
키워드:AlphaEvolve, Gemini, 진화 알고리즘, AI 에이전트, 알고리즘 최적화, 행렬 곱셈, Borg 데이터 센터, 4×4 복소수 행렬 곱셈 최적화, Google DeepMind 알고리즘 발견, AI 자동화 알고리즘 설계, Gemini 2.0 Pro 적용, Borg 자원 스케줄링 최적화
🔥 聚焦
Google DeepMind, AlphaEvolve 출시: Gemini 기반 진화 알고리즘 코딩 에이전트, 수학 및 컴퓨터 과학 분야에서 혁신적인 성과 달성: Google DeepMind가 AlphaEvolve를 발표했습니다. AlphaEvolve는 Gemini 2.0 Pro 대규모 언어 모델을 활용하여 진화 알고리즘을 통해 알고리즘 코드를 자동으로 발견하고 최적화하는 에이전트입니다. AlphaEvolve는 인간이 제공한 초기 코드와 평가 지표를 기반으로 후보 솔루션을 자율적으로 생성, 평가 및 개선할 수 있습니다. 이 시스템은 50개 이상의 수학 문제에서 뛰어난 성능을 보였으며, 약 75%의 사례에서 기존 해법을 재현했고 20%의 사례에서 더 나은 해법을 발견했습니다. 주목할 점은 AlphaEvolve가 4×4 복소 행렬 곱셈의 계산 횟수를 49회에서 48회로 줄여 56년 만에 기록을 경신했다는 것입니다. 또한 Google 내부 Borg 데이터센터의 스케줄링 알고리즘을 최적화하여 전 세계 컴퓨팅 자원의 0.7%를 회수했으며, 차세대 TPU 칩 설계를 개선하여 Gemini 훈련 시간을 1% 단축했습니다. 이 성과는 AI가 자동화된 알고리즘 발견 및 과학 혁신 분야에서 엄청난 잠재력을 가지고 있음을 보여줍니다. 현재는 주로 자동 평가가 가능한 문제를 처리하지만, 신약 개발 등 응용 과학 분야에서의 활용 전망이 밝습니다.
NVIDIA, Computex 2025에서 다수의 AI 진전 발표, Jensen Huang CEO Agentic AI와 Physical AI 비전 강조: NVIDIA CEO Jensen Huang이 Computex 2025 기조연설에서 AI가 “단일 응답”에서 “사고형, 추론형”의 Agentic AI(지능형 에이전트 AI)와 물리 세계를 이해하는 Physical AI(물리 AI)로 진화하고 있다고 강조했습니다. 이러한 추세를 지원하기 위해 NVIDIA는 확장된 Blackwell 플랫폼(Blackwell Ultra AI)을 발표하고 Grace Blackwell GB300 시스템의 전면 생산을 발표했습니다. 이 시스템의 추론 성능은 이전 세대보다 1.5배 향상되었습니다. Jensen Huang은 또한 차세대 AI 슈퍼칩 Rubin Ultra를 미리 선보였는데, 성능은 GB300의 14배입니다. AI 인프라 구축을 추진하기 위해 NVIDIA는 NVLink Fusion 기술을 출시하고 TSMC, Foxconn 등과 협력하여 대만에 AI 슈퍼컴퓨터를 구축합니다. 또한 NVIDIA는 인간형 로봇 기반 모델 Isaac GR00T N1.5를 업데이트하여 환경 적응 및 작업 수행 능력을 향상시켰으며, DeepMind, Disney Research와 공동 개발한 물리 엔진 Newton을 오픈 소스화할 계획입니다. (来源: AI 前线, 量子位, Reddit r/artificial)
OpenAI Codex 팀 AMA에서 GPT-5 및 향후 제품 통합 계획 공개: OpenAI Codex 팀이 Reddit에서 “무엇이든 물어보세요”(AMA) 행사를 열었습니다. 연구 부사장 Jerry Tworek은 차세대 기본 모델 GPT-5의 목표가 기존 모델의 능력을 향상시키고 모델 전환의 필요성을 줄이는 것이라고 밝혔습니다. 또한 Codex, Operator(작업 수행 에이전트), Deep Research(심층 연구 도구), Memory(기억 기능) 등 기존 도구를 통합하여 통일된 AI 비서 경험을 형성할 계획이라고 말했습니다. 팀원들은 Codex 개발 초기 동기(모델 활용 부족에 대한 내부 고민에서 비롯됨), Codex 내부 사용으로 인한 약 3배의 프로그래밍 효율성 향상, 그리고 미래 소프트웨어 엔지니어링에 대한 전망(요구 사항을 실행 가능한 소프트웨어로 효율적이고 안정적으로 전환)을 공유했습니다. Codex는 현재 주로 컨테이너 런타임에 로드된 정보를 활용하며, 향후 RAG 기술과 결합하여 최신 지식을 습득할 수 있습니다. OpenAI는 또한 유연한 가격 책정 방안을 모색하고 있으며, Plus/Pro 사용자에게 Codex CLI 사용을 위한 무료 API 크레딧을 제공할 계획입니다. (来源: 36氪)
VS Code, GitHub Copilot Chat 확장 프로그램 오픈 소스화 발표, 오픈 소스 AI 코드 편집 플랫폼 구축 계획: Visual Studio Code 팀은 VS Code를 개방성, 협업, 커뮤니티 주도를 핵심 원칙으로 하는 오픈 소스 AI 편집기로 발전시킬 계획이라고 발표했습니다. 이 계획의 일환으로 GitHub Copilot Chat 확장 프로그램이 GitHub에 MIT 라이선스로 오픈 소스화되었습니다. 향후 VS Code는 이러한 AI 기능을 편집기 핵심에 점진적으로 통합하여 개발 효율성, 투명성, 보안성을 향상시키는 완전한 오픈 소스, 커뮤니티 주도형 AI 코드 편집 플랫폼을 구축하는 것을 목표로 합니다. 이 조치는 Microsoft가 오픈 소스 분야에서 중요한 발걸음을 내디딘 것으로 평가되며, AI 지원 프로그래밍 도구 생태계에 큰 영향을 미칠 수 있습니다. (来源: dotey, jeremyphoward)
Huawei Ascend와 DeepSeek 협력, MoE 모델 추론 성능 NVIDIA Hopper 능가: Huawei Ascend는 자사의 CloudMatrix 384 슈퍼노드와 Atlas 800I A2 추론 서버가 DeepSeek V3/R1과 같은 초대규모 MoE 모델을 배포할 때 추론 성능에서 큰 돌파구를 마련했으며, 특정 조건에서 NVIDIA Hopper 아키텍처를 능가했다고 발표했습니다. CloudMatrix 384 슈퍼노드는 50ms 지연 시간에서 단일 카드 Decode 처리량이 1920 Tokens/s를 돌파했고, Atlas 800I A2는 100ms 지연 시간에서 단일 카드 처리량이 808 Tokens/s에 도달했습니다. Huawei는 이를 “수학으로 물리를 보완하는” 전략 덕분이라고 설명하며, 알고리즘과 시스템 최적화를 통해 하드웨어 공정의 한계를 극복했다고 밝혔습니다. 관련 기술 보고서가 발표되었으며, 핵심 코드는 한 달 내에 오픈 소스화될 예정입니다. 최적화 조치에는 MoE 모델을 위한 전문가 병렬 솔루션, PD 분리 배포, vLLM 프레임워크 적용, A8W8C16 양자화 전략, 그리고 FlashComm 통신 방안, 계층 내 병렬 변환, FusionSpec 투기적 추론 엔진 및 MLA/MoE 연산자 하드웨어 친화성 최적화 등이 포함됩니다. (来源: 量子位, WeChat)
🎯 动向
Apple, 효율적인 시각 언어 모델 FastVLM 오픈 소스 공개, 엣지 AI 경험 최적화: Apple이 iPhone 등 엣지 디바이스에서 효율적으로 실행되도록 특별히 설계된 시각 언어 모델 FastVLM(Fast Vision Language Model)을 오픈 소스로 공개했습니다. FastVLM은 새로운 하이브리드 시각 인코더 FastViTHD를 도입하여 컨볼루션 레이어와 Transformer 모듈을 결합하고, 다중 스케일 풀링 및 다운샘플링 기술을 사용하여 이미지 처리에 필요한 시각 토큰 수를 크게 줄였습니다(기존 ViT보다 16배 적음). 이를 통해 모델은 높은 정확도를 유지하면서 첫 번째 토큰 출력 속도(TTFT)를 유사 모델 대비 최대 85배 향상시켰습니다. FastVLM은 주류 LLM과 호환되며 iOS/Mac 생태계에 쉽게 적용할 수 있고, 0.5B, 1.5B, 7B 세 가지 파라미터 버전을 제공하여 이미지 설명, 질의응답, 분석 등 다양한 실시간 이미지-텍스트 작업에 적합합니다. (来源: WeChat)
Meta, KernelLLM 8B 모델 발표, 특정 벤치마크에서 GPT-4o 능가: Meta가 Hugging Face에 KernelLLM 8B 모델을 발표했습니다. KernelBench-Triton Level 1 벤치마크에서 이 80억 파라미터 모델이 단일 추론 성능에서 GPT-4o 및 DeepSeek V3와 같은 대규모 모델을 능가했다고 합니다. 다중 추론의 경우에도 KernelLLM의 성능은 DeepSeek R1보다 우수했습니다. 이 발표는 AI 커뮤니티의 주목을 받았으며, 중소형 모델이 특정 작업에서 강력한 경쟁력을 보여주는 또 다른 사례로 간주됩니다. (来源: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Mistral Medium 3 모델, Arena에서 강력한 성능 과시, 특히 기술 분야에서 두각: Mistral AI가 새로 출시한 Mistral Medium 3 모델이 lmarena.ai의 커뮤니티 평가에서 뛰어난 성능을 보여, 전체 채팅 능력 순위 11위를 차지하며 Mistral Large에 비해 현저한 향상(Elo 점수 90점 증가)을 보였습니다. 이 모델은 기술 분야에서 특히 두각을 나타내어 수학 능력 순위 5위, 복잡한 프롬프트 및 코딩 능력 순위 7위, WebDev Arena에서 9위를 차지했습니다. 커뮤니티에서는 기술 분야에서의 성능이 GPT-4.1 수준에 근접하며, 비용은 GPT-4.1 mini와 유사한 가격 책정으로 더 경쟁력 있을 수 있다고 평가했습니다. 사용자는 Mistral 공식 채팅 인터페이스에서 이 모델을 무료로 사용해 볼 수 있습니다. (来源: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets, 채팅 대화 직접 보기 기능 추가: Hugging Face Datasets 플랫폼이 중요한 업데이트를 진행하여, 이제 사용자가 데이터 세트에서 직접 채팅 대화 내용을 읽을 수 있게 되었습니다. 이 기능은 Caleb, Maxime Labonne과 같은 커뮤니티 회원들에 의해 데이터 품질 문제 해결의 큰 진전으로 평가받고 있습니다. 원본 대화 데이터를 직접 확인함으로써 데이터를 더 잘 이해하고, 데이터 정제 및 모델 학습 효과를 향상시키는 데 도움이 되기 때문입니다. 이전에는 특정 대화 내용을 보려면 추가 코드나 도구가 필요했을 수 있지만, 새로운 기능은 이 과정을 단순화하여 데이터 작업의 편의성과 투명성을 높였습니다. (来源: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM, Hugging Face Hub와 통합되어 Mac 로컬 모델 실행 간소화: MLX LM이 이제 Hugging Face Hub에 직접 통합되어 Mac 사용자가 Apple Silicon 장치에서 4400개 이상의 LLM을 로컬로 더 편리하게 실행할 수 있게 되었습니다. 사용자는 Hugging Face Hub의 호환 모델 페이지에서 “Use this model”을 클릭하기만 하면 복잡한 클라우드 구성이나 대기 시간 없이 터미널에서 모델을 빠르게 실행할 수 있습니다. 또한 모델 페이지에서 직접 OpenAI 호환 서버를 시작할 수도 있습니다. 이 통합은 로컬 모델 실행의 장벽을 낮추고 개발 및 실험 효율성을 높이는 것을 목표로 합니다. (来源: awnihannun, ClementDelangue, huggingface, reach_vb)
NVIDIA, 물리 AI 추론 모델 Cosmos-Reason1-7B 오픈 소스 공개: NVIDIA가 Hugging Face에 자사의 Physical AI 모델 시리즈 중 하나인 Cosmos-Reason1-7B를 오픈 소스로 공개했습니다. 이 모델은 물리 세계의 상식을 이해하고 그에 상응하는 구체화된 결정을 생성하도록 설계되었습니다. 이는 NVIDIA가 물리 세계와 AI의 결합을 추진하는 데 있어 새로운 발걸음을 내디뎠음을 의미하며, 로봇 공학, 자율 주행 등 물리 환경과의 상호 작용이 필요한 애플리케이션에 새로운 도구와 연구 기반을 제공합니다. (来源: reach_vb)
Baidu 비디오 생성 모델 Steamer-I2V, VBench 이미지-비디오 생성 부문 1위 등극: Baidu의 비디오 생성 모델 Steamer-I2V가 권위 있는 비디오 생성 평가 벤치마크 VBench의 이미지-비디오 생성(I2V) 부문에서 총점 89.38%로 1위를 차지하며 OpenAI Sora와 Google Imagen Video 등 유명 모델을 앞질렀습니다. Steamer-I2V의 기술적 우위에는 픽셀 수준의 정밀한 화면 제어, 전문가 수준의 카메라 워크, 최대 1080P의 영화급 고화질 및 동적 미학, 그리고 억 단위 중국어 멀티모달 데이터베이스 기반의 정확한 중국어 의미 이해 등이 포함됩니다. 이 성과는 Baidu의 멀티모달 생성 분야에서의 실력을 보여주며, AI 콘텐츠 생태계 구축 전략의 일환이기도 합니다. (来源: 36氪)

LLM, 시계 및 달력 읽기 등 시간 관련 작업에서 저조한 성능 보여: 에든버러 대학교 등 기관의 연구진은 대규모 언어 모델(LLM) 및 다중 모드 대규모 언어 모델(MLLM)이 다양한 작업에서 뛰어난 성능을 보이지만, 바늘 시계 시간 인식이나 달력 날짜 이해와 같이 간단해 보이는 시간 읽기 작업에서는 정확도가 우려스러울 정도로 낮다는 사실을 발견했습니다. 연구팀은 ClockQA와 CalendarQA라는 두 가지 맞춤형 테스트 세트를 구축했으며, 그 결과 AI 시스템의 시계 읽기 정확도는 38.7%, 달력 날짜 판단 정확도는 26.3%에 불과했습니다. Gemini-2.0 및 GPT-o1과 같은 첨단 모델조차도 특히 로마 숫자, 양식화된 바늘 또는 윤년, 특정 날짜의 요일 계산과 같은 복잡한 날짜 계산을 처리하는 데 어려움을 겪었습니다. 연구진은 이것이 현재 모델의 공간 추론, 구조화된 레이아웃 분석 및 흔하지 않은 패턴에 대한 일반화 능력의 부족을 드러낸다고 보았습니다. (来源: 36氪, WeChat)

Microsoft, Build 컨퍼런스에서 Grok 모델 Azure AI Foundry 도입 발표: Microsoft Build 2025 개발자 컨퍼런스에서 Microsoft는 xAI 회사의 Grok 모델이 Azure AI Foundry 모델 시리즈에 합류할 것이라고 발표했습니다. 사용자는 Azure Foundry와 GitHub에서 6월 초까지 Grok-3와 Grok-3-mini를 무료로 사용해 볼 수 있습니다. 이 조치는 Azure AI Foundry가 지원하는 타사 모델 범위를 더욱 확장한다는 것을 의미하며, 향후 사용자는 OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs 등 여러 제조업체의 모델을 통합된 예약 처리량을 통해 사용할 수 있게 됩니다. (来源: TheTuringPost, xai)
Apple, EU iPhone 사용자에게 Siri를 타사 음성 비서로 교체 허용 계획 보도: Mark Gurman의 보도에 따르면, Apple은 EU 지역 iPhone 사용자가 Siri를 타사 음성 비서로 교체할 수 있도록 처음으로 허용할 계획입니다. 이 조치는 EU의 점점 더 엄격해지는 디지털 시장 규제 요구 사항에 대응하기 위한 것일 수 있으며, 플랫폼의 개방성과 사용자 선택권을 강화하는 것을 목표로 합니다. 이 계획이 실행되면 음성 비서 시장 구도에 중요한 영향을 미치고 다른 음성 비서에게 Apple 생태계 진입 기회를 제공할 것입니다. (来源: zacharynado)

Meta, Open Molecules 2025 데이터셋 및 UMA 모델 발표, 분자 및 재료 발견 가속화: Meta AI가 Open Molecules 2025 (OMol25) 및 Meta Universal Atomistic Model (UMA)을 발표했습니다. OMol25는 현재 가장 크고 다양한 고정밀 양자 화학 계산 데이터셋으로, 생체 분자, 금속 착물 및 전해질 등을 포함합니다. UMA는 300억 개 이상의 원자를 기반으로 훈련된 머신러닝 원자 간 잠재력 모델로, 보다 정확한 분자 거동 예측을 제공하는 것을 목표로 합니다. 이러한 도구의 오픈 소스 공개는 분자 및 재료 과학의 발견과 혁신을 가속화하기 위한 것입니다. (来源: AIatMeta)
Hugging Face Datasets, Parquet 파일 증분 편집 기능 추가: Hugging Face Datasets는 자사의 기본 종속 라이브러리인 PyArrow의 야간 버전이 이제 Parquet 파일을 완전히 다시 작성하지 않고도 증분 편집을 지원한다고 발표했습니다. 이 새로운 기능은 대규모 데이터 세트 작업의 효율성을 크게 향상시킬 것이며, 특히 일부 데이터를 자주 업데이트하거나 수정해야 할 때 시간과 컴퓨팅 리소스 소모를 현저히 줄일 수 있습니다. 이 조치는 개발자가 대규모 AI 학습 데이터 세트를 처리하고 유지 관리하는 경험을 개선할 것으로 기대됩니다. (来源: huggingface)
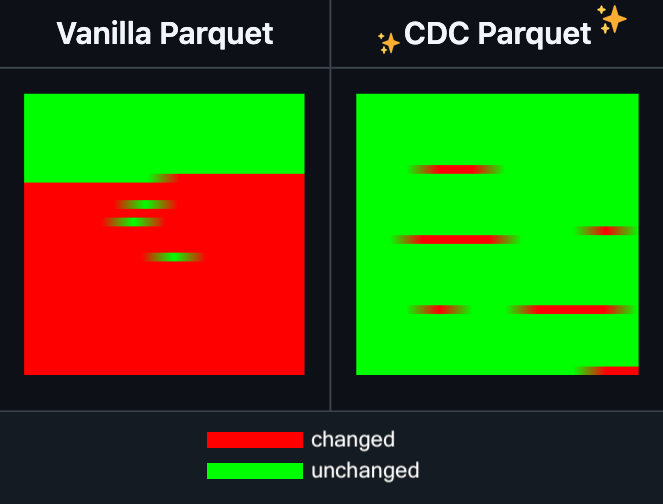
LangGraph, 노드 수준 캐싱 기능 추가로 워크플로우 효율성 향상: LangGraph는 오픈 소스 버전에 노드/작업 캐싱 기능이 추가되었다고 발표했습니다. 이 기능은 반복적인 계산을 피함으로써 워크플로우를 가속화하는 것을 목표로 하며, 특히 공통 부분을 포함하거나 자주 디버깅해야 하는 에이전트(Agent) 워크플로우에 적합합니다. 사용자는 명령형 API 또는 그래픽 API에서 캐시를 사용하여 AI 애플리케이션을 더 빠르게 반복하고 최적화할 수 있습니다. 이는 LangGraph가 이번 주에 발표한 오픈 소스 릴리스 시리즈 업데이트 중 첫 번째입니다. (来源: hwchase17)

Sakana AI, 새로운 AI 아키텍처 “지속적 사고 기계”(CTM) 출시: 도쿄 AI 스타트업 Sakana AI가 “지속적 사고 기계”(Continuous Thought Machines, CTM)라는 새로운 AI 모델 아키텍처를 발표했습니다. CTM은 모델이 인간의 뇌처럼 더 적은 지시로 추론할 수 있도록 하는 것을 목표로 합니다. 이 새로운 아키텍처는 현재 AI 모델이 복잡한 추론 및 자율 학습 측면에서 직면한 과제를 해결하는 데 새로운 아이디어를 제공할 수 있습니다. (来源: dl_weekly)
Microsoft와 NVIDIA, RTX AI PC 협력 심화, TensorRT Windows ML에 탑재: Microsoft Build 및 타이베이 국제 컴퓨터 박람회(COMPUTEX) 기간 동안 NVIDIA와 Microsoft는 RTX AI PC 개발 협력을 더욱 추진한다고 발표했습니다. NVIDIA의 TensorRT 추론 최적화 라이브러리는 Microsoft의 새로운 추론 스택인 Windows ML에 재설계되어 통합되었습니다. 이 조치는 AI 애플리케이션 개발 프로세스를 간소화하고 PC 단의 AI 작업에서 RTX GPU의 최고 성능을 최대한 발휘하여 개인 컴퓨팅 장치에서의 AI 보급 및 응용을 촉진하는 것을 목표로 합니다. (来源: nvidia)
Bilibili, 애니메이션 비디오 생성 모델 Index-AniSora 오픈 소스 공개, 다수 지표에서 SOTA 달성: Bilibili가 자체 개발한 애니메이션 비디오 생성 모델 Index-AniSora를 오픈 소스로 공개한다고 발표했습니다. 이 모델은 IJCAI 2025에 발표되었습니다. AniSora는 2차원 비디오 생성에 특화되어 있으며, 일본 애니메이션, 중국 애니메이션, 만화 각색 등 다양한 스타일을 지원하고, 비디오의 특정 영역 유도, 시퀀스 유도(예: 첫 프레임/마지막 프레임 유도, 키프레임 보간) 등 정교한 제어가 가능합니다. 프로젝트 오픈 소스 내용에는 CogVideoX-5B 기반의 AniSoraV1.0과 Wan2.1-14B 기반의 AniSoraV2.0의 학습 및 추론 코드, 학습 데이터셋 구축 도구, 애니메이션 전용 Benchmark 시스템 및 인간 선호도 강화 학습으로 최적화된 AniSoraV1.0_RL 모델이 포함됩니다. (来源: WeChat)

Tencent Hunyuan, 최초의 멀티모달 통합 CoT 보상 모델 UnifiedReward-Think 오픈 소스 공개: Tencent Hunyuan이 Shanghai AI Lab, Fudan University 등 기관과 협력하여 UnifiedReward-Think를 제안했습니다. 이는 긴 연쇄 추론(CoT) 능력을 갖춘 최초의 통합 멀티모달 보상 모델입니다. 이 모델은 보상 모델이 복잡한 시각적 생성 및 이해 작업을 평가할 때 “생각하는 법을 배우도록” 하여 평가 정확성, 작업 간 일반화 능력 및 추론 해석 가능성을 향상시키는 것을 목표로 합니다. 프로젝트는 모델, 데이터셋, 학습 스크립트 및 평가 도구를 포함하여 전면 오픈 소스화되었습니다. (来源: WeChat)
Alibaba, 비디오 생성 및 편집 모델 Tongyi Wanxiang Wan2.1-VACE 오픈 소스 공개: Alibaba가 자사의 비디오 생성 및 편집 모델 Tongyi Wanxiang Wan2.1-VACE를 공식적으로 오픈 소스 공개했습니다. 이 모델은 텍스트-비디오 생성, 이미지 참조 비디오 생성, 비디오 재구성, 비디오 부분 편집, 비디오 배경 확장 및 비디오 길이 확장 등 다양한 기능을 갖추고 있습니다. 이번 오픈 소스에는 1.3B 및 14B 두 가지 버전이 포함되며, 그중 1.3B 버전은 소비자용 그래픽 카드에서 실행할 수 있어 AIGC 비디오 제작의 장벽을 낮추는 것을 목표로 합니다. (来源: WeChat)
ByteDance, 시각 언어 모델 Seed1.5-VL 발표, 다수 벤치마크에서 선두: ByteDance가 532M 파라미터의 시각 인코더와 20B 활성 파라미터의 전문가 혼합(MoE) LLM으로 구성된 시각 언어 모델 Seed1.5-VL을 구축했습니다. 비교적 컴팩트한 아키텍처에도 불구하고 60개의 공개 벤치마크 중 38개에서 SOTA 성능을 달성했으며, GUI 제어 및 게임 플레이와 같은 에이전트 중심 작업에서 OpenAI CUA 및 Claude 3.7과 같은 모델을 능가하여 강력한 멀티모달 추론 능력을 보여주었습니다. (来源: WeChat)
MiniMax, 자기 회귀 TTS 모델 MiniMax-Speech 출시, 32개 언어 제로샷 음성 복제 지원: MiniMax가 Transformer 기반 자기 회귀 텍스트 음성 변환(TTS) 모델 MiniMax-Speech를 제안했습니다. 이 모델은 참조 오디오에서 전사 없이 음색 특징을 추출하여 제로샷 방식으로 참조 음색과 일치하고 표현력이 풍부한 음성을 생성하며, 단일 샘플 음성 복제를 지원합니다. Flow-VAE 기술을 통해 합성 오디오 품질을 향상시켰으며 32개 언어를 지원합니다. 이 모델은 객관적인 음성 복제 지표에서 SOTA 수준을 달성했으며, 공개 TTS Arena 순위표에서 1위를 차지했고, 음성 감정 제어, 텍스트 음성 변환 및 전문 음성 복제 등으로 확장 적용될 수 있습니다. (来源: WeChat)
OuteTTS 1.0 (0.6B) 출시, 14개 언어 지원 Apache 2.0 오픈소스 TTS 모델: OuteAI가 Qwen-3 0.6B 기반으로 구축된 경량 텍스트 음성 변환(TTS) 모델 OuteTTS-1.0-0.6B를 출시했습니다. 이 모델은 Apache 2.0 라이선스를 채택했으며 중국어, 영어, 일본어, 한국어를 포함한 14개 언어를 지원합니다. Python 추론 라이브러리 OuteTTS v0.4.2는 EXL2 비동기 배치 추론, vLLM 실험적 배치 추론 및 Llama.cpp 서버의 연속 배치 처리 및 외부 URL 모델 추론을 지원하도록 업데이트되었습니다. 단일 NVIDIA L40S GPU에서의 벤치마크 테스트 결과, vLLM OuteTTS-1.0-0.6B FP8은 배치 크기 32에서 RTF(실시간 계수) 0.05를 달성할 수 있습니다. 모델 가중치(ST, GGUF, EXL2, FP8)는 Hugging Face에서 제공됩니다. (来源: Reddit r/LocalLLaMA)

Hugging Face와 Microsoft Azure 협력 심화, 1만 개 이상의 오픈 소스 모델 Azure AI Foundry에 탑재: Microsoft Build 컨퍼런스에서 CEO Satya Nadella는 Hugging Face와의 협력 확대를 발표했습니다. 현재 11,000개 이상의 가장 인기 있는 오픈 소스 모델이 Hugging Face를 통해 Azure AI Foundry에서 제공되어 사용자가 쉽게 배포할 수 있습니다. 이 조치는 Azure의 AI 생태계를 더욱 풍부하게 하고 개발자에게 더 많은 모델 선택권과 더 편리한 개발 경험을 제공합니다. (来源: ClementDelangue, _akhaliq)

Intel, Arc Pro B50/B60 시리즈 GPU 출시, AI 및 워크스테이션 시장 공략, 24GB 버전 약 500달러: Intel이 Computex에서 새로운 Arc Pro B 시리즈 전문가용 그래픽 카드인 Arc Pro B50(16GB VRAM, 약 299달러)과 Arc Pro B60(24GB VRAM, 약 500달러)을 발표했습니다. 이 중 듀얼 B60 GPU로 구성된 48GB VRAM 버전 “Project Battlematrix” 워크스테이션 솔루션도 함께 공개되었으며, 예상 가격은 1000달러 미만입니다. 이 제품들은 AI 컴퓨팅 및 전문 워크스테이션에 고성능 가성비 솔루션을 제공하는 것을 목표로 하며, 특히 고용량 VRAM 구성은 로컬에서 대규모 언어 모델을 실행하는 데 매력적입니다. 신제품은 올해 3분기에 출시될 예정이며, 초기에는 OEM 업체를 통해 제공되고 4분기에는 DIY 버전이 출시될 수 있습니다. (来源: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 工具
Moondream Station, Linux 버전 출시로 로컬 Moondream 실행 간소화: Moondream Station은 로컬 장치에서 Moondream(시각 언어 모델) 실행을 간소화하기 위해 설계된 도구로, 이제 Linux 운영 체제를 지원한다고 발표했습니다. 이는 Linux 사용자가 멀티모달 AI 실험 및 애플리케이션 개발을 위해 Moondream 모델을 더 편리하게 배포하고 사용할 수 있음을 의미합니다. (来源: vikhyatk)
Flowith, 무한 에이전트 NEO 출시, 무한 단계, 컨텍스트 및 도구 호출 지원: AI 애플리케이션 회사 Flowith가 최신 에이전트 제품 NEO를 출시했습니다. NEO는 세계 최초로 무한 단계, 무한 컨텍스트 및 무한 도구 호출을 지원하는 에이전트라고 주장합니다. 이 에이전트는 클라우드에서 장시간 실행되도록 설계되었으며, 벤치마크를 뛰어넘는 지능 수준을 갖추고 있으며 제로 비용, 무제한이라고 선언합니다. 이 출시는 AI 에이전트가 복잡한 장기 작업을 처리하고 외부 기능을 통합하는 데 있어 새로운 진전을 나타낼 수 있습니다. (来源: _akhaliq, op7418)

Kapa AI, Weaviate를 활용하여 대화형 기술 문서 질의응답 도구 “Ask AI” 구축: Kapa AI는 사용자가 자연어 대화 방식으로 기술 문서, 블로그, 튜토리얼, GitHub issues 및 포럼 등 전체 기술 지식 기반을 조회할 수 있는 “Ask AI”라는 스마트 위젯을 개발했습니다. 효율적인 시맨틱 검색 및 지식 검색을 위해 Kapa AI는 Weaviate 벡터 데이터베이스를 채택했으며, 내장된 하이브리드 검색 기능, Docker 호환성 및 다중 테넌트 특성을 중요하게 여겨 빠르게 증가하는 사용자 및 데이터 규모를 지원합니다. (来源: bobvanluijt)

개발자, Gemini Flash를 사용하여 스크린샷을 HTML로 변환하는 MVP 도구 빠르게 구축: 개발자 Daniel Huynh이 Google AI의 Gemini Flash 모델을 사용하여 주말 동안 디자인 시안, 경쟁사 또는 영감 스크린샷을 HTML 코드로 빠르게 변환하는 MVP(최소 실행 가능 제품) 도구를 구축했습니다. 이 도구는 Hugging Face Spaces에서 무료로 사용해 볼 수 있으며, 멀티모달 모델이 프론트엔드 개발 지원 분야에서 잠재력을 보여줍니다. (来源: osanseviero, _akhaliq)
Azure AI Foundry Agent Service 정식 출시, LlamaIndex 통합: Microsoft는 Azure AI Foundry Agent Service가 정식 출시(GA)되었으며 LlamaIndex에 대한 최고 수준의 지원을 제공한다고 발표했습니다. 이 서비스는 기업 고객이 고객 지원 도우미, 프로세스 자동화 봇, 다중 에이전트 시스템 및 기업 데이터 및 도구와 안전하게 통합된 솔루션을 구축하는 데 도움을 주기 위해 설계되었으며, 기업 수준의 AI 에이전트 개발 및 적용을 더욱 촉진합니다. (来源: jerryjliu0)
tinygrad: PyTorch와 micrograd 사이의 극도로 간결한 딥러닝 프레임워크: tinygrad는 단순성을 핵심 설계 철학으로 하는 딥러닝 프레임워크로, 새로운 가속기를 가장 쉽게 추가할 수 있는 프레임워크가 되는 것을 목표로 하며 추론과 학습을 모두 지원합니다. LLaMA 및 Stable Diffusion과 같은 모델을 지원하며, 지연 평가(lazy evaluation)를 사용하여 연산을 융합하고 성능을 최적화합니다. tinygrad는 GPU (OpenCL), CPU (C 코드), LLVM, Metal, CUDA 등 다양한 가속기를 지원합니다. 코드가 간결하고 핵심 기능이 적은 양의 코드로 구현되어 개발자가 이해하고 확장하기 쉽습니다. (来源: GitHub Trending)
나노 AI 검색, “슈퍼 검색” 기능 출시, 다중 모델 및 MCP 도구 상자 통합: 나노 AI 검색(bot.n.cn)에 “슈퍼 검색” 기능이 추가되어 더 심층적인 정보 획득 및 처리 능력을 제공하는 것을 목표로 합니다. 이 기능은 국내외 수백 개의 대형 모델을 통합하고 필요에 따라 자동으로 전환합니다. 내장된 MCP 만능 도구 상자는 수천 가지 AI 도구를 지원하며 웹 페이지, 이미지, 비디오, PDF 등 다양한 형식의 파일을 처리하고 코드 생성, 데이터 분석 등을 수행할 수 있습니다. 동시에 공용 검색과 로컬 지식 기반의 사설 검색을 결합하여 보다 포괄적인 결과를 제공하며, 내장된 텍스트-이미지 생성, 텍스트-비디오 생성 기능을 제공합니다. 사용자 경험에 따르면 이 기능은 검색 결과를 차트가 포함된 상세 보고서와 정교한 웹 페이지로 정리할 수 있어 산업 연구, 쇼핑 비교, 지식 정리 등 다양한 시나리오에 적합합니다. (来源: WeChat)
Clara: 모듈식 오프라인 AI 작업 공간, LLM, 에이전트, 자동화 및 이미지 생성 통합: 개발자가 Clara라는 오픈 소스 프로젝트를 출시하여 완전한 오프라인, 모듈식 AI 작업 공간을 만드는 것을 목표로 합니다. 사용자는 대시보드에서 위젯 형태로 로컬 LLM 채팅(RAG, 이미지, 문서, 코드 실행 지원, Ollama 및 OpenAI 유사 API 호환)을 구성하고, 기억 및 논리 기능을 갖춘 에이전트를 생성하고, 기본 N8N 통합을 통해 자동화 프로세스(1000개 이상의 무료 템플릿 제공)를 실행하고, Stable Diffusion(ComfyUI)을 사용하여 로컬에서 이미지를 생성할 수 있습니다. Clara는 Mac, Windows, Linux 버전을 제공하며, 사용자가 여러 AI 도구 간에 자주 전환하는 문제를 해결하고 원스톱 AI 작업을 실현하는 것을 목표로 합니다. (来源: Reddit r/LocalLLaMA)
AI Playlist Curator: LLM을 활용하여 YouTube 재생 목록을 개인화하여 정리하는 Python 도구: 한 개발자가 AI Playlist Curator라는 Python 프로젝트를 만들어 사용자가 방대하고 무질서한 YouTube 재생 목록을 자동으로 정리하는 데 도움을 주고자 합니다. 이 도구는 LLM을 활용하여 사용자 선호도에 따라 노래를 분류하고 개인화된 하위 재생 목록을 생성하며, 저장된 모든 재생 목록과 좋아하는 노래를 처리할 수 있습니다. 프로젝트는 GitHub에 오픈 소스로 공개되었으며, 개발자는 커뮤니티 피드백을 통해 더욱 개선되기를 바라고 있습니다. (来源: Reddit r/MachineLearning)
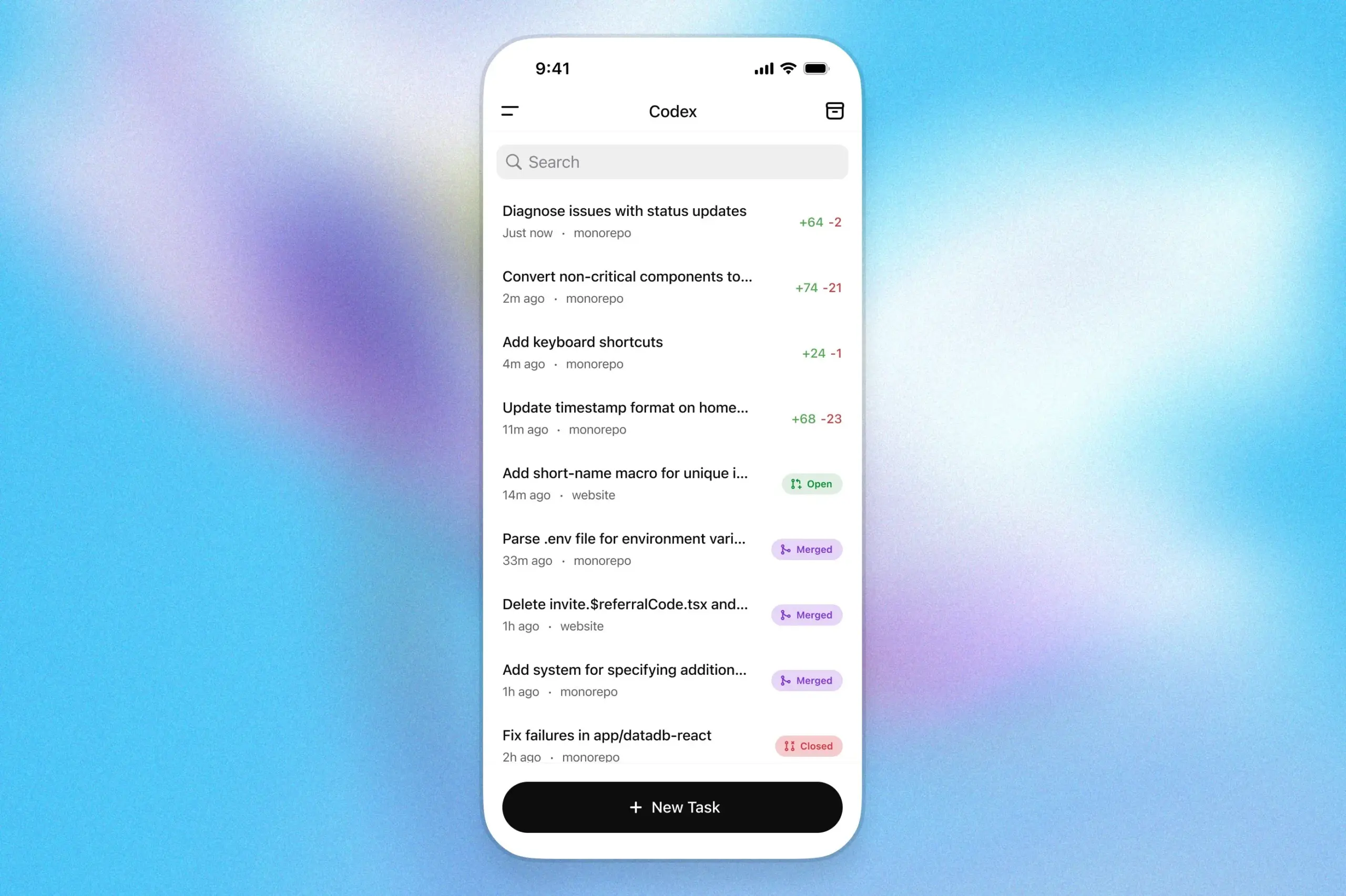
OpenAI Codex 프로그래밍 도우미, ChatGPT iOS 앱에 탑재: OpenAI는 자사의 프로그래밍 도우미 Codex가 이제 ChatGPT의 iOS 애플리케이션에 통합되었다고 발표했습니다. 사용자는 모바일 장치에서 새로운 프로그래밍 작업을 시작하고, 코드 차이를 확인하고, 수정을 요청하고, 심지어 풀 리퀘스트(PR)를 푸시할 수도 있습니다. 이 기능은 또한 잠금 화면 실시간 활동을 통해 Codex의 진행 상황을 추적하여 사용자가 여러 장치 간에 작업을 원활하게 전환할 수 있도록 지원합니다. (来源: openai)
Kollektiv: MCP 프로토콜을 활용하여 LLM 채팅 컨텍스트 반복 붙여넣기 문제 해결 도구: 개발자가 Kollektiv 도구를 출시하여 사용자가 LLM(예: Claude)과 채팅할 때 연구 논문, SDK 문서, 개인 노트, 책 내용과 같은 대량의 컨텍스트를 반복적으로 복사하여 붙여넣어야 하는 문제를 해결하고자 합니다. Kollektiv을 사용하면 이러한 문서 소스를 한 번에 업로드하고, 모든 호환 IDE 또는 MCP 클라이언트(예: Cursor, Windsurf, PyCharm 등)에서 MCP(Model Control Protocol) 서버를 통해 필요에 따라 호출할 수 있습니다. MCP 서버는 사용자 인증, 데이터 격리 및 채팅 인터페이스로의 데이터 주문형 스트리밍을 담당합니다. 이 도구는 현재 민감하거나 기밀 자료에는 사용하지 않는 것이 좋습니다. (来源: Reddit r/ClaudeAI)
📚 学习
Google DeepMind, AlphaEvolve 기술 보고서 발표, 알고리즘 발견 능력 공개: Google DeepMind가 자사의 AI 시스템 AlphaEvolve에 대한 기술 보고서를 발표했습니다. AlphaEvolve는 Gemini 기반의 코딩 에이전트로, 진화 알고리즘을 통해 알고리즘을 설계하고 최적화할 수 있습니다. 보고서는 AlphaEvolve가 구조화된 피드백 루프를 통해 자율적으로 후보 알고리즘 솔루션을 생성, 평가 및 개선하여 여러 수학 및 계산 과학 문제에서 4×4 복소 행렬 곱셈 알고리즘 기록 경신을 포함한 혁신적인 성과를 달성하는 방법을 자세히 설명합니다. 이 보고서는 자동화된 과학 발견 및 알고리즘 혁신 분야에서 AI의 잠재력을 이해하는 데 중요한 참고 자료를 제공합니다.
DeepLearning.AI, “AI 브라우저 에이전트 구축” 과정 출시: DeepLearning.AI가 “Building AI Browser Agents”라는 새로운 과정을 개설했습니다. 이 과정은 AGI 회사의 공동 창립자인 Div Garg와 Naman Agarwal이 강의하며, 학습자가 브라우저와 상호 작용할 수 있는 AI 에이전트(Agent)를 구축하는 기술을 습득하도록 돕는 것을 목표로 합니다. 과정 내용에는 웹 자동화, 정보 추출, 사용자 인터페이스 상호 작용 등 AI가 브라우저 환경에서 활용되는 내용이 포함될 수 있습니다. (来源: DeepLearningAI)
Qwen3 기술 보고서 발표: Alibaba가 최신 세대 대규모 언어 모델 Qwen3의 기술 보고서를 발표했습니다. 이 보고서는 Qwen3의 모델 아키텍처, 학습 방법, 성능 평가 및 다양한 벤치마크에서의 성능을 자세히 설명합니다. Qwen3 시리즈 모델은 더욱 강력한 언어 이해, 생성 및 멀티모달 처리 능력을 제공하는 것을 목표로 하며, 기술 보고서 발표는 연구자와 개발자에게 이 모델의 기술적 세부 사항을 심층적으로 이해할 수 있는 기회를 제공합니다. (来源: _akhaliq)

논문 세미나: 다중 관점 검색 및 데이터 관리를 통한 점진적 정리 증명 향상 (MPS-Prover): 새로운 논문에서 MPS-Prover라는 새로운 점진적 자동 정리 증명(ATP) 시스템을 소개합니다. 이 시스템은 효율적인 학습 후 데이터 관리 전략(성능 저하 없이 중복 데이터 약 40% 제거)과 다중 관점 트리 검색 메커니즘(학습된 비평가 모델과 휴리스틱 규칙 통합)을 통해 기존 점진적 증명기에서 검색 지도가 편향되는 문제를 극복합니다. 실험 결과, MPS-Prover는 miniF2F 및 ProofNet과 같은 여러 벤치마크에서 SOTA 성능을 달성했으며, 더 짧고 다양한 증명을 생성했습니다. (来源: HuggingFace Daily Papers)
논문 세미나: 시각적 계획 – 이미지만으로 생각하기 (Visual Planning): 새로운 논문에서 “시각적 계획” 패러다임을 제안하여 모델이 텍스트에 의존하지 않고 시각적 표현(이미지 시퀀스)만으로 계획을 수립할 수 있도록 합니다. 연구자들은 공간 및 기하학적 정보와 관련된 작업에서 언어가 가장 자연스러운 추론 매체가 아닐 수 있다고 생각합니다. 그들은 강화 학습을 통한 시각적 계획 프레임워크 VPRL을 도입하고 GRPO를 사용하여 대규모 시각 모델을 학습 후 최적화하여 FrozenLake, Maze 및 MiniBehavior와 같은 시각적 탐색 작업에서 현저한 개선을 이루었으며, 순수 텍스트 추론 기반 계획 변형보다 우수한 성능을 보였습니다. (来源: HuggingFace Daily Papers)
논문 세미나: 추론 능력 확장이 대규모 언어 모델의 사실성을 향상시킬 수 있음 (Scaling Reasoning can Improve Factuality): 한 연구에서 대규모 언어 모델(LLM)의 추론 과정을 확장하는 것이 복잡한 개방형 도메인 질의응답(QA)에서의 사실 정확성을 향상시킬 수 있는지 탐구했습니다. 연구자들은 QwQ-32B 및 DeepSeek-R1-671B와 같은 모델에서 추론 궤적을 추출하고 여러 Qwen2.5 시리즈 모델에 대해 미세 조정을 수행하는 동시에 지식 그래프 경로를 추론 궤적에 통합했습니다. 실험 결과, 단일 실행에서 더 작은 추론 모델이 원래 지침 미세 조정 모델에 비해 사실 정확성에서 현저한 향상을 보였습니다. 테스트 시 계산 및 토큰 예산을 늘리면 사실 정확성이 2-8% 안정적으로 향상될 수 있습니다. (来源: HuggingFace Daily Papers)
논문 세미나: Mergenetic – 간단한 진화적 모델 병합 라이브러리: 새로운 논문에서 진화적 모델 병합을 위한 오픈 소스 라이브러리인 Mergenetic을 소개합니다. 모델 병합을 사용하면 추가 학습 없이 기존 모델의 기능을 새로운 모델로 결합할 수 있습니다. Mergenetic은 병합 방법과 진화 알고리즘을 쉽게 결합할 수 있도록 지원하며, 평가 비용을 줄이기 위해 경량 적합도 평가기를 결합합니다. 실험 결과, Mergenetic은 적당한 하드웨어를 사용하여 다양한 작업과 언어에서 경쟁력 있는 결과를 생성할 수 있음을 입증했습니다. (来源: HuggingFace Daily Papers)
논문 세미나: 집단 사고 – 토큰 수준에서 협력하는 다중 동시 추론 에이전트 (Group Think): 새로운 논문에서 “집단 사고”(Group Think)를 제안합니다. 이는 단일 LLM이 여러 동시 추론 에이전트(사고가) 역할을 하도록 하는 것입니다. 이러한 에이전트는 서로의 부분적인 생성 진행 상황에 대한 가시성을 공유하고, 토큰 수준에서 서로의 추론 궤적에 동적으로 적응하여 중복 추론을 줄이고 품질을 향상시키며 지연 시간을 단축합니다. 이 방법은 로컬 GPU에서의 엣지 추론에 적합하며, 실험 결과 특별히 훈련되지 않은 오픈 소스 LLM을 사용할 때도 지연 시간을 개선할 수 있음을 입증했습니다. (来源: HuggingFace Daily Papers)
논문 세미나: 인간은 전략 게임에서 LLM 상대방이 합리성과 협력을 보여주기를 기대함 (Humans expect rationality and cooperation from LLM opponents): 최초의 통제된 금전적 인센티브 실험실 실험 연구에서 인간이 다자간 P-beauty 경쟁에서 다른 인간과 LLM에 대항할 때의 행동 차이를 조사했습니다. 결과에 따르면 인간은 LLM에 대항할 때 훨씬 낮은 숫자를 선택했으며, 이는 주로 “0” 내쉬 균형 선택의 보편성 증가 때문이었습니다. 이러한 변화는 주로 높은 전략적 추론 능력을 가진 피험자에 의해 주도되었으며, 그들은 LLM이 더 강력한 추론 능력과 협력 성향을 가지고 있다고 생각했습니다. (来源: HuggingFace Daily Papers)
논문 세미나: 이중 헤드 최적화를 통한 시각 언어 모델로부터의 간단한 준지도 지식 증류 (Dual-Head Optimization for KD): 새로운 논문에서 DHO(Dual-Head Optimization)라는 간단하고 효과적인 지식 증류(KD) 프레임워크를 제안합니다. 이는 준지도 설정에서 시각 언어 모델(VLM)에서 컴팩트한 작업별 모델로 지식을 이전하는 데 사용됩니다. DHO는 레이블이 지정된 데이터와 교사 예측을 독립적으로 학습하는 이중 예측 헤드를 도입하고, 추론 시 출력을 선형적으로 결합하여 감독 신호와 증류 신호 간의 기울기 충돌을 완화합니다. 실험 결과, DHO는 여러 도메인 및 세분화된 데이터 세트에서 단일 헤드 KD 기준선보다 우수하며 ImageNet에서 SOTA를 달성했습니다. (来源: HuggingFace Daily Papers)
논문 세미나: GuardReasoner-VL – 강화 추론을 통한 VLM 보호: 시각 언어 모델(VLM)의 안전성을 강화하기 위해 새로운 논문에서 추론 기반 VLM 보호 모델 GuardReasoner-VL을 도입했습니다. 핵심 아이디어는 온라인 강화 학습(RL)을 통해 보호 모델이 감사 결정을 내리기 전에 신중한 추론을 하도록 장려하는 것입니다. 연구자들은 123K 샘플과 631K 추론 단계를 포함하는 추론 코퍼스 GuardReasoner-VLTrain을 구축하고, 감독 미세 조정(SFT)을 통해 모델의 추론 능력을 콜드 스타트한 후 온라인 RL을 통해 더욱 강화했습니다. 실험 결과, 이 모델(3B/7B 버전 오픈 소스 공개)은 우수한 성능을 보였으며, 평균 F1 점수에서 차선 모델보다 19.27% 더 높았습니다. (来源: HuggingFace Daily Papers)
논문 세미나: 다중 토큰 예측에는 레지스터가 필요함 (Multi-Token Prediction Needs Registers): 새로운 논문에서 MuToR이라는 간단하고 효과적인 다중 토큰 예측 방법을 제안합니다. 이는 입력 시퀀스에 학습 가능한 레지스터 토큰을 교차 삽입하여 미래 목표를 예측합니다. 기존 방법과 비교하여 MuToR은 파라미터 증가가 무시할 수 있고, 아키텍처 변경이 필요 없으며, 기존 사전 훈련 모델과 호환되고, 다음 토큰 사전 훈련 목표와 일치하여 특히 감독 미세 조정에 적합합니다. 이 방법은 언어 및 시각 분야의 생성 작업에서 효과성과 일반성을 보여줍니다. (来源: HuggingFace Daily Papers)
논문 세미나: MMLongBench – 효과적이고 철저한 장문맥 시각 언어 모델 벤치마크 테스트: 장문맥 시각 언어 모델(LCVLM)의 평가 요구에 부응하여 새로운 논문에서 MMLongBench를 소개합니다. 이는 다양한 장문맥 시각 언어 작업을 포괄하는 최초의 벤치마크입니다. MMLongBench는 시각적 RAG, 다중 샘플 ICL 등 5가지 유형의 작업을 포함하는 13331개 샘플을 포함하며 다양한 이미지 유형을 제공합니다. 모든 샘플은 8K-128K 토큰의 5가지 표준화된 입력 길이로 제공됩니다. 46개의 비공개 및 오픈 소스 LCVLM에 대한 벤치마크 테스트를 통해 연구진은 단일 작업 성능이 전체 장문맥 능력을 대표하지 않으며, 현재 모델은 여전히 개선의 여지가 많고, 추론 능력이 강한 모델이 장문맥 성능이 더 좋은 경향이 있음을 발견했습니다. (来源: HuggingFace Daily Papers)
논문 세미나: MatTools – 재료 과학 도구를 위한 대규모 언어 모델 벤치마크 테스트: 새로운 논문에서 MatTools 벤치마크를 제안합니다. 이는 대규모 언어 모델(LLM)이 물리 기반 계산 재료 과학 소프트웨어 패키지 코드를 생성하고 안전하게 실행하여 재료 과학 문제에 답하는 능력을 평가하기 위한 것입니다. MatTools는 재료 시뮬레이션 도구 질의응답(QA) 벤치마크(pymatgen 기반, 69225개 QA 쌍 포함)와 실제 도구 사용 벤치마크(49개 작업, 138개 하위 작업 포함)를 포함합니다. 다양한 LLM에 대한 평가는 다음을 보여줍니다: 일반 모델이 전문 모델보다 우수함, AI가 AI를 더 잘 이해함, 간단한 방법이 더 효과적임. (来源: HuggingFace Daily Papers)
논문 세미나: LLM 워터마크의 견고성, 텍스트 품질 및 보안 균형을 맞추는 범용 공생 워터마크 프레임워크: 기존 대규모 언어 모델(LLM) 워터마크 방식이 견고성, 텍스트 품질 및 보안 간에 존재하는 절충 문제를 해결하기 위해 새로운 논문에서 범용 공생 워터마크 프레임워크를 제안합니다. 이 프레임워크는 로짓 기반 및 샘플링 기반 방법을 통합하고 직렬, 병렬 및 혼합 세 가지 전략을 설계합니다. 혼합 프레임워크는 토큰 엔트로피와 의미론적 엔트로피를 활용하여 워터마크를 적응적으로 삽입하여 각 측면의 성능을 최적화하는 것을 목표로 합니다. 실험 결과, 이 방법은 기존 기준선보다 우수하며 SOTA 수준에 도달했습니다. (来源: HuggingFace Daily Papers)
논문 세미나: CheXGenBench – 합성 흉부 X선의 충실도, 개인 정보 보호 및 유용성에 대한 통합 벤치마크: 새로운 논문에서 CheXGenBench를 소개합니다. 이는 합성 흉부 X선 생성을 평가하기 위한 다각적인 프레임워크로, 충실도, 개인 정보 보호 위험 및 임상적 유용성을 동시에 평가합니다. 이 프레임워크는 표준화된 데이터 분할과 통합된 평가 프로토콜(20개 이상의 정량적 지표)을 포함하며, 11가지 주요 텍스트-이미지 아키텍처의 생성 품질, 잠재적인 개인 정보 보호 취약성 및 다운스트림 임상 적용 가능성을 분석합니다. 연구 결과, 기존 평가 프로토콜이 생성 충실도 평가에 부족함이 있음을 발견했습니다. 연구팀은 동시에 고품질 합성 데이터 세트 SynthCheX-75K를 발표했습니다. (来源: HuggingFace Daily Papers)
고전 교재 ‘함수 해석학’ 저자 Peter Lax 별세, 향년 99세: 응용 수학의 거장, 아벨상 최초 수상 응용 수학자 Peter Lax가 향년 99세로 별세했습니다. Lax는 그가 편찬한 고전 교재 ‘함수 해석학’으로 유명하며, 편미분 방정식, 유체 역학, 수치 계산 등 분야에서 Lax 등가 정리, Lax-Friedrichs 및 Lax-Wendroff 방법 등과 같은 기초적인 공헌을 했습니다. 그는 또한 컴퓨터 기술을 수학 분석에 최초로 적용한 선구자 중 한 명으로, 그의 연구는 컴퓨터 시대의 수학 발전에 깊은 영향을 미쳤습니다. (来源: 量子位)

전 OpenAI 중국계 VP Lilian Weng, ‘Why We Think’ 장문 기고, 테스트 시간 컴퓨팅과 사고의 연쇄 논의: 전 OpenAI 중국계 부사장 Lilian Weng이 ‘Why We Think’라는 장문의 글을 발표하여 “테스트 시간 컴퓨팅”(Test-time Compute)과 “사고의 연쇄”(Chain-of-Thought, CoT)와 같은 기술이 어떻게 대규모 언어 모델의 성능과 지능 수준을 현저히 향상시키는지 심층적으로 논의했습니다. 이 글은 인간 사고의 “빠른 생각과 느린 생각” 이중 시스템 이론에 비유하여, 모델이 출력 전에 더 많은 “사고”(예: 지능형 디코딩, CoT 추론, 잠재 변수 모델링 등)를 하도록 하는 것이 현재 능력의 병목 현상을 돌파할 수 있다고 지적합니다. 글에서는 토큰 기반 사고, 병렬 샘플링 및 순차적 수정, 강화 학습 및 외부 도구 통합, 사고의 충실성 및 연속 공간 사고 등 여러 연구 방향의 진전과 과제를 자세히 정리했습니다. (来源: 量子位)

하얼빈 공업대학과 펜실베이니아 대학교, PointKAN 공동 출시, KANs 기반 포인트 클라우드 분석 새로운 SOTA: 하얼빈 공업대학(선전)과 펜실베이니아 대학교 연구팀이 Kolmogorov-Arnold Networks (KANs) 기반의 3D 포인트 클라우드 분석 솔루션 PointKAN을 출시했습니다. 이 방법은 기하학적 아핀 모듈과 병렬 로컬 특징 추출 모듈을 통해, 그리고 기존 MLP의 고정 활성화 함수 대신 학습 가능한 활성화 함수를 사용하여 포인트 클라우드의 복잡한 기하학적 특징을 보다 효과적으로 포착합니다. 동시에 연구팀은 유리 함수로 B-스플라인 함수를 대체하고 그룹 내 파라미터 공유를 통해 파라미터 수와 계산 비용을 현저히 줄인 Efficient-KANs 구조를 제안했습니다. 실험 결과, PointKAN과 그 경량 버전인 PointKAN-elite는 분류, 부분 분할 및 소수 샘플 학습과 같은 작업에서 모두 SOTA 또는 경쟁력 있는 성능을 달성했습니다. (来源: WeChat)

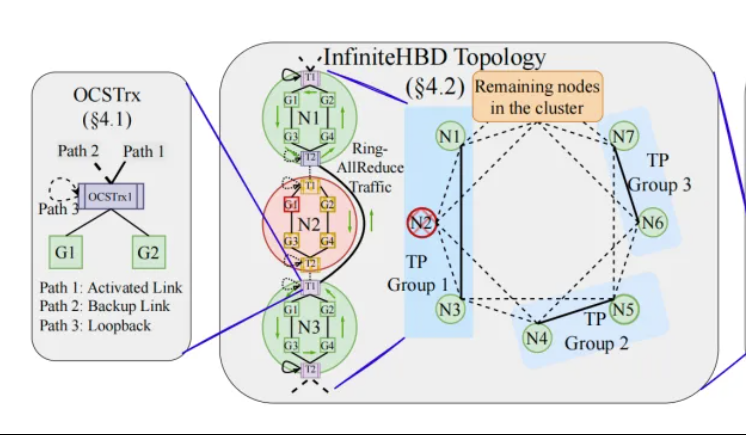
베이징대/StepFun/Enflame, InfiniteHBD 제안: 차세대 고대역폭 GPU 상호 연결 아키텍처, 대규모 모델 훈련 비용 절감: 베이징 대학교, StepFun(阶跃星辰), Enflame(曦智科技) 연구팀이 현재 대규모 모델 분산 훈련에서 고대역폭 도메인(HBD) 아키텍처의 한계를 해결하기 위해 InfiniteHBD 방안을 제안했습니다. 이 아키텍처는 광 경로 교환(OCS) 기능이 내장된 광전 변환 모듈을 핵심으로 하여 동적으로 재구성 가능한 점대다점 연결을 구현하고, 노드 수준의 장애 격리 및 낮은 자원 단편화 능력을 갖추고 있습니다. 연구에 따르면 InfiniteHBD의 단위 비용은 NVIDIA NVL-72의 31%에 불과하며, GPU 낭비율은 거의 0에 가깝고, MFU(모델 FLOPs 활용률)는 NVIDIA DGX에 비해 최대 3.37배 향상될 수 있습니다. 이 연구는 SIGCOMM 2025에 채택되었습니다. (来源: WeChat, 量子位)
ICML 2025 논문 속보: OmniAudio, 360° 비디오에서 공간 오디오 생성: ICML 2025에 발표될 한 연구에서 OmniAudio 프레임워크를 제안하여 360° 파노라마 비디오에서 직접 방향성을 가진 1차 앰비소닉(FOA) 공간 오디오를 생성할 수 있도록 했습니다. 이 연구는 먼저 대규모 360° 비디오와 공간 오디오 쌍 데이터셋 Sphere360을 구축했습니다. OmniAudio는 2단계 훈련을 채택합니다: 먼저 자가지도 학습 방식의 거친-세밀한 흐름 일치 사전 훈련을 수행하여 대규모 비공간 오디오 데이터를 활용하여 일반적인 오디오 특징을 학습합니다. 그런 다음 이중 분기 비디오 인코더(전역 및 로컬 시각 특징 추출)를 결합하여 감독 미세 조정을 수행합니다. 실험 결과, OmniAudio는 객관적 및 주관적 평가 지표 모두에서 기존 기준 모델보다 현저히 우수한 성능을 보였습니다. (来源: WeChat)

Huawei Selftok: 역확산 기반 자기 회귀 시각 토크나이저, 멀티모달 생성 통합: Huawei Pangu 멀티모달 생성팀이 Selftok 기술을 제안했습니다. 이는 혁신적인 시각 토큰화 방안으로, 역확산 과정을 통해 자기 회귀 사전 지식을 시각 토큰에 통합하여 픽셀 흐름을 인과율을 엄격하게 따르는 이산 시퀀스로 변환함으로써 기존 공간 토큰 방안과 자기 회귀(AR) 패러다임 간의 충돌 문제를 해결하는 것을 목표로 합니다. Selftok Tokenizer는 이중 흐름 인코더(이미지 분기는 SD3 VAE 계승, 텍스트 분기는 학습 가능한 연속 벡터 그룹)와 재활성화 메커니즘을 갖춘 양자화기를 채택합니다. 실험 결과, Selftok은 ImageNet 재구성 지표에서 SOTA를 달성했으며, Ascend AI 및 MindSpeed 프레임워크 기반으로 훈련된 Selftok dAR-VLM은 GenEval 등 텍스트-이미지 생성 벤치마크에서 GPT-4o를 능가했습니다. 이 연구는 CVPR 2025 최우수 논문 후보로 선정되었습니다. (来源: WeChat)
Yan Shuicheng 팀 주도, General-Level 평가 프레임워크 및 General-Bench 벤치마크 발표, 멀티모달 범용 모델 등급화: 싱가포르 국립대학교 Yan Shuicheng 교수, 난양 공과대학교 Zhang Hanwang 교수 등이 주도하고 10개 최고 대학이 공동으로 멀티모달 범용 모델을 위한 평가 프레임워크 General-Level과 대규모 벤치마크 데이터셋 General-Bench를 발표했습니다. 이 프레임워크는 자율 주행 등급화 아이디어를 차용하여 5개 등급(Level 1-5)을 설정하여 멀티모달 대규모 언어 모델(MLLM)의 일반성과 성능을 평가하며, 핵심 평가 기준은 “협력적 일반화 효과”(Synergy)로, 모델이 작업 간, 이해와 생성 패러다임 간, 그리고 모달 간 지식 이전 및 강화 능력을 평가합니다. General-Bench는 700개 이상의 작업과 32만 개의 샘플을 포함하며, 100개 이상의 기존 MLLM에 대한 평가 결과 대부분의 모델이 L2-L3 수준에 머물러 있으며 L5에 도달한 모델은 아직 없습니다. (来源: WeChat)

💼 商业
Sakana AI, 미쓰비시 UFJ 은행(MUFG)과 다년간 파트너십 체결: 일본 AI 스타트업 Sakana AI가 일본 최대 은행인 미쓰비시 UFJ 은행(MUFG Bank)과 다년간의 포괄적인 파트너십 계약을 체결했다고 발표했습니다. Sakana AI는 MUFG 은행에 민첩하고 강력한 AI 기술을 제공하여, 100년 역사의 이 은행이 빠르게 발전하는 AI 분야에서 경쟁력을 유지하도록 지원하는 것을 목표로 합니다. 이 협력을 통해 Sakana AI는 1년 내에 수익성을 달성할 것으로 예상됩니다. (来源: SakanaAILabs, SakanaAILabs)

Cohere, Dell과 협력하여 안전한 지능형 에이전트 플랫폼 Cohere North를 Dell의 온프레미스 기업 AI 솔루션에 도입: AI 회사 Cohere가 Dell Technologies와 협력하여 안전하고 지능형 에이전트 기능을 갖춘 기업 AI 솔루션을 가속화한다고 발표했습니다. Dell은 기업에 Cohere의 안전한 지능형 에이전트 플랫폼 Cohere North의 온프레미스 배포 방안을 제공하는 최초의 공급업체가 될 것입니다. 이 협력은 민감한 데이터를 처리하고 엄격한 규정 준수 요구 사항이 있는 산업에 특히 중요하며, 기업이 자체 데이터 센터 내에서 Cohere의 첨단 AI 에이전트 기술을 배포하고 실행할 수 있도록 합니다. (来源: sarahookr)

Mistral AI, MGX 및 Bpifrance와 협력하여 프랑스에 유럽 최대 AI 단지 건설: Mistral AI가 아부다비 지원 기술 투자 회사 MGX 및 프랑스 국립 투자 은행 Bpifrance와 협력하여 프랑스 파리 지역에 유럽 최대 AI 단지를 건설한다고 발표했습니다. 이 단지는 데이터 센터, 고성능 컴퓨팅 자원, 교육 및 연구 시설을 통합할 것입니다. NVIDIA도 기술 지원을 제공하며 참여할 예정입니다. 이 조치는 유럽 AI 생태계 발전을 촉진하고 글로벌 AI 분야에서 프랑스의 전략적 위상을 높이는 것을 목표로 합니다. (来源: arthurmensch, arthurmensch)
🌟 社区
AI 업계 종사자 중 ADHD 유병률 관심 집중, 20-30% 초과 가능성: 소셜 미디어에서 AI 분야 종사자들의 주의력 결핍 과잉 행동 장애(ADHD) 유병률에 대한 논의가 있었습니다. 한 사용자는 이 분야가 신경 다양성을 가진 인재들을 많이 유치하는 것 같다고 관찰했습니다. Minh Nhat Nguyen은 AI 업계 종사자 중 20-30% 이상이 ADHD를 앓고 있을 수 있다고 언급했습니다. 이러한 현상은 AI 연구 개발 업무가 고도의 집중력, 빠른 반복 작업, 창의적 사고를 요구하는 것과 관련이 있을 수 있으며, 이러한 특성은 때때로 ADHD의 일부 증상과 일치합니다. (来源: Dorialexander)
AI 시대 기술 가치 하락에 대한 심층 분석, 도구 습득이 아닌 시스템 재구축이 관건: 한 심층 분석 기사는 AI 시대의 진정한 위기는 “AI 도구를 사용할 줄 아느냐”가 아니라 기술 자체의 가치 하락과 전체 작업 시스템의 재구축이라고 지적합니다. 이 기사는 마지노선, 컨테이너화, 타자기가 워드 프로세서로 대체된 사례 등을 통해 새로운 도구 사용법을 배우는 것만으로는 선두를 보장할 수 없으며, AI가 작업의 구조, 프로세스, 조직 논리를 어떻게 바꾸는지 이해하는 것이 중요하다고 주장합니다. 시스템이 재작성되면 기존의 고부가가치 기술은 빠르게 소외될 수 있습니다. 생산성 향상이 반드시 개인 가치 향상으로 이어지는 것은 아니며, 가치는 새로운 시스템의 조정 계층을 통제하는 주체에게 흘러갈 것입니다. 이 기사는 “AI를 배우면 앞서갈 수 있다”, “AI가 더 많은 일을 하게 해주므로 더 가치 있다”, “일자리는 변하지 않고 방식만 바뀐다” 등 8가지 유행하는 오류를 반박하며, 시스템 차원에서 자신의 위치와 가치를 생각해야 한다고 강조합니다. (来源: 36氪)
전 Google CEO 슈미트: 비인간 지능의 부상이 글로벌 지형을 재편할 것, AI 위험과 도전 경계해야: 전 Google CEO 에릭 슈미트가 인터뷰에서 사회가 “비인간 지능”의 파괴적인 잠재력에 대한 인식이 심각하게 부족하다고 경고했습니다. 그는 AI가 언어 생성에서 전략적 의사 결정으로 나아가 복잡한 작업을 독립적으로 완료할 수 있게 되었다고 보았습니다. 슈미트는 AI가 가져오는 세 가지 핵심 과제를 강조했습니다: 에너지 및 컴퓨팅 파워 병목 현상(미국은 90기가와트의 추가 전력 필요), 공개 데이터 고갈 임박(다음 단계는 AI 생성 데이터 필요), 그리고 AI가 인간의 기존 지식을 넘어 “새로운 지식”을 창출하도록 하는 방법입니다. 그는 또한 세 가지 위험을 지적했습니다: AI의 재귀적 자기 개선 통제 불능, 무기 통제권 획득, 무단 자기 복제. 그는 미중 AI 경쟁이 심화되는 배경에서 오픈 소스 AI의 빠른 확산이 안보 위험을 초래하고 심지어 “핵 억지력”과 유사한 “선제 공격” 상황을 유발할 수 있다고 생각합니다. 슈미트는 즉각적인 글로벌 AI 거버넌스 대화를 촉구하고 시스템 설계 초기부터 인간의 자유 보호를 내재화해야 한다고 강조했습니다. (来源: 36氪)

GitHub CEO, “프로그래밍 무용론” 반박, AI 시대에도 인간 프로그래머 중요성 강조: NVIDIA CEO Jensen Huang 등이 제기한 “미래에는 프로그래밍을 배울 필요가 없을 것”이라는 주장에 대해 GitHub CEO Thomas Dohmke가 인터뷰에서 반대 의사를 밝혔습니다. 그는 2025년이 프로그래밍 에이전트(SWE Agent)의 해가 될 것이지만 인간 프로그래머의 역할은 여전히 중요하다고 생각합니다. Dohmke는 AI가 개발자의 능력을 향상시키는 조력자 역할을 해야 하며, 완전히 대체해서는 안 된다고 강조했습니다. 그는 미래의 소프트웨어 개발이 인간과 AI가 협력하는 형태로 진화하여 개발자가 “지능형 에이전트 악단 지휘자”처럼 작업을 할당하고 결과를 검토하는 역할을 할 것이라고 구상했습니다. GitHub CPO Mario Rodriguez도 회사가 Copilot으로 개인의 능력을 강화하는 데 전념하고 있다고 말했습니다. 그들은 AI가 발전함에 따라 인간의 사고와 행동을 대표할 수 있는 기계를 프로그래밍하고 재프로그래밍하는 방법을 이해하는 것이 중요하며, 코드 학습을 포기하는 것은 지능형 에이전트 미래의 발언권을 포기하는 것과 같다고 생각합니다. (来源: 36氪, 量子位)

AI 생성 저품질 취약점 보고서 범람, curl 창립자 “AI 쓰레기” 차단 필터링 메커니즘 도입: curl 프로젝트 창립자 Daniel Stenberg는 AI가 생성한 저품질, 무효 취약점 보고서가 대량으로 접수되어 골머리를 앓고 있다고 밝혔습니다. 이러한 보고서는 유지보수 인력의 시간을 많이 낭비시켜 DDoS 공격과 다름없다고 합니다. 이에 따라 HackerOne에서 curl 관련 보안 보고서를 제출할 때 AI 사용 여부를 묻는 체크박스가 추가되었습니다. ‘예’라고 답하면 취약점의 실제성을 증명하는 추가 증거를 제공해야 하며, 그렇지 않으면 보고자가 차단될 수 있습니다. Stenberg는 프로젝트가 AI가 생성한 유효한 버그 보고서를 받은 적이 없다고 말했습니다. Python 개발자 Seth Larson도 유사한 우려를 표명하며, 이러한 보고서가 유지보수자에게 혼란, 스트레스, 좌절감을 안겨주고 오픈 소스 프로젝트의 번아웃 문제를 악화시킨다고 지적했습니다. 커뮤니티에서는 AI 생성 보고서의 범람이 정보 과부하와 일부 사람들이 취약점 포상금 제도를 악용하려는 문제를 반영하며, 심지어 고위 관리자들조차 AI가 숙련된 프로그래머를 대체할 수 있다고 오해하고 있다고 논의했습니다. (来源: WeChat)

AI 지원 프로그래밍 열띤 논쟁: 효율성 크게 향상되지만 인간 개발자 역할 여전히 중요: 수십 년 프로그래밍 경력을 가진 한 개발자가 AI(아마도 Codex 또는 유사 도구)가 몇 시간 동안 해결하지 못한 버그를 몇 분 만에 해결하고 코드를 최적화한 경험을 공유하며, AI가 마치 “지치지 않는 초능력 팀원” 같다고 감탄했습니다. 이 경험은 커뮤니티에서 논쟁을 불러일으켰습니다. 대부분의 사람들은 코드 생성, 버그 수정, 정보 요약 측면에서 AI의 강력한 능력을 인정하며 효율성을 크게 향상시킬 수 있다고 동의합니다. 그러나 일부 개발자들은 AI가 현재 여전히 실수를 저지르며, 특히 복잡한 논리, 경계 조건 및 창의적인 솔루션에서는 인간에 미치지 못하고, 그 결과물은 숙련된 개발자의 검토와 비판적 평가가 필요하다고 지적합니다. Microsoft CEO Satya Nadella도 AI가 역량 강화 도구이며 소프트웨어 개발은 더 이상 AI 없이는 불가능하지만 인간의 야망과 주도성은 여전히 중요하다고 강조했습니다. 논의에서는 일반적으로 AI가 프로그래밍 방식을 바꿀 것이며, 개발자는 AI와 협력하는 새로운 패러다임에 적응하고 더 높은 수준의 아키텍처 설계 및 문제 정의에 집중해야 한다고 보고 있습니다. (来源: Reddit r/ChatGPT, WeChat)
AI Agent Manus, 가입 개방했으나 높은 가격 책정, 국내외 거대 기업 경쟁 직면, 중국어 버전 출시 미지수: AI Agent 플랫폼 Manus가 초대 코드 열풍 후 정식으로 가입을 개방했지만, 현재는 해외 사용자에게만 제공되며 중국어 버전은 제공되지 않습니다. 사용자 피드백에 따르면 포인트 소모제를 채택하여 무료 포인트(가입 시 1000점, 매일 300점)로는 간단한 작업만 완료할 수 있고, 복잡한 작업(예: 웹 버전 스도쿠 게임 제작)은 유료로 포인트를 구매해야 하며, 평균 1달러당 100포인트로 가격이 비싼 편입니다. 업계 관계자 분석에 따르면 Manus는 타사 대형 모델(예: 해외 버전은 Claude 사용)에 의존하여 비용이 높고, 클라우드 샌드박스 운영도 비용을 증가시킵니다. 중국어 버전 출시가 늦어지는 것은 국내 모델 등록, 사용자 유료 결제 습관 및 시장 경쟁과 관련이 있을 수 있습니다. ByteDance의 Coze, Baidu의 “心响” 앱 등 국내외 제품이 이미 경쟁 구도를 형성하고 있습니다. Manus는 새로운 투자를 유치했지만, “경량 모델, 중점 애플리케이션” 모델의 해자는 시험대에 올랐습니다. (来源: 36氪)
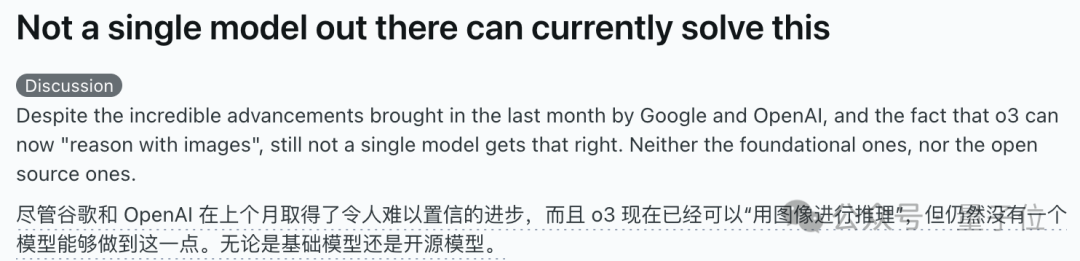
AI 모델, “큐브 완성하기” 시각 추론 문제에서 집단 실패, 실제 이해 능력에 대한 논란 야기: 불완전한 큐브를 완성하는 데 필요한 작은 큐브 블록 수를 계산하도록 요구하는 시각 추론 문제에서 OpenAI o3, Google Gemini 2.5 Pro, DeepSeek, Qwen3를 포함한 여러 주요 AI 모델이 어려움을 겪었습니다. 각 모델이 제시한 답은 다양했으며, 주된 원인은 최종 대형 큐브의 규격(예: 3x3x3, 4x4x4, 5x5x5)에 대한 이해가 달랐기 때문입니다. 힌트를 통해 유도하더라도 모델은 한 번에 정확하게 답하기 어려웠습니다. 일부 네티즌은 문제 자체의 표현이 모호할 수 있으며 인간도 이에 대해 혼란스러워할 수 있다고 지적했습니다. 이러한 현상은 AI 모델이 문제를 실제로 이해하는지 아니면 단순히 패턴 일치에 의존하는지에 대한 논쟁을 불러일으켰으며, 현재 AI가 복잡한 공간 추론 및 시각적 이해 측면에서 한계를 가지고 있음을 강조합니다. (来源: 36氪)
사용자들, LLM의 지시 따르기 및 추론에서의 “과도한 생각” 문제 논의: 소셜 미디어 및 논문에서 대규모 언어 모델(LLM)이 연쇄적 사고(CoT)와 같은 추론 과정을 사용할 때 때때로 “과도하게 생각”하여 오히려 간단한 지시를 정확하게 따르지 못하는 경우가 있다는 지적이 있었습니다. 예를 들어, 특정 단어 수를 쓰거나 특정 문구를 반복하도록 요구받았을 때 CoT는 모델이 작업의 전체 내용에 더 집중하여 이러한 기본 제약 조건을 무시하거나 추가적인 설명 내용을 도입하게 만들 수 있습니다. 연구자들은 이 현상을 정량화하기 위해 “제약 주의력” 지표를 제안하고, 상황 학습, 자기 성찰, 자기 선택 추론 및 분류기 선택 추론과 같은 완화 전략을 테스트했습니다. 이는 모든 작업이 CoT에 적합한 것은 아니며, 간단한 지시는 더 직접적인 실행 방식이 필요할 수 있음을 시사합니다. (来源: menhguin, omarsar0)

AI 경제학 반성: 저렴한 인지 노동이 전통 경제 모델을 깨뜨리고 가치 분배 재편 직면: 논쟁을 불러일으킨 한 관점에 따르면, AI의 부상은 보고서 작성, 데이터 분석, 코드 작성과 같은 인지 노동을 극도로 저렴하게 만들고 있으며, 이는 “인간 지능은 희소하고 비싸다”는 핵심 가정을 가진 고전 경제학 모델에 근본적으로 도전하고 있습니다. AI가 거의 제로 한계 비용으로 대량의 지식 작업을 완료할 수 있게 되면 생산성은 급증할 수 있지만 단일 작업 가치는 폭락하고 전문화의 이점은 침식될 것입니다. 가치 분배는 더 이상 효율성이나 생산량에 따라 단순하게 결정되지 않고, 데이터, 플랫폼, AI 모델 자체와 같은 새로운 희소 자원을 누가 통제하느냐에 따라 결정될 것입니다. 이는 역사적으로 기술 변화(예: 패스트 패션이 의류 산업에, 스트리밍이 음악 산업에 미친 영향)에서 효율성 향상의 혜택이 노동자에게 완전히 돌아가지 않고 시스템 조정자에게 돌아간 것과 유사합니다. 이 글은 AI가 작업을 자동화할 뿐만 아니라 “사고”를 상품화하고 있으며, 이것이 현대 경제사에서 가장 파괴적인 힘이 될 수 있다고 경고합니다. (来源: Reddit r/artificial)
AI 시대 기업 전략: “지능형 회사” 함정 피하고, 기존 프로세스 최적화 아닌 재구축 필요: 많은 기업이 AI를 도입할 때 기존 프로세스를 최적화하고 비용을 절감하며 효율성을 높이는 도구로 사용하는 경향이 있어 “같은 일을 더 똑똑하게 하는” “지능형 회사” 함정에 빠집니다. 그러나 진정한 변화는 기존 프로세스를 더 지능적으로 만드는 것이 아니라 이러한 프로세스가 여전히 존재할 필요가 있는지 생각하고 완전히 새로운 AI 네이티브 시스템과 비즈니스 모델을 구축하는 것입니다. 기술은 단순히 기존 시스템에 적응하는 것이 아니라 시스템을 재편할 것입니다. 기업은 AI에 의해 곧淘汰될 프로세스에 너무 많은 자원을 투자하여 최적화하는 것을 피하고, 새로운 규칙을 정의하고 의사 결정 방식, 조정 메커니즘 및 조직 구조를 근본적으로 바꾸는 데 집중해야 합니다. (来源: 36氪)
💡 其他
LangChain 뉴욕 오프라인 교류 행사: LangChain은 5월 22일(목요일) 뉴욕에서 Tabs 및 TavilyAI와 공동으로 오프라인 교류 행사를 개최한다고 발표했습니다. 행사 내용에는 담화, 제품 시연 및 다른 빌더들과의 교류 세션이 포함됩니다. (来源: hwchase17, LangChainAI)

글로벌 AI 컨퍼런스 도쿄, 6월 개최 예정: “글로벌 AI 컨퍼런스·도쿄”라는 행사가 6월 7일부터 8일까지 일본 도쿄에서 개최될 예정입니다. 이 행사에는 다수의 유명 AI 개발자, 아티스트, 투자자 등이 참여할 예정입니다. AI 분야에 관심이 있고 일본 방문을 계획 중인 분들은 관련 등록 정보를 확인해 보시기 바랍니다. (来源: op7418)

AI 서비스 아키텍처 패러다임, “모델 즉 서비스”에서 “에이전트 즉 서비스”로 전환 중: AI 기술 발전에 따라 AI 서비스 아키텍처는 “모델 즉 서비스”(MaaS)에서 “에이전트 즉 서비스”(AaaS)로 심오한 전환을 겪고 있습니다. AI Agent는 목표 지향적, 환경 인식, 자율적 의사 결정 및 학습 능력을 통해 기존 AI 모델이 수동적으로 지시를 수행하는 패턴을 뛰어넘습니다. 이들은 독립적으로 생각하고, 작업을 분해하고, 경로를 계획하며, 외부 도구를 호출하여 복잡한 목표를 완료할 수 있습니다. 이러한 변화는 산업 체인이 기본 인프라(컴퓨팅 파워, 데이터), 핵심 알고리즘 및 대형 모델에서 중간 계층 Agent 구성 요소 및 플랫폼, 그리고 최종 제품 애플리케이션(범용형, 수직 산업, 임베디드 Agent)으로 전면적으로 발전하도록 촉진하고 있습니다. HeyGen, Laiye Technology, Waveform Intelligence와 같은 중국 AI Agent 기업들도 적극적으로 해외 시장을 개척하고 있습니다. 컴퓨팅 파워 비용이 비싸고 공급이 부족한 등의 문제에 직면하고 있지만, 알고리즘 최적화, 전용 칩, 엣지 컴퓨팅 등의 방안을 통해 AI Agent의 잠재력은 계속해서 발휘되고 있습니다. (来源: 36氪)