
키워드:OpenAI 코덱스, 시각 언어 동작 모델, 언어 모델 메모리 상한, ChatGPT 메모리 기능, DeepSeek-R1-0528, 확산 모델, Suno AI 음악 생성, 메타에이전트X, 코덱스 인터넷 접근 기능, SmolVLA 로봇 모델, GPT 스타일 모델 3.6비트 메모리, ChatGPT 개인화 상호작용 개선, DeepSeek-R1 복잡한 추론 능력
🔥 주요 뉴스
OpenAI Codex, Plus 사용자 대상 공개 및 주요 업데이트: 인터넷 액세스 및 음성 입력 기능 추가: OpenAI는 Codex를 ChatGPT Plus 사용자에게 점진적으로 공개한다고 발표했습니다. 이번 업데이트의 주요 내용에는 AI 에이전트가 작업 수행 시 인터넷에 액세스하여(기본적으로 비활성화, 사용자가 도메인 및 HTTP 메서드 제어 가능) 의존성을 설치하고, 소프트웨어 패키지를 업그레이드하며, 외부 리소스 테스트를 실행할 수 있도록 하는 기능이 포함됩니다. 또한, Codex는 이제 기존 Pull Request를 직접 업데이트할 수 있도록 지원하며, 음성으로 작업을 입력할 수 있습니다. 기타 개선 사항으로는 바이너리 파일 작업 지원(현재 PR에서는 삭제 또는 이름 변경만 가능), 작업 차이(diff) 크기 제한 1MB에서 5MB로 증가, 스크립트 실행 시간 제한 5분에서 10분으로 증가, iOS 플랫폼의 여러 문제 수정 및 실시간 활동 기능 재활성화 등이 있습니다. 이러한 업데이트는 복잡한 프로그래밍 작업에서 Codex의 실용성과 유연성을 향상시키는 것을 목표로 합니다 (출처: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
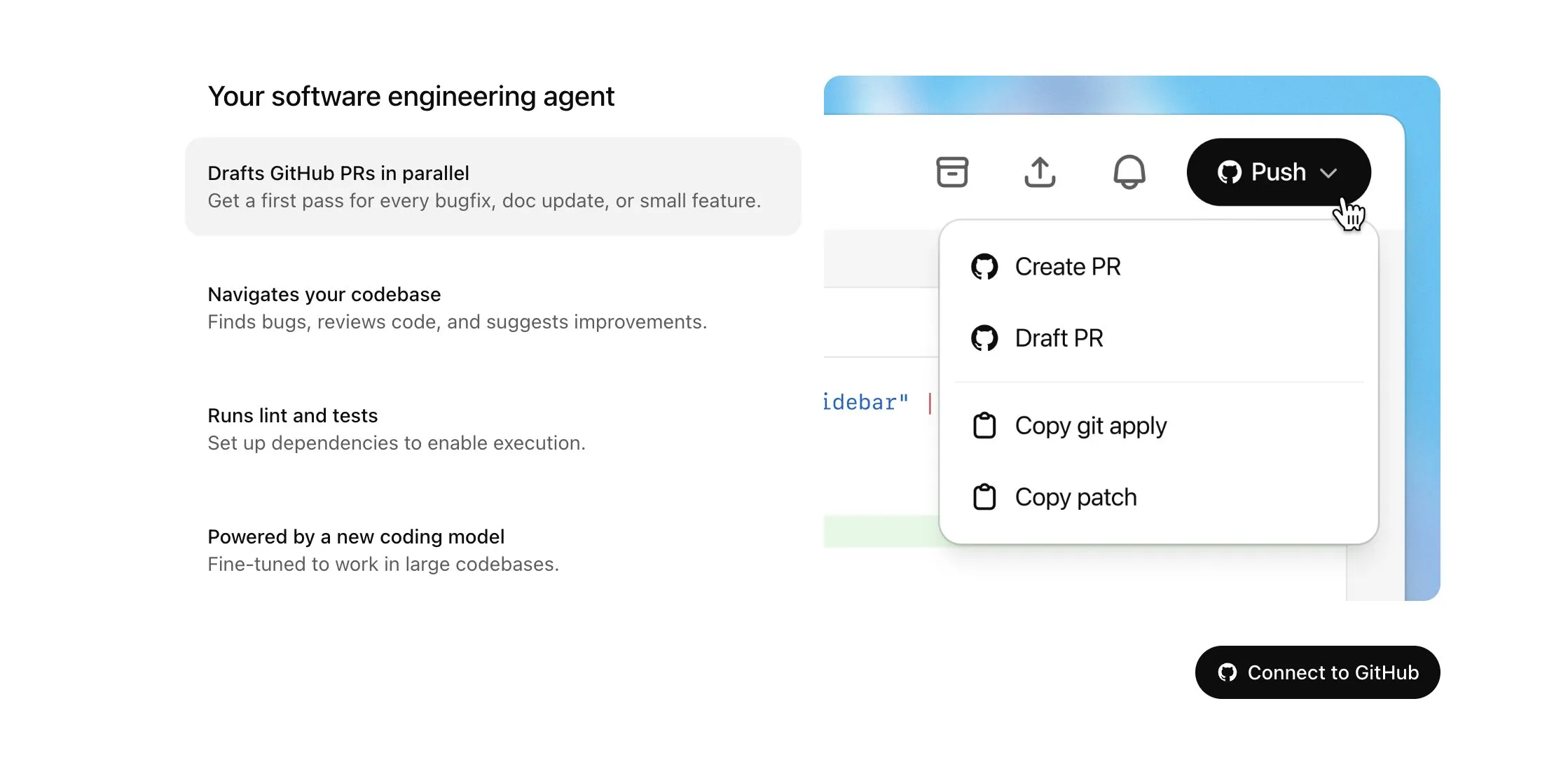
Hugging Face와 H Company, 로봇 기술 발전을 위한 오픈소스 시각 언어 행동(VLA) 모델 공동 발표: Hugging Face와 H Company는 “VLA의 날”에 Hugging Face의 SmolVLA(4억 5천만 파라미터)와 H Company의 Holo-1(30억 및 70억 파라미터)을 포함한 새로운 오픈소스 시각 언어 행동 모델을 발표했습니다. VLA 모델은 로봇이 보고, 듣고, 이해하며 AI 지시에 따라 행동할 수 있도록 설계되었으며, 로봇 분야의 GPT로 불립니다. 이러한 모델을 오픈소스로 공개하는 것은 작동 원리를 이해하고, 잠재적인 백도어를 방지하며, 특정 로봇 및 작업에 맞게 사용자 정의하는 데 중요합니다. SmolVLA는 LeRobotHF 데이터셋에서 훈련되어 우수한 성능과 추론 속도를 보여주었습니다. Holo-1은 웹 및 컴퓨터 에이전트 작업에 중점을 두며 Apache 2.0 라이선스를 지원합니다. 이러한 발표는 오픈소스 AI 로봇 기술의 발전을 가속화할 것으로 예상됩니다 (출처: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

Meta 등 기업 연구, 언어 모델 기억력 상한선 파라미터당 약 3.6비트임을 밝혀내, 기존 통념에 도전: Meta, DeepMind, 코넬 대학교, NVIDIA의 공동 연구에 따르면 GPT 스타일의 언어 모델은 파라미터당 약 3.6비트의 정보를 기억할 수 있습니다. 연구 결과, 모델은 용량 한계에 도달할 때까지 훈련 데이터를 지속적으로 기억하며, 이후에는 예기치 않은 기억력 감소와 함께 모델이 일반화 학습으로 전환하는 “Grokking”(통찰) 현상이 나타나기 시작합니다. 이 발견은 데이터셋의 정보량이 모델의 저장 능력을 초과할 때 모델이 용량 절약을 위해 정보 지점을 공유하게 되어 일반화를 촉진하는 “이중 하강” 현상을 설명합니다. 이 연구는 또한 모델 용량, 데이터 규모와 멤버십 추론 공격 성공률 간의 관계에 대한 스케일링 법칙을 제시하며, 매우 큰 데이터셋에서 훈련된 최신 LLM의 경우 신뢰할 수 있는 멤버십 추론이 어려워진다고 지적합니다 (출처: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI, 개인화된 상호 작용 경험 향상을 위한 ChatGPT 메모리 기능 경량 버전 출시: OpenAI는 무료 사용자에게 경량 버전의 메모리 기능 개선 사항을 출시하기 시작했다고 발표했습니다. 기존의 메모리 저장 외에도 ChatGPT는 이제 사용자의 최근 대화를 참조하여 더욱 개인화된 응답을 제공할 수 있습니다. 이는 사용자의 선호도와 관심사를 활용하여 작문, 조언 얻기, 학습 등에서 더욱 능숙하게 만드는 것을 목표로 합니다. Sam Altman도 메모리 기능이 자신이 가장 좋아하는 ChatGPT 기능 중 하나가 되었으며 향후 더 큰 개선을 기대한다고 말했습니다. 이 업데이트는 AI 상호 작용을 사용자 요구에 더 가깝게 만들고 사용자 참여를 강화하려는 OpenAI의 노력을 보여줍니다 (출처: openai, sama, iScienceLuvr)
🎯 동향
DeepSeek-R1-0528 출시, 복잡한 추론 및 프로그래밍 능력 강화: DeepSeek은 R1 모델의 업그레이드 버전인 DeepSeek-R1-0528을 출시했습니다. 이 버전은 2024년 12월에 출시된 DeepSeek V3 Base 모델을 기반으로 하며, 더 많은 컴퓨팅 성능을 투입하여 후훈련을 진행함으로써 모델의 사고 깊이와 추론 능력을 크게 향상시켰습니다. 새 모델은 복잡한 문제를 처리할 때 더 세밀하게 분해하고 더 오랫동안 생각합니다(예: AIME 2025 테스트에서 문제당 평균 토큰 소모량이 12K에서 23K로 증가). 이를 통해 수학, 프로그래밍, 일반 논리 등 여러 벤치마크 테스트에서 GPT-o3 및 Gemini-2.5-Pro에 근접하는 우수한 성적을 거두었습니다. 또한 새 버전은 환각 감소(약 45%-50%), 창의적인 글쓰기, 도구 호출 측면에서도 크게 최적화되어 “9.9 – 9.11은 얼마인가”와 같은 질문에 더 안정적으로 답변하고, 실행 가능한 프론트엔드 및 백엔드 코드를 한 번에 생성할 수 있습니다 (출처: 科技狐, AI前线, Hacubu)

확산 모델, 언어 및 멀티모달 분야에서 잠재력 선보이며 자기 회귀 패러다임에 도전: Google I/O 2025에서 선보인 Gemini Diffusion 언어 모델은 최대 5배 빠른 생성 속도와 동등한 프로그래밍 성능으로 텍스트 생성 분야에서 확산 모델의 잠재력을 부각시켰습니다. 토큰을 순차적으로 예측하는 자기 회귀 모델과 달리, 확산 모델은 점진적인 노이즈 제거를 통해 출력을 생성하여 빠른 반복과 오류 수정을 지원합니다. Ant Group과 인민대학교 가오링 인공지능 학원이 협력하여 출시한 8B 파라미터 LLaDA 모델과 ByteDance가 개발한 MMaDA 멀티모달 확산 모델은 모두 이 분야에서 중국 팀의 선도적인 탐구를 보여줍니다. 이러한 모델들은 언어 작업에서 뛰어난 성능을 보일 뿐만 아니라, 멀티모달 이해(예: 시각적 지침 미세 조정을 결합한 LLaDA-V) 및 특정 분야(예: 단백질 서열 생성을 위한 DPLM)에서도 진전을 이루며, 확산 모델이 차세대 범용 모델의 새로운 패러다임이 될 수 있음을 예고합니다 (출처: 机器之心)
Suno, AI 음악 창작 편집 기능 강화를 위한 주요 업데이트 발표: AI 음악 창작 플랫폼 Suno는 사용자에게 더 큰 창작의 자유와 제어력을 부여하는 여러 가지 중요한 업데이트를 출시했습니다. 새로운 기능에는 파형도에서 구간별로 트랙을 재정렬, 재작성 및 재제작할 수 있는 업그레이드된 곡 편집기, 트랙을 보컬, 드럼, 베이스 등 12개의 독립적인 음원으로 정확하게 분리하여 미리보기 및 다운로드할 수 있는 스템 추출 기능 도입, 최대 8분 길이의 전체 곡 업로드를 지원하여 사용자가 자신의 오디오 자료를 기반으로 창작할 수 있는 업로드 기능 확장, 생성 전에 출력 결과의 “기괴함”, 구조화 정도 또는 참조 기반 정도를 조정하여 최종 작품을 더 잘 만들 수 있는 크리에이티브 슬라이더 추가 등이 포함됩니다 (출처: SunoMusic)
MetaAgentX, 멀티모달 Agent의 CAPTCHA 해결 능력 평가를 위한 Open CaptchaWorld 출시: 현재 멀티모달 Agent가 CAPTCHA(인간-기계 검증) 문제 해결에 어려움을 겪고 있는 상황에 대응하여 MetaAgentX 팀은 Open CaptchaWorld 플랫폼 및 벤치마크를 발표했습니다. 이 플랫폼에는 20가지 유형의 최신 CAPTCHA, 총 225개의 예시가 포함되어 있으며, Agent가 실제 웹 환경에서 관찰, 클릭, 드래그 등의 상호 작용을 통해 작업을 완료하도록 요구합니다. 테스트 결과, GPT-4o와 같은 최상위 모델조차 성공률이 5%-40%에 불과하여 인간의 평균 성공률 93.3%에 훨씬 못 미치는 것으로 나타났습니다. 연구진은 또한 문제 해결에 필요한 “시각적 이해 + 인지 계획 + 행동 제어” 단계를 정량화하는 “CAPTCHA Reasoning Depth” 지표를 제안했습니다. 이 플랫폼은 Agent가 긴 시퀀스의 동적 상호 작용 및 계획 수립에서 보이는 단점을 밝혀내고, 연구자들이 실제 배포에서 이 중요한 문제를 주목하고 해결하도록 촉진하는 것을 목표로 합니다 (출처: 量子位)

Google NotebookLM, 공개 공유 지원으로 지식 공유 및 협업 촉진: Google은 NotebookLM(이전 Project Tailwind)이 이제 노트북 공개 공유를 지원한다고 발표했습니다. 사용자는 “공유”를 클릭하고 액세스 권한을 “링크를 가진 모든 사람”으로 설정하여 노트 내용을 공유할 수 있습니다. 이 기능을 통해 사용자는 아이디어, 학습 가이드 및 팀 문서를 편리하게 공유할 수 있으며, 수신자는 내용을 탐색하고, 질문하고, 즉각적인 요약 및 음성 개요를 얻을 수 있습니다. 이는 지식 전파 및 협업 편집을 촉진하고 AI 노트 도구로서 NotebookLM의 실용성을 향상시키는 것을 목표로 합니다 (출처: Google, op7418)
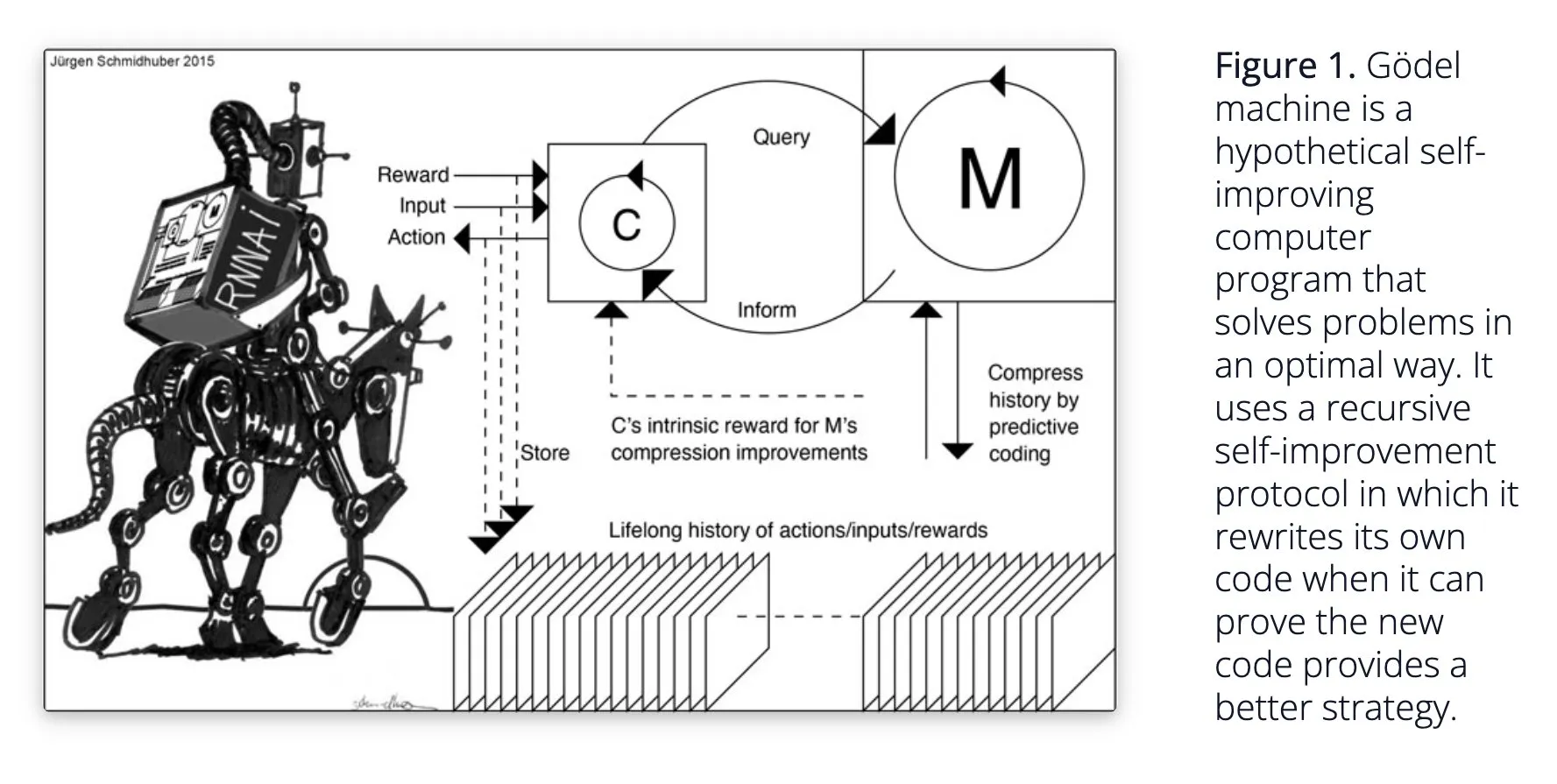
Sakana AI, 자가 학습 AI 시스템 Darwin Gödel Machine (DGM) 제안: Sakana AI는 자가 학습 AI 시스템 Darwin Gödel Machine (DGM)에 대한 연구를 공개했습니다. DGM은 진화 알고리즘을 활용하여 자체 코드를 반복적으로 재작성함으로써 프로그래밍 작업 성능을 지속적으로 향상시킵니다. 이 시스템은 생성된 코딩 에이전트 아카이브를 유지 관리하고, 여기에서 샘플링하여 기본 모델을 활용해 새 버전을 생성함으로써 개방형 탐색을 실현하고 다양하고 고품질의 에이전트를 형성합니다. 실험 결과, DGM은 SWE-bench 및 Polyglot과 같은 벤치마크 테스트에서 코딩 능력이 크게 향상되었음을 보여주었습니다. 이 연구는 자가 개선 AI에 대한 새로운 아이디어를 제공하며, 자율적인 혁신을 통해 AI 발전을 가속화하는 것을 목표로 합니다 (출처: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind, AI 대화 자연스러움 향상 및 네이티브 오디오 기능 공개: Google DeepMind는 네이티브 오디오 기능이 AI 대화를 더욱 자연스럽게 만들고, 어조를 이해하며 표현력 풍부한 음성을 생성할 수 있게 되었다고 발표했습니다. 이 기술은 인간과 AI 간 상호 작용의 새로운 가능성을 열어주는 것을 목표로 합니다. 개발자는 이제 Google AI Studio를 통해 이러한 기능을 시험해 볼 수 있으며, 더욱 자연스러운 음성 비서, 오디오 콘텐츠 생성 등에 활용될 것으로 기대됩니다 (출처: GoogleDeepMind)
Runway Gen-4 이미지 생성 기술 주목, 다중 참조 및 스타일 제어 지원: Runway의 Gen-4 이미지 생성 기술은 고화질과 전례 없는 스타일 제어 능력으로 주목받고 있으며, 특히 다중 참조 기능에서 두드러져 창의적인 탐구를 위한 새로운 공간을 제공합니다. 사용자는 이 기술을 활용하여 다양한 동물, 공룡 또는 상상의 생물을 생성할 수 있으며, 이는 세밀한 시각 콘텐츠 제작에서의 잠재력을 보여줍니다. Runway가 할리우드 등 분야에서 사용되는 것도 이 기술이 전문 콘텐츠 제작에 점진적으로 적용되고 있음을 나타냅니다 (출처: c_valenzuelab, c_valenzuelab)

AssemblyAI, 실시간 음성 인식 새 모델 출시로 음성 AI 애플리케이션 성능 향상: AssemblyAI는 빠른 속도와 정확성으로 주목받는 새로운 실시간 음성 인식(STT) 모델을 출시했습니다. 이 모델은 음성 AI 애플리케이션을 구축하는 개발자를 위해 특별히 설계되었으며, 더욱 원활하고 정확한 음성 인식 경험을 제공하는 것을 목표로 합니다. 동시에 AssemblyAI는 pipecat_ai 프로젝트를 통해 AssemblyAISTTService 구현을 제공하여 개발자의 통합을 용이하게 합니다. 이는 AssemblyAI가 음성 기술 분야에 지속적으로 투자하고 혁신하고 있음을 보여줍니다 (출처: AssemblyAI, AssemblyAI)
Microsoft Bing 16주년, GPT-4 및 DALL·E 통합, Bing Video Creator 출시: Microsoft Bing 검색 엔진이 16주년을 맞이했습니다. 최근 몇 년 동안 Bing은 대화형 생성 AI를 대규모로 통합하는 데 앞장섰으며, GPT-4와 DALL·E를 통합한 최초의 Microsoft 제품이 되었습니다. 최근 Bing은 모바일 앱에서 Copilot Search와 Bing Video Creator를 무료로 출시했으며, 후자는 비디오 콘텐츠 생성에 사용할 수 있습니다. 이는 Bing이 AI 기반 검색 및 콘텐츠 제작 분야에서 지속적으로 혁신하고 발전하고 있음을 나타냅니다 (출처: JordiRib1)
Andrej Karpathy, Veo 3에 깊은 인상, 비디오 생성의 거시적 영향 논의: Andrej Karpathy는 Google의 비디오 생성 모델 Veo 3와 커뮤니티의 창작물에 깊은 인상을 받았다고 밝혔으며, 오디오 추가가 비디오 품질을 크게 향상시켰다고 지적했습니다. 그는 비디오 생성의 몇 가지 거시적 영향에 대해 다음과 같이 논의했습니다: 1. 비디오는 인간 두뇌에 가장 높은 대역폭의 입력 방식입니다. 2. 비디오 생성은 AI에게 세상을 이해하는 “모국어”를 제공합니다. 3. 비디오 생성은 현실 시뮬레이션 및 월드 모델로 가는 핵심 경로입니다. 4. 계산 요구 사항은 하드웨어 발전을 촉진할 것입니다. 이는 비디오 생성 기술이 콘텐츠 제작의 혁신일 뿐만 아니라 AI 인지 및 발전의 중요한 원동력임을 시사합니다 (출처: brickroad7, dilipkay, JonathanRoss321)
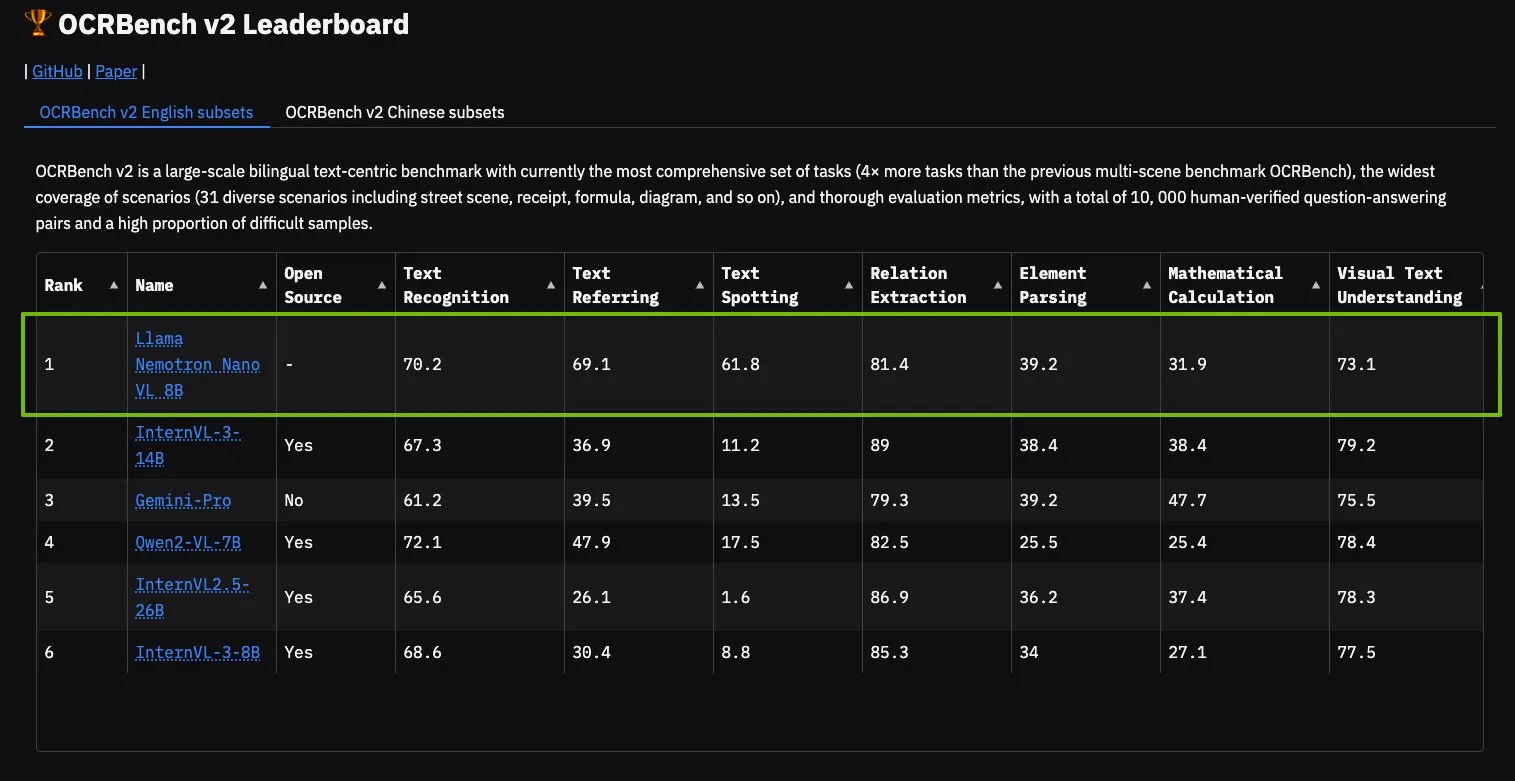
NVIDIA Llama Nemotron Nano VL 모델, OCRBench V2 정상 등극: NVIDIA의 Llama Nemotron Nano VL 모델이 OCRBench V2 순위에서 1위를 차지했습니다. 이 모델은 고급 지능형 문서 처리 및 이해를 위해 특별히 설계되었으며, 단일 GPU에서 복잡한 문서의 다양한 정보를 정확하게 추출할 수 있습니다. 사용자는 NVIDIA NIM을 통해 이 모델을 시험해 볼 수 있으며, 이는 NVIDIA가 문서 이해와 같은 특정 분야에서 소형화되고 효율적인 AI 모델을 개발하는 데 진전을 보이고 있음을 나타냅니다 (출처: ctnzr)
🧰 도구
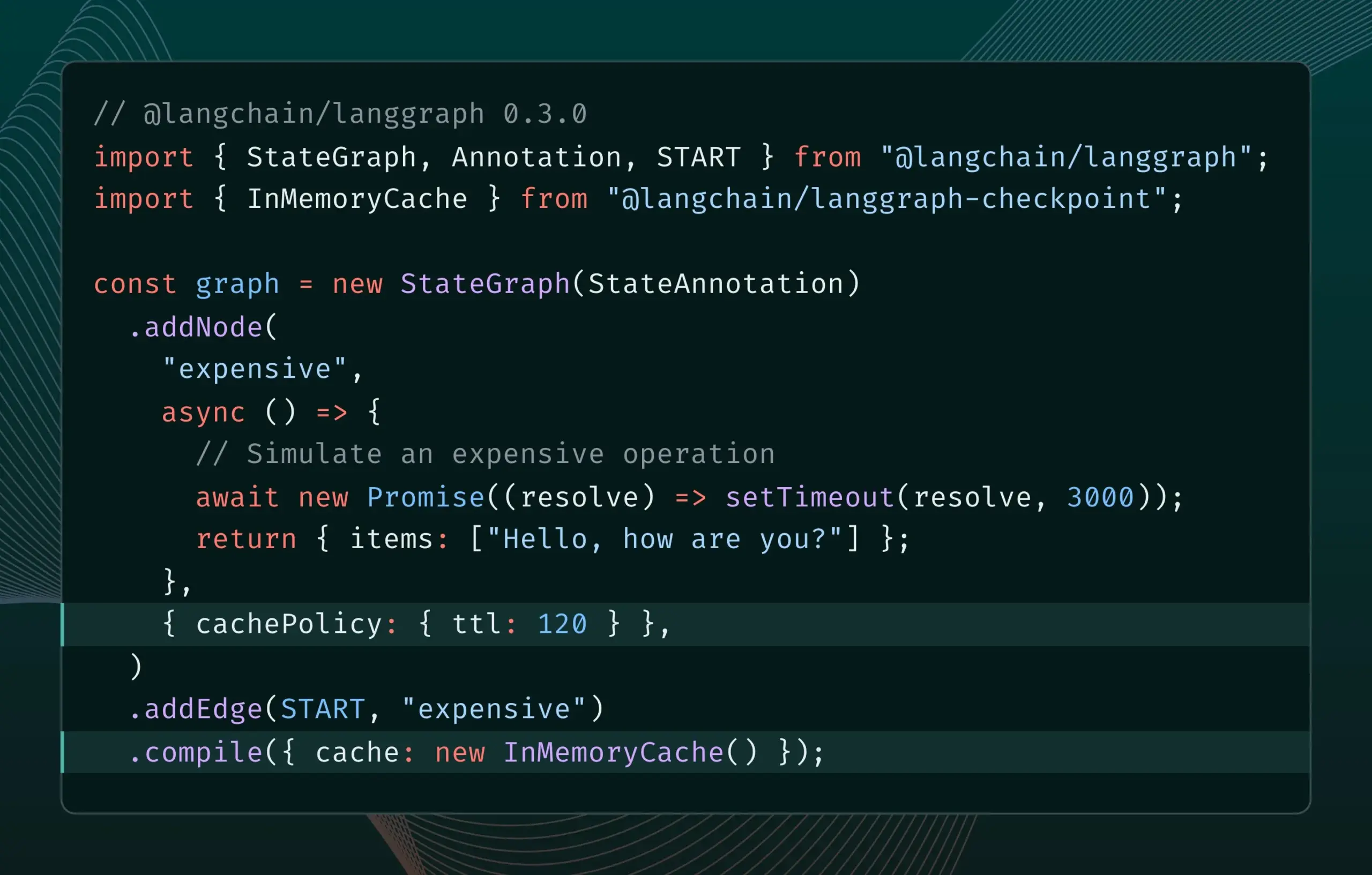
LangGraph.js 0.3 버전, 노드/작업 캐싱 기능 도입: LangGraph.js가 0.3 버전을 출시하며 새로운 노드/작업 캐싱 기능을 추가했습니다. 이 기능은 특히 비용이 많이 들거나 장시간 실행되는 에이전트를 반복할 때 중복 계산을 피해 워크플로우 속도를 높이는 것을 목표로 합니다. 새 버전은 Graph API와 Imperative API를 모두 지원하여 JavaScript 개발자가 복잡한 AI 애플리케이션을 보다 효율적으로 구축할 수 있도록 지원합니다 (출처: Hacubu, hwchase17)
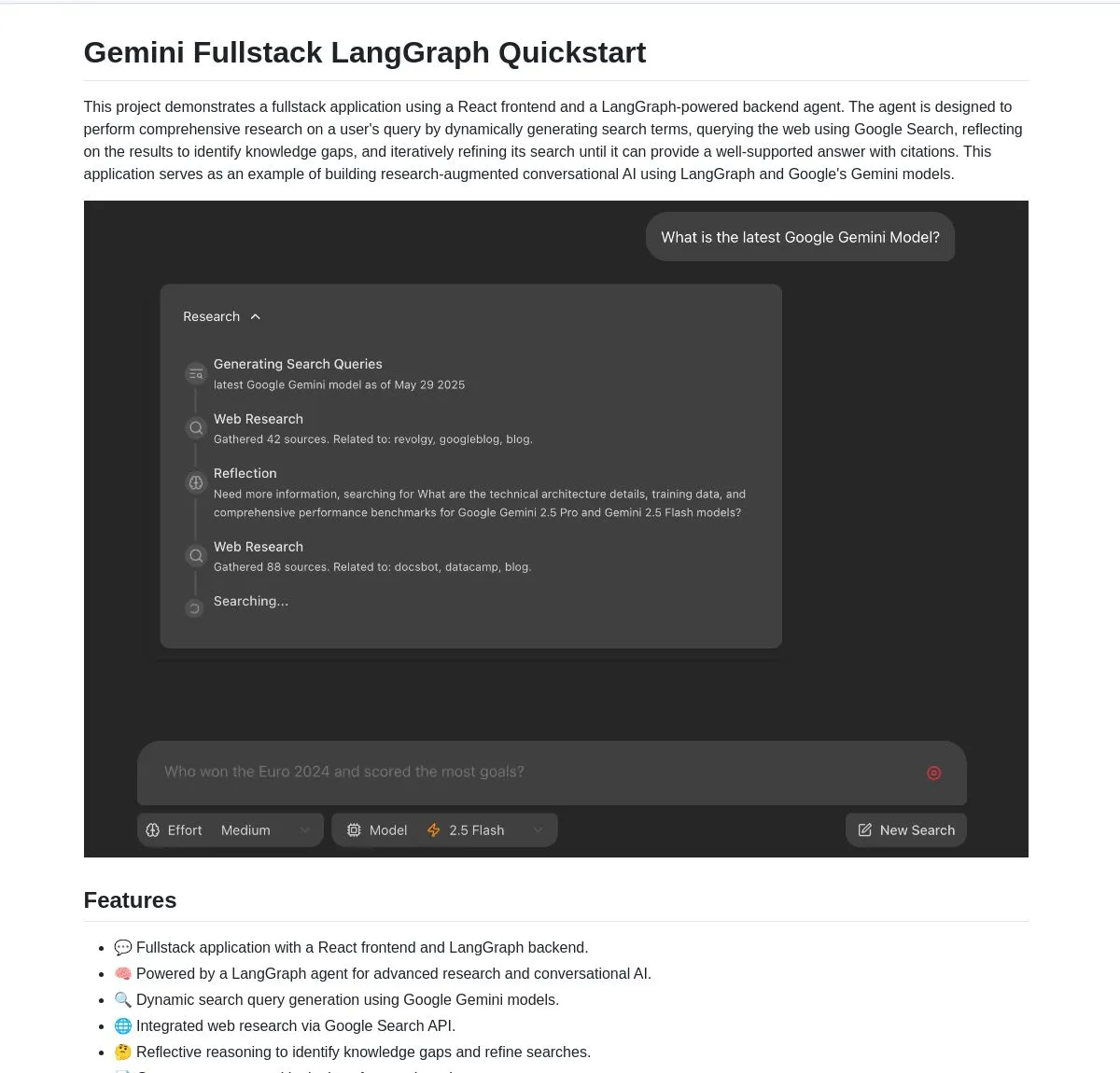
구글, Gemini 및 LangGraph 기반의 Gemini Research Agent 풀스택 애플리케이션 오픈소스 공개: 구글은 Gemini 모델과 LangGraph를 기반으로 구축된 지능형 연구 보조 풀스택 애플리케이션 예제인 gemini-fullstack-langgraph-quickstart를 공개했습니다. 이 애플리케이션은 쿼리를 동적으로 최적화하고, 반복 학습을 통해 인용 정보가 포함된 답변을 제공하며, 다양한 검색 강도 제어를 지원합니다. Gemini의 네이티브 Google 검색 도구를 활용하여 웹 연구 및 성찰적 추론을 수행하며, 개발자에게 고급 연구형 AI 애플리케이션 구축의 시작점을 제공하는 것을 목표로 합니다 (출처: LangChainAI, hwchase17, dotey, karminski3)
FedRAG, RAG 시스템 통합 및 미세 조정을 용이하게 하는 LangChain 브리징 기능 추가: FedRAG는 외부 기여자에 의해 구현된 LangChain과의 브리징 지원을 발표했습니다. 사용자는 FedRAG를 통해 RAG 시스템을 조립하고 생성기/검색기 구성 요소 모델을 특정 지식 기반에 맞게 미세 조정할 수 있습니다. 미세 조정 후에는 LangChain과 같은 인기 있는 RAG 추론 프레임워크에 연결하여 해당 생태계와 기능을 활용할 수 있습니다. 이 업데이트는 RAG 시스템의 구축, 최적화 및 배포 프로세스를 단순화하는 것을 목표로 합니다 (출처: nerdai)

Ollama, “생각” 기능 출시로 사고 과정과 최종 답변 분리 가능: Ollama는 플랫폼을 업데이트하여 “생각” 기능을 지원하는 모델(예: DeepSeek-R1-0528)에 대해 사고 과정과 최종 답변을 분리하는 옵션을 추가했습니다. 사용자는 모델의 “생각” 내용을 볼 수 있으며, 이 기능을 비활성화하여 직접적인 답변을 받을 수도 있습니다. 이 기능은 Ollama의 CLI, API 및 Python/JavaScript 라이브러리에 적용되어 사용자에게 더욱 유연한 모델 상호 작용 방식을 제공합니다 (출처: Hacubu)
Firecrawl, 검색 및 크롤링 기능 통합한 /search 엔드포인트 출시: Firecrawl은 새로운 /search API 엔드포인트를 출시하여 사용자가 한 번의 API 호출로 웹 검색을 완료하고 모든 결과를 LLM 친화적인 형식으로 크롤링할 수 있도록 했습니다. 이 기능은 AI 에이전트와 개발자가 웹 데이터를 발견하고 활용하는 프로세스를 단순화하는 것을 목표로 합니다. LangChain의 StateGraph는 이 기능을 활용하여 경쟁사 자동 검색, 웹사이트 크롤링 및 분석 보고서 생성과 같은 자동화된 프로세스를 구축하는 데 사용할 수 있습니다 (출처: hwchase17, LangChainAI, omarsar0)
LlamaIndex, MCP 통합으로 에이전트 능력 및 워크플로우 배포 강화: LlamaIndex는 MCP(Model Component Protocol) 통합을 발표하여 에이전트의 도구 사용 능력과 워크플로우 배포 유연성을 강화하는 것을 목표로 합니다. 이 통합은 LlamaIndex 에이전트가 MCP 서버 도구를 사용하는 데 도움이 되는 보조 함수를 제공하며, 모든 LlamaIndex 워크플로우를 MCP 서버로 제공할 수 있도록 합니다. 이는 LlamaIndex 에이전트의 도구 세트를 확장하고 워크플로우를 기존 MCP 인프라에 원활하게 통합하는 것을 목표로 합니다 (출처: jerryjliu0)

Modal, 오픈소스 모델 엔진 성능 벤치마크 제공하는 LLM Engine Advisor 출시: Modal은 사용자가 최적의 LLM 엔진과 파라미터를 선택하는 데 도움을 주기 위한 벤치마크 테스트 애플리케이션인 LLM Engine Advisor를 출시했습니다. 이 도구는 다양한 하드웨어(예: 다중 GPU 환경)에서 다양한 추론 엔진(예: vLLM, SGLang)을 사용하여 오픈소스 모델(예: DeepSeek V3, Qwen 2.5 Coder)을 실행할 때의 속도 및 최대 처리량과 같은 성능 데이터를 제공합니다. 이는 자체 호스팅 LLM 실행의 투명성과 의사 결정 효율성을 높이는 것을 목표로 합니다 (출처: charles_irl, akshat_b, sarahcat21)
PlayDiffusion: PlayAI, 오디오 파일 내 대화 내용 교체 가능한 오디오 복원 새 모델 출시: PlayAI는 PlayDiffusion이라는 새 모델을 출시했습니다. 이 모델은 원본 화자의 음성 특징을 유지하면서 오디오 파일 내 대화 내용을 매끄럽게 교체할 수 있습니다. 이러한 “오디오 복원” 기술은 팟캐스트, 오디오북 또는 비디오 더빙에서 특정 단어나 문장을 전체 부분을 다시 녹음할 필요 없이 수정하는 등 오디오 편집에 새로운 가능성을 제공합니다. 프로젝트는 GitHub에 오픈소스로 공개되었습니다 (출처: _mfelfel, karminski3)
Hugging Face, 훈련 데이터셋 품질 최적화를 위한 의미론적 중복 제거 도구 출시: Maxime Labonne의 AutoDedup에서 영감을 받아 Hugging Face Spaces에 새로운 의미론적 중복 제거 애플리케이션이 출시되었습니다. 이 도구를 사용하면 Hugging Face Hub에서 하나 이상의 데이터셋을 선택하고, 각 데이터 행에 대한 의미론적 임베딩을 수행한 다음 설정된 임계값에 따라 거의 중복되는 내용을 제거할 수 있습니다. 이는 연구자와 개발자가 훈련 데이터셋의 품질을 향상시키고 데이터 중복으로 인한 모델 성능 저하 또는 훈련 효율성 저하를 방지하는 데 도움을 주는 것을 목표로 합니다 (출처: ben_burtenshaw, ben_burtenshaw)

Perplexity Labs 수요 급증, 사용자는 맞춤형 소프트웨어를 신속하게 구축 가능: Perplexity Labs는 단일 프롬프트를 통해 맞춤형 소프트웨어를 신속하게 구축할 수 있다는 점 때문에 사용자들에게 인기를 얻으며 수요가 크게 증가했고, 일부 사용자는 더 많은 Labs 쿼리 횟수를 얻기 위해 여러 Pro 계정을 구매하기도 했습니다. 이는 사용자들이 자신의 요구에 따라 소프트웨어 도구를 신속하게 만들고 수정하는 데 대한 강한 관심을 반영하며, AI 기반의 개인화된 소프트웨어 개발이 하나의 추세가 되고 있음을 보여줍니다 (출처: AravSrinivas, AravSrinivas)
Ollama와 Hazy Research, 로컬 및 클라우드 LLM의 비공개 협업을 위한 Secure Minions 출시: 스탠포드 Hazy Research 연구소의 Minions 프로젝트는 Ollama 로컬 모델과 클라우드 첨단 모델을 연결하여 클라우드 비용을 크게 절감(5-30배)하면서 첨단 모델에 근접한 정확도(98%)를 유지하는 것을 목표로 합니다. Secure Minion 프로젝트는 H100과 같은 GPU를 보안 영역으로 전환하여 메모리 및 계산 암호화를 실현하고 데이터 프라이버시를 보장합니다. 이러한 하이브리드 운영 모드는 개인 정보 보호를 강화하는 동시에 사용자에게 보다 경제적이고 효율적인 LLM 사용 방안을 제공합니다 (출처: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa와 OpenRouter, 400개 이상의 LLM에 웹 검색 기능 제공 위해 협력: AI 검색 엔진 Exa는 OpenRouter 플랫폼의 400개 이상의 대규모 언어 모델에 웹 검색 기능을 제공하기 위해 OpenRouter와 협력한다고 발표했습니다. 이는 개발자와 사용자가 이러한 LLM을 사용할 때 Exa의 검색 기능을 편리하게 호출하여 모델의 실시간 정보 획득 및 지식 업데이트 능력을 강화하고, RAG(검색 증강 생성)와 같은 애플리케이션의 성능을 더욱 향상시킬 수 있음을 의미합니다 (출처: menhguin)

📚 학습
마이크로소프트, MCP 입문 과정 《MCP for Beginners》 출시: 마이크로소프트는 MCP(Microsoft Copilot Platform, 오기로 추정되며 Microsoft CoCo Framework 또는 유사 AI Agent 프로토콜을 지칭하는 것으로 보임) 초보자를 위한 입문 과정을 발표했습니다. 이 과정은 초보자가 MCP의 핵심 개념, 구현 방법 및 실제 응용 프로그램을 익힐 수 있도록 돕는 것을 목표로 하며, 프로토콜 아키텍처 사양, 튜토리얼 가이드 및 다양한 프로그래밍 언어의 코드 실습을 포함합니다. 과정 구조는 소개, 핵심 개념, 보안, 시작하기, 고급 과정, 커뮤니티 및 사례 분석으로 구성되며, 기본 및 고급 계산기와 같은 예제 프로젝트를 제공합니다 (출처: dotey)

Bond Capital, 2025년 5월 AI 트렌드 보고서 발표, 산업 발전 통찰: 유명 벤처 캐피털 Bond Capital이 339페이지 분량의 《2025-05 AI 트렌드 보고서》를 발표하여 AI의 다양한 분야에서의 데이터와 통찰을 종합적으로 분석했습니다. 보고서는 ChatGPT 월간 활성 사용자 8억 명(90%가 북미 이외 지역), 일일 검색량 10억 건, AI 관련 IT 직무 448% 증가, 최첨단 모델 훈련 비용 10억 달러 이상/회, LLM의 인프라화 등을 중점적으로 지적했습니다. 보고서는 경쟁의 핵심이 최고의 AI 기반 제품을 만드는 데 있으며, 현재는 빌더의 시장이라고 강조했습니다 (출처: karminski3)
강화 학습과 LLM 추론 능력 관계 논문, ProRL 및 Limit-of-RLVR 주목: 강화 학습(RL)과 대규모 언어 모델(LLM)의 추론 능력에 관한 두 편의 연구 논문이 논의를 불러일으켰습니다. 하나는 《Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?》이고, 다른 하나는 NVIDIA의 《ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models》입니다. 이러한 연구는 RL(특히 RLVR, 즉 검증 가능한 보상의 강화 학습)이 LLM의 기본 추론 능력을 어느 정도까지 향상시킬 수 있는지, 그리고 지속적인 RL 훈련이 LLM 추론 경계를 확장하는 데 미치는 영향을 탐구합니다. 관련 논의에서는 고품질 RLVR 훈련 데이터와 효과적인 보상 메커니즘이 핵심이라고 보고 있습니다 (출처: scaling01, Dorialexander, scaling01)

논문 《How Programming Concepts and Neurons Are Shared in Code Language Models》, 코드 LLM에서 프로그래밍 개념과 뉴런의 공유 메커니즘 탐구: 이 연구는 대규모 언어 모델(LLM)이 여러 프로그래밍 언어(PL)와 영어를 처리할 때 내부 개념 공간의 관계를 조사했습니다. Llama 시리즈 모델에 대한 소수샷 번역 작업을 통해 중간 계층에서는 개념 공간이 영어(PL 키워드 포함)에 더 가깝고 영어 토큰에 높은 확률을 할당하는 경향이 있음을 발견했습니다. 뉴런 활성화 분석 결과, 언어 특정 뉴런은 주로 하위 계층에 집중되어 있고 각 PL 고유의 뉴런은 상위 계층에 나타나는 경향이 있었습니다. 이 연구는 LLM이 내부적으로 PL을 어떻게 표현하는지 이해하는 데 새로운 통찰력을 제공합니다 (출처: HuggingFace Daily Papers)
새 논문 《Pixels Versus Priors》, 시각적 반사실을 통해 MLLM의 지식 사전 통제: 이 연구는 멀티모달 대형 언어 모델(MLLM)이 시각적 질의응답과 같은 작업을 수행할 때 추론이 기억된 세계 지식에 더 의존하는지 아니면 입력 이미지의 시각 정보에 더 의존하는지를 탐구합니다. 연구자들은 세계 지식 사전과 충돌하는 시각적 반사실 이미지(예: 파란 딸기)를 포함하는 Visual CounterFact 데이터셋을 도입했습니다. 실험 결과, 모델 예측 초기에는 기억된 사전을 반영하지만 중후반에는 시각적 증거로 전환되는 것으로 나타났습니다. 논문은 PvP(Pixels Versus Priors) 유도 벡터를 제안하여 활성화 계층 개입을 통해 모델 출력을 세계 지식 또는 시각적 입력으로 편향되도록 제어하여 대부분의 색상 및 크기 예측을 성공적으로 변경했습니다 (출처: HuggingFace Daily Papers)
ICML 2025 논문 GuidedQuant, 종단 손실 지도를 통한 계층적 PTQ 방법 향상 제안: GuidedQuant는 목표에 종단 손실(end loss) 지도를 통합하여 계층적 PTQ 방법의 성능을 향상시키는 새로운 후훈련 양자화(PTQ) 방법입니다. 이 방법은 종단 손실에 대한 특징별 기울기를 활용하여 계층적 출력 오류에 가중치를 부여하며, 이는 채널 내 종속성을 유지하는 블록 대각선 Fisher 정보에 해당합니다. 또한 논문은 양자화 목표 값을 단조롭게 감소시키는 것을 보장하는 비균일 스칼라 양자화 알고리즘인 LNQ를 도입했습니다. 실험 결과, GuidedQuant는 가중치 전용 스칼라, 가중치 전용 벡터, 가중치 및 활성화 양자화 측면에서 기존 SOTA 방법보다 우수하며 Qwen3, Gemma3, Llama3.3 등 모델의 2-4비트 양자화에 적용되었습니다 (출처: Reddit r/MachineLearning)

AI Engineer World’s Fair 샌프란시스코에서 개최, AI 엔지니어링 실무 및 첨단 기술 집중 조명: AI Engineer World’s Fair가 샌프란시스코에서 열려 AI 분야의 수많은 엔지니어, 연구자, 개발자들이 모였습니다. 컨퍼런스 의제에는 강화 학습, 커널, 추론 및 에이전트, 모델 최적화(RFT, DPO, SFT), 에이전트 코딩, 음성 에이전트 구축 등 다양한 인기 주제가 포함됩니다. 행사 기간 동안 OpenAI, Google 등 기업의 전문가들이 발표와 토론을 진행하고 신제품과 기술을 발표할 예정입니다. 커뮤니티 회원들은 적극적으로 참여하여 컨퍼런스 일정을 공유하고 오프라인 교류를 조직하는 등 AI 엔지니어링 커뮤니티의 활력과 첨단 기술에 대한 열정을 보여주었습니다 (출처: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 비즈니스
스두 인텔리전트, 수백만 위안 규모 시드 투자 유치, AI 스마트 안경 다중 시나리오 적용 가속화: 쑤저우 스두 인텔리전트 테크놀로지(苏州师渡智能科技有限公司)는 수백만 위안 규모의 시드 투자를 유치했다고 발표했습니다. 자금은 AI 스마트 안경 핵심 기술 연구 개발, 시장 확장 및 생태계 구축에 사용될 예정입니다. 이 회사는 스마트 건강 관리(예: 스마트 돋보기, 스마트 시각 보조 안경), 스마트 라이프(스마트 패션 안경, 사이클링 안경) 및 스마트 제조(스마트 산업용 안경, 음성 컨트롤러) 등 분야에 AI 스마트 안경을 적용하는 데 주력하고 있습니다. 제품 가격은 200위안에서 1000위안 사이로 책정되어 높은 가성비를 통해 스마트 안경 보급을 추진하는 것을 목표로 합니다 (출처: 36氪)

OpenAI, AI 프로그래밍 도우미 Windsurf 인수설, Anthropic의 Claude 모델 공급 중단 추측 야기: 시장에서는 OpenAI가 약 30억 달러에 AI 프로그래밍 도구 Windsurf(구 Codeium)를 인수할 수 있다는 소문이 돌고 있습니다. 이러한 배경 속에서 Windsurf CEO Varun Mohan은 Anthropic이 Claude 3.5 Sonnet 등을 포함한 거의 모든 Claude 3.x 모델에 대한 직접 액세스 권한을 매우 짧은 통보 기간 내에 차단했다고 게시물을 통해 밝혔습니다. Windsurf는 이에 실망감을 표하며 신속하게 컴퓨팅 성능을 다른 추론 서비스 제공업체로 이전하는 동시에 영향을 받은 사용자에게 Gemini 2.5 Pro 할인을 제공했습니다. 커뮤니티는 Anthropic의 이러한 조치가 OpenAI의 잠재적 인수와 관련이 있을 수 있으며, 이것이 업계 경쟁과 개발자 선택에 영향을 미칠 것을 우려하고 있습니다. 이전에도 Windsurf는 Claude 4 출시 당시 Anthropic의 직접적인 지원을 받지 못했습니다 (출처: AI前线)

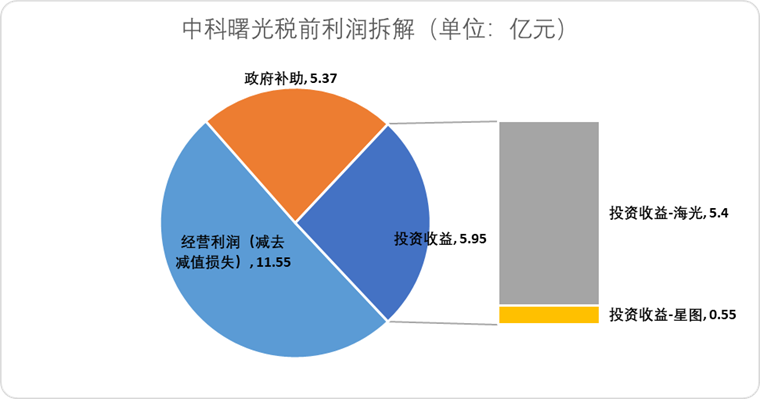
하이광 정보, 중커슈광 주식 교환 방식 합병 추진, 국산 컴퓨팅 파워 산업망 통합: AI 칩 설계 회사 하이광 정보(海光信息)는 자사의 최대 주주이자 서버 제조업체인 중커슈광(中科曙光)을 주식 교환 방식으로 흡수 합병할 계획이라고 공시했습니다. 하이광 정보의 시가총액은 약 3,164억 위안, 중커슈광의 시가총액은 약 905억 위안입니다. 이번 “뱀이 코끼리를 삼키는” 방식의 합병은 칩에서 소프트웨어, 시스템에 이르는 산업 레이아웃을 최적화하고, 산업망의 강화, 보완, 확장을 실현하며, 기술 시너지 효과를 발휘하는 것을 목표로 합니다. 분석가들은 이번 합병이 양측의 복잡한 관계사 거래와 잠재적인 동종 업계 경쟁 문제를 해결하고 운영 비용을 절감하며, AI 시대의 엔드투엔드 컴퓨팅 파워 솔루션 발전 추세에 부응하는 데 도움이 될 것이며, 중국 반도체 기술 권력이 전통적인 컴퓨팅에서 AI 컴퓨팅으로 가속적으로 이양될 수 있음을 시사한다고 보고 있습니다 (출처: 36氪)
🌟 커뮤니티
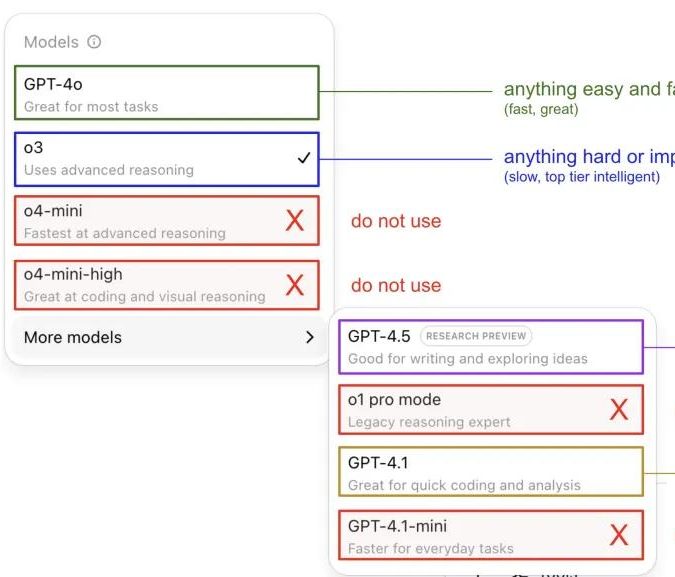
Andrej Karpathy, ChatGPT 모델 사용 후기 공유하며 커뮤니티 토론 촉발: Andrej Karpathy는 개인적으로 여러 ChatGPT 버전을 사용한 후기를 공유했습니다. 중요하거나 어려운 작업에는 추론 능력이 더 뛰어난 o3를 추천하고, 일상적인 중간 난이도 문제에는 4o를, 코드 개선 작업에는 GPT-4.1을, 심층 연구 및 다중 링크 요약이 필요할 때는 심층 연구 기능(o3 기반)을 사용한다고 밝혔습니다. 이 경험 공유는 커뮤니티에서 광범위한 토론을 불러일으켰으며, 많은 사용자가 자신의 사용 선호도와 모델 선택에 대한 견해를 공유하는 동시에 OpenAI 모델 이름 지정의 혼란과 자동 모델 선택 기능 부재에 대한 사용자들의 어려움을 반영했습니다 (출처: 量子位, JeffLadish)
개발자, Agentic AI 프로그래밍 2주 경험 공유: 충격에서 환멸로, 결국 수동 리팩토링 선택: 10년 경력의 기술 책임자가 Agentic AI(특히 AI 프로그래밍 에이전트)를 자신의 소셜 미디어 애플리케이션 개발 프로세스에 통합한 경험을 공유했습니다. 초기에는 AI가 기능 모듈을 빠르게 생성하고 프론트엔드 및 백엔드 로직과 단위 테스트를 작성하는 등 효율성이 놀라웠으며, 2주 만에 약 12,000줄의 코드를 생성했습니다. 그러나 코드베이스의 복잡성이 증가함에 따라 AI는 새로운 기능을 처리할 때 잦은 오류를 발생시키고 루프에 빠졌으며 실패를 인정하기 어려워했습니다. 또한 생성된 코드는 부정확한 이름 지정, 중복 코드 등의 문제를 드러내 코드베이스 유지 관리가 어려워졌고 개발자는 AI에 대한 신뢰를 잃었습니다. 결국 이 개발자는 AI 생성 코드를 “모호한 참조”로만 사용하고 모든 기능을 수동으로 리팩토링하기로 결정했으며, AI는 현재 기능적 코드를 직접 작성하는 것보다 기존 코드를 분석하고 예제를 제공하는 데 더 적합하다고 생각합니다 (출처: CSDN)

AI Agent 정의와 워크플로우 차이점 주목, 미래 응용 잠재력 거대: 커뮤니티에서는 AI Agent와 Workflow(워크플로우)의 개념을 구분하는 논의가 있었습니다. Agent는 일반적으로 LLM이 루프 내에서 도구에 액세스하여 지시에 따라 자유롭게 실행되는 것을 의미하며, Workflow는 LLM이 하위 작업을 완료하는 것을 포함할 수 있는 일련의 주로 결정론적으로 실행되는 단계입니다. 교차점(Agent는 결정론적으로 실행되도록 프롬프트될 수 있고, Workflow는 Agentic 구성 요소를 포함할 수 있음)이 존재하지만, 이러한 구분은 존재론적으로 여전히 의미가 있습니다. 동시에 기업 애플리케이션에서 AI Agent의 잠재력은 널리 인정받고 있으며, 텐센트와 바이트댄스와 같은 대기업들은 모두 지능형 에이전트 분야에 힘을 쏟고 있습니다. 예를 들어 텐센트는 대규모 모델 지식 기반을 지능형 에이전트 개발 플랫폼으로 업그레이드하고 있으며, 바이트댄스는 기업이 네이티브 AI 지능형 에이전트 시스템을 구축하는 데 도움을 주는 것을 목표로 하는 Coze(코즈) 플랫폼을 보유하고 있습니다 (출처: fabianstelzer, 蓝洞商业)
Dwarkesh Patel, LLM과 AGI 타임라인 논하며 지속적인 학습이 핵심 병목이라고 주장: Dwarkesh Patel은 자신의 블로그에서 AGI(범용 인공 지능) 타임라인에 대한 견해를 밝혔습니다. 그는 LLM이 현재 인간이 실습을 통해 컨텍스트를 축적하고, 실패를 반성하며, 미세한 개선을 이루는 능력, 즉 지속적인 학습 능력이 부족하다고 주장했습니다. 그는 이것이 모델 실용성의 거대한 병목이며, 이 문제를 해결하는 데 수년이 걸릴 수 있다고 생각합니다. 이 견해는 Andrej Karpathy를 포함한 여러 AI 연구자들의 논의를 불러일으켰습니다. Karpathy도 LLM의 지속적인 학습 능력 부족에 동의하며 이를 선행성 기억상실증을 앓는 동료에 비유했습니다. 이러한 논의는 진정한 AGI를 실현하는 데 직면한 과제와 모델 학습 메커니즘에 대한 심도 있는 고찰을 강조합니다 (출처: dwarkesh_sp, JeffLadish, dwarkesh_sp)

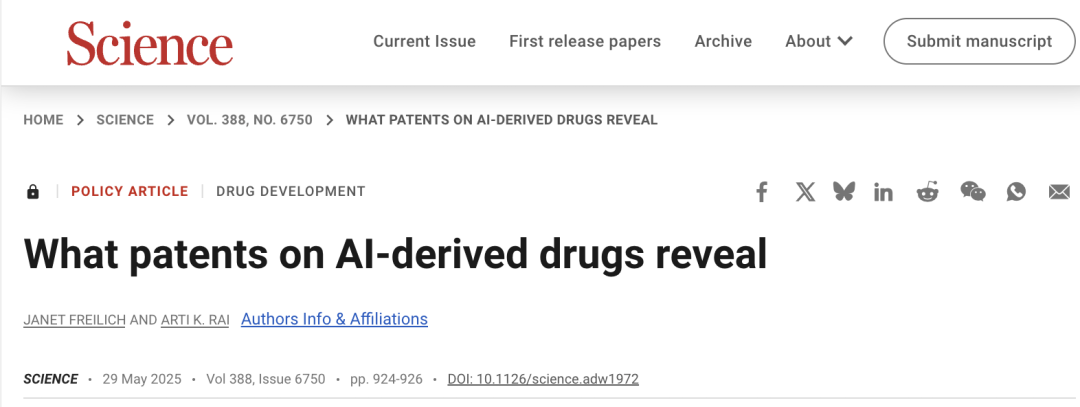
AI의 신약 개발 특허 문제 주목, Science지 신중함 촉구: 《Science》 저널 정책 포럼 기사 《What patents on AI-derived drugs reveal》은 AI의 신약 발견 분야 응용과 특허 제도에 미치는 영향을 논의했습니다. 연구에 따르면 AI 네이티브 기업이 신약 특허를 신청할 때 생체 내 실험 데이터가 전통 제약사보다 적은 경우가 많아, 잠재력 있는 약물이 후속 연구 부족으로 포기될 수 있습니다. 동시에 AI가 생성한 다량의 새로운 분자가 공개되면 “기존 기술”이 되어 다른 회사가 이러한 분자에 대한 특허 신청 및 추가 투자를 방해할 수 있습니다. 기사는 특허 신청 문턱을 높여 더 많은 생체 내 실험 데이터를 요구하고, AI 생성 분자가 테스트되지 않은 경우 다른 회사가 특허를 신청할 수 있도록 허용하며, 신약 임상 시험 단계의 규제 독점권을 강화하여 혁신 장려와 공익 간의 균형을 맞춰야 한다고 제안합니다 (출처: 36氪)
💡 기타
알트만 사태, 영화 《Artificial》로 제작될 수도… 유명 감독 및 제작자 참여: The Hollywood Reporter에 따르면 MGM은 OpenAI 경영진 변동 사건을 영화로 각색할 계획이며, 가제는 《Artificial》입니다. 이탈리아 유명 감독 루카 구아다니노(Luca Guadagnino)가 연출을 맡을 가능성이 있으며, 제작자로는 《해리 포터》 시리즈의 데이비드 헤이먼이 포함됩니다. 배우진은 논의 중이며, 앤드류 가필드(스파이더맨 및 《소셜 네트워크》의 사베린 역)가 샘 알트먼 역을, 율라 보리소프가 일리야 수츠케버 역을, 모니카 바바로가 미라 무라티 역을 맡을 수 있다는 소문이 있습니다. 이 소식은 네티즌들 사이에서 화제가 되었으며 영화 《소셜 네트워크》와 비교되기도 했습니다 (출처: 36氪, janonacct)
AI 고객 서비스 경험 논란, 사용자들 “인공지능 장애”와 상담원 연결 어려움 토로: 최근 전자상거래 대규모 할인 행사 기간 동안 많은 소비자들이 AI 고객 서비스와의 소통 불량, 엉뚱한 답변, 상담원 연결의 어려움 등으로 서비스 경험이 저하되었다고 불만을 제기했습니다. 국가시장감독관리총국 데이터에 따르면 2024년 전자상거래 애프터서비스 분야에서 “스마트 고객 서비스” 관련 불만 건수는 전년 대비 56.3% 증가했습니다. 사용자들은 일반적으로 AI 고객 서비스가 개인화된 문제를 해결하기 어렵고 답변이 딱딱하며 노인 등 특정 계층에 친화적이지 않다고 생각합니다. 기사는 기업이 비용 절감과 효율성 향상을 추구하는 동시에 서비스 품질을 희생해서는 안 되며, AI 기술을 최적화하고 AI 고객 서비스 적용 범위를 명확히 하며 편리한 상담원 서비스 채널을 유지해야 한다고 촉구합니다 (출처: 36氪)

콘텐츠 창작 분야 AI 활용과 창작자의 대응 전략 논의: AI 기술(예: DeepSeek, Suno, Veo 3)이 글, 음악, 영상 등 콘텐츠 창작 분야에 광범위하게 활용되면서 콘텐츠 창작자들의 직업 전망에 대한 불안감이 커지고 있습니다. 분석에 따르면 콘텐츠 패러다임은 “개인화 추천”에서 “개인화 생성”으로 전환되고 있습니다. 단기적으로 플랫폼은 시행착오 비용이 높아 AI로 창작자를 완전히 대체하지 않을 수 있으며, 창작자는 독특한 스타일 모델을 만들고 라이선스를 부여하여 수익을 창출할 수 있습니다. 장기적으로 창작자는 가치 창출 방식을 조정하여 AI가 대체하기 어려운 “혁신 전략”(예: 독창적인 조사, 직접 자료 확보)에 더 집중해야 하며, AI의 도움을 받기 쉬운 “추종 전략”(인기 주제 추종, 2차 자료 의존)은 지양해야 합니다. AI가 이미 과학 연구 등 혁신 분야에 진출하기 시작했지만, 독특한 시각과 깊이 있는 사고를 가진 창작자는 여전히 가치가 있습니다 (출처: 36氪)
