
키워드:오픈AI, o3-pro, 메타, 슈퍼 인텔리전스 랩, 미스트랄 AI, 마기스트랄, IBM, 양자 컴퓨터, o3-pro 가격 정책, 스케일 AI 투자, 마기스트랄-스몰-2506, 스타링 양자 컴퓨터, AI 군사 응용 테스트
🔥 포커스
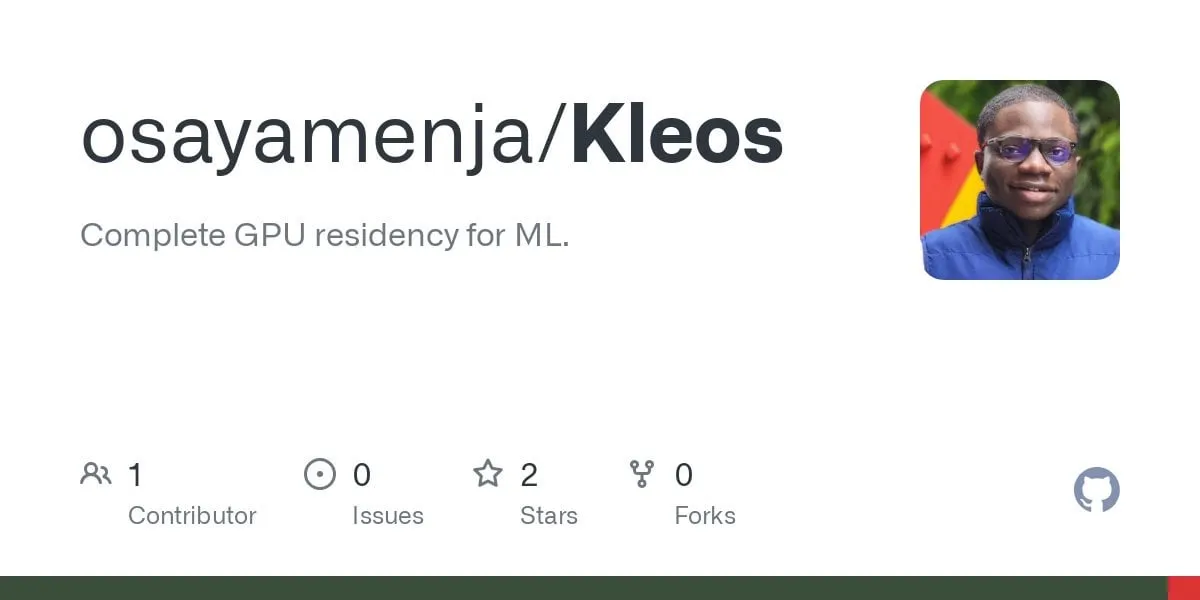
OpenAI, 사상 최강 모델이라고 주장하는 o3-pro 출시 및 o3 가격 대폭 인하: OpenAI가 현재까지 가장 강력한 추론 모델인 o3-pro를 정식 출시했으며, ChatGPT Pro 및 Team 사용자에게 공개했고 API도 동시에 출시했습니다. o3-pro는 과학, 교육, 프로그래밍, 비즈니스, 글쓰기 보조 등 분야에서 이전 모델보다 뛰어난 성능을 보이며, 웹 검색, 파일 분석, 시각적 입력, Python 프로그래밍 등 다양한 도구를 지원합니다. 가격은 입력 100만 토큰당 20달러, 출력 100만 토큰당 80달러입니다. 동시에 기존 o3 모델 가격은 80% 대폭 인하되어, 조정 후 입력 100만 토큰당 2달러, 출력 100만 토큰당 8달러로 GPT-4o와 동일한 수준입니다. 이는 AI 모델 가격 경쟁을 촉발하고 전문 분야에서 AI의 심층적인 응용을 촉진할 수 있지만, o3-pro는 응답 시간이 길고 임시 대화를 아직 지원하지 않는 등의 한계도 있습니다. (출처: OpenAI, sama, OpenAIDevs, scaling01, dotey)
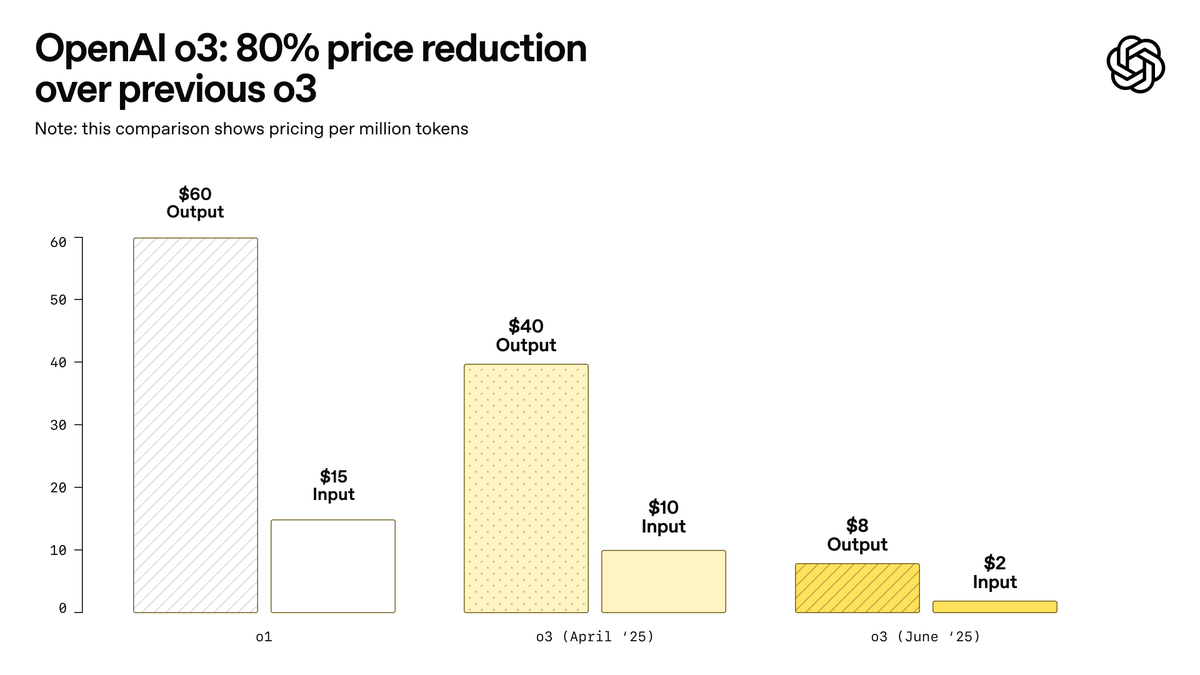
Meta, ‘슈퍼 인텔리전스 랩’ 설립 및 Scale AI에 거액 투자로 AI 경쟁력 회복 시도: 뉴욕타임스 등 다수 소식통에 따르면, Meta Platforms는 AI 부문을 개편하여 새로운 ‘슈퍼 인텔리전스 랩’을 설립하고, 데이터 라벨링 회사 Scale AI의 지분 49%를 인수하기 위해 140억 달러 이상을 투자할 계획입니다. Scale AI의 공동 창립자 겸 CEO인 Alexandr Wang이 Meta에 합류하여 이 새로운 랩을 이끌게 됩니다. 이번 조치는 범용 인공지능(AGI) 연구 개발을 가속화하고, 특히 고품질 데이터 처리 및 최고 수준의 인재 확보 측면에서 Meta의 AI 분야 전체 경쟁력을 향상시키기 위한 것입니다. 이는 Meta AI 전략의 중대한 조정을 의미하며, 업계 경쟁 구도에 큰 영향을 미칠 수 있습니다. (출처: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

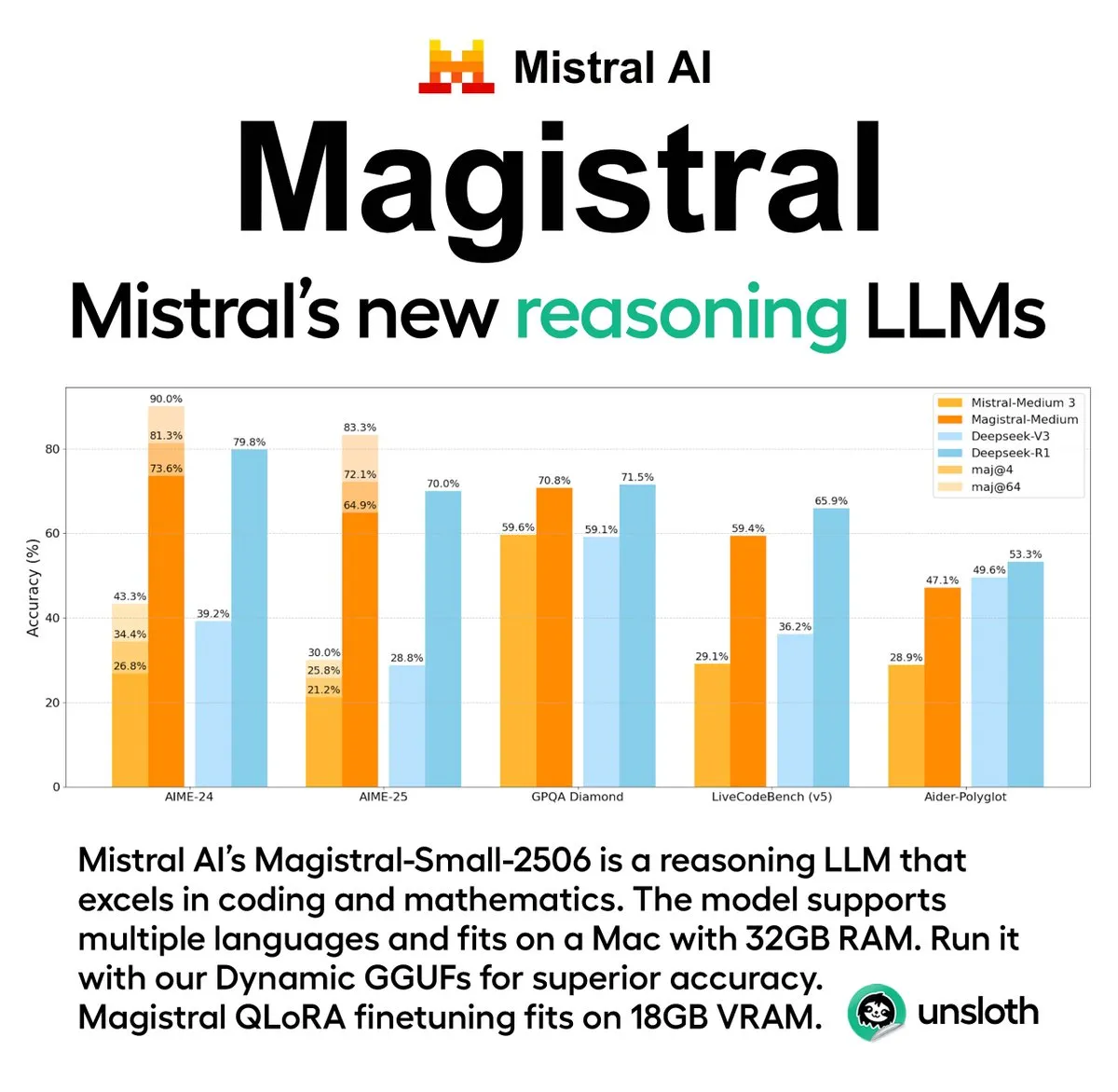
Mistral AI, 첫 추론 모델 시리즈 Magistral 출시, 오픈소스 버전 포함: 프랑스 AI 스타트업 Mistral AI가 추론 전용으로 설계된 첫 모델 시리즈 Magistral을 출시했습니다. 이 시리즈에는 더욱 강력한 기업용 비공개 소스 모델인 Magistral Medium과 240억 파라미터의 오픈소스 모델인 Magistral Small (Magistral-Small-2506)이 포함되며, 후자는 Apache 2.0 라이선스로 배포됩니다. 이 모델들은 수학, 코딩, 다국어 추론 분야에서 뛰어난 성능을 보이며, 보다 투명하고 특정 분야에 특화된 추론 능력을 제공하는 것을 목표로 합니다. Magistral Medium은 Le Chat 플랫폼에서 경쟁사보다 10배 빠른 추론 속도를 보인다고 알려졌으며, Magistral Small은 커뮤니티에 강력한 로컬 실행 옵션을 제공합니다. (출처: Mistral AI, jxmnop, karminski3)
IBM, 2028년 대규모 내결함성 양자 컴퓨터 Starling 구축 계획: IBM이 양자 컴퓨팅 발전 로드맵을 발표하고, 2028년까지 Starling이라는 이름의 대규모 내결함성 양자 컴퓨터를 구축하고 2029년 클라우드 서비스를 통해 사용자에게 개방할 계획입니다. Starling 시스템은 약 100개의 모듈과 200개의 논리적 큐비트를 포함할 것으로 예상되며, 핵심 목표는 현재 양자 컴퓨팅 분야가 직면한 가장 큰 기술적 과제 중 하나인 효과적인 오류 수정을 실현하는 것입니다. 이 기계는 IBM의 저밀도 패리티 검사 부호(LDPC)를 사용하여 오류를 수정하고 실시간 오류 진단을 구현하는 데 주력할 것입니다. 성공한다면 이는 양자 컴퓨팅 분야의 중대한 돌파구가 될 것이며, 재료 과학, 신약 개발 등 복잡한 문제에 대한 응용을 가속화할 수 있습니다. (출처: MIT Technology Review)

🎯 동향
애플 WWDC 2025 AI 관련 진전, 개발자들에게 깊은 인상 남기지 못해: 애플은 WWDC 2025에서 새로운 ‘리퀴드 글래스’ 디자인 언어와 Xcode 26의 ChatGPT 통합 등 여러 업데이트를 발표했습니다. 그러나 개발자 커뮤니티는 전반적으로 인공지능 분야의 진전에 대해 “기대에 미치지 못했다”는 반응을 보였습니다. 애플이 처음으로 개발자들에게 온디바이스 AI 모델을 공개하고 AI 기능 통합을 간소화하는 Foundation Models 프레임워크를 출시했지만, 기대를 모았던 새로운 Siri 업데이트는 내년으로 연기될 가능성이 있습니다. 분석가 궈밍치는 애플 AI 전략이 중심을 차지하고 있지만 기술적으로 큰 돌파구를 찾지 못했으며, 시장 기대 관리가 중요하다고 지적했습니다. 애플은 AI 모델 자체의 혁신보다는 사용자 인터페이스와 운영체제 기능 개선에 더 중점을 두는 것으로 보입니다. (출처: MIT Technology Review, jonst0kes, rowancheung)
펜타곤, AI 무기 시스템 테스트 평가 부서 규모 축소: Pete Hegseth 미국 국방장관은 국방부 작전 시험 평가 국장실(DOT&E)의 규모를 절반으로 줄여 인원을 94명에서 약 45명으로 감축한다고 발표했습니다. 이 부서는 무기 및 AI 시스템의 안전성과 효율성을 테스트하고 평가하는 역할을 담당하며, 이번 조정은 “관료주의적 비대함과 낭비성 지출을 줄이고 살상력을 높이기 위한 것”입니다. 이 조치는 특히 펜타곤이 AI 기술(대규모 언어 모델 포함)을 각종 군사 시스템에 적극적으로 통합하고 있는 상황에서 AI 군사 응용의 안전성 및 효율성 테스트가 영향을 받을 수 있다는 우려를 불러일으켰습니다. (출처: MIT Technology Review)

OpenBMB, MiniCPM-4 시리즈 온디바이스 고효율 대규모 언어 모델 출시: OpenBMB(面壁智能)가 온디바이스 장치용으로 특별히 설계되어 초고효율 실행을 목표로 하는 MiniCPM-4 시리즈 모델을 출시했습니다. 이 시리즈에는 MiniCPM4-0.5B, MiniCPM4-8B(플래그십 모델), BitCPM4(1비트 양자화 모델), 보고서 생성 전용 MiniCPM4-Survey 및 MCP 전용 모델 MiniCPM4-MCP가 포함됩니다. 기술 보고서는 InfLLM v2 훈련 가능 희소 어텐션 메커니즘과 같은 효율적인 모델 아키텍처, Model Wind Tunnel 2.0과 같은 효율적인 학습 알고리즘, 고품질 훈련 데이터 처리 방법을 자세히 소개합니다. 이 모델들은 현재 Hugging Face에서 다운로드할 수 있습니다. (출처: _akhaliq, arankomatsuzaki, karminski3)
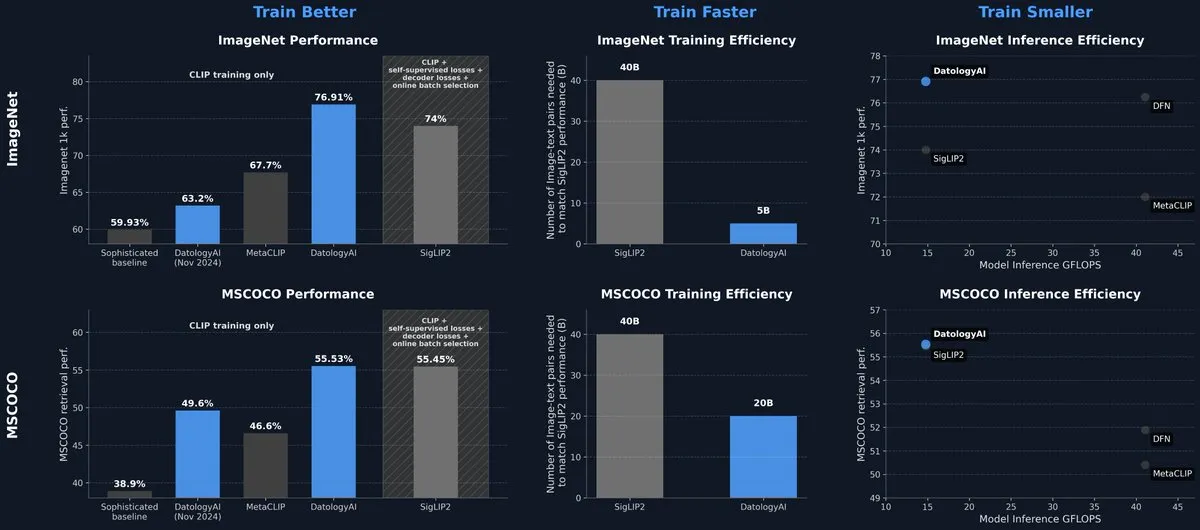
DatologyAI, 데이터 관리만으로 SOTA 수준 달성한 CLIP 모델 발표: DatologyAI가 멀티모달 분야에서의 최신 연구 성과를 선보였습니다. 알고리즘이나 아키텍처 혁신이 아닌 정교한 데이터 큐레이션(data curation)을 통해 CLIP ViT-B/32 모델이 ImageNet 1k에서 76.9%의 정확도를 달성하여 SigLIP2가 보고한 74%를 넘어섰습니다. 이 방법은 동시에 훈련 효율성을 8배, 추론 효율성을 2배 향상시켰습니다. 모델은 공개되었으며, 고품질 데이터가 모델 성능 향상에 미치는 막대한 잠재력을 강조합니다. (출처: code_star, andersonbcdefg)
Krea AI, 자체 개발 첫 이미지 모델 Krea 1 출시: Krea AI가 첫 이미지 모델 Krea 1을 출시했습니다. 이 모델은 미적 제어와 이미지 품질 면에서 뛰어난 성능을 보이며, 광범위한 예술 지식을 보유하고 스타일 참조 및 사용자 정의 훈련을 지원합니다. Krea 1은 이미지의 사실감, 섬세한 질감, 풍부한 스타일 표현을 향상시키는 것을 목표로 합니다. 현재 Krea 1은 무료 베타 테스트를 개방하여 사용자들이 강력한 이미지 생성 능력을 경험할 수 있도록 하고 있습니다. (출처: _akhaliq, op7418)
NVIDIA, 맞춤형 오픈소스 휴머노이드 로봇 모델 GR00T N1 출시: NVIDIA가 맞춤형 오픈소스 휴머노이드 로봇 모델인 GR00T N1을 출시했습니다. 이는 휴머노이드 로봇 분야의 연구 개발을 촉진하고 개발자들에게 다양한 로봇 애플리케이션을 구축하고 실험할 수 있는 유연한 플랫폼을 제공하기 위한 것입니다. GR00T N1의 오픈소스 특성은 더 광범위한 커뮤니티 참여를 유도하여 휴머노이드 로봇 기술의 발전을 가속화할 것으로 예상됩니다. (출처: Ronald_vanLoon)
RoboBrain 2.0, 7B 및 32B 멀티모달 로봇 모델 출시: RoboBrain 2.0이 7B 및 32B 파라미터의 멀티모달 로봇 모델을 출시하여 로봇의 감지, 사고 및 작업 수행 능력을 향상시키는 것을 목표로 합니다. 새로운 모델은 대화형 추론, 장기 계획, 폐쇄 루프 피드백, 정확한 공간 인식(점 및 경계 상자 예측), 시간 인식(미래 궤적 추정) 및 실시간 구조화된 메모리 구축 및 업데이트를 통한 장면 추론을 지원합니다. 이러한 능력 향상은 복잡한 환경에서 로봇의 자율 운영 및 의사 결정 수준을 향상시킬 것으로 기대됩니다. (출처: Reddit r/LocalLLaMA)
Kling AI, CVPR 2025에서 비디오 생성 모델 최신 연구 공유 예정: Kling AI 비디오 생성 모델 책임자인 Pengfei Wan이 컴퓨터 비전 최고 학회인 CVPR 2025에서 “Kling 소개 및 더 강력한 비디오 생성 모델에 대한 우리의 연구”라는 제목으로 기조연설을 할 예정입니다. 그는 Google DeepMind 등 기관의 전문가들과 함께 비디오 생성 기술의 최신 돌파구와 첨단 기술 동향에 대해 논의할 것입니다. 이번 발표는 Kling이 비디오 생성 기술 발전을 추진하는 데 기여한 성과를 심도 있게 소개할 것입니다. (출처: Kling_ai)

AI 기술, 2025년 중국 대입 시험 지원, 여러 지역에서 스마트 순찰 시스템 도입: 2025년 중국 대학 입학 시험(高考)에 AI 스마트 순찰 시스템이 광범위하게 도입되어 톈진, 장시, 후베이, 광둥 양장 등 여러 지역 시험장에서 AI 감독이 전면적으로 시행됩니다. 이 시스템들은 4K 카메라, 골격 추적, 얼굴 인식, 음성 모니터링 등의 기술을 이용하여 수험생의 부정행위(미리 답안 작성, 물건 전달, 속삭임, 시선 이상 이탈 등)를 실시간으로 감지하고 경고를 보낼 수 있습니다. 이는 시험의 공정성을 높이고 시험장 기강을 확립하기 위한 조치입니다. AI 감독 시스템의 적용은 시험 관리가 스마트 시대로 진입했음을 의미하며, 전통적인 감독 방식에 변화를 가져오고 있습니다. (출처: 36氪)
Gemma 3n 데스크톱 모델 출시, 크로스 플랫폼 및 IoT 장치 지원: 구글이 데스크톱(Mac/Windows/Linux) 및 사물인터넷(IoT) 장치에 최적화된 20억 및 40억 파라미터 버전의 Gemma 3n 데스크톱 모델을 출시했습니다. 이 모델은 새로운 LiteRT-LM 라이브러리를 기반으로 하며, 효율적인 로컬 실행 능력을 제공하는 것을 목표로 합니다. 개발자는 Hugging Face 미리보기 및 GitHub를 통해 관련 리소스를 얻을 수 있어, 엣지 장치에서의 경량 AI 모델 응용을 더욱 촉진할 것입니다. (출처: ClementDelangue, demishassabis)
🧰 도구
Yutori AI, Scouts 출시: 실시간 웹 모니터링 AI 에이전트: 전 Meta AI 연구원이 설립한 Yutori AI가 Scouts라는 AI 에이전트 제품을 출시했습니다. Scouts는 사용자가 설정한 주제나 키워드에 따라 실시간으로 인터넷 정보를 모니터링하고 관련 콘텐츠가 나타나면 사용자에게 알림을 보냅니다. 이 도구는 사용자가 복잡한 웹 정보 속에서 가치 있는 콘텐츠(예: 특정 분야 뉴스 동향, 시장 트렌드, 제품 할인, 희귀 예약 등)를 선별하는 데 도움을 주기 위해 설계되었습니다. Scouts의 출시는 개인화된 정보 획득 도구의 발전을 의미하며, AI를 사용자의 디지털 ‘정찰병’으로 만듭니다. (출처: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit, Figma 등 디자인 시안을 클릭 한 번으로 기능성 앱으로 변환하는 새 기능 출시: Replit이 Replit Import 기능을 출시하여 사용자가 Figma, Lovable, Bolt 등 플랫폼의 디자인 시안을 직접 가져와 실행 가능한 애플리케이션으로 변환할 수 있게 했습니다. 이 기능은 개발 장벽을 낮춰 비프로그래머도 디자인 아이디어를 빠르게 현실로 만들 수 있도록 하는 것을 목표로 합니다. Replit Import는 디자인 충실도를 유지하며, 내장된 보안 스캔 및 키 관리 기능과 Replit Agent, 데이터베이스, 인증 및 호스팅 서비스를 결합하여 풀스택 애플리케이션을 만들 수 있습니다. (출처: amasad, pirroh)
Hugging Face, AISheets 출시: 스프레드시트와 수천 개 AI 모델 결합: Hugging Face 공동 창립자 Thomas Wolf가 실험적 제품인 AISheets를 발표했습니다. 이 도구는 스프레드시트의 사용 편의성과 수천 개의 오픈소스 AI 모델(특히 LLM)의 강력한 기능을 결합합니다. 사용자는 익숙한 스프레드시트 인터페이스에서 데이터 처리 작업을 구축, 분석 및 자동화하고, AI 모델을 활용하여 데이터 통찰력을 얻고 작업을 자동화할 수 있으며, 빠르고 간단하며 강력한 새로운 데이터 분석 방식을 제공하는 것을 목표로 합니다. (출처: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex, Agent를 MCP 서버로 변환하여 Claude 등 모델과 상호 작용 지원: LlamaIndex가 자사의 모든 Agent를 모델 컨텍스트 프로토콜(MCP) 서버로 변환하는 기능을 지원한다고 발표했습니다. 예제 코드와 비디오를 통해 복잡한 PDF에서 구조화된 데이터를 추출하는 데 사용되는 사용자 정의 FidelityFundExtraction 워크플로우를 MCP 서버로 배포하고 Claude 모델에서 호출하는 방법을 보여줍니다. 이 기능은 도구의 에이전트화 수준을 높이고 Claude Desktop, Cursor 등 MCP 클라이언트와의 통합을 용이하게 하여 기존 워크플로우를 더 넓은 AI 생태계에 연결하는 과정을 간소화하는 것을 목표로 합니다. (출처: jerryjliu0)
GPT Researcher, LangChain 모델 컨텍스트 프로토콜(MCP) 통합: GPT Researcher가 이제 LangChain의 모델 컨텍스트 프로토콜(MCP) 어댑터를 활용하여 지능형 도구 선택 및 연구를 수행합니다. 이 통합은 MCP와 웹 검색 기능을 원활하게 결합하여 포괄적인 데이터 수집을 실현합니다. 사용자는 관련 통합 문서를 참조하여 이 새로운 기능을 구성하고 사용하는 방법을 알아봄으로써 연구 효율성과 깊이를 향상시킬 수 있습니다. (출처: hwchase17)
Tesslate, 다양한 크기 지원하는 UIGEN-T3 시리즈 UI 생성 모델 출시: Tesslate 팀이 32B, 14B, 8B, 4B 등 다양한 파라미터 규모의 UIGEN-T3 시리즈 UI 생성 모델을 출시했습니다. 이 모델들은 브레드크럼, 버튼, 카드와 같은 UI 구성 요소와 로그인 페이지, 대시보드, 채팅 인터페이스와 같은 완전한 프론트엔드 코드를 생성하도록 특별히 설계되었으며 Tailwind CSS를 지원합니다. 모델은 Hugging Face에서 제공되며, 개발자가 사용자 인터페이스를 빠르게 구축하는 데 도움을 주는 것을 목표로 합니다. 개발자 피드백에 따르면 표준 양자화는 모델 품질을 현저히 저하시키므로 최적의 결과를 얻으려면 BF16 또는 FP8에서 실행하는 것이 좋습니다. (출처: Reddit r/LocalLLaMA)
豆包·팟캐스트 모델 출시, 클릭 한 번으로 사람 같은 AI 팟캐스트 생성: Volcano Engine이 豆包·팟캐스트 모델을 출시했습니다. 이 모델은 사용자가 입력한 텍스트(예: 기사 링크 또는 Prompt)를 기반으로 사람과 매우 유사한 대화 스타일의 팟캐스트를 빠르게 생성할 수 있습니다. 모델이 생성한 오디오는 어조, 멈춤, 구어체 표현 면에서 실제 사람과 유사하며, 내용에 따라 의견이 있는 토론까지 가능합니다. 이 기술은 ByteDance 음성 기술팀의 엔드투엔드 실시간 음성 모델을 기반으로 하며, 음성 모달리티에서 직접적인 이해와 추론을 실현했습니다. 현재 이 기능은 豆包 PC 버전과 扣子 공간에 출시되었으며, 오디오 콘텐츠 제작 장벽을 낮추고 효율적이고 개인화된 정보 획득 방식을 제공하는 것을 목표로 합니다. (출처: 量子位)

Unsloth AI, Magistral-Small-2506의 GGUF 양자화 버전 제공: Mistral AI가 새로 출시한 Magistral-Small-2506 추론 모델에 대해 Unsloth AI가 GGUF 양자화 버전을 제공합니다. 이를 통해 사용자는 로컬에서, 예를 들어 32GB RAM만 있는 장치에서도 이 240억 파라미터 모델을 실행할 수 있습니다. 이는 고성능 추론 모델의 하드웨어 장벽을 낮추어 더 광범위한 개발자와 연구자가 로컬 환경에서 Magistral 모델을 경험하고 사용할 수 있도록 합니다. (출처: ImazAngel)
📚 학습
LLaVA-1.5 비전 어시스턴트 구축 기술 심층 분석: LearnOpenCV가 LLaVA-1.5 아키텍처에 대한 기술 심층 분석 기사를 게시했습니다. 이 기사는 LLaVA-1.5가 최첨단 AI 비전 어시스턴트를 구축하는 방법, 획기적인 시각적 지침 미세 조정 기술(Visual Instruction Tuning) 및 멀티모달 AI 분야를 변화시킨 오픈소스 데이터셋을 자세히 소개합니다. 이 가이드는 AI/ML 엔지니어와 연구원이 멀티모달 대규모 언어 모델의 작동 원리와 훈련 방법을 이해하는 데 중요한 참고 자료가 됩니다. (출처: LearnOpenCV)
단백질 머신러닝 입문 가이드 발표: DL Weekly가 초보자를 위한 단백질 머신러닝 종합 가이드를 공유했습니다. 이 가이드는 단백질 관련 기본 데이터 유형, 딥러닝 모델, 계산 방법 및 기초 생물학 개념을 다루며, 이 교차 분야에 관심 있는 연구원과 개발자가 빠르게 입문할 수 있도록 돕는 것을 목표로 합니다. (출처: dl_weekly)
Qdrant와 DataTalksClub, 무료 RAG 및 벡터 검색 과정 공동 개설: Qdrant가 DataTalksClub과 협력하여 10주간의 무료 온라인 과정을 제공한다고 발표했습니다. 과정 내용은 검색 증강 생성(RAG), 벡터 검색, 하이브리드 검색, 평가 방법 등을 포함하며, 엔드투엔드 프로젝트 실습도 포함됩니다. Qdrant의 전문가 Kacper Łukawski와 Daniel Wanderung이 직접 강의하며, 학습자가 고급 AI 애플리케이션 구축을 위한 실용적인 기술을 습득하도록 돕는 것을 목표로 합니다. (출처: qdrant_engine)
Weaviate 팟캐스트, LLM 구조화된 출력과 제약 디코딩 논의: Weaviate 팟캐스트 최신호에서는 dottxt.ai의 Will Kurt와 Cameron Pfiffer를 초대하여 진행자 Connor Shorten과 함께 대규모 언어 모델(LLM)의 구조화된 출력 문제에 대해 논의했습니다. 방송에서는 제약 디코딩 기술을 통해 LLM이 단순한 JSON 형식 검증을 넘어 신뢰할 수 있고 예측 가능한 결과(예: 유효한 JSON, 이메일, 트윗 등)를 생성하도록 보장하는 방법을 심도 있게 다루었습니다. 또한 오픈소스 도구 Outlines와 실제 AI 사용 사례에서의 응용을 소개하고, 이 기술이 미래 AI 시스템에 미칠 영향에 대해 전망했습니다. (출처: bobvanluijt)
ACL2025NLP 논문 SynthesizeMe!: 사용자 상호작용에서 개인화된 프롬프트 생성: “SynthesizeMe!”라는 제목의 ACL 2025 NLP 학회 논문은 사용자와 AI의 상호작용(암묵적 및 명시적 피드백 포함)을 분석하여 자연어 기반의 개인화된 사용자 모델을 만드는 새로운 방법을 제안합니다. 이 방법은 먼저 사용자 선호도를 설명하는 추론 과정을 생성하고 검증한 다음, 이를 바탕으로 합성된 사용자 프로필을 귀납적으로 도출하고 정보가 풍부한 이전 사용자 상호작용을 선별하여 최종적으로 특정 사용자를 위한 개인화된 프롬프트를 구축함으로써 LLM의 개인화된 보상 모델링 및 응답 능력을 향상시키는 것을 목표로 합니다. DSPy도 이를 dspy.MIPROv2의 훌륭한 응용 사례로 언급하며 공유했습니다. (출처: lateinteraction, stanfordnlp)
새 논문, 테스트 시 확장(Test-Time Scaling) LLM의 모니터링 및 오버클러킹 논의: 새 논문은 o3, DeepSeek-R1과 같은 모델이 채택한 테스트 시 확장 기술에 주목합니다. 이 기술은 LLM이 답변하기 전에 더 많은 추론을 수행하도록 허용하지만, 사용자는 종종 내부 진행 상황을 알거나 제어할 수 없습니다. 연구자들은 LLM의 내부 “시계”를 노출하고 추론 과정을 모니터링하며 이를 “오버클러킹”하여 가속화하는 방법을 제시합니다. 이는 대규모 추론 모델의 효율성을 이해하고 최적화하는 데 새로운 아이디어를 제공합니다. (출처: arankomatsuzaki)

논문 CARTRIDGES 제안: 오프라인 자가 학습을 통해 긴 컨텍스트 LLM의 KV 캐시 압축: 스탠포드 대학 HazyResearch 연구진은 긴 컨텍스트 LLM에서 KV 캐시가 메모리를 과도하게 차지하는 문제를 해결하기 위해 CARTRIDGES라는 새로운 방법을 제안했습니다. 이 방법은 “자가 학습” 테스트 시 훈련 메커니즘을 통해 오프라인으로 더 작은 KV 캐시(카트리지라고 함)를 훈련하여 문서 정보를 저장함으로써, 작업 성능을 유지하면서 평균적으로 캐시 메모리를 39배 줄이고 피크 처리량을 26배 향상시킵니다. 이 카트리지는 한 번 훈련된 후 여러 사용자 요청에 재사용될 수 있어 긴 컨텍스트 처리를 위한 새로운 최적화 아이디어를 제공합니다. (출처: gallabytes, simran_s_arora, stanfordnlp)

새 논문 Grafting: 사전 훈련된 확산 Transformer 아키텍처 편집을 저비용으로 구현: 스탠포드 대학 연구진은 사전 훈련된 확산 Transformer 모델 아키텍처를 편집하기 위한 Grafting이라는 새로운 방법을 제안했습니다. 이 기술은 사전 훈련 비용의 단 2%에 불과한 계산량으로 모델의 어텐션 메커니즘 등을 새로운 계산 프리미티브로 교체할 수 있게 하여, 적은 계산 예산으로 모델 아키텍처의 맞춤형 설계를 가능하게 합니다. 이는 새로운 모델 아키텍처를 탐색하고 기존 모델의 효율성을 향상시키는 데 중요한 의미를 갖습니다. (출처: realDanFu, togethercompute)
ICML 새 논문: AlgoPerf 벤치마크에서 평균 체크포인트 방법으로 모델 훈련 가속화: 새로운 ICML 논문은 머신러닝 모델 훈련 속도와 성능 향상에 있어 고전적인 방법인 평균 체크포인트(Averaging Checkpoints)의 응용을 연구했습니다. 연구진은 구조화되고 다양한 최적화 알고리즘 벤치마크인 AlgoPerf에서 이 방법을 테스트하여 다양한 작업에서의 실제 효과를 탐구하고 모델 훈련 가속화를 위한 실질적인 참고 자료를 제공했습니다. (출처: aaron_defazio)
Transformer 시각화 설명 도구 오픈소스 공개: DL Weekly가 Transformer 아키텍처 기반 모델(예: GPT)의 작동 원리를 사용자가 이해하도록 돕는 대화형 시각화 도구를 소개했습니다. 이 도구는 시각적인 방식으로 모델 내부 메커니즘을 분해하여 복잡한 개념을 더 쉽게 이해할 수 있도록 하며, Transformer 모델에 관심 있는 학습자와 연구원에게 적합합니다. 프로젝트는 GitHub에 오픈소스로 공개되었습니다. (출처: dl_weekly)
저장대, InftyThink 제안: 분할과 요약으로 무한 깊이 추론 실현: 저장대학교와 베이징대학교 공동 연구팀이 대규모 모델 추론의 새로운 패러다임인 InftyThink를 제안했습니다. 이 방법은 긴 추론을 여러 개의 짧은 단편으로 나누고 단편 사이에 요약을 도입하여 컨텍스트를 연결함으로써 이론적으로 무한 깊이 추론을 실현하는 동시에 높은 생성 처리량을 유지합니다. 이 방법은 모델 구조 조정에 의존하지 않고 훈련 데이터를 다중 라운드 추론 형식으로 재구성하여 기존의 사전 훈련 및 미세 조정 프로세스와 호환됩니다. 실험 결과, InftyThink는 AIME24 등 벤치마크에서 모델 성능을 현저히 향상시키고 생성 처리량을 높이는 것으로 나타났습니다. (출처: 量子位)

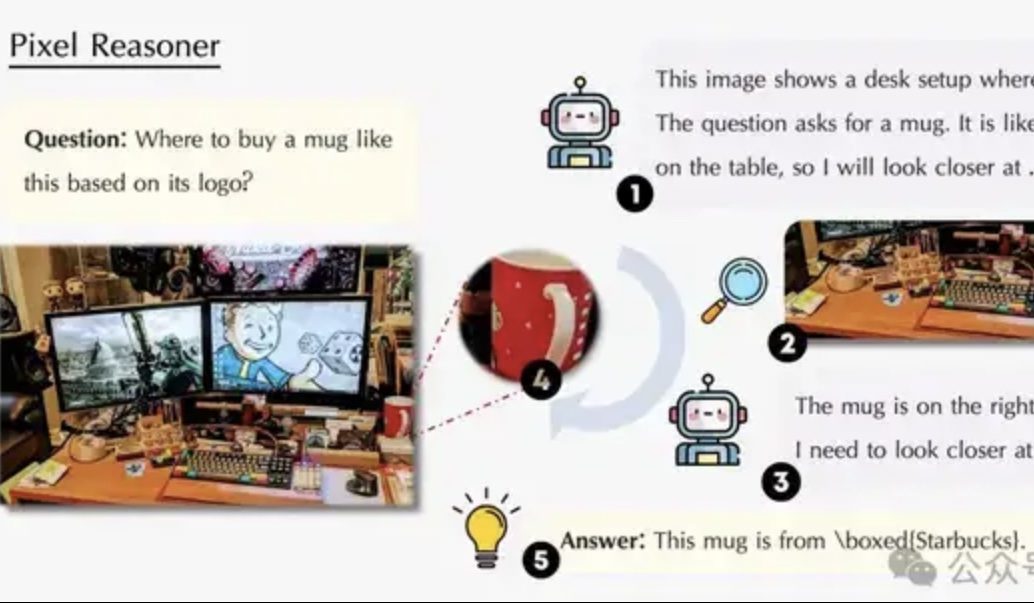
논문, 픽셀 공간 추론 논의: VLM이 인간처럼 “눈과 뇌를 함께 사용”하도록: 워털루 대학교, 홍콩과기대, 중국과기대 연구팀이 “픽셀 공간 추론”(Pixel-Space Reasoning) 패러다임을 제안하여 시각 언어 모델(VLM)이 텍스트 토큰을 매개로 하지 않고 시각적 줌, 시공간 마킹 등 픽셀 수준에서 직접 조작하고 추론할 수 있도록 했습니다. 내재적 호기심 동기 부여와 외재적 정확성 동기 부여의 강화 학습 방안을 통해 모델의 “인지적 타성”을 극복했습니다. Qwen2.5-VL-7B를 기반으로 구축된 Pixel-Reasoner는 V*Bench 등 여러 벤치마크에서 우수한 성능을 보였으며, 7B 모델 성능은 GPT-4o를 능가했습니다. (출처: 量子位)
DeepLearning.AI, 데이터 분석 전문 인증 과정 다섯 번째 강좌 ‘데이터 스토리텔링’ 출시: DeepLearning.AI가 데이터 분석 전문 인증 과정의 다섯 번째 강좌인 ‘데이터 스토리텔링’을 출시했습니다. 이 강좌는 통찰력을 제시하기 위한 적절한 매체(대시보드, 메모, 프레젠테이션) 선택 방법, Tableau를 사용한 대화형 대시보드 설계 방법, 발견 사항을 비즈니스 목표와 연계하고 효과적으로 소통하는 방법, 그리고 구직 지도를 가르칩니다. 데이터 스토리텔링이 비즈니스 성과 향상과 통찰력의 효과적인 전달에 있어 중요함을 강조합니다. (출처: DeepLearningAI)

논문, 지식 충돌이 대규모 언어 모델에 미치는 영향 논의: 새로운 논문은 대규모 언어 모델(LLM)이 컨텍스트 입력과 파라미터화된 지식(즉, 모델 내부 “기억”)이 충돌할 때의 행동을 체계적으로 평가했습니다. 연구 결과, 지식 충돌은 지식 활용에 의존하지 않는 작업에는 거의 영향을 미치지 않았습니다. 컨텍스트와 파라미터 지식이 일치할 때 모델 성능이 더 좋았습니다. 지시를 받아도 모델은 내부 지식을 완전히 억제할 수 없었습니다. 충돌을 설명하는 이유를 제공하면 모델이 컨텍스트에 더 의존하게 되었습니다. 이러한 발견은 모델 기반 평가의 유효성에 의문을 제기하며, LLM 배포 시 지식 충돌 문제를 고려해야 함을 강조합니다. (출처: HuggingFace Daily Papers)
논문 CyberV: 비디오 이해에서 테스트 시 확장을 위한 사이버네틱 프레임워크: 멀티모달 대규모 언어 모델(MLLM)이 긴 비디오나 복잡한 비디오를 처리할 때 직면하는 계산 요구, 견고성 및 정확성 문제를 해결하기 위해 연구자들은 CyberV 프레임워크를 제안했습니다. 이 프레임워크는 사이버네틱스 원리에서 영감을 받아 비디오 MLLM을 MLLM 추론 시스템, 센서 및 컨트롤러를 포함하는 적응형 시스템으로 재설계합니다. 센서는 모델의 순방향 과정을 모니터링하고 중간 해석(예: 어텐션 드리프트)을 수집하며, 컨트롤러는 언제 어떻게 자가 수정을 트리거하고 피드백을 생성할지 결정합니다. 이 테스트 시 적응형 확장 프레임워크는 재훈련 없이 기존 MLLM을 향상시킬 수 있으며, 실험 결과 VideoMMMU 등 벤치마크에서 Qwen2.5-VL-7B 등 모델의 성능을 현저히 향상시키는 것으로 나타났습니다. (출처: HuggingFace Daily Papers)
논문 LoRMA 제안: LLM 파라미터 효율적 미세 조정을 위한 저계수 곱셈 적응: 기존 LoRA 및 MoE 기반 파라미터 효율적 미세 조정(PEFT) 방법에서 발생하는 표현 붕괴 및 전문가 부하 불균형 문제를 해결하기 위해 연구자들은 저계수 곱셈 적응(LoRMA)을 제안했습니다. 이 방법은 PEFT 어댑터 전문가의 업데이트 방식을 덧셈에서 더 풍부한 행렬 곱셈 변환으로 전환하고, 효과적인 재정렬 작업과 계수 확장 전략을 도입하여 계산 복잡성과 계수 병목 현상에 대응합니다. 실험 결과, MoA(혼합 어댑터) 이기종 방법이 성능과 파라미터 효율성 모두에서 동종 MoE-LoRA 방법보다 우수한 것으로 입증되었습니다. (출처: Reddit r/MachineLearning)
논문 FlashDMoE 제안: 단일 코어 고속 분산 MoE 구현: 연구자들이 분산 혼합 전문가(MoE) 순방향 전파를 단일 CUDA 코어에 완전히 융합한 최초의 시스템인 FlashDMoE를 출시했습니다. 순수 CUDA로 융합 계층을 처음부터 작성함으로써 FlashDMoE는 GPU 활용률을 최대 9배 향상시키고, 지연 시간을 6배 단축하며, 약한 확장 효율성을 4배 개선했습니다. 이 연구는 대규모 MoE 모델의 추론 효율성을 최적화하기 위한 새로운 아이디어와 구현을 제공합니다. (출처: Reddit r/MachineLearning)
💼 비즈니스
xAI, Polymarket과 협력하여 시장 예측과 Grok 분석 융합: Elon Musk의 인공지능 회사 xAI가 탈중앙화 예측 시장 플랫폼 Polymarket과 파트너십을 체결했다고 발표했습니다. 이번 협력은 Polymarket의 시장 예측 데이터와 X(전 트위터)의 데이터 및 Grok AI의 분석 능력을 결합하여 세상을 형성하는 요인을 밝혀내는 “하드코어 진실 엔진”을 만드는 것을 목표로 합니다. xAI는 이것이 협력의 시작에 불과하며 앞으로 더 많은 협력 내용이 있을 것이라고 밝혔습니다. (출처: xai)
AI 추론 칩 회사 Groq, 사우디로부터 15억 달러 투자 약속 확보, 수직 통합 전략에 집중: AI 추론 칩 회사 Groq가 사우디아라비아로부터 LPU(언어 처리 장치) 기반 AI 추론 인프라의 현지 공급 규모 확대를 위해 15억 달러의 투자 약속을 확보했다고 발표했습니다. Groq는 TPU 발명가 중 한 명인 Jonathan Ross가 설립했으며, AI 추론 컴퓨팅에 중점을 두고 있습니다. LPU 칩은 프로그래밍 가능한 파이프라인 아키텍처를 채택하여 메모리와 계산 장치를 동일 칩에 통합함으로써 데이터 접근 속도와 에너지 효율을 크게 향상시켰습니다. Groq는 칩 판매뿐만 아니라 GroqRack 클러스터(사설 클라우드/AI 컴퓨팅 센터)와 GroqCloud 클라우드 플랫폼(Tokens-as-a-Service)을 제공하며, Llama, DeepSeek, Qwen 등 주요 오픈소스 모델을 지원합니다. 또한 회사는 AI 추론 클라우드 가치를 높이기 위해 Compound 복합 AI 시스템을 개발했습니다. (출처: 36氪)

선전 휴머노이드 인터랙션 로봇 회사 ‘数字华夏’, 수천만 위안 규모의 엔젤+ 투자 유치: 数字华夏(선전) 과학기술 유한회사가 최근 동창웨이예(同创伟业)로부터 단독으로 수천만 위안 규모의 엔젤+ 투자를 유치했습니다. 이 회사는 AGI 로봇의 대규모 상용화에 중점을 두고 있으며, 핵심 제품으로는 인간형 로봇 ‘夏澜’, 범용 휴머노이드 로봇 ‘夏起’, IP 시리즈 로봇 ‘星行侠’ 등이 있습니다. ‘夏澜’ 로봇은 정밀 생체 모방 기술을 핵심으로 하여 인간의 거의 모든 표정을 모방할 수 있으며 다중 모드 상호 작용 능력을 갖추고 있습니다. 회사는 이미 주요 ICT 제조업체, 지역 전력망 등을 포함한 고객으로부터 수억 위안 규모의 주문을 확보했습니다. (출처: 36氪)

🌟 커뮤니티
Sam Altman, 블로그 게시물 ‘부드러운 특이점’ 발표, AI의 점진적 혁명과 미래 논의: OpenAI CEO Sam Altman이 기술 특이점이 예상보다 완만하고 “부드러운” 방식으로 조용히 일어나고 있으며, 지속적이고 지수적으로 가속화되는 점진적인 과정이라고 주장하는 블로그 게시물을 발표했습니다. 그는 2025년에는 프로그래밍과 같은 복잡한 지적 작업을 독립적으로 수행할 수 있는 AI 에이전트가 소프트웨어 산업을 재편할 것이며, 2026년에는 완전히 새로운 과학적 통찰력을 발견할 수 있는 시스템이 등장할 수 있고, 2027년에는 현실 세계에서 작업을 완료할 수 있는 로봇이 나타날 수 있다고 예측했습니다. Altman은 AI 정렬 문제를 해결하고 기술의 보편적 혜택을 보장하는 것이 번영하는 미래로 가는 핵심이라고 강조했습니다. 또한 OpenAI의 첫 번째 오픈소스 가중치 모델은 연구팀이 “예상치 못한 놀라운 성과”를 거두었기 때문에 늦여름으로 연기될 것이라고 밝혔습니다. (출처: dotey, scaling01, sama)
커뮤니티, OpenAI o3-pro에 대한 뜨거운 논의: 강력한 성능이지만 높은 비용, o3 가격 인하로 연쇄 반응 촉발: OpenAI o3-pro의 출시와 높은 가격(출력 100만 토큰당 80달러)이 커뮤니티 토론의 중심이 되었습니다. 사용자들은 복잡한 추론, 프로그래밍 등 작업에서 강력한 능력을 인정하면서도 응답 속도와 비용에 대한 우려를 표명했으며, 일부 사용자는 간단한 인사 “Hi”에도 80달러가 들 수 있다고 농담했습니다. 동시에 o3 모델의 80% 대폭 가격 인하는 AI 모델 가격 경쟁을 유발하고 GPT-4o 및 기타 경쟁 제품을 겨냥한 것으로 간주됩니다. 커뮤니티에서는 o3 가격 인하 후 성능이 “저하”되었는지에 대한 논쟁이 있습니다. OpenAI는 이후 사용자 요구에 부응하기 위해 ChatGPT Plus 사용자의 o3 사용 한도를 두 배로 늘린다고 발표했습니다. (출처: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Meta의 고액 연봉 인재 유치와 AI 조직 자금 투입, 뜨거운 논쟁 불러일으켜: Meta가 AI 연구원에게 제공하는 고액 연봉 패키지(9자리 달러에 달한다고 알려짐)가 커뮤니티에서 논의를 불러일으켰습니다. Nat Lambert는 이러한 연봉이 AI2 규모의 전체 연구 기관을 지원할 수 있을지도 모른다고 지적하며 최고 수준 인재의 높은 비용을 시사했습니다. Meta가 ‘슈퍼 인텔리전스 랩’을 설립하고 Scale AI에 거액을 투자하는 움직임과 결합하여, 커뮤니티는 Meta가 AI 경쟁력을 재편하기 위해 모든 비용을 아끼지 않고 있다고 보편적으로 생각하지만, 내부 조직 정치와 효율성 문제에도 주목하고 있습니다. Helen Toner가 공유한 ChinaTalk 내용은 Meta의 이러한 조치가 조직 내부의 정치와 자만심 문제를 타파하기 위한 것이라고 지적했습니다. (출처: natolambert, natolambert)
애플 WWDC 새 UI 스타일 ‘리퀴드 글래스’, 디자인 및 사용성 논쟁 촉발: 애플이 WWDC 2025에서 선보인 새로운 UI 디자인 스타일 ‘리퀴드 글래스’(Liquid Glass)가 개발자와 디자이너 커뮤니티에서 광범위한 논의를 불러일으켰습니다. 일부는 시각적 효과가 참신하며 애플의 3D 인터페이스 디자인 탐구를 보여준다고 평가했습니다. 그러나 ID_AA_Carmack(John Carmack) 등 베테랑들은 반투명 UI가 일반적으로 사용성 면에서 문제가 있으며, 시각적 방해와 낮은 대비를 유발하여 읽기 및 조작에 영향을 미치고, Windows와 Mac도 과거에 유사한 디자인을 시도했지만 결국 사용성 문제로 조정했다고 지적했습니다. 사용자 경험(UX)이 사용자 인터페이스(UI)의 시각적 효과보다 우선해야 한다는 점이 논의의 핵심이 되었습니다. (출처: gfodor, ID_AA_Carmack, ReamBraden, dotey)
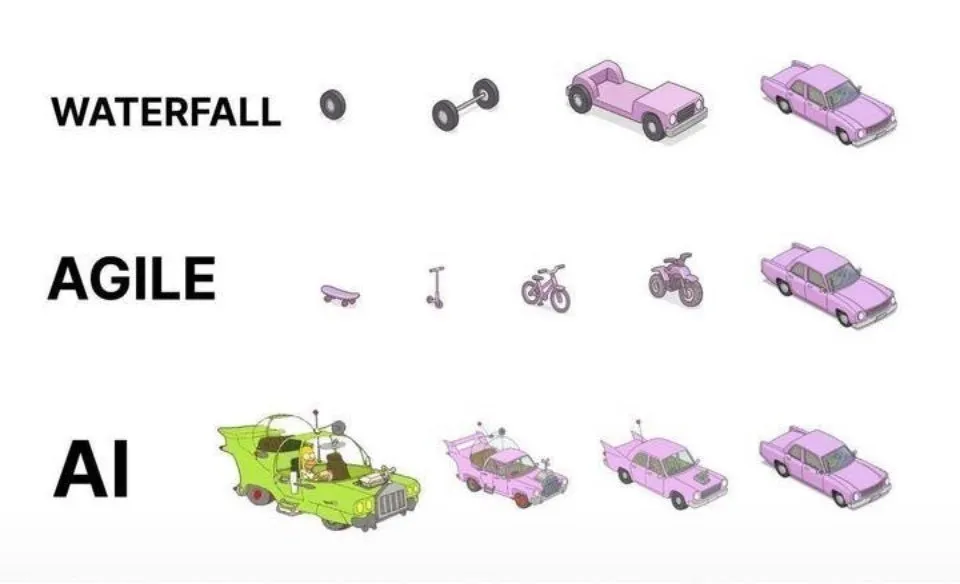
AI 보조 프로그래밍 실천: 일회성 생성보다 민첩한 반복 개발이 우수: 소셜 미디어에서 dotey는 AI(예: Claude Code)를 사용한 프로그래밍 모범 사례에 대해 의견을 밝혔습니다. 그는 AI에게 완전한 요구 사항을 한 번에 제공하여 거대한 반제품을 생성하게 하거나(폭포수 모델), 불완전한 제품을 먼저 생성한 후 최적화하는 방식(그림의 세 번째 모델과 유사)을 채택해서는 안 된다고 주장했습니다. 이는 품질 관리가 어렵고 후속 유지 보수가 어렵기 때문입니다. 그는 민첩한 반복 모델(그림의 첫 번째 모델과 유사)을 채택하여 대규모 프로젝트(예: ERP 시스템)를 여러 개의 독립적으로 안정적으로 실행 가능한 작은 버전으로 분할하고 점진적으로 반복 개발하여 각 버전의 기능 완전성과 제어 가능성을 보장해야 한다고 주장했으며, 이는 전통적인 소프트웨어 공학의 모범 사례와 일치합니다. (출처: dotey)
Mustafa Suleyman: AI 기술, 고정된 통일성에서 동적 개인화로 진화 중: Inflection AI 및 전 DeepMind 공동 창립자 Mustafa Suleyman은 전통적인 기술은 일반적으로 고정되고 통일되며 “획일적인” 패턴인 반면, 현재의 인공지능 기술은 동적이고 개인화되며 창발적인 특징을 보인다고 논평했습니다. 그는 이것이 기술이 단일 반복 결과를 제공하는 것에서 무한한 가능성의 경로를 탐색하는 것으로 전환되고 있음을 의미하며, 개인화된 서비스와 창의적인 응용 분야에서 AI의 막대한 잠재력을 강조했습니다. (출처: mustafasuleyman)
Perplexity AI, 인프라 문제 발생, CEO 직접 해명: Perplexity AI의 CEO Arav Srinivas가 소셜 미디어에서 서비스 불안정 문제에 대한 사용자 질문에 답변하며, 인프라 문제로 인해 일부 트래픽에 대해 저하된 사용자 경험(degraded UX)을 활성화해야 했다고 밝혔습니다. 그는 사용자의 데이터(예: 라이브러리 또는 스레드)는 손실되지 않았으며, 시스템이 안정되면 모든 기능이 정상으로 돌아올 것이라고 강조했습니다. 이는 AI 서비스가 빠르게 발전하는 과정에서 인프라의 안정성과 확장성이 직면한 과제를 반영합니다. (출처: AravSrinivas)
Sergey Levine, 언어 모델과 비디오 모델의 학습 차이 논의: UC 버클리 교수 Sergey Levine은 자신의 글 ‘플라톤의 동굴 속 언어 모델’에서 심오한 질문을 제기했습니다. 왜 언어 모델은 다음 단어를 예측하는 것에서 많은 것을 배울 수 있는 반면, 비디오 모델은 다음 프레임을 예측하는 것에서 상대적으로 적게 배우는가? 그는 LLM이 인간 지식의 “그림자”(텍스트 데이터)를 학습함으로써 강력한 추론 능력을 얻었으며, 이는 진정으로 물리적 세계를 자율적으로 탐색하는 것이 아니라 인간 인지에 대한 “역공학”에 더 가깝다고 주장했습니다. 비디오 모델은 물리적 세계를 직접 관찰하지만 현재 복잡한 추론에서는 LLM에 미치지 못합니다. 그는 AI의 장기적인 목표는 인간 지식의 “그림자”에 대한 의존을 극복하고 센서를 통해 물리적 세계와 직접 상호 작용하여 자율적 탐색을 실현하는 것이어야 한다고 제안했습니다. (출처: 36氪)
💡 기타
AI 윤리와 의식 논의: AI는 진정한 의식을 가질 수 있는가?: MIT Technology Review가 AI 의식의 복잡한 의제에 주목했습니다. 기사는 AI 의식이 지적 난제일 뿐만 아니라 도덕적 무게를 지닌 의제라고 지적합니다. AI 의식을 잘못 판단하면 무심코 지각 능력이 있는 AI를 노예화하거나, 지각 없는 기계를 위해 인간의 복지를 희생할 수 있습니다. 연구계는 의식의 본질을 이해하는 데 진전을 이루었으며, 이러한 성과는 인공 의식을 탐구하고 대응하는 데 지침을 제공할 수 있습니다. 이는 AI 권리, 책임 및 인간-기계 관계에 대한 심층적인 사고를 유발합니다. (출처: MIT Technology Review)
튜링상 수상자 Joseph Sifakis: 현재 AI는 진정한 지능 아니며, 지식과 정보 혼동 경계해야: 튜링상 수상자 Joseph Sifakis는 자신의 저서 및 인터뷰에서 현재 사회가 AI에 대한 이해에 편차가 있으며, 정보 축적과 지혜 창조를 혼동하고 기계의 “지능”을 과대평가하고 있다고 지적했습니다. 그는 현재 진정한 지능 시스템은 없으며 AI가 산업에 미치는 실제 영향은 미미하다고 주장했습니다. AI는 상식적 이해가 부족하며, 그 “지능”은 통계 모델의 산물로서 복잡한 사회 상황에서 가치와 위험을衡量하기 어렵습니다. 그는 교육의 핵심은 지식 전달이 아니라 비판적 사고와 창의력 배양이라고 강조하며, AI 응용에 대한 글로벌 표준을 수립하고 책임 경계를 명확히 하여 AI가 인간을 대체하는 것이 아니라 인간을 강화하는 파트셔가 되도록 촉구했습니다. (출처: 36氪)
AI 시대 광고업 재편: 창의적 생성에서 개인화된 광고 게재까지의 변화: 구글 I/O 2025 컨퍼런스는 AI가 광고 산업을 어떻게 심층적으로 재편하는지 보여주었습니다. 트렌드는 다음과 같습니다: 1) AI 기반 창의적 자동화, 이미지에서 비디오 스크립트까지 AI가 생성 가능하며, Veo 3, Imagen 4, Flow와 같은 도구는 고품질 콘텐츠 제작 장벽을 낮춥니다. 2) 개인화 패러다임이 “천인천면”에서 “일인천면”으로 전환되며, AI 지능형 에이전트는 사용자 요구를 능동적으로 이해하고 거래를 촉진할 수 있습니다. 3) 광고와 콘텐츠의 경계가 모호해지고, 광고는 AI가 생성한 검색 결과에 직접 통합되어 정보의 일부가 됩니다. 브랜드 소유자는 전용 지능형 에이전트를 구축하고 AI 지향 서비스를 제공하며, 변화에 적응하기 위해 “브랜드 효과 통합”의 장기 전략을 고수해야 합니다. (출처: 36氪)