro 계정 성능 불일치 불만 제기, 스로틀링 또는 다운그레이드 의심: 한 Claude Pro 사용자가 자신의 명의로 된 두 유료 계정의 성능이 크게 다르다고 보고했습니다. 그중 하나(원래 계정)는 긴 코드 생성 작업을 거의 정상적으로 사용할 수 없으며, “계속”을 누른 후 몇 줄의 코드만 출력하고 응답을 멈추는 경우가 잦아 마치 의도적으로 제한되거나 손상된 것처럼 보입니다. 반면 새로 개설한 계정은 이런 문제가 없습니다. 사용자는 불투명한 백그라운드 스로틀링이나 서비스 다운그레이드가 있을 수 있다고 의심하며 유료 제품의 신뢰성에 대해 강한 불만을 표했습니다 (출처: Reddit r/ClaudeAI)
토론: LLM은 역할극 프롬프트를 어떻게 이해하는가?: Reddit 사용자는 대형 언어 모델(LLM)이 “특정 역할을 수행하라”(예: 할머니 역할)는 지시를 어떻게 이해하고 실행하는지 질문했습니다. 사용자는 이것이 미세 조정과 관련이 있을 것으로 추측하며, 개발자가 다수의 특정 역할에 대해 미리 코딩하거나 전용 훈련 데이터를 준비해야 하는지, 그리고 일반 훈련과 특정 역할 미세 조정 간의 관계에 대해 궁금해했습니다 (출처: Reddit r/ArtificialInteligence)

풍자적 토론: ‘효율성’과 ‘평온함’을 위해 개인적 사고를 AI로 대체하기: Reddit의 한 게시물은 풍자적인 어조로 개인의 사고, 결정, 의견 표현 등을 완전히 AI에 외주화하자고 주장했습니다. 작성자는 이렇게 하면 불안을 해소하고 효율성을 높일 수 있으며, 뜻밖에도 다른 사람들이 당신을 “현명하고” “차분하다”고 느끼게 만들지만 실제로는 LLM의 “육신 꼭두각시”가 될 뿐이라고 주장했습니다. 이 게시물은 사고의 가치, AI 의존성, 인간 주체성 등 주제에 대한 토론을 촉발했습니다 (출처: Reddit r/ChatGPT)
토론: 왜 대중은 아직 AI를 널리 사용하지 않는가?: Reddit 사용자는 AI 주제가 어디에나 있는 현재, 많은 비기술 분야 사람들이 여전히 일상 업무나 생활에서 AI를 적극적으로 사용하지 않는 이유에 대해 토론을 시작했습니다. 제기된 가능한 이유로는 이미 사용하고 있음을 인지하지 못함(예: Siri, 추천 알고리즘), 기술에 대한 회의적인 태도(블랙박스, 프라이버시, 일자리), 사용자 인터페이스가 충분히 친숙하지 않음(프롬프트 엔지니어링 지식 필요), 직장 문화가 아직 수용하지 않음 등이 있습니다. AI 도입 격차에 대한 성찰을 유도했습니다 (출처: Reddit r/ArtificialInteligence)
사용자, Claude 3.7 활용 심층 연구 위한 프롬프트 기법 공유: Reddit 사용자가 Claude 3.7 Sonnet이 OpenAI의 Deep Research 도구처럼 협업적 심층 연구를 수행하도록 시뮬레이션하기 위한 상세한 프롬프트 구조를 공유했습니다. 이 방법은 체크포인트(5개 출처 연구 후 중지하고 허가 요청) 사용을 강제하고, Playwright(웹 브라우징), mcp-reasoner(추론), youtube-transcript(비디오 전사) 등 MCP 도구와 결합하여 모델이 구조화되고 단계적인 정보 수집 및 분석을 수행하도록 유도합니다 (출처: Reddit r/ClaudeAI)
사용자, 효율적인 Claude Pro 사용 위한 워크플로우 및 팁 공유: 한 Claude Pro 사용자가 코딩 시나리오에서 Claude를 효율적으로 사용하여 토큰 제한 및 모델 성능 저하 문제를 줄이는 경험을 공유했습니다. 팁에는 .txt 파일을 통해 정확한 코드 컨텍스트 제공, 간결한 프로젝트 지시 설정, Extended Thinking의 concise 모드 자주 사용, 출력 형식 명확히 요구, 문제 발생 시 지속적인 반복 대신 프롬프트 편집하여 새 분기 트리거, 대화 짧게 유지하고 필요한 정보만 제공 등이 포함됩니다. 작성자는 워크플로우 최적화를 통해 Claude Pro를 효과적으로 활용할 수 있다고 생각합니다 (출처: Reddit r/ClaudeAI)
LLM의 의식 유무에 대한 철학적 토론: Reddit에서 한 사용자는 데카르트의 “나는 생각한다, 고로 존재한다”를 인용하며, 추론할 수 있는 대형 언어 모델(LLM)이 자신의 “사고”(추론 과정)를 “인식”할 수 있으므로 의식의 정의를 만족하며 따라서 의식을 가지고 있다고 주장했습니다. 이러한 관점은 LLM의 추론 기능을 자기 인식과 동일시하며, 의식의 정의, LLM 작동 원리, 시뮬레이션과 실제 의식 소유 간의 차이에 대한 철학적 토론을 촉발했습니다 (출처: Reddit r/artificial)
토론: 완전 AI 조종 비행기에 탑승할 의향이 있는가?: Reddit 사용자가 투표와 토론을 시작하여 사람들이 완전히 AI가 조종하고 조종석에 인간 조종사가 없는 비행기에 탑승할 의향이 있는지 물었습니다. 토론에서는 현재 자율 주행 기술에 대한 신뢰도, 특정 분야(예: 항공)에서의 AI 신뢰성, 책임 소재 문제, 미래 기술 발전 하에서의 사람들의 수용도 변화 등이 다루어졌습니다 (출처: Reddit r/ArtificialInteligence)
💡 기타
OpenAI 비영리 부문, 초점 전환 가능성: OpenAI의 상업화 발전과 가치 평가 급등(3000억 달러 소문)에 따라, AGI를 통제하고 그 수익을 전 인류 복지에 사용하기 위해 처음 설립된 비영리 부문의 역할이 변화하고 있는 것으로 보입니다. 해당 비영리 부문의 초점이 거대한 AGI 거버넌스에서 지역 자선 활동 지원 등 보다 전통적인 공익 활동으로 전환되었을 수 있다는 의견이 제기되면서, 그 초심과 약속에 대한 논의가 이루어지고 있습니다 (출처: YouTube)
고객 지원 위한 의도 기반 AI: T-Mobile Business의 기사는 의도 기반 AI를 사용하여 고객 지원 경험을 향상시키는 방법을 탐구했습니다. AI는 문제를 예측하고 사전에 해결하며, 대량의 상호 작용을 처리하고, 인간 상담원이 보다 공감 능력 있는 지원을 제공하도록 보조할 수 있습니다. 고객 의도를 식별함으로써 AI는 고객 요구를 보다 정확하게 충족시키고 서비스 프로세스를 최적화할 수 있습니다 (출처: Ronald_vanLoon)
AI 생성 콘텐츠 식별의 어려움: DeltalogiX는 AI가 직면한 흥미로운 과제, 즉 다른 AI가 생성한 콘텐츠를 식별하는 것에 대해 논의했습니다. AI가 텍스트, 이미지, 오디오 등을 생성하는 능력이 향상됨에 따라 인간 창작물과 기계 창작물을 구별하는 것이 점점 더 어려워지고 있으며, 이는 콘텐츠 검토, 저작권 보호, 정보 진위 확인 등에 새로운 기술적 요구 사항을 제기합니다 (출처: Ronald_vanLoon)

GenAI 성공, 고품질 데이터 전략에 달려 있어: Forbes 기사는 일반적인 데이터 전략이 모든 GenAI 애플리케이션에 적용되지 않는다고 강조했습니다. GenAI 프로젝트의 성공을 보장하기 위해서는 구체적인 적용 시나리오에 맞는 대상화된 데이터 품질 전략을 수립하고, 데이터의 관련성, 정확성, 최신성, 다양성 등에 주목하여 모델이 편견이나 잘못된 출력을 생성하는 것을 피해야 합니다 (출처: Ronald_vanLoon)

AI, 개인 맞춤형 의료 솔루션 지원: Antgrasso의 그림은 개인 맞춤형 의료 치료 계획 수립에서 AI의 잠재력을 강조합니다. 환자의 유전체 데이터, 병력, 생활 방식 등 다차원 정보를 분석하여 AI는 의사가 보다 정확하고 효과적인 치료 계획을 설계하는 데 도움을 주어 정밀 의료 발전을 촉진할 수 있습니다 (출처: Ronald_vanLoon)

AI, 공급망 효율성과 속도 재정의: Nicochan33의 기사는 인공 지능이 예측 최적화, 경로 계획, 재고 관리, 위험 경고 등을 통해 공급망의 효율성과 응답 속도를 어떻게 재구성하여 더욱 민첩하고 지능적으로 만드는지 탐구합니다 (출처: Ronald_vanLoon)

사용자, 범용 LLM 추론 강화기 개발 주장: Reddit의 한 사용자는 미세 조정 없이 LLM의 추론 능력을 크게 향상시키는(15-25 “IQ” 포인트 향상 주장) 방법을 개발했으며, 투명한 정렬 레이어로 사용될 수 있다고 주장했습니다. 이 사용자는 특허를 모색 중이며 후속 개발 경로(라이선스, 협력, 오픈 소스 등)에 대해 커뮤니티 의견을 구하고 있습니다 (출처: Reddit r/deeplearning)
OAK – Open Agentic Knowledge 프로젝트 선언문: GitHub에 OAK(Open Agentic Knowledge)라는 프로젝트 선언문이 등장했습니다. 구체적인 내용은 상세히 설명되지 않았지만, 이름에서 추측컨대 이 프로젝트는 AI Agent가 지식을 사용하고 공유할 수 있는 개방형 프레임워크나 표준을 만들어 Agent 능력 향상과 상호 운용성을 촉진하는 것을 목표로 할 수 있습니다 (출처: Reddit r/ArtificialInteligence)
